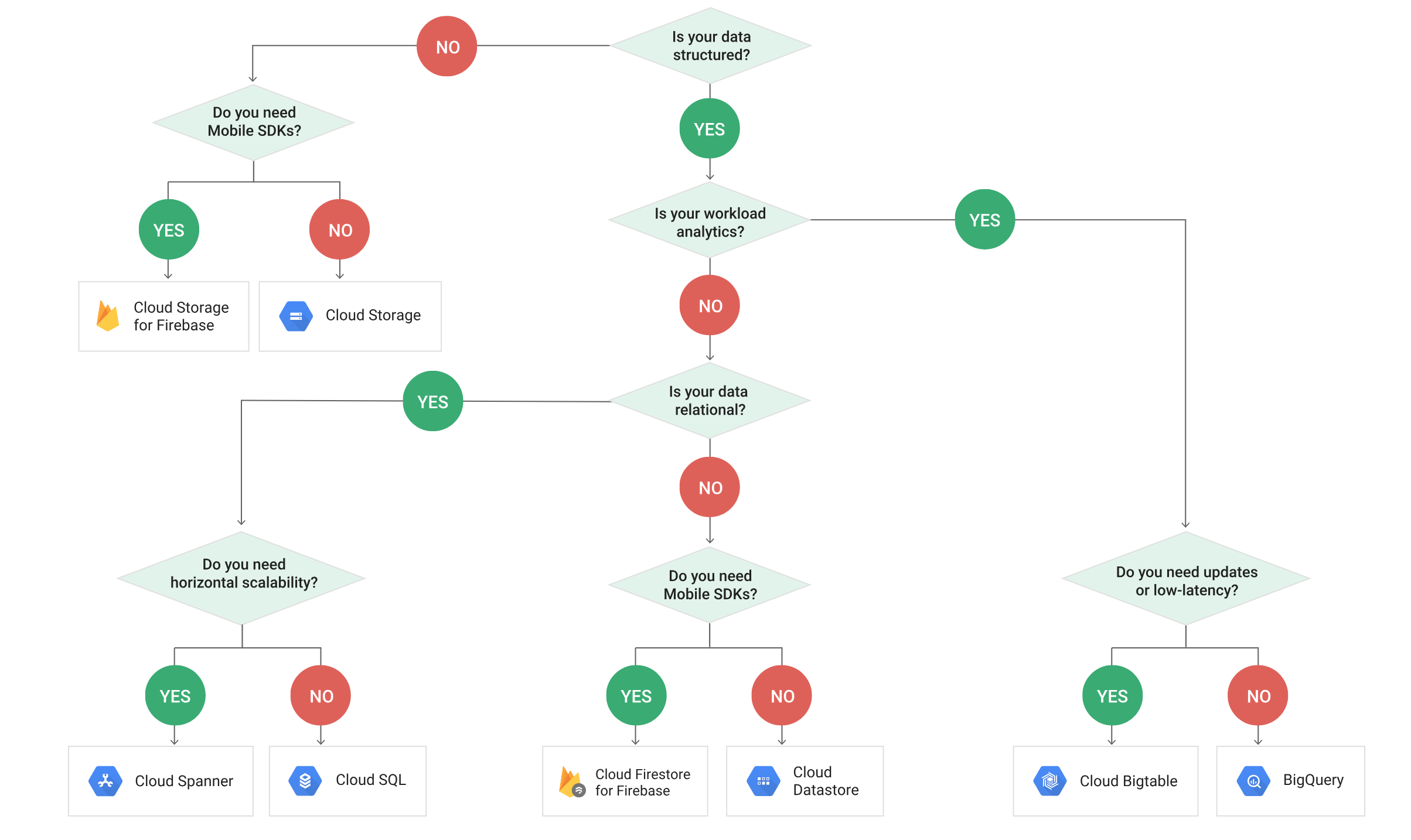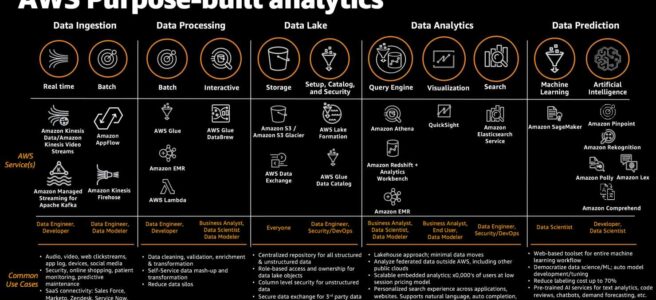
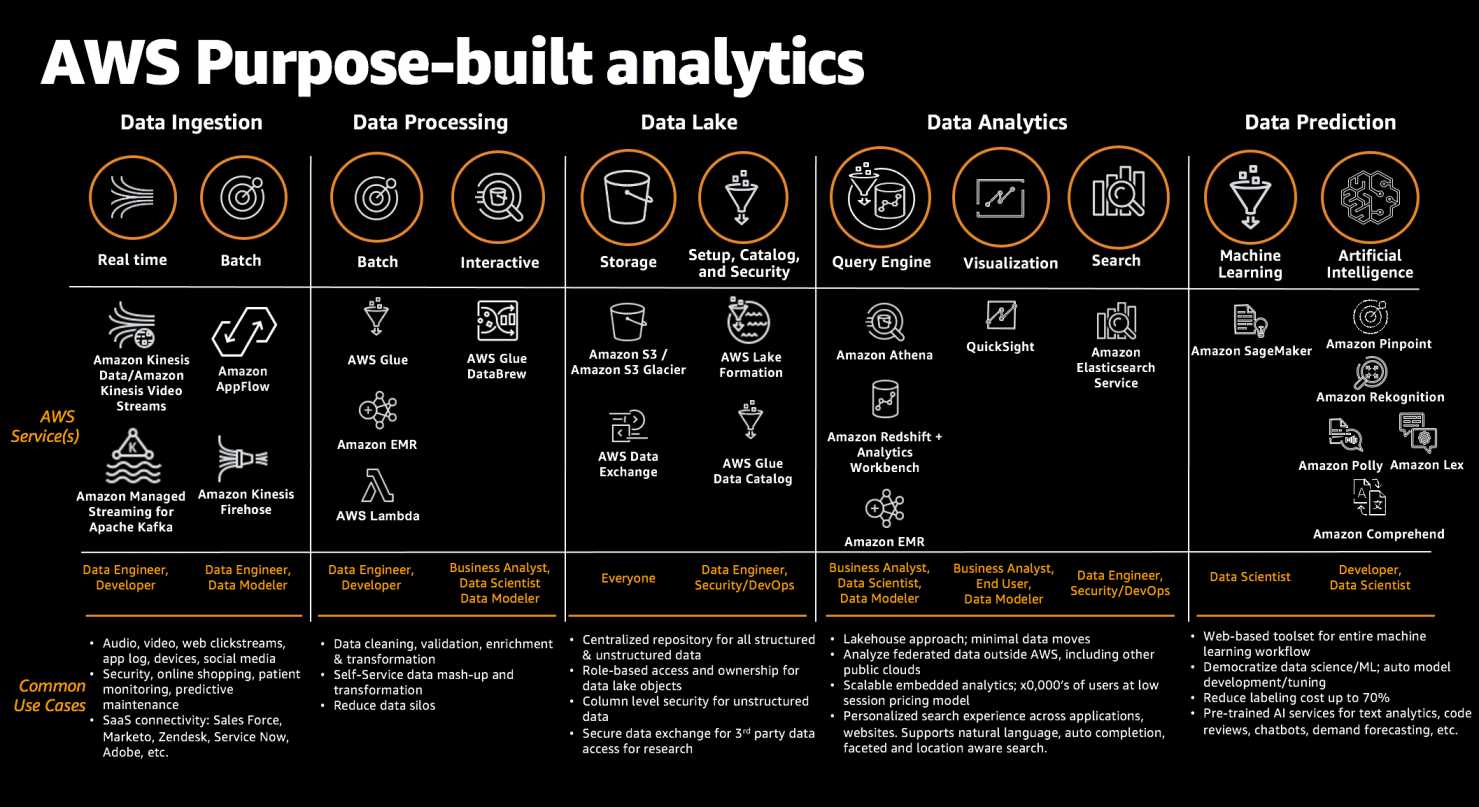
AWS Data Analytics Services Cheat Sheet
📋 Last Updated: June 2026. This post has been updated to reflect service renamings (Kinesis Data Firehose → Amazon Data Firehose, Kinesis Data Analytics → Amazon Managed Service for Apache Flink, Elasticsearch → OpenSearch Service, QuickSight → Quick Suite), deprecations (AWS Data Pipeline, Kinesis Data Analytics for SQL), and major new features (Zero-ETL integrations, MSK Express brokers, Glue 5.0, SageMaker Lakehouse).
Kinesis Data Streams – KDS
- enables real-time processing of streaming data at a massive scale
- provides ordering of records per shard
- provides an ability to read and/or replay records in the same order
- allows multiple applications to consume the same data
- data is replicated across three data centers within a region
- data is preserved for 24 hours, by default, and can be extended to 365 days
- data inserted in Kinesis, it can’t be deleted (immutability) but only expires
- streams can be scaled using multiple shards, based on the partition key
- each shard provides the capacity of 1MB/sec data input and 2MB/sec data output with 1000 PUT requests per second
- supports two capacity modes:
- Provisioned mode – you manage the number of shards
- On-demand mode – automatically scales to accommodate up to 10 GB/s write and 20 GB/s read throughput per stream
- On-demand Advantage mode (launched Nov 2025) – enables on-demand streams to handle instant throughput increases via warm throughput capability, with up to 10GB/s or 10 million events/second, eliminating over-provisioning needs and offering 60%+ cost savings for consistent workloads
- supports record sizes up to 10 MiB (increased from 1 MiB in Oct 2025)
- supports up to 50 enhanced fan-out consumers per stream (increased from 20 in Nov 2025)
- Kinesis vs SQS
- real-time processing of streaming big data vs reliable, highly scalable hosted queue for storing messages
- ordered records, as well as the ability to read and/or replay records in the same order vs no guarantee on data ordering (with the standard queues before the FIFO queue feature was released)
- data storage up to 24 hours, extended to 365 days vs 1 minute to extended to 14 days but cleared if deleted by the consumer.
- supports multiple consumers vs a single consumer at a time and requires multiple queues to deliver messages to multiple consumers.
- Kinesis Producer
- API
- PutRecord and PutRecords are synchronous
- PutRecords uses batching and increases throughput
- might experience ProvisionedThroughputExceeded Exceptions, when sending more data. Use retries with backoff, resharding, or change partition key.
- KPL
- producer supports synchronous or asynchronous use cases
- supports inbuilt batching and retry mechanism
- ⚠️ KPL 0.x reached end-of-support on January 30, 2026. Migrate to KPL 1.x.
- Kinesis Agent can help monitor log files and send them to KDS
- supports third-party libraries like Spark, Flume, Kafka connect, etc.
- API
- Kinesis Consumers
- Kinesis SDK
- Records are polled by consumers from a shard
- Kinesis Client Library (KCL)
- Read records from Kinesis produced with the KPL (de-aggregation)
- supports the checkpointing feature to keep track of the application’s state and resume progress using the DynamoDB table.
- if application receives provisioned-throughput exceptions, increase the provisioned throughput for the DynamoDB table
- ⚠️ KCL 1.x reached end-of-support on January 30, 2026. Migrate to KCL 2.x.
- Kinesis Connector Library – can be replaced using Firehose or Lambda
- Third-party libraries: Spark, Log4J Appenders, Flume, Kafka Connect…
- Amazon Data Firehose, AWS Lambda
- Kinesis Consumer Enhanced Fan-Out
- supports Multiple Consumer applications for the same Stream
- provides Low Latency ~70ms
- Higher costs
- now supports up to 50 consumers per stream
- Kinesis SDK
- Kinesis Security
- allows access/authorization control using IAM policies
- supports Encryption in flight using HTTPS endpoints
- supports data encryption at rest using either server-side encryption with KMS or using client-side encryption before pushing the data to data streams.
- supports VPC Endpoints to access within VPC
Amazon Data Firehose
(Previously known as Amazon Kinesis Data Firehose, renamed February 2024)
- data transfer solution for delivering near real-time streaming data to destinations such as S3, Redshift, OpenSearch Service, Splunk, Snowflake, and other 3rd-party analytics services.
- is a fully managed service that automatically scales to match the throughput of your data and requires no ongoing administration
- is Near Real Time (min. 60 secs) as it buffers incoming streaming data to a certain size or for a certain period of time before delivering it
- supports batching, compression, and encryption of the data before loading it, minimizing the amount of storage used at the destination and increasing security
- supports data compression, minimizing the amount of storage used at the destination. It currently supports GZIP, ZIP, and SNAPPY compression formats. Only GZIP is supported if the data is further loaded to Redshift.
- supports out of box data transformation as well as custom transformation using Lambda function to transform incoming source data and deliver the transformed data to destinations
- uses at least once semantics for data delivery.
- supports multiple producers as datasource, which include Kinesis data stream, KPL, Kinesis Agent, or the Data Firehose API using the AWS SDK, CloudWatch Logs, CloudWatch Events, or AWS IoT
- does NOT support consumers like Spark and KCL
- supports interface VPC endpoint to keep traffic between the VPC and Data Firehose from leaving the Amazon network.
- Apache Iceberg Tables destination (launched 2024) – delivers streaming data directly into Apache Iceberg format tables in S3 and S3 Tables, supporting record routing to different Iceberg tables, CDC replication from databases, schema evolution, and ACID transactions.
- Database CDC replication (Preview 2024) – supports continuous replication of database changes from MySQL and PostgreSQL directly into Apache Iceberg Tables in S3.
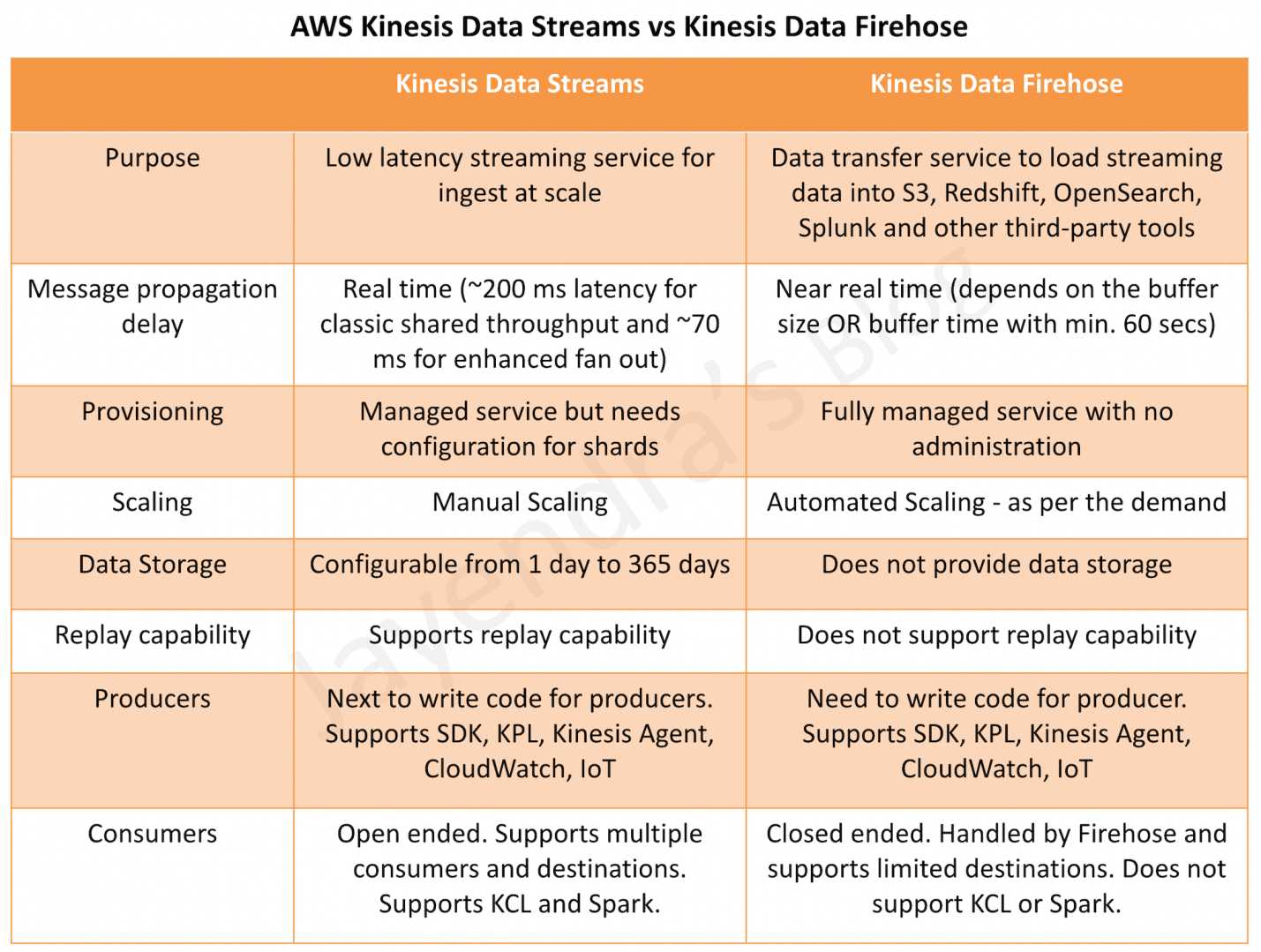
Kinesis Data Streams vs Amazon Data Firehose
Amazon Managed Service for Apache Flink
(Previously known as Amazon Kinesis Data Analytics, renamed August 2023)
⚠️ Kinesis Data Analytics for SQL was discontinued on January 27, 2026. Migrate to Amazon Managed Service for Apache Flink or Apache Flink Studio for real-time stream processing.
- helps analyze streaming data, gain actionable insights, and respond to the business and customer needs in real time.
- is a fully managed and serverless service for building and running real-time streaming applications using Apache Flink.
- reduces the complexity of building, managing, and integrating streaming applications with other AWS services.
- supports Apache Flink applications written in Java, Scala, Python, and SQL.
- provides automatic scaling, high availability, and exactly-once processing semantics.
- integrates with Kinesis Data Streams, Amazon MSK, and Amazon S3 as data sources and sinks.
Managed Streaming for Kafka – MSK
- Managed Streaming for Kafka- MSK is an AWS streaming data service that manages Apache Kafka infrastructure and operations.
- makes it easy for developers and DevOps managers to run Kafka applications and Kafka Connect connectors on AWS, without the need to become experts in operating Kafka.
- operates, maintains, and scales Kafka clusters, provides enterprise-grade security features out of the box, and has built-in AWS integrations that accelerate development of streaming data applications.
- always runs within a VPC managed by the MSK and is available to your own selected VPC, subnet, and security group when the cluster is setup.
- IP addresses from the VPC are attached to the MSK resources through elastic network interfaces (ENIs), and all network traffic stays within the AWS network and is not accessible to the internet by default.
- integrates with CloudWatch for monitoring, metrics, and logging.
- MSK Serverless is a cluster type for MSK that makes it easy for you to run Apache Kafka clusters without having to manage compute and storage capacity.
- MSK Express Brokers (GA November 2024) – a new broker type for MSK Provisioned designed to deliver:
- up to 3x more throughput per broker (500 MBps ingress, 1000 MBps egress on m7g instances)
- up to 20x faster scaling
- 90% faster recovery from failures
- up to 5x more partitions per broker
- virtually unlimited storage with instant storage scaling
- supports Intelligent Rebalancing for 180x faster operation performance
- supports EBS server-side encryption using KMS to encrypt storage.
- supports encryption in transit enabled via TLS for inter-broker communication.
- For provisioned clusters, you have three options:
- IAM Access Control for both AuthN/Z (recommended),
- TLS certificate authentication (CA) for AuthN and access control lists for AuthZ
- SASL/SCRAM for AuthN and access control lists for AuthZ.
- For serverless clusters, IAM Access Control can be used for both authentication and authorization.
Redshift
- Redshift is a fast, fully managed data warehouse
- provides simple and cost-effective solutions to analyze all the data using standard SQL and the existing Business Intelligence (BI) tools.
- manages the work needed to set up, operate, and scale a data warehouse, from provisioning the infrastructure capacity to automating ongoing administrative tasks such as backups, and patching.
- automatically monitors your nodes and drives to help you recover from failures.
- only supported Single-AZ deployments. However, now supports Multi-AZ deployments.
- replicates all the data within the data warehouse cluster when it is loaded and also continuously backs up your data to S3.
- attempts to maintain at least three copies of your data (the original and replica on the compute nodes and a backup in S3).
- supports cross-region snapshot replication to another region for disaster recovery
- Redshift supports four distribution styles; AUTO, EVEN, KEY, or ALL.
- KEY distribution uses a single column as distribution key (DISTKEY) and helps place matching values on the same node slice
- Even distribution distributes the rows across the slices in a round-robin fashion, regardless of the values in any particular column
- ALL distribution replicates whole table in every compute node.
- AUTO distribution lets Redshift assigns an optimal distribution style based on the size of the table data
- Redshift supports Compound and Interleaved sort keys
- Compound key
- is made up of all of the columns listed in the sort key definition, in the order they are listed and is more efficient when query predicates use a prefix, or query’s filter applies conditions, such as filters and joins, which is a subset of the sort key columns in order.
- Interleaved sort key
- gives equal weight to each column in the sort key, so query predicates can use any subset of the columns that make up the sort key, in any order.
- Not ideal for monotonically increasing attributes
- Compound key
- Import/Export Data
- UNLOAD helps copy data from Redshift table to S3
- COPY command
- helps copy data from S3 to Redshift
- also supports EMR, DynamoDB, remote hosts using SSH
- parallelized and efficient
- can decrypt data as it is loaded from S3
- DON’T use multiple concurrent COPY commands to load one table from multiple files as Redshift is forced to perform a serialized load, which is much slower.
- supports data decryption when loading data, if data encrypted
- supports decompressing data, if data is compressed.
- Split the Load Data into Multiple Files
- Load the data in sort key order to avoid needing to vacuum.
- Use a Manifest File
- provides Data consistency, to avoid S3 eventual consistency issues
- helps specify different S3 locations in a more efficient way that with the use of S3 prefixes.
- Zero-ETL Integrations (2024-2025)
- enable near real-time analytics by connecting operational databases and applications to Redshift without building data pipelines
- supports integrations from Aurora (MySQL/PostgreSQL), DynamoDB, RDS, and third-party applications (Salesforce, SAP, Zendesk)
- works with both Redshift Serverless workgroups and provisioned clusters using RA3 instance types
- includes SQL features: QUERY_ALL_STATES, TRUNCATECOLUMNS, and ACCEPTINVCHARS for zero-ETL data handling
- integrates with Amazon SageMaker Lakehouse for unified analytics and AI/ML
- Redshift Distribution Style determines how data is distributed across compute nodes and helps minimize the impact of the redistribution step by locating the data where it needs to be before the query is executed.
- Redshift Enhanced VPC routing forces all COPY and UNLOAD traffic between the cluster and the data repositories through the VPC.
- Workload management (WLM) enables users to flexibly manage priorities within workloads so that short, fast-running queries won’t get stuck in queues behind long-running queries.
- Redshift Spectrum helps query and retrieve structured and semistructured data from files in S3 without having to load the data into Redshift tables.
- Redshift Spectrum external tables are read-only. You can’t COPY or INSERT to an external table.
- Federated Query feature allows querying and analyzing data across operational databases, data warehouses, and data lakes.
- Short query acceleration (SQA) prioritizes selected short-running queries ahead of longer-running queries.
- Redshift Serverless is a serverless option of Redshift that makes it more efficient to run and scale analytics in seconds without the need to set up and manage data warehouse infrastructure.
EMR
- is a web service that utilizes a hosted Hadoop framework running on the web-scale infrastructure of EC2 and S3
- launches all nodes for a given cluster in the same Availability Zone, which improves performance as it provides a higher data access rate.
- seamlessly supports Reserved, On-Demand, and Spot Instances
- consists of Master/Primary Node for management and Slave nodes, which consist of Core nodes holding data and providing compute and Task nodes for performing tasks only.
- is fault tolerant for slave node failures and continues job execution if a slave node goes down
- supports Persistent and Transient cluster types
- Persistent EMR clusters continue to run after the data processing job is complete
- Transient EMR clusters shut down when the job or the steps (series of jobs) are complete
- supports EMRFS which allows S3 to be used as a durable HA data storage
- EMR Serverless helps run big data frameworks such as Apache Spark and Apache Hive without configuring, managing, and scaling clusters.
- now supports Spark Connect (2026) for interactive PySpark development from local environments, IDEs, and SageMaker Unified Studio Notebooks
- eliminates local storage provisioning, reducing costs by up to 20%
- Apache Spark 4.0 support (GA 2026) – includes VARIANT data type, state-management improvements, and Spark Connect, with EMR optimized runtime running workloads up to 4.5x faster than open-source Spark
- EMR Studio is an IDE that helps data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark.
- EMR Notebooks provide a managed environment, based on Jupyter Notebook, that helps prepare and visualize data, collaborate with peers, build applications, and perform interactive analysis using EMR clusters.
Glue
- AWS Glue is a fully managed, ETL service that automates the time-consuming steps of data preparation for analytics.
- is serverless and supports a pay-as-you-go model.
- handles provisioning, configuration, and scaling of the resources required to run the ETL jobs on a fully managed, scale-out Apache Spark environment.
- helps setup, orchestrate, and monitor complex data flows.
- supports custom Scala or Python code and import custom libraries and Jar files into the AWS Glue ETL jobs to access data sources not natively supported by AWS Glue.
- supports server side encryption for data at rest and SSL for data in motion.
- provides development endpoints to edit, debug, and test the code it generates.
- AWS Glue natively supports data stored in RDS, Redshift, DynamoDB, S3, MySQL, Oracle, Microsoft SQL Server, and PostgreSQL databases in the VPC running on EC2 and Data streams from MSK, Kinesis Data Streams, and Apache Kafka.
- Glue ETL engine to Extract, Transform, and Load data that can automatically generate Scala or Python code.
- AWS Glue 5.0/5.1 (2024-2026):
- provides performance-optimized Apache Spark 3.5 runtime for batch and stream processing
- native support for open table formats: Apache Iceberg, Delta Lake, and Apache Hudi
- Spark-native fine-grained access control (FGAC) integration with AWS Lake Formation
- faster job start times and automatic partition pruning
- Glue 5.1 adds support for Apache Iceberg format version 3.0, deletion vectors, and row lineage tracking
- new worker types: G.12X, G.16X general compute, and R.1X/R.2X/R.4X/R.8X memory-optimized
- Glue Materialized Views (2025) – Apache Iceberg-based materialized views for transforming data and accelerating query performance
- supports generative AI assistance for data integration tasks
- Glue Data Catalog is a central repository and persistent metadata store to store structural and operational metadata for all the data assets.
- Glue Crawlers scan various data stores to automatically infer schemas and partition structures to populate the Data Catalog with corresponding table definitions and statistics.
- Glue Job Bookmark tracks data that has already been processed during a previous run of an ETL job by persisting state information from the job run.
- AWS Glue Streaming ETL enables performing ETL operations on streaming data using continuously-running jobs.
- Glue provides flexible scheduler that handles dependency resolution, job monitoring, and retries.
- Glue Studio offers a graphical interface for authoring AWS Glue jobs to process data allowing you to define the flow of the data sources, transformations, and targets in the visual interface and generating Apache Spark code on your behalf.
- Glue Data Quality helps reduces manual data quality effort by automatically measuring and monitoring the quality of data in data lakes and pipelines.
- Glue DataBrew is a visual data preparation tool that makes it easy for data analysts and data scientists to prepare, visualize, clean, and normalize terabytes, and even petabytes of data directly from your data lake, data warehouses, and databases, including S3, Redshift, Aurora, and RDS.
- ⚠️ AWS Glue for Ray will no longer accept new customers starting April 30, 2026. Existing customers can continue using the service. Explore Amazon EKS for similar capabilities.
Lake Formation
- AWS Lake Formation helps create secure data lakes, making data available for wide-ranging analytics.
- is an integrated data lake service that helps to discover, ingest, clean, catalog, transform, and secure data and make it available for analysis and ML.
- automatically manages access to the registered data in S3 through services including AWS Glue, Athena, Redshift, QuickSight, and EMR using Zeppelin notebooks with Apache Spark to ensure compliance with your defined policies.
- helps configure and manage your data lake without manually integrating multiple underlying AWS services.
- uses a shared infrastructure with AWS Glue, including console controls, ETL code creation and job monitoring, blueprints to create workflows for data ingest, the same data catalog, and a serverless architecture.
- can manage data ingestion through AWS Glue. Data is automatically classified, and relevant data definitions, schema, and metadata are stored in the central Glue Data Catalog. Once the data is in the S3 data lake, access policies, including table-and-column-level access controls can be defined, and encryption for data at rest enforced.
- integrates with IAM so authenticated users and roles can be automatically mapped to data protection policies that are stored in the data catalog. The IAM integration also supports Microsoft Active Directory or LDAP to federate into IAM using SAML.
- helps centralize data access policy controls. Users and roles can be defined to control access, down to the table and column level.
- supports fine-grained access control (FGAC) including row-level and cell-level security, and tag-based access control (LF-Tags) for scalable permission management.
- supports private endpoints in the VPC and records all activity in AWS CloudTrail for network isolation and auditability.
- ⚠️ Lake Formation’s Governed Tables feature was deprecated in February 2025. Use Apache Iceberg tables with Lake Formation for transactional data lake capabilities.
Amazon Quick Suite (formerly QuickSight)
(Amazon QuickSight evolved to Amazon Quick Suite on October 9, 2025, expanding from a single BI product to a comprehensive analytics and AI platform)
- is a cloud-powered business analytics service that integrates BI capabilities with AI agents for business insights, deep research, and automation in one unified experience.
- delivers fast and responsive query performance by using a robust in-memory engine (SPICE).
- “SPICE” stands for a Super-fast, Parallel, In-memory Calculation Engine
- can also be configured to keep the data in SPICE up-to-date as the data in the underlying sources change.
- automatically replicates data for high availability and enables Quick Suite to scale to support users to perform simultaneous fast interactive analysis across a wide variety of AWS data sources.
- Amazon Q in QuickSight (GA April 2024) – generative BI capabilities powered by Amazon Bedrock:
- multi-visual data Q&A for asking questions of data not in dashboards
- executive summaries for quick trend and insight discovery
- automated stories – documents and slides explaining data
- natural language generation for pixel-perfect reports
- available to all Enterprise Edition users without separate Q add-on
- supports
- Excel files and flat files like CSV, TSV, CLF, ELF
- on-premises databases like PostgreSQL, SQL Server and MySQL
- SaaS applications like Salesforce
- and AWS data sources such as Redshift, RDS, Aurora, Athena, and S3
- supports various functions to format and transform the data.
- supports assorted visualizations that facilitate different analytical approaches:
- Comparison and distribution – Bar charts (several assorted variants)
- Changes over time – Line graphs, Area line charts
- Correlation – Scatter plots, Heat maps
- Aggregation – Pie graphs, Tree maps
- Tabular – Pivot tables
- Amazon Quick Sight (a capability within Quick Suite) now offers visual data preparation experience for advanced data transformations without code.
Data Pipeline
⚠️ AWS Data Pipeline – No Longer Available to New Customers (July 25, 2024)
AWS Data Pipeline is in maintenance mode and is no longer available to new customers. Console access was removed on April 30, 2023. Existing customers can continue to use the service via CLI and API.
Migration Options:
- Amazon MWAA (Managed Workflows for Apache Airflow) – for complex workflow orchestration
- AWS Step Functions – for serverless workflow orchestration
- AWS Glue – for ETL-focused data movement pipelines
- Amazon EventBridge – for event-driven scheduling
- orchestration service that helps define data-driven workflows to automate and schedule regular data movement and data processing activities
- integrates with on-premises and cloud-based storage systems
- allows scheduling, retry, and failure logic for the workflows
Amazon OpenSearch Service
(Previously known as Amazon Elasticsearch Service, renamed September 8, 2021)
- Amazon OpenSearch Service is a managed service that makes it easy to deploy, operate, and scale OpenSearch clusters in the AWS Cloud.
- OpenSearch Service provides
- real-time, distributed search and analytics engine
- ability to provision all the resources for OpenSearch cluster and launches the cluster
- easy to use cluster scaling options. Scaling OpenSearch Service domain by adding or modifying instances, and storage volumes is an online operation that does not require any downtime.
- provides self-healing clusters, which automatically detects and replaces failed nodes, reducing the overhead associated with self-managed infrastructures
- domain snapshots to back up and restore domains and replicate domains across AZs
- enhanced security with IAM, Network, Domain access policies, and fine-grained access control
- storage volumes for the data using EBS volumes
- ability to span cluster nodes across multiple AZs in the same region, known as zone awareness, for high availability and redundancy. OpenSearch Service automatically distributes the primary and replica shards across instances in different AZs.
- dedicated master nodes to improve cluster stability
- data visualization using OpenSearch Dashboards (formerly Kibana)
- integration with CloudWatch for monitoring domain metrics
- integration with CloudTrail for auditing configuration API calls to domains
- integration with S3, Kinesis, and DynamoDB for loading streaming data
- ability to handle structured and Unstructured data
- supports encryption at rest through KMS, node-to-node encryption over TLS, and the ability to require clients to communicate with HTTPS
- Amazon OpenSearch Serverless
- automatically scales without managing infrastructure
- NextGen architecture (2026) – decoupled compute from storage, provisions in seconds, scales to zero when idle, up to 20x faster autoscaling, and up to 60% lower cost than provisioned clusters
- two collection architectures: Classic (original) and NextGen (default for new collections)
- Vector Database Capabilities
- stores vector embeddings from LLMs for semantic/similarity search
- supports hybrid search combining vector, lexical, and agentic retrieval
- GPU-accelerated vector indexes for billion-scale databases (2025)
- auto-optimized vector indexes for search quality/speed/cost tradeoffs
- integrates with Amazon Bedrock for RAG and agentic AI applications
- Zero-ETL integrations – direct data access from other AWS services without pipeline management
- Extended Support – Standard Support ends Nov 7, 2025 for legacy Elasticsearch versions up to 6.7, ES 7.1-7.8, and OpenSearch 1.0-1.2
Athena
- Amazon Athena is a serverless, interactive analytics service built on open-source frameworks, supporting open-table and file formats.
- provides a simplified, flexible way to analyze petabytes of data in an S3 data lake and 30 data sources, including on-premises data sources or other cloud systems using SQL or Python without loading the data.
- is built on open-source Trino and Presto engines and Apache Spark frameworks, with no provisioning or configuration effort required.
- is highly available and runs queries using compute resources across multiple facilities, automatically routing queries appropriately if a particular facility is unreachable
- can process unstructured, semi-structured, and structured datasets.
- integrates with QuickSight for visualizing the data or creating dashboards.
- supports various standard data formats, including CSV, TSV, JSON, ORC, Avro, and Parquet.
- supports compressed data in Snappy, Zlib, LZO, and GZIP formats. You can improve performance and reduce costs by compressing, partitioning, and using columnar formats.
- can handle complex analysis, including large joins, window functions, and arrays
- uses a managed Glue Data Catalog to store information and schemas about the databases and tables that you create for the data stored in S3
- uses schema-on-read technology, which means that the table definitions are applied to the data in S3 when queries are being applied. There’s no data loading or transformation required. Table definitions and schema can be deleted without impacting the underlying data stored in S3.
- supports fine-grained access control with AWS Lake Formation which allows for centrally managing permissions and access control for data catalog resources in the S3 data lake.
- integrates with Amazon SageMaker Lakehouse for governed federated queries across data sources
Amazon SageMaker Lakehouse
(Launched at re:Invent 2024, GA March 2025)
- part of the next generation of Amazon SageMaker – a unified platform for data, analytics, and AI
- unifies data across S3 data lakes (including S3 Tables), Redshift data warehouses, and operational databases
- supports zero-ETL integrations from Aurora, DynamoDB, RDS, and third-party applications (Salesforce, SAP, Zendesk) for near real-time data access
- enables querying, analyzing, and joining data using Redshift, Athena, EMR, and AWS Glue
- provides unified access through Amazon SageMaker Unified Studio – a single development experience for data engineers, data scientists, and analysts
- supports Apache Iceberg open table format for interoperability
- integrates with Lake Formation for fine-grained access control and governance