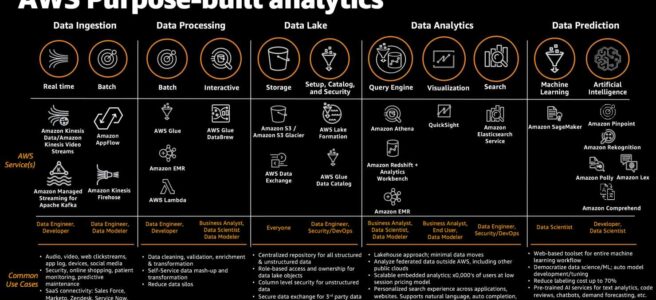
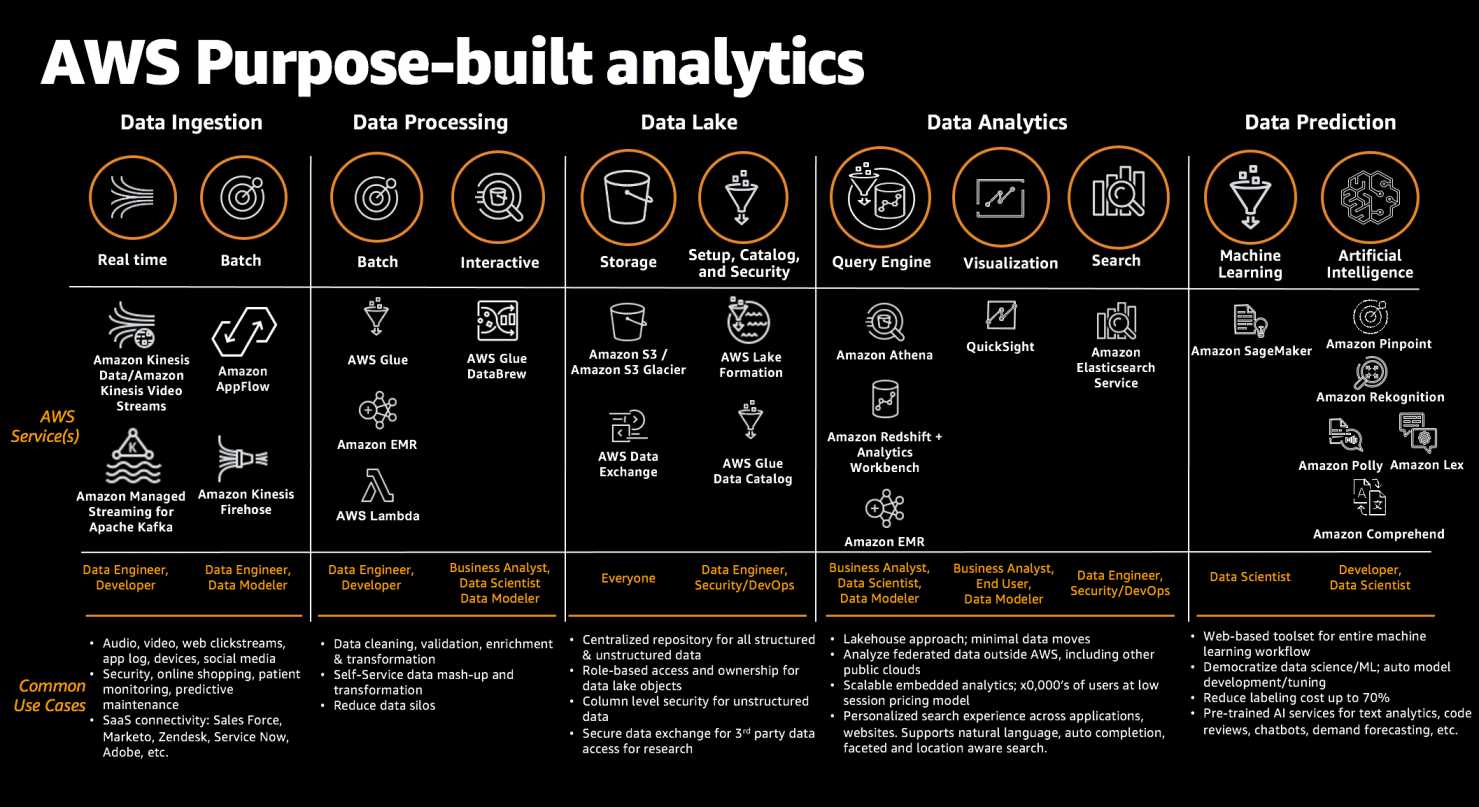
enables real-time processing of streaming data at a massive scale
provides ordering of records per shard
provides an ability to read and/or replay records in the same order
allows multiple applications to consume the same data
data is replicated across three data centers within a region
data is preserved for 24 hours, by default, and can be extended to 365 days
data inserted in Kinesis, it can’t be deleted (immutability) but only expires
streams can be scaled using multiple shards, based on the partition key
each shard provides the capacity of 1MB/sec data input and 2MB/sec data output with 1000 PUT requests per second
Kinesis vs SQS
real-time processing of streaming big data vs reliable, highly scalable hosted queue for storing messages
ordered records, as well as the ability to read and/or replay records in the same order vs no guarantee on data ordering (with the standard queues before the FIFO queue feature was released)
data storage up to 24 hours, extended to 365 days vs 1 minute to extended to 14 days but cleared if deleted by the consumer.
supports multiple consumers vs a single consumer at a time and requires multiple queues to deliver messages to multiple consumers.
Kinesis Producer
API
PutRecord and PutRecords are synchronous
PutRecords uses batching and increases throughput
might experience ProvisionedThroughputExceeded Exceptions, when sending more data. Use retries with backoff, resharding, or change partition key.
KPL
producer supports synchronous or asynchronous use cases
supports inbuilt batching and retry mechanism
Kinesis Agent can help monitor log files and send them to KDS
supports third-party libraries like Spark, Flume, Kafka connect, etc.
Kinesis Consumers
Kinesis SDK
Records are polled by consumers from a shard
Kinesis Client Library (KCL)
Read records from Kinesis produced with the KPL (de-aggregation)
supports the checkpointing feature to keep track of the application’s state and resume progress using the DynamoDB table.
if application receives provisioned-throughput exceptions, increase the provisioned throughput for the DynamoDB table
Kinesis Connector Library – can be replaced using Firehose or Lambda
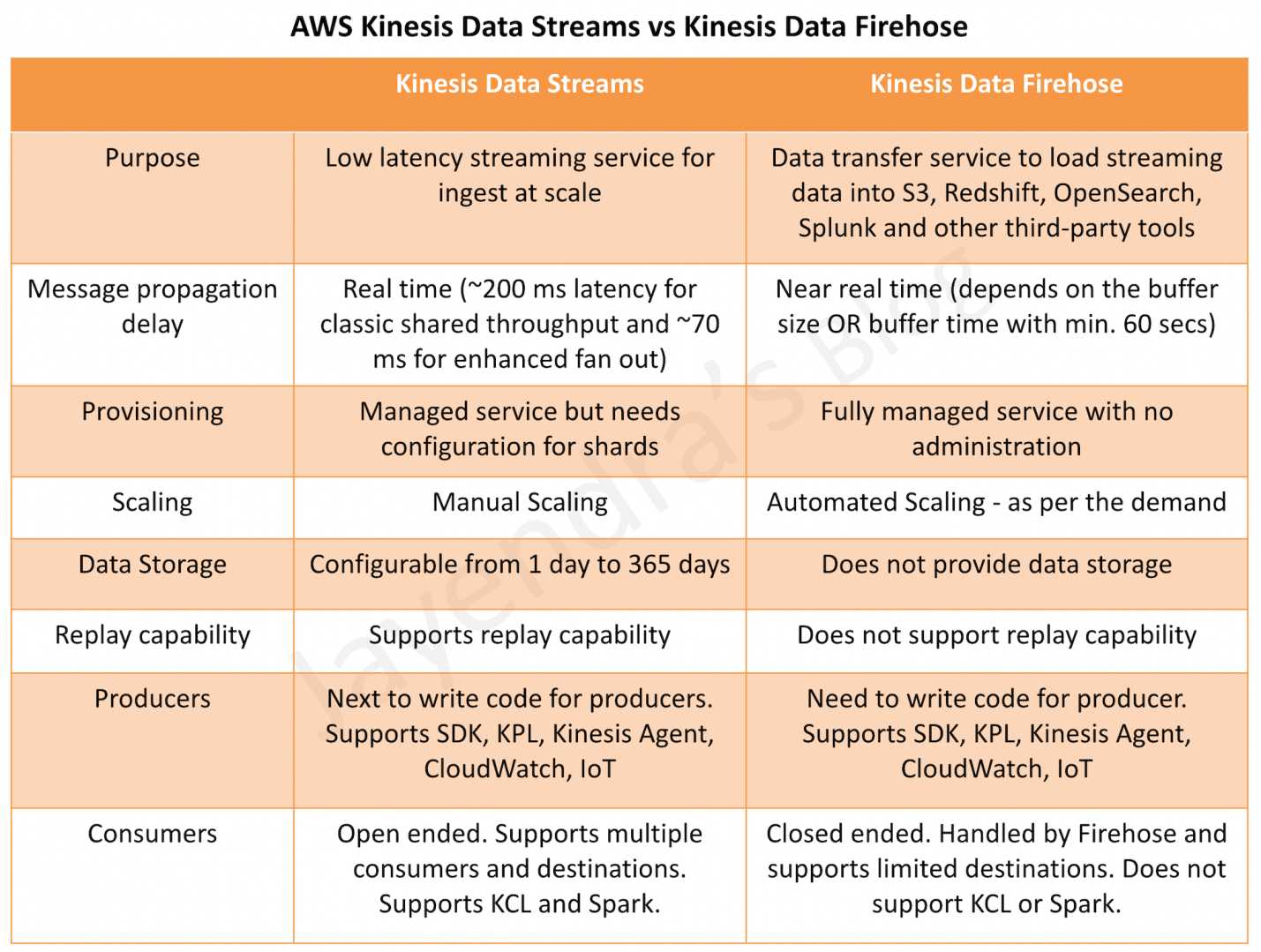
data transfer solution for delivering near real-time streaming data to destinations such as S3, Redshift, OpenSearch service, and Splunk.
is a fully managed service that automatically scales to match the throughput of your data and requires no ongoing administration
is Near Real Time (min. 60 secs) as it buffers incoming streaming data to a certain size or for a certain period of time before delivering it
supports batching, compression, and encryption of the data before loading it, minimizing the amount of storage used at the destination and increasing security
supports data compression, minimizing the amount of storage used at the destination. It currently supports GZIP, ZIP, and SNAPPY compression formats. Only GZIP is supported if the data is further loaded to Redshift.
supports out of box data transformation as well as custom transformationusing Lambda function to transform incoming source data and deliver the transformed data to destinations
uses at least once semantics for data delivery.
supports multiple producers as datasource, which include Kinesis data stream, KPL, Kinesis Agent, or the Kinesis Data Firehose API using the AWS SDK, CloudWatch Logs, CloudWatch Events, or AWS IoT
does NOT support consumers like Spark and KCL
supports interface VPC endpoint to keep traffic between the VPC and Kinesis Data Firehose from leaving the Amazon network.
Managed Streaming for Kafka- MSK is an AWS streaming data service that manages Apache Kafka infrastructure and operations.
makes it easy for developers and DevOps managers to run Kafka applications and Kafka Connect connectors on AWS, without the need to become experts in operating Kafka.
operates, maintains, and scales Kafka clusters, provides enterprise-grade security features out of the box, and has built-in AWS integrations that accelerate development of streaming data applications.
always runs within a VPC managed by the MSK and is available to your own selected VPC, subnet, and security group when the cluster is setup.
IP addresses from the VPC are attached to the MSK resources through elastic network interfaces (ENIs), and all network traffic stays within the AWS network and is not accessible to the internet by default.
integrates with CloudWatch for monitoring, metrics, and logging.
MSK Serverless is a cluster type for MSK that makes it easy for you to run Apache Kafka clusters without having to manage compute and storage capacity.
supports EBS server-side encryption using KMS to encrypt storage.
supports encryption in transit enabled via TLS for inter-broker communication.
provides simple and cost-effective solutions to analyze all the data using standard SQL and the existing Business Intelligence (BI) tools.
manages the work needed to set up, operate, and scale a data warehouse, from provisioning the infrastructure capacity to automating ongoing administrative tasks such as backups, and patching.
automatically monitors your nodes and drives to help you recover from failures.
only supported Single-AZ deployments. However, now supports Multi-AZ deployments.
replicates all the data within the data warehouse cluster when it is loaded and also continuously backs up your data to S3.
attempts to maintain at least three copies of your data (the original and replica on the compute nodes and a backup in S3).
supports cross-region snapshot replication to another region for disaster recovery
is made up of all of the columns listed in the sort key definition, in the order they are listed and is more efficient when query predicates use a prefix, or query’s filter applies conditions, such as filters and joins, which is a subset of the sort key columns in order.
Interleaved sort key
gives equal weight to each column in the sort key, so query predicates can use any subset of the columns that make up the sort key, in any order.
also supports EMR, DynamoDB, remote hosts using SSH
parallelized and efficient
can decrypt data as it is loaded from S3
DON’T use multiple concurrent COPY commands to load one table from multiple files as Redshift is forced to perform a serialized load, which is much slower.
supports data decryption when loading data, if data encrypted
supports decompressing data, if data is compressed.
Split the Load Data into Multiple Files
Load the data in sort key order to avoid needing to vacuum.
Use a Manifest File
provides Data consistency, to avoid S3 eventual consistency issues
helps specify different S3 locations in a more efficient way that with the use of S3 prefixes.
Redshift Distribution Style determines how data is distributed across compute nodes and helps minimize the impact of the redistribution step by locating the data where it needs to be before the query is executed.
Redshift Enhanced VPC routing forces all COPY and UNLOAD traffic between the cluster and the data repositories through the VPC.
Workload management (WLM) enables users to flexibly manage priorities within workloads so that short, fast-running queries won’t get stuck in queues behind long-running queries.
Redshift Spectrum helps query and retrieve structured and semistructured data from files in S3 without having to load the data into Redshift tables.
Redshift Spectrum external tables are read-only. You can’t COPY or INSERT to an external table.
Federated Query feature allows querying and analyzing data across operational databases, data warehouses, and data lakes.
Redshift Serverless is a serverless option of Redshift that makes it more efficient to run and scale analytics in seconds without the need to set up and manage data warehouse infrastructure.
is a web service that utilizes a hosted Hadoop framework running on the web-scale infrastructure of EC2 and S3
launches all nodes for a given cluster in the same Availability Zone, which improves performance as it provides a higher data access rate.
seamlessly supports Reserved, On-Demand, and Spot Instances
consists of Master/Primary Node for management and Slave nodes, which consist of Core nodes holding data and providing compute and Task nodes for performing tasks only.
is fault tolerant for slave node failures and continues job execution if a slave node goes down
supports Persistent and Transient cluster types
Persistent EMR clusters continue to run after the data processing job is complete
Transient EMR clusters shut down when the job or the steps (series of jobs) are complete
supports EMRFS which allows S3 to be used as a durable HA data storage
EMR Serverless helps run big data frameworks such as Apache Spark and Apache Hive without configuring, managing, and scaling clusters.
EMR Studio is an IDE that helps data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark.
EMR Notebooks provide a managed environment, based on Jupyter Notebook, that helps prepare and visualize data, collaborate with peers, build applications, and perform interactive analysis using EMR clusters.
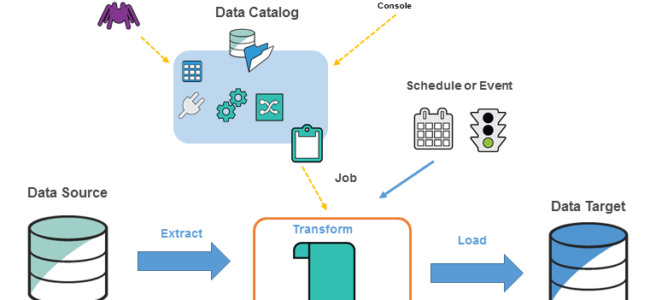
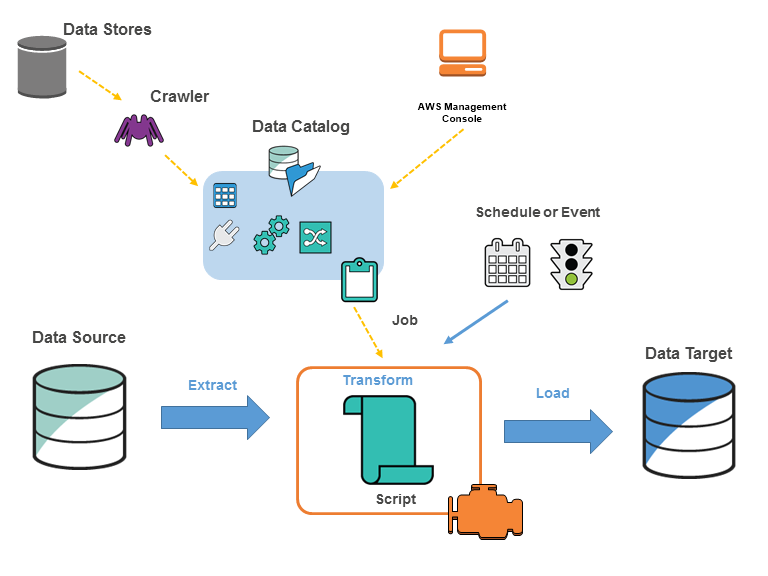
AWS Glue is a fully managed, ETL service that automates the time-consuming steps of data preparation for analytics.
is serverless and supports a pay-as-you-go model.
handles provisioning, configuration, and scaling of the resources required to run the ETL jobs on a fully managed, scale-out Apache Spark environment.
helps setup, orchestrate, and monitor complex data flows.
supports custom Scala or Python code and import custom libraries and Jar files into the AWS Glue ETL jobs to access data sources not natively supported by AWS Glue.
supports server side encryption for data at rest and SSL for data in motion.
provides development endpoints to edit, debug, and test the code it generates.
AWS Glue natively supports data stored in RDS, Redshift, DynamoDB, S3, MySQL, Oracle, Microsoft SQL Server, and PostgreSQL databases in the VPC running on EC2 and Data streams from MSK, Kinesis Data Streams, and Apache Kafka.
Glue ETL engine to Extract, Transform, and Load data that can automatically generate Scala or Python code.
Glue Data Catalog is a central repository and persistent metadata store to store structural and operational metadata for all the data assets.
Glue Crawlers scan various data stores to automatically infer schemas and partition structures to populate the Data Catalog with corresponding table definitions and statistics.
Glue Job Bookmark tracks data that has already been processed during a previous run of an ETL job by persisting state information from the job run.
AWS Glue Streaming ETL enables performing ETL operations on streaming data using continuously-running jobs.
Glue provides flexible scheduler that handles dependency resolution, job monitoring, and retries.
Glue Studio offers a graphical interface for authoring AWS Glue jobs to process data allowing you to define the flow of the data sources, transformations, and targets in the visual interface and generating Apache Spark code on your behalf.
Glue Data Quality helps reduces manual data quality effort by automatically measuring and monitoring the quality of data in data lakes and pipelines.
Glue DataBrew is a visual data preparation tool that makes it easy for data analysts and data scientists to prepare, visualize, clean, and normalize terabytes, and even petabytes of data directly from your data lake, data warehouses, and databases, including S3, Redshift, Aurora, and RDS.
AWS Lake Formation helps create secure data lakes, making data available for wide-ranging analytics.
is an integrated data lake service that helps to discover, ingest, clean, catalog, transform, and secure data and make it available for analysis and ML.
automatically manages access to the registered data in S3 through services including AWS Glue, Athena, Redshift, QuickSight, and EMR using Zeppelin notebooks with Apache Spark to ensure compliance with your defined policies.
helps configure and manage your data lake without manually integrating multiple underlying AWS services.
uses a shared infrastructure with AWS Glue, including console controls, ETL code creation and job monitoring, blueprints to create workflows for data ingest, the same data catalog, and a serverless architecture.
can manage data ingestion through AWS Glue. Data is automatically classified, and relevant data definitions, schema, and metadata are stored in the central Glue Data Catalog. Once the data is in the S3 data lake, access policies, including table-and-column-level access controls can be defined, and encryption for data at rest enforced.
integrates with IAM so authenticated users and roles can be automatically mapped to data protection policies that are stored in the data catalog. The IAM integration also supports Microsoft Active Directory or LDAP to federate into IAM using SAML.
helps centralize data access policy controls. Users and roles can be defined to control access, down to the table and column level.
supports private endpoints in the VPC and records all activity in AWS CloudTrail for network isolation and auditability.
is a very fast, easy-to-use, cloud-powered business analytics service that makes it easy to build visualizations, perform ad-hoc analysis, and quickly get business insights from their data, anytime, on any device.
delivers fast and responsive query performance by using a robust in-memory engine (SPICE).
“SPICE” stands for a Super-fast, Parallel, In-memory Calculation Engine
can also be configured to keep the data in SPICE up-to-date as the data in the underlying sources change.
automatically replicates data for high availability and enables QuickSight to scale to support users to perform simultaneous fast interactive analysis across a wide variety of AWS data sources.
supports
Excel files and flat files like CSV, TSV, CLF, ELF
on-premises databases like PostgreSQL, SQL Server and MySQL
SaaS applications like Salesforce
and AWS data sources such as Redshift, RDS, Aurora, Athena, and S3
supports various functions to format and transform the data.
supports assorted visualizations that facilitate different analytical approaches:
Comparison and distribution – Bar charts (several assorted variants)
Elasticsearch Service is a managed service that makes it easy to deploy, operate, and scale Elasticsearch clusters in the AWS Cloud.
Elasticsearch provides
real-time, distributed search and analytics engine
ability to provision all the resources for Elasticsearch cluster and launches the cluster
easy to use cluster scaling options. Scaling Elasticsearch Service domain by adding or modifying instances, and storage volumes is an online operation that does not require any downtime.
provides self-healing clusters, which automatically detects and replaces failed Elasticsearch nodes, reducing the overhead associated with self-managed infrastructures
domain snapshots to back up and restore ES domains and replicate domains across AZs
enhanced security with IAM, Network, Domain access policies, and fine-grained access control
storage volumes for the data using EBS volumes
ability to span cluster nodes across multiple AZs in the same region, known as zone awareness, for high availability and redundancy. Elasticsearch Service automatically distributes the primary and replica shards across instances in different AZs.
dedicated master nodes to improve cluster stability
data visualization using the Kibana tool
integration with CloudWatch for monitoring ES domain metrics
integration with CloudTrail for auditing configuration API calls to ES domains
integration with S3, Kinesis, and DynamoDB for loading streaming data
ability to handle structured and Unstructured data
supports encryption at rest through KMS, node-to-node encryption over TLS, and the ability to require clients to communicate with HTTPS
Amazon Athena is a serverless, interactive analytics service built on open-source frameworks, supporting open-table and file formats.
provides a simplified, flexible way to analyze petabytes of data in an S3 data lake and 30 data sources, including on-premises data sources or other cloud systems using SQL or Python without loading the data.
is built on open-source Trino and Presto engines and Apache Spark frameworks, with no provisioning or configuration effort required.
is highly available and runs queries using compute resources across multiple facilities, automatically routing queries appropriately if a particular facility is unreachable
can process unstructured, semi-structured, and structured datasets.
integrates with QuickSight for visualizing the data or creating dashboards.
supports various standard data formats, including CSV, TSV, JSON, ORC, Avro, and Parquet.
supports compressed data in Snappy, Zlib, LZO, and GZIP formats. You can improve performance and reduce costs by compressing, partitioning, and using columnar formats.
can handle complex analysis, including large joins, window functions, and arrays
uses a managed Glue Data Catalog to store information and schemas about the databases and tables that you create for the data stored in S3
uses schema-on-read technology, which means that the table definitions are applied to the data in S3 when queries are being applied. There’s no data loading or transformation required. Table definitions and schema can be deleted without impacting the underlying data stored in S3.
supports fine-grained access control with AWS Lake Formation which allows for centrally managing permissions and access control for data catalog resources in the S3 data lake.
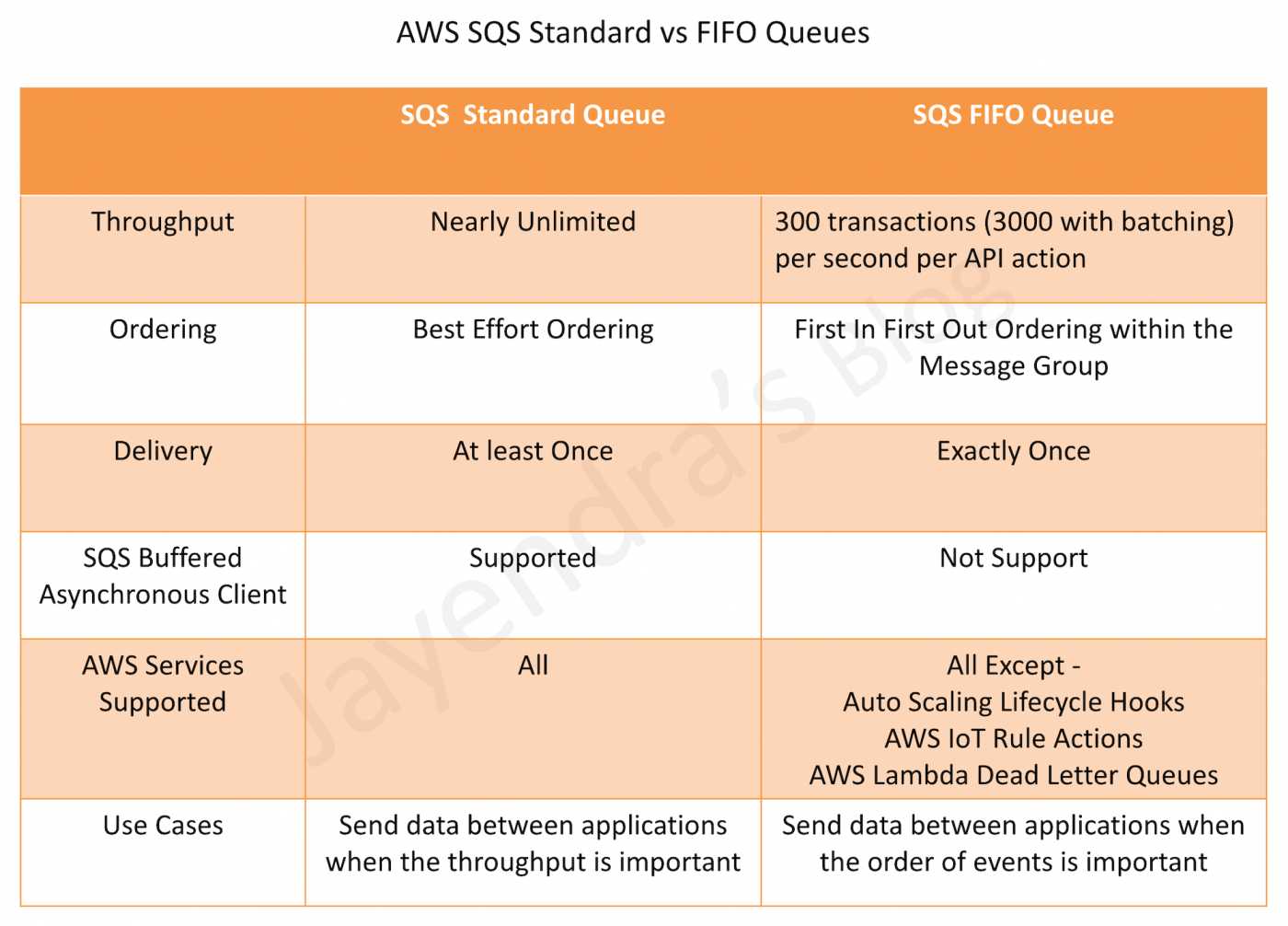
SQS FIFO Queue provides enhanced messaging between applications with the additional features
FIFO (First-In-First-Out) delivery
order in which messages are sent and received is strictly preserved
key when the order of operations & events is critical
Exactly-once processing
a message is delivered once and remains available until consumer processes and deletes it
key when duplicates can’t be tolerated.
limited to 300 or 3000 (with batching) transactions per second (TPS)
FIFO queues provide all the capabilities of Standard queues, improve upon, and complement the standard queue.
FIFO queues support message groups that allow multiple ordered message groups within a single queue.
FIFO Queue name should end with .fifo
SQS Buffered Asynchronous Client doesn’t currently support FIFO queues
Not all the AWS Services support FIFO like
Auto Scaling Lifecycle Hooks
AWS IoT Rule Actions
AWS Lambda Dead-Letter Queues
Amazon S3 Event Notifications
SQS FIFO supports one or more producers and messages are stored in the order that they were successfully received by SQS.
SQS FIFO queues don’t serve messages from the same message group to more than one consumer at a time.
Message Deduplication
SQS APIs provide deduplication functionality that prevents message producers from sending duplicates.
Message deduplication ID is the token used for the deduplication of sent messages.
If a message with a particular message deduplication ID is sent successfully, any messages sent with the same message deduplication ID are accepted successfully but aren’t delivered during the 5-minute deduplication interval.
So basically, any duplicates introduced by the message producer are removed within a 5-minute deduplication interval
Message deduplication applies to an entire queue, not to individual message groups
Message groups
Messages are grouped into distinct, ordered “bundles” within a FIFO queue
Message group ID is the tag that specifies that a message belongs to a specific message group
For each message group ID, all messages are sent and received in strict order
However, messages with different message group ID values might be sent and received out of order.
Every message must be associated with a message group ID, without which the action fails.
SQS delivers the messages in the order in which they arrive for processing if multiple hosts (or different threads on the same host) send messages with the same message group ID
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A restaurant reservation application needs the ability to maintain a waiting list. When a customer tries to reserve a table, and none are available, the customer must be put on the waiting list, and the application must notify the customer when a table becomes free. What service should the Solutions Architect recommend to ensure that the system respects the order in which the customer requests are put onto the waiting list?
Amazon SNS
AWS Lambda with sequential dispatch
A FIFO queue in Amazon SQS
A standard queue in Amazon SQS
In relation to Amazon SQS, how can you ensure that messages are delivered in order? Select 2 answers
Increase the size of your queue
Send them with a timestamp
Using FIFO queues
Give each message a unique id
Use sequence number within the messages with Standard queues
A company has run a major auction platform where people buy and sell a wide range of products. The platform requires that transactions from buyers and sellers get processed in exactly the order received. At the moment, the platform is implemented using RabbitMQ, which is a light weighted queue system. The company consulted you to migrate the on-premise platform to AWS. How should you design the migration plan? (Select TWO)
When the bids are received, send the bids to an SQS FIFO queue before they are processed.
When the users have submitted the bids from frontend, the backend service delivers the messages to an SQS standard queue.
Add a message group ID to the messages before they are sent to the SQS queue so that the message processing is in a strict order.
Use an EC2 or Lambda to add a deduplication ID to the messages before the messages are sent to the SQS queue to ensure that bids are processed in the right order.
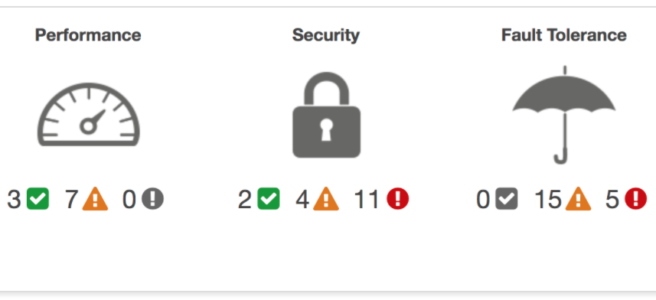
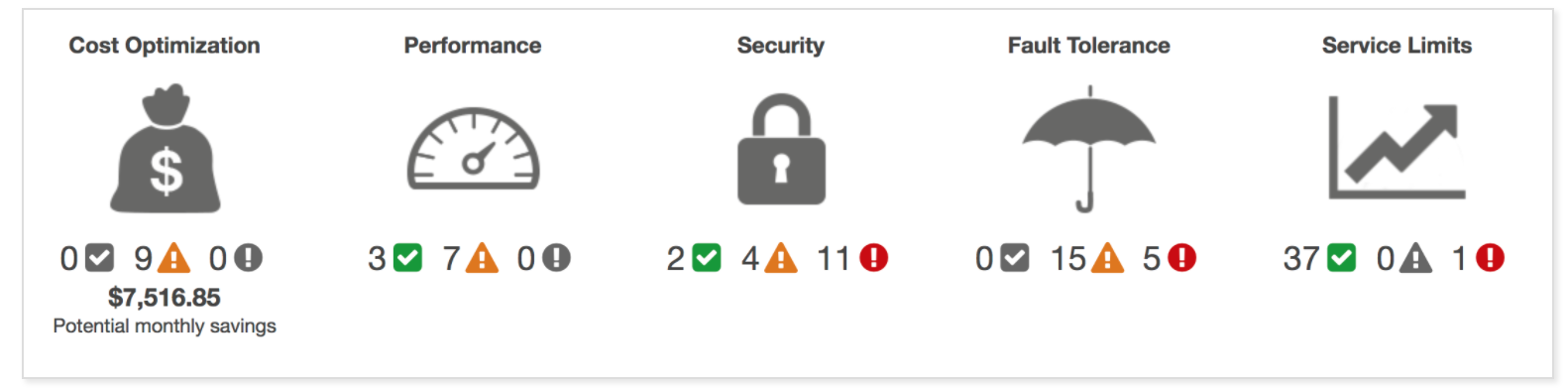
Trusted Advisor inspects the AWS environment to make recommendations for system performance, saving money, availability, and closing security gaps
Trusted Advisor checks the following categories
Cost Optimization
Recommendations that can potentially save money by highlighting unused resources and opportunities to reduce your bill.
Security
Identification of security settings and gaps, inline with the best practices, that could make the AWS solution less secure
Fault Tolerance
Recommendations that help increase the resiliency and availability of the AWS solution by highlighting redundancy shortfalls, current service limits, and over-utilized resources.
Performance
Recommendations that can help to improve the speed and responsiveness of the applications
AWS Support API provides programmatic access to AWS Support Center features to create, manage, and close the Support cases, and operationally manage the Trusted Advisor check requests and status.
Trusted Advisor Priority helps you focus on the most important recommendations to optimize your cloud deployments, improve resilience, and address security gaps.
Trusted Advisor notification feature helps stay up-to-date with the AWS resource deployment by performing an automated weekly refresh.
AWS Support API
API provides two different groups of operations:
Support case management operations to manage the entire life cycle of your AWS support cases, from creating a case to resolving it, and includes
Open a support case
Get a list and detailed information about recent support cases
Filter your search for support cases by dates and case identifiers, including resolved cases
Add communications and file attachments to your cases, and add the email recipients for case correspondence
Resolve your cases
AWS Trusted Advisor operations to access checks
Get the names and identifiers for the checks
Request that a check be run against your AWS account and resources
Get summaries and detailed information for your check results
Refresh the checks
Get the status of each check
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
The Trusted Advisor service provides insight regarding which categories of an AWS account?
Security, fault tolerance, high availability, and connectivity
Security, access control, high availability, and performance
Performance, cost optimization, security, and fault tolerance (Note – Service limits is the latest addition)
Performance, cost optimization, access control, and connectivity
Which of the following are categories of AWS Trusted Advisor? (Select TWO.)
Loose Coupling
Disaster recovery
Infrastructure as a Code
Security
Service limits
Which AWS tool will identify security groups that grant unrestricted Internet access to a limited list of ports?
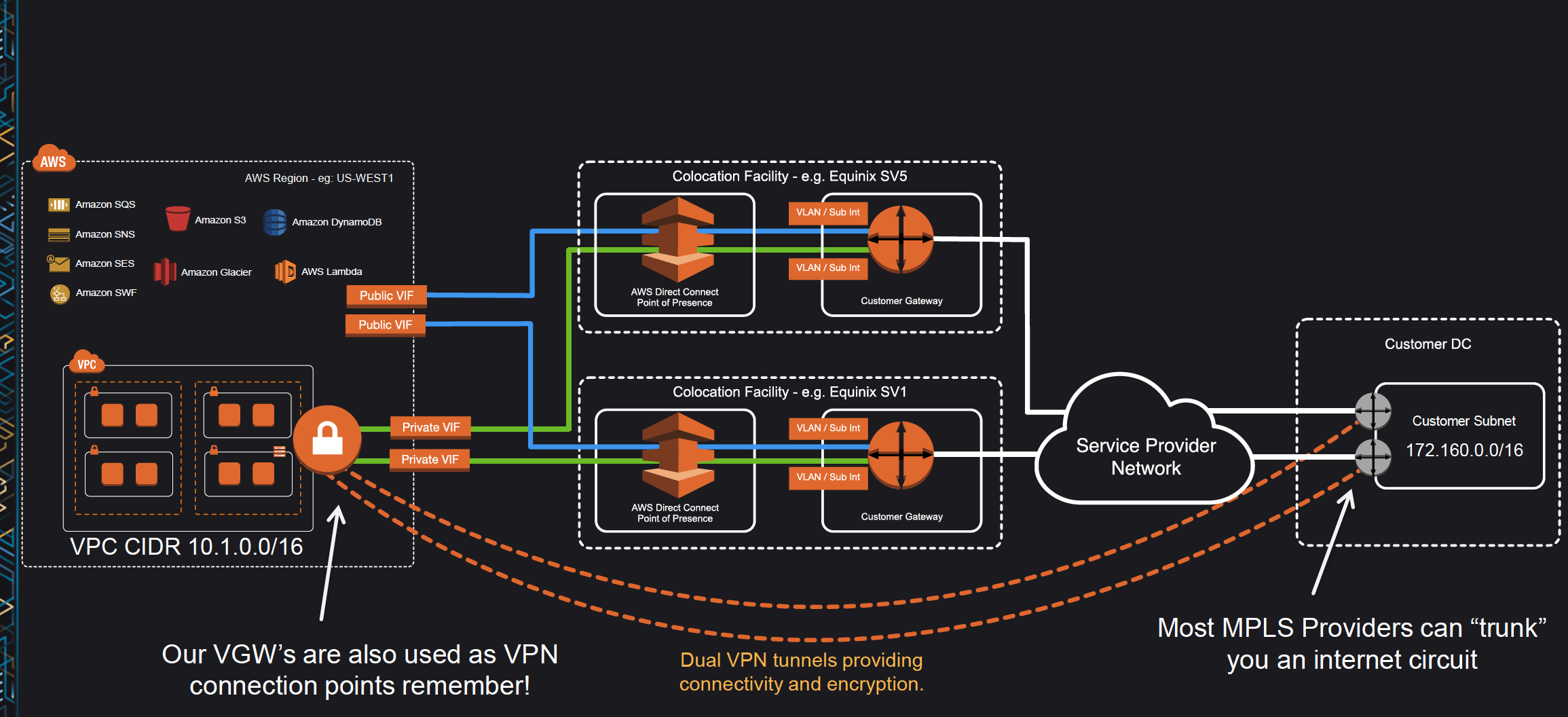
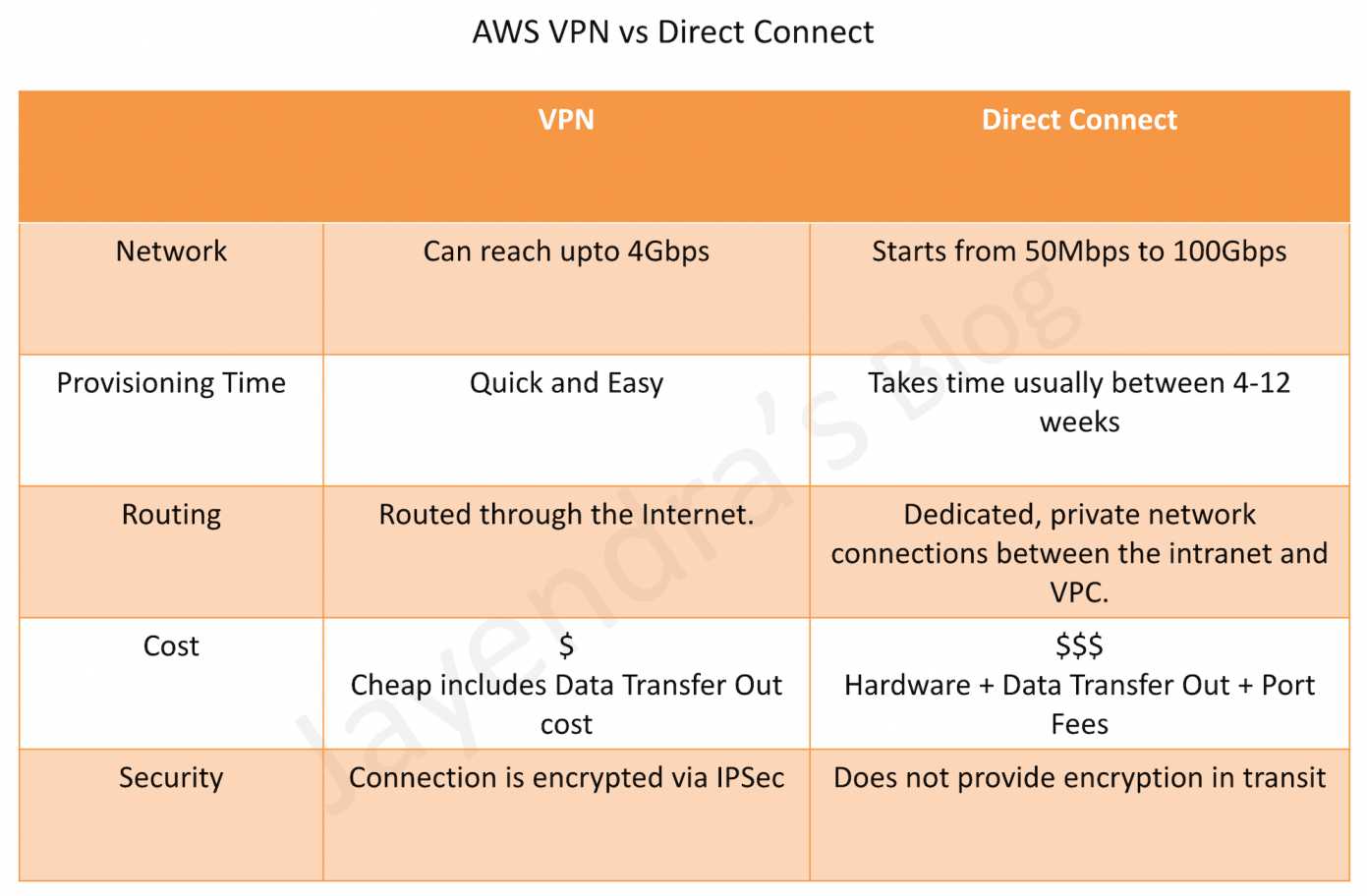
AWS Direct Connect is a network service that provides an alternative to using the Internet to utilize AWS cloud services
DX links your internal network to an AWS Direct Connect location over a standard Ethernet fiber-optic cable with one end of the cable connected to your router, the other to an AWS Direct Connect router.
Connections can be established with
Dedicated connections – 1Gbps, 10Gbps, and 100Gbps capacity.
Hosted connection – Speeds of 50, 100, 200, 300, 400, and 500 Mbps can be ordered from any APN partners supporting AWS DX. Also, supports 1, 2, 5 & 10 Gbps with selected partners.
Virtual interfaces can be created directly to public AWS services ( e.g. S3) or to VPC, bypassing internet service providers in the network path.
DX locations in public Regions or AWS GovCloud (US) can access public services in any other public Region.
Each AWS DX location enables connectivity to all AZs within the geographically nearest AWS region.
DX supports both the IPv4 and IPv6 communication protocols.
Direct Connect Advantages
Reduced Bandwidth Costs
All data transferred over the dedicated connection is charged at the reduced data transfer rate rather than Internet data transfer rates.
Transferring data to and from AWS directly reduces the bandwidth commitment to the Internet service provider
Consistent Network Performance
provides a dedicated connection and a more consistent network performance experience than the Internet which can widely vary.
AWS Services Compatibility
is a network service and works with all of the AWS services like S3, EC2, and VPC
Private Connectivity to AWS VPC
Using DX Private Virtual Interface a private, dedicated, high bandwidth network connection can be established between the network and VPC
Elastic
can be easily scaled to meet the needs by either using a higher bandwidth connection or by establishing multiple connections.
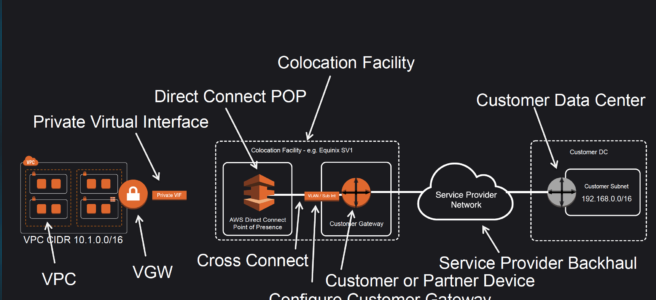
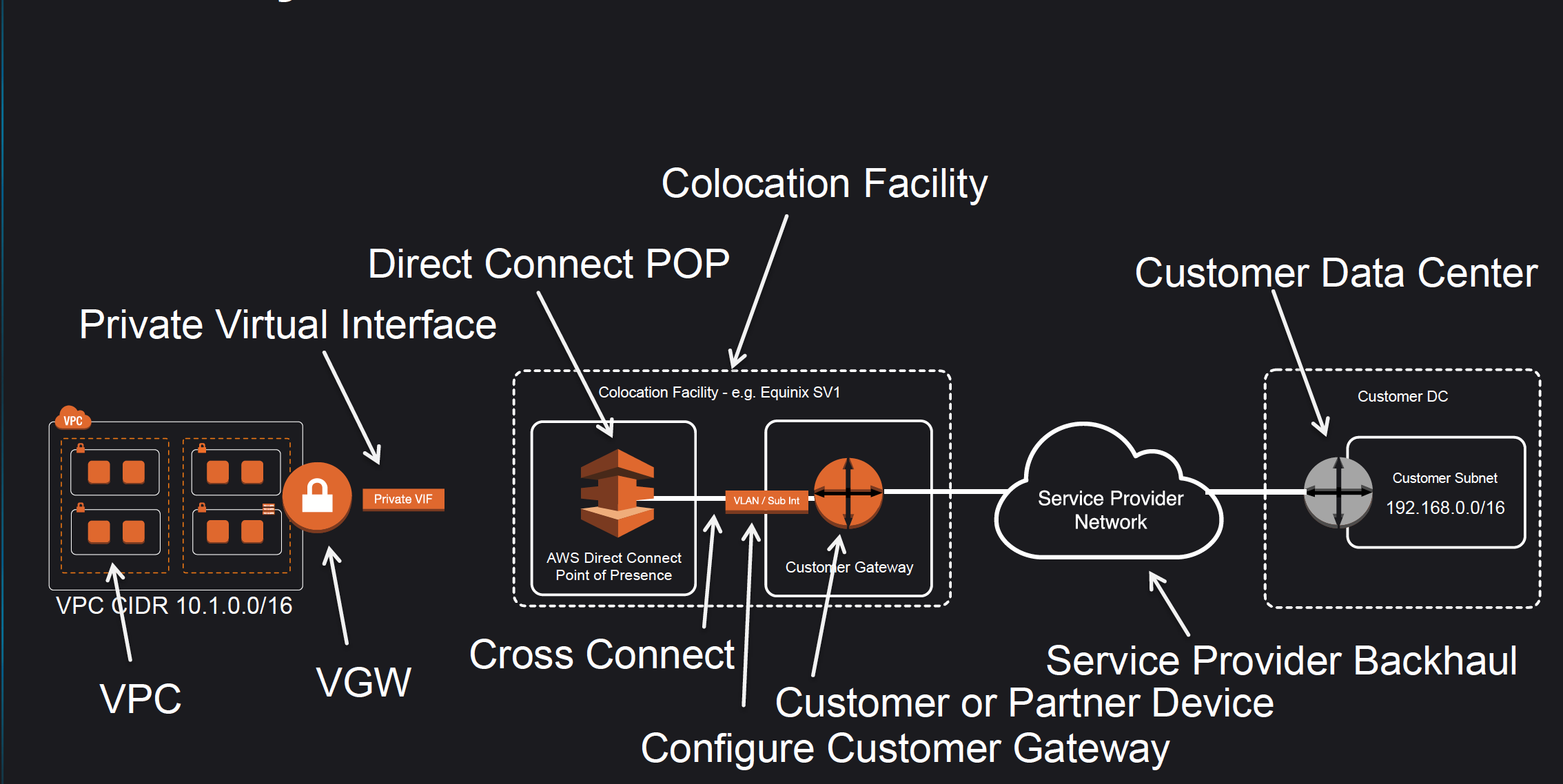
Direct Connect Anatomy
Amazon maintains AWS Direct Connect PoP across different locations (referred to as Colocation Facilities) which are different from AWS regions.
As a consumer, you can either purchase a rack space or use any of the AWS APN Partners which already have the infrastructure within the Colocation Facility and configure a Customer Gateway
Connection from the AWS Direct Connect PoP to the AWS regions is maintained by AWS itself.
Connection from the Customer Gateway to the Customer Data Center can be established using any Service Provider Network.
Connection between the PoP and the Customer gateway within the Colocation Facility is called Cross Connect.
Once a DX connection is created with AWS, an LOA-CFA (Letter Of Authority – Connecting Facility Assignment) would be received.
LOA-CFA can be handover to the Colocation Facility or the APN Partner to establish the Cross Connect
Once the Cross Connect and the connectivity between the CGW and Customer DataCenter are established, Virtual Interfaces can be created
AWS Direct Connect requires a VGW to access the AWS VPC.
Virtual Interfaces – VIF
Each connection requires a Virtual Interface
Each connection can be configured with one or more virtual interfaces.
Supports, Public, Private, and Transit Virtual Interface
Each VIF needs a VLAN ID, interface IP address, ASN, and BGP key.
To use the connection with another AWS account, a hosted virtual interface (Hosted VIF) can be created for that account. These hosted virtual interfaces work the same as standard virtual interfaces and can connect to public resources or a VPC.
Direct Connect Network Requirements
Single-mode fiber with
a 1000BASE-LX (1310 nm) transceiver for 1 gigabit Ethernet,
a 10GBASE-LR (1310 nm) transceiver for 10 gigabits, or
a 100GBASE-LR4 for 100 gigabit Ethernet.
802.1Q VLAN encapsulation must be supported
Auto-negotiation for a port must be disabled so that the speed and mode (half or full duplex) cannot be modified and should be manually configured
Border Gateway Protocol (BGP) and BGP MD5 authentication must be supported
Bidirectional Forwarding Detection (BFD) is optional and helps in quick failure detection.
Direct Connect Connections
Dedicated Connection
provides a physical Ethernet connection associated with a single customer
Customers can request a dedicated connection through the AWS Direct Connect console, the CLI, or the API.
support port speeds of 1 Gbps, 10 Gbps, and 100 Gbps.
supports multiple virtual interfaces (current limit of 50)
Hosted Connection
A physical Ethernet connection that an AWS Direct Connect Partner provisions on behalf of a customer.
Customers request a hosted connection by contacting a partner in the AWS Direct Connect Partner Program, which provisions the connection
Support port speeds of 50 Mbps, 100 Mbps, 200 Mbps, 300 Mbps, 400 Mbps, 500 Mbps, 1 Gbps, 2 Gbps, 5 Gbps, and 10 Gbps
1 Gbps, 2 Gbps, 5 Gbps or 10 Gbps hosted connections are supported by limited partners.
supports a single virtual interface
AWS uses traffic policing on hosted connections and excess traffic is dropped.
Direct Connect Virtual Interfaces – VIF
Public Virtual Interface
enables connectivity to all the AWS Public IP addresses
helps connect to public resources e.g. SQS, S3, EC2, Glacier, etc which are reachable publicly only.
can be used to access all public resources across regions
allows a maximum of 1000 prefixes. You can summarize the prefixes into a larger range to reduce the number of prefixes.
does not support Jumbo frames.
Private Virtual Interface
helps connect to the VPC for e.g. instances with a private IP address
supports
Virtual Private Gateway
Allows connections only to a single specific VPC with the attached VGW in the same region
Private VIF and Virtual Private Gateway – VGW should be in the same region
helps access one or more VPC Transit Gateways associated with Direct Connect Gateways.
supports Jumbo frames with 8500 MTU
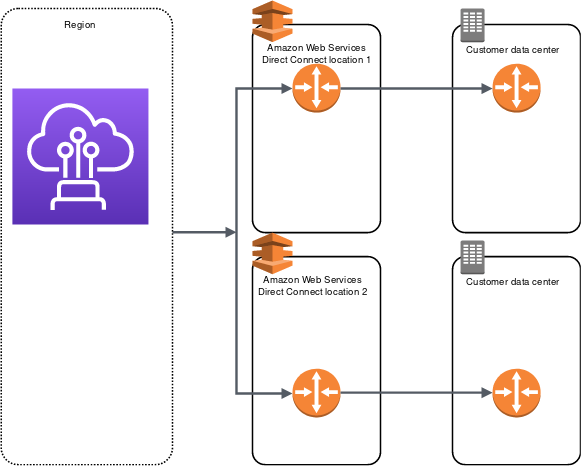
Direct Connect Redundancy
Direct Connect connections do not provide redundancy and have multiple single points of failures w.r.t to the hardware devices as each connection consists of a single dedicated connection between ports on your router and an Amazon router.
Redundancy can be provided by
Establishing a second DX connection, preferably in a different Colocation Facility using a different router and AWS DX PoP.
IPsec VPN connection between the Customer DC to the VGW.
For Multiple ports requested in the same AWS Direct Connect location, Amazon itself makes sure they are provisioned on redundant Amazon routers to prevent impact from a hardware failure
High Resiliency – 99.9%
High resiliency for critical workloads can be achieved by using two single connections to multiple locations.
It provides resiliency against connectivity failures caused by a fiber cut or a device failure. It also helps prevent a complete location failure.
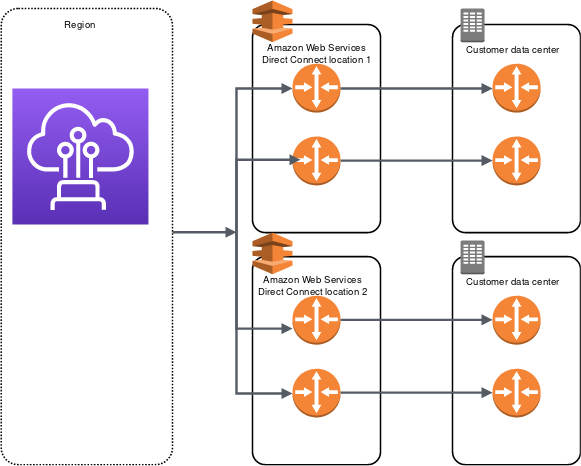
Maximum Resiliency – 99.99%
Maximum resiliency for critical workloads can be achieved using separate connections that terminate on separate devices in more than one location.
It provides resiliency against device, connectivity, and complete location failures.
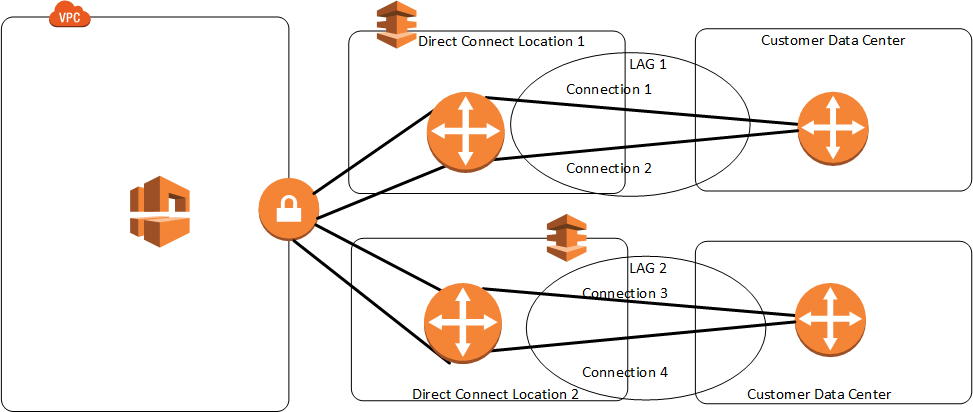
Direct Connect LAG – Link Aggregation Group
A LAG is a logical interface that uses the Link Aggregation Control Protocol (LACP) to aggregate multiple connections at a single AWS Direct Connect endpoint, treating them as a single, managed connection.
LAG can combine multiple connections to increase available bandwidth.
LAG can be created from existing or new connections.
Existing connections (whether standalone or part of another LAG) with the LAG can be associated after LAG creation.
LAG needs following rules
All connections must use the same bandwidth and port speed of 1, 10, 100 Gbps.
All connections must be dedicated connections.
Maximum of four connections in a LAG. Each connection in the LAG counts toward the overall connection limit for the Region.
All connections in the LAG must terminate at the same AWS Direct Connect endpoint.
Multi-chassis LAG (MLAG) is not supported by AWS.
LAG doesn’t make the connectivity to AWS more resilient.
LAG connections operate in Active/Active mode.
LAG supports attributes to define a minimum number of operational connections for the LAG function, with a default value of 0.
Direct Connect Failover
Bidirectional Forwarding Detection – BFD is a detection protocol that provides fast forwarding path failure detection times. These fast failure detection times facilitate faster routing reconvergence times.
When connecting to AWS services over DX connections it is recommended to enable BFD for fast failure detection and failover.
By default, BGP waits for three keep-alives to fail at a hold-down time of 90 seconds. Enabling BFD for the DX connection allows the BGP neighbor relationship to be quickly torn down.
Asynchronous BFD is automatically enabled for each DX virtual interface, but will not take effect until it’s configured on your router.
AWS has set the BFD liveness detection minimum interval to 300, and the BFD liveness detection multiplier to 3
It’s a best practice not to configure graceful restart and BFD at the same time to avoid failover or connection issues. For fast failover, configure BFD without graceful restart enabled.
BFD is supported for LAGs.
Direct Connect Security
Direct Connect does not encrypt the traffic that is in transit by default. To encrypt the data in transit that traverses DX, you must use the transit encryption options for that service.
DX connections can be secured
with IPSec VPN to provide secure, reliable connectivity.
with MACsec to encrypt the data from the corporate data center to the DX location.
MAC Security (MACsec)
is an IEEE standard that provides data confidentiality, data integrity, and data origin authenticity.
provides Layer2 security for 10Gbps and 100Gbps Dedicated Connections only.
delivers native, near line-rate, point-to-point encryption ensuring that data communications between AWS and the data center, office, or colocation facility remain protected.
removes VPN limitation that required the aggregation of multiple IPsec VPN tunnels to work around the throughput limits of using a single VPN connection.
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You are building a solution for a customer to extend their on-premises data center to AWS. The customer requires a 50-Mbps dedicated and private connection to their VPC. Which AWS product or feature satisfies this requirement?
Amazon VPC peering
Elastic IP Addresses
AWS Direct Connect
Amazon VPC virtual private gateway
Is there any way to own a direct connection to Amazon Web Services?
You can create an encrypted tunnel to VPC, but you don’t own the connection.
Yes, it’s called Amazon Dedicated Connection.
No, AWS only allows access from the public Internet.
Yes, it’s called Direct Connect
An organization has established an Internet-based VPN connection between their on-premises data center and AWS. They are considering migrating from VPN to AWS Direct Connect. Which operational concern should drive an organization to consider switching from an Internet-based VPN connection to AWS Direct Connect?
AWS Direct Connect provides greater redundancy than an Internet-based VPN connection.
AWS Direct Connect provides greater resiliency than an Internet-based VPN connection.
AWS Direct Connect provides greater bandwidth than an Internet-based VPN connection.
AWS Direct Connect provides greater control of network provider selection than an Internet-based VPN connection.
Does AWS Direct Connect allow you access to all Availabilities Zones within a Region?
Depends on the type of connection
No
Yes
Only when there’s just one availability zone in a region. If there are more than one, only one availability zone can be accessed directly.
A customer has established an AWS Direct Connect connection to AWS. The link is up and routes are being advertised from the customer’s end, however, the customer is unable to connect from EC2 instances inside its VPC to servers residing in its datacenter. Which of the following options provide a viable solution to remedy this situation? (Choose 2 answers)
Add a route to the route table with an IPSec VPN connection as the target (deals with VPN)
Enable route propagation to the Virtual Private Gateway (VGW)
Enable route propagation to the customer gateway (CGW) (route propagation is enabled on VGW)
Modify the route table of all Instances using the ‘route’ command. (no route command available)
Modify the Instances VPC subnet route table by adding a route back to the customer’s on-premises environment.
A company has configured and peered two VPCs: VPC-1 and VPC-2. VPC-1 contains only private subnets, and VPC-2 contains only public subnets. The company uses a single AWS Direct Connect connection and private virtual interface to connect their on-premises network with VPC-1. Which two methods increase the fault tolerance of the connection to VPC-1? Choose 2 answers
Establish a hardware VPN over the internet between VPC-2 and the on-premises network. (Peered VPC does not support Edge to Edge Routing)
Establish a hardware VPN over the internet between VPC-1 and the on-premises network
Establish a new AWS Direct Connect connection and private virtual interface in the same region as VPC-2 (Peered VPC does not support Edge to Edge Routing)
Establish a new AWS Direct Connect connection and private virtual interface in a different AWS region than VPC-1 (need to be in the same region as VPC-1)
Establish a new AWS Direct Connect connection and private virtual interface in the same AWS region as VPC-1
Your company previously configured a heavily used, dynamically routed VPN connection between your on-premises data center and AWS. You recently provisioned a Direct Connect connection and would like to start using the new connection. After configuring Direct Connect settings in the AWS Console, which of the following options will provide the most seamless transition for your users?
Delete your existing VPN connection to avoid routing loops configure your Direct Connect router with the appropriate settings and verify network traffic is leveraging Direct Connect.
Configure your Direct Connect router with a higher BGP priority than your VPN router, verify network traffic is leveraging Direct Connect, and then delete your existing VPN connection.
Update your VPC route tables to point to the Direct Connect connection configure your Direct Connect router with the appropriate settings verify network traffic is leveraging Direct Connect and then delete the VPN connection.
Configure your Direct Connect router, update your VPC route tables to point to the Direct Connect connection, configure your VPN connection with a higher BGP priority. And verify network traffic is leveraging the Direct Connect connection
You are designing the network infrastructure for an application server in Amazon VPC. Users will access all the application instances from the Internet as well as from an on-premises network The on-premises network is connected to your VPC over an AWS Direct Connect link. How would you design routing to meet the above requirements?
Configure a single routing table with a default route via the Internet gateway. Propagate a default route via BGP on the AWS Direct Connect customer router. Associate the routing table with all VPC subnets (propagating the default route would cause conflict)
Configure a single routing table with a default route via the internet gateway. Propagate specific routes for the on-premises networks via BGP on the AWS Direct Connect customer router. Associate the routing table with all VPC subnets.
Configure a single routing table with two default routes: one to the internet via an Internet gateway the other to the on-premises network via the VPN gateway use this routing table across all subnets in your VPC. (there cannot be 2 default routes)
Configure two routing tables one that has a default route via the Internet gateway and another that has a default route via the VPN gateway Associate both routing tables with each VPC subnet. (as the instances have to be in the public subnet and should have a single routing table associated with them)
You are implementing AWS Direct Connect. You intend to use AWS public service endpoints such as Amazon S3, across the AWS Direct Connect link. You want other Internet traffic to use your existing link to an Internet Service Provider. What is the correct way to configure AWS Direct Connect for access to services such as Amazon S3?
Configure a public Interface on your AWS Direct Connect link. Configure a static route via your AWS Direct Connect link that points to Amazon S3. Advertise a default route to AWS using BGP.
Create a private interface on your AWS Direct Connect link. Configure a static route via your AWS Direct Connect link that points to Amazon S3 Configure specific routes to your network in your VPC.
Create a public interface on your AWS Direct Connect link. Redistribute BGP routes into your existing routing infrastructure advertise specific routes for your network to AWS
Create a private interface on your AWS Direct connect link. Redistribute BGP routes into your existing routing infrastructure and advertise a default route to AWS.
You have been asked to design network connectivity between your existing data centers and AWS. Your application’s EC2 instances must be able to connect to existing backend resources located in your data center. Network traffic between AWS and your data centers will start small, but ramp up to 10s of GB per second over the course of several months. The success of your application is dependent upon getting to market quickly. Which of the following design options will allow you to meet your objectives?
Quickly create an internal ELB for your backend applications, submit a DirectConnect request to provision a 1 Gbps cross-connect between your data center and VPC, then increase the number or size of your DirectConnect connections as needed.
Allocate EIPs and an Internet Gateway for your VPC instances to use for quick, temporary access to your backend applications, then provision a VPN connection between a VPC and existing on-premises equipment.
Provision a VPN connection between a VPC and existing on-premises equipment, submit a DirectConnect partner request to provision cross connects between your data center and the DirectConnect location, then cut over from the VPN connection to one or more DirectConnect connections as needed.
Quickly submit a DirectConnect request to provision a 1 Gbps cross connect between your data center and VPC, then increase the number or size of your DirectConnect connections as needed.
You are tasked with moving a legacy application from a virtual machine running inside your datacenter to an Amazon VPC. Unfortunately, this app requires access to a number of on-premises services and no one who configured the app still works for your company. Even worse there’s no documentation for it. What will allow the application running inside the VPC to reach back and access its internal dependencies without being reconfigured? (Choose 3 answers)
An AWS Direct Connect link between the VPC and the network housing the internal services (VPN or a DX for communication)
An Internet Gateway to allow a VPN connection. (Virtual and Customer gateway is needed)
An Elastic IP address on the VPC instance (Don’t need a EIP as private subnets can also interact with on-premises network)
An IP address space that does not conflict with the one on-premises (IP address cannot conflict)
Entries in Amazon Route 53 that allow the Instance to resolve its dependencies’ IP addresses (Route 53 is not required)
A VM Import of the current virtual machine (VM Import to copy the VM to AWS as there is no documentation it can’t be configured from scratch)
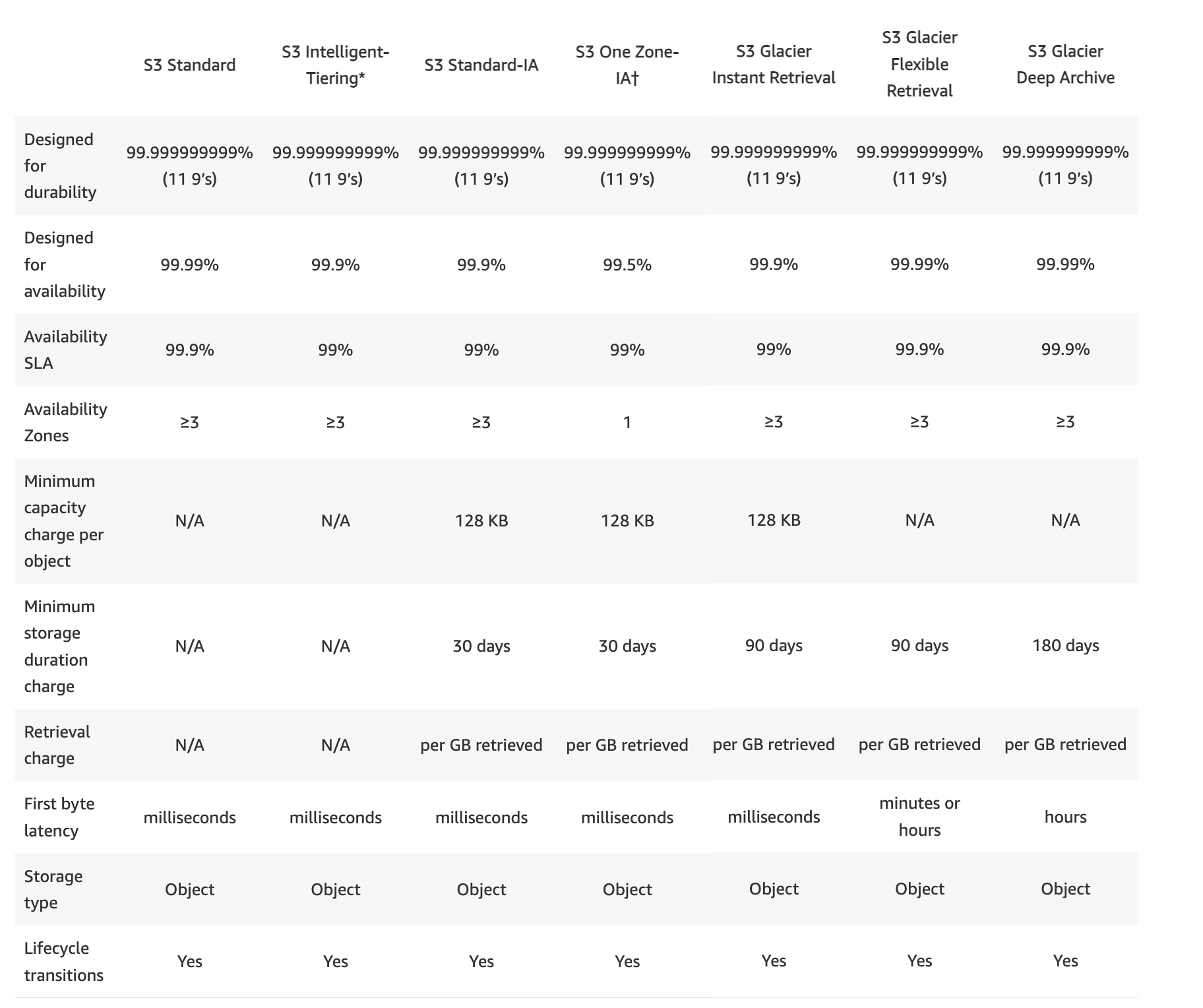
S3 Glacier is a storage service optimized for archival, infrequently used data, or “cold data.”
S3 Glacier is an extremely secure, durable, and low-cost storage service for data archiving and long-term backup.
provides average annual durability of 99.999999999% (11 9’s) for an archive.
redundantly stores data in multiple facilities and on multiple devices within each facility.
synchronously stores the data across multiple facilities before returning SUCCESS on uploading archives, to enhance durability.
performs regular, systematic data integrity checks and is built to be automatically self-healing.
enables customers to offload the administrative burdens of operating and scaling storage to AWS, without having to worry about capacity planning, hardware provisioning, data replication, hardware failure detection, recovery, or time-consuming hardware migrations.
offers a range of storage classes and patterns
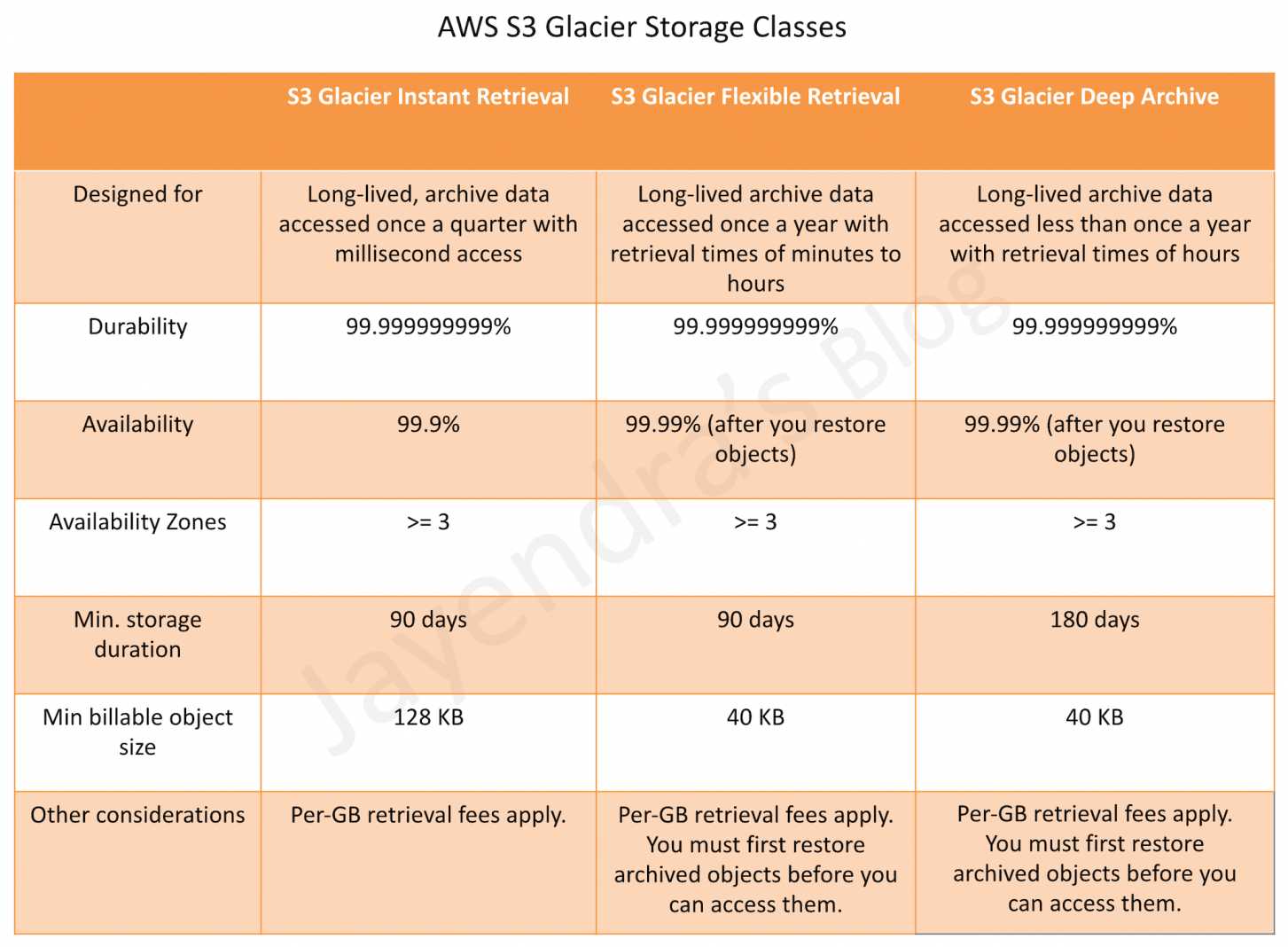
S3 Glacier Instant Retrieval
Use for archiving data that is rarely accessed and requires milliseconds retrieval.
S3 Glacier Flexible Retrieval (formerly the S3 Glacier storage class)
Use for archives where portions of the data might need to be retrieved in minutes.
offers a range of data retrievals options where the retrieval time varies from minutes to hours.
Expedited retrieval: 1-5 mins
Standard retrieval: 3-5 hours
Bulk retrieval: 5-12 hours
S3 Glacier Deep Archive
Use for archiving data that rarely need to be accessed.
Data stored has a default retrieval time of 12 hours.
S3 Glacier Flexible Retrieval and S3 Glacier Deep Archive objects are not available for real-time access.
is a great storage choice when low storage cost is paramount, with data rarely retrieved, and retrieval latency is acceptable. S3 should be used if applications require fast, frequent real-time access to the data.
can store virtually any kind of data in any format.
allows interaction through AWS Management Console, Command Line Interface CLI, and SDKs or REST-based APIs.
AWS Management console can only be used to create and delete vaults.
Rest of the operations to upload, download data, and create jobs for retrieval need CLI, SDK, or REST-based APIs.
Use cases include
Digital media archives
Data that must be retained for regulatory compliance
Financial and healthcare records
Raw genomic sequence data
Long-term database backups
S3 Glacier Storage Classes
S3 Glacier Instant Retrieval
Use for archiving data that is rarely accessed and requires milliseconds retrieval.
Use for archives where portions of the data might need to be retrieved in minutes.
Data has a minimum storage duration period of 90 days and can be accessed in as little as 1-5 minutes by using an expedited retrieval
You can also request free Bulk retrievals in up to 5-12 hours.
S3 supports restore requests at a rate of up to 1,000 transactions per second, per AWS account.
S3 Glacier Deep Archive
Use for archiving data that rarely needs to be accessed.
S3 Glacier Deep Archive is the lowest cost storage option in AWS.
Retrieval costs can be reduced further using bulk retrieval, which returns data within 48 hours.
Data stored has a minimum storage duration period of 180 days
Data stored has a default retrieval time of 12 hours.
S3 supports restore requests at a rate of up to 1,000 transactions per second, per AWS account.
S3 Glacier Flexible Data Retrievals Options
Glacier provides three options for retrieving data with varying access times and costs: Expedited, Standard, and Bulk retrievals.
Expedited Retrievals
Expedited retrievals allow quick access to the data when occasional urgent requests for a subset of archives are required.
Data has a minimum storage duration period of 90 days
Data accessed are typically made available within 1-5 minutes.
There are two types of Expedited retrievals: On-Demand and Provisioned.
On-Demand requests are like EC2 On-Demand instances and are available the vast majority of the time.
Provisioned requests are guaranteed to be available when needed.
Standard Retrievals
Standard retrievals allow access to any of the archives within several hours.
Standard retrievals typically complete within 3-5 hours.
Bulk Retrievals
Bulk retrievals are Glacier’s lowest-cost retrieval option, enabling retrieval of large amounts, even petabytes, of data inexpensively in a day.
Bulk retrievals typically complete within 5-12 hours.
S3 Glacier Data Model
Glacier data model core concepts include vaults and archives and also include job and notification configuration resources
Vault
A vault is a container for storing archives.
Each vault resource has a unique address, which comprises the region the vault was created and the unique vault name within the region and account for e.g. https://glacier.us-west-2.amazonaws.com/111122223333/vaults/examplevault
Vault allows the storage of an unlimited number of archives.
Glacier supports various vault operations which are region-specific.
An AWS account can create up to 1,000 vaults per region.
Archive
An archive can be any data such as a photo, video, or document and is a base unit of storage in Glacier.
Each archive has a unique ID and an optional description, which can only be specified during the upload of an archive.
Glacier assigns the archive an ID, which is unique in the AWS region in which it is stored.
An archive can be uploaded in a single request. While for large archives, Glacier provides a multipart upload API that enables uploading an archive in parts.
An Archive can be up to 40TB.
Jobs
A Job is required to retrieve an Archive and vault inventory list
Data retrieval requests are asynchronous operations, are queued and some jobs can take about four hours to complete.
A job is first initiated and then the output of the job is downloaded after the job is completed.
Vault inventory jobs need the vault name.
Data retrieval jobs need both the vault name and the archive id, with an optional description
A vault can have multiple jobs in progress at any point in time and can be identified by Job ID, assigned when is it created for tracking
Glacier maintains job information such as job type, description, creation date, completion date, and job status and can be queried
After the job completes, the job output can be downloaded in full or partially by specifying a byte range.
Notification Configuration
As the jobs are asynchronous, Glacier supports a notification mechanism to an SNS topic when the job completes
SNS topic for notification can either be specified with each individual job request or with the vault
Glacier stores the notification configuration as a JSON document
Glacier Supported Operations
Vault Operations
Glacier provides operations to create and delete vaults.
A vault can be deleted only if there are no archives in the vault as of the last computed inventory and there have been no writes to the vault since the last inventory (as the inventory is prepared periodically)
Vault Inventory
Vault inventory helps retrieve a list of archives in a vault with information such as archive ID, creation date, and size for each archive
Inventory for each vault is prepared periodically, every 24 hours
Vault inventory is updated approximately once a day, starting on the day the first archive is uploaded to the vault.
When a vault inventory job is, Glacier returns the last inventory it generated, which is a point-in-time snapshot and not real-time data.
Vault Metadata or Description can also be obtained for a specific vault or for all vaults in a region, which provides information such as
creation date,
number of archives in the vault,
total size in bytes used by all the archives in the vault,
and the date the vault inventory was generated
S3 Glacier also provides operations to set, retrieve, and delete a notification configuration on the vault. Notifications can be used to identify vault events.
Archive Operations
S3 Glacier provides operations to upload, download and delete archives.
All archive operations must either be done using AWS CLI or SDK. It cannot be done using AWS Management Console.
An existing archive cannot be updated, it has to be deleted and uploaded.
Archive Upload
An archive can be uploaded in a single operation (1 byte to up to 4 GB in size) or in parts referred to as Multipart upload (40 TB)
Multipart Upload helps to
improve the upload experience for larger archives.
upload archives in parts, independently, parallelly and in any order
faster recovery by needing to upload only the part that failed upload and not the entire archive.
upload archives without even knowing the size
upload archives from 1 byte to about 40,000 GB (10,000 parts * 4 GB) in size
To upload existing data to Glacier, consider using the AWS Import/Export Snowball service, which accelerates moving large amounts of data into and out of AWS using portable storage devices for transport. AWS transfers the data directly onto and off of storage devices using Amazon’s high-speed internal network, bypassing the Internet.
Glacier returns a response that includes an archive ID that is unique in the region in which the archive is stored.
Glacier does not support any additional metadata information apart from an optional description. Any additional metadata information required should be maintained on the client side.
Archive Download
Downloading an archive is an asynchronous operation and is the 2 step process
Initiate an archive retrieval job
When a Job is initiated, a job ID is returned as a part of the response.
Job is executed asynchronously and the output can be downloaded after the job completes.
A job can be initiated to download the entire archive or a portion of the archive.
After the job completes, download the bytes
An archive can be downloaded as all the bytes or a specific byte range to download only a portion of the output
Downloading the archive in chunks helps in the event of a download failure, as only that part needs to be downloaded
Job completion status can be checked by
Check status explicitly (Not Recommended)
periodically poll the describe job operation request to obtain job information
Completion notification
An SNS topic can be specified, when the job is initiated or with the vault, to be used to notify job completion
About Range Retrievals
S3 Glacier allows retrieving an archive either in whole (default) or a range, or a portion.
Range retrievals need a range to be provided that is megabyte aligned.
Glacier returns a checksum in the response which can be used to verify if any errors in the download by comparing it with the checksum computed on the client side.
Specifying a range of bytes can be helpful when:
Control bandwidth costs
Glacier allows retrieval of up to 5 percent of the average monthly storage (pro-rated daily) for free each month
Scheduling range retrievals can help in two ways.
meet the monthly free allowance of 5 percent by spreading out the data requested
if the amount of data retrieved doesn’t meet the free allowance percentage, scheduling range retrievals enable a reduction of the peak retrieval rate, which determines the retrieval fees.
Manage your data downloads
Glacier allows retrieved data to be downloaded for 24 hours after the retrieval request completes
Only portions of the archive can be retrieved so that the schedule of downloads can be managed within the given download window.
Retrieve a targeted part of a large archive
Retrieving an archive in a range can be useful if an archive is uploaded as an aggregate of multiple individual files, and only a few files need to be retrieved
Archive Deletion
An archive can be deleted from the vault only one at a time
This operation is idempotent. Deleting an already-deleted archive does not result in an error
AWS applies a pro-rated charge for items that are deleted prior to 90 days, as it is meant for long-term storage
Archive Update
An existing archive cannot be updated and must be deleted and re-uploaded, which would be assigned a new archive id
S3 Glacier Vault Lock
S3 Glacier Vault Lock helps deploy and enforce compliance controls for individual S3 Glacier vaults with a vault lock policy.
Specify controls such as “write once read many” (WORM) can be enforced using a vault lock policy and the policy can be locked for future edits.
Once locked, the policy can no longer be changed.
S3 Glacier Security
S3 Glacier supports data in transit encryption using Secure Sockets Layer (SSL) or client-side encryption.
All data is encrypted on the server side with Glacier handling key management and key protection. It uses AES-256, one of the strongest block ciphers available
Security and compliance of S3 Glacier are assessed by third-party auditors as part of multiple AWS compliance programs including SOC, HIPAA, PCI DSS, FedRAMP, etc.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
What is Amazon Glacier?
You mean Amazon “Iceberg”: it’s a low-cost storage service.
A security tool that allows to “freeze” an EBS volume and perform computer forensics on it.
A low-cost storage service that provides secure and durable storage for data archiving and backup
It’s a security tool that allows to “freeze” an EC2 instance and perform computer forensics on it.
Amazon Glacier is designed for: (Choose 2 answers)
Active database storage
Infrequently accessed data
Data archives
Frequently accessed data
Cached session data
An organization is generating digital policy files which are required by the admins for verification. Once the files are verified they may not be required in the future unless there is some compliance issue. If the organization wants to save them in a cost effective way, which is the best possible solution?
AWS RRS
AWS S3
AWS RDS
AWS Glacier
A user has moved an object to Glacier using the life cycle rules. The user requests to restore the archive after 6 months. When the restore request is completed the user accesses that archive. Which of the below mentioned statements is not true in this condition?
The archive will be available as an object for the duration specified by the user during the restoration request
The restored object’s storage class will be RRS (After the object is restored the storage class still remains GLACIER. Read more)
The user can modify the restoration period only by issuing a new restore request with the updated period
The user needs to pay storage for both RRS (restored) and Glacier (Archive) Rates
To meet regulatory requirements, a pharmaceuticals company needs to archive data after a drug trial test is concluded. Each drug trial test may generate up to several thousands of files, with compressed file sizes ranging from 1 byte to 100MB. Once archived, data rarely needs to be restored, and on the rare occasion when restoration is needed, the company has 24 hours to restore specific files that match certain metadata. Searches must be possible by numeric file ID, drug name, participant names, date ranges, and other metadata. Which is the most cost-effective architectural approach that can meet the requirements?
Store individual files in Amazon Glacier, using the file ID as the archive name. When restoring data, query the Amazon Glacier vault for files matching the search criteria. (Individual files are expensive and does not allow searching by participant names etc)
Store individual files in Amazon S3, and store search metadata in an Amazon Relational Database Service (RDS) multi-AZ database. Create a lifecycle rule to move the data to Amazon Glacier after a certain number of days. When restoring data, query the Amazon RDS database for files matching the search criteria, and move the files matching the search criteria back to S3 Standard class. (As the data is not needed can be stored to Glacier directly and the data need not be moved back to S3 standard)
Store individual files in Amazon Glacier, and store the search metadata in an Amazon RDS multi-AZ database. When restoring data, query the Amazon RDS database for files matching the search criteria, and retrieve the archive name that matches the file ID returned from the database query. (Individual files and Multi-AZ is expensive)
First, compress and then concatenate all files for a completed drug trial test into a single Amazon Glacier archive. Store the associated byte ranges for the compressed files along with other search metadata in an Amazon RDS database with regular snapshotting. When restoring data, query the database for files that match the search criteria, and create restored files from the retrieved byte ranges.
Store individual compressed files and search metadata in Amazon Simple Storage Service (S3). Create a lifecycle rule to move the data to Amazon Glacier, after a certain number of days. When restoring data, query the Amazon S3 bucket for files matching the search criteria, and retrieve the file to S3 reduced redundancy in order to move it back to S3 Standard class. (Once the data is moved from S3 to Glacier the metadata is lost, as Glacier does not have metadata and must be maintained externally)
A user is uploading archives to Glacier. The user is trying to understand key Glacier resources. Which of the below mentioned options is not a Glacier resource?
AWS Glue is a fully-managed, ETL i.e extract, transform, and load service that automates the time-consuming steps of data preparation for analytics
is serverless and supports pay-as-you-go model. There is no infrastructure to provision or manage.
handles provisioning, configuration, and scaling of the resources required to run the ETL jobs on a fully managed, scale-out Apache Spark environment.
makes it simple and cost-effective to categorize the data, clean it, enrich it, and move it reliably between various data stores and streams.
also helps setup, orchestrate, and monitor complex data flows.
help automate much of the undifferentiated heavy lifting involved with discovering, categorizing, cleaning, enriching, and moving data, so more time can be spent on analyzing the data.
also supports custom Scala or Python code and import custom libraries and Jar files into the AWS Glue ETL jobs to access data sources not natively supported by AWS Glue.
supports server side encryption for data at rest and SSL for data in motion.
provides development endpoints to edit, debug, and test the code it generates.
Glue ETL engine to Extract, Transform, and Load data that can automatically generate Scala or Python code.
Glue Data Catalog is a central repository and persistent metadata store to store structural and operational metadata for all the data assets.
Glue crawlers scan various data stores to automatically infer schemas and partition structures to populate the Data Catalog with corresponding table definitions and statistics.
AWS Glue Streaming ETL enables performing ETL operations on streaming data using continuously-running jobs.
Glue Flexible scheduler that handles dependency resolution, job monitoring, and retries.
Glue Studio offers a graphical interface for authoring AWS Glue jobs to process data allowing you to define the flow of the data sources, transformations, and targets in the visual interface and generating Apache Spark code on your behalf.
Glue Data Quality helps reduces manual data quality efforts by automatically measuring and monitoring the quality of data in data lakes and pipelines.
Glue DataBrew is a visual data preparation tool that makes it easy for data analysts and data scientists to prepare data with an interactive, point-and-click visual interface without writing code. It helps to visualize, clean, and normalize data directly from the data lake, data warehouses, and databases, including S3, Redshift, Aurora, and RDS.
AWS Glue Data Catalog
AWS Glue Data Catalog is a central repository and persistent metadata store to store structural and operational metadata for all the data assets.
AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos, and use that metadata to query and transform the data.
For a given data set, Data Catalog can store its table definition, physical location, add business-relevant attributes, as well as track how this data has changed over time.
Data Catalog is Apache Hive Metastore compatible and is a drop-in replacement for the Hive Metastore for Big Data applications running on EMR.
Data Catalog also provides out-of-box integration with Athena, EMR, and Redshift Spectrum.
Table definitions once added to the Glue Data Catalog, are available for ETL and also readily available for querying in Athena, EMR, and Redshift Spectrum to provide a common view of the data between these services.
Data Catalog supports bulk import of the metadata from existing persistent Apache Hive Metastore by using our import script.
Data Catalog provides comprehensive audit and governance capabilities, with schema change tracking and data access controls, which helps ensure that data is not inappropriately modified or inadvertently shared
Each AWS account has one AWS Glue Data Catalog per region.
AWS Glue Crawlers
AWS Glue crawler connects to a data store, progresses through a prioritized list of classifiers to extract the schema of the data and other statistics, and then populates the Data Catalog with this metadata.
Glue crawlers scan various data stores to automatically infer schemas and partition structures to populate the Data Catalog with corresponding table definitions and statistics.
Glue crawlers can be scheduled to run periodically so that the metadata is always up-to-date and in-sync with the underlying data.
Crawlers automatically add new tables, new partitions to existing tables, and new versions of table definitions.
Dynamic Frames
AWS Glue is designed to work with semi-structured data and introduces a dynamic frame component, which can be used in the ETL scripts.
Dynamic frame is a distributed table that supports nested data such as structures and arrays.
Each record is self-describing, designed for schema flexibility with semi-structured data. Each record contains both data and the schema that describes that data.
A Dynamic Frame is similar to an Apache Spark dataframe, which is a data abstraction used to organize data into rows and columns, except that each record is self-describing so no schema is required initially.
Dynamic frames provide schema flexibility and a set of advanced transformations specifically designed for dynamic frames.
Conversion can be done between Dynamic frames and Spark dataframes, to take advantage of both AWS Glue and Spark transformations to do the kinds of analysis needed.
AWS Glue Streaming ETL
AWS Glue enables performing ETL operations on streaming data using continuously-running jobs.
AWS Glue streaming ETL is built on the Apache Spark Structured Streaming engine, and can ingest streams from Kinesis Data Streams and Apache Kafka using Amazon Managed Streaming for Apache Kafka.
Streaming ETL can clean and transform streaming data and load it into S3 or JDBC data stores.
Use Streaming ETL in AWS Glue to process event data like IoT streams, clickstreams, and network logs.
Glue Job Bookmark
Glue Job Bookmark tracks data that has already been processed during a previous run of an ETL job by persisting state information from the job run.
Job bookmarks help Glue maintain state information and prevent the reprocessing of old data.
Job bookmarks help process new data when rerunning on a scheduled interval
Job bookmark is composed of the states for various elements of jobs, such as sources, transformations, and targets. for e.g, an ETL job might read new partitions in an S3 file. Glue tracks which partition the job has processed successfully to prevent duplicate processing and duplicate data in the job’s target data store.
Glue Databrew
Glue DataBrew is a visual data preparation tool that enables users to clean and normalize data without writing any code.
is serverless, and can help explore and transform terabytes of raw data without needing to create clusters or manage any infrastructure.
helps reduce the time it takes to prepare data for analytics and machine learning (ML).
provides 250 ready-made transformations to automate data preparation tasks, such as filtering anomalies, converting data to standard formats, and correcting invalid values.
business analysts, data scientists, and data engineers can more easily collaborate to get insights from raw data.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
An organization is setting up a data catalog and metadata management environment for their numerous data stores currently running on AWS. The data catalog will be used to determine the structure and other attributes of data in the data stores. The data stores are composed of Amazon RDS databases, Amazon Redshift, and CSV files residing on Amazon S3. The catalog should be populated on a scheduled basis, and minimal administration is required to manage the catalog. How can this be accomplished?
Set up Amazon DynamoDB as the data catalog and run a scheduled AWS Lambda function that connects to data sources to populate the database.
Use an Amazon database as the data catalog and run a scheduled AWS Lambda function that connects to data sources to populate the database.
Use AWS Glue Data Catalog as the data catalog and schedule crawlers that connect to data sources to populate the database.
Set up Apache Hive metastore on an Amazon EC2 instance and run a scheduled bash script that connects to data sources to populate the metastore.
I recently recertified for the AWS Certified SysOps Administrator – Associate (SOA-C02) exam.
SOA-C02 is the updated version of the SOA-C01 AWS exam with hands-on labs included, which is the first with AWS.
NOTE: As of March 28, 2023, the AWS Certified SysOps Administrator – Associate exam will not include exam labs until further notice. This removal of exam labs is temporary while we evaluate the exam labs and make improvements to provide an optimal candidate experience.
SOA-C02 is the first AWS exam that included 2 sections
Objective questions
Hands-on labs
With Labs
SOA-C02 Exam consists of around 50 objective-type questions and 3 Hands-on labs to be answered in 190 minutes.
Labs are performed in a separate instance. Copy-paste works, so make sure you copy the exact names on resource creation.
Labs are pretty easy if you have worked on AWS.
Plan to leave 20 minutes to complete each exam lab.
NOTE: Once you complete a section and click next you cannot go back to the section. The same is for the labs. Once a lab is completed, you cannot return back to the lab.
Practice the Sample Lab provided when you book the exam, which would give you a feel of how the hands-on exam would actually be.
Without Labs
SOA-C02 exam consists of 65 questions in 130 minutes, and the time is more than sufficient if you are well-prepared.
SOA-C02 exam includes two types of questions, multiple-choice and multiple-response.
SOA-C02 has a scaled score between 100 and 1,000. The scaled score needed to pass the exam is 720.
Associate exams currently cost $ 150 + tax.
You can get an additional 30 minutes if English is your second language by requesting Exam Accommodations. It might not be needed for Associate exams but is helpful for Professional and Specialty ones.
AWS exams can be taken either remotely or online, I prefer to take them online as it provides a lot of flexibility. Just make sure you have a proper place to take the exam with no disturbance and nothing around you.
Also, if you are taking the AWS Online exam for the first time try to join at least 30 minutes before the actual time as I have had issues with both PSI and Pearson with long wait times.
Signed up with AWS for the Free Tier account which provides a lot of the Services to be tried for free with certain limits which are more than enough to get things going. Be sure to decommission anything, if you using anything beyond the free limits, preventing any surprises 🙂
Elastic Beanstalk helps to quickly deploy and manage applications in the AWS Cloud without having to worry about the infrastructure that runs those applications.
Understand Elastic Beanstalk overall – Applications, Versions, and Environments
SCP provides the maximum permission that a user can have, however, the user still needs to be explicitly given IAM policy.
Consolidated billing enables consolidating payments from multiple AWS accounts and includes combined usage and volume discounts including sharing of Reserved Instances across accounts.
Systems Manager is the operations hub and provides various services like parameter store, patch manager
Parameter Store provides secure, scalable, centralized, hierarchical storage for configuration data and secret management. Does not support secrets rotation. Use Secrets Manager instead
Session Manager provides secure and auditable instance management without the need to open inbound ports, maintain bastion hosts, or manage SSH keys.
Patch Manager helps automate the process of patching managed instances with both security-related and other types of updates.
collects monitoring and operational data in the form of logs, metrics, and events, and visualizes it.
EC2 metrics can track (disk, network, CPU, status checks) but do not capture metrics like memory, disk swap, disk storage, etc.
CloudWatch unified agent can be used to gather custom metrics like memory, disk swap, disk storage, etc.
CloudWatch Alarm actions can be configured to perform actions based on various metrics for e.g. CPU below 5%
CloudWatch alarm can monitor StatusCheckFailed_System status on an EC2 instance and automatically recover the instance if it becomes impaired due to an underlying hardware failure or a problem that requires AWS involvement to repair.
Load Balancer metrics SurgeQueueLength and SpilloverCount
HealthyHostCount, UnHealthyHostCount determines the number of healthy and unhealthy instances registered with the load balancer.
Reasons for 4XX and 5XX errors
CloudWatch logs can be used to monitor, store, and access log files from EC2 instances, CloudTrail, Route 53, and other sources. You can create metric filters over the logs.
With Organizations, the trail can be configured to log CloudTrail from all accounts to a central account.
CloudTrail log file integrity validation can be used to check whether a log file was modified, deleted, or unchanged after being delivered.
AWS Config is a fully managed service that provides AWS resource inventory, configuration history, and configuration change notifications to enable security, compliance, and governance.
supports managed as well as custom rules that can be evaluated on periodic basis or as the event occurs for compliance and trigger automatic remediation
Conformance pack is a collection of AWS Config rules and remediation actions that can be easily deployed as a single entity in an account and a Region or across an organization in AWS Organizations.
Egress-Only Internet Gateway – relevant to IPv6 only to allow egress traffic from private subnet to internet, without allowing ingress traffic
VPC Flow Logs enables you to capture information about the IP traffic going to and from network interfaces in the VPC and can help in monitoring the traffic or troubleshooting any connectivity issues
VPC Peering provides a connection between two VPCs that enables routing of traffic between them using private IP addresses.
VPC Endpoints enables the creation of a private connection between VPC to supported AWS services and VPC endpoint services powered by PrivateLink using its private IP address
Ability to debug networking issues like EC2 not accessible, EC2 not reachable, or not able to communicate with others or Internet.
Failover routing policy helps to configure active-passive failover.
Geolocation routing policy helps route traffic based on the location of the users.
Geoproximity routing policy helps route traffic based on the location of the resources and, optionally, shift traffic from resources in one location to resources in another.
Latency routing policy use with resources in multiple AWS Regions and you want to route traffic to the Region that provides the best latency with less round-trip time.
Weighted routing policy helps route traffic to multiple resources in specified proportions.
Focus on Weighted, Latency routing policies
Understand ELB, ALB, and NLB and what features they provide like
InstanceLimitExceeded – Concurrent running instance limit, default is 20, has been reached in a region. Request increase in limits.
InsufficientInstanceCapacity – AWS does not currently have enough available capacity to service the request. Change AZ or Instance Type.
Monitoring EC2 instances
System status checks failure – Stop and Start
Instance status checks failure – Reboot
EC2 supports Instance Recovery where the recovered instance is identical to the original instance, including the instance ID, private IP addresses, Elastic IP addresses, and all instance metadata.
EC2 Image Builder can be used to pre-baked images with software to speed up booting and launching time.
Lambda functions can be hosted in VPC with internet access controlled by a NAT instance.
RDS Proxy acts as an intermediary between the application and an RDS database. RDS Proxy establishes and manages the necessary connection pools to the database so that the application creates fewer database connections.
S3 data protection provides encryption at rest and encryption in transit
S3 default encryption can be used to encrypt the data with S3 bucket policies to prevent or reject unencrypted object uploads.
Multi-part handling for fault-tolerant and performant large file uploads
static website hosting, CORS
S3 Versioning can help recover from accidental deletes and overwrites.
Pre-Signed URLs for both upload and download
S3 Transfer Acceleration enables fast, easy, and secure transfers of files over long distances between the client and an S3 bucket using globally distributed edge locations in CloudFront.
Understand Glacier as archival storage. Glacier does not provide immediate access to the data even with expediated retrievals.
Storage Gateway allows storage of data in the AWS cloud for scalable and cost-effective storage while maintaining data security.
Gateway-cached volumes stores data is stored in S3 and retains a copy of recently read data locally for low latency access to the frequently accessed data
Gateway-stored volumes maintain the entire data set locally to provide low latency access
EFS is a cost-optimized, serverless, scalable, and fully managed file storage for use with AWS Cloud and on-premises resources.
supports data at rest encryption only during the creation. After creation, the file system cannot be encrypted and must be copied over to a new encrypted disk.
supports General purpose and Max I/O performance mode.
If hitting PercentIOLimit issue move to Max I/O performance mode.
FSx makes it easy and cost-effective to launch, run, and scale feature-rich, high-performance file systems in the cloud
FSx for Windows supports SMB protocol and a Multi-AZ file system to provide high availability across multiple AZs.
AWS Backup can be used to automate backup for EC2 instances and EFS file systems
Data Lifecycle Manager to automate the creation, retention, and deletion of EBS snapshots and EBS-backed AMIs.
AWS DataSync automates moving data between on-premises storage and S3 or Elastic File System (EFS).
Databases
RDS provides cost-efficient, resizable capacity for an industry-standard relational database and manages common database administration tasks.
Multi-AZ deployment provides high availability, durability, and failover support
Read replicas enable increased scalability and database availability in the case of an AZ failure.
Automated backups and database change logs enable point-in-time recovery of the database during the backup retention period, up to the last five minutes of database usage.
Aurora is a fully managed, MySQL- and PostgreSQL-compatible, relational database engine
Backtracking “rewinds” the DB cluster to the specified time and performs in-place restore and does not create a new instance.
Automated Backups that help restore the DB as a new instance
Know ElastiCache use cases, mainly for caching performance
Understand ElastiCache Redis vs Memcached
Redis provides Multi-AZ support helps provide high availability across AZs and Online resharding to dynamically scale.
ElastiCache can be used as a caching layer for RDS.
S3 default encryption can help encrypt objects, however, it does not encrypt existing objects before the setting was enabled. You can use S3 Inventory to list the objects and S3 Batch to encrypt them.
Understand KMS for key management and envelope encryption
KMS with imported customer key material does not support rotation and has to be done manually.
AWS WAF – Web Application Firewall helps protect the applications against common web exploits like XSS or SQL Injection and bots that may affect availability, compromise security, or consume excessive resources
AWS GuardDuty is a threat detection service that continuously monitors the AWS accounts and workloads for malicious activity and delivers detailed security findings for visibility and remediation.
AWS Secrets Manager can help securely expose credentials as well as rotate them.
Secrets Manager integrates with Lambda and supports credentials rotation
AWS Shield is a managed Distributed Denial of Service (DDoS) protection service that safeguards applications running on AWS
is an automated security assessment service that helps improve the security and compliance of applications deployed on AWS.
automatically assesses applications for exposure, vulnerabilities, and deviations from best practices.
AWS Certificate Manager (ACM) handles the complexity of creating, storing, and renewing public and private SSL/TLS X.509 certificates and keys that protect the AWS websites and applications.
Know AWS Artifact as on-demand access to compliance reports
Analytics
Amazon Athena can be used to query S3 data without duplicating the data and using SQL queries
OpenSearch (Elasticsearch) service is a distributed search and analytics engine built on Apache Lucene.
Opensearch production setup would be 3 AZs, 3 dedicated master nodes, 6 nodes with two replicas in each AZ.
Integration Tools
Understand SQS as a message queuing service and SNS as pub/sub notification service
Focus on SQS as a decoupling service
Understand SQS FIFO, make sure you know the differences between standard and FIFO
Understand CloudWatch integration with SNS for notification
Practice Labs
Create IAM users, IAM roles with specific limited policies.
Create a private S3 bucket
enable versioning
enable default encryption
enable lifecycle policies to transition and expire the objects
enable same region replication
Create a public S3 bucket with static website hosting
Set up a VPC with public and private subnets with Routes, SGs, NACLs.
Set up a VPC with public and private subnets and enable communication from private subnets to the Internet using NAT gateway
Create EC2 instance, create a Snapshot and restore it as a new instance.
Set up Security Groups for ALB and Target Groups, and create ALB, Launch Template, Auto Scaling Group, and target groups with sample applications. Test the flow.
Create Multi-AZ RDS instance and instance force failover.
Set up SNS topic. Use Cloud Watch Metrics to create a CloudWatch alarm on specific thresholds and send notifications to the SNS topic
Set up SNS topic. Use Cloud Watch Logs to create a CloudWatch alarm on log patterns and send notifications to the SNS topic.
Update a CloudFormation template and re-run the stack and check the impact.
Use AWS Data Lifecycle Manager to define snapshot lifecycle.
Use AWS Backup to define EFS backup with hourly and daily backup rules.
AWS Certified SysOps Administrator – Associate (SOA-C02) Exam Day
Make sure you are relaxed and get some good night’s sleep. The exam is not tough if you are well-prepared.
If you are taking the AWS Online exam
Try to join at least 30 minutes before the actual time as I have had issues with both PSI and Pearson with long wait times.
The online verification process does take some time and usually, there are glitches.
Remember, you would not be allowed to take the take if you are late by more than 30 minutes.
Make sure you have your desk clear, no hand-watches, or external monitors, keep your phones away, and nobody can enter the room.
AWS Certified DevOps Engineer – Professional (DOP-C02) Exam Learning Path
AWS Certified DevOps Engineer – Professional (DOP-C02) exam is the upgraded pattern of the DevOps Engineer – Professional (DOP-C01) exam which was released in March 2023.
I recently attempted the latest pattern and DOP-C02 is quite similar to DOP-C01 with the inclusion of new services and features.
AWS Certified DevOps Engineer – Professional (DOP-C02) Exam Content
AWS Certified DevOps Engineer – Professional (DOP-C02) exam is intended for individuals who perform a DevOps engineer role and focuses on provisioning, operating, and managing distributed systems and services on AWS.
DOP-C02 basically validates
Implement and manage continuous delivery systems and methodologies on AWS
Implement and automate security controls, governance processes, and compliance validation
Define and deploy monitoring, metrics, and logging systems on AWS
Implement systems that are highly available, scalable, and self-healing on the AWS platform
Design, manage, and maintain tools to automate operational processes
AWS Certified DevOps Engineer – Professional (DOP-C02) Exam Summary
Professional exams are tough, lengthy, and tiresome. Most of the questions and answers options have a lot of prose and a lot of reading that needs to be done, so be sure you are prepared and manage your time well.
Each solution involves multiple AWS services.
DOP-C02 exam has 75 questions to be solved in 170 minutes. Only 65 affect your score, while 10 unscored questions are for evaluation for future use.
DOP-C02 exam includes two types of questions, multiple-choice and multiple-response.
DOP-C02 has a scaled score between 100 and 1,000. The scaled score needed to pass the exam is 750.
Each question mainly touches multiple AWS services.
Professional exams currently cost $ 300 + tax.
You can get an additional 30 minutes if English is your second language by requesting Exam Accommodations. It might not be needed for Associate exams but is helpful for Professional and Specialty ones.
As always, mark the questions for review and move on and come back to them after you are done with all.
As always, having a rough architecture or mental picture of the setup helps focus on the areas that you need to improve. Trust me, you will be able to eliminate 2 answers for sure and then need to focus on only the other two. Read the other 2 answers to check the difference area and that would help you reach the right answer or at least have a 50% chance of getting it right.
AWS exams can be taken either remotely or online, I prefer to take them online as it provides a lot of flexibility. Just make sure you have a proper place to take the exam with no disturbance and nothing around you.
Also, if you are taking the AWS Online exam for the first time try to join at least 30 minutes before the actual time as I have had issues with both PSI and Pearson with long wait times.
AWS Certified DevOps Engineer – Professional (DOP-C02) Exam Topics
AWS Certified DevOps Engineer – Professional exam covers a lot of concepts and services related to Automation, Deployments, Disaster Recovery, HA, Monitoring, Logging, and Troubleshooting. It also covers security and compliance related topics.
AWS Systems Manager and its various services like parameter store, patch manager
Parameter Store provides secure, scalable, centralized, hierarchical storage for configuration data and secret management. Does not support secrets rotation. Use Secrets Manager instead
Session Manager provides secure and auditable instance management without the need to open inbound ports, maintain bastion hosts, or manage SSH keys.
Patch Manager helps automate the process of patching managed instances with both security-related and other types of updates.
CloudWatch logs can be used to monitor, store, and access log files from EC2 instances, CloudTrail, Route 53, and other sources. You can create metric filters over the logs.
With Organizations, the trail can be configured to log CloudTrail from all accounts to a central account.
Config is a fully managed service that provides AWS resource inventory, configuration history, and configuration change notifications to enable security, compliance, and governance.
supports managed as well as custom rules that can be evaluated on periodic basis or as the event occurs for compliance and trigger automatic remediation
Conformance pack is a collection of AWS Config rules and remediation actions that can be easily deployed as a single entity in an account and a Region or across an organization in AWS Organizations.
CodePipeline is a fully managed continuous delivery service that helps automate the release pipelines for fast and reliable application and infrastructure updates.
CodePipeline pipeline structure (Hint : run builds parallelly using runorder)
Understand how to configure notifications on events and failures
CodePipeline supports Manual Approval
CodeArtifact is a fully managed artifact repository service that makes it easy for organizations of any size to securely store, publish, and share software packages used in their software development process.
CodeGuru provides intelligent recommendations to improve code quality and identify an application’s most expensive lines of code. Reviewer helps improve code quality and Profiler helps optimize performance for applications
EC2 Image Builder helps to automate the creation, management, and deployment of customized, secure, and up-to-date server images that are pre-installed and pre-configured with software and settings to meet specific IT standards.
Disaster Recovery
Disaster recovery is mainly covered as a part of Re-silent cloud solutions.
Disaster Recovery whitepaper, although outdated, make sure you understand the differences and implementation for each type esp. pilot light, warm standby w.r.t RTO, and RPO.
Compute
Make components available in an alternate region,
Backup and Restore using either snapshots or AMIs that can be restored.
Use minimal low-scale capacity running which can be scaled once the failover happens
Use fully running compute in active-active confirmation with health checks.
CloudFormation to create, and scale infra as needed
Storage
S3 and EFS support cross-region replication
DynamoDB supports Global tables for multi-master, active-active inter-region storage needs.
RDS supports cross-region read replicas which can be promoted to master in case of a disaster. This can be done using Route 53, CloudWatch, and lambda functions.
Network
Route 53 failover routing with health checks to failover across regions.
CloudFront Origin Groups support primary and secondary endpoints with failover.
is a threat detection service that continuously monitors the AWS accounts and workloads for malicious activity and delivers detailed security findings for visibility and remediation.
AWS Security Hub is a cloud security posture management service that performs security best practice checks, aggregates alerts and enables automated remediation.
Firewall Manager helps centrally configure and manage firewall rules across the accounts and applications in AWS Organizations which includes a variety of protections, including WAF, Shield Advanced, VPC security groups, Network Firewall, and Route 53 Resolver DNS Firewall.
S3 Access Logs enable tracking access requests to an S3 bucket.
S3 Event Notification enables notifications to be triggered when certain events happen in the bucket and supports SNS, SQS, and Lambda as the destination. S3 needs permission to be able to integrate with the services.
helps define reserved concurrency limits to reduce the impact
Lambda Alias now supports canary deployments
Reserved Concurrency guarantees the maximum number of concurrent instances for the function
Provisioned Concurrency
provides greater control over the performance of serverless applications and helps keep functions initialized and hyper-ready to respond in double-digit milliseconds.
supports Application Auto Scaling.
Step Functions helps developers use AWS services to build distributed applications, automate processes, orchestrate microservices, and create data and machine learning (ML) pipelines.
SQS supports dead letter queues and redrive policy which specifies the source queue, the dead-letter queue, and the conditions under which SQS moves messages from the former to the latter if the consumer of the source queue fails to process a message a specified number of times.
CloudWatch integration with SNS and Lambda for notifications.
AWS S3 offers a range of S3 Storage Classes to match the use case scenario and performance access requirements.
S3 storage classes are designed to sustain the concurrent loss of data in one or two facilities.
S3 storage classes allow lifecycle management for automatic transition of objects for cost savings.
All S3 storage classes provide the same durability, first-byte latency, and support SSL encryption of data in transit, and data encryption at rest.
S3 also regularly verifies the integrity of the data using checksums and provides the auto-healing capability.
S3 Storage Classes Comparison
S3 Standard
STANDARD is the default storage class, if none specified during upload
Low latency and high throughput performance
Designed for 99.999999999% i.e. 11 9’s Durability of objects across AZs
Designed for 99.99% availability over a given year
Resilient against events that impact an entire Availability Zone and is designed to sustain the loss of data in a two facilities
Ideal for performance-sensitive use cases and frequently accessed data
S3 Standard is appropriate for a wide variety of use cases, including cloud applications, dynamic websites, content distribution, mobile and gaming applications, and big data analytics.
S3 Intelligent Tiering (S3 Intelligent-Tiering)
S3 Intelligent Tiering storage class is designed to optimize storage costs by automatically moving data to the most cost-effective storage access tier, without performance impact or operational overhead.
Delivers automatic cost savings by moving data on a granular object-level between two access tiers
one tier that is optimized for frequent access and
another lower-cost tier that is optimized for infrequently accessed data.
a frequent access tier and a lower-cost infrequent access tier, when access patterns change.
Ideal to optimize storage costs automatically for long-lived data when access patterns are unknown or unpredictable.
For a small monthly monitoring and automation fee per object, S3 monitors access patterns of the objects and moves objects that have not been accessed for 30 consecutive days to the infrequent access tier.
There are no separate retrieval fees when using the Intelligent Tiering storage class. If an object in the infrequent access tier is accessed, it is automatically moved back to the frequent access tier.
No additional fees apply when objects are moved between access tiers
Suitable for objects greater than 128 KB (smaller objects are charged for 128 KB only) kept for at least 30 days (charged for a minimum of 30 days)
Same low latency and high throughput performance of S3 Standard
Designed for 99.999999999% i.e. 11 9’s Durability of objects across AZs
Designed for 99.9% availability over a given year
S3 Standard-Infrequent Access (S3 Standard-IA)
S3 Standard-Infrequent Access storage class is optimized for long-lived and less frequently accessed data. for e.g. for backups and older data where access is limited, but the use case still demands high performance
Ideal for use for the primary or only copy of data that can’t be recreated.
Data stored redundantly across multiple geographically separated AZs and are resilient to the loss of an Availability Zone.
offers greater availability and resiliency than the ONEZONE_IA class.
Objects are available for real-time access.
Suitable for larger objects greater than 128 KB (smaller objects are charged for 128 KB only) kept for at least 30 days (charged for minimum 30 days)
Same low latency and high throughput performance of Standard
Designed for 99.999999999% i.e. 11 9’s Durability of objects across AZs
Designed for 99.9% availability over a given year
S3 charges a retrieval fee for these objects, so they are most suitable for infrequently accessed data.
S3 One Zone-Infrequent Access (S3 One Zone-IA)
S3 One Zone-Infrequent Access storage classes are designed for long-lived and infrequently accessed data, but available for millisecond access (similar to the STANDARD and STANDARD_IA storage class).
Ideal when the data can be recreated if the AZ fails, and for object replicas when setting cross-region replication (CRR).
Objects are available for real-time access.
Suitable for objects greater than 128 KB (smaller objects are charged for 128 KB only) kept for at least 30 days (charged for a minimum of 30 days)
Stores the object data in only one AZ, which makes it less expensive than Standard-Infrequent Access
Data is not resilient to the physical loss of the AZ resulting from disasters, such as earthquakes and floods.
One Zone-Infrequent Access storage class is as durable as Standard-Infrequent Access, but it is less available and less resilient.
Designed for 99.999999999% i.e. 11 9’s Durability of objects in a single AZ
Designed for 99.5% availability over a given year
S3 charges a retrieval fee for these objects, so they are most suitable for infrequently accessed data.
Reduced Redundancy Storage – RRS
NOTE – AWS recommends not to use this storage class. The STANDARD storage class is more cost-effective now.
Reduced Redundancy Storage (RRS) storage class is designed for non-critical, reproducible data stored at lower levels of redundancy than the STANDARD storage class, which reduces storage costs
Designed for durability of 99.99% of objects
Designed for 99.99% availability over a given year
Lower level of redundancy results in less durability and availability
RRS stores object on multiple devices across multiple facilities, providing 400 times the durability of a typical disk drive,
RRS does not replicate objects as many times as S3 standard storage and is designed to sustain the loss of data in a single facility.
If an RRS object is lost, S3 returns a 405 error on requests made to that object
S3 can send an event notification, configured on the bucket, to alert a user or start a workflow when it detects that an RRS object is lost which can be used to replace the lost object
S3 Glacier Instant Retrieval
Use for archiving data that is rarely accessed and requires milliseconds retrieval.
Storage class has a minimum storage duration period of 90 days
Designed for 99.999999999% i.e. 11 9’s Durability of objects across AZs
Designed for 99.99% availability
S3 Glacier Flexible Retrieval – S3 Glacier
S3 GLACIER storage class is suitable for low-cost data archiving where data access is infrequent and retrieval time of minutes to hours is acceptable.
Storage class has a minimum storage duration period of 90 days
Provides configurable retrieval times, from minutes to hours
Expedited retrieval: 1-5 mins
Standard retrieval: 3-5 hours
Bulk retrieval: 5-12 hours
GLACIER storage class uses the very low-cost Glacier storage service, but the objects in this storage class are still managed through S3
For accessing GLACIER objects,
the object must be restored which can take anywhere between minutes to hours
objects are only available for the time period (the number of days) specified during the restoration request
object’s storage class remains GLACIER
charges are levied for both the archive (GLACIER rate) and the copy restored temporarily
Vault Lock feature enforces compliance via a lockable policy.
Offers the same durability and resiliency as the STANDARD storage class
Designed for 99.999999999% i.e. 11 9’s Durability of objects across AZs
Designed for 99.99% availability
S3 Glacier Deep Archive
Glacier Deep Archive storage class provides the lowest-cost data archiving where data access is infrequent and retrieval time of hours is acceptable.
Has a minimum storage duration period of 180 days and can be accessed at a default retrieval time of 12 hours.
Supports long-term retention and digital preservation for data that may be accessed once or twice a year
Designed for 99.999999999% i.e. 11 9’s Durability of objects across AZs
Designed for 99.9% availability over a given year
DEEP_ARCHIVE retrieval costs can be reduced by using bulk retrieval, which returns data within 48 hours.
Ideal alternative to magnetic tape libraries
S3 Analytics – S3 Storage Classes Analysis
S3 Analytics – Storage Class Analysis helps analyze storage access patterns to decide when to transition the right data to the right storage class.
S3 Analytics feature observes data access patterns to help determine when to transition less frequently accessed STANDARD storage to the STANDARD_IA (IA, for infrequent access) storage class.
Storage Class Analysis can be configured to analyze all the objects in a bucket or filters to group objects.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
What does RRS stand for when talking about S3?
Redundancy Removal System
Relational Rights Storage
Regional Rights Standard
Reduced Redundancy Storage
What is the durability of S3 RRS?
99.99%
99.95%
99.995%
99.999999999%
What is the Reduced Redundancy option in Amazon S3?
Less redundancy for a lower cost
It doesn’t exist in Amazon S3, but in Amazon EBS.
It allows you to destroy any copy of your files outside a specific jurisdiction.
It doesn’t exist at all
An application is generating a log file every 5 minutes. The log file is not critical but may be required only for verification in case of some major issue. The file should be accessible over the internet whenever required. Which of the below mentioned options is a best possible storage solution for it?
AWS S3
AWS Glacier
AWS RDS
AWS S3 RRS (Reduced Redundancy Storage (RRS) is an Amazon S3 storage option that enables customers to store noncritical, reproducible data at lower levels of redundancy than Amazon S3’s standard storage. RRS is designed to sustain the loss of data in a single facility.)
A user has moved an object to Glacier using the life cycle rules. The user requests to restore the archive after 6 months. When the restore request is completed the user accesses that archive. Which of the below mentioned statements is not true in this condition?
The archive will be available as an object for the duration specified by the user during the restoration request
The restored object’s storage class will be RRS (After the object is restored the storage class still remains GLACIER. Read more)
The user can modify the restoration period only by issuing a new restore request with the updated period
The user needs to pay storage for both RRS (restored) and Glacier (Archive) Rates
Your department creates regular analytics reports from your company’s log files. All log data is collected in Amazon S3 and processed by daily Amazon Elastic Map Reduce (EMR) jobs that generate daily PDF reports and aggregated tables in CSV format for an Amazon Redshift data warehouse. Your CFO requests that you optimize the cost structure for this system. Which of the following alternatives will lower costs without compromising average performance of the system or data integrity for the raw data? [PROFESSIONAL]
Use reduced redundancy storage (RRS) for PDF and CSV data in Amazon S3. Add Spot instances to Amazon EMR jobs. Use Reserved Instances for Amazon Redshift. (Spot instances impacts performance)
Use reduced redundancy storage (RRS) for all data in S3. Use a combination of Spot instances and Reserved Instances for Amazon EMR jobs. Use Reserved instances for Amazon Redshift (Combination of the Spot and reserved with guarantee performance and help reduce cost. Also, RRS would reduce cost and guarantee data integrity, which is different from data durability )
Use reduced redundancy storage (RRS) for all data in Amazon S3. Add Spot Instances to Amazon EMR jobs. Use Reserved Instances for Amazon Redshift (Spot instances impacts performance)
Use reduced redundancy storage (RRS) for PDF and CSV data in S3. Add Spot Instances to EMR jobs. Use Spot Instances for Amazon Redshift. (Spot instances impacts performance)
Which of the below mentioned options can be a good use case for storing content in AWS RRS?
Storing mission critical data Files
Storing infrequently used log files
Storing a video file which is not reproducible
Storing image thumbnails
A newspaper organization has an on-premises application which allows the public to search its back catalogue and retrieve individual newspaper pages via a website written in Java. They have scanned the old newspapers into JPEGs (approx. 17TB) and used Optical Character Recognition (OCR) to populate a commercial search product. The hosting platform and software is now end of life and the organization wants to migrate its archive to AWS and produce a cost efficient architecture and still be designed for availability and durability. Which is the most appropriate? [PROFESSIONAL]
Use S3 with reduced redundancy to store and serve the scanned files, install the commercial search application on EC2 Instances and configure with auto-scaling and an Elastic Load Balancer. (RRS impacts durability and commercial search would add to cost)
Model the environment using CloudFormation. Use an EC2 instance running Apache webserver and an open source search application, stripe multiple standard EBS volumes together to store the JPEGs and search index. (Using EBS is not cost effective for storing files)
Use S3 with standard redundancy to store and serve the scanned files, use CloudSearch for query processing, and use Elastic Beanstalk to host the website across multiple availability zones. (Standard S3 and Elastic Beanstalk provides availability and durability, Standard S3 and CloudSearch provides cost effective storage and search)
Use a single-AZ RDS MySQL instance to store the search index and the JPEG images use an EC2 instance to serve the website and translate user queries into SQL. (RDS is not ideal and cost effective to store files, Single AZ impacts availability)
Use a CloudFront download distribution to serve the JPEGs to the end users and Install the current commercial search product, along with a Java Container for the website on EC2 instances and use Route53 with DNS round-robin. (CloudFront needs a source and using commercial search product is not cost effective)
A research scientist is planning for the one-time launch of an Elastic MapReduce cluster and is encouraged by her manager to minimize the costs. The cluster is designed to ingest 200TB of genomics data with a total of 100 Amazon EC2 instances and is expected to run for around four hours. The resulting data set must be stored temporarily until archived into an Amazon RDS Oracle instance. Which option will help save the most money while meeting requirements? [PROFESSIONAL]
Store ingest and output files in Amazon S3. Deploy on-demand for the master and core nodes and spot for the task nodes.
Optimize by deploying a combination of on-demand, RI and spot-pricing models for the master, core and task nodes. Store ingest and output files in Amazon S3 with a lifecycle policy that archives them to Amazon Glacier. (Master and Core must be RI or On Demand. Cannot be Spot)
Store the ingest files in Amazon S3 RRS and store the output files in S3. Deploy Reserved Instances for the master and core nodes and on-demand for the task nodes. (Need better durability for ingest file. Spot instances can be used for task nodes for cost saving.)
Deploy on-demand master, core and task nodes and store ingest and output files in Amazon S3 RRS (Input must be in S3 standard)
AWS Compute Optimizer helps analyze the configuration and utilization metrics of the AWS resources.
reports whether the resources are optimal, and generates optimization recommendations to reduce the cost and improve the performance of the workloads.
delivers intuitive and easily actionable resource recommendations to help quickly identify optimal AWS resources for the workloads without requiring specialized expertise or investing substantial time and money.
provides a global, cross-account view of all resources
analyzes the specifications and the utilization metrics of the resources from CloudWatch for the last 14 days.
provides graphs showing recent utilization metric history data, as well as projected utilization for recommendations, which can be used to evaluate which recommendation provides the best price-performance trade-off.
Analysis and visualization of the usage patterns can help decide when to move or resize the running resources, and still meet your performance and capacity requirements.
generates recommendations for the following resources:
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company must assess the business’s EC2 instances and Elastic Block Store (EBS) volumes to determine how effectively the business is using resources. The company has not detected a pattern in how these EC2 instances are used by the apps that access the databases. Which option best fits these criteria in terms of cost-effectiveness?
Use AWS Systems Manager OpsCenter.
Use Amazon CloudWatch for detailed monitoring.
Use AWS Compute Optimizer.
Sign up for the AWS Enterprise Support plan. Turn on AWS Trusted Advisor.