AWS Application Auto Scaling
- Application Auto Scaling is a web service for developers and system administrators who need a solution for automatically scaling their scalable resources for individual AWS services beyond Amazon EC2 Auto Scaling.
- Application Auto Scaling allows you to automatically scale your scalable resources according to conditions that you define.
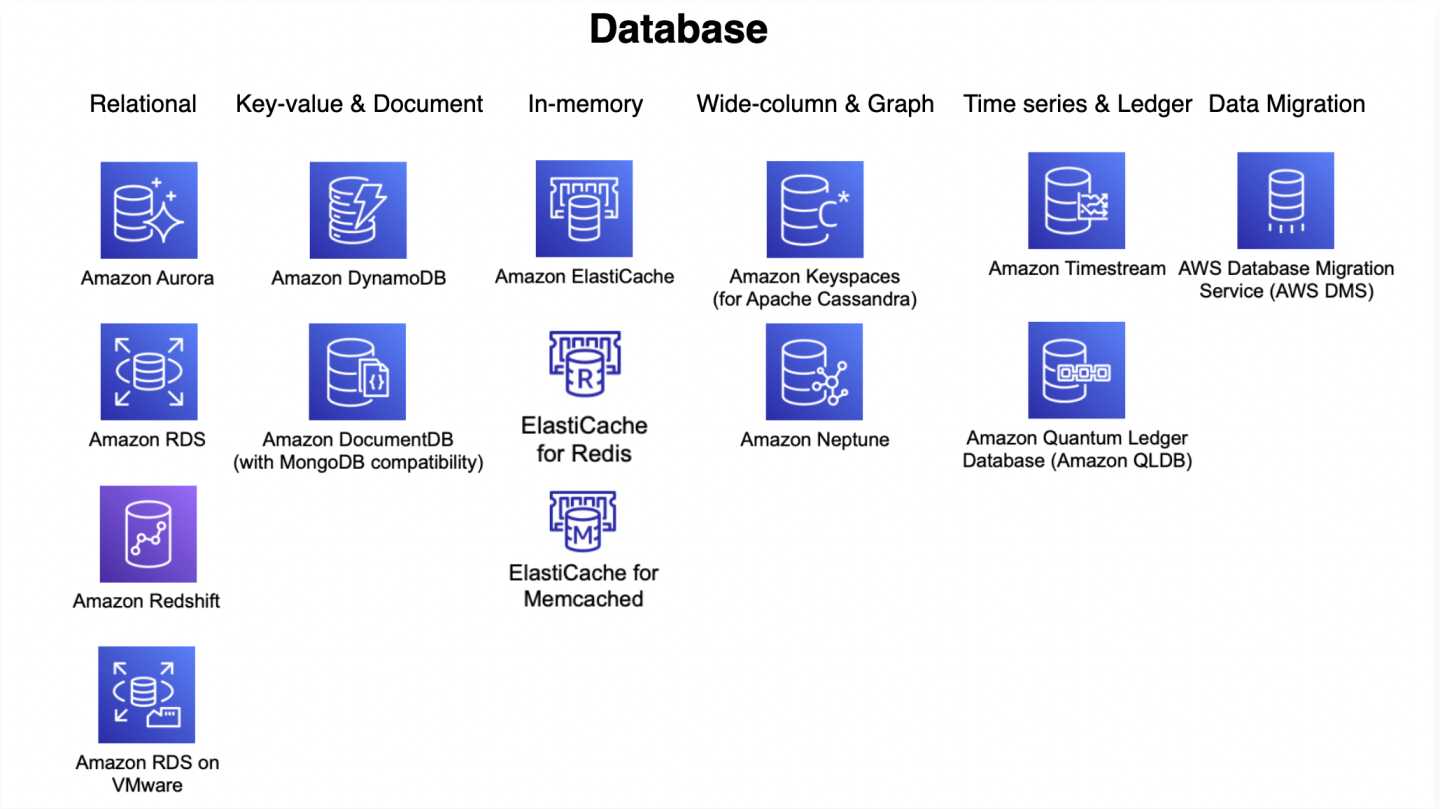
Supported Services
- Application Auto Scaling integrates with the following AWS services:
- Amazon WorkSpaces Applications (formerly AppStream 2.0) fleets
- Amazon Aurora replicas
- Amazon Comprehend document classification and entity recognizer endpoints
- Amazon DynamoDB tables and global secondary indexes
- Amazon ECS services
- Amazon ElastiCache replication groups (Redis OSS and Valkey) and Memcached clusters
- Amazon EMR clusters
- Amazon Keyspaces (for Apache Cassandra) tables
- AWS Lambda function provisioned concurrency
- Amazon MSK (Managed Streaming for Apache Kafka) broker storage
- Amazon Neptune clusters
- Amazon SageMaker AI endpoint variants, inference components, and Serverless provisioned concurrency
- Spot Fleet requests
- Amazon WorkSpaces pools
- Custom resources provided by your own applications or services
Scaling Policy Types
- Application Auto Scaling supports four types of scaling policies:
- Target Tracking Scaling – Scale a resource based on a target value for a specific CloudWatch metric.
- Step Scaling – Scale a resource based on a set of scaling adjustments that vary based on the size of the alarm breach.
- Scheduled Scaling – Scale a resource one time only or on a recurring schedule.
- Predictive Scaling – Scale a resource proactively to match anticipated load based on historical data using machine learning algorithms.
Predictive Scaling
- Predictive scaling uses machine learning algorithms to analyze historical metric data and forecast future demand.
- It looks at past load data from up to the past 14 days to analyze daily or weekly patterns in traffic flows.
- Generates an hourly forecast of capacity requirements for the next 48 hours.
- Proactively scales resources ahead of demand surges, reducing overprovisioning costs while improving application responsiveness.
- Predictive scaling is currently supported on Amazon ECS services (launched November 2024).
- Predictive scaling can be used in combination with other scaling policies (e.g., target tracking) for comprehensive scaling coverage.
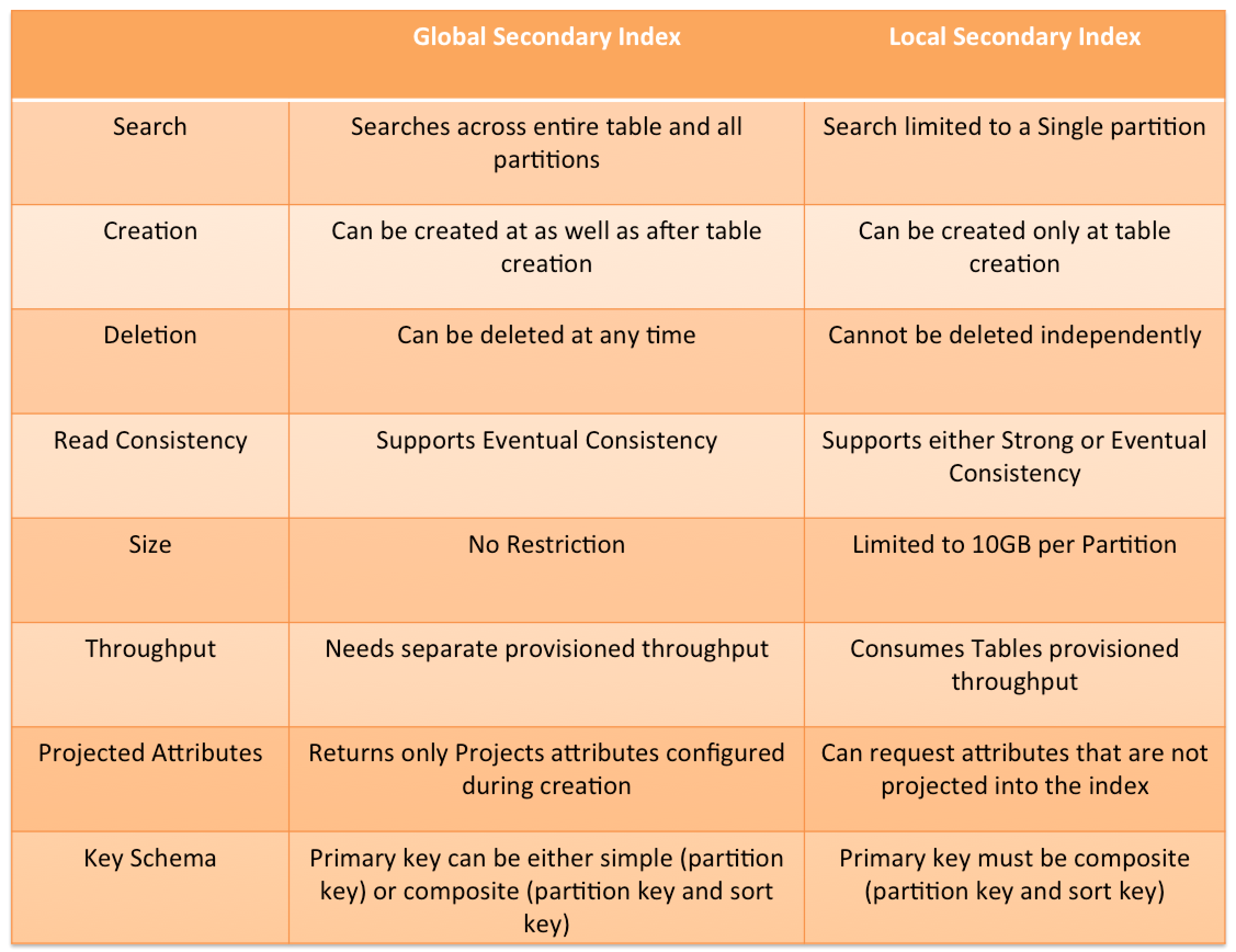
DynamoDB Auto Scaling
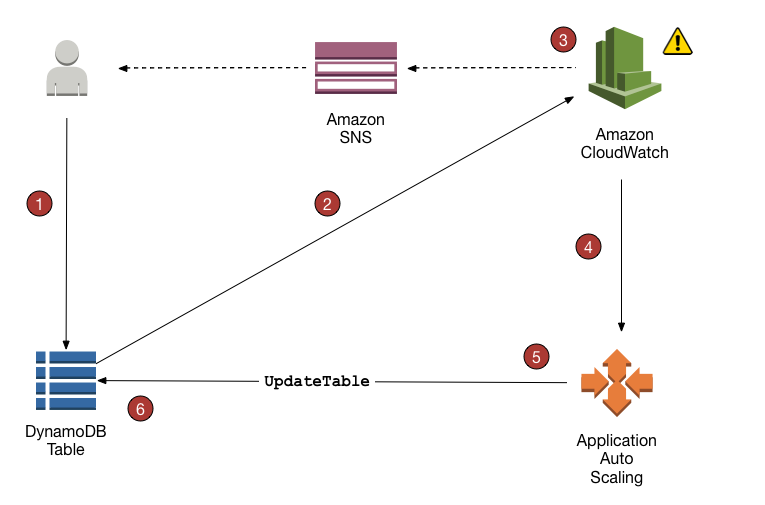
- DynamoDB tables and global secondary indexes can be scaled using target tracking scaling policies and scheduled scaling.
- DynamoDB Auto Scaling helps dynamically adjust provisioned throughput capacity on your behalf, in response to actual traffic patterns.
- DynamoDB Auto Scaling enables a table or a global secondary index to increase its provisioned read and write capacity to handle sudden increases in traffic, without throttling.
- When the workload decreases, Application Auto Scaling decreases the throughput so that you don’t pay for unused provisioned capacity.
Aurora Auto Scaling
- Aurora DB clusters can be scaled using target tracking scaling policies, step scaling policies, and scheduled scaling.
- Aurora Auto Scaling dynamically adjusts the number of Aurora Replicas provisioned for an Aurora DB cluster using single-master replication.
- Aurora Auto Scaling helps add read replicas with min and max replica count based on scaling CloudWatch CPU or connections metrics condition.
- Aurora Auto Scaling enables the Aurora DB cluster to handle sudden increases in connectivity or workload.
- As the workload decreases, Aurora Auto Scaling removes unnecessary Aurora Replicas so that you don’t pay for unused provisioned DB instances.
ECS Service Auto Scaling
- Amazon ECS services can be scaled using target tracking scaling policies, step scaling policies, predictive scaling policies, and scheduled scaling.
- ECS service auto scaling automatically adjusts the desired count of tasks in an ECS service based on CloudWatch metrics such as CPU utilization, memory utilization, or request count per target.
- Supports custom metrics such as queue depth for scaling decisions.
- Predictive Scaling (November 2024) – Leverages advanced machine learning algorithms to proactively scale ECS services ahead of demand surges based on historical traffic patterns.
- ECS Cluster Auto Scaling works with capacity providers to manage the underlying EC2 instances in the cluster.
Lambda Auto Scaling
- AWS Lambda provisioned concurrency can be scaled using target tracking scaling policies and scheduled scaling.
- Helps maintain a pool of pre-initialized execution environments ready to respond immediately to function invocations.
- Target tracking can scale based on the provisioned concurrency utilization metric.
ElastiCache Auto Scaling
- Amazon ElastiCache replication groups (Redis OSS and Valkey) and Memcached self-designed clusters can be horizontally scaled using target tracking scaling policies and scheduled scaling.
- Automatically increases or decreases the desired shards or replicas to optimize performance or cost.
- ElastiCache Serverless provides automatic scaling without managing clusters, scaling capacity up or down based on workload demands.
- Supports console access for both scaling policies and scheduled scaling configuration.
SageMaker AI Auto Scaling
- Amazon SageMaker AI endpoint variants, inference components, and Serverless provisioned concurrency can be scaled using target tracking scaling policies, step scaling policies, and scheduled scaling.
- Scale Down to Zero (November 2024) – Endpoints can automatically scale to zero instances when not in use and scale back up when traffic resumes, reducing costs for intermittent workloads.
- Faster Auto Scaling for Generative AI (July 2024) – Sub-minute CloudWatch metrics enable up to 6x faster scale-out detection for generative AI models.
- Container Caching (December 2024) – Stores container images and model artifacts on running instances, reducing scaling latency by up to 56% for new model copies.
- Capacity-Aware Inference (April 2026) – Automatic instance fallback when preferred instance types have insufficient capacity, keeping autoscaling running smoothly.
- Supports multi-model endpoints with automatic scaling of model replicas based on traffic patterns.
Neptune Auto Scaling
- Amazon Neptune clusters can be scaled by automatically adding or removing read replicas in response to changes in performance metrics.
- Neptune auto scaling works with Amazon CloudWatch to continuously monitor performance metrics of read replicas.
- Supports up to 15 Neptune replicas in a DB cluster for read scaling.
- Uses target tracking scaling policies based on CPU utilization or connections metrics.
Amazon Keyspaces Auto Scaling
- Amazon Keyspaces (for Apache Cassandra) tables can be scaled using target tracking scaling policies and scheduled scaling.
- Automatically adjusts read and write capacity of tables to handle traffic changes without throttling.
Amazon MSK Auto Scaling
- Amazon Managed Streaming for Apache Kafka (MSK) broker storage can be scaled using target tracking scaling policies.
- Automatically increases broker storage capacity when utilization reaches a defined threshold.
EC2 Auto Scaling
- EC2 Auto Scaling ensures a correct number of EC2 instances are always running to handle the load of the application.
- Auto Scaling helps
- to achieve better fault tolerance, better availability, and cost management.
- helps specify scaling policies that can be used to launch and terminate EC2 instances to handle any increase or decrease in demand.
- Auto Scaling attempts to distribute instances evenly between the AZs that are enabled for the Auto Scaling group.
- Auto Scaling does this by attempting to launch new instances in the AZ with the fewest instances. If the attempt fails, it attempts to launch the instances in another AZ until it succeeds.
- Note: EC2 Auto Scaling uses Auto Scaling groups and is separate from Application Auto Scaling, which handles scaling for other AWS services.
WorkSpaces Applications Auto Scaling
- Amazon WorkSpaces Applications (formerly AppStream 2.0) fleets can be scaled using target tracking scaling policies, step scaling policies, and scheduled scaling.
- Fleet Auto Scaling automatically adjusts the size of Always-On or On-Demand fleets to match the supply of available instances to user demand.
- Supports multi-session fleets where more than one user can use a single instance.
- Elastic fleets have capacity automatically managed without requiring auto scaling rules.
- Supports console access for both scaling policies and scheduled scaling configuration.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- A company runs an application on Amazon ECS with fluctuating traffic that has predictable daily patterns. The application experiences slow response times during morning traffic spikes because scaling policies react too slowly. Which scaling approach should the Solutions Architect recommend?
- Use step scaling with lower thresholds
- Use target tracking scaling with reduced cooldown period
- Use predictive scaling to proactively scale ECS tasks based on historical patterns
- Increase the minimum number of tasks to handle peak load at all times
Answer: c. Predictive scaling uses ML algorithms to analyze historical traffic patterns and proactively scale ECS services ahead of demand surges.
- Which of the following are valid scaling policy types supported by AWS Application Auto Scaling? (Choose 3)
- Target Tracking Scaling
- Simple Scaling
- Step Scaling
- Predictive Scaling
- Proportional Scaling
Answer: a, c, d. Application Auto Scaling supports Target Tracking, Step Scaling, Scheduled Scaling, and Predictive Scaling. Simple Scaling is only for EC2 Auto Scaling groups.
- A machine learning team wants to reduce costs for their SageMaker AI inference endpoints that receive intermittent traffic with long idle periods. Which feature should they use?
- Use Spot Instances for inference
- Configure Scale Down to Zero for SageMaker inference endpoints
- Use scheduled scaling to turn off endpoints during idle hours
- Switch to Lambda for inference
Answer: b. SageMaker AI Scale Down to Zero (launched November 2024) allows endpoints to automatically scale to zero instances when not in use and scale back up when traffic resumes.
- Which AWS services can be scaled using Application Auto Scaling? (Choose 3)
- Amazon DynamoDB tables
- Amazon EC2 instances in an Auto Scaling group
- Amazon ECS services
- Amazon ElastiCache replication groups
- Amazon S3 storage
Answer: a, c, d. Application Auto Scaling supports DynamoDB, ECS, and ElastiCache among others. EC2 Auto Scaling groups use Amazon EC2 Auto Scaling (separate service). S3 does not use auto scaling.
- A company uses Amazon Aurora with read-heavy workloads that vary throughout the day. They want to automatically add and remove read replicas based on CPU utilization. Which approach should they use?
- Configure Aurora Auto Scaling with a target tracking policy on CPU utilization
- Use AWS Lambda to monitor CPU and add replicas
- Set up CloudWatch alarms to trigger SNS notifications for manual scaling
- Use Aurora Serverless which automatically scales compute
Answer: a. Aurora Auto Scaling through Application Auto Scaling supports target tracking policies based on CPU utilization or connections to dynamically adjust the number of Aurora Replicas.
- How does Application Auto Scaling predictive scaling determine future capacity needs?
- It uses fixed schedules defined by the administrator
- It analyzes historical metric data from up to the past 14 days to identify daily or weekly patterns
- It only monitors current metrics and reacts to breaches
- It requires manual input of expected traffic patterns
Answer: b. Predictive scaling analyzes metric data from up to the past 14 days to identify patterns and generates an hourly forecast of capacity requirements for the next 48 hours.