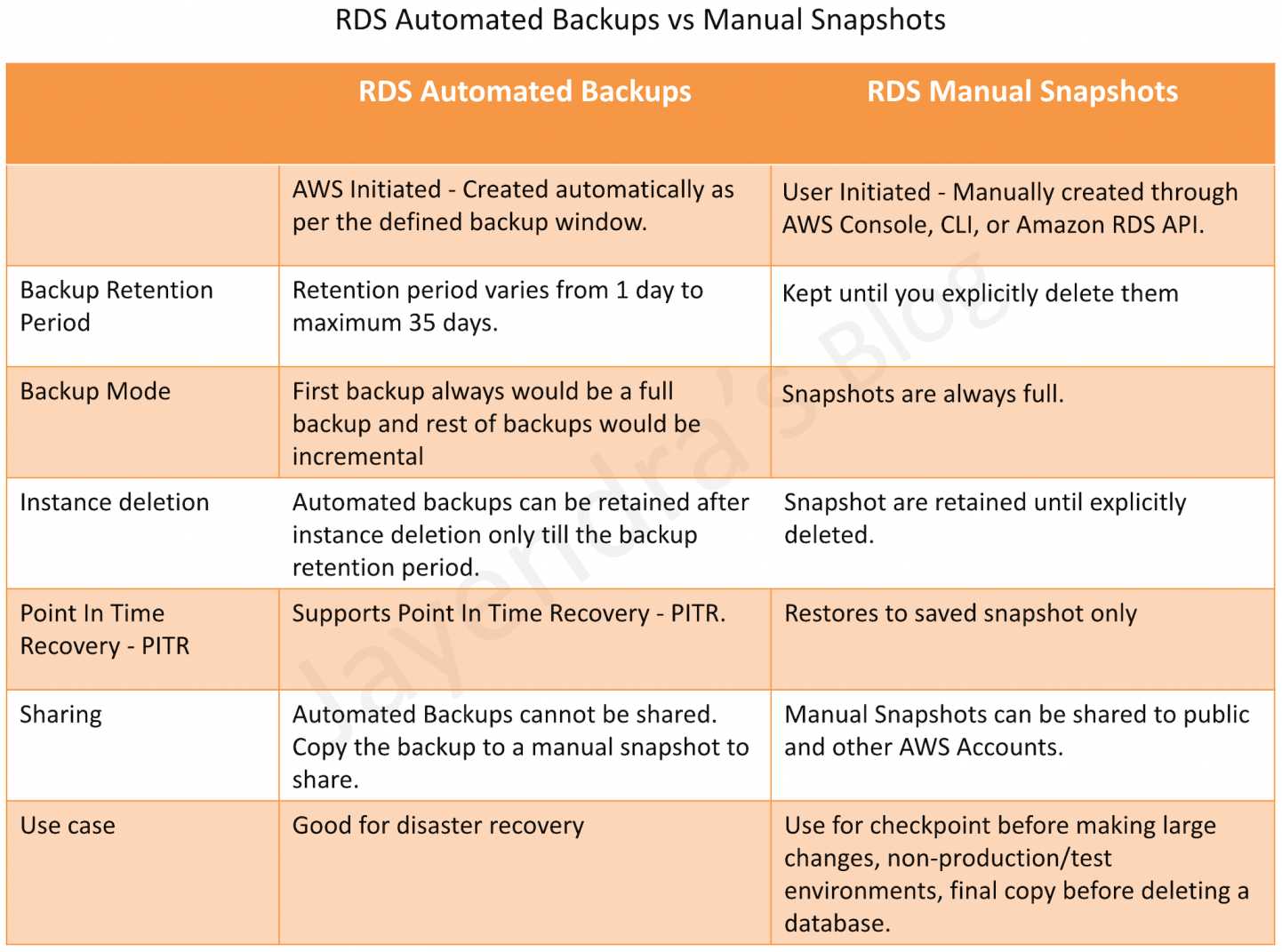
Choosing the Right Data Science Specialization: Where to Focus Your Skills
In the rapidly evolving world of technology, data science stands out as a field of endless opportunities and diverse pathways. With its foundations deeply rooted in statistics, computer science, and domain-specific knowledge, data science has become indispensable for organizations seeking to make data-driven decisions. However, the vastness of this field can be overwhelming, making specialization a strategic necessity for aspiring data scientists.
This article aims to navigate through the labyrinth of data science specializations, helping you align your career with your interests, skills, and the evolving demands of the job market.
Understanding the Breadth of Data Science
Data science is a multidisciplinary field that uses scientific methods, processes, algorithms, and systems to draw knowledge and discover insights from structured and unstructured data. It includes multiranged activities, from data collection and cleaning to complex algorithmic computations and predictive modeling.
Key Areas Within Data Science
- Machine Learning: This involves creating algorithms that can learn from pre-fed data and make predictions or decisions based on it.
- Deep Learning: A specialized subdomain of machine learning, focusing on neural networks and algorithms inspired by the structure and function of the brain.
- Data Engineering: This is the backbone of data science, focusing on the practical aspects of data collection, storage, and retrieval.
- Data Visualization: It involves converting complex data sets into understandable and interactive graphical representations.
- Big Data Analytics: This deals with extracting meaningful insights from very large, diverse data sets that are often beyond the capability of traditional data-processing applications.
- AI and Robotics: This cutting-edge field combines data science with robotics, focusing on creating machines that can perform actions/operations that typically require human intelligence.
Interconnectivity of These Areas
While these specializations are distinct, they are interconnected. For instance, data engineering is foundational for machine learning, and AI applications often rely on insights derived from big data analytics.
Factors to Consider When Choosing a Specialization
- Personal Interests and Strengths
- Your choice should resonate with your personal interests. If you are fascinated by how algorithms can mimic human learning, deep learning could be your calling. Alternatively, if you enjoy the challenges of handling and organizing large data sets, data engineering might suit you.
- Industry Demand and Job Market Trends
- It’s crucial to align your specialization with the market demand. Fields like AI and machine learning are rapidly growing and offer numerous job opportunities. Tracking industry trends can provide valuable insights into which specializations are most in demand.
- Long-term Career Goals
- Consider where you want to be in your career in the next five to ten years. Some specializations may offer more opportunities for growth, leadership roles, or transitions into different areas of data science.
- Impact of Emerging Technologies
- Emerging technologies can redefine the landscape of data science. Continuously updating with the knowledge about these changes can help you choose a specialization that remains relevant in the future.
Deep Dive into Popular Data Science Specializations
- Machine Learning
- Overview and Applications: From predictive modeling in finance to recommendation systems in e-commerce, machine learning is revolutionizing various industries.
- Required Skills and Tools: Proficiency in programming languages like Python or R, understanding of algorithms, and familiarity with TensorFlow or Scikit-learn like machine learning frameworks are essential.
- Data Engineering
- Role in Data Science: Data engineers build and maintain the infrastructure that allows data scientists to analyze and utilize data effectively.
- Key Skills and Technologies: Skills in database management, ETL (Extract, Transform, Load) processes, and knowledge of SQL, NoSQL, Hadoop, and Spark are crucial.
- Big Data Analytics
- Understanding Big Data: This specialization deals with extremely large data sets that discover patterns, trends, and associations, particularly relating to human behavior and interactions.
- Tools and Techniques: Familiarity with big data platforms like Apache Hadoop and Spark, along with data mining and statistical analysis, is important.
- AI and Robotics
- The Frontier of Data Science: This field is at the cutting edge, developing intelligent systems with the capability of performing tasks that particularly require human intelligence.
- Skills and Knowledge Base: A deep understanding of AI principles, programming, and robotics is necessary, along with skills in machine learning and neural networks.
Educational Pathways for Each Specialization
- Academic Courses and Degrees
- Pursuing a formal education in data science or a related field can provide a strong theoretical foundation. Many universities like MIT now offer specialized courses in machine learning, AI, and big data analytics, like the Data Analysis Certificate program.
- Online Courses and Bootcamps
- Online platforms like Great Learning offer specialized courses that are more flexible and often industry-oriented. Bootcamps, on the other hand, provide intensive, hands-on training in specific areas of data science.
- Certifications and Workshops
- Professional certifications from recognized bodies can add significant value to your resume. Educational choices like the Data Science course showcase your expertise and commitment to professional development.
- Self-learning Resources
- The internet is replete with resources for self-learners. From online tutorials and forums to webinars and eBooks, the opportunities for self-paced learning in data science are abundant.
Building Experience in Your Chosen Specialization
- Internships and Entry-level Positions
- Gaining practical experience is crucial. Internships and entry-level positions provide real-world experience and help you understand the practical challenges and applications of your chosen specialization.
- Personal and Open-source Projects
- Working on personal data science projects or contributing to open-source projects can be a great way to apply your skills. These projects can also be a valuable addition to your portfolio.
- Networking and Community Involvement
- Building a professional network and participating in data science communities can lead to job opportunities and collaborations. Attending industry conferences and seminars is also a great way to stay updated and connected.
- Industry Conferences and Seminars
- These events are excellent for learning about the latest industry trends, best data science practices, and emerging technologies. They also offer opportunities to meet industry leaders and peers.
Future Trends and Evolving Specializations
- Predicting the Future of Data Science
- The field of data science is constantly evolving. Staying informed about future trends is crucial for choosing a specialization that will remain relevant and in demand.
- Emerging Specializations and Technologies
- Areas like quantum computing, edge analytics, and ethical AI are emerging as new frontiers in data science. These fields are likely to offer exciting new opportunities for specialization in the coming years.
- Staying Adaptable and Continuous Learning
- The work-way to a successful career in data science is adaptability and a commitment to continuous learning. The field is dynamic, and staying abreast of new developments is essential.
Conclusion
Choosing the right data science specialization is a critical decision that can shape your career trajectory. It requires a careful consideration of your personal interests, the current job market, and future industry trends. Whether your passion lies in the intricate algorithms of machine learning, the structural challenges of data engineering, or the innovative frontiers of AI and robotics, there is a niche for every aspiring data scientist. The journey is one of continuous learning, adaptability, and an unwavering curiosity about the power of data. As the field continues to grow and diversify, the opportunities for data scientists are bound to expand, offering a rewarding and dynamic career path.