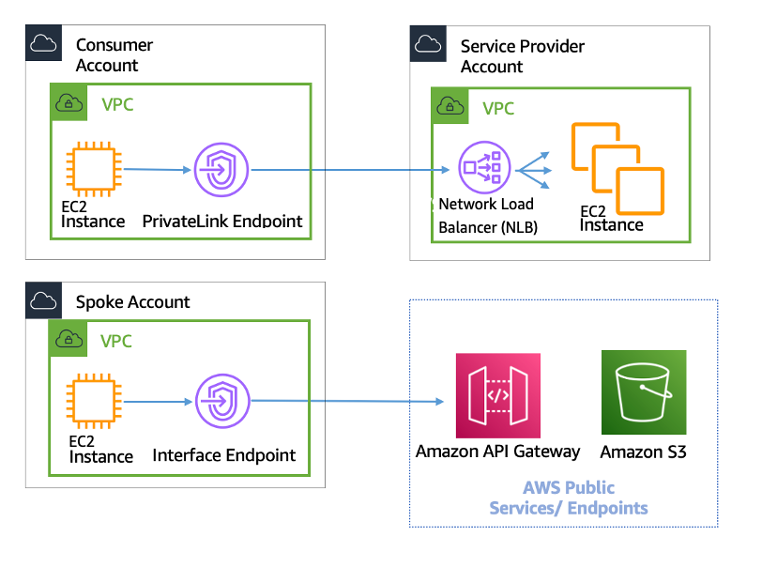
VPC Interface Endpoints – PrivateLink
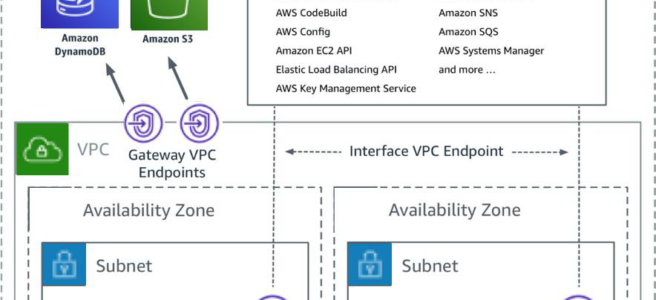
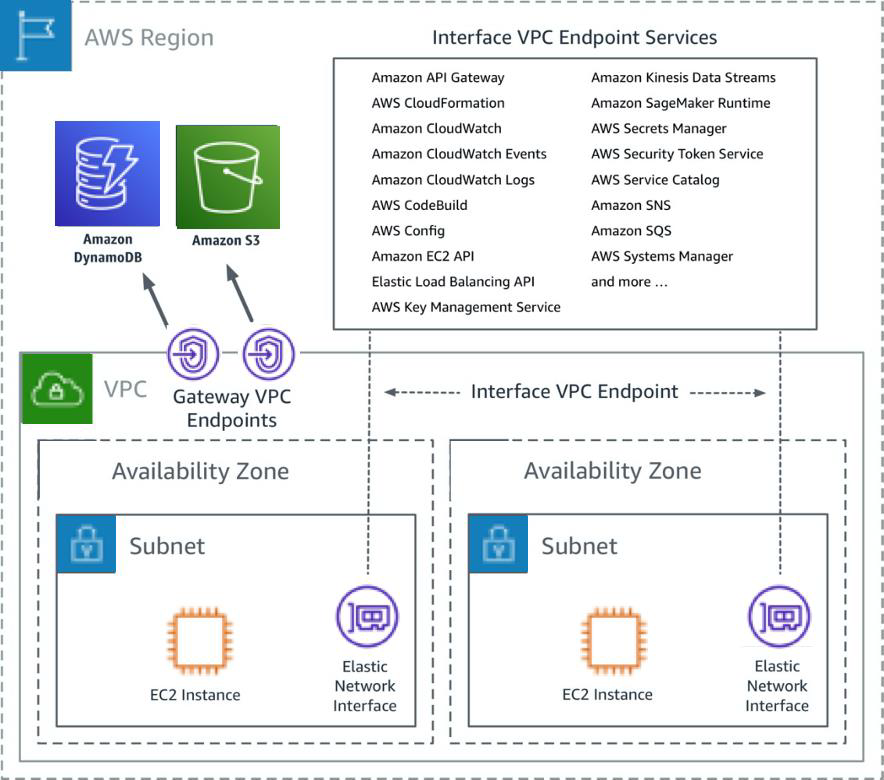
- VPC Interface endpoints enable connectivity to services powered by AWS PrivateLink.
- Services include AWS services like CloudTrail, CloudWatch, etc., services hosted by other AWS customers and partners in their own VPCs (referred to as endpoint services), and supported AWS Marketplace partner services.
- VPC Interface Endpoints only allow traffic from VPC resources to the endpoints and not vice versa
- PrivateLink endpoints can be accessed across both intra- and inter-region VPC peering connections, Direct Connect, and VPN connections.
- VPC Interface Endpoints, by default, have an address like
vpce-svc-01234567890abcdef.us-east-1.vpce.amazonaws.comwhich needs application changes to point to the service. - Private DNS name feature allows consumers to use AWS service public default DNS names which would point to the private VPC endpoint service.
- Interface Endpoints can be used to create custom applications in VPC and configure them as an AWS PrivateLink-powered service (referred to as an endpoint service) exposed through a Network Load Balancer or Gateway Load Balancer.
- Custom applications can be hosted within AWS or on-premises (via Direct Connect or VPN)
Interface Endpoints Configuration
- Create an interface endpoint, and provide the name of the AWS service, endpoint service, or AWS Marketplace service
- Choose the subnet to use the interface endpoint by creating an endpoint network interface.
- An endpoint network interface is assigned a private IP address from the IP address range of the subnet and keeps this IP address until the interface endpoint is deleted
- A private IP address also ensures the traffic remains private without any changes to the route table.
Cross-Region PrivateLink (Announced November 2025)
- AWS PrivateLink now supports native cross-region connectivity through Interface VPC endpoints.
- Previously, Interface VPC endpoints only supported connectivity to services in the same Region.
- You can now connect to:
- AWS services hosted in other Regions (e.g., S3, Route53, ECR, and other supported services)
- VPC endpoint services (custom applications) hosted in other Regions
- Enables simpler and more secure inter-region connectivity without the need for cross-region peering or exposing data over the public internet.
- Helps build globally distributed private networks that comply with data residency requirements.
- Traffic remains on the AWS backbone and does not traverse the public internet.
- Available within the same AWS partition (e.g., commercial regions, GovCloud, China).
- Service providers can offer SaaS solutions privately to a global audience from a single Region.
Resource Endpoints (Announced December 2024)
- AWS PrivateLink now supports Resource VPC Endpoints — a new endpoint type that provides private access to specific VPC resources without requiring a load balancer.
- Resource endpoints allow you to privately access resources such as databases (e.g., Amazon RDS), EC2 instances, application endpoints, domain-name targets, or IP addresses in another VPC or on-premises environment.
- Previously, accessing services via PrivateLink required a Network Load Balancer or Gateway Load Balancer. Resource endpoints eliminate this requirement.
- A VPC resource is represented by a resource configuration, which is associated with a resource gateway.
- Resources can be shared across accounts using AWS Resource Access Manager (AWS RAM).
- Resource endpoints can be combined with Amazon VPC Lattice service networks to pool multiple resources and access them via a single service network VPC endpoint.
- Resource endpoints support IPv4, IPv6, or dualstack addresses.
- Key considerations:
- TCP traffic is supported; UDP is not supported for resource endpoints.
- Network connections must be initiated from the VPC containing the resource endpoint (unidirectional).
- The only supported ARN-based resources are Amazon RDS resources.
- At least one Availability Zone of the VPC endpoint and resource gateway must overlap.
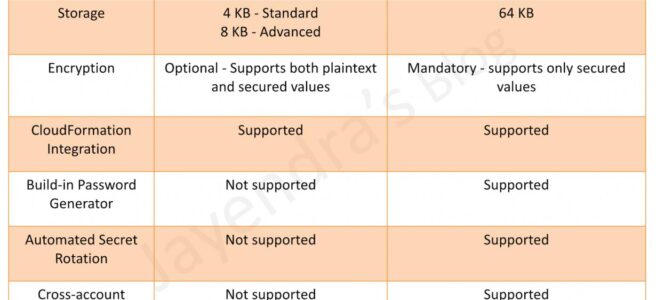
VPC Endpoint policy
- VPC Endpoint policy is an IAM resource policy attached to an endpoint for controlling access from the endpoint to the specified service.
- Endpoint policy, by default, allows full access to any user or service within the VPC, using credentials from any AWS account to any S3 resource; including S3 resources for an AWS account other than the account with which the VPC is associated
- Endpoint policy does not override or replace IAM user policies or service-specific policies (such as S3 bucket policies).
- Endpoint policy can be used to restrict which specific resources can be accessed using the VPC Endpoint.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "Sid": "AccessToSpecificBucket", "Effect": "Allow", "Principal": "*", "Action": [ "s3:ListBucket", "s3:GetObject", ], "Resource": [ "arn:aws:s3:::example-bucket", "arn:aws:s3:::example-bucket/*" ] } |
New VPC Endpoint Condition Keys (August 2025)
- AWS IAM introduced three new global condition keys for scalable network perimeter controls:
aws:VpceAccount— restricts access based on the account that owns the VPC endpointaws:VpceOrgID— restricts access based on the AWS Organization that owns the VPC endpointaws:VpceOrgPaths— restricts access based on the organizational unit (OU) path of the VPC endpoint owner
- These condition keys help ensure that requests to AWS resources are made through VPC endpoints owned by your organization.
- They automatically scale with VPC endpoint usage — no need to enumerate individual VPC endpoint IDs in policies.
- Can be used with SCPs, RCPs, resource-based policies, and identity-based policies.
- Previously,
aws:SourceVpcandaws:SourceVpcerequired listing specific VPC/endpoint IDs, which was difficult to scale across large organizations.
Interface Endpoint Limitations
- For each interface endpoint, only one subnet per AZ can be selected.
- Interface Endpoint supports TCP and UDP traffic (UDP support added October 2024 via dual-stack NLBs).
- Endpoints support IPv4, IPv6, and dual-stack traffic (IPv6 support added May 2022, expanded for additional services in 2024-2025).
- Each interface endpoint can support a bandwidth of up to 10 Gbps per AZ, by default, and automatically scales up to 100 Gbps. Additional capacity may be added by reaching out to AWS support.
- NACLs for the subnet can restrict traffic, and needs to be configured properly
- Endpoints cannot be transferred from one VPC to another, or from one service to another.
- Cross-region PrivateLink is available within the same AWS partition only (cannot connect across partitions like Commercial to GovCloud).
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- An application server needs to be in a private subnet without access to the internet. The solution must retrieve and upload data to an Amazon Kinesis. How should a Solutions Architect design a solution to meet these requirements?
- Use Amazon VPC Gateway endpoints
- Use a NAT Gateway
- Use Amazon VPC Interface endpoints
- Use a private Amazon Kinesis Data Stream
- A company needs to access Amazon S3 buckets in a different AWS Region privately without exposing traffic to the public internet. Which solution should they use? (Assume November 2025 or later)
- Use Gateway VPC Endpoints for cross-region S3 access
- Use Interface VPC Endpoints with cross-region PrivateLink for S3
- Set up VPC peering between regions and use Gateway Endpoints
- Use AWS Direct Connect with public VIF
- A SaaS provider wants to offer their service hosted in us-east-1 to customers in multiple AWS regions privately. Which solution enables this? (Assume November 2025 or later)
- Deploy the service in every region
- Use VPC peering between all regions
- Use cross-region PrivateLink to expose the service from us-east-1
- Use Transit Gateway with inter-region peering
- What is the maximum bandwidth that an Interface VPC Endpoint can automatically scale to per Availability Zone?
- 10 Gbps
- 40 Gbps
- 100 Gbps
- 1 Tbps
- A team needs to provide private access to an Amazon RDS database in one VPC to an application in another VPC, without deploying a load balancer. Which PrivateLink feature should they use?
- Interface VPC Endpoint with an NLB
- Gateway VPC Endpoint
- Resource VPC Endpoint with a resource gateway
- VPC Peering with private subnet routing
- A security team wants to write a single SCP that restricts API calls to only those made through VPC endpoints owned by their AWS Organization, without enumerating individual endpoint IDs. Which condition key should they use?
aws:SourceVpceaws:SourceVpcaws:VpceOrgIDaws:PrincipalOrgID
- Which protocols are now supported by AWS PrivateLink Interface Endpoints? (Select TWO)
- TCP
- UDP
- ICMP
- SCTP
References
AWS PrivateLink Cross-Region Connectivity Announcement
Introducing Cross-Region Connectivity for AWS PrivateLink
Access VPC Resources over AWS PrivateLink (Resource Endpoints)