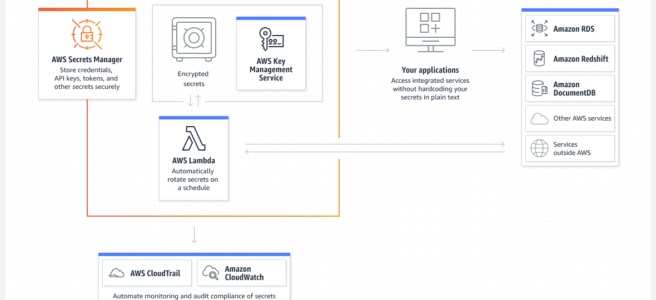
AWS Secrets Manager helps protect secrets needed to access applications, services, and IT resources.
enables you to easily rotate, manage, and retrieve database credentials, API keys, and other secrets throughout their lifecycle.
secure secrets by encrypting them with encryption keys managed using AWS KMS.
offers native secret rotation with built-in integration for RDS, Redshift, and DocumentDB.
supports Lambda functions to extend secret rotation to other types of secrets, including API keys and OAuth tokens.
supports IAM and resource-based policies for fine-grained access control to secrets and centralized secret rotation audit for resources in the AWS Cloud, third-party services, and on-premises.
enables secret replication in multiple AWS regions to support multi-region applications and disaster recovery scenarios.
stores the encrypted data key with the protected secret data.
Decryption
requests AWS KMS to decrypt the encrypted data key
uses the plain text data key to decrypt the protected secret data.
never stores the data key in unencrypted form, and always disposes of the data key immediately after use.
Secrets Manager Rotation
AWS Secrets Manager enables database credential rotation on a schedule.
When Secrets Manager initiates a rotation
it uses the provided super database credentials to create a clone user with the same privileges, but with a different password.
communicates the clone user information to databases and applications retrieving the database credentials.
integrates with CloudWatch Events to send a notification when it rotates a secret.
Credentials rotation does not impact the already open connections as they are not re-authenticated. Authentication happens when a connection is established.
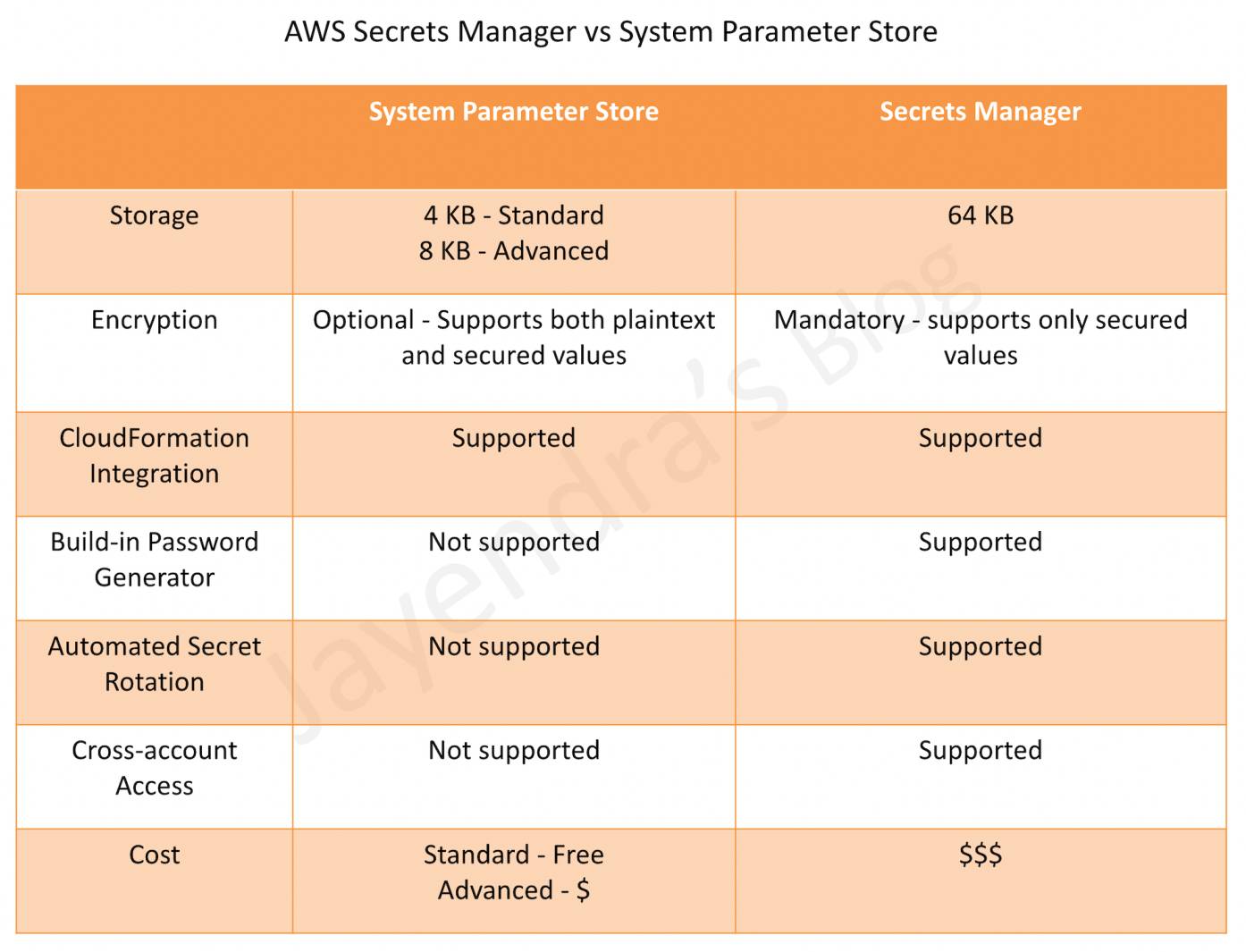
Secrets Manager vs Systems Parameter Store
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Which AWS service makes it easy for you to easily rotate, manage, and retrieve database credentials, API keys, and other secrets throughout their lifecycle?
AWS WAF
AWS Secrets Manager
AWS Systems Manager
AWS Shield
A company uses Amazon RDS for PostgreSQL databases for its data tier. The company must implement password rotation for the databases. Which solution meets this requirement with the LEAST operational overhead?
Store the password in AWS Secrets Manager. Enable automatic rotation on the secret.
Store the password in AWS Systems Manager Parameter Store. Enable automatic rotation on the parameter.
Store the password in AWS Systems Manager Parameter Store. Write an AWS Lambda function that rotates the password.
Store the password in AWS Key Management Service (AWS KMS). Enable automatic rotation on the customer master key (CMK).
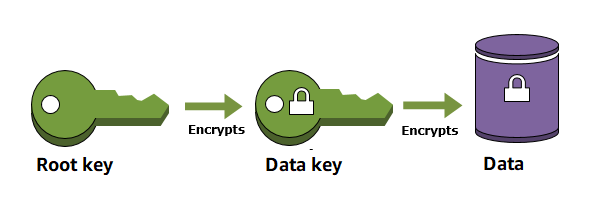
Envelope encryption is an optimized method for encrypting data that uses two different keys (Master key and Data key)
Master key is also known as Key Encryption Key – KEK and Data key is also known as Data Encryption Key – DEK.
Envelope encryption reduces the network load for the application or the cloud service as only the request and fulfillment of the much smaller data key through KMS must go over the network.
The data key is used locally by the encrypting service, avoiding the need to send the entire block of data to KMS and suffer network latency.
Root Key
A root key is an encryption key that is used to encrypt other encryption keys, such as data keys and key encryption keys. Unlike data keys and key encryption keys, root keys must be kept in plaintext so they can be used to decrypt the keys that they encrypted.
Key Management Service (KMS) generates and protects the root keys.
Key Encryption Key – KEK
A key encryption key is an encryption key that is used to encrypt a data key or another key encryption key. To protect the
Key encryption key is encrypted by using a root key.
Data Encryption Key – DEK
A data key or data encryption key is an encryption key that is used to protect data.
Data keys differ from root keys and key encryption keys, which are typically used to encrypt other encryption keys.
Envelop Encryption Process
Encryption
Create a Master Key
Generate data key.
KMS returns the plaintext and ciphertext of the data key.
The plaintext data key is used to encrypt each piece of data or resource.
The data key is encrypted under a master key defined in KMS.
The encrypted data key and encrypted data are then stored by the service.
Decryption
Retrieve the ciphertext data key and encrypted files from the persistent storage device or service.
Decrypt the ciphertext data key using the Master key. The plaintext data key is returned.
Use the plaintext data key to decrypt the files.
Encrypting the data key is more efficient than reencrypting the data under the new key because it is quicker and produces a much smaller ciphertext.
Envelope Encryption Benefits
Protecting data keys
When you encrypt a data key, you don’t have to worry about storing the encrypted data key, because the data key is inherently protected by encryption. You can safely store the encrypted data key alongside the encrypted data.
Encrypting the same data under multiple keys
Encryption operations can be time-consuming, particularly when the data being encrypted are large objects.
Instead of re-encrypting raw data multiple times with different keys, you can re-encrypt only the data keys that protect the raw data.
Combining the strengths of multiple algorithms
In general, symmetric key algorithms are faster and produce smaller ciphertexts than public key algorithms.
But public key algorithms provide inherent separation of roles and easier key management.
Envelope encryption lets you combine the strengths of each strategy.
Network Load Balancer – NLB operates at the connection level (Layer 4), routing connections to targets – EC2 instances, and containers based on IP protocol data.
NLB is suited for load balancing of TCP traffic
NLB is capable of handling millions of requests per second while maintaining ultra-low latencies (~100 ms vs 400 ms for ALB)
NLB is optimized to handle sudden and volatile traffic patterns while using a single static IP address per Availability Zone.
NLB also supports TLS termination, preserves the source IP of the clients, and provides stable IP support and Zonal isolation.
NLB supports long-running connections that are very useful for WebSocket-type applications.
the load balancer selects a target using a flow hash algorithm based on the protocol, source IP address, source port, destination IP address, destination port, and TCP sequence number.
TCP connections from a client having different source ports and sequence numbers and can be routed to different targets.
Each individual TCP connection is routed to a single target for the life of the connection.
For UDP traffic,
the load balancer selects a target using a flow hash algorithm based on the protocol, source IP address, source port, destination IP address, and destination port.
A UDP flow has the same source and destination, so it is consistently routed to a single target throughout its lifetime.
Different UDP flows have different source IP addresses and ports, so they can be routed to different targets.
back-end server authentication (MTLS) is not supported.
session stickiness is not supported
Classic Load Balancer vs Application Load Balancer vs Network Load Balancer
Allows load balancing of both TCP and UDP traffic, routing connections to targets – EC2 instances, microservices, and containers.
High Availability
is highly available.
accepts incoming traffic from clients and distributes this traffic across the targets within the same AZ (except for Cross-zone load balancing).
monitors the health of its registered targets and routes the traffic only to healthy targets
if a health check fails and an unhealthy target is detected, it stops routing traffic to that target and reroutes traffic to remaining healthy targets.
if configured with multiple AZs and if all the targets in a single AZ fail, it routes traffic to healthy targets in the other AZs
Availability Zones
can be used to route traffic across multiple Availability Zones.
However, AZ must be enabled before the traffic is routed to that AZ.
AZ can be enabled, even after the NLB creation.
AZ once enabled, cannot be removed.
Cross-zone load balancing works only for AZs enabled with NLB.
High Throughput
is designed to handle traffic as it grows and can load balance millions of requests/sec.
can also handle sudden volatile traffic patterns.
Low Latency
offers extremely low latencies for latency-sensitive applications.
Cross Zone Load Balancing
enables cross-zone loading balancing only after creating the NLB
is disabled, by default, and charges apply for inter-az traffic.
only works for the AZs that are enabled on the AZ
Sticky Sessions
Sticky sessions (source IP affinity) are a mechanism to route requests from the same client to the same target.
Stickiness is defined at the target group level
Load Balancing using IP addresses as Targets
allows load balancing of any application hosted in AWS or on-premises using IP addresses of the application backends as targets.
allows load balancing to an application backend hosted on any IP address and any interface on an instance.
ability to load balance across AWS and on-premises resources help migrate-to-cloud, burst-to-cloud or failover-to-cloud.
applications hosted in on-premises locations can be used as targets over a Direct Connect connection and EC2-Classic (using ClassicLink).
Preserve Source IP Address
preserves client-side source IP allowing the back-end to see the client IP address.
Target groups can be created with target type as instance ID or IP address.
If targets are registered by instance ID or ECS tasks, the source IP addresses of the clients are preserved and provided to the applications.
If targets are registered by IP address
for TCP & TLS, the source IP addresses are the private IP addresses of the load balancer nodes. Use Proxy Protocol.
for UDP & TCP_UDP, it is enabled by default and the source IP addresses of the clients are preserved.
Static IP support
automatically provides a static IP per Availability Zone (subnet) that can be used by applications as the front-end IP of the load balancer.
creates a network interface for each enabled AZ. Each load balancer node in the AZ uses this network interface to get a static IP address.
Internet-facing load balancer can optionally associate one Elastic IP address per subnet.
Elastic IP support
an Elastic IP per Availability Zone (subnet) can also be assigned, optionally, thereby providing a fixed IP.
Health Checks
supports both network and application target health checks using HTTP, HTTPS, and TCP.
Network-level health check
is based on the overall response of the underlying target (instance or a container) to normal traffic.
target is marked unavailable if it is slow or unable to respond to new connection requests
Application-level health check
is based on a specific URL on a given target to test the application health deeper
Route 53 will direct traffic to load balancer nodes in other AZs, if there are no healthy targets with NLB or if the NLB itself is unhealthy
if NLB is unresponsive, Route 53 will remove the unavailable load balancer IP address from service and direct traffic to an alternate Network Load Balancer in another region.
supports long-lived TCP connections ideal for WebSocket-type of applications
Central API Support
uses the same API as Application Load Balancer.
enables you to work with target groups, health checks, and load balance across multiple ports on the same EC2 instance to support containerized applications.
Robust Monitoring and Auditing
integrated with CloudWatch to report Network Load Balancer metrics.
CloudWatch provides metrics such as Active Flow count, Healthy Host Count, New Flow Count, Processed bytes, and more.
integrated with CloudTrail to track API calls to the NLB
Enhanced Logging
Flow Logs feature helps record all requests sent to the load balancer.
Flow Logs capture information about the IP traffic going to and from network interfaces in the VPC.
Flow log data is stored using CloudWatch Logs.
Zonal Isolation
is designed for application architectures in a single zone.
can be enabled in a single AZ to support architectures that require zonal isolation
automatically fails-over to other healthy AZs, if something fails in an AZ
it’s recommended to configure the load balancer and targets in multiple AZs for achieving high availability
Zonal DNS Name
supports DNS names for each of its nodes.
by default, resolving the Regional NLB DNS name returns the IP address for all NLB nodes in all enabled AZs.
can be used to determine the IP address of each node.
useful to minimize latency and inter-az data transfer costs.
Advantages over Classic Load Balancer
Ability to handle volatile workloads and scale to millions of requests per second, without the need of pre-warming
Support for static IP/Elastic IP addresses for the load balancer
Support for registering targets by IP address, including targets outside the VPC (on-premises) for the load balancer.
Support for routing requests to multiple applications on a single EC2 instance. A single instance or IP address can be registered with the same target group using multiple ports.
Support for containerized applications. Using Dynamic port mapping, ECS can select an unused port when scheduling a task and register the task with a target group using this port.
Support for monitoring the health of each service independently, as health checks are defined at the target group level and many CloudWatch metrics are reported at the target group level. Attaching a target group to an Auto Scaling group enables scaling each service dynamically based on demand
Network Load Balancer Limitations
can’t associate Security Groups with NLBs
can’t disable/remove an AZ once you enable it.
can’t modify ENIs created by NLB in each AZ
can’t change EIPs and Private IPs attached to the ENIs after NLB creation.
can’t register EC2 instances by instance ID for instances in another VPC even if VPC peering is done.
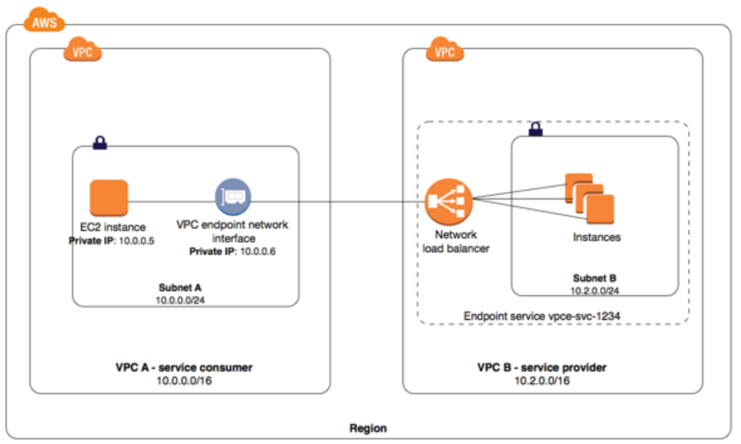
Network Load Balancer with AWS PrivateLink
Interface Endpoints can be used to create custom applications in VPC and configure them as an AWS PrivateLink-powered service (referred to as an endpoint service) exposed through a Network Load Balancer. The custom applications can be hosted within AWS or on-premises.
Network Load Balancer Pricing
charged for each hour or partial hour that an NLB is running and the number of Load Balancer Capacity Units (LCU) used per hour.
An LCU is a new metric for determining NLB pricing
An LCU defines the maximum resource consumed in any one of the dimensions (new connections/flows, active connections/flows, bandwidth and rule evaluations) the Network Load Balancer processes your traffic.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company wants to use load balancer for their application. However, the company wants to forward the requests without any header modification. What service should the company use?
Classic Load Balancer
Network Load Balancer
Application Load Balancer
Use Route 53
A company is hosting an application in AWS for third party access. The third party needs to whitelist the application based on the IP. Which AWS service can the company use in the whitelisting of the IP address?
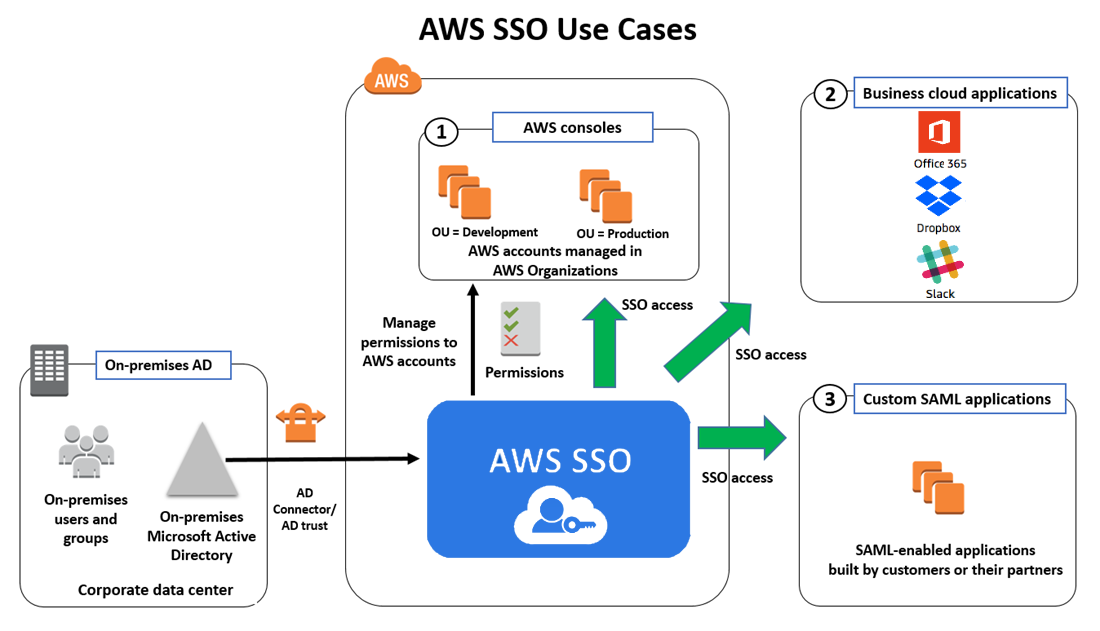
AWS Single Sign-On is a cloud-based single sign-on (SSO) service that makes it easy to centrally manage SSO access to all of the AWS accounts and cloud applications.
AWS SSO also helps manage access and permissions to commonly used third-party software as a service (SaaS) applications, AWS SSO-integrated applications as well as custom applications that support SAML 2.0.
AWS SSO includes a user portal where the end-users can find and access all their assigned AWS accounts, cloud applications, and custom applications in one place.
AWS SSO Features
AWS Organizations Integration
natively integrates with AWS Organizations and enumerates all the AWS accounts.
SSO access to AWS accounts and cloud applications
helps manage Single Sign-On across all the AWS accounts, cloud applications, AWS SSO-integrated applications, and custom SAML 2.0–based applications, without custom scripts or third-party SSO solutions.
Create and manage users and groups in AWS SSO
provides a default store to manage the users and groups directly in the console.
It also connects to an existing AWS Managed Microsoft AD directory and manages the users with standard Active Directory management tools provided in Windows Server.
Leverage your existing corporate identities
is integrated with Microsoft AD through the AWS Directory Service to allow sign-in to the AWS Single Sign-On user portal using their corporate Active Directory credentials.
Compatible with commonly used cloud applications
supports commonly used cloud applications such as Salesforce, Box, and Office 365.
Easy to set up and monitor usage
Is quick to set up, highly available and provides a completely secure infrastructure that scales to the needs and does not require software or hardware to manage.
Integrates with AWS CloudTrail providing the visibility to monitor and audit Single Sign-On activity in one place.
Co-exists with existing IAM users, roles, and policies
has no impact on the users, roles, or policies that are already managed in IAM.
No-cost identity management
available at no additional cost.
AWS SSO Identity Source
AWS SSO identity store
provides a default store to create and manage the users and groups, and assign their level of access to the AWS accounts and applications.
Active Directory
Supports self-managed Active Directory (AD) or AWS Managed Microsoft AD directory using AWS Directory Service.
External identity provider
Supports external identity providers (IdP) such as Okta or Azure AD.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Which of the following can a customer use to enable single sign-on (SSO) to the AWS Console?
AWS Route 53 routing policy determines how AWS would respond to the DNS queries and provides multiple routing policy options.
Simple Routing Policy
Simple routing policy is a simple round-robin policy and can be applied when there is a single resource doing the function for the domain e.g. web server that serves content for the website.
Simple routing helps configure standard DNS records, with no special Route 53 routing such as weighted or latency.
Route 53 responds to the DNS queries based on the values in the resource record set e.g. IP address in an A record.
Simple routing does not allow the creation of multiple records with the same name and type, but multiple values can be specified in the same record, such as multiple IP addresses.
Route 53 displays all the values to resolve it recursively in random order and the resolver displays the values for the client. The client then chooses a value and resends the query.
Simple routing policy does not support health checks, so the record would be returned to the client even if it is unhealthy.
With Alias record enabled, only one AWS resource or one record can be specified in the current hosted zone.
Weighted Routing Policy
Weighted routing policy helps route traffic to different resources in specified proportions (weights) e.g., 75% to one server and 25% to theother during a pilot release
Weights can be assigned between any number from 0 to 255 inclusive.
Weighted routing policy can be applied when there are multiple resources that perform the same function e.g., webservers serving the same site
Weighted resource record sets allow associating multiple resources with a single DNS name.
Weighted routing policy use cases include
load balancing between regions
A/B testing and piloting new versions of software
To create a group of weighted resource record sets, two or more resource record sets can be created that has the same combination of DNS name and type, and each resource record set is assigned a unique identifier and a relative weight.
When processing a DNS query, Route 53 searches for a resource record set or a group of resource record sets that have the specified name and type.
Route 53 selects one from the group. The probability of any one resource record set being selected depends on its weight as a proportion of the total weight for all resource record sets in the group for e.g., suppose www.example.com has three resource record sets with weights of 1 (20%), 1 (20%), and 3 (60%)(sum = 5). On average, Route 53 selects each of the first two resource records sets one-fifth of the time and returns the third resource record set three-fifths of the time.
Weighted routing policy supports health checks.
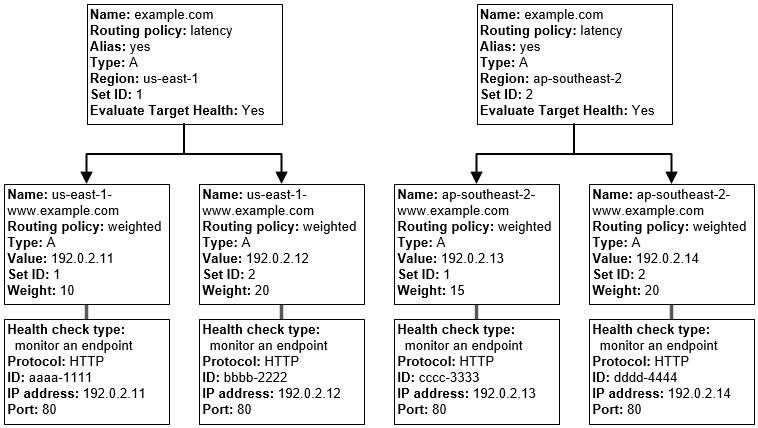
Latency-based Routing (LBR) Policy
Latency-based Routing Policy helps respond to the DNS query based on which data center gives the user the lowest network latency.
Latency-based routing policy can be used when there are multiple resources performing the same function and Route 53 needs to be configured to respond to the DNS queries with the resources that provide the fastest response with the lowest latency.
A latency resource record set can be created for the EC2 resource in each region that hosts the application. When Route 53 receives a query for the corresponding domain, it selects the latency resource record set for the EC2 region that gives the user the lowest latency. Route 53 then responds with the value associated with that resource record set for e.g., you might have web servers for example.com in the EC2 data centers in Ireland and in Tokyo. When a user browses example.com from Singapore, Route 53 will pick up the data center (Tokyo) which has the lowest latency from the user’s location
Latency between hosts on the Internet can change over time as a result of changes in network connectivity and routing. Latency-based routing is based on latency measurements performed over a period of time, and the measurements reflect these changes for e.g. if the latency from the user in Singapore to Ireland improves, the user can be routed to Ireland
Latency-based routing cannot guarantee users from the same geographic will be served from the same location for any compliance reason
Latency resource record sets can be created using any record type that Route 53 supports except NS or SOA.
Latency-based routing policy supports health checks.
Failover Routing Policy
Failover routing policy allows active-passive failover configuration, in which one resource (primary) takes all traffic when it’s healthy and the other resource (secondary) takes all traffic when the first isn’t healthy.
Route 53 health checking agents will monitor each location/endpoint of the application to determine its availability.
Failover routing policy is applicable for Public hosted zones only.
Geolocation Routing Policy
Geolocation routing policy helps respond to DNS queries based on the geographic location of the users i.e. location from which the DNS queries originate.
Geolocation routing policy use cases include
localization of content and presenting some or all of the website in the user’s language
restrict distribution of content to only the locations in which you have distribution rights.
balancing load across endpoints in a predictable, easy-to-manage way, so that each user location is consistently routed to the same endpoint.
Geolocation routing policy allows geographic locations to be specified by continent, country, or by state (only in the US)
Geolocation record sets, if created, for overlapping geographic regions for e.g. continent, and then for the country within the same continent, priority goes to the smallest geographic region, which allows some queries for a continent to be routed to one resource and queries for selected countries on that continent to a different resource
Geolocation works by mapping IP addresses to locations, which might not be mapped to an exact geographic location.
A default resource record set can be created to handle these queries and also the ones which do not have an explicit record set created.
Route 53 returns a “no answer” response for queries from those locations if a default resource record set is not created.
Two geolocation resource record sets that specify the same geographic location cannot be created.
Route 53 supports the edns-client-subnet extension of EDNS0 (EDNS0 adds several optional extensions to the DNS protocol.) to improve the accuracy of geolocation routing.
Geoproximity Routing Policy
Geoproximity routing helps route traffic to the resources based on the geographic location of the users and the resources.
Geoproximity routing can be configured with a bias to optionally choose to route more traffic or less to a given resource. A bias expands or shrinks the size of the geographic region from which traffic is routed to a resource.
Route 53 Traffic flow can be used to create Geoproximity routing flows.
Route 53 supports both the AWS region where the resource is created and the latitude and longitude of the resource.
Multivalue Routing Policy
Multivalue routing helps return multiple values, e.g. IP addresses for the web servers, in response to DNS queries.
Multivalue routing also helps check the health of each resource, so only the values for healthy resources are returned.
Route 53 responds to DNS queries with up to eight healthy records and gives different answers to different DNS resolvers.
Multivalue answer routing is not a substitute for a load balancer, but the ability to return multiple health-checkable IP addresses is a way to use DNS to improve availability and load balancing.
To route traffic approximately randomly to multiple resources, such as web servers, one multivalue answer record can be created for each resource and, optionally, associate a Route 53 health check with each record. If a web server becomes unavailable after the resolver caches a response, client software can try another IP address in the response.
Route 53 Traffic Flow
Route 53 Traffic Flow helps easily manage traffic globally through a variety of routing types combined with DNS Failover in order to enable a variety of low-latency, fault-tolerant architectures.
Traffic Flow provides a simple visual editor, to easily manage how the end-users are routed to the application’s endpoints – whether in a single AWS region or distributed around the globe.
Traffic Flow routes traffic based on multiple criteria, such as endpoint health, geographic location, and latency.
Traffic Flow’s versioning feature maintains a history of changes to the traffic policies to allow easy rollback to the previous version.
Route 53 Complex Routing Policies
Route 53 can be used to define more complex and nested routing policies
A combination of alias records (such as weighted alias and failover alias) and non-alias records can be used to build a decision tree that gives you greater control over how Route 53 responds to requests.
Resources would be created from the bottom of the tree
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You have deployed a web application targeting a global audience across multiple AWS Regions under the domain name example.com. You decide to use Route 53 Latency-Based Routing to serve web requests to users from the region closest to the user. To provide business continuity in the event of server downtime you configure weighted record sets associated with two web servers in separate Availability Zones per region. During a DR test you notice that when you disable all web servers in one of the regions Route 53 does not automatically direct all users to the other region. What could be happening? (Choose 2 answers)
Latency resource record sets cannot be used in combination with weighted resource record sets.
You did not setup an http health check for one or more of the weighted resource record sets associated with the disabled web servers
The value of the weight associated with the latency alias resource record set in the region with the disabled servers is higher than the weight for the other region.
One of the two working web servers in the other region did not pass its HTTP health check
You did not set “Evaluate Target Health” to “Yes” on the latency alias resource record set associated with example.com in the region where you disabled the servers.
The compliance department within your multi-national organization requires that all data for your customers that reside in the European Union (EU) must not leave the EU and also data for customers that reside in the US must not leave the US without explicit authorization. What must you do to comply with this requirement for a web based profile management application running on EC2?
Run EC2 instances in multiple AWS Availability Zones in single Region and leverage an Elastic Load Balancer with session stickiness to route traffic to the appropriate zone to create their profile (should be in 2 different regions – US and Europe)
Run EC2 instances in multiple Regions and leverage Route 53’s Latency Based Routing capabilities to route traffic to the appropriate region to create their profile (Latency based routing policy would not guarantee the compliance requirement)
Run EC2 instances in multiple Regions and leverage a third party data provider to determine if a user needs to be redirect to the appropriate region to create their profile
Run EC2 instances in multiple AWS Availability Zones in a single Region and leverage a third party data provider to determine if a user needs to be redirect to the appropriate zone to create their profile(should be in 2 different regions – US and Europe)
A US-based company is expanding their web presence into Europe. The company wants to extend their AWS infrastructure from Northern Virginia (us-east-1) into the Dublin (eu-west-1) region. Which of the following options would enable an equivalent experience for users on both continents?
Use a public-facing load balancer per region to load-balance web traffic, and enable HTTP health checks.
Use a public-facing load balancer per region to load-balance web traffic, and enable sticky sessions.
Use Amazon Route 53, and apply a geolocation routing policy to distribute traffic across both regions
Use Amazon Route 53, and apply a weighted routing policy to distribute traffic across both regions.
You have been asked to propose a multi-region deployment of a web-facing application where a controlled portion of your traffic is being processed by an alternate region. Which configuration would achieve that goal?
Route 53 record sets with weighted routing policy
Route 53 record sets with latency based routing policy
Auto Scaling with scheduled scaling actions set
Elastic Load Balancing with health checks enabled
Your company is moving towards tracking web page users with a small tracking image loaded on each page. Currently you are serving this image out of us-east, but are starting to get concerned about the time it takes to load the image for users on the west coast. What are the two best ways to speed up serving this image? Choose 2 answers
Use Route 53’s Latency Based Routing and serve the image out of us-west-2 as well as us-east-1
Serve the image out through CloudFront
Serve the image out of S3 so that it isn’t being served of your web application tier
Use EBS PIOPs to serve the image faster out of your EC2 instances
Your API requires the ability to stay online during AWS regional failures. Your API does not store any state, it only aggregates data from other sources – you do not have a database. What is a simple but effective way to achieve this uptime goal?
Use a CloudFront distribution to serve up your API. Even if the region your API is in goes down, the edge locations CloudFront uses will be fine.
Use an ELB and a cross-zone ELB deployment to create redundancy across datacenters. Even if a region fails, the other AZ will stay online.
Create a Route53 Weighted Round Robin record, and if one region goes down, have that region redirect to the other region.
Create a Route53 Latency Based Routing Record with Failover and point it to two identical deployments of your stateless API in two different regions. Make sure both regions use Auto Scaling Groups behind ELBs. (Refer link)
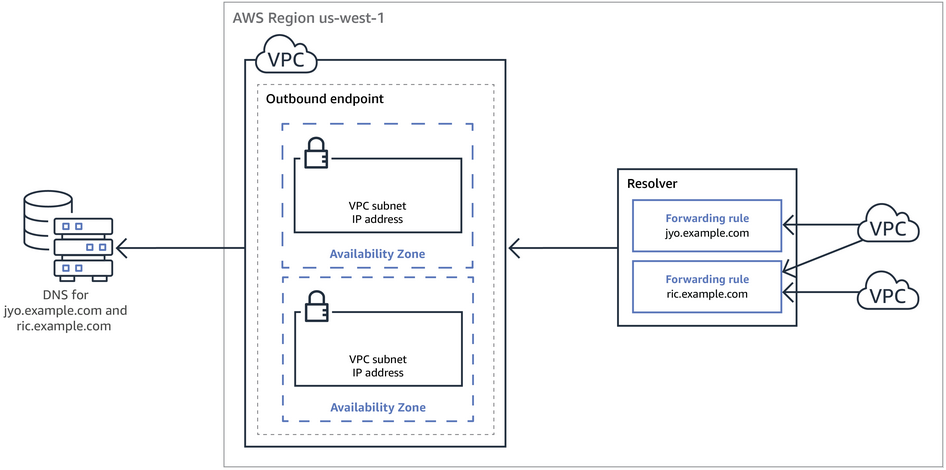
Route 53 Resolver provides automatic DNS resolution within the VPC. It can help resolve DNS queries between VPCs and on-premises networks.
By default, Resolver answers DNS queries for VPC domain names such as domain names for EC2 instances or ELB load balancers.
Route 53 Resolver performs recursive lookups against public name servers for all other domain names.
However, on-premises instances cannot resolve Route 53 DNS entries and Route 53 cannot resolve on-premises DNS entries.
DNS resolution between VPC and on-premises network can be configured over a Direct Connect or VPN connection.
Route 53 Resolver is regional.
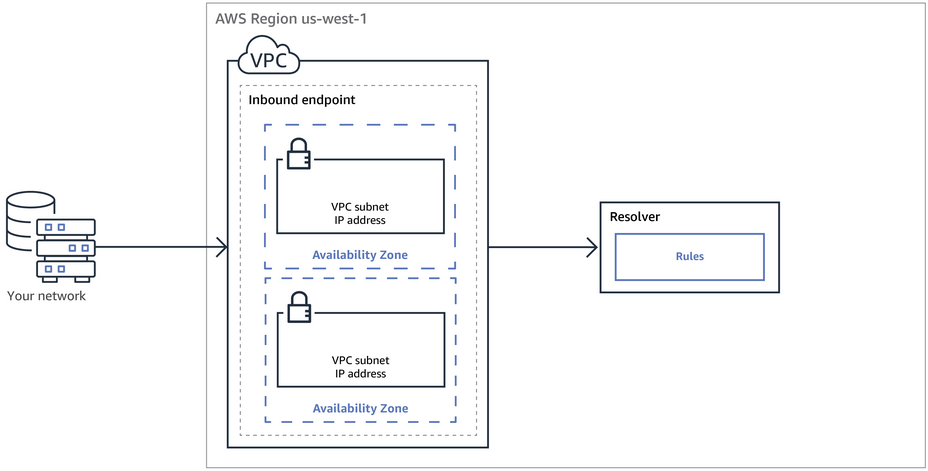
To use inbound or outbound forwarding, create a Resolver endpoint in the VPC.
As part of the definition of an endpoint, specify the IP addresses to forward inbound DNS queries to or the IP addresses that outbound queries originate from. For each IP address specified, Resolver automatically creates a VPC elastic network interface.
Inbound Endpoint – Forward DNS queries from resolvers on your network to AWS
DNS resolvers on the on-premises networks can forward DNS queries to Resolver in a specified VPC.
This enables DNS resolvers to easily resolve domain names for AWS resources such as EC2 instances or records in a Route 53 private hosted zone.
Outbound Endpoint – Conditionally forward queries from a VPC to resolvers on your network
Route 53 Resolver can be configured to forward queries that it receives from EC2 instances in the VPCs to DNS resolvers on the on-premises networks.
To forward selected queries, Resolver rules can be created that specify the domain names for the DNS queries that you want to forward (such as example.com), and the IP addresses of the DNS resolvers on the on-premises network that you want to forward the queries to.
If a query matches multiple rules (example.com, acme.example.com), Resolver chooses the rule with the most specific match (acme.example.com) and forwards the query to the IP addresses that you specified in that rule.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company wants to install a new private intranet service using Amazon EC2 instances inside a Virtual Private Cloud (VPC). The VPC is connected to the company’s on-premises network using an AWS Site-to-Site VPN. The new service must communicate with the on-premises services already in place. On-premises services are accessed using company-owned hostnames. for instance, a DNS zone. This DNS zone is entirely on-premises and accessible only via the company’s private network. To connect the new service with current services, a solutions architect must guarantee that the new service can resolve hostnames on the company’s example domain. Which solution satisfies these criteria?
Create an empty private zone in Route 53 for company.example . Add an additional NS record to the company’s on-premises company.example zone that points to the authoritative name servers for the new private zone in Route 53.
Turn on DNS hostnames for the VPC. Configure a new outbound endpoint with Route 53 Resolver. Create a Resolver rule to forward requests for company.example to the on-premises name servers.
Turn on DNS hostnames for the VPC. Configure a new inbound resolver endpoint with Route 53 Resolver. Configure the on-premises DNS server to forward requests for company.example to the new resolver.
Use AWS Systems Manager to configure a run document that will install a hosts file that contains any required hostnames. Use an Amazon EventBridge (Amazon CloudWatch Events) rule to run the document when an instance is entering the running state.
EBS provides durable block-level storage for use with EC2 instances
EBS volumes are off-instance, network-attached storage (NAS) that persists independently from the running life of a single EC2 instance.
EBS volume is attached to an instance and can be used as a physical hard drive, typically by formatting it with the file system of your choice and using the file I/O interface provided by the instance operating system.
EBS volume can be used to boot an EC2 instance (EBS-root AMIs only), and multiple EBS volumes can be attached to a single EC2 instance.
EBS volume can be attached to a single EC2 instance only at any point in time.
EBS Multi-Attach volume can be attached to multiple EC2 instances.
EBS provides the ability to take point-in-time snapshots, which are persisted in S3. These snapshots can be used to instantiate new EBS volumes and to protect data for long-term durability
EBS snapshots can be copied across AWS regions as well, making it easier to leverage multiple AWS regions for geographical expansion, data center migration, and disaster recovery
Ideal Usage Patterns
EBS is meant for data that changes relatively frequently and requires long-term persistence.
EBS volume provides access to raw block-level storage and is particularly well-suited for use as the primary storage for a database or file system
EBS Provisioned IOPS volumes are particularly well-suited for use with databases applications that require a high and consistent rate of random disk reads and writes
Anti-Patterns
Temporary Storage
EBS volume persists independent of the attached EC2 life cycle.
For temporary storage such as caches, buffers, queues, etc it is better to use local instance store volumes, SQS, or Elastic Cache
Highly-durable storage
EBS volumes with less than 20 GB of modified data since the last snapshot are designed for between 99.5% and 99.9% annual durability; volumes with more modified data can be expected to have proportionally lower durability
For highly durable storage, use S3 or Glacier which provides 99.999999999% annual durability per object
Static data or web content
For static web content, where data infrequently changes, EBS with EC2 would require a web server to serve the pages.
S3 may represent a more cost-effective and scalable solution for storing this fixed information and is served directly out of S3.
EBS Performance
EBS provides two volume types: standard volumes and Provisioned IOPS volumes which differ in performance characteristics and pricing model, allowing you to tailor the storage performance and cost to the needs of the applications.
EBS Volumes can be attached and striped across multiple similarly-provisioned EBS volumes using RAID 0 or logical volume manager software, thus aggregating available IOPs, total volume throughput, and total volume size.
Standard volumes offer cost-effective storage for applications with moderate or bursty I/O requirements. Standard volumes are also well suited for use as boot volumes, where the burst capability provides fast instance start-up times.
Provisioned IOPS volumes are designed to deliver predictable, high performance for I/O intensive workloads such as databases. With Provisioned IOPS, you specify an IOPS rate when creating a volume, and then EBS provisions that rate for the lifetime of the volume.
As EBS volumes are network-attached devices, other network I/O performed by the instance, as well as the total load on the shared network, can affect individual EBS volume performance.
EBS-optimized instances can be launched which deliver dedicated throughput between EC2 and EBS and enables instances to fully utilize the Provisioned IOPS on an EBS volume,
Each separate EBS volume can be configured as EBS standard or EBS Provisioned IOPS as needed. Alternatively, you could stripe the data.
EBS Durability & Availability
EBS volumes are designed to be highly available and reliable.
EBS volume data is replicated across multiple servers in a single AZ to prevent the loss of data from the failure of any single component.
EBS volume durability depends on both the size of the volume and the amount of data that has changed since your last snapshot
EBS snapshots are incremental, point-in-time backups, containing only the data blocks changed since the last snapshot.
Frequent snapshots are recommended to maximize both the durability and availability of their EBS data
EBS snapshots provide an easy-to-use disk clone or disk image mechanism for backup, sharing, and disaster recovery.
EBS Cost Model
EBS pricing has 3 components: provisioned storage, I/O requests, and snapshot storage
Standard volumes are charged per GB-month of provisioned storage and per million I/O requests
EBS Provisioned IOPS volumes are charged per GB-month of provisioned storage and per Provisioned IOPS-month
For both volumes, EBS snapshots are charged per GB-month of data stored. EBS snapshot copy is charged for the data transferred between regions, and for the standard EBS snapshot charges in the destination region.
EBS volume storage capacity is allocated at the time of volume creation, and you are charged for this allocated storage even if not used.
For EBS snapshots, you are charged only for storage actually used (consumed). Note that EBS snapshots are incremental and compressed, so the storage used in any snapshot is generally much less than the storage consumed on an EBS volume
EBS Scalability and Elasticity
EBS volumes can easily and rapidly be provisioned and released to scale in and out with the changing total storage demands
EBS volumes cannot be resized, and if additional storage is needed either
An additional volume can be attached
Create a snapshot and create a new volume from the snapshot with a higher volume size
EBS volumes can be resized dynamically, but cannot be reduced by size.
Interfaces
AWS offers management APIs for EBS in both SOAP and REST formats which can be used to create, delete, describe, attach, and detach EBS volumes for the EC2 instances as well as to create, delete, and describe snapshots from EBS to S3; and to copy snapshots across regions.
Amazon also offers the same capabilities through AWS Management Console
Instance Store volumes are also referred to as Ephemeral Storage.
Instance Store volumes provide temporary block-level storage and consist of a preconfigured and pre-attached block of disk storage on the same physical server as the EC2 instance
Instance storage’s amount of disk storage depends on the Instance type and larger instances provide both more and larger instance store volumes. Smaller instance types such as micro instances can only be launched with EBS volumes.
Storage-optimized instances provide special purpose instance storage targeted to specific uses case for e.g. HI1 provides very fast solid-state drive (SSD) backed instance storage capable of supporting over 120,000 random read IOPS, and is optimized for very high random I/O performance and low cost per IOPS. While, HS1 instances are optimized for very high storage density, low storage cost, and high sequential I/O performance.
Instance store volumes, unlike EBS volumes, cannot be detached or attached to another instance.
Ideal Usage Patterns
EC2 local instance store volumes are fast, free (that is, included in the price of the EC2 instance) “scratch volumes” best suited for storing temporary data that is continually changing, such as buffers, caches, scratch data or can easily be regenerated, or data that is replicated for durability
High I/O instances provide instance store volumes backed by SSD, and are ideally suited for many high performance database workloads. for e.g. applications include NoSQL databases like Cassandra and MongoDB.
High storage instances support much higher storage density per EC2 instance and are ideally suited for applications that benefit from high sequential I/O performance across very large datasets. e.g. applications include data warehouses, Hadoop storage nodes, seismic analysis, cluster file systems, etc.
Anti-Patterns
Persistent storage
For persistent virtual disk storage similar to a physical disk drive for files or other data that must persist longer than the lifetime of a single EC2 instance, EBS volumes or S3 are more appropriate.
Relational database storage
In most cases, relational databases require storage that persists beyond the lifetime of a single EC2 instance, making EBS volumes the natural choice.
Shared storage
Instance store volumes are dedicated to a single EC2 instance, and cannot be shared with other systems or users.
If you need storage that can be detached from one instance and attached to a different instance, or if you need the ability to share data easily, S3 or EBS volumes are the better choices.
Snapshots
If you need the convenience, long-term durability, availability, and shareability of point-in-time disk snapshots, EBS volumes are a better choice.
Instance Store Performance
Non-SSD-based instance store volumes in most EC2 instance families have performance characteristics similar to standard EBS volumes.
EC2 instance virtual machine and the local instance store volumes are located in the same physical server, and interaction with the storage is very fast, particularly for sequential access.
To further increase aggregate IOPS, or to improve sequential disk throughput, multiple instance store volumes can be grouped together using RAID 0 (disk striping) software.
Because the bandwidth to the disks is not limited by the network, aggregate sequential throughput for multiple instance volumes can be higher than for the same number of EBS volumes.
SSD instance store volumes in the EC2 high I/O instances provide from tens of thousands to hundreds of thousands of low-latency, random 4 KB random IOPS.
Because of the I/O characteristics of SSD devices, write performance can be variable.
Instance store volumes on EC2 high storage instances provide very high storage density and high sequential read and write performance. High storage instances are capable of delivering 2.6 GB/sec of sequential read and write performance when using a block size of 2 MB.
Instance Store Durability and Availability
EC2 local instance store volumes are not intended to be used as durable disk storage and they persist only during the life of the associate EC2 instance
Cost Model
Cost of the EC2 instance includes any local instance store volumes if the instance type provides them.
While there is no additional charge for data storage on local instance store volumes, note that data transferred to and from EC2 instance store volumes from other AZs or outside of an EC2 region may incur data transfer charges, and additional charges will apply for use of any persistent storage, such as S3, Glacier, EBS volumes, and EBS snapshots
Scalability and Elasticity
Local instance store volumes are tied to a particular EC2 instance and are fixed in number and size for a given EC2 instance type, so the scalability and elasticity of this storage are tied to the number of EC2 instances.
Interfaces
Instance store volumes are specified using the block device mapping feature of the EC2 API and the AWS Management Console
To the EC2 instance, an instance store volume appears just like a local disk drive. To write to and read data from instance store volumes, use the native file system I/O interfaces of the chosen operating system.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Which of the following provides the fastest storage medium?
Amazon S3
Amazon EBS using Provisioned IOPS (PIOPS)
SSD Instance (ephemeral) store (SSD Instance Storage provides 100,000 IOPS on some instance types, much faster than any network-attached storage)
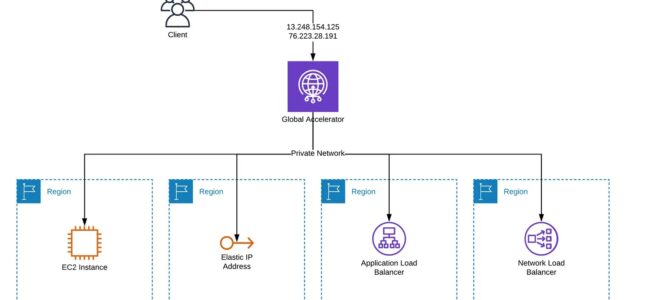
AWS Global Accelerator is a networking service that helps improve the availability and performance of the applications to global users.
AWS Global Accelerator optimizes the path to applications to keep packet loss, jitter, and latency consistently low.
helps improve the performance of the applications by lowering first-byte latency (the round trip time for a packet to go from a client to your endpoint and back again) and jitter (the variation of latency), and increasing throughput (amount of data transferred in a second) as compared to the public internet.
Global Accelerator uses the vast, well-monitored, congestion-free, redundant AWS global network to route TCP and UDP traffic to a healthy application endpoint in the closest AWS Region to the user.
is a global service that supports endpoints in multiple AWS Regions.
supports AWS application endpoints, such as ALBs, NLBs, EC2 Instances, and Elastic IPs without making user-facing changes.
provides two global static public IPs that act as a fixed entry point to the application hosted in one or more AWS Regions, improving availability.
helps anycast the static IP addresses from the AWS edge network which serves as the frontend interface of the applications.
Using static IP addresses ensures you don’t need to make any client-facing changes or update DNS records as you modify or replace endpoints.
allows you to bring your own IP addresses (BYOIP) and use them as a fixed entry point to the application endpoints
Global Accelerator allocates two static IPv4 addresses serviced by independent network zones which isolated units with their own set of physical infrastructure and service IP addresses from a unique IP subnet. If one IP address from a network zone becomes unavailable, due to network disruptions or IP address blocking by certain client networks, the client applications can retry using the healthy static IP address from the other isolated network zone.
currently supports IPv4 addresses.
continuously monitors the health of the application endpoints by using TCP, HTTP, and HTTPS health checks.
automatically re-routes the traffic to the nearest healthy available endpoint to mitigate endpoint failure.
terminates TCP connections from clients at AWS edge locations and, almost concurrently, establishes a new TCP connection with your endpoints. This gives clients faster response times (lower latency) and increased throughput.
supports Client Affinity which helps build stateful applications.
supports Client IP address preservation except for NLBs and EIPs endpoints.
integrates with AWS Shield Standard, which minimizes application downtime and latency from DDoS attacks by using always-on network flow monitoring and automated in-line mitigation.
does not support on-premises endpoints. However, an NLB can be configured to address the on-premises endpoints while Global Accelerator points to the NLB.
Global Accelerator and CloudFront both use the AWS global network and its edge locations around the world.
Both services integrate with AWS Shield for DDoS protection.
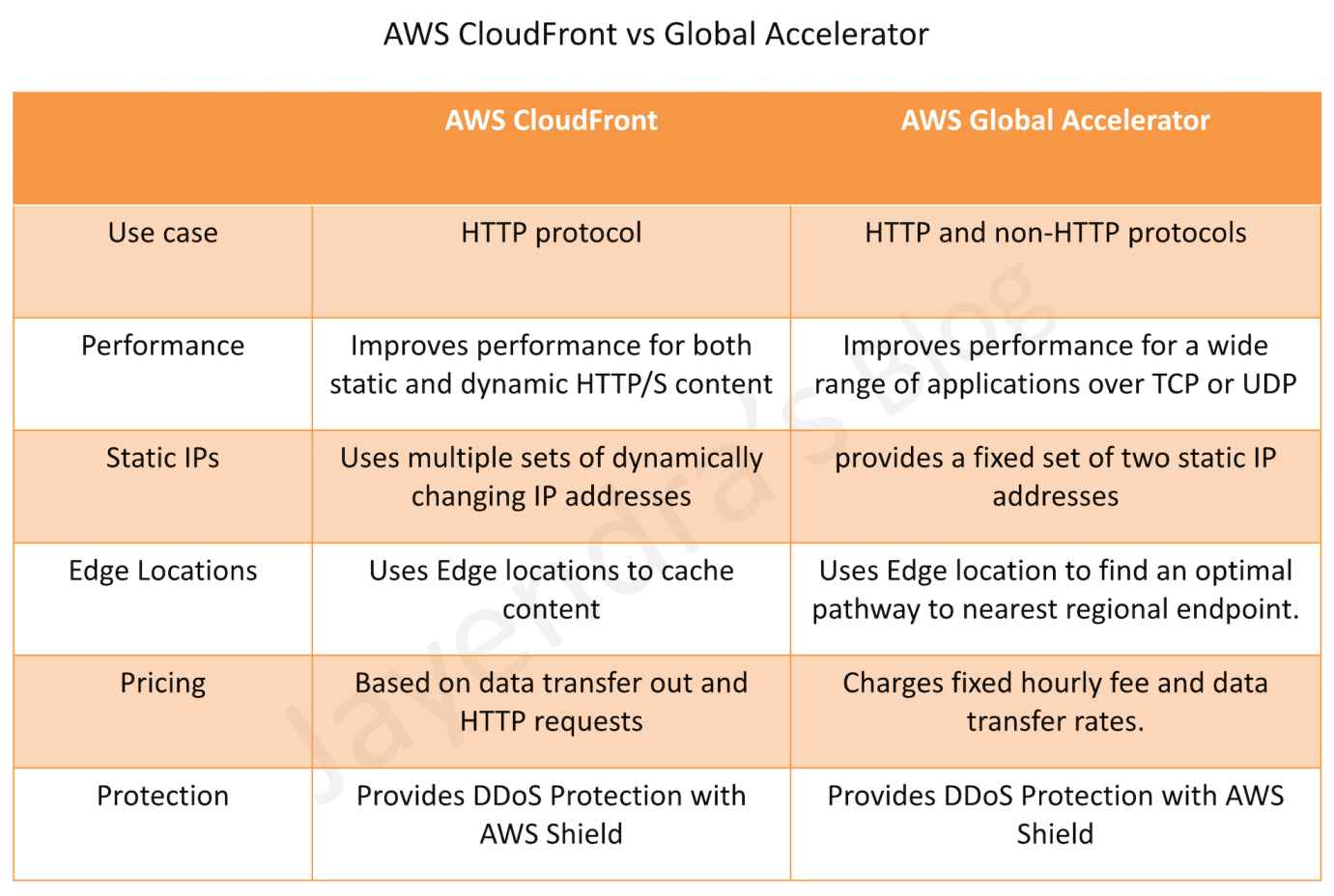
Performance
CloudFront improves performance for both cacheable content (such as images and videos) and dynamic content (such as API acceleration and dynamic site delivery).
Global Accelerator improves performance for a wide range of applications over TCP or UDP by proxying packets at the edge to applications running in one or more AWS Regions.
Use Cases
CloudFront is a good fit for HTTP use cases
Global Accelerator is a good fit for non-HTTP use cases, such as gaming (UDP), IoT (MQTT), or VoIP, as well as for HTTP use cases that require static IP addresses or deterministic, fast regional failover.
Caching
CloudFront supports Edge caching
Global Accelerator does not support Edge Caching.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
What features does AWS Global Accelerator provide? (Select TWO)
Improved security
Improved durability
Improved performance
Improved cost optimization
Improved availability
A company that develops web applications has launched hundreds of Application Load Balancers (ALBs) in multiple Regions. The company wants to create an allow list for the IPs of all the load balancers on its firewall device. A solutions architect is looking for a one-time, highly available solution to address this request, which will also help reduce the number of IPs that need to be allowed by the firewall. What should the solutions architect recommend to meet these requirements?
Create an AWS Lambda function to keep track of the IPs for all the ALBs in different Regions. Keep refreshing this list.
Set up a Network Load Balancer (NLB) with Elastic IPs. Register the private IPs of all the ALBs as targets to this NLB.
Launch AWS Global Accelerator and create endpoints for all the Regions. Register all the ALBs in different Regions to the corresponding endpoints.
Set up an Amazon EC2 instance, assign an Elastic IP to this EC2 instance, and configure the instance as a proxy to forward traffic to all the ALBs.
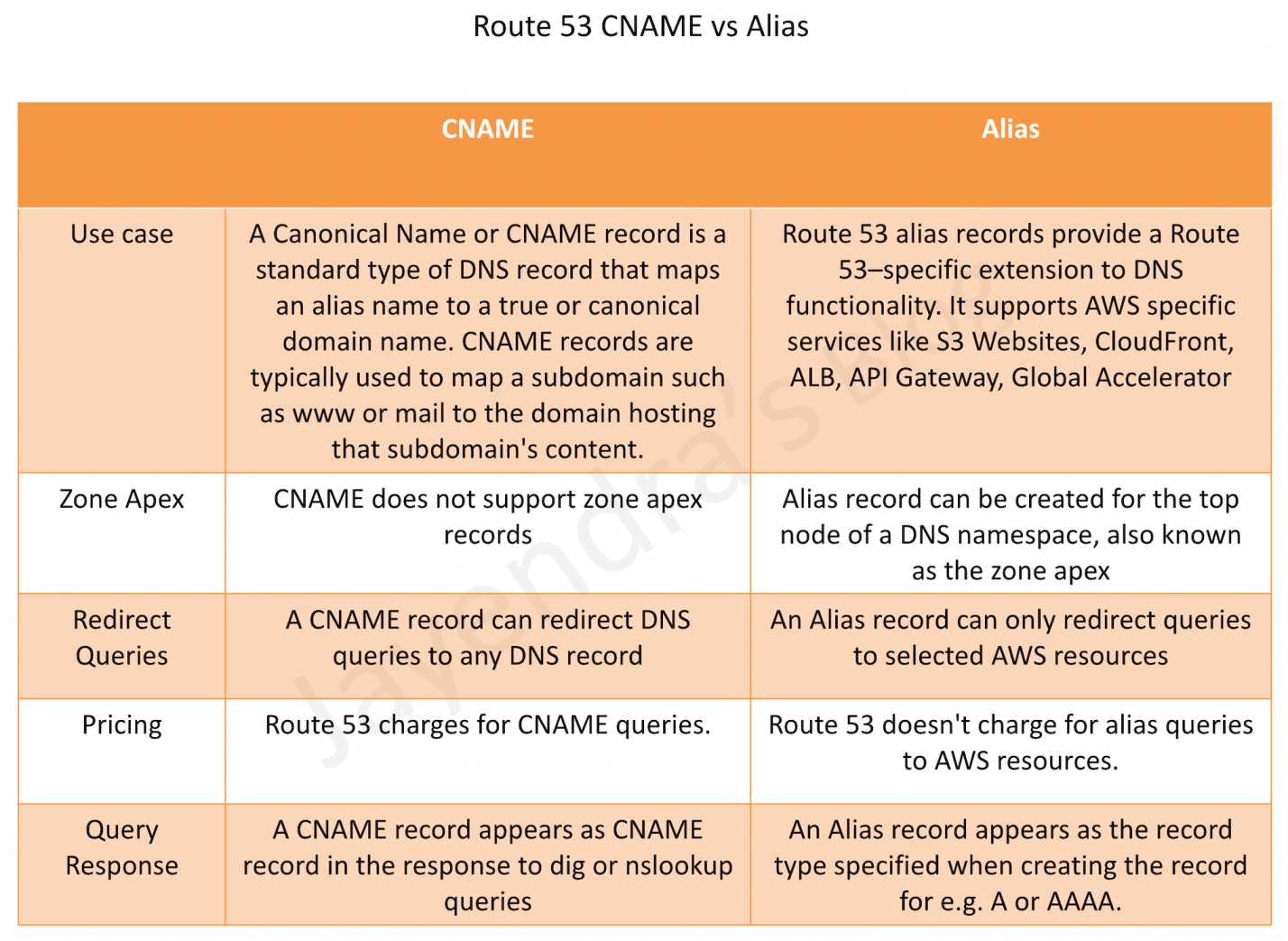
Route 53 Alias records are similar to CNAME records, but there are some important differences.
Supported Resources
Alias records support selected AWS resources
Elastic Load Balancers
CloudFront distributions
API Gateway
Elastic Beanstalk
S3 Website
Global Accelerator
VPC Interface Endpoints
Route 53 record in the same hosted zone
Alias records do not support
EC2 DNS endpoint
RDS DNS endpoint
CNAME record can redirect DNS queries to any DNS record
Zone Apex or Root domain like example.com
Alias record supports mapping Zone Apex records
CNAME record does not support Zone Apex records
Charges
Route 53 doesn’t charge for alias queries to AWS resources
Route 53 charges for CNAME queries.
Record Type
Alias records only support A or AAAA record types
CNAME record redirects DNS queries for a record name regardless of the record type specified in the DNS query, such as A or AAAA.
Route 53 Alias vs CNAME Comparison
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Which of the following statements are true about Amazon Route 53 resource records? Choose 2 answers
An Alias record can map one DNS name to another Amazon Route 53 DNS name.
A CNAME record can be created for your zone apex.
An Amazon Route 53 CNAME record can point to any DNS record hosted anywhere.
TTL can be set for an Alias record in Amazon Route 53.
An Amazon Route 53 Alias record can point to any DNS record hosted anywhere.
How can the domain’s zone apex for example “myzoneapexdomain com” be pointed towards an Elastic Load Balancer?
AWS CloudFront helps write your own code to customize how the CloudFront distributions process HTTP requests and responses.
The code runs close to the viewers (users) to minimize latency, and without having to manage servers or other infrastructure.
Custom code can manipulate the requests and responses that flow through CloudFront, perform basic authentication and authorization, generate HTTP responses at the edge, and more.
CloudFront Edge Functions currently supports two types
CloudFront Functions
Lambda@Edge
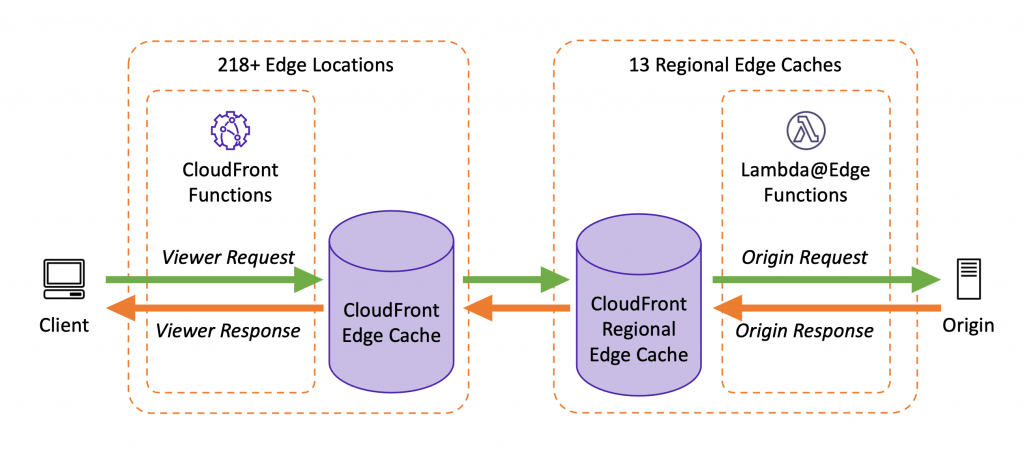
CloudFront Functions
is a CloudFront native feature (code is managed entirely within CloudFront) and visible only on the CloudFront dashboard.
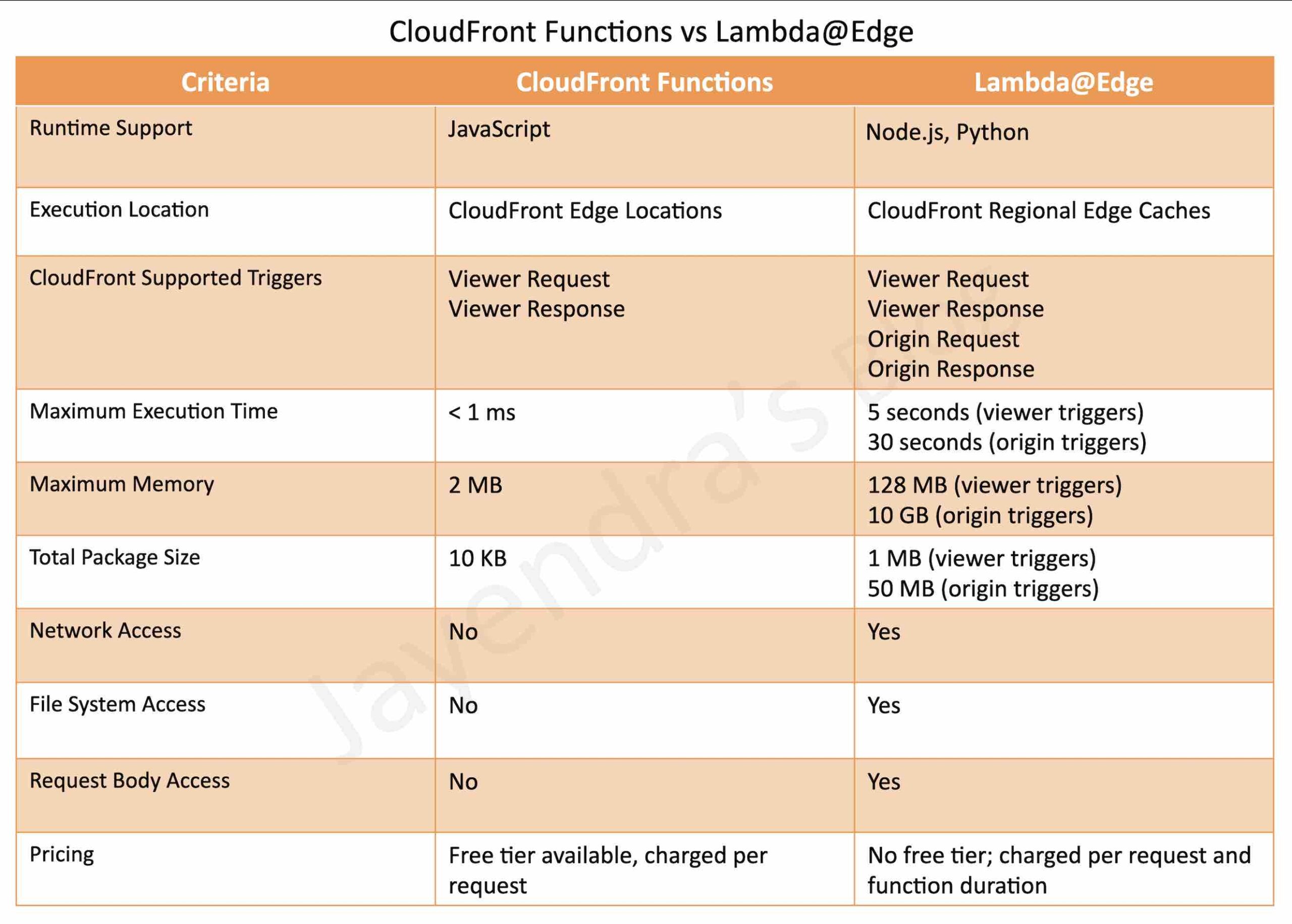
supports lightweight functions written only in JavaScript language
runs in Edge Locations
has process-based isolation
supports Viewer Request, Viewer Response trigger events only
Viewer Request: after CloudFront receives the request from the Viewer
Viewer Response: before CloudFront forwards the response to the Viewer
supports sub-millisecond execution time
scales to millions of requests/second
as they are built to be more scalable, performant, and cost-effective, they have the following limitations
no network access
no file system access
cannot access the request body
use-cases ideal for lightweight processing of web requests like
Cache-key manipulations and normalization
URL rewrites and redirects
HTTP header manipulation
Access authorization
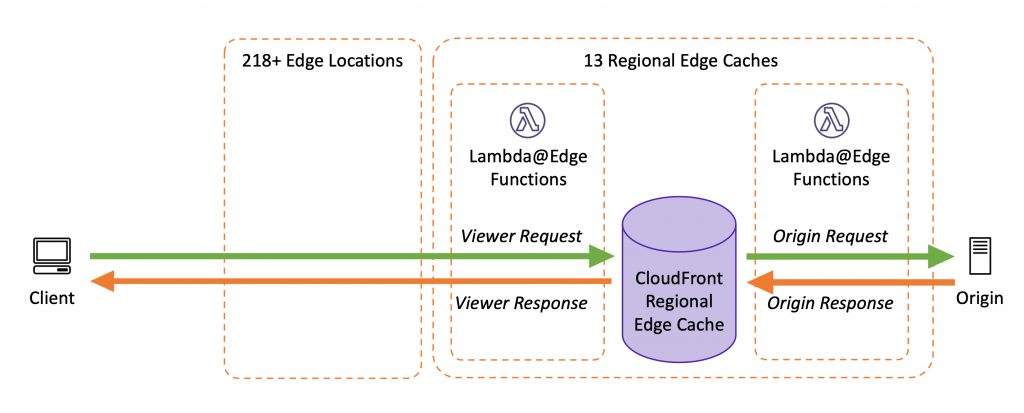
Lambda@Edge
are Lambda functions and visible on the Lambda dashboard.
Each event type (viewer request, origin request, origin response, and viewer response) can have only one edge function association.
CloudFront Functions and Lambda@Edge in viewer events (viewer request and viewer response) cannot be combined.
CloudFront does not invoke edge functions for viewer response events when the origin returns an HTTP status code 400 or higher.
Edge functions for viewer response events cannot modify the HTTP status code of the response, regardless of whether the response came from the origin or the CloudFront cache.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You’ve been given the requirement to customize the content which is distributed to users via a CloudFront Distribution. The content origin is an S3 bucket. How could you achieve this?
Add an event to the S3 bucket. Make the event invoke a Lambda function to customize the content before rendering
Add a Step Function. Add a step with a Lambda function just before the content gets delivered to the users.
Use Lambda@Edge
Use a separate application on an EC2 Instance for this purpose.
A company’s packaged application dynamically creates and returns single-use text files in response to user requests. The company is using Amazon CloudFront for distribution but wants to further reduce data transfer costs. The company cannot modify the application’s source code. What should a solutions architect do to reduce costs?
Use Lambda@Edge to compress the files as they are sent to users.
Enable Amazon S3 Transfer Acceleration to reduce the response times.
Enable caching on the CloudFront distribution to store generated files at the edge.
Use Amazon S3 multipart uploads to move the files to Amazon S3 before returning them to users.