Table of Contents
hide
AWS FSx for Lustre
- FSx for Lustre is a fully managed service that makes it easy and cost-effective to launch and run the world’s most popular high-performance Lustre file system.
- FSx for Lustre is built on the open-source Lustre file system designed for applications that require fast storage, where the storage needs to keep up with the compute.
- handles the traditional complexity of setting up and managing high-performance Lustre file systems.
- is POSIX-compliant and can be used with existing Linux-based applications without having to make any changes.
- provides a native file system interface and works as any file system does with the Linux operating system.
- provides read-after-write consistency and supports file locking.
- is compatible with the most popular Linux-based AMIs, including Amazon Linux, Amazon Linux 2, Amazon Linux 2023, Red Hat Enterprise Linux (RHEL), CentOS, SUSE Linux, and Ubuntu.
- is accessible from compute workloads running on EC2 instances and containers running on Amazon EKS, and from on-premises servers.
- can be accessed from a Linux instance by installing the open-source Lustre client and mounting the file system using standard Linux commands.
- is ideal for use cases where speed matters, such as machine learning, high-performance computing (HPC), video processing, financial modelling, genome sequencing, electronic design automation (EDA), and AI/ML training workloads.
- delivers the fastest storage performance for GPU instances in the cloud with up to 1,200 Gbps per-client throughput using Elastic Fabric Adapter (EFA) and NVIDIA GPUDirect Storage (GDS).
- delivers virtually unlimited storage capacity, millions of IOPS, up to terabytes per second of throughput, and sub-millisecond latencies.
- supports Lustre LTS versions 2.10, 2.12, and 2.15, with in-place version upgrades supported.
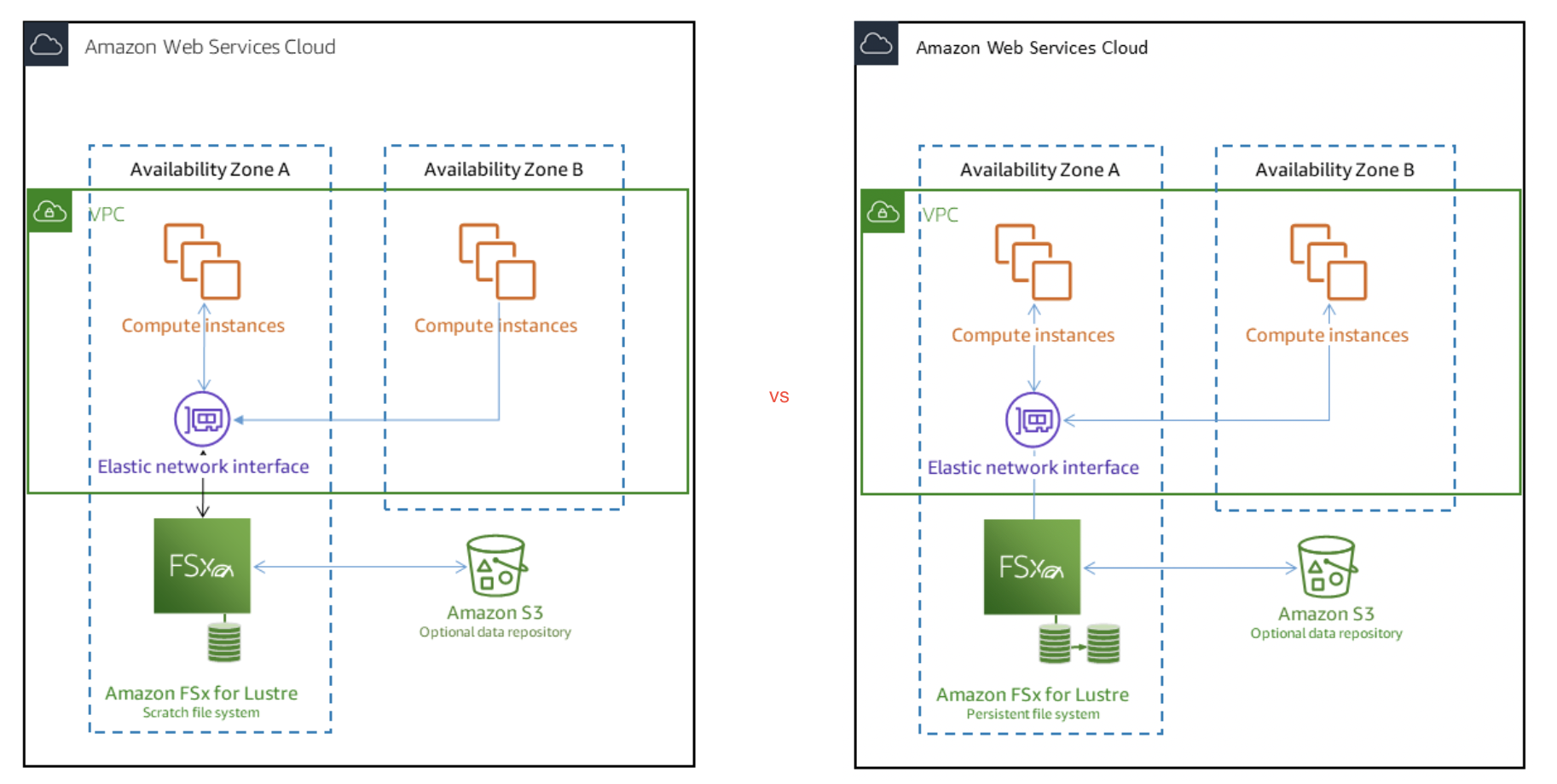
FSx for Lustre Deployment Options
- FSx for Lustre provides two file system deployment options: Scratch and Persistent.
Scratch file systems
- designed for temporary storage and short-term processing of data.
- provide high burst throughput of up to six times the baseline throughput of 200 MBps per TiB of storage capacity.
- data is not replicated and does not persist if a file server fails.
- ideal for cost-optimized storage for short-term, processing-heavy workloads.
Persistent file systems
- designed for long-term storage and workloads.
- is highly available, and data is automatically replicated within the AZ that is associated with the file system.
- data volumes attached to the file servers are replicated independently from the file servers to which they are attached.
- if a file server becomes unavailable, it is replaced automatically within minutes of failure.
- continuously monitored for hardware failures, and automatically replaces infrastructure components in the event of a failure.
- ideal for workloads that run for extended periods or indefinitely, and that might be sensitive to disruptions in availability.
- Persistent-2 file systems are the latest generation, built on AWS Graviton processors, providing higher throughput per TiB (up to 1 GB/s per TiB) and lower cost of throughput compared to previous generation file systems.
FSx for Lustre Storage Classes
- FSx for Lustre provides three storage classes: SSD, Intelligent-Tiering, and HDD.
SSD Storage Class
- delivers consistent sub-millisecond latencies for the entire dataset.
- ideal for latency-sensitive workloads that require all-flash performance.
- available with both scratch and persistent deployment types.
Intelligent-Tiering Storage Class (New – 2025)
- launched in May 2025, delivers virtually unlimited scalability, fully elastic Lustre file storage, and the lowest-cost Lustre file storage in the cloud.
- automatically scales storage up and down based on access patterns — pay only for what you use.
- automatically tiers data between three access tiers:
- Frequent Access tier for actively used data.
- Infrequent Access tier for less frequently accessed data.
- Archive Instant Access tier for rarely accessed data.
- offers an optional SSD read cache that delivers SSD-level performance at HDD pricing for latency-sensitive workloads.
- delivers up to 34% better price-performance compared to on-premises HDD file storage.
- delivers up to 70% better price-performance compared to other cloud-based Lustre storage.
- starting at less than $0.005 per GB-month.
- optimized for HDD-based or mixed HDD/SSD workloads with a mix of hot and cold data.
- ideal for workloads like weather forecasting, seismic imaging, genomic analysis, and ADAS training.
HDD Storage Class
- provides lower-cost storage for throughput-oriented workloads that don’t require sub-millisecond latencies.
- suitable for workloads with large sequential I/O patterns.
FSx for Lustre Performance
- FSx for Lustre file systems scale to terabytes per second of throughput and millions of IOPS.
- supports concurrent access to the same file or directory from thousands of compute instances.
- provides consistent, sub-millisecond latencies for file operations.
Elastic Fabric Adapter (EFA) and GPUDirect Storage (GDS) Support (2024)
- launched in November 2024, provides the fastest storage performance for GPU instances in the cloud.
- delivers up to 12x higher throughput per client instance (up to 1,200 Gbps) compared to previous FSx for Lustre systems.
- NVIDIA GPUDirect Storage (GDS) creates a direct data path between storage and GPU memory, bypassing CPU and system memory.
- supported on Nitro v4 (or higher) EC2 instances with EFA support (e.g., P5 GPU instances).
- accelerates machine learning training jobs and reduces workload costs.
- also supports ENA Express for enhanced networking.
Scalable Metadata Performance (2024)
- increased maximum metadata IOPS by 15x (launched June 2024).
- allows provisioning metadata IOPS independently of file system storage capacity.
- supports up to 192,000 metadata IOPS per file system.
- metadata IOPS can be configured in AUTOMATIC mode (scales with storage capacity) or USER_PROVISIONED mode.
- available on Persistent-2 file systems.
- up to 5x faster directory listing performance (launched November 2025).
Data Compression
- uses the LZ4 compression algorithm optimized to deliver high levels of compression without adversely impacting performance.
- newly written files are automatically compressed before writing to disk and uncompressed when read.
- reduces storage consumption of both file system storage and backups.
FSx for Lustre with S3
- FSx for Lustre integrates natively with S3, making it easy to process cloud data sets with the Lustre high-performance file system.
- FSx for Lustre file system transparently presents S3 objects as files and allows writing changed data back to S3.
- supports Data Repository Associations (DRAs) — links between a directory on the file system and an S3 bucket or prefix.
- supports up to 8 DRAs per file system, enabling links to multiple S3 buckets or prefixes.
- provides full bi-directional synchronization including deleted files and objects.
- S3 objects are lazy-loaded by default:
- FSx automatically loads the corresponding objects from S3 only when first accessed by applications.
- Subsequent reads are served directly from the file system with low, consistent latencies.
- FSx for Lustre file system can optionally be batch hydrated.
- FSx for Lustre uses parallel data transfer techniques to transfer data from S3 at up to hundreds of GBs/s.
- Files from the file system can be exported back to the S3 bucket.
- supports automatic import and export policies to keep file system and S3 synchronized.
- DRAs are supported on Lustre 2.12 and newer file systems (excluding scratch_1 deployment type).
- supports cross-account S3 access for sharing data across AWS accounts.
FSx for Lustre Security
- FSx for Lustre provides encryption at rest for the file system and the backups, by default, using KMS.
- FSx encrypts data-in-transit when accessed from supported EC2 instances.
- complies with PCI DSS, ISO 9001, 27001, 27017, and 27018, and SOC 1, 2, and 3.
- is HIPAA eligible.
- file systems are accessed from endpoints in a VPC, enabling network isolation.
- integrated with AWS IAM for resource-level permissions.
- supports storage quotas for monitoring and controlling user- and group-level storage consumption.
FSx for Lustre Availability and Durability
- On a scratch file system, file servers are not replaced if they fail and data is not replicated.
- On a persistent file system, if a file server becomes unavailable it is replaced automatically and within minutes.
- FSx for Lustre provides a parallel file system, where data is stored across multiple network file servers to maximize performance and reduce bottlenecks, and each server has multiple disks.
- FSx takes daily automatic incremental backups of the file systems, and allows manual backups at any point.
- Backups are stored in Amazon S3 with 99.999999999% (11 9’s) of durability.
- Backups are highly durable and file-system-consistent.
- Supports cross-region and cross-account backup copies using AWS Backup for disaster recovery.
- Supports copying backups across AWS opt-in Regions (launched April 2026).
FSx for Lustre Lustre Version Management
- Supports Lustre LTS versions 2.10, 2.12, and 2.15.
- In-place Lustre version upgrades supported (launched February 2025) — upgrade file systems to newer versions within minutes using the console or CLI/SDK.
- Newer versions provide performance enhancements, new features, and support for the latest Linux kernel versions.
- No downtime required for version upgrades.
FSx for Lustre Monitoring
- Provides enhanced monitoring dashboard with performance insights and recommendations (launched September 2024).
- Provides additional performance metrics for improved visibility into file system activity.
- Integrates with Amazon CloudWatch for file system metrics.
- Provides performance warnings and recommendations when metrics exceed thresholds.
FSx for Lustre Integration with Compute Services
- Accessible from Amazon EC2 instances, containers on Amazon EKS, and on-premises servers.
- Integrates with Amazon SageMaker as an input data source for ML training jobs.
- Integrates with AWS Batch through EC2 Launch Templates for batch scheduling.
- Integrates with AWS ParallelCluster for HPC cluster deployments.
- Supports Lustre client on Amazon Linux, Amazon Linux 2, Amazon Linux 2023, RHEL, CentOS, SUSE Linux, and Ubuntu (including Ubuntu 24.04 with Kernel 6.14).
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- A solutions architect is designing storage for a high performance computing (HPC) environment based on Amazon Linux. The workload stores and processes a large amount of engineering drawings that require shared storage and heavy computing. Which storage option would be the optimal solution?
- Amazon Elastic File System (Amazon EFS)
- Amazon FSx for Lustre
- Amazon EC2 instance store
- Amazon EBS Provisioned IOPS SSD (io1)
- A company is planning to deploy a High Performance Computing (HPC) cluster in its VPC that requires a scalable, high performance file system. The storage service must be optimized for efficient workload processing, and the data must be accessible via a fast and scalable file system interface. It should also work natively with Amazon S3 that enables you to easily process your S3 data with a high-performance POSIX interface. Which of the following is the MOST suitable service that you should use for this scenario?
- Amazon Elastic File System (Amazon EFS)
- Amazon FSx for Lustre
- Amazon Elastic Block Store
- Amazon EBS Provisioned IOPS SSD (io1)
- A machine learning team needs to train large language models using GPU instances and requires the fastest possible storage throughput to keep GPUs fully utilized. The training data is stored in S3 and the team wants sub-millisecond latency access. Which FSx for Lustre feature should they enable for maximum GPU throughput?
- HDD storage class with burst throughput
- Scratch file system with increased storage capacity
- EFA-enabled file system with NVIDIA GPUDirect Storage (GDS)
- Persistent file system with data compression enabled
- A company runs large-scale genomics workloads with petabytes of data that has a mix of frequently and infrequently accessed files. They want the lowest-cost Lustre storage that automatically scales with their data and eliminates the need to provision capacity upfront. Which FSx for Lustre configuration best meets these requirements?
- Persistent SSD file system with data compression
- Scratch file system with HDD storage
- Intelligent-Tiering storage class with SSD read cache
- Persistent-2 file system with maximum throughput per TiB
- A company needs to link their FSx for Lustre file system to data in multiple S3 buckets for different teams. How many Data Repository Associations (DRAs) can be configured on a single FSx for Lustre file system?
- 1
- 4
- 8
- 16
- An organization is running metadata-intensive workloads on FSx for Lustre and needs to increase the number of file creation and listing operations. Which feature allows them to scale metadata performance independently of storage capacity?
- Increasing storage capacity
- Enabling data compression
- User-provisioned metadata IOPS on Persistent-2 file systems
- Switching to scratch file system deployment