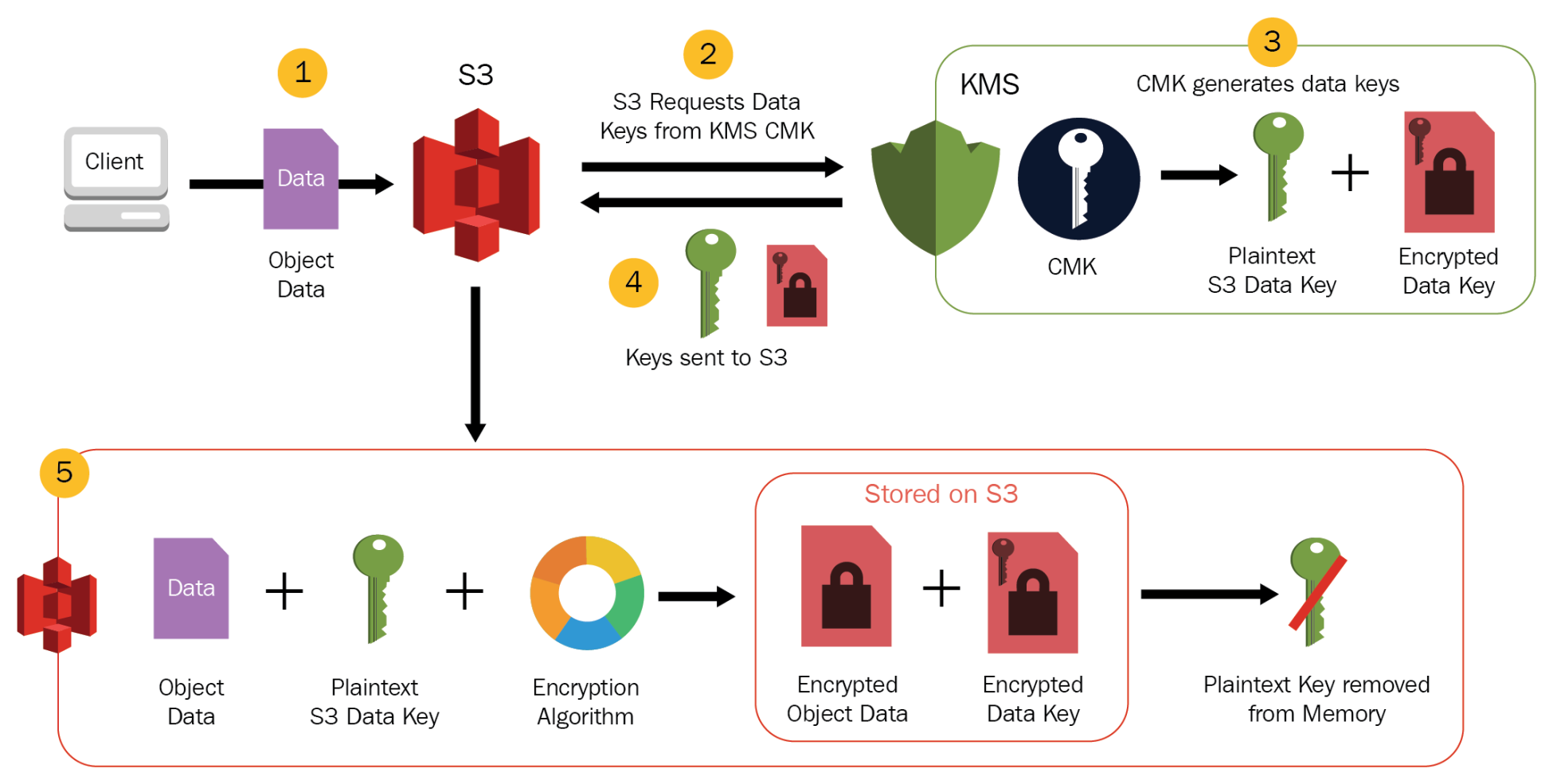
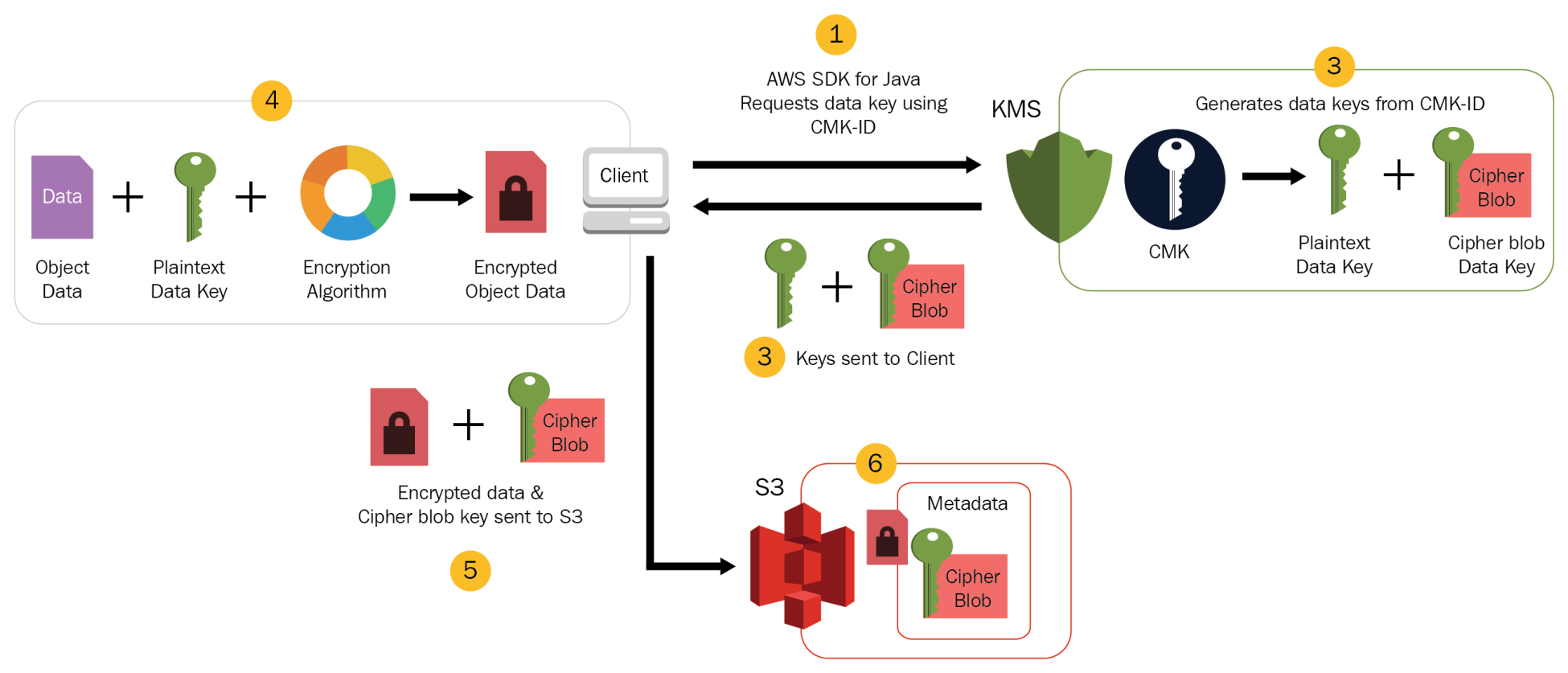
AWS Lambda Event Source
- Lambda Event Source is an AWS service or developer-created application that produces events that trigger an AWS Lambda function to run.
- Event sources can be either AWS Services or Custom applications.
- Event sources can be both push and pull sources
- Services like S3, and SNS publish events to Lambda by invoking the cloud function directly.
- Lambda can also poll resources in services like Kafka, and Kinesis streams that do not publish events to Lambda.
- Events are passed to a Lambda function as an event input parameter. For batch event sources, such as Kinesis Streams, the event parameter may contain multiple events in a single call, based on the requested batch size
Lambda Event Source Mapping
- Lambda Event source mapping refers to the configuration which maps an event source to a Lambda function.
- Event source mapping
- enables automatic invocation of the Lambda function when events occur.
- identifies the type of events to publish and the Lambda function to invoke when events occur.
- Event source mappings support the following services:
- Amazon DynamoDB Streams
- Amazon Kinesis
- Amazon SQS
- Amazon MSK (Managed Streaming for Apache Kafka)
- Self-managed Apache Kafka
- Amazon MQ
- Amazon DocumentDB (with MongoDB compatibility)
Event Source Mapping – Event Filtering
- Lambda supports event filtering for event source mappings, allowing you to control which events are sent to your function.
- Event filtering reduces unnecessary function invocations and can lower costs.
- Filtering is supported for Amazon SQS, Amazon Kinesis, Amazon DynamoDB Streams, Amazon MSK, Self-managed Apache Kafka, and Amazon MQ.
- Lambda does not support event filtering for Amazon DocumentDB.
- Filter criteria can be encrypted with AWS KMS Customer Managed Keys (CMK) for enhanced security (announced August 2024).
Event Source Mapping – Provisioned Mode
- Provisioned Mode allows you to optimize the throughput of your event source mapping by provisioning event polling resources that remain ready to handle sudden spikes in traffic.
- In provisioned mode, you define minimum and maximum limits for event pollers dedicated to your ESM.
- Initially launched for Apache Kafka ESMs (November 2024), and extended to Amazon SQS ESMs (November 2025).
- For Kafka, each event poller can handle up to 5 MB/sec of throughput.
- SQS Provisioned Mode provides 3x faster scaling (up to 1,000 concurrent executions per minute) and 16x higher capacity (up to 20,000 concurrency).
- Kafka ESMs with Provisioned Mode support grouping to optimize costs up to 90% (November 2025).
- Lambda natively supports Avro and Protobuf formatted Kafka events with Provisioned Mode, with integration to schema registries (June 2025).
Event Source Mapping – CloudWatch Metrics
- New opt-in CloudWatch metrics for ESMs were introduced in November 2024 for SQS, Kinesis, and DynamoDB event sources.
- Metrics include: PolledEventCount, InvokedEventCount, FilteredOutEventCount, FailedInvokeEventCount, DeletedEventCount, DroppedEventCount, and OnFailureDestinationDeliveredEventCount.
- These metrics help diagnose processing issues by tracking events through their processing states.
Event Source Mapping – Failed-Event Destinations
- Lambda supports on-failure destinations for event source mappings to retain records of failed invocations.
- Supported destinations include Amazon SQS, Amazon SNS, Kafka topics, and Amazon S3 (added November 2024).
- S3 destinations include the full invocation record along with metadata, enabling further processing via S3 Event Notifications.
- For Kafka ESMs, you can configure a Kafka topic as an on-failure destination.
Lambda Event Sources Type
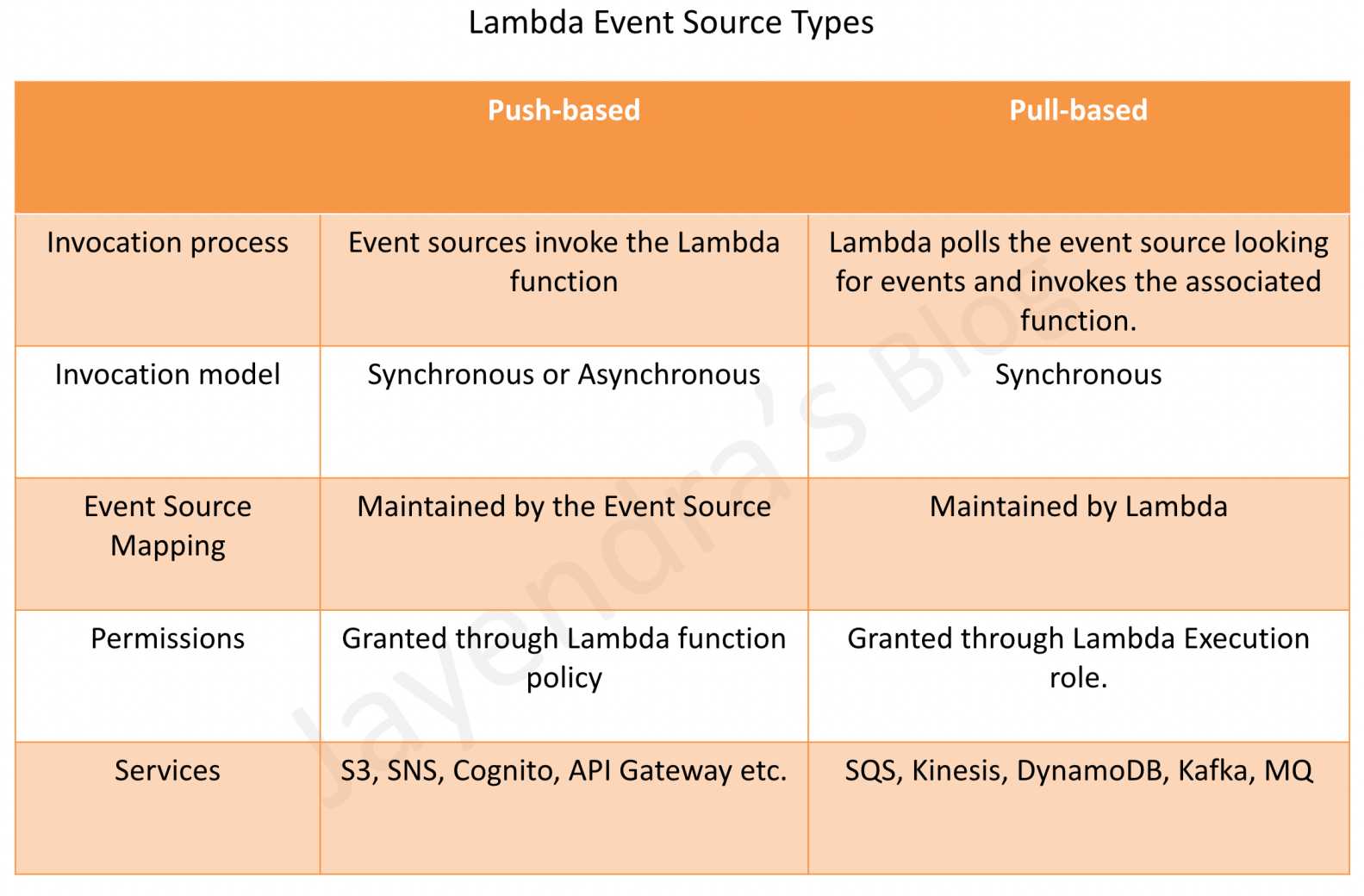
Push-based (Triggers)
- also referred to as the Push model
- includes services like S3, SNS, SES, API Gateway, EventBridge, etc.
- Event source mapping maintained on the event source side
- as the event sources invoke the Lambda function, a resource-based policy should be used to grant the event source the necessary permissions.
Pull-based (Event Source Mappings)
- also referred to as the Pull model
- covers stream and queue-based event sources like DynamoDB Streams, Kinesis, MQ, SQS, Kafka (MSK and self-managed), and Amazon DocumentDB
- Event source mapping maintained on the Lambda side
- Lambda polls the event source and invokes the function synchronously with a batch of records.
Lambda Event Sources Invocation Model
Synchronously
- You wait for the function to process the event and return a response.
- Error handling and retries need to be handled by the Client.
- Invocation includes API Gateway, ALB, Lambda Function URLs, Cognito, Lex, and SDK calls.
Asynchronously
- queues the event for processing and returns a response immediately.
- handles retries and can send invocation records to a destination for successful and failed events.
- Supported destinations for failed events include SQS, SNS, EventBridge, another Lambda function, or Amazon S3 (added November 2024).
- Invocation includes S3, SNS, EventBridge, CloudWatch Logs, CloudFormation, SES, IoT, CodeCommit, CodePipeline, and Config.
Lambda Supported Event Sources
AWS Lambda can be configured as an event source for multiple AWS services.
- Amazon Kinesis Data Firehose renamed to Amazon Data Firehose (Feb 2024)
- Amazon DocumentDB, AWS Step Functions, and Amazon VPC Lattice added as supported event sources
- AWS IoT Events deprecated (EOL May 20, 2026)
- EventBridge now supports both synchronous and asynchronous invocation (via Pipes)
| Service | Method of invocation |
|---|---|
| Amazon MSK – Managed Streaming for Apache Kafka | Event source mapping |
| Self-managed Apache Kafka | Event source mapping |
| Amazon API Gateway | Event-driven; synchronous invocation |
| AWS CloudFormation | Event-driven; asynchronous invocation |
| Amazon CloudFront (Lambda@Edge) | Event-driven; synchronous invocation |
| Amazon EventBridge (formerly CloudWatch Events) | Event-driven; asynchronous invocation (event buses and schedules), synchronous or asynchronous invocation (Pipes) |
| Amazon CloudWatch Logs | Event-driven; asynchronous invocation |
| AWS CodeCommit | Event-driven; asynchronous invocation |
| AWS CodePipeline | Event-driven; asynchronous invocation |
| Amazon Cognito | Event-driven; synchronous invocation |
| AWS Config | Event-driven; asynchronous invocation |
| Amazon Connect | Event-driven; synchronous invocation |
| Amazon DocumentDB | Event source mapping |
| Amazon DynamoDB | Event source mapping |
| Elastic Load Balancing (Application Load Balancer) | Event-driven; synchronous invocation |
| AWS IoT | Event-driven; asynchronous invocation |
| Amazon Kinesis | Event source mapping |
| Amazon Data Firehose (formerly Kinesis Data Firehose) | Event-driven; synchronous invocation |
| Amazon Lex | Event-driven; synchronous invocation |
| Amazon MQ | Event source mapping |
| Amazon Simple Email Service | Event-driven; asynchronous invocation |
| Amazon Simple Notification Service | Event-driven; asynchronous invocation |
| Amazon Simple Queue Service | Event source mapping |
| Amazon S3 | Event-driven; asynchronous invocation |
| Amazon Simple Storage Service Batch | Event-driven; synchronous invocation |
| Secrets Manager | Secret rotation |
| AWS Step Functions | Event-driven; synchronous or asynchronous invocation |
| Amazon VPC Lattice | Event-driven; synchronous invocation |
⚠️ AWS IoT Events – DEPRECATED
AWS IoT Events reached End of Life (EOL) on May 20, 2026. The service no longer accepts new customers (since May 20, 2025) and the console and resources are no longer accessible.
Migration: Use Amazon EventBridge with AWS IoT Core rules to achieve similar event-driven functionality.
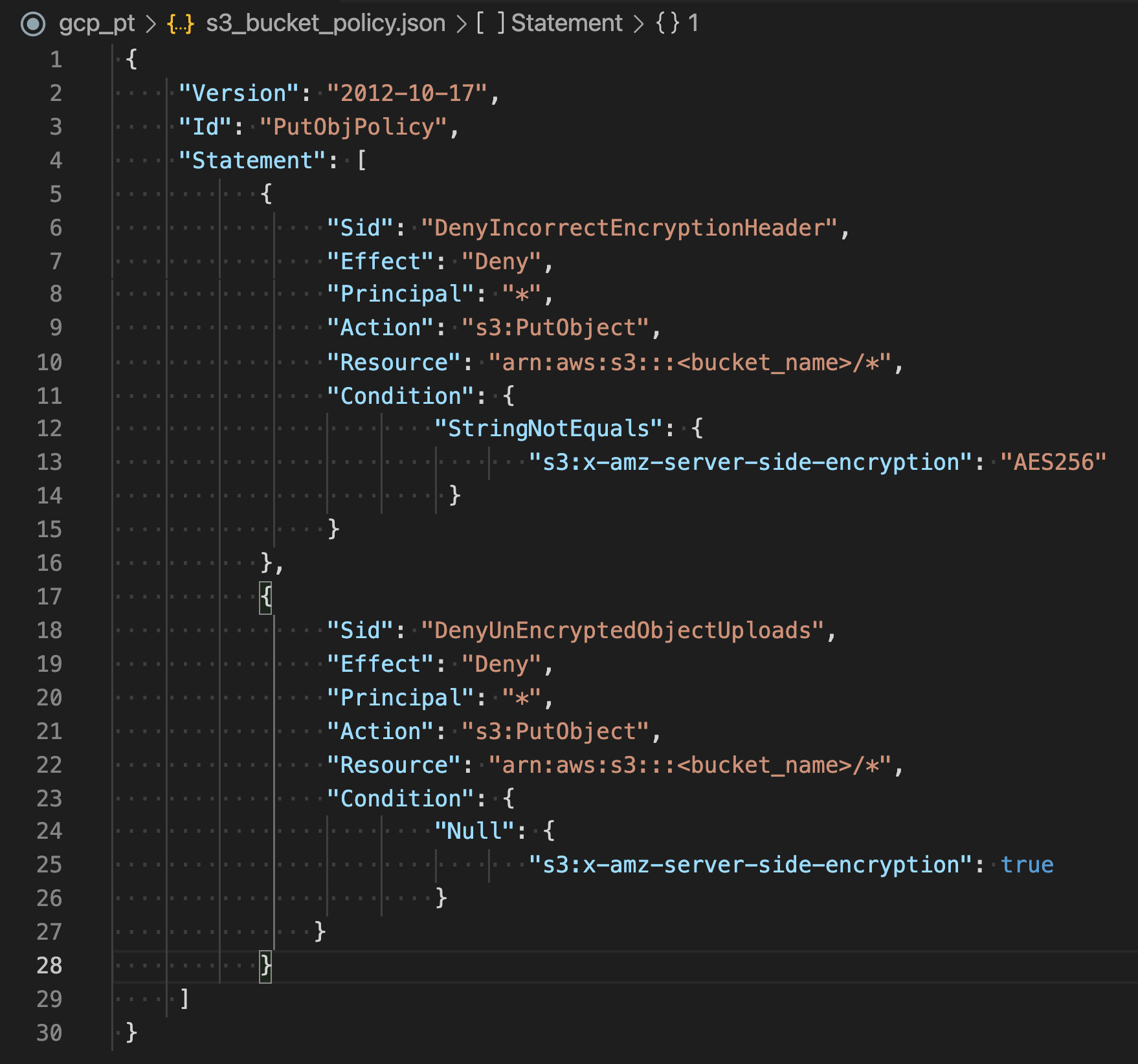
Amazon S3
- S3 bucket events, such as the object-created or object-deleted events can be processed using Lambda functions for e.g., the Lambda function can be invoked when a user uploads a photo to a bucket to read the image and create a thumbnail.
- S3 bucket notification configuration feature can be configured for the event source mapping, to identify the S3 bucket events and the Lambda function to invoke.
- S3 events can also be routed through Amazon EventBridge for more advanced filtering and routing capabilities.
- Error handling for an event source depends on how Lambda is invoked
- S3 invokes your Lambda function asynchronously.
DynamoDB
- Lambda functions can be used as triggers for the DynamoDB table to take custom actions in response to updates made to the DynamoDB table.
- Trigger can be created by
- Enabling DynamoDB Streams for the table.
- Lambda polls the stream and processes any updates published to the stream
- DynamoDB is a stream-based event source and with stream-based service, the event source mapping is created in Lambda, identifying the stream to poll and which Lambda function to invoke.
- Supports event filtering to only process relevant changes.
- Supports on-failure destinations (SQS, SNS, S3) for failed event processing.
- Error handling for an event source depends on how Lambda is invoked
Kinesis Streams
- AWS Lambda can be configured to automatically poll the Kinesis stream periodically (once per second) for new records.
- Lambda can process any new records such as social media feeds, IT logs, website click streams, financial transactions, and location-tracking events
- Kinesis Streams is a stream-based event source and with stream-based service, the event source mapping is created in Lambda, identifying the stream to poll and which Lambda function to invoke.
- Supports event filtering to only invoke the function for relevant records.
- Supports on-failure destinations (SQS, SNS, S3) for failed event processing.
- Error handling for an event source depends on how Lambda is invoked
Simple Notification Service – SNS
- SNS notifications can be processed using Lambda
- When a message is published to an SNS topic, the service can invoke Lambda function by passing the message payload as parameter, which can then process the event
- Lambda function can be triggered in response to CloudWatch alarms and other AWS services that use SNS.
- SNS via topic subscription configuration feature can be used for the event source mapping, to identify the SNS topic and the Lambda function to invoke
- Error handling for an event source depends on how Lambda is invoked
- SNS invokes your Lambda function asynchronously.
Simple Email Service – SES
- SES can be used to receive messages and can be configured to invoke Lambda function when messages arrive, by passing in the incoming email event as parameter
- SES using the rule configuration feature can be used for the event source mapping
- Error handling for an event source depends on how Lambda is invoked
- SES invokes your Lambda function asynchronously.
Amazon Cognito
- Cognito Events feature enables Lambda function to run in response to events in Cognito for e.g. Lambda function can be invoked for the Sync Trigger events, that is published each time a dataset is synchronized.
- Cognito User Pool triggers can invoke Lambda at various points in the authentication flow (pre sign-up, pre authentication, post confirmation, etc.).
- Cognito event subscription configuration feature can be used for the event source mapping
- Error handling for an event source depends on how Lambda is invoked
- Cognito is configured to invoke a Lambda function synchronously
CloudFormation
- Lambda function can be specified as a custom resource to execute any custom commands as a part of deploying CloudFormation stacks and can be invoked whenever the stacks are created, updated, or deleted.
- CloudFormation using stack definition can be used for the event source mapping
- Error handling for an event source depends on how Lambda is invoked
- CloudFormation invokes the Lambda function asynchronously
CloudWatch Logs
- Lambda functions can be used to perform custom analysis on CloudWatch Logs using CloudWatch Logs subscriptions.
- CloudWatch Logs subscriptions provide access to a real-time feed of log events from CloudWatch Logs and deliver it to the AWS Lambda function for custom processing, analysis, or loading to other systems.
- CloudWatch Logs using the log subscription configuration can be used for the event source mapping
- Error handling for an event source depends on how Lambda is invoked
- CloudWatch Logs invokes the Lambda function asynchronously
Amazon EventBridge (formerly CloudWatch Events)
- Amazon EventBridge (formerly CloudWatch Events) helps respond to state changes in AWS resources and receives events from AWS services, SaaS applications, and custom sources.
- Rules that match selected events can be created to route them to the Lambda function to take action for e.g., the Lambda function can be invoked to log the state of an EC2 instance or AutoScaling Group.
- EventBridge by using a rule target definition can be used for the event source mapping
- EventBridge Pipes can invoke Lambda either synchronously or asynchronously, providing point-to-point integrations between event sources and targets with optional filtering, enrichment, and transformation.
- EventBridge Scheduler invokes Lambda functions asynchronously on a schedule (replacing the older CloudWatch Events scheduled rules).
- Error handling for an event source depends on how Lambda is invoked
- EventBridge event buses invoke Lambda asynchronously; Pipes can invoke synchronously (REQUEST_RESPONSE) or asynchronously (FIRE_AND_FORGET).
CodeCommit
- Trigger can be created for a CodeCommit repository so that events in the repository will invoke a Lambda function for e.g., Lambda function can be invoked when a branch or tag is created or when a push is made to an existing branch.
- CodeCommit by using a repository trigger can be used for the event source mapping
- Error handling for an event source depends on how Lambda is invoked
- CodeCommit Events invokes the Lambda function asynchronously
Scheduled Events (powered by Amazon EventBridge)
- AWS Lambda can be invoked regularly on a scheduled basis using Amazon EventBridge Scheduler or EventBridge rules with schedule expressions.
- EventBridge Scheduler supports rate and cron expressions for flexible scheduling.
- EventBridge by using a rule target definition or Scheduler can be used for the event source mapping
- Error handling for an event source depends on how Lambda is invoked
- EventBridge Scheduler invokes the Lambda function asynchronously
AWS Config
- Lambda functions can be used to evaluate whether the AWS resource configurations comply with custom Config rules.
- As resources are created, deleted, or changed, AWS Config records these changes and sends the information to the Lambda functions, which can then evaluate the changes and report results to AWS Config. AWS Config can be used to assess overall resource compliance
- AWS Config by using a rule target definition can be used for the event source mapping
- Error handling for an event source depends on how Lambda is invoked
- AWS Config invokes the Lambda function asynchronously
Amazon API Gateway
- Lambda function can be invoked over HTTPS by defining a custom REST API and endpoint using Amazon API Gateway.
- Individual API operations, such as GET and PUT, can be mapped to specific Lambda functions.
- When an HTTPS request to the API endpoint is received, the API Gateway service invokes the corresponding Lambda function.
- Error handling for an event source depends on how Lambda is invoked.
- API Gateway is configured to invoke a Lambda function synchronously.
Amazon DocumentDB
- Lambda can process events from Amazon DocumentDB (with MongoDB compatibility) change streams.
- Lambda polls the DocumentDB change stream and invokes the function with batches of documents.
- Requires an AWS Secrets Manager secret to store database credentials for the event source mapping.
- Supports DocumentDB versions 4.0 and 5.0 only (version 3.6 is not supported).
- Event filtering is not supported for DocumentDB event source mappings.
- DocumentDB uses the event source mapping model (pull-based).
Amazon VPC Lattice
- Amazon VPC Lattice can invoke Lambda functions as targets for service network traffic.
- Enables Lambda functions to be registered as targets in VPC Lattice target groups.
- Provides service-to-service communication with built-in authentication and authorization.
- VPC Lattice invokes Lambda functions synchronously.
AWS Step Functions
- AWS Step Functions can invoke Lambda functions as part of state machine workflows.
- Supports both synchronous (RequestResponse) and asynchronous (Event) invocation types.
- Provides orchestration capabilities for complex multi-step workflows involving Lambda functions.
Other Event Sources: Invoking a Lambda Function On Demand
- Lambda functions can be invoked on-demand without the need to preconfigure any event source mapping in this case.
- Lambda Function URLs provide a dedicated HTTPS endpoint for your function, enabling direct HTTP invocation without API Gateway.
Lambda Durable Functions (re:Invent 2025)
- Lambda durable functions enable building reliable, fault-tolerant, multi-step applications that can execute for up to one year.
- Durable functions automatically checkpoint progress, suspend execution during long-running tasks, and recover from failures without requiring custom state management code.
- Extends the Lambda programming model with primitives like “steps” and “waits” in your event handler.
- Durable functions can be used with event source mappings for processing streams or queues with complex multi-step workflows.
- Compute charges are not incurred during suspension for on-demand functions.
- Useful for human-in-the-loop processes, AI workflows, and long-running multi-step applications.
Lambda Tenant Isolation Mode (re:Invent 2025)
- Lambda tenant isolation mode provides per-tenant compute boundaries within a single Lambda function.
- Reduces operational complexity of managing separate functions per tenant while maintaining strict isolation.
- Can be integrated with event source mappings to process events with tenant-level isolation.
- Tenant identifier is available in the function context object for tenant-specific logic.
- Must be enabled on new functions (cannot be enabled on existing functions).
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- A company needs to process DynamoDB table changes and only invoke Lambda for items where the “status” field equals “COMPLETED”. What is the most efficient approach?
- Use a Lambda function to check the status field and return early if not “COMPLETED”
- Use DynamoDB Streams with Lambda event source mapping event filtering
- Use EventBridge Pipes with DynamoDB as source and Lambda as target
- Use a Step Functions workflow to check conditions before invoking Lambda
Answer: b – Event source mapping event filtering allows you to define filter criteria so Lambda is only invoked for matching records, reducing costs and unnecessary invocations.
- A company has a Kafka-based event pipeline using Amazon MSK that experiences significant traffic spikes. They need to ensure near-real-time processing with minimal lag during spikes. What should they configure?
- Increase Lambda concurrency limits
- Use Lambda Provisioned Concurrency
- Enable Provisioned Mode for the Kafka event source mapping
- Add more partitions to the Kafka topic
Answer: c – Provisioned Mode for Kafka ESMs provisions event polling resources that remain ready to handle sudden spikes in traffic, providing optimized throughput for the event source mapping.
- An application processes events from an SQS queue through Lambda. The team needs visibility into how many events are being filtered out and how many are failing. What should they use?
- CloudWatch Lambda function metrics (Invocations, Errors)
- SQS queue metrics (ApproximateNumberOfMessagesVisible)
- Event Source Mapping CloudWatch metrics (FilteredOutEventCount, FailedInvokeEventCount)
- AWS X-Ray tracing
Answer: c – The ESM CloudWatch metrics launched in November 2024 provide detailed visibility into event processing states including filtered, failed, and delivered counts.
- A company’s Lambda function processes Kinesis stream records. Failed batches need to be preserved for later analysis without blocking stream processing. What is the recommended approach?
- Configure a dead-letter queue on the Lambda function
- Configure an S3 bucket as an on-failure destination on the event source mapping
- Write failed records to DynamoDB from within the function code
- Use Kinesis Data Firehose to capture all records
Answer: b – S3 as an on-failure destination for stream event source mappings (added Nov 2024) captures the full invocation record with metadata for failed batches.
- Which of the following event sources use Lambda’s event source mapping (pull-based) model? (Choose 3)
- Amazon S3
- Amazon DocumentDB
- Amazon SNS
- Amazon DynamoDB Streams
- Amazon SQS
- Amazon EventBridge
Answer: b, d, e – DocumentDB, DynamoDB Streams, and SQS all use event source mappings where Lambda polls the source. S3, SNS, and EventBridge use the push model.