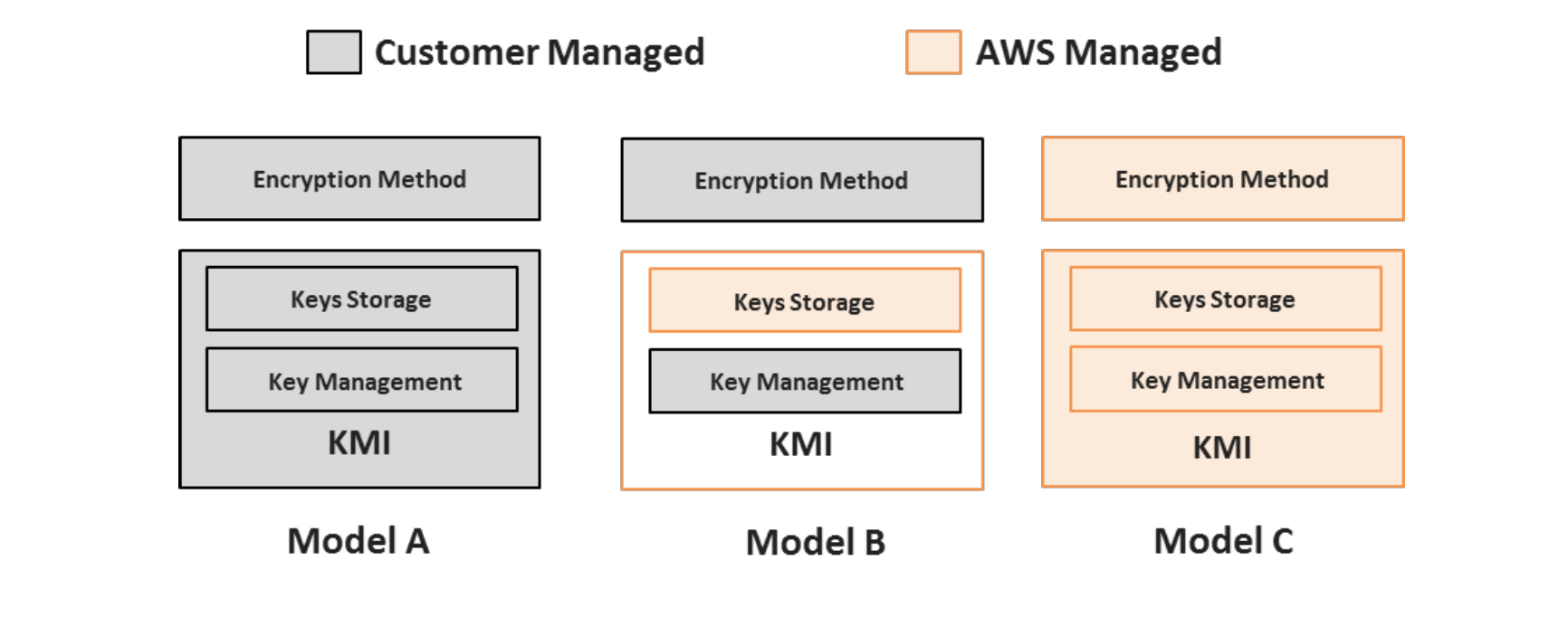
Amazon S3
- highly-scalable, reliable, and low-latency data storage infrastructure at very low costs.
- provides a simple web services interface that can be used to store and retrieve any amount of data, at any time, from within Amazon EC2 or from anywhere on the web.
- allows you to write, read, and delete objects containing from 1 byte to 5 terabytes of data each.
- number of objects you can store in an Amazon S3 bucket is virtually unlimited.
- highly secure, supporting encryption at rest, and providing multiple mechanisms to provide fine-grained control of access to Amazon S3 resources.
- highly scalable, allowing concurrent read or write access to Amazon S3 data by many separate clients or application threads.
- provides data lifecycle management capabilities, allowing users to define rules to automatically archive Amazon S3 data to Amazon Glacier, or to delete data at end of life.
Ideal Use Cases
- Storage & Distribution of static web content and media
- frequently used to host static websites and provides a highly-available and highly-scalable solution for websites with only static content, including HTML files, images, videos, and client-side scripts such as JavaScript
- works well for fast growing websites hosting data intensive, user-generated content, such as video and photo sharing sites as no storage provisioning is required
- content can either be directly served from Amazon S3 since each object in Amazon S3 has a unique HTTP URL address
- can also act as an Origin store for the Content Delivery Network (CDN) such as Amazon CloudFront
- it works particularly well for hosting web content with extremely spiky bandwidth demands because of S3’s elasticity
- Data Store for Large Objects
- can be paired with RDS or NoSQL database and used to store large objects for e.g. file or objects, while the associated metadata for e.g. name, tags, comments etc. can be stored in RDS or NoSQL database where it can be indexed and queried providing faster access to relevant data
- Data store for computation and large-scale analytics
- commonly used as a data store for computation and large-scale analytics, such as analyzing financial transactions, clickstream analytics, and media transcoding.
- data can be accessed from multiple computing nodes concurrently without being constrained by a single connection because of its horizontal scalability
- Backup and Archival of critical data
- used as a highly durable, scalable, and secure solution for backup and archival of critical data, and to provide disaster recovery solutions for business continuity.
- stores objects redundantly on multiple devices across multiple facilities, it provides the highly-durable storage infrastructure needed for these scenarios.
- it’s versioning capability is available to protect critical data from inadvertent deletion
Anti-Patterns
Amazon S3 has following Anti-Patterns where it is not an optimal solution
- Dynamic website hosting
- While Amazon S3 is ideal for hosting static websites, dynamic websites requiring server side interaction, scripting or database interaction cannot be hosted and should rather be hosted on Amazon EC2
- Backup and archival storage
- Data requiring long term archival storage with infrequent read access can be stored more cost effectively in Amazon Glacier
- Structured Data Query
- Amazon S3 doesn’t offer query capabilities, so to read an object the object name and key must be known. Instead pair up S3 with RDS or Dynamo DB to store, index and query metadata about Amazon S3 objects
- NOTE – S3 now provides query capabilities and also Athena can be used
- Rapidly Changing Data
- Data that needs to updated frequently might be better served by a storage solution with lower read/write latencies, such as Amazon EBS volumes, RDS or Dynamo DB.
- File System
- Amazon S3 uses a flat namespace and isn’t meant to serve as a standalone, POSIX-compliant file system. However, by using delimiters (commonly either the ‘/’ or ‘’ character) you are able construct your keys to emulate the hierarchical folder structure of file system within a given bucket.
Performance
- Access to Amazon S3 from within Amazon EC2 in the same region is fast.
- Amazon S3 is designed so that server-side latencies are insignificant relative to Internet latencies.
- Amazon S3 is also built to scale storage, requests, and users to support a virtually unlimited number of web-scale applications.
- If Amazon S3 is accessed using multiple threads, multiple applications, or multiple clients concurrently, total Amazon S3 aggregate throughput will typically scale to rates that far exceed what any single server can generate or consume.
Durability & Availability
- Amazon S3 storage provides provides the highest level of data durability and availability, by automatically and synchronously storing your data across both multiple devices and multiple facilities within the selected geographical region
- Error correction is built-in, and there are no single points of failure. Amazon S3 is designed to sustain the concurrent loss of data in two facilities, making it very well-suited to serve as the primary data storage for mission-critical data.
- Amazon S3 is designed for 99.999999999% (11 nines) durability per object and 99.99% availability over a one-year period.
- Amazon S3 data can be protected from unintended deletions or overwrites using Versioning.
- Versioning can be enabled with MFA (Multi Factor Authentication) Delete on the bucket, which would require two forms of authentication to delete an object
- For Non Critical and Reproducible data for e.g. thumbnails, transcoded media etc., S3 Reduced Redundancy Storage (RRS) can be used, which provides a lower level of durability at a lower storage cost
- RRS is designed to provide 99.99% durability per object over a given year. While RRS is less durable than standard Amazon S3, it is still designed to provide 400 times more durability than a typical disk drive
Cost Model
- With Amazon S3, you pay only for what you use and there is no minimum fee.
- Amazon S3 has three pricing components: storage (per GB per month), data transfer in or out (per GB per month), and requests (per n thousand requests per month).
Scalability & Elasticity
- Amazon S3 has been designed to offer a very high level of scalability and elasticity automatically
- Amazon S3 supports a virtually unlimited number of files in any bucket
- Amazon S3 bucket can store a virtually unlimited number of bytes
- Amazon S3 allows you to store any number of objects (files) in a single bucket, and Amazon S3 will automatically manage scaling and distributing redundant copies of your information to other servers in other locations in the same region, all using Amazon’s high-performance infrastructure.
Interfaces
- Amazon S3 provides standards-based REST and
SOAP web servicesAPIs for both management and data operations. - NOTE – SOAP support over HTTP is deprecated, but it is still available over HTTPS. New Amazon S3 features will not be supported for SOAP. We recommend that you use either the REST API or the AWS SDKs.
- Amazon S3 provides easier to use higher level toolkit or SDK in different languages (Java, .NET, PHP, and Ruby) that wraps the underlying APIs
- Amazon S3 Command Line Interface (CLI) provides a set of high-level, Linux-like Amazon S3 file commands for common operations, such as ls, cp, mv, sync, etc. They also provide the ability to perform recursive uploads and downloads using a single folder-level Amazon S3 command, and supports parallel transfers.
- AWS Management Console provides the ability to easily create and manage Amazon S3 buckets, upload and download objects, and browse the contents of your Amazon S3 buckets using a simple web-based user interface
- All interfaces provide the ability to store Amazon S3 objects (files) in uniquely-named buckets (top-level folders), with each object identified by an unique Object key within that bucket.
Glacier
- extremely low-cost storage service that provides highly secure, durable, and flexible storage for data backup and archival
- can reliably store their data for as little as $0.01 per gigabyte per month.
- to offload the administrative burdens of operating and scaling storage to AWS such as capacity planning, hardware provisioning, data replication, hardware failure detection and repair, or time consuming hardware migrations
- Data is stored in Amazon Glacier as Archives where an archive can represent a single file or multiple files combined into a single archive
- Archives are stored in Vaults for which the access can be controlled through IAM
- Retrieving archives from Vaults require initiation of a job and can take anywhere around 3-5 hours
- Amazon Glacier integrates seamlessly with Amazon S3 by using S3 data lifecycle management policies to move data from S3 to Glacier
- AWS Import/Export can also be used to accelerate moving large amounts of data into Amazon Glacier using portable storage devices for transport
Ideal Usage Patterns
- Amazon Glacier is ideally suited for long term archival solution for infrequently accessed data with archiving offsite enterprise information, media assets, research and scientific data, digital preservation and magnetic tape replacement
Anti-Patterns
Amazon Glacier has following Anti-Patterns where it is not an optimal solution
- Rapidly changing data
- Data that must be updated very frequently might be better served by a storage solution with lower read/write latencies such as Amazon EBS or a Database
- Real time access
- Data stored in Glacier can not be accessed at real time and requires an initiation of a job for object retrieval with retrieval times ranging from 3-5 hours. If immediate access is needed, Amazon S3 is a better choice.
Performance
- Amazon Glacier is a low-cost storage service designed to store data that is infrequently accessed and long lived.
- Amazon Glacier jobs typically complete in 3 to 5 hours
Durability and Availability
- Amazon Glacier redundantly stores data in multiple facilities and on multiple devices within each facility
- Amazon Glacier is designed to provide average annual durability of 99.999999999% (11 nines) for an archive
- Amazon Glacier synchronously stores your data across multiple facilities before returning SUCCESS on uploading archives.
- Amazon Glacier also performs regular, systematic data integrity checks and is built to be automatically self-healing.
Cost Model
- Amazon Glacier has three pricing components: storage (per GB per month), data transfer out (per GB per month), and requests (per thousand UPLOAD and RETRIEVAL requests per month).
- Amazon Glacier is designed with the expectation that retrievals are infrequent and unusual, and data will be stored for extended periods of time and allows you to retrieve up to 5% of your average monthly storage (pro-rated daily) for free each month. Any additional amount of data retrieved is charged per GB
- Amazon Glacier also charges a pro-rated charge (per GB) for items deleted prior to 90 days
Scalability & Elasticity
- A single archive is limited to 40 TBs, but there is no limit to the total amount of data you can store in the service.
- Amazon Glacier scales to meet your growing and often unpredictable storage requirements whether you’re storing petabytes or gigabytes, Amazon Glacier automatically scales your storage up or down as needed.
Interfaces
- Amazon Glacier provides a native, standards-based REST web services interface, as well as Java and .NET SDKs.
- AWS Management Console or the Amazon Glacier APIs can be used to create vaults to organize the archives in Amazon Glacier.
- Amazon Glacier APIs can be used to upload and retrieve archives, monitor the status of your jobs and also configure your vault to send you a notification via Amazon Simple Notification Service (Amazon SNS) when your jobs complete.
- Amazon Glacier can be used as a storage class in Amazon S3 by using object lifecycle management to provide automatic, policy-driven archiving from Amazon S3 to Amazon Glacier.
- Amazon S3 api provides a RESTORE operation and the retrieval process takes the same 3-5 hours
- On retrieval, a copy of the retrieved object is placed in Amazon S3 RRS storage for a specified retention period; the original archived object remains stored in Amazon Glacier and you are charged for both the storage.
- When using Amazon Glacier as a storage class in Amazon S3, use the Amazon S3 APIs, and when using “native” Amazon Glacier, you use the Amazon Glacier APIs
- Objects archived to Amazon Glacier via Amazon S3 can only be listed and retrieved via the Amazon S3 APIs or the AWS Management Console—they are not visible as archives in an Amazon Glacier vault.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- You want to pass queue messages that are 1GB each. How should you achieve this?
- Use Kinesis as a buffer stream for message bodies. Store the checkpoint id for the placement in the Kinesis Stream in SQS.
- Use the Amazon SQS Extended Client Library for Java and Amazon S3 as a storage mechanism for message bodies. (Amazon SQS messages with Amazon S3 can be useful for storing and retrieving messages with a message size of up to 2 GB. To manage Amazon SQS messages with Amazon S3, use the Amazon SQS Extended Client Library for Java. Refer link)
- Use SQS’s support for message partitioning and multi-part uploads on Amazon S3.
- Use AWS EFS as a shared pool storage medium. Store filesystem pointers to the files on disk in the SQS message bodies.
- Company ABCD has recently launched an online commerce site for bicycles on AWS. They have a “Product” DynamoDB table that stores details for each bicycle, such as, manufacturer, color, price, quantity and size to display in the online store. Due to customer demand, they want to include an image for each bicycle along with the existing details. Which approach below provides the least impact to provisioned throughput on the “Product” table?
- Serialize the image and store it in multiple DynamoDB tables
- Create an “Images” DynamoDB table to store the Image with a foreign key constraint to the “Product” table
- Add an image data type to the “Product” table to store the images in binary format
- Store the images in Amazon S3 and add an S3 URL pointer to the “Product” table item for each image