AWS Disaster Recovery Whitepaper
📋 Content Update Notice (June 2026)
This post has been updated to reflect the latest AWS DR whitepaper “Disaster Recovery of Workloads on AWS: Recovery in the Cloud” which replaces the original AWS Disaster Recovery whitepaper. Key updates include AWS Elastic Disaster Recovery (DRS), AWS Backup, AWS Resilience Hub, deprecation of OpsWorks and AWS Import/Export, and rebranding of Amazon Glacier to S3 Glacier storage classes.
AWS Disaster Recovery Whitepaper is one of the very important Whitepaper for both the Associate & Professional AWS Certification exam
Disaster Recovery Overview
- AWS Disaster Recovery whitepaper “Disaster Recovery of Workloads on AWS: Recovery in the Cloud” highlights AWS services and features that can be leveraged for disaster recovery (DR) processes to significantly minimize the impact on data, system, and overall business operations.
- It outlines best practices to improve your DR processes, from minimal investments to full-scale availability and fault tolerance, and describes how AWS services can be used to reduce cost and ensure business continuity during a DR event
- Disaster recovery (DR) is about preparing for and recovering from a disaster. Any event that has a negative impact on a company’s business continuity or finances could be termed a disaster. One of the AWS best practice is to always design your systems for failures
- Resiliency is a shared responsibility between AWS and the customer. AWS is responsible for “Resiliency of the Cloud” (infrastructure), while customers are responsible for “Resiliency in the Cloud” (workload architecture)
Disaster Recovery Key AWS services
- Region
- AWS services are available in multiple regions around the globe, and the DR site location can be selected as appropriate, in addition to the primary site location
- Each AWS Region is fully isolated and consists of multiple Availability Zones, which are physically isolated partitions of infrastructure
- All traffic between AZs is encrypted and interconnected with high-bandwidth, low-latency networking
- Storage
- Amazon S3
- provides a highly durable (99.999999999%) storage infrastructure designed for mission-critical and primary data storage.
- stores Objects redundantly on multiple devices across multiple facilities within a region
- supports cross-region replication for DR scenarios
- Amazon S3 Glacier Storage Classes (formerly Amazon Glacier)
- S3 Glacier Instant Retrieval – millisecond retrieval for archives that need immediate access
- S3 Glacier Flexible Retrieval (formerly S3 Glacier) – retrieval times of minutes to hours, suitable for backup data
- S3 Glacier Deep Archive – lowest cost storage, retrieval time of 12-48 hours for long-term archive
- Note: Amazon Glacier (original standalone vault-based service) no longer accepts new customers as of December 15, 2025. Use S3 Glacier storage classes instead.
- Amazon EBS
- provides the ability to create point-in-time snapshots of data volumes.
- Snapshots can then be used to create volumes and attached to running instances
- Snapshots can be copied across regions for cross-region DR
- AWS Storage Gateway
- a service that provides seamless and highly secure integration between on-premises IT environment and the storage infrastructure of AWS.
- Supports File Gateway (S3 File Gateway, FSx File Gateway), Volume Gateway (cached and stored), and Tape Gateway
- AWS Snow Family (formerly AWS Import/Export)
- accelerates moving large amounts of data into and out of AWS by using portable storage devices for transport bypassing the Internet
- ⚠️ Important: Effective November 7, 2025, AWS Snowball Edge devices are only available to existing customers. New customers should explore:
- AWS DataSync – for online data transfers
- AWS Data Transfer Terminal – secure physical locations for high-speed data upload using 100 GbE connections
- AWS Partner solutions – for specialized transfer needs
- AWS Backup
- Fully managed service that centralizes and automates data protection across AWS services and hybrid workloads
- Define central backup policies (backup plans) that work across compute, storage, and database services
- Supports cross-region and cross-account backup for DR
- Provides ransomware detection and recovery capabilities
- Includes compliance insights and analytics for data protection policies
- Amazon S3
- Compute
- Amazon EC2
- provides resizable compute capacity in the cloud which can be easily created and scaled.
- EC2 instance creation using Preconfigured AMIs
- EC2 instances can be launched in multiple AZs, which are engineered to be insulated from failures in other AZs
- Amazon EC2
- Networking
- Amazon Route 53
- is a highly available and scalable DNS web service
- includes a number of global load-balancing capabilities that can be effective when dealing with DR scenarios for e.g. DNS endpoint health checks and the ability to failover between multiple endpoints
- Amazon Route 53 Application Recovery Controller (ARC)
- Provides readiness checks and routing controls to manage application failover across AZs and Regions
- Zonal Shift – temporarily moves traffic away from an impaired Availability Zone within minutes
- Zonal Autoshift – AWS automatically shifts traffic away from an AZ when a potential failure is detected
- No additional charge for zonal autoshift
- Elastic IP
- addresses enables masking of instance or Availability Zone failures by programmatically remapping
- addresses are static IP addresses designed for dynamic cloud computing.
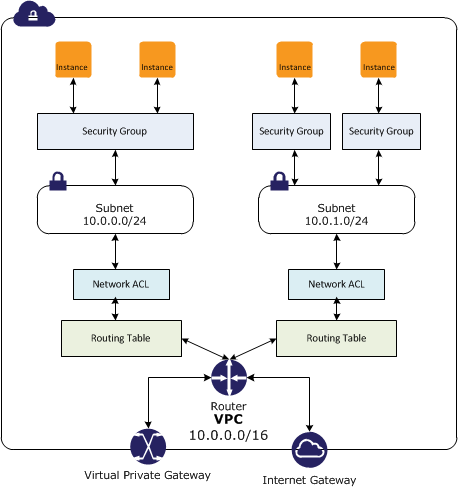
- Elastic Load Balancing (ELB)
- performs health checks and automatically distributes incoming application traffic across multiple EC2 instances
- Amazon Virtual Private Cloud (Amazon VPC)
- allows provisioning of a private, isolated section of the AWS cloud where resources can be launched in a defined virtual network
- Amazon Direct Connect
- makes it easy to set up a dedicated network connection from on-premises environment to AWS
- Amazon Route 53
- Databases
- RDS, DynamoDB, Redshift provided as a fully managed RDBMS, NoSQL and data warehouse solutions which can scale up easily
- DynamoDB offers global tables with multi-region, active-active replication
- RDS provides Multi-AZ and Read Replicas and also ability to snapshot data from one region to other
- Amazon Aurora Global Database provides cross-region replication with RPO typically measured in seconds and RTO in under a minute for failover
- Deployment Orchestration
- CloudFormation
- gives developers and systems administrators an easy way to create a collection of related AWS resources and provision them in an orderly and predictable fashion
- Infrastructure as Code (IaC) enables rapid re-creation of environments in DR regions
- Elastic Beanstalk
- is an easy-to-use service for deploying and scaling web applications and services
OpsWorks(EOL – May 26, 2024)- ⚠️ AWS OpsWorks reached End of Life on May 26, 2024 and has been disabled for both new and existing customers.
- The OpsWorks console, API, CLI, and CloudFormation resources have been discontinued in all AWS Regions.
- Migration alternatives: AWS Systems Manager, AWS CloudFormation, AWS CDK, or third-party tools like Ansible, Puppet, or Chef directly.
- CloudFormation
- Disaster Recovery Services
- AWS Elastic Disaster Recovery (AWS DRS)
- Minimizes downtime and data loss with fast, reliable recovery of on-premises and cloud-based applications
- Achieves RPOs in seconds and RTOs in minutes (typically 5-20 minutes)
- Uses lightweight staging environment with minimal resources to keep costs down
- Supports automated failover and failback
- Supports physical, VMware vSphere, Microsoft Hyper-V, and cloud infrastructure sources
- Provides point-in-time recovery capability for ransomware protection
- Supports servers with up to 60 volumes
- Supports AWS Outposts for on-premises recovery
- Note: AWS DRS replaced CloudEndure Disaster Recovery (CEDR), which was discontinued on March 31, 2024
- AWS Resilience Hub
- Central location to define resilience goals, assess resilience posture, and implement recommendations
- Continuously validates and tracks the resilience of AWS workloads
- Assesses whether RTO and RPO targets can be met
- Provides automated DR testing and compliance reporting
- Integrates with AWS Well-Architected Framework for improvement recommendations
- Next generation (GA May 2026) includes generative AI-based SRE resilience journey
- AWS Elastic Disaster Recovery (AWS DRS)
Key factors for Disaster Planning

Recovery Time Objective (RTO) – The time it takes after a disruption to restore a business process to its service level, as defined by the operational level agreement (OLA) for e.g. if the RTO is 1 hour and disaster occurs @ 12:00 p.m (noon), then the DR process should restore the systems to an acceptable service level within an hour i.e. by 1:00 p.m
Recovery Point Objective (RPO) – The acceptable amount of data loss measured in time before the disaster occurs. for e.g., if a disaster occurs at 12:00 p.m (noon) and the RPO is one hour, the system should recover all data that was in the system before 11:00 a.m.
Disaster Recovery Scenarios
- Disaster Recovery scenarios can be implemented with the Primary infrastructure running in your data center in conjunction with the AWS
- Disaster Recovery Scenarios still apply if Primary site is running in AWS using AWS multi region feature.
- Combination and variation of the below is always possible.
- Use AWS Resilience Hub to continuously validate and track the resilience of your workloads, including whether you are likely to meet your RTO and RPO targets.
Disaster Recovery Scenarios Options
- Backup & Restore (Data backed up and restored)
- Pilot Light (Only Minimal critical functionalities)
- Warm Standby (Fully Functional Scaled down version)
- Multi-Site Active/Active
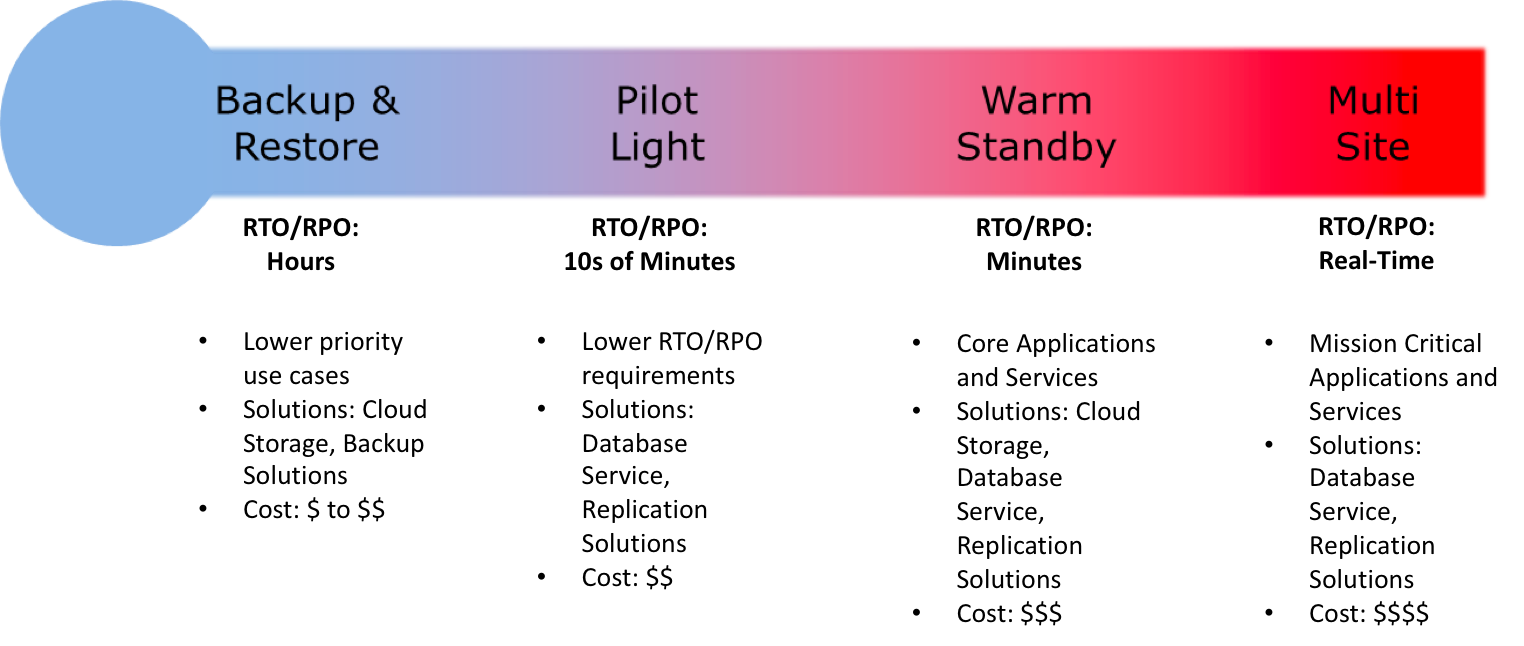
For the DR scenarios options, RTO and RPO reduces with an increase in Cost as you move from Backup & Restore option (left) to Multi-Site option (right)
Note: For a disaster event based on disruption or loss of one physical data center for a well-architected, highly available workload, you may only require a backup and restore approach. If your definition of a disaster goes beyond the disruption of a physical data center to that of a Region or if you are subject to regulatory requirements, then consider Pilot Light, Warm Standby, or Multi-Site Active/Active.
Backup & Restore
AWS can be used to backup the data in a cost effective, durable and secure manner as well as recover the data quickly and reliably.
Backup phase
In most traditional environments, data is backed up to tape and sent off-site regularly taking longer time to restore the system in the event of a disruption or disaster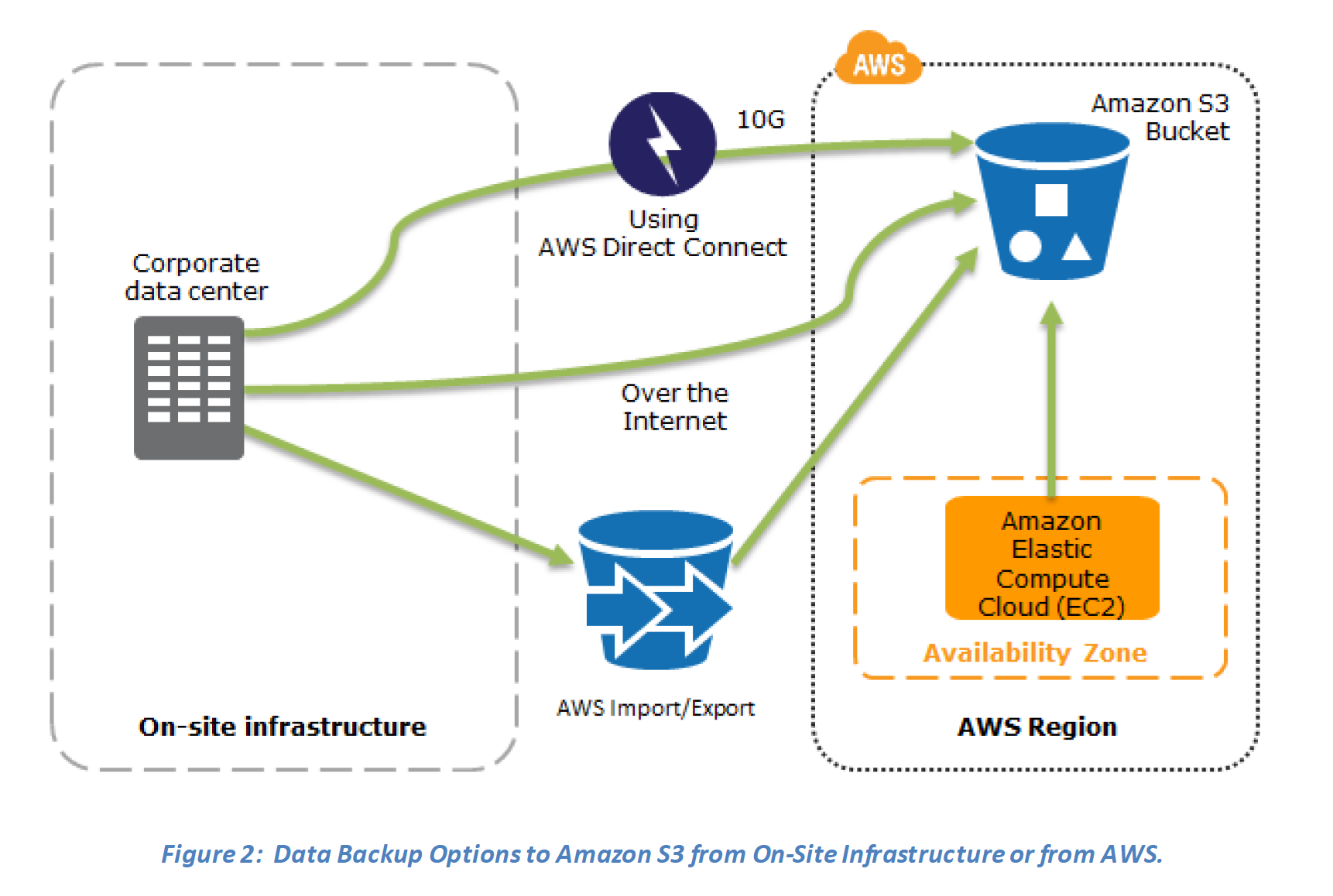
- Amazon S3 can be used to backup the data and perform a quick restore and is also available from any location
- AWS Snow Family (for existing customers) or AWS Data Transfer Terminal (for new customers) can be used to transfer large data sets bypassing the Internet
- Amazon S3 Glacier storage classes can be used for archiving data – use S3 Glacier Flexible Retrieval for hours or S3 Glacier Instant Retrieval for millisecond access
- AWS Storage Gateway enables snapshots (used to created EBS volumes) of the on-premises data volumes to be transparently copied into S3 for backup. It can be used either as a backup solution (Volume Gateway – stored volumes) or as a primary data store (Volume Gateway – cached volumes)
- AWS Direct Connect can be used to transfer data directly from On-Premise to Amazon consistently and at high speed
- Snapshots of Amazon EBS volumes, Amazon RDS databases, and Amazon Redshift data warehouses can be stored in Amazon S3
- AWS Backup can centrally manage backup policies across all AWS services with automated scheduling, retention management, and cross-region/cross-account copying
Restore phase
Data backed up then can be used to quickly restore and create Compute and Database instances
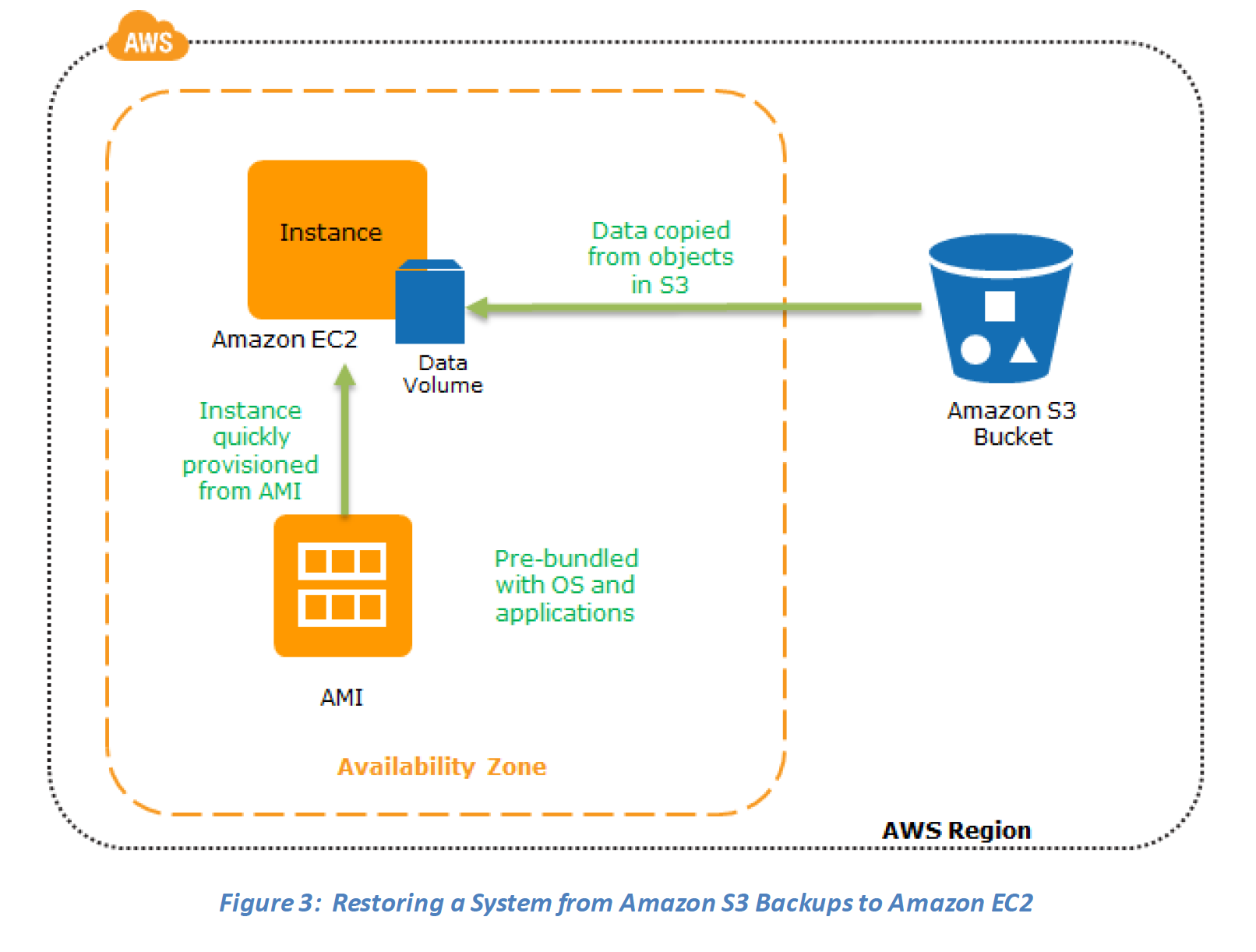 Key steps for Backup and Restore:
Key steps for Backup and Restore:
1. Select an appropriate tool or method to back up the data into AWS.
2. Ensure an appropriate retention policy for this data.
3. Ensure appropriate security measures are in place for this data, including encryption and access policies.
4. Regularly test the recovery of this data and the restoration of the system.
Pilot Light
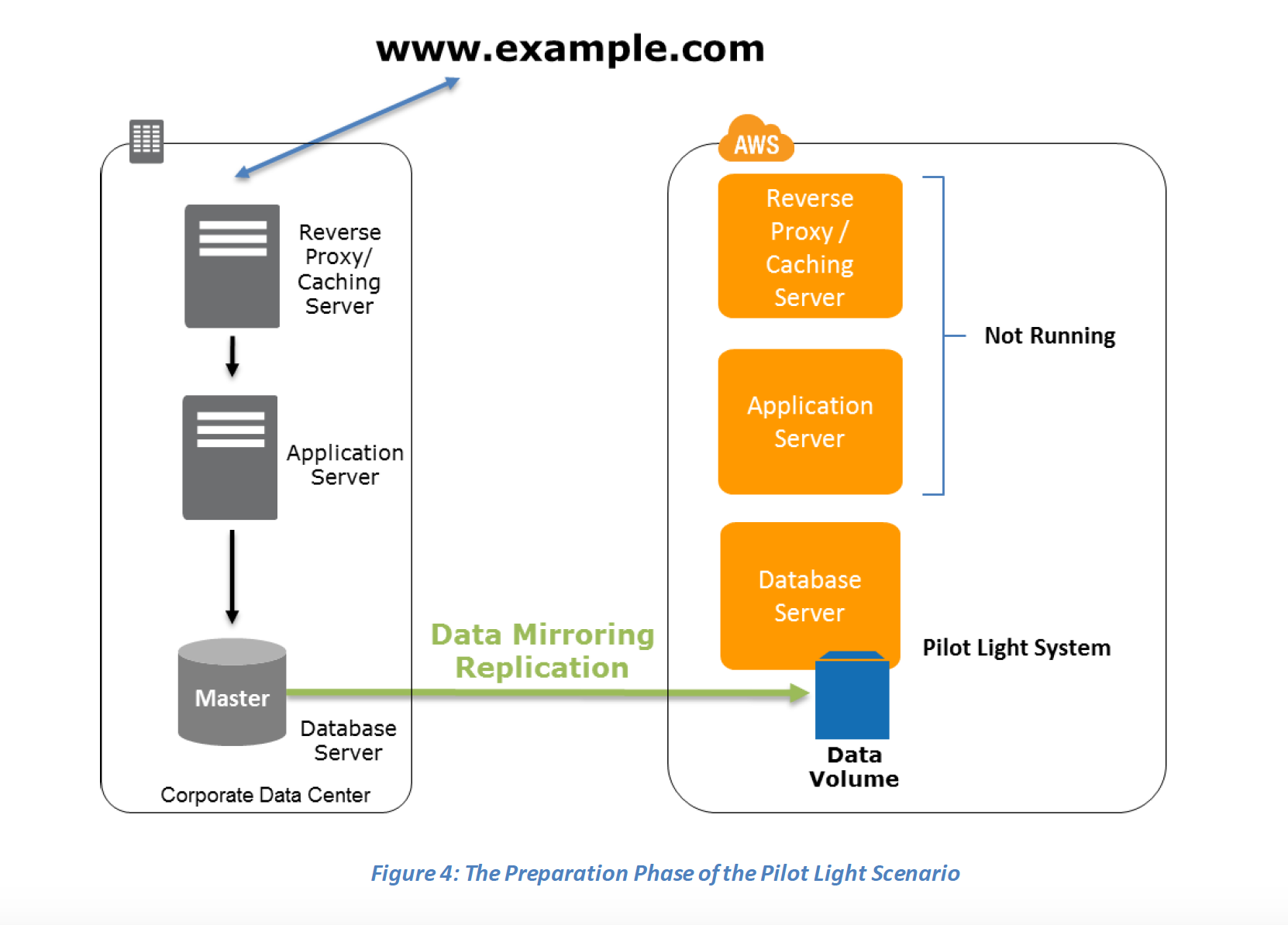
In a Pilot Light Disaster Recovery scenario option a minimal version of an environment is always running in the cloud, which basically host the critical functionalities of the application for e.g. databases
In this approach :-
- Maintain a pilot light by configuring and running the most critical core elements of your system in AWS for e.g. Databases where the data needs to be replicated and kept updated.
- During recovery, a full-scale production environment, for e.g. application and web servers, can be rapidly provisioned (using preconfigured AMIs and EBS volume snapshots) around the critical core
- For Networking, either a ELB to distribute traffic to multiple instances and have DNS point to the load balancer or preallocated Elastic IP address with instances associated can be used
- AWS Elastic Disaster Recovery (DRS) can automate the pilot light approach with continuous replication and rapid failover capabilities
- Set up Amazon EC2 instances or RDS instances to replicate or mirror data critical data
- Ensure that all supporting custom software packages available in AWS.
- Create and maintain AMIs of key servers where fast recovery is required.
- Regularly run these servers, test them, and apply any software updates and configuration changes.
- Consider automating the provisioning of AWS resources.
- Use AWS Resilience Hub to validate your DR posture and ensure RTO/RPO targets can be met.
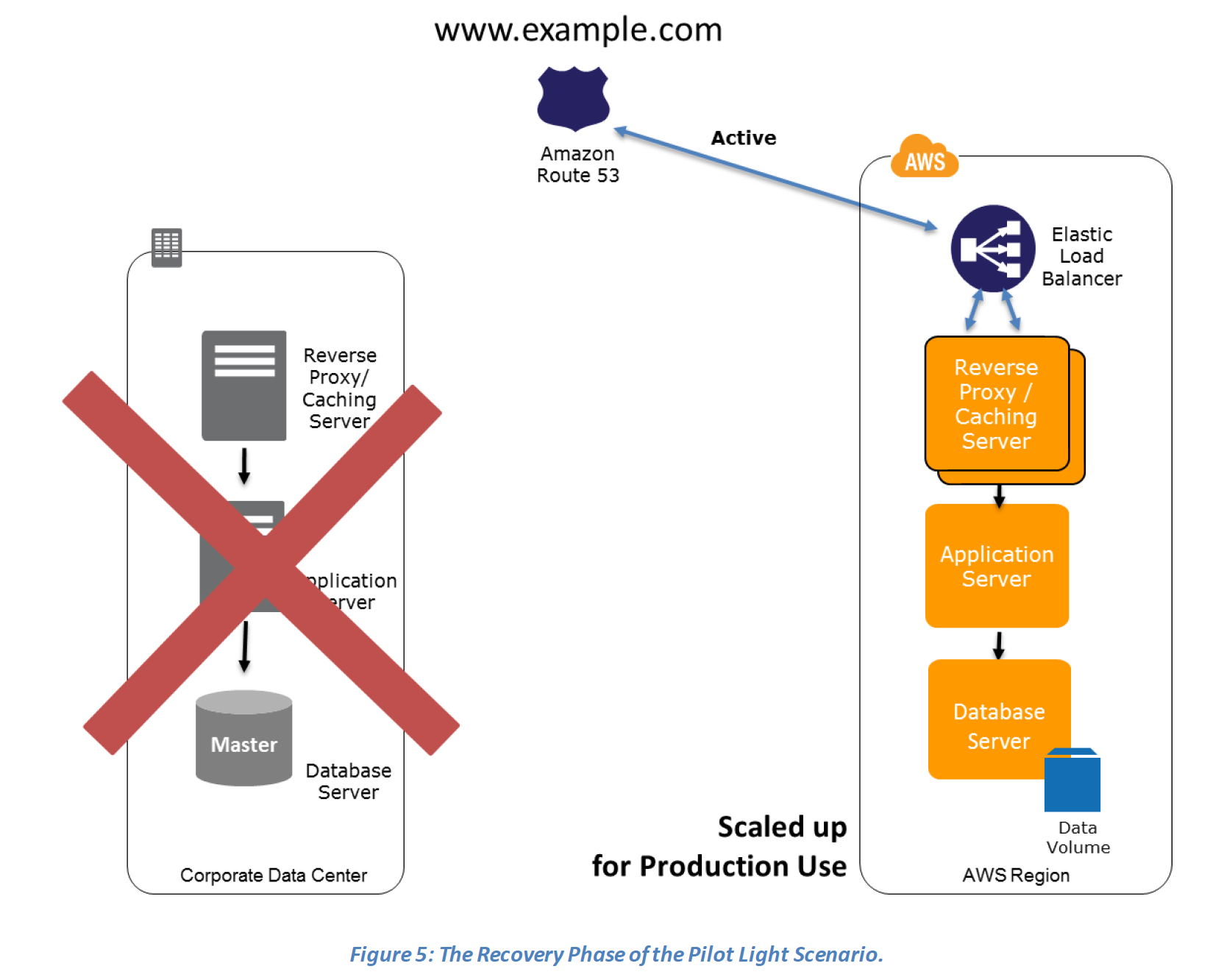
Recovery Phase steps :
- Start the application EC2 instances from your custom AMIs.
- Resize existing database/data store instances to process the increased traffic for e.g. If using RDS, it can be easily scaled vertically while EC2 instances can be easily scaled horizontally
- Add additional database/data store instances to give the DR site resilience in the data tier for e.g. turn on Multi-AZ for RDS to improve resilience.
- Change DNS to point at the Amazon EC2 servers.
- Install and configure any non-AMI based systems, ideally in an automated way.
Warm Standby
- In a Warm standby DR scenario a scaled-down version of a fully functional environment identical to the business critical systems is always running in the cloud
- This setup can be used for testing, quality assurances or for internal use.
- In case of an disaster, the system can be easily scaled up or out to handle production load.
Preparation phase steps :
- Set up Amazon EC2 instances to replicate or mirror data.
- Create and maintain AMIs for faster provisioning
- Run the application using a minimal footprint of EC2 instances or AWS infrastructure.
- Patch and update software and configuration files in line with your live environment.
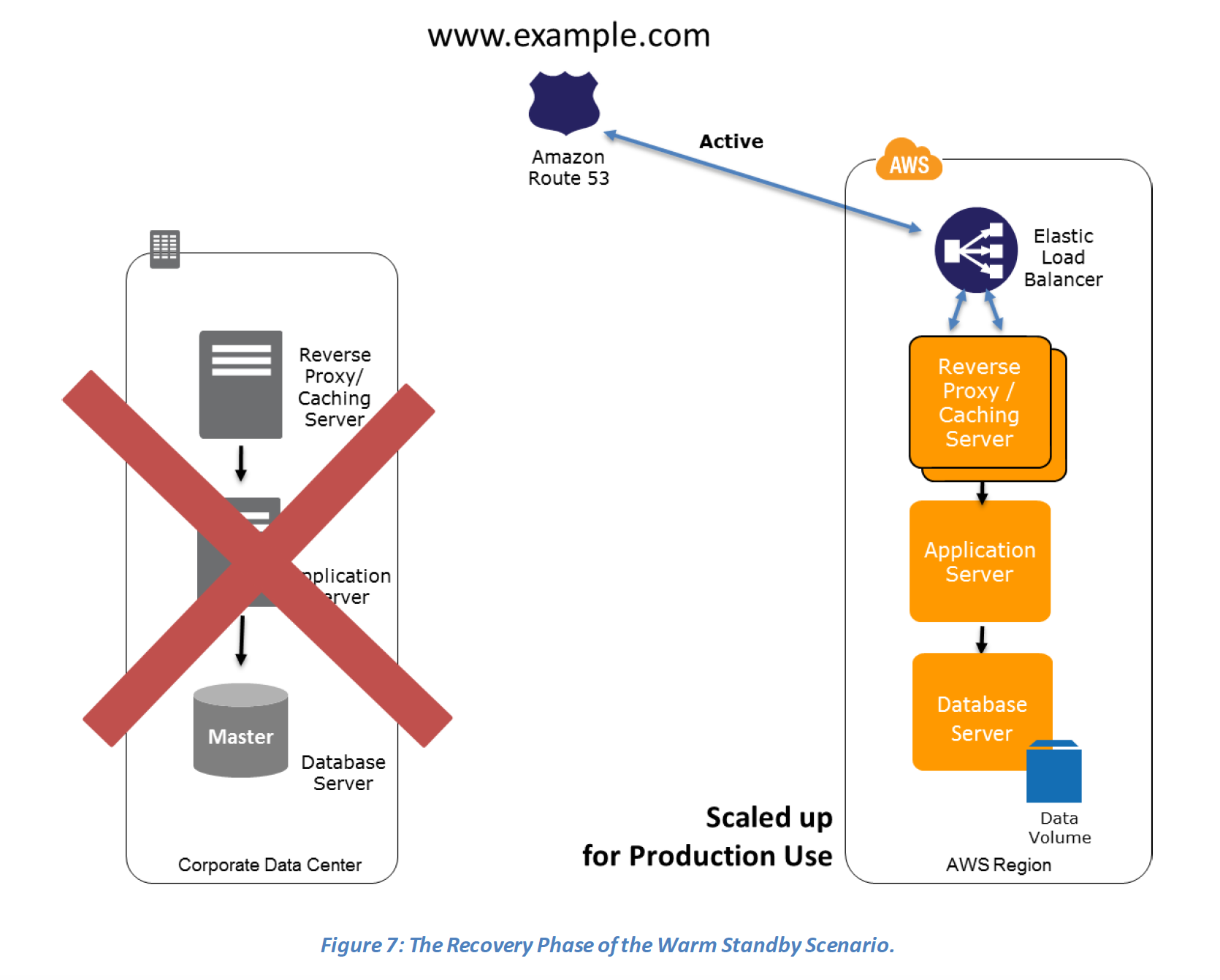
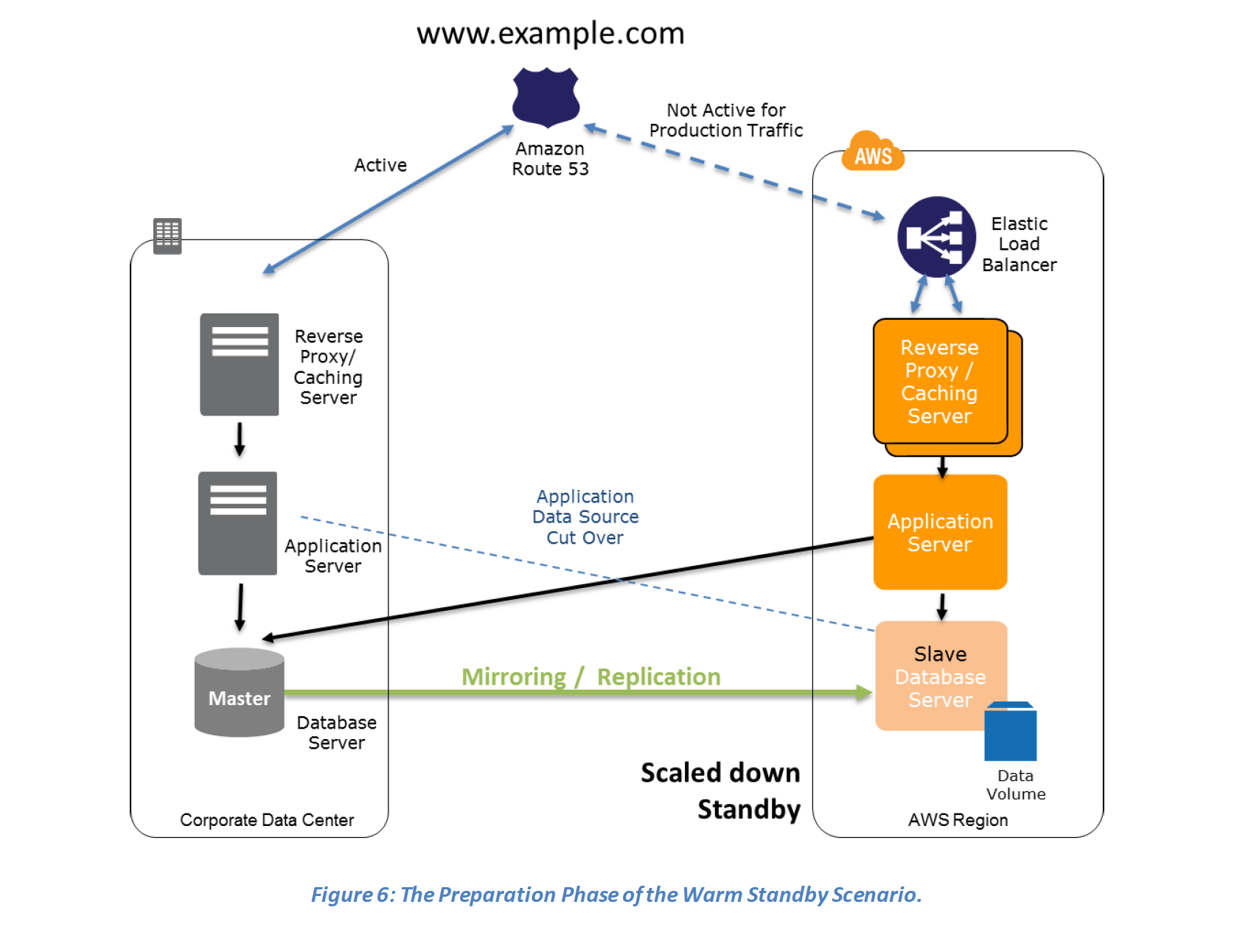 Recovery phase Steps:
Recovery phase Steps:
- Increase the size of the Amazon EC2 fleets in service with the load balancer (horizontal scaling).
- Start applications on larger Amazon EC2 instance types as needed (vertical scaling).
- Either manually change the DNS records, or use Route 53 automated health checks to route all the traffic to the AWS environment.
- Consider using Auto Scaling to right-size the fleet or accommodate the increased load.
- Add resilience or scale up your database to guard against DR going down
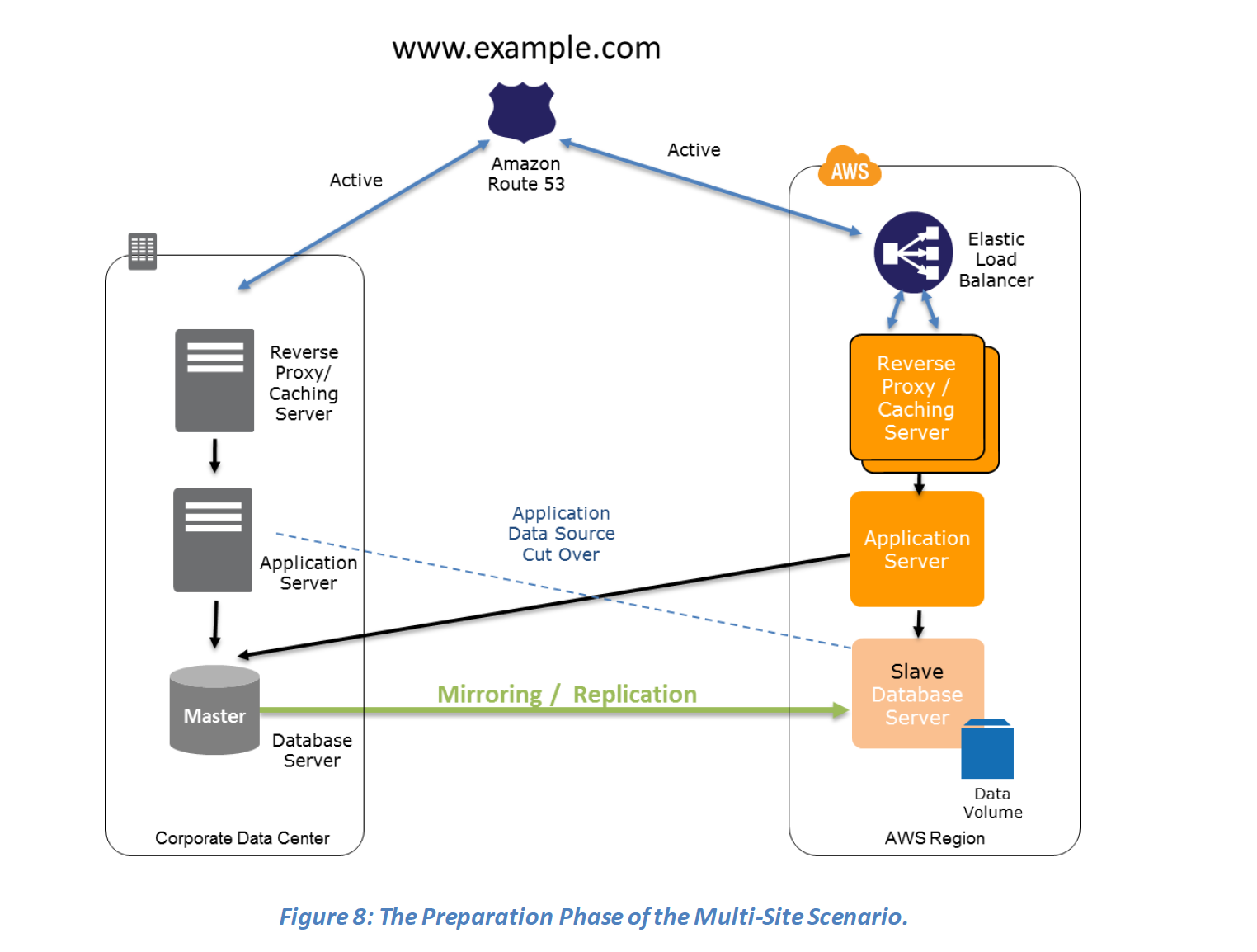
Multi-Site Active/Active
- Multi-Site is an active-active configuration DR approach, where in an identical solution runs on AWS as your on-site infrastructure.
- Traffic can be equally distributed to both the infrastructure as needed by using DNS service weighted routing approach.
- In case of a disaster the DNS can be tuned to send all the traffic to the AWS environment and the AWS infrastructure scaled accordingly.
- Route 53 Application Recovery Controller (ARC) can manage failover with readiness checks and routing controls for multi-site architectures.
Preparation phase steps :
- Set up your AWS environment to duplicate the production environment.
- Set up DNS weighting, or similar traffic routing technology, to distribute incoming requests to both sites.
- Configure automated failover to re-route traffic away from the affected site. for e.g. application to check if primary DB is available if not then redirect to the AWS DB
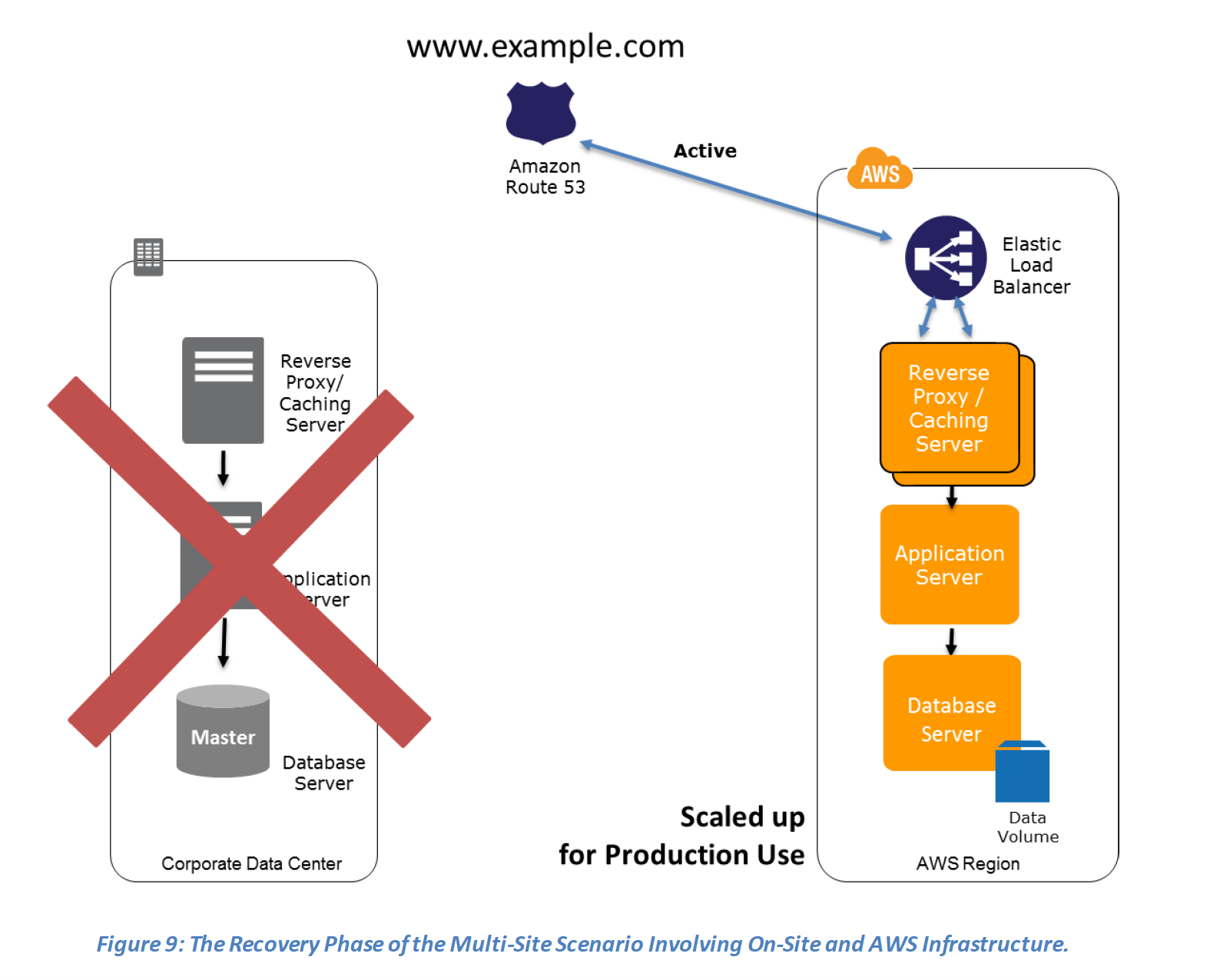
Recovery phase steps :
- Either manually or by using DNS failover, change the DNS weighting so that all requests are sent to the AWS site.
- Have application logic for failover to use the local AWS database servers for all queries.
- Consider using Auto Scaling to automatically right-size the AWS fleet.

AWS Elastic Disaster Recovery (AWS DRS)
- AWS Elastic Disaster Recovery (DRS) is the primary AWS service for disaster recovery, replacing CloudEndure Disaster Recovery which was discontinued in March 2024.
- Provides continuous block-level replication of source servers to a lightweight staging area in the target AWS Region
- Achieves RPOs in seconds and RTOs in minutes (typically 5-20 minutes)
- Uses cost-effective AWS resources – you only pay for the full recovery site during drills or actual recovery
- Supports recovery from:
- Physical infrastructure (on-premises)
- VMware vSphere environments
- Microsoft Hyper-V workloads
- Other cloud providers (e.g., Azure to AWS)
- AWS EC2 instances (cross-region DR)
- Point-in-time recovery – launch previous versions of servers from before a ransomware attack without paying ransom
- Automated failover and failback – reduces RTO and eliminates manual intervention
- Supports source servers with up to 60 volumes
- Supports AWS Outposts for on-premises DR targets
- Integrates with AWS CloudTrail, IAM, and CloudWatch for security and monitoring
- Can be used alongside any DR scenario (Pilot Light, Warm Standby, Multi-Site) for automated recovery
AWS Resilience Hub
- Central service for defining resilience goals, assessing resilience posture, and implementing improvements
- Continuously validates and tracks whether workloads can meet defined RTO and RPO targets
- Provides automated resilience assessments based on the AWS Well-Architected Framework
- Generates compliance evidence for auditors without manually spinning up DR environments
- Detects drift in infrastructure and triggers remediation
- Sends notifications to operators to launch recovery processes during outages
- Available at no additional charge in the AWS Management Console
- Supports multi-account application resilience assessment
- Next Generation (GA May 2026): Includes generative AI-based SRE resilience journey for structured alignment on resilience policy expectations
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- Which of these Disaster Recovery options costs the least?
- Pilot Light (most systems are down and brought up only after disaster)
- Fully Working Low capacity Warm standby
- Multi site Active-Active
- Your company currently has a 2-tier web application running in an on-premises data center. You have experienced several infrastructure failures in the past two months resulting in significant financial losses. Your CIO is strongly agreeing to move the application to AWS. While working on achieving buy-in from the other company executives, he asks you to develop a disaster recovery plan to help improve Business continuity in the short term. He specifies a target Recovery Time Objective (RTO) of 4 hours and a Recovery Point Objective (RPO) of 1 hour or less. He also asks you to implement the solution within 2 weeks. Your database is 200GB in size and you have a 20Mbps Internet connection. How would you do this while minimizing costs?
- Create an EBS backed private AMI which includes a fresh install or your application. Setup a script in your data center to backup the local database every 1 hour and to encrypt and copy the resulting file to an S3 bucket using multi-part upload (while AMI is a right approach to keep cost down, Upload to S3 very Slow)
- Install your application on a compute-optimized EC2 instance capable of supporting the application’s average load synchronously replicate transactions from your on-premises database to a database instance in AWS across a secure Direct Connect connection. (EC2 running in Compute Optimized as well as Direct Connect is expensive to start with also Direct Connect cannot be implemented in 2 weeks)
- Deploy your application on EC2 instances within an Auto Scaling group across multiple availability zones asynchronously replicate transactions from your on-premises database to a database instance in AWS across a secure VPN connection. (While VPN can be setup quickly asynchronous replication using VPN would work, running instances in DR is expensive)
- Create an EBS backed private AMI that includes a fresh install of your application. Develop a CloudFormation template which includes your AMI and the required EC2. Auto-Scaling and ELB resources to support deploying the application across Multiple Availability Zones. Asynchronously replicate transactions from your on-premises database to a database instance in AWS across a secure VPN connection. (Pilot Light approach with only DB running and replicate while you have preconfigured AMI and autoscaling config. Note: Today, AWS Elastic Disaster Recovery (DRS) could also achieve this more easily with automated failover.)
- You are designing an architecture that can recover from a disaster very quickly with minimum down time to the end users. Which of the following approaches is best?
- Leverage Route 53 health checks to automatically fail over to backup site when the primary site becomes unreachable
- Implement the Pilot Light DR architecture so that traffic can be processed seamlessly in case the primary site becomes unreachable
- Implement either Fully Working Low Capacity Standby or Multi-site Active-Active architecture so that the end users will not experience any delay even if the primary site becomes unreachable
- Implement multi-region architecture to ensure high availability
- Your customer wishes to deploy an enterprise application to AWS that will consist of several web servers, several application servers and a small (50GB) Oracle database. Information is stored, both in the database and the file systems of the various servers. The backup system must support database recovery, whole server and whole disk restores, and individual file restores with a recovery time of no more than two hours. They have chosen to use RDS Oracle as the database. Which backup architecture will meet these requirements?
- Backup RDS using automated daily DB backups. Backup the EC2 instances using AMIs and supplement with file-level backup to S3 using traditional enterprise backup software to provide file level restore (RDS automated backups with file-level backups can be used. Note: AWS Backup can now centrally manage all of these backups.)
- Backup RDS using a Multi-AZ Deployment Backup the EC2 instances using AMIs, and supplement by copying file system data to S3 to provide file level restore (Multi-AZ is more of a High Availability solution, not a backup solution)
- Backup RDS using automated daily DB backups. Backup the EC2 instances using EBS snapshots and supplement with file-level backups to Amazon S3 Glacier using traditional enterprise backup software to provide file level restore (S3 Glacier Flexible Retrieval (formerly Glacier) retrieval time may not meet the 2 hours RTO depending on retrieval option selected)
- Backup RDS database to S3 using Oracle RMAN. Backup the EC2 instances using AMIs, and supplement with EBS snapshots for individual volume restore. (Will use RMAN only if Database hosted on EC2 and not when using RDS)
- Which statements are true about the Pilot Light Disaster recovery architecture pattern?
- Pilot Light is a hot standby (Cold Standby)
- Enables replication of all critical data to AWS
- Very cost-effective DR pattern
- Can scale the system as needed to handle current production load
- An ERP application is deployed across multiple AZs in a single region. In the event of failure, the Recovery Time Objective (RTO) must be less than 3 hours, and the Recovery Point Objective (RPO) must be 15 minutes. The customer realizes that data corruption occurred roughly 1.5 hours ago. What DR strategy could be used to achieve this RTO and RPO in the event of this kind of failure?
- Take hourly DB backups to S3, with transaction logs stored in S3 every 5 minutes
- Use synchronous database master-slave replication between two availability zones. (Replication won’t help to backtrack and would be sync always)
- Take hourly DB backups to EC2 Instance store volumes with transaction logs stored In S3 every 5 minutes. (Instance store not a preferred storage)
- Take 15 minute DB backups stored in S3 Glacier with transaction logs stored in S3 every 5 minutes. (S3 Glacier Flexible Retrieval does not meet the RTO)
- Your company’s on-premises content management system has the following architecture:
– Application Tier – Java code on a JBoss application server
– Database Tier – Oracle database regularly backed up to Amazon Simple Storage Service (S3) using the Oracle RMAN backup utility
– Static Content – stored on a 512GB gateway stored Storage Gateway volume attached to the application server via the iSCSI interfaceWhich AWS based disaster recovery strategy will give you the best RTO?
- Deploy the Oracle database and the JBoss app server on EC2. Restore the RMAN Oracle backups from Amazon S3. Generate an EBS volume of static content from the Storage Gateway and attach it to the JBoss EC2 server.
- Deploy the Oracle database on RDS. Deploy the JBoss app server on EC2. Restore the RMAN Oracle backups from Amazon S3 Glacier. Generate an EBS volume of static content from the Storage Gateway and attach it to the JBoss EC2 server. (S3 Glacier retrieval does not help to give best RTO)
- Deploy the Oracle database and the JBoss app server on EC2. Restore the RMAN Oracle backups from Amazon S3. Restore the static content by attaching an AWS Storage Gateway running on Amazon EC2 as an iSCSI volume to the JBoss EC2 server. (No need to attach the Storage Gateway as an iSCSI volume can just create an EBS volume)
- Deploy the Oracle database and the JBoss app server on EC2. Restore the RMAN Oracle backups from Amazon S3. Restore the static content from an AWS Storage Gateway-VTL running on Amazon EC2 (VTL is Virtual Tape library and doesn’t fit the RTO)
- [New] A company wants to implement disaster recovery for their on-premises application with an RPO of seconds and RTO of minutes. They want to minimize idle DR resources and costs. Which AWS service should they use?
- AWS Backup with cross-region copy (AWS Backup provides RPO in hours, not seconds)
- AWS Elastic Disaster Recovery (DRS) (DRS provides RPO in seconds and RTO in minutes using continuous replication with minimal staging resources)
- Amazon S3 Cross-Region Replication with CloudFormation templates (This is a Backup & Restore approach, not suitable for seconds RPO)
- Multi-Site Active-Active with Route 53 failover (Achieves the RPO/RTO but does not minimize costs – full duplicate environment runs at all times)
- [New] Which AWS service provides a centralized way to define resilience goals, assess whether applications can meet their RTO and RPO targets, and provides recommendations for improvement?
- AWS CloudWatch
- AWS Config
- AWS Resilience Hub (Resilience Hub provides centralized resilience assessment, RTO/RPO validation, and improvement recommendations based on the Well-Architected Framework)
- AWS Systems Manager
- [New] A company wants to automatically shift traffic away from an impaired Availability Zone without manual intervention. Which AWS service provides this capability?
- Amazon Route 53 weighted routing
- AWS Global Accelerator
- Amazon Route 53 Application Recovery Controller (ARC) with Zonal Autoshift (ARC Zonal Autoshift automatically moves traffic away from an AZ when AWS detects a potential failure, at no additional charge)
- Elastic Load Balancing cross-zone load balancing