Cloud Identity is an Identity as a Service (IDaaS) solution that helps centrally manage the users and groups.
can be configured to federate identities between Google and other identity providers, such as Active Directory and Azure Active Directory
also gives more control over the accounts that are used in the organization.
Cloud Identity account is created for each of your users and groups and IAM can be used to manage access to Google Cloud resources for each Cloud Identity account.
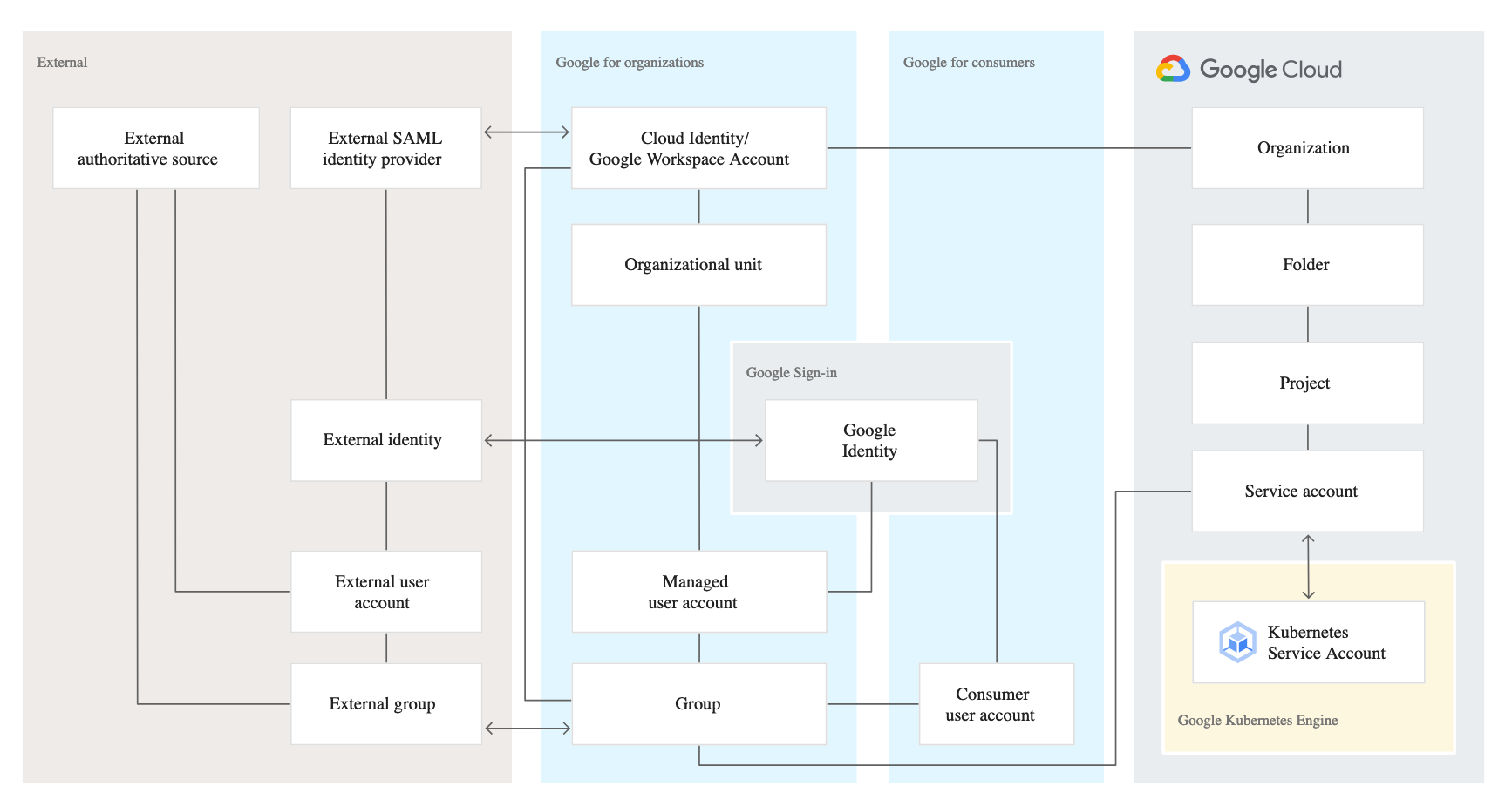
Google Cloud Identity Management
Google identity is related to a number of other entities that are all relevant in the context of managing identities:
Google for consumers contains the entities that are relevant for consumer-focused usage of Google services such as Gmail.
Google for organizations contains entities managed by Cloud Identity or Google Workspace. These entities are the most relevant for managing corporate identities.
Google Cloud contains entities that are specific to Google Cloud.
External contains entities that are relevant if you integrate Google with an external Identity Provider (IdP).
A Cloud Identity or Google Workspace (G Suite) account is the top-level container for users, groups, configuration, and data.
A Cloud Identity or Google Workspace account is created when a company signs up for Cloud Identity or Google Workspace and corresponds to the notion of a tenant.
Cloud Identity or Google Workspace account federation with an external IdP enables employees to use their existing identity and credentials to sign in to Google services.
External IdP is the source of truth and the sole system for authentication and provides a SSO experience for the employees across applications
With single sign-on enabled, Cloud Identity or Google Workspace relays authentication decisions to the SAML IdP.
In SAML terms, Cloud Identity or Google Workspace acts as a service provider that trusts the SAML IdP to verify a user’s identity on its behalf.
Each Cloud Identity or Google Workspace account can refer to at most one external IdP
Single Sign-on – SSO
Cloud Identity or Google Workspace account can be configured to use a single sign-on (SSO).
With SSO enabled, users are redirected to an external identity provider (IdP) for authentication.
Using SSO can provide several advantages:
better experience for users because they can use their existing credentials to authenticate and don’t have to enter credentials as often.
existing IdP remains the system of record for authenticating users.
don’t need to synchronize passwords to Cloud Identity or Google Workspace
Cloud Identity and Google Workspace support Security Assertion Markup Language (SAML) 2.0 for single sign-on.
SAML is an open standard for exchanging authentication and authorization data between a SAML IdP and SAML service providers.
With SSO for Cloud Identity or Google Workspace, the external IdP is the SAML IdP and Google is the SAML service provider.
Google implements SAML 2.0 HTTP Redirect binding.
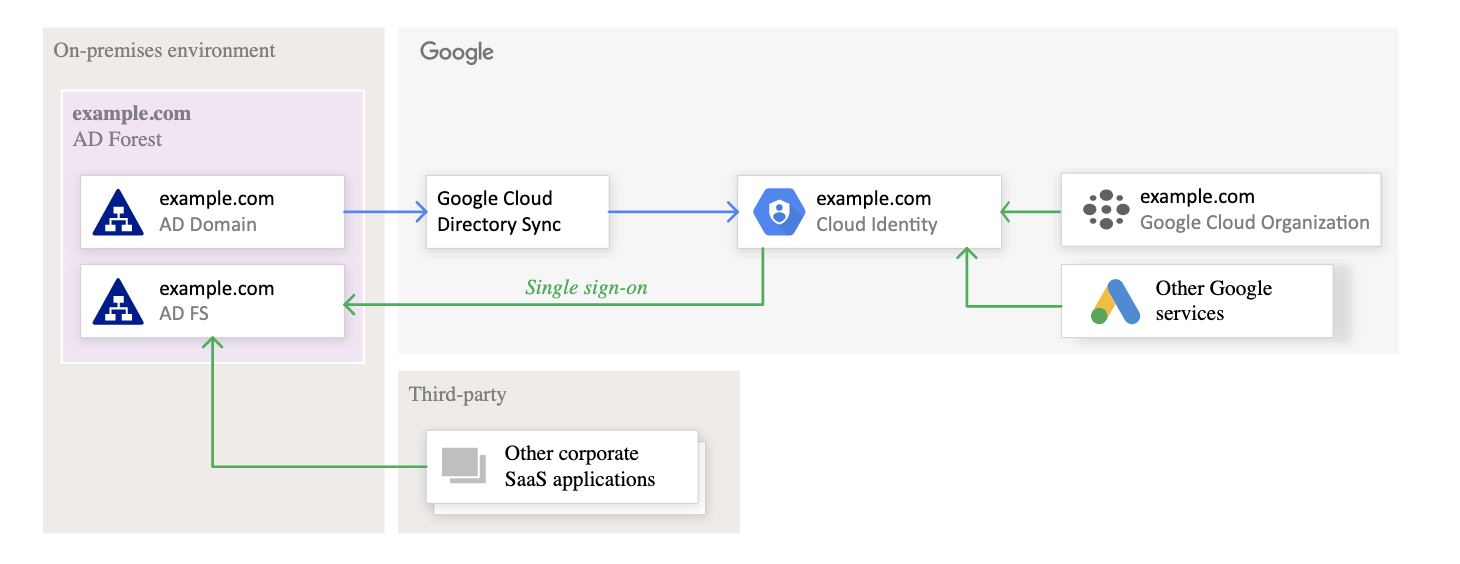
Federating Google Cloud with Active Directory
Federating user identities between Google Cloud and existing identity management systems helps automate the maintenance of Google identities and tie their lifecycle to existing users in Active Directory.
Federation can be supported using the following tools
Google Cloud Directory Sync – GCDS
is a free Google-provided tool that implements the synchronization process from Active Directory or LDAP server to Google Domain
communicates with Google Cloud over Secure Sockets Layer (SSL) and usually runs in the existing computing environment.
Active Directory Federation Services (AD FS)
is provided by Microsoft as part of Windows Server.
helps use Active Directory for federated authentication.
runs within the existing computing environment.
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Your organization has user identities in Active Directory. Your organization wants to use Active Directory as its source of truth for identities. Your organization wants to have full control over the Google accounts used by employees for all Google services, including your Google Cloud Platform (GCP) organization. What should you do?
Use Google Cloud Directory Sync (GCDS) to synchronize users into Cloud Identity.
Use the Cloud Identity APIs and write a script to synchronize users to Cloud Identity.
Export users from Active Directory as a CSV and import them to Cloud Identity via the Admin Console.
Ask each employee to create a Google account using self signup. Require that each employee use their company email address and password.
Your company has a single sign-on (SSO) identity provider that supports Security Assertion Markup Language (SAML) integration with service providers. Your company has users in Cloud Identity. You would like users to authenticate using your company’s SSO provider. What should you do?
In Cloud Identity, set up SSO with Google as an identity provider to access custom SAML apps.
In Cloud Identity, set up SSO with a third-party identity provider with Google as a service provider.
Obtain OAuth 2.0 credentials, configure the user consent screen, and set up OAuth 2.0 for Mobile & Desktop Apps.
Obtain OAuth 2.0 credentials, configure the user consent screen, and set up OAuth 2.0 for Web Server Applications.
App Engine helps build highly scalable applications on a fully managed serverless platform
App Engine provides PaaS and helps build and deploy apps quickly using popular languages or bring your own language runtimes and frameworks.
App Engine allows to scale the applications from zero to planet scale without having to manage infrastructure
Each Cloud project can contain only a single App Engine application
App Engine is regional, which means the infrastructure that runs the apps is located in a specific region, and Google manages it so that it is available redundantly across all of the zones within that region
App Engine application location or region cannot be changed once created
App Engine is well suited to applications that are designed using a microservice architecture
App Engine creates a default bucket in Cloud Storage for each app creation
App Engine can automatically create and shut down instances as traffic fluctuates, or a number of instances can be specified to run regardless of the amount of traffic
App Engine supports the following scaling types, which controls how and when instances are created:
Basic (Standard Only)
creates instances when the application receives requests.
each instance will be shut down when the application becomes idle.
is ideal for work that is intermittent or driven by user activity.
Automatic
creates instances based on request rate, response latencies, and other application metrics.
thresholds can be specified for each of these metrics, as well as a minimum number instances to keep running at all times.
Manual
specifies the number of instances that continuously run regardless of the load level.
allows tasks such as complex initializations and applications that rely on the state of the memory over time.
Managing Traffic
App engine allows traffic management to an application version by migrating or splitting traffic.
Gradually moves traffic from the versions currently receiving traffic to one or more specified versions
Standard environment allows you to choose to route requests to the target version, either immediately or gradually.
Flexible environment only allows immediate traffic migration
Traffic Splitting
Traffic splitting distributes a percentage of traffic to versions of the application.
Allows canary deployments or conduct A/B testing between the versions and provides control over the pace when rolling out features
Traffic can be split to move 100% of traffic to a single version or to route percentages of traffic to multiple versions.
Traffic splitting is applied to URLs that do not explicitly target a version.
Traffic split is supported by using either an IP address or HTTP cookie.
Default behaviour for splitting traffic is to do it by IP.
Setting up IP address traffic split is easier, but a cookie split is more precise
For traffic splitting, execute gcloud app deploy --no-promote to make a new version of the application available and then run gcloud app services set-traffic to start sending the new version traffic. Use --splits flag with two versions and weight
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You have a website hosted on App Engine standard environment. You want 1% of your users to see a new test version of the website. You want to minimize complexity. What should you do?
Deploy the new version in the same application and use the –migrate option.
Deploy the new version in the same application and use the –splits option to give a weight of 99 to the current version and a weight of 1 to the new version.
Create a new App Engine application in the same project. Deploy the new version in that application. Use the App Engine library to proxy 1% of the requests to the new version.
Create a new App Engine application in the same project. Deploy the new version in that application. Configure your network load balancer to send 1% of the traffic to that new application.
You have created an App engine application in the us-central region. However, you found out the network team has configured all the VPN connections in the asia-east2 region, which are not possible to move. How can you change the location efficiently?
Change the region in app.yaml and redeploy
From App Engine console, change the region of the application
Change the region in application.xml within the application and redeploy
Create a new project in the asia-east2 region and create app engine in the project
Cloud Logging is a service for storing, viewing and interacting with logs.
Answers the questions “Who did what, where and when” within the GCP projects
Maintains non-tamperable audit logs for each project and organizations
Logs buckets are a regional resource, which means the infrastructure that stores, indexes, and searches the logs are located in a specific geographical location. Google manages that infrastructure so that the applications are available redundantly across the zones within that region.
Cloud Logging is scoped by the project.
Cloud Logging Process
For each Google Cloud project, Logging automatically creates two logs buckets: _Required and _Default.
_Required bucket
holds Admin Activity audit logs, System Event audit logs, and Access Transparency logs
retains them for 400 days.
the retention period of the logs stored here cannot be modified.
aren’t charged for the logs stored in _Required, and
cannot delete this bucket.
_Default bucket
holds all other ingested logs in a Google Cloud project except for the logs held in the _Required bucket.
are charged
are retained for 30 days, by default, and can be customized from 1 to 3650 days
these buckets cannot be deleted
All logs generated in the project are stored in the _Required and _Default logs buckets, which live in the project that the logs are generated in
Logs buckets only have regional availability, including those created in the global region.
Cloud Logging Types
Cloud Platform Logs
Cloud platform logs are service-specific logs that can help troubleshoot and debug issues, as well as better understand the Google Cloud services.
Cloud Platform logs are logs generated by GCP services and vary depending on which Google Cloud resources are used in your Google Cloud project or organization.
Security Logs
Audit Logs
Cloud Audit Logs includes three types of audit logs:
Admin Activity,
Data Access, and
System Event.
Cloud Audit Logs provide audit trails of administrative changes and data accesses of the Google Cloud resources.
admin activity – administrative actions and API calls
have 400-day retention
System Events
captures system initiated resource configuration changes
enabled by default
no additional charge
system events – GCE system events like live migration
have 400-day retention
Data Access logs
Log API calls that create, modify or read user-provided data for e.g. object created in a GCS bucket.
30-day retention
disabled by default
size can be huge
charged beyond free limits
Available for GCP-visible services only. Not available for public resources.
Access Transparency Logs
provides logs of actions taken by Google staff when accessing the Google Cloud content.
can help track compliance with the organization’s legal and regulatory requirements.
have 400-day retention
User Logs
User logs are generated by user software, services, or applications and written to Cloud Logging using a logging agent, the Cloud Logging API, or the Cloud Logging client libraries
Agent logs
produced by logging agent installed that collects logs from user applications and VMs
covers log data from third-party applications
charged beyond free limits
30-day retention
Cloud Logging Export
Log entries are stored in logs buckets for a specified length of time i.e. retention period and are then deleted and cannot be recovered
Logs can be exported by configuring log sinks, which then continue to export log entries as they arrive in Logging.
A sink includes a destination and a filter that selects the log entries to export.
Exporting involves writing a filter that selects the log entries to be exported, and choosing a destination from the following options:
Cloud Storage: JSON files stored in buckets for long term retention
BigQuery: Tables created in BigQuery datasets. for analytics
Pub/Sub: JSON messages delivered to Pub/Sub topics to stream to other resources. Supports third-party integrations, such as Splunk
Another Google Cloud Cloud project: Log entries held in Cloud Logging logs buckets.
Every time a log entry arrives in a project, folder, billing account, or organization resource, Logging compares the log entry to the sinks in that resource. Each sink whose filter matches the log entry writes a copy of the log entry to the sink’s export destination.
Exporting happens for new log entries only, it is not retrospective
Log-based Metrics
Log-based metrics are based on the content of log entries for e.g., the metrics can record the number of log entries containing particular messages, or they can extract latency information reported in log entries.
Log-based metrics can be used in Cloud Monitoring charts and alerting policies.
Log-based metrics apply only to a single Google Cloud project. You can’t create them for Logging buckets or for other Google Cloud resources such as Cloud Billing accounts or organizations.
Log-based metrics are of two kinds
System-defined log-based metrics
provided by Cloud Logging for use by all Google Cloud projects.
System log-based metrics are calculated from included logs only i.e. they are calculated only from logs that have been ingested by Logging. If a log has been explicitly excluded from ingestion by Logging, it isn’t included in these metrics.
User-defined log-based metric
user-created to track things in the Google Cloud project for e.g. a log-based metric to count the no. of log entries that match a given filter.
User-defined log-based metrics are calculated from both included and excluded logs. i.e. are calculated from all logs received by the Logging API for the Cloud project, regardless of any inclusion filters or exclusion filters that may apply to the Cloud project.
Log-based metrics support the following types
Counter metrics count the number of log entries matching a given filter.
Distribution metrics accumulate numeric data from log entries matching a filter.
Cloud Logging Agent
Cloud Logging agent streams logs from VM instances and from selected third-party software packages to Cloud Logging.
Cloud Logging Agent helps capture logs from GCE and AWS EC2 instances
VM images for GCE and Amazon EC2 don’t include the Logging agent and must be installed explicitly.
Cloud Logging Agent uses fluentd for capturing logs
Logging features include:
Standard system logs (/var/log/syslog and /var/log/messages for Linux, Windows Event Log) collected with no setup.
High throughput capability, taking full advantage of multi-core architecture.
Efficient resource (e.g. memory, CPU) management.
Custom log files.
JSON logs.
Plain text logs.
Regex-based parsing.
JSON-based parsing.
Logging agent is pre-configured to send logs from VM instances to Cloud Logging which include syslogs, and other third-party applications like Redis,
Cloud Logging Agent provides additional plugins and configurations like filter_record_transformer that can help modify, delete log entries before the logs are pushed to Cloud Logging for e.g. masking of sensitive PII information
Ops Agent doesn’t directly support automatic log parsing for third-party applications, but it can be configured to parse these files.
Cloud Logging IAM Roles
Logs Viewer – View logs except Data Access/Access Transperancy logs
Private Logs Viewer – View all logs
Logging Admin – Full access to all logging actions
Project Viewer – View logs except Data Access/Access Transperancy logs
Project Editor – Write, view, and delete logs. Create log based metrics. However, it cannot create export sinks or view Data Access/Access Transperancy logs.
Project Owner – Full access to all logging actions
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Your organization is a financial company that needs to store audit log files for 3 years. Your organization has hundreds of Google Cloud projects. You need to implement a cost-effective approach for log file retention. What should you do?
Create an export to the sink that saves logs from Cloud Audit to BigQuery.
Create an export to the sink that saves logs from Cloud Audit to a Coldline Storage bucket.
Write a custom script that uses logging API to copy the logs from Stackdriver logs to BigQuery.
Export these logs to Cloud Pub/Sub and write a Cloud Dataflow pipeline to store logs to Cloud SQL.
Your organization is a financial company that needs to store audit log files for 3 years. Your organization has hundreds of Google Cloud projects. You need to implement a cost-effective approach for log file retention. What should you do?
Create an export to the sink that saves logs from Cloud Audit to BigQuery.
Create an export to the sink that saves logs from Cloud Audit to a Coldline Storage bucket.
Write a custom script that uses logging API to copy the logs from Stackdriver logs to BigQuery.
Export these logs to Cloud Pub/Sub and write a Cloud Dataflow pipeline to store logs to Cloud SQL.
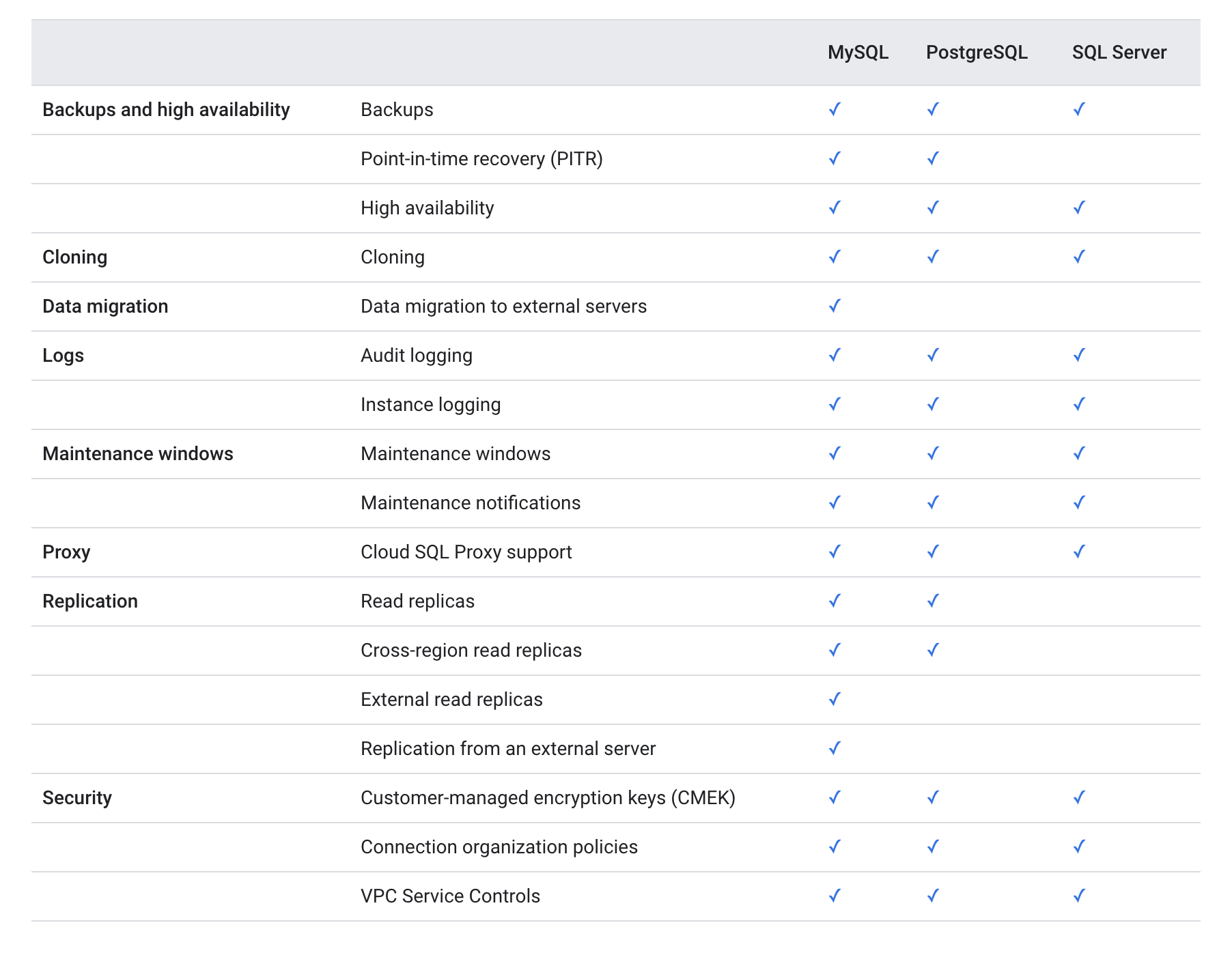
Cloud SQL provides a cloud-based alternative to local MySQL, PostgreSQL, and Microsoft SQL Server databases
Cloud SQL is a managed solution that helps handles backups, replication, high availability and failover, data encryption, monitoring, and logging.
Cloud SQL is ideal for lift and shift migration from existing on-premises relational databases
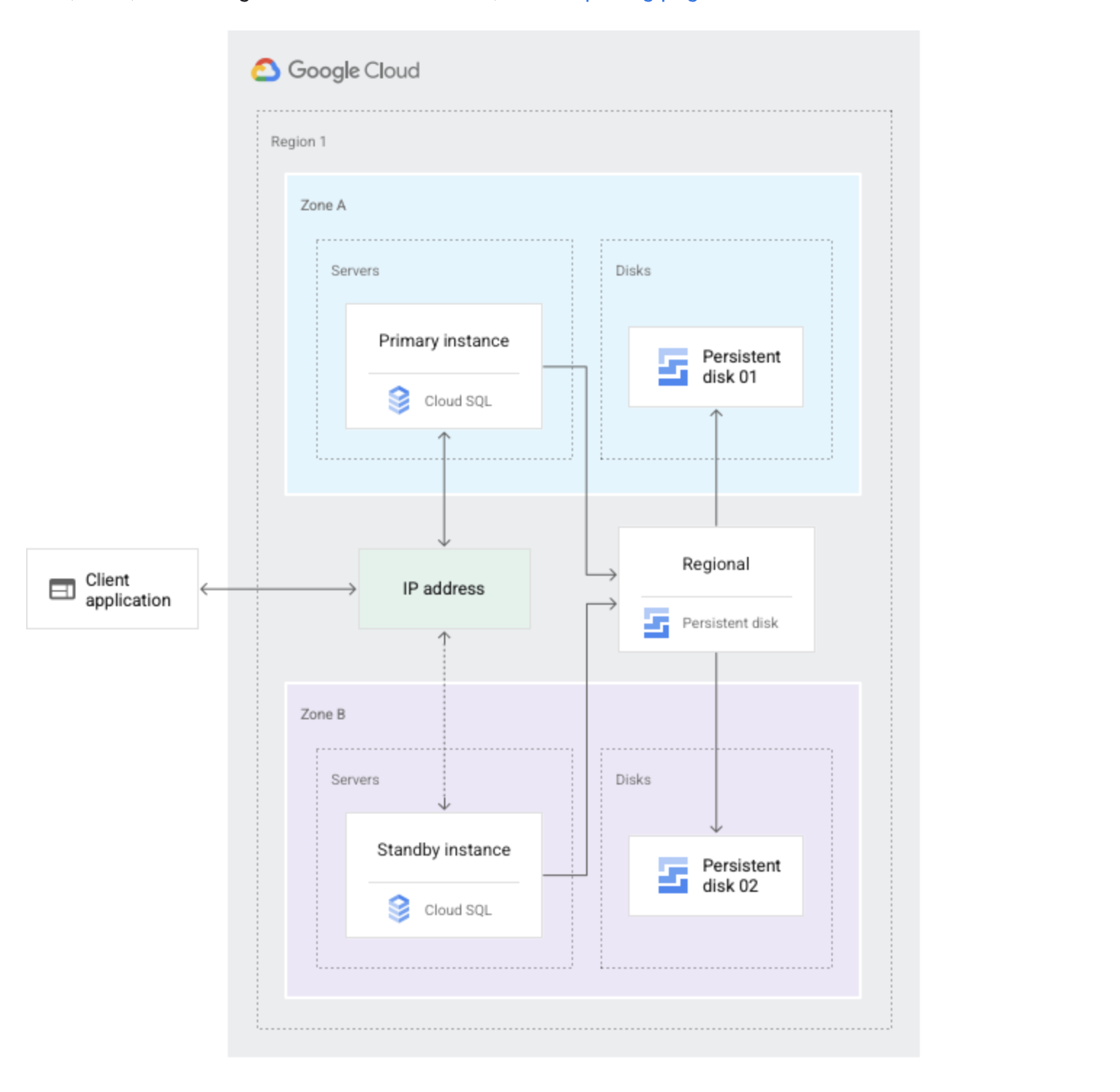
Cloud SQL High Availability
Cloud SQL instance HA configuration provides data redundancy and failover capability with minimal downtime, when a zone or instance becomes unavailable due to a zonal outage, or an instance corruption
HA configuration is also called a regional instance or cluster
With HA, the data continues to be available to client applications.
HA is made up of a primary and a standby instance and is located in a primary and secondary zone within the configured region
If an HA-configured instance becomes unresponsive, Cloud SQL automatically switches to serving data from the standby instance.
Data is synchronously replicated to each zone’s persistent disk, all writes made to the primary instance are replicated to disks in both zones before a transaction is reported as committed.
In the event of an instance or zone failure, the persistent disk is attached to the standby instance, and it becomes the new primary instance.
After a failover, the instance that received the failover continues to be the primary instance, even after the original instance comes back online.
Once the zone or instance that experienced an outage becomes available again, the original primary instance is destroyed and recreated and It becomes the new standby instance.
If a failover occurs in the future, the new primary will failover to the original instance in the original zone.
Cloud SQL Standby instance does not increase scalability and cannot be used for read queries
To see if failover has occurred, check the operation log’s failover history.
Cloud SQL Failover Process
Each second, the primary instance writes to a system database as a heartbeat signal.
Primary instance or zone fails.
If multiple heartbeats aren’t detected, failover is initiated. This occurs if the primary instance is unresponsive for approximately 60 seconds or the zone containing the primary instance experiences an outage.
Standby instance now serves data upon reconnection.
Through a shared static IP address with the primary instance, the standby instance now serves data from the secondary zone.
Users are then automatically rerouted to the new primary.
Cloud SQL Read Replica
Read replicas help scale horizontally the use of data in a database without degrading performance
Read replica is an exact copy of the primary instance. Data and other changes on the primary instance are updated in almost real time on the read replica.
Read replica can be promoted if the original instance becomes corrupted.
Primary instance and read replicas all reside in Cloud SQL
Read replicas are read-only; you cannot write to them
Read replicas do not provide failover capability
Read replicas cannot be made highly available like primary instances.
Cloud SQL currently supports 10 read replicas per primary instance
During a zonal outage, traffic to read replicas in that zone stops.
Once the zone becomes available again, any read replicas in the zone will resume replication from the primary instance.
If read replicas are in a zone that is not in an outage, they are connected to the standby instance when it becomes the primary instance.
GCP recommends putting read replicas in a different zone from the primary and standby instances. for e.g., if you have a primary instance in zone A and a standby instance in zone B, put the read replicas in zone C. This practice ensures that read replicas continue to operate even if the zone for the primary instance goes down.
Client application needs to be configured to send reads to the primary instance when read replicas are unavailable.
Cloud SQL supports Cross-region replication that lets you create a read replica in a different region from the primary instance.
Cloud SQL supports External read replicas that are external MySQL instances which replicate from a Cloud SQL primary instance
Cloud SQL Point In Time Recovery
Point-in-time recovery (PITR) uses binary logs or write-ahead logs
PITR requires
Binary logging and backups enabled for the instance, with continuous binary logs since the last backup before the event you want to recover from
A binary log file name and the position of the event you want to recover from (that event and all events that came after it will not be reflected in the new instance)
Point-in-time recovery is enabled by default when a new Cloud SQL instance is created
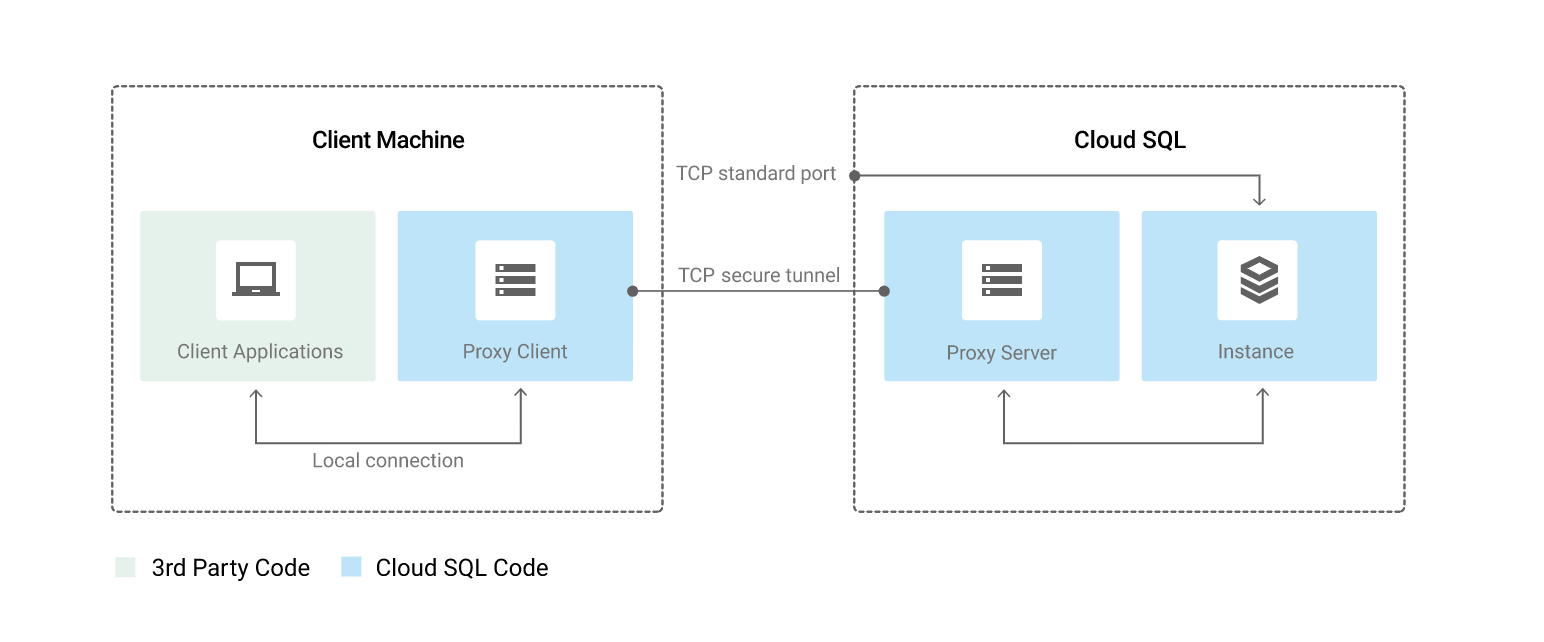
Cloud SQL Proxy
Cloud SQL Proxy provides secure access to the instances without the need for Authorized networks or for configuring SSL.
Secure connections : Cloud SQL Proxy automatically encrypts traffic to and from the database using TLS 1.2 with a 128-bit AES cipher; SSL certificates are used to verify client and server identities.
Easier connection management : Cloud SQL Proxy handles authentication removing the need to provide static IP addresses.
Cloud SQL Proxy does not provide a new connectivity path; it relies on existing IP connectivity. To connect to a Cloud SQL instance using private IP, the Cloud SQL Proxy must be on a resource with access to the same VPC network as the instance.
Cloud SQL Proxy works by having a local client running in the local environment. The application communicates with the Cloud SQL Proxy with the standard database protocol used by the database.
Cloud SQL Proxy uses a secure tunnel to communicate with its companion process running on the server.
While the proxy can listen on any port, it only creates outgoing connections to the Cloud SQL instance on port 3307.
Cloud SQL Features Comparison
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You work for a mid-sized enterprise that needs to move its operational system transaction data from an on-premises database to GCP. The database is about 20 TB in size. Which database should you choose?
Cloud SQL
Cloud Bigtable
Cloud Spanner
Cloud Datastore
An application that relies on Cloud SQL to read infrequently changing data is predicted to grow dramatically. How can you increase capacity for more read-only clients?
Configure high availability on the master node
Establish an external replica in the customer’s data center
Use backups so you can restore if there’s an outage
Configure read replicas.
A Company is using Cloud SQL to host critical data. They want to enable high availability in case a complete zone goes down. How should you configure the same?
Create a Read replica in the same region different zone
Create a Read replica in the different region different zone
Create a Failover replica in the same region different zone
Create a Failover replica in the different region different zone
A Company is using Cloud SQL to host critical data. They want to enable Point In Time recovery (PIT) to be able to recover the instance to a specific point in. How should you configure the same?
Create a Read replica for the instance
Switch to Spanner 3 node cluster
Create a Failover replica for the instance
Enable Binary logging and backups for the instance
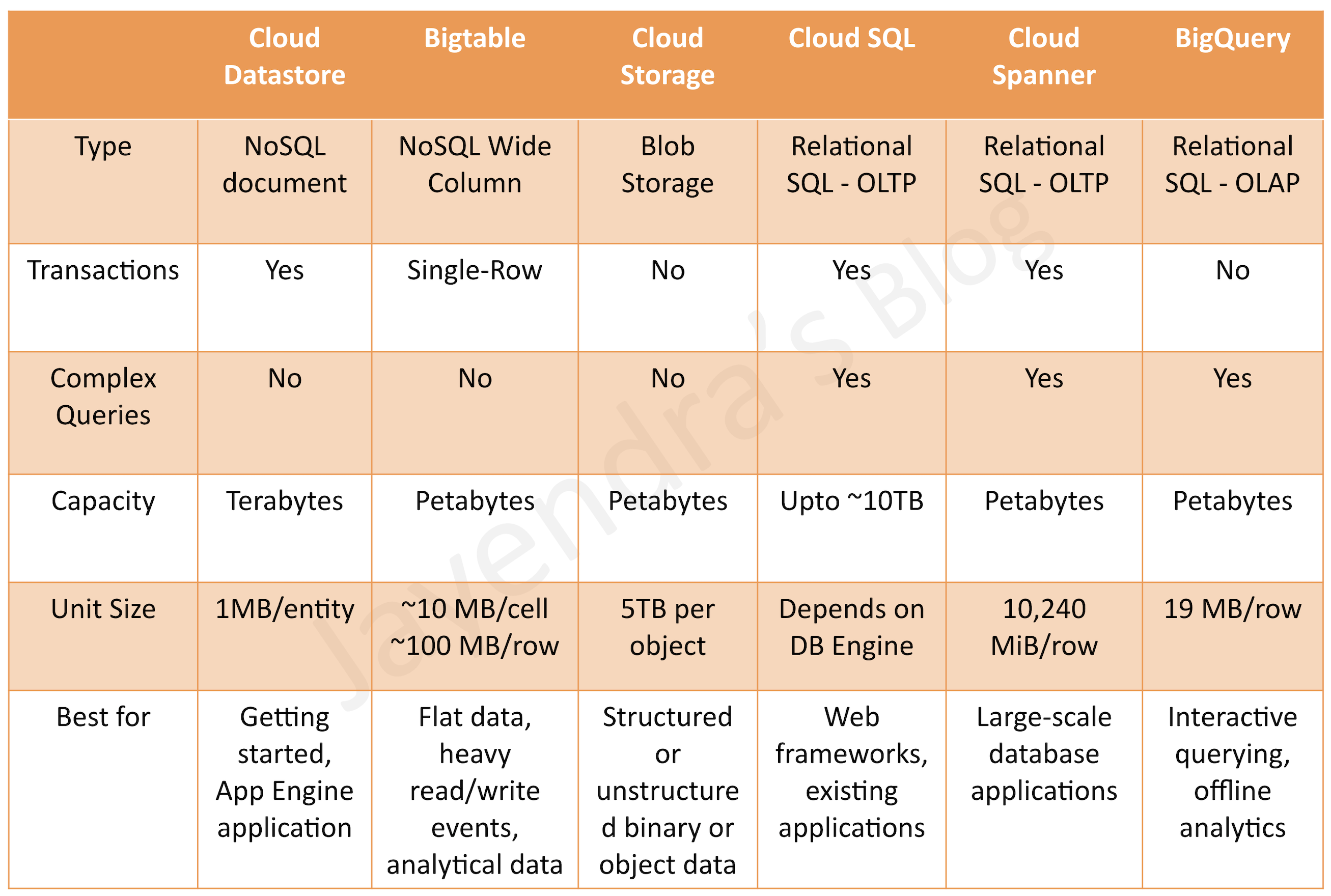
Bigtable provides a scalable, fully managed, non-relational NoSQL wide-column analytical big data database service suitable for both low-latency single-point lookups and precalculated analytics.
supports large quantities (>1 TB) of semi-structured or structured data (vs Datastore)
supports high throughput or rapidly changing data (vs BigQuery)
managed, but needs provisioning of nodes and can be expensive (vs Datastore and BigQuery)
does not support transactions or strong relational semantics (vs Datastore)
does not support SQL queries (vs BigQuery and Datastore)
Not Transactional and does not support ACID
provides eventual consistency
ideal for time-series or natural semantic ordering data
can run asynchronous batch or real-time processing on the data
can run machine learning algorithms on the data
provides petabytes of capacity with a maximum unit size of 10 MB per cell and 100 MB per row.
Usage Patterns
Low-latency read/write access
High-throughput data processing
Time series support
Anti Patterns
Not an ideal storage option for future analysis – Use BigQuery instead
Not an ideal storage option for transactional data – Use relational database or Datastore
Common Use cases
IoT, finance, adtech
Personalization, recommendations
Monitoring
Geospatial datasets
Graphs
Consider using Cloud Bigtable, if you need high-performance datastore to perform analytics on a large number of structured objects
Cloud Storage provides durable and highly available object storage.
fully managed, simple administration, cost-effective, and scalable service that does not require capacity management
supports unstructured data storage like binary or raw objects
provides high performance, internet-scale
supports data encryption at rest and in transit
Consider using Cloud Storage, if you need to store immutable blobs larger than 10 MB, such as large images or movies. This storage service provides petabytes of capacity with a maximum unit size of 5 TB per object.
offers MySQL, PostgreSQL, MSSQL databases as a service
manages OS & Software installation, patches and updates, backups and configuring replications, failover however needs to select and provision machines (vs Cloud Spanner)
single region only – although it now supports cross-region read replicas (vs Cloud Spanner)
Scaling
provides vertical scalability (Max. storage of 10TB)
storage can be increased without incurring any downtime
provides an option to increase the storage automatically
storage CANNOT be decreased
supports Horizontal scaling for read-only using read replicas (vs Cloud Spanner)
performance is linked to the disk size
Security
data is encrypted when stored in database tables, temporary files, and backups.
external connections can be encrypted by using SSL, or by using the Cloud SQL Proxy.
High Availability
fault-tolerance across zones can be achieved by configuring the instance for high availability by adding a failover replica
failover is automatic
can be created from primary instance only
replication from the primary instance to failover replica is semi-synchronous.
failover replica must be in the same region as the primary instance, but in a different zone
only one instance for every primary instance allowed
supports managed backups and backups are created on primary instance only
supports automatic replication
Backups
Automated backups can be configured and are stored for 7 days
Manual backups (snapshots) can be created and are not deleted automatically
Point-in-time recovery
requires binary logging enabled.
every update to the database is written to an independent log, which involves a small reduction in write performance.
performance of the read operations is unaffected by binary logging, regardless of the size of the binary log files.
Usage Patterns
direct lift and shift for MySQL, PostgreSQL, MSSQL database only
relational database service with strong consistency
OLTP workloads
Anti Patterns
need data storage more than 10TB, use Cloud Spanner
need global availability with low latency, use Cloud Spanner
not a direct replacement for Oracle use installation on GCE
Common Use cases
Websites, blogs, and content management systems (CMS)
Business intelligence (BI) applications
ERP, CRM, and eCommerce applications
Geospatial applications
Consider using Cloud SQL for full relational SQL support for OTLP and lift and shift of MySQL, PostgreSQL databases
provides fully managed, no-ops, OLAP, enterprise data warehouse (EDW) with SQL and fast ad-hoc queries.
provides high capacity, data warehousing analytics solution
ideal for big data exploration and processing
not ideal for operational or transactional databases
provides SQL interface
A scalable, fully managed
Usage Patterns
OLAP workloads up to petabyte-scale
Big data exploration and processing
Reporting via business intelligence (BI) tools
Anti Patterns
Not an ideal storage option for transactional data or OLTP – Use Cloud SQL or Cloud Spanner instead
Low-latency read/write access – Use Bigtable instead
Common Use cases
Analytical reporting on large data
Data science and advanced analyses
Big data processing using SQL
Memorystore
provides scalable, secure, and highly available in-memory service for Redis and Memcached.
fully managed as provisioning, replication, failover, and patching are all automated, which drastically reduces the time spent doing DevOps.
provides 100% compatibility with open source Redis and Memcached
is protected from the internet using VPC networks and private IP and comes with IAM integration
Usage Patterns
Lift and shift migration of applications
Low latency data caching and retrieval
Anti Patterns
Relational or NoSQL database
Analytics solution
Common Use cases
User session management
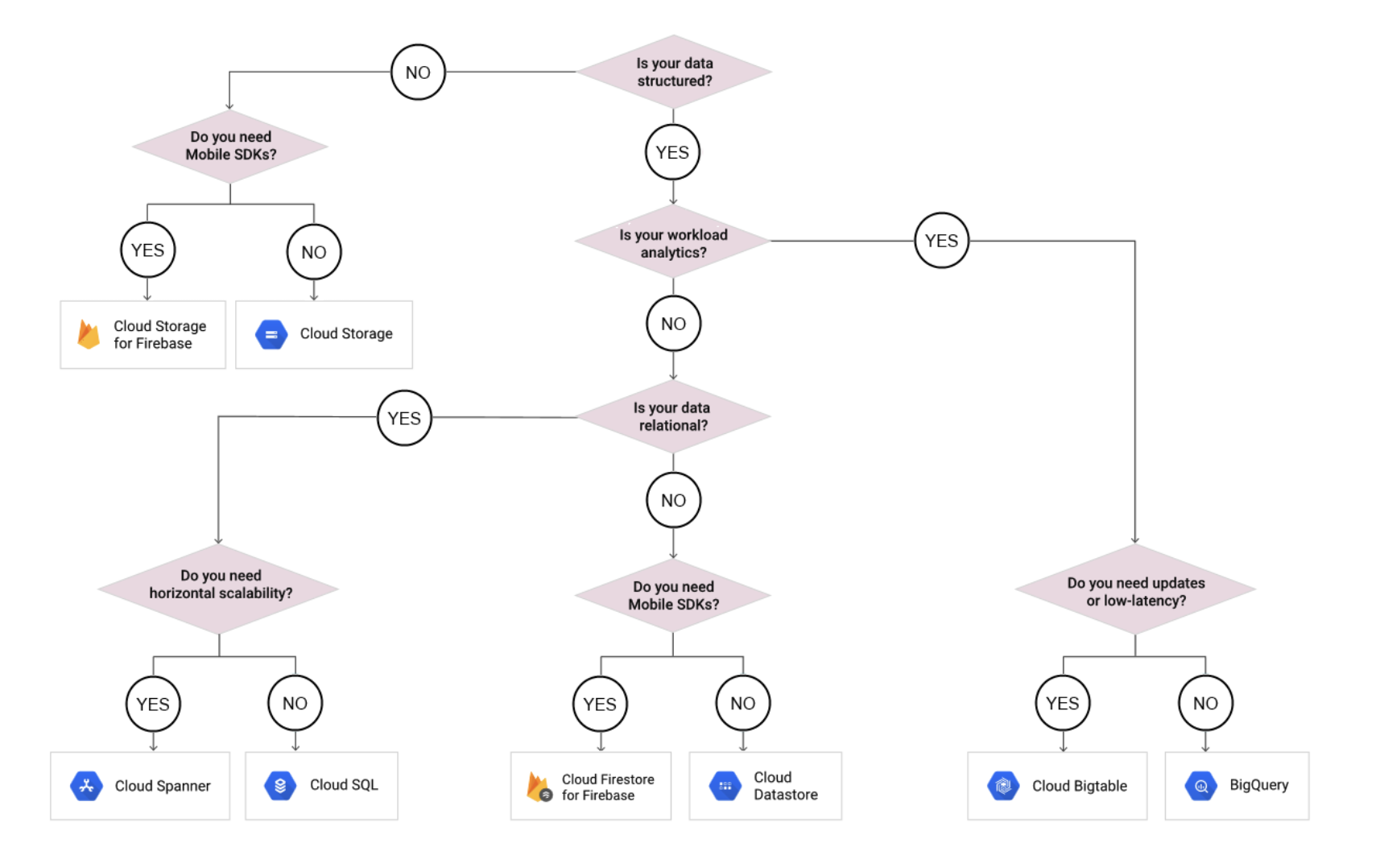
GCP Storage Options Decision Tree
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Your application is hosted across multiple regions and consists of both relational database data and static images. Your database has over 10 TB of data. You want to use a single storage repository for each data type across all regions. Which two products would you choose for this task? (Choose two)
Cloud Bigtable
Cloud Spanner
Cloud SQL
Cloud Storage
You are building an application that stores relational data from users. Users across the globe will use this application. Your CTO is concerned about the scaling requirements because the size of the user base is unknown. You need to implement a database solution that can scale with your user growth with minimum configuration changes. Which storage solution should you use?
Cloud SQL
Cloud Spanner
Cloud Firestore
Cloud Datastore
Your company processes high volumes of IoT data that are time-stamped. The total data volume can be several petabytes. The data needs to be written and changed at a high speed. You want to use the most performant storage option for your data. Which product should you use?
Cloud Datastore
Cloud Storage
Cloud Bigtable
BigQuery
Your App Engine application needs to store stateful data in a proper storage service. Your data is non-relational database data. You do not expect the database size to grow beyond 10 GB and you need to have the ability to scale down to zero to avoid unnecessary costs. Which storage service should you use?
Cloud Bigtable
Cloud Dataproc
Cloud SQL
Cloud Datastore
A financial organization wishes to develop a global application to store transactions happening from different part of the world. The storage system must provide low latency transaction support and horizontal scaling. Which GCP service is appropriate for this use case?
Bigtable
Datastore
Cloud Storage
Cloud Spanner
You work for a mid-sized enterprise that needs to move its operational system transaction data from an on-premises database to GCP. The database is about 20 TB in size. Which database should you choose?
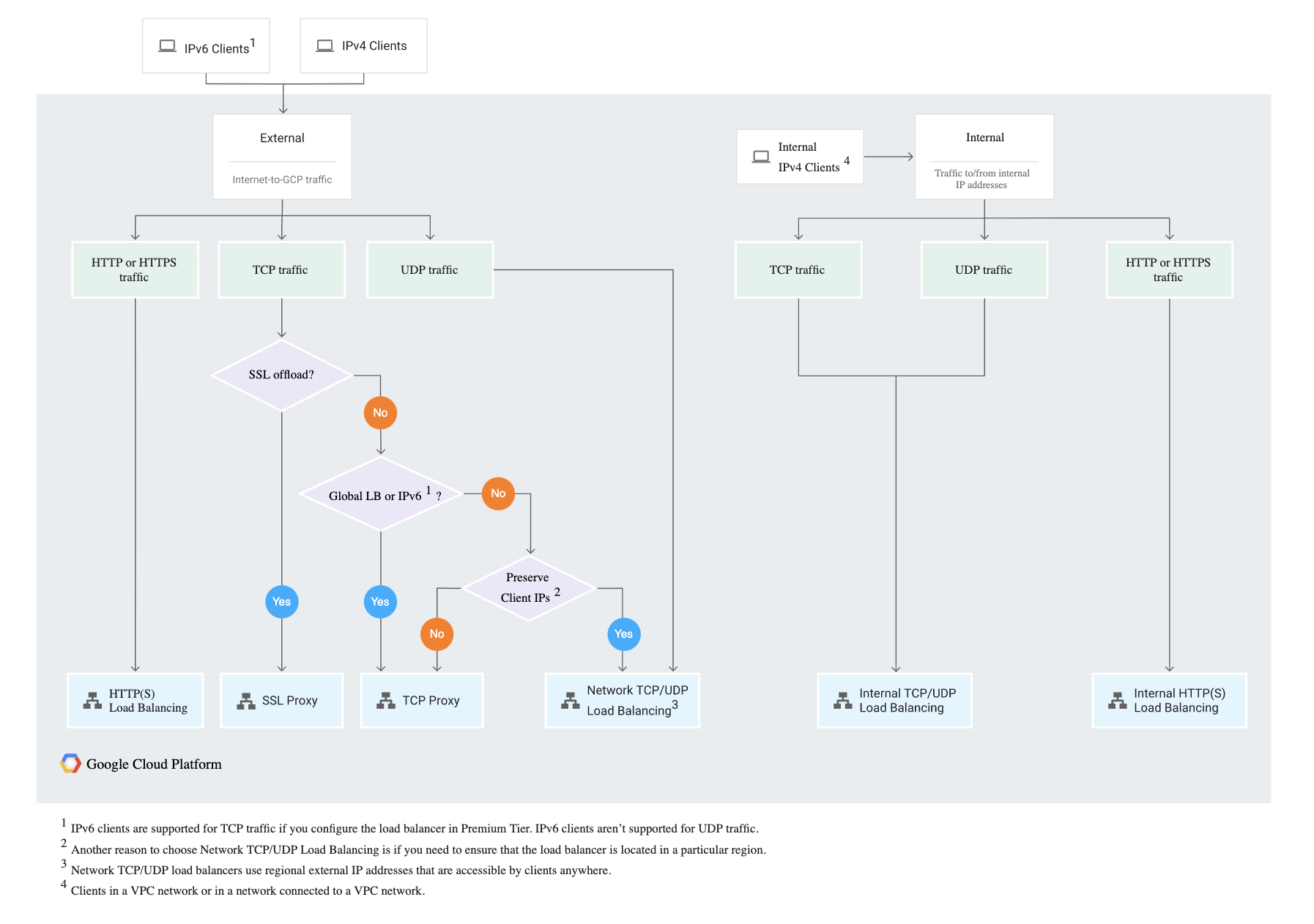
Cloud Load Balancing distributes user traffic across multiple instances of the applications and reduces the risk that the of performance issues for the applications experience by spreading the load
Cloud Load Balancing helps serve content as close as possible to the users on a system that can respond to over one million queries per second.
Cloud Load Balancing is a fully distributed, software-defined managed service. It isn’t hardware-based and there is no need to manage a physical load balancing infrastructure.
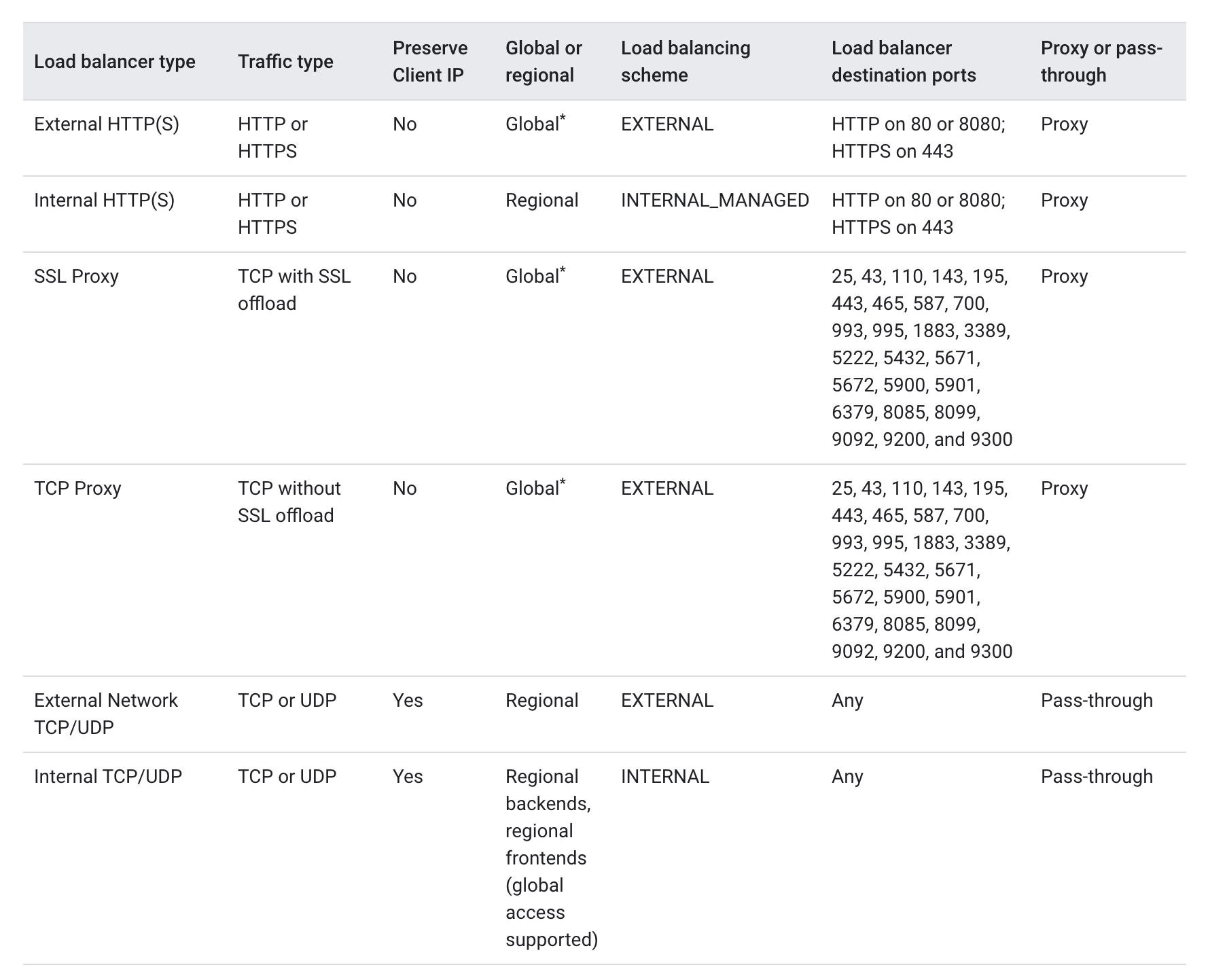
Cloud Load Balancing Features
External versus Internal load balancing
External load balancing
for internet based applications
requires Premium Tier of Network Service Tiers
Types
External HTTP/S Load Balancing
SSL Proxy Load Balancing
TCP Proxy Load Balancing
External TCP/UDP Network Load Balancing
Internal load balancing
for internal clients inside of Google Cloud
can use Standard Tier
Types
Internal HTTP/S Load Balancing
Internal TCP/UDP Network Load Balancing
Global versus Regional Load Balancing
Regional load balancing
for single region applications.
supports only IPv4 termination.
Types
Internal HTTP/S Load Balancing
External TCP/UDP Network Load Balancing
Internal TCP/UDP Network Load Balancing
External HTTP/S Load Balancing (Standard Tier)
SSL Proxy Load Balancing (Standard Tier)
TCP Proxy Load Balancing (Standard Tier)
Global load balancing
for globally distributed applications
provides access by using a single anycast IP address
supports IPv4 and IPv6 termination.
Types
External HTTP/S Load Balancing (Premium Tier)
SSL Proxy Load Balancing (Premium Tier)
TCP Proxy Load Balancing (Premium Tier)
Pass-through vs Proxy-based load balancing
Proxy-based load balancing
acts as a proxy performing address and port translation and terminating the request before forwarding to the backend service
clients and backends interact with the load balancer
original client IP, port and protocol is forwarded using x-forwarded-for headers
automatically all proxy-based external load balancers inherit DDoS protection from Google Front Ends (GFEs)
Google Cloud Armor can be configured for external HTTP(S) load balancers
Types
Internal HTTP/S Load Balancing
External HTTP/S Load Balancing
SSL Proxy Load Balancing
TCP Proxy Load Balancing
Pass-through load balancing
does not modify the request or headers and passes to unchanged to the underlying backend
Types
External TCP/UDP Network Load Balancing
Internal TCP/UDP Network Load Balancing
Layer 4 vs Layer 7
Layer 4-based load balancing
directs traffic based on data from network and transport layer protocols, such as IP address and TCP or UDP port
Layer 7-based load balancing
adds content-based routing decisions based on attributes, such as the HTTP header and the URI
Traffic type
Supports various traffic types including HTTP(S), TCP, UDP
A backend is a group of endpoints that receive traffic from a Google Cloud load balancer, a Traffic Director-configured Envoy proxy, or a proxyless gRPC client.
Google Cloud supports several types of backends:
Instance group containing virtual machine (VM) instances.
Zonal NEG
Serverless NEG
Internet NEG
Cloud Storage bucket
A backend service is either global or regional in scope.
Forwarding Rules
A forwarding rule and its corresponding IP address represent the frontend configuration of a Google Cloud load balancer.
Health Checks
Google Cloud provides health checking mechanisms that determine if backends, such as instance groups and zonal network endpoint groups (NEGs), are healthy and properly respond to traffic.
Google Cloud provides global and regional health check systems that connect to backends on a configurable, periodic basis.
Each connection attempt is called a probe, and each health check system is called a prober. Google Cloud records the success or failure of each probe
Google Cloud computes an overall health state for each backend in the load balancer or Traffic Director based on a configurable number of sequential successful or failed probes.
Backends that respond successfully for the configured number of times are considered healthy.
Backends that fail to respond successfully for a separate number of times are unhealthy.
IPv6 termination
Google Cloud supports IPv6 clients with HTTP(S) Load Balancing, SSL Proxy Load Balancing, and TCP Proxy Load Balancing.
Load balancer accepts IPv6 connections from the users, and then proxies those connections to the backends.
SSL Certificates
Load balancer must have an SSL certificate and the certificate’s corresponding private key.
Communication between the client and the load balancer remains private – illegible to any third party that doesn’t have this private key.
Google Cloud uses SSL certificates to provide privacy and security from a client to a load balancer. To achieve this, the
Allows multiple SSL certificates when serving from multiple domains using the same load balancer IP address and port, and a different SSL certificate for each domain is needed
SSL Policies
SSL policies provide the ability to control the features of SSL that the SSL proxy load balancer or external HTTP(S) load balancer negotiates with clients
HTTP(S) Load Balancing and SSL Proxy Load Balancing uses a set of SSL features that provides good security and wide compatibility.
SSL policies help control the features of SSL like SSL versions and ciphers that the load balancer negotiates with clients.
URL Maps
URL map helps to direct requests to a destination based on defined rules
When a request arrives at the load balancer, the load balancer routes the request to a particular backend service or backend bucket based on configurations in a URL map.
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
is a proxy-based, regional Layer 7 load balancer that enables running and scaling services behind an internal IP address.
distributes HTTP and HTTPS traffic to backends hosted on Compute Engine and GKE
is accessible only in the chosen region of the Virtual Private Cloud (VPC) network on an internal IP address.
enables rich traffic control capabilities based on HTTP(S) parameters.
is a managed service based on the open source Envoy proxy.
needs one proxy-only subnet in each region of a VPC network where internal HTTP(S) load balancers is used. All the internal HTTP(S) load balancers in a region and VPC network share the same proxy-only subnet because all internal HTTP(S) load balancers in the region and VPC network share a pool of Envoy proxies.
supports path based routing
preserves the Host header of the original client request and also appends two IP addresses (Client and LB )to the X-Forwarded-For header
supports a regional backend service, which distributes requests to healthy backends (either instance groups containing Compute Engine VMs or NEGs containing GKE containers).
supports a regional health check that periodically monitors the readiness of the backends. This reduces the risk that requests might be sent to backends that can’t service the request.
if a backend becomes unhealthy, traffic is automatically redirected to healthy backends within the same region.
has native support for the WebSocket protocol when using HTTP or HTTPS as the protocol to the backend
accepts only TLS 1.0, 1.1, 1.2, and 1.3 when terminating client SSL requests.
isn’t compatible with the following features:
Cloud CDN
Google Cloud Armor
Cloud Storage buckets
Google-managed SSL certificates
SSL policies
External HTTP(S) Load Balancing
is a global, proxy-based Layer 7 load balancer that enables running and scaling the services worldwide behind a single external IP address.
distributes HTTP and HTTPS traffic to backends hosted on Compute Engine and GKE
is implemented on Google Front Ends (GFEs). GFEs are distributed globally and operate together using Google’s global network and control plane.
In the Premium Tier, GFEs offer global load balancing
With Standard Tier, the load balancing is handled regionally.
provides cross-regional or location-based load balancing, directing traffic to the closest healthy backend that has the capacity and terminating HTTP(S) traffic as close as possible to your users.
supports content-based load balancing using URL maps to select a backend service based on the requested host name, request path, or both.
Serverless NEGs: One or more App Engine, Cloud Run, or Cloud Functions services
Internet NEGs, for endpoints that are outside of Google Cloud (also known as custom origins)
Buckets in Cloud Storage
preserves the Host header of the original client request and also appends two IP addresses (Client and LB )to the X-Forwarded-For header
supports Cloud Load Balancing Autoscaler, which allows users to perform autoscaling on the instance groups in a backend service.
supports connection draining on backend services to ensure minimal interruption to the users when an instance that is serving traffic is terminated, removed manually, or removed by an autoscaler.
supports Session affinity as a best-effort attempt to send requests from a particular client to the same backend for as long as the backend is healthy and has the capacity, according to the configured balancing mode. It offers three types of session affinity:
NONE. Session affinity is not set for the load balancer.
Client IP affinity sends requests from the same client IP address to the same backend.
Generated cookie affinity sets a client cookie when the first request is made, and then sends requests with that cookie to the same backend.
if a backend becomes unhealthy, traffic is automatically redirected to healthy backends within the same region.
has native support for the WebSocket protocol when using HTTP or HTTPS as the protocol to the backend
accepts only TLS 1.0, 1.1, 1.2, and 1.3 when terminating client SSL requests.
does not support client certificate-based authentication, also known as mutual TLS authentication.
Internal TCP/UDP Load Balancing
is a managed, internal, pass-through, regionalLayer 4 load balancer that enables running and scaling services behind an internal IP address.
distributes traffic among VM instances in the same region in a VPC network by using an internal IP address.
provides a high-performance, pass-through Layer 4 load balancer for TCP or UDP traffic.
routes original connections directly from clients to the healthy backends, without any interruption.
Responses from the healthy backend VMs go directly to the clients, not back through the load balancer. TCP responses use direct server return.
does not terminate SSL traffic and SSL traffic can be terminated by the backends instead of by the load balancer
Unlike proxy load balancer, it doesn’t terminate connections from clients and then opens new connections to backends.
provides access through VPC Network Peering, Cloud VPN or Cloud Interconnect
supports Session affinity as a best-effort attempt for TCP traffic to send requests from a particular client to the same backend for as long as the backend is healthy and has the capacity, according to the configured balancing mode. It offers three types of session affinity:
None : default setting, effectively same as Client IP, protocol, and port.
Client IP : Directs a particular client’s requests to the same backend VM based on a hash created from the client’s IP address and the destination IP address.
Client IP and protocol : Directs a particular client’s requests to the same backend VM based on a hash created from three pieces of information: the client’s IP address, the destination IP address, and the load balancer’s protocol (TCP or UDP).
Client IP, protocol, and port : Directs a particular client’s requests to the same backend VM based on a hash created from these five pieces of information:
Source IP address of the client sending the request
supports health check that periodically monitors the readiness of the backends. If a backend becomes unhealthy, traffic is automatically redirected to healthy backends within the same region.
supports HTTP(S), HTTP2, TCP, and SSL as health check protocols; the protocol of the health check does not have to match the protocol of the load balancer:
does not offer a health check that uses the UDP protocol, but can be done using TCP-based health checks
does not support Network endpoint groups (NEGs) as backends
support some backends to be configured as failover backends. These backends are only used when the number of healthy VMs in the primary backend instance groups has fallen below a configurable threshold.
External TCP/UDP Network Load Balancing
is a managed, external, pass-through, regionalLayer 4 load balancer that distributes TCP or UDP traffic originating from the internet to among virtual machine (VM) instances in the same region
are not proxies, but pass-through
Load-balanced packets are received by backend VMs with their source IP unchanged.
Load-balanced connections are terminated by the backend VMs.
Responses from the backend VMs go directly to the clients, not back through the load balancer.
TCP responses use direct server return.
scope of a network load balancer is regional, not global. A network load balancer cannot span multiple regions. Within a single region, the load balancer services all zones.
distributes connections among backend VMs contained within managed or unmanaged instance groups.
supports regional health check that periodically monitors the readiness of the backends. If a backend becomes unhealthy, traffic is automatically redirected to healthy backends within the same region.
supports HTTP(S), HTTP2, TCP, and SSL as health check protocols; the protocol of the health check does not have to match the protocol of the load balancer:
does not offer a health check that uses the UDP protocol, but can be done using TCP-based health checks
supports connection tracking table and a configurable consistent hashing algorithm to determine how traffic is distributed to backend VMs.
supports Session affinity as a best-effort attempt for TCP traffic to send requests from a particular client to the same backend for as long as the backend is healthy and has the capacity, according to the configured balancing mode. It offers three types of session affinity:
None : default setting, effectively same as Client IP, protocol, and port.
Client IP : Directs a particular client’s requests to the same backend VM based on a hash created from the client’s IP address and the destination IP address.
Client IP and protocol : Directs a particular client’s requests to the same backend VM based on a hash created from three pieces of information: the client’s IP address, the destination IP address, and the load balancer’s protocol (TCP or UDP).
Client IP, protocol, and port : Directs a particular client’s requests to the same backend VM based on a hash created from these five pieces of information:
Source IP address of the client sending the request
supports connection draining which allows established TCP connections to persist until the VM no longer exists. If connection draining is disabled, established TCP connections are terminated as quickly as possible.
is a reverse proxy, layer 4, an external load balancer that distributes SSL traffic coming from the internet to VM instances in the VPC network.
with SSL traffic, supports SSL offload where user SSL (TLS) connections are terminated at the load balancing layer, and then proxied to the closest available backend instances by using either SSL (recommended) or TCP.
supports global load balancing service with the Premium Tier
supports regional load balancing service with the Standard Tier
is intended for non-HTTP(S) traffic. For HTTP(S) traffic, GCP recommends using HTTP(S) Load Balancing.
supports proxy protocol header to preserve the original source IP addresses of incoming connections to the load balancer
performs traffic distribution based on the balancing mode and the hashing method selected to choose a backend (session affinity).
supports two types of balancing mode :
CONNECTION : the load is spread based on how many concurrent connections the backend can handle.
UTILIZATION: the load is spread based on the utilization of instances in an instance group.
supports Session Affinity and offers client IP affinity, which forwards all requests from the same client IP address to the same backend.
supports a single backend service resource. Changes to the backend service are not instantaneous and would take several minutes for changes to propagate to Google Front Ends (GFEs).
do not support client certificate-based authentication, also known as mutual TLS authentication.
External TCP Proxy Load Balancing
is a reverse proxy, external, layer 4 load balancer that distributes TCP traffic coming from the internet to VM instances in the VPC network
terminates traffic coming over a TCP connection at the load balancing layer, and then forwards to the closest available backend using TCP or SSL
use a single IP address for all users worldwide and automatically routes traffic to the backends that are closest to the user
supports global load balancing service with the Premium Tier
supports regional load balancing service with the Standard Tier
performs traffic distribution based on the balancing mode and the hashing method selected to choose a backend (session affinity).
supports proxy protocol header to preserve the original source IP addresses of incoming connections to the load balancer
supports two types of balancing mode
CONNECTION : the load is spread based on how many concurrent connections the backend can handle.
UTILIZATION: the load is spread based on the utilization of instances in an instance group.
supports Session Affinity and offers client IP affinity, which forwards all requests from the same client IP address to the same backend.
GCP Cloud Load Balancing Decision Tree
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Your development team has asked you to set up an external TCP load balancer with SSL offload. Which load balancer should you use?
SSL proxy
HTTP load balancer
TCP proxy
HTTPS load balancer
You have an instance group that you want to load balance. You want the load balancer to terminate the client SSL session. The instance group is used to serve a public web application over HTTPS. You want to follow Google-recommended practices. What should you do?
Configure a HTTP(S) load balancer.
Configure an internal TCP load balancer.
Configure an external SSL proxy load balancer.
Configure an external TCP proxy load balancer.
Your development team has asked you to set up load balancer with SSL termination. The website would be using HTTPS protocol. Which load balancer should you use?
SSL proxy
HTTP load balancer
TCP proxy
HTTPS load balancer
You have an application that receives SSL-encrypted TCP traffic on port 443. Clients for this application are located all over the world. You want to minimize latency for the clients. Which load balancing option should you use?
HTTPS Load Balancer
Network Load Balancer
SSL Proxy Load Balancer
Internal TCP/UDP Load Balancer. Add a firewall rule allowing ingress traffic from 0.0.0.0/0 on the target instances.
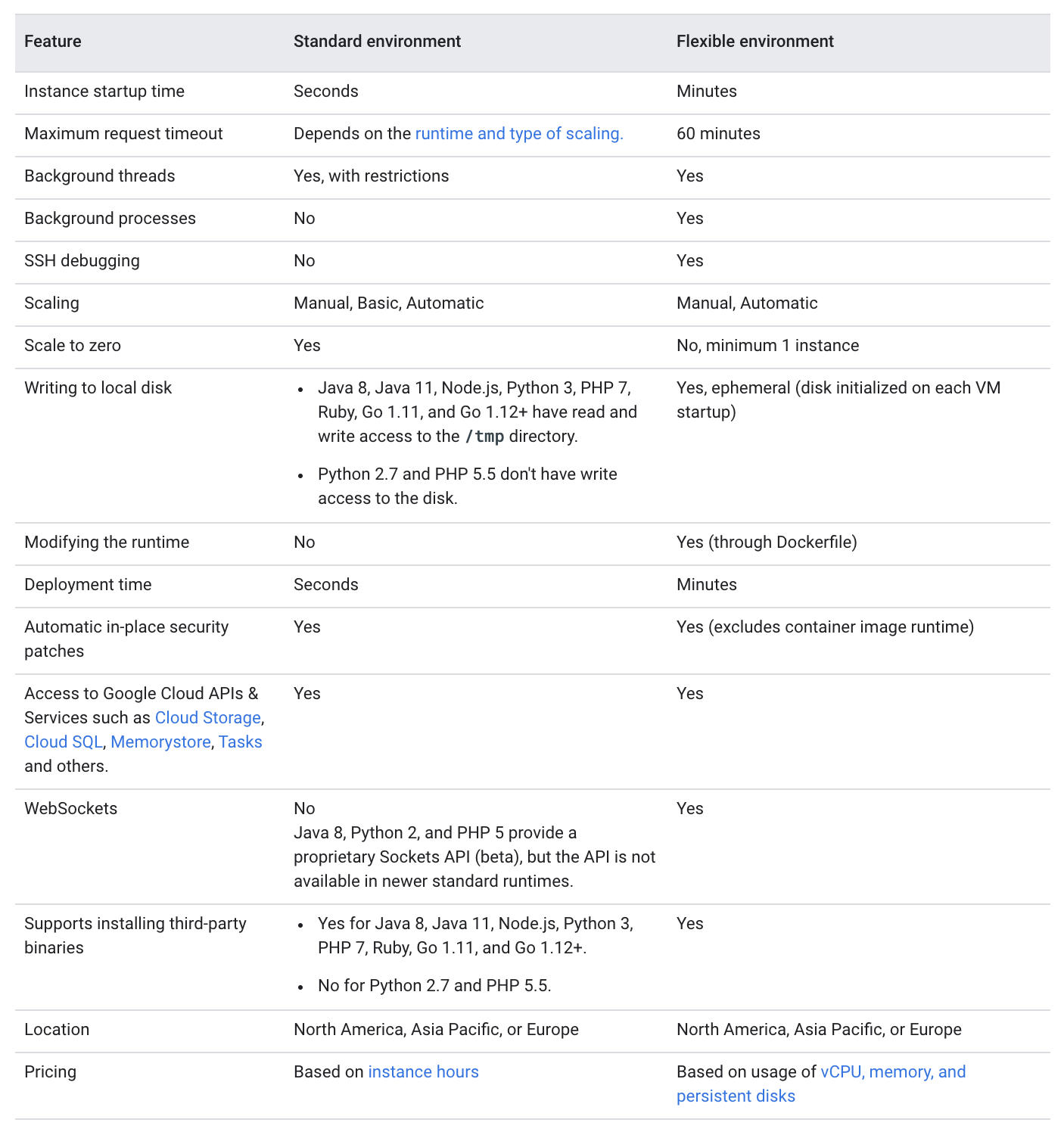
Google Cloud – App Engine Standard vs Flexible Environment
Application Execution
Standard environment
Application instances that run in a sandbox, using the runtime environment of a supported language only.
Sandbox restricts what the application can do
only allows the app to use a limited set of binary libraries
app cannot write to disk
limits the CPU and memory options available to the application
Sandbox does not support
SSH debugging
Background processes
Background threads (limited capability)
Using Cloud VPN
Flexible environment
Application instances run within Docker containers on Compute Engine virtual machines (VM).
As Flexible environment supports docker it can support custom runtime or source code written in other programming languages.
Allows selection of any Compute Engine machine type for instances so that the application has access to more memory and CPU.
Accessing external services
Standard environment
application can accesses services such as Datastore via the built-in google.appengine APIs.
Flexible environment
Google APIs are no longer available.
GCP recommends using the Google Cloud client libraries, which make the application more portable.
Scaling
Standard Environment
Rapid scaling and Zero downscaling is possible, can scale from zero instances up to thousands very quickly.
uses a custom-designed autoscaling algorithm.
Flexible Environment
must have at least one instance running for each active version and can take longer to scale up in response to traffic.
uses the Compute Engine Autoscaler.
Health Checks
Standard environment
does not use health checks to determine whether or not to send traffic to an instance.
Flexible environment
Instances are health-checked, that will be used by the load balancer to determine whether or not to send traffic to an instance and whether or not it should be autohealed.
Traffic Migration
Standard environment
allows you to choose to route requests to the target version, either immediately or gradually.
Flexible environment
only allows immediate traffic migration
Single zone failures
Standard environment
applications are single-zoned and all instances of the application live in a single availability zone
In the event of a zone failure, the application starts new instances in a different zone in the same region and the load balancer routes traffic to the new instances.
Latency spike can be observed due to loading requests and also a Memcache flush.
Flexible environment
applications use Regional Managed Instance Groups with instances distributed among multiple availability zones within a region.
In the event of a single zone failure, the load balancer stops routing traffic to that zone.
Deployment
Standard Environment
Deployments are generally faster than deployments in flexible environment.
VM Instance comes up in seconds in case of auto scaling
Flexible Environment
Instance startup time in minutes rather than seconds when compared to standard environment
Deployment time in minutes rather than seconds when compared to standard environment
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You’re writing a Python application and want your application to run in a sandboxed managed environment with the ability to scale up in seconds to account for huge spikes in demand. Which service should you host your application on?
Compute Engine
App Engine Flexible Environment
Kubernetes Engine
App Engine Standard Environment
A Company is planning the migration of their web application to Google App Engine. However, they would still continue to use their on-premises database. How can they setup application?
Setup the application using App Engine Standard environment with Cloud VPN to connect to database
Setup the application using App Engine Flexible environment with Cloud VPN to connect to database
Setup the application using App Engine Standard environment with Cloud Router to connect to database
Setup the application using App Engine Flexible environment with Cloud Router to connect to database
TerramEarth manufactures heavy equipment for the mining and agricultural industries. They currently have over 500 dealers and service centers in 100 countries. Their mission is to build products that make their customers more productive.
Key points here are 500 dealers and service centers are spread across the world and they want to make their customers more productive.
Solution Concept
There are 2 million TerramEarth vehicles in operation currently, and we see 20% yearly growth. Vehicles collect telemetry data from many sensors during operation. A small subset of critical data is transmitted from the vehicles in real time to facilitate fleet management. The rest of the sensor data is collected, compressed, and uploaded daily when the vehicles return to home base. Each vehicle usually generates 200 to 500 megabytes of data per day
Key points here are TerramEarth has 2 million vehicles. Only critical data is transferred in real-time while the rest of the data is uploaded in bulk daily.
Executive Statement
Our competitive advantage has always been our focus on the customer, with our ability to provide excellent customer service and minimize vehicle downtimes. After moving multiple systems into Google Cloud, we are seeking new ways to provide best-in-class online fleet management services to our customers and improve operations of our dealerships. Our 5-year strategic plan is to create a partner ecosystem of new products by enabling access to our data, increasing autonomous operation capabilities of our vehicles, and creating a path to move the remaining legacy systems to the cloud.
Key point here is the company wants to improve further in operations, customer experience, and partner ecosystem by allowing them to reuse the data.
Existing Technical Environment
TerramEarth’s vehicle data aggregation and analysis infrastructure resides in Google Cloud and serves clients from all around the world. A growing amount of sensor data is captured from their two main manufacturing plants and sent to private data centers that contain their legacy inventory and logistics management systems. The private data centers have multiple network interconnects configured to Google Cloud. The web frontend for dealers and customers is running in Google Cloud and allows access to stock management and analytics.
Key point here is the company is hosting its infrastructure in Google Cloud and private data centers. GCP has web frontend and vehicle data aggregation & analysis. Data is sent to private data centers.
Business Requirements
Predict and detect vehicle malfunction and rapidly ship parts to dealerships for just-in-time repair where possible.
Cloud IoT core can provide a fully managed service to easily and securely connect, manage, and ingest data from globally dispersed devices.
Existing legacy inventory and logistics management systems running in the private data centers can be migrated to Google Cloud.
Existing data can be migrated one time using Transfer Appliance.
Decrease cloud operational costs and adapt to seasonality.
Google Cloud provides configuring elasticity and scalability for resources based on the demand.
Increase speed and reliability of development workflow.
Google Cloud CI/CD tools like Cloud Build and open-source tools like Spinnaker can be used to increase the speed and reliability of the deployments.
Allow remote developers to be productive without compromising code or data security.
Cloud Function to Function authentication
Create a flexible and scalable platform for developers to create custom API services for dealers and partners.
Google Cloud provides multiple fully managed serverless and scalable application hosting solutions like Cloud Run and Cloud Functions
Managed Instance group with Compute Engines and GKE cluster with scaling can also be used to provide scalable, highly available compute services.
Technical Requirements
Create a new abstraction layer for HTTP API access to their legacy systems to enable a gradual move into the cloud without disrupting operations.
Google Cloud API Gateway & Cloud Endpoints can be used to provide an abstraction layer to expose the data externally over a variety of backends.
Modernize all CI/CD pipelines to allow developers to deploy container-based workloads in highly scalable environments.
Google Cloud provides DevOps tools like Cloud Build and supports open-source tools like Spinnaker to provide CI/CD features.
Cloud Build is a fully-managed, serverless service that executes builds on Google Cloud Platform’s infrastructure.
Container Registry is a private container image registry that supports Docker Image Manifest V2 and OCI image formats.
Artifact Registry is a fully-managed service with support for both container images and non-container artifacts, Artifact Registry extends the capabilities of Container Registry.
Allow developers to run experiments without compromising security and governance requirements
Google Cloud deployments can be configured for Canary or A/B testing to allow experimentation.
Create a self-service portal for internal and partner developers to create new projects, request resources for data analytics jobs, and centrally manage access to the API endpoints.
Use cloud-native solutions for keys and secrets management and optimize for identity-based access
Google Cloud supports Key Management Service – KMS and Secrets Manager for managing secrets and key management.
Improve and standardize tools necessary for application and network monitoring and troubleshooting.
Google Cloud provides Cloud Operations Suite which includes Cloud Monitoring and Logging to cover both on-premises and Cloud resources.
Cloud Monitoring collects measurements of key aspects of the service and of the Google Cloud resources used
Cloud Monitoring Uptime check is a request sent to a publicly accessible IP address on a resource to see whether it responds.
Cloud Logging is a service for storing, viewing, and interacting with logs.
Error Reporting aggregates and displays errors produced in the running cloud services.
Cloud Profiler helps with continuous CPU, heap, and other parameters profiling to improve performance and reduce costs.
Cloud Trace is a distributed tracing system that collects latency data from the applications and displays it in the Google Cloud Console.
Cloud Debugger helps inspect the state of an application, at any code location, without stopping or slowing down the running app.
Mountkirk Games makes online, session-based, multiplayer games for mobile platforms. They have recently started expanding to other platforms after successfully migrating their on-premises environments to Google Cloud. Their most recent endeavor is to create a retro-style first-person shooter (FPS) game that allows hundreds of simultaneous players to join a geo-specific digital arena from multiple platforms and locations. A real-time digital banner will display a global leaderboard of all the top players across every active arena.
Solution Concept
Mountkirk Games is building a new multiplayer game that they expect to be very popular. They plan to deploy the game’s backend on Google Kubernetes Engine so they can scale rapidly and use Google’s global load balancer to route players to the closest regional game arenas. In order to keep the global leader board in sync, they plan to use a multi-region Spanner cluster.
So the key here is the company wants to deploy the new game to Google Kubernetes Engine exposed globally using a Global Load Balancer and configured to scale rapidly and bring it closer to the users. Backend DB would be managed using a multi-region Cloud Spanner cluster.
Executive Statement
Our last game was the first time we used Google Cloud, and it was a tremendous success. We were able to analyze player behavior and game telemetry in ways that we never could before. This success allowed us to bet on a full migration to the cloud and to start building all-new games using cloud-native design principles. Our new game is our most ambitious to date and will open up doors for us to support more gaming platforms beyond mobile. Latency is our top priority, although cost management is the next most important challenge. As with our first cloud-based game, we have grown to expect the cloud to enable advanced analytics capabilities so we can rapidly iterate on our deployments of bug fixes and new functionality.
So the key points here are the company has moved to Google Cloud with great success and wants to build new games in the cloud. Key priorities are high performance, low latency, cost, advanced analytics, quick deployment, and time-to-market cycles.
Can be handled using Deployment Manager and IaaC services like Terraform to automate infrastructure provisioning
Cloud Build + Cloud Deploy/Spinnaker can be used for rapid continuous integration and deployment
Minimize latency
can be reduced using a Global HTTP load balancer, which would route the user to the closest region
using multi-regional resources like Cloud Spanner would also help reduce latency
Optimize for dynamic scaling
can be done using GKE Cluster Autoscaler and Horizontal Pod Autoscaling to dynamically scale the nodes and applications as per the demand
Cloud Spanner can be scaled dynamically
Use managed services and pooled resources.
Using GKE, with Global Load Balancer for computing and Cloud Spanner would help cover the application stack using managed services
Minimize costs.
Using minimal resources and enabling auto-scaling as per the demand would help minimize costs
Existing Technical Environment
The existing environment was recently migrated to Google Cloud, and five games came across using lift-and-shift virtual machine migrations, with a few minor exceptions. Each new game exists in an isolated Google Cloud project nested below a folder that maintains most of the permissions and network policies. Legacy games with low traffic have been consolidated into a single project. There are also separate environments for development and testing.
Key points here are the resource hierarchy exists with a project for each new game under a folder to control access using Service Control Permissions. Also, some of the small games would be hosted in a single project. There are also different environments for development, testing, and production.
Technical Requirements
Dynamically scale based on game activity.
can be done using GKE Cluster Autoscaler and Horizontal Pod Autoscaling to dynamically scale the nodes and applications as per the demand
Publish scoring data on a near-real-time global leaderboard.
can be handled using Pub/Sub for capturing data and Cloud DataFlow for processing the data on the fly i.e real time
Store game activity logs in structured files for future analysis.
can be handled using Cloud Storage to store logs for future analysis
analysis can be handled using BigQuery either loading the data or using federated data source
data can also be stored directly using BigQuery as it would provide a low-cost data storage (as compared to Bigtable) for analytics
another advantage of BigQuery over Bigtable in this case its multi-regional, meeting the global footprint and latency requirements
Use GPU processing to render graphics server-side for multi-platform support.
Support eventual migration of legacy games to this new platform.