AWS Certified Database – Specialty (DBS-C01) Exam Learning Path
⚠️ CERTIFICATION RETIRED
AWS Certified Database – Specialty (DBS-C01) was retired on April 30, 2024. The last day to take this exam was April 29, 2024.
Certifications earned before retirement remain active for the standard three-year period but cannot be renewed.
Recommended Alternatives:
This content remains valuable as a study guide for AWS database services regardless of certification status.
I recently revalidated my AWS Certified Database – Specialty (DBS-C01) certification just before it expired. The format and domains are pretty much the same as the previous exam, however, it has been enhanced to cover a lot of new services.
AWS Certified Database – Specialty (DBS-C01) Exam Content
AWS Certified Database – Specialty (DBS-C01) exam validates your understanding of databases, including the concepts of design, migration, deployment, access, maintenance, automation, monitoring, security, and troubleshooting, and covers the following tasks:
- Understand and differentiate the key features of AWS database services.
- Analyze needs and requirements to design and recommend appropriate database solutions using AWS services
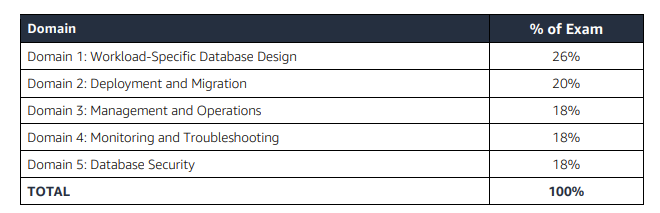
Refer to AWS Database – Specialty Exam Guide
AWS Certified Database – Specialty (DBS-C01) Exam Summary
-
Specialty exams are tough, lengthy, and tiresome. Most of the questions and answers options have a lot of prose and a lot of reading that needs to be done, so be sure you are prepared and manage your time well.
- DBS-C01 exam has 65 questions to be solved in 170 minutes which gives you roughly 2 1/2 minutes to attempt each question.
- DBS-C01 exam includes two types of questions, multiple-choice and multiple-response.
- DBS-C01 has a scaled score between 100 and 1,000. The scaled score needed to pass the exam is 750.
- Specialty exams currently cost $ 300 + tax.
- You can get an additional 30 minutes if English is your second language by requesting Exam Accommodations. It might not be needed for Associate exams but is helpful for Professional and Specialty ones.
- As always, mark the questions for review, move on, and come back to them after you are done with all.
- As always, having a rough architecture or mental picture of the setup helps focus on the areas that you need to improve. Trust me, you will be able to eliminate 2 answers for sure and then need to focus on only the other two. Read the other 2 answers to check the difference area and that would help you reach the right answer or at least have a 50% chance of getting it right.
- AWS exams can be taken either remotely or online, I prefer to take them online as it provides a lot of flexibility. Just make sure you have a proper place to take the exam with no disturbance and nothing around you.
- Also, if you are taking the AWS Online exam for the first time try to join at least 30 minutes before the actual time as I have had issues with both PSI and Pearson with long wait times.
AWS Certified Database – Specialty (DBS-C01) Exam Resources
- Online Courses
- Practice tests
AWS Certified Data Engineer – Associate (DEA-C01)
💡 Recommended Replacement Certification
The AWS Certified Data Engineer – Associate (DEA-C01) launched in March 2024 and is the closest active certification covering database and data services.
- Exam domains: Data Ingestion & Transformation (34%), Data Store Management (26%), Data Operations & Support (22%), Data Security & Governance (18%)
- Format: 65 questions, 130 minutes, $150 + tax, passing score 720
- Key services: DynamoDB, Aurora, RDS, Redshift, S3, Glue, Kinesis, MSK, Lake Formation, DMS
AWS Database Services – Study Summary
- AWS Certified Database – Specialty exam focuses completely on AWS Data services from relational, non-relational, graph, caching, and data warehousing. It also covers deployments, automation, migration, security, monitoring, and troubleshooting aspects of them.
Database Services
- Make sure you know and cover all the services in-depth, as 80% of the exam is focused on topics like Aurora, RDS, DynamoDB
- DynamoDB
- is a fully managed NoSQL database service providing single-digit millisecond latency.
- DynamoDB provisioned throughput supports On-demand and provisioned throughput capacity modes.
- On-demand mode
- provides a flexible billing option capable of serving thousands of requests per second without capacity planning
- does not support reserved capacity
- [Updated 2024] AWS reduced DynamoDB on-demand pricing by 50% (November 2024), making on-demand mode significantly more cost-effective.
- Provisioned mode
- requires you to specify the number of reads and writes per second as required by the application
- Understand the provisioned capacity calculations
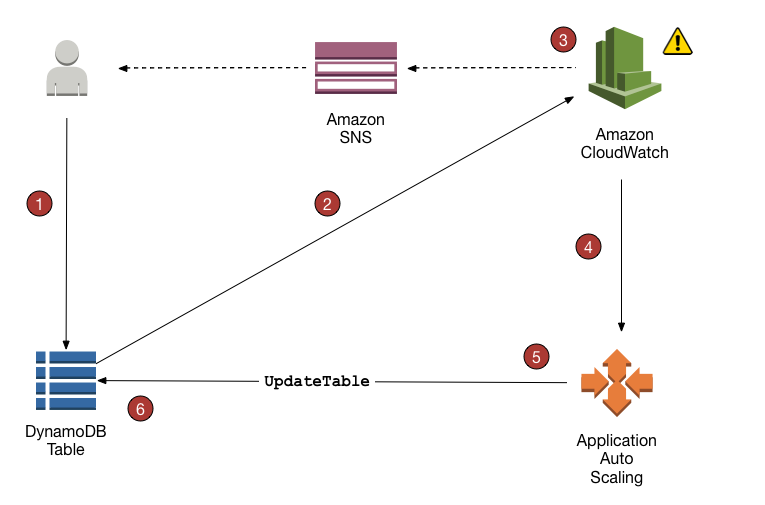
- DynamoDB Auto Scaling uses the AWS Application Auto Scaling service to dynamically adjust provisioned throughput capacity on your behalf, in response to actual traffic patterns.
- Know DynamoDB Burst capacity, Adaptive capacity
- DynamoDB Consistency mode determines the manner and timing in which the successful write or update of a data item is reflected in a subsequent read operation of that same item.
- supports eventual and strongly consistent reads.
- Eventual requires less throughput but might return stale data, whereas, Strongly consistent reads require higher throughput but would always return correct data.
- DynamoDB secondary indexes provide efficient access to data with attributes other than the primary key.
- LSI uses the same partition key but a different sort key, whereas, GSI is a separate table with a different partition key and/or sort key.
- GSI can cause primary table throttling if under-provisioned.
- Make sure you understand the difference between the Local Secondary Index and the Global Secondary Index
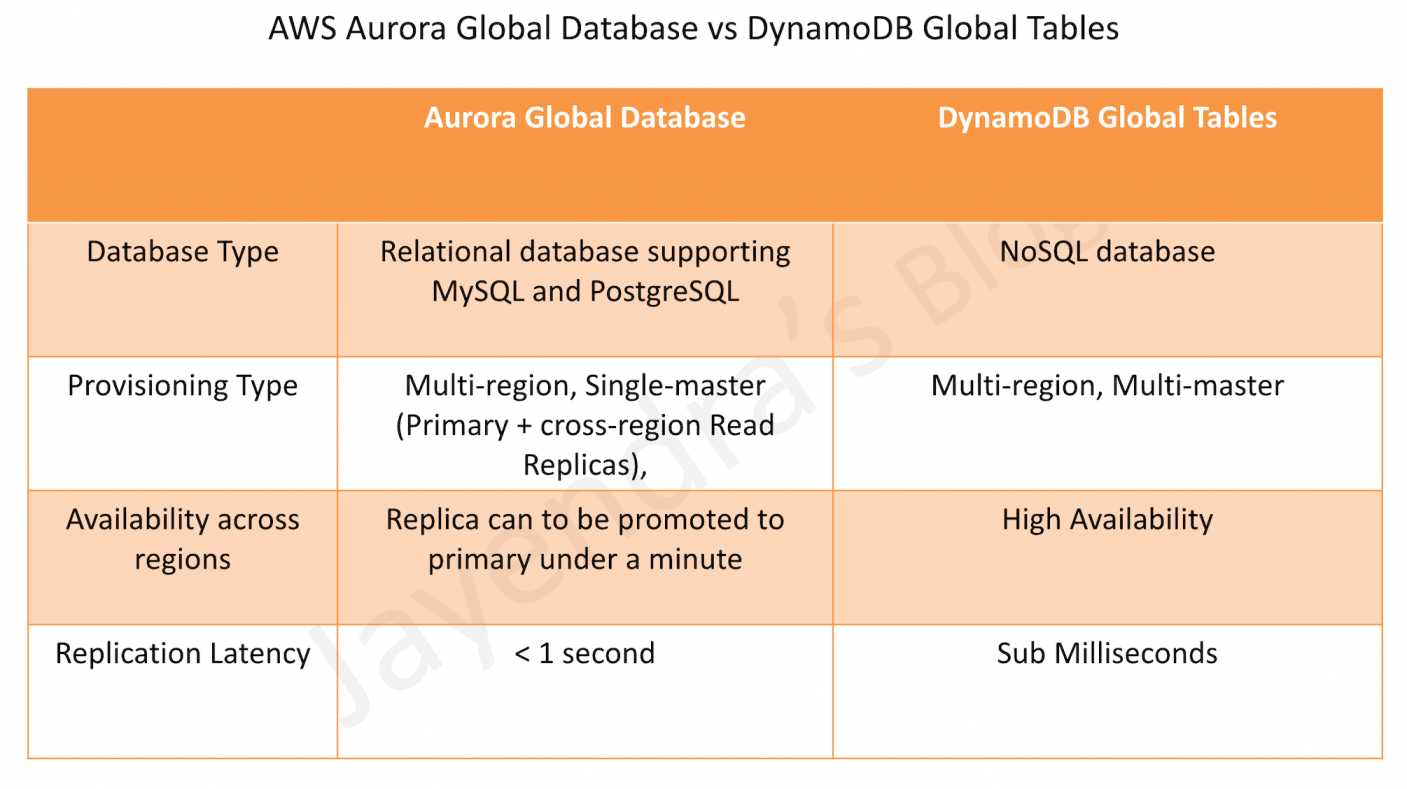
- DynamoDB Global Tables is a multi-active, cross-region replication capability of DynamoDB to support data access locality and regional fault tolerance for database workloads.
- DynamoDB Time to Live – TTL enables a per-item timestamp to determine when an item is no longer needed. (hint: know TTL can expire the data and this can be captured by using DynamoDB Streams)
- DynamoDB cross-region replication allows identical copies (called replicas) of a DynamoDB table (called master table) to be maintained in one or more AWS regions.
- DynamoDB Streams provides a time-ordered sequence of item-level changes made to data in a table.
- DynamoDB Triggers (just like database triggers) is a feature that allows the execution of custom actions based on item-level updates on a table.
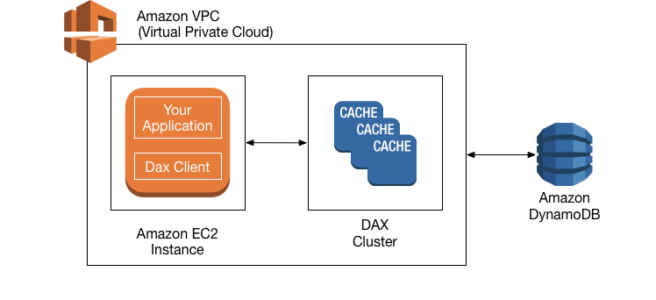
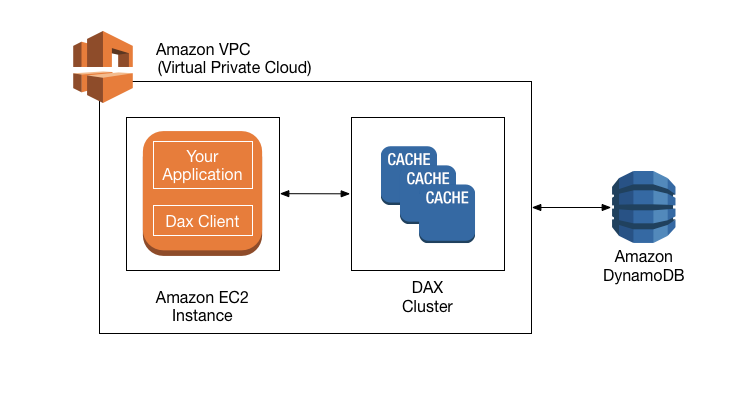
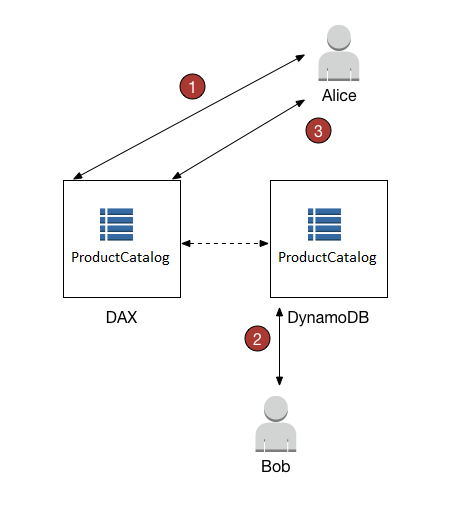
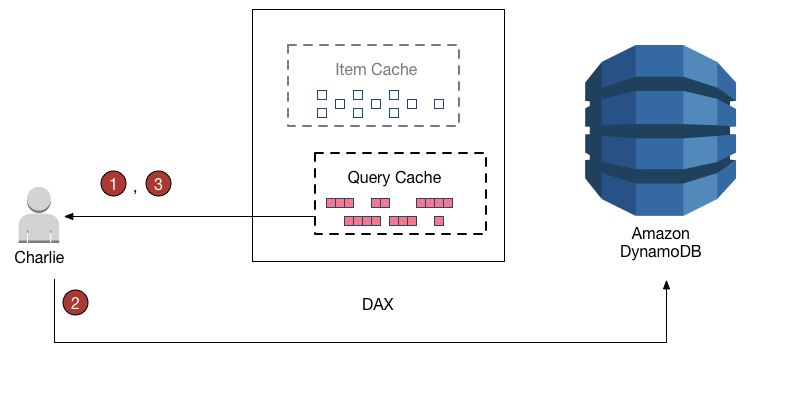
- DynamoDB Accelerator – DAX is a fully managed, highly available, in-memory cache for DynamoDB that delivers up to a 10x performance improvement even at millions of requests per second.
- DAX does not support fine-grained access control like DynamoDB.
- DynamoDB Backups support PITR
- AWS Backup can be used to backup and restore, and it supports cross-region snapshot copy as well.
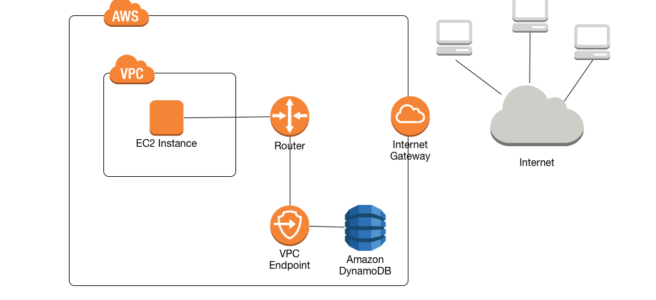
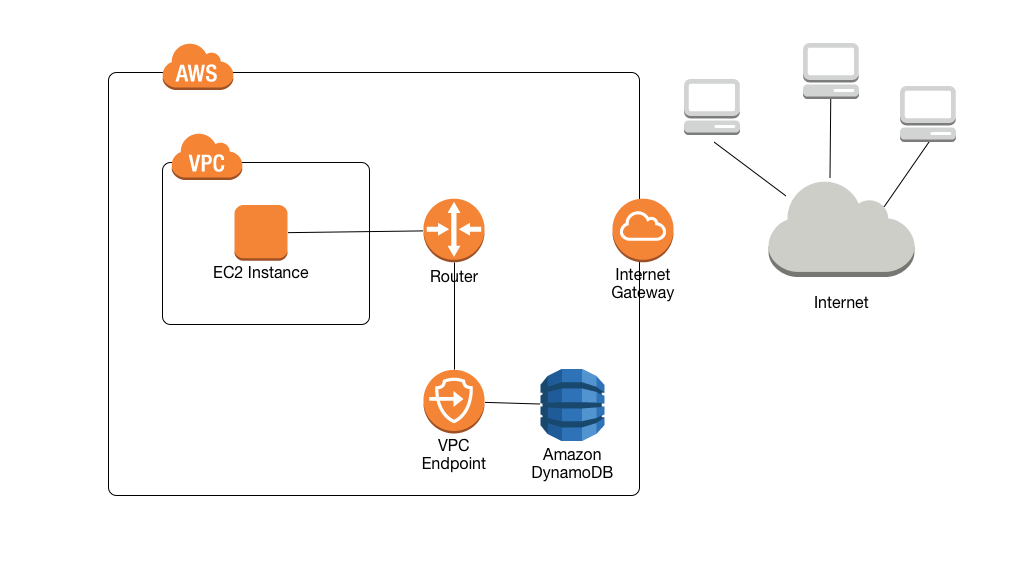
- VPC Gateway Endpoints provide private access to DynamoDB from within a VPC without the need for an internet gateway or NAT gateway
- Understand DynamoDB Best practices (hint: selection of keys to avoid hot partitions and creation of LSI and GSI)
- [New 2024] DynamoDB supports zero-ETL integration with Amazon Redshift (GA October 2024), enabling near real-time analytics on DynamoDB data without building ETL pipelines.
- Aurora
- is a relational database engine that combines the speed and reliability with the simplicity and cost-effectiveness of open-source databases.
- provides MySQL and PostgreSQL compatibility
- Aurora Disaster Recovery & High Availability can be achieved using Read Replicas with very minimal downtime.
- Aurora promotes read replicas as per the priority tier (tier 0 is the highest), the largest size if the tier matches
- Aurora Global Database provides cross-region read replicas for low-latency reads. Remember it is not multi-master and would not provide low latency writes across regions as DynamoDB Global tables.
- Aurora Connection endpoints support
- Cluster for primary read/write
- Reader for read replicas
- Custom for a specific group of instances
- Instance for specific single instance – Not recommended
- Aurora Fast Failover techniques
- set TCP keepalives low
- set Java DNS caching timeouts low
- Set the timeout variables used in the JDBC connection string as low
- Use the provided read and write Aurora endpoints
- Use cluster cache management for Aurora PostgreSQL. Cluster cache management ensures that application performance is maintained if there’s a failover.
- Aurora Serverless is an on-demand, autoscaling configuration for the MySQL-compatible and PostgreSQL-compatible editions of Aurora.
- [Updated 2024-2025] Aurora Serverless v2 now supports scaling from 0 to 256 ACUs (Aurora Capacity Units). Scale-to-zero (November 2024) eliminates costs during inactivity, while the 256 ACU maximum (October 2024) supports larger workloads.
- [New 2025] Aurora Serverless v2 platform version 4 delivers up to 30% better performance and 45% faster scaling at no additional cost.
- Aurora Backtrack feature helps rewind the DB cluster to the specified time. It is not a replacement for backups.
- Aurora Server Auditing Events for different activities cover log-in, DML, permission changes DCL, schema changes DDL, etc.
- Aurora Cluster Cache management feature which helps fast failover
- Aurora Clone feature which allows you to create quick and cost-effective clones
- Aurora supports fault injection queries to simulate various failovers like node down, primary failover, etc.
- RDS PostgreSQL and MySQL can be migrated to Aurora, by creating an Aurora Read Replica from the instance. Once the replica lag is zero, switch the DNS with no data loss
- Aurora Database Activity Streams help stream audit logs to external services like Kinesis
- Supports stored procedures calling lambda functions
- [New 2024] Aurora PostgreSQL Limitless Database (GA November 2024) enables horizontal write scaling by distributing workloads across multiple Aurora writer instances while maintaining single-database semantics and transactional consistency.
- [New 2024] Aurora supports zero-ETL integration with Amazon Redshift, enabling near real-time analytics without building ETL pipelines.
- Relational Database Service (RDS)
- provides a relational database in the cloud with multiple database options.
- RDS Snapshots, Backups, and Restore
- restoring a DB from a snapshot does not retain the parameter group and security group
- automated snapshots cannot be shared. Make a manual backup from the snapshot before sharing the same.
- RDS Read Replicas
- allow elastic scaling beyond the capacity constraints of a single DB instance for read-heavy database workloads.
- increased scalability and database availability in the case of an AZ failure.
- supports cross-region replicas.
- RDS Multi-AZ provides high availability and automatic failover support for DB instances.
- Understand the differences between RDS Multi-AZ vs Read Replicas
- Multi-AZ failover can be simulated using Reboot with Failure option
- Read Replicas require automated backups enabled
- [New] RDS Multi-AZ DB Cluster deployments provide a primary and two readable standby instances across three AZs, offering lower write latency, faster failover (~35 seconds), and readable standbys compared to traditional Multi-AZ.
- Understand DB components esp. DB parameter group, DB options groups
- Dynamic parameters are applied immediately
- Static parameters need manual reboot.
- Default parameter group cannot be modified. Need to create custom parameter group and associate to RDS
- Know max connections also depends on DB instance size
- RDS Custom automates database administration tasks and operations. while making it possible for you as a database administrator to access and customize the database environment and operating system.
- RDS Performance Insights is a database performance tuning and monitoring feature that helps you quickly assess the load on the database, and determine when and where to take action.
- RDS Security
- RDS supports security groups to control who can access RDS instances
- RDS supports data at rest encryption and SSL for data in transit encryption
- RDS supports IAM database authentication with temporary credentials.
- Existing RDS instance cannot be encrypted, create a snapshot -> encrypt it –> restore as encrypted DB
- RDS PostgreSQL requires
rds.force_ssl=1 and sslmode=ca/verify-full to enable SSL encryption
- Know RDS Encrypted Database limitations
- Understand RDS Monitoring and Notification
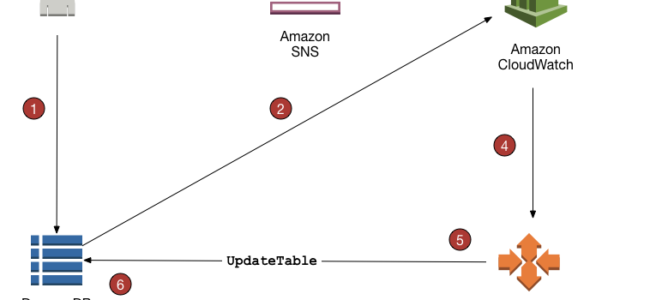
- Know RDS supports notification events through SNS for events like database creation, deletion, snapshot creation, etc.
- CloudWatch gathers metrics about CPU utilization from the hypervisor for a DB instance, and Enhanced Monitoring gathers its metrics from an agent on the instance.
- Enhanced Monitoring metrics are useful to understand how different processes or threads on a DB instance use the CPU.
- RDS Performance Insights is a database performance tuning and monitoring feature that helps illustrate the database’s performance and help analyze any issues that affect it
- RDS instance cannot be stopped if with read replicas
- [New 2024] RDS supports zero-ETL integration with Amazon Redshift for MySQL and PostgreSQL, enabling near real-time analytics.
- [New 2026] RDS now supports ENA Express for Multi-AZ replication, improving replication performance through multiple network paths.
- ElastiCache
- is a managed web service that helps deploy and run Memcached or Redis protocol-compliant cache clusters in the cloud easily.
- Understand the differences between Redis vs. Memcached
- [New 2024] ElastiCache now supports Valkey, a community-driven, open-source fork of Redis. Valkey is the recommended engine on ElastiCache with 33% lower Serverless pricing and 20% lower node-based pricing than other engines.
- [Updated 2026] Valkey 9.0 is now available for ElastiCache, offering improved performance. Valkey has become the default high-performance key-value datastore across major cloud providers.
- [New] ElastiCache Serverless enables creating a cache in under a minute with automatic scaling based on traffic patterns, eliminating the need to right-size clusters.
- Neptune
- is a fully managed database service built for the cloud that makes it easier to build and run graph applications. Neptune provides built-in security, continuous backups, serverless compute, and integrations with other AWS services.
- provides Neptune loader to quickly import data from S3
- supports VPC endpoints
- [New 2024] Neptune Analytics provides a serverless graph analytics engine for running algorithms on large graphs without managing infrastructure. Supports NetworkX integration for Python-based graph workflows.
- Neptune Serverless automatically scales capacity based on workload demands.
- Amazon Keyspaces (for Apache Cassandra) is a scalable, highly available, and managed Apache Cassandra–compatible database service.
Amazon Quantum Ledger Database (Amazon QLDB) is a fully managed ledger database that provides a transparent, immutable, and cryptographically verifiable transaction log.
⚠️ Amazon QLDB reached End of Support on July 31, 2025. All data not migrated was permanently deleted. AWS recommends migrating to
Amazon Aurora PostgreSQL for audit use cases using the ledger functionality with cryptographic verification.
- Redshift
- is a fully managed, fast, and powerful, petabyte-scale data warehouse service. It is not covered in depth.
- Know Redshift Best Practices w.r.t selection of Distribution style, Sort key, importing/exporting data
- COPY command which allows parallelism, and performs better than multiple COPY commands
- COPY command can use manifest files to load data
- COPY command handles encrypted data
- Know Redshift cross region encrypted snapshot copy
- Create a new key in destination region
- Use CreateSnapshotCopyGrant to allow Amazon Redshift to use the KMS key from the destination region.
- In the source region, enable cross-region replication and specify the name of the copy grant created.
- Know Redshift supports Audit logging which covers authentication attempts, connections and disconnections usually for compliance reasons.
- [New 2024-2025] Redshift supports zero-ETL integrations from Aurora MySQL/PostgreSQL, RDS MySQL, DynamoDB, and SaaS applications (Salesforce, SAP, Zendesk), eliminating the need for custom ETL pipelines.
- [New] Redshift Serverless provides automatic scaling and pay-per-use pricing without managing clusters.
- Data Migration Service (DMS)
- DMS helps in migration of homogeneous and heterogeneous database
- DMS with Full load plus Change Data Capture (CDC) migration capability can be used to migrate databases with zero downtime and no data loss.
- DMS with SCT (Schema Conversion Tool) can be used to migrate heterogeneous databases.
- Premigration Assessment evaluates specified components of a database migration task to help identify any problems that might prevent a migration task from running as expected.
- Multiserver assessment report evaluates multiple servers based on input that you provide for each schema definition that you want to assess.
- DMS provides support for data validation to ensure that your data was migrated accurately from the source to the target.
- DMS supports LOB migration as a 2-step process. It can do a full or limited LOB migration
- In full LOB mode, AWS DMS migrates all LOBs from source to target regardless of size. Full LOB mode can be quite slow.
- In limited LOB mode, a maximum LOB size can be set that AWS DMS should accept. Doing so allows AWS DMS to pre-allocate memory and load the LOB data in bulk. LOBs that exceed the maximum LOB size are truncated and a warning is issued to the log file. In limited LOB mode, you get significant performance gains over full LOB mode.
- Recommended to use limited LOB mode whenever possible.
- [New 2024] DMS Homogeneous Data Migrations is a serverless feature for like-to-like migrations (e.g., PostgreSQL to Aurora PostgreSQL) that uses native database tooling. No replication instances to manage. Supports PostgreSQL, MySQL, MariaDB, and MongoDB.
- [New 2024] DMS Schema Conversion now uses generative AI to automatically convert up to 90% of schema objects from commercial databases to PostgreSQL.
- [Deprecated 2026] AWS DMS Fleet Advisor reached end of support on May 20, 2026.
Security, Identity & Compliance
- Identity and Access Management (IAM)
- Key Management Services
- is a managed encryption service that allows the creation and control of encryption keys to enable data encryption.
- provides data at rest encryption for the databases.
- AWS Secrets Manager
- protects secrets needed to access applications, services, etc.
- enables you to easily rotate, manage, and retrieve database credentials, API keys, and other secrets throughout their lifecycle
- supports automatic rotation of credentials for RDS, DocumentDB, etc.
- Secrets Manager vs. Systems Manager Parameter Store
- Secrets Manager supports automatic rotation while SSM Parameter Store does not
- Parameter Store is cost-effective as compared to Secrets Manager.
- Trusted Advisor provides RDS Idle instances
Management & Governance Tools
- Understand AWS CloudWatch for Logs and Metrics.
- EventBridge (CloudWatch Events) provides real-time alerts
- CloudWatch can be used to store RDS logs with a custom retention period, which is indefinite by default.
- CloudWatch Application Insights support .Net and SQL Server monitoring
- Know CloudFormation for provisioning, in terms of
- Stack drifts – to understand the difference between current state and on actual environment with any manual changes
- Change Set – allows you to verify the changes before being propagated
- parameters – allows you to configure variables or environment-specific values
- Stack policy defines the update actions that can be performed on designated resources.
- Deletion policy for RDS allows you to configure if the resources are retained, snapshot, or deleted once destroy is initiated
- Supports secrets manager for DB credentials generation, storage, and easy rotation
- System parameter store for environment-specific parameters
Whitepapers and articles
On the Exam Day
- Make sure you are relaxed and get some good night’s sleep. The exam is not tough if you are well-prepared.
- If you are taking the AWS Online exam
- Try to join at least 30 minutes before the actual time as I have had issues with both PSI and Pearson with long wait times.
- The online verification process does take some time and usually, there are glitches.
- Remember, you would not be allowed to take the take if you are late by more than 30 minutes.
- Make sure you have your desk clear, no hand-watches, or external monitors, keep your phones away, and nobody can enter the room.
Finally, All the Best 🙂
.png)