Google Cloud Dataflow vs Dataproc (Managed Service for Apache Spark)
📌 2025-2026 Update: Google Cloud has rebranded Dataproc to Managed Service for Apache Spark (formerly known as “Dataproc on Compute Engine” for cluster deployment and “Google Cloud Serverless for Apache Spark” for serverless deployment). The core functionality remains unchanged. Additionally, GCP AI Platform Training (Cloud ML Engine) has been superseded by Vertex AI, which is now part of the Gemini Enterprise Agent Platform.
Cloud Dataproc (Managed Service for Apache Spark)
- Cloud Dataproc, now rebranded as Managed Service for Apache Spark, is a managed Spark and Hadoop service that lets you take advantage of open-source data tools for batch processing, querying, streaming, and machine learning.
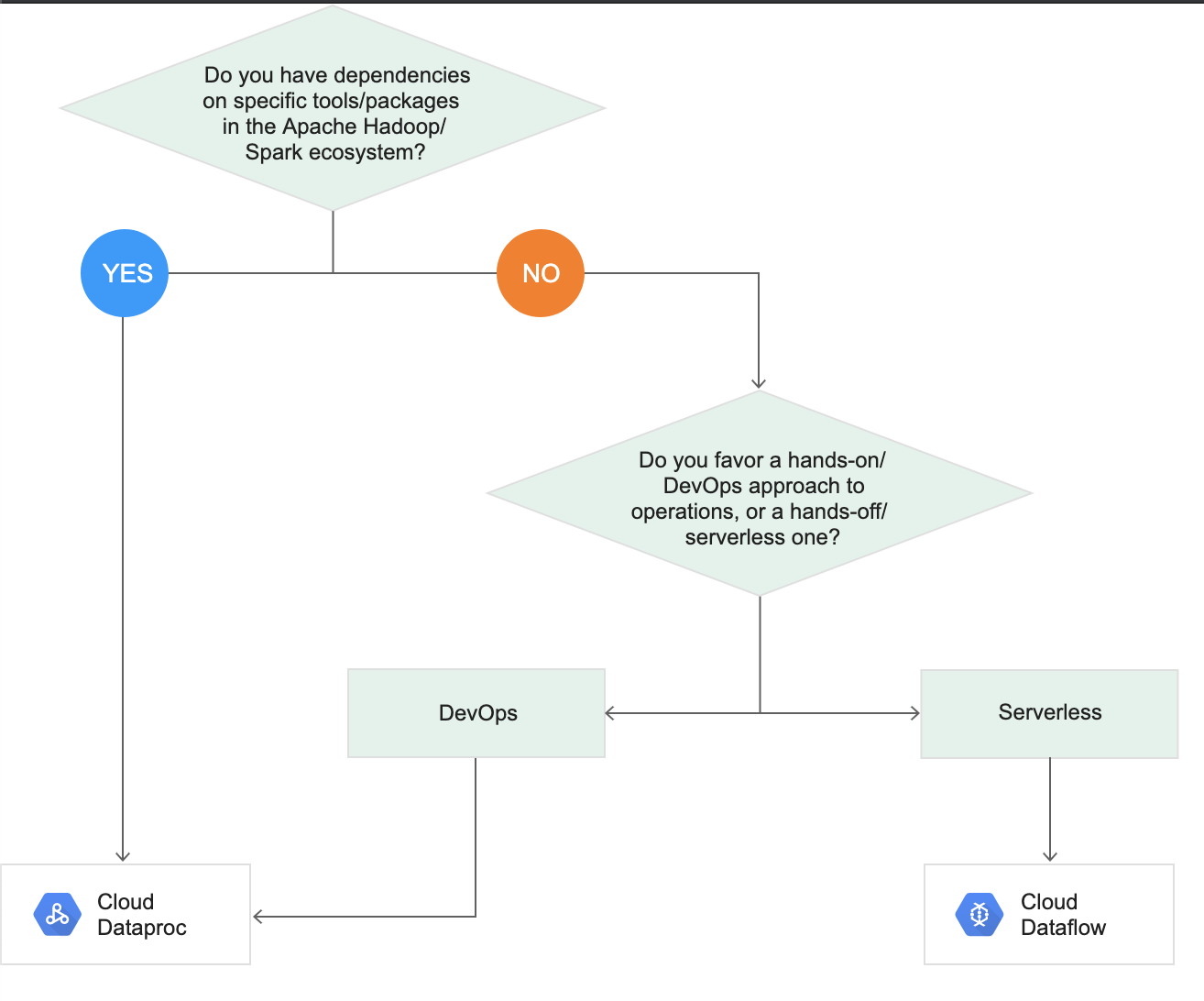
- Provides a Hadoop cluster on GCP with access to Hadoop-ecosystem tools (e.g., Apache Pig, Hive, and Spark); this has strong appeal if already familiar with Hadoop tools and have Hadoop jobs.
- Ideal for Lift and Shift migration of existing Hadoop environment.
- Offers two deployment modes:
- Cluster deployment — managed Spark clusters on Compute Engine (you pay for cluster uptime)
- Serverless deployment — Spark-jobs-as-a-service on fully managed Google Cloud infrastructure (you pay for job runtime only, zero cluster management)
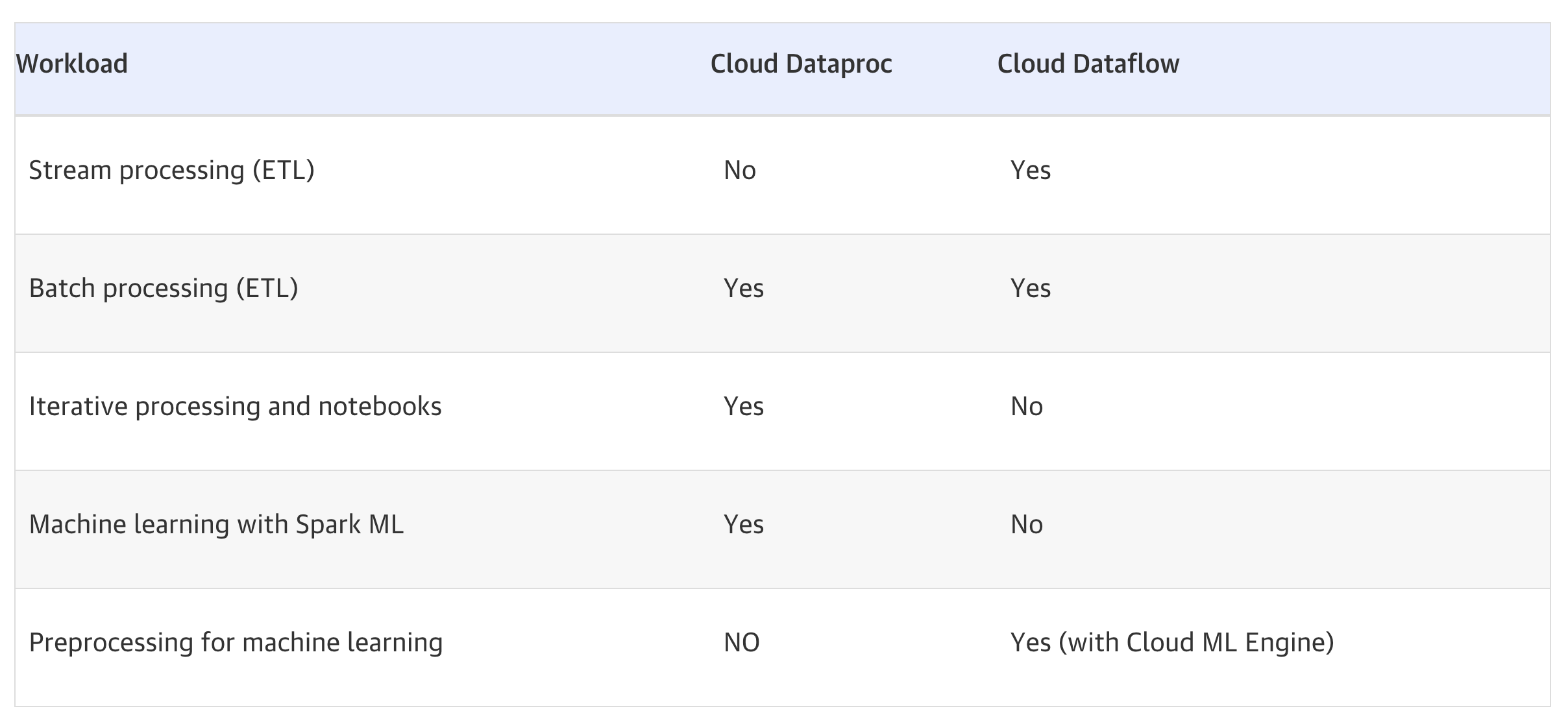
- Consider Dataproc (Managed Service for Apache Spark) when:
- You have a substantial investment in Apache Spark or Hadoop on-premise and are considering moving to the cloud
- You are looking at a Hybrid cloud and need portability across a private/multi-cloud environment
- In the current environment, Spark is the primary machine learning tool and platform
- The code depends on custom packages along with distributed computing needs
- You need fine-grained cluster configuration, custom libraries, or specific Hadoop ecosystem tool versions
Key Features (2024-2026)
- Lightning Engine — next-generation native C++ vectorized execution engine that delivers up to 4.9x faster performance than open-source Spark with zero code changes. Uses SIMD vectorization, intelligent caching, and optimized columnar shuffling. Available on the premium pricing tier.
- Serverless Spark (Zero-Ops) — zero cluster management with intelligent autoscaling. Resources scale up and down automatically to match job needs, ensuring maximum performance and cost-efficiency without paying for idle time.
- Enhanced Autoscaling — reduces cluster VM expenditures by up to 40% and cumulative job runtime by 10%.
- BigQuery Integration — Serverless for Apache Spark is deeply integrated with the BigQuery unified data-to-AI platform, offering a unified developer experience in BigQuery Studio.
- Vertex AI / Gemini Enterprise Agent Platform Integration — seamless interoperability for ML workflows.
- Dataproc on GKE — run Spark workloads on Google Kubernetes Engine for containerized environments.
Cloud Dataflow
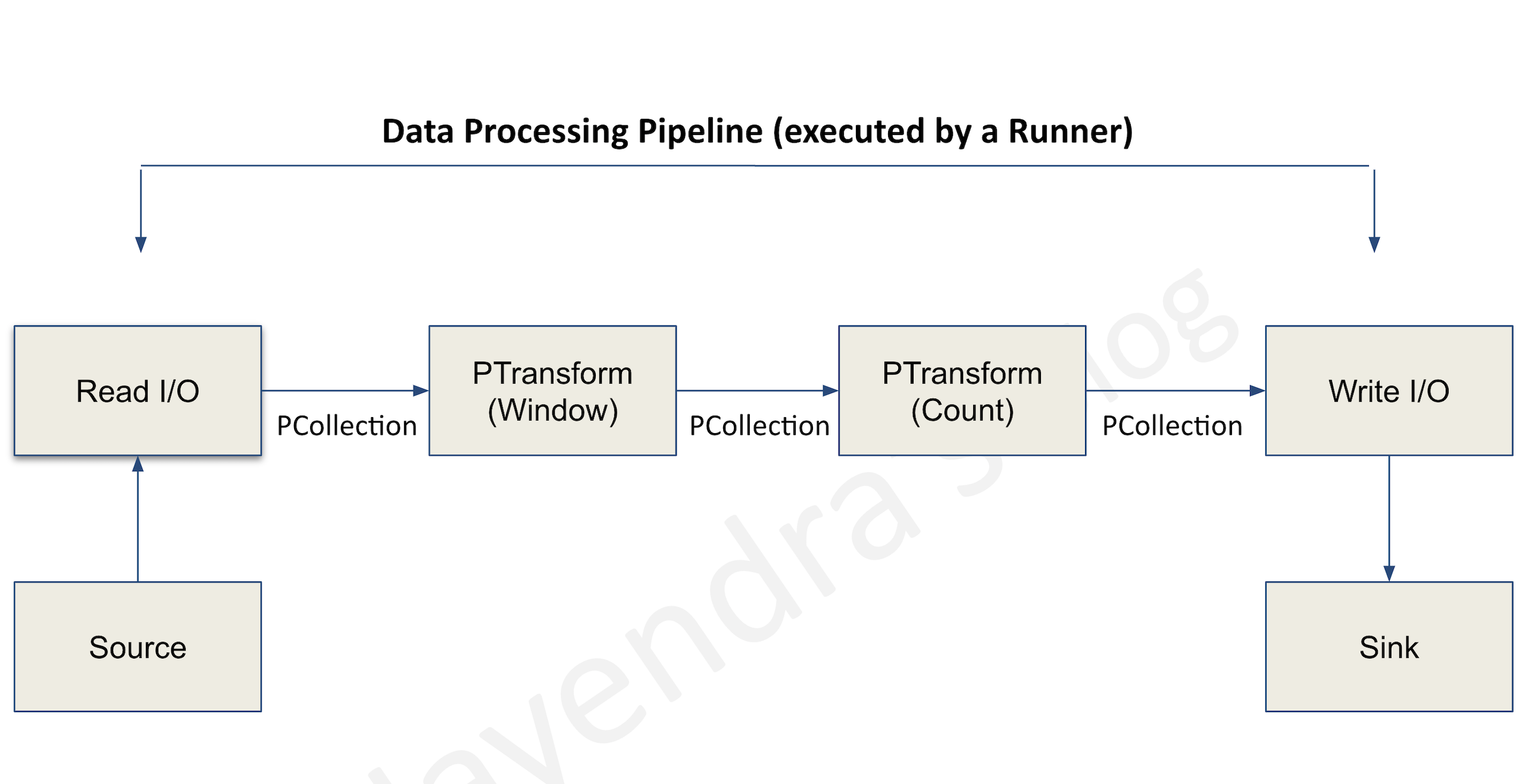
- Google Cloud Dataflow is a fully managed, serverless service for unified stream and batch data processing at scale, based on the open-source Apache Beam SDK.
- Scales to 4,000 workers per job and routinely processes petabytes of data with built-in autoscaling.
- Ideal for new pipelines with minimal infrastructure management, event stream processing, and real-time analytics.
- Consider Dataflow when:
- Building new, greenfield data pipelines (no existing Spark/Hadoop code to migrate)
- Requiring truly serverless, zero-ops data processing
- Working with unified batch and streaming in a single pipeline
- Using it as a pre-processing pipeline for ML models deployed in Vertex AI (Gemini Enterprise Agent Platform)
- None of the above considerations made for Cloud Dataproc are relevant
Key Features (2024-2026)
- Dataflow Prime — supports both horizontal autoscaling (more machines) and vertical autoscaling (larger machines) automatically for streaming and batch workloads.
- AI/ML Integration (Dataflow ML) — RunInference API enables running ML models (PyTorch, TensorFlow, scikit-learn, ONNX, TensorRT) directly within Dataflow pipelines. MLTransform API for data preparation.
- GPU Support — supports NVIDIA T4, L4, A100, H100, V100, and RTX Pro 6000 GPUs for ML inference workloads.
- TPU Support — TPU V5E, V5P, and V6E for high-volume, low-latency ML inference at scale directly within Dataflow jobs.
- Global Compute — dynamically schedules workloads across Google’s global infrastructure, automatically determining optimal location based on data locality and resource availability.
- Streaming AI — build streaming AI with Gemini models and Gemma models, run remote inference, and streamline data processing.
⚠️ Deprecation Notice: Dataflow SQL was deprecated on July 31, 2024, and fully removed on January 31, 2025. Users should use BigQuery for SQL-based analytics instead.
Cloud Dataflow vs Dataproc — Key Differences
| Criteria | Dataflow | Dataproc (Managed Service for Apache Spark) |
|---|---|---|
| Programming Model | Apache Beam (Java, Python, Go) | Apache Spark, Hadoop, Pig, Hive, Flink, Trino |
| Infrastructure | Fully serverless, zero ops | Managed clusters OR Serverless Spark |
| Cluster Management | None (fully managed) | User-managed (cluster) or None (serverless) |
| Best For | New pipelines, streaming, minimal ops | Existing Spark/Hadoop jobs, lift-and-shift |
| Streaming | Native, unified batch + stream | Spark Structured Streaming |
| ML/AI | RunInference API, GPU/TPU support | SparkML, Vertex AI integration |
| Scaling | Auto (up to 4K workers), Global Compute | Auto or manual, Lightning Engine (4.9x faster) |
| Code Changes | Requires Apache Beam rewrite | Minimal (run existing Spark/Hadoop code) |
Cloud Dataflow vs Dataproc Decision Tree
GCP Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- Your company is forecasting a sharp increase in the number and size of Apache Spark and Hadoop jobs being run on your local data center. You want to utilize the cloud to help you scale this upcoming demand with the least amount of operations work and code change. Which product should you use?
- Google Cloud Dataflow
- Google Cloud Dataproc (Managed Service for Apache Spark)
- Google Compute Engine
- Google Kubernetes Engine
- A startup plans to use a data processing platform, which supports both batch and streaming applications. They would prefer to have a hands-off/serverless data processing platform to start with. Which GCP service is suited for them?
- Dataproc
- Dataprep
- Dataflow
- BigQuery
- A company has existing Apache Spark ML pipelines running on-premises and wants to migrate to Google Cloud with minimal code changes while achieving better performance. Which service should they use?
- Cloud Dataflow
- Managed Service for Apache Spark (Dataproc) with Lightning Engine
- BigQuery ML
- Vertex AI Training
- An organization needs to run real-time ML inference on streaming data with GPU acceleration in a fully serverless manner. Which GCP service best fits this requirement?
- Dataproc Serverless
- Google Cloud Dataflow with RunInference API
- Cloud Functions
- GKE with Spark Streaming
- A team wants to run Apache Spark batch jobs without managing any infrastructure and wants to pay only for the time their jobs are running. Which deployment option should they choose?
- Dataproc Cluster deployment
- Managed Service for Apache Spark – Serverless deployment
- Cloud Dataflow
- Compute Engine with Spark installed
Frequently Asked Questions
What is the difference between Dataflow and Dataproc?
Dataflow is a fully managed serverless stream/batch processing service based on Apache Beam. Dataproc (now Managed Service for Apache Spark) is a managed Hadoop/Spark cluster for lift-and-shift big data workloads.
When should I use Dataproc instead of Dataflow?
Use Dataproc when you have existing Spark/Hadoop code to migrate, need specific Hadoop ecosystem tools (Hive, Pig, Presto), or want fine-grained cluster control. Use Dataflow for new pipelines or unified stream+batch processing.
Is Dataflow serverless?
Yes, Dataflow is fully serverless — it automatically provisions, manages, and scales workers based on workload. You only pay for resources consumed during pipeline execution with no idle cluster costs.
Related Posts
- Google Cloud Logging – Setup, Queries & Best Practices [2026]
- Container Registry vs Artifact Registry – Differences & Migration
References
 Instance
Instance