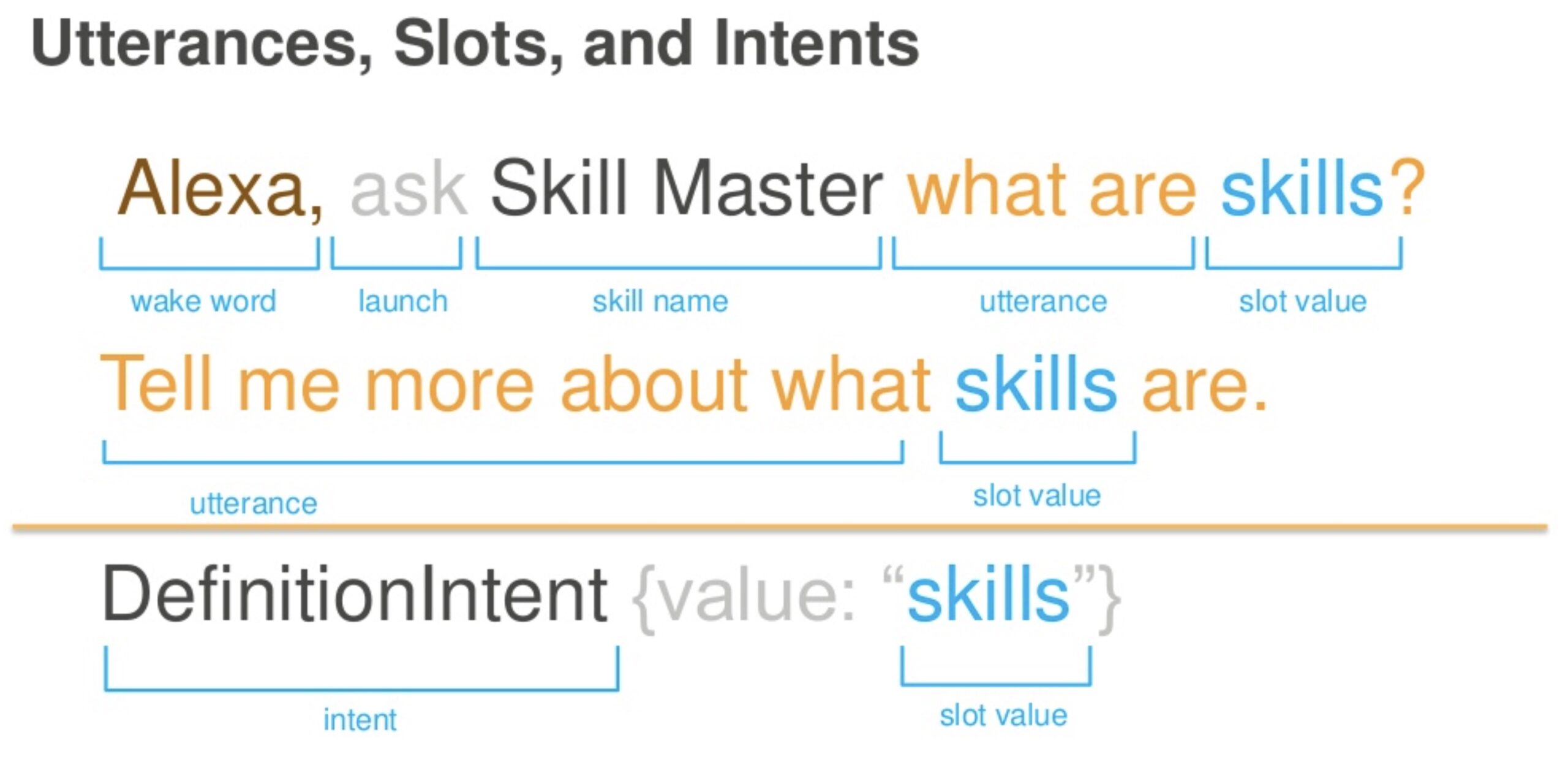
Google Cloud – Professional Cloud DevOps Engineer Certification Learning Path
📋 Last Updated: June 2026 — Updated with current exam guide (5 domains), Cloud Deploy, deprecated services (Cloud Debugger shutdown, Cloud Source Repositories end-of-sale, Container Registry shutdown), GKE Autopilot, Workload Identity Federation, Ops Agent, Managed Service for Prometheus, and OpenTelemetry.
Continuing on the Google Cloud Journey, glad to have passed the 8th certification with the Professional Cloud DevOps Engineer certification. Google Cloud – Professional Cloud DevOps Engineer certification exam focuses on almost all of the Google Cloud DevOps services with Cloud Developer tools, Operations Suite, and SRE concepts.
Google Cloud – Professional Cloud DevOps Engineer Certification Summary
- Has 50-60 questions to be answered in 2 hours.
- Certification is valid for 2 years from the date of passing.
- Covers a wide range of Google Cloud services mainly focusing on DevOps toolset including Cloud Build, Cloud Deploy, Artifact Registry, Cloud Operations Suite with a focus on monitoring and logging, and SRE concepts.
- The exam is heavily SRE-focused (~28% of the exam) — understanding SLI/SLO/error-budget design, toil reduction, and incident management is essential.
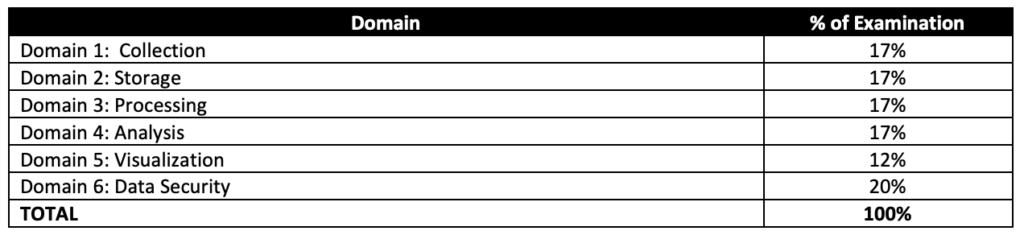
- The exam covers 5 domains:
- Applying site reliability engineering principles to a service (~28%)
- Building and implementing CI/CD pipelines for a service (~24%)
- Applying service monitoring strategies (~22%)
- Optimizing service performance (~13%)
- Managing service incidents (~13%)
- The exam uses:
- Cloud Operations (Cloud Monitoring & Logging) and does not refer to Stackdriver.
- Artifact Registry instead of Container Registry (which was shut down in March 2025).
- Cloud Deploy as the managed CD service — this is a key exam topic.
- Ops Agent instead of legacy Monitoring/Logging agents.
- There are no case studies for the exam.
- GKE knowledge is essential — deployments, services, autoscaling, and Workload Identity Federation for GKE are all tested.
- As mentioned for all the exams, Hands-on is a MUST. If you have not worked on GCP before, make sure you do lots of labs else you would be absolutely clueless about some of the questions and commands.
Google Cloud – Professional Cloud DevOps Engineer Certification Resources
- Google Cloud – Professional Cloud DevOps Engineer Exam Guide
- Google Cloud – Professional Cloud DevOps Engineer Certification Page
- Google SRE Book (free online — essential reading for the largest exam domain)
- Courses
- Udemy – Google Cloud Certified – Professional Cloud DevOps Engineer Certification
- Coursera – Preparing for Google Cloud Certification: Cloud DevOps Engineer
- Pluralsight Cloud+ (formerly A Cloud Guru) – Google Cloud Professional Cloud DevOps Engineer
- Practice tests
- Use Google Free Tier and Google Cloud Skills Boost (formerly Qwiklabs) as much as possible.
Google Cloud – Professional Cloud DevOps Engineer Certification Topics
Developer Tools – CI/CD
- Google Cloud Build
- Cloud Build integrates with GitHub, GitLab, Bitbucket, and Cloud Source Repositories (legacy) and can be used for Continuous Integration and Deployments.
- Cloud Build can import source code, execute build to the specifications, and produce artifacts such as Docker containers or Java archives.
- Cloud Build can trigger builds on source commits using 2nd gen repository connections (GitHub, GitLab, Bitbucket) or legacy 1st gen triggers.
- Cloud Build build config file specifies the instructions to perform, with steps defined for each task like the test, build, and deploy.
- Cloud Build step specifies an action to be performed and is run in a Docker container.
- Cloud Build supports custom images as well for the steps.
- Cloud Build integrates with Pub/Sub to publish messages on build state changes.
- Cloud Build Private Pools provide dedicated, customer-owned build infrastructure for builds requiring VPC connectivity or enhanced security.
- Cloud Build generates SLSA Level 3 build provenance for artifacts stored in Artifact Registry, providing verifiable supply chain security metadata including image digests, source locations, and build arguments.
- Cloud Build should use a Service Account with a Container Developer role to perform deployments on GKE.
- Cloud Build uses a directory named
/workspaceas a working directory and the assets produced by one step can be passed to the next one via the persistence of the/workspacedirectory.
- Google Cloud Deploy (Managed CD)
- Cloud Deploy is a managed, opinionated Continuous Delivery service that automates delivery of applications to a series of target environments (dev → staging → production).
- Cloud Deploy uses Skaffold for rendering and deploying Kubernetes manifests or Cloud Run services.
- Cloud Deploy supports deployment to GKE, Cloud Run, and GKE Enterprise targets.
- Cloud Deploy supports multiple deployment strategies: standard (rolling), canary, and blue/green deployments.
- Cloud Deploy canary deployments allow progressive rollouts with configurable traffic percentages (e.g., 10% → 50% → 100%).
- Cloud Deploy supports automated promotion between targets when a release succeeds in the previous environment.
- Cloud Deploy supports deploy verification — automated tests that run after deployment to validate the release before promotion.
- Cloud Deploy integrates with Cloud Build (CI triggers release creation) and Binary Authorization (policy enforcement).
- Hint: For managed, structured delivery pipelines with progressive rollout to GKE/Cloud Run, choose Cloud Deploy over Spinnaker or custom scripts.
- Binary Authorization and Software Supply Chain Security
- Binary Authorization provides software supply-chain security for container-based applications. It enables you to configure a policy that the service enforces when an attempt is made to deploy a container image on one of the supported container-based platforms.
- Binary Authorization uses attestations to verify that an image was built by a specific build system or continuous integration (CI) pipeline.
- Binary Authorization integrates with Cloud Build’s SLSA provenance to verify build authenticity.
- Artifact Analysis (formerly Container Analysis) helps scan images for vulnerabilities.
- Hint: For security and compliance reasons if the image deployed needs to be trusted, use Binary Authorization with attestation-based policies.
- Google Artifact Registry
- Artifact Registry is the single registry service for all artifact types — container images, Maven, npm, Python, Go, Apt, Yum, and more.
- Container Registry was shut down on March 18, 2025. All container image storage must use Artifact Registry.
- Artifact Registry supports both regional and multi-regional repositories.
- Artifact Registry supports gcr.io domain routing for backward compatibility with Container Registry URLs.
- Artifact Registry integrates with Artifact Analysis for vulnerability scanning and SBOM generation.
- Google Cloud Source Repositories (Legacy)
⚠️ End of Sale: Cloud Source Repositories is not available to new customers as of June 17, 2024. Existing customers can continue to use it, but new projects should use Secure Source Manager or third-party repositories (GitHub, GitLab, Bitbucket).
- Cloud Source Repositories are fully-featured, private Git repositories hosted on Google Cloud.
- Secure Source Manager is the recommended replacement — a regionally deployed, single-tenant, managed source code repository on Google Cloud.
- Cloud Build 2nd gen repository connections support direct integration with GitHub, GitLab, and Bitbucket without requiring Cloud Source Repositories.
- Hint: If the code needs to be version controlled and needs collaboration with multiple members, choose Git-related options (GitHub/GitLab integration or Secure Source Manager).
- Google Cloud Code
- Cloud Code helps write, debug, and deploy the cloud-based applications for IntelliJ, VS Code, or in the browser.
- Google Cloud Client Libraries
- Google Cloud Client Libraries provide client libraries and SDKs in various languages for calling Google Cloud APIs.
- If the language is not supported, Cloud REST APIs can be used.
- Deployment Techniques
- Recreate deployment – fully scale down the existing application version before you scale up the new application version.
- Rolling update – update a subset of running application instances instead of simultaneously updating every application instance.
- Blue/Green deployment – (also known as a red/black deployment), you perform two identical deployments of your application.
- Canary deployment – progressively roll out a change, increasing traffic percentages to the new version.
- GKE supports Rolling and Recreate deployments natively.
- Rolling deployments support
maxSurge(new pods created) andmaxUnavailable(existing pods deleted).
- Rolling deployments support
- Cloud Deploy supports canary and blue/green for GKE and Cloud Run targets.
- Managed Instance Groups support Rolling deployments using
maxSurgeandmaxUnavailableconfigurations.
- Testing Strategies
- Canary testing – partially roll out a change and then evaluate its performance against a baseline deployment.
- A/B testing – test a hypothesis by using variant implementations. A/B testing is used to make business decisions (not only predictions) based on the results derived from data.
- Cloud Deploy supports deploy verification to automatically validate releases after deployment.
- Spinnaker
- Spinnaker is an open-source, multi-cloud continuous delivery platform for releasing software changes.
- Spinnaker supports Blue/Green rollouts by dynamically enabling and disabling traffic to a particular Kubernetes resource.
- Spinnaker recommends comparing canary against an equivalent baseline, deployed at the same time instead of production deployment.
- Note: For new GCP-native deployments, Google Cloud Deploy is the recommended managed alternative to self-hosted Spinnaker.
Cloud Operations Suite (Observability)
- Google Cloud Observability (formerly Operations Suite) provides monitoring, alerting, error reporting, metrics, tracing, profiling, and logging.
- Google Cloud Monitoring
- Cloud Monitoring helps gain visibility into the performance, availability, and health of your applications and infrastructure.
- Ops Agent is the recommended unified agent (replaces legacy Monitoring and Logging agents). It uses OpenTelemetry and Fluent Bit to collect metrics and logs from Compute Engine VMs.
- Legacy Monitoring Agent and Logging Agent are still functional but should be migrated to Ops Agent for new deployments.
- Cloud Monitoring supports SLO monitoring — define SLOs directly in Cloud Monitoring with burn-rate alerts based on error budget consumption.
- Cloud Monitoring supports log exports where the logs can be sunk to Cloud Storage, Pub/Sub, BigQuery, or an external destination like Splunk.
- Cloud Monitoring API supports push or export custom metrics.
- Uptime checks help check if the resource responds. It can check the availability of any public service on VM, App Engine, URL, GKE, or AWS Load Balancer.
- Process health checks can be used to check if any process is healthy.
- Managed Service for Prometheus
- Managed Service for Prometheus lets you globally monitor and alert on workloads using Prometheus and OpenTelemetry, without manually managing Prometheus at scale.
- Supports both managed collection (Google manages the collector) and self-deployed collection (you run your own Prometheus or OpenTelemetry Collector).
- Integrates natively with GKE for Kubernetes workload monitoring.
- Supports PromQL for querying and alerting, compatible with existing Prometheus dashboards and rules.
- Hint: For Prometheus-based monitoring on GKE at scale, use Managed Service for Prometheus instead of self-managed Prometheus.
- OpenTelemetry Integration
- Google Cloud supports OpenTelemetry Protocol (OTLP) for sending metrics, traces, and logs directly to Cloud Monitoring, Cloud Trace, and Cloud Logging.
- OpenTelemetry Collector can be deployed as a sidecar or DaemonSet on GKE to collect and export telemetry data.
- GKE supports Managed OpenTelemetry with an Instrumentation custom resource that automatically injects configuration into workloads.
- Google Cloud Logging
- Cloud Logging provides real-time log management and analysis.
- Cloud Logging allows ingestion of custom log data from any source.
- Logs can be exported by configuring log sinks to BigQuery, Cloud Storage, or Pub/Sub.
- Log Analytics allows SQL-based querying of logs using BigQuery-integrated log buckets.
- The Ops Agent collects application logs from VMs (replaces legacy Logging Agent which used fluentd).
- VPC Flow Logs helps record network flows sent from and received by VM instances.
- Cloud Logging Log-based metrics can be used to create alerts on logs.
- Hint: If the logs from VM do not appear on Cloud Logging, check if the Ops Agent is installed and running and it has proper permissions to write the logs to Cloud Logging.
- Cloud Error Reporting
- Counts, analyzes, and aggregates the crashes in the running cloud services.
- Cloud Profiler
- Cloud Profiler allows continuous profiling of CPU and memory usage in production applications with minimal overhead.
- Helps identify performance bottlenecks in code running on GCP and on-premises resources.
- Cloud Trace
- Is a distributed tracing system that collects latency data from the applications and displays it in the Google Cloud Console.
- Supports OpenTelemetry-based instrumentation for automatic trace collection.
- Cloud Debugger
⚠️ SHUT DOWN: Cloud Debugger was deprecated on May 16, 2022 and the service was shut down on May 31, 2023. It is no longer available and is not tested on the exam.
- Cloud Debugger previously allowed inspecting the state of a running application in real-time.
- For runtime debugging needs, use Cloud Logging with structured logs, Cloud Trace for latency analysis, or snapshot-based debugging tools.
Compute Services
- Compute services like Google Compute Engine and Google Kubernetes Engine are tested from the DevOps, scaling, and security aspects.
- Google Compute Engine
- Google Compute Engine is the IaaS option for computing and provides fine-grained control.
- Spot VMs (formerly Preemptible VMs) and their use cases. HINT – use for short-term, fault-tolerant workloads.
- Committed Usage Discounts (CUDs) help provide cost benefits for long-term stable and predictable usage.
- Managed Instance Groups can help scale VMs as per the demand. It also helps provide auto-healing and high availability with health checks, in case an application fails.
- Google Kubernetes Engine
- GKE Autopilot is the recommended and default mode of operation — Google fully manages nodes, scaling, security, and node configuration.
- Autopilot provides a Pod-level SLA and eliminates node management overhead.
- Supports burstable workloads, GPUs, and StatefulSets.
- GKE Standard provides full control over node configuration for specialized workloads.
- GKE can be scaled using:
- Cluster Autoscaler to scale the cluster node pools.
- Vertical Pod Autoscaler (VPA) to adjust pod resource requests/limits based on actual usage.
- Horizontal Pod Autoscaler (HPA) to scale the number of pods based on CPU, memory, or custom/external metrics.
- Multidimensional Pod Autoscaling — combines HPA (scale out on CPU) and VPA (scale up on memory) simultaneously.
- Workload Identity Federation for GKE (formerly GKE Workload Identity) is the recommended way for GKE workloads to authenticate to Google Cloud APIs without service account keys.
- Eliminates the need for service account key files in containers.
- Pods authenticate with short-lived federated tokens tied to their Kubernetes ServiceAccount.
- Kubernetes Secrets can be used to store secrets (although they are just base64 encoded values). For production, use Secret Manager integration.
- Kubernetes supports rolling and recreate deployment strategies.
- GKE Autopilot is the recommended and default mode of operation — Google fully manages nodes, scaling, security, and node configuration.
Security
- Cloud Key Management Service – KMS
- Cloud KMS can be used to manage cryptographic keys and encrypt data in Cloud Storage and other integrated services.
- Secret Manager
- Secret Manager stores, manages, and provides access to secrets (API keys, passwords, certificates) as binary blobs or text strings.
- Supports automatic rotation, versioning, and fine-grained IAM access control.
- Integrates with GKE via Workload Identity Federation for secure secret access from pods.
Site Reliability Engineering – SRE
- SRE is a DevOps implementation and focuses on increasing reliability and observability, collaboration, and reducing toil using automation.
- SRE is the largest domain (~28%) of the Professional Cloud DevOps Engineer exam.
- SLOs help specify a target level for the reliability of your service using SLIs which provide actual measurements.
- SLI Types:
- Availability
- Freshness
- Latency
- Quality
- SLOs – Choosing the measurement method:
- Synthetic clients to measure user experience
- Client-side instrumentation
- Application and infrastructure metrics
- Logs processing
- SLOs define Error Budget and Error Budget Policy which need to be aligned with all stakeholders and help plan releases to focus on features vs reliability.
- Burn-rate alerts can be configured in Cloud Monitoring to alert when error budget is being consumed too quickly.
- When error budget is exhausted, the team should prioritize reliability over new features (feature freeze).
- SRE focuses on Reducing Toil – Identifying repetitive, manual, automatable tasks and eliminating them through automation.
- Production Readiness Review – PRR
- Applications should be performance tested for volumes before being deployed to production.
- SLOs should not be modified/adjusted to facilitate production deployments. Teams should work to make the applications SLO compliant before they are deployed to production.
- SRE Practices include:
- Incident Management and Response
- Priority should be to mitigate the issue, and then investigate and find the root cause. Mitigating would include:
- Rolling back the release that caused the issue.
- Routing traffic to a working site to restore user experience.
- Incident Live State Document helps track the events and decision making which can be useful for postmortem.
- Involves the following roles:
- Incident Commander/Manager
- Sets up a communication channel for all to collaborate.
- Assigns and delegates roles. IC would assume any role, if not delegated.
- Responsible for Incident Live State Document.
- Communications Lead
- Provides periodic updates to all the stakeholders and customers.
- Operations Lead
- Responds to the incident and should be the only group modifying the system during an incident.
- Incident Commander/Manager
- Priority should be to mitigate the issue, and then investigate and find the root cause. Mitigating would include:
- Postmortem
- Should contain the root cause.
- Should be Blameless — focus on systems and processes, not individuals.
- Should be shared with all for collaboration and feedback.
- Should be shared with all the stakeholders.
- Should have proper action items to prevent recurrence with an owner and collaborators, if required.
- Chaos Engineering
- Proactively testing system resilience by intentionally introducing failures.
- Helps identify weaknesses before they cause real incidents.
- Should be conducted in controlled environments with proper safeguards.
- Incident Management and Response
All the Best !!