Amazon WorkSpaces is a fully managed, secure desktop computing service that runs on the AWS cloud.
WorkSpaces is a cloud-based virtual desktop that can act as a replacement for a traditional desktop.
WorkSpaces eliminates the need to procure and deploy hardware or install complex software and the complexity of managing inventory, OS versions and patches, and VDI, which helps simplify the desktop delivery strategy.
A WorkSpace is available as a bundle of compute resources, storage space, and software applications that allow a user to perform day-to-day tasks just like using a traditional desktop
WorkSpaces allows users to easily provision cloud-based virtual desktops and provide users access to the documents, applications, and resources they need from any supported device, including computers, Chromebooks, iPads, Fire tablets, and Android tablets.
Each WorkSpace runs on an individual instance for the assigned user and Applications and users’ documents and settings are persistent.
WorkSpaces client application needs a supported client device (PC, Mac, iPad, Kindle Fire, or Android tablet), and an Internet connection with TCP ports 443 & 4172, and UDP port 4172 open
WorkSpaces Application Manager – WAM
WAM offers a fast, flexible, and secure way to deploy and manage applications for WorkSpaces.
WAM accelerates software deployment, upgrades, patching, and retirement by packaging Microsoft Windows desktop applications into virtualized application containers that run as though they are natively installed.
WorkSpaces need an Internet connection to receive applications via WAM
Applications can be packaged using the WAM Studio, validated using the WAM Player, and then uploaded to WAM for use.
WorkSpaces Security
Users can be quickly added or removed.
Users can log in to the WorkSpace using their own credentials set when the instance is provisioned
integrates with the existing Active Directory domain, users can sign in with their regular Active Directory credentials.
integrates with the existing RADIUS server to enable multi-factor authentication (MFA).
supports access restriction based on the client OS type and using digital certificates
VPC Security groups to limit access to resources in the network or the Internet from the WorkSpaces
IP Access Control Group enables the configuration of trusted IP addresses that are permitted to access the WorkSpaces.
is PCI compliant and conforms to the Payment Card Industry Data Security Standard (PCI DSS)
WorkSpaces Maintenance & Backup
WorkSpaces enables maintenance windows for both AlwaysOn and AutoStop WorkSpaces by default.
AlwaysOn WorkSpaces has a default from 00h00 to 04h00 on Sunday morning
AutoStop WorkSpaces automatically start once a month to install updates
User volume is backed-up every 12 hours and if the WorkSpace fails, AWS can restore the volume from the backup
WorkSpaces Encryption
supports root volume and user volume encryption
uses EBS volumes that can be encrypted on WorkSpace creation, providing encryption for data stored at rest, disk I/O to the volume, and snapshots created from the volume.
integrates with the AWS KMS service to allow you to specify the keys you want to use to encrypt the volumes.
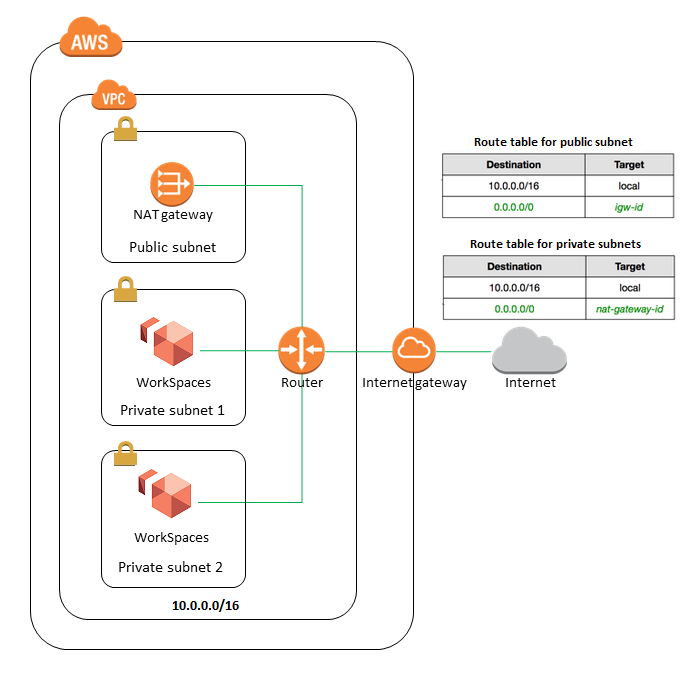
WorkSpaces Architecture
WorkSpaces launches the WorkSpaces in a VPC.
If using AWS Directory Service to create an AWS Managed Microsoft or a Simple AD, it is recommended to configure the VPC with one public subnet and two private subnets.
To provide internet access to WorkSpaces in a private subnet, configure a NAT gateway in the public subnet. Configure the directory to launch the WorkSpaces in the private subnets.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company needs to deploy virtual desktops to its customers in a virtual private cloud, leveraging existing security controls. Which set of AWS services and features will meet the company’s requirements?
Virtual Private Network connection. AWS Directory Services, and ClassicLink (ClassicLink allows you to link an EC2-Classic instance to a VPC in your account, within the same region)
Virtual Private Network connection. AWS Directory Services, and Amazon Workspaces (WorkSpaces for Virtual desktops, and AWS Directory Services to authenticate to an existing on-premises AD through VPN)
AWS Directory Service, Amazon Workspaces, and AWS Identity and Access Management (AD service needs a VPN connection to interact with an On-premise AD directory)
Amazon Elastic Compute Cloud, and AWS Identity and Access Management (Need WorkSpaces for virtual desktops)
Your company is planning on testing out Amazon workspaces for their account. They are going to allocate a set of workstations with static IP addresses for this purpose. They need to ensure that only these IP addresses have access to Amazon Workspaces. How can you achieve this?
AWS CloudHSM is a cloud-based hardware security module (HSM) that provides secure cryptographic key storage and enables you to easily generate and use your own encryption keys on the AWS Cloud.
CloudHSM helps manage your own encryption keys using FIPS 140-2 Level 3 validated HSMs.
AWS CloudHSM helps meet corporate, contractual and regulatory compliance requirements for data security by using dedicated HSM appliances within the AWS cloud.
A hardware security module (HSM)
is a hardware appliance that provides secure key storage and cryptographic operations within a tamper-resistant hardware module.
are designed with physical and logical mechanisms, to securely store cryptographic key material and use the key material without exposing it outside the cryptographic boundary of the appliance.
physical protections include tamper detection and tamper response. When a tampering event is detected, the HSM is designed to securely destroy the keys rather than risk compromise.
logical protections include role-based access controls that provide separation of duties
CloudHSM allows encryption key protection within HSMs, designed and validated to government standards for secure key management.
CloudHSM helps comply with strict key management requirements within the AWS cloud without sacrificing application performance
CloudHSM uses SafeNet Luna SA HSM appliances
HSMs are located in AWS data centres, managed and monitored by AWS, but AWS does not have access to the keys.
CloudHSM makes periodic backups of the users, keys, and policies in the cluster.
CloudHSM is a fully-managed service that automates time-consuming administrative tasks, such as hardware provisioning, software patching, high availability, and backups.
CloudHSM also enables you to scale quickly by adding and removing HSM capacity on-demand, with no up-front costs.
CloudHSM automatically load balances requests and securely duplicates keys stored in any HSM to all of the other HSMs in the cluster.
Only you have access to the keys and operations to generate, store and manage the keys.
AWS can’t help recover the key material if the credentials are lost
CloudHSM provides single tenant dedicated access to each HSM appliance
HSMs are inside your VPC and isolated from the rest of the network
Placing HSM appliances near the EC2 instances decreases network latency, which can improve application performance
Integrated with Amazon Redshift and Amazon RDS for Oracle
Other use cases like EBS volume encryption and S3 object encryption and key management can be handled by writing custom applications and integrating them with CloudHSM
CloudHSM can perform a variety of cryptographic tasks:
Generate, store, import, export, and manage cryptographic keys, including symmetric keys and asymmetric key pairs.
Use symmetric and asymmetric algorithms to encrypt and decrypt data.
Use cryptographic hash functions to compute message digests and hash-based message authentication codes (HMACs).
Cryptographically sign data (including code signing) and verify signatures.
Generate cryptographically secure random data.
CloudHSM Use Cases
Offload SSL/TLS processing for the web servers.
Store the Transparent Data Encryption (TDE) master encryption key for Oracle database servers that support TDE.
Store private keys and sign certificate requests acting act as an issuing CA to issue certificates for your organization.
CloudHSM Clusters
CloudHSM Cluster is a collection of individual HSMs kept in sync.
HSMs can be placed in different AZs to provide high availability. Spreading clusters across AZs provides redundancy and high availability.
Cluster can be added with more HSMs for scalability and performance.
Cluster with more than one HSM is automatically load balanced.
CloudHSM helps keep the cluster synchronized, redundant, and highly available.
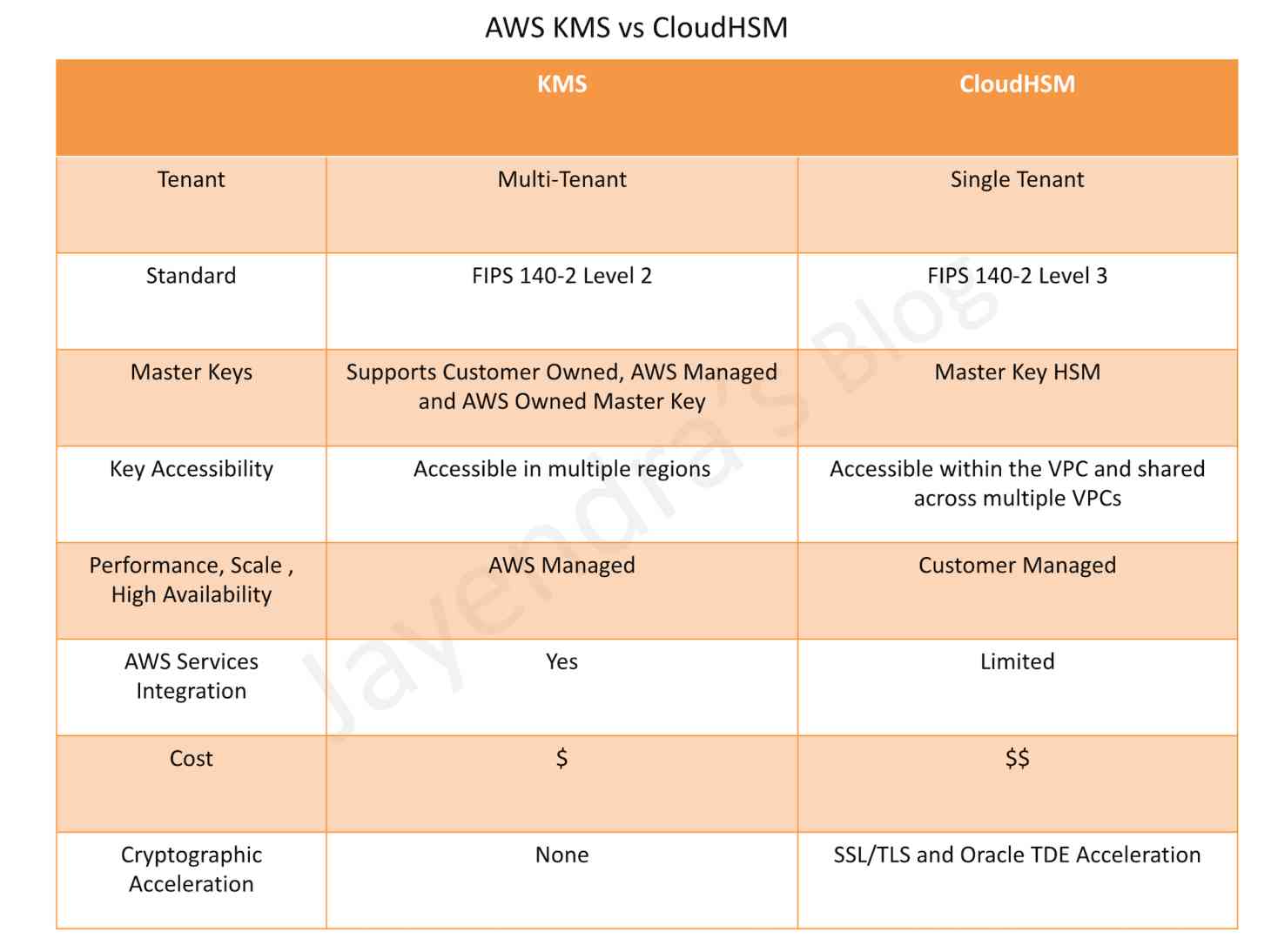
CloudHSM vs KMS
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
With which AWS services CloudHSM can be used (select 2)
S3
DynamoDb
RDS
ElastiCache
Amazon Redshift
An AWS customer is deploying a web application that is composed of a front-end running on Amazon EC2 and of confidential data that is stored on Amazon S3. The customer security policy that all access operations to this sensitive data must be authenticated and authorized by a centralized access management system that is operated by a separate security team. In addition, the web application team that owns and administers the EC2 web front-end instances is prohibited from having any ability to access the data that circumvents this centralized access management system. Which of the following configurations will support these requirements:
Encrypt the data on Amazon S3 using a CloudHSM that is operated by the separate security team. Configure the web application to integrate with the CloudHSM for decrypting approved data access operations for trusted end-users. (S3 doesn’t integrate directly with CloudHSM, also there is no centralized access management system control)
Configure the web application to authenticate end-users against the centralized access management system. Have the web application provision trusted users STS tokens entitling the download of approved data directly from Amazon S3 (Controlled access and admins cannot access the data as it needs authentication)
Have the separate security team create and IAM role that is entitled to access the data on Amazon S3. Have the web application team provision their instances with this role while denying their IAM users access to the data on Amazon S3 (Web team would have access to the data)
Configure the web application to authenticate end-users against the centralized access management system using SAML. Have the end-users authenticate to IAM using their SAML token and download the approved data directly from S3. (not the way SAML auth works and not sure if the centralized access management system is SAML complaint)
AWS Risk and Compliance Whitepaper is intended to provide information to assist AWS customers with integrating AWS into their existing control framework supporting their IT environment.
AWS does communicate its security and control environment relevant to customers. AWS does this by doing the following:
Obtaining industry certifications and independent third-party attestations described in this document
Publishing information about the AWS security and control practices in whitepapers and web site content
Providing certificates, reports, and other documentation directly to AWS customers under NDA (as required)
Shared Responsibility model
AWS’ part in the shared responsibility includes
providing its services on a highly secure and controlled platform and providing a wide array of security features customers can use
relieves the customer’s operational burden as AWS operates, manages and controls the components from the host operating system and virtualization layer down to the physical security of the facilities in which the service operates
Customers’ responsibility includes
configuring their IT environments in a secure and controlled manner for their purposes
responsibility and management of the guest operating system (including updates and security patches), other associated application software as well as the configuration of the AWS provided security group firewall
stringent compliance requirements by leveraging technology such as host based firewalls, host based intrusion detection/prevention, encryption and key management
relieve customer burden of operating controls by managing those controls associated with the physical infrastructure deployed in the AWS environment
Risk and Compliance Governance
AWS provides a wide range of information regarding its IT control environment to customers through white papers, reports, certifications, and other third-party attestations
AWS customers are required to continue to maintain adequate governance over the entire IT control environment regardless of how IT is deployed.
Leading practices include
an understanding of required compliance objectives and requirements (from relevant sources),
establishment of a control environment that meets those objectives and requirements,
an understanding of the validation required based on the organization’s risk tolerance,
and verification of the operating effectiveness of their control environment.
Strong customer compliance and governance might include the following basic approach:
Review information available from AWS together with other information to understand as much of the entire IT environment as possible, and then document all compliance requirements.
Design and implement control objectives to meet the enterprise compliance requirements.
Identify and document controls owned by outside parties.
Verify that all control objectives are met and all key controls are designed and operating effectively.
Approaching compliance governance in this manner helps companies gain a better understanding of their control environment and will help clearly delineate the verification activities to be performed.
AWS Certifications, Programs, Reports, and Third-Party Attestations
AWS engages with external certifying bodies and independent auditors to provide customers with considerable information regarding the policies, processes, and controls established and operated by AWS.
AWS provides third-party attestations, certifications, Service Organization Controls (SOC) reports and other relevant compliance reports directly to our customers under NDA.
Key Risk and Compliance Questions
Shared Responsibility
AWS controls the physical components of that technology.
Customer owns and controls everything else, including control over connection points and transmissions
Auditing IT
Auditing for most layers and controls above the physical controls remains the responsibility of the customer
AWS ISO 27001 and other certifications are available for auditors review
AWS-defined logical and physical controls is documented in the SOC 1 Type II report and available for review by audit and compliance teams
Data location
AWS customers control which physical region their data and their servers will be located
AWS replicates the data only within the region
AWS will not move customers’ content from the selected Regions without notifying the customer, unless required to comply with the law or requests of governmental entities
Data center tours
As AWS host multiple customers, AWS does not allow data center tours by customers, as this exposes a wide range of customers to physical access of a third party.
An independent and competent auditor validates the presence and operation of controls as part of our SOC 1 Type II report.
This third-party validation provides customers with the independent perspective of the effectiveness of controls in place.
AWS customers that have signed a non-disclosure agreement with AWS may request a copy of the SOC 1 Type II report.
Third-party access
AWS strictly controls access to data centers, even for internal employees.
Third parties are not provided access to AWS data centers except when explicitly approved by the appropriate AWS data center manager per the AWS access policy
Multi-tenancy
AWS environment is a virtualized, multi-tenant environment.
AWS has implemented security management processes, PCI controls, and other security controls designed to isolate each customer from other customers.
AWS systems are designed to prevent customers from accessing physical hosts or instances not assigned to them by filtering through the virtualization software.
Hypervisor vulnerabilities
Amazon EC2 utilizes a highly customized version of Xen hypervisor.
Hypervisor is regularly assessed for new and existing vulnerabilities and attack vectors by internal and external penetration teams, and is well suited for maintaining strong isolation between guest virtual machines
Vulnerability management
AWS is responsible for patching systems supporting the delivery of service to customers, such as the hypervisor and networking services
Encryption
AWS allows customers to use their own encryption mechanisms for nearly all the services, including S3, EBS, SimpleDB, and EC2.
IPSec tunnels to VPC are also encrypted
Data isolation
All data stored by AWS on behalf of customers has strong tenant isolation security and control capabilities
Composite services
AWS does not leverage any third-party cloud providers to deliver AWS services to customers.
Distributed Denial Of Service (DDoS) attacks
AWS network provides significant protection against traditional network security issues and the customer can implement further protection
Data portability
AWS allows customers to move data as needed on and off AWS storage
Service & Customer provider business continuity
AWS does operate a business continuity program
AWS data centers incorporate physical protection against environmental risks.
AWS’ physical protection against environmental risks has been validated by an independent auditor and has been certified
AWS provides customers with the capability to implement a robust continuity plan with multi region/AZ deployment architectures, backups, data redundancy replication
Capability to scale
AWS cloud is distributed, highly secure and resilient, giving customers massive scale potential.
Customers may scale up or down, paying for only what they use
Service availability
AWS does commit to high levels of availability in its service level agreements (SLA) for e.g. S3 99.9%
Application Security
AWS system development lifecycle incorporates industry best practices which include formal design reviews by the AWS Security Team, source code analysis, threat modeling and completion of a risk assessment
AWS does not generally outsource development of software.
AWS Security regularly scans all Internet facing service endpoint IP addresses for vulnerabilities, but do not include customer instances
AWS Security notifies the appropriate parties to remediate any identified vulnerabilities.
Customers can request permission to conduct scans and Penetration tests of their cloud infrastructure as long as they are limited to the customer’s instances and do not violate the AWS Acceptable Use Policy. Advance approval for these types of scans is required
Data Security
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
When preparing for a compliance assessment of your system built inside of AWS. What are three best practices for you to prepare for an audit? Choose 3 answers
Gather evidence of your IT operational controls (Customer still needs to gather all the IT operation controls inline with their environment)
Request and obtain applicable third-party audited AWS compliance reports and certifications (Customers can request the reports and certifications produced by our third-party auditors or can request more information about AWS Compliance)
Request and obtain a compliance and security tour of an AWS data center for a pre-assessment security review (AWS does not allow data center tour)
Request and obtain approval from AWS to perform relevant network scans and in-depth penetration tests of your system’s Instances and endpoints (AWS requires prior approval to be taken to perform penetration tests)
Schedule meetings with AWS’s third-party auditors to provide evidence of AWS compliance that maps to your control objectives (Customers can request the reports and certifications produced by our third-party auditors or can request more information about AWS Compliance)
In the shared security model, AWS is responsible for which of the following security best practices (check all that apply) :
Penetration testing
Operating system account security management
Threat modeling
User group access management
Static code analysis
You are running a web-application on AWS consisting of the following components an Elastic Load Balancer (ELB) an Auto-Scaling Group of EC2 instances running Linux/PHP/Apache, and Relational DataBase Service (RDS) MySQL. Which security measures fall into AWS’s responsibility?
Protect the EC2 instances against unsolicited access by enforcing the principle of least-privilege access (Customer owned)
Protect against IP spoofing or packet sniffing
Assure all communication between EC2 instances and ELB is encrypted (Customer owned)
Install latest security patches on ELB, RDS and EC2 instances (Customer owned)
Which of the following statements is true about achieving PCI certification on the AWS platform? (Choose 2)
Your organization owns the compliance initiatives related to anything placed on the AWS infrastructure
Amazon EC2 instances must run on a single-tenancy environment (dedicated instance)
AWS manages card-holder environments
AWS Compliance provides assurance related to the underlying infrastructure
AWS Import/Export accelerates moving large amounts of data into and out of AWS using portable storage devices for transport
AWS transfers the data directly onto and off of storage devices using Amazon’s high-speed internal network, bypassing the Internet, and can be much faster and more cost effective than upgrading connectivity.
AWS Import/Export can be implemented in two different ways
AWS Import/Export Disk (Disk)
originally the only service offered by AWS for data transfer by mail
Disk supports transfers data directly onto and off of storage devices you own using the Amazon high-speed internal network
AWS Snowball
is generally faster and cheaper to use than Disk for importing data into Amazon S3
AWS Import/Export supports
importing data to several types of AWS storage, including EBS snapshots, S3 buckets, and Glacier vaults.
exporting data out from S3 only
Data load typically begins the next business day after the storage device arrives at AWS and after the data export or import completes, the storage device is returned
Ideal Usage Patterns
AWS Import/Export is ideal for transferring large amounts of data in and out of the AWS cloud, especially in cases where transferring the data over the Internet would be too slow (a week or more) or too costly.
Common use cases include
first time migration – initial data upload to AWS
content distribution or regular data interchange to/from your customers or business associates,
off-site backup – transfer to Amazon S3 or Amazon Glacier for off-site backup and archival storage, and
disaster recovery – quick retrieval (export) of large backups from Amazon S3 or Amazon Glacier
AWS Import/Export Disk Jobs
AWS Import/Export jobs can be created in 2 steps
Submit a Job request to AWS where each job corresponds to exactly one storage device
Send your storage device to AWS, which after the data is uploaded or downloaded is returned back
AWS Import/Export jobs can be created
using a command line tool, which requires no programming or
programmatically using the AWS SDK for Java or the REST API to send requests to AWS or
even through third party tools
AWS Import/Export Data Encrption
supports data encryption methods
PIN-code encryption, Hardware-based device encryption that uses a physical PIN pad for access to the data.
TrueCrypt software encryption, Disk encryption using TrueCrypt, which is an open-source encryption application.
Creating an import or export job with encryption requires providing the PIN code or password for the selected encryption method
Although is is not mandatory for the data to be encrypted for import jobs, it is highly recommended
All export jobs require data encryption can use either hardware encryption or software encryption or both methods.
AWS Import/Export supported Job Types
Import to S3
Import to Glacier (Import to Glacier is no longer supported by AWS. Refer Updates)
Import to EBS
Export to S3
AWS erases the device after every import job prior to return shipping.
Guidelines and Limitations
AWS Import/Export does not support Server-Side Encryption (SSE) when importing data.
Maximum file size of a single file or object to be imported is 5 TB. Files and objects larger than 5 TB won’t be imported.
Maximum device capacity is 16 TB for Amazon Simple Storage Service (Amazon S3) and Amazon EBS jobs.
Maximum device capacity is 4 TB for Amazon Glacier jobs.
AWS Import/Export exports only the latest version from an Amazon S3 bucket that has versioning turned on.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You are working with a customer who has 10 TB of archival data that they want to migrate to Amazon Glacier. The customer has a 1-Mbps connection to the Internet. Which service or feature provides the fastest method of getting the data into Amazon Glacier?
Amazon Glacier multipart upload
AWS Storage Gateway
VM Import/Export
AWS Import/Export (Normal upload will take ~900 days as the internet max speed is capped)
I would like to share my preparation leading to and experience for the exams
AWS Certification exams are pretty tough to crack as they cover a lot of topics from a wide range of services offered by them.
I cleared both the Solution Architect and SysOps Associate certifications in a time frame of 2 months.
I had 6 months of prior hands-on experience with AWS primarily on IAM, VPC, EC2, S3 & RDS which helped a lot
There are lot of resources online which can be helpful but are overwhelming as well as misguide you (I found lot of dumps which have sample exam questions but the answers are marked wrong)
AWS Associate certifications although can be cleared with complete theoretical knowledge, a bit of hands on really helps a lot.
Also, AWS services are update literally everyday with new features being added, issues resolved and so on, which the exam questions surely don’t keep a track off. Not sure how often the exam questions are updated.
So my suggestion is if you see a question which focuses on a scenario which added latest by AWS within a month, still don’t go with that answer and stick to the answer which was relevant before the update for e.g. encryption of Root volume usually made in the certification exam with options to use external tools and was enabled by AWS recently.
AWS Certification Exam Preparation
As I mentioned there are lot of resources and courses online for the Certification exam which can be overwhelming, this is what I did for my preparation to clear the exams
Signed up with AWS for the Free Tier account which provides a lot of the Services to be tried for free with certain limits which are more then enough to get things going. Be sure to decommission anything, if you using any thing beyond the free limits, preventing any surprises 🙂
Also, used the QwikLabs for all the introductory courses which are free and allow you to try out the services multiple times (I think its max 5, as I got the warnings couple of times)
Update: Qwiklabs seems to have reduced the free courses quite a lot and now provide targeted labs for AWS Certification exams which are charged
Read the FAQs atleast for the important topics, as they cover important points and are good for quick review
Went through multiple sites to consolidate the Sample exam questions and worked on them to get the correct answers. I have tried to consolidate them further in this blog topic wise.
Went through multiple discussion topics on the acloud guru course which are pretty interesting and provides further insights and some of them are actually certification exam questions
I did not purchase the AWS Practice exams, as the questions are available all around. But if you want to check the format, it might be useful.
Opinion : acloud guru course are good by itself but is not sufficient to pass the exam but might help to counter about 50-60% of exam questions
Also, if you are well prepared the time for the certification exam is more then enough and I could answer all the questions within an hour and was able to run a review on all them once.
Important Exam Time Tip: Only mark the questions which you doubt as Mark for Review and then go through them only. I did the mistake marking quite a few as Mark for Review, even though I was confident on the answers, and wasting time on them again.
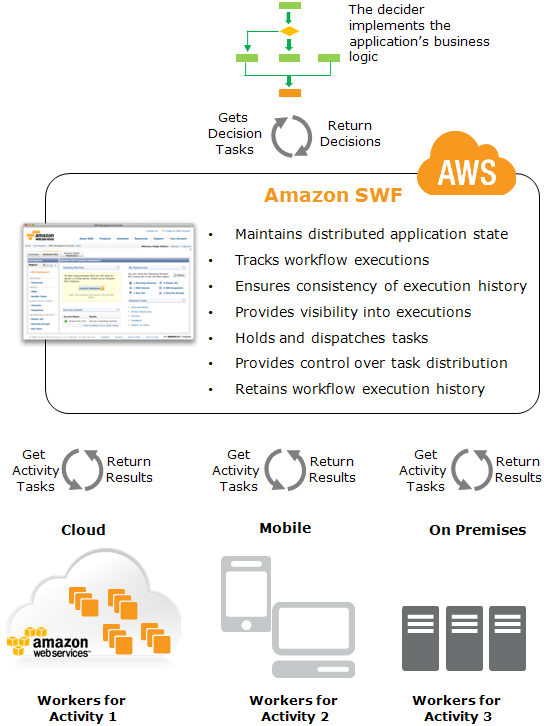
AWS SWF makes it easy to build applications that coordinate work across distributed components
SWF makes it easier to develop asynchronous and distributed applications by providing a programming model and infrastructure for coordinating distributed components, tracking and maintaining their execution state in a reliable way
SWF does the following
stores metadata about a workflow and its component parts.
stores task for workers and queues them until a Worker needs them.
assigns task to workers, which can run either on cloud or on-premises
routes information between executions of a workflow and the associated Workers.
tracks the progress of workers on Tasks, with configurable timeouts.
maintains workflow state in a durable fashion
SWF helps coordinating tasks across the application which involves managing intertask dependencies, scheduling, and concurrency in accordance with the logical flow of the application.
SWF gives full control over implementing tasks and coordinating them without worrying about underlying complexities such as tracking their progress and maintaining their state.
SWF tracks and maintains the workflow state in a durable fashion, so that the application is resilient to failures in individual components, which can be implemented, deployed, scaled, and modified independently
SWF offers capabilities to support a variety of application requirements and is suitable for a range of use cases that require coordination of tasks, including media processing, web application back-ends, business process workflows, and analytics pipelines.
Simple Workflow Concepts
Workflow
Fundamental concept in SWF is the Workflow, which is the automation of a business process
A workflow is a set of activities that carry out some objective, together with logic that coordinates the activities.
Workflow Execution
A workflow execution is a running instance of a workflow
Workflow History
SWF maintains the state and progress of each workflow execution in its Workflow History, which saves the application from having to store the state in a durable way.
It enables applications to be stateless as all information about a workflow execution is stored in its workflow history.
For each workflow execution, the history provides a record of which activities were scheduled, their current status, and their results. The workflow execution uses this information to determine next steps.
History provides a detailed audit trail that can be used to monitor running workflow executions and verify completed workflow executions.
Operations that do not change the state of the workflow for e.g. polling execution do not typically appear in the workflow history
Markers can be used to record information in the workflow history of a workflow execution that is specific to the use case
Domain
Each workflow runs in an AWS resource called a Domain, which controls the workflow’s scope
An AWS account can have multiple domains, with each containing multiple workflows
Workflows in different domains cannot interact with each other
Activities
Designing an SWF workflow, Activities need to be precisely defined and then registered with SWF as an activity type with information such as name, version and timeout
Activity Task & Activity Worker
An Activity Worker is a program that receives activity tasks, performs them, and provides results back. An activity worker can be a program or even a person who performs the task using an activity worker software
Activity tasks—and the activity workers that perform them can
run synchronously or asynchronously, can be distributed across multiple computers, potentially in different geographic regions, or run on the same computer,
be written in different programming languages and run on different operating systems
be created that are long-running, or that may fail, time out require restarts or that may complete with varying throughput & latency
Decider
A Decider implements a Workflow’s coordination logic.
Decider schedules activity tasks, provides input data to the activity workers, processes events that arrive while the workflow is in progress, and ends (or closes) the workflow when the objective has been completed.
Decider directs the workflow by receiving decision tasks from SWF and responding back to SWF with decisions. A decision represents an action or set of actions which are the next steps in the workflow which can either be to schedule an activity task, set timers to delay the execution of an activity task, to request cancellation of activity tasks already in progress, and to complete or close the workflow.
Workers and Deciders are both stateless, and can respond to increased traffic by simply adding additional Workers and Deciders as needed
Role of SWF service is to function as a reliable central hub through which data is exchanged between the decider, the activity workers, and other relevant entities such as the person administering the workflow.
Mechanism by which both the activity workers and the decider receive their tasks (activity tasks and decision tasks resp.) is by polling the SWF
SWF allows “long polling”, requests will be held open for up to 60 seconds if necessary, to reduce network traffic and unnecessary processing
SWF informs the decider of the state of the workflow by including with each decision task, a copy of the current workflow execution history. The workflow execution history is composed of events, where an event represents a significant change in the state of the workflow execution for e.g events would be the completion of a task, notification that a task has timed out, or the expiration of a timer that was set earlier in the workflow execution. The history is a complete, consistent, and authoritative record of the workflow’s progress
Workflow Implementation & Execution
Implement Activity workers with the processing steps in the Workflow.
Implement Decider with the coordination logic of the Workflow.
Register the Activities and workflow with SWF.
Start the Activity workers and Decider. Once started, the decider and activity workers should start polling Amazon SWF for tasks.
Start one or more executions of the Workflow. Each execution runs independently and can be provided with its own set of input data.
When an execution is started, SWF schedules the initial decision task. In response, the decider begins generating decisions which initiate activity tasks. Execution continues until your decider makes a decision to close the execution.
View and Track workflow executions
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
What does Amazon SWF stand for?
Simple Web Flow
Simple Work Flow
Simple Wireless Forms
Simple Web Form
Regarding Amazon SWF, the coordination logic in a workflow is contained in a software program called a ____.
Handler
Decider
Coordinator
Worker
For which of the following use cases are Simple Workflow Service (SWF) and Amazon EC2 an appropriate solution? Choose 2 answers
Using as an endpoint to collect thousands of data points per hour from a distributed fleet of sensors
Managing a multi-step and multi-decision checkout process of an e-commerce website
Orchestrating the execution of distributed and auditable business processes
Using as an SNS (Simple Notification Service) endpoint to trigger execution of video transcoding jobs
Using as a distributed session store for your web application
Amazon SWF is designed to help users…
… Design graphical user interface interactions
… Manage user identification and authorization
… Store Web content
… Coordinate synchronous and asynchronous tasks which are distributed and fault tolerant.
What does a “Domain” refer to in Amazon SWF?
A security group in which only tasks inside can communicate with each other
A special type of worker
A collection of related Workflows
The DNS record for the Amazon SWF service
Your company produces customer commissioned one-of-a-kind skiing helmets combining nigh fashion with custom technical enhancements Customers can show oft their Individuality on the ski slopes and have access to head-up-displays. GPS rear-view cams and any other technical innovation they wish to embed in the helmet. The current manufacturing process is data rich and complex including assessments to ensure that the custom electronics and materials used to assemble the helmets are to the highest standards Assessments are a mixture of human and automated assessments you need to add a new set of assessment to model the failure modes of the custom electronics using GPUs with CUD across a cluster of servers with low latency networking. What architecture would allow you to automate the existing process using a hybrid approach and ensure that the architecture can support the evolution of processes over time? [PROFESSIONAL]
Use AWS Data Pipeline to manage movement of data & meta-data and assessments. Use an auto-scaling group of G2 instances in a placement group. (Involves mixture of human assessments)
Use Amazon Simple Workflow (SWF) to manage assessments, movement of data & meta-data. Use an autoscaling group of G2 instances in a placement group. (Human and automated assessments with GPU and low latency networking)
Use Amazon Simple Workflow (SWF) to manage assessments movement of data & meta-data. Use an autoscaling group of C3 instances with SR-IOV (Single Root I/O Virtualization). (C3 and SR-IOV won’t provide GPU as well as Enhanced networking needs to be enabled)
Use AWS data Pipeline to manage movement of data & meta-data and assessments use auto-scaling group of C3 with SR-IOV (Single Root I/O virtualization). (Involves mixture of human assessments)
Your startup wants to implement an order fulfillment process for selling a personalized gadget that needs an average of 3-4 days to produce with some orders taking up to 6 months you expect 10 orders per day on your first day. 1000 orders per day after 6 months and 10,000 orders after 12 months. Orders coming in are checked for consistency men dispatched to your manufacturing plant for production quality control packaging shipment and payment processing. If the product does not meet the quality standards at any stage of the process employees may force the process to repeat a step Customers are notified via email about order status and any critical issues with their orders such as payment failure. Your case architecture includes AWS Elastic Beanstalk for your website with an RDS MySQL instance for customer data and orders. How can you implement the order fulfillment process while making sure that the emails are delivered reliably? [PROFESSIONAL]
Add a business process management application to your Elastic Beanstalk app servers and re-use the ROS database for tracking order status use one of the Elastic Beanstalk instances to send emails to customers. (Would use a SWF instead of BPM)
Use SWF with an Auto Scaling group of activity workers and a decider instance in another Auto Scaling group with min/max=1. Use the decider instance to send emails to customers. (Decider sending emails might not be reliable)
Use SWF with an Auto Scaling group of activity workers and a decider instance in another Auto Scaling group with min/max=1. Use SES to send emails to customers.
Use an SQS queue to manage all process tasks. Use an Auto Scaling group of EC2 Instances that poll the tasks and execute them. Use SES to send emails to customers. (Does not provide an ability to repeat a step)
Select appropriate use cases for SWF with Amazon EC2? (Choose 2)
Video encoding using Amazon S3 and Amazon EC2. In this use case, large videos are uploaded to Amazon S3 in chunks. Application is built as a workflow where each video file is handled as one workflow execution.
Processing large product catalogs using Amazon Mechanical Turk. While validating data in large catalogs, the products in the catalog are processed in batches. Different batches can be processed concurrently.
Order processing system with Amazon EC2, SQS, and SimpleDB. Use SWF notifications to orchestrate an order processing system running on EC2, where notifications sent over HTTP can trigger real-time processing in related components such as an inventory system or a shipping service.
Using as an SQS (Simple Queue Service) endpoint to trigger execution of video transcoding jobs.
When you register an activity in Amazon SWF, you provide the following information, except:
a name
timeout values
a domain
version
Regarding Amazon SWF, at times you might want to record information in the workflow history of a workflow execution that is specific to your use case. ____ enable you to record information in the workflow execution history that you can use for any custom or scenario-specific purpose.
Markers
Tags
Hash keys
Events
Which of the following statements about SWF are true? Choose 3 answers.
makes it easy to route traffic across a dynamically changing fleet of EC2 instances
acts as a single point of contact for all incoming traffic to the instances in an Auto Scaling group.
Auto Scaling dynamically adds and removes EC2 instances, while Elastic Load Balancing manages incoming requests by optimally routing traffic so that no one instance is overwhelmed
Auto Scaling helps to automatically increase the number of EC2 instances when the user demand goes up, and decrease the number of EC2 instances when demand goes down
ELB service helps to distribute the incoming web traffic (called the load) automatically among all the running EC2 instances
ELB uses load balancers to monitor traffic and handle requests that come through the Internet.
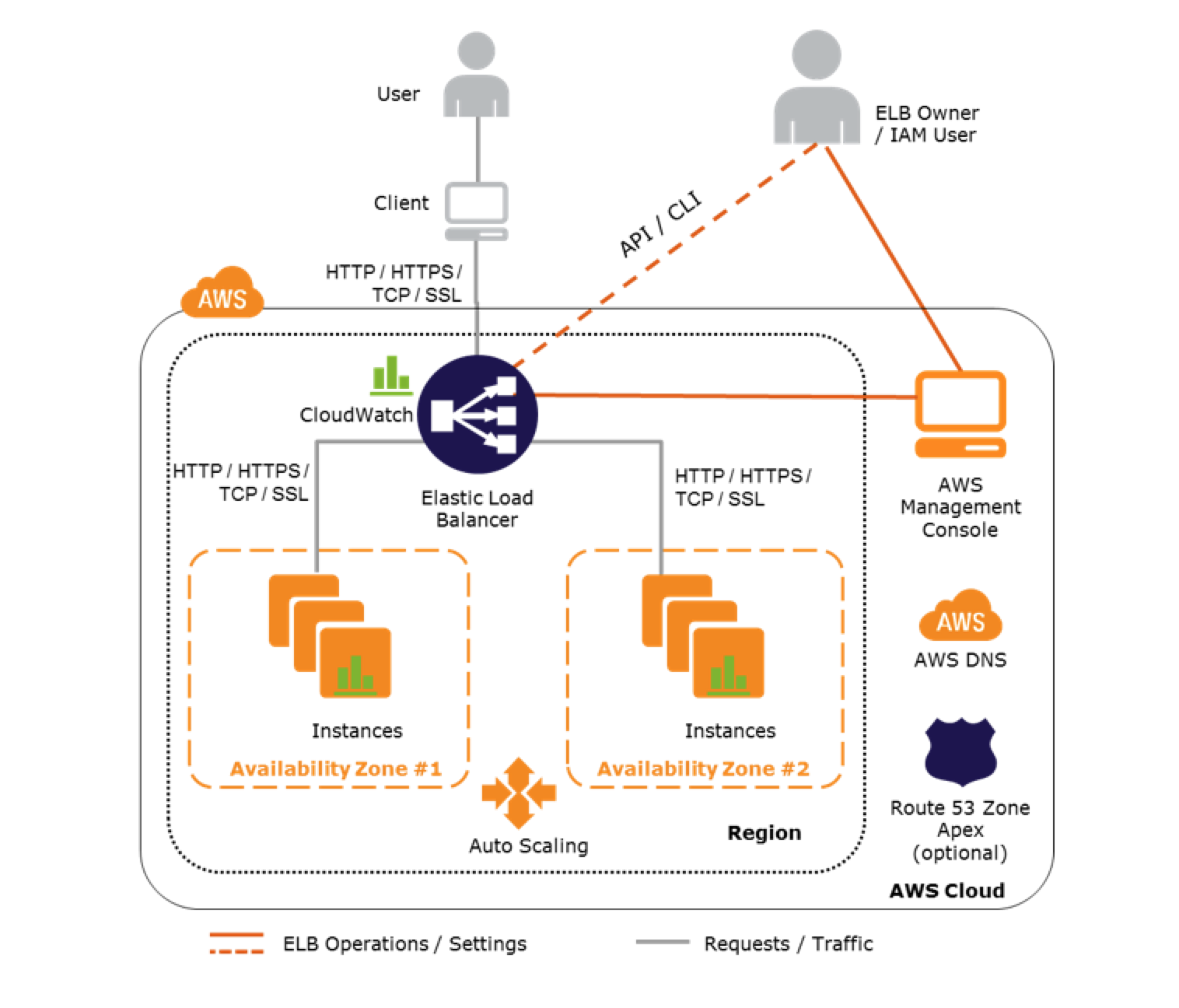
Using ELB & Auto Scaling
makes it easy to route traffic across a dynamically changing fleet of EC2 instances
load balancer acts as a single point of contact for all incoming traffic to the instances in an Auto Scaling group.
Attaching/Detaching ELB with Auto Scaling Group
Auto Scaling integrates with Elastic Load Balancing and enables attaching one or more load balancers to an existing Auto Scaling group.
ELB registers the EC2 instance using its IP address and routes requests to the primary IP address of the primary interface (eth0) of the instance.
After the ELB is attached, it automatically registers the instances in the group and distributes incoming traffic across the instances
When ELB is detached, it enters the Removing state while deregistering the instances in the group.
If connection draining is enabled, ELB waits for in-flight requests to complete before deregistering the instances.
Instances remain running after they are deregistered from the ELB
Auto Scaling adds instances to the ELB as they are launched, but this can be suspended. Instances launched during the suspension period are not added to the load balancer, after the resumption, and must be registered manually.
High Availability & Redundancy
Auto Scaling can span across multiple AZs, within the same region.
When one AZ becomes unhealthy or unavailable, Auto Scaling launches new instances in an unaffected AZ.
When the unhealthy AZ recovers, Auto Scaling redistributes the traffic across all the healthy AZ.
Elastic Load balancer can be set up to distribute incoming requests across EC2 instances in a single AZ or multiple AZs within a region.
Using Auto Scaling & ELB by spanning Auto Scaling groups across multiple AZs within a region and then setting up ELB to distribute incoming traffic across those AZs helps take advantage of the safety and reliability of geographic redundancy.
Incoming traffic is load balanced equally across all the AZs enabled for ELB.
Health Checks
Auto Scaling group determines the health state of each instance by periodically checking the results of EC2 instance status checks.
Auto Scaling marks the instance as unhealthy and replaces the instance if the instance fails the EC2 instance status check.
ELB also performs health checks on the EC2 instances that are registered with it for e.g. the application is available by pinging a health check page
ELB health check with the instances should be used to ensure that traffic is routed only to the healthy instances.
Auto Scaling, by default, does not replace the instance, if the ELB health check fails.
After a load balancer is registered with an Auto Scaling group, it can be configured to use the results of the ELB health check in addition to the EC2 instance status checks to determine the health of the EC2 instances in the Auto Scaling group.
Monitoring
Elastic Load Balancing sends data about the load balancers and EC2 instances to CloudWatch. CloudWatch collects data about the performance of your resources and presents it as metrics.
After registering one or more load balancers with the Auto Scaling group, the Auto Scaling group can be configured to use ELB metrics (such as request latency or request count) to scale the application automatically.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company is building a two-tier web application to serve dynamic transaction-based content. The data tier is leveraging an Online Transactional Processing (OLTP) database. What services should you leverage to enable an elastic and scalable web tier?
Elastic Load Balancing, Amazon EC2, and Auto Scaling
Elastic Load Balancing, Amazon RDS with Multi-AZ, and Amazon S3
Amazon RDS with Multi-AZ and Auto Scaling
Amazon EC2, Amazon DynamoDB, and Amazon S3
You have been given a scope to deploy some AWS infrastructure for a large organization. The requirements are that you will have a lot of EC2 instances but may need to add more when the average utilization of your Amazon EC2 fleet is high and conversely remove them when CPU utilization is low. Which AWS services would be best to use to accomplish this?
Amazon CloudFront, Amazon CloudWatch and Elastic Load Balancing
Auto Scaling, Amazon CloudWatch and AWS CloudTrail
Auto Scaling, Amazon CloudWatch and Elastic Load Balancing
Auto Scaling, Amazon CloudWatch and AWS Elastic Beanstalk
A user has configured ELB with Auto Scaling. The user suspended the Auto Scaling AddToLoadBalancer, which adds instances to the load balancer. process for a while. What will happen to the instances launched during the suspension period?
The instances will not be registered with ELB and the user has to manually register when the process is resumed
The instances will be registered with ELB only once the process has resumed
Auto Scaling will not launch the instance during this period due to process suspension
It is not possible to suspend only the AddToLoadBalancer process
You have an Auto Scaling group associated with an Elastic Load Balancer (ELB). You have noticed that instances launched via the Auto Scaling group are being marked unhealthy due to an ELB health check, but these unhealthy instances are not being terminated. What do you need to do to ensure trial instances marked unhealthy by the ELB will be terminated and replaced?
Change the thresholds set on the Auto Scaling group health check
Add an Elastic Load Balancing health check to your Auto Scaling group
Increase the value for the Health check interval set on the Elastic Load Balancer
Change the health check set on the Elastic Load Balancer to use TCP rather than HTTP checks
You are responsible for a web application that consists of an Elastic Load Balancing (ELB) load balancer in front of an Auto Scaling group of Amazon Elastic Compute Cloud (EC2) instances. For a recent deployment of a new version of the application, a new Amazon Machine Image (AMI) was created, and the Auto Scaling group was updated with a new launch configuration that refers to this new AMI. During the deployment, you received complaints from users that the website was responding with errors. All instances passed the ELB health checks. What should you do in order to avoid errors for future deployments? (Choose 2 answer) [PROFESSIONAL]
Add an Elastic Load Balancing health check to the Auto Scaling group. Set a short period for the health checks to operate as soon as possible in order to prevent premature registration of the instance to the load balancer.
Enable EC2 instance CloudWatch alerts to change the launch configuration’s AMI to the previous one. Gradually terminate instances that are using the new AMI.
Set the Elastic Load Balancing health check configuration to target a part of the application that fully tests application health and returns an error if the tests fail.
Create a new launch configuration that refers to the new AMI, and associate it with the group. Double the size of the group, wait for the new instances to become healthy, and reduce back to the original size. If new instances do not become healthy, associate the previous launch configuration.
Increase the Elastic Load Balancing Unhealthy Threshold to a higher value to prevent an unhealthy instance from going into service behind the load balancer.
What is the order of most-to-least rapidly-scaling (fastest to scale first)? A) EC2 + ELB + Auto Scaling B) Lambda C) RDS
B, A, C (Lambda is designed to scale instantly. EC2 + ELB + Auto Scaling require single-digit minutes to scale out. RDS will take at least 15 minutes, and will apply OS patches or any other updates when applied.)
C, B, A
C, A, B
A, C, B
A user has hosted an application on EC2 instances. The EC2 instances are configured with ELB and Auto Scaling. The application server session time out is 2 hours. The user wants to configure connection draining to ensure that all in-flight requests are supported by ELB even though the instance is being deregistered. What time out period should the user specify for connection draining?
5 minutes
1 hour (max allowed is 3600 secs that is close to 2 hours to keep the in flight requests alive)
CloudFront is a fully managed, fast content delivery network (CDN) service that speeds up the distribution of static, dynamic web, or streaming content to end-users.
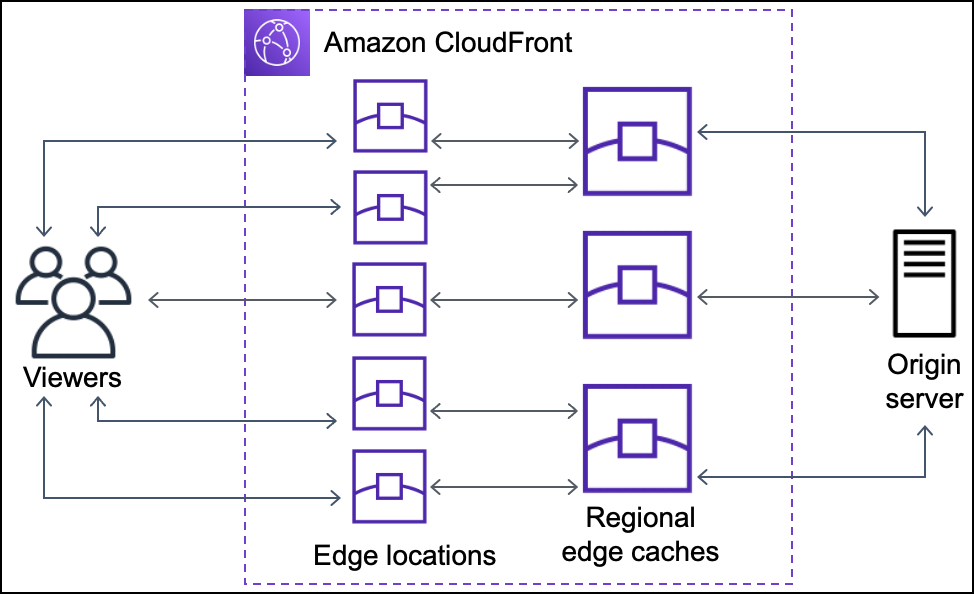
CloudFront delivers the content through a worldwide network of data centers called edge locations or Point of Presence (POP).
CloudFront securely delivers data, videos, applications, and APIs to customers globally with low latency, and high transfer speeds, all within a developer-friendly environment.
CloudFront gives businesses and web application developers an easy and cost-effective way to distribute content with low latency and high data transfer speeds.
CloudFront speeds up the distribution of the content by routing each user request to the edge location that can best serve the content thus providing the lowest latency (time delay).
CloudFront uses the AWS backbone network that dramatically reduces the number of network hops that users’ requests must pass through and helps improve performance, provide lower latency and higher data transfer rate
CloudFront is a good choice for the distribution of frequently accessed static content that benefits from edge delivery – like popular website images, videos, media files, or software downloads
CloudFront Benefits
CloudFront eliminates the expense and complexity of operating a network of cache servers in multiple sites across the internet and eliminates the need to over-provision capacity in order to serve potential spikes in traffic.
CloudFront also provides increased reliability and availability because copies of objects are held in multiple edge locations around the world.
CloudFront keeps persistent connections with the origin servers so that those files can be fetched from the origin servers as quickly as possible.
CloudFront also uses techniques such as collapsing simultaneous viewer requests at an edge location for the same file into a single request to the origin server reducing the load on the origin.
CloudFront offers the most advanced security capabilities, including field-level encryption and HTTPS support.
CloudFront Edge Locations or POPs make sure that popular content can be served quickly to the viewers.
CloudFront also has Regional Edge Caches that help bring more content closer to the viewers, even when the content is not popular enough to stay at a POP, to help improve performance for that content.
Regional Edge Caches are deployed globally, close to the viewers, and are located between the origin servers and the Edge Locations.
Regional edge caches support multiple Edge Locations and support a larger cache size so objects remain in the cache longer at the nearest regional edge cache location.
Regional edge caches help with all types of content, particularly content that tends to become less popular over time.
Configuration & Content Delivery
Configuration
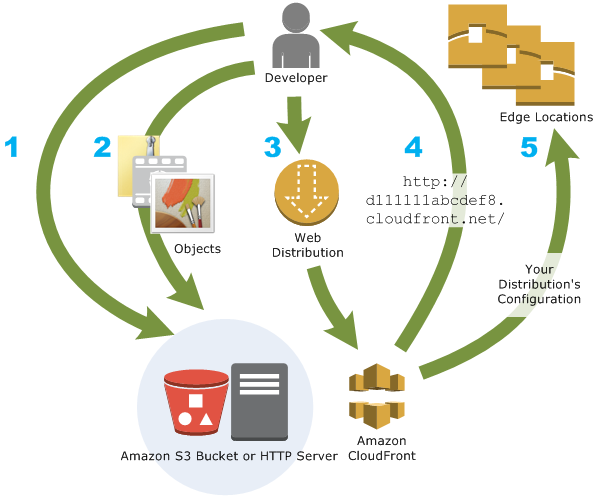
Origin servers need to be configured to get the files for distribution. An origin server stores the original, definitive version of the objects and can be an AWS hosted service for e.g. S3, EC2, or an on-premise server
Files or objects can be added/uploaded to the Origin servers with public read permissions or permissions restricted to Origin Access Identity (OAI).
Create a CloudFront distribution, which tells CloudFront which origin servers to get the files from when users request the files.
CloudFront sends the distribution configuration to all the edge locations.
The website can be used with the CloudFront provided domain name or a custom alternate domain name.
An origin server can be configured to limit access protocols, caching behaviour, add headers to the files to add TTL, or the expiration time.
Content delivery to Users
When a user accesses the website, file, or object – the DNS routes the request to the CloudFront edge location that can best serve the user’s request with the lowest latency.
CloudFront returns the object immediately if the requested object is present in the cache at the Edge location.
If the requested object does not exist in the cache at the edge location, the POP typically goes to the nearest regional edge cache to fetch it.
If the object is in the regional edge cache, CloudFront forwards it to the POP that requested it.
For objects not cached at either the POP or the regional edge cache location, the objects are requested from the origin server and returned it to the user via the regional edge cache and POP
CloudFront begins to forward the object to the user as soon as the first byte arrives from the regional edge cache location.
CloudFront also adds the object to the cache in the regional edge cache location in addition to the POP for the next time a viewer requests it.
When the object reaches its expiration time, for any new request CloudFront checks with the Origin server for any latest versions, if it has the latest it uses the same object. If the Origin server has the latest version the same is retrieved, served to the user, and cached as well
CloudFront Origins
Each origin is either an S3 bucket, a MediaStore container, a MediaPackage channel, or a custom origin like an EC2 instance or an HTTP server
For the S3 bucket, use the bucket URL or the static website endpoint URL, and the files either need to be publicly readable or secured using OAI.
Origin restrict access, for S3 only, can be configured using Origin Access Identity to prevent direct access to the S3 objects.
For the HTTP server as the origin, the domain name of the resource needs to be mapped and files must be publicly readable.
Distribution can have multiple origins for each bucket with one or more cache behaviors that route requests to each origin. Path pattern in a cache behavior determines which requests are routed to the origin (S3 bucket) that is associated with that cache behavior.
CloudFront Origin Groups
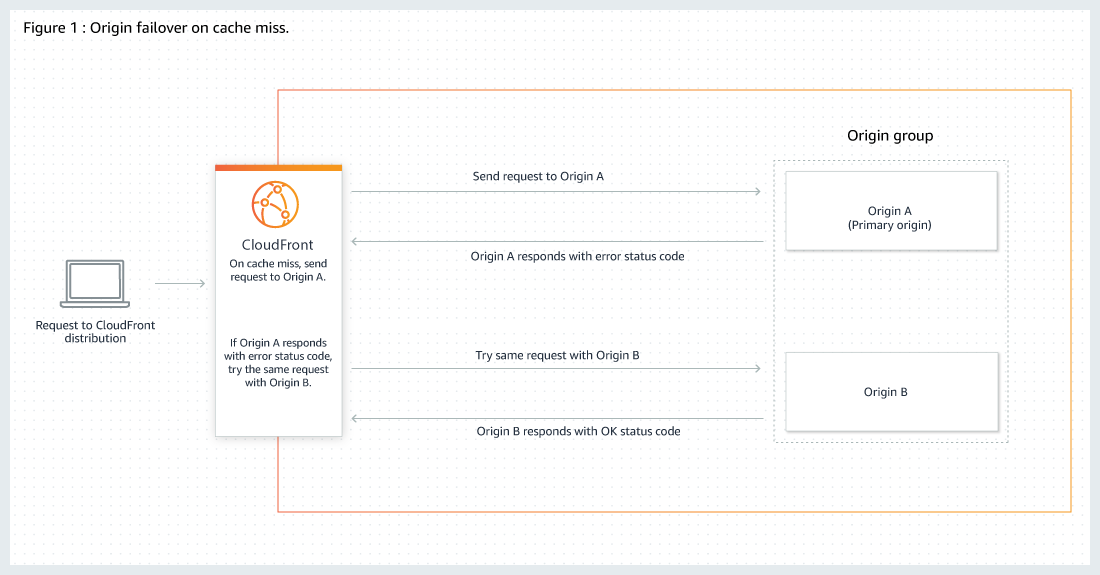
Origin Groups can be used to specify two origins to configure origin failover for high availability.
Origin failover can be used to designate a primary origin plus a second origin that CloudFront automatically switches to when the primary origin returns specific HTTP status code failure responses.
An origin group includes two origins (a primary origin and a second origin to failover to) and specified failover criteria.
CloudFront routes all incoming requests to the primary origin, even when a previous request has failed over to the secondary origin. CloudFront only sends requests to the secondary origin after a request fails to the primary origin.
CloudFront fails over to a secondary origin only when the HTTP method of the consumer request is GET, HEAD, or OPTIONS and does not fail over when the consumer sends a different HTTP method (for example POST, PUT, etc.).
CloudFront Delivery Methods
Web distributions
supports both static and dynamic content for e.g. HTML, CSS, js, images, etc using HTTP or HTTPS.
supports multimedia content on-demand using progressive download and Apple HTTP Live Streaming (HLS).
supports a live event, such as a meeting, conference, or concert, in real-time. For live streaming, distribution can be created automatically using an AWS CloudFormation stack.
origin servers can be either an S3 bucket or an HTTP server, for e.g., a web server or an AWS ELB, etc.
RMTP distributions (Support Discontinued)
supports streaming of media files using Adobe Media Server and the Adobe Real-Time Messaging Protocol (RTMP)
must use an S3 bucket as the origin.
To stream media files using CloudFront, two types of files are needed
Media files
Media player for e.g. JW Player, Flowplayer, or Adobe flash
End-users view media files using the media player that is provided; not the locally installed on the computer of the device
When an end-user streams the media file, the media player begins to play the file content while the file is still being downloaded from CloudFront.
The media file is not stored locally on the end user’s system.
Two CloudFront distributions are required, Web distribution for media Player and RMTP distribution for media files
Media player and Media files can be stored in a same-origin S3 bucket or different buckets
Cache Behavior Settings
Path Patterns
Path Patterns help define which path the Cache behaviour would apply to.
A default (*) pattern is created and multiple cache distributions can be added with patterns to take priority over the default path.
Viewer Protocol Policy (Viewer -> CloudFront)
Viewer Protocol policy can be configured to define the allowed access protocol.
Between CloudFront & Viewers, cache distribution can be configured to either allow
HTTPS only – supports HTTPS only
HTTP and HTTPS – supports both
HTTP redirected to HTTPS – HTTP is automatically redirected to HTTPS
Origin Protocol Policy (CloudFront -> Origin)
Between CloudFront & Origin, cache distribution can be configured with
HTTP only (for S3 static website).
HTTPS only – CloudFront fetches objects from the origin by using HTTPS.
Match Viewer – CloudFront uses the protocol that the viewer used to request the objects.
For S3 as origin,
For the website, the protocol has to be HTTP as HTTPS is not supported.
For the S3 bucket, the default Origin protocol policy is Match Viewer and cannot be changed. So When CloudFront is configured to require HTTPS between the viewer and CloudFront, it automatically uses HTTPS to communicate with S3.
HTTPS Connection
CloudFront can also be configured to work with HTTPS for alternate domain names by using:-
Serving HTTPS Requests Using Dedicated IP Addresses
CloudFront associates the alternate domain name with a dedicated IP address, and the certificate is associated with the IP address when a request is received from a DNS server for the IP address.
CloudFront uses the IP address to identify the distribution and the SSL/TLS certificate to return to the viewer.
This method works for every HTTPS request, regardless of the browser or other viewer that the user is using.
An additional monthly charge (of about $600/month) is incurred for using a dedicated IP address.
Serving HTTPS Requests Using Server Name Indication – SNI
SNI Custom SSL relies on the SNI extension of the TLS protocol, which allows multiple domains to be served over the same IP address by including the hostname, viewers are trying to connect to
With the SNI method, CloudFront associates an IP address with the alternate domain name, but the IP address is not dedicated.
CloudFront can’t determine, based on the IP address, which domain the request is for as the IP address is not dedicated.
Browsers that support SNI automatically get the domain name from the request URL & add it to a new field in the request header.
When CloudFront receives an HTTPS request from a browser that supports SNI, it finds the domain name in the request header and responds to the request with the applicable SSL/TLS certificate.
Viewer and CloudFront perform SSL negotiation, and CloudFront returns the requested content to the viewer.
Older browsers do not support SNI.
SNI Custom SSL is available at no additional cost beyond standard CloudFront data transfer and request fees
For End-to-End HTTPS connections certificate needs to be applied both between the Viewers and CloudFront & CloudFront and Origin, with the following requirements
HTTPS between viewers and CloudFront
A certificate that was issued by a trusted certificate authority (CA) such as Comodo, DigiCert, or Symantec;
If the origin is not an ELB load balancer, the certificate must be issued by a trusted CA such as Comodo, DigiCert, or Symantec.
For load balancer, a certificate provided by ACM can be used
Self-signed certificates CAN NOT be used.
ACM certificate for CloudFront must be requested or imported in the US East (N. Virginia) region. ACM certificates in this region that are associated with a CloudFront distribution are distributed to all the geographic locations configured for that distribution.
Allowed HTTP methods
CloudFront supports GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE to get, add, update, and delete objects, and to get object headers.
GET, HEAD methods to use to get objects, object headers
GET, HEAD, OPTIONS methods to use to get objects, object headers or retrieve a list of the options supported from the origin
GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE operations can also be performed for e.g. submitting data from a web form, which are directly proxied back to the Origin server
CloudFront only caches responses to GET and HEAD requests and, optionally, OPTIONS requests. CloudFront does not cache responses to PUT, POST, PATCH, DELETE request methods and these requests are directed to the origin.
PUT, POST HTTP methods also help for accelerated content uploads, as these operations will be sent to the origin e.g. S3 via the CloudFront edge location, improving efficiency, reducing latency, and allowing the application to benefit from the monitored, persistent connections that CloudFront maintains from the edge locations to the origin servers.
CloudFront Edge Caches
Control the cache max-age
To increase the cache hit ratio, the origin can be configured to add a Cache-Control: max-age directive to the objects.
Longer the interval less frequently it would be retrieved from the origin
Caching Based on Query String Parameters
CloudFront can be configured to cache based on the query parameters
None (Improves Caching) – if the origin returns the same version of an object regardless of the values of query string parameters.
Forward all, cache based on whitelist – if the origin server returns different versions of the objects based on one or more query string parameters. Then specify the parameters that you want CloudFront to use as a basis for caching in the Query String Whitelist field.
Forward all, cache based on all – if the origin server returns different versions of the objects for all query string parameters.
Caching performance can be improved by
Configure CloudFront to forward only the query strings for which the origin will return unique objects.
Using the same case for the parameters’ values for e.g. parameter value A or a, CloudFront would cache the same request twice even if the response or object returned is identical
Using the same parameter order for e.g. for request a=x&b=y and b=y&a=x, CloudFront would cache the same request twice even though the response or object returned is identical
For RTMP distributions, when CloudFront requests an object from the origin server, it removes any query string parameters.
Caching Based on Cookie Values
CloudFront can be configured to cache based on cookie values.
By default, it doesn’t consider cookies while caching on edge locations
Caching performance can be improved by
Configure CloudFront to forward only specified cookies instead of forwarding all cookies for e.g. if the request has 2 cookies with 3 possible values, CloudFront would cache all possible combinations even if the response takes into account a single cookie
Cookie names and values are both case sensitive so better to stick with the same case
Create separate cache behaviors for static and dynamic content, and configure CloudFront to forward cookies to the origin only for dynamic content for e.g. for CSS files, the cookies do not make sense as the object does not change with the cookie value
If possible, create separate cache behaviors for dynamic content for which cookie values are unique for each user (such as a user ID) and dynamic content that varies based on a smaller number of unique values reducing the number of combinations
For RTMP distributions, CloudFront cannot be configured to process cookies. When CloudFront requests an object from the origin server, it removes any cookies before forwarding the request to your origin. If your origin returns any cookies along with the object, CloudFront removes them before returning the object to the viewer.
Caching Based on Request Headers
CloudFront can be configured to cache based on request headers
By default, CloudFront doesn’t consider headers when caching the objects in edge locations.
CloudFront configured to cache based on request headers, does not change the headers that CloudFront forwards, only whether CloudFront caches objects based on the header values.
Caching performance can be improved by
Configure CloudFront to forward and cache based only on specified headers instead of forwarding and caching based on all headers.
Try to avoid caching based on request headers that have large numbers of unique values.
CloudFront is configured to forward all headers to the origin, CloudFront doesn’t cache the objects associated with this cache behaviour. Instead, it sends every request to the origin
CloudFront caches based on header values, it doesn’t consider the case of the header name but considers the case of the header value
For RTMP distributions, CloudFront cannot be configured to cache based on header values.
Object Caching & Expiration
Object expiration determines how long the objects stay in a CloudFront cache before it fetches it again from Origin.
Low expiration time helps serve content that changes frequently and high expiration time helps improve performance and reduce the origin load.
By default, each object automatically expires after 24 hours
After expiration time, CloudFront checks if it still has the latest version
If the cache already has the latest version, the origin returns a 304 status code (Not Modified).
If the CloudFront cache does not have the latest version, the origin returns a 200 status code (OK), and the latest version of the object
If an object in an edge location isn’t frequently requested, CloudFront might evict the object, and remove the object before its expiration date to make room for objects that have been requested more recently.
For Web distributions, the default behaviour can be changed by
for the entire path pattern, cache behaviour can be configured by the setting Minimum TTL, Maximum TTL, and Default TTL values
for individual objects, the origin can be configured to add a Cache-Control max-age or Cache-Control s-maxage directive, or an Expires header field to the object.
AWS recommends using Cache-Control max-age directive over Expires header to control object caching behaviour.
CloudFront uses only the value of Cache-Control max-age , if both the Cache-Control max-age directive and Expires header is specified
HTTP Cache-Control or Pragma header fields in a GET request from a viewer can’t be used to force CloudFront to go back to the origin server for the object
By default, when the origin returns an HTTP 4xx or 5xx status code, CloudFront caches these error responses for five minutes and then submit the next request for the object to the origin to see whether
the requested object is available and the problem has been resolved
For RTMP distributions
Cache-Control or Expires headers can be added to objects to change the amount of time that CloudFront keeps objects in edge caches before it forwards another request to the origin.
Minimum duration is 3600 seconds (one hour). If you specify a lower value, CloudFront uses 3600 seconds.
CloudFront Origin Shield
CloudFront Origin Shield provides an additional layer in the CloudFront caching infrastructure that helps to minimize the origin’s load, improve its availability, and reduce its operating costs.
Origin Shield provides a centralized caching layer that helps increase the cache hit ratio to reduce the load on your origin.
Origin Shield decreases the origin operating costs by collapsing requests across regions so as few as one request goes to the origin per object.
Origin Shield can be configured by choosing the Regional Edge Cache closest to the origin to become the Origin Shield Region
CloudFront Origin Shield is beneficial for many use cases like
Viewers that are spread across different geographical regions
Origins that provide just-in-time packaging for live streaming or on-the-fly image processing
On-premises origins with capacity or bandwidth constraints
Workloads that use multiple content delivery networks (CDNs)
Serving Compressed Files
CloudFront can be configured to automatically compress files of certain types and serve the compressed files when viewer requests include Accept-Encoding in the request header
Compressing content, downloads are faster because the files are smaller as well as less expensive as the cost of CloudFront data transfer is based on the total amount of data served.
CloudFront can compress objects using the Gzip and Brotli compression formats.
If serving from a custom origin, it can be used to
configure to compress files with or without CloudFront compression
compress file types that CloudFront doesn’t compress.
If the origin returns a compressed file, CloudFront detects compression by the Content-Encoding header value and doesn’t compress the file again.
CloudFront serves content using compression as below
CloudFront distribution is created and configured to compress content.
A viewer requests a compressed file by adding the Accept-Encoding header with includes gzip, br, or both to the request.
At the edge location, CloudFront checks the cache for a compressed version of the file that is referenced in the request.
If the compressed file is already in the cache, CloudFront returns the file to the viewer and skips the remaining steps.
If the compressed file is not in the cache, CloudFront forwards the request to the origin server (S3 bucket or a custom origin)
Even if CloudFront has an uncompressed version of the file in the cache, it still forwards a request to the origin.
Origin server returns an uncompressed version of the requested file
CloudFront determines whether the file is compressible:
file must be of a type that CloudFront compresses.
file size must be between 1,000 and 10,000,000 bytes.
response must include a Content-Length header to determine the size within valid compression limits. If the Content-Length header is missing, CloudFront won’t compress the file.
value of the Content-Encoding header on the file must not be gzip i.e. the origin has already compressed the file.
the response should have a body.
response HTTP status code should be 200, 403, or 404
If the file is compressible, CloudFront compresses it, returns the compressed file to the viewer, and adds it to the cache.
The viewer uncompresses the file.
Distribution Details
Price Class
CloudFront has edge locations all over the world and the cost for each edge location varies and the price charged for serving the requests also varies
CloudFront edge locations are grouped into geographic regions, and regions have been grouped into price classes
Price Class – includes all the regions
Another price class includes most regions (the United States; Europe; Hong Kong, Korea, and Singapore; Japan; and India regions) but excludes the most expensive regions
Price Class 200 – Includes All regions except South America and Australia and New Zealand.
Price Class 100 – A third price class includes only the least-expensive regions (North America and Europe regions)
Price class can be selected to lower the cost but this would come only at the expense of performance (higher latency), as CloudFront would serve requests only from the selected price class edge locations
CloudFront may, sometimes, service requests from a region not included within the price class, however, you would be charged the rate for the least-expensive region in your selected price class
WAF Web ACL
AWS WAF can be used to allow or block requests based on specified criteria, choose the web ACL to associate with this distribution.
Alternate Domain Names (CNAMEs)
CloudFront by default assigns a domain name for the distribution for e.g. d111111abcdef8.cloudfront.net
An alternate domain name, also known as a CNAME, can be used to use own custom domain name for links to objects
Both web and RTMP distributions support alternate domain names.
CloudFront supports * wildcard at the beginning of a domain name instead of specifying subdomains individually.
However, a wildcard cannot replace part of a subdomain name for e.g. *domain.example.com, or cannot replace a subdomain in the middle of a domain name for e.g. subdomain.*.example.com.
Distribution State
Distribution state indicates whether you want the distribution to be enabled or disabled once it’s deployed.
Geo-Restriction – Geoblocking
Geo restriction can help allow or prevent users in selected countries from accessing the content,
CloudFront distribution can be configured either to allow users in
whitelist of specified countries to access the content or to
deny users in a blacklist of specified countries to access the content
Geo restriction can be used to restrict access to all of the files that are
associated with distribution and to restrict access at the country level
CloudFront responds to a request from a viewer in a restricted country with an HTTP status code 403 (Forbidden)
Use a third-party geolocation service, if access is to be restricted to a subset of the files that are associated with a distribution or to restrict access at a finer granularity than the country level.
CloudFront provides Encryption in Transit and can be configured to require that viewers use HTTPS to request the files so that connections are encrypted when CloudFront communicates with viewers.
CloudFront provides Encryption at Rest
uses SSDs which are encrypted for edge location points of presence (POPs), and encrypted EBS volumes for Regional Edge Caches (RECs).
Function code and configuration are always stored in an encrypted format on the encrypted SSDs on the edge location POPs, and in other storage locations used by CloudFront.
Restricting access to content
Configure HTTPS connections
Use signed URLs or cookies to restrict access for selected users
Restrict access to content in S3 buckets using origin access identity – OAI, to prevent users from using the direct URL of the file.
Restrict direct to load balancer using custom headers, to prevent users from using the direct load balancer URLs.
Set up field-level encryption for specific content fields
Use AWS WAF web ACLs to create a web access control list (web ACL) to restrict access to your content.
Use geo-restriction, also known as geoblocking, to prevent users in specific geographic locations from accessing content served through a CloudFront distribution.
CloudFront can be configured to create log files that contain detailed information about every user request that CloudFront receives.
Access logs are available for both web and RTMP distributions.
With logging enabled, an S3 bucket can be specified where CloudFront would save the files
CloudFront delivers access logs for a distribution periodically, up to several times an hour
CloudFront usually delivers the log file for that time period to the S3 bucket within an hour of the events that appear in the log. Note, however, that some or all log file entries for a time period can sometimes be delayed by up to 24 hours
CloudFront Cost
CloudFront charges are based on actual usage of the service in four areas:
Data Transfer Out to Internet
charges are applied for the volume of data transferred out of the CloudFront edge locations, measured in GB
Data transfer out from AWS origin (e.g., S3, EC2, etc.) to CloudFront are no longer charged. This applies to data transfer from all AWS regions to all global CloudFront edge locations
HTTP/HTTPS Requests
number of HTTP/HTTPS requests made for the content
Invalidation Requests
per path in the invalidation request
A path listed in the invalidation request represents the URL (or multiple URLs if the path contains a wildcard character) of the object you want to invalidate from the CloudFront cache
Dedicated IP Custom SSL certificates associated with a CloudFront distribution
$600 per month for each custom SSL certificate associated with one or more CloudFront distributions using the Dedicated IP version of custom SSL certificate support, pro-rated by the hour
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Your company Is moving towards tracking web page users with a small tracking Image loaded on each page Currently you are serving this image out of US-East, but are starting to get concerned about the time It takes to load the image for users on the west coast. What are the two best ways to speed up serving this image? Choose 2 answers
Use Route 53’s Latency Based Routing and serve the image out of US-West-2 as well as US-East-1
Serve the image out through CloudFront
Serve the image out of S3 so that it isn’t being served oft of your web application tier
Use EBS PIOPs to serve the image faster out of your EC2 instances
You deployed your company website using Elastic Beanstalk and you enabled log file rotation to S3. An Elastic Map Reduce job is periodically analyzing the logs on S3 to build a usage dashboard that you share with your CIO. You recently improved overall performance of the website using Cloud Front for dynamic content delivery and your website as the origin. After this architectural change, the usage dashboard shows that the traffic on your website dropped by an order of magnitude. How do you fix your usage dashboard’? [PROFESSIONAL]
Enable CloudFront to deliver access logs to S3 and use them as input of the Elastic Map Reduce job
Turn on Cloud Trail and use trail log tiles on S3 as input of the Elastic Map Reduce job
Change your log collection process to use Cloud Watch ELB metrics as input of the Elastic Map Reduce job
Use Elastic Beanstalk “Rebuild Environment” option to update log delivery to the Elastic Map Reduce job.
Use Elastic Beanstalk ‘Restart App server(s)” option to update log delivery to the Elastic Map Reduce job.
An AWS customer runs a public blogging website. The site users upload two million blog entries a month. The average blog entry size is 200 KB. The access rate to blog entries drops to negligible 6 months after publication and users rarely access a blog entry 1 year after publication. Additionally, blog entries have a high update rate during the first 3 months following publication; this drops to no updates after 6 months. The customer wants to use CloudFront to improve his user’s load times. Which of the following recommendations would you make to the customer? [PROFESSIONAL]
Duplicate entries into two different buckets and create two separate CloudFront distributions where S3 access is restricted only to Cloud Front identity
Create a CloudFront distribution with “US & Europe” price class for US/Europe users and a different CloudFront distribution with All Edge Locations for the remaining users.
Create a CloudFront distribution with S3 access restricted only to the CloudFront identity and partition the blog entry’s location in S3 according to the month it was uploaded to be used with CloudFront behaviors
Create a CloudFront distribution with Restrict Viewer Access Forward Query string set to true and minimum TTL of 0.
Your company has on-premises multi-tier PHP web application, which recently experienced downtime due to a large burst in web traffic due to a company announcement. Over the coming days, you are expecting similar announcements to drive similar unpredictable bursts, and are looking to find ways to quickly improve your infrastructures ability to handle unexpected increases in traffic. The application currently consists of 2 tiers a web tier, which consists of a load balancer, and several Linux Apache web servers as well as a database tier which hosts a Linux server hosting a MySQL database. Which scenario below will provide full site functionality, while helping to improve the ability of your application in the short timeframe required? [PROFESSIONAL]
Offload traffic from on-premises environment Setup a CloudFront distribution and configure CloudFront to cache objects from a custom origin Choose to customize your object cache behavior, and select a TTL that objects should exist in cache.
Migrate to AWS Use VM Import/Export to quickly convert an on-premises web server to an AMI create an Auto Scaling group, which uses the imported AMI to scale the web tier based on incoming traffic Create an RDS read replica and setup replication between the RDS instance and on-premises MySQL server to migrate the database.
Failover environment: Create an S3 bucket and configure it tor website hosting Migrate your DNS to Route53 using zone (lie import and leverage Route53 DNS failover to failover to the S3 hosted website.
Hybrid environment Create an AMI which can be used of launch web serfers in EC2 Create an Auto Scaling group which uses the * AMI to scale the web tier based on incoming traffic Leverage Elastic Load Balancing to balance traffic between on-premises web servers and those hosted in AWS.
You are building a system to distribute confidential training videos to employees. Using CloudFront, what method could be used to serve content that is stored in S3, but not publically accessible from S3 directly?
Create an Origin Access Identity (OAI) for CloudFront and grant access to the objects in your S3 bucket to that OAI.
Add the CloudFront account security group “amazon-cf/amazon-cf-sg” to the appropriate S3 bucket policy.
Create an Identity and Access Management (IAM) User for CloudFront and grant access to the objects in your S3 bucket to that IAM User.
Create a S3 bucket policy that lists the CloudFront distribution ID as the Principal and the target bucket as the Amazon Resource Name (ARN).
A media production company wants to deliver high-definition raw video for preproduction and dubbing to customer all around the world. They would like to use Amazon CloudFront for their scenario, and they require the ability to limit downloads per customer and video file to a configurable number. A CloudFront download distribution with TTL=0 was already setup to make sure all client HTTP requests hit an authentication backend on Amazon Elastic Compute Cloud (EC2)/Amazon RDS first, which is responsible for restricting the number of downloads. Content is stored in S3 and configured to be accessible only via CloudFront. What else needs to be done to achieve an architecture that meets the requirements? Choose 2 answers [PROFESSIONAL]
Enable URL parameter forwarding, let the authentication backend count the number of downloads per customer in RDS, and return the content S3 URL unless the download limit is reached.
Enable CloudFront logging into an S3 bucket, leverage EMR to analyze CloudFront logs to determine the number of downloads per customer, and return the content S3 URL unless the download limit is reached. (CloudFront logs are logged periodically and EMR not being real time, hence not suitable)
Enable URL parameter forwarding, let the authentication backend count the number of downloads per customer in RDS, and invalidate the CloudFront distribution as soon as the download limit is reached. (Distribution are not invalidated but Objects)
Enable CloudFront logging into the S3 bucket, let the authentication backend determine the number of downloads per customer by parsing those logs, and return the content S3 URL unless the download limit is reached. (CloudFront logs are logged periodically and EMR not being real time, hence not suitable)
Configure a list of trusted signers, let the authentication backend count the number of download requests per customer in RDS, and return a dynamically signed URL unless the download limit is reached.
Your customer is implementing a video on-demand streaming platform on AWS. The requirements are to support for multiple devices such as iOS, Android, and PC as client devices, using a standard client player, using streaming technology (not download) and scalable architecture with cost effectiveness [PROFESSIONAL]
Store the video contents to Amazon Simple Storage Service (S3) as an origin server. Configure the Amazon CloudFront distribution with a streaming option to stream the video contents
Store the video contents to Amazon S3 as an origin server. Configure the Amazon CloudFront distribution with a download option to stream the video contents (Refer link)
Launch a streaming server on Amazon Elastic Compute Cloud (EC2) (for example, Adobe Media Server), and store the video contents as an origin server. Configure the Amazon CloudFront distribution with a download option to stream the video contents
Launch a streaming server on Amazon Elastic Compute Cloud (EC2) (for example, Adobe Media Server), and store the video contents as an origin server. Launch and configure the required amount of streaming servers on Amazon EC2 as an edge server to stream the video contents
You are an architect for a news -sharing mobile application. Anywhere in the world, your users can see local news on of topics they choose. They can post pictures and videos from inside the application. Since the application is being used on a mobile phone, connection stability is required for uploading content, and delivery should be quick. Content is accessed a lot in the first minutes after it has been posted, but is quickly replaced by new content before disappearing. The local nature of the news means that 90 percent of the uploaded content is then read locally (less than a hundred kilometers from where it was posted). What solution will optimize the user experience when users upload and view content (by minimizing page load times and minimizing upload times)? [PROFESSIONAL]
Upload and store the content in a central Amazon Simple Storage Service (S3) bucket, and use an Amazon Cloud Front Distribution for content delivery.
Upload and store the content in an Amazon Simple Storage Service (S3) bucket in the region closest to the user, and use multiple Amazon Cloud Front distributions for content delivery.
Upload the content to an Amazon Elastic Compute Cloud (EC2) instance in the region closest to the user, send the content to a central Amazon Simple Storage Service (S3) bucket, and use an Amazon Cloud Front distribution for content delivery.
Use an Amazon Cloud Front distribution for uploading the content to a central Amazon Simple Storage Service (S3) bucket and for content delivery.
To enable end-to-end HTTPS connections from the user‘s browser to the origin via CloudFront, which of the following options are valid? Choose 2 answers [PROFESSIONAL]
Use self signed certificate in the origin and CloudFront default certificate in CloudFront. (Origin cannot be self signed)
Use the CloudFront default certificate in both origin and CloudFront (CloudFront cert cannot be applied to origin)
Use 3rd-party CA certificate in the origin and CloudFront default certificate in CloudFront
Use 3rd-party CA certificate in both origin and CloudFront
Use a self signed certificate in both the origin and CloudFront (Origin cannot be self signed)
Your application consists of 10% writes and 90% reads. You currently service all requests through a Route53 Alias Record directed towards an AWS ELB, which sits in front of an EC2 Auto Scaling Group. Your system is getting very expensive when there are large traffic spikes during certain news events, during which many more people request to read similar data all at the same time. What is the simplest and cheapest way to reduce costs and scale with spikes like this? [PROFESSIONAL]
Create an S3 bucket and asynchronously replicate common requests responses into S3 objects. When a request comes in for a precomputed response, redirect to AWS S3
Create another ELB and Auto Scaling Group layer mounted on top of the other system, adding a tier to the system. Serve most read requests out of the top layer
Create a CloudFront Distribution and direct Route53 to the Distribution. Use the ELB as an Origin and specify Cache Behaviors to proxy cache requests, which can be served late. (CloudFront can server request from cache and multiple cache behavior can be defined based on rules for a given URL pattern based on file extensions, file names, or any portion of a URL. Each cache behavior can include the CloudFront configuration values: origin server name, viewer connection protocol, minimum expiration period, query string parameters, cookies, and trusted signers for private content.)
Create a Memcached cluster in AWS ElastiCache. Create cache logic to serve requests, which can be served late from the in-memory cache for increased performance.
You are designing a service that aggregates clickstream data in batch and delivers reports to subscribers via email only once per week. Data is extremely spikey, geographically distributed, high-scale, and unpredictable. How should you design this system?
Use a large RedShift cluster to perform the analysis, and a fleet of Lambdas to perform record inserts into the RedShift tables. Lambda will scale rapidly enough for the traffic spikes.
Use a CloudFront distribution with access log delivery to S3. Clicks should be recorded as query string GETs to the distribution. Reports are built and sent by periodically running EMR jobs over the access logs in S3. (CloudFront is a Gigabit-Scale HTTP(S) global request distribution service and works fine with peaks higher than 10 Gbps or 15,000 RPS. It can handle scale, geo-spread, spikes, and unpredictability. Access Logs will contain the GET data and work just fine for batch analysis and email using EMR. Other streaming options are expensive as not required as the need is to batch analyze)
Use API Gateway invoking Lambdas which PutRecords into Kinesis, and EMR running Spark performing GetRecords on Kinesis to scale with spikes. Spark on EMR outputs the analysis to S3, which are sent out via email.
Use AWS Elasticsearch service and EC2 Auto Scaling groups. The Autoscaling groups scale based on click throughput and stream into the Elasticsearch domain, which is also scalable. Use Kibana to generate reports periodically.
Your website is serving on-demand training videos to your workforce. Videos are uploaded monthly in high resolution MP4 format. Your workforce is distributed globally often on the move and using company-provided tablets that require the HTTP Live Streaming (HLS) protocol to watch a video. Your company has no video transcoding expertise and it required you might need to pay for a consultant. How do you implement the most cost-efficient architecture without compromising high availability and quality of video delivery? [PROFESSIONAL]
Elastic Transcoder to transcode original high-resolution MP4 videos to HLS. S3 to host videos with lifecycle Management to archive original flies to Glacier after a few days. CloudFront to serve HLS transcoded videos from S3
A video transcoding pipeline running on EC2 using SQS to distribute tasks and Auto Scaling to adjust the number or nodes depending on the length of the queue S3 to host videos with Lifecycle Management to archive all files to Glacier after a few days CloudFront to serve HLS transcoding videos from Glacier
Elastic Transcoder to transcode original high-resolution MP4 videos to HLS EBS volumes to host videos and EBS snapshots to incrementally backup original rues after a few days. CloudFront to serve HLS transcoded videos from EC2.
A video transcoding pipeline running on EC2 using SQS to distribute tasks and Auto Scaling to adjust the number of nodes depending on the length of the queue. EBS volumes to host videos and EBS snapshots to incrementally backup original files after a few days. CloudFront to serve HLS transcoded videos from EC2
Tags are key/value pairs that can be attached to AWS resources
Tags are metadata: that means that they don’t actually do anything, they’re purely for labeling purposes and helps to organize AWS resources
Tagging allows the user to assign her own (words/phrases/labels) metadata to each resource in the form of tags.
Tags don’t have any semantic meaning to the resources it is assigned and are interpreted strictly as a string of characters
Tags can
help to manage AWS resources & services for e.g. instances, images, security groups, etc.
help categorize AWS resources in different ways, for e.g., by purpose, owner (Developer, Finance, etc), or environment (DEV, TEST, PROD, etc).
help search and filter the resources
be used as a mechanism to organize resource costs on the cost allocation report.
Tags are not automatically assigned to the resources, however, are (sometimes) inherited for e.g. services such as Auto Scaling, Elastic Beanstalk, and CloudFormation can create other resources, such as RDS or EC2 instances, and usually tag that resource with a reference to itself. These tags do count toward the total tag limit for a resource
Tags can be defined using the
AWS Management Console,
AWS CLI
Amazon API.
Tags can be assigned only to resources that already exist and cannot be assigned when you create a resource; for e.g., when you use the run-instances AWS CLI command.
However, when using the AWS Management console, some resource creation screens enable you to specify tags that are applied immediately after the resource is created.
Each tag consists of a key and value
key and an optional value, both of which are user-controlled
defining a new tag that has the same key as an existing tag on that resource, the new value overwrites the old value.
keys and values can be edited, removed from a resource at any time.
value can be defined as an empty string, but can’t be set to null.
IAM allows you the ability to control which users in the AWS account have permission to create, edit, or delete tags.
Common examples of tags are Environment, Application, Owner, Cost Center, Purpose, Stack, etc.
Tags Restriction
Maximum number of tags per resource – 50
Maximum key length – 128 Unicode characters in UTF-8
Maximum value length – 256 Unicode characters in UTF-8
Tag keys and values are case-sensitive.
Do not use the aws: prefix in the tag names or values because it is reserved for AWS use. Tags with this prefix can’t be edited or deleted and they do not count against the tags per resource limit.
Tags allowed characters are: letters, spaces, and numbers representable in UTF-8, plus the following special characters: + – = . _ : / @.
Tagging Strategy
AWS does not enforce any tagging naming conventions and can be used as per the user convenience
As the number of tags allows per resource are limited, Complex Tagging can be used for e.g. keyName = value1|value2|value3 or keyName = key1|value1;key2|value2
EC2 Resources Tags
For tags on EC2 instances, instances can’t terminate, stop, or delete a resource based solely on its tags; the resource identifier must be specified
Public or shared resources can be tagged, but the tags assigned are available only to the AWS account and not to the other accounts sharing the resource.
Almost all resources can be tagged, with some can only be tagged using API actions or the command line or during creation.
Cost Allocation Tags
Tags can be used as a mechanism to organize the resource costs on the cost allocation report.
Cost allocation tags can be used to categorize and track AWS costs.
When tags are applied to AWS resources such as EC2 instances or S3 buckets and activated in the billing console, AWS generates a cost allocation report as a (CSV file) with the usage and costs aggregated by active tags.
Tags can be applied so that they represent business categories (such as cost centers, application names, or owners) to organize costs across multiple services.
Cost allocation report includes all of the AWS costs for each billing period and includes both tagged and untagged resources
Tags can also be used to filter views in Cost Explorer
A Resource Group is a collection of resources that share one or more tags
Resource groups help combine information for multiple resources and services on a single screen for e.g. for a Dev tag there might be multiple resources for ELB, EC2, and RDS. Using Resource Groups all the resources and their status can be views on a single page
Tag Editor
Tag Editor allows the addition of tags to multiple resources at once
Tag Editor allows searching of resources using tags and then add, edit, remove tags for these resources
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Fill in the blanks: _________ let you categorize your EC2 resources in different ways, for example, by purpose, owner, or environment.
Wildcards
Pointers
Tags
Special filters
Please select the Amazon EC2 resource, which can be tagged.
Key pairs
Elastic IP addresses
Placement groups
Amazon EBS snapshots
Can the string value of ‘Key’ be prefixed with aws:?
No
Only for EC2 not S3
Yes
Only for S3 not EC
What is the maximum key length of a tag?
512 Unicode characters
64 Unicode characters
256 Unicode characters
128 Unicode characters
An organization has launched 5 instances: 2 for production and 3 for testing. The organization wants that one particular group of IAM users should only access the test instances and not the production ones. How can the organization set that as a part of the policy?
Launch the test and production instances in separate regions and allow region wise access to the group (possible using location constraint condition but not flexible)
Define the IAM policy which allows access based on the instance ID (not flexible as it would change)
Create an IAM policy with a condition which allows access to only small instances (not flexible as it would change)
Define the tags on the test and production servers and add a condition to the IAM policy which allows access to specific tags (possible using ResourceTag condition)
A user has launched multiple EC2 instances for the purpose of development and testing in the same region. The user wants to find the separate cost for the production and development instances. How can the user find the cost distribution?
The user should download the activity report of the EC2 services as it has the instance ID wise data
It is not possible to get the AWS cost usage data of single region instances separately
User should use Cost Distribution Metadata and AWS detailed billing
User should use Cost Allocation Tags and AWS billing reports
An organization is using cost allocation tags to find the cost distribution of different departments and projects. One of the instances has two separate tags with the key/value as “InstanceName/HR”, “CostCenter/HR”. What will AWS do in this case?
InstanceName is a reserved tag for AWS. Thus, AWS will not allow this tag
AWS will not allow the tags as the value is the same for different keys
AWS will allow tags but will not show correctly in the cost allocation report due to the same value of the two separate keys
AWS will allow both the tags and show properly in the cost distribution report
A user is launching an instance. He is on the “Tag the instance” screen. Which of the below mentioned information will not help the user understand the functionality of an AWS tag?
Each tag will have a key and value
The user can apply tags to the S3 bucket
The maximum value of the tag key length is 64 unicode characters
AWS tags are used to find the cost distribution of various resources
Your system recently experienced down time during the troubleshooting process. You found that a new administrator mistakenly terminated several production EC2 instances. Which of the following strategies will help prevent a similar situation in the future? The administrator still must be able to:- launch, start stop, and terminate development resources. – launch and start production instances.
Create an IAM user, which is not allowed to terminate instances by leveraging production EC2 termination protection. (EC2 termination protection is enabled on EC2 instance)
Leverage resource based tagging along with an IAM user, which can prevent specific users from terminating production EC2 resources. (Identify production resources using tags and add explicit deny)
Leverage EC2 termination protection and multi-factor authentication, which together require users to authenticate before terminating EC2 instances. (Does not still prevent user from terminating instance)
Create an IAM user and apply an IAM role, which prevents users from terminating production EC2 instances. (Role is not applied to User but assumed by the User also need a way to identify production EC2 instances)
Your manager has requested you to tag EC2 instances to organize and manage a load balancer. Which of the following statements about tag restrictions is incorrect?
The maximum key length is 127 Unicode characters.
The maximum value length is 255 Unicode characters.
Tag keys and values are case sensitive.
The maximum number of tags per load balancer is 20. (50 is the limit)
What is the maximum number of tags that a user can assign to an EC2 instance?
CloudWatch offers either basic or detailed monitoring for supported AWS services.
Basic monitoring means that a service sends data points to CloudWatch every five minutes.
Detailed monitoring means that a service sends data points to CloudWatch every minute.
If the AWS service supports both basic and detailed monitoring, the basic would be enabled by default and the detailed monitoring needs to be enabled for details metrics
AWS Services with Monitoring support
Auto Scaling
By default, basic monitoring is enabled when the launch configuration is created using the AWS Management Console, and detailed monitoring is enabled when the launch configuration is created using the AWS CLI or an API
Auto Scaling sends data to CloudWatch every 5 minutes by default when created from Console.
For an additional charge, you can enable detailed monitoring for Auto Scaling, which sends data to CloudWatch every minute.
Amazon CloudFront
Amazon CloudFront sends data to CloudWatch every minute by default.
Amazon CloudSearch
Amazon CloudSearch sends data to CloudWatch every minute by default.
Amazon CloudWatch Events
Amazon CloudWatch Events sends data to CloudWatch every minute by default.
Amazon CloudWatch Logs
Amazon CloudWatch Logs sends data to CloudWatch every minute by default.
Amazon DynamoDB
Amazon DynamoDB sends data to CloudWatch every minute for some metrics and every 5 minutes for other metrics.
Amazon EC2 Container Service
Amazon EC2 Container Service sends data to CloudWatch every minute.
Amazon ElastiCache
Amazon ElastiCache sends data to CloudWatch every minute.
Amazon Elastic Block Store
Amazon Elastic Block Store sends data to CloudWatch every 5 minutes.
Amazon EC2 sends data to CloudWatch every 5 minutes by default. For an additional charge, you can enable detailed monitoring for Amazon EC2, which sends data to CloudWatch every minute.
Elastic Load Balancing
Elastic Load Balancing sends data to CloudWatch every minute.
Amazon Elastic MapReduce
Amazon Elastic MapReduce sends data to CloudWatch every 5 minutes.
Amazon Elasticsearch Service
Amazon Elasticsearch Service sends data to CloudWatch every minute.
Amazon Kinesis Streams
Amazon Kinesis Streams sends data to CloudWatch every minute.
Amazon Kinesis Firehose
Amazon Kinesis Firehose sends data to CloudWatch every minute.
AWS Lambda
AWS Lambda sends data to CloudWatch every minute.
Amazon Machine Learning
Amazon Machine Learning sends data to CloudWatch every 5 minutes.
AWS OpsWorks
AWS OpsWorks sends data to CloudWatch every minute.
Amazon Redshift
Amazon Redshift sends data to CloudWatch every minute.
Amazon Relational Database Service
Amazon Relational Database Service sends data to CloudWatch every minute.
Amazon Route 53
Amazon Route 53 sends data to CloudWatch every minute.
Amazon Simple Notification Service
Amazon Simple Notification Service sends data to CloudWatch every 5 minutes.
Amazon Simple Queue Service
Amazon Simple Queue Service sends data to CloudWatch every 5 minutes.
Amazon Simple Storage Service
Amazon Simple Storage Service sends data to CloudWatch once a day.
Amazon Simple Workflow Service
Amazon Simple Workflow Service sends data to CloudWatch every 5 minutes.
AWS Storage Gateway
AWS Storage Gateway sends data to CloudWatch every 5 minutes.
AWS WAF
AWS WAF sends data to CloudWatch every minute.
Amazon WorkSpaces
Amazon WorkSpaces sends data to CloudWatch every 5 minutes.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
What is the minimum time Interval for the data that Amazon CloudWatch receives and aggregates?
One second
Five seconds
One minute
Three minutes
Five minutes
In the ‘Detailed’ monitoring data available for your Amazon EBS volumes, Provisioned IOPS volumes automatically send _____ minute metrics to Amazon CloudWatch.
3
1
5
2
Using Amazon CloudWatch’s Free Tier, what is the frequency of metric updates, which you receive?
5 minutes
500 milliseconds.
30 seconds
1 minute
What is the type of monitoring data (for Amazon EBS volumes) which is available automatically in 5-minute periods at no charge called?
Basic
Primary
Detailed
Local
A user has created an Auto Scaling group using CLI. The user wants to enable CloudWatch detailed monitoring for that group. How can the user configure this?
When the user sets an alarm on the Auto Scaling group, it automatically enables detail monitoring
By default detailed monitoring is enabled for Auto Scaling (Detailed monitoring is enabled when you create the launch configuration using the AWS CLI or an API)
Auto Scaling does not support detailed monitoring
Enable detail monitoring from the AWS console
A user is trying to understand the detailed CloudWatch monitoring concept. Which of the below mentioned services provides detailed monitoring with CloudWatch without charging the user extra?
AWS Auto Scaling
AWS Route 53
AWS EMR
AWS SNS
A user is trying to understand the detailed CloudWatch monitoring concept. Which of the below mentioned services does not provide detailed monitoring with CloudWatch?
AWS EMR
AWS RDS
AWS ELB
AWS Route53
A user has enabled detailed CloudWatch monitoring with the AWS Simple Notification Service. Which of the below mentioned statements helps the user understand detailed monitoring better?
SNS will send data every minute after configuration
There is no need to enable since SNS provides data every minute
AWS CloudWatch does not support monitoring for SNS
SNS cannot provide data every minute
A user has configured an Auto Scaling group with ELB. The user has enabled detailed CloudWatch monitoring on Auto Scaling. Which of the below mentioned statements will help the user understand the functionality better?
It is not possible to setup detailed monitoring for Auto Scaling
In this case, Auto Scaling will send data every minute and will charge the user extra
Detailed monitoring will send data every minute without additional charges
Auto Scaling sends data every minute only and does not charge the user