AWS Certified Machine Learning Engineer – Associate (MLA-C01) Exam Learning Path
🔄 July 2026 Update: Refreshed with Amazon Bedrock AgentCore (GA Oct 2025), SageMaker Lakehouse, SageMaker AI with MLflow 3.0 (serverless), SageMaker HyperPod elastic training, and Amazon Nova models. The AWS Certified Machine Learning – Specialty (MLS-C01) was retired on March 31, 2026, making MLA-C01 the primary AWS certification for ML practitioners.
- Certified for the last pending AWS Certified Machine Learning Engineer – Associate (MLA-C01) certification, which was newly introduced on October 8, 2024, following its beta period.
- Machine Learning Engineer – Associate exam validates knowledge to build, operationalize, deploy, and maintain machine learning (ML) solutions and pipelines by using the AWS Cloud.
- Exam also validates a candidate’s ability to complete the following tasks:
- Ingest, transform, validate, and prepare data for ML modeling.
- Select general modeling approaches, train models, tune hyperparameters, analyze model performance, and manage model versions.
- Choose deployment infrastructure and endpoints, provision compute resources, and configure auto scaling based on requirements.
- Set up continuous integration and continuous delivery (CI/CD) pipelines to automate orchestration of ML workflows.
- Monitor models, data, and infrastructure to detect issues.
- Secure ML systems and resources through access controls, compliance features, and best practices.
Refer AWS Certified Machine Learning Engineer – Associate (MLA-C01) Exam Guide
AWS Certified Machine Learning Engineer – Associate (MLA-C01) Exam Summary
- MLA-C01 exam consists of 65 questions (50 scored and 15 unscored) in 130 minutes, and the time is more than sufficient if you are well-prepared.
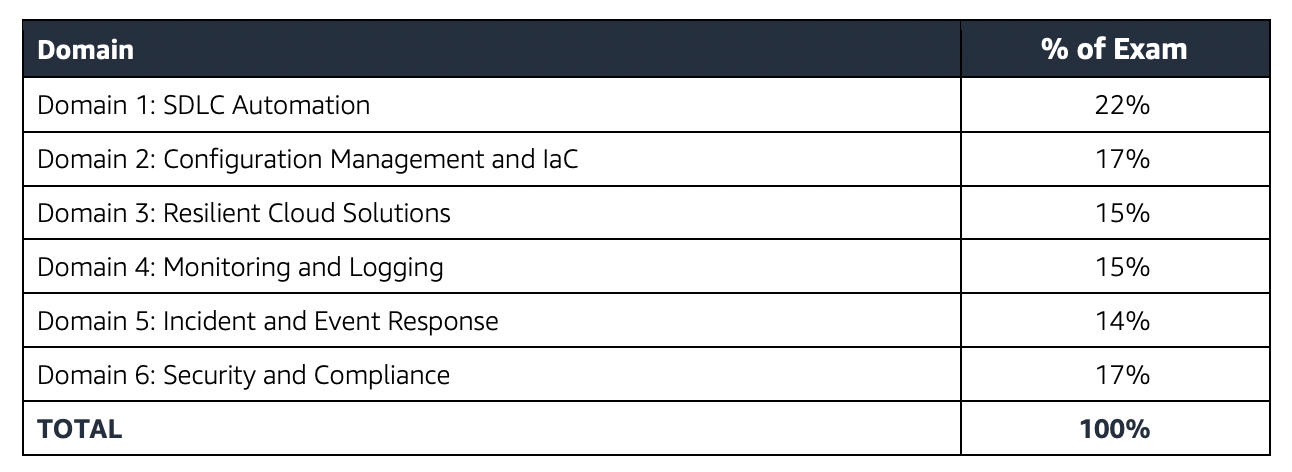
- MLA-C01 exam covers four domains:
- Domain 1: Data Preparation for Machine Learning (28%)
- Domain 2: ML Model Development (26%)
- Domain 3: Deployment and Orchestration of ML Workflows (22%)
- Domain 4: ML Solution Monitoring, Maintenance, and Security (24%)
- In addition to the usual types of multiple-choice and multiple-response questions, the MLA-C01 exam has introduced the following new types
- Ordering: Has a list of 3-5 responses which you need to select and place in the correct order to complete a specified task.
- Matching: Has a list of responses to match with a list of 3-7 prompts. You must match all the pairs correctly to receive credit for the question.
- Case study: A case study presents a single scenario with multiple questions. Each question is evaluated independently, and credit is given for each correct answer.
- MLA-C01 has a scaled score between 100 and 1,000. The scaled score needed to pass the exam is 720.
- Associate exams currently cost $150 + tax.
- You can get an additional 30 minutes if English is your second language by requesting Exam Accommodations. It might not be needed for Associate exams but is helpful for Professional and Specialty ones.
- AWS exams can be taken either remotely or online, I prefer to take them online as it provides a lot of flexibility. Just make sure you have a proper place to take the exam with no disturbance and nothing around you.
- Also, if you are taking the AWS Online exam for the first time try to join at least 30 minutes before the actual time as I have had issues with both PSI and Pearson with long wait times.
AWS Certified Machine Learning Engineer – Associate (MLA-C01) Exam Resources
- Online Courses
- Stephane Maarek – AWS Certified Machine Learning Engineer Associate: Hands On!
- Whizlabs – AWS Certified Machine Learning Engineer Associate (MLA-C01)
- KodeKloud – AWS Certified Machine Learning Engineer Associate
- Practice tests
- Braincert – AWS Machine Learning Engineer – Associate (MLA-C01) Practice Exams
- Stephane Maarek – Practice Exams: AWS Machine Learning Engineer Associate Certification
- Tutorials Dojo – AWS Certified Machine Learning Engineer Associate Practice Exams MLA-C01
- Whizlabs – AWS Certified Machine Learning Engineer Associate (MLA-C01)
- Read the FAQs at least for the important topics, as they cover important points and are good for quick review
AWS Certified Machine Learning Engineer – Associate (MLA-C01) Exam Topics
- AWS Certified Machine Learning Engineer – Associate exam covers a lot of Machine Learning concepts in addition to the AWS ML Services.
- AWS Certified Machine Learning exam covers the Machine Learning lifecycle, data collection, transformation, making it usable and efficient for Machine Learning, pre-processing data for Machine Learning, training and validation, and implementation.
- With the Q1 2026 refresh, the exam now includes increased coverage of Amazon Bedrock (Knowledge Bases, Agents, Guardrails, AgentCore), Generative AI workflows, and the unified SageMaker AI platform including Lakehouse and MLflow.
Machine Learning Concepts
- Exploratory Data Analysis
- Feature selection and Engineering
- remove features that are not related to training
- remove features that have the same values, very low correlation, very little variance, or a lot of missing values
- Apply techniques like Principal Component Analysis (PCA) for dimensionality reduction i.e. reduce the number of features.
- Apply techniques such as One-hot encoding and label encoding to help convert strings to numeric values, which are easier to process.
- Apply Normalization i.e. values between 0 and 1 to handle data with large variance.
- Apply feature engineering for feature reduction e.g. using a single height/weight feature instead of both features.
- Handle Missing data
- remove the feature or rows with missing data
- impute using Mean/Median values – valid only for Numeric values and not categorical features also does not factor correlation between features
- impute using k-NN, Multivariate Imputation by Chained Equation (MICE), Deep Learning – more accurate and helps factors correlation between features
- Handle unbalanced data
- Source more data
- Oversample minority or Undersample majority
- Data augmentation using techniques like Synthetic Minority Oversampling Technique (SMOTE).
- Feature selection and Engineering
- Modeling
- Know about Algorithms – Supervised, Unsupervised and Reinforcement and which algorithm is best suitable based on the available data either labelled or unlabelled.
- Supervised learning trains on labeled data e.g. Linear regression. Logistic regression, Decision trees, Random Forests
- Unsupervised learning trains on unlabelled data e.g. PCA, SVD, K-means
- Reinforcement learning trained based on actions and rewards e.g. Q-Learning
- Hyperparameters
- are parameters exposed by machine learning algorithms that control how the underlying algorithm operates and their values affect the quality of the trained models
- some of the common hyperparameters are learning rate, batch, epoch (hint: If the learning rate is too large, the minimum slope might be missed and the graph would oscillate. If the learning rate is too small, it requires too many steps which would take the process longer and is less efficient)
- Know about Algorithms – Supervised, Unsupervised and Reinforcement and which algorithm is best suitable based on the available data either labelled or unlabelled.
- Evaluation
- Know difference in evaluating model accuracy
- Use Area Under the (Receiver Operating Characteristic) Curve (AUC) for Binary classification
- Use root mean square error (RMSE) metric for regression
- Understand Confusion matrix
- A true positive is an outcome where the model correctly predicts the positive class. Similarly, a true negative is an outcome where the model correctly predicts the negative class.
- A false positive is an outcome where the model incorrectly predicts the positive class. A false negative is an outcome where the model incorrectly predicts the negative class.
- Recall or Sensitivity or TPR (True Positive Rate): Number of items correctly identified as positive out of total true positives- TP/(TP+FN) (hint: use this for cases like fraud detection, cost of marking non fraud as frauds is lower than marking fraud as non-frauds)
- Specificity or TNR (True Negative Rate): Number of items correctly identified as negative out of total negatives- TN/(TN+FP) (hint: use this for cases like videos for kids, the cost of dropping few valid videos is lower than showing few bad ones)
- Handle Overfitting problems
- Simplify the model, by reducing the number of layers
- Early Stopping – form of regularization while training a model with an iterative method, such as gradient descent
- Data Augmentation
- Regularization – technique to reduce the complexity of the model
- Dropout is a regularization technique that prevents overfitting
- Never train on test data
- Know difference in evaluating model accuracy
Machine Learning Services
SageMaker AI (formerly SageMaker)
Note: At re:Invent 2024, AWS rebranded Amazon SageMaker to Amazon SageMaker AI as part of the next-generation SageMaker platform that unifies data, analytics, and AI. The next-gen SageMaker umbrella includes SageMaker AI, SageMaker Lakehouse, and SageMaker Unified Studio.
- supports both File mode, Pipe mode, and Fast File mode
- File mode loads all of the data from S3 to the training instance volumes VS Pipe mode streams data directly from S3
- File mode needs disk space to store both the final model artifacts and the full training dataset. VS Pipe mode which helps reduce the required size for EBS volumes.
- Fast File mode combines the ease of use of the existing File Mode with the performance of Pipe Mode.
- Using RecordIO format allows algorithms to take advantage of Pipe mode when training the algorithms that support it.
- supports Model tracking capability to manage up to thousands of machine learning model experiments
- supports automatic scaling for production variants. Automatic scaling dynamically adjusts the number of instances provisioned for a production variant in response to changes in your workload
- provides pre-built Docker images for its built-in algorithms and the supported deep learning frameworks used for training & inference
- SageMaker Automatic Model Tuning
- is the process of finding a set of hyperparameters for an algorithm that can yield an optimal model.
- Best practices
- limit the search to a smaller number as the difficulty of a hyperparameter tuning job depends primarily on the number of hyperparameters that Amazon SageMaker has to search
- DO NOT specify a very large range to cover every possible value for a hyperparameter as it affects the success of hyperparameter optimization.
- log-scaled hyperparameter can be converted to improve hyperparameter optimization.
- running one training job at a time achieves the best results with the least amount of compute time.
- Design distributed training jobs so that they report the objective metric that you want.
- know how to take advantage of multiple GPUs (hint: increase learning rate and batch size w.r.t to the increase in GPUs)
Elastic Inference(deprecated April 2023, replaced by AWS Inferentia) — previously helped attach low-cost GPU-powered acceleration to EC2 and SageMaker instances for deep learning inference. Use AWS Inferentia (Inf2 instances) or AWS Trainium (Trn1/Trn2 instances) for cost-effective ML acceleration.- SageMaker AI Inference options.
- Real-time inference is ideal for online inferences that have low latency or high throughput requirements.
- Serverless Inference is ideal for intermittent or unpredictable traffic patterns as it manages all of the underlying infrastructure with no need to manage instances or scaling policies.
- Batch Transform is suitable for offline processing when large amounts of data are available upfront and you don’t need a persistent endpoint.
- Asynchronous Inference is ideal when you want to queue requests and have large payloads with long processing times.
- SageMaker AI Model deployment allows deploying multiple variants of a model to the same SageMaker endpoint to test new models without impacting the user experience
- Production Variants
- supports A/B or Canary testing where you can allocate a portion of the inference requests to each variant.
- helps compare production variants’ performance relative to each other.
- Shadow Variants
- replicates a portion of the inference requests that go to the production variant to the shadow variant.
- logs the responses of the shadow variant for comparison and not returned to the caller.
- helps test the performance of the shadow variant without exposing the caller to the response produced by the shadow variant.
- Production Variants
- SageMaker Managed Spot training can help use spot instances to save cost and with Checkpointing feature can save the state of ML models during training
- SageMaker Feature Store
- helps to create, share, and manage features for ML development.
- is a centralized store for features and associated metadata so features can be easily discovered and reused.
- now supports Apache Iceberg table format, streaming ingestion, scalable batch ingestion, and fine-grained access control through AWS Lake Formation.
- SageMaker Debugger provides tools to debug training jobs and resolve problems such as overfitting, saturated activation functions, and vanishing gradients to improve the model’s performance.
- SageMaker Model Monitor monitors the quality of SageMaker machine learning models in production and can help set alerts that notify when there are deviations in the model quality.
- SageMaker Automatic Model Tuning helps find a set of hyperparameters for an algorithm that can yield an optimal model.
- SageMaker Data Wrangler
- reduces the time it takes to aggregate and prepare tabular and image data for ML from weeks to minutes.
- Note: Data Wrangler has been integrated into Amazon SageMaker Canvas. The new Data Wrangler experience in SageMaker Canvas includes a natural language interface in addition to the visual interface for data exploration and transformation.
- SageMaker Experiments is a capability of SageMaker that lets you create, manage, analyze, and compare machine learning experiments.
- SageMaker Clarify helps improve the ML models by detecting potential bias and helping to explain the predictions that the models make.
- Pre-training bias metrics: CI, DPL, KL Divergence, JS Divergence
- Post-training bias metrics: DI, DPD, DCA, AD, CDDPL
- SHAP values for feature importance and individual prediction explanations
- Foundation model evaluation for accuracy, toxicity, and robustness
- Integrates with Model Monitor for continuous bias drift detection
- SageMaker Model Governance is a framework that gives systematic visibility into ML model development, validation, and usage.
- SageMaker Model Cards
- helps document critical details about the ML models in a single place for streamlined governance and reporting.
- helps capture key information about the models throughout their lifecycle and implement responsible AI practices.
- SageMaker Autopilot
- is an automated machine learning (AutoML) feature set that automates the end-to-end process of building, training, tuning, and deploying machine learning models.
- Note: Autopilot UI has been migrated to Amazon SageMaker Canvas. Use SageMaker Canvas for no-code/low-code AutoML capabilities.
- SageMaker Neo enables machine learning models to train once and run anywhere in the cloud and at the edge.
- SageMaker API and SageMaker Runtime support VPC interface endpoints powered by AWS PrivateLink that helps connect VPC directly to the SageMaker API or SageMaker Runtime using AWS PrivateLink without using an internet gateway, NAT device, VPN connection, or AWS Direct Connect connection.
- SageMaker managed warm pools retain and reuse provisioned infrastructure after the training job completion to reduce latency for repetitive workloads.
- SageMaker supports Elastic File System (EFS) and FSx for Lustre file systems as data sources for training machine learning models.
- SageMaker MLOps
- ML Lineage Tracking creates and stores tracking information about the steps of a ML workflow from data preparation to model deployment that can help reproduce the workflow steps, track model and dataset lineage, and establish model governance and audit standards.
- Model Registry provides a model catalog, helps manage model versions, associate metadata, manage model approval status, deploy models to production and share models with other users.
SageMaker AI with MLflow (New – 2024/2025)
- provides fully managed, serverless MLflow tracking for experiment tracking, model packaging, and model registry — no infrastructure to manage.
- supports MLflow 3.0 (GA July 2025) with tracing capabilities to record inputs, outputs, and metadata at every step of a generative AI application.
- helps track multiple training runs as experiments, compare runs with visualizations, evaluate models, and register the best models.
- models registered in MLflow are automatically registered to SageMaker Model Registry with an associated SageMaker Model Card.
- supports cross-account sharing, automated version upgrades, and integration with SageMaker Pipelines.
- integrates with SageMaker HyperPod to track foundation model training experiments at scale.
SageMaker HyperPod (New – 2023/2024/2025)
- purpose-built infrastructure for training and inference of foundation models at scale, reducing training time by up to 40%.
- efficiently distributes and parallelizes training workloads across hundreds or thousands of AI accelerators (GPUs/Trainium chips).
- continuously checks for hardware problems, resolves them automatically, and ensures workloads recover without manual intervention.
- key features:
- Checkpointless Training — maintains forward training progress despite failures using peer-to-peer transfer of model and optimizer states from healthy accelerators, enabling 95%+ training goodput and 80-93% reduction in recovery time.
- Elastic Training (Dec 2025) — automatically adjusts the number of data-parallel replicas based on cluster utilization and priority of workloads.
- Flexible Training Plans — helps meet training timelines and budgets with automated capacity planning.
- Amazon EKS Integration — orchestrates HyperPod clusters via Amazon EKS, supporting containerized workloads, PyTorchJob auto-resume, and inference on the same cluster.
- Interactive IDEs — supports running interactive workloads alongside training jobs with fractional GPU allocations.
- integrates with Amazon CloudWatch Container Insights, Amazon Managed Prometheus, and Amazon Managed Grafana for observability.
SageMaker Lakehouse (New – re:Invent 2024)
- a unified, open, and secure data lakehouse architecture built on Apache Iceberg that unifies data across S3 data lakes and Amazon Redshift data warehouses.
- enables running analytics and ML workloads — including Apache Spark jobs, SQL dashboards, ML models, and generative AI applications — on a single copy of data.
- key capabilities:
- Unified access to Amazon S3 data lakes (including S3 Tables), Amazon Redshift data warehouses, and operational databases via zero-ETL integrations.
- Fine-grained access control through AWS Lake Formation with consistent permissions across all query engines.
- Compatible with Amazon Athena, Amazon EMR, AWS Glue, and Amazon Redshift for querying and analysis.
- Fully compatible with Apache Iceberg REST API for open interoperability.
- relevant to MLA-C01 Domain 1 (Data Preparation) — provides unified data access for ML feature engineering and training data preparation.
SageMaker Unified Studio (New – re:Invent 2024)
- a unified interface combining data preparation, ML model development, generative AI, and governance.
- integrates SageMaker AI, Amazon Bedrock, analytics, and data governance into a single platform.
- supports one-click onboarding with existing IAM roles and permissions.
- provides collaborative workspace for data engineers, ML engineers, and business analysts.
SageMaker Canvas
- a visual, no-code/low-code ML service that enables building, evaluating, and deploying production-ready models without writing code.
- now integrates Data Wrangler and Autopilot capabilities.
- supports petabyte-scale data preparation and time series forecasting (replacing Amazon Forecast).
- supports fine-tuning foundation models via Amazon Bedrock integration.
SageMaker Ground Truth
- provides automated data labeling using machine learning
- helps build highly accurate training datasets for machine learning quickly using Amazon Mechanical Turk
- provides annotation consolidation to help improve the accuracy of the data object’s labels. It combines the results of multiple worker’s annotation tasks into one high-fidelity label.
- automated data labeling uses machine learning to label portions of the data automatically without having to send them to human workers
Amazon Bedrock (Critical for 2026 Exam)
- Amazon Bedrock is a fully managed service providing access to foundation models (FMs) from Amazon and third-party providers through a unified API.
- supports models from Amazon (Nova, Titan), Anthropic (Claude), Meta (Llama), Mistral, Cohere, and others.
- provides serverless experience — no infrastructure to manage.
- Bedrock Knowledge Bases
- enables RAG (Retrieval-Augmented Generation) by grounding FM responses in enterprise data.
- automatically chunks documents, creates embeddings, and stores them in a vector database.
- supports vector stores including Amazon OpenSearch Serverless, Amazon Aurora, Pinecone, and Redis Enterprise.
- Managed Knowledge Base (GA June 2026) — fully managed RAG without managing vector databases or data pipelines.
- integrates with Amazon Kendra GenAI Index for enhanced semantic retrieval.
- Bedrock Agents
- orchestrate multi-step generative AI workflows by connecting FMs to APIs and data sources.
- automatically break down tasks, create orchestration plans, and execute actions.
- support action groups (Lambda functions) and knowledge base integration.
- Bedrock AgentCore (Preview Jul 2025, GA Oct 2025)
- a dedicated platform to build, deploy, and operate AI agents at any scale with enterprise-grade security.
- framework-agnostic and model-agnostic — works with any open-source agent framework (LangChain, CrewAI, AutoGen) and any model.
- key components:
- AgentCore Runtime — serverless, scalable environment to host and run agents without managing infrastructure; supports VPC, PrivateLink, and CloudFormation.
- AgentCore Tools — pre-built tools including Code Interpreter, browser automation, and MCP (Model Context Protocol) connectors for enterprise data.
- AgentCore Identity — manages authentication and fine-grained access control for agents connecting to third-party tools and data sources.
- AgentCore Observability — tracing and monitoring for agent execution in production.
- AgentCore Harness (GA 2026) — go from idea to production-grade agent in minutes with automated container packaging and deployment.
- now included in MLA-C01 exam scope per Q1 2026 refresh.
- Bedrock Guardrails
- configurable safeguards to filter harmful content, block sensitive data (PII), and ensure compliance.
- enforces deterministic controls independent of model’s reasoning quality.
- supports content filters, denied topics, word filters, sensitive information filters, and contextual grounding checks.
- can be associated with agents, knowledge bases, and direct model invocations.
- Bedrock Model Evaluation
- evaluate, compare, and select the best FM for a specific use case.
- supports automatic evaluation (built-in metrics) and human evaluation.
- Bedrock Model Customization
- supports continued pre-training and fine-tuning of FMs with proprietary data.
- supports Reinforcement Fine-Tuning (RFT) for Amazon Nova and open-source models.
- Custom Model Import allows bringing SageMaker-trained models into Bedrock for serverless inference.
- Model Distillation enables creating smaller, faster, cost-effective models from larger teacher models (e.g., Nova Premier → Nova Pro/Lite/Micro).
- Bedrock Flows
- visual builder for creating generative AI workflows connecting prompts, models, knowledge bases, and agents.
Amazon Nova Models
- Amazon’s own family of foundation models available exclusively in Amazon Bedrock, launched at re:Invent 2024.
- Nova Micro — text-only, fastest and lowest cost; optimized for summarization, translation, classification, and simple reasoning. 128K context.
- Nova Lite — multimodal (text, image, video input → text output); cost-efficient for simple automation and document processing.
- Nova Pro — multimodal; balanced capability, accuracy, speed, and cost for a wide range of tasks including agentic workflows.
- Nova Premier — most capable; excels at complex tasks requiring deep context understanding, multistep planning, and multi-tool execution. Ideal as a teacher model for distillation.
- All Nova models support fine-tuning and model distillation through Amazon Bedrock.
- Nova 2 family (2025) offers next-generation improvements in intelligence and cost-efficiency.
Machine Learning & AI Managed Services
- Comprehend
- natural language processing (NLP) service to find insights and relationships in text.
- identifies the language of the text; extracts key phrases, places, people, brands, or events; understands how positive or negative the text is; analyzes text using tokenization and parts of speech; and automatically organizes a collection of text files by topic.
- Rekognition – analyze images and video to identify objects, people, text, scenes, and activities in images and videos, as well as detect any inappropriate content.
- Transcribe – automatic speech recognition (ASR) speech-to-text
- Kendra – an intelligent search service that uses NLP and advanced ML algorithms to return specific answers to search questions from your data.
- Kendra GenAI Index (New – re:Invent 2024) — delivers highest accuracy for RAG and intelligent search using latest information retrieval technologies and semantic models.
- integrates with Amazon Q Business and Amazon Bedrock Knowledge Bases.
- Augmented AI (Amazon A2I) is an ML service that makes it easy to build the workflows required for human review.
- Amazon Q Developer (formerly CodeWhisperer) — AI-powered coding assistant for building, deploying, and operating applications on AWS.
Generative AI
Refer: AWS AI & Generative AI Services Cheat Sheet
- MLA-C01 covers Generative AI concepts with increased emphasis post-Q1 2026 refresh, including practical AWS Bedrock integration.
- Foundation Models:
- Large, pre-trained models built on diverse data that can be fine-tuned for specific tasks like text, image, and speech generation. for e.g. GPT, BERT, DALL·E, Amazon Nova, Claude, Llama.
- Large Language Models (LLMs):
- A subset of foundation models designed to understand and generate human-like text. Capable of answering questions, summarizing, translating, and more.
- LLM Components
- Tokens: Basic units of text (words, subwords, or characters) that LLMs process.
- Vectors: Numerical representations of tokens in high-dimensional space, enabling the model to perform mathematical operations on text.
- Embeddings: Pre-trained numerical vector representations of tokens that capture their semantic meaning.
- Attention Mechanism: Allows models to weigh the importance of different tokens in a sequence relative to each other (e.g., self-attention in Transformers).
- Prompt Engineering:
- Crafting effective input instructions to guide generative AI toward desired outputs. Key for improving performance without fine-tuning the model.
- Techniques include zero-shot, few-shot, chain-of-thought (CoT), and ReAct prompting.
- Retrieval-Augmented Generation (RAG):
- Combines LLMs with external knowledge bases to retrieve accurate and up-to-date information during text generation.
- Reduces hallucinations by grounding responses in verified enterprise data.
- AWS Implementation: Amazon Bedrock Knowledge Bases + vector stores.
- Fine-Tuning:
- Adjusting pre-trained models using domain-specific data to optimize performance for specific applications.
- AWS options: Amazon Bedrock fine-tuning, SageMaker AI fine-tuning (SFT, DPO, RLVR, RLAIF).
- Responsible AI Features:
- Incorporates fairness, transparency, and bias mitigation techniques to ensure ethical AI outputs.
- Amazon Bedrock Guardrails provides managed responsible AI controls.
- Multi-Modal Capabilities:
- Models that process and generate outputs across multiple data types, such as text, images, and audio.
- Amazon Nova models support text, image, and video generation.
- Controls
- Temperature: Adjusts randomness in the output; lower values (e.g., 0.2) produce focused and deterministic results, while higher values (e.g., 1.0+) generate creative and diverse outputs.
- Top P (Nucleus Sampling): Determines the probability threshold for token selection — with Top P = 0.9, the model considers only the smallest set of tokens whose cumulative probability is 90%.
- Top K: Limits the token selection to the top K most probable tokens — with Top K = 10, the model randomly chooses tokens only from the 10 most likely options.
- Token Length (Max Tokens): Sets the maximum number of tokens the model can generate in a response.
Analytics
- Kinesis
- Understand Kinesis Data Streams and Kinesis Data Firehose in depth
- Glue is a fully managed, ETL (extract, transform, and load) service that automates the time-consuming steps of data preparation for analytics
- helps setup, orchestrate, and monitor complex data flows.
- Glue Data Catalog is a central repository to store structural and operational metadata for all the data assets.
- Glue crawler connects to a data store, extracts the schema of the data, and then populates the Glue Data Catalog with this metadata
- Glue DataBrew is a visual data preparation tool that enables users to clean and normalize data without writing any code.
Security, Identity & Compliance
- SageMaker can read data from KMS-encrypted S3. Make sure, the KMS key policies include the role attached with SageMaker
- Amazon Bedrock supports AWS PrivateLink for private connectivity, encryption at rest and in transit, and IAM-based access control.
- Bedrock AgentCore supports VPC isolation, PrivateLink, and fine-grained IAM permissions for agent-to-tool authentication.
Management & Governance Tools
- Understand AWS CloudWatch for Logs and Metrics. (hint: SageMaker is integrated with CloudWatch and logs and metrics are all stored in it)
Deprecated Services to Be Aware Of
- Amazon Elastic Inference — deprecated April 2023. Use AWS Inferentia (Inf2 instances) or AWS Trainium (Trn1/Trn2 instances) for cost-effective ML inference/training acceleration.
- SageMaker Edge Manager — discontinued April 26, 2024. Use AWS IoT Greengrass V2 with ONNX format for edge ML deployments.
- Amazon Forecast — closed to new customers July 29, 2024. Use SageMaker Canvas for time series forecasting.
- SageMaker Studio Classic — replaced by the updated SageMaker Studio experience and SageMaker Unified Studio.
- AWS Certified Machine Learning – Specialty (MLS-C01) — retired March 31, 2026. MLA-C01 is now the primary ML certification.
Practice Questions (2025-2026 Updates)
- A company is training a large language model with 70 billion parameters across 256 GPUs. During training, individual GPU nodes occasionally fail, causing the entire job to restart from the last checkpoint. This adds days to the training timeline. Which AWS service minimizes the impact of hardware failures on foundation model training?
- Amazon SageMaker AI training jobs with managed spot instances
- Amazon SageMaker HyperPod with checkpointless training
- Amazon EC2 P5 instances with EBS snapshots
- AWS Batch with retry strategies
Show Answer
Answer: B. – SageMaker HyperPod with checkpointless training automatically detects and replaces faulty nodes, then recovers training using peer-to-peer transfer of model states from healthy accelerators — achieving 95%+ training goodput and 80-93% reduction in recovery time without relying on checkpoint files.
- A machine learning team wants to deploy an AI agent that can access company databases, execute code, and call external APIs autonomously. The agent must run in a production environment with enterprise security controls, VPC isolation, and the ability to scale to thousands of concurrent requests. The team uses LangChain as their agent framework. Which AWS service should they use?
- Amazon Bedrock Agents
- Amazon Bedrock AgentCore
- AWS Lambda with Amazon Bedrock API calls
- Amazon ECS with a custom agent container
Show Answer
Answer: B. – Amazon Bedrock AgentCore provides a framework-agnostic (including LangChain) and model-agnostic platform for deploying production-grade AI agents with serverless scaling, VPC/PrivateLink support, built-in identity management for tool authentication, and observability — all without managing infrastructure.
- A data science team needs to track experiments across multiple foundation model fine-tuning runs on SageMaker HyperPod, compare metrics visually, and automatically register the best model for deployment. They want to avoid managing any tracking infrastructure. Which solution meets these requirements with LEAST operational overhead?
- Deploy a self-managed MLflow server on Amazon EC2 and configure SageMaker to log metrics
- Use Amazon SageMaker AI with serverless MLflow and SageMaker Model Registry integration
- Use Amazon CloudWatch custom metrics with CloudWatch dashboards
- Use SageMaker Experiments with manual model registration
Show Answer
Answer: B. – SageMaker AI with serverless MLflow provides fully managed, infrastructure-free experiment tracking that integrates with HyperPod, automatically scales, and automatically registers models to SageMaker Model Registry with an associated Model Card — the least operational overhead for this workflow.
- A company wants to build a RAG-based chatbot that answers questions using internal documents. They need to ensure the chatbot never reveals personally identifiable information (PII) from the documents and does not generate responses about competitors. Which combination of Amazon Bedrock features should they use? (Choose TWO)
- Bedrock Knowledge Bases
- Bedrock Model Customization with continued pre-training
- Bedrock Guardrails with sensitive information filters and denied topics
- Bedrock AgentCore Code Interpreter
- Amazon Comprehend PII detection
Show Answer
Answer: A, C – Bedrock Knowledge Bases provides the RAG capability to ground responses in internal documents. Bedrock Guardrails with sensitive information filters (PII blocking) and denied topics (competitor mentions) enforces deterministic controls to prevent PII leakage and off-topic responses regardless of the model’s reasoning.
- An organization is preparing ML training datasets that span data in Amazon S3 data lakes, Amazon Redshift data warehouses, and Amazon DynamoDB operational tables. They want to access all this data through a unified interface with consistent fine-grained access controls for their SageMaker AI training jobs. Which service provides this unified data access?
- AWS Glue Data Catalog with Lake Formation permissions
- Amazon SageMaker Lakehouse
- Amazon Athena federated queries
- Amazon Redshift Spectrum
Show Answer
Answer: B. – Amazon SageMaker Lakehouse provides a unified, open (Apache Iceberg-based) data lakehouse that unifies access to S3 data lakes (including S3 Tables), Redshift data warehouses, and operational databases via zero-ETL integrations — all with consistent fine-grained access controls through AWS Lake Formation.
Whitepapers and Articles
- AWS AI & Generative AI Services Cheat Sheet
- AWS Machine Learning Services Cheat Sheet
- AWS Analytics Services Cheat Sheet
- Machine Learning Concepts Cheat Sheet
- Amazon Bedrock
- Amazon Bedrock Agents, Knowledge Bases & Guardrails
- Amazon Nova Models
- AWS SageMaker AI
- AWS Machine Learning & AI Learning Hub
- Amazon Bedrock User Guide
- SageMaker AI with MLflow Documentation
Related AWS AI/ML Certifications
- AWS Certified AI Practitioner (AIF-C01) — foundational-level certification for understanding AI/ML concepts and AWS AI services.
- AWS Certified Generative AI Developer – Professional (AIP-C01) — professional-level certification for building production-ready generative AI solutions using Amazon Bedrock. Launched late 2025 (GA April 2026).
AWS Certified Machine Learning – Specialty (MLS-C01)— retired March 31, 2026. Holders retain active certification for 3 years from date earned.
AWS Architecture Patterns for MLA-C01
- MLOps Pipeline – SageMaker Pipelines, Model Registry & Monitoring
- Data Lake & Analytics – Feature Engineering from S3
- Bedrock vs SageMaker – When to Use Each
On the Exam Day
- Make sure you are relaxed and get some good night’s sleep. The exam is not tough if you are well-prepared.
- If you are taking the AWS Online exam
- Try to join at least 30 minutes before the actual time as I have had issues with both PSI and Pearson with long wait times.
- The online verification process does take some time and usually, there are glitches.
- Remember, you would not be allowed to take the take if you are late by more than 30 minutes.
- Make sure you have your desk clear, no hand-watches, or external monitors, keep your phones away, and nobody can enter the room.
Finally, All the Best 🙂