Amazon SageMaker AI
📝 Naming Update (December 2024): On December 3, 2024, Amazon SageMaker was renamed to Amazon SageMaker AI. The “SageMaker” brand now refers to the next-generation unified platform for data, analytics, and AI. SageMaker AI remains available as a standalone service for building, training, and deploying ML models at scale, and is also integrated within the broader next-generation SageMaker platform.
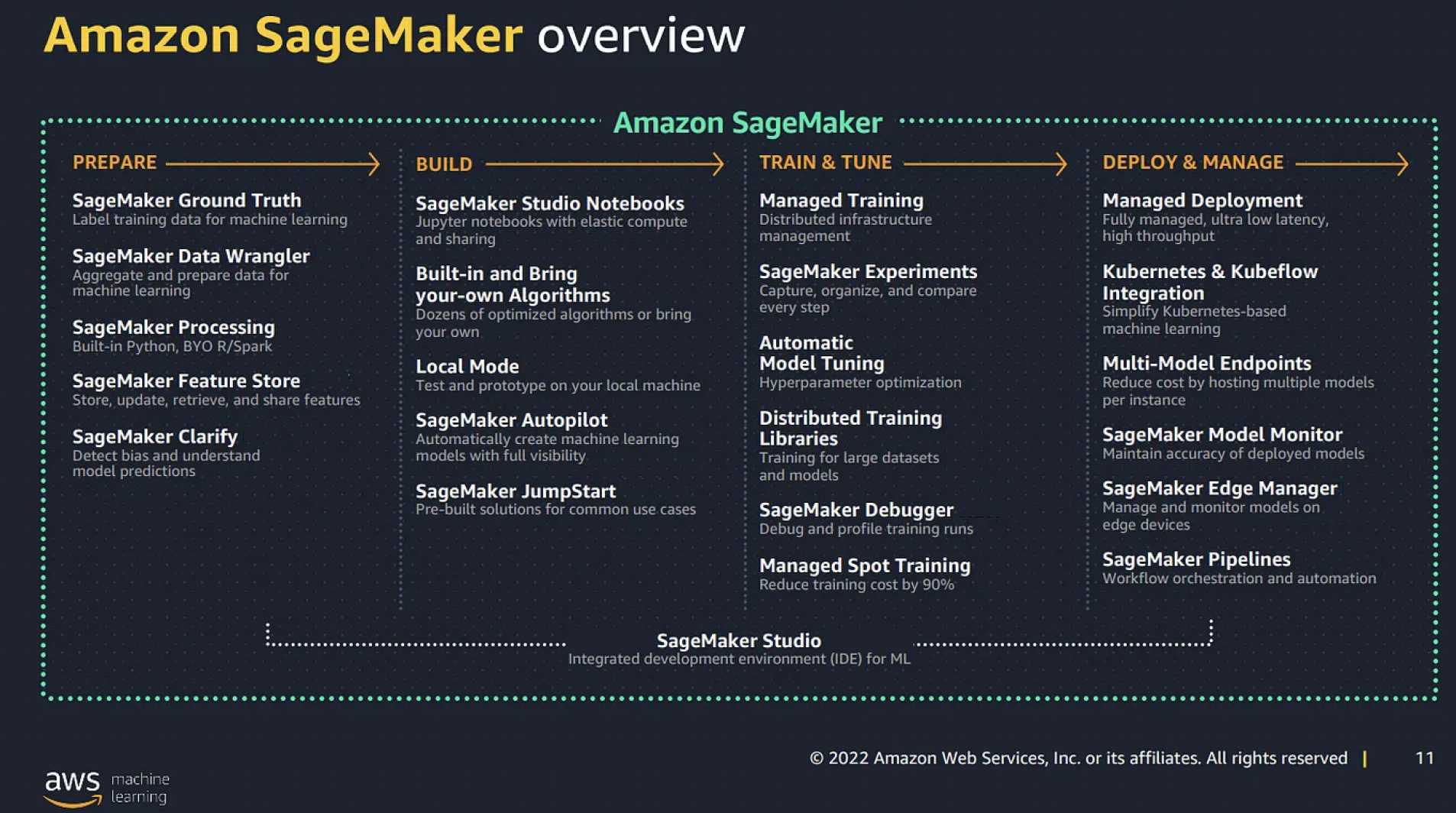
Amazon SageMaker AI is a fully managed machine learning service that enables data scientists, ML engineers, and developers to build, train, and deploy machine learning models at scale. It provides a complete end-to-end ML workflow — from data preparation and model training to deployment and monitoring — while offering the flexibility to use preferred tools, frameworks, and infrastructure.
- SageMaker AI removes the heavy lifting from each step of the machine learning process, making it easier to develop production-quality models.
- It is designed for high availability with no maintenance windows or scheduled downtimes, with service stack replication across three facilities in each AWS region.
- SageMaker AI supports the full ML lifecycle: data labeling, data preparation, feature engineering, training, tuning, deployment, monitoring, and MLOps automation.
- It integrates with popular ML frameworks including PyTorch, TensorFlow, Hugging Face, scikit-learn, and XGBoost.
- SageMaker AI is part of the next-generation Amazon SageMaker platform, which unifies data, analytics, and AI in a single governed environment.
Next-Generation Amazon SageMaker Platform (Dec 2024)
At AWS re:Invent 2024, AWS unveiled the next generation of Amazon SageMaker — a unified platform for data, analytics, and AI. This represents a major evolution beyond the original ML-focused service.
Platform Components
- Amazon SageMaker Unified Studio (GA March 2025): A single IDE for data engineering, SQL analytics, ML model development, and generative AI application development. Brings together tools previously spread across EMR, Glue, Redshift, Athena, SageMaker AI, and Bedrock.
- Amazon SageMaker Lakehouse: An open data architecture built on Apache Iceberg that unifies data across S3 data lakes (including S3 Tables), Redshift data warehouses, and federated sources.
- Amazon SageMaker Catalog: Governance layer enabling secure discovery, access control, metadata management, lineage tracking, and collaboration for data and AI assets.
- Amazon SageMaker AI: The ML service (formerly “Amazon SageMaker”) for building, training, and deploying ML models. Includes HyperPod, JumpStart, MLOps, and all inference/training capabilities.
📖 Deep Dive Guides: Bedrock vs SageMaker | RAG Architecture | Prompt Engineering | Responsible AI | AI Services Decision Guide
Deprecated and Discontinued Features
⚠️ Deprecated Services and Features
| Feature | Status | EOL Date | Replacement |
|---|---|---|---|
| SageMaker Edge Manager | End of Life | April 26, 2024 | SageMaker Neo + IoT Greengrass |
| SageMaker Studio Classic | End of Maintenance | December 31, 2024 | SageMaker Studio (new experience) |
| Amazon Elastic Inference | Discontinued | April 15, 2023 | AWS Inferentia2 (Inf2 instances) |
| SageMaker Training Compiler | No new releases | N/A | Neuron SDK / framework-native optimizations |
| Data Wrangler (standalone) | Merged into Canvas | N/A | SageMaker Canvas with Data Wrangler |
| JupyterLab 1 & 3 (Notebook Instances) | End of Support | June 30, 2025 | JupyterLab 4 |
SageMaker Studio
SageMaker Studio is the fully integrated development environment (IDE) for machine learning on AWS, providing a web-based visual interface for the entire ML workflow.
- Provides a unified interface for all ML development tasks — notebooks, code editors, terminals, experiment tracking, and model deployment.
- Supports JupyterLab notebooks with flexible compute (switch instance types without restarting).
- Integrates with Amazon Q Developer for AI-assisted code generation and optimization suggestions.
- Built-in MLflow integration for experiment tracking, model registry, and generative AI observability (serverless MLflow, no infrastructure management).
- Supports collaborative development — team members share notebooks, experiments, and models within a domain.
- Integrates MLOps capabilities for CI/CD pipelines and automated workflows.
- Enables cross-account collaboration while maintaining governance via IAM and SageMaker Role Manager.
SageMaker Unified Studio (Next-Gen Platform)
SageMaker Unified Studio is the development environment for the next-generation SageMaker platform (GA March 2025):
- Single environment for data engineering, SQL analytics, ML development, and generative AI application building.
- Serverless notebooks combining SQL queries, Python code, Apache Spark processing, and natural language prompts.
- Backed by Amazon Athena for Apache Spark, scaling from interactive exploration to petabyte-scale jobs.
- Integrated with Amazon Bedrock IDE for generative AI application development with guardrails.
- Project-based collaboration with fine-grained access control via SageMaker Catalog.
SageMaker Canvas
SageMaker Canvas is a no-code/low-code ML service that enables business analysts, citizen data scientists, and non-technical users to build, train, and deploy ML models without writing code.
- Visual Point-and-Click Interface: Import data, build models, and generate predictions through an intuitive UI.
- Natural Language Interface: Use natural language to describe data preparation tasks — Canvas translates instructions into transformations automatically.
- Data Wrangler Integration: Canvas now includes full SageMaker Data Wrangler capabilities with 300+ built-in transforms and access to 50+ data sources (S3, Redshift, Snowflake, SaaS applications).
- Ready-Made Models: Pre-trained models available for common tasks without needing to build a custom model:
- Sentiment analysis and text classification
- Object detection and image classification
- Document analysis (entity extraction, key-value pairs)
- Foundation models for text generation (via Bedrock and JumpStart integration)
- Custom Model Building: Supports tabular prediction (numeric/categorical), time series forecasting, computer vision, and NLP use cases.
- LLM Fine-Tuning: No-code fine-tuning of foundation models from SageMaker JumpStart and Amazon Bedrock with your own data.
- Collaboration: Share models and insights with data scientists in SageMaker Studio; models can be deployed to production endpoints.
- Petabyte-Scale Processing: Data transformation at petabyte scale leveraging distributed compute under the hood.
Model Training
SageMaker AI provides flexible, scalable options for training ML models — from using optimized built-in algorithms to bringing your own custom code and containers.
Built-in Algorithms
SageMaker AI provides numerous built-in algorithms optimized for distributed training at scale:
Tabular Data:
- XGBoost — Gradient-boosted trees for classification and regression (versions 1.0–3.0)
- Linear Learner — Linear models for classification and regression
- CatBoost — Gradient boosting with native categorical feature support
- LightGBM — Fast gradient boosting framework
- AutoGluon-Tabular — AutoML for tabular data
- TabTransformer — Transformer-based tabular model
- K-Nearest Neighbors (k-NN) — Instance-based classification/regression
- Factorization Machines — For high-dimensional sparse data
Time Series:
- DeepAR Forecasting — Autoregressive RNN for time series
Natural Language Processing:
- BlazingText — Word2Vec and text classification
- Sequence-to-Sequence — Translation, summarization
- Object2Vec — Embeddings for paired data
Computer Vision:
- Image Classification (MXNet) — ResNet-based image classification
- Object Detection — Identify objects in images
- Semantic Segmentation — Pixel-level labeling
Unsupervised Learning:
- K-Means — Clustering
- Principal Component Analysis (PCA) — Dimensionality reduction
- Random Cut Forest — Anomaly detection
- IP Insights — Learn usage patterns for IP addresses
- Latent Dirichlet Allocation (LDA) — Topic modeling
- Neural Topic Model (NTM) — Topic modeling with neural networks
For a detailed list with input/output formats, see SageMaker Built-in Algorithms Summary.
Bring Your Own (BYO) Training
- Script Mode: Use pre-built framework containers (PyTorch, TensorFlow, Hugging Face, scikit-learn, MXNet) and supply your training script.
- BYO Container: Package your own Docker container with any framework or library and register it with Amazon ECR.
- BYO Algorithm: Create custom algorithms that integrate with SageMaker’s managed training infrastructure.
Training Data Input Modes
- File mode: Downloads all data from S3 to the training instance before starting. Best for datasets that fit on disk.
- Fast File mode: Combines the ease of File mode with streaming performance — data is fetched on demand from S3 with POSIX-compatible access.
- Pipe mode: Streams data directly from S3 in real time, reducing storage requirements and startup time.
- Storage options: Amazon S3, Amazon EFS, Amazon FSx for Lustre (recommended for large-scale distributed training).
Distributed Training
SageMaker AI provides built-in distributed training libraries for scaling across multiple GPUs and instances:
- Data Parallelism: Splits the dataset across multiple GPUs/instances; each processes a subset and synchronizes gradients. Supports AllReduce and parameter server strategies.
- Model Parallelism: Splits large models across multiple GPUs when a model doesn’t fit in a single GPU’s memory. Supports tensor parallelism and pipeline parallelism.
- Sharded Data Parallelism: Combines data parallelism with model state sharding (similar to DeepSpeed ZeRO/PyTorch FSDP) to train large models efficiently.
- Native support for PyTorch DDP, PyTorch FSDP, Horovod, and framework-native distribution strategies.
Managed Spot Training
- Uses Amazon EC2 Spot Instances to reduce training costs by up to 90% compared to On-Demand instances.
- SageMaker handles Spot interruptions automatically — checkpoints are saved to S3 and training resumes from the last checkpoint.
- Specify
MaxWaitTimeInSecondsto control the maximum time to wait for Spot capacity. - Best suited for fault-tolerant training jobs (not recommended for time-critical training).
Warm Pools
- Keep training instances in a warm (pre-provisioned) state between consecutive training jobs to eliminate cold start delays.
- Reduces startup time from minutes to seconds for iterative training workflows (hyperparameter tuning, experiment iterations).
- Specify
KeepAlivePeriodInSecondsto control how long instances remain warm after a job completes. - Billed at a reduced rate during the warm period (idle but reserved).
SageMaker HyperPod
SageMaker HyperPod is purpose-built managed infrastructure for training and deploying foundation models at scale. It reduces training time by up to 40% through fault-tolerant infrastructure and automated cluster management.
Core Capabilities
- Resilient Training Clusters: HyperPod continuously monitors cluster health and automatically detects and recovers from hardware failures without manual intervention. Training resumes from the last saved state.
- Orchestration Options:
- Slurm: Traditional HPC job scheduler for multi-node training with familiar sbatch/srun workflows.
- Amazon EKS: Kubernetes-native orchestration with the HyperPod Training Operator, enabling cloud-native tooling, auto-scaling via Karpenter, and container-based workflows.
- Automatic Health Checks: Deep health diagnostics (GPU, network, storage) run continuously. Faulty nodes are automatically replaced without stopping the training job.
- Task Governance: Job queuing, prioritization, scheduling, and fair-share resource allocation via Kueue integration (EKS) or Slurm policies.
Checkpointless Training (Dec 2025)
A paradigm shift that eliminates the need for traditional checkpoint-restart cycles:
- Enables peer-to-peer state recovery — when a node fails, the training state is reconstructed from peer nodes rather than loading from storage.
- Achieves 80–93% reduction in recovery time (from 15–30+ minutes to under 2 minutes).
- Enables up to 95% training goodput on clusters with thousands of AI accelerators.
- Built on NVIDIA NeMo Framework; available through pre-built HyperPod recipes.
- Supports both pre-training and fine-tuning (including PEFT/LoRA) for NeMo-supported models.
Elastic Training (Dec 2025)
Automatically scales training jobs based on compute resource availability and workload priority:
- Training jobs start with the minimum required compute and dynamically scale up or down by adjusting the number of data-parallel replicas.
- During high utilization, lower-priority elastic jobs scale down gracefully (not forcibly evicted) to yield resources to higher-priority workloads.
- When capacity becomes available during off-peak periods, elastic jobs automatically scale back up to accelerate training.
- Uses PyTorch Distributed Checkpoint (DCP) for seamless checkpointing and resumption across different node configurations (world sizes).
- Supports PyTorch DDP and FSDP frameworks.
- Integrates with Task Governance (Kueue) for priority-based scheduling and gang scheduling.
HyperPod Training Recipes
Pre-built, optimized recipes that simplify training and fine-tuning of popular foundation models:
- Support models including DeepSeek-R1, Llama 3, Mistral, and others.
- Pre-configured for optimal distributed training settings (parallelism strategy, batch size, learning rate).
- Available for both Slurm and EKS orchestration.
- Include recipes for checkpointless training and PEFT/LoRA fine-tuning.
- Reduce time-to-train by eliminating manual configuration of distributed training parameters.
Infrastructure Features
- Flexible Instance Groups (2026): Specify multiple instance types and subnets within a single instance group, simplifying auto-scaling with Karpenter.
- Flexible Training Plans: Reserve accelerated compute capacity (P4d, P5, P5e, P5en, Trn1, Trn2) up to 8 weeks in advance with start times as soon as 30 minutes. Now also supports inference endpoints.
- Custom AMIs: Use custom Amazon Machine Images for specialized software stacks.
- CMK Integration: Customer-managed encryption keys for data security.
- Auto-Scaling: Cluster-level auto-scaling with Karpenter on EKS orchestration.
Inference and Model Deployment
SageMaker AI provides multiple deployment options for serving ML models in production, each optimized for different latency, throughput, cost, and payload requirements.
Inference Options Comparison
| Inference Type | Best For | Payload Size | Processing Time | Key Features |
|---|---|---|---|---|
| Real-time | Low-latency, high-throughput | Up to 6 MB | Up to 60 seconds | Persistent HTTPS endpoint, auto-scaling, A/B testing |
| Serverless | Intermittent/unpredictable traffic | Up to 4 MB | Up to 60 seconds | No instance management, pay-per-use, scales to zero |
| Batch Transform | Offline processing of large datasets | GB-scale | Hours/Days | No persistent endpoint, cost-effective for bulk inference |
| Asynchronous | Large payloads, long processing | Up to 1 GB | Up to 1 hour | Request queuing (SQS), scale to zero, SNS notifications |
| Bidirectional Streaming (2025) | Real-time multi-modal (voice, live transcription) | Streaming | Continuous | Persistent WebSocket, simultaneous send/receive |
Inference Components
Inference Components provide an abstraction layer for deploying multiple models on shared infrastructure with fine-grained resource control:
- Assign dedicated compute resources (CPU, memory, GPU, accelerators) per model component.
- Define individual scaling policies per model — each component scales independently based on its own traffic patterns.
- Enable intelligent model packing — SageMaker optimizes placement of multiple models on shared instances for cost efficiency.
- Rolling Updates (2025): Deploy model updates in configurable batches with CloudWatch alarm-based automatic rollbacks, eliminating the need for duplicate infrastructure during deployments.
- Container Caching (2026): Stores container images and model artifacts on already-running instances to reduce cold start latency when scaling up.
Multi-Model Endpoints
- Host thousands of models behind a single endpoint, sharing compute resources.
- Models are loaded/unloaded dynamically from S3 based on invocation patterns.
- Support both CPU and GPU-backed models.
- Cost-effective for scenarios with many models that have sparse or intermittent traffic.
Shadow Testing
- Validate new models by sending copies of production traffic to a shadow variant without exposing responses to end users.
- Compare latency, error rates, and response quality between production and shadow models.
- Supports up to one shadow variant per endpoint.
- Enables safe testing of model updates, instance type changes, or container modifications before promotion.
Additional Deployment Features
- Production Variants: A/B testing with configurable traffic splitting between model versions.
- Inference Pipelines: Chain multiple containers (preprocessing → model → postprocessing) in a single endpoint.
- Auto-scaling: Target tracking, step scaling, and scheduled scaling policies for endpoints.
- Inference Recommender: Automatically benchmarks model performance across instance types to recommend the optimal cost/performance configuration.
- SageMaker Neo: Compile and optimize models for specific hardware targets (CPUs, GPUs, Inferentia, Graviton) for faster inference.
MLOps
SageMaker AI provides a comprehensive set of MLOps tools for automating, governing, and monitoring the ML lifecycle at scale.
SageMaker Pipelines
- Purpose-built, serverless workflow orchestration for ML and LLMOps automation.
- Define end-to-end ML workflows as directed acyclic graphs (DAGs) using the Python SDK or a visual drag-and-drop UI.
- Built-in step types: Processing, Training, Tuning, Transform, Model Registration, Condition, Callback, Lambda, and Quality Check.
- Supports parameterized pipelines, conditional execution, and caching of previously computed steps.
- Multi-account support for separating dev/staging/production environments.
- Integration with CI/CD tools (CodePipeline, Jenkins, GitLab CI) for automated retraining.
Model Registry
- Central catalog for versioning, managing, and approving trained models before deployment.
- Tracks model versions with metadata: training metrics, hyperparameters, data lineage, and approval status.
- Supports model approval workflows (Pending → Approved → Rejected) for governed deployments.
- Cross-account model sharing for enterprise ML governance.
- Integrated with Model Cards and ML Lineage for complete audit trails.
- Now supports generative AI assets — register datasets, custom evaluators, and fine-tuned models with automatic lineage capture.
Model Monitor
- Continuously monitors deployed models for data quality, model quality, bias drift, and feature attribution drift.
- Four monitoring types:
- Data Quality: Detects schema violations, missing values, and statistical drift in input features.
- Model Quality: Monitors accuracy, precision, recall, and other performance metrics against ground truth.
- Bias Drift: Detects changes in fairness metrics over time (integrated with Clarify).
- Feature Attribution Drift: Monitors changes in feature importance and SHAP values.
- Configurable alerts via CloudWatch alarms when violations exceed thresholds.
- Schedule monitoring jobs hourly, daily, or on custom schedules.
- Supports foundation model monitoring including prompt drift and output quality.
Model Cards
- Standardized documentation for ML models — capture intended use, risk ratings, training details, evaluation results, and ethical considerations.
- Integrated with Model Registry — automatically attach Model Cards to registered model versions.
- Export Model Cards as PDF for compliance, audit, and regulatory reporting.
- Include evaluation metrics, bias reports (from Clarify), and custom business context.
Feature Store
- Centralized repository for storing, sharing, and managing ML features across teams.
- Dual-store architecture:
- Online Store: Low-latency (single-digit ms) feature retrieval for real-time inference. Stores only the latest feature values.
- Offline Store: Historical feature data in S3 (Parquet format) for training and batch inference. Supports time-travel queries.
- Features organized into Feature Groups with schema definitions and metadata.
- Supports feature ingestion via streaming (Kinesis, Kafka) or batch (Processing jobs).
- Enables feature reuse — create once, use across multiple models and teams.
ML Lineage Tracking
- Automatically tracks relationships between datasets, algorithms, training jobs, models, and endpoints.
- Creates an end-to-end graph showing how a deployed model was produced — from raw data through all transformations.
- Supports reproducibility and audit requirements by recording all inputs, parameters, and outputs.
- Query lineage via APIs to answer questions like “What data was used to train this model?” or “Which endpoints use this model version?”
- Now supports generative AI lineage — automatically captures relationships when fine-tuning, evaluating, and deploying foundation models.
SageMaker AI with MLflow
SageMaker AI provides fully managed, serverless MLflow for tracking experiments, managing models, and observing AI application behavior — without infrastructure management.
- Serverless MLflow (Dec 2025): Auto-scaling MLflow tracking servers with no server patching, capacity planning, or storage management. Spins up in minutes.
- MLflow 3.0 Support (Jul 2025): End-to-end observability for generative AI development — experiment tracking, model registry, and tracing for GenAI applications in a single tool.
- Experiment Tracking: Log parameters, metrics, and artifacts from training runs. Compare experiments with built-in visualization.
- Model Registry (MLflow): Version and stage models (Staging/Production/Archived) using MLflow’s native model registry alongside SageMaker Model Registry.
- GenAI Observability: Trace LLM calls, agent interactions, and RAG pipelines. Analyze latency, token usage, and quality metrics across generations.
- Cross-Account Sharing: Share MLflow tracking servers across AWS accounts with fine-grained access management.
- Integration with SageMaker AI: Seamless integration with Pipelines, Model Customization (automatic logging during fine-tuning), and training jobs.
- Migration Support: Tools to migrate self-managed MLflow servers (EC2, on-premises) to SageMaker managed MLflow with minimal disruption.
SageMaker Lakehouse
SageMaker Lakehouse provides a unified, open, and secure data lakehouse architecture that enables analytics and AI on a single copy of data — eliminating data silos and redundant ETL.
- Apache Iceberg Foundation: Built entirely on the open Apache Iceberg table format, ensuring interoperability with any Iceberg-compatible engine.
- Unified Data Access: Query data in place across:
- Amazon S3 data lakes (including S3 Tables with built-in Iceberg support)
- Amazon Redshift Managed Storage (RMS) — access Redshift tables via Iceberg APIs
- Federated and third-party data sources
- Zero-ETL Integration: Stream data from operational databases (DynamoDB, Aurora, RDS) directly into Lakehouse without building ETL pipelines.
- AWS Glue Iceberg REST Catalog: Serves as the unified catalog, compatible with Spark, Trino, Presto, Databricks, and other engines.
- Automated Optimization (2026): Catalog-level configuration that automatically compacts, sorts, and optimizes Iceberg tables for query performance.
- Single Copy of Data: Eliminate data duplication — ML training jobs, BI dashboards, and AI applications all access the same governed data.
- Fine-Grained Access Control: Row-level and column-level security via AWS Lake Formation integration.
- S3 Tables Integration (GA March 2025): Access tables stored in Amazon S3 Tables through the Iceberg REST catalog.
SageMaker JumpStart
SageMaker JumpStart provides a model hub with hundreds of pre-trained foundation models and solution templates for accelerated ML development.
- Foundation Model Hub: Access hundreds of pre-trained, open-source models including:
- LLMs: Llama 3/3.1/4, DeepSeek-R1, Mistral/Mixtral, Falcon, Qwen
- Embedding models: BGE, GTE, various sentence transformers
- Image generation: Stable Diffusion XL, SDXL Turbo
- Vision models: CLIP, DINOv2, various ViT models
- One-Click Deployment: Deploy models to real-time endpoints with pre-configured instance types and container settings.
- Fine-Tuning: Fine-tune foundation models on your data using parameter-efficient methods:
- Full fine-tuning, LoRA (Low-Rank Adaptation), QLoRA (quantized LoRA)
- Instruction tuning for task-specific customization
- Domain adaptation for specialized vocabularies
- Bedrock Integration: Models deployed via JumpStart can be registered with Amazon Bedrock via Custom Model Import, enabling access through Bedrock APIs with guardrails.
- Model Evaluation: Evaluate and compare foundation models using SageMaker Clarify’s FM evaluation capabilities.
- Solution Templates: Pre-built ML solutions for common use cases (fraud detection, demand forecasting, recommendation engines).
SageMaker Ground Truth
SageMaker Ground Truth provides data labeling capabilities using a combination of human labelers and machine learning for automated annotation.
Ground Truth (Self-Service)
- Create custom labeling workflows for text, image, video, audio, point cloud (3D), and multi-modal data.
- Automated Data Labeling: Uses active learning to train a labeling model as human labels accumulate — progressively automates labeling, reducing costs by up to 70%.
- Workforce Options:
- Amazon Mechanical Turk (public crowd)
- Private workforce (your in-house annotators)
- Third-party vendor workforce
- Built-in task types: bounding boxes, semantic segmentation, named entity recognition, text classification, image classification, and more.
- Custom task UI via Liquid templates for specialized labeling requirements.
- Annotation consolidation with configurable consensus algorithms.
Ground Truth Plus (Managed Service)
- Turnkey labeling service — AWS manages the entire labeling pipeline including workforce, quality control, and project management.
- Expert AWS-managed annotation team handles complex labeling tasks without you building labeling applications.
- Generates demonstration data for model customization (RLHF) — captions, summaries, answers, comparative rankings.
- Reduces labeling costs by up to 40% compared to self-managed labeling.
- Per-label pricing (bounding box, cuboid, key-value pair, etc.).
- Supports human-in-the-loop workflows for foundation model customization: preference labeling, reward model training data.
SageMaker Clarify
SageMaker Clarify detects bias in data and models, provides model explainability, and evaluates foundation models.
- Bias Detection:
- Pre-training bias metrics: Detect bias in training data before model building (e.g., Class Imbalance, Difference in Proportions of Labels).
- Post-training bias metrics: Detect bias in model predictions (e.g., Disparate Impact, Demographic Parity Difference).
- Supports multiple sensitive attributes (race, gender, age, etc.) simultaneously.
- Explainability:
- SHAP (SHapley Additive exPlanations): Feature importance values showing how each feature contributes to individual predictions.
- Partial Dependence Plots: Show marginal effect of features on predictions.
- Supports both tabular and NLP models.
- Foundation Model Evaluation:
- Evaluate FMs for accuracy, robustness, and toxicity using built-in and custom evaluation criteria.
- Compare multiple FMs from JumpStart to select the best fit for your use case.
- Supports both automatic evaluation (benchmark metrics) and human evaluation workflows.
- Integrated with Model Cards for automatic documentation of fairness and explainability insights.
- Integrated with Model Monitor for continuous bias drift detection in production.
- Generates compliance-ready reports for regulatory requirements (EU AI Act, Fair Lending).
SageMaker AI vs Amazon Bedrock
Understanding when to use SageMaker AI vs Amazon Bedrock (based on the official AWS Decision Guide, updated June 2025):
| Criteria | Amazon SageMaker AI | Amazon Bedrock |
|---|---|---|
| Best For | Custom model development, extensive fine-tuning, full infrastructure control, training from scratch | Serverless FM inference via API, rapid prototyping, application integration without ML expertise |
| Target Users | Data scientists, ML engineers, developers with ML expertise | Developers and businesses without deep ML expertise |
| Customization | Full control: custom architectures, any framework, full fine-tuning, PEFT (LoRA/QLoRA), DPO, RLVR, RLAIF, distillation, pre-training from scratch | API-based fine-tuning, continued pre-training, model distillation, custom model import |
| Model Selection | Open-source models via JumpStart (Llama, DeepSeek, Mistral, Falcon, Qwen) — wider selection including specialized models | Proprietary + open models (Claude, Amazon Nova/Titan, Llama, Mistral, Cohere, AI21) — includes exclusive proprietary models |
| Infrastructure | Customer-managed instances (GPU, Trainium, Inferentia) — full control over compute, scaling, placement | Fully managed/serverless — no instance provisioning or management |
| Pricing | Pay for compute resources (instances, storage, data transfer) — variable based on usage | Pay-per-API-call (per token) — simpler, predictable pricing |
| Deployment | Serverful (real-time endpoints, batch) + serverless options; granular control over scaling | Serverless by default; no endpoint management |
| Integration | JumpStart models can be imported into Bedrock via Custom Model Import | Bedrock IDE available in SageMaker Unified Studio; both accessible from same platform |
| Use Together | Prototype with Bedrock APIs → Fine-tune with SageMaker AI → Deploy via Bedrock (Custom Model Import) or SageMaker endpoints. Most mature enterprises use both. | |
When to Choose SageMaker AI:
- You need to train models from scratch or perform extensive custom fine-tuning
- High token volume with predictable workloads (dedicated instances are more cost-effective)
- Compliance requires complete VPC data isolation and infrastructure control
- AI/ML is your core product requiring full customization of model architecture
- You need specialized hardware (Trainium, specific GPU types) for training
When to Choose Bedrock:
- You primarily need inference from pre-trained foundation models via API
- You want serverless, no-infrastructure generative AI integration
- You need access to proprietary models (Claude, Amazon Nova)
- Your team lacks deep ML expertise but wants to leverage AI capabilities
- You need built-in guardrails, RAG (Knowledge Bases), and agent orchestration
AWS ML Accelerators
AWS offers custom silicon optimized for machine learning workloads, providing significant cost-performance advantages over general-purpose GPUs:
- AWS Trainium2 (GA December 2024):
- 4x faster, 4x more memory bandwidth, 3x more memory capacity than Trn1.
- 30–40% better price-performance than GPU-based P5e/P5en instances.
- Supports training models with hundreds of billions to trillion+ parameters.
- Available via EC2 Trn2 and Trn2 UltraServer instances.
- AWS Trainium3 (Announced re:Invent 2025):
- Built on TSMC 3nm process; delivers 2.52 PFLOPS per chip.
- Supports NVLink Fusion for hybrid GPU/Trainium clusters.
- AWS Inferentia2:
- 3x higher compute, 4x larger memory, up to 10x lower latency vs. first-gen Inferentia.
- Optimized for LLMs, diffusion models, and vision transformers.
- Available via EC2 Inf2 instances.
- AWS Trainium (first gen): EC2 Trn1 instances; up to 50% cost savings over comparable GPUs.
SageMaker AI Pricing
SageMaker AI follows a pay-as-you-go pricing model with no upfront commitments:
- Notebooks: Billed per instance-hour based on the instance type (ml.t3.medium through ml.p5.48xlarge).
- Training: Per-second billing for training instance usage; choice of On-Demand, Spot (up to 90% savings), or Reserved (Flexible Training Plans).
- Inference: Per-second billing for endpoint instances (real-time), per-request (serverless), or per-job (batch).
- Serverless Model Customization: Pay-per-token pricing for both training and inference — no infrastructure management.
- Storage: EBS volumes for notebooks, S3 for training data and model artifacts, Feature Store storage fees.
- Data Labeling: Per-label pricing for Ground Truth (varies by annotation type).
Cost Optimization Features:
- Managed Spot Training — Up to 90% savings on training jobs
- Inference Components — Intelligent model packing for multi-model cost efficiency
- Multi-Model Endpoints — Share infrastructure across hundreds of models
- Serverless Inference — Scale to zero, pay only for invocations
- Auto-Scaling — Match compute to demand automatically
- SageMaker Savings Plans — Up to 64% savings for committed usage (1 or 3 year)
- Flexible Training Plans — Reserved compute capacity at predictable pricing
- Trainium/Inferentia Instances — 50–70% cost savings vs. comparable GPUs
- Warm Pools — Reduce idle time billing between iterative training jobs
Certification Exam Relevance
SageMaker AI is heavily tested across multiple AWS certification exams:
| Certification | SageMaker AI Coverage |
|---|---|
| AWS Certified Machine Learning Engineer – Associate (MLA-C01) | Core exam focus. Covers SageMaker Pipelines, training, deployment, MLOps, Feature Store, Model Monitor, distributed training, hyperparameter tuning. ~60-70% of questions involve SageMaker AI. |
| AWS Certified Solutions Architect – Associate (SAA-C03) | High-level understanding of SageMaker AI as a managed ML service. Know inference options, when to use SageMaker vs Bedrock, integration with S3/VPC/IAM. |
| AWS Certified AI Practitioner (AIF-C01) | Foundational understanding of SageMaker AI capabilities. Know SageMaker Canvas (no-code), JumpStart, basic training/deployment concepts, and how it compares to Bedrock. |
| AWS Certified Machine Learning – Specialty (MLS-C01) | Deep coverage of SageMaker algorithms, training optimization, deployment strategies, security, and ML lifecycle. Being replaced by MLA-C01. |
AWS Certification Exam Practice Questions
- Questions are collected from various sources and answers reflect our understanding, which may differ from yours.
- AWS services are updated frequently, so some information may become outdated.
- We welcome feedback and corrections to improve accuracy.
- A company wants to train a large language model with hundreds of billions of parameters but is concerned about hardware failures interrupting multi-week training jobs. They need the fastest possible recovery time when failures occur. Which SageMaker AI capability should they use?
- SageMaker Managed Spot Training with checkpoints
- SageMaker HyperPod with checkpointless training
- SageMaker Distributed Training with data parallelism
- SageMaker Warm Pools
Show Answer
Answer: B – SageMaker HyperPod with checkpointless training enables peer-to-peer state recovery with 80–93% reduction in recovery time (under 2 minutes vs. 15–30+ minutes for traditional checkpoint-based recovery), achieving up to 95% training goodput on large clusters.
- A data science team needs to fine-tune a foundation model but wants to avoid managing infrastructure. They want automatic compute provisioning and pay-per-token pricing. Which SageMaker AI feature should they use?
- SageMaker HyperPod with Training Recipes
- SageMaker JumpStart fine-tuning
- SageMaker Serverless Model Customization
- SageMaker Canvas LLM fine-tuning
Answer: C — SageMaker Serverless Model Customization automatically provisions compute resources based on model and data size, supports advanced techniques (SFT, DPO, RLVR, RLAIF), and uses pay-per-token pricing without any infrastructure management.
- An organization is deploying multiple foundation models and wants to optimize costs by efficiently sharing GPU resources while maintaining independent scaling policies for each model. Which approach should they use?
- Deploy each model on a separate real-time endpoint with auto-scaling
- Use SageMaker Multi-Model Endpoints
- Use SageMaker Inference Components with per-model scaling policies
- Use SageMaker Serverless Inference
Answer: C — Inference Components enable assigning dedicated resources per model while optimizing utilization through intelligent model packing on shared infrastructure. Each component scales independently based on its own traffic patterns, unlike multi-model endpoints which share all resources.
- A company wants their ML training jobs to automatically expand when cluster resources are idle and shrink when higher-priority workloads need capacity, without manual intervention. Which SageMaker HyperPod feature enables this?
- Flexible Training Plans
- Checkpointless training
- Elastic training
- Managed Spot Training
Answer: C — Elastic training on SageMaker HyperPod automatically scales training jobs by adjusting the number of data-parallel replicas based on resource availability. Jobs scale down for higher-priority workloads and scale back up when resources free up, using automatic checkpointing and resumption across different world sizes.
- A solutions architect needs to provide a unified data architecture where data scientists can access data from S3 data lakes and Redshift data warehouses using a single query interface, without copying data between systems. Which service provides this? (Select TWO)
- Amazon SageMaker Lakehouse
- Amazon SageMaker Feature Store
- AWS Glue Iceberg REST Catalog
- Amazon SageMaker Data Wrangler
- Amazon SageMaker Pipelines
Answer: A, C — SageMaker Lakehouse provides the unified open lakehouse architecture built on Apache Iceberg, and the AWS Glue Iceberg REST Catalog serves as the unified metadata catalog that enables querying data across S3 data lakes (including S3 Tables) and Redshift Managed Storage without data movement.
Frequently Asked Questions
What is Amazon SageMaker AI?
Amazon SageMaker AI (rebranded in 2024) is a fully managed platform for building, training, and deploying machine learning models at scale. It provides Studio IDE, no-code Canvas, HyperPod training clusters, managed MLflow, inference endpoints, and MLOps capabilities.
What is SageMaker HyperPod?
HyperPod provides managed training clusters with resilient infrastructure. Key features include checkpointless training (80-93% faster failure recovery without checkpoints), elastic training (auto-scale compute mid-job), and training recipes for popular model architectures.
When should I use SageMaker vs Bedrock?
Use SageMaker when you need custom model training, full control over algorithms, or specialized ML workflows. Use Bedrock when you want to build gen AI applications using pre-trained foundation models with features like RAG, agents, and guardrails without ML expertise.
References
Amazon SageMaker AI Documentation
AWS Decision Guide: Bedrock or SageMaker AI?
2 thoughts on “Amazon SageMaker AI – End-to-End ML Platform”
Comments are closed.