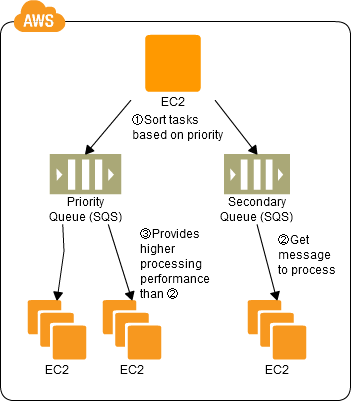Auto Scaling Launch Template vs Launch Configuration
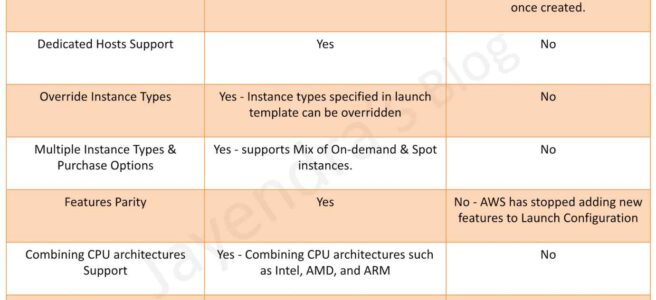
Launch Configuration
Launch configuration is an instance configuration template that an Auto Scaling Group uses to launch EC2 instances.
Launch configuration is similar to EC2 configuration and involves the selection of the Amazon Machine Image (AMI), block devices, key pair, instance type, security groups, user data, EC2 instance monitoring, instance profile, kernel, ramdisk, the instance tenancy, whether the instance has a public IP address, and is EBS-optimized.
Launch configuration can be associated with multiple ASGs
Launch configuration can’t be modified after creation and needs to be created new if any modification is required.
Basic or detailed monitoring for the instances in the ASG can be enabled when a launch configuration is created.
By default, basic monitoring is enabled when you create the launch configuration using the AWS Management Console, and detailed monitoring is enabled when you create the launch configuration using the AWS CLI or an API
AWS recommends using Launch Template instead.
Launch Template
A Launch Template is similar to a launch configuration, with additional features, and is recommended by AWS.
Launch Template allows multiple versions of a template to be defined.
With versioning, a subset of the full set of parameters can be created and then reused to create other templates or template versions for e.g, a default template that defines common configuration parameters can be created and allow the other parameters to be specified as part of another version of the same template.
Launch Template allows the selection of both Spot and On-Demand Instances or multiple instance types.
Launch templates support EC2 Dedicated Hosts. Dedicated Hosts are physical servers with EC2 instance capacity that are dedicated to your use.
Launch templates provide the following features
Support for multiple instance types and purchase options in a single ASG.
Launching Spot Instances with the capacity-optimized allocation strategy.
Support for launching instances into existing Capacity Reservations through an ASG.
Support for unlimited mode for burstable performance instances.
Support for Dedicated Hosts.
Combining CPU architectures such as Intel, AMD, and ARM (Graviton2)
Improved governance through IAM controls and versioning.
Automating instance deployment with Instance Refresh.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company is launching a new workload. The workload will run on Amazon EC2 instances in an Amazon EC2 Auto Scaling group. The company needs to maintain different versions of the EC2 configurations. The company also needs the Auto Scaling group to automatically scale to maintain CPU utilization of 60%. How can a SysOps administrator meet these requirements?
Configure the Auto Scaling group to use a launch configuration with a target tracking scaling policy.
Configure the Auto Scaling group to use a launch configuration with a simple scaling policy.
Configure the Auto Scaling group to use a launch template with a target tracking scaling policy.
Configure the Auto Scaling group to use a launch template with a simple scaling policy.
AWS Certified Developer – Associate DVA-C02 exam is the latest AWS exam released on 27th February 2023 and has replaced the previous AWS Developer – Associate DVA-C01 certification exam.
I passed the AWS Developer – Associate DVA-C02 exam with a score of 835/1000.
DVA-C02 exam consists of 65 questions in 130 minutes, and the time is more than sufficient if you are well-prepared.
DVA-C02 exam includes two types of questions, multiple-choice and multiple-response.
DVA-C02 has a scaled score between 100 and 1,000. The scaled score needed to pass the exam is 720.
Associate exams currently cost $ 150 + tax.
You can get an additional 30 minutes if English is your second language by requesting Exam Accommodations. It might not be needed for Associate exams but is helpful for Professional and Specialty ones.
AWS exams can be taken either remotely or online, I prefer to take them online as it provides a lot of flexibility. Just make sure you have a proper place to take the exam with no disturbance and nothing around you.
Also, if you are taking the AWS Online exam for the first time try to join at least 30 minutes before the actual time as I have had issues with both PSI and Pearson with long wait times.
Signed up with AWS for the Free Tier account which provides a lot of Services to be tried for free with certain limits which are more than enough to get things going. Be sure to decommission anything, if you using anything beyond the free limits, preventing any surprises 🙂
Read the FAQs at least for the important topics, as they cover important points and are good for quick review
AWS DVA-C02 exam concepts cover solutions that fall within AWS Well-Architected framework to cover scalable, highly available, cost-effective, performant, and resilient pillars.
AWS Certified Developer – Associate DVA-C02 exam covers a lot of the latest AWS services like Amplify, X-Ray while focusing majorly on other services like Lambda, DynamoDB, Elastic Beanstalk, S3, EC2
AWS Certified Developer – Associate DVA-C02 exam is similar to DVA-C01 with more focus on the hands-on development and deployment concepts rather than just the architectural concepts.
If you had been preparing for the DVA-C01, DVA-C02 is pretty much similar except for the addition of some new services covering Amplify, X-Ray, etc.
S3 Client-side encryption encrypts data before storing it in S3
S3 encryption in transit can be enforced with S3 bucket policies using secureTransport attributes.
S3 encryption at rest can be enforced with S3 bucket policies using x-amz-server-side-encryption attribute.
S3 features including
S3 provides cost-effective static website hosting. However, it does not support HTTPS endpoint. Can be integrated with CloudFront for HTTPS, caching, performance, and low-latency access.
S3 versioning provides protection against accidental overwrites and deletions. Used with MFA Delete feature.
S3 Pre-Signed URLs for both upload and download provide access without needing AWS credentials.
simple, fully managed, scalable, serverless, and cost-optimized file storage for use with AWS Cloud and on-premises resources.
provides shared volume across multiple EC2 instances, while EBS can be attached to a single instance within the same AZ or EBS Multi-Attach can be attached to multiple instances within the same AZ
can be mounted with Lambda functions
supports the NFS protocol, and is compatible with Linux-based AMIs
supports cross-region replication and storage classes for cost management.
is a fully managed service that makes it easy for developers to publish, maintain, monitor, and secure APIs at any scale.
Powerful, flexible authentication mechanisms, such as AWS IAM policies, Lambda authorizer functions, and Amazon Cognito user pools.
supports Canary release deployments for safely rolling out changes.
define usage plans to meter, restrict third-party developer access, configure throttling, and quota limits on a per API key basis
integrates with AWS X-Ray for understanding and triaging performance latencies.
API Gateway CORS allows cross-domain calls
Amplify
is a complete solution that lets frontend web and mobile developers easily build, ship, and host full-stack applications on AWS, with the flexibility to leverage the breadth of AWS services as use cases evolve.
easy way to create and manage a collection of related AWS resources, and provision and update them in an orderly and predictable fashion.
Supports Serverless Application Model – SAM for the deployment of serverless applications including Lambda.
CloudFormation StackSets extends the functionality of stacks by enabling you to create, update, or delete stacks across multiple accounts and Regions with a single operation.
CodeCommit is a secure, scalable, fully-managed source control service that helps to host secure and highly scalable private Git repositories.
CodeBuild is a fully managed build service that compiles source code, runs tests, and produces software packages that are ready to deploy.
CodeDeploy helps automate code deployments to any instance, including EC2 instances and instances running on-premises.
CodePipeline is a fully managed continuous delivery service that helps automate the release pipelines for fast and reliable application and infrastructure updates.
CodeArtifact is a fully managed artifact repository service that makes it easy for organizations of any size to securely store, publish, and share software packages used in their software development process.
Auto Scaling ensures a steady minimum (or desired if specified) count of Instances will always be running.
If an instance is found unhealthy, Auto Scaling will terminate the Instance and launch a new one.
ASG determines the health state of each instance by periodically checking the results of EC2 instance status checks.
ASG can be associated with an Elastic load balancer enabled to use the Elastic Load Balancing health check, Auto Scaling determines the health status of the instances by checking the results of both EC2 instance status and Elastic Load Balancing instance health.
Auto Scaling marks an instance unhealthy and launches a replacement if
the instance is in a state other than running,
the system status is impaired, or
Elastic Load Balancing reports the instance state as OutOfService.
After an instance has been marked unhealthy as a result of an EC2 or ELB health check, it is almost immediately scheduled for replacement. It never automatically recovers its health.
For an unhealthy instance, the instance’s health check can be changed back to healthy manually but you will encounter an error if the instance is already terminating.
Because the interval between marking an instance unhealthy and its actual termination is so small, attempting to set an instance’s health status back to healthy is probably useful only for a suspended group.
When the instance is terminated, any associated Elastic IP addresses are disassociated and are not automatically associated with the new instance.
Elastic IP addresses must be associated with the new instance manually.
Similarly, when the instance is terminated, its attached EBS volumes are detached and must be attached to the new instance manually.
Manual Scaling
Manual scaling can be performed by
Changing the desired capacity limit of the ASG
Attaching/Detaching instances to the ASG
Attaching/Detaching an EC2 instance can be done only if
Instance is in the running state.
AMI used to launch the instance must still exist.
Instance is not a member of another ASG.
Instance is in the same Availability Zone as the ASG.
If the ASG is associated with a load balancer, the instance and the load balancer must both be in the same VPC.
Auto Scaling increases the desired capacity of the group by the number of instances being attached. But if the number of instances being attached plus the desired capacity exceeds the maximum size, the request fails.
When Detaching instances, an option to decrement the desired capacity for the ASG by the number of instances being detached is provided. If chosen not to decrement the capacity, Auto Scaling launches new instances to replace the ones that you detached.
If an instance is detached from an ASG that is also registered with a load balancer, the instance is deregistered from the load balancer. If connection draining is enabled for the load balancer, Auto Scaling waits for the in-flight requests to complete.
Scheduled Scaling
Scaling based on a schedule allows you to scale the application in response to predictable load changesfor e.g. last day of the month, the last day of a financial year.
Scheduled scaling requires the configuration of Scheduled actions, which tells Auto Scaling to perform a scaling action at a certain time in the future, with the start time at which the scaling action should take effect, and the new minimum, maximum, and desired size of group should have.
Auto Scaling guarantees the order of execution for scheduled actions within the same group, but not for scheduled actions across groups.
Multiple Scheduled Actions can be specified but should have unique time values and they cannot have overlapping times scheduled which will lead to their rejection.
Cooldown periods are not supported.
Dynamic Scaling
Allows automatic scaling in response to the changing demand for e.g. scale-out in case CPU utilization of the instance goes above 70% and scale in when the CPU utilization goes below 30%
ASG uses a combination of alarms & policies to determine when the conditions for scaling are met.
An alarm is an object that watches over a single metric over a specified time period. When the value of the metric breaches the defined threshold, for the number of specified time periods the alarm performs one or more actions (such as sending messages to Auto Scaling).
A policy is a set of instructions that tells Auto Scaling how to respond to alarm messages.
Dynamic scaling process works as below
CloudWatch monitors the specified metrics for all the instances in the Auto Scaling Group.
Changes are reflected in the metrics as the demand grows or shrinks
When the change in the metrics breaches the threshold of the CloudWatch alarm, the CloudWatch alarm performs an action. Depending on the breach, the action is a message sent to either the scale-in policy or the scale-out policy
After the Auto Scaling policy receives the message, Auto Scaling performs the scaling activity for the ASG.
This process continues until you delete either the scaling policies or the ASG.
When a scaling policy is executed, if the capacity calculation produces a number outside of the minimum and maximum size range of the group, EC2 Auto Scaling ensures that the new capacity never goes outside of the minimum and maximum size limits.
When the desired capacity reaches the maximum size limit, scaling out stops. If demand drops and capacity decreases, Auto Scaling can scale out again.
Dynamic Scaling Policy Types
Target tracking scaling
Increase or decrease the current capacity of the group based on a target value for a specific metric.
Step scaling
Increase or decrease the current capacity of the group based on a set of scaling adjustments, known as step adjustments, that vary based on the size of the alarm breach.
Simple scaling
Increase or decrease the current capacity of the group based on a single scaling adjustment.
Multiple Policies
ASG can have more than one scaling policy attached at any given time.
Each ASG would have at least two policies: one to scale the architecture out and another to scale the architecture in.
If an ASG has multiple policies, there is always a chance that both policies can instruct the Auto Scaling to Scale Out or Scale In at the same time.
When these situations occur, Auto Scaling chooses the policy that has the greatest impact i.e. provides the largest capacity for both scale out and scale in on the ASG for e.g. if two policies are triggered at the same time and Policy 1 instructs to scale out the instance by 1 while Policy 2 instructs to scale out the instances by 2, Auto Scaling will use the Policy 2 and scale out the instances by 2 as it has a greater impact.
Predictive Scaling
Predictive scaling can be used to increase the number of EC2 instances in the ASG in advance of daily and weekly patterns in traffic flows.
Predictive scaling is well suited for situations where you have:
Cyclical traffic, such as high use of resources during regular business hours and low use of resources during evenings and weekends
Recurring on-and-off workload patterns, such as batch processing, testing, or periodic data analysis
Applications that take a long time to initialize, causing a noticeable latency impact on application performance during scale-out events
Predictive scaling provides proactive scaling that can help scale faster by launching capacity in advance of forecasted load, compared to using only dynamic scaling, which is reactive in nature.
Predictive scaling uses machine learning to predict capacity requirements based on historical data from CloudWatch. The machine learning algorithm consumes the available historical data and calculates the capacity that best fits the historical load pattern, and then continuously learns based on new data to make future forecasts more accurate.
Predictive scaling supports forecast only mode so that you can evaluate the forecast before you allow predictive scaling to actively scale capacity
When you are ready to start scaling with predictive scaling, switch the policy from forecast only mode to forecast and scale mode.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A user has created a web application with Auto Scaling. The user is regularly monitoring the application and he observed that the traffic is highest on Thursday and Friday between 8 AM to 6 PM. What is the best solution to handle scaling in this case?
Add a new instance manually by 8 AM Thursday and terminate the same by 6 PM Friday
Schedule Auto Scaling to scale up by 8 AM Thursday and scale down after 6 PM on Friday
Schedule a policy which may scale up every day at 8 AM and scales down by 6 PM
Configure a batch process to add a instance by 8 AM and remove it by Friday 6 PM
A customer has a website which shows all the deals available across the market. The site experiences a load of 5 large EC2 instances generally. However, a week before Thanksgiving vacation they encounter a load of almost 20 large instances. The load during that period varies over the day based on the office timings. Which of the below mentioned solutions is cost effective as well as help the website achieve better performance?
Keep only 10 instances running and manually launch 10 instances every day during office hours.
Setup to run 10 instances during the pre-vacation period and only scale up during the office time by launching 10 more instances using the AutoScaling schedule.
During the pre-vacation period setup a scenario where the organization has 15 instances running and 5 instances to scale up and down using Auto Scaling based on the network I/O policy.
During the pre-vacation period setup 20 instances to run continuously.
A user has setup Auto Scaling with ELB on the EC2 instances. The user wants to configure that whenever the CPU utilization is below 10%, Auto Scaling should remove one instance. How can the user configure this?
The user can get an email using SNS when the CPU utilization is less than 10%. The user can use the desired capacity of Auto Scaling to remove the instance
Use CloudWatch to monitor the data and Auto Scaling to remove the instances using scheduled actions
Configure CloudWatch to send a notification to Auto Scaling Launch configuration when the CPU utilization is less than 10% and configure the Auto Scaling policy to remove the instance
Configure CloudWatch to send a notification to the Auto Scaling group when the CPU Utilization is less than 10% and configure the Auto Scaling policy to remove the instance
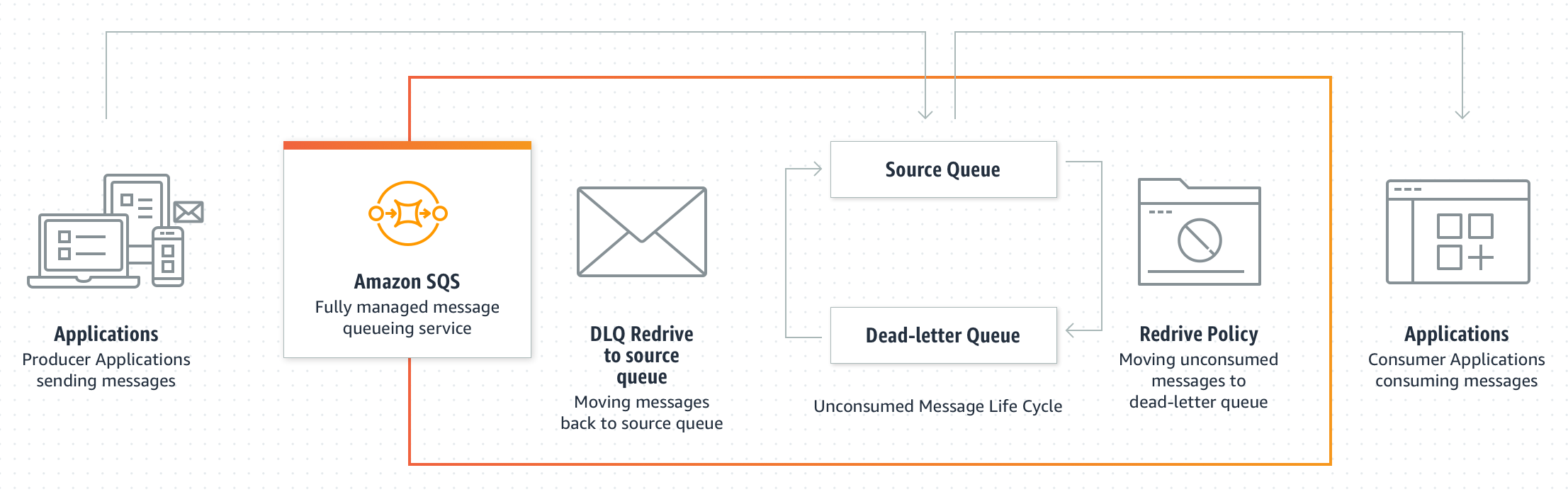
Visibility timeout defines the period where SQS blocks the visibility of the message and prevents other consuming components from receiving and processing that message.
DLQ Redrive policy specifies the source queue, the dead-letter queue, and the conditions under which messages are moved from the former to the latter if the consumer of the source queue fails to process a message a specified number of times.
Short and Long polling control how the queues would be polled and Long polling help reduce empty responses.
Queue and Message Identifiers
Queue URLs
Queue is identified by a unique queue name within the same AWS account
Each queue is assigned with a Queue URL identifier for e.g. http://sqs.us-east-1.amazonaws.com/123456789012/queue2
Queue URL is needed to perform any operation on the Queue.
Message ID
Message IDs are useful for identifying messages
Each message receives a system-assigned message ID that is returned with the SendMessage response.
To delete a message, the message’s receipt handle instead of the message ID is needed
Message ID can be of is 100 characters max
Receipt Handle
When a message is received from a queue, a receipt handle is returned with the message which is associated with the act of receiving the message rather than the message itself.
Receipt handle is required, not the message id, to delete a message or to change the message visibility.
If a message is received more than once, each time it is received, a different receipt handle is assigned and the latest should be used always.
Message Deduplication ID
Message Deduplication ID is used for the deduplication of sent messages.
Message Deduplication ID is applicable for FIFO queues.
If a message with a particular message deduplication ID is sent successfully, any messages sent with the same message deduplication ID are accepted successfully but aren’t delivered during the 5-minute deduplication interval.
Message Group ID
Message Group ID specifies that a message belongs to a specific message group.
Message Group ID is applicable for FIFO queues.
Messages that belong to the same message group are always processed one by one, in a strict order relative to the message group.
However, messages that belong to different message groups might be processed out of order.
Visibility timeout
SQS does not delete the message once it is received by a consumer, because the system is distributed, there’s no guarantee that the consumer will actually receive the message (it’s possible the connection could break or the component could fail before receiving the message)
The consumer should explicitly delete the message from the Queue once it is received and successfully processed.
As the message is still available in the Queue, other consumers would be able to receive and process and this needs to be prevented.
SQS handles the above behavior using Visibility timeout.
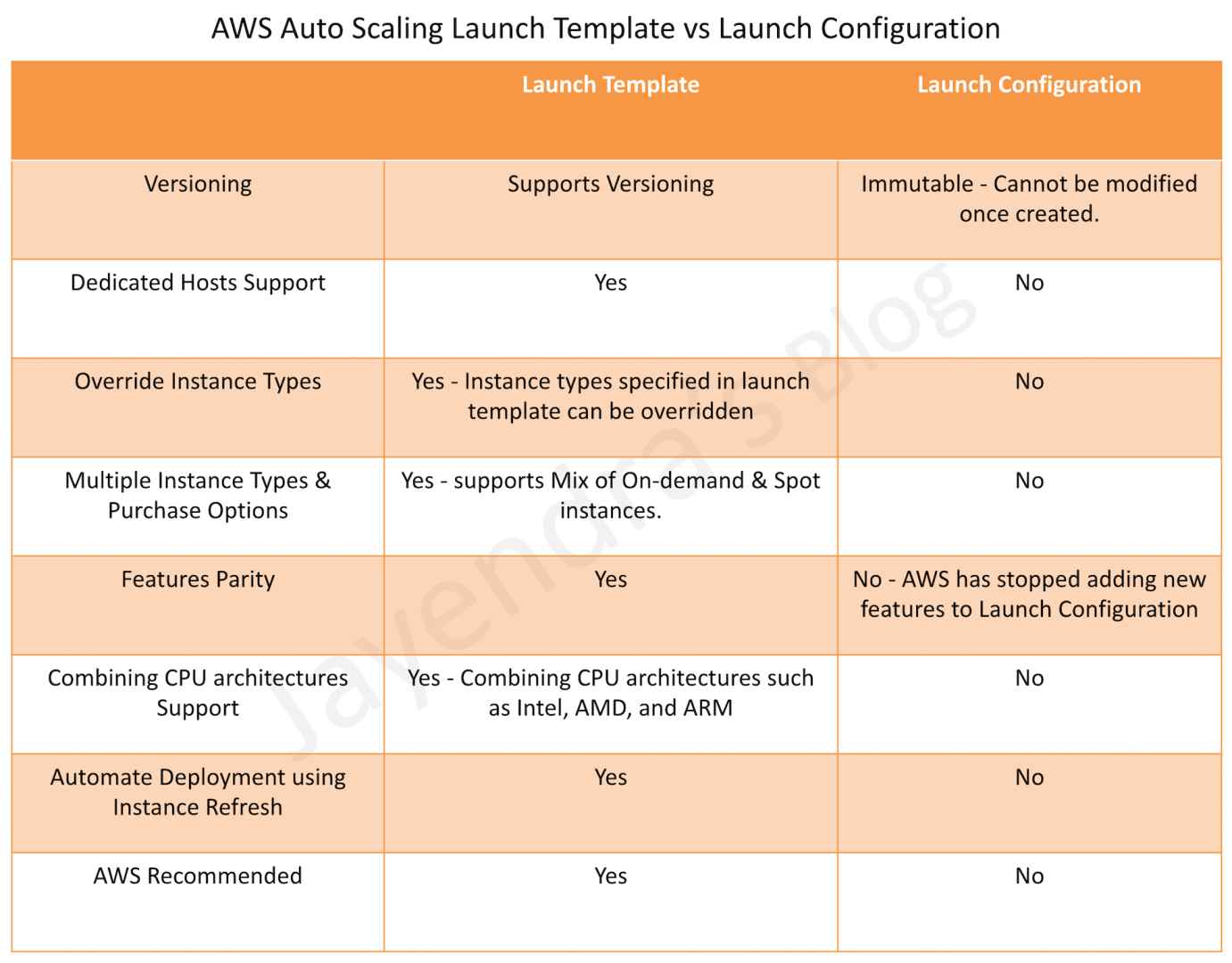
SQS blocks the visibility of the message for the Visibility timeout period, which is the time during which SQS prevents other consuming components from receiving and processing that message.
Consumer should delete the message within the Visibility timeout. If the consumer fails to delete the message before the visibility timeout expires, the message is visible again to other consumers.
Once Visible the message is available for other consumers to consume and can lead to duplicate messages.
Visibility timeout considerations
Clock starts ticking once SQS returns the message
should be large enough to take into account the processing time for each message
default Visibility timeout for each Queue is 30 seconds and can be changed at the Queue level
when receiving messages, a special visibility timeout for the returned messages can be set without changing the overall queue timeout using the receipt handle
can be extended by the consumer, using ChangeMessageVisibility , if the consumer thinks it won’t be able to process the message within the current visibility timeout period. SQS restarts the timeout period using the new value.
a message’s Visibility timeout extension applies only to that particular receipt of the message and does not affect the timeout for the queue or later receipts of the message
SQS has a 120,000 limit for the number of inflight messages per queue i.e. messages received but not yet deleted and any further messages would receive an error after reaching the limit
Message Lifecycle
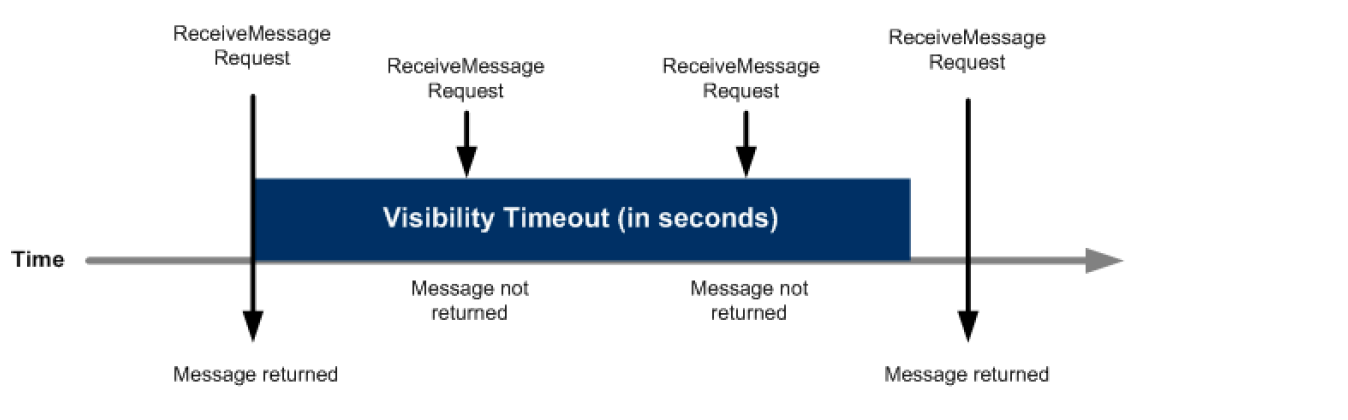
Component 1 sends Message A to a queue, and the message is redundantly distributed across the SQS servers.
When Component 2 is ready to process a message, it retrieves messages from the queue, and Message A is returned. While Message A is being processed, it remains in the queue but is not returned to subsequent receive requests for the duration of the visibility timeout.
Component 2 deletes Message A from the queue to avoid the message being received and processed again once the visibility timeout expires.
SQS Dead Letter Queues – DLQ
SQS supports dead-letter queues (DLQ), which other queues (source queues – Standard and FIFO) can target for messages that can’t be processed (consumed) successfully.
Dead-letter queues are useful for debugging the application or messaging system because DLQ help isolates unconsumed messages to determine why their processing doesn’t succeed.
DLQ redrive policy
specifies the source queue, the dead-letter queue, and the conditions under which SQS moves messages from the former to the latter if the consumer of the source queue fails to process a message a specified number of times.
specifies which source queues can access the dead-letter queue.
also helps move the messages back to the source queue.
SQS does not create the dead-letter queue automatically. DLQ must first be created before being used.
DLQ for the source queue should be of the same type i.e. Dead-letter queue of a FIFO queue must also be a FIFO queue. Similarly, the dead-letter queue of a standard queue must also be a standard queue.
DLQ should be in the same account and region as the source queue.
SQS Delay Queues
Delay queues help postpone the delivery of new messages to consumers for a number of seconds
Messages sent to the delay queue remain invisible to consumers for the duration of the delay period.
Minimum delay is 0 seconds (default) and the Maximum is 15 minutes.
Delay queues are similar to visibility timeouts as both features make messages unavailable to consumers for a specific period of time.
The difference between the two is that, for delay queues, a message is hidden when it is first added to the queue, whereas for visibility timeouts a message is hidden only after it is consumed from the queue.
Short and Long polling
SQS provides short polling and long polling to receive messages from a queue.
Short Polling
ReceiveMessage request queries only a subset of the servers (based on a weighted random distribution) to find messages that are available to include in the response.
SQS sends the response right away, even if the query found no messages.
By default, queues use short polling.
Long Polling
ReceiveMessage request queries all of the servers for messages.
SQS sends a response after it collects at least one available message, up to the maximum number of messages specified in the request.
SQS sends an empty response only if the polling wait time expires.
Wait time greater than 0 triggers long polling with a max of 20 secs.
Long polling helps
reduce the cost of using SQS by eliminating the number of empty responses (when there are no messages available for a ReceiveMessage request)
reduce false empty responses (when messages are available but aren’t included in a response).
Return messages as soon as they become available.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
How does Amazon SQS allow multiple readers to access the same message queue without losing messages or processing them many times?
By identifying a user by his unique id
By using unique cryptography
Amazon SQS queue has a configurable visibility timeout
Multiple readers can’t access the same message queue
If a message is retrieved from a queue in Amazon SQS, how long is the message inaccessible to other users by default?
0 seconds
1 hour
1 day
forever
30 seconds
When a Simple Queue Service message triggers a task that takes 5 minutes to complete, which process below will result in successful processing of the message and remove it from the queue while minimizing the chances of duplicate processing?
Retrieve the message with an increased visibility timeout, process the message, delete the message from the queue
Retrieve the message with an increased visibility timeout, delete the message from the queue, process the message
Retrieve the message with increased DelaySeconds, process the message, delete the message from the queue
Retrieve the message with increased DelaySeconds, delete the message from the queue, process the message
You need to process long-running jobs once and only once. How might you do this?
Use an SNS queue and set the visibility timeout to long enough for jobs to process.
Use an SQS queue and set the reprocessing timeout to long enough for jobs to process.
Use an SQS queue and set the visibility timeout to long enough for jobs to process.
Use an SNS queue and set the reprocessing timeout to long enough for jobs to process.
You are getting a lot of empty receive requests when using Amazon SQS. This is making a lot of unnecessary network load on your instances. What can you do to reduce this load?
Subscribe your queue to an SNS topic instead.
Use as long of a poll as possible, instead of short polls.
Alter your visibility timeout to be shorter.
Use sqsd on your EC2 instances.
Company B provides an online image recognition service and utilizes SQS to decouple system components for scalability. The SQS consumers poll the imaging queue as often as possible to keep end-to-end throughput as high as possible. However, Company B is realizing that polling in tight loops is burning CPU cycles and increasing costs with empty responses. How can Company B reduce the number of empty responses?
Set the imaging queue visibility Timeout attribute to 20 seconds
Set the Imaging queue ReceiveMessageWaitTimeSeconds attribute to 20 seconds (Long polling. Refer link)
Set the imaging queue MessageRetentionPeriod attribute to 20 seconds
Set the DelaySeconds parameter of a message to 20 seconds
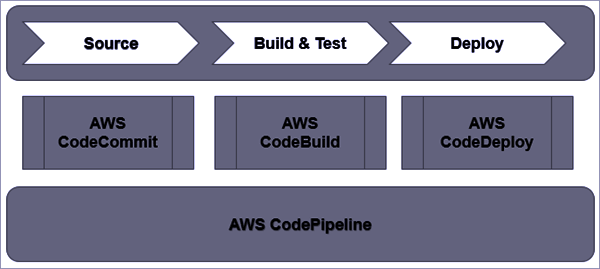
AWS Developer Tools provide a set of services designed to enable developers and IT operations professionals practicing DevOps to rapidly and safely deliver software.
AWS Developer Tools help securely store and version control the application’s source code and automatically build, test, and deploy the application to AWS or the on-premises environment.
AWS CodeCommit
CodeCommit is a secure, scalable, fully-managed source control service that helps to host secure and highly scalable private Git repositories.
eliminates the need to operate your own source control system or worry about scaling its infrastructure.
can be used to securely store anything from source code to binaries, and it works seamlessly with your existing Git tools.
provide high availability as it is built on highly scalable, redundant, and durable AWS services such as S3 and DynamoDB.
is designed for collaborative software development and it manages batches of changes across multiple files, offers parallel branching, and includes version differencing.
automatically encrypts the files in transit and at rest.
supports resource-level permissions at the repository level. Permissions can specify which users can perform which actions including MFA.
supports HTTPS or SSH or both communication protocols.
supports repository triggers, to send notifications and create HTTP webhooks with SNS or invoke Lambda functions.
AWS CodeBuild
AWS CodeBuild is a fully managed build service that compiles source code, runs tests, and produces software packages that are ready to deploy.
helps provision, manage, and scale the build servers.
scales continuously and processes multiple builds concurrently, so the builds are not left waiting in a queue.
provides prepackaged build environments or the creation of custom build environments that use your own build tools.
supports AWS CodeCommit, S3, GitHub, and GitHub Enterprise and Bitbucket to pull source code for builds.
provides security and separation at the infrastructure and execution levels
runs the build in fresh environments isolated from other users and discards each build environment upon completion.
AWS CodeDeploy
AWS CodeDeploy helps automate code deployments to any instance, including EC2 instances and instances running on-premises.
helps to rapidly release new features, avoid downtime during application deployment, and handles the complexity of updating the applications.
helps automate software deployments, eliminating the need for error-prone manual operations.
scales with the infrastructure and can be used to easily deploy from one instance or thousands.
performs a deployment with the following parameters
Revision – what to deploy
Deployment group – where to deploy
Deployment configuration – how to deploy
Deployment group is an entity for grouping EC2 instances or Lambda functions in deployment and supports instances by specifying a tag, an Auto Scaling group.
AppSpec file provides the instructions and is a configuration file that specifies the files to be copied and scripts to be executed.
supports both in-place deployments, where rolling updates are performed, and blue/green deployments.
AWS CodePipeline
AWS CodePipeline is a fully managed continuous delivery service that helps automate the release pipelines for fast and reliable application and infrastructure updates.
automates the builds, tests, and deploys the code every time there is a code change, based on the defined release process models
enables rapid and reliable delivery of features and updates.
can be integrated with third-party services such as GitHub or with your own custom plugin.
pay per use with no upfront fees or long-term commitments.
supports resource-level permissions. Permissions can specify which users can perform what action on a pipeline.
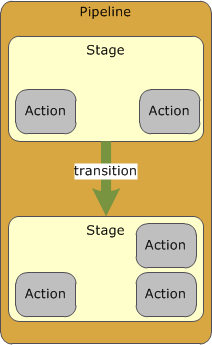
CodePipeline concepts
A Pipeline describes how software changes go through a release process
A revision is a change made to the source location defined for the pipeline.
Pipeline is a sequence of stages and actions.
A stage is a group of one or more actions. A pipeline can have two or more stages.
An action is a task performed on a revision.
Pipeline actions occur in a specified order, in serial or in parallel, as determined in the stage configuration.
Stages are connected by transitions
Transitions can be disabled or enabled between stages.
A pipeline can have multiple revisions flowing through it at the same time.
Action acts upon a file or set of files are called artifacts. These artifacts can be worked upon by later actions in the pipeline.
AWS CodeArtifact
AWS CodeArtifact is a fully managed artifact repository service that makes it easy for organizations of any size to securely store, publish, and share software packages used in their software development process.
CodeArtifact can be configured to automatically fetch software packages and dependencies from public artifact repositories so developers have access to the latest versions.
CodeArtifact works with commonly used package managers and build tools like Maven, Gradle, npm, yarn, twine, pip, and NuGet making it easy to integrate into existing development workflows.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Which AWS service’s PRIMARY purpose is to provide a fully managed continuous delivery service?
Amazon CodeStar
Amazon CodePipeline
Amazon Cognito
AWS CodeCommit
Which AWS service’s PRIMARY purpose is quickly develop, build, and deploy applications on AWS?
Amazon CodeStar
AWS Command Line Interface (AWS CLI)
Amazon Cognito
AWS CodeCommit
Which AWS service’s PRIMARY purpose is software version control?
Amazon CodeStar
AWS Command Line Interface (AWS CLI)
Amazon Cognito
AWS CodeCommit
Which of the following services could be used to deploy an application to servers running on-premises?
Simple Queue Service – SQS is a highly available distributed queue system
A queue is a temporary repository for messages awaiting processing and acts as a buffer between the component producer and the consumer
is a message queue service used by distributed applications to exchange messages through a polling model, and can be used to decouple sending and receiving components.
is fully managed and requires no administrative overhead and little configuration
offers a reliable, highly-scalable, hosted queue for storing messages in transit between applications.
provides fault-tolerant, loosely coupled, flexibility of distributed components of applications to send & receive without requiring each component to be concurrently available
helps build distributed applications with decoupled components
supports encryption at rest and encryption in transit using the HTTP over SSL (HTTPS) and Transport Layer Security (TLS) protocols for security.
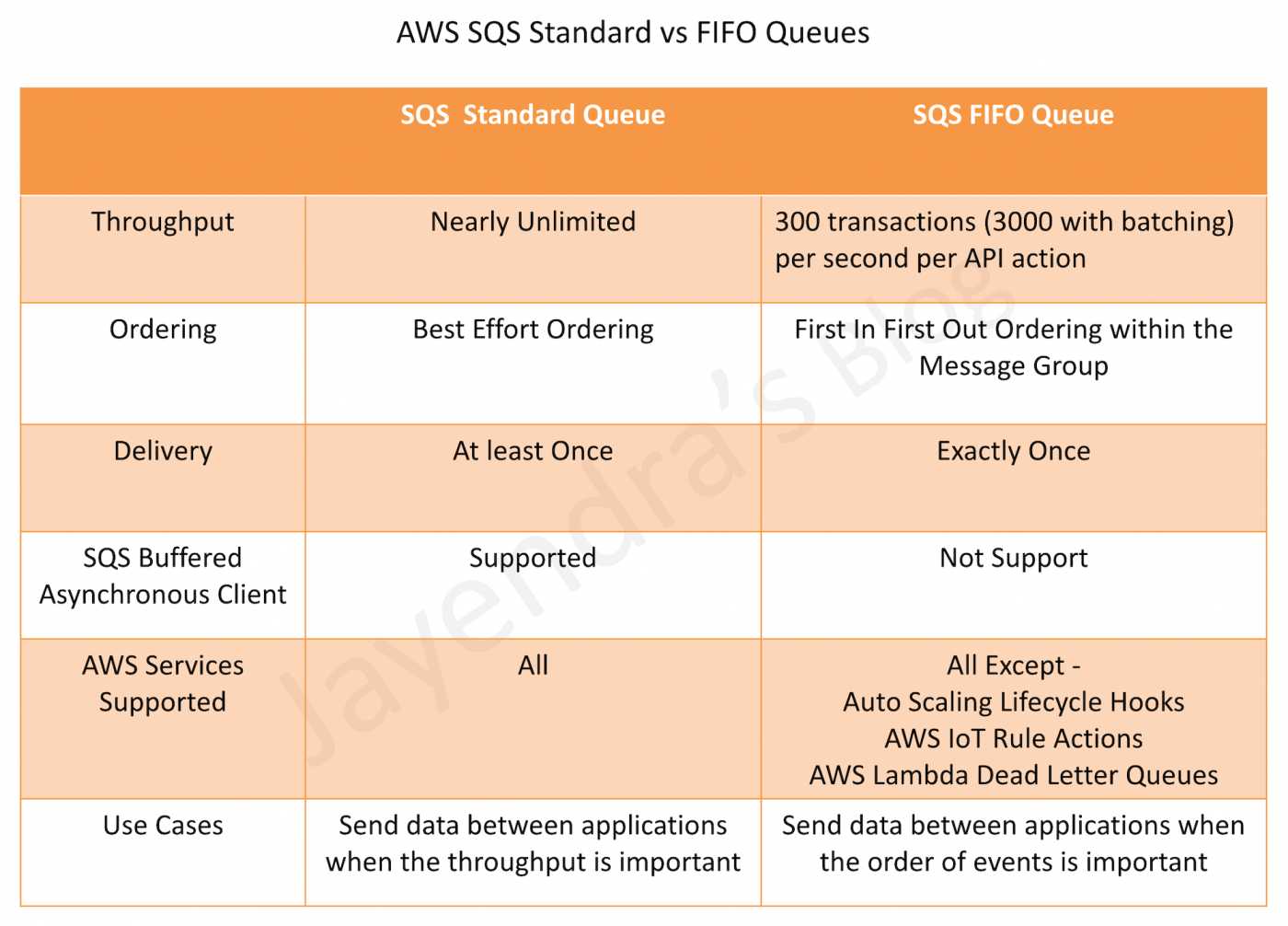
Standard queues support at-least-once message delivery. However, occasionally (because of the highly distributed architecture that allows nearly unlimited throughput), more than one copy of a message might be delivered out of order.
Standard queues support a nearly unlimited number of API calls per second, per API action (SendMessage, ReceiveMessage, or DeleteMessage).
Standard queues provide best-effort ordering which ensures that messages are generally delivered in the same order as they’re sent.
FIFO (First-In-First-Out) queues provide messages in order and exactly once delivery.
FIFO queues have all the capabilities of the standard queues but are designed to enhance messaging between applications when the order of operations and events is critical, or where duplicates can’t be tolerated.
Decouple components of a distributed application that may not all process the same amount of work simultaneously.
Buffer and Batch Operations
Add scalability and reliability to the architecture and smooth out temporary volume spikes without losing messages or increasing latency
Request Offloading
Move slow operations off of interactive request paths by enqueueing the request.
Fan-out
Combine SQS with SNS to send identical copies of a message to multiple queues in parallel for simultaneous processing.
Auto Scaling
SQS queues can be used to determine the load on an application, and combined with Auto Scaling, the EC2 instances can be scaled in or out, depending on the volume of traffic
How SQS Queues Works
SQS allows queues to be created, deleted and messages can be sent and received from it
SQS queue retains messages for four days, by default.
Queues can be configured to retain messages for 1 minute to 14 days after the message has been sent.
SQS can delete a queue without notification if any action hasn’t been performed on it for 30 consecutive days.
SQS allows the deletion of the queue with messages in it
Visibility timeout defines the period where SQS blocks the visibility of the message and prevents other consuming components from receiving and processing that message.
DLQ Redrive policy specifies the source queue, the dead-letter queue, and the conditions under which SQS moves messages from the former to the latter if the consumer of the source queue fails to process a message a specified number of times.
SQS Short and Long polling control how the queues would be polled and Long polling help reduce empty responses.
SQS Buffered Asynchronous Client
Amazon SQS Buffered Async Client for Java provides an implementation of the AmazonSQSAsyncClient interface and adds several important features:
Automatic batching of multiple SendMessage, DeleteMessage, or ChangeMessageVisibility requests without any required changes to the application
Prefetching of messages into a local buffer that allows the application to immediately process messages from SQS without waiting for the messages to be retrieved
Working together, automatic batching and prefetching increase the throughput and reduce the latency of the application while reducing the costs by making fewer SQS requests.
SQS Security and reliability
SQS stores all message queues and messages within a single, highly-available AWS region with multiple redundant Availability Zones (AZs)
SQS supports HTTP over SSL (HTTPS) and Transport Layer Security (TLS) protocols.
SQS supports Encryption at Rest. SSE encrypts messages as soon as SQS receives them and decrypts messages only when they are sent to an authorized consumer.
SQS also supports resource-based permissions
SQS Design Patterns
Priority Queue Pattern
Use SQS to prepare multiple queues for the individual priority levels.
Place those processes to be executed immediately (job requests) in the high priority queue.
Prepare numbers of batch servers, for processing the job requests of the queues, depending on the priority levels.
Queues have a message “Delayed Send” function, which can be used to delay the time for starting a process.
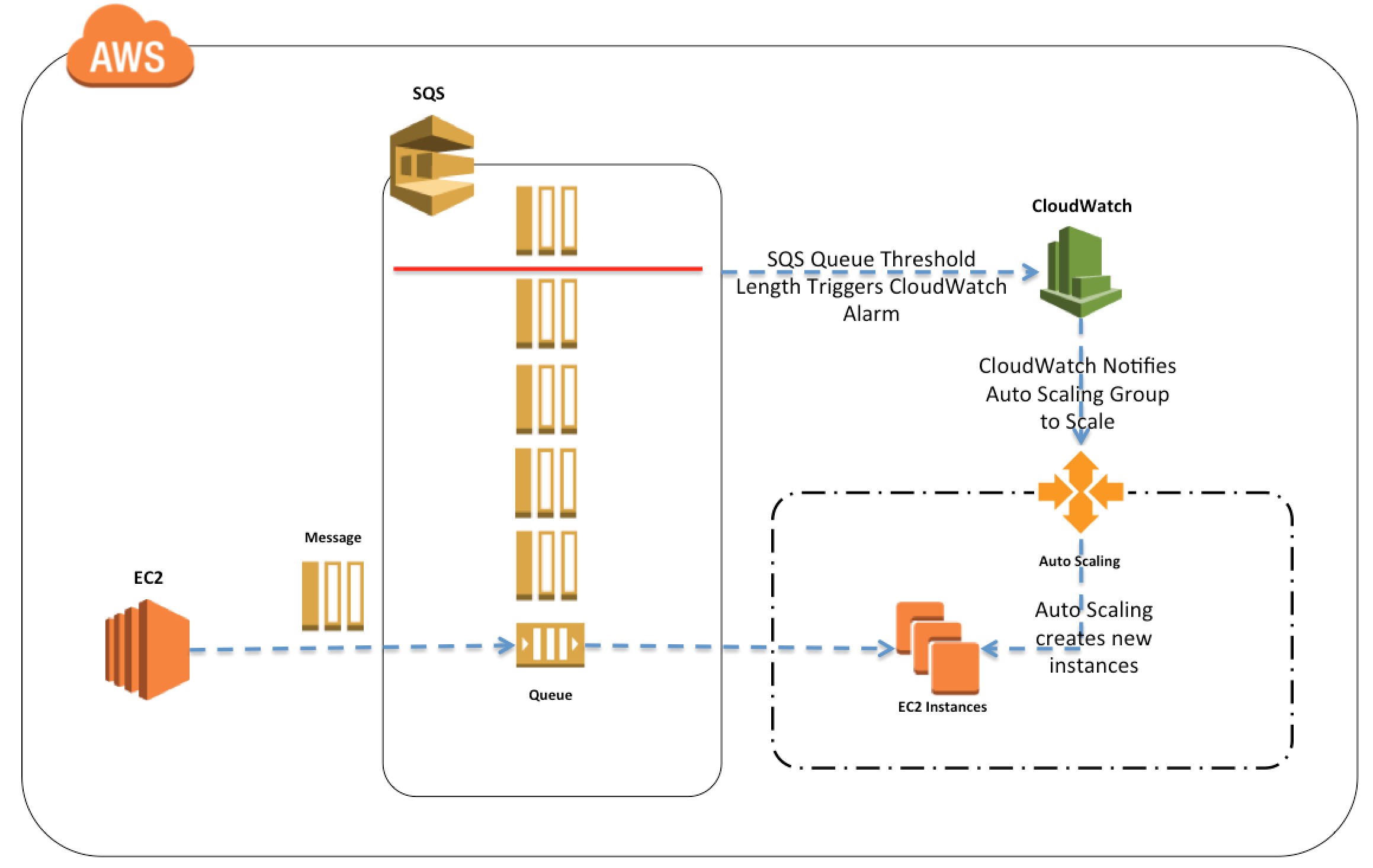
SQS Job Observer Pattern
Enqueue job requests as SQS messages.
Have the batch server dequeue and process messages from SQS.
Set up Auto Scaling to automatically increase or decrease the number of batch servers, using the number of SQS messages, with CloudWatch, as the trigger to do so.
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Which AWS service can help design architecture to persist in-flight transactions?
Elastic IP Address
SQS
Amazon CloudWatch
Amazon ElastiCache
A company has a workflow that sends video files from their on-premise system to AWS for transcoding. They use EC2 worker instances that pull transcoding jobs from SQS. Why is SQS an appropriate service for this scenario?
SQS guarantees the order of the messages.
SQS synchronously provides transcoding output.
SQS checks the health of the worker instances.
SQS helps to facilitate horizontal scaling of encoding tasks
Which statement best describes an Amazon SQS use case?
Automate the process of sending an email notification to administrators when the CPU utilization reaches 70% on production servers (Amazon EC2 instances) (CloudWatch + SNS + SES)
Create a video transcoding website where multiple components need to communicate with each other, but can’t all process the same amount of work simultaneously (SQS provides loose coupling)
Coordinate work across distributed web services to process employee’s expense reports (SWF – Steps in order and might need manual steps)
Distribute static web content to end users with low latency across multiple countries (CloudFront + S3)
Your application provides data transformation services. Files containing data to be transformed are first uploaded to Amazon S3 and then transformed by a fleet of spot EC2 instances. Files submitted by your premium customers must be transformed with the highest priority. How should you implement such a system?
Use a DynamoDB table with an attribute defining the priority level. Transformation instances will scan the table for tasks, sorting the results by priority level.
Use Route 53 latency based-routing to send high priority tasks to the closest transformation instances.
Use two SQS queues, one for high priority messages, and the other for default priority. Transformation instances first poll the high priority queue; if there is no message, they poll the default priority queue
Use a single SQS queue. Each message contains the priority level. Transformation instances poll high-priority messages first.
Your company plans to host a large donation website on Amazon Web Services (AWS). You anticipate a large and undetermined amount of traffic that will create many database writes. To be certain that you do not drop any writes to a database hosted on AWS. Which service should you use?
Amazon RDS with provisioned IOPS up to the anticipated peak write throughput.
Amazon Simple Queue Service (SQS) for capturing the writes and draining the queue to write to the database
Amazon ElastiCache to store the writes until the writes are committed to the database.
Amazon DynamoDB with provisioned write throughput up to the anticipated peak write throughput.
A customer has a 10 GB AWS Direct Connect connection to an AWS region where they have a web application hosted on Amazon Elastic Computer Cloud (EC2). The application has dependencies on an on-premises mainframe database that uses a BASE (Basic Available, Soft state, Eventual consistency) rather than an ACID (Atomicity, Consistency, Isolation, Durability) consistency model. The application is exhibiting undesirable behavior because the database is not able to handle the volume of writes. How can you reduce the load on your on-premises database resources in the most cost-effective way?
Use an Amazon Elastic Map Reduce (EMR) S3DistCp as a synchronization mechanism between the onpremises database and a Hadoop cluster on AWS.
Modify the application to write to an Amazon SQS queue and develop a worker process to flush the queue to the on-premises database
Modify the application to use DynamoDB to feed an EMR cluster which uses a map function to write to the on-premises database.
Provision an RDS read-replica database on AWS to handle the writes and synchronize the two databases using Data Pipeline.
An organization has created a Queue named “modularqueue” with SQS. The organization is not performing any operations such as SendMessage, ReceiveMessage, DeleteMessage, GetQueueAttributes, SetQueueAttributes, AddPermission, and RemovePermission on the queue. What can happen in this scenario?
AWS SQS sends notification after 15 days for inactivity on queue
AWS SQS can delete queue after 30 days without notification
AWS SQS marks queue inactive after 30 days
AWS SQS notifies the user after 2 weeks and deletes the queue after 3 weeks.
A user is using the AWS SQS to decouple the services. Which of the below mentioned operations is not supported by SQS?
SendMessageBatch
DeleteMessageBatch
CreateQueue
DeleteMessageQueue
A user has created a queue named “awsmodule” with SQS. One of the consumers of queue is down for 3 days and then becomes available. Will that component receive message from queue?
Yes, since SQS by default stores message for 4 days
No, since SQS by default stores message for 1 day only
No, since SQS sends message to consumers who are available that time
Yes, since SQS will not delete message until it is delivered to all consumers
A user has created a queue named “queue2” in US-East region with AWS SQS. The user’s AWS account ID is 123456789012. If the user wants to perform some action on this queue, which of the below Queue URL should he use?
A user has created a queue named “myqueue” with SQS. There are four messages published to queue, which are not received by the consumer yet. If the user tries to delete the queue, what will happen?
A user can never delete a queue manually. AWS deletes it after 30 days of inactivity on queue
It will delete the queue
It will initiate the delete but wait for four days before deleting until all messages are deleted automatically.
I t will ask user to delete the messages first
A user has developed an application, which is required to send the data to a NoSQL database. The user wants to decouple the data sending such that the application keeps processing and sending data but does not wait for an acknowledgement of DB. Which of the below mentioned applications helps in this scenario?
AWS Simple Notification Service
AWS Simple Workflow
AWS Simple Queue Service
AWS Simple Query Service
You are building an online store on AWS that uses SQS to process your customer orders. Your backend system needs those messages in the same sequence the customer orders have been put in. How can you achieve that?
It is not possible to do this with SQS
You can use sequencing information on each message
You can do this with SQS but you also need to use SWF
Messages will arrive in the same order by default
A user has created a photo editing software and hosted it on EC2. The software accepts requests from the user about the photo format and resolution and sends a message to S3 to enhance the picture accordingly. Which of the below mentioned AWS services will help make a scalable software with the AWS infrastructure in this scenario?
AWS Glacier
AWS Elastic Transcoder
AWS Simple Notification Service
AWS Simple Queue Service
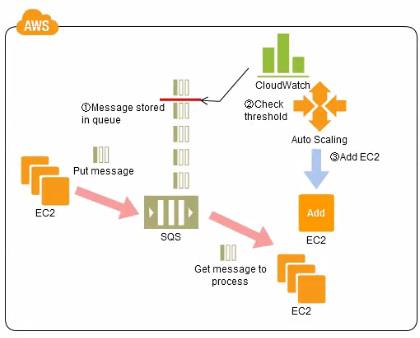
Refer to the architecture diagram of a batch processing solution using Simple Queue Service (SQS) to set up a message queue between EC2 instances, which are used as batch processors. Cloud Watch monitors the number of Job requests (queued messages) and an Auto Scaling group adds or deletes batch servers automatically based on parameters set in Cloud Watch alarms. You can use this architecture to implement which of the following features in a cost effective and efficient manner?
Reduce the overall time for executing jobs through parallel processing by allowing a busy EC2 instance that receives a message to pass it to the next instance in a daisy-chain setup.
Implement fault tolerance against EC2 instance failure since messages would remain in SQS and worn can continue with recovery of EC2 instances implement fault tolerance against SQS failure by backing up messages to S3.
Implement message passing between EC2 instances within a batch by exchanging messages through SOS.
Coordinate number of EC2 instances with number of job requests automatically thus Improving cost effectiveness
Handle high priority jobs before lower priority jobs by assigning a priority metadata field to SQS messages.
How does Amazon SQS allow multiple readers to access the same message queue without losing messages or processing them many times?
By identifying a user by his unique id
By using unique cryptography
Amazon SQS queue has a configurable visibility timeout
Multiple readers can’t access the same message queue
A user has created photo editing software and hosted it on EC2. The software accepts requests from the user about the photo format and resolution and sends a message to S3 to enhance the picture accordingly. Which of the below mentioned AWS services will help make a scalable software with the AWS infrastructure in this scenario?
AWS Elastic Transcoder
AWS Simple Notification Service
AWS Simple Queue Service
AWS Glacier
How do you configure SQS to support longer message retention?
Set the MessageRetentionPeriod attribute using the SetQueueAttributes method
Using a Lambda function
You can’t. It is set to 14 days and cannot be changed
You need to request it from AWS
A user has developed an application, which is required to send the data to a NoSQL database. The user wants to decouple the data sending such that the application keeps processing and sending data but does not wait for an acknowledgement of DB. Which of the below mentioned applications helps in this scenario?
AWS Simple Notification Service
AWS Simple Workflow
AWS Simple Query Service
AWS Simple Queue Service
If a message is retrieved from a queue in Amazon SQS, how long is the message inaccessible to other users by default?
0 seconds
1 hour
1 day
forever
30 seconds
Which of the following statements about SQS is true?
Messages will be delivered exactly once and messages will be delivered in First in, First out order
Messages will be delivered exactly once and message delivery order is indeterminate
Messages will be delivered one or more times and messages will be delivered in First in, First out order
Messages will be delivered one or more times and message delivery order is indeterminate (Before the introduction of FIFO queues)
How long can you keep your Amazon SQS messages in Amazon SQS queues?
From 120 secs up to 4 weeks
From 10 secs up to 7 days
From 60 secs up to 2 weeks
From 30 secs up to 1 week
When a Simple Queue Service message triggers a task that takes 5 minutes to complete, which process below will result in successful processing of the message and remove it from the queue while minimizing the chances of duplicate processing?
Retrieve the message with an increased visibility timeout, process the message, delete the message from the queue
Retrieve the message with an increased visibility timeout, delete the message from the queue, process the message
Retrieve the message with increased DelaySeconds, process the message, delete the message from the queue
Retrieve the message with increased DelaySeconds, delete the message from the queue, process the message
You need to process long-running jobs once and only once. How might you do this?
Use an SNS queue and set the visibility timeout to long enough for jobs to process.
Use an SQS queue and set the reprocessing timeout to long enough for jobs to process.
Use an SQS queue and set the visibility timeout to long enough for jobs to process.
Use an SNS queue and set the reprocessing timeout to long enough for jobs to process.
You are getting a lot of empty receive requests when using Amazon SQS. This is making a lot of unnecessary network load on your instances. What can you do to reduce this load?
Subscribe your queue to an SNS topic instead.
Use as long of a poll as possible, instead of short polls. (Refer link)
Alter your visibility timeout to be shorter.
Use <code>sqsd</code> on your EC2 instances.
You have an asynchronous processing application using an Auto Scaling Group and an SQS Queue. The Auto Scaling Group scales according to the depth of the job queue. The completion velocity of the jobs has gone down, the Auto Scaling Group size has maxed out, but the inbound job velocity did not increase. What is a possible issue?
Some of the new jobs coming in are malformed and unprocessable. (As other options would cause the job to stop processing completely, the only reasonable option seems that some of the recent messages must be malformed and unprocessable)
The routing tables changed and none of the workers can process events anymore. (If changed, none of the jobs would be processed)
Someone changed the IAM Role Policy on the instances in the worker group and broke permissions to access the queue. (If IAM role changed no jobs would be processed)
The scaling metric is not functioning correctly. (scaling metric did work fine as the autoscaling caused the instances to increase)
Company B provides an online image recognition service and utilizes SQS to decouple system components for scalability. The SQS consumers poll the imaging queue as often as possible to keep end-to-end throughput as high as possible. However, Company B is realizing that polling in tight loops is burning CPU cycles and increasing costs with empty responses. How can Company B reduce the number of empty responses?
Set the imaging queue visibility Timeout attribute to 20 seconds
Set the Imaging queue ReceiveMessageWaitTimeSeconds attribute to 20 seconds (Long polling. Refer link)
Set the imaging queue MessageRetentionPeriod attribute to 20 seconds
Set the DelaySeconds parameter of a message to 20 seconds
Functions are automatically monitored, and real-time metrics are reported through CloudWatch, including total requests, latency, error rates, and throttled requests.
Lambda automatically integrates with CloudWatch logs, creating a log group for each function and providing basic application lifecycle event log entries, including logging the resources consumed for each use of that function.
Functions support code written in
Node.js (JavaScript)
Python
Ruby
Java (Java 8 compatible)
C# (.NET Core)
Go
Custom runtime
Container images are also supported.
Failure Handling
For S3 bucket notifications and custom events, Lambda will attempt execution of the function three times in the event of an error condition in the code or if a service or resource limit is exceeded.
For ordered event sources that Lambda polls, e.g. DynamoDB Streams and Kinesis streams, it will continue attempting execution in the event of a developer code error until the data expires.
Dead Letter Queues (SNS or SQS) can be configured for events to be placed, once the retry policy for asynchronous invocations is exceeded
Lambda Layers
Lambda Layers provide a convenient way to package libraries and other dependencies that you can use with your Lambda functions.
Layers help reduce the size of uploaded deployment archives and make it faster to deploy your code.
A layer is a .zip file archive that can contain additional code or data.
A layer can contain libraries, a custom runtime, data, or configuration files.
Layers promote reusability, code sharing, and separation of responsibilities so that you can iterate faster on writing business logic.
Layers can be used only with Lambda functions deployed as a .zip file archive.
For functions defined as a container image, the preferred runtime and all code dependencies can be packaged when the container image is created.
A Layer can be created by bundling the content into a .zip file archive and uploading the .zip file archive to the layer from S3 or the local machine.
Lambda extracts the layer contents into the /opt directory when setting up the execution environment for the function.
Environment Variables
Environment variables can be used to adjust the function’s behavior without updating the code.
An environment variable is a pair of strings that are stored in a function’s version-specific configuration.
The Lambda runtime makes environment variables available to the code and sets additional environment variables that contain information about the function and invocation request.
Environment variables are not evaluated prior to the function invocation.
Lambda stores environment variables securely by encrypting them at rest.
AWS recommends using Secrets Manager instead of storing secrets in the environment variables.
Function versions can be used to manage the deployment of the functions.
Each function has a single, current version of the code.
Lambda creates a new version of the function each time it’s published.
A function version includes the following information:
The function code and all associated dependencies.
The Lambda runtime that invokes the function.
All the function settings, including the environment variables.
A unique Amazon Resource Name (ARN) to identify the specific version of the function.
Function versions are immutable, however, support Aliases which are mutable.
Lambda Functions Alias
Lambda supports creating aliases, which are mutable, for each function version.
Alias is a pointer to a specific function version, with a unique ARN.
Each alias maintains an ARN for a function version to which it points.
An alias can only point to a function version, not to another alias
Alias helps in rolling out new changes or rolling back to old versions
Alias supports routing configuration to point to a maximum of two Lambda function versions. It can be used for canary testing to send a portion of traffic to a second function version.
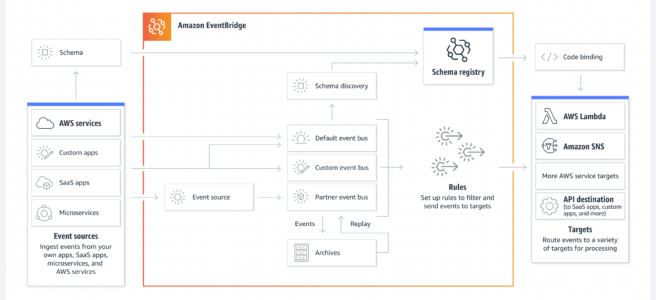
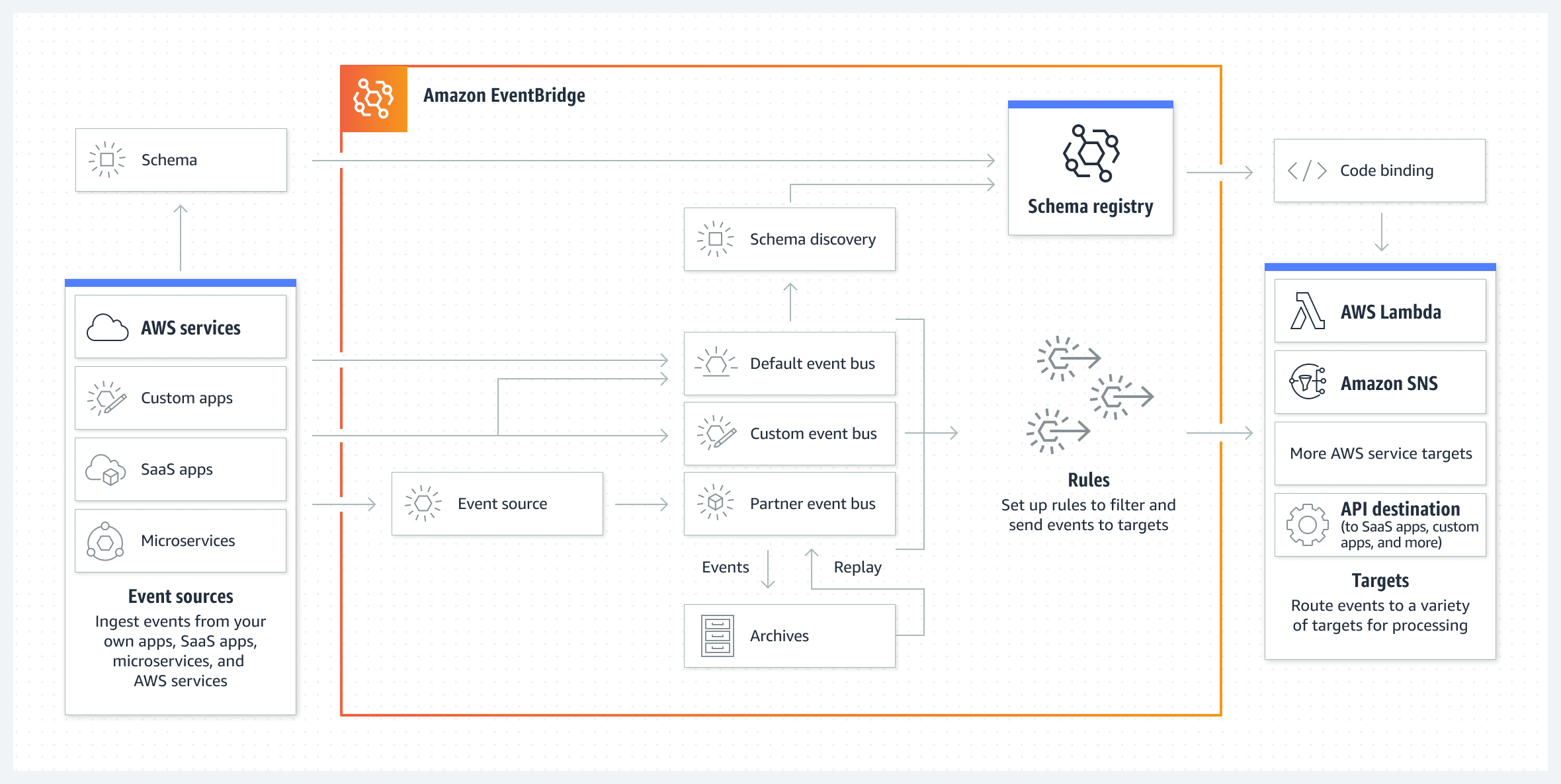
Amazon EventBridge is a serverless event bus service that makes it easy to connect applications with data from a variety of sources.
enables building loosely coupled and distributed event-driven architectures.
provides a simple and consistent way to ingest, filter, transform, and deliver events so you can build new applications quickly.
delivers a stream of real-time data from applications, SaaS applications, and AWS services, and routes that data to targets such as AWS Lambda.
supports routing rules to determine where to send the data to build application architectures that react in real-time to all of the data sources.
supports event buses for many-to-many routing of events between event-driven services.
provides Pipes for point-to-point integrations between these sources and targets, with support for advanced transformations and enrichment.
provides schemas, which define the structure of events, for all events that are generated by AWS services.
EventBridge Components
EventBridge receives an event on an event bus and applies a rule to route the event to a target.
Event sources
An event source is used to ingest events from AWS Services, applications, or SaaS partners.
Events
An event is a real-time indicator of a change in the environment such as an AWS environment, a SaaS partner service or application, or one of your applications or services.
All events are associated with an event bus.
Events are represented as JSON objects and they all have a similar structure and the same top-level fields.
Contents of the detail top-level field are different depending on which service generated the event and what the event is.
An event pattern defines the event structure and the fields that a rule matches.
Event buses
Event bus is a pipeline that receives events.
Each account has a default event bus that receives events from AWS services. Custom event buses can be created to send or receive events from a different account or Region.
Rules
Rules associated with the event bus evaluate events as they arrive.
Rules match incoming events to targets based either on the structure of the event, called an event pattern, or on a schedule.
Each rule checks whether an event matches the rule’s criteria.
A single rule can send an event to multiple targets, which then run in parallel.
Rules that are based on a schedule perform an action at regular intervals.
Targets
A target is a resource or endpoint that EventBridge sends an event to when the event matches the event pattern defined for a rule.
The rule processes the event data and sends the relevant information to the target.
EventBridge needs permission to access the target resource to be able to deliver event data to the target.
Up to five targets can be defined for each rule.
EventBridge allows events to be archived and replayed later.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company wants to be alerted through email when IAM CreateUser API calls are made within its AWS account. Which combination of actions should a SysOps administrator take to meet this requirement? (Choose two.)
Create an Amazon EventBridge (Amazon CloudWatch Events) rule with AWS CloudTrail as the event source and IAM CreateUser as the specific API call for the event pattern.
Create an Amazon EventBridge (Amazon CloudWatch Events) rule with Amazon CloudSearch as the event source and IAM CreateUser as the specific API call for the event pattern.
Create an Amazon EventBridge (Amazon CloudWatch Events) rule with AWS IAM Access Analyzer as the event source and IAM CreateUser as the specific API call for the event pattern.
Use an Amazon Simple Notification Service (Amazon SNS) topic as an event target with an email subscription.
Use an Amazon Simple Email Service (Amazon SES) notification as an event target with an email subscription.
Amazon Cognito provides authentication, authorization, and user management for the web and mobile apps.
Users can sign in directly with a username and password, or through a third party such as Facebook, Amazon, Google, or Apple.
Cognito has two main components.
User pools are user directories that provide sign-up and sign-in options for the app users.
Identity pools enable you to grant the users access to other AWS services.
Cognito Sync helps synchronize data across a user’s devices so that their app experience remains consistent when they switch between devices or upgrade to a new device.
Cognito User Pools
User pools are for authentication (identity verification).
User pools are user directories that provide sign-up and sign-in options for web and mobile app users.
User pool helps users sign in to the web or mobile app, or federate through a third-party identity provider (IdP).
All user pool members have a directory profile, whether the users sign in directly or through a third party, that can be accessed through an SDK.
After successfully authenticating a user, Cognito issues JSON web tokens (JWT) that can be used to secure and authorize access to your own APIs, or exchange for AWS credentials.
User pools provide:
Sign-up and sign-in services.
A built-in, customizable web UI to sign in users.
Social sign-in with Facebook, Google, Apple, or Amazon, and through SAML and OIDC identity providers from the user pool.
User directory management and user profiles.
Security features such as MFA, checks for compromised credentials, account takeover protection, and phone and email verification.
Customized workflows and user migration through Lambda triggers.
Use cases
Design sign-up and sign-in webpages for your app.
Access and manage user data.
Track user device, location, and IP address, and adapt to sign-in requests of different risk levels.
Use a custom authentication flow for your app.
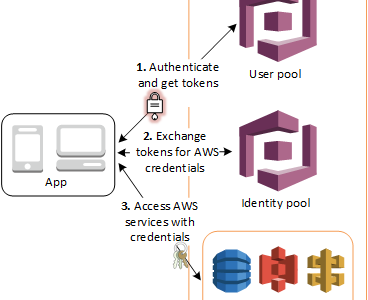
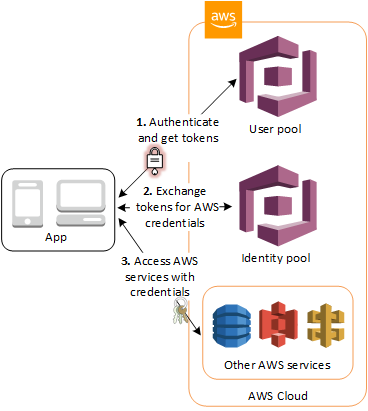
Cognito Identity Pools
Identity pools are for authorization (access control).
Identity pool helps users obtain temporary AWS credentials to access AWS services,
Identity pools support both authenticated and unauthenticated identities.
Unauthenticated identities typically belong to guest users.
Authenticated identities belong to users who are authenticated by any supported identity provider:
Cognito user pools
Social sign-in with Facebook, Google, Login with Amazon, and Sign in with Apple
OpenID Connect (OIDC) providers
SAML identity providers
Developer authenticated identities
Each identity type has a role with policies assigned that determines the AWS services that the role can access.
Identity Pools do not store any user profiles.
Use cases
Give your users access to AWS resources, such as S3 and DynamoDB.
Generate temporary AWS credentials for unauthenticated users.
Cognito Sync
Cognito Sync is an AWS service and client library that makes it possible to sync application-related user data across devices.
Cognito Sync can synchronize user profile data across mobile devices and the web without using your own backend.
The client libraries cache data locally so that the app can read and write data regardless of device connectivity status.
When the device is online, the data can be synchronized.
If you set up push sync, other devices can be notified immediately that an update is available.
Sync store is a key/value pair store linked to an identity.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company is building a social media mobile and web app for consumers. They want the application to be available on all desktop and mobile platforms, while being able to maintain user preferences across platforms. How can they implement the authentication to support the requirement?
Use AWS Cognito
Use AWS Glue
Use Web Identity Federation
Use AWS IAM
A Developer needs to create an application that supports Security Assertion Markup Language (SAML) and Facebook authentication. It must also allow access to AWS services, such as Amazon DynamoDB. Which AWS service or feature will meet these requirements with the LEAST amount of additional coding?
AWS AppSync
Amazon Cognito identity pools
Amazon Cognito user pools
Amazon Lambda@Edge
A development team is designing a mobile app that requires multi-factor authentication. Which steps should be taken to achieve this? (Choose two.)
Use Amazon Cognito to create a user pool and create users in the user pool.
Send multi-factor authentication text codes to users with the Amazon SNS Publish API call in the app code.
Enable multi-factor authentication for the Amazon Cognito user pool.
Use AWS IAM to create IAM users.
Enable multi-factor authentication for the users created in AWS IAM.
A Developer is building a mobile application and needs any update to user profile data to be pushed to all devices accessing the specific identity. The Developer does not want to manage a back end to maintain the user profile data. What is the MOST efficient way for the Developer to achieve these requirements using Amazon Cognito?
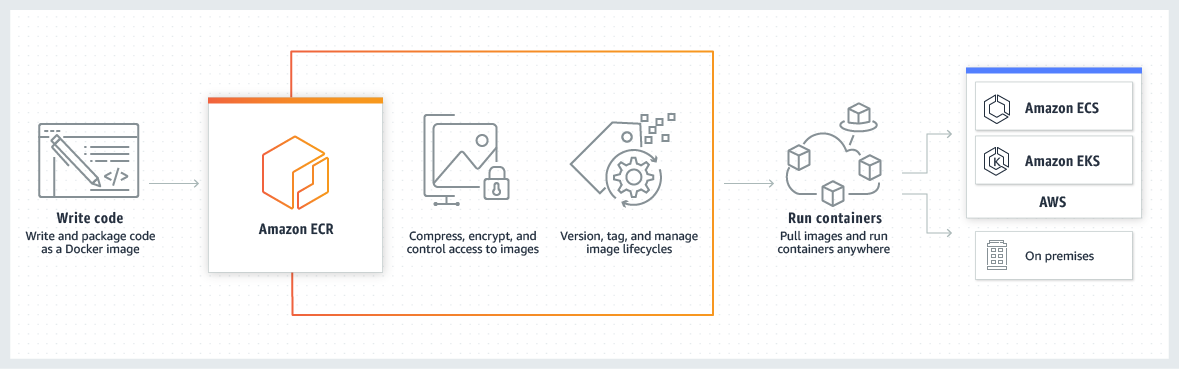
Amazon Elastic Container Registry – ECR is a fully managed, secure, scalable, reliable container image registry service.
makes it easy for developers to share and deploy container images and artifacts.
is integrated with ECS, EKS, Fargate, and Lambda, simplifying the development to production workflow.
eliminates the need to operate your own container repositories or worry about scaling the underlying infrastructure.
hosts the images, using S3, in a highly available and scalable architecture, allowing you to deploy containers for the applications reliably.
is a Regional service with the ability to push/pull images to the same AWS Region. Images can be pulled between Regions or out to the internet with additional latency and data transfer costs.
supports cross-region and cross-account image replication.
integrates with AWS IAM and supports resource-based permissions
supports public and private repositories.
automatically encrypts images at rest using S3 server-side encryption or AWS KMS encryption and transfers the container images over HTTPS.
supports tools and docker CLI to push, pull and manage Docker images, Open Container Initiative (OCI) images, and OCI-compatible artifacts.
automatically scans the container images for a broad range of operating system vulnerabilities.
supports ECR Lifecycle policies that help with managing the lifecycle of the images in the repositories.
ECR Components
Registry
ECR private registry hosts the container images in a highly available and scalable architecture.
A default ECR private registry is provided to each AWS account.
One or more repositories can be created in the registry and images stored in them.
Repositories can be configured for either cross-Region or cross-account replication.
Private Registry is enabled for basic scanning, by default.
Enhanced scanning can be enabled which provides an automated, continuous scanning mode that scans for both operating system and programming language package vulnerabilities.
Repository
An ECR repository contains Docker images, Open Container Initiative (OCI) images, and OCI compatible artifacts.
Repositories can be controlled with both user access policies and individual repository policies.
Image
Images can be pushed and pulled to the repositories.
Images can be used locally on the development system, or in ECS task definitions and EKS pod specifications
Repository policy
Repository policies are resource-based policies that can help control access to the repositories and the images within them.
Repository policies are a subset of IAM policies that are scoped for, and specifically used for, controlling access to individual ECR repositories.
A user or role only needs to be allowed permission for an action through either a repository policy or an IAM policy but not both for the action to be allowed.
Resource-based policies also help grant the usage permission to other accounts on a per-resource basis.
Authorization token
A client must authenticate to the registries as an AWS user before they can push and pull images.
An authentication token is used to access any ECR registry that the IAM principal has access to and is valid for 12 hours.
Authorization token’s permission scope matches that of the IAM principal used to retrieve the authentication token.
ECR with VPC Endpoints
ECR can be configured to use an Interface VPC endpoint, that enables you to privately access Amazon ECR APIs through private IP addresses.
AWS PrivateLink restricts all network traffic between the VPC and ECR to the Amazon network. You don’t need an internet gateway, a NAT device, or a virtual private gateway.
VPC endpoints currently don’t support cross-Region requests.
VPC endpoints currently don’t support ECR Public repositories.
VPC endpoints only support AWS provided DNS through Route 53.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company is using Amazon Elastic Container Service (Amazon ECS) to run its container-based application on AWS. The company needs to ensure that the container images contain no severe vulnerabilities. Which solution will meet these requirements with the LEAST management overhead?
Pull images from the public container registry. Publish the images to Amazon ECR repositories with scan on push configured.
Pull images from the public container registry. Publish the images to a private container registry hosted on Amazon EC2 instances. Deploy host-based container scanning tools to EC2 instances that run ECS.
Pull images from the public container registry. Publish the images to Amazon ECR repositories with scan on push configured.
Pull images from the public container registry. Publish the images to AWS CodeArtifact repositories in a centralized AWS account.