📋 Post Overview
This comprehensive comparison covers Google Cloud’s three primary database services — Cloud Spanner, Firestore, and Cloud SQL — analyzing their data models, scaling capabilities, consistency guarantees, pricing, availability, global distribution, and transaction support to help you choose the right database for your workload.
Last updated: June 2026
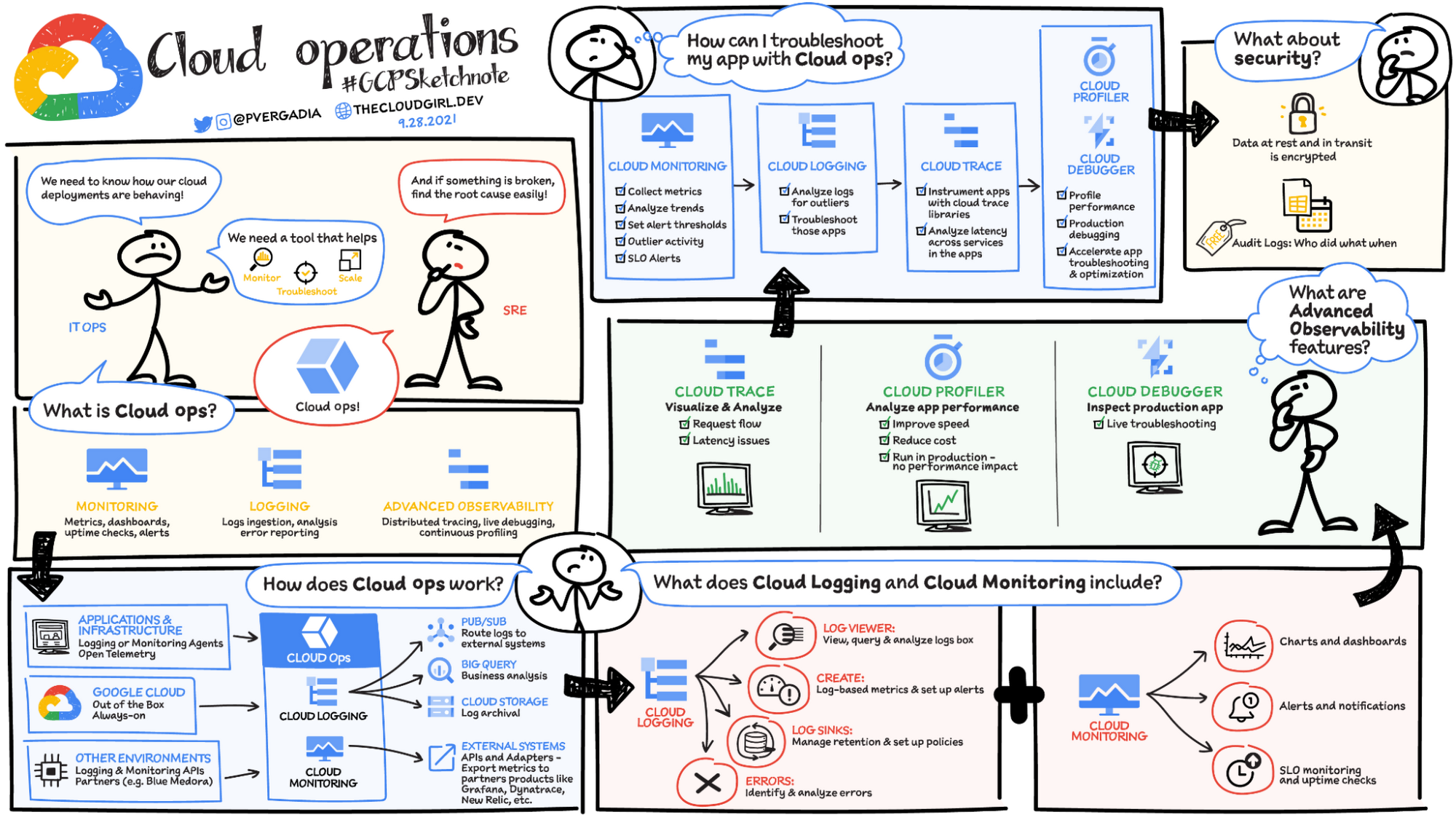
Overview
- Cloud Spanner is a fully managed, globally distributed, horizontally scalable relational database with strong (external) consistency, designed for mission-critical OLTP workloads requiring unlimited scale.
- Firestore is a fully managed, serverless NoSQL document database with real-time synchronization, offline support, and automatic scaling — ideal for mobile/web apps and rapid development.
- Cloud SQL is a fully managed relational database service supporting MySQL, PostgreSQL, and SQL Server — best suited for traditional applications needing familiar RDBMS capabilities within a single region.
Data Model
Cloud Spanner
- Relational data model with schemas, tables, rows, and columns
- Supports both GoogleSQL and PostgreSQL interface (dialect)
- Multi-model support (2024-2025): relational, graph (Spanner Graph), key-value, vector search (ANN with ScaNN), and full-text search in a single database
- Interleaved tables for parent-child relationships with data co-location
- Secondary indexes, JSON columns, and JSON indexing
- Maximum row size: 100 MB; maximum database size: virtually unlimited
Firestore
- NoSQL document-oriented data model with collections and documents
- Schema-flexible: documents contain fields with various data types (strings, numbers, booleans, arrays, maps, references, timestamps, geopoints)
- Hierarchical data with subcollections and nested documents
- Two modes: Native mode (document DB with real-time) and Datastore mode (backward compatible)
- MongoDB compatibility mode (2025-2026) with support for documents up to 16 MiB
- Enterprise edition adds pipeline queries, full-text search, JOINs via subqueries, and geospatial queries (2025-2026)
Cloud SQL
- Traditional relational data model (tables, rows, columns, foreign keys)
- Supports MySQL (up to 8.4), PostgreSQL (up to 17), and SQL Server (up to 2025)
- Full SQL support including JOINs, stored procedures, triggers, views
- Maximum storage: 64 TB per instance
- Enterprise edition (up to 96 vCPUs, 624 GB RAM) and Enterprise Plus edition (up to 128 vCPUs, 864 GB RAM)
Scaling
Cloud Spanner
- Horizontal scaling — add nodes/processing units to scale reads and writes linearly
- Compute measured in processing units (PUs): 1 node = 1000 PUs; minimum 100 PUs
- Automatic sharding (splits) distributes data across nodes; manual split points available for anticipated traffic spikes
- Managed autoscaler (GA 2025) scales nodes automatically based on load, including independent read-only replica scaling
- Handles 6+ billion queries per second at peak (Google internal)
- No practical upper limit on database size or throughput
Firestore
- Automatic serverless scaling — scales to zero during inactivity and up elastically during spikes
- No capacity planning or provisioning required
- Scales to millions of concurrent connections
- Write throughput: up to 10,000 writes/second per database (can be increased)
- Read throughput: virtually unlimited with proper data modeling
- Sub-second provisioning for new databases
Cloud SQL
- Vertical scaling — scale up by increasing vCPUs, memory, and storage
- Read scaling via up to 20 read replicas (cross-region supported)
- No automatic horizontal write scaling — single primary instance handles all writes
- Maximum: 128 vCPUs, 864 GB RAM (Enterprise Plus)
- Storage auto-resize available
- Fast clone operations (GA 2026) for creating copies within the same zone
Consistency Model
Cloud Spanner
- External consistency (strongest possible) — stronger than serializable isolation
- All reads see the latest committed data, globally
- Bounded staleness and exact staleness reads available for reduced latency
- Repeatable read isolation (Preview 2025) for workloads with low read-write contention
- Read leases improve read latency in multi-region configs by trading off some write performance
Firestore
- Strong consistency for all reads (Native mode, since 2021 upgrade)
- All queries return the most recent data at the time of the query
- Real-time listeners receive updates with strong consistency
- Search indexes are strongly consistent with transactional data (unlike eventual consistency in separate search systems)
- Multi-region deployments maintain strong consistency
Cloud SQL
- Strong consistency on the primary instance (standard RDBMS guarantees)
- Read replicas use asynchronous replication — eventual consistency with slight lag
- Consistency level depends on the underlying database engine (MySQL, PostgreSQL, SQL Server)
- Synchronous replication available within a region for HA configurations
Pricing Model
Cloud Spanner
- Provisioned capacity pricing — pay per node/processing unit per hour
- Three editions: Standard, Enterprise, Enterprise Plus (different capabilities and prices)
- Compute: starts at ~$0.90/hour per node (regional, varies by edition and region)
- Storage: per GB/month (SSD); tiered storage offers HDD at ~80% less for cold data
- Minimum cost: ~$65/month for a production-ready 100 PU instance
- Free 90-day trial instance available
- Committed Use Discounts: 20% (1-year), 40% (3-year)
- Data Boost for analytics charged separately per GB processed
Firestore
- Pay-per-use (serverless) pricing — pay only for operations performed
- Document reads, writes, and deletes each have per-operation costs
- Storage: per GB/month
- Free tier: 50,000 reads, 20,000 writes, 20,000 deletes, 1 GB storage per day
- Enterprise edition: additional pricing for advanced features (pipelines, full-text search)
- Network egress charges for data transfer
- Scales to zero cost during inactivity
Cloud SQL
- Instance-based pricing — pay per vCPU-hour + memory-hour + storage
- Two editions: Enterprise (~$0.0413/vCPU-hour) and Enterprise Plus (higher cost, better performance)
- Storage: per GB/month (SSD or HDD)
- Backup storage: per GB/month
- Network egress charges apply
- Committed Use Discounts available
- Shared-core instances available for dev/test (f1-micro, g1-small) at lower cost
- No free tier (use $300 free trial credits)
Availability & SLA
Cloud Spanner
- Regional: 99.99% SLA (Standard and Enterprise editions)
- Multi-region: 99.999% SLA (Enterprise Plus edition)
- Automatic failover with zero downtime
- No planned maintenance downtime
- Drop protection for schema objects (2025) prevents accidental deletions
- Default backup schedules ensure data protection from day one
Firestore
- Multi-region: 99.999% SLA
- Regional: 99.99% SLA
- Automatic replication across zones/regions
- Offline support for mobile/web — apps continue working without network
- Zero operational overhead — fully serverless
Cloud SQL
- Enterprise Plus with HA: 99.99% SLA (includes maintenance)
- Enterprise with HA: 99.95% SLA
- Regional availability only (no multi-region active-active)
- High Availability via regional persistent disk and automatic failover
- Planned maintenance windows required for updates
- Cross-region read replicas for disaster recovery
Global Distribution
Cloud Spanner
- Native multi-region support with synchronous replication across continents
- Pre-defined multi-region configurations (nam6, eur6, nam-eur-asia1, etc.)
- Custom configurations with read-only replicas in additional regions
- Spanner Omni (2026 Preview): run Spanner on-premises, across clouds (AWS EKS, etc.), or on a laptop
- Geo-partitioning to keep data in specific regions for compliance
- Consistent reads globally with TrueTime technology
Firestore
- Multi-region locations available (e.g., nam5, eur3)
- Data automatically replicated across multiple zones within the chosen configuration
- Cannot selectively place data in specific regions (entire database in one location config)
- Real-time sync to global clients via SDKs
- No active-active multi-region write support
Cloud SQL
- Single region only for primary instance
- Cross-region read replicas for read distribution
- Cross-region replica promotion for disaster recovery (manual)
- No native multi-region write capability
- Available in 35+ Google Cloud regions
Transactions
Cloud Spanner
- Full ACID transactions across rows, tables, and even across regions
- Distributed transactions with external consistency
- Read-write and read-only transaction types
- Partitioned DML for large-scale data changes
- No practical limit on transaction scope — can span the entire database globally
Firestore
- ACID transactions within a single database
- Supports up to 500 documents per transaction
- Batched writes for atomic operations on multiple documents
- Optimistic concurrency control
- Transactions limited to 60 seconds
- Cannot span multiple databases
Cloud SQL
- Full ACID transactions per database engine capabilities
- Standard SQL transaction isolation levels (READ COMMITTED, REPEATABLE READ, SERIALIZABLE)
- Transactions limited to a single instance
- No distributed transactions across instances
- Supports savepoints, nested transactions (where engine supports)
Comparison Table
| Feature | Cloud Spanner | Firestore | Cloud SQL |
|---|---|---|---|
| Type | Distributed Relational | NoSQL Document | Managed Relational (MySQL/PostgreSQL/SQL Server) |
| Data Model | Relational + Graph + Vector + Full-text | Document (Collections/Documents) | Relational (Tables/Rows/Columns) |
| Query Language | GoogleSQL, PostgreSQL interface | Client SDKs, Pipeline queries, MongoDB-compatible queries | MySQL/PostgreSQL/T-SQL (native) |
| Scaling | Horizontal (virtually unlimited) | Automatic serverless | Vertical (up to 128 vCPUs) |
| Max Storage | Unlimited (10 TB per node) | Unlimited (1 MB/doc, 16 MiB MongoDB mode) | 64 TB per instance |
| Consistency | External (strongest) | Strong | Strong (primary), Eventual (replicas) |
| Availability SLA | 99.99% (regional) / 99.999% (multi-region) | 99.99% (regional) / 99.999% (multi-region) | 99.99% (Enterprise Plus HA) |
| Global Distribution | Multi-region with synchronous replication | Multi-region (pre-defined configs) | Single region (cross-region read replicas) |
| Transactions | Distributed ACID (global scope) | ACID (up to 500 documents) | ACID (single instance) |
| Pricing Model | Provisioned (per node-hour + storage) | Pay-per-use (per operation + storage) | Instance-based (per vCPU-hour + memory + storage) |
| Minimum Cost | ~$65/month (100 PUs) | Free tier available (scales to zero) | ~$7/month (shared-core f1-micro) |
| Schema | Schema-required (with flexible JSON support) | Schema-flexible | Schema-required |
| Real-time Sync | No (use Change Streams) | Yes (built-in real-time listeners) | No |
| Offline Support | No | Yes (mobile/web SDKs) | No |
| Maintenance Downtime | None | None | Required (maintenance windows) |
| AI/ML Integration | Built-in (ML.PREDICT, Vertex AI, Vector Search, Graph) | Vector search, AI Studio integration, MCP support | pgvector (PostgreSQL), AlloyDB integration |
| Multi-cloud / On-prem | Yes (Spanner Omni, 2026 Preview) | No (Google Cloud only) | No (Google Cloud only) |
When to Choose Each
Choose Cloud Spanner When:
- You need globally distributed transactions with strong consistency
- Your workload requires horizontal scaling beyond a single node’s capacity (>100,000 reads/writes per second)
- You need 99.999% availability for mission-critical applications
- Your application serves users across multiple continents with low-latency requirements
- You’re running financial services, gaming, or supply chain workloads requiring both relational structure and massive scale
- You need multi-model capabilities (graph, vector, full-text search) in a single transactional database
- You’re migrating from Cassandra or sharded MySQL and want to eliminate operational complexity
Choose Firestore When:
- You’re building mobile or web applications requiring real-time data synchronization
- You need offline support for mobile apps
- Your data model is hierarchical or document-oriented (user profiles, product catalogs, content management)
- You want serverless scaling to zero with no capacity planning
- You’re in the rapid prototyping / MVP phase and need schema flexibility
- Your budget requires pay-per-use pricing with a free tier
- You’re building with Firebase ecosystem (Authentication, Cloud Functions, Hosting)
- You need agentic AI application backends with AI Studio integration
Choose Cloud SQL When:
- You have existing applications using MySQL, PostgreSQL, or SQL Server and want managed infrastructure
- Your workload fits within a single region and a single instance’s capacity (up to 128 vCPUs)
- You need full SQL compatibility including stored procedures, triggers, and complex JOINs
- You’re performing a lift-and-shift migration from on-premises RDBMS
- Your application requires specific database engine features (e.g., PostGIS, MySQL full-text, SQL Server CLR)
- Budget is constrained and workload is predictable — instance-based pricing is cost-effective
- You need third-party tool compatibility (ORMs, admin tools, connectors) without modification
Key Differences Summary
- Scale direction: Spanner scales horizontally (add nodes), Cloud SQL scales vertically (bigger instance), Firestore scales automatically (serverless)
- Cost at low scale: Firestore is cheapest (free tier, pay-per-use); Cloud SQL moderate (small instances from ~$7/month); Spanner highest minimum (~$65/month)
- Cost at high scale: Spanner provides best price-performance for high-throughput global workloads; Cloud SQL becomes expensive when hitting vertical limits; Firestore operation costs can grow with high read volumes
- Global writes: Only Spanner supports consistent multi-region writes natively
- Developer experience: Firestore offers the fastest path from idea to production with real-time SDKs; Cloud SQL offers familiar tooling; Spanner requires understanding distributed database concepts
- Migration path: Cloud SQL → Spanner is natural when outgrowing regional limits; Firestore is a different paradigm (NoSQL) and typically chosen at project start
GCP Certification Exam Tips
- If the question mentions “global,” “multi-region,” “horizontal scale,” and “relational” → Cloud Spanner
- If the question mentions “mobile app,” “real-time sync,” “offline,” “document,” or “serverless database” → Firestore
- If the question mentions “MySQL,” “PostgreSQL,” “lift-and-shift,” “existing application,” or “single region” → Cloud SQL
- If the question mentions “99.999% availability” with relational data → Cloud Spanner (multi-region)
- If the question mentions “schema flexibility” with automatic scaling → Firestore
- Cloud Spanner is NOT a good fit for small, single-region workloads where Cloud SQL suffices (over-engineering)
- Firestore is NOT a good fit for complex relational queries with multiple JOINs or strict schemas
Practice Questions
Question 1
A global e-commerce company needs a database to manage inventory across 5 regions. The application requires strongly consistent reads after writes, support for complex SQL queries, and the ability to handle 500,000 transactions per second during peak sales events. Which Google Cloud database service should they use?
- Cloud SQL with read replicas in each region
- Cloud Spanner with a multi-region configuration
- Firestore in Native mode with multi-region location
- Cloud SQL Enterprise Plus with cross-region failover
Show Answer
Answer: B –
Explanation: Cloud Spanner is the only Google Cloud database that provides globally distributed, strongly consistent relational transactions with horizontal scaling to handle 500,000+ TPS. Cloud SQL cannot scale horizontally and is limited to a single region for writes. Firestore is NoSQL and doesn’t support complex SQL queries natively. Spanner’s multi-region configuration (Enterprise Plus) provides 99.999% availability with synchronous replication across regions.
Question 2
A startup is building a mobile application that needs to sync user data in real-time across devices, work offline when connectivity is poor, and scale automatically during viral growth — all while minimizing operational costs during the early stages. Which database should they choose?
- Cloud Spanner with managed autoscaler
- Cloud SQL for PostgreSQL with pgpool
- Firestore in Native mode
- Cloud Bigtable with single-cluster routing
Show Answer
Answer: C –
Explanation: Firestore in Native mode provides built-in real-time synchronization, offline support for mobile SDKs, automatic serverless scaling (including scaling to zero), and a generous free tier — making it ideal for startups with unpredictable growth. Cloud Spanner’s minimum cost (~$65/month) and Cloud SQL’s always-on instances are overkill for early-stage apps. Bigtable doesn’t provide real-time sync or offline support.
Question 3
A company is migrating an on-premises PostgreSQL application to Google Cloud. The application uses stored procedures, triggers, PostGIS extensions, and serves a single-region user base with predictable traffic of about 5,000 queries per second. They need minimal code changes. Which service is most appropriate?
- Cloud Spanner with PostgreSQL interface
- Cloud SQL for PostgreSQL
- Firestore in Datastore mode
- AlloyDB for PostgreSQL
Show Answer
Answer: B –
Explanation: Cloud SQL for PostgreSQL provides full compatibility with PostgreSQL including stored procedures, triggers, and extensions like PostGIS. It’s ideal for lift-and-shift migrations with minimal code changes. Cloud Spanner’s PostgreSQL interface is a compatibility layer that doesn’t support all PostgreSQL features (no stored procedures, limited extensions). Firestore is NoSQL and incompatible. AlloyDB could work but isn’t the most straightforward lift-and-shift for a standard workload already within Cloud SQL’s capacity limits.
Question 4
An organization needs to choose a database for a new application with the following requirements: schema-flexible data model, ACID transactions across multiple documents, 99.999% availability, built-in full-text search, and integration with AI development tools. Which combination of service and edition meets ALL requirements?
- Cloud Spanner Enterprise Plus edition
- Firestore Enterprise edition in a multi-region location
- Cloud SQL Enterprise Plus with Cloud Search integration
- Cloud Spanner Enterprise edition with managed autoscaler
Show Answer
Answer: B –
Explanation: Firestore Enterprise edition in a multi-region location satisfies all requirements: schema-flexible document model, ACID transactions (up to 500 documents), 99.999% SLA for multi-region deployments, built-in full-text search (GA 2026), and native integration with AI Studio and MCP tools. Cloud Spanner requires schemas. Cloud SQL doesn’t offer 99.999% availability or built-in full-text search as a managed feature. Spanner Enterprise edition is regional only (99.99%).
Question 5
A financial services company currently uses Cloud SQL for PostgreSQL but is experiencing issues with write throughput during peak trading hours and needs to expand to serve users in Asia-Pacific while maintaining ACID compliance and strong consistency for all transactions globally. What is the recommended migration path?
- Add more read replicas in Asia-Pacific regions
- Migrate to Cloud Spanner with a multi-region instance configuration
- Migrate to Firestore for automatic scaling
- Upgrade to Cloud SQL Enterprise Plus and increase vCPUs
Show Answer
Answer: B –
Explanation: Cloud Spanner is the appropriate choice for scaling beyond Cloud SQL’s single-region write limits while maintaining ACID transactions and strong consistency globally. Read replicas (A) only help with read scaling and don’t provide strong consistency or solve write throughput issues. Firestore (C) is NoSQL and unsuitable for financial transaction processing requiring complex SQL and strict relational integrity. Upgrading Cloud SQL (D) has a vertical scaling ceiling and doesn’t solve multi-region write requirements.
Frequently Asked Questions
What is the difference between Cloud Spanner and Firestore?
Cloud Spanner is a horizontally-scalable relational database with SQL, strong consistency, and global distribution for mission-critical transactional workloads. Firestore is a serverless document database optimized for mobile/web apps with offline sync, real-time listeners, and automatic scaling.
When should I use Cloud SQL instead of Spanner?
Use Cloud SQL for traditional relational workloads under 64TB that don’t need horizontal scaling or global distribution. Cloud SQL costs significantly less for small-to-medium databases and supports MySQL, PostgreSQL, and SQL Server with minimal migration effort.
Is Cloud Spanner expensive?
Spanner starts at ~$0.90/node-hour (approximately $657/month per node minimum). It’s cost-effective for large-scale global workloads but expensive for small databases. For workloads under 10GB, Firestore or Cloud SQL are significantly cheaper options.
.png)