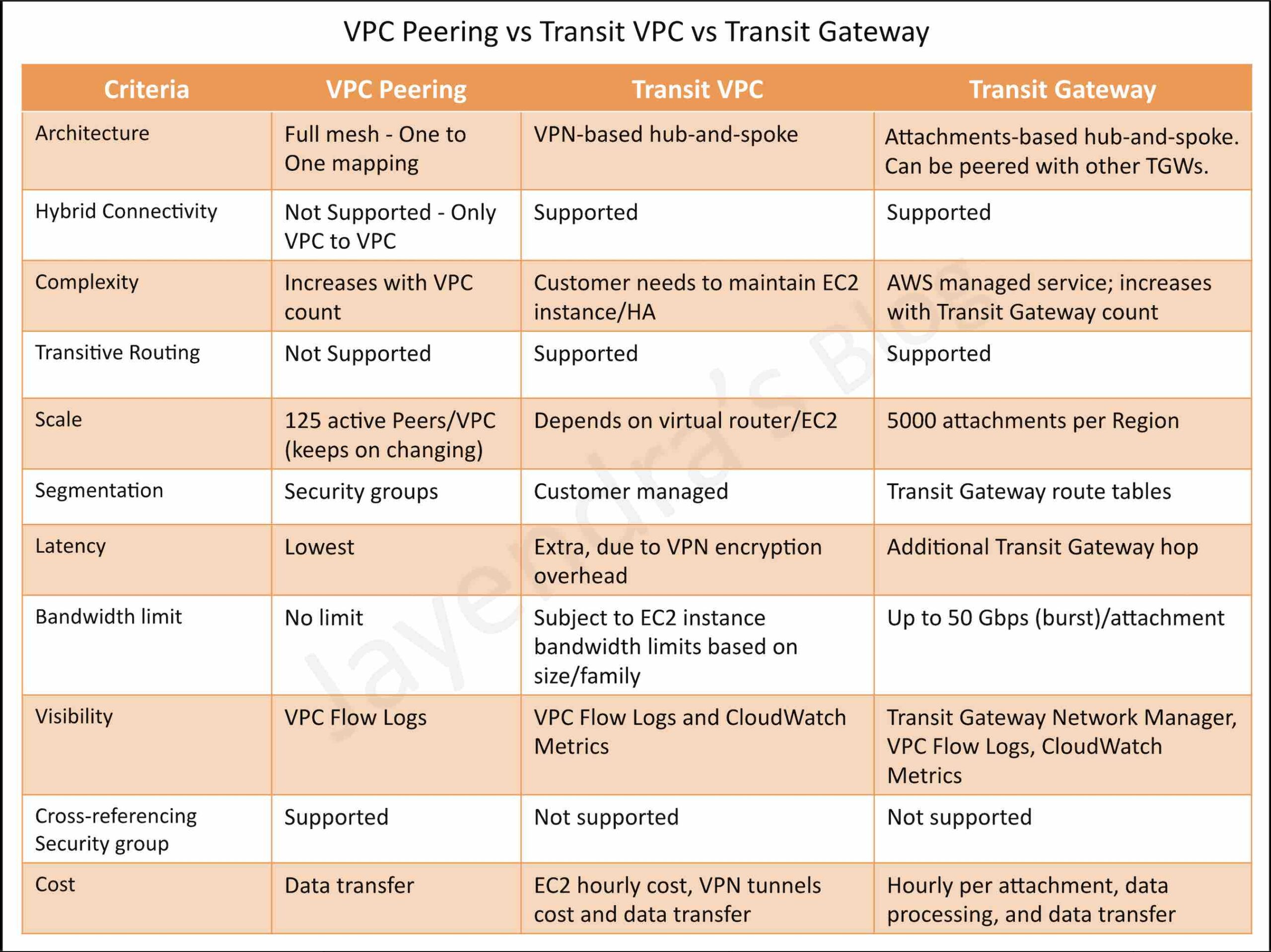
AWS VPC VPN
- AWS VPN connections are used to extend on-premises data centers to AWS.
- VPN connections provide secure IPSec connections between the data center or branch office and the AWS resources.
- AWS Site-to-Site VPN or AWS Hardware VPN or AWS Managed VPN
- Connectivity can be established by creating an IPSec, hardware VPN connection between the VPC and the remote network.
- On the AWS side of the VPN connection, a Virtual Private Gateway (VGW) provides two VPN endpoints for automatic failover.
- On the customer side, a customer gateway (CGW) needs to be configured, which is the physical device or software application on the remote side of the VPN connection
- AWS Client VPN
- AWS Client VPN is a managed client-based VPN service that enables secure access to AWS resources and resources in the on-premises network.
- AWS VPN CloudHub
- For more than one remote network e.g. multiple branch offices, multiple AWS hardware VPN connections can be created via the VPC to enable communication between these networks
- AWS Software VPN
- A VPN connection can be created to the remote network by using an EC2 instance in the VPC that’s running a third-party software VPN appliance.
- AWS does not provide or maintain third-party software VPN appliances; however, there is a range of products provided by partners and open source communities.
- AWS Direct Connect provides a dedicated private connection from a remote network to the VPC. Direct Connect can be combined with an AWS hardware VPN connection to create an IPsec-encrypted connection
VPN Components
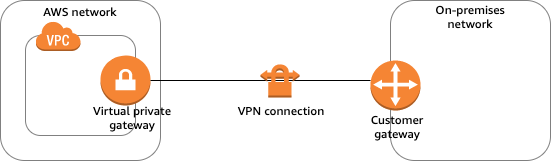
- Virtual Private Gateway – VGW
- A virtual private gateway is the VPN concentrator on the AWS side of the VPN connection
- Customer Gateway – CGW
- A customer gateway is a physical device or software application on the customer side of the VPN connection.
- When a VPN connection is created, the VPN tunnel comes up when traffic is generated from the remote side of the VPN connection.
- By default, VGW is not the initiator; CGW must bring up the tunnels for the Site-to-Site VPN connection by generating traffic and initiating the Internet Key Exchange (IKE) negotiation process.
- If the VPN connection experiences a period of idle time, usually 10 seconds, depending on the configuration, the tunnel may go down. To prevent this, a network monitoring tool to generate keepalive pings; for e.g. by using IP SLA.
- Transit Gateway
- A transit gateway is a transit hub that can be used to interconnect VPCs and on-premises networks.
- A Site-to-Site VPN connection on a transit gateway can support either IPv4 traffic or IPv6 traffic inside the VPN tunnels.
- A Site-to-Site VPN connection offers two VPN tunnels between a VGW or a transit gateway on the AWS side, and a CGW (which represents a VPN device) on the remote (on-premises) side.
VPN Routing Options
- For a VPN connection, the route table for the subnets should be updated with the type of routing (static or dynamic) that you plan to use.
- Route tables determine where network traffic is directed. Traffic destined for the VPN connections must be routed to the virtual private gateway.
- The type of routing can depend on the make and model of the CGW device
- Static Routing
- If your device does not support BGP, specify static routing.
- Using static routing, the routes (IP prefixes) can be specified that should be communicated to the virtual private gateway.
- Devices that don’t support BGP may also perform health checks to assist failover to the second tunnel when needed.
- BGP Dynamic Routing
- If the VPN device supports Border Gateway Protocol (BGP), specify dynamic routing with the VPN connection.
- When using a BGP device, static routes need not be specified to the VPN connection because the device uses BGP for auto-discovery and to advertise its routes to the virtual private gateway.
- BGP-capable devices are recommended as the BGP protocol offers robust liveness detection checks that can assist failover to the second VPN tunnel if the first tunnel goes down.
- Static Routing
- Only IP prefixes known to the virtual private gateway, either through BGP advertisement or static route entry, can receive traffic from the VPC.
- Virtual private gateway does not route any other traffic destined outside of the advertised BGP, static route entries, or its attached VPC CIDR.
VPN Route Priority
- Longest prefix match applies.
- If the prefixes are the same, then the VGW prioritizes routes as follows, from most preferred to least preferred:
- BGP propagated routes from an AWS Direct Connect connection
- Manually added static routes for a Site-to-Site VPN connection
- BGP propagated routes from a Site-to-Site VPN connection
- Prefix with the shortest AS PATH is preferred for matching prefixes where each Site-to-Site VPN connection uses BGP
- Path with the lowest multi-exit discriminators (MEDs) value is preferred when the AS PATHs are the same length and if the first AS in the AS_SEQUENCE is the same across multiple paths.
VPN Limitations
- supports only IPSec tunnel mode. Transport mode is currently not supported.
- supports only one VGW can be attached to a VPC at a time.
- does not support IPv6 traffic on a virtual private gateway.
- does not support Path MTU Discovery.
- does not support overlapping CIDR blocks for the networks. It is recommended to use non-overlapping CIDR blocks.
- does not support transitive routing. So for traffic from on-premises to AWS via a virtual private gateway, it
- does not support Internet connectivity through Internet Gateway
- does not support Internet connectivity through NAT Gateway
- does not support VPC Peered resources access through VPC Peering
- does not support S3, DynamoDB access through VPC Gateway Endpoint
- However, Internet connectivity through NAT instance and VPC Interface Endpoint or PrivateLink services are accessible.
- provides a bandwidth of 1.25 Gbps, currently.
VPN Monitoring
- AWS Site-to-Site VPN automatically sends notifications to the AWS AWS Health Dashboard
- AWS Site-to-Site VPN is integrated with CloudWatch with the following metrics available
- TunnelState
- The state of the tunnels.
- For static VPNs, 0 indicates DOWN and 1 indicates UP.
- For BGP VPNs, 1 indicates ESTABLISHED and 0 is used for all other states.
- For both types of VPNs, values between 0 and 1 indicate at least one tunnel is not UP.
- TunnelDataIn
- The bytes received on the AWS side of the connection through the VPN tunnel from a customer gateway.
- TunnelDataOut
- The bytes sent from the AWS side of the connection through the VPN tunnel to the customer gateway.
- TunnelState
VPN Connection Redundancy
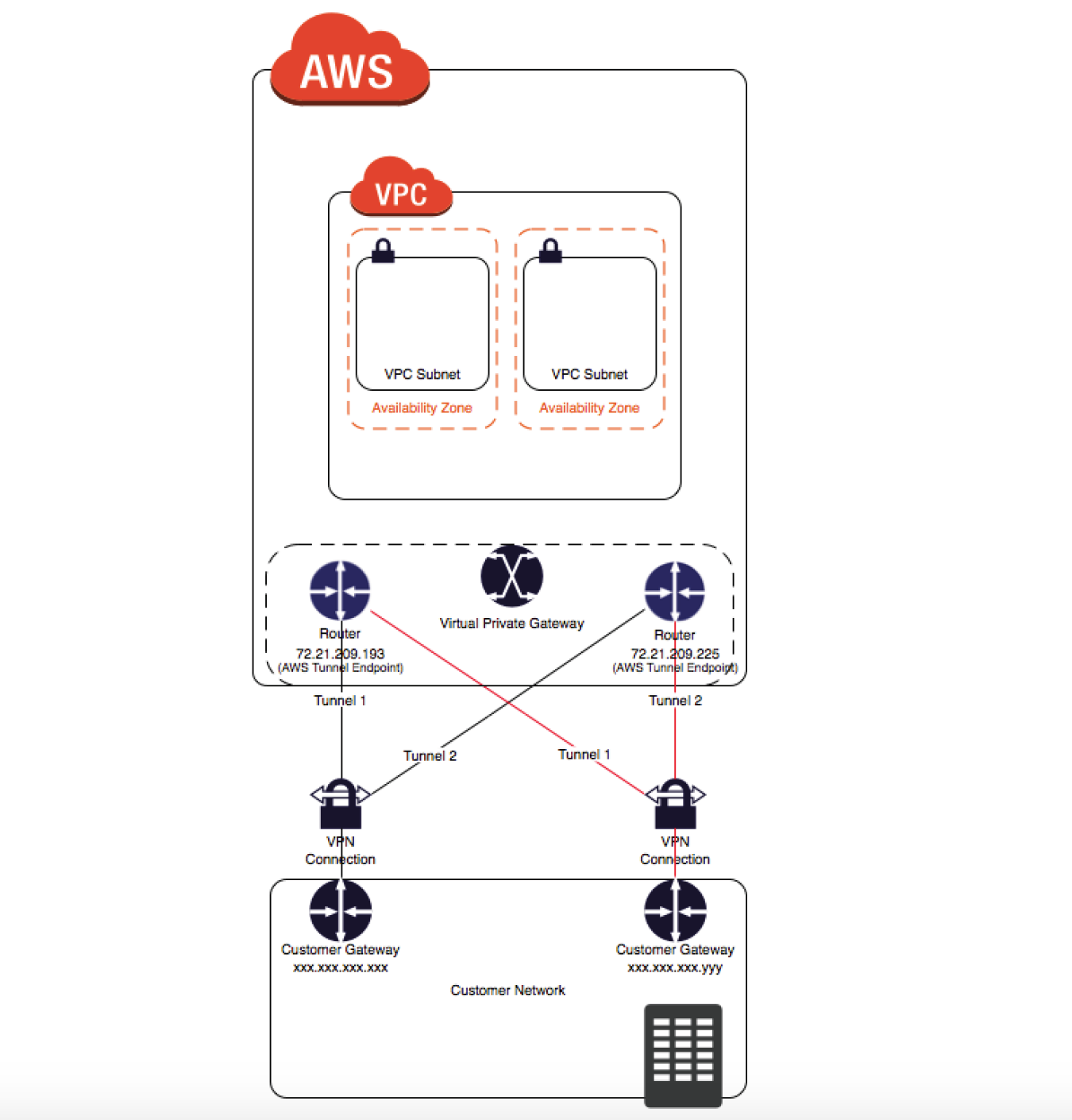
- A VPN connection is used to connect the customer network to a VPC.
- Each VPN connection has two tunnels to help ensure connectivity in case one of the VPN connections becomes unavailable, with each tunnel using a unique virtual private gateway public IP address.
- Both tunnels should be configured for redundancy.
- When one tunnel becomes unavailable, for e.g. down for maintenance, network traffic is automatically routed to the available tunnel for that specific VPN connection.
- To protect against a loss of connectivity in case the customer gateway becomes unavailable, a second VPN connection can be set up to the VPC and virtual private gateway by using a second customer gateway.
- Customer gateway IP address for the second VPN connection must be publicly accessible.
- By using redundant VPN connections and CGWs, maintenance on one of the customer gateways can be performed while traffic continues to flow over the second customer gateway’s VPN connection.
- Dynamically routed VPN connections using the Border Gateway Protocol (BGP) are recommended, if available, to exchange routing information between the customer gateways and the virtual private gateways.
- Statically routed VPN connections require static routes for the network to be entered on the customer gateway side.
- BGP-advertised and statically entered route information allow gateways on both sides to determine which tunnels are available and reroute traffic if a failure occurs.
Multiple Site-to-Site VPN Connections
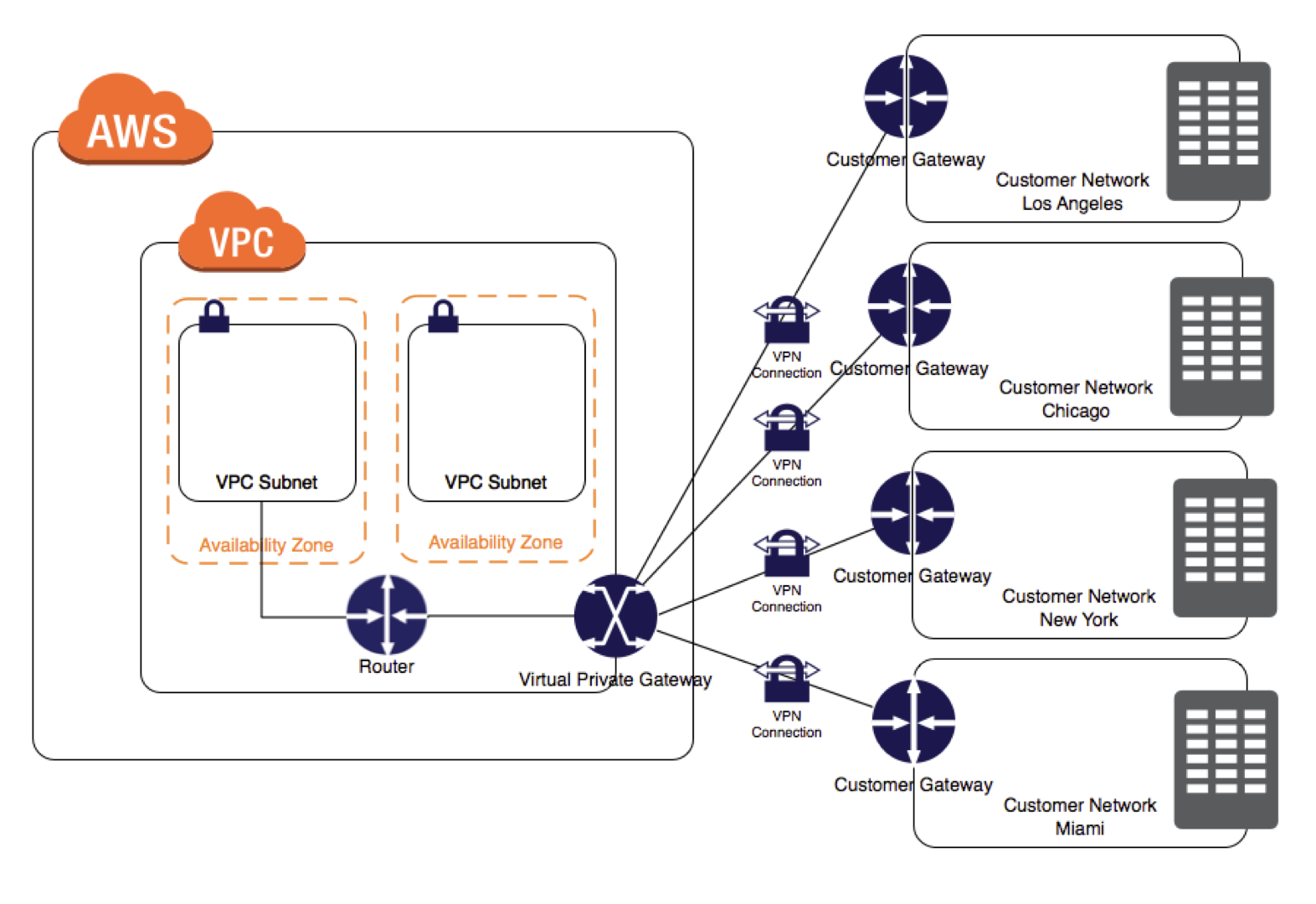
- VPC has an attached virtual private gateway, and the remote network includes a customer gateway, which must be configured to enable the
VPN connection. - Routing must be set up so that any traffic from the VPC bound for the remote network is routed to the virtual private gateway.
- Each VPN has two tunnels associated with it that can be configured on the customer router, as is not a single point of failure
- Multiple VPN connections to a single VPC can be created, and a second CGW can be configured to create a redundant connection to the same external location or to create VPN connections to multiple geographic locations.
VPN CloudHub
- VPN CloudHub can be used to provide secure communication between multiple on-premises sites if you have multiple VPN connections
- VPN CloudHub operates on a simple hub-and-spoke model using a Virtual Private gateway in a detached mode that can be used without a VPC.
- Design is suitable for customers with multiple branch offices and existing
Internet connections who’d like to implement a convenient, potentially low-cost hub-and-spoke model for primary or backup connectivity between these remote offices
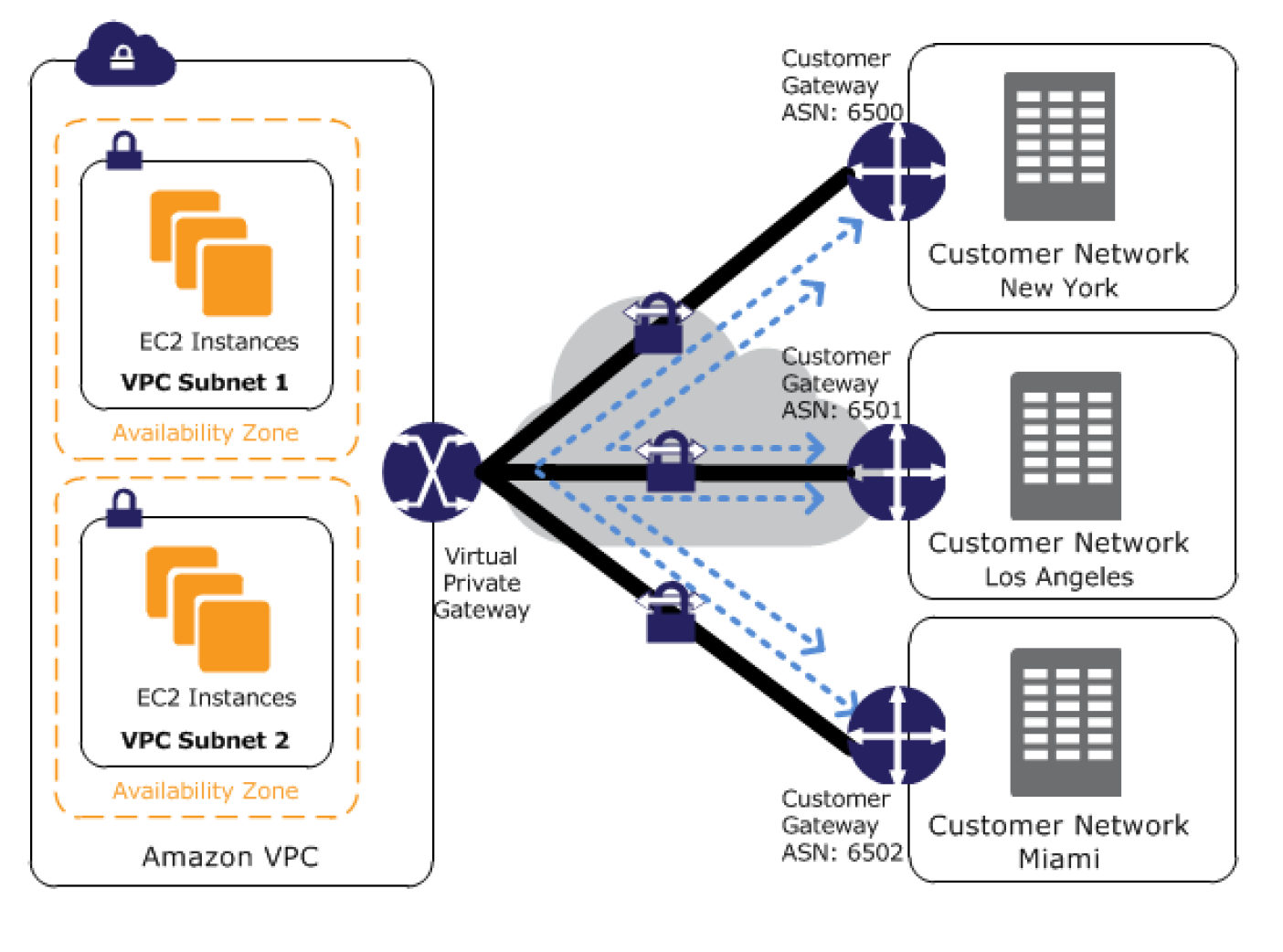
- VPN CloudHub architecture with blue dashed lines indicates network
traffic between remote sites being routed over their VPN connections. - AWS VPN CloudHub requires a virtual private gateway with multiple customer gateways.
- Each customer gateway must use a unique Border Gateway Protocol (BGP) Autonomous System Number (ASN)
- Customer gateways advertise the appropriate routes (BGP prefixes) over their VPN connections.
- Routing advertisements are received and re-advertised to each BGP peer, enabling each site to send data to and receive data from the other sites.
- Routes for each spoke must have unique ASNs and the sites must not have overlapping IP ranges.
- Each site can also send and receive data from the VPC as if they were using a standard VPN connection.
- Sites that use AWS Direct Connect connections to the virtual private gateway can also be part of the AWS VPN CloudHub.
- To configure the AWS VPN CloudHub,
- multiple customer gateways can be created, each with the unique public IP address of the gateway and the ASN.
- a VPN connection can be created from each customer gateway to a common virtual private gateway.
- each VPN connection must advertise its specific BGP routes. This is done using the network statements in the VPN configuration files for the VPN connection.
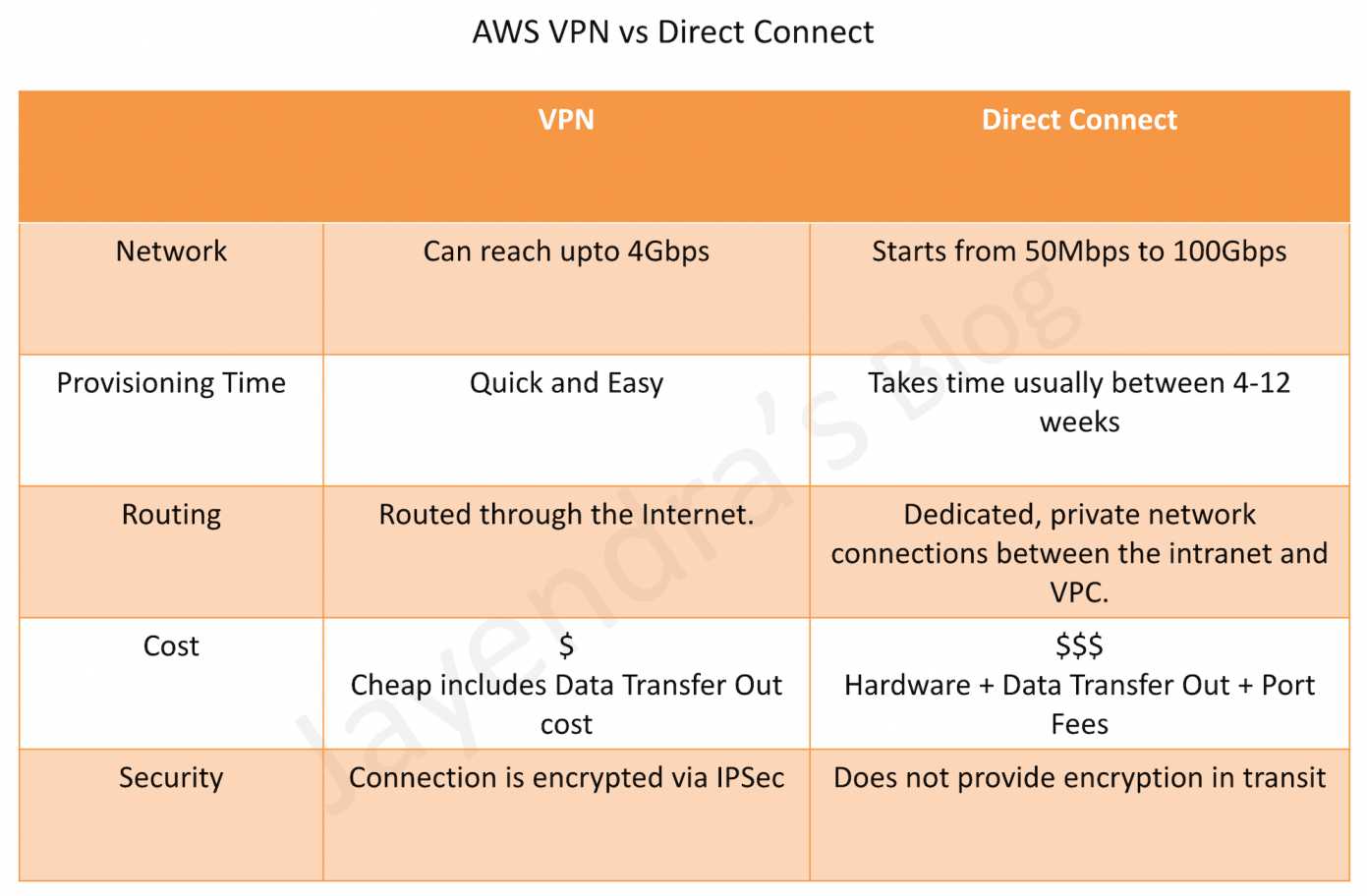
VPN vs Direct Connect
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- You have in total 5 offices, and the entire employee-related information is stored under AWS VPC instances. Now all the offices want to connect the instances in VPC using VPN. Which of the below help you to implement this?
- you can have redundant customer gateways between your data center and your VPC
- you can have multiple locations connected to the AWS VPN CloudHub
- You have to define 5 different static IP addresses in route table.
- 1 and 2
- 1,2 and 3
- You have in total of 15 offices, and the entire employee-related information is stored under AWS VPC instances. Now all the offices want to connect the instances in VPC using VPN. What problem do you see in this scenario?
- You can not create more than 1 VPN connections with single VPC (Can be created)
- You can not create more than 10 VPN connections with single VPC (soft limit can be extended)
- When you create multiple VPN connections, the virtual private gateway can not sends network traffic to the appropriate VPN connection using statically assigned routes. (Can route the traffic to correct connection)
- Statically assigned routes cannot be configured in case of more than 1 VPN with the virtual private gateway. (can be configured)
- None of above
- You have been asked to virtually extend two existing data centers into AWS to support a highly available application that depends on existing, on-premises resources located in multiple data centers and static content that is served from an Amazon Simple Storage Service (S3) bucket. Your design currently includes a dual-tunnel VPN connection between your CGW and VGW. Which component of your architecture represents a potential single point of failure that you should consider changing to make the solution more highly available?
- Add another VGW in a different Availability Zone and create another dual-tunnel VPN connection.
- Add another CGW in a different data center and create another dual-tunnel VPN connection. (Refer link)
- Add a second VGW in a different Availability Zone, and a CGW in a different data center, and create another dual-tunnel.
- No changes are necessary: the network architecture is currently highly available.
- You are designing network connectivity for your fat client application. The application is designed for business travelers who must be able to connect to it from their hotel rooms, cafes, public Wi-Fi hotspots, and elsewhere on the Internet. You do not want to publish the application on the Internet. Which network design meets the above requirements while minimizing deployment and operational costs? [PROFESSIONAL]
- Implement AWS Direct Connect, and create a private interface to your VPC. Create a public subnet and place your application servers in it. (High Cost and does not minimize deployment)
- Implement Elastic Load Balancing with an SSL listener that terminates the back-end connection to the application. (Needs to be published to internet)
- Configure an IPsec VPN connection, and provide the users with the configuration details. Create a public subnet in your VPC, and place your application servers in it. (Instances still in public subnet are internet accessible)
- Configure an SSL VPN solution in a public subnet of your VPC, then install and configure SSL VPN client software on all user computers. Create a private subnet in your VPC and place your application servers in it. (Cost effective and can be in private subnet as well)
- You are designing a connectivity solution between on-premises infrastructure and Amazon VPC Your server’s on-premises will De communicating with your VPC instances You will De establishing IPSec tunnels over the internet You will be using VPN gateways and terminating the IPsec tunnels on AWS-supported customer gateways. Which of the following objectives would you achieve by implementing an IPSec tunnel as outlined above? (Choose 4 answers) [PROFESSIONAL]
- End-to-end protection of data in transit
- End-to-end Identity authentication
- Data encryption across the Internet
- Protection of data in transit over the Internet
- Peer identity authentication between VPN gateway and customer gateway
- Data integrity protection across the Internet
- A development team that is currently doing a nightly six-hour build which is lengthening over time on-premises with a large and mostly under utilized server would like to transition to a continuous integration model of development on AWS with multiple builds triggered within the same day. However, they are concerned about cost, security and how to integrate with existing on-premises applications such as their LDAP and email servers, which cannot move off-premises. The development environment needs a source code repository; a project management system with a MySQL database resources for performing the builds and a storage location for QA to pick up builds from. What AWS services combination would you recommend to meet the development team’s requirements? [PROFESSIONAL]
- A Bastion host Amazon EC2 instance running a VPN server for access from on-premises, Amazon EC2 for the source code repository with attached Amazon EBS volumes, Amazon EC2 and Amazon RDS MySQL for the project management system, EIP for the source code repository and project management system, Amazon SQL for a build queue, An Amazon Auto Scaling group of Amazon EC2 instances for performing builds and Amazon Simple Email Service for sending the build output. (Bastion is not for VPN connectivity also SES should not be used)
- An AWS Storage Gateway for connecting on-premises software applications with cloud-based storage securely, Amazon EC2 for the resource code repository with attached Amazon EBS volumes, Amazon EC2 and Amazon RDS MySQL for the project management system, EIPs for the source code repository and project management system, Amazon Simple Notification Service for a notification initiated build, An Auto Scaling group of Amazon EC2 instances for performing builds and Amazon S3 for the build output. (Storage Gateway does provide secure connectivity but still needs VPN. SNS alone cannot handle builds)
- An AWS Storage Gateway for connecting on-premises software applications with cloud-based storage securely, Amazon EC2 for the resource code repository with attached Amazon EBS volumes, Amazon EC2 and Amazon RDS MySQL for the project management system, EIPs for the source code repository and project management system, Amazon SQS for a build queue, An Amazon Elastic Map Reduce (EMR) cluster of Amazon EC2 instances for performing builds and Amazon CloudFront for the build output. (Storage Gateway does not provide secure connectivity, still needs VPN. EMR is not ideal for performing builds as it needs normal EC2 instances)
- A VPC with a VPN Gateway back to their on-premises servers, Amazon EC2 for the source-code repository with attached Amazon EBS volumes, Amazon EC2 and Amazon RDS MySQL for the project management system, EIPs for the source code repository and project management system, SQS for a build queue, An Auto Scaling group of EC2 instances for performing builds and S3 for the build output. (VPN gateway is required for secure connectivity. SQS for build queue and EC2 for builds)