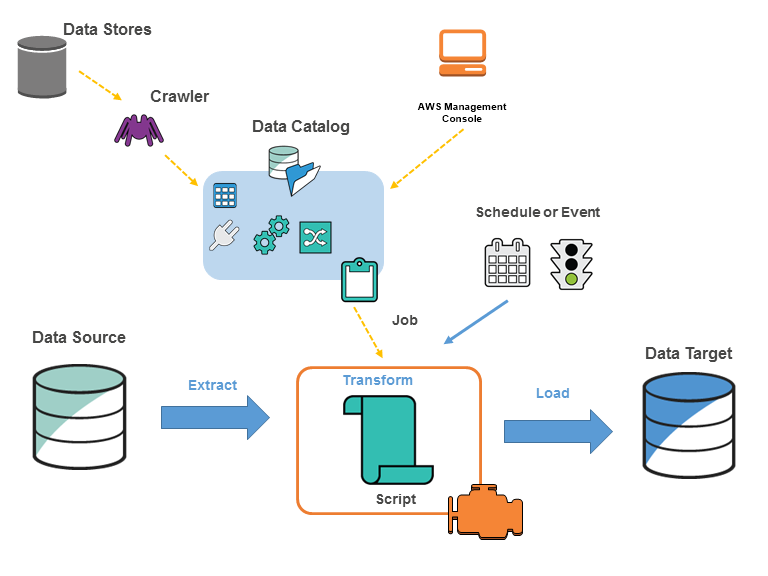
AWS Glue
- AWS Glue is a fully-managed, serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development.
- is serverless and supports pay-as-you-go model. There is no infrastructure to provision or manage.
- handles provisioning, configuration, and scaling of the resources required to run ETL jobs on a fully managed, scale-out Apache Spark environment.
- makes it simple and cost-effective to categorize the data, clean it, enrich it, and move it reliably between various data stores and streams.
- consolidates major data integration capabilities into a single service including data discovery, modern ETL, cleansing, transforming, and centralized cataloging.
- supports custom Scala or Python code and import custom libraries and Jar files into the AWS Glue ETL jobs to access data sources not natively supported by AWS Glue.
- supports server side encryption for data at rest and SSL for data in motion.
- AWS Glue natively supports data stored in
- RDS (Aurora, MySQL, Oracle, PostgreSQL, SQL Server)
- Redshift
- DynamoDB
- S3 (including S3 Tables)
- MySQL, Oracle, Microsoft SQL Server, and PostgreSQL databases in the Virtual Private Cloud (VPC) running on EC2.
- Data streams from MSK, Kinesis Data Streams, and Apache Kafka.
- Glue ETL engine to Extract, Transform, and Load data that can automatically generate Scala or Python code.
- Glue Data Catalog is a central repository and persistent metadata store to store structural and operational metadata for all the data assets.
- Glue crawlers scan various data stores to automatically infer schemas and partition structures to populate the Data Catalog with corresponding table definitions and statistics.
- AWS Glue Streaming ETL enables performing ETL operations on streaming data using continuously-running jobs.
- Glue Flexible scheduler that handles dependency resolution, job monitoring, and retries.
- Glue Studio offers a graphical interface for authoring AWS Glue jobs to process data allowing you to define the flow of the data sources, transformations, and targets in the visual interface and generating Apache Spark code on your behalf.
- Glue Data Quality helps reduce manual data quality efforts by automatically measuring and monitoring the quality of data in data lakes and pipelines.
- Glue DataBrew is a visual data preparation tool that makes it easy for data analysts and data scientists to prepare data with an interactive, point-and-click visual interface without writing code.
AWS Glue Versions
- AWS Glue versions define the underlying Spark, Python, and library versions used in ETL jobs.
- AWS Glue 5.0 (released Dec 2024) — Apache Spark 3.5.4, Python 3.11
- Spark-native fine-grained access control with AWS Lake Formation (table, column, row, and cell-level permissions on S3 data lakes)
- Support for Amazon SageMaker Lakehouse to unify data across S3 data lakes and Redshift data warehouses
- Updated Open Table Formats: Apache Iceberg, Apache Hudi, and Delta Lake
- Performance-optimized runtime for batch and stream processing
- AWS Glue 5.1 (GA Nov 2025, default version) — Apache Spark 3.5.6, Python 3.11
- Support for Apache Iceberg Materialized Views
- Apache Iceberg format version 3.0 with deletion vectors, default column values, multi-argument transforms, and row lineage tracking
- Data writes into Iceberg and Hive tables with Spark-native fine-grained access control via Lake Formation
- Updated OTF: Hudi 1.0.2, Iceberg 1.10.0, Delta Lake 3.3
- Generative AI Upgrades for Apache Spark — enables automated migration of Glue ETL jobs from older versions (≥ 2.0) to the latest Glue version using AI-generated upgrade plans and code modifications.
Version End of Support / End of Life
- Glue 0.9 (Spark 2.2) — EOS June 2022, EOL April 1, 2026
- Glue 1.0 (Spark 2.4) — EOS June/Sep 2022, EOL April 1, 2026
- Glue 2.0 (Spark 2.4, Python 3) — EOS Jan 2024, EOL April 1, 2026
- After EOL, jobs cannot be created or started on these versions. AWS strongly recommends migrating to Glue 5.1.
AWS Glue Data Catalog
- AWS Glue Data Catalog is a central repository and persistent metadata store to store structural and operational metadata for all the data assets.
- AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos, and use that metadata to query and transform the data.
- For a given data set, Data Catalog can store its table definition, physical location, add business-relevant attributes, as well as track how this data has changed over time.
- Data Catalog is Apache Hive Metastore compatible and is a drop-in replacement for the Hive Metastore for Big Data applications running on EMR.
- Data Catalog also provides out-of-box integration with Athena, EMR, and Redshift Spectrum.
- Table definitions once added to the Glue Data Catalog, are available for ETL and also readily available for querying in Athena, EMR, and Redshift Spectrum to provide a common view of the data between these services.
- Data Catalog provides comprehensive audit and governance capabilities, with schema change tracking and data access controls, which helps ensure that data is not inappropriately modified or inadvertently shared.
- Each AWS account has one AWS Glue Data Catalog per region.
Iceberg REST Catalog Endpoint
- AWS Glue Data Catalog now provides an Iceberg REST Catalog endpoint fully aligned with the Apache Iceberg REST Catalog Open API specification.
- Enables interoperability with third-party engines (Databricks, Snowflake, open-source Apache Spark) through a unified standard set of REST APIs.
- Allows querying Iceberg tables in S3 and S3 Tables using any Iceberg REST-compatible client, secured by AWS Lake Formation permissions.
Catalog Federation
- AWS Glue Data Catalog supports catalog federation for remote Iceberg catalogs (GA November 2025).
- Provides direct and secure access to Iceberg tables stored in S3 and cataloged in remote catalogs (e.g., Databricks Unity Catalog, Snowflake Horizon Catalog) without moving or duplicating tables.
- Synchronizes metadata in real-time across AWS Glue Data Catalog and remote catalogs.
- Supported by Amazon Redshift, Amazon EMR, Amazon Athena, AWS Glue, and third-party engines.
Business Context and Semantic Search (Preview – June 2026)
- AWS Glue Data Catalog now supports business context and semantic search to discover and understand data by semantic meaning.
- Enrich Data Catalog tables (including S3 Tables) with glossary terms and custom metadata fields.
- Enables data discovery through natural language semantic queries rather than exact keyword matching.
AWS Glue Crawlers
- AWS Glue crawler connects to a data store, progresses through a prioritized list of classifiers to extract the schema of the data and other statistics, and then populates the Data Catalog with this metadata.
- Glue crawlers scan various data stores to automatically infer schemas and partition structures to populate the Data Catalog with corresponding table definitions and statistics.
- Glue crawlers can be scheduled to run periodically so that the metadata is always up-to-date and in-sync with the underlying data.
- Crawlers automatically add new tables, new partitions to existing tables, and new versions of table definitions.
Dynamic Frames
- AWS Glue is designed to work with semi-structured data and introduces a dynamic frame component, which can be used in the ETL scripts.
- Dynamic frame is a distributed table that supports nested data such as structures and arrays.
- Each record is self-describing, designed for schema flexibility with semi-structured data. Each record contains both data and the schema that describes that data.
- A Dynamic Frame is similar to an Apache Spark dataframe, which is a data abstraction used to organize data into rows and columns, except that each record is self-describing so no schema is required initially.
- Dynamic frames provide schema flexibility and a set of advanced transformations specifically designed for dynamic frames.
- Conversion can be done between Dynamic frames and Spark dataframes, to take advantage of both AWS Glue and Spark transformations to do the kinds of analysis needed.
AWS Glue Streaming ETL
- AWS Glue enables performing ETL operations on streaming data using continuously-running jobs.
- AWS Glue streaming ETL is built on the Apache Spark Structured Streaming engine, and can ingest streams from Kinesis Data Streams and Apache Kafka using Amazon Managed Streaming for Apache Kafka.
- Streaming ETL can clean and transform streaming data and load it into S3 or JDBC data stores.
- Use Streaming ETL in AWS Glue to process event data like IoT streams, clickstreams, and network logs.
- Supports streaming auto-scaling — AWS Glue monitors each stage of the streaming job and automatically adds or removes workers based on the rate of incoming data.
Glue Job Bookmark
- Glue Job Bookmark tracks data that has already been processed during a previous run of an ETL job by persisting state information from the job run.
- Job bookmarks help Glue maintain state information and prevent the reprocessing of old data.
- Job bookmarks help process new data when rerunning on a scheduled interval.
- Job bookmark is composed of the states for various elements of jobs, such as sources, transformations, and targets. for e.g, an ETL job might read new partitions in an S3 file. Glue tracks which partition the job has processed successfully to prevent duplicate processing and duplicate data in the job’s target data store.
AWS Glue Auto Scaling
- AWS Glue Auto Scaling automatically adds and removes workers from the cluster depending on the parallelism at each stage or microbatch of the job run.
- Eliminates the need to plan Spark cluster capacity in advance — just set the maximum number of workers.
- Available for both batch and streaming jobs (Glue 3.0 and later).
- Auto Scaling for Interactive Sessions is now GA (Oct 2024), monitoring each stage and scaling workers for cost optimization.
AWS Glue Worker Types
- Standard — 1 DPU (4 vCPUs, 16 GB memory)
- G.1X — 1 DPU (4 vCPUs, 16 GB memory, 94 GB disk). Recommended for data transforms, joins, and queries.
- G.2X — 2 DPU (8 vCPUs, 32 GB memory, 138 GB disk). For memory-intensive jobs.
- G.4X — 4 DPU (16 vCPUs, 64 GB memory). For demanding workloads.
- G.8X — 8 DPU (32 vCPUs, 128 GB memory). For large-scale workloads.
- G.12X (New 2025) — 12 DPU (48 vCPUs, 192 GB memory, 768 GB disk). For very large resource-intensive workloads.
- G.16X (New 2025) — 16 DPU (64 vCPUs, 256 GB memory). For the most intensive data integration jobs.
- R type workers (New 2025) — Memory-Optimized DPUs (M-DPUs) providing double the memory allocation (32 GB per M-DPU). Ideal for memory-intensive Spark applications like large aggregations and ML transforms.
- G.025X — 0.25 DPU (2 vCPUs, 4 GB memory). For low-volume streaming jobs.
AWS Glue Interactive Sessions
- AWS Glue Interactive Sessions provide a programmatic and visual interface for building and testing ETL scripts.
- Provides on-demand access to a remote Spark runtime environment with a 1-minute billing minimum.
- Spark Connect support (June 2026) — enables development from preferred environments including Amazon SageMaker Unified Studio, Jupyter, Visual Studio Code, and other IDEs.
- Spark Connect simplifies upgrades and improves stability by isolating client dependencies from the server-side Spark runtime.
- Each Spark Connect session has its own AWS resource with a unique ARN for per-session IAM permissions and CloudTrail audit.
Glue Data Quality
- AWS Glue Data Quality automatically measures and monitors the quality of data in data lakes and pipelines.
- Computes statistics for datasets and recommends quality rules that check for freshness, accuracy, integrity, and hard-to-find issues.
- Uses the Data Quality Definition Language (DQDL) for authoring validation rules.
- Integrates with Amazon DataZone to display data quality scores for Glue Data Catalog assets.
- Rule labeling (GA Nov 2025) — apply custom key-value pair labels to data quality rules for improved organization, filtering, and targeted reporting.
- Pre-processing queries (Nov 2025) — create derived metrics, limit columns for recommendations, or filter datasets to focus quality checks on specific subsets.
- Pay-as-you-go pricing with no annual licenses required.
Glue DataBrew
- Glue DataBrew is a visual data preparation tool that enables users to clean and normalize data without writing any code.
- is serverless, and can help explore and transform terabytes of raw data without needing to create clusters or manage any infrastructure.
- helps reduce the time it takes to prepare data for analytics and machine learning (ML).
- provides 250+ ready-made transformations to automate data preparation tasks, such as filtering anomalies, converting data to standard formats, and correcting invalid values.
- DataBrew is integrated with AWS Glue Studio for orchestrating DataBrew recipes within Glue ETL jobs and workflows.
- Supports multiple file formats including CSV, JSON, Parquet, and Apache ORC.
AWS Glue for Ray
⚠️ Note: AWS Glue for Ray is no longer open to new customers as of April 30, 2026. Existing customers can continue to use the service. For similar capabilities, AWS recommends exploring Amazon EKS.
- AWS Glue for Ray allowed running distributed Python workloads using the Ray open-source framework on a serverless infrastructure.
- Supported Python-based data processing workloads that don’t require Apache Spark.
Open Table Format Support
- AWS Glue (3.0 and later) supports open table formats for data lakes:
- Apache Iceberg — high-performance table format with ACID transactions, time travel, and schema evolution. Glue 5.1 supports Iceberg 1.10.0 and format version 3.0.
- Apache Hudi — supports record-level inserts, updates, and deletes. Glue 5.1 supports Hudi 1.0.2.
- Delta Lake — open-source storage layer with ACID transactions. Glue 5.1 supports Delta Lake 3.3.
- Integrated with Amazon SageMaker Lakehouse for unified access across S3 data lakes and Redshift data warehouses.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- An organization is setting up a data catalog and metadata management environment for their numerous data stores currently running on AWS. The data catalog will be used to determine the structure and other attributes of data in the data stores. The data stores are composed of Amazon RDS databases, Amazon Redshift, and CSV files residing on Amazon S3. The catalog should be populated on a scheduled basis, and minimal administration is required to manage the catalog. How can this be accomplished?
- Set up Amazon DynamoDB as the data catalog and run a scheduled AWS Lambda function that connects to data sources to populate the database.
- Use an Amazon database as the data catalog and run a scheduled AWS Lambda function that connects to data sources to populate the database.
- Use AWS Glue Data Catalog as the data catalog and schedule crawlers that connect to data sources to populate the database.
- Set up Apache Hive metastore on an Amazon EC2 instance and run a scheduled bash script that connects to data sources to populate the metastore.
- A data engineering team needs to ensure their ETL jobs process only new data on each scheduled run and avoid reprocessing data from previous runs. Which AWS Glue feature should they use?
- AWS Glue Data Catalog versioning
- AWS Glue crawlers with recrawl policy
- AWS Glue Job Bookmarks
- AWS Glue workflow triggers
- A company wants to allow their Databricks and Snowflake environments to query Apache Iceberg tables managed in the AWS Glue Data Catalog without duplicating data. Which AWS Glue feature enables this?
- AWS Glue crawlers
- AWS Glue ETL jobs with cross-account access
- AWS Glue Iceberg REST Catalog endpoint
- AWS Glue Data Catalog resource policies
- An organization needs to query Iceberg tables that are cataloged in a Databricks Unity Catalog using AWS analytics services like Athena and Redshift, without copying table metadata. Which feature should they use?
- AWS Glue crawlers to import external metadata
- AWS Lake Formation cross-account sharing
- AWS Glue ETL with JDBC connections
- AWS Glue Data Catalog catalog federation
- A company is running AWS Glue Spark ETL jobs on version 2.0 and wants to modernize to the latest version. Which approach reduces migration effort using AI-generated plans? (Select TWO)
- Use Generative AI Upgrades for Apache Spark to scan jobs and generate upgrade plans
- Manually rewrite all PySpark scripts for Spark 3.5 compatibility
- Use Generative AI Upgrades to execute plans and validate outputs automatically
- Create new jobs from scratch in Glue 5.1
- Use AWS Glue crawlers to detect code changes
- A data team needs to run memory-intensive Spark workloads including large aggregations and ML transforms. Which AWS Glue worker type is most appropriate?
- G.1X workers
- G.2X workers
- G.4X workers
- R type (memory-optimized) workers
Great work Jayendra.
Thanks Suresh