Elasticsearch Service is a managed service that makes it easy to deploy, operate, and scale Elasticsearch clusters in the AWS Cloud.
Elasticsearch is a popular open-source search and analytics engine for use cases such as log analytics, real-time application monitoring, and clickstream analytics
Elasticsearch provides
real-time, distributed search and analytics engine
ability to provision all the resources for the Elasticsearch cluster and launches the cluster
easy to use cluster scaling options. Scaling the Elasticsearch Service domain by adding or modifying instances, and storage volumes is an online operation that does not require any downtime.
provides self-healing clusters, which automatically detects and replaces failed Elasticsearch nodes, reducing the overhead associated with self-managed infrastructures
domain snapshots to back up and restore ES domains and replicate domains across AZs
data durability
enhanced security with IAM access control and security groups
node monitoring
multiple configurations of CPU, memory, and storage capacity, known as instance types
storage volumes for the data using EBS volumes
Multiple geographical locations for your resources, known as regions and Availability Zones
ability to span cluster nodes across multiple AZs in the same region, known as zone awareness, for high availability and redundancy. Elasticsearch Service automatically distributes the primary and replica shards across instances in different AZs.
dedicated master nodes to improve cluster stability
data visualization using the Kibana tool
integration with CloudWatch for monitoring ES domain metrics
integration with CloudTrail for auditing configuration API calls to ES domains
integration with S3, Kinesis, and DynamoDB for loading streaming data
ability to handle structured and unstructured data
HTTP Rest APIs
Elasticsearch Domains
Elasticsearch Service domains are Elasticsearch clusters created using the Elasticsearch Service console, CLI, or API.
Each domain is the cluster in the cloud with the specified compute and storage resources.
Enables you to create and delete domains, define infrastructure attributes, and control access and security.
Elasticsearch Service automates common administrative tasks, such as performing backups, monitoring instances and patching software once the domain is running
Elasticsearch Security
Access to Elasticsearch Service management APIs for operations such as creating and scaling domains are controlled with AWS IAM policies.
Elasticsearch Service domains can be configured to be accessible with an endpoint within the VPC or a public endpoint accessible to the internet.
Network access for VPC endpoints is controlled by security groups and for public endpoints, access can be granted or restricted by IP address.
Elasticsearch Service provides user authentication via IAM and basic authentication using username and password.
Authorization can be granted at the domain level (via Domain Access Policies) as well as at the index, document, and field level (via the fine-grained access control feature powered by Open Distro for Elasticsearch).
Fine-grained access control feature extends Kibana with read-only views and secure multi-tenant support.
Elasticsearch Service supports integration with Cognito, to allow your end-users to log-in to Kibana through enterprise identity providers such as Microsoft Active Directory using SAML 2.0, Cognito User Pools, and more
Elasticsearch Service supports encryption at rest through AWS Key Management Service (KMS), node-to-node encryption over TLS, and the ability to require clients to communicate with HTTPS.
Encryption at rest encrypts shards, log files, swap files, and automated S3 snapshots.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You need to perform ad-hoc analysis on log data, including searching quickly for specific error codes and reference numbers. Which should you evaluate first?
AWS Elasticsearch Service (Elasticsearch Service (ES) is a managed service that makes it easy to deploy, operate, and scale Elasticsearch clusters in the AWS cloud. Elasticsearch is a popular open-source search and analytics engine for use cases such as log analytics, real-time application monitoring, and click stream analytics. Refer link)
AWS RedShift
AWS EMR
AWS DynamoDB
You are hired as the new head of operations for a SaaS company. Your CTO has asked you to make debugging any part of your entire operation simpler and as fast as possible. She complains that she has no idea what is going on in the complex, service-oriented architecture, because the developers just log to disk, and it’s very hard to find errors in logs on so many services. How can you best meet this requirement and satisfy your CTO?
Copy all log files into AWS S3 using a cron job on each instance. Use an S3 Notification Configuration on the <code>PutBucket</code> event and publish events to AWS Lambda. Use the Lambda to analyze logs as soon as they come in and flag issues.
Begin using CloudWatch Logs on every service. Stream all Log Groups into S3 objects. Use AWS EMR cluster jobs to perform adhoc MapReduce analysis and write new queries when needed.
Copy all log files into AWS S3 using a cron job on each instance. Use an S3 Notification Configuration on the <code>PutBucket</code> event and publish events to AWS Kinesis. Use Apache Spark on AWS EMR to perform at-scale stream processing queries on the log chunks and flag issues.
Begin using CloudWatch Logs on every service. Stream all Log Groups into an AWS Elasticsearch Service Domain running Kibana 4 and perform log analysis on a search cluster. (AWS Elasticsearch with Kibana stack is designed specifically for real-time, ad-hoc log analysis and aggregation)
Clearing the AWS certification for Solution Architect, SysOps Associate and Solution Architect Professional has been a long journey of over an year now.
I always remember starting fresh on AWS with no knowledge and a plethora of resources, courses and documentation can be very confusing, overwhelming and tough
So I have just put some resources, courses and deals which might help you get started at a reasonable cost
NOTE: This is my personal recommendations and tried & tested ones.
AWS documentation
Nothing can replace the fantastic AWS documentation that the team has put and maintained
AWS documentation includes
AWS Developer, User guides
AWS FAQs – Very Important to get a quick summary for important questions targeted in the exams
AWS Re-Invent Videos – quick way to know details of the services
AWS Whitepapers – covers condensed knowledge of important topics and services
Online Courses
Udemy
However, they are not sufficient to clear the exams
Udemy does not have aCloud Guru professional courses
They are listed at a very high price, however, wait for offers from Udemy and you can get the Associate ones for $10-$15
I will keep on listing any Udemy offers as belowFor Associate, I started with aCloud Guru courses from Udemy and they provide a nice overview of the exam topics
A Cloud Guru
As mentioned above, Associate courses from A Cloud Guru are good to get started and can be purchased from Udemy
A Cloud Guru forums have very nice discussion over the topics, highly recommended going through them
I had purchased Solution Architect – Professional course from A Cloud Guru site directly
Personally, I find it very expensive and it does not cover the topics in great details
Linux Academy
I haven’t tried Linux Academy courses for Associate, so any of you have any opinion let me
I had purchased the Solution Architect – Professional course and found is detailed and exhaustive with labs
Personally, would recommend it over the A Cloud Guru
You can try Linux Academy Trail for 7 days and then for monthly $29 which would give you access to everything but limited period
Free Linux Academy, PluralSight and Opsgility courses
I started preparing for Azure and was checking for resources, and stumbled upon 3 months Free subscription for LinuxAcademy, PluralSight and OpsUtility.
Microsoft would provide 3 months access to the courses as their Education Program
Activate the code and you are good to go
Enjoy the same till is lasts
Practice Quiz
Personally, I have not taken any Practice test either officially from AWS or from any other provider
However, there are lot of sites, apart from my blog, which provide AWS questions & Answers, but I had found them to provide incorrect answers. So always research from your side
I have got a lot of positive feedback from colleagues taking tests on Braincert.
RDS supports automated backups as well as manual snapshots
Automated Backups
enable point-in-time recovery of the DB Instance
perform a full daily backup and captures transaction logs (as updates to your DB instance are made
are performed during the defined preferred backup window and is retained for user-specified period of time called the retention period (default 1 day with a max of 35 days)
When a point-in-time recovery is initiated, transaction logs are applied to the most appropriate daily backup in order to restore the DB instance to the specific requested time.
allows a point-in-time restore and an ability to specify any second during the retention period, up to the Latest Restorable Time
are deleted when the DB instance is deleted
Snapshots
are user-initiated and enable to back up the DB instance in a known state as frequently as needed, and then restored to that specific state at any time.
can be created with the AWS Management Console or by using the CreateDBSnapshot API call.
are not deleted when the DB instance is deleted
Automated backups and snapshots can result in a performance hit, if Multi-AZ is not enabled
ElastiCache Automated Backups
ElastiCache supports Automated backups for Redis cluster only
ElastiCache creates a backup of the cluster on a daily basis
Snapshot will degrade performance, so should be performed during least bust part of the day
Backups are performed during the Backup period and retained for backup retention limit defined, with a maximum of 35 days
ElastiCache also allows manual snapshots of the cluster
Redshift Automated Backups
Amazon Redshift enables automated backups, by default
Redshift replicates all the data within your data warehouse cluster when it is loaded and also continuously backs up the data to S3
Redshift retains backups for 1 day which can be extended to max 35 days
Redshift only backs up data that has changed and are incremental so most snapshots use up a small amount of storage
Redshift also allows manual snapshots of the data warehouse
EBS snapshots can be created by using the AWS Management Console, the command line interface (CLI), or the APIs
Backups degrade performance
Stored on S3
EBS Snapshots are incremental and block-based, and they consume space only for changed data after the initial snapshot is created
Data can be restored from snapshots by created a volume from the snapshot
EBS snapshots are region specific and can be copied between AWS regions
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Which two AWS services provide out-of-the-box user configurable automatic backup-as-a-service and backup rotation options? Choose 2 answers
Amazon S3
Amazon RDS
Amazon EBS
Amazon Redshift
You have been asked to automate many routine systems administrator backup and recovery activities. Your current plan is to leverage AWS-managed solutions as much as possible and automate the rest with the AWS CLI and scripts. Which task would be best accomplished with a script?
Creating daily EBS snapshots with a monthly rotation of snapshots
Creating daily RDS snapshots with a monthly rotation of snapshots
Automatically detect and stop unused or underutilized EC2 instances
Automatically add Auto Scaled EC2 instances to an Amazon Elastic Load Balancer
AWS Billing and Cost Management is the service that you use to pay AWS bill, monitor your usage, and budget your costs
Analyzing Costs with Graphs
AWS provides Cost Explorer tool which allows filter graphs by API operations, Availability Zones, AWS service, custom cost allocation tags, EC2 instance type, purchase options, region, usage type, usage type groups, or, if Consolidated Billing used, by linked account.
Budgets
Budgets can be used to track AWS costs to see usage-to-date and current estimated charges from AWS
Budgets use the cost visualization provided by Cost Explorer to show the status of the budgets and to provide forecasts of your estimated costs.
Budgets can be used to create CloudWatch alarms that notify when you go over your budgeted amounts, or when the estimated costs exceed budgets
Notifications can be sent to an SNS topic and to email addresses associated with your budget notification
Cost Allocation Tags
Tags can be used to organize AWS resources, and cost allocation tags to track the AWS costs on a detailed level.
Upon cost allocation tags activation, AWS uses the cost allocation tags to organize the resource costs on the cost allocation report making it easier to categorize and track your AWS costs.
AWS provides two types of cost allocation tags,
an AWS-generated tag AWS defines, creates, and applies the AWS-generated tag for you,
and user-defined tags that you define, create,
Both types of tags must be activated separately before they can appear in Cost Explorer or on a cost allocation report
Alerts on Cost Limits
CloudWatch can be used to create billing alerts when the AWS costs exceed specified thresholds
When the usage exceeds threshold amounts, AWS sends an email notification
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
An organization is using AWS since a few months. The finance team wants to visualize the pattern of AWS spending. Which of the below AWS tool will help for this requirement?
AWS Consolidated Billing (Will not help visualize)
Your company wants to understand where cost is coming from in the company’s production AWS account. There are a number of applications and services running at any given time. Without expending too much initial development time, how best can you give the business a good understanding of which applications cost the most per month to operate?
Create an automation script, which periodically creates AWS Support tickets requesting detailed intra-month information about your bill.
Use custom CloudWatch Metrics in your system, and put a metric data point whenever cost is incurred.
Use AWS Cost Allocation Tagging for all resources, which support it. Use the Cost Explorer to analyze costs throughout the month. (Refer link)
Use the AWS Price API and constantly running resource inventory scripts to calculate total price based on multiplication of consumed resources over time.
You need to know when you spend $1000 or more on AWS. What’s the easy way for you to see that notification?
AWS CloudWatch Events tied to API calls, when certain thresholds are exceeded, publish to SNS.
Scrape the billing page periodically and pump into Kinesis.
AWS CloudWatch Metrics + Billing Alarm + Lambda event subscription. When a threshold is exceeded, email the manager.
Scrape the billing page periodically and publish to SNS.
A user is planning to use AWS services for his web application. If the user is trying to set up his own billing management system for AWS, how can he configure it?
Set up programmatic billing access. Download and parse the bill as per the requirement
It is not possible for the user to create his own billing management service with AWS
Enable the AWS CloudWatch alarm which will provide APIs to download the alarm data
Use AWS billing APIs to download the usage report of each service from the AWS billing console
An organization is setting up programmatic billing access for their AWS account. Which of the below mentioned services is not required or enabled when the organization wants to use programmatic access?
Programmatic access
AWS bucket to hold the billing report
AWS billing alerts
Monthly Billing report
A user has setup a billing alarm using CloudWatch for $200. The usage of AWS exceeded $200 after some days. The user wants to increase the limit from $200 to $400? What should the user do?
Create a new alarm of $400 and link it with the first alarm
It is not possible to modify the alarm once it has crossed the usage limit
Update the alarm to set the limit at $400 instead of $200 (Refer link)
Create a new alarm for the additional $200 amount
A user is trying to configure the CloudWatch billing alarm. Which of the below mentioned steps should be performed by the user for the first time alarm creation in the AWS Account Management section?
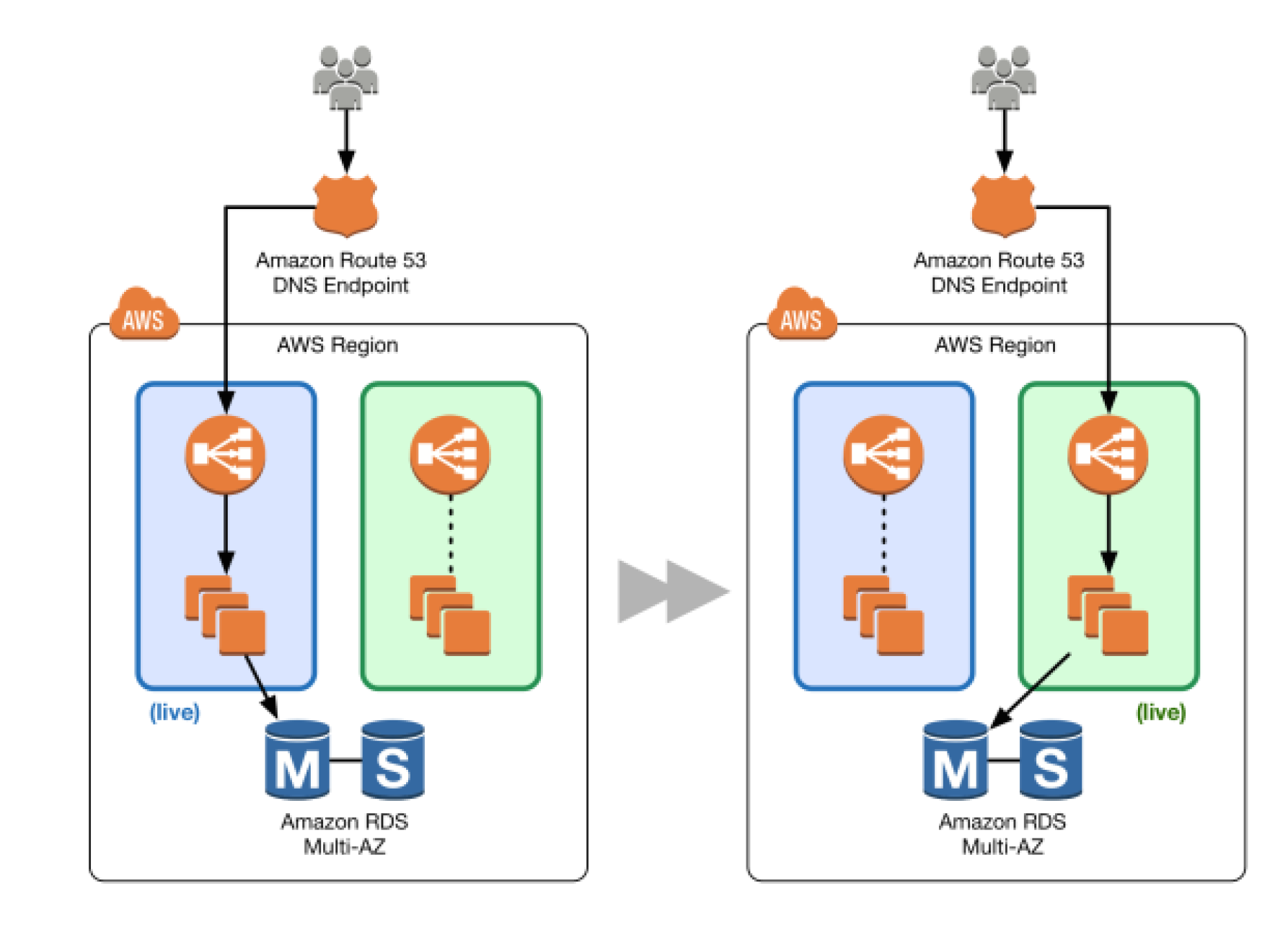
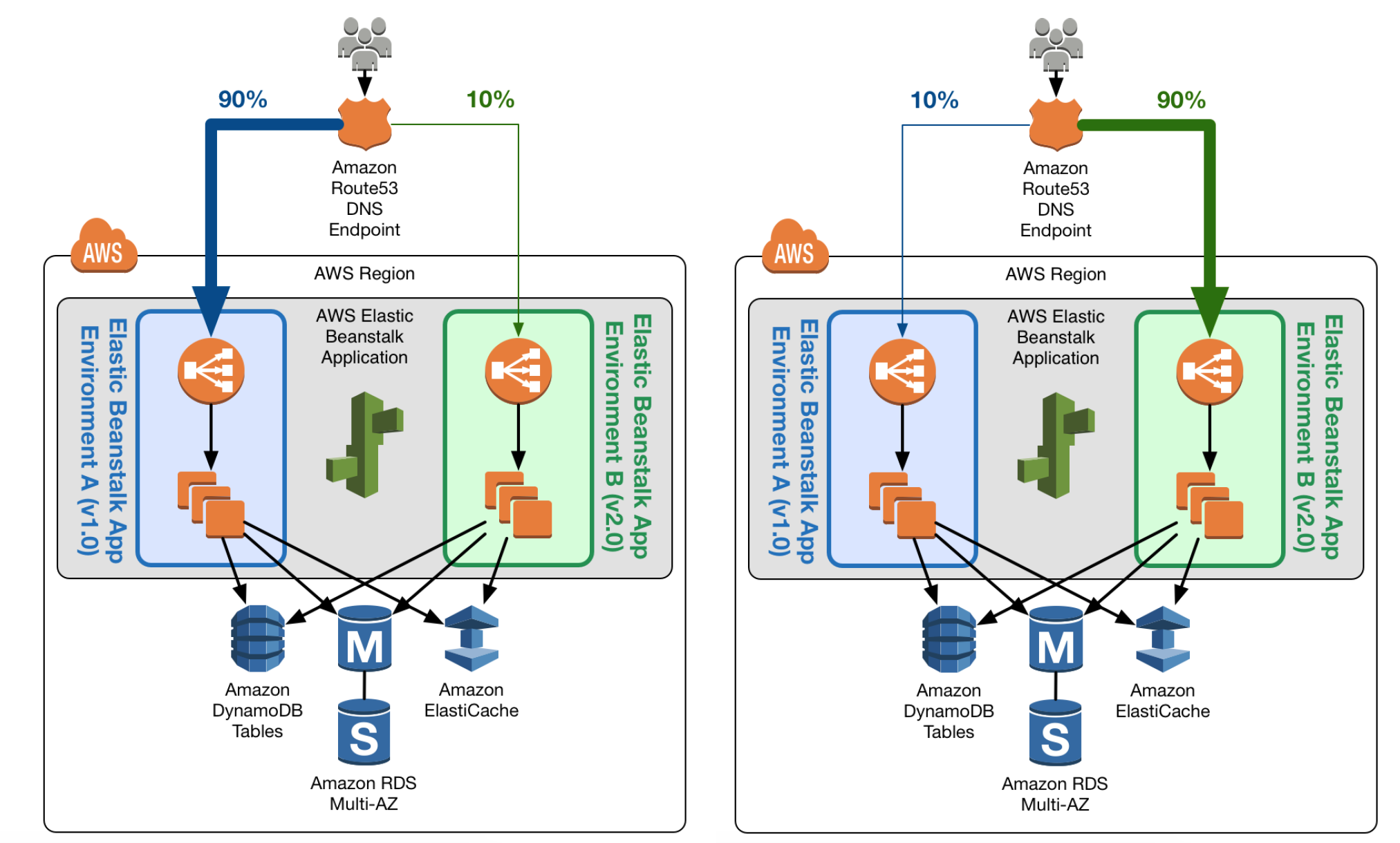
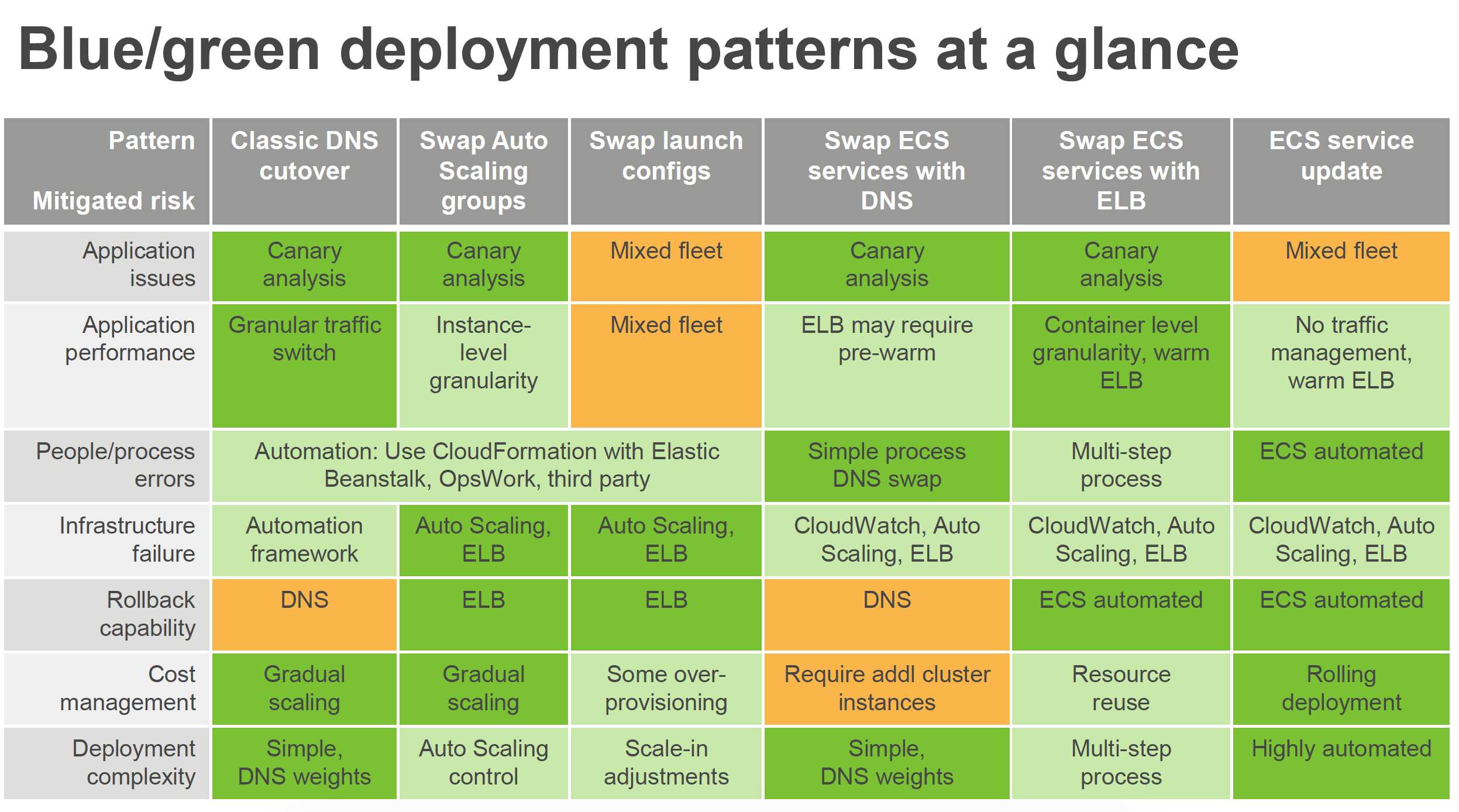
Blue/green deployments provide near zero-downtime release and rollback capabilities.
Blue/green deployment works by shifting traffic between two identical environments that are running different versions of the application
Blue environment represents the current application version serving production traffic.
In parallel, the green environment is staged running a different version of your application.
After the green environment is ready and tested, production traffic is redirected from blue to green.
If any problems are identified, you can roll back by reverting traffic back to the blue environment.
NOTE: Advanced Topic required for DevOps Professional Exam Only
AWS Services
Route 53
Route 53 is a highly available and scalable authoritative DNS service that route user requests
Route 53 with its DNS service allows administrators to direct traffic by simply updating DNS records in the hosted zone
TTL can be adjusted for resource records to be shorter which allow record changes to propagate faster to clients
Elastic Load Balancing
Elastic Load Balancing distributes incoming application traffic across EC2 instances
Elastic Load Balancing scales in response to incoming requests, performs health checking against Amazon EC2 resources, and naturally integrates with other AWS tools, such as Auto Scaling.
ELB also helps perform health checks of EC2 instances to route traffic only to the healthy instances
Auto Scaling
Auto Scaling allows different versions of launch configuration, which define templates used to launch EC2 instances, to be attached to an Auto Scaling group to enable blue/green deployment.
Auto Scaling’s termination policies and Standby state enable blue/green deployment
Termination policies in Auto Scaling groups to determine which EC2 instances to remove during a scaling action.
Auto Scaling also allows instances to be placed in Standby state, instead of termination, which helps with quick rollback when required
Auto Scaling with Elastic Load Balancing can be used to balance and scale the traffic
Elastic Beanstalk
Elastic Beanstalk makes it easy to run multiple versions of the application and provides capabilities to swap the environment URLs, facilitating blue/green deployment.
Elastic Beanstalk supports Auto Scaling and Elastic Load Balancing, both of which enable blue/green deployment
OpsWorks
OpsWorks has the concept of stacks, which are logical groupings of AWS resources with a common purpose & should be logically managed together
Stacks are made of one or more layers with each layer represents a set of EC2 instances that serve a particular purpose, such as serving applications or hosting a database server.
OpsWorks simplifies cloning entire stacks when preparing for blue/green environments.
CloudFormation
CloudFormation helps describe the AWS resources through JSON formatted templates and provides automation capabilities for provisioning blue/green environments and facilitating updates to switch traffic, whether through Route 53 DNS, Elastic Load Balancing, etc
CloudFormation provides infrastructure as code strategy, where infrastructure is provisioned and managed using code and software development techniques, such as version control and continuous integration, in a manner similar to how application code is treated
CloudWatch
CloudWatch monitoring can provide early detection of application health in blue/green deployments
Deployment Techniques
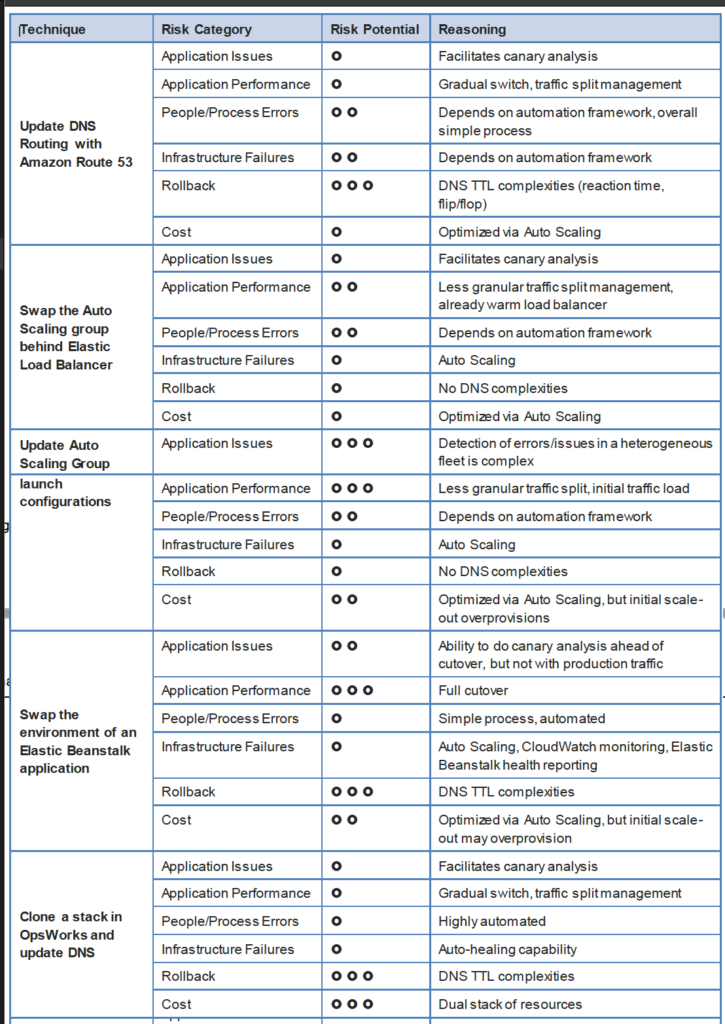
DNS Routing using Route 53
Route 53 DNS service can help switch traffic from the blue environment to the green and vice versa, if rollback is necessary
Route 53 can help either switch the traffic completely or through a weighted distribution
Weighted distribution
helps distribute percentage of traffic to go to the green environment and gradually update the weights until the green environment carries the full production traffic
provides the ability to perform canary analysis where a small percentage of production traffic is introduced to a new environment
helps manage cost by using auto scaling for instances to scale based on the actual demand
Route 53 can handle Public or Elastic IP address, Elastic Load Balancer, Elastic Beanstalk environment web tiers etc.
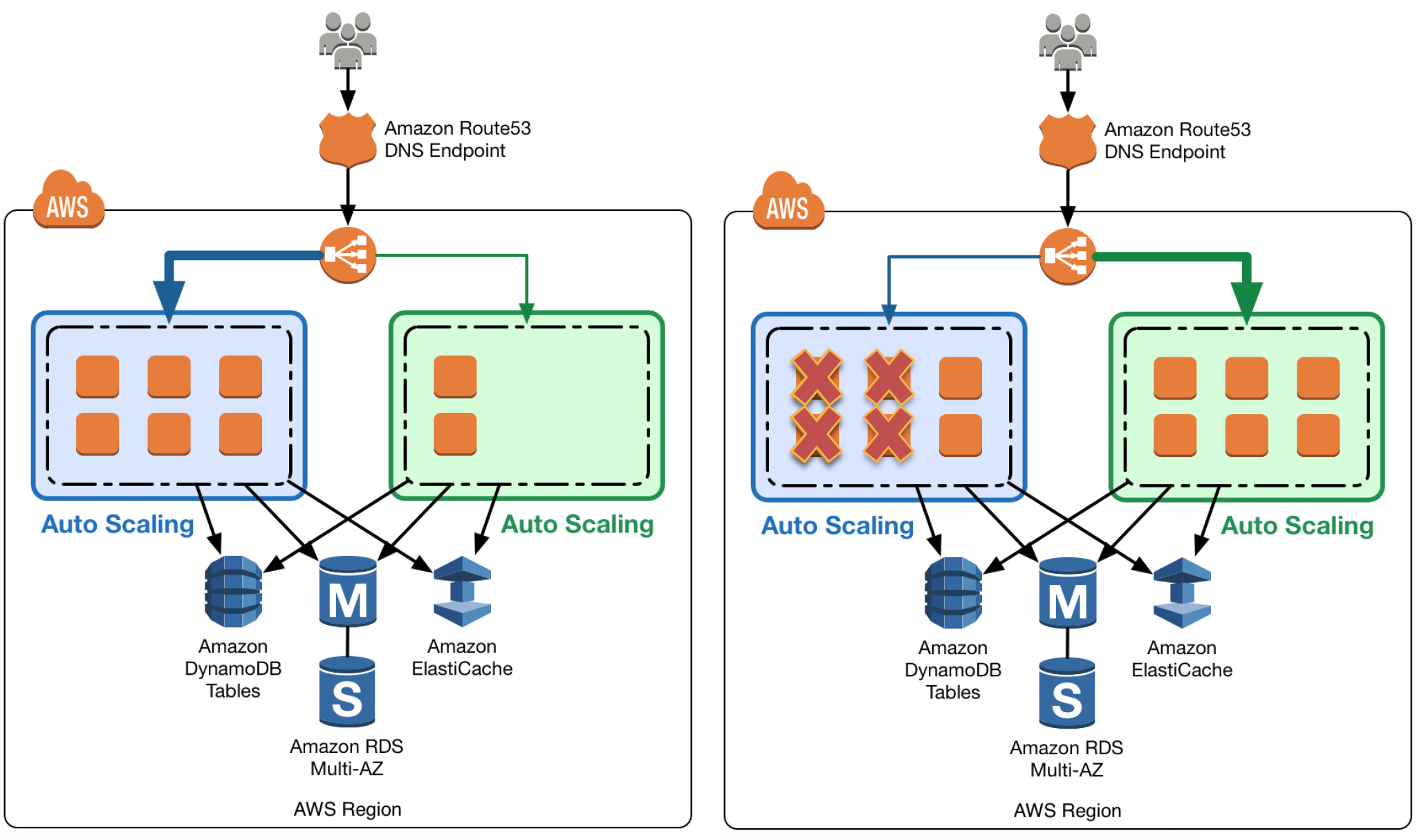
Auto Scaling Group Swap Behind Elastic Load Balancer
Elastic Load Balancing with Auto Scaling to manage EC2 resources as per the demand can be used for Blue Green deployments
Multiple Auto Scaling groups can be attached to the Elastic Load Balancer
Green ASG can be attached to an existing ELB while Blue ASG is already attached to the ELB to serve traffic
ELB would start routing requests to the Green Group as for HTTP/S listener it uses a least outstanding requests routing algorithm
Green group capacity can be increased to process more traffic while the Blue group capacity can be reduced either by terminating the instances or by putting the instances in a standby mode
Standby is a good option because if roll back to the blue environment needed, blue server instances can be put back in service and they’re ready to go
If no issues with the Green group, the blue group can be decommissioned by adjusting the group size to zero
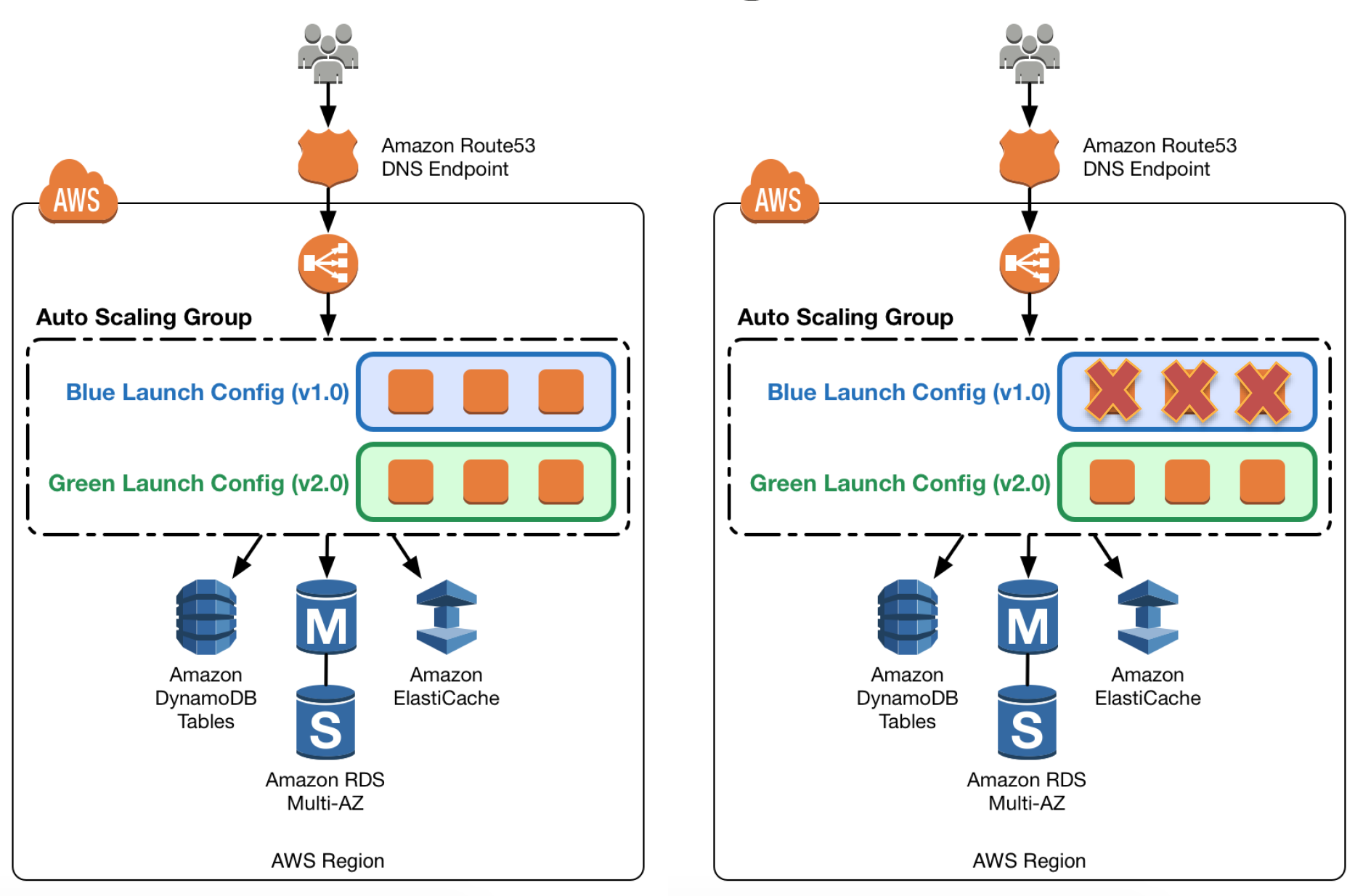
Update Auto Scaling Group Launch Configurations
Auto Scaling groups have their own launch configurations which define template for EC2 instances to be launched
Auto Scaling group can have only one launch configuration at a time, and it can’t be modified. If needs modification, a new launch configuration can be created and attached to the existing Auto Scaling Group
After a new launch configuration is in place, any new instances that are launched use the new launch configuration parameters, but existing instances are not affected.
When Auto Scaling removes instances (referred to as scaling in) from the group, the default termination policy is to remove instances with the oldest launch configuration
To deploy the new version of the application in the green environment, update the Auto Scaling group with the new launch configuration, and then scale the Auto Scaling group to twice its original size.
Then, shrink the Auto Scaling group back to the original size
To perform a rollback, update the Auto Scaling group with the old launch configuration. Then, do the preceding steps in reverse
Elastic Beanstalk Application Environment Swap
Elastic Beanstalk multiple environment and environment url swap feature helps enable Blue Green deployment
Elastic Beanstalk can be used to host the blue environment exposed via URL to access the environment
Elastic Beanstalk provides several deployment policies, ranging from policies that perform an in-place update on existing instances, to immutable deployment using a set of new instances.
Elastic Beanstalk performs an in-place update when the application versions are updated, however application may become unavailable to users for a short period of time.
To avoid the downtime, a new version can be deployed to a separate Green environment with its own URL, launched with the existing environment’s configuration
Elastic Beanstalk’s Swap Environment URLs feature can be used to promote the green environment to serve production traffic
Elastic Beanstalk performs a DNS switch, which typically takes a few minutes
To perform a rollback, invoke Swap Environment URL again.
Clone a Stack in AWS OpsWorks and Update DNS
OpsWorks can be used to create
Blue environment stack with the current version of the application and serving production traffic
Green environment stack with the newer version of the application and is not receiving any traffic
To promote to the green environment/stack into production, update DNS records to point to the green environment/stack’s load balancer
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
What is server immutability?
Not updating a server after creation. (During the new release, a new set of EC2 instances are rolled out by terminating older instances and are disposable. EC2 instance usage is considered temporary or ephemeral in nature for the period of deployment until the current release is active)
The ability to change server counts.
Updating a server after creation.
The inability to change server counts.
You need to deploy a new application version to production. Because the deployment is high-risk, you need to roll the new version out to users over a number of hours, to make sure everything is working correctly. You need to be able to control the proportion of users seeing the new version of the application down to the percentage point. You use ELB and EC2 with Auto Scaling Groups and custom AMIs with your code pre-installed assigned to Launch Configurations. There are no database-level changes during your deployment. You have been told you cannot spend too much money, so you must not increase the number of EC2 instances much at all during the deployment, but you also need to be able to switch back to the original version of code quickly if something goes wrong. What is the best way to meet these requirements?
Create a second ELB, Auto Scaling Launch Configuration, and Auto Scaling Group using the Launch Configuration. Create AMIs with all code pre-installed. Assign the new AMI to the second Auto Scaling Launch Configuration. Use Route53 Weighted Round Robin Records to adjust the proportion of traffic hitting the two ELBs. (Use Weighted Round Robin DNS Records and reverse proxies allow such fine-grained tuning of traffic splits. Blue-Green option does not meet the requirement that we mitigate costs and keep overall EC2 fleet size consistent, so we must select the 2 ELB and ASG option with WRR DNS tuning)
Use the Blue-Green deployment method to enable the fastest possible rollback if needed. Create a full second stack of instances and cut the DNS over to the new stack of instances, and change the DNS back if a rollback is needed. (Full second stack is expensive)
Create AMIs with all code pre-installed. Assign the new AMI to the Auto Scaling Launch Configuration, to replace the old one. Gradually terminate instances running the old code (launched with the old Launch Configuration) and allow the new AMIs to boot to adjust the traffic balance to the new code. On rollback, reverse the process by doing the same thing, but changing the AMI on the Launch Config back to the original code. (Cannot modify the existing launch config)
Migrate to use AWS Elastic Beanstalk. Use the established and well-tested Rolling Deployment setting AWS provides on the new Application Environment, publishing a zip bundle of the new code and adjusting the wait period to spread the deployment over time. Re-deploy the old code bundle to rollback if needed.
When thinking of AWS Elastic Beanstalk, the ‘Swap Environment URLs’ feature most directly aids in what?
Immutable Rolling Deployments
Mutable Rolling Deployments
Canary Deployments
Blue-Green Deployments (Complete switch from one environment to other)
You were just hired as a DevOps Engineer for a startup. Your startup uses AWS for 100% of their infrastructure. They currently have no automation at all for deployment, and they have had many failures while trying to deploy to production. The company has told you deployment process risk mitigation is the most important thing now, and you have a lot of budget for tools and AWS resources. Their stack: 2-tier API Data stored in DynamoDB or S3, depending on type, Compute layer is EC2 in Auto Scaling Groups, They use Route53 for DNS pointing to an ELB, An ELB balances load across the EC2 instances. The scaling group properly varies between 4 and 12 EC2 servers. Which of the following approaches, given this company’s stack and their priorities, best meets the company’s needs?
Model the stack in AWS Elastic Beanstalk as a single Application with multiple Environments. Use Elastic Beanstalk’s Rolling Deploy option to progressively roll out application code changes when promoting across environments. (Does not support DynamoDB also need Blue Green deployment for zero downtime deployment as cost is not a constraint)
Model the stack in 3 CloudFormation templates: Data layer, compute layer, and networking layer. Write stack deployment and integration testing automation following Blue-Green methodologies.
Model the stack in AWS OpsWorks as a single Stack, with 1 compute layer and its associated ELB. Use Chef and App Deployments to automate Rolling Deployment. (Does not support DynamoDB also need Blue Green deployment for zero downtime deployment as cost is not a constraint)
Model the stack in 1 CloudFormation template, to ensure consistency and dependency graph resolution. Write deployment and integration testing automation following Rolling Deployment methodologies. (Need Blue Green deployment for zero downtime deployment as cost is not a constraint)
You are building out a layer in a software stack on AWS that needs to be able to scale out to react to increased demand as fast as possible. You are running the code on EC2 instances in an Auto Scaling Group behind an ELB. Which application code deployment method should you use?
SSH into new instances those come online, and deploy new code onto the system by pulling it from an S3 bucket, which is populated by code that you refresh from source control on new pushes. (is slow and manual)
Bake an AMI when deploying new versions of code, and use that AMI for the Auto Scaling Launch Configuration. (Pre baked AMIs can help to get started quickly)
Create a Dockerfile when preparing to deploy a new version to production and publish it to S3. Use UserData in the Auto Scaling Launch configuration to pull down the Dockerfile from S3 and run it when new instances launch. (is slow)
Create a new Auto Scaling Launch Configuration with UserData scripts configured to pull the latest code at all times. (is slow)
You company runs a complex customer relations management system that consists of around 10 different software components all backed by the same Amazon Relational Database (RDS) database. You adopted AWS OpsWorks to simplify management and deployment of that application and created an AWS OpsWorks stack with layers for each of the individual components. An internal security policy requires that all instances should run on the latest Amazon Linux AMI and that instances must be replaced within one month after the latest Amazon Linux AMI has been released. AMI replacements should be done without incurring application downtime or capacity problems. You decide to write a script to be run as soon as a new Amazon Linux AMI is released. Which solutions support the security policy and meet your requirements? Choose 2 answers
Assign a custom recipe to each layer, which replaces the underlying AMI. Use AWS OpsWorks life-cycle events to incrementally execute this custom recipe and update the instances with the new AMI.
Create a new stack and layers with identical configuration, add instances with the latest Amazon Linux AMI specified as a custom AMI to the new layer, switch DNS to the new stack, and tear down the old stack. (Blue-Green Deployment)
Identify all Amazon Elastic Compute Cloud (EC2) instances of your AWS OpsWorks stack, stop each instance, replace the AMI ID property with the ID of the latest Amazon Linux AMI ID, and restart the instance. To avoid downtime, make sure not more than one instance is stopped at the same time.
Specify the latest Amazon Linux AMI as a custom AMI at the stack level, terminate instances of the stack and let AWS OpsWorks launch new instances with the new AMI.
Add new instances with the latest Amazon Linux AMI specified as a custom AMI to all AWS OpsWorks layers of your stack, and terminate the old ones.
Your company runs an event management SaaS application that uses Amazon EC2, Auto Scaling, Elastic Load Balancing, and Amazon RDS. Your software is installed on instances at first boot, using a tool such as Puppet or Chef, which you also use to deploy small software updates multiple times per week. After a major overhaul of your software, you roll out version 2.0 new, much larger version of the software of your running instances. Some of the instances are terminated during the update process. What actions could you take to prevent instances from being terminated in the future? (Choose two)
Use the zero downtime feature of Elastic Beanstalk to deploy new software releases to your existing instances. (No such feature, you can perform environment url swap)
Use AWS CodeDeploy. Create an application and a deployment targeting the Auto Scaling group. Use CodeDeploy to deploy and update the application in the future. (Referlink)
Run “aws autoscaling suspend-processes” before updating your application. (Refer link)
Use the AWS Console to enable termination protection for the current instances. (Termination protection does not work with Auto Scaling)
Run “aws autoscaling detach-load-balancers” before updating your application. (Does not prevent Auto Scaling to terminate the instances)
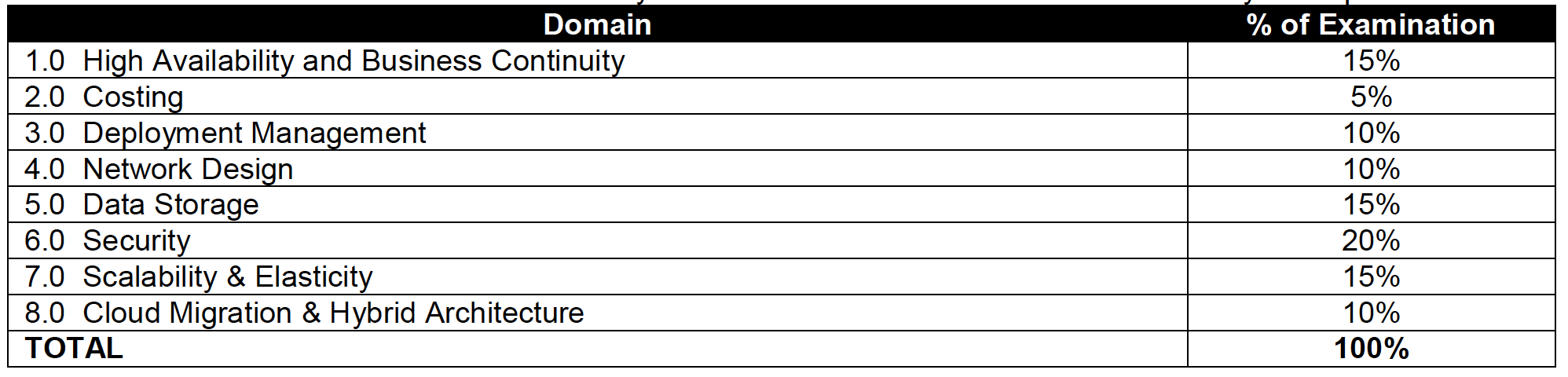
I recently cleared the AWS Certified Solution Architect Professional Exam with 93% after almost 2 months of preparation
Topic Level Scoring: 1.0 High Availability and Business Continuity: 100% 2.0 Costing: 75% 3.0 Deployment Management: 100% 4.0 Network Design: 85% 5.0 Data Storage: 90% 6.0 Security: 92% 7.0 Scalability & Elasticity: 100% 8.0 Cloud Migration & Hybrid Architecture: 85%
AWS Solution Architect – Professional exam is quite an exhaustive exam with 77 questions in 180 minutes and covers a lot of AWS services and the combinations how they work and integrate together. However, the questions are bit old and has not kept pace with the fast changing AWS enhancements
If looking for Associate Preparation Guide, please refer
AWS Solution Architect – Professional exam basically validates the following
Identify and gather requirements in order to define a solution to be built on AWS
Evolve systems by introducing new services and features
Assess the tradeoffs and implications of architectural decisions and choices for applications deployed in AWS
Design an optimal system by meeting project requirements while maximizing characteristics such as scalability, security, reliability, durability, and cost effectiveness
Evaluate project requirements and make recommendations for implementation, deployment, and provisioning applications on AWS
Provide best practice and architectural guidance over the lifecycle of a project
Linux Academy Course which is far more exhaustive and covers a wide range of topics with labs. It also has a free 7 day for you the try it out and offers monthly subscription
AWS Certification Exams cover a lot of topics and a wide range of services with minute details for features, patterns, anti patterns and their integration with other services. This blog post is just to have a quick summary of all the services and key points for a quick glance before you appear for the exam
AWS Global Infrastructure
AWS Region, AZs, Edge locations
Each region is a separate geographic area, completely independent, isolated from the other regions & helps achieve the greatest possible fault tolerance and stability
Communication between regions is across the public Internet
Each region has multiple Availability Zones
Each AZ is physically isolated, geographically separated from each other and designed as an independent failure zone
AZs are connected with low-latency private links (not public internet)
Edge locations are locations maintained by AWS through a worldwide network of data centers for the distribution of content to reduce latency.
AWS Local Zones
AWS Local Zones place select AWS services closer to end-users, which allows running highly-demanding applications that require single-digit millisecond latencies to the end-users such as media & entertainment content creation, real-time gaming, machine learning etc.
AWS Local Zones provide a high-bandwidth, secure connection between local workloads and those running in the AWS Region, allowing you to seamlessly connect to the full range of in-region services through the same APIs and tool sets.
AWS Wavelength
AWS infrastructure deployments embed AWS compute and storage services within the telecommunications providers’ datacenters and help seamlessly access the breadth of AWS services in the region.
AWS Wavelength brings services to the edge of the 5G network, without leaving the mobile provider’s network reducing the extra network hops, minimizing the latency to connect to an application from a mobile device.
AWS Outposts
AWS Outposts bring native AWS services, infrastructure, and operating models to virtually any data center, co-location space, or on-premises facility.
AWS Outposts is designed for connected environments and can be used to support workloads that need to remain on-premises due to low latency, compliance or local data processing needs.
AWS Organizations offers policy-based management for multiple AWS accounts
Organizations allows creation of groups of accounts and then apply policies to those groups
Organizations enables you to centrally manage policies across multiple accounts, without requiring custom scripts and manual processes.
Organizations helps simplify the billing for multiple accounts by enabling the setup of a single payment method for all the accounts in the organization through consolidated billing
Consolidate Billing
Paying account with multiple linked accounts
Paying account is independent and should be only used for billing purpose
Paying account cannot access resources of other accounts unless given exclusively access through Cross Account roles
All linked accounts are independent and soft limit of 20
One bill per AWS account
provides Volume pricing discount for usage across the accounts
allows unused Reserved Instances to be applied across the group
Free tier is not applicable across the accounts
Tags & Resource Groups
are metadata, specified as key/value pairs with the AWS resources
are for labelling purposes and helps managing, organizing resources
can be inherited when created resources created from Auto Scaling, Cloud Formation, Elastic Beanstalk etc
can be used for
Cost allocation to categorize and track the AWS costs
Conditional Access Control policy to define permission to allow or deny access on resources based on tags
Resource Group is a collection of resources that share one or more tags
IDS/IPS
Promiscuous mode is not allowed, as AWS and Hypervisor will not deliver any traffic to instances this is not specifically addressed to the instance
IDS/IPS strategies
Host Based Firewall – Forward Deployed IDS where the IDS itself is installed on the instances
Host Based Firewall – Traffic Replication where IDS agents installed on instances which send/duplicate the data to a centralized IDS system
In-Line Firewall – Inbound IDS/IPS Tier (like a WAF configuration) which identifies and drops suspect packets
DDOS Mitigation
Minimize the Attack surface
use ELB/CloudFront/Route 53 to distribute load
maintain resources in private subnets and use Bastion servers
Scale to absorb the attack
scaling helps buy time to analyze and respond to an attack
auto scaling with ELB to handle increase in load to help absorb attacks
CloudFront, Route 53 inherently scales as per the demand
Safeguard exposed resources
user Route 53 for aliases to hide source IPs and Private DNS
use CloudFront geo restriction and Origin Access Identity
use WAF as part of the infrastructure
Learn normal behavior (IDS/WAF)
analyze and benchmark to define rules on normal behavior
use CloudWatch
Create a plan for attacks
AWS Services Region, AZ, Subnet VPC limitations
Services like IAM (user, role, group, SSL certificate), Route 53, STS are Global and available across regions
All other AWS services are limited to Region or within Region and do not exclusively copy data across regions unless configured
AMI are limited to region and need to be copied over to other region
EBS volumes are limited to the Availability Zone, and can be migrated by creating snapshots and copying them to another region
Reserved instances are limited to Availability Zone and (can be migrated to other Availability Zone now) cannot be migrated to another region
RDS instances are limited to the region and can be recreated in a different region by either using snapshots or promoting a Read Replica
Placement groups are limited to the Availability Zone
Cluster Placement groups are limited to single Availability Zones
Spread Placement groups can span across multiple Availability Zones
S3 data is replicated within the region and can be move to another region using cross region replication
DynamoDB maintains data within the region can be replicated to another region using DynamoDB cross region replication (using DynamoDB streams) or Data Pipeline using EMR (old method)
Redshift Cluster span within an Availability Zone only, and can be created in other AZ using snapshots
Disaster Recovery Whitepaper
RTO is the time it takes after a disruption to restore a business process to its service level and RPO acceptable amount of data loss measured in time before the disaster occurs
Techniques (RTO & RPO reduces and the Cost goes up as we go down)
Backup & Restore – Data is backed up and restored, within nothing running
Pilot light – Only minimal critical service like RDS is running and rest of the services can be recreated and scaled during recovery
Warm Standby – Fully functional site with minimal configuration is available and can be scaled during recovery
Multi-Site – Fully functional site with identical configuration is available and processes the load
Services
Region and AZ to launch services across multiple facilities
EC2 instances with the ability to scale and launch across AZs
EBS with Snapshot to recreate volumes in different AZ or region
AMI to quickly launch preconfigured EC2 instances
ELB and Auto Scaling to scale and launch instances across AZs
VPC to create private, isolated section
Elastic IP address as static IP address
ENI with pre allocated Mac Address
Route 53 is highly available and scalable DNS service to distribute traffic across EC2 instances and ELB in different AZs and regions
Direct Connect for speed data transfer (takes time to setup and expensive then VPN)
S3 and Glacier (with RTO of 3-5 hours) provides durable storage
RDS snapshots and Multi AZ support and Read Replicas across regions
DynamoDB with cross region replication
Redshift snapshots to recreate the cluster
Storage Gateway to backup the data in AWS
Import/Export to move large amount of data to AWS (if internet speed is the bottleneck)
CloudFormation, Elastic Beanstalk and Opsworks as orchestration tools for automation and recreate the infrastructure
stores copies of the messages on multiple servers for redundancy and high availability
guarantees At-Least-Once Delivery, but does not guarantee Exact One Time Delivery which might result in duplicate messages (Not true anymore with the introduction of FIFO queues)
does not maintain or guarantee message order, and if needed sequencing information needs to be added to the message itself (Not true anymore with the introduction of FIFO queues)
supports multiple readers and writers interacting with the same queue as the same time
holds message for 4 days, by default, and can be changed from 1 min – 14 days after which the message is deleted
message needs to be explicitly deleted by the consumer once processed
allows send, receive and delete batching which helps club up to 10 messages in a single batch while charging price for a single message
handles visibility of the message to multiple consumers using Visibility Timeout, where the message once read by a consumer is not visible to the other consumers till the timeout occurs
can handle load and performance requirements by scaling the worker instances as the demand changes (Job Observer pattern)
message sample allowing short and long polling
returns immediately vs waits for fixed time for e.g. 20 secs
might not return all messages as it samples a subset of servers vs returns all available messages
repetitive vs helps save cost with long connection
supports delay queues to make messages available after a certain delay, can you used to differentiate from priority queues
supports dead letter queues, to redirect messages which failed to process after certain attempts instead of being processed repeatedly
Design Patterns
Job Observer Pattern can help coordinate number of EC2 instances with number of job requests (Queue Size) automatically thus Improving cost effectiveness and performance
Priority Queue Pattern can be used to setup different queues with different handling either by delayed queues or low scaling capacity for handling messages in lower priority queues
SNS
delivery or sending of messages to subscribing endpoints or clients
publisher-subscriber model
Producers and Consumers communicate asynchronously with subscribers by producing and sending a message to a topic
supports Email (plain or JSON), HTTP/HTTPS, SMS, SQS
supports Mobile Push Notifications to push notifications directly to mobile devices with services like Amazon Device Messaging (ADM), Apple Push Notification Service (APNS), Google Cloud Messaging (GCM) etc. supported
order is not guaranteed and No recall available
integrated with Lambda to invoke functions on notifications
for Email notifications, use SNS or SES directly, SQS does not work
SWF
orchestration service to coordinate work across distributed components
helps define tasks, stores, assigns tasks to workers, define logic, tracks and monitors the task and maintains workflow state in a durable fashion
helps define tasks which can be executed on AWS cloud or on-premises
helps coordinating tasks across the application which involves managing intertask dependencies, scheduling, and concurrency in accordance with the logical flow of the application
supports built-in retries, timeouts and logging
supports manual tasks
Characteristics
deliver exactly once
uses long polling, which reduces number of polls without results
Visibility of task state via API
Timers, signals, markers, child workflows
supports versioning
keeps workflow history for a user-specified time
AWS SWF vs AWS SQS
task-oriented vs message-oriented
track of all tasks and events vs needs custom handling
SES
highly scalable and cost-effective email service
uses content filtering technologies to scan outgoing emails to check standards and email content for spam and malware
supports full fledged emails to be sent as compared to SNS where only the message is sent in Email
ideal for sending bulk emails at scale
guarantees first hop
eliminates the need to support custom software or applications to do heavy lifting of email transport
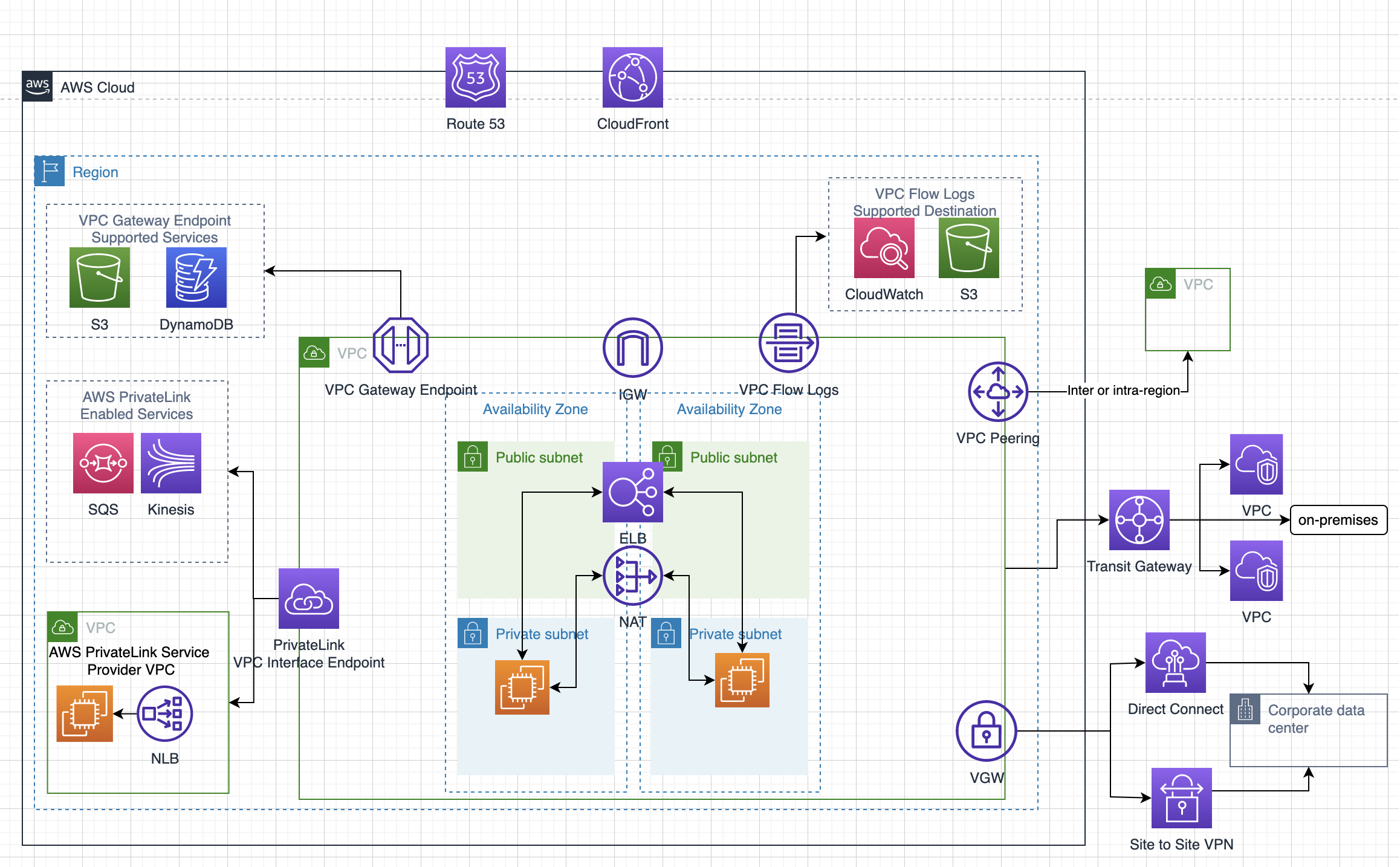
Flow logs – Capture information about the IP traffic going to and from network interfaces in your VPC
Tenancy option for instances
shared, by default, allows instances to be launched on shared tenancy
dedicated allows instances to be launched on a dedicated hardware
Route Tables
defines rules, termed as routes, which determine where network traffic from the subnet would be routed
Each VPC has a Main Route table and can have multiple custom route tables created
Every route table contains a local route that enables communication within a VPC which cannot be modified or deleted
Route priority is decided by matching the most specific route in the route table that matches the traffic
Subnets
map to AZs and do not span across AZs
have a CIDR range that is a portion of the whole VPC.
CIDR ranges cannot overlap between subnets within the VPC.
AWS reserves 5 IP addresses in each subnet – first 4 and last one
Each subnet is associated with a route table which define its behavior
Public subnets – inbound/outbound Internet connectivity via IGW
Private subnets – outbound Internet connectivity via an NAT or VGW
Protected subnets – no outbound connectivity and used for regulated workloads
Elastic Network Interface (ENI)
a default ENI, eth0, is attached to an instance which cannot be detached with one or more secondary detachable ENIs (eth1-ethn)
has primary private, one or more secondary private, public, Elastic IP address, security groups, MAC address and source/destination check flag attributes associated
AN ENI in one subnet can be attached to an instance in the same or another subnet, in the same AZ and the same VPC
Security group membership of an ENI can be changed
with pre-allocated Mac Address can be used for applications with special licensing requirements
allows internet access to instances in the private subnets.
performs the function of both address translation and port address translation (PAT)
needs source/destination check flag to be disabled as it is not the actual destination of the traffic for NAT Instance.
NAT gateway is an AWS managed NAT service that provides better availability, higher bandwidth, and requires less administrative effort
are not supported for IPv6 traffic
NAT Gateway supports private NAT with fixed private IPs.
Egress-Only Internet Gateways
outbound communication over IPv6 from instances in the VPC to the Internet, and prevents the Internet from initiating an IPv6 connection with your instances
supports IPv6 traffic only
Shared VPCs
allows multiple AWS accounts to create their application resources, such as EC2 instances, RDS databases, Redshift clusters, and AWS Lambda functions, into shared, centrally-managed VPCs
enables private connectivity from VPC to supported AWS services and VPC endpoint services powered by PrivateLink
does not require a public IP address, access over the Internet, NAT device, a VPN connection, or Direct Connect
traffic between VPC & AWS service does not leave the Amazon network
are virtual devices.
are horizontally scaled, redundant, and highly available VPC components that allow communication between instances in the VPC and services without imposing availability risks or bandwidth constraints on the network traffic.
Gateway Endpoints
is a gateway that is a target for a specified route in the route table, used for traffic destined to a supported AWS service.
only S3 and DynamoDB are currently supported
Interface Endpoints OR Private Links
is an elastic network interface with a private IP address that serves as an entry point for traffic destined to a supported service
supports services include AWS services, services hosted by other AWS customers and partners in their own VPCs (referred to as endpoint services), and supported AWS Marketplace partner services.
provides low latency and high data transfer speeds for the distribution of static, dynamic web, or streaming content to web users.
delivers the content through a worldwide network of data centers called Edge Locations or Point of Presence (PoPs)
keeps persistent connections with the origin servers so that the files can be fetched from the origin servers as quickly as possible.
dramatically reduces the number of network hops that users’ requests must pass through
supports multiple origin server options, like AWS hosted service for e.g. S3, EC2, ELB, or an on-premise server, which stores the original, definitive version of the objects
single distribution can have multiple origins and Path pattern in a cache behavior determines which requests are routed to the origin
Web distribution supports static, dynamic web content, on-demand using progressive download & HLS, and live streaming video content
supports HTTPS using either
dedicated IP address, which is expensive as a dedicated IP address is assigned to each CloudFront edge location
Server Name Indication (SNI), which is free but supported by modern browsers only with the domain name available in the request header
For E2E HTTPS connection,
Viewers -> CloudFront needs either a certificate issued by CA or ACM
CloudFront -> Origin needs a certificate issued by ACM for ELB and by CA for other origins
Security
Origin Access Identity (OAI) can be used to restrict the content from S3 origin to be accessible from CloudFront only
supports Geo restriction (Geo-Blocking) to whitelist or blacklist countries that can access the content
Signed URLs
to restrict access to individual files, for e.g., an installation download for your application.
users using a client, for e.g. a custom HTTP client, that doesn’t support cookies
Signed Cookies
provide access to multiple restricted files, for e.g., video part files in HLS format or all of the files in the subscribers’ area of a website.
don’t want to change the current URLs
integrates with AWS WAF, a web application firewall that helps protect web applications from attacks by allowing rules configured based on IP addresses, HTTP headers, and custom URI strings
supports GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE to get object & object headers, add, update, and delete objects
only caches responses to GET and HEAD requests and, optionally, OPTIONS requests
does not cache responses to PUT, POST, PATCH, DELETE request methods and these requests are proxied back to the origin
object removal from the cache
would be removed upon expiry (TTL) from the cache, by default 24 hrs
can be invalidated explicitly, but has a cost associated, however, might continue to see the old version until it expires from those caches
objects can be invalidated only for Web distribution
use versioning or change object name, to serve a different version
supports adding or modifying custom headers before the request is sent to origin which can be used to
validate if a user is accessing the content from CDN
identifying CDN from which the request was forwarded, in case of multiple CloudFront distributions
for viewers not supporting CORS to return the Access-Control-Allow-Origin header for every request
supports Partial GET requests using range header to download objects in smaller units improving the efficiency of partial downloads and recovery from partially failed transfers
supports compression to compress and serve compressed files when viewer requests include Accept-Encoding: gzip in the request header
supports different price classes to include all regions, or only the least expensive regions and other regions without the most expensive regions
supports access logs which contain detailed information about every user request for both web and RTMP distribution
is a network service that uses a private dedicated network connection to connect to AWS services.
helps reduce costs (long term), increases bandwidth, and provides a more consistent network experience than internet-based connections.
supports Dedicated and Hosted connections
Dedicated connection is made through a 1 Gbps, 10 Gbps, or 100 Gbps Ethernet port dedicated to a single customer.
Hosted connections are sourced from an AWS Direct Connect Partner that has a network link between themselves and AWS.
provides Virtual Interfaces
Private VIF to access instances within a VPC via VGW
Public VIF to access non VPC services
requires time to setup probably months, and should not be considered as an option if the turnaround time is less
does not provide redundancy, use either second direct connection or IPSec VPN connection
Virtual Private Gateway is on the AWS side and Customer Gateway is on the Customer side
route propagation is enabled on VGW and not on CGW
A link aggregation group (LAG) is a logical interface that uses the link aggregation control protocol (LACP) to aggregate multiple dedicated connections at a single AWS Direct Connect endpoint and treat them as a single, managed connection
Direct Connect vs VPN IPSec
Expensive to Setup and Takes time vs Cheap & Immediate
Dedicated private connections vs Internet
Reduced data transfer rate vs Internet data transfer cost
Consistent performance vs Internet inherent variability
It’s similar to a CNAME resource record set, but supports both for root domain – zone apex e.g. example.com, and for subdomains for e.g. www.example.com.
supports ELB load balancers, CloudFront distributions, Elastic Beanstalk environments, API Gateways, VPC interface endpoints, and S3 buckets that are configured as websites.
CNAME resource record sets can be created only for subdomains and cannot be mapped to the zone apex record
supports Private DNS to provide an authoritative DNS within the VPCs without exposing the DNS records (including the name of the resource and its IP address(es) to the Internet.
Split-view (Split-horizon) DNS enables mapping the same domain publicly and privately. Requests are routed as per the origin.
Weighted routing – assign weights to resource records sets to specify the proportion for e.g. 80%:20%
Latency based routing – helps improve global applications as requests are sent to the server from the location with minimal latency, is based on the latency and cannot guarantee users from the same geography will be served from the same location for any compliance reasons
Geolocation routing – Specify geographic locations by continent, country, the state limited to the US, is based on IP accuracy
Geoproximity routing policy – Use to route traffic based on the location of the resources and, optionally, shift traffic from resources in one location to resources in another.
Multivalue answer routing policy – Use to respond to DNS queries with up to eight healthy records selected at random.
Failover routing – failover to a backup site if the primary site fails and becomes unreachable
Weighted, Latency and Geolocation can be used for Active-Active while Failover routing can be used for Active-Passive multi-region architecture
Traffic Flow is an easy-to-use and cost-effective global traffic management service. Traffic Flow supports versioning and helps create policies that route traffic based on the constraints they care most about, including latency, endpoint health, load, geoproximity, and geography.
Route 53 Resolver is a regional DNS service that helps with hybrid DNS
Inbound Endpoints are used to resolve DNS queries from an on-premises network to AWS
Outbound Endpoints are used to resolve DNS queries from AWS to an on-premises network
is a networking service that helps you improve the availability and performance of the applications to global users.
utilizes the Amazon global backbone network, improving the performance of the applications by lowering first-byte latency, and jitter, and increasing throughput as compared to the public internet.
provides two static IP addresses serviced by independent network zones that provide a fixed entry point to the applications and eliminate the complexity of managing specific IP addresses for different AWS Regions and AZs.
always routes user traffic to the optimal endpoint based on performance, reacting instantly to changes in application health, the user’s location, and configured policies
improves performance for a wide range of applications over TCP or UDP by proxying packets at the edge to applications running in one or more AWS Regions.
is a good fit for non-HTTP use cases, such as gaming (UDP), IoT (MQTT), or Voice over IP, as well as for HTTP use cases that specifically require static IP addresses or deterministic, fast regional failover.
is a highly available and scalable service to consolidate the AWS VPC routing configuration for a region with a hub-and-spoke architecture.
acts as a Regional virtual router and is a network transit hub that can be used to interconnect VPCs and on-premises networks.
traffic always stays on the global AWS backbone, data is automatically encrypted, and never traverses the public internet, thereby reducing threat vectors, such as common exploits and DDoS attacks.
is a Regional resource and can connect VPCs within the same AWS Region.
TGWs across the same or different regions can peer with each other.
provides simpler VPC-to-VPC communication management over VPC Peering with a large number of VPCs.
scales elastically based on the volume of network traffic.
AWS Organizations is an account management service that enables consolidating multiple AWS accounts into an organization that can be created and centrally managed.
AWS Organizations enables you to
Automate AWS account creation and management, and provision resources with AWS CloudFormation Stacksets
Maintain a secure environment with policies and management of AWS security services
Govern access to AWS services, resources, and regions
Centrally manage policies across multiple AWS accounts
gives developers and systems administrators an easy way to create and manage a collection of related AWS resources
Resources can be updated, deleted, and modified in an orderly, controlled and predictable fashion, in effect applying version control to the AWS infrastructure as code done for software code
CloudFormation Template is an architectural diagram, in JSON format, and Stack is the end result of that diagram, which is actually provisioned
template can be used to set up the resources consistently and repeatedly over and over across multiple regions and consists of
List of AWS resources and their configuration values
An optional template file format version number
An optional list of template parameters (input values supplied at stack creation time)
An optional list of output values like public IP address using the Fn::GetAtt function
An optional list of data tables used to lookup static configuration values for e.g., AMI names per AZ
supports Chef & Puppet Integration to deploy and configure right down the application layer
supports Bootstrap scripts to install packages, files, and services on the EC2 instances by simply describing them in the CF template
automatic rollback on error feature is enabled, by default, which will cause all the AWS resources that CF created successfully for a stack up to the point where an error occurred to be deleted
provides a WaitCondition resource to block the creation of other resources until a completion signal is received from an external source
allows DeletionPolicy attribute to be defined for resources in the template
retain to preserve resources like S3 even after stack deletion
snapshot to backup resources like RDS after stack deletion
DependsOn attribute to specify that the creation of a specific resource follows another
Service role is an IAM role that allows AWS CloudFormation to make calls to resources in a stack on the user’s behalf
Nested stacks can separate out reusable, common components and create dedicated templates to mix and match different templates but use nested stacks to create a single, unified stack
Change Sets presents a summary or preview of the proposed changes that CloudFormation will make when a stack is updated
Drift detection enables you to detect whether a stack’s actual configuration differs, or has drifted, from its expected configuration.
Termination protection helps prevent a stack from being accidentally deleted.
Stack policy can prevent stack resources from being unintentionally updated or deleted during a stack update.
StackSets extends the functionality of stacks by enabling you to create, update, or delete stacks across multiple accounts and Regions with a single operation.
makes it easier for developers to quickly deploy and manage applications in the AWS cloud.
automatically handles the deployment details of capacity provisioning, load balancing, auto-scaling and application health monitoring
CloudFormation supports ElasticBeanstalk
provisions resources to support
a web application that handles HTTP(S) requests or
a web application that handles background-processing (worker) tasks
supports Out Of the Box
Apache Tomcat for Java applications
Apache HTTP Server for PHP applications
Apache HTTP server for Python applications
Nginx or Apache HTTP Server for Node.js applications
Passenger for Ruby applications
MicroSoft IIS 7.5 for .Net applications
Single and Multi Container Docker
supports custom AMI to be used
is designed to support multiple running environments such as one for Dev, QA, Pre-Prod and Production.
supports versioning and stores and tracks application versions over time allowing easy rollback to prior version
can provision RDS DB instance and connectivity information is exposed to the application by environment variables, but is NOT recommended for production setup as the RDS is tied up with the Elastic Beanstalk lifecycle and if deleted, the RDS instance would be deleted as well
is a configuration management service that helps to configure and operate applications in a cloud enterprise by using Chef
helps deploy and monitor applications in stacks with multiple layers
supports preconfigured layers for Applications, Databases, Load Balancers, Caching
OpsWorks Stacks features is a set of lifecycle events – Setup, Configure, Deploy, Undeploy, and Shutdown – which automatically runs specified set of recipes at the appropriate time on each instance
Layers depend on Chef recipes to handle tasks such as installing packages on instances, deploying apps, running scripts, and so on
OpsWorks Stacks runs the recipes for each layer, even if the instance belongs to multiple layers
supports Auto Healing and Auto Scaling to monitor instance health, and provision new instances
allows monitoring of AWS resources and applications in real time, collect and track pre configured or custom metrics and configure alarms to send notification or make resource changes based on defined rules
does not aggregate data across regions
stores the log data indefinitely, and the retention can be changed for each log group at any time
alarm history is stored for only 14 days
can be used an alternative to S3 to store logs with the ability to configure Alarms and generate metrics, however logs cannot be made public
Alarms exist only in the created region and the Alarm actions must reside in the same region as well
records access to API calls for the AWS account made from AWS management console, SDKs, CLI and higher level AWS service
support many AWS services and tracks who did, from where, what & when
can be enabled per-region basis, a region can include global services (like IAM, STS etc), is applicable to all the supported services within that region
log files from different regions can be sent to the same S3 bucket
can be integrated with SNS to notify logs availability, CloudWatch logs log group for notifications when specific API events occur
call history enables security analysis, resource change tracking, trouble shooting and compliance auditing