Table of Contents
hide
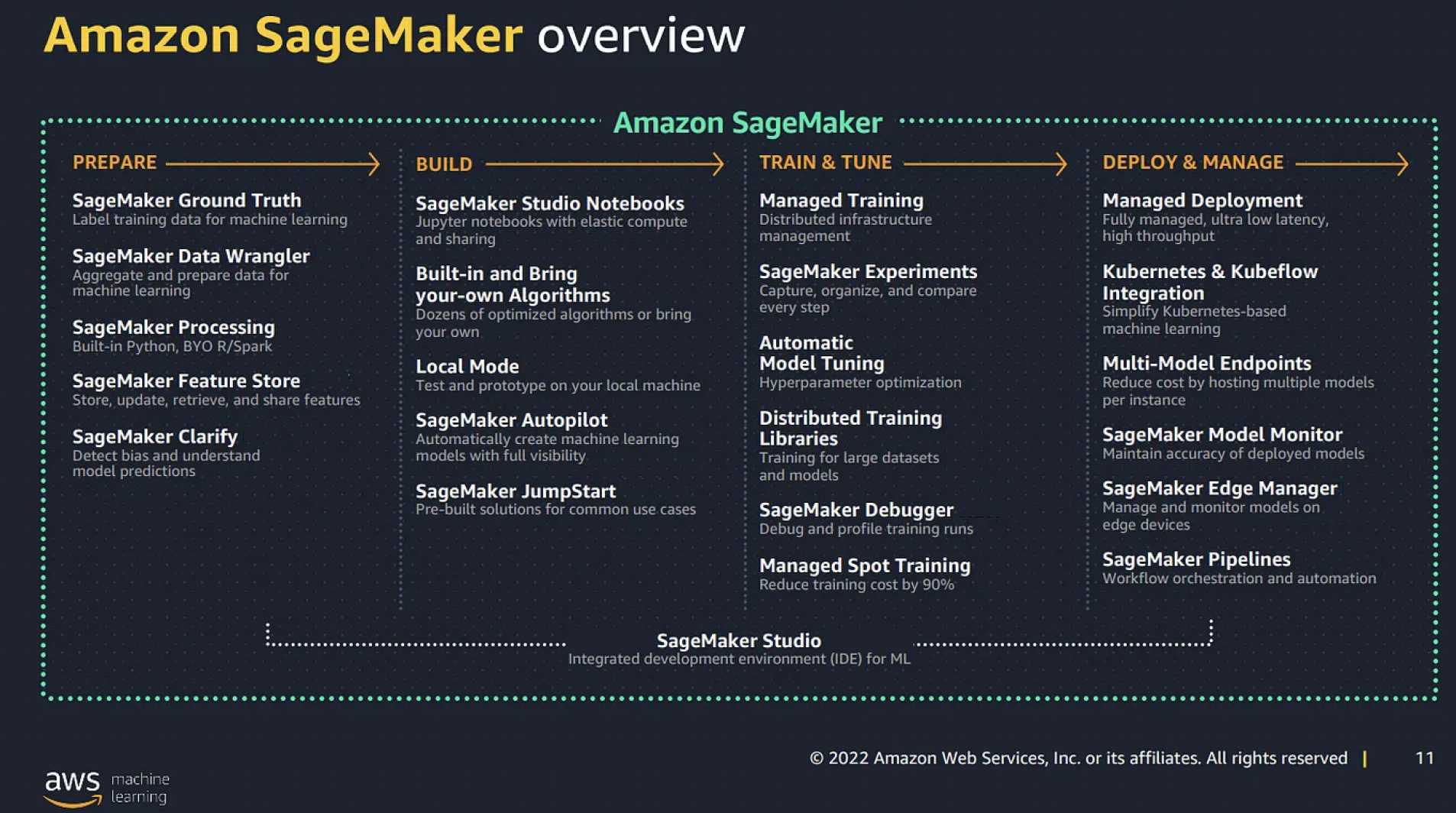
AWS SageMaker
- SageMaker is a fully managed machine learning service to build, train, and deploy machine learning (ML) models quickly.
- removes the heavy lifting from each step of the machine learning process to make it easier to develop high-quality models.
- is designed for high availability with no maintenance windows or scheduled downtimes
- APIs run in Amazon’s proven, high-availability data centers, with service stack replication configured across three facilities in each AWS region to provide fault tolerance in the event of a server failure or AZ outage
- provides a full end-to-end workflow, but users can continue to use their existing tools with SageMaker.
- supports Jupyter notebooks.
- allows users to select the number and type of instance used for the hosted notebook, training & model hosting.
SageMaker Machine Learning
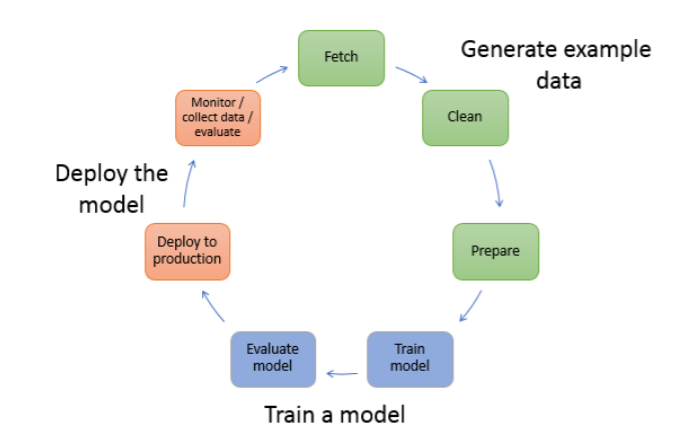
Generate example data
- Involves exploring and preprocessing, or “wrangling,” example data before using it for model training.
- To preprocess data, you typically do the following:
- Fetch the data
- Clean the data
- Prepare or transform the data
Train a model
- Model training includes both training and evaluating the model, as follows:
- Training the model
- Needs an algorithm, which depends on several factors.
- Need compute resources for training.
- Evaluating the model
- determines whether the accuracy of the inferences is acceptable.
Training Data Format – File mode vs Pipe mode vs Fast File mode
- SageMaker supports Simple Storage Service (S3), Elastic File System (
EFS), and FSx for Lustre. for training dataset location. - Most SageMaker algorithms work best when using the optimized protobuf recordIO format for the training data.
- Using RecordIO format allows algorithms to take advantage of Pipe mode when training the algorithms that support it.
- File mode
- loads all the data from S3 to the training instance volumes.
- downloads training data to an encrypted EBS volume attached to the training instance.
- download needs to finish before model training starts
- needs disk space to store both the final model artifacts and the full training dataset.
- In Pipe mode
- streams data directly from S3.
- Streaming can provide faster start times for training jobs and better throughput.
- helps reduce the size of the EBS volumes for the training instances as it needs only enough disk space to store the final model artifacts.
- needs code changes
- Fast File mode
- combines the ease of use of the existing File Mode with the performance of Pipe Mode.
- provides access to data as if it were downloaded locally while offering the performance benefit of streaming the data directly from S3.
- training can start without waiting for the entire dataset to be downloaded to the training instances.
Build Model
- SageMaker provides several built-in machine-learning algorithms that can be used for a variety of problem types.
- Write a custom training script in a machine learning framework that SageMaker supports, and use one of the pre-built framework containers to run it in SageMaker.
- Bring your algorithm or model to train or host in SageMaker.
- SageMaker provides pre-built Docker images for its built-in algorithms and the supported deep-learning frameworks used for training and inference.
- By using containers, machine learning algorithms can be trained and deployed quickly and reliably at any scale.
- Use an algorithm that you subscribe to from AWS Marketplace.
Model Deployment
- Model deployment helps deploy the ML code to make predictions, also known as Inference.
- supports auto-scaling for the hosted models to dynamically adjust the number of instances provisioned in response to changes in the workload.
- supports Multi-model endpoints to provide a scalable and cost-effective solution for deploying large numbers of models using a shared
- can provide high availability and reliability by deploying multiple instances of the production endpoint across multiple AZs.
- SageMaker provides multiple inference options.
- Real-time inference
- is ideal for online inferences that have low latency or high throughput requirements.
- provides a persistent and fully managed endpoint (REST API) that can handle sustained traffic, backed by the instance type of your choice.
- can support payload sizes up to 6 MB and processing times of 60 seconds.
- Serverless Inference
- is ideal for intermittent or unpredictable traffic patterns.
- manages all of the underlying infrastructure with no need to manage instances or scaling policies.
- provides a pay-as-you-use model, and charges only for what you use and not for idle time.
- can support payload sizes up to 4 MB and processing times up to 60 seconds.
- Batch Transform
- is suitable for offline processing when large amounts of data are available upfront and you don’t need a persistent endpoint.
- can be used for pre-processing datasets.
- can support large datasets that are GBs in size and processing times of days.
- Asynchronous Inference
- is ideal when you want to queue requests and have large payloads with long processing times.
- can support payloads up to 1 GB and long processing times up to one hour.
- can also scale down the endpoint to 0 when there are no requests to process.
- Real-time inference
- Inference pipeline
- is a SageMaker model that is composed of a linear sequence of multiple (2-15) containers that process requests for inferences on data.
- can be used to define and deploy any combination of pre-trained SageMaker built-in algorithms and your custom algorithms packaged in Docker containers.
Real-Time Inference Variants
- SageMaker supports testing multiple models or model versions behind the same endpoint using variants.
- A variant consists of an ML instance and the serving components specified in a SageMaker model.
- Each variant can have a different instance type or a SageMaker model that can be autoscaled independently of the others.
- Models within the variants can be trained using different datasets, algorithms, ML frameworks, or any combination of all of these.
- All the variants behind an endpoint share the same inference code.
- SageMaker supports two types of variants, production variants and shadow variants.
- Production Variants
- supports A/B or Canary testing where you can allocate a portion of the inference requests to each variant.
- helps compare production variants performance relative to each other.
- Shadow Variants
- replicates a portion of the inference requests that go to the production variant to the shadow variant.
- logs the responses of the shadow variant for comparison and not returned to the caller.
- helps test the performance of the shadow variant without exposing the caller to the response produced by the shadow variant.
- Production Variants
SageMaker Training Optimization
- SageMaker Managed Spot Training
- uses EC2 Spot instances to optimize the cost of training models over on-demand instances.
- Spot interruptions are managed by SageMaker on your behalf.
- SageMaker Checkpoints
- help save the state of ML models during training.
- are snapshots of the model and can be configured by the callback functions of ML frameworks.
- saved checkpoints can be used to restart a training job from the last saved checkpoint.
- SageMaker managed spot training with checkpoints help save on training costs.
- SageMaker Inference Recommender
- helps select the best instance type and configuration (such as instance count, container parameters, and model optimizations) or serverless configuration (such as max concurrency and memory size) for the ML models and workloads.
- help deploy the model to a real-time or serverless inference endpoint that delivers the best performance at the lowest cost.
- reduces the time required to get ML models in production by automating load testing and model tuning across SageMaker ML instances.
- provides two types of recommendations
- Default, run a set of load tests on the recommended instance types.
- Advanced, based on a custom load test where you can select desired ML instances or a serverless endpoint, provide a custom traffic pattern, and provide requirements for latency and throughput based on your production requirements.
SageMaker Security
- SageMaker ensures that ML model artifacts and other system artifacts are encrypted in transit and at rest.
- SageMaker allows using encrypted S3 buckets for model artifacts and data, as well as pass a KMS key to SageMaker notebooks, training jobs, and endpoints, to encrypt the attached ML storage volume.
- Requests to the SageMaker API and console are made over a secure (SSL) connection.
- SageMaker stores code in ML storage volumes, secured by security groups and optionally encrypted at rest.
- SageMaker API and SageMaker Runtime support VPC interface endpoints powered by AWS PrivateLink that helps connect VPC directly to the SageMaker API or SageMaker Runtime using AWS PrivateLink without using an internet gateway, NAT device, VPN connection, or AWS Direct Connect connection.
- SageMaker Network Isolation makes sure
- containers can’t make any outbound network calls, even to other AWS services such as S3.
- no AWS credentials are made available to the container runtime environment.
- network inbound and outbound traffic is limited to the peers of each training container, in the case of a training job with multiple instances.
- S3 download and upload operation is performed using the SageMaker execution role in isolation from the training or inference container.
SageMaker Notebooks
- SageMaker notebooks are collaborative notebooks that are built into SageMaker Studio running the Jupyter Notebook App.
- can be accessed without setting up compute instances and file storage.
- charged only for the resources consumed when notebooks are running
- instance types can be easily switched if more or less computing power is needed, during the experimentation phase.
- come with multiple environments already installed containing Jupyter kernels and Python packages including scikit, Pandas, NumPy, MXNet, and TensorFlow.
- use a lifecycle configuration that includes both a script that runs each time during notebook instance creation and restarts to install custom environments and kernels on the notebook instance’s EBS volume.
- restart the notebooks to automatically apply patches.
SageMaker Built-in Algorithms
Please refer SageMaker Built-in Algorithms for details
SageMaker Feature Store
- SageMaker Feature Store helps to create, share, and manage features for ML development.
- is a centralized store for features and associated metadata so features can be easily discovered and reused.
- helps by reducing repetitive data processing and curation work required to convert raw data into features for training an ML algorithm.
- consists of FeatureGroup which is a group of features defined to describe a Record.
- Data processing logic is developed only once and the features generated can be used for both training and inference, reducing the training-serving skew.
- supports online and offline store
- Online store
- is used for low-latency real-time inference use cases
- retains only the latest feature data.
- Offline store
- is used for training and batch inference.
- is an append-only store and can be used to store and access historical feature data.
- data is stored in Parquet format for optimized storage and query access.
- Online store

Inferentia
- AWS Inferentia is designed to accelerate deep learning workloads by providing high-performance inference in the cloud.
- helps deliver higher throughput and up to 70% lower cost per inference than comparable current generation GPU-based Amazon EC2 instances.
Elastic Inference (EI)
- helps speed up the throughput and decrease the latency of getting real-time inferences from the deep learning models deployed as SageMaker-hosted models
- add inference acceleration to a hosted endpoint for a fraction of the cost of using a full GPU instance.
- NOTE: Elastic Inference has been deprecated and replaced by Inferentia.
SageMaker Ground Truth
- SageMaker Ground Truth provides automated data labeling using machine learning
- helps build highly accurate training datasets for machine learning quickly.
- offers easy access to labelers through Mechanical Turk and provides them with built-in workflows and interfaces for common labeling tasks.
- allows using your labelers as a private workforce or vendors recommended by Amazon through AWS Marketplace.
- helps lower the labeling costs by up to 70% using automatic labeling, which works by training Ground Truth from data labeled by humans so that the service learns to label data independently.
- significantly reduces the time and effort required to create datasets for training to reduce costs
- automated data labeling uses active learning to automate the labeling of your input data for certain built-in task types.
- provides annotation consolidation to help improve the accuracy of the data object’s labels. It combines the results of multiple worker’s annotation tasks into one high-fidelity label.
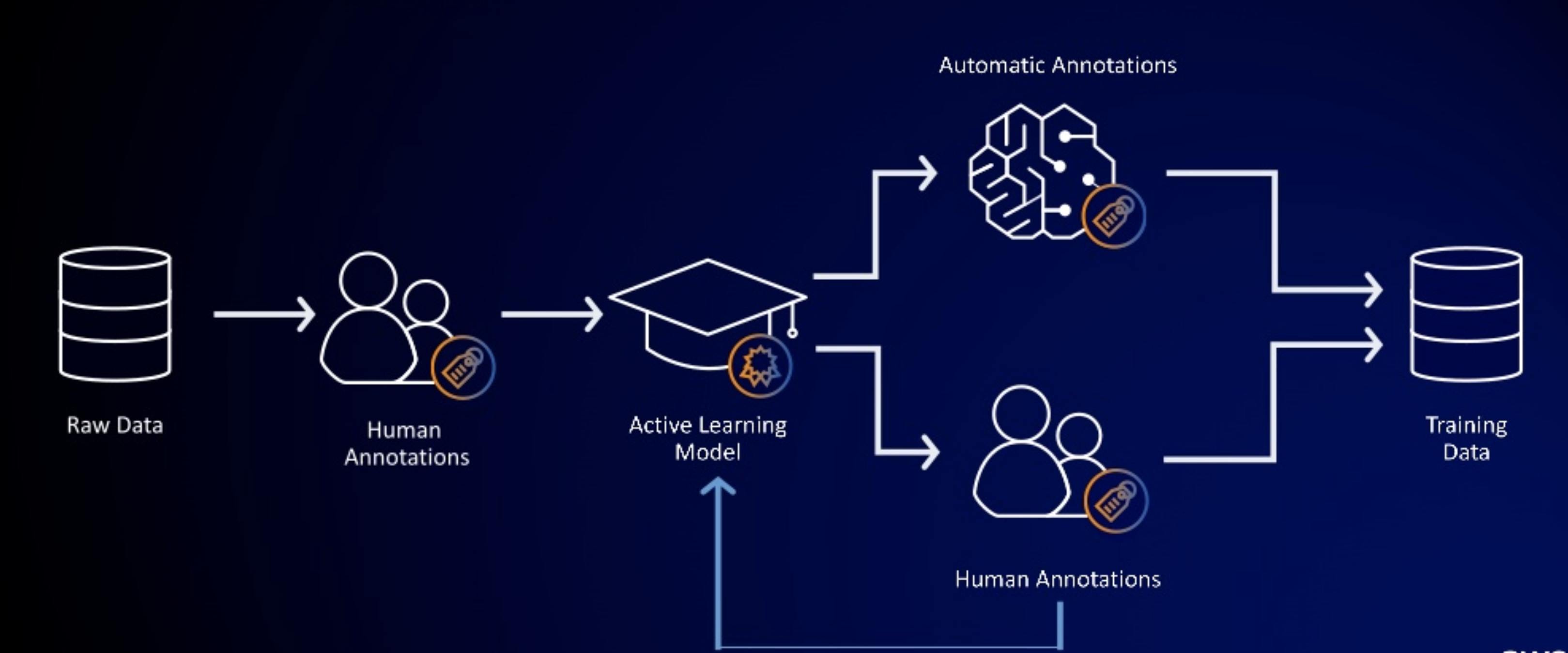
- first selects a random sample of data and sends it to Amazon Mechanical Turk to be labeled.
- results are then used to train a labeling model that attempts to label a new sample of raw data automatically.
- labels are committed when the model can label the data with a confidence score that meets or exceeds a threshold you set.
- for a confidence score falling below the defined threshold, the data is sent to human labelers.
- Some of the data labeled by humans is used to generate a new training dataset for the labeling model, and the model is automatically retrained to improve its accuracy.
- process repeats with each sample of raw data to be labeled.
- labeling model becomes more capable of automatically labeling raw data with each iteration, and less data is routed to humans.
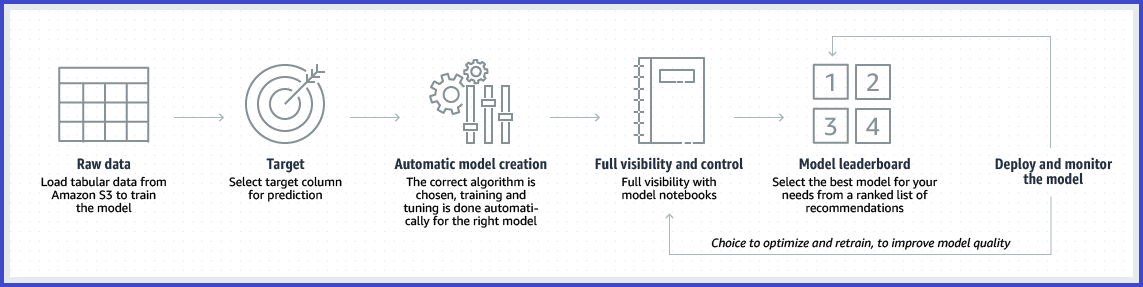
SageMaker AutoPilot
- SageMaker Autopilot is an automated machine learning (AutoML) feature set that automates the end-to-end process of building, training, tuning, and deploying machine learning models.
- analyzes the data, selects algorithms suitable for the problem type, preprocesses the data to prepare it for training, handles automatic model training, and performs hyperparameter optimization to find the best-performing model for the dataset.
- helps users understand how models make predictions by automatically generating reports that show the importance of each individual feature providing transparency and insights into the factors influencing the predictions, which can be used by risk and compliance teams and external regulators.
SageMaker JumpStart
- SageMaker JumpStart provides pretrained, open-source models for various problem types to help get started with machine learning.
- can incrementally train and tune these models before deployment.
- provides solution templates that set up infrastructure for common use cases, and executable example notebooks for machine learning with SageMaker.
SageMaker Automatic Model Tuning
- Hyperparameters are parameters exposed by ML algorithms that control how the underlying algorithm operates and their values affect the quality of the trained models.
- Automatic model tuning helps find a set of hyperparameters for an algorithm that can yield an optimal model.
- SageMaker automatic model tuning can use managed spot training
- Best Practices for Hyperparameter tuning
- Choosing the Number of Hyperparameters – limit the search to a smaller number as the difficulty of a hyperparameter tuning job depends primarily on the number of hyperparameters that SageMaker has to search.
- Choosing Hyperparameter Ranges – DO NOT specify a very large range to cover every possible value for a hyperparameter. Range of values for hyperparameters that you choose to search can significantly affect the success of hyperparameter optimization.
- Using Logarithmic Scales for Hyperparameters – log-scaled hyperparameter can be converted to improve hyperparameter optimization.
- Choosing the Best Number of Concurrent Training Jobs – running one training job at a time achieves the best results with the least amount of compute time.
- Running Training Jobs on Multiple Instances – Design distributed training jobs so that you can target the objective metric that you want.
- Warm start can be used to start a hyperparameter tuning job using one or more previous tuning jobs as a starting point.
SageMaker Experiments
- SageMaker Experiments is a capability of SageMaker that lets you create, manage, analyze, and compare your machine-learning experiments.
- helps organize, view, analyze, and compare iterative ML experimentation to gain comparative insights and track the best-performing models.
- automatically tracks the inputs, parameters, configurations, and results of the iterations as runs.
SageMaker Debugger
- SageMaker Debugger provides tools to debug training jobs and resolve problems such as overfitting, saturated activation functions, and vanishing gradients to improve the performance of the model.
- offers tools to send alerts when training anomalies are found, take actions against the problems, and identify the root cause of them by visualizing collected metrics and tensors.
- supports the Apache MXNet, PyTorch, TensorFlow, and XGBoost frameworks.
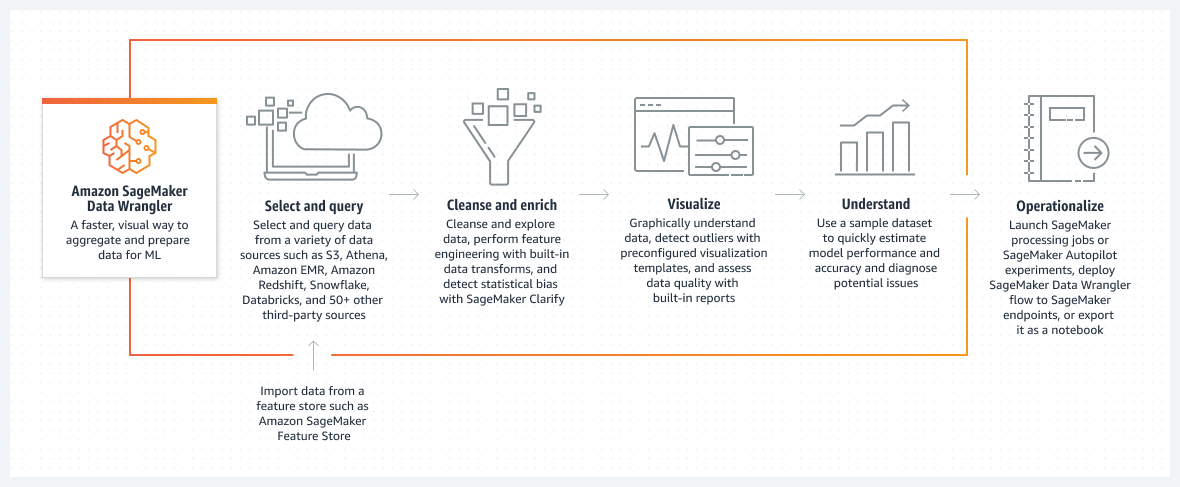
SageMaker Data Wrangler
- SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for ML from weeks to minutes.
- simplifies the process of data preparation and feature engineering, and completes each step of the data preparation workflow (including data selection, cleansing, exploration, visualization, and processing at scale) from a single visual interface.
- supports SQL to select the data from various data sources and import it quickly.
- provides data quality and insights reports to automatically verify data quality and detect anomalies, such as duplicate rows and target leakage.
- contains over 300 built-in data transformations, so you can quickly transform data without writing any code.
SageMaker Clarify
- SageMaker Clarify helps improve the ML models by detecting potential bias and helping to explain the predictions that the models make.
- provides purpose-built tools to gain greater insights into the ML models and data, based on metrics such as accuracy, robustness, toxicity, and bias to improve model quality and support responsible AI initiatives.
- can help to
- detect bias in and help explain the model predictions.
- identify types of bias in pre-training data.
- identify types of bias in post-training data that can emerge during training or when the model is in production.
- integrates with SageMaker Data Wrangler, Model Monitor, and Auto Pilot.
SageMaker Model Monitor
- SageMaker Model Monitor monitors the quality of SageMaker machine learning models in production.
- Continuous monitoring can be setup with a real-time endpoint (or a batch transform job that runs regularly), or on-schedule monitoring for asynchronous batch transform jobs.
- helps set alerts that notify when there are deviations in the model quality.
- provides early and proactive detection of deviations enabling you to take corrective actions, such as retraining models, auditing upstream systems, or fixing quality issues without having to monitor models manually or build additional tooling.
- provides prebuilt monitoring capabilities that do not require coding with the flexibility to monitor models by coding to provide custom analysis.
- provides the following types of monitoring:
- Monitor data quality – Monitor drift in data quality.
- Monitor model quality – Monitor drift in model quality metrics, such as accuracy.
- Monitor Bias Drift for Models in Production – Monitor bias in the model’s predictions.
- Monitor Feature Attribution Drift for Models in Production – Monitor drift in feature attribution.
SageMaker Neo
- SageMaker Neo enables machine learning models to train once and run anywhere in the cloud and at the edge.
- automatically optimizes machine learning models for inference on cloud instances and edge devices to run faster with no loss in accuracy.
- Optimized models run up to two times faster and consume less than a tenth of the resources of typical machine learning models.
- can be used with IoT Greengrass to help perform machine learning inference locally on devices.
SageMaker Model Goverance
- SageMaker Model Governance is a framework that gives systematic visibility into machine learning (ML) model development, validation, and usage.
- SageMaker provides purpose-built ML governance tools for managing control access, activity tracking, and reporting across the ML lifecycle.
SageMaker Pricing
- Users pay for ML compute, storage, and data processing resources they use for hosting the notebook, training the model, performing predictions & logging the outputs.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- A company has built a deep learning model and now wants to deploy it using the SageMaker Hosting Services. For inference, they want a cost-effective option that guarantees low latency but still comes at a fraction of the cost of using a GPU instance for your endpoint. As a machine learning Specialist, what feature should be used?
- Inference Pipeline
- Elastic Inference
- SageMaker Ground Truth
- SageMaker Neo
- A trading company is experimenting with different datasets, algorithms, and hyperparameters to find the best combination for the machine learning problem. The company doesn’t want to limit the number of experiments the team can perform but wants to track the several hundred to over a thousand experiments throughout the modeling effort. Which Amazon SageMaker feature should they use to help manage your team’s experiments at scale?
- SageMaker Inference Pipeline
- SageMaker model tracking
- SageMaker Neo
- SageMaker model containers
- A Machine Learning Specialist needs to monitor Amazon SageMaker in a production environment for analyzing record of actions
taken by a user, role, or an AWS service.
Which service should the Specialist use to meet these needs?- AWS CloudTrail
- Amazon CloudWatch
- AWS Systems Manager
- AWS Config
2 thoughts on “AWS SageMaker”
Comments are closed.