Google Cloud Virtual Private Cloud – VPC
Virtual Private Cloud – VPC provides networking functionality for the cloud-based resources and services that is global, scalable, and flexible.
VPC Networks
- VPC network is a virtual version of a physical network
- A VPC network is a global resource that consists of a list of regional virtual subnets in data centers, all connected by a global wide area network.
- VPC networks are logically isolated from each other in Google Cloud.
- VPC networks
- provides connectivity for the VMs and products built on it like GKE
- offers built-in Internal TCP/UDP Load Balancing and proxy systems for Internal HTTP(S) Load Balancing.
- connects to on-premises networks using Cloud VPN tunnels and Cloud Interconnect attachments.
- distributes traffic from GCP external load balancers to backends
Specifications
- VPC networks are global resources, including the associated routes and firewall rules, and are not associated with any particular region or zone.
- Subnets are regional resources and each subnet defines a range of IP addresses
- Network firewall rules control the Traffic to and from instances. Rules are implemented on the VMs themselves, so traffic can only be controlled and logged as it leaves or arrives at a VM.
- Resources within a VPC network can communicate with one another by using internal IPv4 addresses, subject to applicable network firewall rules.
- Private access options for services allow instances with internal IP addresses can communicate with Google APIs and services.
- Network administration can be secured by using IAM roles.
- An organization can use Shared VPC to keep a VPC network in a common host project. Authorized IAM members from other projects in the same organization can create resources that use Shared VPC network subnets.
- VPC Network Peering allows VPC networks to be connected with other VPC networks in different projects or organizations.
- VPC networks can be securely connected in hybrid environments by using Cloud VPN or Cloud Interconnect.
- VPC networks only support IPv4 unicast traffic. They do not support broadcast, multicast, or IPv6 traffic within the network; VMs in the VPC network can only send to IPv4 destinations and only receive traffic from IPv4 sources.
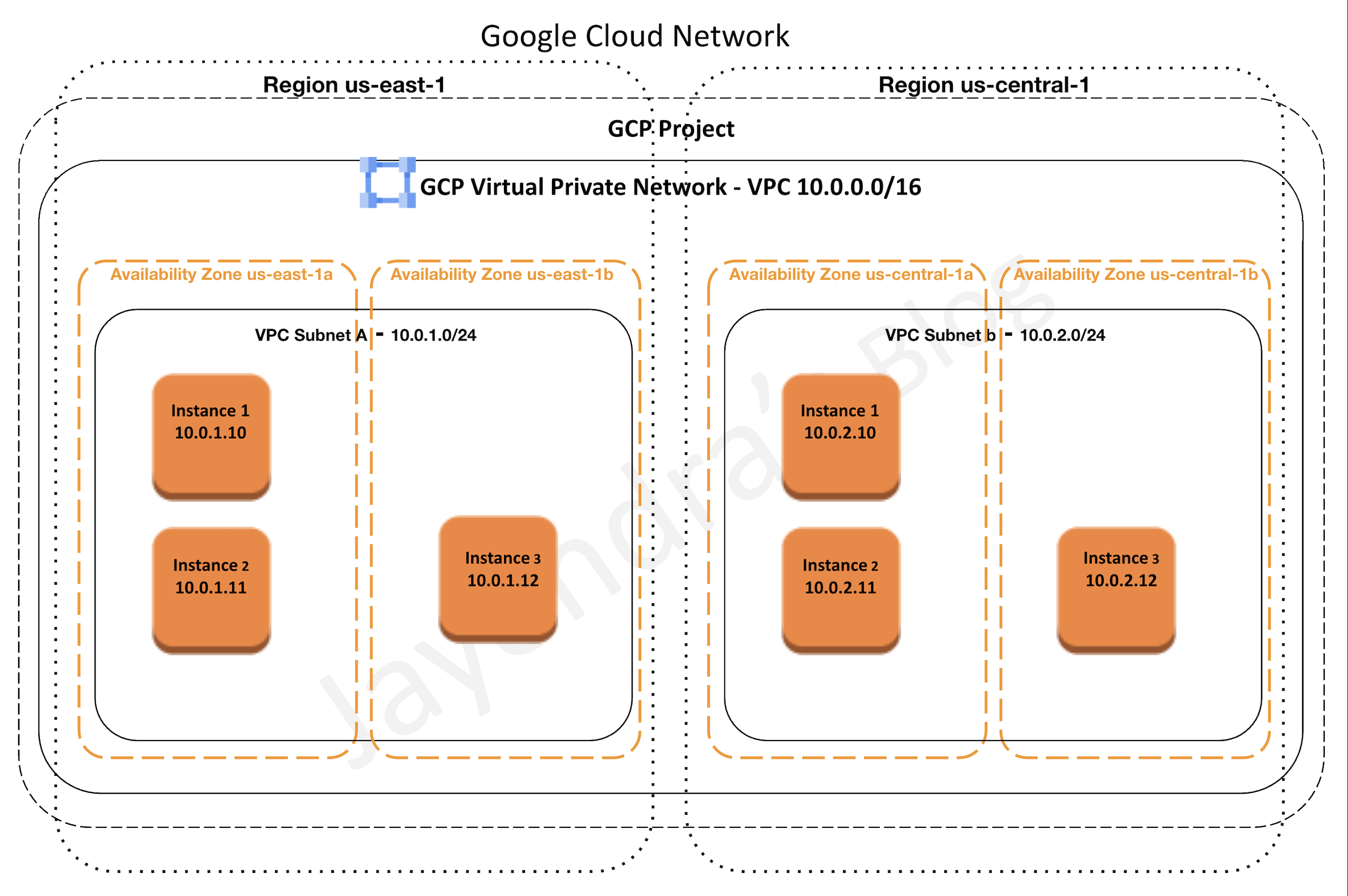
VPC Subnets
- VPC networks do not have any IP address ranges associated with them.
- Each VPC network consists of one or more useful IP range partitions called subnets and IP ranges are defined for the subnets.
- Subnets are regional resources and each subnet is associated with a region.
- A network must have at least one subnet before it can be used.
- More than one subnet per region can be created
- VPC Network supports the following subnet creation mode
- Auto mode VPC networks
- create subnets in each region automatically
- adds new subnets automatically, if a new region becomes available
- can be switched to custom mode VPC networks
- Custom mode VPC networks
- start with no subnets, giving full control over subnet creation.
- are more flexible and are better suited for production
- cannot be switched to auto mode VPC networks
- Auto mode VPC networks
- Subnet must have a defined primary IP address range, and any resources created within are assigned an IP address from the defined range.
- Subnets can be assigned a secondary IP address range, which is only used by alias IP ranges. This is useful if you have multiple services running on a VM and want to assign each service a different IP address.
- Primary IP range of an existing subnet can be expanded by modifying its subnet mask, setting the prefix length to a smaller number.
VPC Routes
- Routes define paths for packets leaving instances (egress traffic), either inside the network or outside of Google Cloud
- A route consists of
- a single destination prefix in CIDR format (0.0.0.0/0) and
- a single next hop (for e.g Internet Gateway)
- When an instance in a VPC network sends a packet, GCP delivers the packet to the route’s next hop if the packet’s destination address is within the route’s destination range.
- Routes are defined at the VPC network level but implemented at each VM instance level.
- Each VM instance has a controller that is kept informed of all applicable routes from the network’s routing table. Each packet leaving a VM is delivered to the appropriate next hop of an applicable route based on a routing order. When a route is added or deleted, the set of changes is propagated to the VM controllers by using an eventually consistent design.
- Routes are divided into two categories: system-generated and custom.
- system-generated routes
- default – send traffic from eligible instances to the internet and can be removed or replaced
- subnet routes – route traffic among its subnets and updated automatically by Google Cloud
- are applied at the VPC level to all the instances
- custom routes
- are either static routes created manually or dynamic routes maintained automatically by one or more of the Cloud Routers
- can be applied to all the instances or specific instance using network tag
- system-generated routes
VPC Firewall Rules
Refer blog post @ Google Cloud VPC Firewall Rules
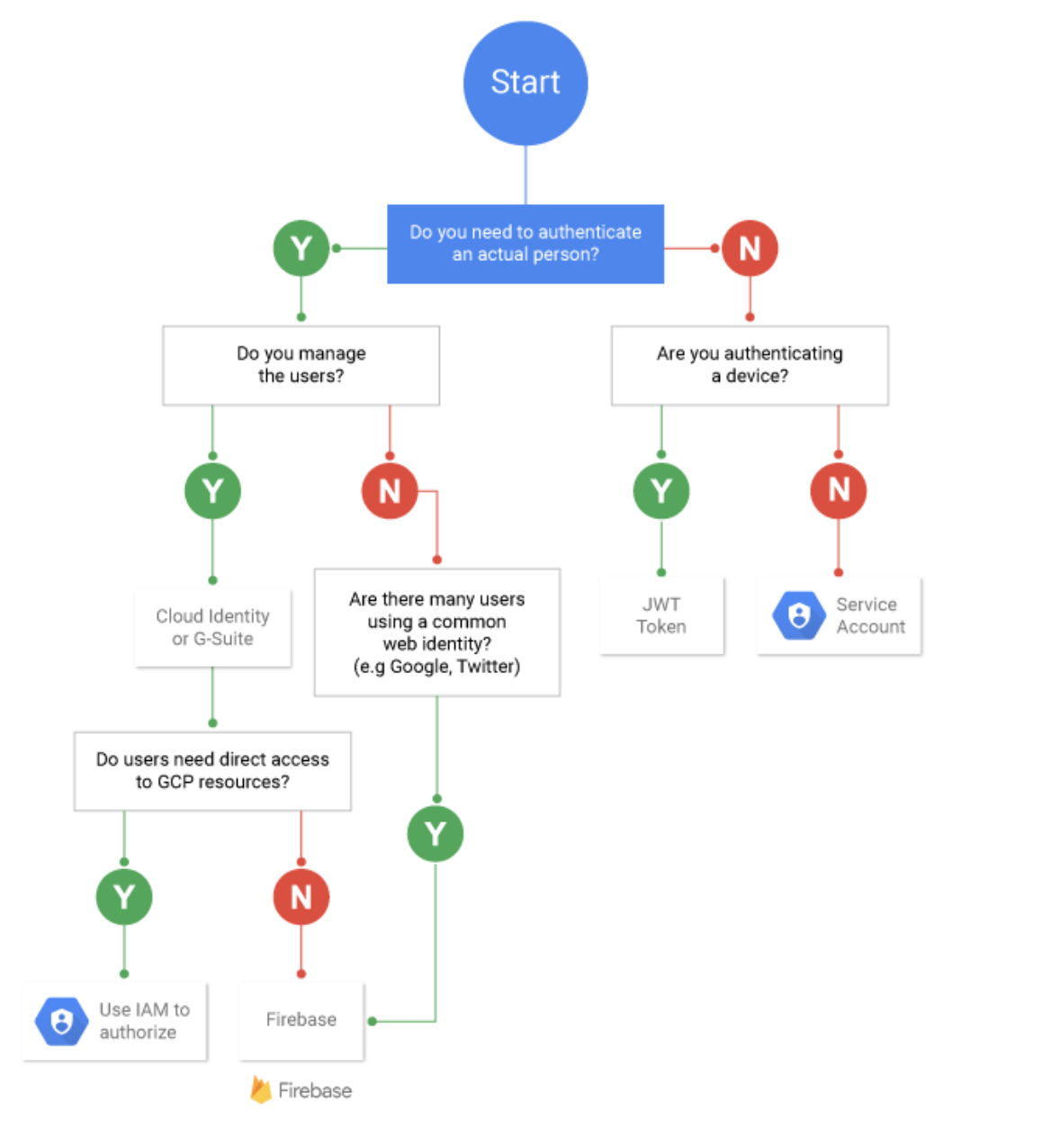
VPC Private Access Options
- Google Cloud provides several private access options which allow VM instances with internal IP addresses to reach certain APIs and services
- Private Google Access
- allows VMs to connect to the set of external IP addresses used by Google APIs and services by enabling Private Google Access on the subnet used by the VM’s network interface.
- allows access to the external IP addresses used by App Engine, including third-party App Engine-based services.
- configured on a subnet by subnet basis
- provides following routing options
- use default route with its next-hop being the default internet gateway, and it provides a path to the default domains,
private.googleapis.com, andrestricted.googleapis.com. - use custom static routes, each having a more specific destination, and each using the default internet gateway next hop.
- use default route with its next-hop being the default internet gateway, and it provides a path to the default domains,
- Use this option to connect to Google APIs and services without giving the Google Cloud resources external IP addresses.
- Private services access
- is a private connection between the VPC network and a network owned by Google or a third party i.e. service producers
- enables VM instances in the VPC network and the accessed services to communicate exclusively by using internal IP addresses.
- VM instances don’t need Internet access or external IP addresses to reach services that are available through private services access.
- Use this option to connect to specific Google and third-party services without assigning external IP addresses to the Google Cloud and Google or third-party resources.
Shared VPC – VPC Sharing
Refer blog post GCP Shared VPC
VPC Peering
Refer blog post GCP VPC Peering
VPC Flow Logs
- VPC Flow Logs records a sample of network flows sent from and received by VM instances, including instances used as GKE nodes.
- Flow Logs can be used for network monitoring, forensics, real-time security analysis, and expense optimization.
- Flow logs are enabled on the VPC subnet level.
- Flow logs only record TCP and UDP connections.
- With GCP Shared VPC, all Flow logs are in the host project.
- Cloud Logging can be used to view the flow logs and it can be exported to any destination that Cloud Logging export supports.
- Flow logs are aggregated by the connection from Compute Engine VMs and exported in real-time.
- Flow logs can be analyzed using real-time streaming APIs by subscribing to Pub/Sub.
- Flow logs are collected for each VM connection at specific intervals (sampling period). All packets collected for a given interval for a given connection are aggregated for a period of time (aggregation interval) into a single flow log entry
GCP Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- Your VMs are running in a subnet that has a subnet mask of 255.255.255.240. The current subnet has no more free IP addresses and you require an additional 10 IP addresses for new VMs. The existing and new VMs should all be able to reach each other without additional routes. What should you do?
- Use
gcloudto expand the IP range of the current subnet. - Delete the subnet, and recreate it using a wider range of IP addresses.
- Create a new project. Use Shared VPC to share the current network with the new project.
- Create a new subnet with the same starting IP but a wider range to overwrite the current subnet
- Use
- An IT company has a set of compute engine instances hosted in a VPC. They are not exposed to the internet. These instances now need to install an important security patch. How can the security patch be installed on the instances?
- Upload to Cloud Storage and enable VPC peering
- Upload to Cloud Storage and whitelist instance IP address
- Upload to Cloud Storage and enable Private Google Access
- Upload to Cloud Source Repository and enable VPC peering
- Your security team wants to be able to audit network traffic inside of your network. What’s the best way to ensure they have access to the data they need?
- Disable flow logs.
- Enable flow logs.
- Enable VPC Network logs
- Add a firewall capture filter.