Table of Contents
hide
Amazon Data Firehose (formerly Kinesis Data Firehose)
📢 Service Renamed (February 2024): Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. The functionality remains the same. Existing applications, API endpoints, and IAM policies continue to work without changes.
- Amazon Data Firehose is a fully managed service for delivering real-time streaming data to data stores and analytics tools.
- Amazon Data Firehose automatically scales to match the throughput of the data (gigabytes per second or more) and requires no ongoing administration or need to write applications or manage resources.
- is a data transfer solution for delivering real-time streaming data to destinations such as S3, Redshift, OpenSearch Service, OpenSearch Serverless, Apache Iceberg Tables, Amazon S3 Tables, Snowflake, Splunk, and third-party HTTP endpoints.
- is NOT Real Time, but Near Real Time as it supports batching and buffers streaming data to a certain size (Buffer Size in MBs) or for a certain period of time (Buffer Interval in seconds) before delivering it to destinations.
- Zero Buffering (December 2023): Firehose now supports zero buffering, delivering data within ~5 seconds with no buffering delay for real-time use cases.
- supports data compression, minimizing the amount of storage used at the destination. It currently supports GZIP, ZIP, and SNAPPY compression formats. Only GZIP is supported if the data is further loaded to Redshift.
- supports Apache Parquet and ORC format conversion — converts incoming JSON data to columnar formats optimized for analytics with Athena, Redshift Spectrum, and EMR before storing in S3.
- supports data at rest encryption using KMS after the data is delivered to the S3 bucket.
- supports 20+ data sources including Amazon Kinesis Data Streams, Amazon MSK (and MSK Serverless), Direct PUT API, Kinesis Agent, CloudWatch Logs, CloudWatch Events, AWS IoT Core, Amazon SNS, AWS WAF web ACL logs, and Amazon VPC Flow Logs.
- supports out of box data transformation as well as custom transformation using the Lambda function to transform incoming source data and deliver the transformed data to destinations.
- supports Dynamic Partitioning — groups streaming data by static or dynamically defined keys (e.g., customer_id, region) and delivers into key-unique S3 prefixes for optimized analytics.
- supports source record backup with custom data transformation with Lambda, where Data Firehose will deliver the un-transformed incoming data to a separate S3 bucket.
- uses at least once semantics for data delivery. In rare circumstances such as request timeout upon data delivery attempt, delivery retry by Firehose could introduce duplicates if the previous request eventually goes through.
- supports Interface VPC Interface Endpoint (AWS Private Link) to keep traffic between the VPC and Data Firehose from leaving the Amazon network.
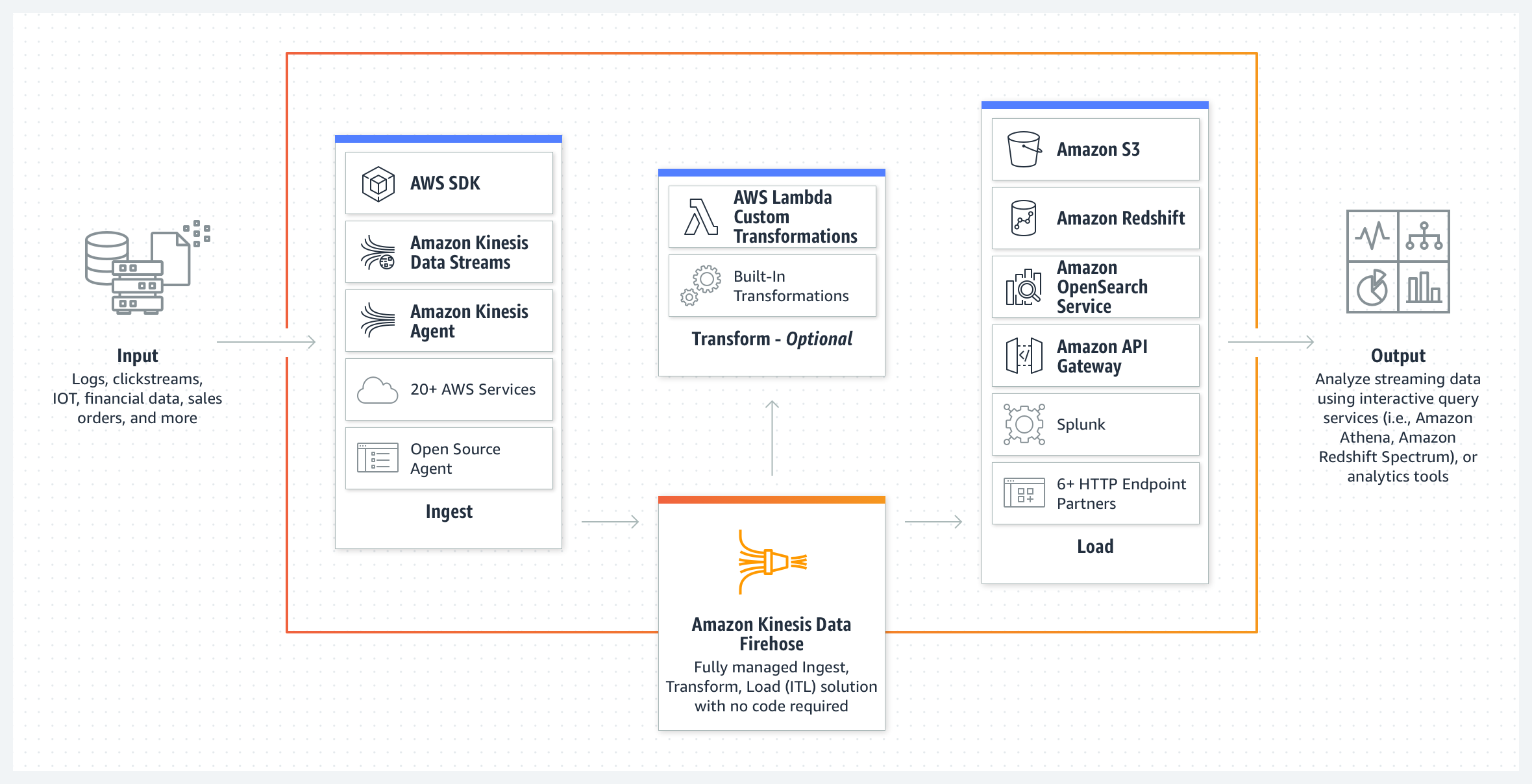
Amazon Data Firehose Key Concepts
- Data Firehose delivery stream
- Underlying entity of Data Firehose, where the data is sent
- Record
- Data sent by data producer to a Data Firehose delivery stream
- Maximum size of a record (before Base64-encoding) is 1024 KB.
- With Amazon MSK as source, maximum record size is 10 MB (6 MB if Lambda transformation is enabled).
- Data producer
- Producers send records to Data Firehose delivery streams.
- Buffer size and buffer interval
- Data Firehose buffers incoming streaming data to a certain size or for a certain time period before delivering it to destinations
- Buffer size and buffer interval can be configured while creating the delivery stream
- Buffer size is in MBs and ranges from 1MB to 128MB for the S3 destination and 1MB to 100MB for the OpenSearch Service destination.
- Buffer interval is in seconds and ranges from 0 secs (zero buffering) to 900 secs
- Zero Buffering (December 2023): Set buffer interval to 0 seconds to deliver data within ~5 seconds with no buffering delay
- Firehose raises buffer size dynamically to catch up and make sure that all data is delivered to the destination, if data delivery to the destination is falling behind data writing to the delivery stream
- Buffer size is applied before compression.
- Source
- Data Firehose supports 20+ data sources:
- Amazon Kinesis Data Streams — read directly from a KDS stream
- Amazon MSK / MSK Serverless — consume from Kafka topics
- Direct PUT — via Firehose API, SDK, or Kinesis Agent
- AWS Services — CloudWatch Logs, CloudWatch Events, AWS IoT Core, Amazon SNS, AWS WAF web ACL logs, Amazon VPC Flow Logs, and others
- Data Firehose supports 20+ data sources:
- Destination
- A destination is the data store where the data will be delivered.
- supports the following destinations:
- Amazon S3 — with optional dynamic partitioning and format conversion
- Amazon Redshift — via intermediate S3 COPY
- Amazon OpenSearch Service
- Amazon OpenSearch Serverless (added November 2022)
- Apache Iceberg Tables in S3 (GA September 2024) — stream into Iceberg format tables with ACID transactions
- Amazon S3 Tables (GA March 2025) — purpose-built managed Iceberg tables with automatic optimization
- Snowflake — real-time streaming via Snowpipe Streaming
- Splunk
- Third-party HTTP endpoints — Datadog, Dynatrace, New Relic, MongoDB, Coralogix, Elastic, and others
Zero Buffering (December 2023)
- Amazon Data Firehose now supports zero buffering for real-time data delivery
- Delivers data within ~5 seconds with no buffering delay
- Available for destinations: S3, OpenSearch Service, Redshift, and third-party HTTP endpoints
- Enables real-time use cases that previously required Kinesis Data Streams
- Trade-off: More frequent deliveries may result in more small files and higher costs
Dynamic Partitioning
- Dynamically partition streaming data before delivery to S3 using static or dynamically defined keys (e.g., customer_id, transaction_id, region)
- Firehose groups data by these keys and delivers into key-unique S3 prefixes
- Enables high-performance, cost-efficient analytics with Athena, EMR, and Redshift Spectrum
- Supports inline parsing (JQ expressions) to extract keys from JSON records without Lambda
- Can be combined with data transformation (Lambda) for complex routing logic
- Available only for S3 destination
Format Conversion (Parquet and ORC)
- Firehose can convert incoming JSON data to columnar formats (Apache Parquet or Apache ORC) before storing in S3
- Columnar formats are optimized for analytics cost and performance with Athena, Redshift Spectrum, and EMR
- Uses AWS Glue Data Catalog schema for conversion
- Reduces storage costs and improves query performance compared to raw JSON
Apache Iceberg Tables Support (GA September 2024)
- Amazon Data Firehose can stream data directly into Apache Iceberg tables in S3
- Iceberg brings SQL table reliability and ACID transactions to S3 data lakes
- Supports automatic schema management, partitioning, and compaction
- Compatible with Athena, EMR, Redshift, Spark, Flink, and other analytics engines
- Simplifies data lake ingestion without custom ETL code
- Content-based routing: Route records from a single stream to different Iceberg tables based on record content
- Row-level operations: Apply update or delete operations for data correction and right-to-forget scenarios
- Use cases: Real-time data lake ingestion, streaming analytics, CDC to data lake
Amazon S3 Tables Support (GA March 2025)
- Amazon Data Firehose can deliver streaming data directly into Amazon S3 Tables — a purpose-built, managed Apache Iceberg table store
- S3 Tables provide storage optimized for analytics workloads with built-in Apache Iceberg support
- Delivers up to 3x faster query performance and 10x higher transactions per second compared to self-managed Iceberg tables in general purpose S3 buckets
- Automatic continuous table optimization (compaction, snapshot management) without additional infrastructure
- Supports content-based routing to different S3 Tables and row-level update/delete operations
- Integrated with AWS Glue Data Catalog multi-catalog hierarchy (May 2025) — no resource links needed between default catalog and S3TablesCatalog
- Compatible with Athena, EMR, Redshift, SageMaker Lakehouse, and other analytics engines
- Use cases: Real-time data lake analytics, IoT data ingestion, streaming to data lakehouse
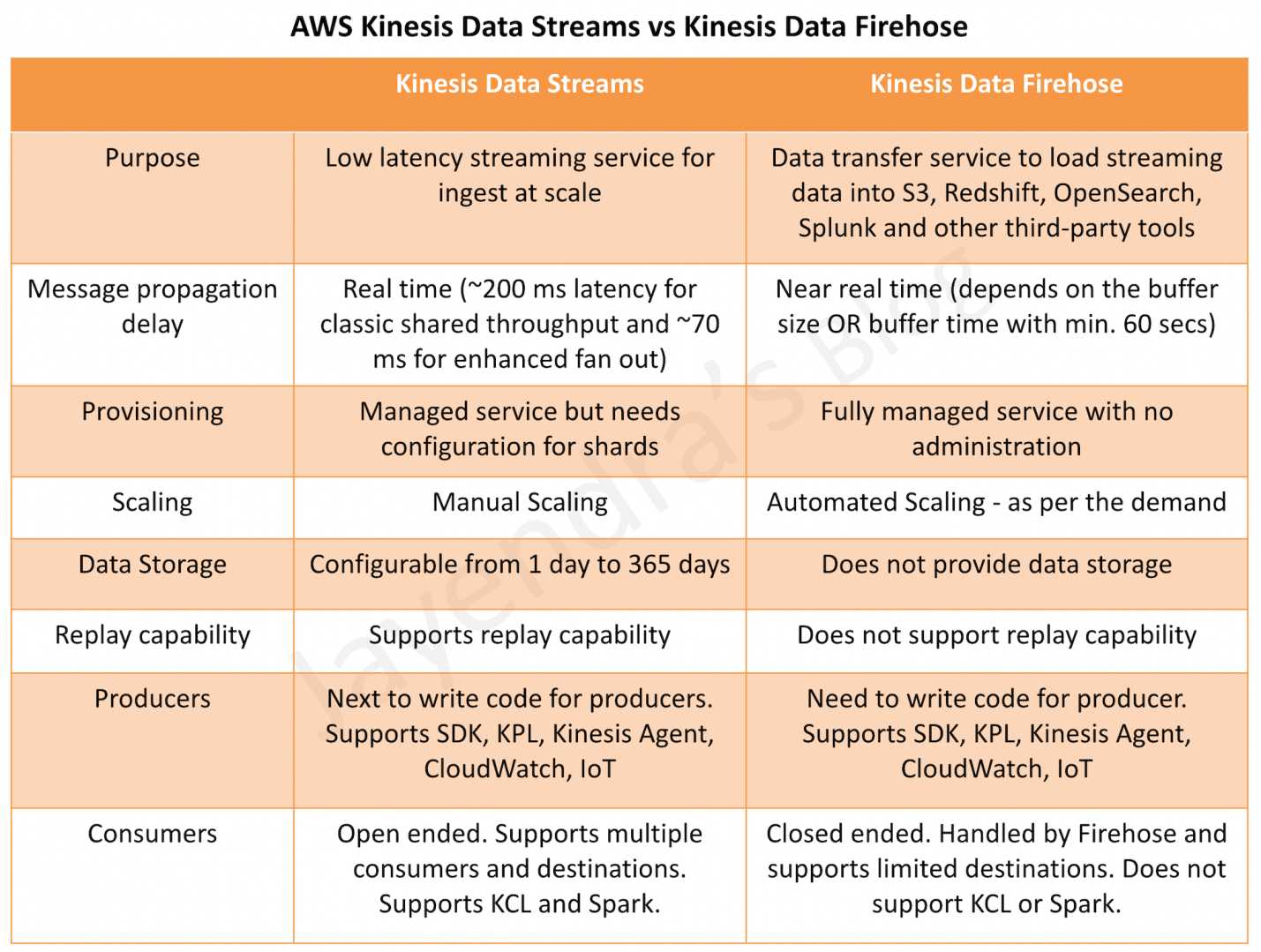
Amazon Data Firehose vs Kinesis Data Streams
AWS Certification Exam Practice Questions
- A user is designing a new service that receives location updates from 3600 rental cars every hour. The cars location needs to be uploaded to an Amazon S3 bucket. Each location must also be checked for distance from the original rental location. Which services will process the updates and automatically scale?
- Amazon EC2 and Amazon EBS
- Amazon Data Firehose and Amazon S3
- Amazon ECS and Amazon RDS
- Amazon S3 events and AWS Lambda
- You need to perform ad-hoc SQL queries on massive amounts of well-structured data. Additional data comes in constantly at a high velocity, and you don’t want to have to manage the infrastructure processing it if possible. Which solution should you use?
- Data Firehose and RDS
- EMR running Apache Spark
- Data Firehose and Redshift
- EMR using Hive
- Your organization needs to ingest a big data stream into their data lake on Amazon S3. The data may stream in at a rate of hundreds of megabytes per second. What AWS service will accomplish the goal with the least amount of management?
- Amazon Data Firehose
- Amazon Kinesis Data Streams
- Amazon CloudFront
- Amazon SQS
- A startup company is building an application to track the high scores for a popular video game. Their Solution Architect is tasked with designing a solution to allow real-time processing of scores from millions of players worldwide. Which AWS service should the Architect use to provide reliable data ingestion from the video game into the datastore?
- AWS Data Pipeline
- Amazon Data Firehose
- Amazon DynamoDB Streams
- Amazon OpenSearch Service
- A company has an infrastructure that consists of machines which keep sending log information every 5 minutes. The number of these machines can run into thousands and it is required to ensure that the data can be analyzed at a later stage. Which of the following would help in fulfilling this requirement?
- Use Data Firehose with S3 to take the logs and store them in S3 for further processing.
- Launch an Elastic Beanstalk application to take the processing job of the logs.
- Launch an EC2 instance with enough EBS volumes to consume the logs which can be used for further processing.
- Use CloudTrail to store all the logs which can be analyzed at a later stage.
- A company needs to stream data to Amazon S3 with the lowest possible latency (under 10 seconds). Which configuration should they use?
- Data Firehose with 60-second buffer
- Data Firehose with zero buffering enabled
- Kinesis Data Streams with Lambda consumer
- Direct PUT to S3
- A data analytics team needs to stream real-time data into Apache Iceberg tables in S3 for analytics with automatic table optimization and up to 3x faster queries. Which destination should they use?
- Apache Iceberg Tables in general-purpose S3 bucket
- Amazon S3 Tables
- Amazon Redshift with COPY command
- AWS Glue Streaming ETL
- A company streams millions of events per day from different applications. They need to route events to different analytics tables in S3 based on event type, with ACID transaction support. Which Data Firehose feature enables this?
- Dynamic Partitioning to S3 prefixes
- Content-based routing to Apache Iceberg Tables
- Lambda transformation with multiple outputs
- Multiple delivery streams
- A company wants to consume streaming data from an Amazon MSK cluster and load it into S3 in Parquet format without managing consumers or infrastructure. Which solution requires the LEAST effort?
- Write a custom Kafka consumer with Spark
- Use Amazon MSK Connect with S3 Sink Connector
- Amazon Data Firehose with MSK as source and Parquet format conversion
- AWS Glue Streaming ETL job
Question 4 asks for real time processing of scores but the answer is firehose. At the top you said firehose isn’t realtime.
there are 2 aspects here Kinesis can handle real time data for consumption and thats what the question focuses on. It can easily scale to handle this load. The focus of the question is data ingestion platform and the other options mentioned do not fit the requirement.
Hi,
Could you explain what’s the answer of this question ?
An organization has 10,000 devices that generate 100 GB of telemetry data per day, with each record size around 10 KB. Each record has 100 fields, and one field consists of unstructured log data with a String data type in the English language. Some fields are required for the real-time dashboard, but all fields must be available for long-term generation. The organization also has 10 PB of previously cleaned and structured data, partitioned by Date, in a SAN that must be migrated to AWS within one month.
Currently, the organization does not have any real-time capabilities in their solution. Because of storage limitations in the on-premises data warehouse, selective data is loaded while generating the long-term trend with ANSI SQL queries through JDBC for visualization. In addition to the one-time data loading, the organization needs a cost-effective and real-time solution.
How can these requirements be met? (Choose two.)
A.Use AWS IoT to send data from devices to an Amazon SQS queue, create a set of workers in an Auto Scaling group and read records in batch from the queue to process and save the data. Fan out to an Amazon SNS queue attached with an AWS Lambda function to filter the request dataset and save it to Amazon Elasticsearch Service for real-time analytics.
B. Create a Direct Connect connection between AWS and the on-premises data center and copy the data to Amazon S3 using S3 Acceleration. Use Amazon Athena to query the data.
C. Use AWS IoT to send the data from devices to Amazon Kinesis Data Streams with the IoT rules engine. Use one Kinesis Data Firehose stream attached to a Kinesis stream to batch and stream the data partitioned by date. Use another Kinesis Firehose stream attached to the same Kinesis stream to filter out
the required fields to ingest into Elasticsearch for real-time analytics.
D. Use AWS IoT to send the data from devices to Amazon Kinesis Data Streams with the IoT rules engine. Use one Kinesis Data Firehose stream attached to a Kinesis stream to stream the data into an Amazon S3
bucket partitioned by date. Attach an AWS Lambda function with the same Kinesis stream to filter out the required fields for ingestion into Amazon DynamoDB for real-time analytics.
E. Use multiple AWS Snowball Edge devices to transfer data to Amazon S3, and use Amazon Athena to query the data.
Would go with D and E. D for real time ingestion, filtering and Dynamodb for analytics. Snowball for one time transfer.
A & C would not work for real time and B would not work for one time transfer.
Hi, for question 1, shouldn’t the answer be d(s3 and lambda)? How will kinesis firehose do the calculation:Each location must also be checked for distance from the original rental location?
Kinesis Firehose can invoke Lambda functions. Refer AWS documentation @ https://docs.aws.amazon.com/firehose/latest/dev/data-transformation.html