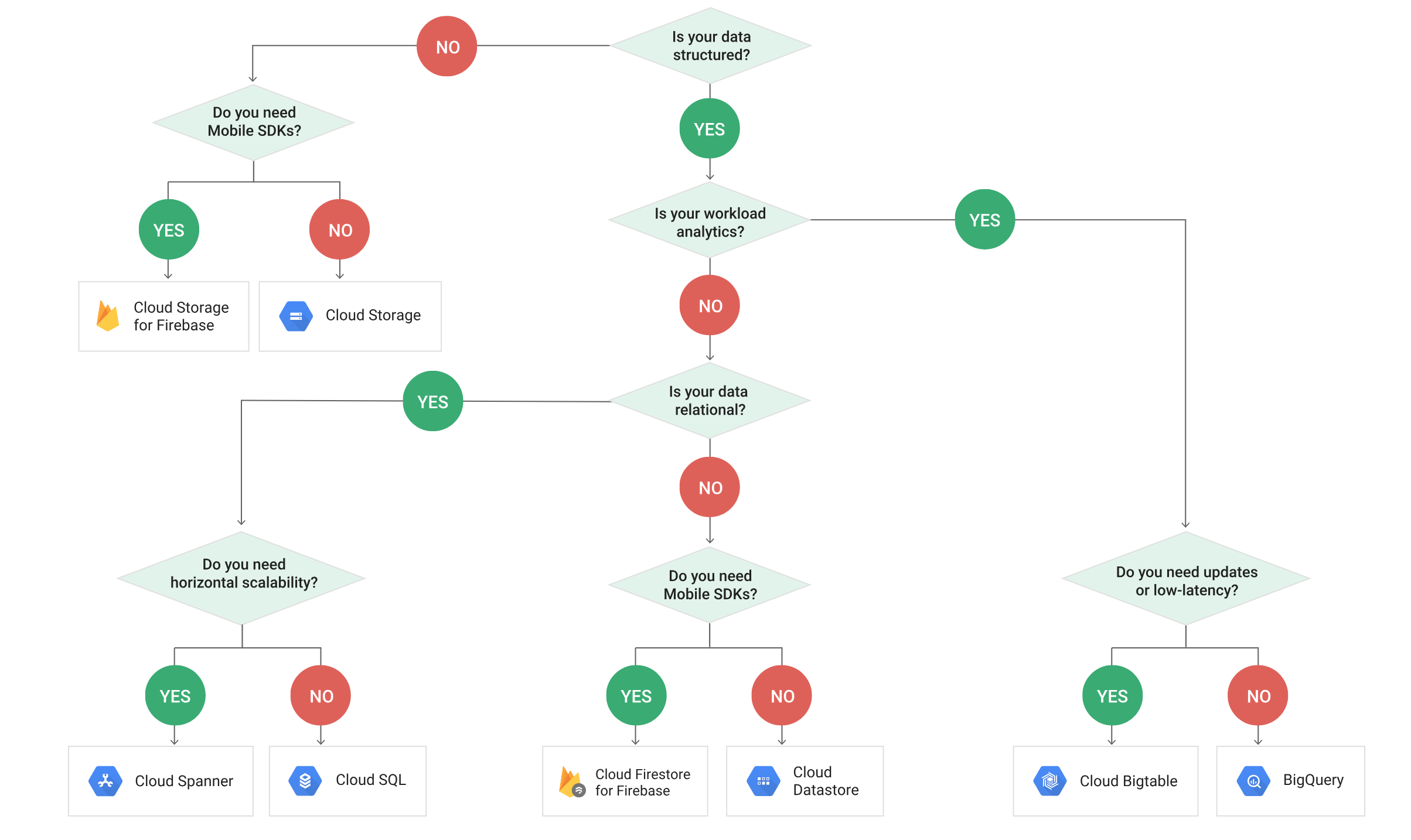
Google Cloud Storage Options
- Relational (SQL) – Cloud SQL & Cloud Spanner
- Non-Relational (NoSQL) – Datastore & Bigtable
- Structured & Semi-structured – Cloud SQL, Cloud Spanner, Datastore & Bigtable
- Unstructured – Cloud Storage
- Block Storage – Persistent disk
- Transactional (OLTP) – Cloud SQL & Cloud Spanner
- Analytical (OLAP) – Bigtable & BigQuery
- Fully Managed (Serverless) – Cloud Spanner, Datastore, BigQuery
- Requires Provisioning – Cloud SQL, Bigtable
- Global – Cloud Spanner
- Regional – Cloud SQL, Bigtable, Datastore
Google Cloud Storage – GCS
- provides service for storing unstructured data i.e. objects
- consists of bucket and objects where an object is an immutable piece of data consisting of a file of any format stored in containers called buckets.
- support different location types
- regional
- A region is a specific geographic place, such as London.
- helps optimize latency and network bandwidth for data consumers, such as analytics pipelines, that are grouped in the same region.
- dual-region
- is a specific pair of regions, such as Finland and the Netherlands.
- provides higher availability that comes with being geo-redundant.
- multi-region
- is a large geographic area, such as the United States, that contains two or more geographic places.
- allows serving content to data consumers that are outside of the Google network and distributed across large geographic areas
- provides higher availability that comes with being geo-redundant.
- Objects stored in a multi-region or dual-region are geo-redundant i.e. data is stored redundantly in at least two separate geographic places separated by at least 100 miles.
- regional
- Storage class affects the object’s availability and pricing model
- Standard Storage is best for data that is frequently accessed (hot data) and/or stored for only brief periods of time.
- Nearline Storage is a low-cost, highly durable storage service for storing infrequently accessed data (warm data)
- Coldline Storage provides a very-low-cost, highly durable storage service for storing infrequently accessed data (cold data)
- Archive Storage is the lowest-cost, highly durable storage service for data archiving, online backup, and disaster recovery. (coldest data)
- Object Versioning prevents accidental overwrites and deletion. It retains a noncurrent object version when the live object version gets replaced, overwritten or deleted
- Object Lifecycle Management sets Time To Live (TTL) on an object and helps configure transition or expiration of the objects based on specified rules for e.g.
SetStorageClassto change the storage class,deleteto expire noncurrent or archived objects - Resumable uploads are the recommended method for uploading large files, because they don’t need to be restarted from the beginning if there is a network failure while the upload is underway.
- Parallel composite uploads divides a file into up to 32 chunks, which are uploaded in parallel to temporary objects, the final object is recreated using the temporary objects, and the temporary objects are deleted
- Requester Pays on the bucket that requires requester to include a billing project in their requests, thus billing the requester’s project.
- supports upload and storage of any MIME type of data up to 5 TB in size.
- Retention policy on a bucket ensures that all current and future objects in the bucket cannot be deleted or replaced until they reach the defined age
- Retention policy locks will lock a retention policy on a bucket and prevents the policy from ever being removed or the retention period from ever being reduced (although it can be increased). Locking a retention policy is irreversible
- Bucket Lock feature provides immutable storage on Cloud Storage
- Object holds, when set on individual objects, prevents the object from being deleted or replaced, however allows metadata to be edited.
- Signed URLs provide time-limited read or write access to an object through a generated URL.
- Signed policy documents helps specify what can be uploaded to a bucket.
- Cloud Storage supports encryption at rest and in transit as well
- Cloud Storage supports both
- Server-side encryption with support for Google managed, Customer managed and Customer supplied encryption keys
- Client-side encryption: encryption that occurs before data is sent to Cloud Storage, encrypted at client side.
- Cloud Storage operations are
- strongly consistent for read after writes or deletes and listing
- eventually consistent for granting access to or revoking access
- Cloud Storage allows setting CORS configuration at the bucket level only
Cloud SQL
- provides relational MySQL, PostgreSQL and MSSQL databases as a service
- managed, however, needs to select and provision machines
- supports automatic replication, managed backups, vertical scaling for read and write, Horizontal scaling (using read replicas)
- provides High Availability configuration provides data redundancy and failover capability with minimal downtime, when a zone or instance becomes unavailable due to a zonal outage, or an instance corruption
- HA standby instance does not increase scalability and cannot be used for read queries.
- Read replicas help scale horizontally the use of data in a database without degrading performance
- is regional – although it now supports cross region read replicas
- supports data encryption at rest and in transit
- supports Point-In-Time recovery with binary logging and backups
Cloud Spanner
Datastore
- Ancestor Paths + Best Practices
BigQuery
- user- or project- level custom query quota
- dry-run
- on-demand to flat rate
- supports dry-run which helps in pricing queries based on the amount of bytes read i.e.
--dry_runflag in thebqcommand-line tool ordryRunparameter when submitting a query job using the API
Google Cloud Datastore OR Filestore
MemoryStore
Google Persistent Disk
Google Local SSD
Cloud SQL now supports SQL server as one of the managed databases.
https://cloud.google.com/sql
Thanks Adarsh, updated the same.