Table of Contents
hide
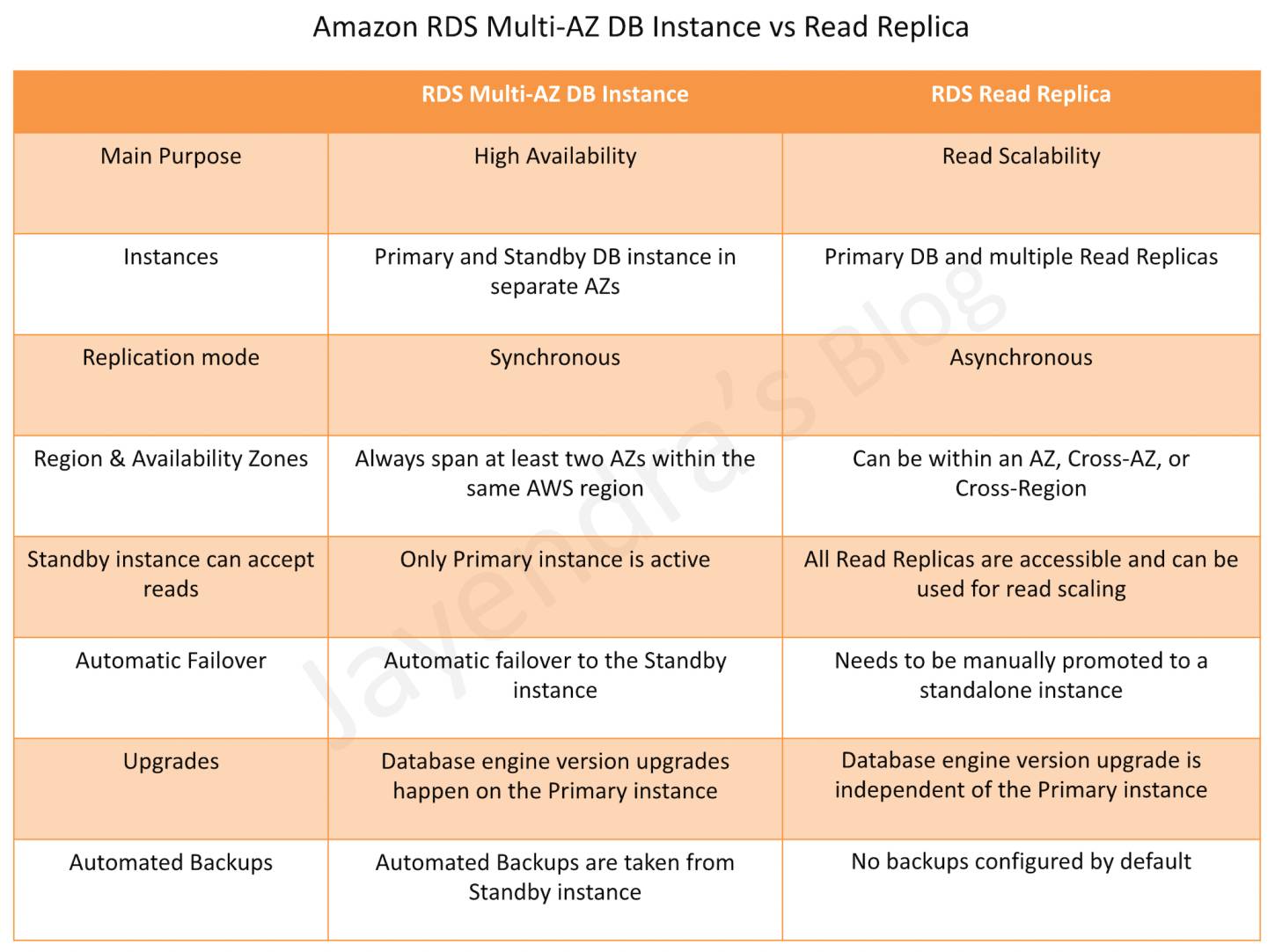
RDS Multi-AZ vs Read Replica
RDS DB instances replicas can be created in two ways Multi-AZ & Read Replica, which provide high availability, durability, and scalability to RDS.
📌 Update (2025): AWS now offers two Multi-AZ deployment options:
- Multi-AZ DB Instance – One primary + one standby (non-readable). Failover typically 60–120 seconds.
- Multi-AZ DB Cluster – One writer + two readable standbys across 3 AZs. Failover typically under 35 seconds. Supported for MySQL and PostgreSQL only.
For a detailed comparison, see RDS Multi-AZ DB Instance vs DB Cluster Deployment.
Purpose
- Multi-AZ DB Instance deployments provide high availability, durability, and automatic failover support.
- Multi-AZ DB Cluster deployments provide high availability with readable standbys, faster failover (under 35 seconds), improved write latency, and increased read capacity.
- Read replicas enable increased scalability and database availability in the case of an AZ failure. Read Replicas allow elastic scaling beyond the capacity constraints of a single DB instance for read-heavy database workloads.
Region & Availability Zones
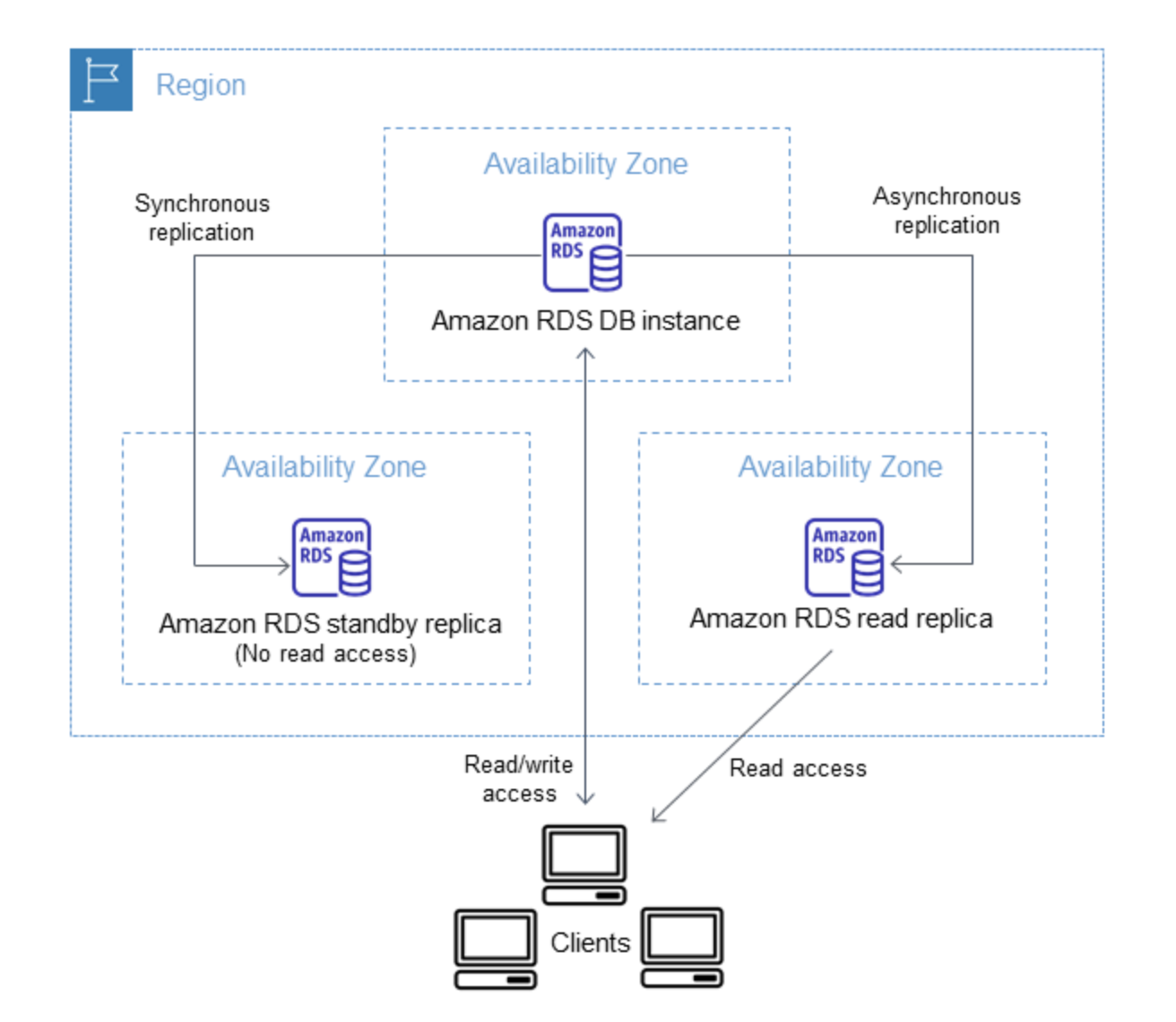
- RDS Multi-AZ DB Instance deployment automatically provisions and manages a standby instance in a different AZ (independent infrastructure in a physically separate location) within the same AWS region.
- RDS Multi-AZ DB Cluster deployment provisions a writer DB instance and two readable standby DB instances across three different AZs within the same region.
- RDS Read Replicas can be provisioned within the same AZ, Cross-AZ or even as a Cross-Region replica.
Replication Mode
- RDS Multi-AZ DB Instance deployment manages a synchronous standby instance in a different AZ.
- RDS Multi-AZ DB Cluster deployment uses semi-synchronous replication (transaction acknowledged when at least one standby confirms write) for high durability with improved write latency.
- RDS Read Replicas have data replicated asynchronously from the Primary instance to the read replicas.
Standby Instance can Accept Reads
- Multi-AZ DB Instance deployment is a high-availability solution and the standby instance does not support read requests.
- Multi-AZ DB Cluster deployment provides two readable standby instances that can serve read traffic, increasing application read throughput.
- Read Replica deployment provides readable instances to increase application read-throughput.
Automatic Failover & Failover Time
- Multi-AZ DB Instance deployment performs an automatic failover to the standby instance without administrative intervention, and the failover time is typically 60–120 seconds based on crash recovery.
- Planned database maintenance
- Software patching
- Rebooting the Primary instance with failover
- Primary DB instance connectivity or host failure, or an
- Availability Zone failure
- Multi-AZ DB Cluster deployment provides automated failover typically under 35 seconds with zero data loss. When combined with RDS Proxy, failover downtime can be reduced to under 1 second.
- RDS maintains the same endpoint for the DB Instance after a failover, so the application can resume database operation without the need for manual administrative intervention.
- Read Replica deployment does not provide automatic failover. Read Replica instance needs to be manually promoted to a Standalone instance.
Upgrades
- For a Multi-AZ DB Instance deployment, database engine version upgrades happen on the Primary instance with downtime of 60–120 seconds for failover.
- For a Multi-AZ DB Cluster deployment, minor version upgrades can be completed with 35 seconds or less of downtime (under 1 second with RDS Proxy).
- RDS Blue/Green Deployments provide a safer upgrade mechanism by creating a staging (green) environment, testing changes, and then switching over with typically under 5 seconds of downtime (as of Jan 2026).
- For Read Replicas, the database engine version upgrade is independent of the Primary instance.
Automated Backups
- Multi-AZ DB Instance deployment has the Automated Backups taken from the Standby instance (reducing I/O impact on Primary).
- Multi-AZ DB Cluster deployment takes automated backups from one of the reader instances.
- Read Replicas do not have any backups configured by default, but automated backups can be enabled on read replicas.
Cascading (Chained) Read Replicas
- RDS supports creating a Read Replica of another Read Replica (cascading), which helps scale reads without adding overhead to the source DB instance.
- MySQL: Supports cascading read replicas with up to 3 levels of chaining.
- PostgreSQL: Supports cascading read replicas from version 14.1 onwards, with up to 3 levels of chaining and 5 replicas per instance (up to 155 total read replicas per source).
- Cross-Region cascading read replicas are also supported for PostgreSQL.
Delayed Read Replicas (New – 2025)
- RDS for PostgreSQL now supports delayed read replicas (Aug 2025), allowing you to specify a minimum time period (0 to 24 hours) that a replica lags behind the source.
- Creates a time buffer that helps protect against accidental data loss from human errors such as table drops or unintended data modifications.
- When data corruption occurs on primary, the delayed replica can be promoted before the problematic operation is applied, providing recovery within minutes.
- Configured using the
recovery_min_apply_delayparameter. - Available with RDS for PostgreSQL versions 14.19, 15.14, 16.10, 17.6 and later.
- RDS for MySQL also supports delayed replication using the
mysql.rds_set_source_delaystored procedure.
RDS Proxy for Improved Failover
- Amazon RDS Proxy is a fully managed, highly available database proxy that can significantly reduce failover times.
- RDS Proxy eliminates DNS propagation delay by continuously monitoring both primary and standby instances, allowing faster failover response.
- When used with Multi-AZ DB Cluster deployments, RDS Proxy can reduce minor version upgrade downtime to under 1 second.
- RDS Proxy also helps manage connection pooling and reduces database connection overhead for applications using many connections (e.g., Lambda functions).
SQL Server Multi-AZ Replication Technologies
- RDS for SQL Server supports Multi-AZ using Always On Availability Groups (AGs) for Enterprise and Standard editions.
- SQL Server Database Mirroring (DBM) was the legacy approach but is deprecated; AWS recommends migrating to Always On AGs.
- New (Nov 2025): RDS for SQL Server Web Edition now supports Multi-AZ using block-level replication, eliminating the need for more expensive Enterprise/Standard editions for high availability.
- SQL Server Read Replicas now support cross-region deployment in 16+ additional AWS Regions (Jan 2026) and additional storage volumes up to 256 TiB (May 2026).
Comparison Summary Table
| Feature | Multi-AZ DB Instance | Multi-AZ DB Cluster | Read Replica |
|---|---|---|---|
| Purpose | High Availability | HA + Read Scaling + Low Write Latency | Read Scalability |
| Replication | Synchronous | Semi-synchronous | Asynchronous |
| Standby Readable | No | Yes (2 readable standbys) | Yes |
| Failover Time | 60–120 seconds | Under 35 seconds | Manual promotion required |
| Failover (with RDS Proxy) | Improved | Under 1 second | N/A |
| Supported Engines | All RDS engines | MySQL, PostgreSQL only | All RDS engines |
| Number of Standbys | 1 | 2 | Up to 5 (15 with cascading) |
| Cross-Region | No | No | Yes |
| Automated Backups | From standby | From reader instance | Optional |
| Data Loss on Failover | Zero | Zero | Potential (async lag) |
Related Posts
- RDS Multi-AZ DB Instance
- RDS Multi-AZ DB Cluster
- RDS Multi-AZ DB Instance vs DB Cluster Deployment
- RDS Read Replicas
- RDS Cross-Region Read Replicas
- Amazon RDS Proxy
- Amazon RDS Blue/Green Deployments
📖 Related: AWS RDS Backup, Snapshots & Restore – Complete Guide
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- You are running a successful multi-tier web application on AWS and your marketing department has asked you to add a reporting tier to the application. The reporting tier will aggregate and publish status reports every 30 minutes from user-generated information that is being stored in your web applications database. You are currently running a Multi-AZ RDS MySQL instance for the database tier. You also have implemented ElastiCache as a database caching layer between the application tier and database tier. Please select the answer that will allow you to successfully implement the reporting tier with as little impact as possible to your database.
- Continually send transaction logs from your master database to an S3 bucket and generate the reports of the S3 bucket using S3 byte range requests.
- Generate the reports by querying the synchronously replicated standby RDS MySQL instance maintained through Multi-AZ (Standby instance cannot be used as a scaling solution)
- Launch an RDS Read Replica connected to your Multi-AZ master database and generate reports by querying the Read Replica.
- Generate the reports by querying the ElastiCache database caching tier. (ElasticCache does not maintain full data and is simply a caching solution)
- A company is deploying a new two-tier web application in AWS. The company has limited staff and requires high availability, and the application requires complex queries and table joins. Which configuration provides the solution for the company’s requirements?
- MySQL Installed on two Amazon EC2 Instances in a single Availability Zone (does not provide High Availability out of the box)
- Amazon RDS for MySQL with Multi-AZ
- Amazon ElastiCache (Just a caching solution)
- Amazon DynamoDB (Not suitable for complex queries and joins)
- Your company is getting ready to do a major public announcement of a social media site on AWS. The website is running on EC2 instances deployed across multiple Availability Zones with a Multi-AZ RDS MySQL Extra Large DB Instance. The site performs a high number of small reads and writes per second and relies on an eventual consistency model. After comprehensive tests you discover that there is read contention on RDS MySQL. Which are the best approaches to meet these requirements? (Choose 2 answers)
- Deploy ElastiCache in-memory cache running in each availability zone
- Implement sharding to distribute load to multiple RDS MySQL instances (this is only a read contention, the writes work fine)
- Increase the RDS MySQL Instance size and Implement provisioned IOPS (not scalable, this is only a read contention, the writes work fine)
- Add an RDS MySQL read replica in each availability zone
- Your company has HQ in Tokyo and branch offices all over the world and is using logistics software with a multi-regional deployment on AWS in Japan, Europe and US. The logistic software has a 3-tier architecture and currently uses MySQL 5.6 for data persistence. Each region has deployed its own database. In the HQ region you run an hourly batch process reading data from every region to compute cross-regional reports that are sent by email to all offices this batch process must be completed as fast as possible to quickly optimize logistics. How do you build the database architecture in order to meet the requirements?
- For each regional deployment, use RDS MySQL with a master in the region and a read replica in the HQ region
- For each regional deployment, use MySQL on EC2 with a master in the region and send hourly EBS snapshots to the HQ region
- For each regional deployment, use RDS MySQL with a master in the region and send hourly RDS snapshots to the HQ region
- For each regional deployment, use MySQL on EC2 with a master in the region and use S3 to copy data files hourly to the HQ region
- Use Direct Connect to connect all regional MySQL deployments to the HQ region and reduce network latency for the batch process
- What would happen to an RDS (Relational Database Service) Multi-Availability Zone deployment if the primary DB instance fails?
- IP of the primary DB Instance is switched to the standby DB Instance.
- A new DB instance is created in the standby availability zone.
- The canonical name record (CNAME) is changed from primary to standby.
- The RDS (Relational Database Service) DB instance reboots.
- Your business is building a new application that will store its entire customer database on a RDS MySQL database, and will have various applications and users that will query that data for different purposes. Large analytics jobs on the database are likely to cause other applications to not be able to get the query results they need to, before time out. Also, as your data grows, these analytics jobs will start to take more time, increasing the negative effect on the other applications. How do you solve the contention issues between these different workloads on the same data?
- Enable Multi-AZ mode on the RDS instance
- Use ElastiCache to offload the analytics job data
- Create RDS Read-Replicas for the analytics work
- Run the RDS instance on the largest size possible
- Will my standby RDS instance be in the same Availability Zone as my primary?
- Only for Oracle RDS types
- Yes
- Only if configured at launch
- No
- Is creating a Read Replica of another Read Replica supported?
- Only in certain regions
Only with MySQL based RDSYes, for MySQL and PostgreSQL (14.1+). Both support cascading read replicas with up to 3 levels of chaining.- Only for Oracle RDS types
- No
- A user is planning to set up the Multi-AZ feature of RDS. Which of the below mentioned conditions won’t take advantage of the Multi-AZ feature?
- Availability zone outage
- A manual failover of the DB instance using Reboot with failover option
- Region outage
- When the user changes the DB instance’s server type
- When you run a DB Instance as a Multi-AZ deployment, the “_____” serves database writes and reads
- secondary
- backup
- stand by
- primary
- When running my DB Instance as a Multi-AZ deployment, can I use the standby for read or write operations?
- Yes
- Only with MSSQL based RDS
- Only for Oracle RDS instances
- No (for Multi-AZ DB Instance deployment. Note: Multi-AZ DB Cluster deployment provides readable standbys)
- Read Replicas require a transactional storage engine and are only supported for the _________ storage engine
- OracleISAM
- MSSQLDB
- InnoDB
- MyISAM
- A user is configuring the Multi-AZ feature of an RDS DB. The user came to know that this RDS DB does not use the AWS technology, but uses server mirroring to achieve replication. Which DB is the user using right now?
- MySQL
- Oracle
- MS SQL (Note: AWS now recommends Always On Availability Groups over Database Mirroring. SQL Server Web Edition uses block-level replication for Multi-AZ as of Nov 2025.)
- PostgreSQL
- If I have multiple Read Replicas for my master DB Instance and I promote one of them, what happens to the rest of the Read Replicas?
- The remaining Read Replicas will still replicate from the older master DB Instance
- The remaining Read Replicas will be deleted
- The remaining Read Replicas will be combined to one read replica
- If you have chosen Multi-AZ deployment, in the event of a planned or unplanned outage of your primary DB Instance, Amazon RDS automatically switches to the standby replica. The automatic failover mechanism simply changes the ______ record of the main DB Instance to point to the standby DB Instance.
- DNAME
- CNAME
- TXT
- MX
- When automatic failover occurs, Amazon RDS will emit a DB Instance event to inform you that automatic failover occurred. You can use the _____ to return information about events related to your DB Instance
- FetchFailure
- DescriveFailure
- DescribeEvents
- FetchEvents
- The new DB Instance that is created when you promote a Read Replica retains the backup window period.
- TRUE
- FALSE
- Will I be alerted when automatic failover occurs?
- Only if SNS configured
- No
- Yes
- Only if Cloudwatch configured
- Can I initiate a “forced failover” for my MySQL Multi-AZ DB Instance deployment?
- Only in certain regions
- Only in VPC
- Yes
- No
- A user is accessing RDS from an application. The user has enabled the Multi-AZ feature with the MS SQL RDS DB. During a planned outage how will AWS ensure that a switch from DB to a standby replica will not affect access to the application?
- RDS will have an internal IP which will redirect all requests to the new DB
- RDS uses DNS to switch over to standby replica for seamless transition
- The switch over changes Hardware so RDS does not need to worry about access
- RDS will have both the DBs running independently and the user has to manually switch over
- Which of the following is part of the failover process for a Multi-AZ Amazon Relational Database Service (RDS) instance?
- The failed RDS DB instance reboots.
- The IP of the primary DB instance is switched to the standby DB instance.
- The DNS record for the RDS endpoint is changed from primary to standby.
- A new DB instance is created in the standby availability zone.
- Which of these is not a reason a Multi-AZ RDS instance will failover?
- An Availability Zone outage
- A manual failover of the DB instance was initiated using Reboot with failover
- To autoscale to a higher instance class (Refer link)
- Master database corruption occurs
- The primary DB instance fails
- You need to scale an RDS deployment. You are operating at 10% writes and 90% reads, based on your logging. How best can you scale this in a simple way?
- Create a second master RDS instance and peer the RDS groups.
- Cache all the database responses on the read side with CloudFront.
- Create read replicas for RDS since the load is mostly reads.
- Create a Multi-AZ RDS installs and route read traffic to standby.
- How does Amazon RDS multi Availability Zone model work?
- A second, standby database is deployed and maintained in a different availability zone from master, using synchronous replication. (Refer link)
- A second, standby database is deployed and maintained in a different availability zone from master using asynchronous replication.
- A second, standby database is deployed and maintained in a different region from master using asynchronous replication.
- A second, standby database is deployed and maintained in a different region from master using synchronous replication.
- A customer is running an application in US-West (Northern California) region and wants to setup disaster recovery failover to the Asian Pacific (Singapore) region. The customer is interested in achieving a low Recovery Point Objective (RPO) for an Amazon RDS multi-AZ MySQL database instance. Which approach is best suited to this need?
- Synchronous replication
- Asynchronous replication
- Route53 health checks
- Copying of RDS incremental snapshots
- A user is using a small MySQL RDS DB. The user is experiencing high latency due to the Multi AZ feature. Which of the below mentioned options may not help the user in this situation?
- Schedule the automated back up in non-working hours
- Use a large or higher size instance
- Use PIOPS
- Take a snapshot from standby Replica
- Are Reserved Instances available for Multi-AZ Deployments?
- Only for Cluster Compute instances
- Yes for all instance types
- Only for M3 instance types
- My Read Replica appears “stuck” after a Multi-AZ failover and is unable to obtain or apply updates from the source DB Instance. What do I do?
- You will need to delete the Read Replica and create a new one to replace it.
- You will need to disassociate the DB Engine and re-associate it.
- The instance should be deployed to Single AZ and then moved to Multi-AZ once again
- You will need to delete the DB Instance and create a new one to replace it.
- What is the charge for the data transfer incurred in replicating data between your primary and standby?
- No charge. It is free.
- Double the standard data transfer charge
- Same as the standard data transfer charge
- Half of the standard data transfer charge
- A user has enabled the Multi-AZ feature with the MS SQL RDS database server. Which of the below mentioned statements will help the user understand the Multi-AZ feature better?
- In a Multi-AZ, AWS runs two DBs in parallel and copies the data asynchronously to the replica copy
- In a Multi-AZ, AWS runs two DBs in parallel and copies the data synchronously to the replica copy
- In a Multi-AZ, AWS runs just one DB but copies the data synchronously to the standby replica
- AWS MS SQL does not support the Multi-AZ feature
- A company is running a batch analysis every hour on their main transactional DB running on an RDS MySQL instance to populate their central Data Warehouse running on Redshift. During the execution of the batch their transactional applications are very slow. When the batch completes they need to update the top management dashboard with the new data. The dashboard is produced by another system running on-premises that is currently started when a manually sent email notifies that an update is required The on-premises system cannot be modified because is managed by another team. How would you optimize this scenario to solve performance issues and automate the process as much as possible?
- Replace RDS with Redshift for the batch analysis and SNS to notify the on-premises system to update the dashboard
- Replace RDS with Redshift for the batch analysis and SQS to send a message to the on-premises system to update the dashboard
- Create an RDS Read Replica for the batch analysis and SNS to notify the on-premises system to update the dashboard
- Create an RDS Read Replica for the batch analysis and SQS to send a message to the on-premises system to update the dashboard.
New Practice Questions (Multi-AZ DB Cluster & Recent Features)
- A company needs a highly available MySQL database with the fastest possible automatic failover time and the ability to offload read queries to standby instances. Which RDS deployment option should they choose?
- Multi-AZ DB Instance deployment with Read Replicas
- Single-AZ with automated backups
- Multi-AZ DB Cluster deployment
- Aurora Global Database
- What is the typical failover time for an RDS Multi-AZ DB Cluster deployment?
- 60–120 seconds
- 5–10 minutes
- Under 35 seconds
- Under 5 seconds
- Which replication method does the RDS Multi-AZ DB Cluster deployment use?
- Asynchronous replication
- Synchronous replication
- Semi-synchronous replication
- Logical replication
- A database administrator wants to protect against accidental table drops by maintaining a replica that lags behind the primary by 1 hour. Which RDS feature should they use?
- Multi-AZ DB Instance standby
- Cross-Region Read Replica
- Delayed Read Replica
- Blue/Green Deployment
- Which of the following DB engines support Multi-AZ DB Cluster deployments? (Choose 2)
- Oracle
- MySQL
- SQL Server
- PostgreSQL
- MariaDB
- How can you reduce RDS Multi-AZ DB Cluster minor version upgrade downtime to under 1 second?
- Use Blue/Green Deployments
- Use Amazon RDS Proxy
- Use cross-region read replicas
- Use ElastiCache for connection pooling
Question (2)
i am not sure about the answer cause Multi-AZ only without specifying that it will be a read replica will not help, i thought (c. Amazon ElastiCache) would be better answer , what do you think ?
Key point in the questions is
1. limited staff and requires high availability,
2. application requires complex queries and table joins
#A is ruled out cause of 1, as it would need manual failover
#C is rules out cause its not a DB but a caching solution
#D is rules out cause of 2
#B is the correct option as Multi AZ provides complex queries and table joins with ability to failover without manual intervention
Thanks for clarification
Excellent article with real-life scenarios and explainations right to the point. It sums up more than a whole semester in our colleges these days (Germany). Thank you for this high-quality information, I will use it in the next few weeks when I’ll be building a data-warehouse & a report-section for one of my bigger clients. It was a pleasure to read – thank you very much!
Tet this moment MySQL only supports RR of RR. (Not MSSQL)
Thanks Srinivasu for the correction, update the Answer option.
Question(6)
Can you please clarify why not ElastiCache ?
Thanks
Elastic cache is for mere caching of the query results for improving performance by not hitting the database.
Whereas the Analytics job would require actual data to perform the analysis on but mostly in read only mode
Postgres now supporting cross region read replicas, as of June 2016. But … when will exams reflect this?
Thanks for update, will update the answer. However, the exam is slow to reflect any updates.
FROM : https://aws.amazon.com/rds/faqs/
Q: Will I be alerted when automatic failover occurs?
Yes, Amazon RDS will emit a DB Instance event to inform you that automatic failover occurred. You can use the DescribeEvents to return information about events related to your DB Instance, or click the “DB Events” section of the AWS Management Console.
Automatic failover alerts are possible, however need to setup SNS, SMS or email for notification
For question (3), I believe that answers are A and C. How does read replica helps for Read and Writes? Thx.
The question targets Read Contention and write is not an issue and hence the Read Replicas.
Hey..
I have a postgres in an ec2 on AWS . Now we are planing to move on RDS . & we do not want any downtime . We were planning on postgres replication between the post gres on ec2 & RDS postgres . Is this possible ? If yes can you give me pointers. ?
I would prefer to create a database backup and import it directly to the RDS database. Is the database a production database ? Whats the size ? as the operation can be performed with minimal downtime given both the resources are within AWS.
Yes its a prod database . The size is around 500gb . for that i will have to take incremental backups..which i don’t want to.
AWS migration tools is there vut the source version must be 9.4 or above we r on 9.3
Maybe just taking a dump and exporting to RDS would be the best option with some downtime.
You can also refer to some more options @ https://www.theguardian.com/info/developer-blog/2016/feb/04/migrating-postgres-to-rds-without-downtime
Can someone explain me Q 25
RPO diff between asynchronous replication or DB snapshot ?
We can also minimizes RPO by frequent snapshots as replication also has some lag depend upon various factor like network available etc.
As per my undetstanding,
With asynchronous replication, the RPO is very very low, it should, in fact RDS should start the asynchronous process almost instantaneously when master transaction is complete.
Where as with frequent snapshots as you mentioned, you can only reduce the RPO, but in practise asynchronous replication would win over frequent snapshots.
#29 is marked with two (2) answers and I am thinking it should just be A as Amazon doesn’t charge for replication bandwidth…was there a typo or did i miss something?
Thanks,
Prince
Thanks Prince, yup its by error. Its A as it the data transfer between primary and standby is free.
Jayendra – A stupendous effort on your part to maintain this blog. Hats off to you.
#25. For multi-AZ scenario, the replication mode would be Synchronous and asynchronous is typically associated with Read Replicas. The answer should be a and not b.
Am i missing something here?
Regards
Anand
Multi-AZ does not work across Region, so you have to setup up Read Replica across Region, which in this would need asynchronous replication.
Hello Jayendra,
Q says: ‘The customer is interested in achieving a low Recovery Point Objective (RPO) for an Amazon RDS multi-AZ MySQL database instance.’ Not cross-region. So, shouldn’t the answer be synchronous here?
If we are to consider 1rst statement which talks about cross-region and ignore multi-az, then wouldn’t read replica (being asynchronous in nature) fall behind because we have different regions. So, in this case ‘snapshots’ might make more sense.
The wording is a little confusing. Can you please explain your approach to this q?
Thanks,
Manisha
Read Replica can be created across region for MySQL, even though it can fall behind but it would still have the lowest RPO. Also, Read Replica can be easily converted to Master/Primary database and be ready to use.
Snapshots are taken only daily, during the backup window which would need to be copied over. Also, they are supplemented by transaction logs for point in time recovery, which would not work across region.
Hello Jayendra,
Can you please explain for Q 4, why is A the right answer.
Here is my thought process. I’m trying to eliminate options.
B and D gets eliminated because you always to use managed services db over creating your own DB on EBS.
A – Read Replica are asynchronous by nature. So over time, replicas can lag from the original db and thus you cannot guarantee the accuracy of the reports.
So A gets eliminated.
C – If you send snapshots, there is time spent in extracting data from snapshots (which may be minimal). So if I have to compare C and E, I would choose between C and E.
I think I’m overthinking the problem. Anyway, hope to hear back from you.
Regards,
Manisha
The key point here is to reduce the time. Hence A as you can create a Cross Region Read replica in the Tokyo HQ for DB in each region and use them to compute reports as the Read Replica will always almost have the latest data.
Option B, C & D are wrong as it would take time for data, snapshots to be transferred and restored to perform the batch analysis
Option E is wrong as there Direct Connect would be expensive and take time to setup.
Thanks. Well I think setup time cost should not be the point here, what is asking here is “this batch process must be completed as fast as possible to quickly optimize logistics.”, so it is not about the initial setup, it is about how to implement the right solution to deliver the “as fast as possible” service AFTER the setup
I am open to discussion but the answer is absolutely E in my understanding.
Direct Connect is usually to connect your data center to AWS, usually within the same region. In this case, the setup is already available in AWS but across multiple regions, so there is no need for Direct Connect. Also, it does not mention if the instances in other regions are read replicas or active-active.
Which of these is not a reason a Multi-AZ RDS instance will failover?
based on this link
vertical scaling will also be a reason for a failover
https://aws.amazon.com/blogs/database/scaling-your-amazon-rds-instance-vertically-and-horizontally/
Thanks Amit, that right. Vertical scaling does result in automatic failover although the scaling is first performed on the standby and once successful the failover happens. Have corrected the question.
Hello jayendrapatil,
If we are migrating a 4 X DB server to RDS (1 master, 3 salves, each with 100GB storage and there will be 1 TB analytics data), what will be the best architechture to migrate to RDS? Does the below make sense to you?
1 Multi-AZ DB instance with 100 GB storage. (db.m5.2xlarge)
1 Single-AZ DB read replica in the same AZ as the master DB (upgrade the storage to 1TB, db.m5.2xlarge)
2 Single-AZ DB rea replica with 100GB (in different regions)
Thank you.
Nick HE
with 1TB of data, you will need all instances 1TB and more ?
great resource, keep up the good work, you ae to be commended, the subject matter is huge, so any coverage and to this depth too, is an great help
please update your content as read replica is available for SQL SERVER and AMAZON AURORA as well.
thanks Neeraj, updated.
Hi sir, pls answer this..
A company wants to increase the availability and durability of a critical business application. The application currently uses a MySQL database running on anAmazon EC2 instance. The company wants to minimize application changes. How should the company meet these requirements?
* A. Shut down the EC2 instance. Enable multi-AZ replication within the EC2 instance, then restart the instance.
* B. Launch a secondary EC2 instance running MySQL. Configure a cron job that backs up the database on the primary EC2 instance and copies it to the secondary instance every 30 minutes.
* C. Migrate the database to an Amazon RDS Aurora DB instance and create a Read Replica in another Availability Zone.
* D. Create an Amazon RDS Microsoft SQL DB instance and enable multi-AZ replication. Back up the existing data and import it into the new database.
Option C would work fine with any application changes and increasing the availability and durability.