Pub/Sub is a fully managed, asynchronous messaging service designed to be highly reliable and scalable.
Pub/Sub service allows applications to exchange messages reliably, quickly, and asynchronously
Pub/Sub allows services to communicate asynchronously, with latencies on the order of 100 milliseconds.
Pub/Sub enables the creation of event producers and consumers, called publishers and subscribers.
Publishers communicate with subscribers asynchronously by broadcasting events, rather than by synchronous remote procedure calls.
Pub/Sub offers at-least-once message delivery and best-effort ordering to existing subscribers
Pub/Sub accepts a maximum of 1,000 messages in a batch, and the size of a batch can not exceed 10 megabytes.
Pub/Sub Core Concepts
Topic: A named resource to which messages are sent by publishers.
Publisher: An application that creates and sends messages to a topic(s).
Subscriber: An application with a subscription to a topic(s) to receive messages from it.
Subscription: A named resource representing the stream of messages from a single, specific topic, to be delivered to the subscribing application.
Message: The combination of data and (optional) attributes that a publisher sends to a topic and is eventually delivered to subscribers.
Message attribute: A key-value pair that a publisher can define for a message.
Acknowledgment (or “ack”): A signal sent by a subscriber to Pub/Sub after it has received a message successfully. Acked messages are removed from the subscription’s message queue.
Schema: A schema is a format that messages must follow, creating a contract between publisher and subscriber that Pub/Sub will enforce
Push and pull: The two message delivery methods. A subscriber receives messages either by Pub/Sub pushing them to the subscriber’s chosen endpoint or by the subscriber pulling them from the service.
Pub/Sub Subscription Properties
Delivery method
Messages can be received with pull or push delivery.
In pull delivery, the subscriber application initiates requests to the Pub/Sub server to retrieve messages.
In push delivery, Pub/Sub initiates requests to the subscriber application to deliver messages. The push endpoint must be a publicly accessible HTTPS address.
If unspecified, Pub/Sub subscriptions use pull delivery.
Messages published before a subscription is created will not be delivered to that subscription
Acknowledgment deadline
Message not acknowledged before the deadline is sent again.
Default acknowledgment deadline is 10 secs. with a max of 10 mins.
Message retention duration
Message retention duration specifies how long Pub/Sub retains messages after publication.
Acknowledged messages are no longer available to subscribers and are deleted, by default
After the message retention duration, Pub/Sub might discard the message, regardless of its acknowledgment state.
Default message retention duration is 7 days with a min-max of 10 mins – 7 days
Dead-letter topics
If a subscriber can’t acknowledge a message, Pub/Sub can forward the message to a dead-letter topic.
With a dead-letter topic, message ordering can’t be enabled
With a dead-letter topic, the maximum number of delivery attempts can be specified.
Default is 5 delivery attempts; with a min-max of 5-100
Expiration period
Subscriptions expire without any subscriber activity such as open connections, active pulls, or successful pushes
Subscription deletion clock restarts, if subscriber activity is detected
Default expiration period is 31 days with a min-max of 1 day-never
Retry policy
If the acknowledgment deadline expires or a subscriber responds with a negative acknowledgment, Pub/Sub can send the message again using exponential backoff.
If the retry policy isn’t set, Pub/Sub resends the message as soon as the acknowledgment deadline expires or a subscriber responds with a negative acknowledgment.
Message ordering
If publishers send messages with an ordering key, are in the same region and message ordering is set, Pub/Sub delivers the messages in order.
If not set, Pub/Sub doesn’t deliver messages in order, including messages with ordering keys.
Filter
Filter is a string with a filtering expression where the subscription only delivers the messages that match the filter.
Pub/Sub service automatically acknowledges the messages that don’t match the filter.
Message can be filtered using their attributes.
Pub/Sub Seek Feature
Acknowledged messages are no longer available to subscribers and are deleted
Subscriber clients must process every message in a subscription even if only a subset is needed.
Seek feature extends subscriber functionality by allowing you to alter the acknowledgment state of messages in bulk
Timestamp Seeking
With Seek feature, you can replay previously acknowledged messages or purge messages in bulk
Seeking to a time marks every message received by Pub/Sub before the time as acknowledged, and all messages received after the time as unacknowledged.
Seeking to a time in the future allows you to purge messages.
Seeking to a time in the past allows replay and reprocess previously acknowledged messages
Timestamp seeking approach is imprecise as
Possible clock skew among Pub/Sub servers.
Pub/Sub has to work with the arrival time of the publish request rather than when an event occurred in the source system.
Snapshot Seeking
State of one subscription can be copied to another by using seek in combination with a Snapshot.
Once a snapshot is created, it retains:
All messages that were unacknowledged in the source subscription at the time of the snapshot’s creation.
Any messages published to the topic thereafter.
Pub/Sub Locations
Pub/Sub servers run in all GCP regions around the world, which helps offer fast, global data access while giving users control over where messages are stored
Cloud Pub/Sub offers global data access in that publisher and subscriber clients are not aware of the location of the servers to which they connect or how those services route the data.
Pub/Sub’s load balancing mechanisms direct publisher traffic to the nearest GCP data center where data storage is allowed, as defined in the Resource Location Restriction
Publishers in multiple regions may publish messages to a single topic with low latency. Any individual message is stored in a single region. However, a topic may have messages stored in many regions.
Subscriber client requesting messages published to this topic connects to the nearest server which aggregates data from all messages published to the topic for delivery to the client.
Message Storage Policy
Message Storage Policy helps ensure that messages published to a topic are never persisted outside a set of specified Google Cloud regions, regardless of where the publish requests originate.
Pub/Sub chooses the nearest allowed region, when multiple regions are allowed by the policy
Pub/Sub Security
Pub/Sub encrypts messages with Google-managed keys, by default.
Every message is encrypted at the following states and layers:
At rest
Hardware layer
Infrastructure layer
Application layer
Pub/Sub individually encrypts incoming messages as soon as the message is received
In transit
Pub/Sub does not encrypt message attributes at the application layer.
Message attributes are still encrypted at the hardware and infrastructure layers.
Common use cases
Ingestion user interaction and server events
Real-time event distribution
Replicating data among databases
Parallel processing and workflows
Data streaming from IoT devices
Refreshing distributed caches
Load balancing for reliability
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Google Kubernetes Engine – GKE Security provides multiple layers of security to secure workloads including the contents of the container image, the container runtime, the cluster network, and access to the cluster API server.
Authentication and Authorization
Kubernetes supports two types of authentication:
User accounts are accounts that are known to Kubernetes but are not managed by Kubernetes
Service accounts are accounts that are created and managed by Kubernetes but can only be used by Kubernetes-created entities, such as pods.
In a GKE cluster, Kubernetes user accounts are managed by Google Cloud and can be of the following type
Google Account
Google Cloud service account
Once authenticated, these identities need to be authorized to create, read, update or delete Kubernetes resources.
Kubernetes service accounts and Google Cloud service accounts are different entities.
Kubernetes service accounts are part of the cluster in which they are defined and are typically used within that cluster.
Google Cloud service accounts are part of a Google Cloud project, and can easily be granted permissions both within clusters and to Google Cloud project clusters themselves, as well as to any Google Cloud resource using IAM.
Control Plane Security
In GKE, the Kubernetes control plane components are managed and maintained by Google.
Control plane components host the software that runs the Kubernetes control plane, including the API server, scheduler, controller manager, and the etcd database where the Kubernetes configuration is persisted.
By default, the control plane components use a public IP address.
Kubernetes API server can be protected by using authorized networks, and private clusters, which allow assigning a private IP address to the control plane and disable access on the public IP address.
Control plane can also be secured by doing credential rotation on a regular basis. When credential rotation is initiated, the SSL certificates and cluster certificate authority are rotated. This process is automated by GKE and also ensures that your control plane IP address rotates.
Node Security
Container-Optimized OS
GKE nodes, by default, use Google’s Container-Optimized OS as the operating system on which to run Kubernetes and its components.
Container-Optimized OS features include
Locked-down firewall
Read-only filesystem where possible
Limited user accounts and disabled root login
Node upgrades
GKE recommends upgrading nodes on regular basis to patch the OS for security issues in the container runtime, Kubernetes itself, or the node operating system
GKE also allows automatic as well as manual upgrades
Protecting nodes from untrusted workloads
GKE Sandbox can be enabled on the cluster to isolate untrusted workloads in sandboxes on the node if the clusters run unknown or untrusted workloads.
GKE Sandbox is built using gVisor, an open-source project.
Securing instance metadata
GKE nodes run as CE instances and have access to instance metadata by default, which a Pod running on the node does not necessarily need.
Sensitive instance metadata paths can be locked down by disabling legacy APIs and by using metadata concealment.
Metadata concealment ensures that Pods running in a cluster are not able to access sensitive data by filtering requests to fields such as the kube-env
Network Security
Network Policies help cluster administrators and users to lock down the ingress and egress connections created to and from the Pods in a namespace
Network policies allow you to use tags to define the traffic flowing through the Pods.
MTLS for Pod to Pod communication can be enabled using the Istio service mesh
Giving Pods Access to Google Cloud resources
Workload Identity (recommended)
Simplest and most secure way to authorize Pods to access Google Cloud resources is with Workload Identity.
Workload identity allows a Kubernetes service account to run as a Google Cloud service account.
Pods that run as the Kubernetes service account have the permissions of the Google Cloud service account.
Node Service Account
Pods can authenticate to Google Cloud using the Kubernetes clusters’ service account credentials from metadata.
Node Service Account credentials can be reached by any Pod running in the cluster if Workload Identity is not enabled.
It is recommended to create and configure a custom service account that has the minimum IAM roles required by all the Pods running in the cluster.
Service Account JSON key
Applications can access Google Cloud resources by using the service account’s key.
This approach is NOT recommended because of the difficulty of securely managing account keys.
Each service account is assigned only the IAM roles that are needed for its paired application to operate successfully. Keeping the service account application-specific makes it easier to revoke its access in the case of a compromise without affecting other applications.
A JSON service account key can be created and then mounted into the Pod using a Kubernetes Secret.
Binary Authorization
Binary Authorization works with images deployed to GKE from Container Registry or another container image registry.
Binary Authorization helps ensure that internal processes that safeguard the quality and integrity of the software have successfully completed before an application is deployed to the production environment.
Binary Authorization provides:
A policy model that lets you describe the constraints under which images can be deployed
An attestation model that lets you define trusted authorities who can attest or verify that required processes in your environment have completed before deployment
A deploy-time enforcer that prevents images that violate the policy from being deployed
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You are building a product on top of Google Kubernetes Engine (GKE). You have a single GKE cluster. For each of your customers, a Pod is running in that cluster, and your customers can run arbitrary code inside their Pod. You want to maximize the isolation between your customers’ Pods. What should you do?
Use Binary Authorization and whitelist only the container images used by your customers’ Pods.
Use the Container Analysis API to detect vulnerabilities in the containers used by your customers’ Pods.
Create a GKE node pool with a sandbox type configured to gVisor. Add the parameter runtimeClassName: gvisor to the specification of your customers’ Pods.
Use the cos_containerd image for your GKE nodes. Add a nodeSelector with the value cloud.google.com/gke-os-distribution: cos_containerd to the specification of your customers’ Pods.
Cloud Functions is a serverless execution environment for building and connecting cloud services
Cloud Functions provide scalable pay-as-you-go functions as a service (FaaS) to run code with zero server management.
Cloud Functions are attached to events emitted from the cloud services and infrastructure and are triggered when an event being watched is fired.
Cloud Functions supports multiple language runtimes including Node.js, Python, Go, Java, .Net, Ruby, PHP, etc.
Cloud Functions features include
Zero server management
No servers to provision, manage or upgrade
Google Cloud handles the operational infrastructure including managing servers, configuring software, updating frameworks, and patching operating systems
Provisioning of resources happens automatically in response to events
Automatically scale based on the load
Cloud Function can scale from a few invocations a day to many millions of invocations without any work from you.
Integrated monitoring, logging, and debugging capability
Built-in security at role and per function level based on the principle of least privilege
Cloud Functions uses Google Service Account credential to seamlessly authenticate with the majority of Google Cloud services
Key networking capabilities for hybrid and multi-cloud scenarios
Cloud Functions Execution Environment
Cloud Functions handles incoming requests by assigning them to instances of the function and based on the volume or existing functions, it can assign it to an existing one or spawn a new instance.
Each instance of a function handles only one concurrent request at a time and can use the full amount of resources i.e. CPU and Memory
Cloud Functions may start multiple new instances to handle requests, thus provide auto-scaling and parallelism.
Cloud Functions must be stateless i.e. one function invocation should not rely on an in-memory state set by a previous invocation, to allow Google to automatically manage and scale the functions
Every deployed function is isolated from all other functions – even those deployed from the same source file. In particular, they don’t share memory, global variables, file systems, or other state.
Cloud Functions allows you to set a limit on the total number of function instances that can co-exist at any given time
Cloud Function instance is created when its deployed or the function needs to be scaled
Cloud Functions can have a Cold Start, which is the time involved in loading the runtime and the code.
Function execution time is limited by the timeout duration specified at function deployment time. By default, a function times out after 1 minute but can be extended up to 9 minutes.
Cloud Function provides a writeable filesystem i.e. /tmp directory only, which can be used to store temporary files in a function instance. The rest of the file system is read-only and accessible to the function
Cloud Functions has 2 scopes
Global Scope
contain the function definition,
is executed on every cold start, but not if the instance has already been initialized.
can be used for initialization like database connections etc.
Function Scope
only the body of the function declared as the entry point
is executed for each request and should include the actual logic
Cloud Functions Execution Guarantees
Functions are typically invoked once for each incoming event. However, Cloud Functions does not guarantee a single invocation in all cases
HTTP functions are invoked at most once as they are synchronous and the execution is not retried in an event of a failure
Event-driven functions are invoked at least once as they are asynchronous and can be retried
Cloud Functions Events and Triggers
Events are things that happen within the cloud environment that you might want to take action on.
Trigger is creating a response to that event. Trigger type determines how and when the function executes.
Cloud Functions supports the following native trigger mechanisms:
HTTP Triggers
Cloud Functions can be invoked with an HTTP request using the POST, PUT, GET, DELETE, and OPTIONS HTTP methods
HTTP invocations are synchronous and the result of the function execution will be returned in the response to the HTTP request.
Cloud Endpoints Triggers
Cloud Functions can be invoked through Cloud Endpoints, which uses the Extensible Service Proxy V2 (ESPv2) as an API gateway
ESPv2 intercepts all requests to the functions and performs any necessary checks (such as authentication) before invoking the function. ESPv2 also gathers and reports telemetry
Cloud Pub/Sub Triggers
Cloud Functions can be triggered by messages published to Pub/Sub topics in the same Cloud project as the function.
Pub/Sub is a globally distributed message bus that automatically scales as needed and provides a foundation for building robust, global services.
Cloud Functions can respond to change notifications emerging from Google Cloud Storage.
Notifications can be configured to trigger in response to various events inside a bucket – object creation, deletion, archiving, and metadata updates.
Cloud Functions can only be triggered by Cloud Storage buckets in the same Google Cloud Platform project.
Direct Triggers
Cloud Functions provides a call command in the command-line interface and testing functionality in the Cloud Console UI to support quick iteration and debugging
Function can be directly invoked to ensure it is behaving as expected. This causes the function to execute immediately, even though it may have been deployed to respond to a specific event.
Cloud Firestore
Cloud Functions can handle events in Cloud Firestore in the same Cloud project as the function.
Cloud Firestore can be read or updated in response to these events using the Firestore APIs and client libraries.
Analytics for Firebase
Firebase Realtime Database
Firebase Authentication
Cloud Functions can be triggered by events from Firebase Authentication in the same Cloud project as the function.
Cloud Functions can also be integrated with any other Google service that supports Cloud Pub/Sub for e.g. Cloud Scheduler, or any service that provides HTTP callbacks (webhooks)
Google Cloud Logging events can be exported to a Cloud Pub/Sub topic from which they can then be consumed by Cloud Functions.
Cloud Functions Best Practices
Write Idempotent functions – produce same events when invoke multiple times with the same parameters
Do not start background activities i.e. activity after function has terminated. Any code run after graceful termination cannot access the CPU and will not make any progress.
Always delete temporary files – As files can persist between invocations, failing to delete files may lead to memory issues
Use dependencies wisely – Import only what is required as it would impact the cold starts due to invocation latency
Use global variables to reuse objects in future invocations for e.g. database connections
Do lazy initialization of global variables
Use retry to handle only transient and retryable errors, with the handling being idempotent
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
HipLocal is a community application designed to facilitate communication between people in close proximity. It is used for event planning and organizing sporting events, and for businesses to connect with their local communities. HipLocal launched recently in a few neighborhoods in Dallas and is rapidly growing into a global phenomenon. Its unique style of hyper-local community communication and business outreach is in demand around the world.
Key point here is HipLocal is expanding globally
HipLocal Solution Concept
HipLocal wants to expand their existing service with updated functionality in new locations to better serve their global customers. They want to hire and train a new team to support these locations in their time zones. They will need to ensure that the application scales smoothly and provides clear uptime data, and that they analyze and respond to any issues that occur.
Key points here are HipLocal wants to expand globally, with an ability to scale and provide clear observability, alerting and ability to react.
HipLocal Existing Technical Environment
HipLocal’s environment is a mixture of on-premises hardware and infrastructure running in Google Cloud. The HipLocal team understands their application well, but has limited experience in globally scaled applications. Their existing technical environment is as follows:
Existing APIs run on Compute Engine virtual machine instances hosted in Google Cloud.
Expand availability of the application to new locations.
Support 10x as many concurrent users.
State is stored in a single instance MySQL database in Google Cloud.
Release cycles include development freezes to allow for QA testing.
The application has no consistent logging.
Applications are manually deployed by infrastructure engineers during periods of slow traffic on weekday evenings.
There are basic indicators of uptime; alerts are frequently fired when the APIs are unresponsive.
Business requirements
HipLocal’s investors want to expand their footprint and support the increase in demand they are experiencing. Their requirements are:
Expand availability of the application to new locations.
deploying the applications across multiple regions.
Support 10x as many concurrent users.
As the APIs run on Compute Engine, the scale can be implemented using Managed Instance Groups frontend by a Load Balancer OR App Engine OR Container-based application deployment
Scaling policies can be defined to scale as per the demand.
Ensure a consistent experience for users when they travel to different locations.
Consistent experience for the users can be provided using either
Google Cloud Global Load Balancer which uses GFE and routes traffic close to the users
multi-region setup targeting each region
Obtain user activity metrics to better understand how to monetize their product.
User activity data can also be exported to BigQuery for analytics and monetization
Cloud Monitoring and Logging can be configured for application logs and metrics to provide observability, alerting, and reporting.
Cloud Logging can be exported to BigQuery for analytics
Ensure compliance with regulations in the new regions (for example, GDPR).
Compliance is shared responsibility, while Google Cloud ensures compliance of its services, application hosted on Google Cloud would be customer responsibility
GDPR or other regulations for data residency can be met using setup per region, so that the data resides with the region
Reduce infrastructure management time and cost.
As the infrastructure is spread across on-premises and Google Cloud, it would make sense to consolidate the infrastructure into one place i.e. Google Cloud
Consolidation would help in automation, maintenance, as well as provide cost benefits.
Adopt the Google-recommended practices for cloud computing:
Develop standardized workflows and processes around application lifecycle management.
Define service level indicators (SLIs) and service level objectives (SLOs).
Technical requirements
Provide secure communications between the on-premises data center and cloud hosted applications and infrastructure
Secure communications can be enabled between the on-premise data centers and the Cloud using Cloud VPN and Interconnect.
The application must provide usage metrics and monitoring.
Cloud Monitoring and Logging can be configured for application logs and metrics to provide observability, alerting, and reporting.
APIs require authentication and authorization.
APIs can be configured for various Authentication mechanisms.
APIs can be exposed through a centralized Cloud Endpoints gateway
Internal Applications can be exposed using Cloud Identity-Aware Proxy
Implement faster and more accurate validation of new features.
QA Testing can be improved using automated testing
Production Release cycles can be improved using canary deployments to test the applications on a smaller base before rolling out to all.
Application can be deployed to App Engine which supports traffic spilling out of the box for canary releases
Logging and performance metrics must provide actionable information to be able to provide debugging information and alerts.
Cloud Monitoring and Logging can be configured for application logs and metrics to provide observability, alerting, and reporting.
Cloud Logging can be exported to BigQuery for analytics
Must scale to meet user demand.
As the APIs run on Compute Engine, the scale can be implemented using Managed Instance Groups frontend by a Load Balancer and using scaling policies as per the demand.
Single instance MySQL instance can be migrated to Cloud SQL. This would not need any application code changes and can be as-is migration. With read replicas to scale both horizontally and vertically seamlessly.
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Which database should HipLocal use for storing state while minimizing application changes?
Firestore
BigQuery
Cloud SQL
Cloud Bigtable
Which architecture should HipLocal use for log analysis?
Use Cloud Spanner to store each event.
Start storing key metrics in Memorystore.
Use Cloud Logging with a BigQuery sink.
Use Cloud Logging with a Cloud Storage sink.
HipLocal wants to improve the resilience of their MySQL deployment, while also meeting their business and technical requirements. Which configuration should they choose?
Use the current single instance MySQL on Compute Engine and several read-only MySQL servers on Compute Engine.
Use the current single instance MySQL on Compute Engine, and replicate the data to Cloud SQL in an external master configuration.
Replace the current single instance MySQL instance with Cloud SQL, and configure high availability.
Replace the current single instance MySQL instance with Cloud SQL, and Google provides redundancy without further configuration.
Which service should HipLocal use to enable access to internal apps?
Cloud VPN
Cloud Armor
Virtual Private Cloud
Cloud Identity-Aware Proxy
Which database should HipLocal use for storing user activity?
Cloud Storage does not permanently store the key on Google’s servers or otherwise manage your key.
Customer provides the key for each GCS operation, and the key is purged from Google’s servers after the operation is complete
Cloud Storage stores only a cryptographic hash of the key so that future requests can be validated against the hash.
The key cannot be recovered from this hash, and the hash cannot be used to decrypt the data.
Client-side encryption: encryption that occurs before data is sent to Cloud Storage, encrypted at the client-side. This data also undergoes server-side encryption.
Cloud Storage supports Transport Layer Security, commonly known as TLS or HTTPS for data encryption in transit
Signed URLs
Signed URLs provide time-limited read or write access to an object through a generated URL.
Anyone having access to the URL can access the object for the duration of time specified, regardless of whether or not they have a Google account.
Signed Policy Documents
Signed policy documents help specify what can be uploaded to a bucket.
Policy documents allow greater control over size, content type, and other upload characteristics than signed URLs, and can be used by website owners to allow visitors to upload files to Cloud Storage.
Retention Policies
Retention policy on a bucket ensures that all current and future objects in the bucket cannot be deleted or replaced until they reach the defined age
Retention policy can be applied when creating a bucket or to an existing bucket
Retention policy retroactively applies to existing objects in the bucket as well as new objects added to the bucket.
Retention Policy Locks
Retention policy locks will lock a retention policy on a bucket, which prevents the policy from ever being removed or the retention period from ever being reduced (although it can be increased)
Once a retention policy is locked, the bucket cannot be deleted until every object in the bucket has met the retention period.
Locking a retention policy is irreversible
Bucket Lock
Bucket Lock feature provides immutable storage i.e. Write Once Read Many (WORM) on Cloud Storage
Bucket Lock feature allows configuring a data retention policy for a bucket that governs how long objects in the bucket must be retained
Bucket Lock feature also locks the data retention policy, permanently preventing the policy from being reduced or removed.
Bucket Lock can help with regulatory, legal, and compliance requirements
Object Holds
Object holds, when set on individual objects, prevents the object from being deleted or replaced, however allows metadata to be edited.
Cloud Storage offers the following types of holds:
Event-based holds.
Temporary holds.
When an object is stored in a bucket without a retention policy, both hold types behave exactly the same.
When an object is stored in a bucket with a retention policy, the hold types have different effects on the object when the hold is released:
An event-based hold resets the object’s time in the bucket for the purposes of the retention period.
A temporary hold does not affect the object’s time in the bucket for the purposes of the retention period.
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You have an object in a Cloud Storage bucket that you want to share with an external company. The object contains sensitive data. You want access to the content to be removed after four hours. The external company does not have a Google account to which you can grant specific user-based access privileges. You want to use the most secure method that requires the fewest steps. What should you do?
Create a signed URL with a four-hour expiration and share the URL with the company.
Set object access to “public” and use object lifecycle management to remove the object after four hours.
Configure the storage bucket as a static website and furnish the object’s URL to the company. Delete the object from the storage bucket after four hours.
Create a new Cloud Storage bucket specifically for the external company to access. Copy the object to that bucket. Delete the bucket after four hours have passed
AWS Partnerships That Have Upgraded the Way Businesses Collaborate
Credit: Unsplash
Through the AWS Partner Network (APN), brands have been able to reach customers and help improve businesses across the globe. AWS channel chief Doug Yeum explains that the benefits to brands in the APN can be tremendous. In his keynote presentation at the AWS re:Invest 2020 conference, he said, “Companies are looking for AWS partners who can deliver end-to-end solutions, develop cloud-native applications in addition to managing the cloud infrastructure, and have deep specializations across industries, use cases, specific workloads like SAP and AWS services. Partners who can meet these customer requirements and truly understand that speed matters — there will be lots of opportunities.”
Indeed, we’ve seen some great AWS partnerships present innovative ways to solve every business need imaginable. Here are some of the most memorable AWS partnerships to have upgraded the way businesses collaborate:
AliCloud
Having been an AWS Premier Consulting Partner and AWS Managed Services Provider since 2008, AliCloud is at the forefront of AWS partnerships. With the help of AWS resources like training, marketing, and solutions development assistance, the company aims to improve AWS adoption by onboarding new startup and enterprise customers. AliCloud hopes to use its many years of experience to introduce new customers to the wonders of cloud services.
Altium
Altium is a leading provider of electronics designing software that aims to streamline the process for both beginning and experienced engineers. In an effort to make the development and realization of printed circuit boards more streamlined, they developed Altium 365, a completely cloud-based design platform that creates seamless collaboration points across the electronics development process. In 2020, Altium selected AWS to host Altium 365, making it more accessible to individual and enterprise clients alike.
Deloitte
Professional services network Deloitte is known for providing support to companies across over 150 countries worldwide, and through its collaboration with AWS, it has developed Smart Factory Fabric. With it, they now empower smart factory transformations at both the plant and enterprise level. The Smart Factory Fabric is a pre-configured suite of cloud-based applications that help industrial enterprises quickly transition to the digital world, improving operational performance and reducing costs.
Infostretch
Offering three services on AWS, InfoStretch aims to enable enterprise clients to accelerate their digital initiatives through DevSecOps, Internet of Things (IoT) offerings, data engineering, and data analytics services, among others. Through their “Go, Be, Evolve” digital approach, they assist clients in the digital maturity journey from strategy, planning, migration, and execution, all the way to automation.
Lemongrass
Specializing in providing SAP solutions for enterprises on AWS, Lemongrass became an AWS partner because of the latter’s position as a leader in cloud infrastructure. Eamonn O’Neill, director of Lemongrass Consulting, has stated that the infrastructure of AWS was perfect for their services, as it’s “incredibly resilient, and incredibly well built.”
Whats Next !
But what’s next for AWS? Following amazing partnerships that seek to revolutionize the way we do business, Amazon is rolling out some great features, including the mainstreaming of Graviton2 processors, which promise to streamline cloud computing. AWS is also constantly working to re-evaluate its systems to ensure better cost-savings management for customers. Improvements are also being made to Aurora Serverless, enabling it to support customers who want to continue scaling up.
AWS can be a game-changer for many businesses. With a robust operations hub like AWS Systems Manager, businesses have great control over operational tasks, troubleshooting, and resource and application management. With AWS announcing that it adds 50 new partners to the APN daily, the network has become a great resource for end-to-end solutions and cloud-native application development.
Google Cloud – Professional Cloud Security Engineer Certification learning path
Continuing on the Google Cloud Journey, have just cleared the Professional Cloud Security certification. Google Cloud – Professional Cloud Security Engineer certification exam focuses on almost all of the Google Cloud security services with storage, compute, networking services with their security aspects only.
Google Cloud -Professional Cloud Security Engineer Certification Summary
Has 50 questions to be answered in 2 hours.
Covers a wide range of Google Cloud services mainly focusing on security and network services
As mentioned for all the exams, Hands-on is a MUST, if you have not worked on GCP before make sure you do lots of labs else you would be absolutely clueless about some of the questions and commands
I did Coursera and ACloud Guru which is really vast, but hands-on or practical knowledge is MUST.
Google Cloud – Professional Cloud Security Engineer Certification Resources
Cloud KMS provides a centralized, scalable, fast cloud key management service to manage encryption keys
KMS Key is a named object containing one or more key versions, along with metadata for the key.
KMS KeyRing provides grouping keys with related permissions that allow you to grant, revoke, or modify permissions to those keys at the key ring level without needing to act on each key individually.
Cloud Armor
Cloud Armor protects the applications from multiple types of threats, including DDoS attacks and application attacks like XSS and SQLi
works with the external HTTP(S) load balancer to automatically block network protocol and volumetric DDoS attacks such as protocol floods (SYN, TCP, HTTP, and ICMP) and amplification attacks (NTP, UDP, DNS)
with GKE needs to be configured with GKE Ingress
can be used to blacklist IPs
supports preview mode to understand patterns without blocking the users
Cloud Identity-Aware Proxy
Identity-Aware Proxy IAP allows managing access to HTTP-based apps both on Google Cloud and outside of Google Cloud.
IAP uses Google identities and IAM and can leverage external identity providers as well like OAuth with Facebook, Microsoft, SAML, etc.
Signed headers using JWT provide secondary security in case someone bypasses IAP.
Cloud Data Loss Prevention – DLP
Cloud Data Loss Prevention – DLP is a fully managed service designed to help discover, classify, and protect the most sensitive data.
provides two key features
Classification is the process to inspect the data and know what data we have, how sensitive it is, and the likelihood.
De-identification is the process of removing, masking, redaction, replacing information from data.
supports text, image, and storage classification with scans on data stored in Cloud Storage, Datastore, and BigQuery
supports scanning of binary, text, image, Microsoft Word, PDF, and Apache Avro files
Web Security Scanner
Web Security Scanner identifies security vulnerabilities in the App Engine, GKE, and Compute Engine web applications.
scans provide information about application vulnerability findings, like OWASP, XSS, Flash injection, outdated libraries, cross-site scripting, clear-text passwords, or use of mixed content
Security Command Center – SCC
is a Security and risk management platform that helps generate curated insights and provides a unique view of incoming threats and attacks to the assets
displays possible security risks, called findings, that are associated with each asset.
Forseti Security
the open-source security toolkit, and third-party security information and event management (SIEM) applications
keeps track of the environment with inventory snapshots of GCP resources on a recurring cadence
Access Context Manager
Access Context Manager allows organization administrators to define fine-grained, attribute-based access control for projects and resources
Access Context Manager helps reduce the size of the privileged network and move to a model where endpoints do not carry ambient authority based on the network.
Access Context Manager helps prevent data exfiltration with proper access levels and security perimeter rules
FIPS 140-2 Validated certification was established to aid in the protection of digitally stored unclassified, yet sensitive, information.
Google Cloud uses a FIPS 140-2 validated encryption module called BoringCrypto in the production environment. This means that both data in transit to the customer and between data centers, and data at rest are encrypted using FIPS 140-2 validated encryption.
BoringCrypto module that achieved FIPS 140-2 validation is part of the BoringSSL library.
BoringSSL library as a whole is not FIPS 140-2 validated
PCI/DSS compliance is a shared responsibility model
Egress rules cannot be controlled for App Engine, Cloud Functions, and Cloud Storage. Google recommends using compute Engine and GKE to ensure that all egress traffic is authorized.
Antivirus software and File Integrity monitoring must be used on all systems commonly affected by malware to protect systems from current and evolving malicious software threats including containers
For payment processing, the security can be improved and compliance proved by isolating each of these environments into its own VPC network and reduce the scope of systems subject to PCI audit standards
Firewall rules control the Traffic to and from instances. HINT: rules with lower integers indicate higher priorities. Firewall rules can be applied to specific tags.
Know implied firewall rules which deny all ingress and allow all egress
Understand the difference between using Service Account vs Network Tags for filtering in Firewall rules. HINT: Use SA over tags as it provides access control while tags can be easily inferred.
VPC Peering allows internal or private IP address connectivity across two VPC networks regardless of whether they belong to the same project or the same organization. HINT: VPC Peering uses private IPs and does not support transitive peering
Shared VPC allows an organization to connect resources from multiple projects to a common VPC network so that they can communicate with each other securely and efficiently using internal IPs from that network
Private Access options for services allow instances with internal IP addresses can communicate with Google APIs and services.
Private Google Access allows VMs to connect to the set of external IP addresses used by Google APIs and services by enabling Private Google Access on the subnet used by the VM’s network interface.
VPC Flow Logs records a sample of network flows sent from and received by VM instances, including instances used as GKE nodes.
Firewall Rules Logging enables auditing, verifying, and analyzing the effects of the firewall rules
Cloud VPN provides secure connectivity from the on-premises data center to the GCP network through the public internet. Cloud VPN does not provide internal or private IP connectivity
Cloud Interconnect provides direct connectivity from the on-premises data center to the GCP network
Cloud NAT
Cloud NAT allows VM instances without external IP addresses and private GKE clusters to send outbound packets to the internet and receive any corresponding established inbound response packets.
Requests would not be routed through Cloud NAT if they have an external IP address
supports DNSSEC, a feature of DNS, that authenticates responses to domain name lookups and protects the domains from spoofing and cache poisoning attacks
Cloud Load Balancing
Google Cloud Load Balancing provides scaling, high availability, and traffic management for your internet-facing and private applications.
Understand Google Load Balancing options and their use cases esp. which is global, internal and does they support SSL offloading
Network Load Balancer – regional, external, pass through and supports TCP/UDP
Internal TCP/UDP Load Balancer – regional, internal, pass through and supports TCP/UDP
HTTP/S Load Balancer – regional/global, external, pass through and supports HTTP/S
Internal HTTP/S Load Balancer – regional/global, internal, pass through and supports HTTP/S
IAM Policy inheritance is transitive and resources inherit the policies of all of their parent resources.
Effective policy for a resource is the union of the policy set on that resource and the policies inherited from higher up in the hierarchy.
Identity and Access Management
Identify and Access Management – IAM provides administrators the ability to manage cloud resources centrally by controlling who can take what action on specific resources.
A service account is a special kind of account used by an application or a virtual machine (VM) instance, not a person.
Service Account, if accidentally deleted, can be recovered if the time gap is less than 30 days and a service account by the same name wasn’t created
Use groups for users requiring the same responsibilities
Use service accounts for server-to-server interactions.
Use Organization Policy Service to get centralized and programmatic control over the organization’s cloud resources.
Domain-wide delegation of authority to grant third-party and internal applications access to the users’ data for e.g. Google Drive etc.
Cloud Identity
Cloud Identity provides IDaaS (Identity as a Service) and provides single sign-on functionality and federation with external identity provides like Active Directory.
Compute services like Google Compute Engine and Google Kubernetes Engine are lightly covered more from the security aspects
Google Compute Engine
Google Compute Engine is the best IaaS option for compute and provides fine-grained control
Managing access using OS Login or project and instance metadata
Compute Engine is recommended to be used with Service Account with the least privilege to provide access to Google services and the information can be queried from instance metadata.
Understand various Data Encryption techniques including Envelope Encryption, CMEK, and CSEK. HINT: CSEK works with Cloud Storage and Persistent Disks only. CSEK manages KEK and not DEK.
Cloud Storage default encryption uses AES256
Understand Signed URL to give temporary access and the users do not need to be GCP users
Understand access control and permissions – IAM (Uniform) vs ACLs (fine-grained control)
Bucket Lock feature allows configuring a data retention policy for a bucket that governs how long objects in the bucket must be retained. The feature also allows locking the data retention policy, permanently preventing the policy from being reduced or removed
Access Context Manager allows organization administrators to define fine-grained, attribute-based access control for projects and resources
Access Context Manager helps prevent data exfiltration
Access Context Manager helps reduce the size of the privileged network and move to a model where endpoints do not carry ambient authority based on the network.
Access Context Manager helps define desired rules and policy but isn’t responsible for policy enforcement. The policy is configured and enforced across various points, such as VPC Service Controls.
Administrators define an access policy, which is an organization-wide container for access levels and service perimeters.
Access levels are used for permitting access to resources based on contextual information about the request.
Access is granted based on the context of the request, such as device type, user identity, and more, while still checking for corporate network access when necessary.
Access Context Manager provides two ways to define access levels: basic and custom.
Basic Access level
is a collection of conditions that are used to test requests.
Conditions are a group of attributes to be tested, such as device type, IP address, or user identity.
Access level attributes represent contextual information about a request.
Custom access levels
are created using a subset of Common Expression Language.
helps to permit requests based on data from third-party services.
Service perimeters define sandboxes of resources that can freely exchange data within the perimeter but are not allowed to export data outside of it.
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
An “app” is considered to be a single piece of software, with a unique parent process, and potentially several child processes.
A container is designed to have the same lifecycle as the app it hosts, so each of the containers should contain only one app. When a container starts, so should the app, and when the app stops, so should the container. for e.g. in the case of the classic Apache/MySQL/PHP stack, each component must be hosted in a separate container.
Properly handle PID 1, signal handling, and zombie processes
Linux signals are the main way to control the lifecycle of processes inside a container.
The app within the container should handle the Linux signals, as well as the best practice of a single app per container should be implemented.
Process identifiers (PIDs) are unique identifiers that the Linux kernel gives to each process.
PIDs are namespace, i.e. the containers PIDs are different from the host and are mapped to the PIDs on the host system.
Docker and Kubernetes use signals to communicate with the processes inside containers, most notably to terminate them.
Both Docker and Kubernetes can only send signals to the process that has PID 1 inside a container.
For Signal handling and Zombie processes following can be followed
Run as PID 1 and register signal handlers
Launch the process with the CMD and/or ENTRYPOINT instructions in the Dockerfile, which would give the PID 1 to the process
Use the built-in exec command to launch the process from the shell script. The exec command replaces the script with the program and the process then inherits PID 1.
Enable process namespace sharing in Kubernetes
Process namespace sharing for a Pod can be enabled where Kubernetes uses a single process namespace for all the containers in that Pod.
Kubernetes Pod infrastructure container becomes PID 1 and automatically reaps orphaned processes.
Use a specialized init system
Init system such as tini created especially for containers that can be used to handle signals and reaps any zombie processes
Optimize for the Docker build cache
Images are built layer by layer, and in a Dockerfile, each instruction creates a layer in the resulting image.
Docker build cache can accelerate the building of container images.
During a build, when possible, Docker reuses a layer from a previous build and skips a potentially costly step.
Docker can use its build cache only if all previous build steps used it.
Remove unnecessary tools
Remove unnecessary tools helps reduce the attack surface of the app by removing any unnecessary tools.
Avoid running as root inside the container: this method offers the first layer of security and could prevent attackers from modifying files
Launch the container in read-only mode using the --read-only flag from the docker run or by using the readOnlyRootFilesystem option in Kubernetes.
Build the smallest image possible
Smaller image offers advantages such as faster upload and download times
To reduce the size of the image, install only what is strictly needed
Scan images for vulnerabilities
For vulnerabilities, as the containers are supposed to be immutable, the best practice is to rebuild the image, patches included, and redeploy it
As containers have a shorter lifecycle and a less well-defined identity than servers, a centralized inventory system would not work effectively
Container Analysis can scan the images for security vulnerabilities in publicly monitored packages
Using public image
Consider before using public images as you cannot control what’s inside them
Public image such as Debian or Alpine can be used as the base image and building everything on top of that image
Managed Base Images
Managed base images are base container images that are automatically patched by Google for security vulnerabilities, using the most recent patches available from the project upstream
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
When creating a secure container image, which two items should you incorporate into the build if possible?
Use public container images as a base image for the app.
Build the smallest image possible
Use many container image layers to hide sensitive information.
Google Cloud KMS – Key Management Service provides a centralized, scalable, fast cloud key management service to manage encryption keys
KMS helps apply hardware security modules (HSMs) effortlessly to the most sensitive data by just a toggle between software- and hardware-protected encryption keys with the press of a button.
KMS provides support for external keys using Cloud External Key Manager to protect the data in Google Cloud and separate the data from the key
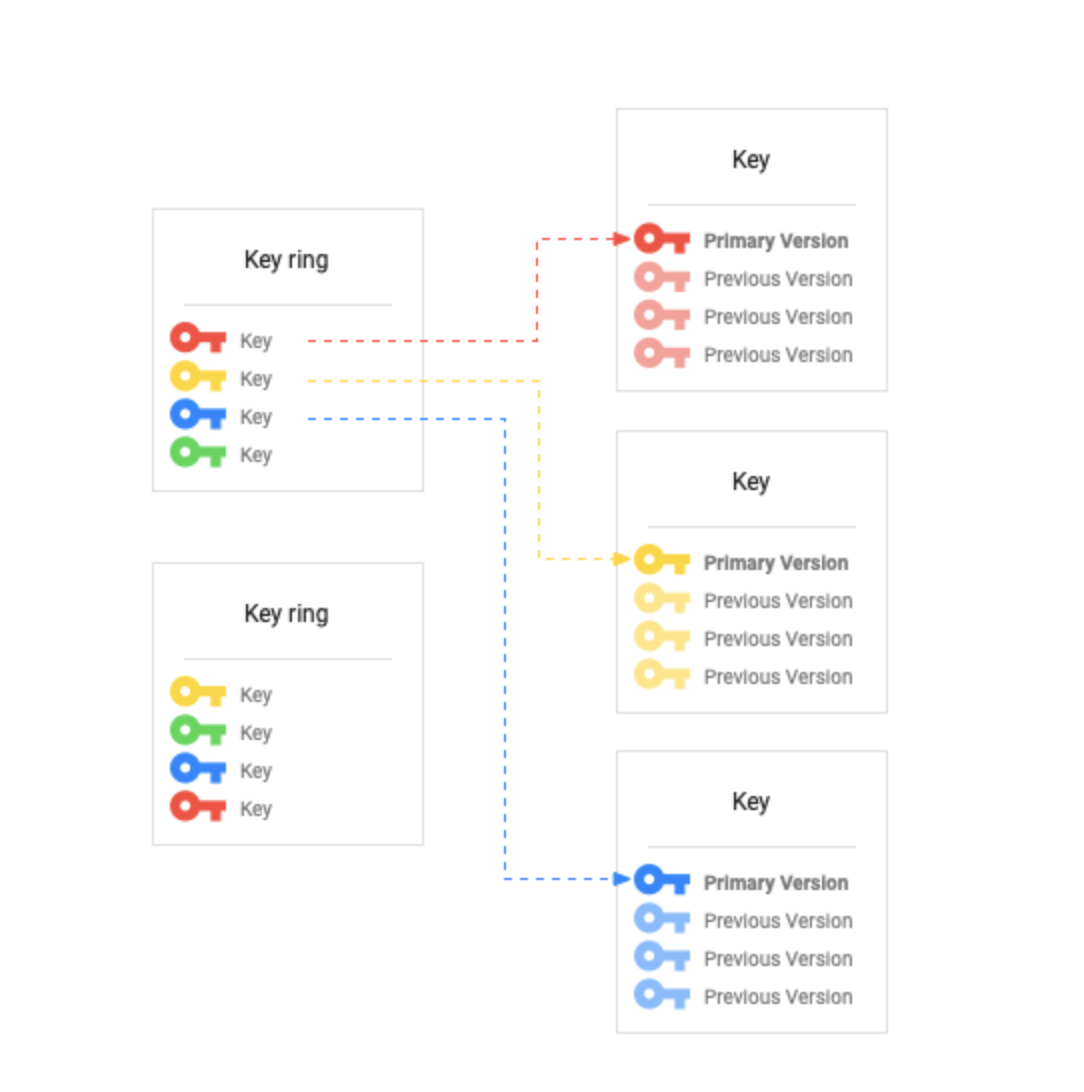
Cloud KMS Keys, Keys Versions, and Key Rings
A Cloud KMS key is a named object containing one or more key versions, along with metadata for the key.
A key exists on exactly one key ring tied to a specific location.
After creation, a key cannot be moved to another location or exported.
Key
A named object representing a cryptographic key that is used for a specific purpose. The key material – the actual bits used for cryptographic operations – can change over time as new key versions are created
Key is the most important object for understanding KMS usage.
Key purpose and other attributes of the key are connected with and managed using the key.
IAM permissions and roles can be used to allow and deny access to keys
Cloud KMS supports both asymmetric keys and symmetric keys.
Symmetric key
is used for symmetric encryption to protect some corpus of data for e.g., using AES-256 to encrypt a block of plaintext.
Asymmetric key
consists of a public and private key.
can be used for asymmetric encryption, or for creating digital signatures.
Key’s type (symmetric or asymmetric) can’t be changed after key creation
Key Ring
A grouping of keys for organizational purposes.
Key ring belongs to Google Cloud project and resides in a specific location
Keys inherit IAM policies from the Key Ring that contains them.
Grouping keys with related permissions in a key ring allows you to grant, revoke, or modify permissions to those keys at the key ring level without needing to act on each key individually.
Key rings provide convenience and categorization
To prevent resource name collisions, a key ring cannot be deleted.
Key rings and keys do not have billable costs or quota limitations, so their continued existence does not affect costs or production limits.
Key Metadata
Includes resource names, properties of KMS resources such as IAM policies, key type, key size, key state, and any other derived data
Key metadata can be managed differently than the key material.
Key Version
Represents the key material associated with a key at some point in time.
Key version is the resource that contains the actual key material.
Granting access to a key also grants access to all of its enabled versions. Access to a key version cannot be managed.
A key version can be disabled or destroyed without affecting other versions
Disabling or destroying a key also disables or destroys each key version.
Versions are numbered sequentially, beginning with version 1.
When a key is rotated, a new key version is created with new key material.
The same logical key can have multiple versions over time, thus limiting the use of any single version.
Symmetric keys will always have a primary version. This version is used for encrypting by default, if not version is specified
Asymmetric keys do not have primary versions, and a version must be specified when using the key.
When Cloud KMS performs decryption using symmetric keys, it identifies automatically which key version is needed to perform the decryption.
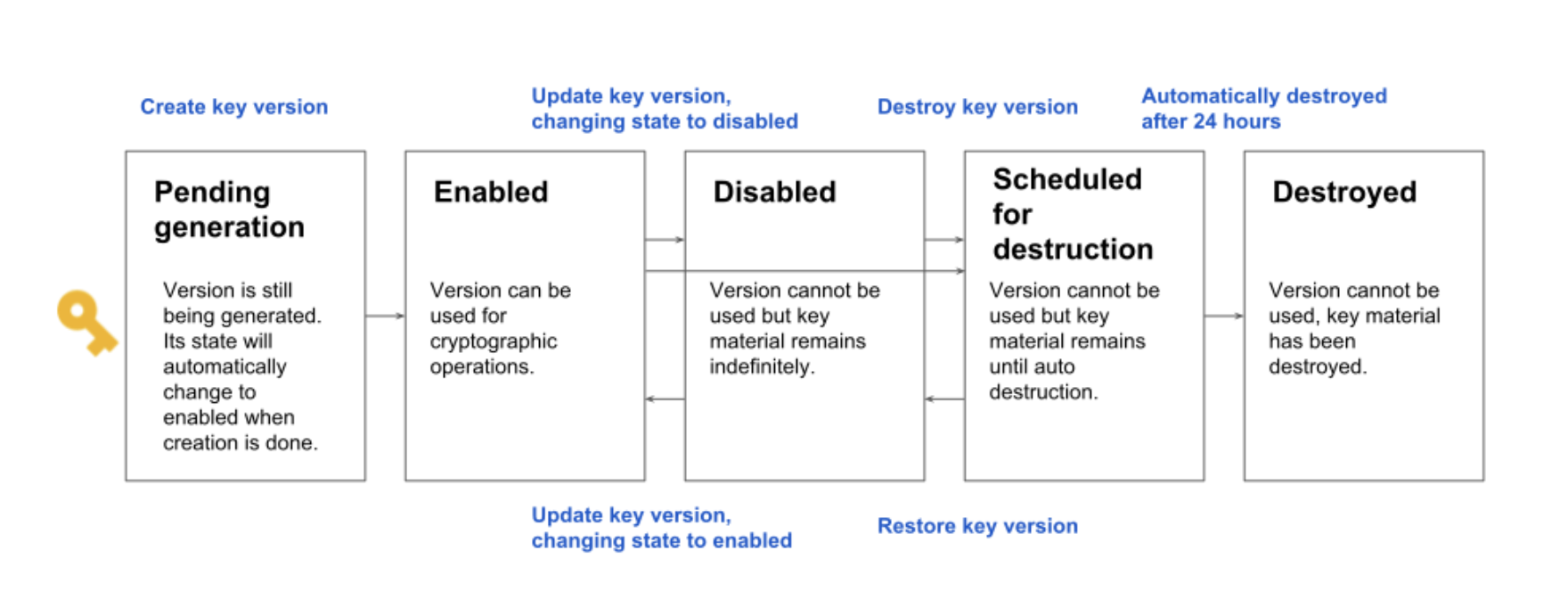
Key States
A key version’s state is always one of the following:
Pending generation (PENDING_GENERATION)
Applies to asymmetric keys only
is still being generated and can’t be used, enabled, disabled, or destroyed yet.
KMS will automatically change the state to enabled as soon as the version is ready.
Enabled (ENABLED)
is ready for use.
Disabled (DISABLED)
may not be used, but the key material is still available, and the version can be placed back into the enabled state.
Scheduled for destruction (DESTROY_SCHEDULED):
is scheduled for destruction, and will be destroyed soon.
can be placed back into the disabled state.
Destroyed (DESTROYED)
is destroyed, and the key material is no longer stored in Cloud KMS.
If the key version was used
for asymmetric or symmetric encryption, any ciphertext encrypted with this version is not recoverable.
for digital signing, new signatures cannot be created.
may not leave the destroyed state once entered.
A key version can only be used when it is enabled.
Key Rotation
For symmetric encryption, periodically and automatically rotating keys is a recommended security practice
Cloud MS does not support automatic rotation of asymmetric keys and has to be done manually
With key rotation, data encrypted with previous key versions is not automatically re-encrypted with the new key version.
Rotating keys provides several benefits:
Limiting the number of messages encrypted with the same key version helps prevent brute-force attacks enabled by cryptanalysis.
In the event that a key is compromised, regular rotation limits the number of actual messages vulnerable to compromise.
If you suspect that a key version is compromised, disable it and revoke access to it as soon as possible.
Regular key rotation helps validate the key rotation procedures before a real-life security incident occurs.
Regular key rotation ensures that the system is resilient to manual rotation, whether due to a security breach or the need to migrate your application to a stronger cryptographic algorithm.
Key Hierarchy
Data Encryption Key (DEK)
A key used to encrypt data.
Key Encryption Key (KEK)
A key used to encrypt, or wrap, a DEK.
All Cloud KMS platform options (software, hardware, and external backends) allow you to control KEK.
KMS Master Key
The key used to encrypt the KEK.
This key is distributed in memory.
KMS Master Key is backed up on hardware devices.
Root KMS
Google’s internal key management service.
Cloud KMS Locations
Within a project, Cloud KMS resources can be created in one of many locations.
A key’s location impacts the performance of applications using the key
Regional
data centers exist in a specific geographical place
Dual-regional
data centers exist in two specific geographical places.
Multi-regional
data centers are spread across a general geographical area
Global
special multi-region with its data centers spread throughout the world
Reading and writing resources or associated metadata in dual-regional or multi-regional locations, including the global location may be slower than reading or writing from a single region.
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.



 Key
Key