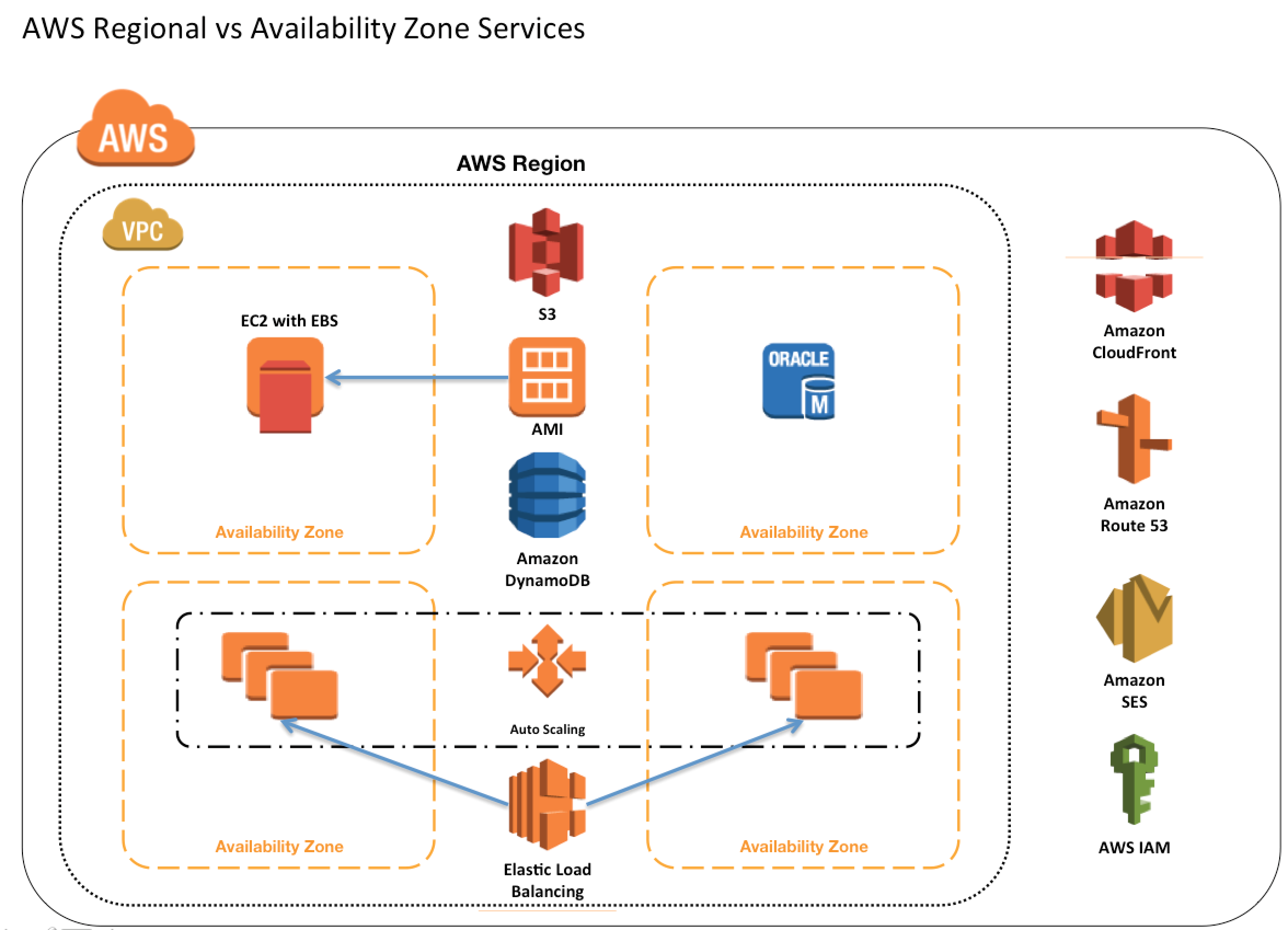
Each resource identifier, such as an AMI ID, instance ID, EBS volume ID, or EBS snapshot ID, is tied to its region and can be used only in the region where you created the resource.
Instances – Availability Zone
An instance is tied to the Availability Zones in which you launched it. However, note that its instance ID is tied to the region.
EBS Volumes – Availability Zone
Amazon EBS volume is tied to its Availability Zone and can be attached only to instances in the same Availability Zone.
EBS Snapshot – Regional
An EBS snapshot is tied to its region and can only be used to create volumes in the same region and has to be copied from one region to another if needed.
AMIs – Regional
AMI provides templates to launch EC2 instances
AMI is tied to the Region where its files are located with Amazon S3. For using AMI in different regions, the AMI can be copied to other regions
Auto Scaling – Regional
Auto Scaling spans across multiple Availability Zones within the same region but cannot span across regions
is a new multi-master, cross-region replication capability of DynamoDB to support data access locality and regional fault tolerance for database workloads
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You would like to create a mirror image of your production environment in another region for disaster recovery purposes. Which of the following AWS resources do not need to be recreated in the second region? (Choose 2 answers)
Route 53 Record Sets
IAM Roles
Elastic IP Addresses (EIP) (are specific to a region)
EC2 Key Pairs (are specific to a region)
Launch configurations
Security Groups (are specific to a region)
When using the following AWS services, which should be implemented in multiple Availability Zones for high availability solutions? Choose 2 answers
Amazon DynamoDB (already replicates across AZs)
Amazon Elastic Compute Cloud (EC2)
Amazon Elastic Load Balancing
Amazon Simple Notification Service (SNS) (Global Managed Service)
Amazon Simple Storage Service (S3) (Global Managed Service)
What is the scope of an EBS volume?
VPC
Region
Placement Group
Availability Zone
What is the scope of AWS IAM?
Global (IAM resources are all global; there is not regional constraint)
Availability Zone
Region
Placement Group
What is the scope of an EC2 EIP?
Placement Group
Availability Zone
Region (An Elastic IP address is tied to a region and can be associated only with an instance in the same region. Refer link)
VPC
What is the scope of an EC2 security group?
Availability Zone
Placement Group
Region (A security group is tied to a region and can be assigned only to instances in the same region)
Resource-based policies allow attaching a policy directly to the resource you want to share, instead of using a role as a proxy.
Resource-based policies allow granting usage permission to other AWS accounts or organizations on a per-resource basis.
Resource-based policy specifies the Principal, in the form of a list of AWS account ID numbers, can access that resource and what they can access.
Using cross-account access with a resource-based policy, the User still works in the trusted account and does not have to give up their permissions in place of the role permissions.
Users can work on the resources from both accounts at the same time and this can be useful for scenarios e.g. copying objects from one bucket to the other bucket in a different AWS account.
Resources that you want to share are limited to resources that support resource-based policies
S3 allows you to define Bucket policy to grant access to the bucket and the objects
Resource-based policies need the trusted account to create users with permissions to be able to access the resources from the trusted account.
Only permissions equivalent to, or less than, the permissions granted to the account by the resource owning account can be delegated.
S3 Bucket Policy
S3 Bucket policy can be used to grant cross-account access to other AWS accounts or IAM users in other accounts for the bucket and objects in it.
Bucket policies provide centralized, access control to buckets and objects based on a variety of conditions, including S3 operations, requesters, resources, and aspects of the request (e.g. IP address).
Permissions attached to a bucket apply to all of the objects in that bucket created and owned by the bucket owner
Policies can either add or deny permissions across all (or a subset) of objects within a bucket
Only the bucket owner is allowed to associate a policy with a bucket
Bucket policies can cater to multiple use cases
Granting permissions to multiple accounts with added conditions
Granting read-only permission to an anonymous user
Limiting access to specific IP addresses
Restricting access to a specific HTTP referer
Restricting access to a specific HTTP header for e.g. to enforce encryption
Granting permission to a CloudFront OAI
Adding a bucket policy to require MFA
Granting cross-account permissions to upload objects while ensuring the bucket owner has full control
Granting permissions for S3 inventory and Amazon S3 analytics
Granting permissions for S3 Storage Lens
Glacier Vault Policy
S3 Glacier vault access policy is a resource-based policy that can be used to manage permissions to the vault.
A Vault Lock policy is a Vault Access policy that can be locked. After you lock a Vault Lock policy, the policy can’t be changed. You can use a Vault Lock Policy to enforce compliance controls.
KMS Key Policy
KMS Key Policy helps determine who can use and manage those keys and is a primary mechanism for controlling access to a key.
KMS Key Policy can be used alone to control access to the keys.
A KMS key policy MUST be used, either alone or in combination with IAM policies or grants to allow access to a KMS CMK.
IAM policies by themselves are not sufficient to allow access to keys, though they can be used in combination with a key policy.
IAM user who creates a KMS key is not considered to be the key owner and they don’t automatically have permission to use or manage the KMS key that they created.
API Gateway Resource Policy
API Gateway resource policies are attached to an API to control whether a specified principal (typically an IAM role or group) can invoke the API.
API Gateway resource policies can be used to allow the API to be securely invoked by:
Users from a specified AWS account.
Specified source IP address ranges or CIDR blocks.
Specified virtual private clouds (VPCs) or VPC endpoints (in any account).
Resource policies can be used for all API endpoint types in API Gateway: private, edge-optimized, and Regional.
Lambda Function Policy
Lambda supports resource-based permissions policies for Lambda functions and layers.
Resource-based policy can be used to allow an AWS service to invoke the function on your behalf.
Resource-based policies apply to a single function, version, alias, or layer version.
EFS File System Policy
EFS supports IAM resource policy using file system policy.
EFS evaluates file system policy, along with any identity-based IAM policies to determine the appropriate file system access permissions to grant.
An “allow” permission on an action in either an IAM identity policy or a file system resource policy allows access for that action.
ECR Repository policy
Repository policies are resource-based policies that can help control access to the repositories and the images within them.
Repository policies are a subset of IAM policies that are scoped for, and specifically used for, controlling access to individual ECR repositories.
A user or role only needs to be allowed permission for an action through either a repository policy or an IAM policy but not both for the action to be allowed.
Resource-based policies also help grant the usage permission to other accounts on a per-resource basis.
SNS Policy
SNS policy can be used with a particular topic to restrict who can work with that topic e.g, who can publish messages to it, subscribe to it, etc.
SNS policies can grant access to other AWS accounts, or to users within your own AWS account.
SQS Policy
SQS policy system lets you grant permission to other AWS Accounts, whereas IAM doesn’t.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
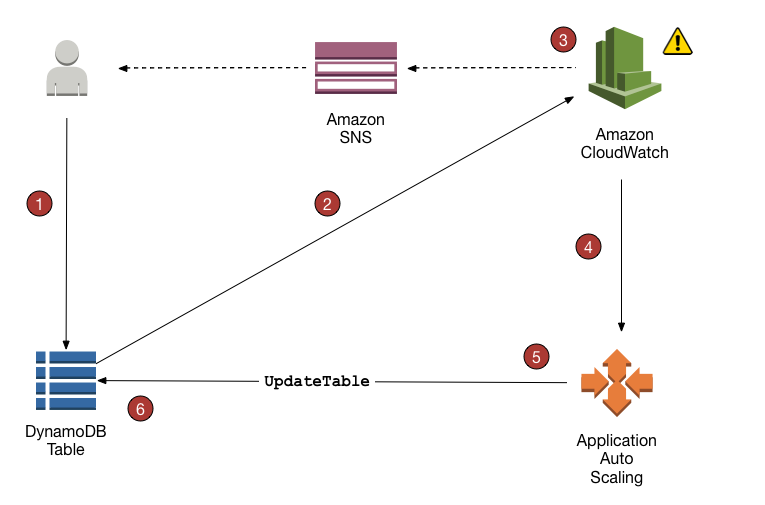
Application Auto Scaling is a web service for developers and system administrators who need a solution for automatically scaling their scalable resources for individual AWS services beyond EC2.
DynamoDB tables and global secondary indexes can be scaled using target tracking scaling policies and scheduled scaling.
DynamoDB Auto Scaling helps dynamically adjust provisioned throughput capacity on your behalf, in response to actual traffic patterns.
DynamoDB Auto Scaling enables a table or a global secondary index to increase its provisioned read and write capacity to handle sudden increases in traffic, without throttling.
When the workload decreases, Application Auto Scaling decreases the throughput so that you don’t pay for unused provisioned capacity.
EC2 Auto Scaling ensures a correct number of EC2 instances are always running to handle the load of the application.
Auto Scaling helps
to achieve better fault tolerance, better availability, and cost management.
helps specify scaling policies that can be used to launch and terminate EC2 instances to handle any increase or decrease in demand.
Auto Scaling attempts to distribute instances evenly between the AZs that are enabled for the Auto Scaling group.
Auto Scaling does this by attempting to launch new instances in the AZ with the fewest instances. If the attempt fails, it attempts to launch the instances in another AZ until it succeeds.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
DynamoDB table classes are designed to help you optimize for cost.
DynamoDB currently supports two table classes
DynamoDB Standard table class is the default, and is recommended for the vast majority of workloads.
DynamoDB Standard-Infrequent Access (DynamoDB Standard-IA) table class which is optimized for tables where storage is the dominant cost. e.g, tables that store infrequently accessed data, such as logs, old social media posts, e-commerce order history, and past gaming achievements
Every DynamoDB table is associated with a table class.
All secondary indexes associated with the table use the same table class.
DynamoDB table class can be
set when creating the table (DynamoDB Standard by default) or
updating the table class of an existing table using the AWS Management Console, AWS CLI, or AWS SDK.
DynamoDB also supports managing the table class using AWS CloudFormation for single-region tables (tables that are not global tables).
Each table class offers different pricing for data storage as well as read and write requests.
You can select the most cost-effective table class for your table based on its storage and throughput usage patterns.
DynamoDB Table Classes Considerations
DynamoDB Standard table class offers lower throughput costs than DynamoDB Standard-IA and is the most cost-effective option for tables where throughput is the dominant cost.
DynamoDB Standard-IA table class offers lower storage costs than DynamoDB Standard and is the most cost-effective option for tables where storage is the dominant cost.
DynamoDB Standard-IA tables offer the same performance, durability, and availability as DynamoDB Standard tables.
Switching between the DynamoDB Standard and DynamoDB Standard-IA table classes does not require changing the application code. You use the same DynamoDB APIs and service endpoints regardless of the table class your tables use.
Cost-effectiveness of table class for the table depends on the table’s expected storage and throughput usage patterns. It is recommended to look at the table’s historical storage and throughput cost and usage with AWS Cost and Usage Reports and the AWS Cost Explorer.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
supports MySQL, MariaDB, PostgreSQL, Oracle, Microsoft SQL Server, and the new, MySQL-compatible Amazon Aurora DB engine
as it is a managed service, shell (root ssh) access is not provided
manages backups, software patching, automatic failure detection, and recovery
supports use initiated manual backups and snapshots
daily automated backups with database transaction logs enables Point in Time recovery up to the last five minutes of database usage
snapshots are user-initiated storage volume snapshot of DB instance, backing up the entire DB instance and not just individual databases that can be restored as a independent RDS instance
RDS Security
support encryption at rest using KMS as well as encryption in transit using SSL endpoints
supports IAM database authentication, which prevents the need to store static user credentials in the database, because authentication is managed externally using IAM.
supports Encryption only during creation of an RDS DB instance
existing unencrypted DB cannot be encrypted and you need to create a snapshot, created a encrypted copy of the snapshot and restore as encrypted DB
supports Secret Manager for storing and rotating secrets
for encrypted database
logs, snapshots, backups, read replicas are all encrypted as well
cross region replicas and snapshots does not work across region (Note – this is possible now with latest AWS enhancement)
Multi-AZ deployment
provides high availability and automatic failover support and is NOT a scaling solution
maintains a synchronous standby replica in a different AZ
transaction success is returned only if the commit is successful both on the primary and the standby DB
Oracle, PostgreSQL, MySQL, and MariaDB DB instances use Amazon technology, while SQL Server DB instances use SQL Server Mirroring
snapshots and backups are taken from standby & eliminate I/O freezes
during automatic failover, its seamless and RDS switches to the standby instance and updates the DNS record to point to standby
failover can be forced with the Reboot with failover option
Read Replicas
uses the PostgreSQL, MySQL, and MariaDB DB engines’ built-in replication functionality to create a separate Read Only instance
updates are asynchronously copied to the Read Replica, and data might be stale
can help scale applications and reduce read only load
requires automatic backups enabled
replicates all databases in the source DB instance
for disaster recovery, can be promoted to a full fledged database
can be created in a different region for disaster recovery, migration and low latency across regions
can’t create encrypted read replicas from unencrypted DB or read replica
RDS does not support all the features of underlying databases, and if required the database instance can be launched on an EC2 instance
RDS Components
DB parameter groups contains engine configuration values that can be applied to one or more DB instances of the same instance type for e.g. SSL, max connections etc.
Default DB parameter group cannot be modified, create a custom one and attach to the DB
Supports static and dynamic parameters
changes to dynamic parameters are applied immediately (irrespective of apply immediately setting)
changes to static parameters are NOT applied immediately and require a manual reboot.
RDS Monitoring & Notification
integrates with CloudWatch and CloudTrail
CloudWatch provides metrics about CPU utilization from the hypervisor for a DB instance, and Enhanced Monitoring gathers its metrics from an agent on the instance
Performance Insights is a database performance tuning and monitoring feature that helps illustrate the database’s performance and help analyze any issues that affect it
supports RDS Event Notification which uses the SNS to provide notification when an RDS event like creation, deletion or snapshot creation etc occurs
is a relational database engine that combines the speed and reliability of high-end commercial databases with the simplicity and cost-effectiveness of open source databases
is a managed services and handles time-consuming tasks such as provisioning, patching, backup, recovery, failure detection and repair
is a proprietary technology from AWS (not open sourced)
provides PostgreSQL and MySQL compatibility
is “AWS cloud optimized” and claims 5x performance improvement
over MySQL on RDS, over 3x the performance of PostgreSQL on RDS
scales storage automatically in increments of 10GB, up to 64 TB with no impact to database performance. Storage is striped across 100s of volumes.
no need to provision storage in advance.
provides self-healing storage. Data blocks and disks are continuously scanned for errors and repaired automatically.
provides instantaneous failover
replicates each chunk of my the database volume six ways across three Availability Zones i.e. 6 copies of the data across 3 AZ
requires 4 copies out of 6 needed for writes
requires 3 copies out of 6 need for reads
costs more than RDS (20% more) – but is more efficient
Read Replicas
can have 15 replicas while MySQL has 5, and the replication process is faster (sub 10 ms replica lag)
share the same data volume as the primary instance in the same AWS Region, there is virtually no replication lag
supports Automated failover for master in less than 30 seconds
supports Cross Region Replication using either physical or logical replication.
Security
supports Encryption at rest using KMS
supports Encryption in flight using SSL (same process as MySQL or Postgres)
Automated backups, snapshots and replicas are also encrypted
Possibility to authenticate using IAM token (same method as RDS)
supports protecting the instance with security groups
does not support SSH access to the underlying servers
allows a single Aurora database to span multiple AWS regions.
provides Physical replication, which uses dedicated infrastructure that leaves the databases entirely available to serve the application
supports 1 Primary Region (read / write)
replicates across up to 5 secondary (read-only) regions, replication lag is less than 1 second
supports up to 16 Read Replicas per secondary region
recommended for low-latency global reads and disaster recovery with an RTO of < 1 minute
failover is not automated and if the primary region becomes unavailable, a secondary region can be manually removed from an Aurora Global Database and promote it to take full reads and writes. Application needs to be updated to point to the newly promoted region.
Backtracking “rewinds” the DB cluster to the specified time
Backtracking performs in place restore and does not create a new instance. There is a minimal downtime associated with it.
Aurora Clone feature allows quick and cost-effective creation of Aurora Cluster duplicates
supports parallel or distributed query using Aurora Parallel Query, which refers to the ability to push down and distribute the computational load of a single query across thousands of CPUs in Aurora’s storage layer.
DynamoDB Global Tables provide multi-master, cross-region replication capability of DynamoDB to support data access locality and regional fault tolerance for database workloads.
DynamoDB Streams provides a time-ordered sequence of item-level changes made to data in a table
enables a per-item timestamp to determine when an item expiry
expired items are deleted from the table without consuming any write throughput.
DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for DynamoDB that delivers up to a 10x performance improvement – from milliseconds to microseconds – even at millions of requests per second.
allows identical copies (called replicas) of a DynamoDB table (called master table) to be maintained in one or more AWS regions.
using DynamoDB streams which leverages Kinesis and provides time-ordered sequence of item-level changes and can help for lower RPO, lower RTO disaster recovery
DynamoDB Triggers (just like database triggers) are a feature that allows the execution of custom actions based on item-level updates on a table.
VPC Gateway Endpoints provide private access to DynamoDB from within a VPC without the need for an internet gateway or NAT gateway.
managed web service that provides in-memory caching to deploy and run Memcached or Redis protocol-compliant cache clusters
ElastiCache with Redis,
like RDS, supports Multi-AZ, Read Replicas and Snapshots
Read Replicas are created across AZ within same region using Redis’s asynchronous replication technology
Multi-AZ differs from RDS as there is no standby, but if the primary goes down a Read Replica is promoted as primary
Read Replicas cannot span across regions, as RDS supports
cannot be scaled out and if scaled up cannot be scaled down
allows snapshots for backup and restore
AOF can be enabled for recovery scenarios, to recover the data in case the node fails or service crashes. But it does not help in case the underlying hardware fails
Enabling Redis Multi-AZ as a Better Approach to Fault Tolerance
ElastiCache with Memcached
can be scaled up by increasing size and scaled out by adding nodes
nodes can span across multiple AZs within the same region
cached data is spread across the nodes, and a node failure will always result in some data loss from the cluster
supports auto discovery
every node should be homogenous and of same instance type
ElastiCache Redis vs Memcached
complex data objects vs simple key value storage
persistent vs non persistent, pure caching
automatic failover with Multi-AZ vs Multi-AZ not supported
scaling using Read Replicas vs using multiple nodes
backup & restore supported vs not supported
can be used state management to keep the web application stateless
fully managed, fast and powerful, petabyte scale data warehouse service
uses replication and continuous backups to enhance availability and improve data durability and can automatically recover from node and component failures
provides Massive Parallel Processing (MPP) by distributing & parallelizing queries across multiple physical resources
columnar data storage improving query performance and allowing advance compression techniques
only supports Single-AZ deployments and the nodes are available within the same AZ, if the AZ supports Redshift clusters
Amazon DynamoDB is a fully managed NoSQL database service that
makes it simple and cost-effective to store and retrieve any amount of data and serve any level of request traffic.
provides fast and predictable performance with seamless scalability
DynamoDB enables customers to offload the administrative burdens of operating and scaling distributed databases to AWS, without having to worry about hardware provisioning, setup and configuration, replication, software patching, or cluster scaling.
DynamoDB tables do not have fixed schemas, and the table consists of items and each item may have a different number of attributes.
DynamoDB synchronously replicates data across three facilities in an AWS Region, giving high availability and data durability.
DynamoDB supports fast in-place updates. A numeric attribute can be incremented or decremented in a row using a single API call.
DynamoDB uses proven cryptographic methods to securely authenticate users and prevent unauthorized data access.
Durability, performance, reliability, and security are built in, with SSD (solid state drive) storage and automatic 3-way replication.
DynamoDB supports two different kinds of primary keys:
Partition Key (previously called the Hash key)
A simple primary key, composed of one attribute
The partition key value is used as input to an internal hash function; the output from the hash function determines the partition where the item will be stored.
No two items in a table can have the same partition key value.
Partition Key and Sort Key (previously called the Hash and Range key)
A composite primary key is composed of two attributes. The first attribute is the partition key, and the second attribute is the sort key.
The partition key value is used as input to an internal hash function; the output from the hash function determines the partition where the item will be stored.
All items with the same partition key are stored together, in sorted order by sort key value.
The combination of the partition key and sort key must be unique.
It is possible for two items to have the same partition key value, but those two items must have different sort key values.
add flexibility to the queries, without impacting performance.
are automatically maintained as sparse objects, items will only appear in an index if they exist in the table on which the index is defined making queries against an index very efficient
DynamoDB throughput and single-digit millisecond latency make it a great fit for gaming, ad tech, mobile, and many other applications
ElastiCache or DAX can be used in front of DynamoDB in order to offload a high amount of reads for non-frequently changed data
DynamoDB Consistency
Each DynamoDB table is automatically stored in the three geographically distributed locations for durability.
Read consistency represents the manner and timing in which the successful write or update of a data item is reflected in a subsequent read operation of that same item.
DynamoDB allows the user to specify whether the read should be eventually consistent or strongly consistent at the time of the request
Eventually Consistent Reads (Default)
Eventual consistency option maximizes the read throughput.
Consistency across all copies is usually reached within a second
However, an eventually consistent read might not reflect the results of a recently completed write.
Repeating a read after a short time should return the updated data.
DynamoDB uses eventually consistent reads, by default.
Strongly Consistent Reads
Strongly consistent read returns a result that reflects all writes that received a successful response prior to the read
Strongly consistent reads are 2x the cost of Eventually consistent reads
Strongly Consistent Reads come with disadvantages
A strongly consistent read might not be available if there is a network delay or outage. In this case, DynamoDB may return a server error (HTTP 500).
Strongly consistent reads may have higher latency than eventually consistent reads.
Strongly consistent reads are not supported on global secondary indexes.
Strongly consistent reads use more throughput capacity than eventually consistent reads.
Read operations (such as GetItem, Query, and Scan) provide a ConsistentRead parameter, if set to true, DynamoDB uses strongly consistent reads during the operation.
Query, GetItem, and BatchGetItem operations perform eventually consistent reads by default.
Query and GetItem operations can be forced to be strongly consistent
Query operations cannot perform strongly consistent reads on Global Secondary Indexes
BatchGetItem operations can be forced to be strongly consistent on a per-table basis
add flexibility to the queries, without impacting performance.
are automatically maintained as sparse objects, items will only appear in an index if they exist in the table on which the index is defined making queries against an index very efficient
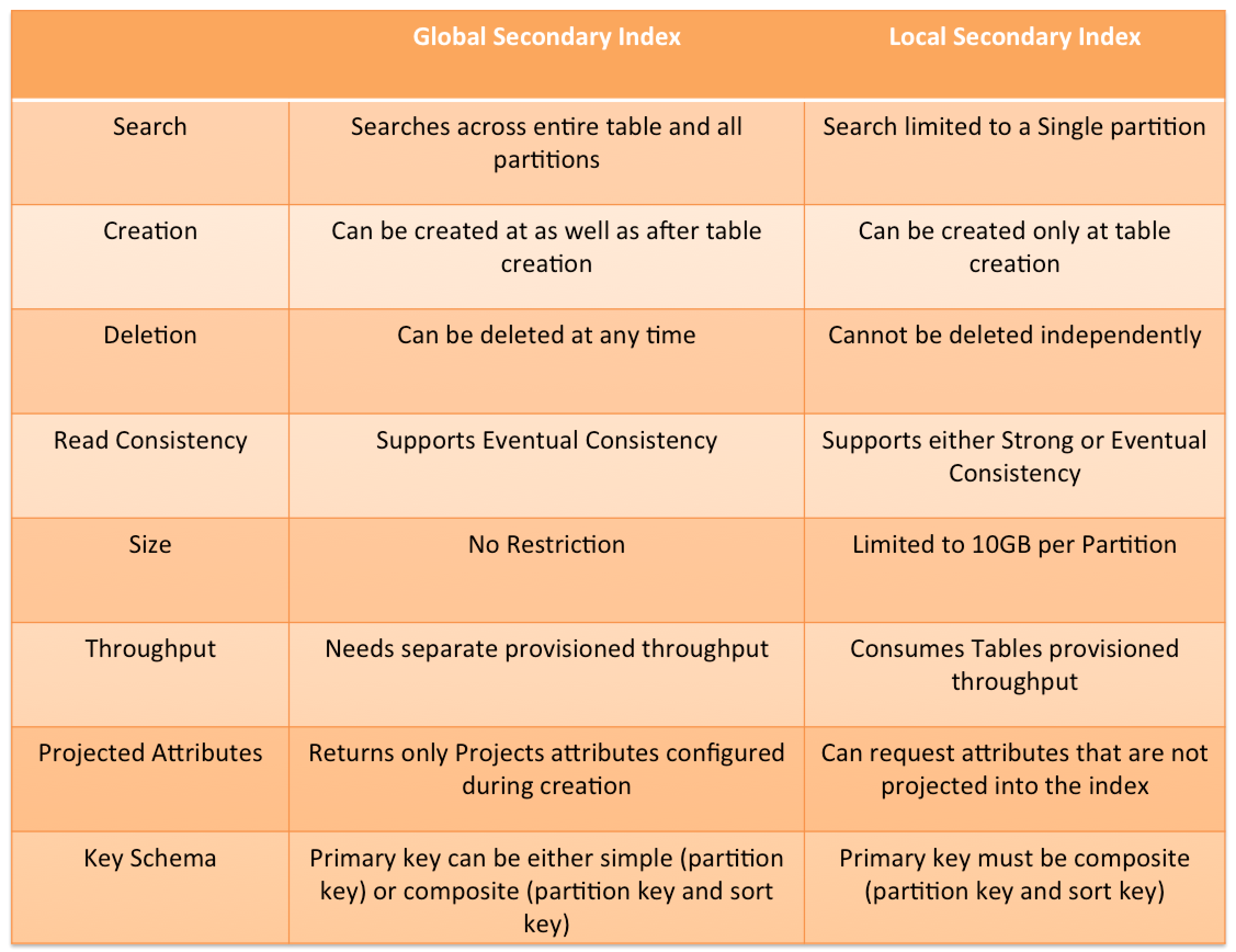
DynamoDB Secondary indexes on a table allow efficient access to data with attributes other than the primary key.
DynamoDB Secondary indexes support two types
Global secondary index – an index with a partition key and a sort key that can be different from those on the base table.
Local secondary index – an index that has the same partition key as the base table, but a different sort key.
DynamoDB cross-region replication allows identical copies (called replicas) of a DynamoDB table (called master table) to be maintained in one or more AWS regions.
DynamoDB Global Tables is a new multi-master, cross-region replication capability of DynamoDB to support data access locality and regional fault tolerance for database workloads.
DynamoDB Streams provides a time-ordered sequence of item-level changes made to data in a table.
DynamoDB Triggers (just like database triggers) are a feature that allows the execution of custom actions based on item-level updates on a table.
DynamoDB Accelerator – DAX is a fully managed, highly available, in-memory cache for DynamoDB that delivers up to a 10x performance improvement – from ms to µs – even at millions of requests per second.
VPC Gateway Endpoints provide private access to DynamoDB from within a VPC without the need for an internet gateway or NAT gateway.
DynamoDB Performance
Automatically scales horizontally
runs exclusively on Solid State Drives (SSDs).
SSDs help achieve the design goals of predictable low-latency response times for storing and accessing data at any scale.
SSDs High I/O performance enables them to serve high-scale request workloads cost-efficiently and to pass this efficiency along in low request pricing.
allows provisioned table reads and writes
Scale up throughput when needed
Scale down throughput four times per UTC calendar day
automatically partitions, reallocates and re-partitions the data and provisions additional server capacity as the
AWS handles basic security tasks like guest operating system (OS) and database patching, firewall configuration, and disaster recovery.
DynamoDB protects user data stored at rest and in transit between on-premises clients and DynamoDB, and between DynamoDB and other AWS resources within the same AWS Region.
Encryption at rest is enabled on all DynamoDB table data and cannot be disabled.
Encryption at rest includes the base tables, primary key, local and global secondary indexes, streams, global tables, backups, and DynamoDB Accelerator (DAX) clusters.
Fine-Grained Access Control (FGAC) gives a high degree of control over data in the table and helps control who (caller) can access which items or attributes of the table and perform what actions (read/write capability).
VPC Endpoints allow private connectivity from within a VPC only to DynamoDB.
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Which of the following are use cases for Amazon DynamoDB? Choose 3 answers
Storing BLOB data.
Managing web sessions
Storing JSON documents
Storing metadata for Amazon S3 objects
Running relational joins and complex updates.
Storing large amounts of infrequently accessed data.
You are configuring your company’s application to use Auto Scaling and need to move user state information. Which of the following AWS services provides a shared data store with durability and low latency?
AWS ElastiCache Memcached (does not allow writes)
Amazon Simple Storage Service (does not provide low latency)
Amazon EC2 instance storage (not durable)
Amazon DynamoDB
Does Dynamo DB support in-place atomic updates?
It is not defined
No
Yes
It does support in-place non-atomic updates
What is the maximum write throughput I can provision for a single Dynamic DB table?
1,000 write capacity units
100,000 write capacity units
Dynamic DB is designed to scale without limits, but if you go beyond 10,000 you have to contact AWS first
10,000 write capacity units
For a DynamoDB table, what happens if the application performs more reads or writes than your provisioned capacity?
Nothing
requests above the provisioned capacity will be performed but you will receive 400 error codes.
requests above the provisioned capacity will be performed but you will receive 200 error codes.
requests above the provisioned capacity will be throttled and you will receive 400 error codes.
In which of the following situations might you benefit from using DynamoDB? (Choose 2 answers)
You need fully managed database to handle highly complex queries
You need to deal with massive amount of “hot” data and require very low latency
You need a rapid ingestion of clickstream in order to collect data about user behavior
Your on-premises data center runs Oracle database, and you need to host a backup in AWS cloud
You are designing a file-sharing service. This service will have millions of files in it. Revenue for the service will come from fees based on how much storage a user is using. You also want to store metadata on each file, such as title, description and whether the object is public or private. How do you achieve all of these goals in a way that is economical and can scale to millions of users? [PROFESSIONAL]
Store all files in Amazon Simple Storage Service (S3). Create a bucket for each user. Store metadata in the filename of each object, and access it with LIST commands against the S3 API. (expensive and slow as it returns only 1000 items at a time)
Store all files in Amazon S3. Create Amazon DynamoDB tables for the corresponding key-value pairs on the associated metadata, when objects are uploaded.
Create a striped set of 4000 IOPS Elastic Load Balancing volumes to store the data. Use a database running in Amazon Relational Database Service (RDS) to store the metadata.(not economical with volumes)
Create a striped set of 4000 IOPS Elastic Load Balancing volumes to store the data. Create Amazon DynamoDB tables for the corresponding key-value pairs on the associated metadata, when objects are uploaded. (not economical with volumes)
A utility company is building an application that stores data coming from more than 10,000 sensors. Each sensor has a unique ID and will send a datapoint (approximately 1KB) every 10 minutes throughout the day. Each datapoint contains the information coming from the sensor as well as a timestamp. This company would like to query information coming from a particular sensor for the past week very rapidly and want to delete all the data that is older than 4 weeks. Using Amazon DynamoDB for its scalability and rapidity, how do you implement this in the most cost effective way? [PROFESSIONAL]
One table, with a primary key that is the sensor ID and a hash key that is the timestamp (Single table impacts performance)
One table, with a primary key that is the concatenation of the sensor ID and timestamp (Single table and concatenation impacts performance)
One table for each week, with a primary key that is the concatenation of the sensor ID and timestamp (Concatenation will cause queries would be slower, if at all)
One table for each week, with a primary key that is the sensor ID and a hash key that is the timestamp (Composite key with Sensor ID and timestamp would help for faster queries)
You have recently joined a startup company building sensors to measure street noise and air quality in urban areas. The company has been running a pilot deployment of around 100 sensors for 3 months. Each sensor uploads 1KB of sensor data every minute to a backend hosted on AWS. During the pilot, you measured a peak of 10 IOPS on the database, and you stored an average of 3GB of sensor data per month in the database. The current deployment consists of a load-balanced auto scaled Ingestion layer using EC2 instances and a PostgreSQL RDS database with 500GB standard storage. The pilot is considered a success and your CEO has managed to get the attention or some potential investors. The business plan requires a deployment of at least 100K sensors, which needs to be supported by the backend. You also need to store sensor data for at least two years to be able to compare year over year Improvements. To secure funding, you have to make sure that the platform meets these requirements and leaves room for further scaling. Which setup will meet the requirements? [PROFESSIONAL]
Add an SQS queue to the ingestion layer to buffer writes to the RDS instance (RDS instance will not support data for 2 years)
Ingest data into a DynamoDB table and move old data to a Redshift cluster (Handle 10K IOPS ingestion and store data into Redshift for analysis)
Replace the RDS instance with a 6 node Redshift cluster with 96TB of storage (Does not handle the ingestion issue)
Keep the current architecture but upgrade RDS storage to 3TB and 10K provisioned IOPS (RDS instance will not support data for 2 years)
Does Amazon DynamoDB support both increment and decrement atomic operations?
No, neither increment nor decrement operations.
Only increment, since decrement are inherently impossible with DynamoDB’s data model.
Only decrement, since increment are inherently impossible with DynamoDB’s data model.
Yes, both increment and decrement operations.
What is the data model of DynamoDB?
“Items”, with Keys and one or more Attribute; and “Attribute”, with Name and Value.
“Database”, which is a set of “Tables”, which is a set of “Items”, which is a set of “Attributes”.
“Table”, a collection of Items; “Items”, with Keys and one or more Attribute; and “Attribute”, with Name and Value.
“Database”, a collection of Tables; “Tables”, with Keys and one or more Attribute; and “Attribute”, with Name and Value.
In regard to DynamoDB, for which one of the following parameters does Amazon not charge you?
Cost per provisioned write units
Cost per provisioned read units
Storage cost
I/O usage within the same Region
Which statements about DynamoDB are true? Choose 2 answers.
DynamoDB uses a pessimistic locking model
DynamoDB uses optimistic concurrency control
DynamoDB uses conditional writes for consistency
DynamoDB restricts item access during reads
DynamoDB restricts item access during writes
Which of the following is an example of a good DynamoDB hash key schema for provisioned throughput efficiency?
User ID, where the application has many different users.
Status Code where most status codes is the same.
Device ID, where one is by far more popular than all the others.
Game Type, where there are three possible game types.
You are inserting 1000 new items every second in a DynamoDB table. Once an hour these items are analyzed and then are no longer needed. You need to minimize provisioned throughput, storage, and API calls. Given these requirements, what is the most efficient way to manage these Items after the analysis?
Retain the items in a single table
Delete items individually over a 24 hour period
Delete the table and create a new table per hour
Create a new table per hour
When using a large Scan operation in DynamoDB, what technique can be used to minimize the impact of a scan on a table’s provisioned throughput?
In regard to DynamoDB, which of the following statements is correct?
An Item should have at least two value sets, a primary key and another attribute.
An Item can have more than one attributes
A primary key should be single-valued.
An attribute can have one or several other attributes.
Which one of the following statements is NOT an advantage of DynamoDB being built on Solid State Drives?
serve high-scale request workloads
low request pricing
high I/O performance of WebApp on EC2 instance (Not related to DynamoDB)
low-latency response times
Which one of the following operations is NOT a DynamoDB operation?
BatchWriteItem
DescribeTable
BatchGetItem
BatchDeleteItem (DeleteItem deletes a single item in a table by primary key, but BatchDeleteItem doesn’t exist)
What item operation allows the retrieval of multiple items from a DynamoDB table in a single API call?
GetItem
BatchGetItem
GetMultipleItems
GetItemRange
An application stores payroll information nightly in DynamoDB for a large number of employees across hundreds of offices. Item attributes consist of individual name, office identifier, and cumulative daily hours. Managers run reports for ranges of names working in their office. One query is. “Return all Items in this office for names starting with A through E”. Which table configuration will result in the lowest impact on provisioned throughput for this query? [PROFESSIONAL]
Configure the table to have a hash index on the name attribute, and a range index on the office identifier
Configure the table to have a range index on the name attribute, and a hash index on the office identifier
Configure a hash index on the name attribute and no range index
Configure a hash index on the office Identifier attribute and no range index
You need to migrate 10 million records in one hour into DynamoDB. All records are 1.5KB in size. The data is evenly distributed across the partition key. How many write capacity units should you provision during this batch load?
6667
4166
5556 ( 2 write units (1 for each 1KB) * 10 million/3600 secs, refer link)
2778
A meteorological system monitors 600 temperature gauges, obtaining temperature samples every minute and saving each sample to a DynamoDB table. Each sample involves writing 1K of data and the writes are evenly distributed over time. How much write throughput is required for the target table?
1 write capacity unit
10 write capacity units ( 1 write unit for 1K * 600 gauges/60 secs)
60 write capacity units
600 write capacity units
3600 write capacity units
You are building a game high score table in DynamoDB. You will store each user’s highest score for each game, with many games, all of which have relatively similar usage levels and numbers of players. You need to be able to look up the highest score for any game. What’s the best DynamoDB key structure?
HighestScore as the hash / only key.
GameID as the hash key, HighestScore as the range key. (hash (partition) key should be the GameID, and there should be a range key for ordering HighestScore. Refer link)
GameID as the hash / only key.
GameID as the range / only key.
You are experiencing performance issues writing to a DynamoDB table. Your system tracks high scores for video games on a marketplace. Your most popular game experiences all of the performance issues. What is the most likely problem?
DynamoDB’s vector clock is out of sync, because of the rapid growth in request for the most popular game.
You selected the Game ID or equivalent identifier as the primary partition key for the table. (Referlink)
Users of the most popular video game each perform more read and write requests than average.
You did not provision enough read or write throughput to the table.
You are writing to a DynamoDB table and receive the following exception:” ProvisionedThroughputExceededException”. Though according to your Cloudwatch metrics for the table, you are not exceeding your provisioned throughput. What could be an explanation for this?
You haven’t provisioned enough DynamoDB storage instances
You’re exceeding your capacity on a particular Range Key
You’re exceeding your capacity on a particular Hash Key (Hash key determines the partition and hence the performance)
You’re exceeding your capacity on a particular Sort Key
You haven’t configured DynamoDB Auto Scaling triggers
Your company sells consumer devices and needs to record the first activation of all sold devices. Devices are not activated until the information is written on a persistent database. Activation data is very important for your company and must be analyzed daily with a MapReduce job. The execution time of the data analysis process must be less than three hours per day. Devices are usually sold evenly during the year, but when a new device model is out, there is a predictable peak in activation’s, that is, for a few days there are 10 times or even 100 times more activation’s than in average day. Which of the following databases and analysis framework would you implement to better optimize costs and performance for this workload? [PROFESSIONAL]
Amazon RDS and Amazon Elastic MapReduce with Spot instances.
Amazon DynamoDB and Amazon Elastic MapReduce with Spot instances.
Amazon RDS and Amazon Elastic MapReduce with Reserved instances.
Amazon DynamoDB and Amazon Elastic MapReduce with Reserved instances
NOTE – Provisioned mode is covered in the AWS Certified Developer – Associate exam (DVA-C01) esp. the calculations. On-demand capacity mode is latest enhancement and does not yet feature in the exams.
Provisioned Mode
Provisioned mode requires you to specify the number of reads and writes per second as required by the application
Provisioned throughput is the maximum amount of capacity that an application can consume from a table or index
If the provisioned throughput capacity on a table or index is exceeded, it is subject to request throttling
Provisioned mode provides the following capacity units
Read Capacity Units (RCU)
Total number of read capacity units required depends on the item size, and the consistent read model (eventually or strongly)
one RCU represents
two eventually consistent reads per second, for an item up to 4 KB in size i.e. 8 KB
one strongly consistent read per second for an item up to 4 KB in size i.e. 2x cost of eventually consistent reads
Transactional read requests require two read capacity units to perform one read per second for items up to 4 KB. i.e. 2x cost of strongly consistent reads
DynamoDB must consume additional read capacity units for items greater than 4 KB for e.g. for an 8 KB item size, 2 read capacity units to sustain one strongly consistent read per second, 1 read capacity unit if you choose eventually consistent reads, or 4 read capacity units for a transactional read request would be required
Item size is rounded off to 4 KB equivalents for e.g. a 6 KB or a 8 KB item in size would require the same RCU
Write Capacity Units (WCU)
Total number of write capacity units required depends on the item size only
one write per second for an item up to 1 KB in size
Transactional write requests require 2 write capacity units to perform one write per second for items up to 1 KB. i.e. 2x cost of general write.
DynamoDB must consume additional read capacity units for items greater than 1 KB for an 2 KB item size, 2 write capacity units would be required to sustain one write request per second or 4 write capacity units for a transactional write request
Item size is rounded off to 1 KB equivalents for e.g. a 0.5 KB or a 1 KB item would need the same WCU
Provisioned capacity mode might be best for use cases where you
Have predictable application traffic
Run applications whose traffic is consistent or ramps gradually
Can forecast capacity requirements to control costs
Provisioned Mode Examples
DynamoDB table with provisioned capacity of 10 RCUs and 10 WCUs can support
On-demand mode provides a flexible billing option capable of serving thousands of requests per second without capacity planning.
No need to specify the expected read and write throughput.
Charged for only the reads and writes that the application performs on the tables in terms of read request units and write request units.
Offers pay-per-request pricing for read and write requests so that you pay only for what you use.
DynamoDB adapts rapidly to accommodate the changing load.
DynamoDB on-demand using Request units which are similar to provisioned capacity Units.
On-demand mode does not support reserved capacity.
On-demand capacity mode might be best for use cases where you
Create new tables with unknown workloads
Have unpredictable application traffic
Prefer the ease of paying for only what you use
DynamoDB Throttling
DynamoDB distributes the data across partitions and the provisioned throughput capacity is distributed equally across these partitions and these are physical partitions and not the logical partitions based on the primary key.
Each partition on a DynamoDB table is subject to a hard limit of 1,000 write capacity units and 3,000 read capacity units.
DynamoDB would throttle requests
If the workload is unevenly distributed across partitions, or if the workload relies on short periods of time with high usage (a burst of read or write activity), the table might be throttled.
When data access is imbalanced, a hot partition can receive a higher volume of read and write traffic compared to other partitions leading to throttling errors on that partition.
If the write throughput capacity on the GSI is not sufficient it would lead to throttling on a GSI and this would affect the base table.
To avoid and handle throttling issues, you can
Distribute read and write operations as evenly as possible across your table. A hot partition can degrade the overall performance of your table.
Implement a caching solution. If the workload is mostly read access to static data, then query results can be delivered much faster if the data is in a well‑designed cache rather than in a database. DynamoDB Accelerator (DAX) is a caching service that offers fast in‑memory performance for your application. ElastiCache can be used as well.
Implement error retries and exponential backoff. Exponential backoff can improve an application’s reliability by using progressively longer waits between retries. If using an AWS SDK, this logic is built‑in.
DynamoDB Burst Capacity
DynamoDB provides some flexibility in the per-partition throughput provisioning by providing burst capacity.
If partition’s throughput is not fully used, DynamoDB reserves a portion of that unused capacity for later bursts of throughput to handle usage spikes.
DynamoDB currently retains up to 5 minutes (300 seconds) of unused read and write capacity.
During an occasional burst of read or write activity, these extra capacity units can be consumed quickly – even faster than the per-second provisioned throughput capacity that you’ve defined for your table.
DynamoDB can also consume burst capacity for background maintenance and other tasks without prior notice.
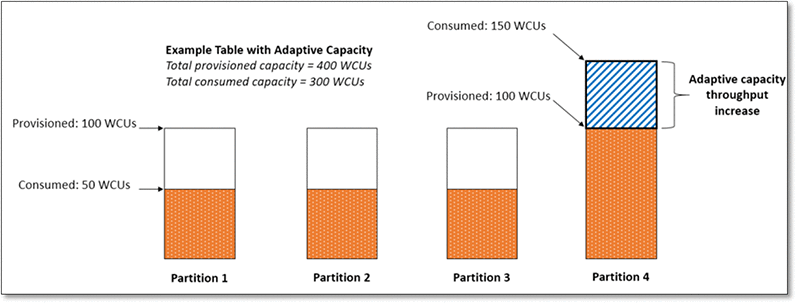
DynamoDB Adaptive Capacity
DynamoDB Adaptive capacity is a feature that enables DynamoDB to run imbalanced workloads indefinitely.
Adaptive capacity enables the application to continue read/write to hot partitions without being throttled, provided that traffic does not exceed the table’s total provisioned capacity or the partition’s maximum capacity.
It minimizes throttling due to throughput exceptions.
It also helps reduce costs by enabling the provisioning of only the needed throughput capacity.
Adaptive capacity is enabled automatically for every DynamoDB table, at no additional cost.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You need to migrate 10 million records in one hour into DynamoDB. All records are 1.5KB in size. The data is evenly distributed across the partition key. How many write capacity units should you provision during this batch load?
6667
4166
5556 ( 2 write units (1 for each 1KB) * 10 million/3600 secs)
2778
A meteorological system monitors 600 temperature gauges, obtaining temperature samples every minute and saving each sample to a DynamoDB table. Each sample involves writing 1K of data and the writes are evenly distributed over time. How much write throughput is required for the target table?
1 write capacity unit
10 write capacity units ( 1 write unit for 1K * 600 gauges/60 secs)
60 write capacity units
600 write capacity units
3600 write capacity units
A company is building a system to collect sensor data from its 36000 trucks, which is stored in DynamoDB. The trucks emit 1KB of data once every hour. How much write throughput is required for the target table. Choose an answer from the options below
10
60
600
150
A company is using DynamoDB to design storage for their IOT project to store sensor data. Which combination would give the highest throughput?
5 Eventual Consistent reads capacity with Item Size of 4KB (40KB/s)
15 Eventual Consistent reads capacity with Item Size of 1KB (30KB/s)
5 Strongly Consistent reads capacity with Item Size of 4KB (20KB/s)
15 Strongly Consistent reads capacity with Item Size of 1KB (15KB/s)
If your table item’s size is 3KB and you want to have 90 strongly consistent reads per second, how many read capacity units will you need to provision on the table? Choose the correct answer from the options below
Each instance launched into a VPC has a tenancy attribute.
default
is the default option
instances run on shared hardware.
all instances launched would be shared, unless you explicitly specify a different tenancy during the instance launch.
dedicated
instance runs on single-tenant hardware.
all instances launched would be dedicated
can’t be changed to default after creation
host
instance runs on a Dedicated Host, which is an isolated server with configurations that you can control.
default tenancy can’t be changed to dedicatedor hostand vice versa. Changes reflect the next time when the instance starts.
dedicatedtenancy can be changed to hostand vice versa only for the stopped instance after launch.
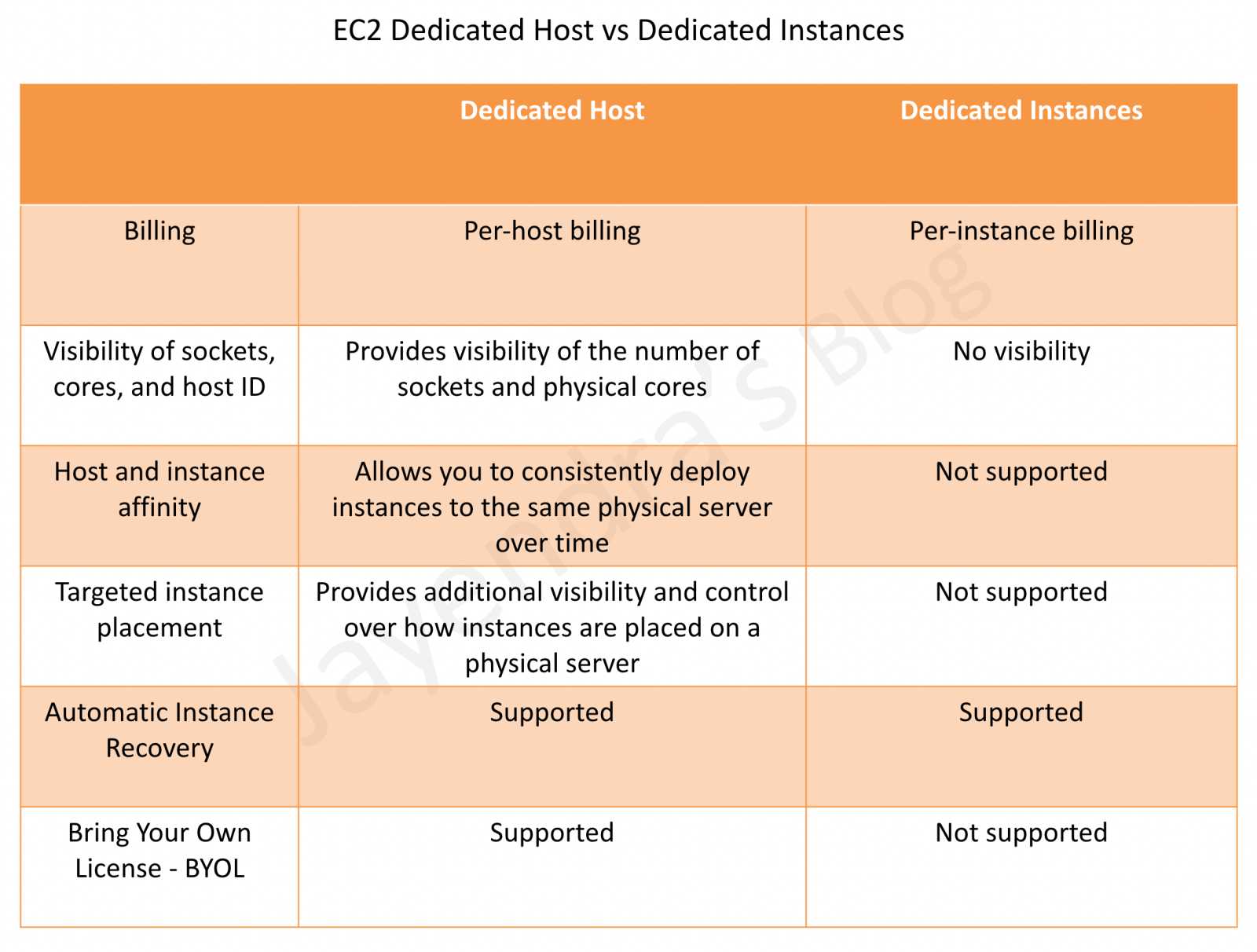
Dedicated Hosts and Dedicated Instances can both be used to launch EC2 instances onto physical servers that are dedicated for your use.
There are no performance, security, or physical differences between Dedicated Instances and instances on Dedicated Hosts.
Dedicated Host vs Dedicated Instances
Dedicated Hosts
EC2 Dedicated Host is a physical server with EC2 instance capacity fully dedicated to your use.
provides Affinity that allows you to specify which Dedicated Host an instance will run on after it has been stopped and restarted.
Dedicated Hosts provide visibility and the option to control how you place your instances on a specific, physical server. This enables you to deploy instances using configurations that help address corporate compliance and regulatory requirements.
Dedicated Hosts allow using existing per-socket, per-core, or per-VM software licenses, including Windows Server, Microsoft SQL Server, SUSE, and Linux Enterprise Server.
Dedicated Host is also integrated with AWS License Manager, a service that helps you manage your software licenses, including Microsoft Windows Server and Microsoft SQL Server licenses.
Dedicated Instances are EC2 instances that run in a VPC on hardware that’s dedicated to a single customer
Dedicated Instances are physically isolated at the host hardware level from the instances that aren’t Dedicated Instances and from instances that belong to other AWS accounts.
Dedicated Instances can be launched using
Create the VPC with the instance tenancy set to dedicated, all instances launched into this VPC are Dedicated Instances even if you mark the tenancy as shared.
Create the VPC with the instance tenancy set to default, and specify dedicated tenancy for any instances that should be Dedicated Instances when launched.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company wants its instances to run on single-tenant hardware with dedicated hardware for compliance reasons. Which value should they have to set the instance’s tenancy attribute to?
Dedicated
Isolated
Default
Reserved
A company is performing migration from on-premises to AWS cloud. They have a compliance requirement for application hosting on physical servers to be able to use existing server-bound software licenses. Which AWS EC2 purchase type would help fulfill the requirement?
DynamoDB provides a highly durable storage infrastructure for mission-critical and primary data storage.
Data is redundantly stored on multiple devices across multiple facilities in a DynamoDB Region.
AWS handles basic security tasks like guest operating system (OS) and database patching, firewall configuration, and disaster recovery.
DynamoDB protects user data stored at rest and in transit between on-premises clients and DynamoDB, and between DynamoDB and other AWS resources within the same AWS Region.
Fine-Grained Access Control (FGAC) gives a high degree of control over data in the table.
FGAC helps control who (caller) can access which items or attributes of the table and perform what actions (read/write capability).
FGAC is integrated with IAM, which manages the security credentials and the associated permissions.
VPC Endpoints allow private connectivity from within a VPC only to DynamoDB.
DynamoDB Encryption
DynamoDB Security supports both encryption at rest and in transit.
Encryption in Transit
DynamoDB Data in Transit encryption can be done by encrypting sensitive data on the client side or using encrypted connections (TLS).
DAX supports encryption in transit, ensuring that all requests and responses between the application and the cluster are encrypted by transport level security (TLS), and connections to the cluster can be authenticated by verification of a cluster x509 certificate.
All the data in DynamoDB is encrypted in transit
communications to and from DynamoDB using the HTTPS protocol, which protects network traffic using SSL/TLS encryption.
Data can also be protected using client-side encryption
Encryption at Rest
Encryption at rest enables encryption for the data persisted (data at rest) in the DynamoDB tables.
Encryption at rest includes the base tables, primary key, local and global secondary indexes, streams, global tables, backups, and DynamoDB Accelerator (DAX) clusters.
Encryption at rest is enabled on all DynamoDB table data and cannot be disabled.
Encryption at rest automatically integrates with AWS KMS for managing the keys used for encrypting the tables.
Encryption at rest also supports the following KMS keys
AWS owned CMK – Default encryption type. The key is owned by DynamoDB (no additional charge).
AWS managed CMK – the key is stored in your account and is managed by AWS KMS (AWS KMS charges apply).
Customer managed CMK – the key is stored in your account and is created, owned, and managed by you. You have full control over the KMS key (AWS KMS charges apply).
Encryption at rest can be enabled only for a new table and encryption keys can be switched for an existing table.
DynamoDB streams can be used with encrypted tables and are always encrypted with a table-level encryption key.
On-Demand Backups of encrypted DynamoDB tables are encrypted using S3’s Server-Side Encryption
Encryption at rest encrypts the data using 256-bit AES encryption.
DAX clusters cannot use customer-managed key encryption.
DynamoDB Encryption Client
DynamoDB Encryption Client is a software library that helps protect the table data before sending it to DynamoDB.
Encrypting the sensitive data in transit and at rest helps ensure that the plaintext data isn’t available to any third party, including AWS.
helps in end-to-end data encryption.
encrypts attribute values that can be controlled but do not encrypt the entire table, attribute names, or primary key.
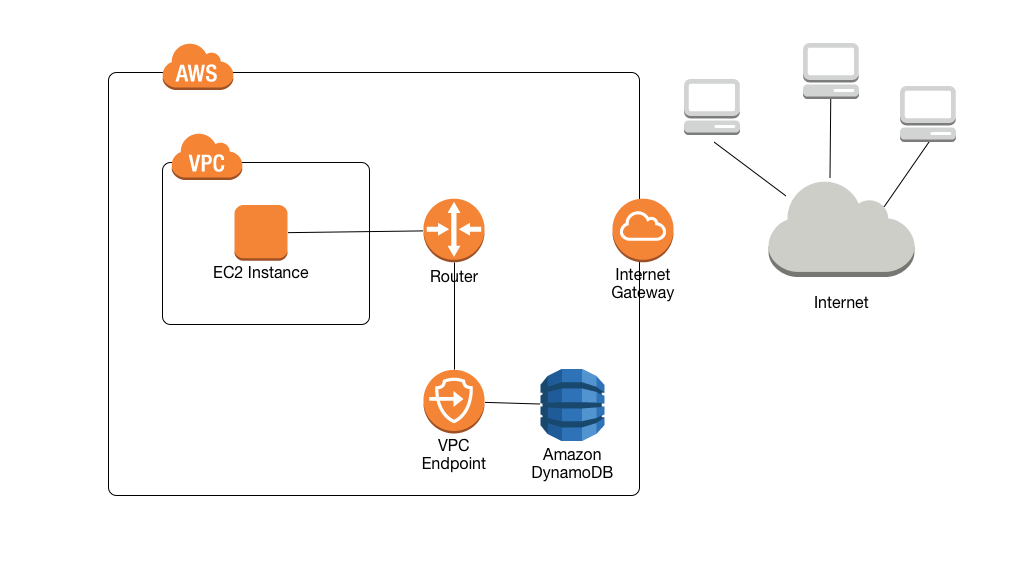
VPC Endpoints
By default, communications to and from DynamoDB use the HTTPS protocol, which protects network traffic by using SSL/TLS encryption.
A VPC endpoint for DynamoDB enables EC2 instances in the VPC to use their private IP addresses to access DynamoDB with no exposure to the public internet.
Traffic between the VPC and the AWS service does not leave the Amazon network.
EC2 instances do not require public IP addresses, an internet gateway, a NAT device, or a virtual private gateway in the VPC.
VPC Endpoint Policies to control access to DynamoDB.
DynamoDB Security Best Practices
DynamoDB encrypts at rest all user data stored in tables, indexes, streams, and backups using encryption keys stored in KMS.
DynamoDB can be configured to use an AWS owned key (default encryption type), an AWS managed key, or a customer managed key to encrypt user data.
DynamoDB Encryption Client is a software library that helps in client-side encryption and protects the table data before you send it to DynamoDB.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
What are the services supported by VPC endpoints, using the Gateway endpoint type?
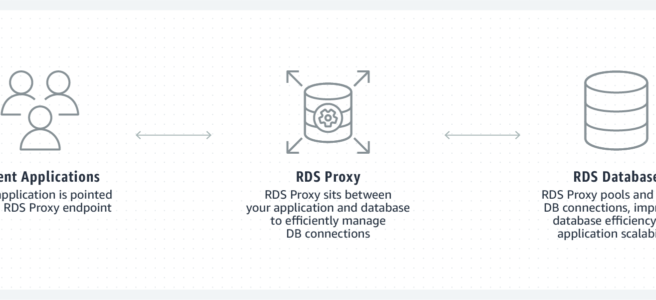
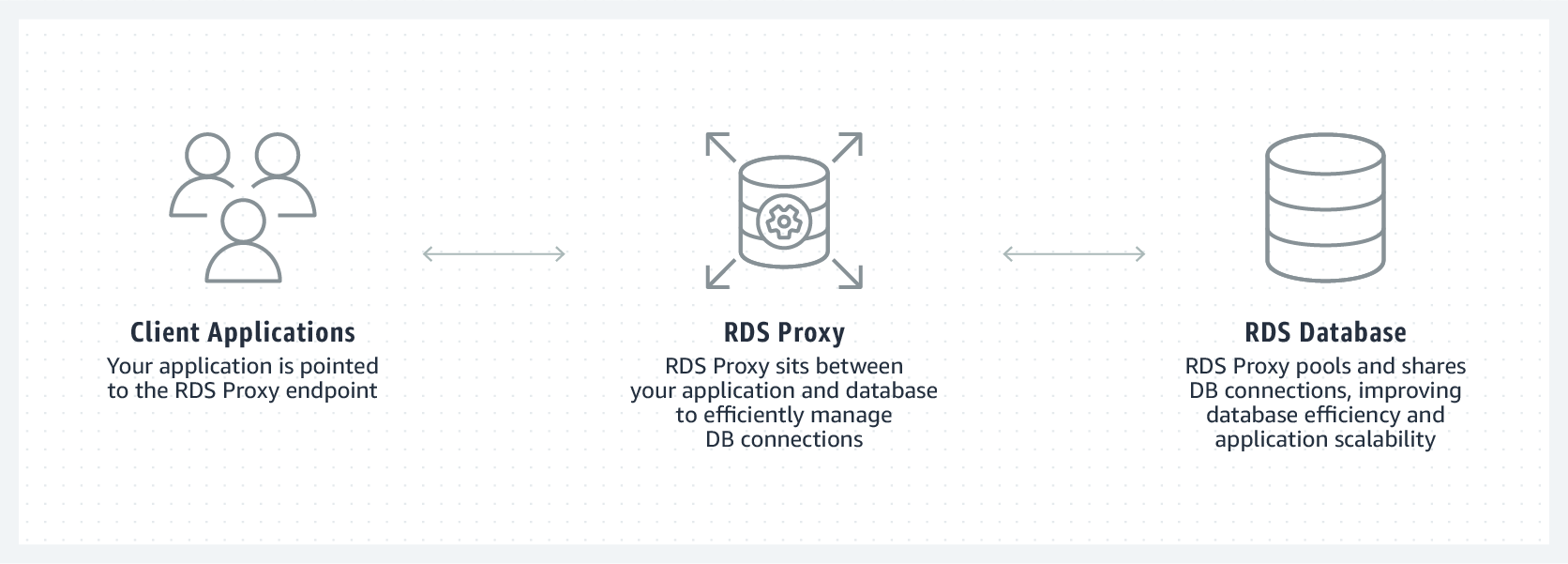
fully managed, highly available database proxy for RDS that makes applications more secure, scalable, more resilient to database failures.
allows apps to pool and share DB connections established with the database
improves database efficiency by reducing stress on the database resources (e.g. CPU, RAM) by minimizing open connections and creation of new connections.
is serverless and scales automatically to accommodate your workload.
is highly available and deployed across multiple Availability Zones.
increases resiliency to database failures by automatically connecting to a standby DB instance while preserving application connections.
reduces RDS and Aurora failover time by up to 66%.
protects the database against oversubscription by providing control over the number of database connections that are created.
queues or throttles application connections that can’t be served immediately from the pool of connections.
supports RDS (MySQL, PostgreSQL, MariaDB) and Aurora
is fully managed and there is no need to provision or manage any additional infrastructure.
required no code changes for most apps, just need to point to the RDS proxy endpoint instead of the RDS endpoint
enforce IAM Authentication for DB, and securely store credentials in AWS Secrets Manager
is never publicly accessible (must be accessed from VPC)
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company migrated one of its business-critical database workloads to an Amazon Aurora Multi-AZ DB cluster. The company requires a very low RTO and needs to improve the application recovery time after database failover. Which approach meets these requirements?
Set the max_connections parameter to 16,000 in the instance-level parameter group.
Modify the client connection timeout to 300 seconds.
Create an Amazon RDS Proxy database proxy and update client connections to point to the proxy endpoint.
Enable the query cache at the instance level.
A company is running a serverless application on AWS Lambda that stores data in an Amazon RDS for MySQL DB instance. Usage has steadily increased, and recently there have been numerous “too many connections” errors when the Lambda function attempts to connect to the database. The company already has configured the database to use the maximum max_connections value that is possible. What should a SysOps administrator do to resolve these errors?
Create a read replica of the database. Use Amazon Route 53 to create a weighted DNS record that contains both databases.
Use Amazon RDS Proxy to create a proxy. Update the connection string in the Lambda function.
Increase the value in the max_connect_errors parameter in the parameter group that the database uses.
Update the Lambda function’s reserved concurrency to a higher value.