Cloud SQL is a web service that allows you to create, configure, and use relational databases that live in Google’s cloud. It is a fully-managed service that maintains, manages, and administers your databases, allowing you to focus on your applications and services.
provides service for storing unstructured data i.e. objects
consists of bucket and objects where an object is an immutable piece of data consisting of a file of any format stored in containers called buckets.
support different location types
regional
A region is a specific geographic place, such as London.
helps optimize latency and network bandwidth for data consumers, such as analytics pipelines, that are grouped in the same region.
dual-region
is a specific pair of regions, such as Finland and the Netherlands.
provides higher availability that comes with being geo-redundant.
multi-region
is a large geographic area, such as the United States, that contains two or more geographic places.
allows serving content to data consumers that are outside of the Google network and distributed across large geographic areas
provides higher availability that comes with being geo-redundant.
Objects stored in a multi-region or dual-region are geo-redundanti.e. data is stored redundantly in at least two separate geographic places separated by at least 100 miles.
Storage class affects the object’s availability and pricing model
Standard Storage is best for data that is frequently accessed (hot data) and/or stored for only brief periods of time.
Nearline Storage is a low-cost, highly durable storage service for storing infrequently accessed data (warm data)
Coldline Storage provides a very-low-cost, highly durable storage service for storing infrequently accessed data (cold data)
Archive Storage is the lowest-cost, highly durable storage service for data archiving, online backup, and disaster recovery. (coldest data)
Object Versioning prevents accidental overwrites and deletion. It retains a noncurrent object version when the live object version gets replaced, overwritten or deleted
Object Lifecycle Management sets Time To Live (TTL) on an object and helps configure transition or expiration of the objects based on specified rules for e.g. SetStorageClass to change the storage class, delete to expire noncurrent or archived objects
Resumable uploads are the recommended method for uploading large files, because they don’t need to be restarted from the beginning if there is a network failure while the upload is underway.
Parallel composite uploads divides a file into up to 32 chunks, which are uploaded in parallel to temporary objects, the final object is recreated using the temporary objects, and the temporary objects are deleted
Requester Pays on the bucket that requires requester to include a billing project in their requests, thus billing the requester’s project.
supports upload and storage of any MIME type of data up to 5 TB in size.
Retention policy on a bucket ensures that all current and future objects in the bucket cannot be deleted or replaced until they reach the defined age
Retention policy locks will lock a retention policy on a bucket and prevents the policy from ever being removed or the retention period from ever being reduced (although it can be increased). Locking a retention policy is irreversible
Bucket Lock feature provides immutable storage on Cloud Storage
Object holds, when set on individual objects, prevents the object from being deleted or replaced, however allows metadata to be edited.
Signed URLs provide time-limited read or write access to an object through a generated URL.
Signed policy documents helps specify what can be uploaded to a bucket.
Cloud Storage supports encryption at rest and in transit as well
Cloud Storage supports both
Server-side encryption with support for Google managed, Customer managed and Customer supplied encryption keys
Client-side encryption: encryption that occurs before data is sent to Cloud Storage, encrypted at client side.
Cloud Storage operations are
strongly consistent for read after writes or deletes and listing
eventually consistent for granting access to or revoking access
Cloud Storage allows setting CORS configuration at the bucket level only
provides relational MySQL, PostgreSQL and MSSQL databases as a service
managed, however, needs to select and provision machines
supports automatic replication, managed backups, vertical scaling for read and write, Horizontal scaling (using read replicas)
provides High Availability configuration provides data redundancy and failover capability with minimal downtime, when a zone or instance becomes unavailable due to a zonal outage, or an instance corruption
HA standby instance does not increase scalability and cannot be used for read queries.
Read replicas help scale horizontally the use of data in a database without degrading performance
is regional – although it now supports cross region read replicas
supports data encryption at rest and in transit
supports Point-In-Time recovery with binary logging and backups
Cloud Spanner
Datastore
Ancestor Paths + Best Practices
BigQuery
user- or project- level custom query quota
dry-run
on-demand to flat rate
supports dry-run which helps in pricing queries based on the amount of bytes read i.e. --dry_run flag in the bq command-line tool or dryRun parameter when submitting a query job using the API
Cloud SQL provides a cloud-based alternative to local MySQL, PostgreSQL, and Microsoft SQL Server databases
Cloud SQL is a managed solution that helps handles backups, replication, high availability and failover, data encryption, monitoring, and logging.
Cloud SQL is ideal for lift and shift migration from existing on-premises relational databases
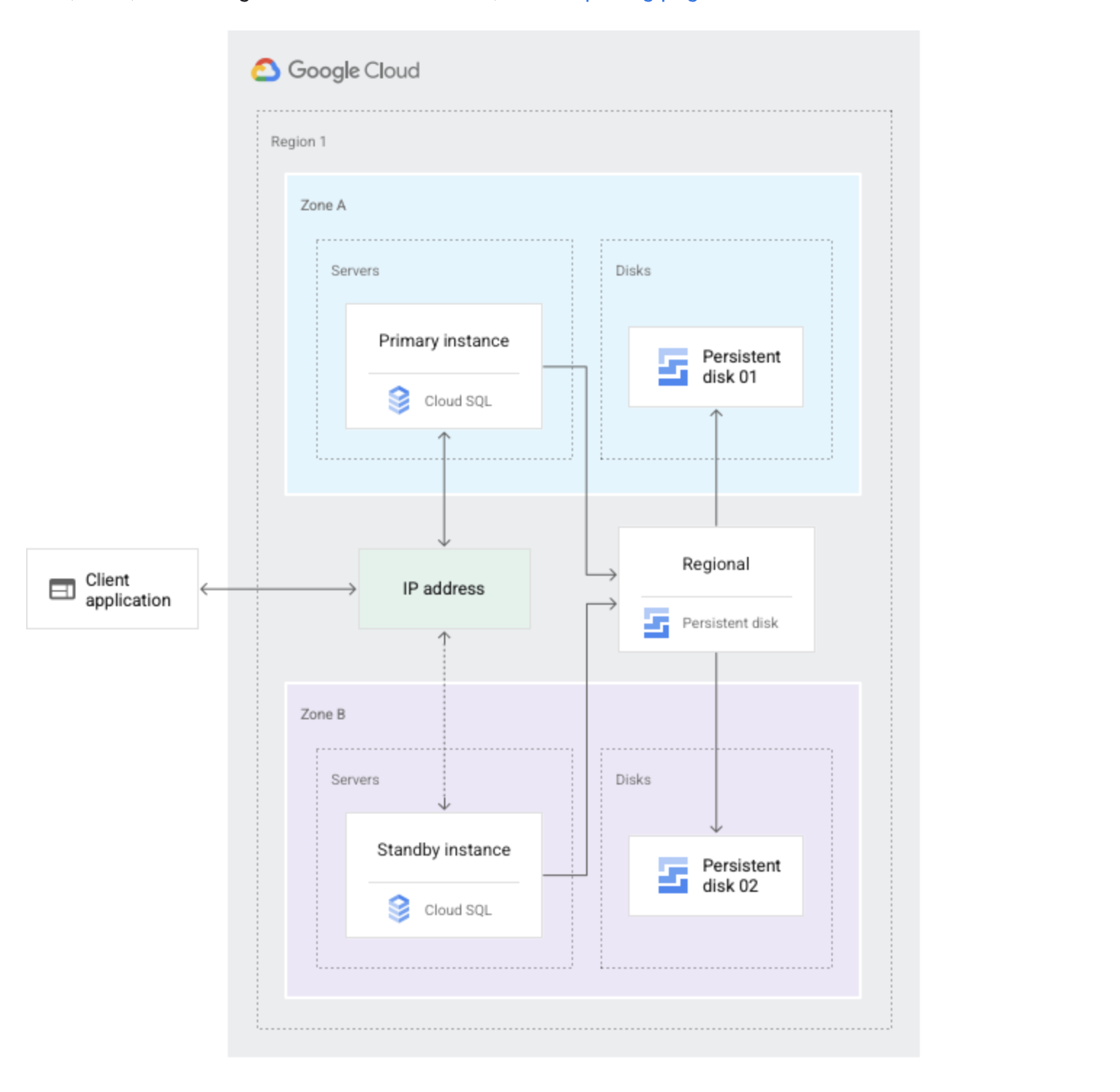
Cloud SQL High Availability
Cloud SQL instance HA configuration provides data redundancy and failover capability with minimal downtime, when a zone or instance becomes unavailable due to a zonal outage, or an instance corruption
HA configuration is also called a regional instance or cluster
With HA, the data continues to be available to client applications.
HA is made up of a primary and a standby instance and is located in a primary and secondary zone within the configured region
If an HA-configured instance becomes unresponsive, Cloud SQL automatically switches to serving data from the standby instance.
Data is synchronously replicated to each zone’s persistent disk, all writes made to the primary instance are replicated to disks in both zones before a transaction is reported as committed.
In the event of an instance or zone failure, the persistent disk is attached to the standby instance, and it becomes the new primary instance.
After a failover, the instance that received the failover continues to be the primary instance, even after the original instance comes back online.
Once the zone or instance that experienced an outage becomes available again, the original primary instance is destroyed and recreated and It becomes the new standby instance.
If a failover occurs in the future, the new primary will failover to the original instance in the original zone.
Cloud SQL Standby instance does not increase scalability and cannot be used for read queries
To see if failover has occurred, check the operation log’s failover history.
Cloud SQL Failover Process
Each second, the primary instance writes to a system database as a heartbeat signal.
Primary instance or zone fails.
If multiple heartbeats aren’t detected, failover is initiated. This occurs if the primary instance is unresponsive for approximately 60 seconds or the zone containing the primary instance experiences an outage.
Standby instance now serves data upon reconnection.
Through a shared static IP address with the primary instance, the standby instance now serves data from the secondary zone.
Users are then automatically rerouted to the new primary.
Cloud SQL Read Replica
Read replicas help scale horizontally the use of data in a database without degrading performance
Read replica is an exact copy of the primary instance. Data and other changes on the primary instance are updated in almost real time on the read replica.
Read replica can be promoted if the original instance becomes corrupted.
Primary instance and read replicas all reside in Cloud SQL
Read replicas are read-only; you cannot write to them
Read replicas do not provide failover capability
Read replicas cannot be made highly available like primary instances.
Cloud SQL currently supports 10 read replicas per primary instance
During a zonal outage, traffic to read replicas in that zone stops.
Once the zone becomes available again, any read replicas in the zone will resume replication from the primary instance.
If read replicas are in a zone that is not in an outage, they are connected to the standby instance when it becomes the primary instance.
GCP recommends putting read replicas in a different zone from the primary and standby instances. for e.g., if you have a primary instance in zone A and a standby instance in zone B, put the read replicas in zone C. This practice ensures that read replicas continue to operate even if the zone for the primary instance goes down.
Client application needs to be configured to send reads to the primary instance when read replicas are unavailable.
Cloud SQL supports Cross-region replication that lets you create a read replica in a different region from the primary instance.
Cloud SQL supports External read replicas that are external MySQL instances which replicate from a Cloud SQL primary instance
Cloud SQL Point In Time Recovery
Point-in-time recovery (PITR) uses binary logs or write-ahead logs
PITR requires
Binary logging and backups enabled for the instance, with continuous binary logs since the last backup before the event you want to recover from
A binary log file name and the position of the event you want to recover from (that event and all events that came after it will not be reflected in the new instance)
Point-in-time recovery is enabled by default when a new Cloud SQL instance is created
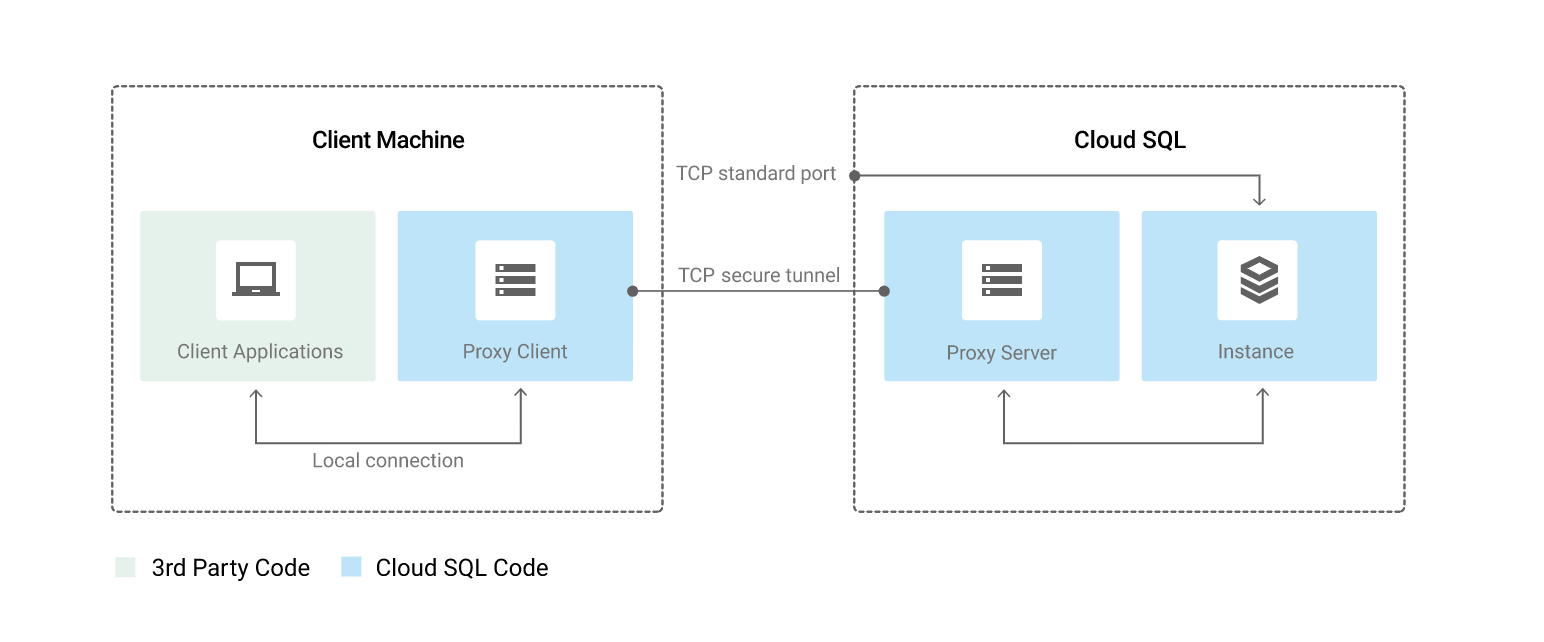
Cloud SQL Proxy
Cloud SQL Proxy provides secure access to the instances without the need for Authorized networks or for configuring SSL.
Secure connections : Cloud SQL Proxy automatically encrypts traffic to and from the database using TLS 1.2 with a 128-bit AES cipher; SSL certificates are used to verify client and server identities.
Easier connection management : Cloud SQL Proxy handles authentication removing the need to provide static IP addresses.
Cloud SQL Proxy does not provide a new connectivity path; it relies on existing IP connectivity. To connect to a Cloud SQL instance using private IP, the Cloud SQL Proxy must be on a resource with access to the same VPC network as the instance.
Cloud SQL Proxy works by having a local client running in the local environment. The application communicates with the Cloud SQL Proxy with the standard database protocol used by the database.
Cloud SQL Proxy uses a secure tunnel to communicate with its companion process running on the server.
While the proxy can listen on any port, it only creates outgoing connections to the Cloud SQL instance on port 3307.
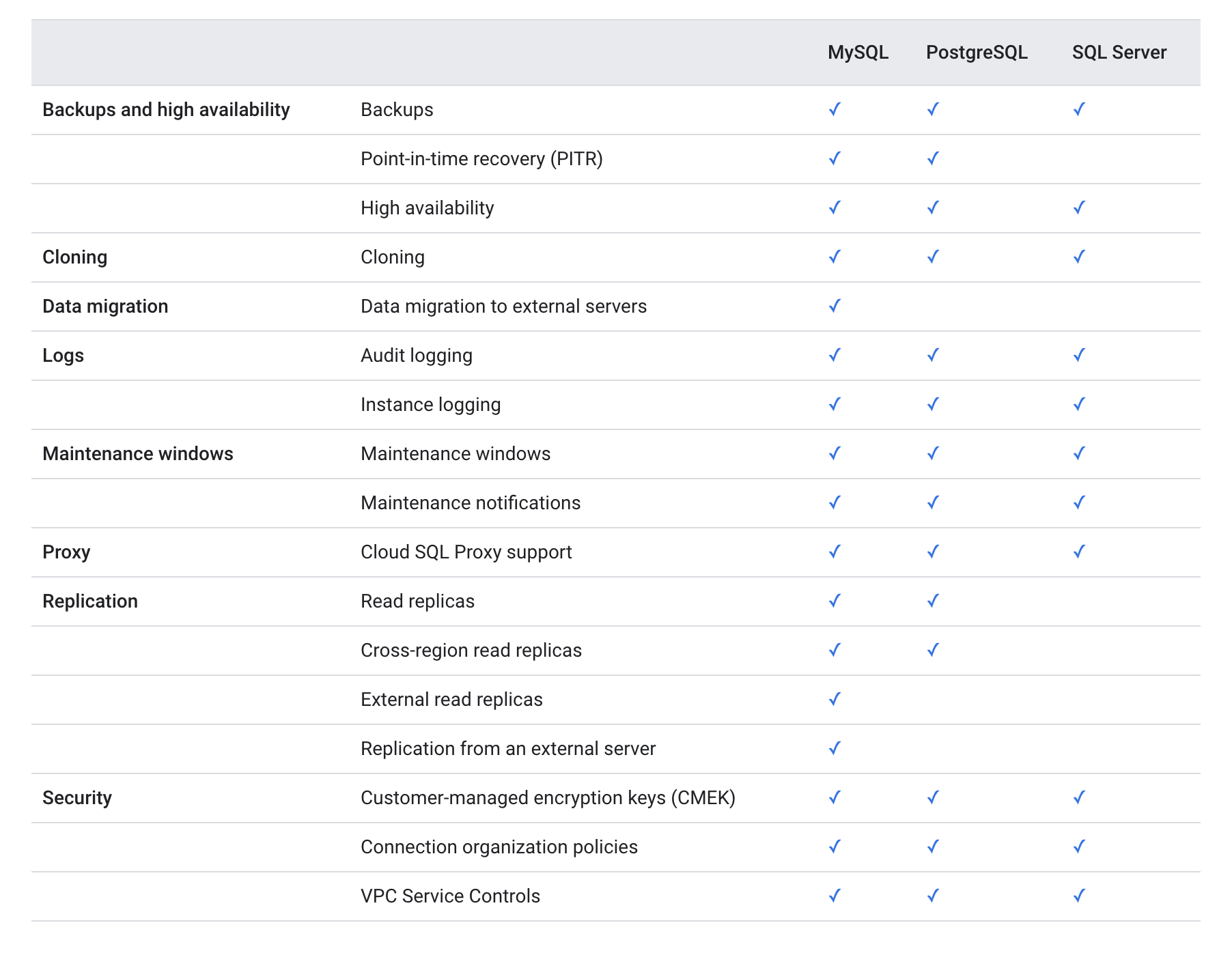
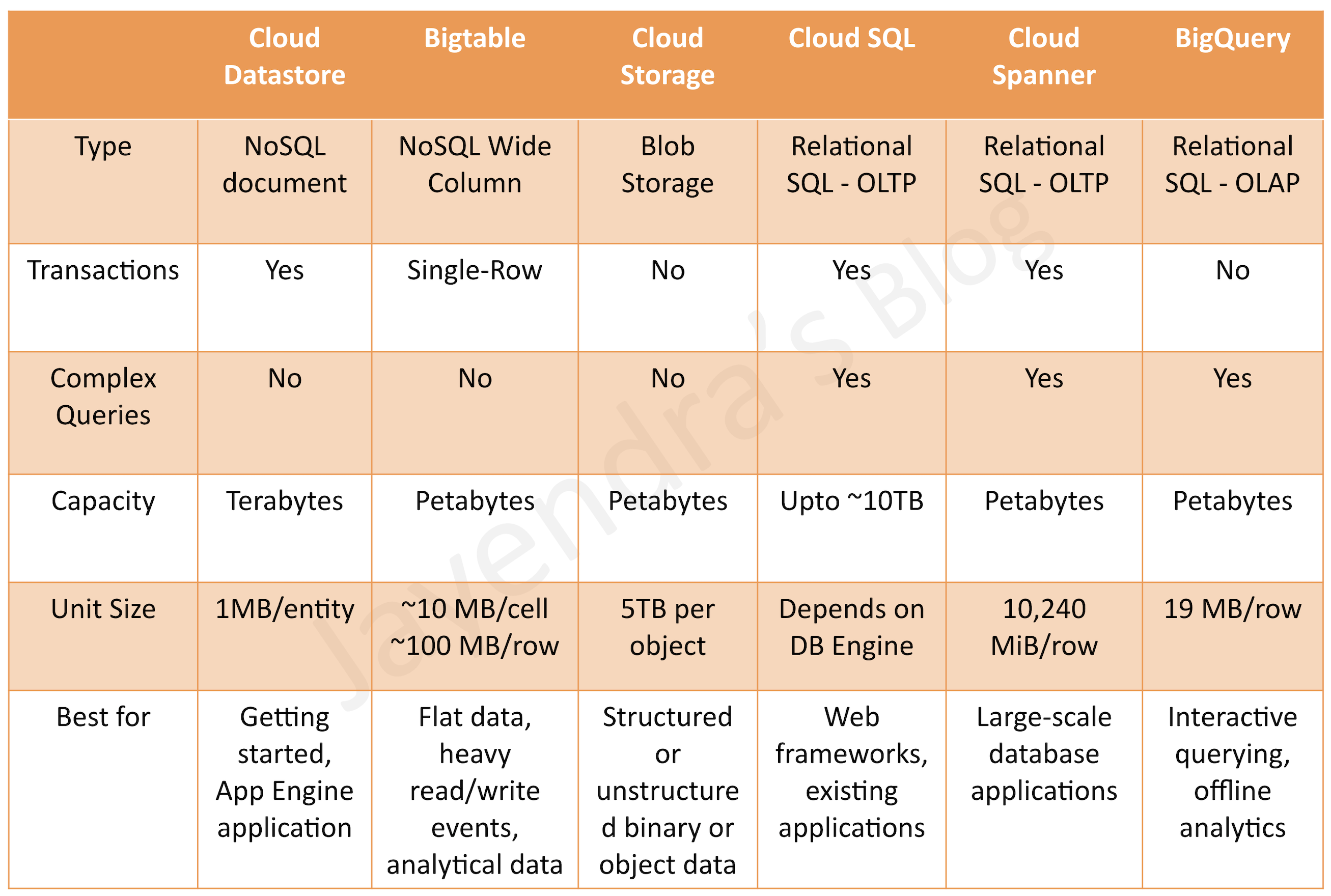
Cloud SQL Features Comparison
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You work for a mid-sized enterprise that needs to move its operational system transaction data from an on-premises database to GCP. The database is about 20 TB in size. Which database should you choose?
Cloud SQL
Cloud Bigtable
Cloud Spanner
Cloud Datastore
An application that relies on Cloud SQL to read infrequently changing data is predicted to grow dramatically. How can you increase capacity for more read-only clients?
Configure high availability on the master node
Establish an external replica in the customer’s data center
Use backups so you can restore if there’s an outage
Configure read replicas.
A Company is using Cloud SQL to host critical data. They want to enable high availability in case a complete zone goes down. How should you configure the same?
Create a Read replica in the same region different zone
Create a Read replica in the different region different zone
Create a Failover replica in the same region different zone
Create a Failover replica in the different region different zone
A Company is using Cloud SQL to host critical data. They want to enable Point In Time recovery (PIT) to be able to recover the instance to a specific point in. How should you configure the same?
Create a Read replica for the instance
Switch to Spanner 3 node cluster
Create a Failover replica for the instance
Enable Binary logging and backups for the instance
Bigtable provides a scalable, fully managed, non-relational NoSQL wide-column analytical big data database service suitable for both low-latency single-point lookups and precalculated analytics.
supports large quantities (>1 TB) of semi-structured or structured data (vs Datastore)
supports high throughput or rapidly changing data (vs BigQuery)
managed, but needs provisioning of nodes and can be expensive (vs Datastore and BigQuery)
does not support transactions or strong relational semantics (vs Datastore)
does not support SQL queries (vs BigQuery and Datastore)
Not Transactional and does not support ACID
provides eventual consistency
ideal for time-series or natural semantic ordering data
can run asynchronous batch or real-time processing on the data
can run machine learning algorithms on the data
provides petabytes of capacity with a maximum unit size of 10 MB per cell and 100 MB per row.
Usage Patterns
Low-latency read/write access
High-throughput data processing
Time series support
Anti Patterns
Not an ideal storage option for future analysis – Use BigQuery instead
Not an ideal storage option for transactional data – Use relational database or Datastore
Common Use cases
IoT, finance, adtech
Personalization, recommendations
Monitoring
Geospatial datasets
Graphs
Consider using Cloud Bigtable, if you need high-performance datastore to perform analytics on a large number of structured objects
Cloud Storage provides durable and highly available object storage.
fully managed, simple administration, cost-effective, and scalable service that does not require capacity management
supports unstructured data storage like binary or raw objects
provides high performance, internet-scale
supports data encryption at rest and in transit
Consider using Cloud Storage, if you need to store immutable blobs larger than 10 MB, such as large images or movies. This storage service provides petabytes of capacity with a maximum unit size of 5 TB per object.
offers MySQL, PostgreSQL, MSSQL databases as a service
manages OS & Software installation, patches and updates, backups and configuring replications, failover however needs to select and provision machines (vs Cloud Spanner)
single region only – although it now supports cross-region read replicas (vs Cloud Spanner)
Scaling
provides vertical scalability (Max. storage of 10TB)
storage can be increased without incurring any downtime
provides an option to increase the storage automatically
storage CANNOT be decreased
supports Horizontal scaling for read-only using read replicas (vs Cloud Spanner)
performance is linked to the disk size
Security
data is encrypted when stored in database tables, temporary files, and backups.
external connections can be encrypted by using SSL, or by using the Cloud SQL Proxy.
High Availability
fault-tolerance across zones can be achieved by configuring the instance for high availability by adding a failover replica
failover is automatic
can be created from primary instance only
replication from the primary instance to failover replica is semi-synchronous.
failover replica must be in the same region as the primary instance, but in a different zone
only one instance for every primary instance allowed
supports managed backups and backups are created on primary instance only
supports automatic replication
Backups
Automated backups can be configured and are stored for 7 days
Manual backups (snapshots) can be created and are not deleted automatically
Point-in-time recovery
requires binary logging enabled.
every update to the database is written to an independent log, which involves a small reduction in write performance.
performance of the read operations is unaffected by binary logging, regardless of the size of the binary log files.
Usage Patterns
direct lift and shift for MySQL, PostgreSQL, MSSQL database only
relational database service with strong consistency
OLTP workloads
Anti Patterns
need data storage more than 10TB, use Cloud Spanner
need global availability with low latency, use Cloud Spanner
not a direct replacement for Oracle use installation on GCE
Common Use cases
Websites, blogs, and content management systems (CMS)
Business intelligence (BI) applications
ERP, CRM, and eCommerce applications
Geospatial applications
Consider using Cloud SQL for full relational SQL support for OTLP and lift and shift of MySQL, PostgreSQL databases
provides fully managed, no-ops, OLAP, enterprise data warehouse (EDW) with SQL and fast ad-hoc queries.
provides high capacity, data warehousing analytics solution
ideal for big data exploration and processing
not ideal for operational or transactional databases
provides SQL interface
A scalable, fully managed
Usage Patterns
OLAP workloads up to petabyte-scale
Big data exploration and processing
Reporting via business intelligence (BI) tools
Anti Patterns
Not an ideal storage option for transactional data or OLTP – Use Cloud SQL or Cloud Spanner instead
Low-latency read/write access – Use Bigtable instead
Common Use cases
Analytical reporting on large data
Data science and advanced analyses
Big data processing using SQL
Memorystore
provides scalable, secure, and highly available in-memory service for Redis and Memcached.
fully managed as provisioning, replication, failover, and patching are all automated, which drastically reduces the time spent doing DevOps.
provides 100% compatibility with open source Redis and Memcached
is protected from the internet using VPC networks and private IP and comes with IAM integration
Usage Patterns
Lift and shift migration of applications
Low latency data caching and retrieval
Anti Patterns
Relational or NoSQL database
Analytics solution
Common Use cases
User session management
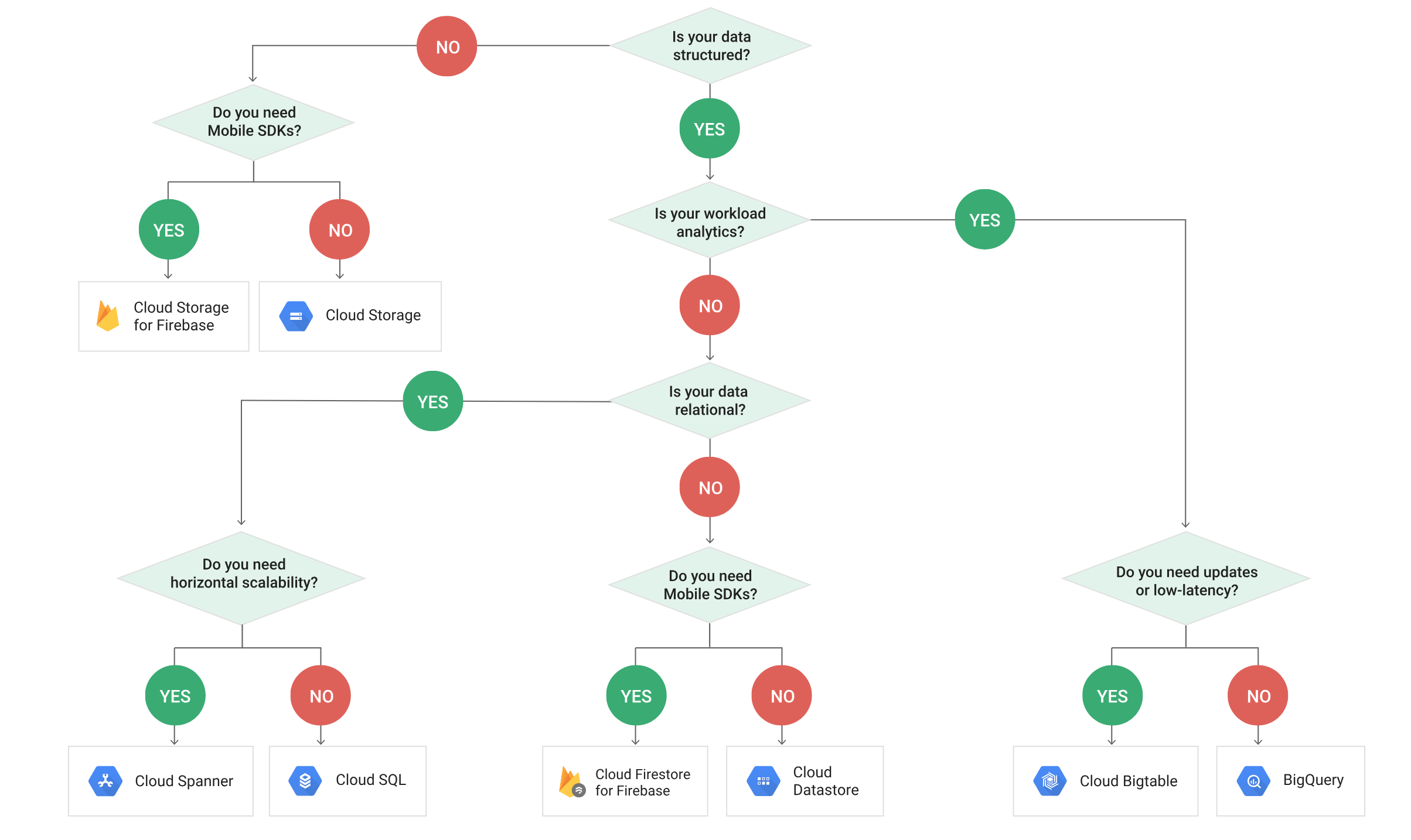
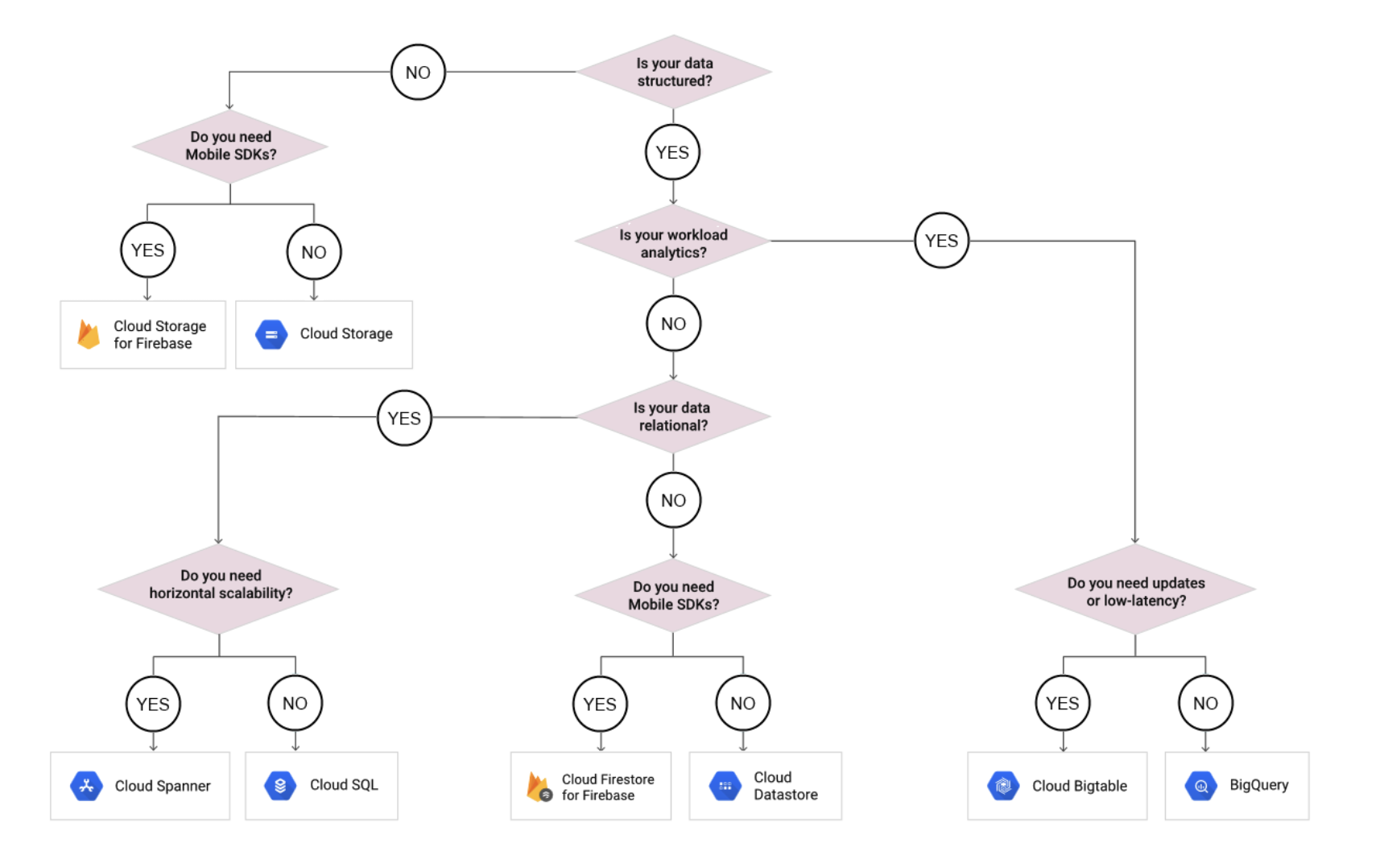
GCP Storage Options Decision Tree
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Your application is hosted across multiple regions and consists of both relational database data and static images. Your database has over 10 TB of data. You want to use a single storage repository for each data type across all regions. Which two products would you choose for this task? (Choose two)
Cloud Bigtable
Cloud Spanner
Cloud SQL
Cloud Storage
You are building an application that stores relational data from users. Users across the globe will use this application. Your CTO is concerned about the scaling requirements because the size of the user base is unknown. You need to implement a database solution that can scale with your user growth with minimum configuration changes. Which storage solution should you use?
Cloud SQL
Cloud Spanner
Cloud Firestore
Cloud Datastore
Your company processes high volumes of IoT data that are time-stamped. The total data volume can be several petabytes. The data needs to be written and changed at a high speed. You want to use the most performant storage option for your data. Which product should you use?
Cloud Datastore
Cloud Storage
Cloud Bigtable
BigQuery
Your App Engine application needs to store stateful data in a proper storage service. Your data is non-relational database data. You do not expect the database size to grow beyond 10 GB and you need to have the ability to scale down to zero to avoid unnecessary costs. Which storage service should you use?
Cloud Bigtable
Cloud Dataproc
Cloud SQL
Cloud Datastore
A financial organization wishes to develop a global application to store transactions happening from different part of the world. The storage system must provide low latency transaction support and horizontal scaling. Which GCP service is appropriate for this use case?
Bigtable
Datastore
Cloud Storage
Cloud Spanner
You work for a mid-sized enterprise that needs to move its operational system transaction data from an on-premises database to GCP. The database is about 20 TB in size. Which database should you choose?