Google Cloud Storage Security
Google Cloud Storage Security includes controlling access using
- Uniform Bucket or Fine-grained ACL access control policies
- Public Access Prevention
- VPC Service Controls for data perimeter security
- Managed Folders for granular IAM
- Data encryption at rest and transit
- Retention policies, Object Retention Lock, and Bucket Lock
- Soft Delete for recovery from accidental deletion
- Signed URLs
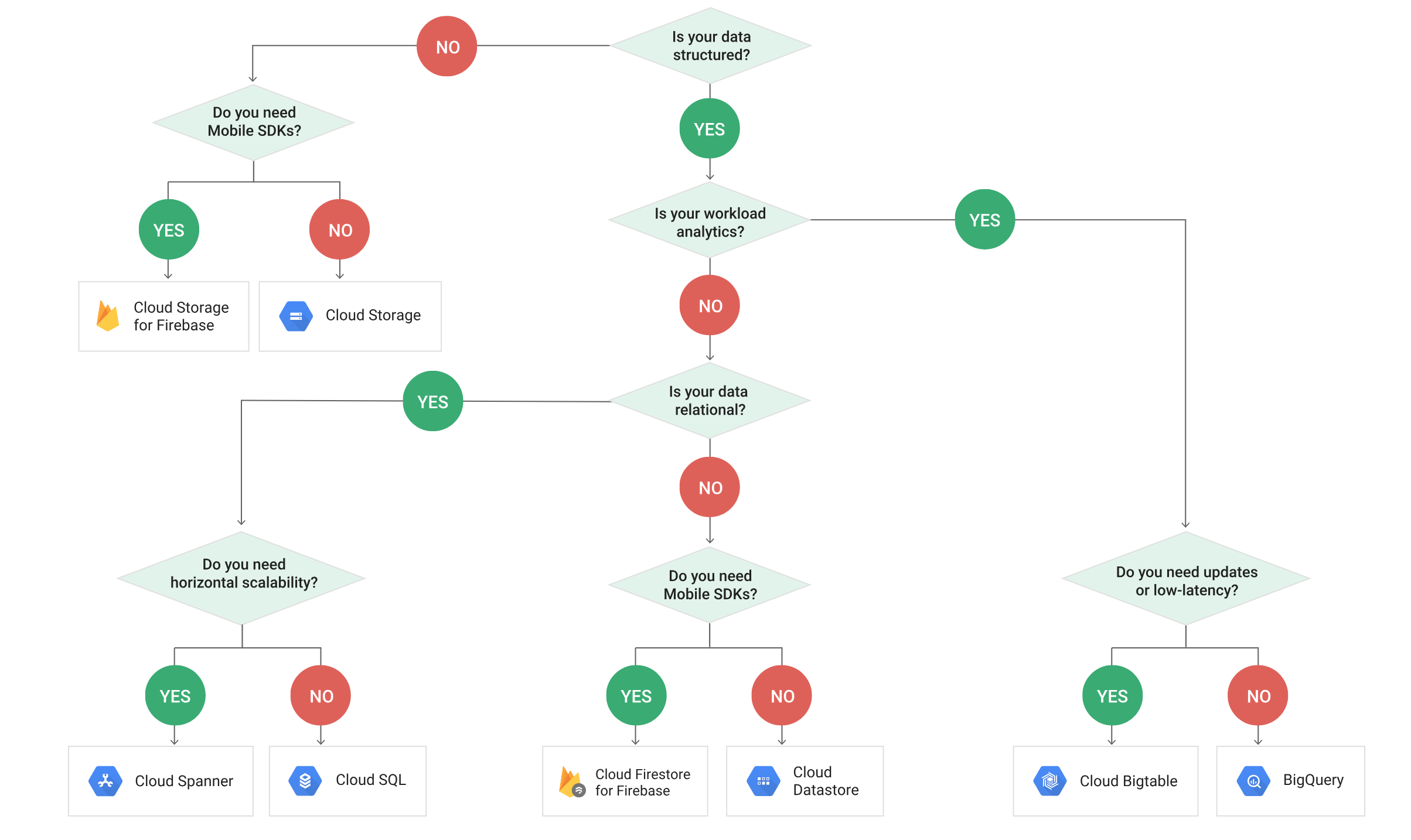
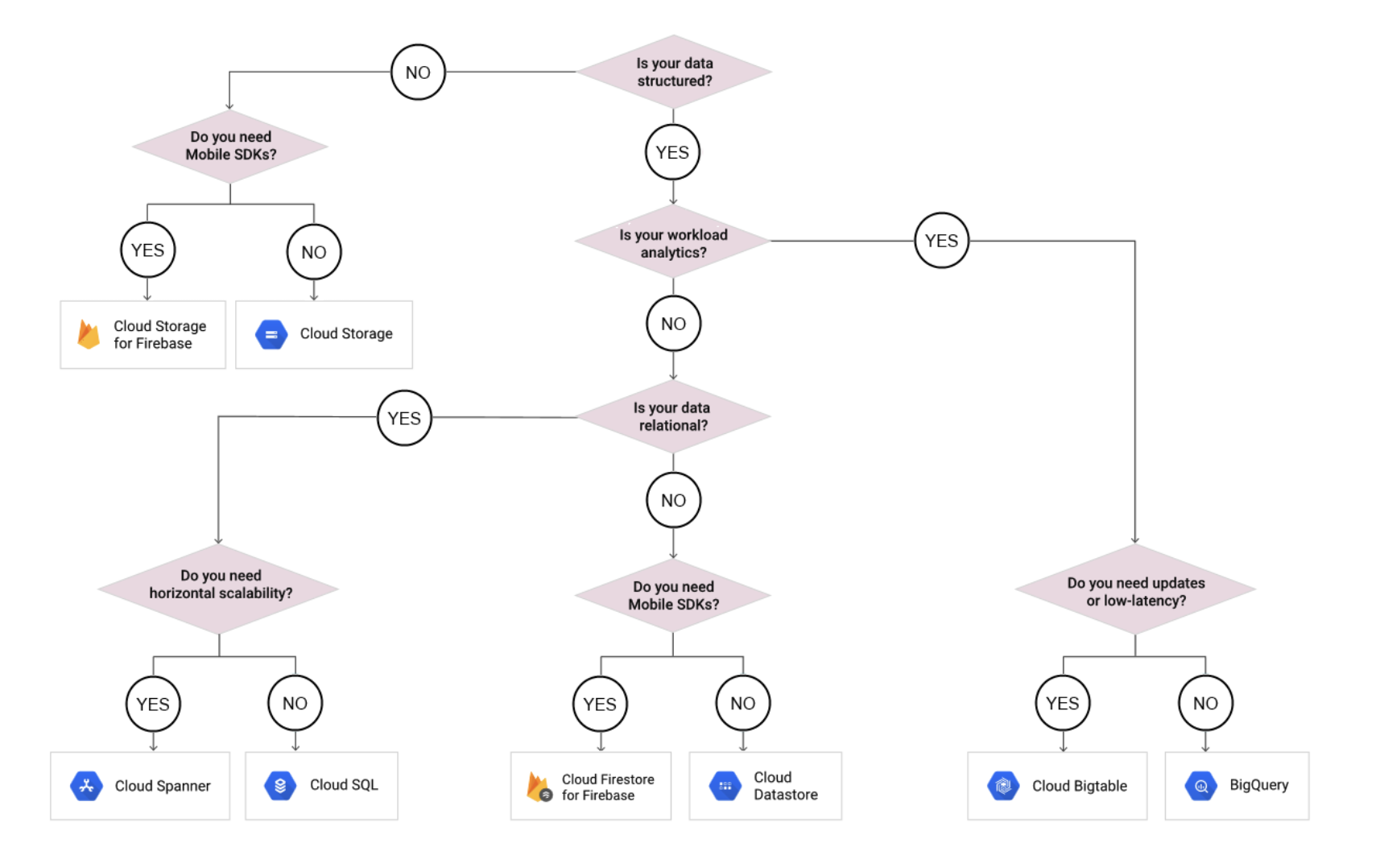
GCS Access Control
- Cloud Storage offers two systems for granting users permission to access the buckets and objects: IAM and Access Control Lists (ACLs)
- IAM and ACLs can be used on the same resource, Cloud Storage grants the broader permission set on the resource
- Cloud Storage access control can be performed using
- Uniform (recommended)
- Uniform bucket-level access allows using IAM alone to manage permissions.
- IAM applies permissions to all the objects contained inside the bucket or groups of objects with common name prefixes.
- IAM also allows using features that are not available when working with ACLs, such as IAM Conditions and Cloud Audit Logs.
- Enabling uniform bucket-level access disables ACLs, but it can be reversed before 90 days
- Fine-grained
- Fine-grained option enables using IAM and Access Control Lists (ACLs) together to manage permissions.
- ACLs are a legacy access control system for Cloud Storage designed for interoperability with S3.
- Access and apply permissions can be specified at both the bucket level and per individual object.
- Uniform (recommended)
- Objects in the bucket can be made public using ACLs
AllUsers:Ror IAMallUsers:objectViewerpermissions
Public Access Prevention
- Public Access Prevention protects Cloud Storage buckets and objects from being accidentally exposed to the public.
- When enforced, no one can make data in applicable buckets public through IAM policies or ACLs.
- Can be set at the bucket level or enforced at the project, folder, or organization level using the
storage.publicAccessPreventionorganization policy constraint. - When applied at the organization level, public access is restricted for all buckets and objects, both new and existing, under that resource.
- Public access prevention does not apply to Signed URLs, since signed URLs grant access through scoped service account permissions.
Managed Folders
- Managed folders allow granting IAM roles on specific groups of objects within a bucket, providing more fine-grained access control.
- IAM policies can be set on managed folders to control access to objects that share a common name prefix.
- Managed folders can be nested up to 15 levels deep.
- Requires uniform bucket-level access to be enabled on the bucket.
- Useful for meeting data security and compliance requirements by restricting access to specific data partitions within a shared bucket.
VPC Service Controls
- VPC Service Controls create a security perimeter around Cloud Storage resources to prevent data exfiltration.
- Data cannot be copied to unauthorized resources outside the perimeter using operations such as
gcloud storage cp. - Protects against data exfiltration risks such as stolen credentials, misconfigured permissions, or malicious insiders.
- Fine-grained perimeter controls can be enforced across multiple Google Cloud services and projects.
- Supports access levels, ingress/egress rules, and perimeter bridges for controlled data sharing.
Bucket IP Filtering
- Bucket IP filtering allows restricting access to a bucket based on the source IP address of incoming requests.
- IP filtering rules can be configured to allow or deny access from specific IP ranges.
- Provides an additional layer of network-level security for sensitive buckets.
- Can be bypassed by authorized principals with specific IAM permissions when needed.
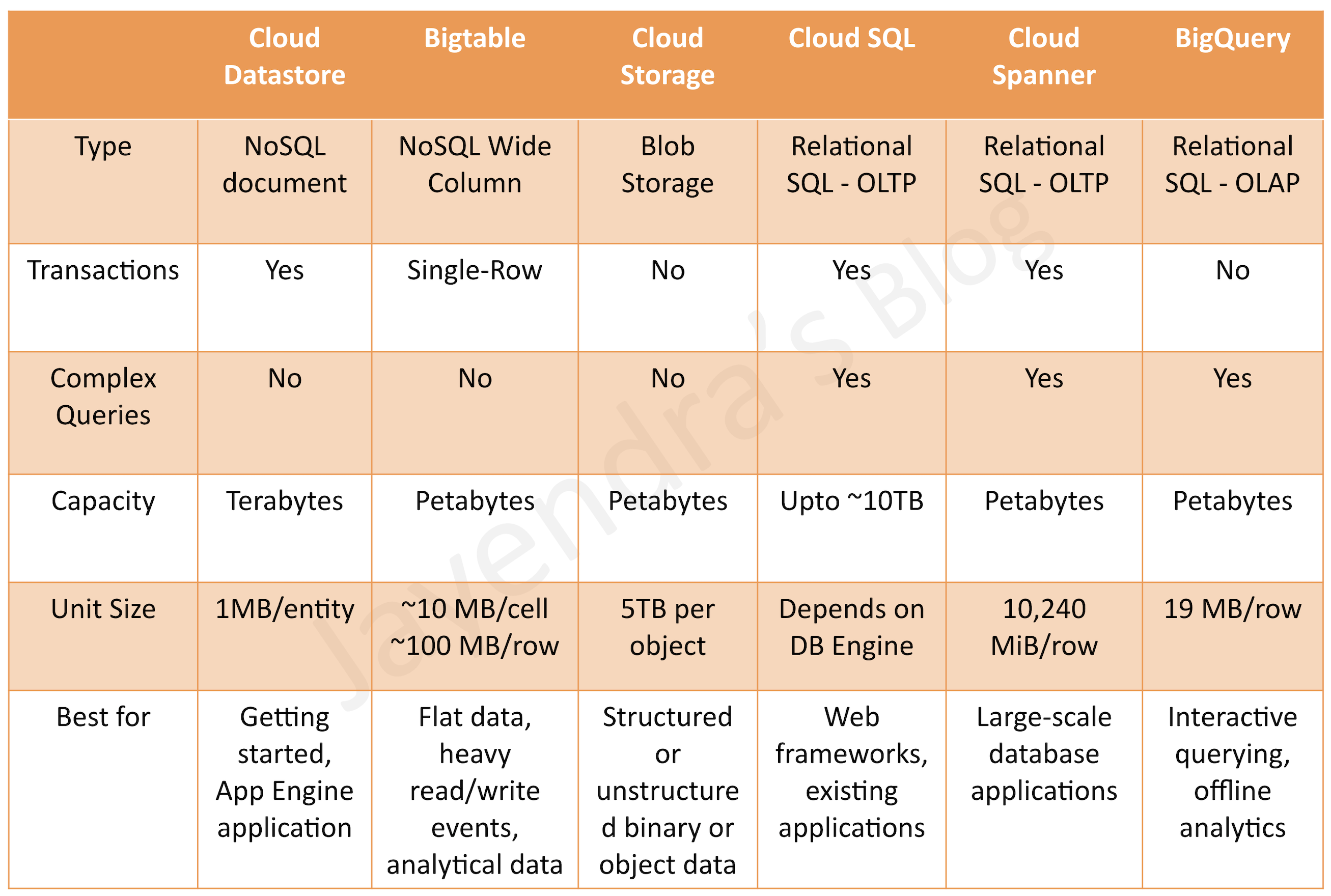
Data Encryption
- Cloud Storage always encrypts the data on the server-side, before it is written to disk, at no additional charge.
- Cloud supports the following encryption
- Server-side encryption: encryption that occurs after Cloud Storage receives the data, but before the data is written to disk and stored.
- Google-managed encryption keys (default)
- Cloud Storage always encrypts the data on the server-side, before it is written to disk
- Cloud Storage manages server-side encryption keys using the same hardened key management systems, including strict key access controls and auditing.
- Cloud Storage encrypts user data at rest using AES-256.
- Data is automatically decrypted when read by an authorized user
- Customer-managed encryption keys (CMEK)
- Customers manage their own encryption keys generated by Cloud Key Management Service (KMS)
- CMEK keys can be set as the default encryption key for a bucket, which then applies to all new objects.
- Supports organization policy constraints (
constraints/gcp.restrictNonCmekServices) to enforce CMEK usage across the organization. - Cloud KMS Autokey (GA 2024) simplifies CMEK by automatically provisioning key rings, keys, and service agent IAM roles on demand during resource creation — eliminating manual key planning and assignment.
- CMEK keys can be stored as software keys, in an HSM cluster, or externally (Cloud External Key Manager).
- Customer-supplied encryption keys (CSEK)
- Customers create and manage their own encryption keys outside of Google Cloud.
- Customer provides the key for each GCS operation, and the key is purged from Google’s servers after the operation is complete.
- Cloud Storage stores only a cryptographic hash of the key so that future requests can be validated against the hash.
- The key cannot be recovered from this hash, and the hash cannot be used to decrypt the data.
- Google-managed encryption keys (default)
- Client-side encryption: encryption that occurs before data is sent to Cloud Storage, encrypted at the client-side. This data also undergoes server-side encryption.
- Server-side encryption: encryption that occurs after Cloud Storage receives the data, but before the data is written to disk and stored.
- Cloud Storage supports Transport Layer Security, commonly known as TLS or HTTPS for data encryption in transit
- Organization policy constraints can be used to enforce or restrict encryption types (e.g., require CMEK for all new buckets).
Signed URLs
- Signed URLs provide time-limited read or write access to an object through a generated URL.
- Anyone having access to the URL can access the object for the duration of time specified, regardless of whether or not they have a Google account.
- Uses the V4 signing process with a maximum expiration of 604,800 seconds (7 days).
- Signed URLs can only be used to access resources through XML API endpoints.
- Can be signed using a service account private key or HMAC key credentials.
- Public access prevention does not block access via signed URLs.
Signed Policy Documents
- Signed policy documents help specify what can be uploaded to a bucket.
- Policy documents allow greater control over size, content type, and other upload characteristics than signed URLs, and can be used by website owners to allow visitors to upload files to Cloud Storage.
Soft Delete
- Soft delete (GA 2024) provides bucket-level protection against accidental or malicious deletion by retaining recently deleted objects for a configurable retention period.
- Soft delete is enabled by default on all buckets with a retention duration of 7 days.
- Retention duration can be set between 7 and 90 days, or soft delete can be disabled entirely.
- Soft-deleted objects can be restored within the retention window.
- Soft-deleted buckets can also be restored.
- Organization-level tags can be used to set a default soft delete retention duration for new buckets.
- Soft-deleted objects incur storage charges at the same rate as active objects.
Retention Policies
- Retention policy on a bucket ensures that all current and future objects in the bucket cannot be deleted or replaced until they reach the defined age
- Retention policy can be applied when creating a bucket or to an existing bucket
- Retention policy retroactively applies to existing objects in the bucket as well as new objects added to the bucket.
Retention Policy Locks
- Retention policy locks will lock a retention policy on a bucket, which prevents the policy from ever being removed or the retention period from ever being reduced (although it can be increased)
- Once a retention policy is locked, the bucket cannot be deleted until every object in the bucket has met the retention period.
- Locking a retention policy is irreversible
Bucket Lock
- Bucket Lock feature provides immutable storage i.e. Write Once Read Many (WORM) on Cloud Storage
- Bucket Lock feature allows configuring a data retention policy for a bucket that governs how long objects in the bucket must be retained
- Bucket Lock feature also locks the data retention policy, permanently preventing the policy from being reduced or removed.
- Bucket Lock applies the retention policy uniformly to all objects in the bucket.
- Bucket Lock can help with regulatory, legal, and compliance requirements
Object Retention Lock
- Object Retention Lock (GA 2024) allows defining data retention requirements on a per-object basis, unlike Bucket Lock which applies uniformly to all objects.
- A retention configuration on an object contains:
- Retain-until time — a date and time until which the object cannot be deleted or replaced (max 100 years from current date).
- Retention mode:
- Unlocked (Governance) — authorized users can modify or remove the retention configuration.
- Locked (Compliance) — permanently prevents the retention date from being reduced or removed; the mode cannot be changed and retention can only be increased.
- Object Retention Lock must be enabled on the bucket before retention configurations can be set on objects. Once enabled, it cannot be disabled.
- Can help with regulatory and compliance requirements such as FINRA, SEC, CFTC, and health care regulations.
- An object can be subject to both its own Object Retention Lock and a Bucket Lock retention policy — the object is retained until both are satisfied.
- Storage batch operations can be used to set or update retention configurations on millions of objects in a single job.
Object Holds
- Object holds, when set on individual objects, prevents the object from being deleted or replaced, however allows metadata to be edited.
- Cloud Storage offers the following types of holds:
- Event-based holds.
- Temporary holds.
- When an object is stored in a bucket without a retention policy, both hold types behave exactly the same.
- When an object is stored in a bucket with a retention policy, the hold types have different effects on the object when the hold is released:
- An event-based hold resets the object’s time in the bucket for the purposes of the retention period.
- A temporary hold does not affect the object’s time in the bucket for the purposes of the retention period.
Organization Policy Constraints
- Cloud Storage supports predefined and custom organization policy constraints to enforce security standards across the organization.
- Key predefined constraints include:
storage.publicAccessPrevention— enforce public access prevention on all buckets.storage.uniformBucketLevelAccess— require uniform bucket-level access (disable ACLs).storage.retentionPolicySeconds— enforce minimum retention policies.gcp.restrictNonCmekServices— require CMEK encryption for Cloud Storage.storage.restrictAuthTypes— restrict authentication types.
- Custom constraints can be created to enforce specific bucket or object behaviors not covered by predefined constraints.
- Detailed audit logging mode logs request and response details for Cloud Storage, helping with regulatory compliance.
GCP Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- You have an object in a Cloud Storage bucket that you want to share with an external company. The object contains sensitive data. You want access to the content to be removed after four hours. The external company does not have a Google account to which you can grant specific user-based access privileges. You want to use the most secure method that requires the fewest steps. What should you do?
- Create a signed URL with a four-hour expiration and share the URL with the company.
- Set object access to “public” and use object lifecycle management to remove the object after four hours.
- Configure the storage bucket as a static website and furnish the object’s URL to the company. Delete the object from the storage bucket after four hours.
- Create a new Cloud Storage bucket specifically for the external company to access. Copy the object to that bucket. Delete the bucket after four hours have passed
- Your organization requires that all Cloud Storage buckets in production must use Customer-Managed Encryption Keys (CMEK) and must not be publicly accessible. How should you enforce this?
- Set organization policy constraints
gcp.restrictNonCmekServiceswith Cloud Storage in the deny list andstorage.publicAccessPreventionenforced at the organization level. - Create a Cloud Function that checks each new bucket and deletes it if not compliant.
- Use IAM conditions to prevent bucket creation without CMEK.
- Train developers to always use CMEK and enable public access prevention manually.
- Set organization policy constraints
- A compliance requirement states that certain objects in a shared bucket must be retained for 5 years and cannot be deleted, while other objects in the same bucket have no retention requirement. What is the best approach?
- Create separate buckets with different Bucket Lock retention policies for each set of objects.
- Use Object Retention Lock with Locked (Compliance) mode and set a retain-until time of 5 years on the specific objects that require retention.
- Use Object Lifecycle Management to prevent deletion of specific objects.
- Set a Bucket Lock retention policy of 5 years on the entire bucket.
- Your team accidentally deleted critical objects from a Cloud Storage bucket yesterday. The bucket has default settings. What is the best recovery option?
- Recover from a backup bucket if one was configured.
- Restore the soft-deleted objects, since soft delete is enabled by default with a 7-day retention duration.
- Contact Google Cloud support to recover the objects.
- Use Object Versioning to retrieve previous versions.
- You need to provide granular access to a specific set of objects within a bucket that uses uniform bucket-level access, without granting access to the entire bucket. What should you use?
- Switch to fine-grained access control and use ACLs on individual objects.
- Create signed URLs for each object.
- Create a managed folder for the objects and set IAM policies on the managed folder.
- Create a separate bucket for those objects.