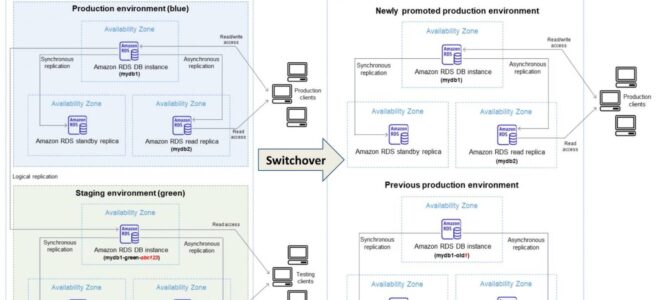
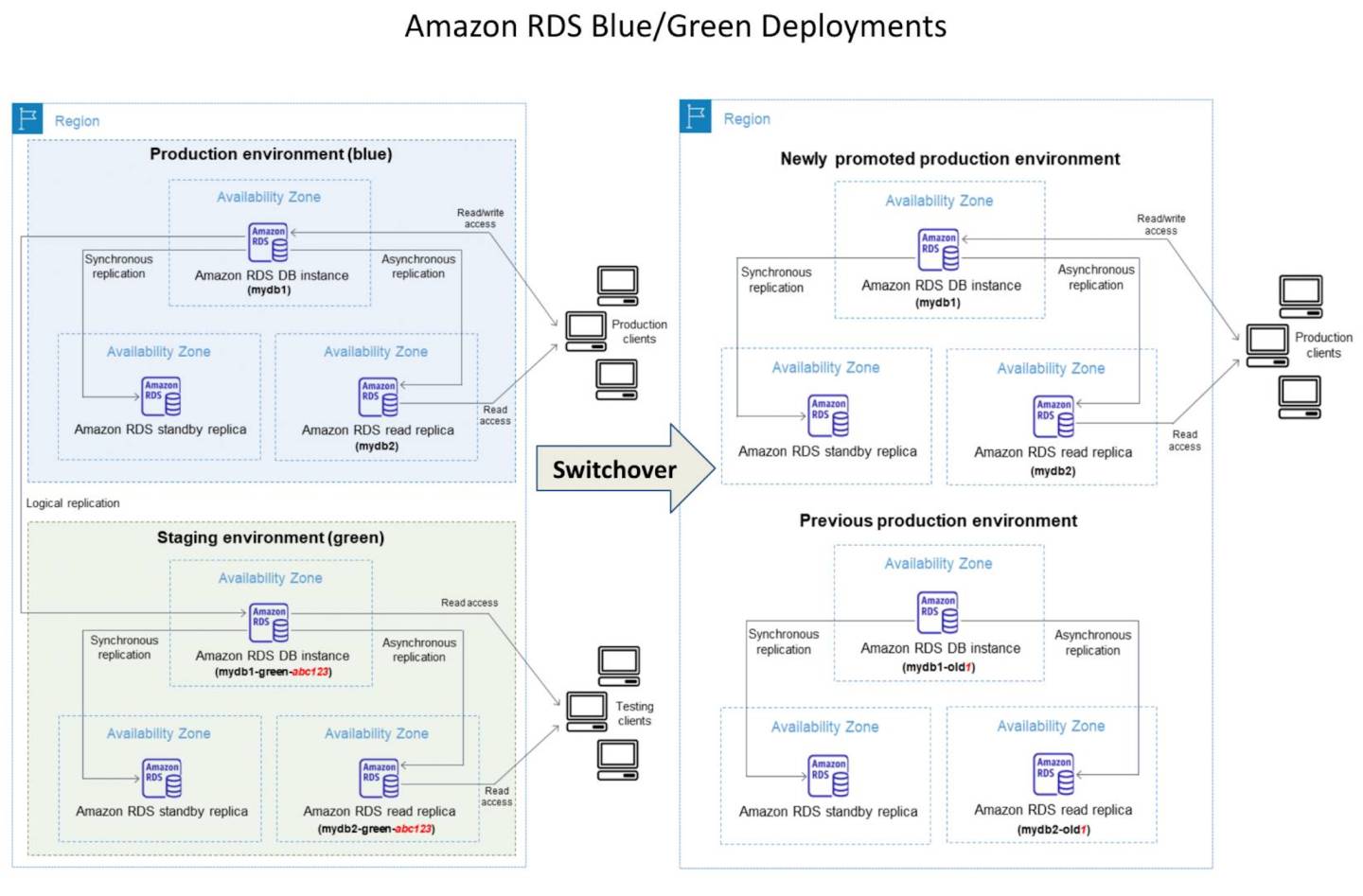
Amazon RDS Blue/Green Deployments help make and test database changes before implementing them in a production environment.
RDS Blue/Green Deployment has the blue environment as the current production environment and the green environment as the staging environment.
RDS Blue/Green Deployment creates a staging or green environment that exactly copies the production environment.
Green environment is a copy of the topology of the production environment and includes the features used by the DB instance including the Multi-AZ deployment, read replicas, the storage configuration, DB snapshots, automated backups, Performance Insights, and Enhanced Monitoring.
Green environment or the staging environment always stays in sync with the current production environment using logical replication.
RDS DB instances in the green environment can be changed without affecting production workloads. Changes can include the upgrade of major or minor DB engine versions, upgrade of underlying file system configuration, or change of database parameters in the staging environment.
Changes can be thoroughly tested in the green environment and when ready, the environments can be switched over to promote the green environment to be the new production environment.
Switchover typically takes under a minute with no data loss and no need for application changes.
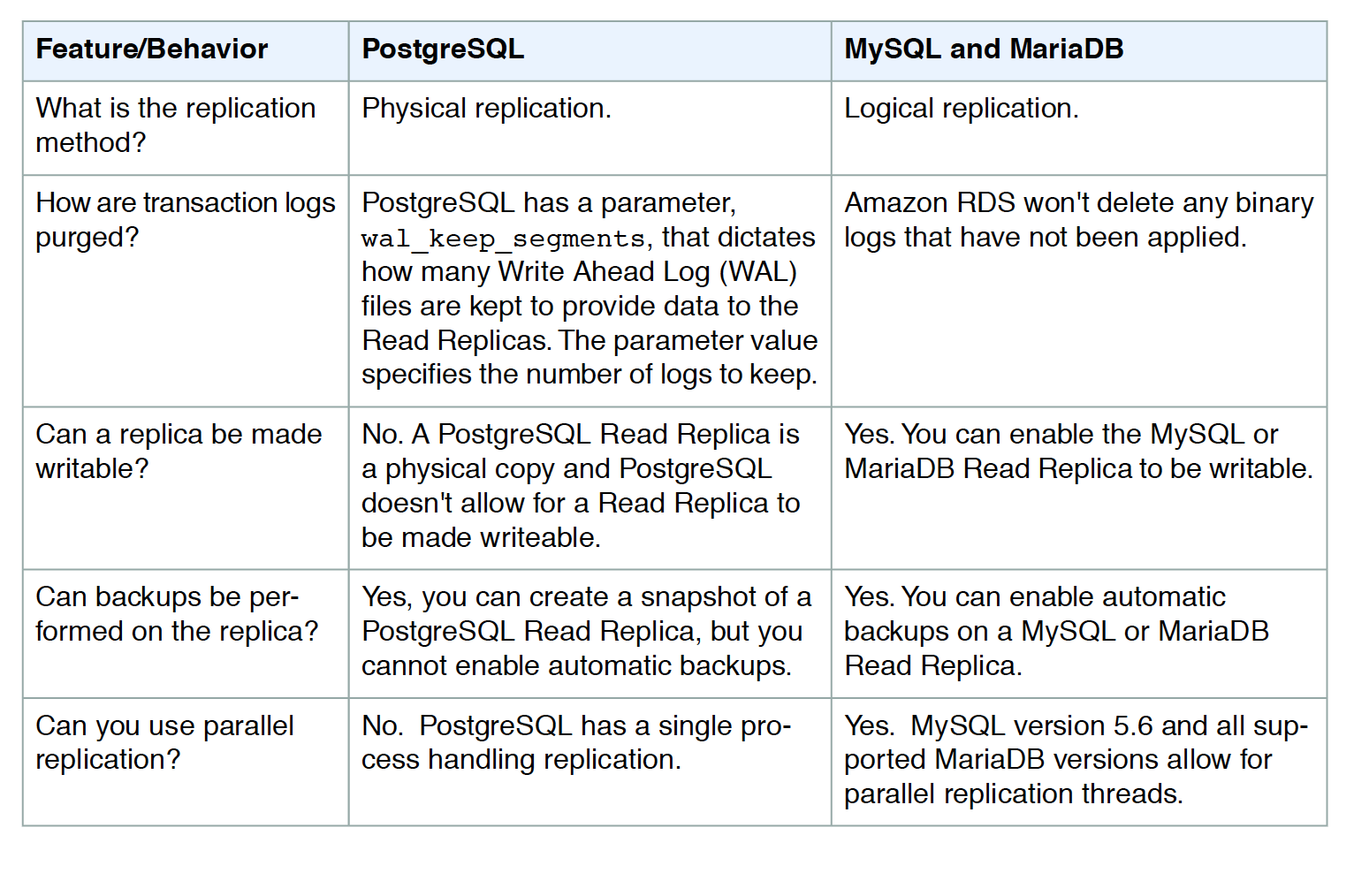
Blue/Green Deployments are currently supported only for RDS for MariaDB, MySQL, and PostgreSQL.
RDS Blue/Green Deployments Benefits
Easily create a production-ready staging environment.
Automatically replicate database changes from the production environment to the staging environment.
Test database changes in a safe staging environment without affecting the production environment.
Stay current with database patches and system updates.
Implement and test newer database features.
Switch over your staging environment to be the new production environment without changes to your application.
Safely switch over through the use of built-in switchover guardrails.
Eliminate data loss during switchover.
Switch over quickly, typically under a minute depending on your workload.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
IAM can be used to control which RDS operations each individual user has permission to call.
RDS Encryption at Rest
RDS encrypted instances use the industry-standard AES-256 encryption algorithm to encrypt data on the server that hosts the RDS instance.
RDS handles authentication of access and decryption of the data with a minimal impact on performance, and with no need to modify the database client applications
Data at Rest Encryption
can be enabled on RDS instances to encrypt the underlying storage
once enabled, the encryption keys cannot be changed
if the key is lost, the DB can only be restored from the backup
Once encryption is enabled for an RDS instance,
logs are encrypted
snapshots are encrypted
automated backups are encrypted
read replicas are encrypted
Cross-region replicas and snapshots copy does not work since the key is only available in a single region
Encrypted snapshots from one AWS Region can’t be copied to another, by specifying the KMS key identifier of the destination AWS Region as KMS encryption keys are specific to the AWS Region that they are created.
Encrypted snapshots can be copied to another region by specifying a KMS key valid in the destination AWS Region. It can be a Region-specific KMS key, or a multi-Region key.
RDS DB Snapshot considerations
DB snapshot encrypted using a KMS encryption key can be copied
Copying an encrypted DB snapshot results in an encrypted copy of the DB snapshot
When copying, the DB snapshot can either be encrypted with the same KMS encryption key as the original DB snapshot, or a different KMS encryption key to encrypt the copy of the DB snapshot.
An unencrypted DB snapshot can be copied to an encrypted snapshot, to add encryption to a previously unencrypted DB instance.
Encrypted snapshot can be restored only to an encrypted DB instance
If a KMS encryption key is specified when restoring from an unencrypted DB cluster snapshot, the restored DB cluster is encrypted using the specified KMS encryption key
Copying an encrypted snapshot shared from another AWS account requires access to the KMS encryption key used to encrypt the DB snapshot.
Because KMS encryption keys are specific to the region that they are created in, an encrypted snapshot cannot be copied to another region
Transparent Data Encryption (TDE)
Automatically encrypts the data before it is written to the underlying storage device and decrypts when it is read from the storage device
is supported by Oracle and SQL Server
Oracle requires key storage outside of the KMS and integrates with CloudHSM for this
SQL Server requires a key but is managed by RDS
RDS Encryption in Transit – SSL
Encrypt connections using SSL for data in transit between the applications and the DB instance
RDS creates an SSL certificate and installs the certificate on the DB instance when RDS provisions the instance.
SSL certificates are signed by a certificate authority. SSL certificate includes the DB instance endpoint as the Common Name (CN) for the SSL certificate to guard against spoofing attacks
While SSL offers security benefits, be aware that SSL encryption is a compute-intensive operation and will increase the latency of the database connection.
For encrypted and unencrypted DB instances, data that is in transit between the source and the read replicas is encrypted, even when replicating across AWS Regions.
IAM Database Authentication
IAM database authentication works with MySQL and PostgreSQL.
IAM database authentication prevents the need to store static user credentials in the database because authentication is managed externally using IAM.
Authorization still happens within RDS (not IAM).
IAM database authentication does not require a password but needs an authentication token
An authentication token is a unique string of characters that RDS generates on request.
Authentication tokens are generated using AWS Signature Version 4.
Each Authentication token has a lifetime of 15 minutes
IAM database authentication provides the following benefits:
Network traffic to and from the database is encrypted using the Secure Sockets Layer (SSL).
helps centrally manage access to the database resources, instead of managing access individually on each DB instance.
enables using IAM Roles to access the database instead of a password, for greater security.
RDS Security Groups
Security groups control the access that traffic has in and out of a DB instance
VPC security groups act like a firewall controlling network access to your DB instance.
VPC security groups can be configured and associated with the DB instance to allow access from an IP address range, port, or EC2 security group
Database security groups default to a “deny all” access mode and customers must specifically authorize network ingress.
Secrets Manager uses a Lambda function Secrets Manager provides.
Secrets Manager provides the following benefits
Rotate secrets safely – rotate secrets automatically without disrupting the applications.
Secrets Manager offers built-in integrations for rotating credentials for RDS databases for MySQL, PostgreSQL, and Aurora.
Secrets Manager can be extended to meet custom rotation requirements by creating a Lambda function to rotate other types of secrets
Manage secrets centrally – to store, view, and manage all the secrets.
Security – By default, Secrets Manager encrypts these secrets with encryption keys that you own and control. Using fine-grained IAM policies, access to secrets can be controlled
Monitor and audit easily – Secrets Manager integrates with AWS logging and monitoring services to enable meet your security and compliance requirements.
Pay as you go – Pay for the secrets stored and for the use of these secrets; there are no long-term contracts or licensing fees.
Master User Account Privileges
When you create a new DB instance, the default master user that is used gets certain privileges for that DB instance
Subsequently, other users with permissions can be created.
Event Notification
Event notifications can be configured for important events that occur on the DB instance
Notifications of a variety of important events that can occur on the RDS instance, such as whether the instance was shut down, a backup was started, a failover occurred, the security group was changed, or your storage space is low can be received
RDS Encrypted DB Instances Limitations
RDS Encryption can be enabled only during the creation of an RDS DB instance, not after the DB instance is created.
DB instances that are encrypted can’t be modified to disable encryption.
Encrypted snapshot of an unencrypted DB instance cannot be created.
An unencrypted backup or snapshot can’t be restored to an encrypted DB instance.
An unencrypted DB instance or an unencrypted read replica of an encrypted DB instance can’t have an encrypted read replica.
DB snapshot of an encrypted DB instance must be encrypted using the same KMS key as the DB instance.
Encrypted read replicas must be encrypted with the same CMK as the source DB instance when both are in the same AWS Region.
For encrypting an unencrypted RDS database, the following approaches can be used.
Using Snapshots, however, this option is feasible if you can afford downtime.
Create a DB snapshot of the DB instance, which would be unencrypted.
Copy the unencrypted DB snapshot to an encrypted snapshot.
Restore a DB instance from the encrypted snapshot, which would be an encrypted DB instance.
For minimal to no downtime you can use AWS Database Migration Service (AWS DMS) to migrate and continuously replicate the data so that the cutover to the new, encrypted database.
RDS API with Interface Endpoints (AWS PrivateLink)
DB instances in the VPC don’t need public IP addresses to communicate with RDS API endpoints to launch, modify, or terminate DB instances.
DB instances also don’t need public IP addresses to use any of the available RDS API operations.
Traffic between the VPC and RDS doesn’t leave the Amazon network.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Can I encrypt connections between my application and my DB Instance using SSL?
No
Yes
Only in VPC
Only in certain regions
Which of these configuration or deployment practices is a security risk for RDS?
Storing SQL function code in plaintext
Non-Multi-AZ RDS instance
Having RDS and EC2 instances exist in the same subnet
RDS in a public subnet (Making RDS accessible to the public internet in a public subnet poses a security risk, by making your database directly addressable and spammable. DB instances deployed within a VPC can be configured to be accessible from the Internet or from EC2 instances outside the VPC. If a VPC security group specifies a port access such as TCP port 22, you would not be able to access the DB instance because the firewall for the DB instance provides access only via the IP addresses specified by the DB security groups the instance is a member of and the port defined when the DB instance was created. Refer link)
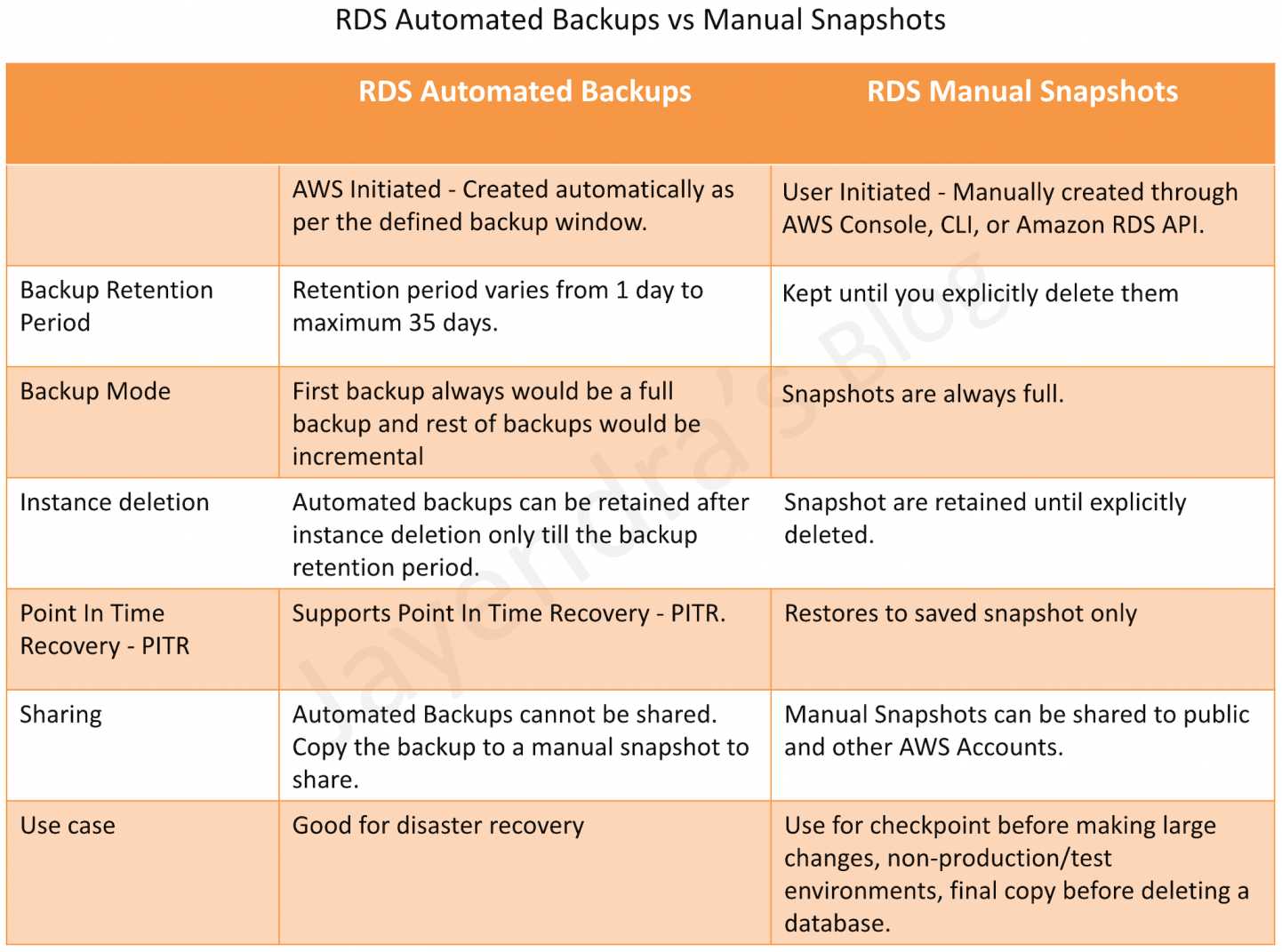
Amazon RDS Automated Backups are AWS Initiated. Backups are created automatically as per the defined backup window. Backups are also created when a read replica is created.
Amazon RDS DB snapshots are manual, user-initiated backups that enable a DB instance backup to be restored to that specific state at any time.
Instance Deletion & Backup Retention Period
Amazon RDS Backups can be configured with a retention period varying from 1 day to a maximum of 35 days.
RDS Automated Backups are deleted when the DB instance is deleted. However, RDS can now be configured to retain the automated backups on RDS instance deletion. These backups would be retained only till their retention window.
RDS Snapshots don’t expire and RDS keeps all manual DB snapshots until explicitly deleted and aren’t subject to the backup retention period.
Backup Mode
RDS Backups are incremental. The first snapshot of a DB instance contains the data for the full database. Subsequent backups of the same database are incremental, meaning only the data that has changed after your most recent backup is saved.
RDS Snapshots are always full.
Point In Time Recovery – PITR
RDS Automated Backups with transaction logs help support Point In Time Recovery – PITR. You can restore your DB by rewinding it to a specific time you choose.
RDS Snapshots restores to saved snapshot data only. It cannot be used for PITR.
Sharing
RDS Automated Backups cannot be shared. You can copy the automated backup to a manual snapshot to share.
RDS Manual Snapshots can be shared with the public and with other AWS Accounts.
Use case
RDS Backups are Good for disaster recovery
RDS Snapshots can be used for checkpoint before making large changes, non-production/test environments, and final copy before deleting a database.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You receive a frantic call from a new DBA who accidentally dropped a table containing all your customers. Which Amazon RDS feature will allow you to reliably restore your database within 5 minutes of when the mistake was made?
RDS Cross-Region Read Replicas create an asynchronously replicated read-only DB instance in a secondary AWS Region.
Supported for MySQL, PostgreSQL, MariaDB, Oracle, and SQL Server
Cross-Region Read Replicas help to improve
disaster recovery capabilities (reduces RTO and RPO),
scale read operations into a region closer to end users,
migration from a data center in one region to another region
RDS Cross-Region Read Replicas Process
RDS configures the source DB instance as a replication source and setups the specified read replica in the destination AWS Region.
RDS creates an automated DB snapshot of the source DB instance in the source AWS Region.
RDS begins a cross-Region snapshot copy for the initial data transfer.
RDS then uses the copied DB snapshot for the initial data load on the read replica. When the load is complete the DB snapshot copy is deleted.
RDS starts by replicating the changes made to the source instance since the start of the create read replica operation.
RDS Cross-Region Read Replicas Considerations
A source DB instance can have cross-region read replicas in multiple AWS Regions.
Replica lags are higher for Cross-region replicas. This lag time comes from the longer network channels between regional data centers.
RDS can’t guarantee more than five cross-region read replica instances, due to the limit on the number of access control list (ACL) entries for a VPC
Read Replica uses the default DB parameter group and DB option group for the specified DB engine when configured from AWS console.
Read Replica uses the default security group.
Cross-Region RDS read replica can be created from a source RDS DB instance that is not a read replica of another RDS DB instance for Microsoft SQL Server, Oracle, and PostgreSQL DB instances. This limitation doesn’t apply to MariaDB and MySQL DB instances.
Deleting the source for a cross-region read replica will result in
read replica promotion for MariaDB, MySQL, and Oracle DB instances
no read replica promotion for PostgreSQL DB instances and the replication status of the read replica is set to terminated.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Your company has HQ in Tokyo and branch offices worldwide and is using logistics software with a multi-regional deployment on AWS in Japan, Europe, and US. The logistic software has a 3-tier architecture and uses MySQL 5.6 for data persistence. Each region has deployed its database. In the HQ region, you run an hourly batch process reading data from every region to compute cross-regional reports that are sent by email to all offices this batch process must be completed as fast as possible to optimize logistics quickly. How do you build the database architecture to meet the requirements?
For each regional deployment, use RDS MySQL with a master in the region and a read replica in the HQ region
For each regional deployment, use MySQL on EC2 with a master in the region and send hourly EBS snapshots to the HQ region
For each regional deployment, use RDS MySQL with a master in the region and send hourly RDS snapshots to the HQ region
For each regional deployment, use MySQL on EC2 with a master in the region and use S3 to copy data files hourly to the HQ region
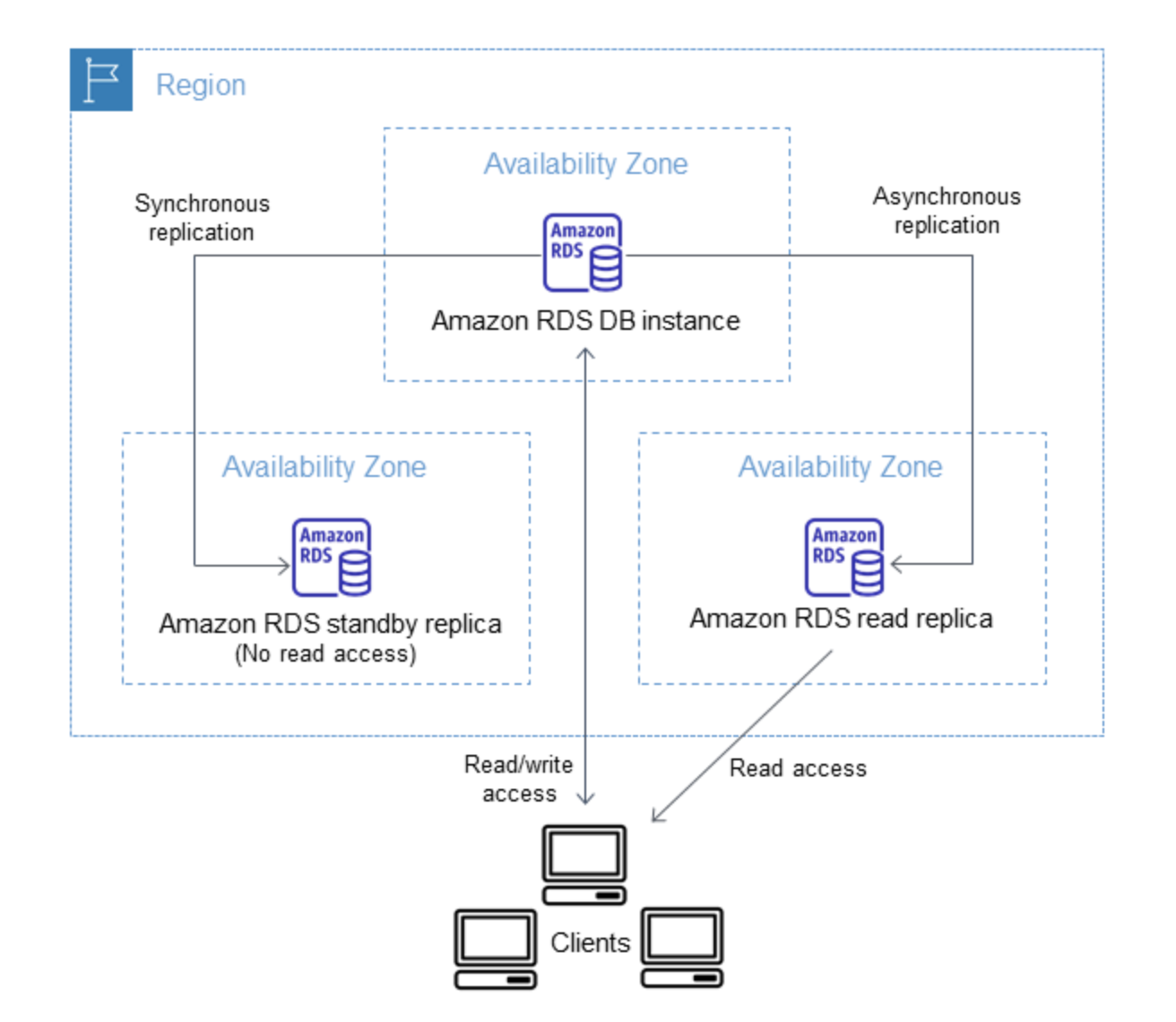
Read replicas enable increased scalability and database availability in the case of an AZ failure. Read Replicas allow elastic scaling beyond the capacity constraints of a single DB instance for read-heavy database workloads
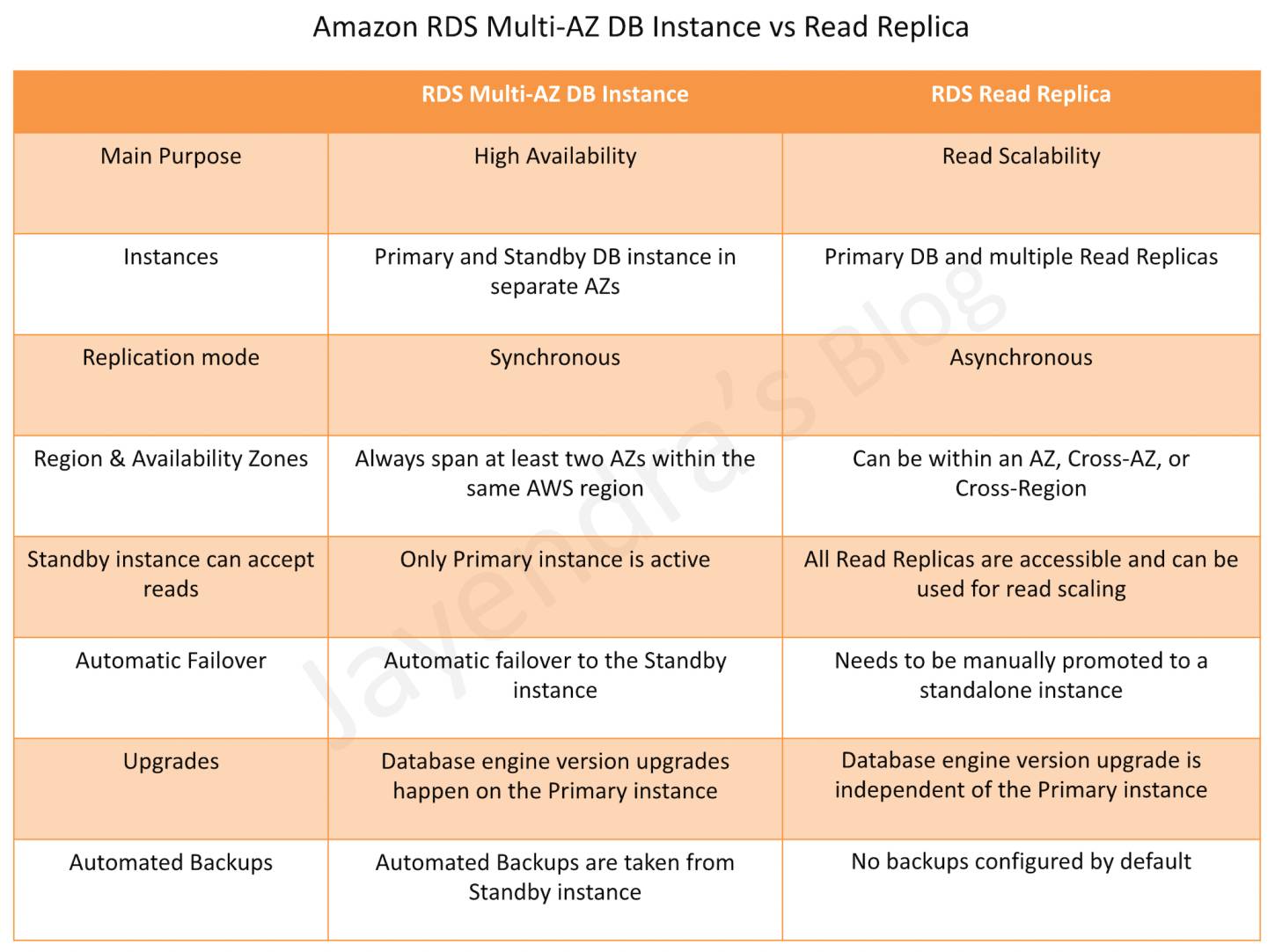
Region & Availability Zones
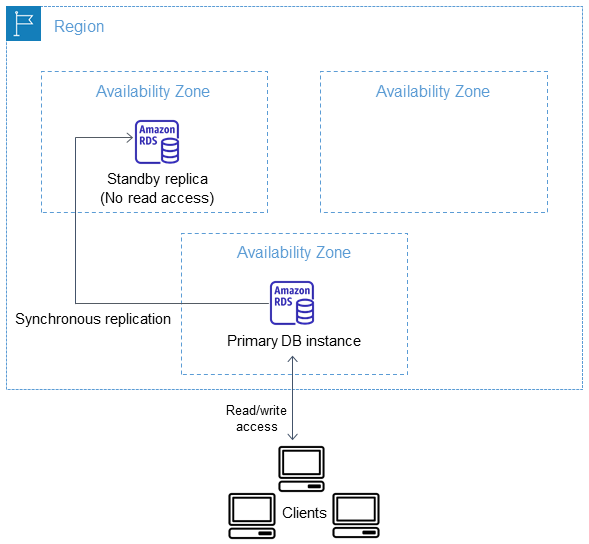
RDS Multi-AZ deployment automatically provisions and manages a standby instance in a different AZ (independent infrastructure in a physically separate location) within the same AWS region.
RDS Read Replicas can be provisioned within the same AZ, Cross-AZ or even as a Cross-Region replica.
Replication Mode
RDS Multi-AZ deployment manages a synchronous standby instance in a different AZ
RDS Read Replicas has the data replicated asynchronously from the Primary instance to the read replicas
Standby Instance can Accept Reads
Multi-AZ DB instance deployment is a high-availability solution and the standby instance does not support requests.
Read Replica deployment provides readable instances to increase application read-throughput.
Automatic Failover & Failover Time
Multi-AZ DB instance deployment performs an automatic failover to the standby instance without administrative intervention, and the failover time can be up to 120 seconds based on the crash recovery.
Planned database maintenance
Software patching
Rebooting the Primary instance with failover
Primary DB instance connectivity or host failure, or an
Availability Zone failure
RDS maintains the same endpoint for the DB Instance after a failover, so the application can resume database operation without the need for manual administrative intervention.
Read Replica deployment does not provide automatic failover. Read Replica instance needs to be manually promoted to a Standalone instance.
Upgrades
For a Multi-AZ deployment, Database engine version upgrades happen on the Primary instance.
For Read Replicas, the Database engine version upgrade is independent of the Primary instance.
Automated Backups
Multi-AZ deployment has the Automated Backups taken from the Standby instance
Read Replicas do not have any backups configured, by default.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You are running a successful multi-tier web application on AWS and your marketing department has asked you to add a reporting tier to the application. The reporting tier will aggregate and publish status reports every 30 minutes from user-generated information that is being stored in your web applications database. You are currently running a Multi-AZ RDS MySQL instance for the database tier. You also have implemented ElastiCache as a database caching layer between the application tier and database tier. Please select the answer that will allow you to successfully implement the reporting tier with as little impact as possible to your database.
Continually send transaction logs from your master database to an S3 bucket and generate the reports of the S3 bucket using S3 byte range requests.
Generate the reports by querying the synchronously replicated standby RDS MySQL instance maintained through Multi-AZ (Standby instance cannot be used as a scaling solution)
Launch an RDS Read Replica connected to your Multi-AZ master database and generate reports by querying the Read Replica.
Generate the reports by querying the ElastiCache database caching tier. (ElasticCache does not maintain full data and is simply a caching solution)
A company is deploying a new two-tier web application in AWS. The company has limited staff and requires high availability, and the application requires complex queries and table joins. Which configuration provides the solution for the company’s requirements?
MySQL Installed on two Amazon EC2 Instances in a single Availability Zone (does not provide High Availability out of the box)
Amazon RDS for MySQL with Multi-AZ
Amazon ElastiCache (Just a caching solution)
Amazon DynamoDB (Not suitable for complex queries and joins)
Your company is getting ready to do a major public announcement of a social media site on AWS. The website is running on EC2 instances deployed across multiple Availability Zones with a Multi-AZ RDS MySQL Extra Large DB Instance. The site performs a high number of small reads and writes per second and relies on an eventual consistency model. After comprehensive tests you discover that there is read contention on RDS MySQL. Which are the best approaches to meet these requirements? (Choose 2 answers)
Deploy ElastiCache in-memory cache running in each availability zone
Implement sharding to distribute load to multiple RDS MySQL instances (this is only a read contention, the writes work fine)
Increase the RDS MySQL Instance size and Implement provisioned IOPS (not scalable, this is only a read contention, the writes work fine)
Add an RDS MySQL read replica in each availability zone
Your company has HQ in Tokyo and branch offices all over the world and is using logistics software with a multi-regional deployment on AWS in Japan, Europe and US. The logistic software has a 3-tier architecture and currently uses MySQL 5.6 for data persistence. Each region has deployed its own database. In the HQ region you run an hourly batch process reading data from every region to compute cross-regional reports that are sent by email to all offices this batch process must be completed as fast as possible to quickly optimize logistics. How do you build the database architecture in order to meet the requirements?
For each regional deployment, use RDS MySQL with a master in the region and a read replica in the HQ region
For each regional deployment, use MySQL on EC2 with a master in the region and send hourly EBS snapshots to the HQ region
For each regional deployment, use RDS MySQL with a master in the region and send hourly RDS snapshots to the HQ region
For each regional deployment, use MySQL on EC2 with a master in the region and use S3 to copy data files hourly to the HQ region
Use Direct Connect to connect all regional MySQL deployments to the HQ region and reduce network latency for the batch process
What would happen to an RDS (Relational Database Service) Multi-Availability Zone deployment if the primary DB instance fails?
IP of the primary DB Instance is switched to the standby DB Instance.
A new DB instance is created in the standby availability zone.
The canonical name record (CNAME) is changed from primary to standby.
The RDS (Relational Database Service) DB instance reboots.
Your business is building a new application that will store its entire customer database on a RDS MySQL database, and will have various applications and users that will query that data for different purposes. Large analytics jobs on the database are likely to cause other applications to not be able to get the query results they need to, before time out. Also, as your data grows, these analytics jobs will start to take more time, increasing the negative effect on the other applications. How do you solve the contention issues between these different workloads on the same data?
Enable Multi-AZ mode on the RDS instance
Use ElastiCache to offload the analytics job data
Create RDS Read-Replicas for the analytics work
Run the RDS instance on the largest size possible
Will my standby RDS instance be in the same Availability Zone as my primary?
Only for Oracle RDS types
Yes
Only if configured at launch
No
Is creating a Read Replica of another Read Replica supported?
Only in certain regions
Only with MySQL based RDS
Only for Oracle RDS types
No
A user is planning to set up the Multi-AZ feature of RDS. Which of the below mentioned conditions won’t take advantage of the Multi-AZ feature?
Availability zone outage
A manual failover of the DB instance using Reboot with failover option
Region outage
When the user changes the DB instance’s server type
When you run a DB Instance as a Multi-AZ deployment, the “_____” serves database writes and reads
secondary
backup
stand by
primary
When running my DB Instance as a Multi-AZ deployment, can I use the standby for read or write operations?
Yes
Only with MSSQL based RDS
Only for Oracle RDS instances
No
Read Replicas require a transactional storage engine and are only supported for the _________ storage engine
OracleISAM
MSSQLDB
InnoDB
MyISAM
A user is configuring the Multi-AZ feature of an RDS DB. The user came to know that this RDS DB does not use the AWS technology, but uses server mirroring to achieve replication. Which DB is the user using right now?
MySQL
Oracle
MS SQL
PostgreSQL
If I have multiple Read Replicas for my master DB Instance and I promote one of them, what happens to the rest of the Read Replicas?
The remaining Read Replicas will still replicate from the older master DB Instance
The remaining Read Replicas will be deleted
The remaining Read Replicas will be combined to one read replica
If you have chosen Multi-AZ deployment, in the event of a planned or unplanned outage of your primary DB Instance, Amazon RDS automatically switches to the standby replica. The automatic failover mechanism simply changes the ______ record of the main DB Instance to point to the standby DB Instance.
DNAME
CNAME
TXT
MX
When automatic failover occurs, Amazon RDS will emit a DB Instance event to inform you that automatic failover occurred. You can use the _____ to return information about events related to your DB Instance
FetchFailure
DescriveFailure
DescribeEvents
FetchEvents
The new DB Instance that is created when you promote a Read Replica retains the backup window period.
TRUE
FALSE
Will I be alerted when automatic failover occurs?
Only if SNS configured
No
Yes
Only if Cloudwatch configured
Can I initiate a “forced failover” for my MySQL Multi-AZ DB Instance deployment?
Only in certain regions
Only in VPC
Yes
No
A user is accessing RDS from an application. The user has enabled the Multi-AZ feature with the MS SQL RDS DB. During a planned outage how will AWS ensure that a switch from DB to a standby replica will not affect access to the application?
RDS will have an internal IP which will redirect all requests to the new DB
RDS uses DNS to switch over to standby replica for seamless transition
The switch over changes Hardware so RDS does not need to worry about access
RDS will have both the DBs running independently and the user has to manually switch over
Which of the following is part of the failover process for a Multi-AZ Amazon Relational Database Service (RDS) instance?
The failed RDS DB instance reboots.
The IP of the primary DB instance is switched to the standby DB instance.
The DNS record for the RDS endpoint is changed from primary to standby.
A new DB instance is created in the standby availability zone.
Which of these is not a reason a Multi-AZ RDS instance will failover?
An Availability Zone outage
A manual failover of the DB instance was initiated using Reboot with failover
To autoscale to a higher instance class (Refer link)
Master database corruption occurs
The primary DB instance fails
You need to scale an RDS deployment. You are operating at 10% writes and 90% reads, based on your logging. How best can you scale this in a simple way?
Create a second master RDS instance and peer the RDS groups.
Cache all the database responses on the read side with CloudFront.
Create read replicas for RDS since the load is mostly reads.
Create a Multi-AZ RDS installs and route read traffic to standby.
How does Amazon RDS multi Availability Zone model work?
A second, standby database is deployed and maintained in a different availability zone from master, using synchronous replication. (Refer link)
A second, standby database is deployed and maintained in a different availability zone from master using asynchronous replication.
A second, standby database is deployed and maintained in a different region from master using asynchronous replication.
A second, standby database is deployed and maintained in a different region from master using synchronous replication.
A customer is running an application in US-West (Northern California) region and wants to setup disaster recovery failover to the Asian Pacific (Singapore) region. The customer is interested in achieving a low Recovery Point Objective (RPO) for an Amazon RDS multi-AZ MySQL database instance. Which approach is best suited to this need?
Synchronous replication
Asynchronous replication
Route53 health checks
Copying of RDS incremental snapshots
A user is using a small MySQL RDS DB. The user is experiencing high latency due to the Multi AZ feature. Which of the below mentioned options may not help the user in this situation?
Schedule the automated back up in non-working hours
Use a large or higher size instance
Use PIOPS
Take a snapshot from standby Replica
Are Reserved Instances available for Multi-AZ Deployments?
Only for Cluster Compute instances
Yes for all instance types
Only for M3 instance types
My Read Replica appears “stuck” after a Multi-AZ failover and is unable to obtain or apply updates from the source DB Instance. What do I do?
You will need to delete the Read Replica and create a new one to replace it.
You will need to disassociate the DB Engine and re-associate it.
The instance should be deployed to Single AZ and then moved to Multi-AZ once again
You will need to delete the DB Instance and create a new one to replace it.
What is the charge for the data transfer incurred in replicating data between your primary and standby?
No charge. It is free.
Double the standard data transfer charge
Same as the standard data transfer charge
Half of the standard data transfer charge
A user has enabled the Multi-AZ feature with the MS SQL RDS database server. Which of the below mentioned statements will help the user understand the Multi-AZ feature better?
In a Multi-AZ, AWS runs two DBs in parallel and copies the data asynchronously to the replica copy
In a Multi-AZ, AWS runs two DBs in parallel and copies the data synchronously to the replica copy
In a Multi-AZ, AWS runs just one DB but copies the data synchronously to the standby replica
AWS MS SQL does not support the Multi-AZ feature
A company is running a batch analysis every hour on their main transactional DB running on an RDS MySQL instance to populate their central Data Warehouse running on Redshift. During the execution of the batch their transactional applications are very slow. When the batch completes they need to update the top management dashboard with the new data. The dashboard is produced by another system running on-premises that is currently started when a manually sent email notifies that an update is required The on-premises system cannot be modified because is managed by another team. How would you optimize this scenario to solve performance issues and automate the process as much as possible?
Replace RDS with Redshift for the batch analysis and SNS to notify the on-premises system to update the dashboard
Replace RDS with Redshift for the batch analysis and SQS to send a message to the on-premises system to update the dashboard
Create an RDS Read Replica for the batch analysis and SNS to notify me on-premises system to update the dashboard
Create an RDS Read Replica for the batch analysis and SQS to send a message to the on-premises system to update the dashboard.
RDS creates a storage volume snapshot of the DB instance, backing up the entire DB instance and not just individual databases.
RDS provides two different methods Automated and Manual for backing up the DB instances.
Automated backups
Backups of the DB instance are automatically created and retained.
RDS Backups are incremental. The first snapshot of a DB instance contains the data for the full database. Subsequent snapshots of the same database are incremental, which means that only the data that has changed after your most recent snapshot is saved.
Automated backups are enabled by default for a new DB instance.
Automated backups occur during a daily user-configurable period of time, known as the preferred backup window.
If a preferred backup window is not specified when a DB instance is created, RDS assigns a default 30-minute backup window which is selected at random from an 8-hour block of time per region.
Changes to the backup window take effect immediately.
Backup window cannot overlap with the weekly maintenance window for the DB instance.
Backups created during the backup window are retained for a user-configurable number of days, known as the backup retention period
If the backup retention period is not set, RDS defaults the period retention period to one day, if created using RDS API or the AWS CLI, or seven days if created from AWS Console.
Backup retention period can be modified with valid values are 0 (for no backup retention) to a maximum of 35 days.
Manual snapshot limits (50 per region) do not apply to automated backups
If the backup requires more time than allotted to the backup window, the backup will continue to completion.
An immediate outage occurs if the backup retention period is changed
from 0 to a non-zero value as the first backup occurs immediately or
from a non-zero value to 0 as it turns off automatic backups, and deletes all existing automated backups for the instance.
RDS uses the periodic data backups in conjunction with the transaction logs to enable restoration of the DB Instance to any second during the retention period, up to the LatestRestorableTime (typically up to the last few minutes).
During the backup window,
for Single AZ instance, storage I/O may be briefly suspended while the backup process initializes (typically under a few seconds) and a brief period of elevated latency might be experienced.
for Multi-AZ DB deployments, there is No I/O suspension since the backup is taken from the standby instance
The first backup is a full backup, while the others are incremental.
Automated DB backups are deleted when
the retention period expires
the automated DB backups for a DB instance are disabled
the DB instance is deleted
When a DB instance is deleted,
a final DB snapshot can be created upon deletion; which can be used to restore the deleted DB instance at a later date.
RDS retains the final user-created DB snapshot along with all other manually created DB snapshots
all automated backups are deleted and cannot be recovered
NOTE: RDS can now be configured to retain the automated backups on RDS instance deletion.
Point-In-Time Recovery
In addition to the daily automated backup, RDS archives database change logs. This enables recovery of the database to any point in time during the backup retention period, up to the last five minutes of database usage.
Disabling automated backups also disables point-in-time recovery
RDS stores multiple copies of the data, but for Single-AZ DB instances these copies are stored in a single availability zone.
If for any reason a Single-AZ DB instance becomes unusable, point-in-time recovery can be used to launch a new DB instance with the latest restorable data
DB Snapshots (User Initiated – Manual)
DB snapshots are manual, user-initiated backups that enable a DB instance backup to a known state, and restore to that specific state at any time.
RDS keeps all manual DB snapshots until explicitly deleted.
DB Snapshots Creation
DB snapshot is a user-initiated storage volume snapshot of DB instance, backing up the entire DB instance and not just individual databases.
DB snapshots enable backing up of the DB instance in a known state as needed, and can then be restored to that specific state at any time.
DB snapshots are kept until explicitly deleted.
Creating DB snapshot on a Single-AZ DB instance results in a brief I/O suspension that typically lasts no more than a few minutes.
Multi-AZ DB instances are not affected by this I/O suspension since the backup is taken on the standby instance
DB Snapshot Restore
DB instance can be restored to any specific time during this retention period, creating a new DB instance.
DB restore creates a New DB instance with a different endpoint.
RDS uses the periodic data backups in conjunction with the transaction logs to enable restoration of the DB Instance to any second during the retention period, up to the LatestRestorableTime (typically up to the last few minutes).
Option group associated with the DB snapshot is associated with the restored DB instance once it is created. However, the option group is associated with the VPC, so would apply only when the instance is restored in the same VPC as the DB snapshot.
Default DB parameter and security groups are associated with the restored instance. After the restoration is complete, any custom DB parameter or security groups used by the restored instance should be associated explicitly.
A DB instance can be restored with a different storage type than the source DB snapshot. In this case, the restoration process will be slower because of the additional work required to migrate the data to the new storage type e.g. from GP2 to Provisioned IOPS
A DB instance can be restored with a different edition of the DB engine only if the DB snapshot has the required storage allocated for the new edition for e.g., to change from SQL Server Web Edition to SQL Server Standard Edition, the DB snapshot must have been created from a SQL Server DB instance that had at least 200 GB of allocated storage, which is the minimum allocated storage for SQL Server Standard edition
DB Snapshot Copy
RDS supports two types of DB snapshot copying.
Copy an automated DB snapshot to create a manual DB snapshot in the same AWS region. Manual DB snapshots are not deleted automatically and can be kept indefinitely.
Copy either an automated or manual DB snapshot from one region to another region. By copying the DB snapshot to another region, a manual DB snapshot is created that is retained in that region
Automated backups cannot be shared. They need to be copied to a manual snapshot, and the manual snapshot can be shared.
Manual DB snapshots can be shared with other AWS accounts and snapshots shared can be copied by other AWS accounts.
Snapshot Copy Encryption
DB snapshot that has been encrypted using an AWS Key Management System (AWS KMS) encryption key can be copied.
Copying an encrypted DB snapshot results in an encrypted copy of the DB snapshot
When copying, DB snapshot can either be encrypted with the same KMS encryption key as the original DB snapshot, or a different KMS encryption key to encrypt the copy of the DB snapshot.
An unencrypted DB snapshot can be copied to an encrypted snapshot, a quick way to add encryption to a previously encrypted DB instance.
Encrypted snapshot can be restored only to an encrypted DB instance.
If a KMS encryption key is specified when restoring from an unencrypted DB cluster snapshot, the restored DB cluster is encrypted using the specified KMS encryption key.
Copying an encrypted snapshot shared from another AWS account requires access to the KMS encryption key that was used to encrypt the DB snapshot.
Because KMS encryption keys are specific to the region that they are created in, encrypted snapshot cannot be copied to another region
Manual DB snapshots or DB cluster snapshots can be shared with up to 20 other AWS accounts.
Manual snapshots shared with other AWS accounts can copy the snapshot, or restore a DB instance or DB cluster from that snapshot.
Manual snapshots can also be shared as public, which makes the snapshot available to all AWS accounts. Care should be taken when sharing a snapshot as public so that none of the private information is included
Shared snapshot can be copied to another region.
However, following limitations apply when sharing manual snapshots with other AWS accounts:
When a DB instance or DB cluster is restored from a shared snapshot using the AWS CLI or RDS API, the Amazon Resource Name (ARN) of the shared snapshot as the snapshot identifier should be specified.
DB snapshot that uses an option group with permanent or persistent options cannot be shared.
A permanent option cannot be removed from an option group. Option groups with persistent options cannot be removed from a DB instance once the option group has been assigned to the DB instance.
DB snapshots that have been encrypted “at rest” using the AES-256 encryption algorithm can be shared
Users can only copy encrypted DB snapshots if they have access to the AWS Key Management Service (AWS KMS) encryption key that was used to encrypt the DB snapshot.
AWS KMS encryption keys can be shared with another AWS account by adding the other account to the KMS key policy.
However, KMS key policy must first be updated by adding any accounts to share the snapshot with, before sharing an encrypted DB snapshot
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Amazon RDS automated backups and DB Snapshots are currently supported for only the __________ storage engine
InnoDB
MyISAM
Automated backups are enabled by default for a new DB Instance.
TRUE
FALSE
Amazon RDS DB snapshots and automated backups are stored in
Amazon S3
Amazon EBS Volume
Amazon RDS
Amazon EMR
You receive a frantic call from a new DBA who accidentally dropped a table containing all your customers. Which Amazon RDS feature will allow you to reliably restore your database to within 5 minutes of when the mistake was made?
Multi-AZ RDS
RDS snapshots
RDS read replicas
RDS automated backup
Disabling automated backups ______ disable the point-in-time recovery.
if configured to can
will never
will
Changes to the backup window take effect ______.
from the next billing cycle
after 30 minutes
immediately
after 24 hours
You can modify the backup retention period; valid values are 0 (for no backup retention) to a maximum of ___________ days.
45
35
15
5
Amazon RDS automated backups and DB Snapshots are currently supported for only the ______ storage engine
MyISAM
InnoDB
What happens to the I/O operations while you take a database snapshot?
I/O operations to the database are suspended for a few minutes while the backup is in progress.
I/O operations to the database are sent to a Replica (if available) for a few minutes while the backup is in progress.
I/O operations will be functioning normally
I/O operations to the database are suspended for an hour while the backup is in progress
True or False: When you perform a restore operation to a point in time or from a DB Snapshot, a new DB Instance is created with a new endpoint.
FALSE
TRUE
True or False: Manually created DB Snapshots are deleted after the DB Instance is deleted.
TRUE
FALSE
A user is running a MySQL RDS instance. The user will not use the DB for the next 3 months. How can the user save costs?
Pause the RDS activities from CLI until it is required in the future
Stop the RDS instance
Create a snapshot of RDS to launch in the future and terminate the instance now
RDS Multi-AZ deployments provide high availability and automatic failover support for DB instances
Multi-AZ helps improve the durability and availability of a critical system, enhancing availability during planned system maintenance, DB instance failure, and Availability Zone disruption.
A Multi-AZ DB instance deployment has one standby DB instance that provides failover support but doesn’t serve read traffic.
A Multi-AZ DB cluster deployment has two standby DB instances that provide failover support and can also serve read traffic.
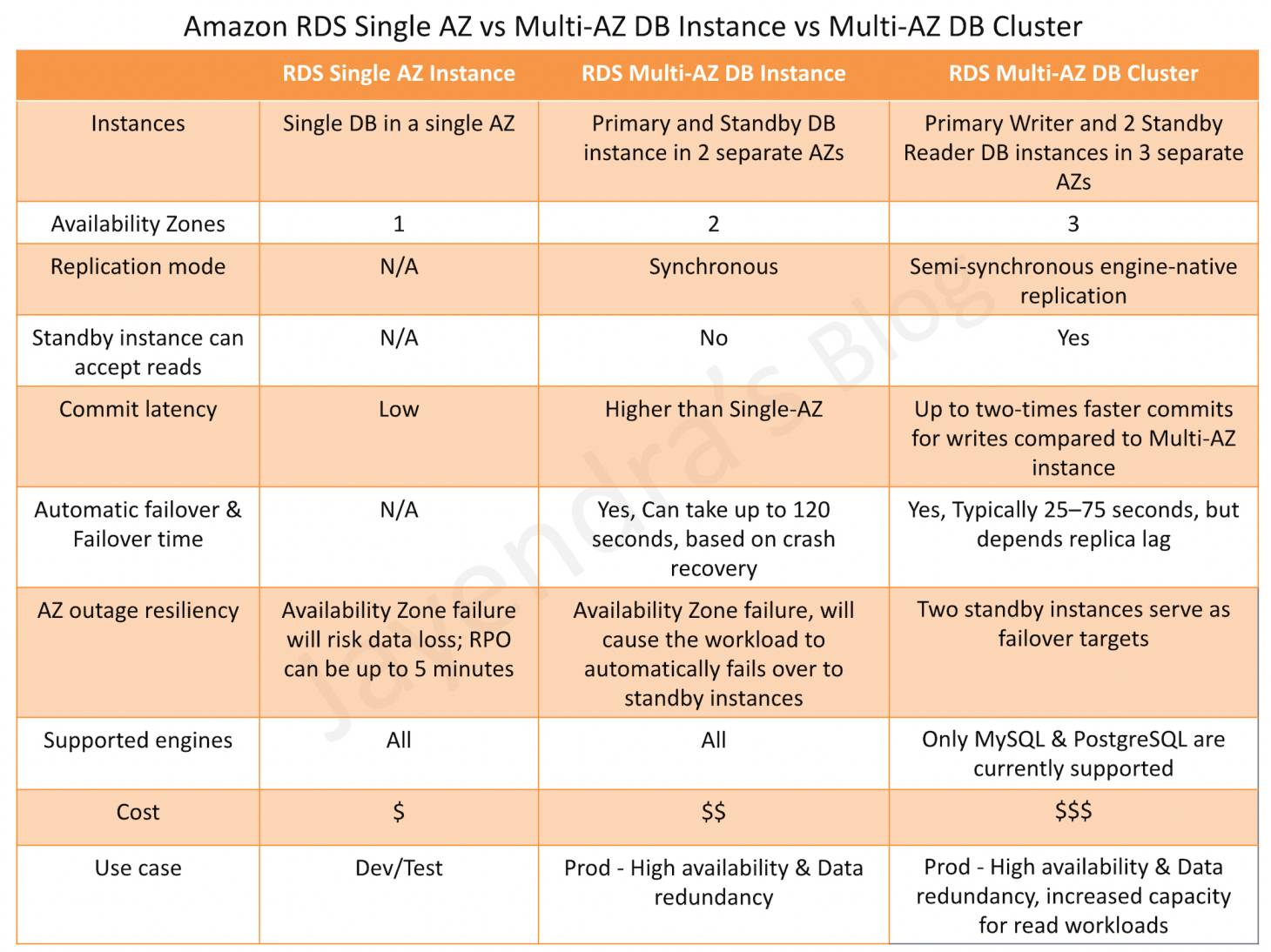
Instances & Availability Zones
A Single AZ instance creates a single DB instance in any specified AZ.
A Multi-AZ DB Instance deployment creates a Primary and a Standby instance in two different AZs
A Multi-AZ DB Cluster deployment creates a Primary Writer and two Readable Standby instances in three different AZs
Replication Mode
Multi-AZ DB instance deployment synchronously replicates the data from the primary DB instance to a standby instance in a different AZ.
Multi-AZ DB cluster deployment semi-synchronously replicates data from the writer DB instance to both reader DB instances using the DB engine’s native replication capabilities.
Standby Instance can Accept Reads
Multi-AZ DB instance deployment is a high-availability solution and the standby instance does not support requests.
Multi-AZ DB cluster deployment provides readable standby instances to increase application read-throughput.
Commit Latency
Single AZ instance has the lowest commit latency.
Multi-AZ DB instance deployment has a high commit latency as compared to the Single AZ instance as the data needs to be synchronously replicated to the standby instance.
Multi-AZ DB cluster deployment provides up to two thirds faster commits for commits compared to Multi-AZ DB instance as it performs semi-synchronous replication.
Automatic Failover & Failover Time
Single AZ instances do not support automatic failover and failure would result in data loss. Use point-in-time recovery with backups to restore the database.
Multi-AZ DB instance deployment performs an automatic failover to the standby instance, and the failover time can be up to 120 seconds based on the crash recovery.
Multi-AZ DB cluster deployment performs an automatic failover to a reader DB instance in a different AZ, and the failover time can be up to 75 seconds depending on the replica lag.
Supported Engines
Single AZ and Multi-AZ DB instance deployments support all DB engines
Multi-AZ DB clusters are supported only for the MySQL and PostgreSQL DB engines.
Cost
Single AZ is the most cost-effective option.
Multi-AZ DB Instance deployment costs more than a Single AZ as it maintains a synchronous standby instance.
Multi-AZ DB Cluster would be an expensive option as it creates 3 instances, supports specific instance classes that do not include burstable classes, and does not support general-purpose SSD volumes.
Use Cases
Single AZ deployments are suitable for non-critical dev, test environments.
Multi-AZ deployments are suitable for critical, production-based environments requiring high availability, data redundancy, and scalability for read workloads.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
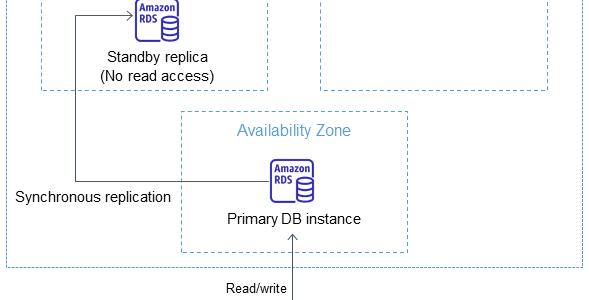
RDS automatically creates a primary DB Instance and synchronously replicates the data to a standby instance in a different AZ.
RDS performs an automatic failover to the standby, so that database operations can be resumed as soon as the failover is complete.
RDS Multi-AZ deployment maintains the same endpoint for the DB Instance after a failover, so the application can resume database operation without the need for manual administrative intervention.
Multi-AZ is a High Availability feature and NOT a scaling solution for read-only scenarios; a standby replica can’t be used to serve read traffic. To service read-only traffic, use a Read Replica.
Multi-AZ deployments for Oracle, PostgreSQL, MySQL, and MariaDB DB instances use Amazon technology, while SQL Server DB instances use SQL Server Mirroring.
In a Multi-AZ deployment,
RDS automatically provisions and maintains a synchronous standby replica in a different Availability Zone.
Copies of data are stored in different AZs for greater levels of data durability.
Primary DB instance is synchronously replicated across Availability Zones to a standby replica to provide
data redundancy,
eliminate I/O freezes during snapshots and backups
and minimize latency spikes during system backups.
DB instances may have increased write and commit latency compared to a Single AZ deployment, due to the synchronous data replication
Transaction success is returned only if the commit is successful both on the primary and the standby DB
There might be a change in latency if the deployment fails over to the standby replica, although AWS is engineered with low-latency network connectivity between Availability Zones.
When using the BYOL licensing model, a license for both the primary instance and the standby replica is required
For production workloads, it is recommended to use Multi-AZ deployment with Provisioned IOPS and DB instance classes (m1.large and larger), optimized for Provisioned IOPS for fast, consistent performance.
When Single-AZ deployment is modified to a Multi-AZ deployment (for engines other than SQL Server or Amazon Aurora)
RDS takes a snapshot of the primary DB instance from the deployment and restores the snapshot into another Availability Zone.
RDS then sets up synchronous replication between the primary DB instance and the new instance.
This avoids downtime during conversion from Single AZ to Multi-AZ.
An existing Single AZ instance can be converted into a Multi-AZ instance by modifying the DB instance without any downtime.
RDS Multi-AZ Failover Process
In the event of a planned or unplanned outage of the DB instance,
RDS automatically switches to a standby replica in another AZ, if enabled for Multi-AZ.
The time taken for the failover to complete depends on the database activity and other conditions at the time the primary DB instance became unavailable.
Failover times are typically 60-120 secs. However, large transactions or a lengthy recovery process can increase failover time.
Failover mechanism automatically changes the DNS record of the DB instance to point to the standby DB instance.
Multi-AZ switch is seamless to the applications as there is no change in the endpoint URLs but just needs to re-establish any existing connections to the DB instance.
RDS handles failover automatically so that database operations can be resumed as quickly as possible without administrative intervention.
Primary DB instance switches over automatically to the standby replica if any of the following conditions occur:
Primary Availability Zone outage
Loss of network connectivity to primary
Primary DB instance fails
DB instance’s server type is changed
Operating system of the DB instance is undergoing software patching
Compute unit failure on the primary
Storage failure on the primary
A manual failover of the DB instance was initiated using Reboot with failover (also referred to as Forced Failover)
If the Multi-AZ DB instance has failed over, can be determined by
DB event subscriptions can be set up to notify you via email or SMS that a failover has been initiated.
DB events can be viewed via the Amazon RDS console or APIs.
The current state of the Multi-AZ deployment can be viewed via the RDS console and APIs.
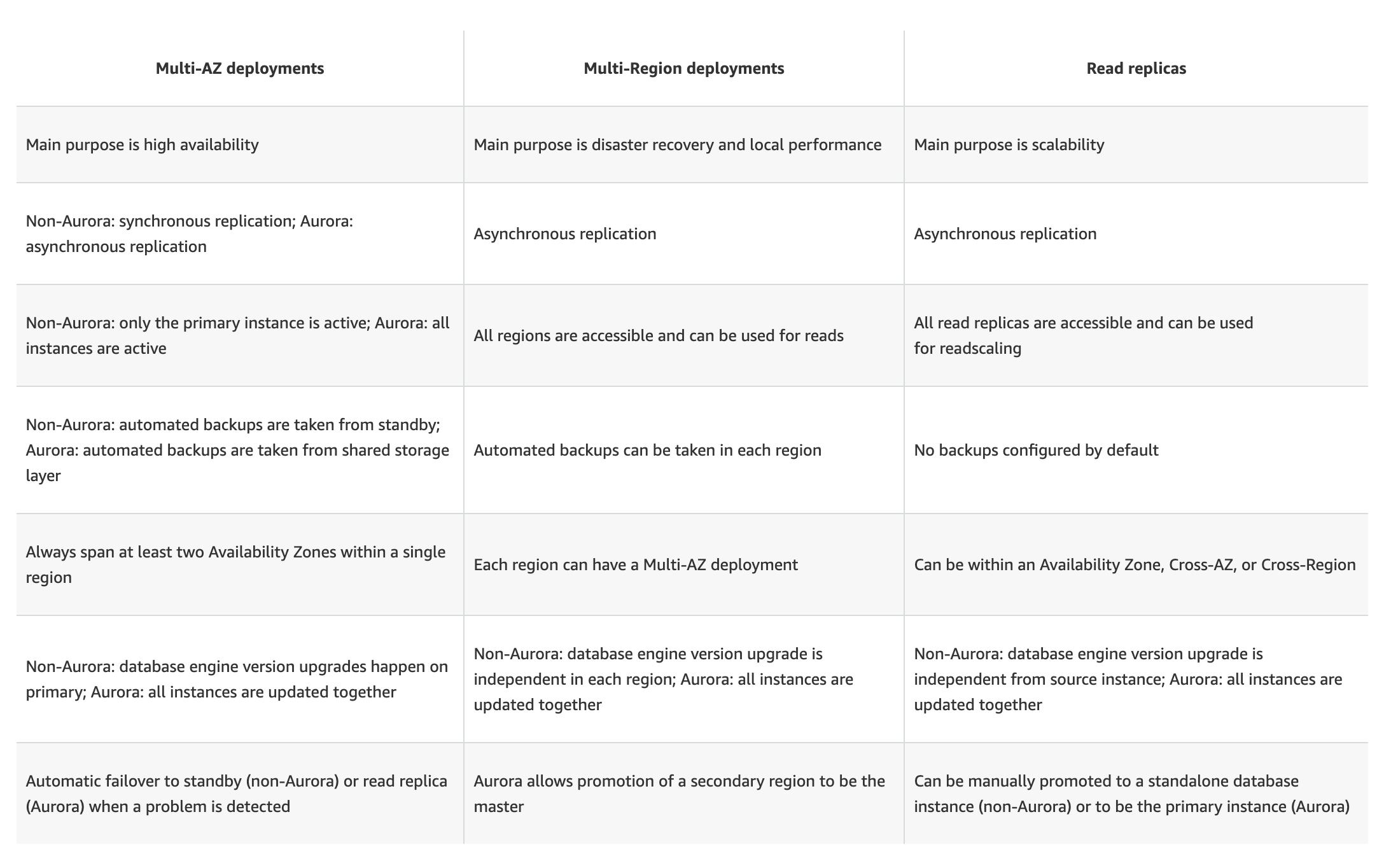
Multi-AZ DB Instance vs Multi-AZ DB Cluster
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
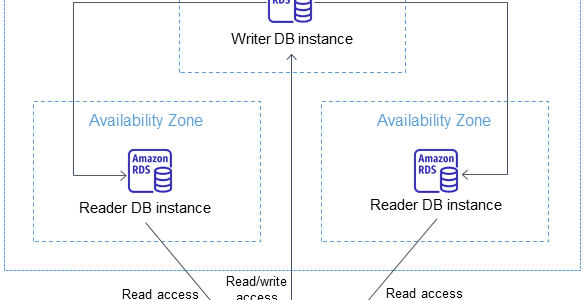
RDS Multi-AZ DB cluster deployment is a high-availability deployment mode of RDS with two readable standby DB instances.
RDS Multi-AZ DB cluster has a writer DB instance and two reader DB instances in three separate AZs in the same AWS Region.
Multi-AZ DB clusters provide high availability, increased capacity for read workloads, and lower write latency when compared to Multi-AZ DB instance deployments.
Multi-AZ DB clusters aren’t the same as Aurora DB clusters.
With a Multi-AZ DB cluster, RDS replicates data from the writer DB instance to both of the reader DB instances using the DB engine’s native replication capabilities.
When a change is made on the writer DB instance, it’s sent to each reader DB instance. Acknowledgment from at least one reader DB instance is required for a change to be committed.
Reader DB instances act as automatic failover targets and also serve read traffic to increase application read throughput.
If an outage occurs on the writer DB instance, RDS manages failover to one of the reader DB instances. RDS does this based on which reader DB instance has the most recent change record.
Multi-AZ DB clusters typically have lower write latency when compared to Multi-AZ DB instance deployments.
They also allow read-only workloads to run on reader DB instances.
Supports two endpoints
Cluster or Writer endpoint connects to the writer DB instance of the DB cluster, which supports both read and write operations.
Reader endpoint connects to either of the two reader DB instances, which support only read operations.
Instance endpoint connects to a specific DB instance within a Multi-AZ DB cluster.
Multi-AZ DB Cluster Limitations
Multi-AZ DB clusters are supported only for the MySQL and PostgreSQL DB engines.
Multi-AZ DB clusters support only Provisioned IOPS storage.
Single-AZ DB instance deployment or Multi-AZ DB instance deployment can’t be upgraded into a Multi-AZ DB cluster.
Multi-AZ DB clusters don’t support modifications at the DB instance level because all modifications are done at the DB cluster level.
Multi-AZ DB clusters don’t support the following features:
Support for IPv6 connections (dual-stack mode)
Cross-Region automated backups
Exporting Multi-AZ DB cluster snapshot data to an Amazon S3 bucket
IAM DB authentication
Kerberos authentication
Modifying the port
Option groups
Point-in-time-recovery (PITR) for deleted clusters
Restoring a Multi-AZ DB cluster snapshot from an Amazon S3 bucket
Storage autoscaling by setting the maximum allocated storage. Manually scale the storage.
Stopping and starting the DB cluster
Copying a snapshot of a Multi-AZ DB cluster
Encrypting an unencrypted Multi-AZ DB cluster
RDS Multi-AZ DB Cluster Failover
RDS automatically fails over to a reader DB instance in a different AZ in case of a planned or unplanned outage of the writer DB instance, as quickly as possible without administrative intervention
Failover time taken depends on the database activity and other conditions when the writer DB instance becomes unavailable and is typically under 35 seconds.
Failover completes when both reader DB instances have applied outstanding transactions from the failed writer.
Multi-AZ DB Instance vs Multi-AZ DB Cluster
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
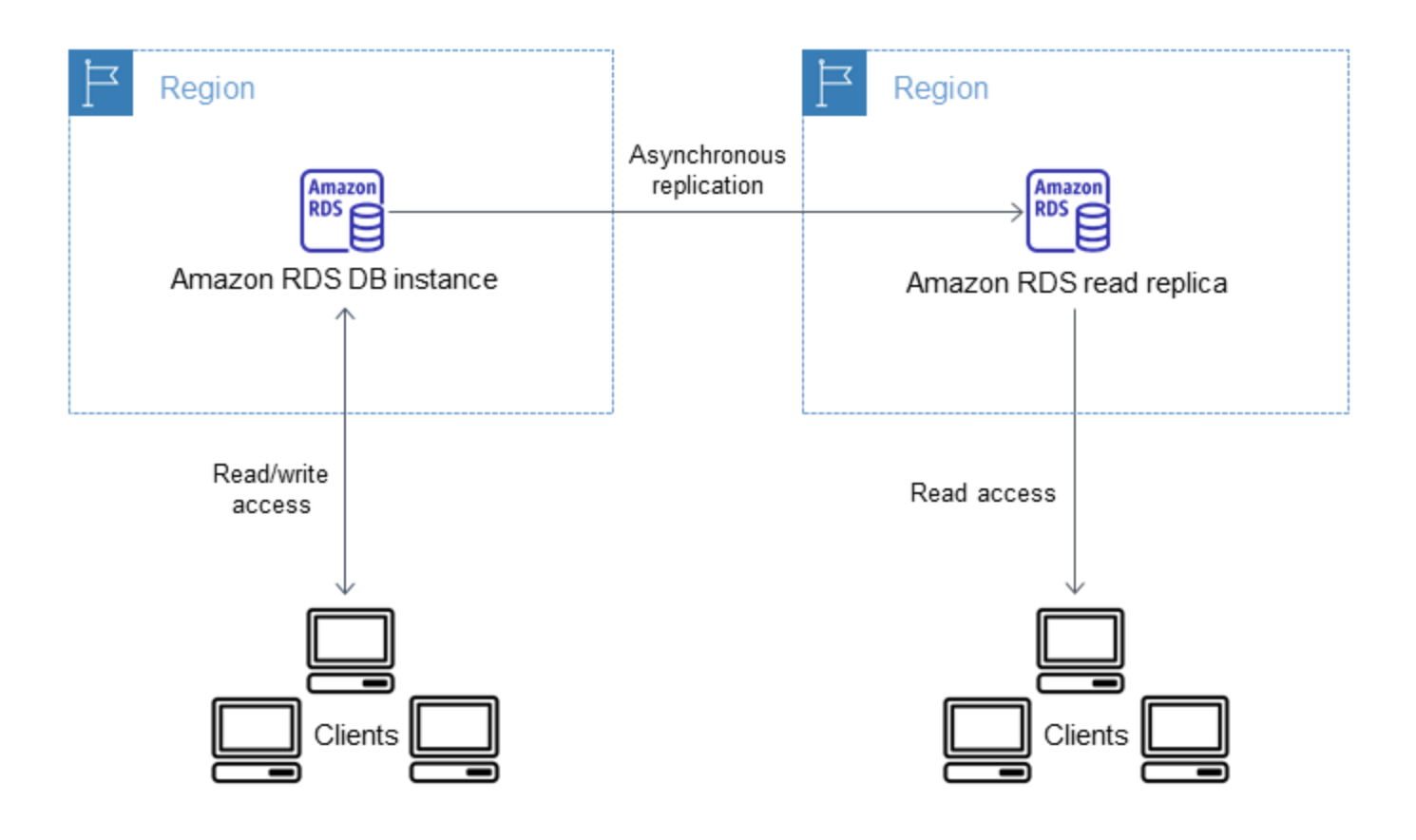
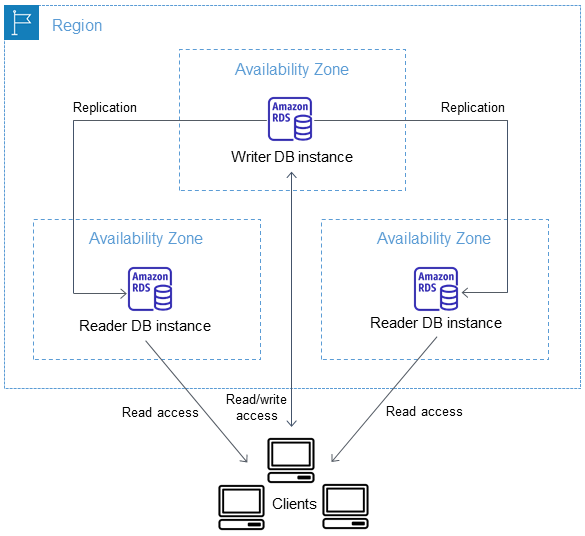
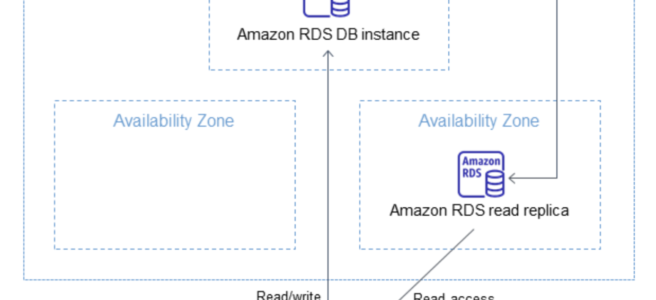
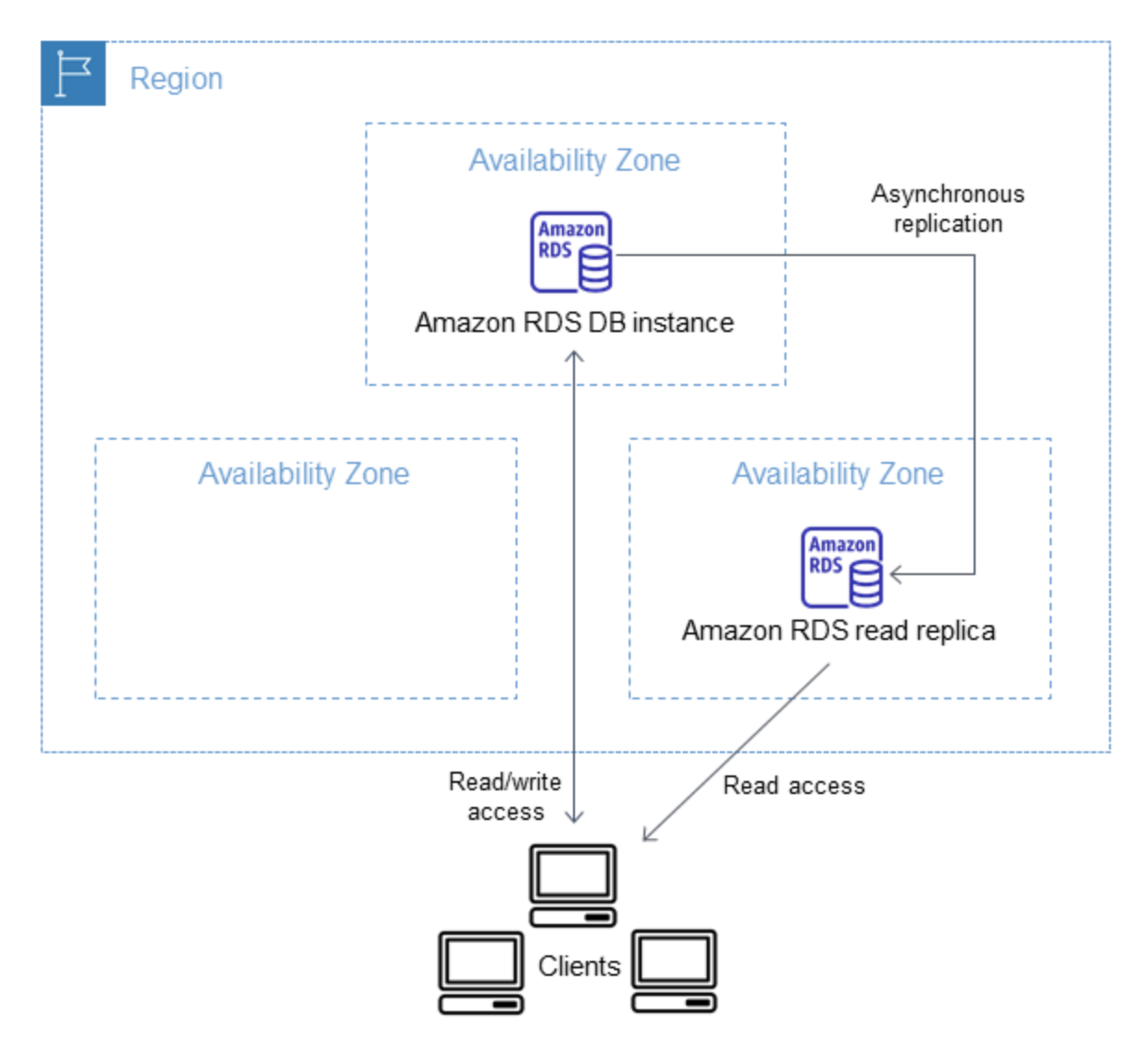
RDS Read Replica is a read-only copy of the DB instance.
RDS Read Replicas provide enhanced performance and durability for RDS.
RDS Read Replicas allow elastic scaling beyond the capacity constraints of a single DB instance for read-heavy database workloads.
RDS Read replicas enable increased scalability and database availability in the case of an AZ failure.
Read Replicas can help reduce the load on the source DB instance by routing read queries from applications to the Read Replica.
Read replicas can also be promoted when needed to become standalone DB instances.
RDS read replicas can be Multi-AZ i.e. set up with their own standby instances in a different AZ.
One or more replicas of a given source DB Instance can serve high-volume application read traffic from multiple copies of the data, thereby increasing aggregate read throughput.
RDS uses DB engines’ built-in replication functionality to create a special type of DB instance called a Read Replica from a source DB instance. It uses the engines’ native asynchronous replication to update the read replica whenever there is a change to the source DB instance.
Read Replicas are eventually consistent due to asynchronous replication.
RDS sets up a secure communications channel using public-key encryption between the source DB instance and the read replica, even when replicating across regions.
Read replica operates as a DB instance that allows only read-only connections. Applications can connect to a read replica just as they would to any DB instance.
Read replicas are available in RDS for MySQL, MariaDB, PostgreSQL, Oracle, and SQL Server as well as Aurora.
RDS replicates all databases in the source DB instance.
RDS supports replication between an RDS MySQL or MariaDB DB instance and a MySQL or MariaDB instance that is external to RDS using Binary Log File Position or Global Transaction Identifiers (GTIDs) replication.
Read Replicas Creation
Read Replicas can be created within the same AZ, different AZ within the same region, and cross-region as well.
Up to five Read Replicas can be created from one source DB instance.
Creation process
Automatic backups must be enabled on the source DB instance by setting the backup retention period to a value other than 0
An existing DB instance needs to be specified as the source.
RDS takes a snapshot of the source instance and creates a read-only instance from the snapshot.
RDS then uses the asynchronous replication method for the DB engine to update the Read Replica for any changes to the source DB instance.
RDS replicates all databases in the source DB instance.
RDS sets up a secure communications channel between the source DB instance and the Read Replica if that Read Replica is in a different AWS region from the DB instance.
RDS establishes any AWS security configurations, such as adding security group entries, needed to enable the secure channel.
During the Read Replica creation, a brief I/O suspension on the source DB instance can be experienced as the DB snapshot occurs.
I/O suspension typically lasts about one minute and can be avoided if the source DB instance is a Multi-AZ deployment (in the case of Multi-AZ deployments, DB snapshots are taken from the standby).
Read Replica creation time can be slow if any long-running transactions are being executed and should wait for completion
For multiple Read Replicas created in parallel from the same source DB instance, only one snapshot is taken at the start of the first create action.
A Read Replica can be promoted to a new independent source DB, in which case the replication link is broken between the Read Replica and the source DB. However, the replication continues for other replicas using the original source DB as the replication source
Read Replica Deletion & DB Failover
Read Replicas must be explicitly deleted, using the same mechanisms for deleting a DB instance.
If the source DB instance is deleted without deleting the replicas, each replica is promoted to a stand-alone, single-AZ DB instance.
If the source instance of a Multi-AZ deployment fails over to the standby, any associated Read Replicas are switched to use the secondary as their replication source.
Read Replica Storage & Compute requirements
A Read Replica, by default, is created with the same storage type as the source DB instance.
For replication to operate effectively, each Read Replica should have the same amount of compute & storage resources as the source DB instance.
Read Replicas should be scaled accordingly if the source DB instance is scaled.
Read Replicas Promotion
A read replica can be promoted into a standalone DB instance.
When the read replica is promoted
New DB instance is rebooted before it becomes available.
New DB instance that is created retains the option group and the parameter group of the former read replica.
The promotion process can take several minutes or longer to complete, depending on the size of the read replica.
If a source DB instance has several read replicas, promoting one of the read replicas to a DB instance has no effect on the other replicas.
If you plan to promote a read replica to a standalone instance, AWS recommends that you enable backups and complete at least one backup prior to promotion.
Read Replicas Promotion can help with
Performing DDL operations (MySQL and MariaDB only)
DDL Operations such as creating or rebuilding indexes can take time and can be performed on the read replica once it is in sync with its primary DB instance.
Sharding
Sharding embodies the “share-nothing” architecture and essentially involves breaking a large database into several smaller databases.
Read Replicas can be created and promoted corresponding to each of the shards and then using a hashing algorithm to determine which host receives a given update.
Implementing failure recovery
Read replica promotion can be used as a data recovery scheme if the primary DB instance fails.
Read Replicas Multi-AZ
RDS read replicas can be Multi-AZ and we can have read-only standby instances in a different AZ.
Read Replicas is currently supported for MySQL, MariaDB, PostgreSQL, and Oracle database engines.
Read Replicas with Multi-AZ help build a resilient disaster recovery strategy and simplify the database engine upgrade process.
Read replica as Multi-AZ, allows you to use the read replica as a DR target providing automatic failover.
Also, when you promote the read replica to be a standalone database, it will already be Multi-AZ enabled.
Cross-Region Read Replicas
Supported for MySQL, PostgreSQL, MariaDB, and Oracle.
Not supported for SQL Server
Cross-Region Read Replicas help to improve
disaster recovery capabilities (reduces RTO and RPO),
scale read operations into a region closer to end users,
migration from a data center in one region to another region
A source DB instance can have cross-region read replicas in multiple AWS Regions.
Cross-Region RDS read replica can be created from a source RDS DB instance that is not a read replica of another RDS DB instance.
Replica lags are higher for Cross-region replicas. This lag time comes from the longer network channels between regional data centers.
RDS can’t guarantee more than five cross-region read replica instances, due to the limit on the number of access control list (ACL) entries for a VPC
Read Replica uses the default DB parameter group and DB option group for the specified DB engine.
Read Replica uses the default security group.
Deleting the source for a cross-Region read replica will result in
read replica promotion for MariaDB, MySQL, and Oracle DB instances
no read replica promotion for PostgreSQL DB instances and the replication status of the read replica is set to terminated.
Read Replica Features & Limitations
RDS does not support circular replication.
DB instance cannot be configured to serve as a replication source for an existing DB instance; a new Read Replica can be created only from an existing DB instance for e.g., if MyDBInstance replicates to ReadReplica1, ReadReplica1 can’t be configured to replicate back to MyDBInstance. From ReadReplica1, only a new Read Replica can be created, such as ReadRep2.
Read Replica can be created from other Read replicas as well. However, the replica lag is higher for these instances and there cannot be more than four instances involved in a replication chain.
RDS Read Replicas Use Cases
Scaling beyond the compute or I/O capacity of a single DB instance for read-heavy database workloads, directing excess read traffic to Read Replica(s)
Serving read traffic while the source DB instance is unavailable for e.g. If the source DB instance cannot take I/O requests due to backups I/O suspension or scheduled maintenance, the read traffic can be directed to the Read Replica(s). However, the data might be stale.
Business reporting or data warehousing scenarios where business reporting queries can be executed against a Read Replica, rather than the primary, production DB instance.
Implementing disaster recovery by promoting the read replica to a standalone instance as a disaster recovery solution, if the primary DB instance fails.
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You are running a successful multi-tier web application on AWS and your marketing department has asked you to add a reporting tier to the application. The reporting tier will aggregate and publish status reports every 30 minutes from user-generated information that is being stored in your web applications database. You are currently running a Multi-AZ RDS MySQL instance for the database tier. You also have implemented ElastiCache as a database caching layer between the application tier and database tier. Please select the answer that will allow you to successfully implement the reporting tier with as little impact as possible to your database.
Continually send transaction logs from your master database to an S3 bucket and generate the reports off the S3 bucket using S3 byte range requests.
Generate the reports by querying the synchronously replicated standby RDS MySQL instance maintained through Multi-AZ (Standby instance cannot be used as a scaling solution)
Launch a RDS Read Replica connected to your Multi-AZ master database and generate reports by querying the Read Replica.
Generate the reports by querying the ElastiCache database caching tier. (ElasticCache does not maintain full data and is simply a caching solution)
Your company is getting ready to do a major public announcement of a social media site on AWS. The website is running on EC2 instances deployed across multiple Availability Zones with a Multi-AZ RDS MySQL Extra Large DB Instance. The site performs a high number of small reads and writes per second and relies on an eventual consistency model. After comprehensive tests you discover that there is read contention on RDS MySQL. Which are the best approaches to meet these requirements? (Choose 2 answers)
Deploy ElastiCache in-memory cache running in each availability zone
Implement sharding to distribute load to multiple RDS MySQL instances (this is only a read contention, the writes work fine)
Increase the RDS MySQL Instance size and Implement provisioned IOPS (not scalable, this is only a read contention, the writes work fine)
Add an RDS MySQL read replica in each availability zone
Your company has HQ in Tokyo and branch offices all over the world and is using logistics software with a multi-regional deployment on AWS in Japan, Europe and US. The logistic software has a 3-tier architecture and currently uses MySQL 5.6 for data persistence. Each region has deployed its own database. In the HQ region you run an hourly batch process reading data from every region to compute cross-regional reports that are sent by email to all offices this batch process must be completed as fast as possible to quickly optimize logistics. How do you build the database architecture in order to meet the requirements?
For each regional deployment, use RDS MySQL with a master in the region and a read replica in the HQ region
For each regional deployment, use MySQL on EC2 with a master in the region and send hourly EBS snapshots to the HQ region
For each regional deployment, use RDS MySQL with a master in the region and send hourly RDS snapshots to the HQ region
For each regional deployment, use MySQL on EC2 with a master in the region and use S3 to copy data files hourly to the HQ region
Use Direct Connect to connect all regional MySQL deployments to the HQ region and reduce network latency for the batch process
Your business is building a new application that will store its entire customer database on a RDS MySQL database, and will have various applications and users that will query that data for different purposes. Large analytics jobs on the database are likely to cause other applications to not be able to get the query results they need to, before time out. Also, as your data grows, these analytics jobs will start to take more time, increasing the negative effect on the other applications. How do you solve the contention issues between these different workloads on the same data?
Enable Multi-AZ mode on the RDS instance
Use ElastiCache to offload the analytics job data
Create RDS Read-Replicas for the analytics work
Run the RDS instance on the largest size possible
If I have multiple Read Replicas for my master DB Instance and I promote one of them, what happens to the rest of the Read Replicas?
The remaining Read Replicas will still replicate from the older master DB Instance
The remaining Read Replicas will be deleted
The remaining Read Replicas will be combined to one read replica
You need to scale an RDS deployment. You are operating at 10% writes and 90% reads, based on your logging. How best can you scale this in a simple way?
Create a second master RDS instance and peer the RDS groups.
Cache all the database responses on the read side with CloudFront.
Create read replicas for RDS since the load is mostly reads.
Create a Multi-AZ RDS installs and route read traffic to standby.
A customer is running an application in US-West (Northern California) region and wants to setup disaster recovery failover to the Asian Pacific (Singapore) region. The customer is interested in achieving a low Recovery Point Objective (RPO) for an Amazon RDS multi-AZ MySQL database instance. Which approach is best suited to this need?
Synchronous replication
Asynchronous replication
Route53 health checks
Copying of RDS incremental snapshots
A user is using a small MySQL RDS DB. The user is experiencing high latency due to the Multi AZ feature. Which of the below mentioned options may not help the user in this situation?
Schedule the automated back up in non-working hours
Use a large or higher size instance
Use PIOPS
Take a snapshot from standby Replica
My Read Replica appears “stuck” after a Multi-AZ failover and is unable to obtain or apply updates from the source DB Instance. What do I do?
You will need to delete the Read Replica and create a new one to replace it.
You will need to disassociate the DB Engine and re associate it.
The instance should be deployed to Single AZ and then moved to Multi- AZ once again
You will need to delete the DB Instance and create a new one to replace it.
A company is running a batch analysis every hour on their main transactional DB running on an RDS MySQL instance to populate their central Data Warehouse running on Redshift. During the execution of the batch their transactional applications are very slow. When the batch completes they need to update the top management dashboard with the new data. The dashboard is produced by another system running on-premises that is currently started when a manually-sent email notifies that an update is required The on-premises system cannot be modified because is managed by another team. How would you optimize this scenario to solve performance issues and automate the process as much as possible?
Replace RDS with Redshift for the batch analysis and SNS to notify the on-premises system to update the dashboard
Replace RDS with Redshift for the batch analysis and SQS to send a message to the on-premises system to update the dashboard
Create an RDS Read Replica for the batch analysis and SNS to notify me on-premises system to update the dashboard
Create an RDS Read Replica for the batch analysis and SQS to send a message to the on-premises system to update the dashboard.

 RDS Read Replicas Use Cases
RDS Read Replicas Use Cases