Google Cloud – HipLocal Case Study
HipLocal is a community application designed to facilitate communication between people in close proximity. It is used for event planning and organizing sporting events, and for businesses to connect with their local communities. HipLocal launched recently in a few neighborhoods in Dallas and is rapidly growing into a global phenomenon. Its unique style of hyper-local community communication and business outreach is in demand around the world.
Key point here is HipLocal is expanding globally
HipLocal Solution Concept
HipLocal wants to expand their existing service with updated functionality in new locations to better serve their global customers. They want to hire and train a new team to support these locations in their time zones. They will need to ensure that the application scales smoothly and provides clear uptime data, and that they analyze and respond to any issues that occur.
Key points here are HipLocal wants to expand globally, with an ability to scale and provide clear observability, alerting and ability to react.
HipLocal Existing Technical Environment
HipLocal’s environment is a mixture of on-premises hardware and infrastructure running in Google Cloud. The HipLocal team understands their application well, but has limited experience in globally scaled applications. Their existing technical environment is as follows:
- Existing APIs run on Compute Engine virtual machine instances hosted in Google Cloud.
- Expand availability of the application to new locations.
- Support 10x as many concurrent users.
- State is stored in a single instance MySQL database in Google Cloud.
- Release cycles include development freezes to allow for QA testing.
- The application has no consistent logging.
- Applications are manually deployed by infrastructure engineers during periods of slow traffic on weekday evenings.
- There are basic indicators of uptime; alerts are frequently fired when the APIs are unresponsive.
Business requirements
HipLocal’s investors want to expand their footprint and support the increase in demand they are experiencing. Their requirements are:
- Expand availability of the application to new locations.
- Availability can be achieved using either
- scaling the application and exposing it through Global Load Balancer OR
- deploying the applications across multiple regions.
- Support 10x as many concurrent users.
- As the APIs run on Compute Engine, the scale can be implemented using Managed Instance Groups frontend by a Load Balancer OR App Engine OR Container-based application deployment
- Scaling policies can be defined to scale as per the demand.
- Ensure a consistent experience for users when they travel to different locations.
- Consistent experience for the users can be provided using either
- Google Cloud Global Load Balancer which uses GFE and routes traffic close to the users
- multi-region setup targeting each region
- Obtain user activity metrics to better understand how to monetize their product.
- User activity data can also be exported to BigQuery for analytics and monetization
- Cloud Monitoring and Logging can be configured for application logs and metrics to provide observability, alerting, and reporting.
- Cloud Logging can be exported to BigQuery for analytics
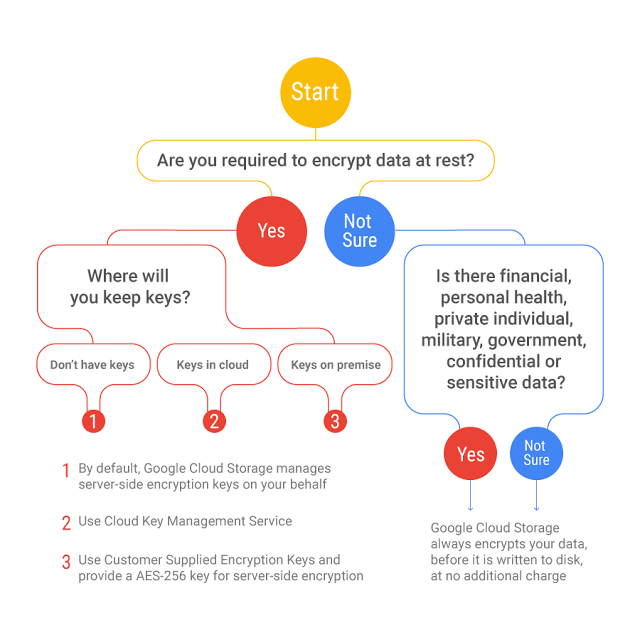
- Ensure compliance with regulations in the new regions (for example, GDPR).
- Compliance is shared responsibility, while Google Cloud ensures compliance of its services, application hosted on Google Cloud would be customer responsibility
- GDPR or other regulations for data residency can be met using setup per region, so that the data resides with the region
- Reduce infrastructure management time and cost.
- As the infrastructure is spread across on-premises and Google Cloud, it would make sense to consolidate the infrastructure into one place i.e. Google Cloud
- Consolidation would help in automation, maintenance, as well as provide cost benefits.
- Adopt the Google-recommended practices for cloud computing:
- Develop standardized workflows and processes around application lifecycle management.
- Define service level indicators (SLIs) and service level objectives (SLOs).
Technical requirements
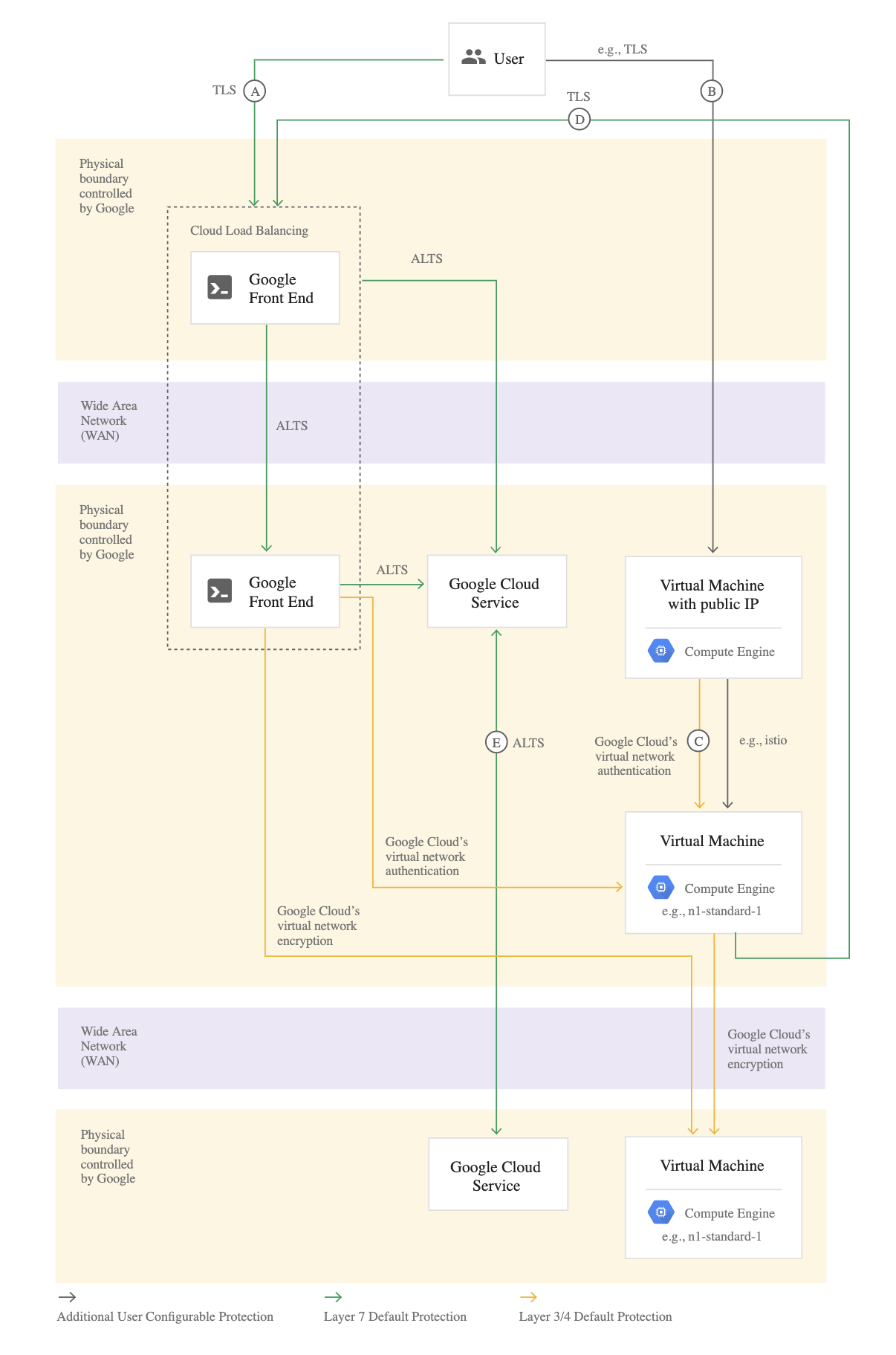
- Provide secure communications between the on-premises data center and cloud hosted applications and infrastructure
- Secure communications can be enabled between the on-premise data centers and the Cloud using Cloud VPN and Interconnect.
- The application must provide usage metrics and monitoring.
- Cloud Monitoring and Logging can be configured for application logs and metrics to provide observability, alerting, and reporting.
- APIs require authentication and authorization.
- APIs can be configured for various Authentication mechanisms.
- APIs can be exposed through a centralized Cloud Endpoints gateway
- Internal Applications can be exposed using Cloud Identity-Aware Proxy
- Implement faster and more accurate validation of new features.
- QA Testing can be improved using automated testing
- Production Release cycles can be improved using canary deployments to test the applications on a smaller base before rolling out to all.
- Application can be deployed to App Engine which supports traffic spilling out of the box for canary releases
- Logging and performance metrics must provide actionable information to be able to provide debugging information and alerts.
- Cloud Monitoring and Logging can be configured for application logs and metrics to provide observability, alerting, and reporting.
- Cloud Logging can be exported to BigQuery for analytics
- Must scale to meet user demand.
- As the APIs run on Compute Engine, the scale can be implemented using Managed Instance Groups frontend by a Load Balancer and using scaling policies as per the demand.
- Single instance MySQL instance can be migrated to Cloud SQL. This would not need any application code changes and can be as-is migration. With read replicas to scale both horizontally and vertically seamlessly.
GCP Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- Which database should HipLocal use for storing state while minimizing application changes?
- Firestore
- BigQuery
- Cloud SQL
- Cloud Bigtable
- Which architecture should HipLocal use for log analysis?
- Use Cloud Spanner to store each event.
- Start storing key metrics in Memorystore.
- Use Cloud Logging with a BigQuery sink.
- Use Cloud Logging with a Cloud Storage sink.
- HipLocal wants to improve the resilience of their MySQL deployment, while also meeting their business and technical requirements. Which configuration should they choose?
- Use the current single instance MySQL on Compute Engine and several read-only MySQL servers on Compute Engine.
- Use the current single instance MySQL on Compute Engine, and replicate the data to Cloud SQL in an external master configuration.
- Replace the current single instance MySQL instance with Cloud SQL, and configure high availability.
- Replace the current single instance MySQL instance with Cloud SQL, and Google provides redundancy without further configuration.
- Which service should HipLocal use to enable access to internal apps?
- Cloud VPN
- Cloud Armor
- Virtual Private Cloud
- Cloud Identity-Aware Proxy
- Which database should HipLocal use for storing user activity?
- BigQuery
- Cloud SQL
- Cloud Spanner
- Cloud Datastore
Reference
Case_Study_HipLocal


 Key
Key