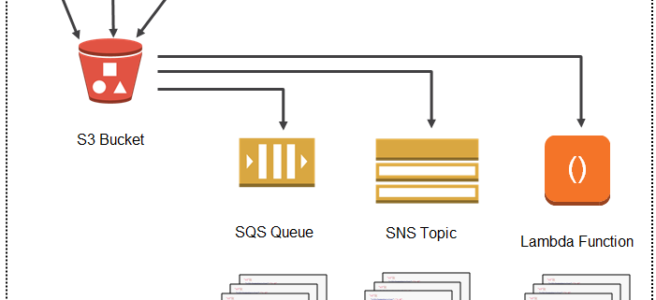
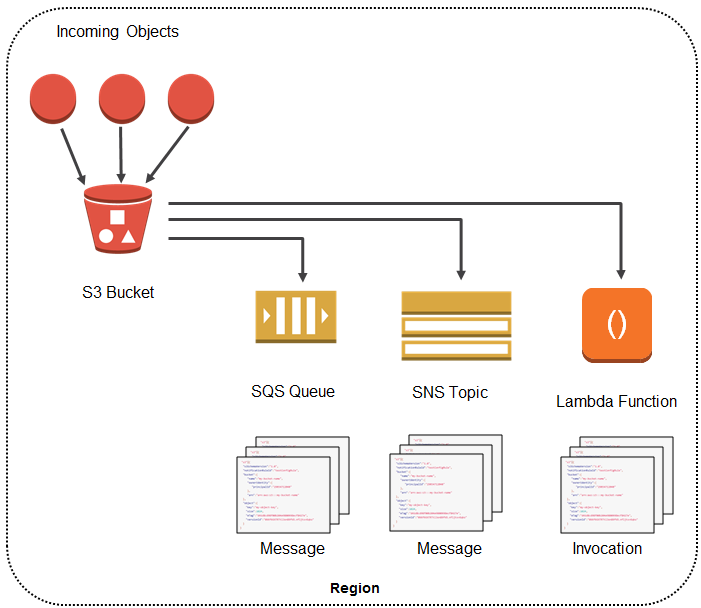
Amazon EMR – Elastic MapReduce is a web service that utilizes a hosted Hadoop framework running on the web-scale infrastructure of EC2 and S3.
enables businesses, researchers, data analysts, and developers to easily and cost-effectively process vast amounts of data.
uses Apache Hadoop as its distributed data processing engine, which is an open-source, Java software that supports data-intensive distributed applications running on large clusters of commodity hardware
provides data processing, interactive analysis, and machine learning using open-source frameworks such as Apache Spark, Apache Hive, Presto/Trino, and Apache Flink.
is ideal for problems that necessitate fast and efficient processing of large amounts of data.
helps focus on crunching, transforming, and analyzing data without having to worry about time-consuming set-up, the management, or tuning of Hadoop clusters, the compute capacity, or open-source applications.
can help perform data-intensive tasks for applications such as web indexing, data mining, log file analysis, machine learning, financial analysis, scientific simulation, bioinformatics research, etc
provides web service interface to launch the clusters and monitor processing-intensive computation on clusters.
workloads can be deployed using EC2, Elastic Kubernetes Service (EKS), or on-premises AWS Outposts.
seamlessly supports On-Demand, Spot, and Reserved Instances.
EMR launches all nodes for a given cluster in the same AZ, which improves performance as it provides a higher data access rate.
EMR supports different EC2 instance types including Standard, High CPU, High Memory, Cluster Compute, High I/O, High Storage, and AWS Graviton-based instances for improved price-performance.
EMR pricing is per-second with a one-minute minimum charge per instance.
EMR integrates with CloudTrail to record AWS API calls
EMR features a performance-optimized runtime that is 100% API-compatible with open-source Apache Spark, executing up to 4.5x faster than open-source equivalents.
EMR supports building open, transactional data lakes with Apache Spark and Apache Iceberg, delivering 2.7x faster Iceberg write performance.
EMR Serverless helps run big data frameworks such as Apache Spark and Apache Hive without configuring, managing, and scaling clusters.
EMR Studio is an IDE that helps data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark.
EMR Notebooks are now available as EMR Studio Workspaces in the console. AWS recommends using EMR Studio instead.
EMR Architecture
EMR uses industry-proven, fault-tolerant Hadoop software as its data processing engine.
Hadoop is an open-source, Java software that supports data-intensive distributed applications running on large clusters of commodity hardware
Hadoop splits the data into multiple subsets and assigns each subset to more than one EC2 instance. So, if an EC2 instance fails to process one subset of data, the results of another Amazon EC2 instance can be used.
EMR consists of Master node, one or more Slave nodes
Master Node Or Primary Node
Master node or Primary node manages the cluster by running software components to coordinate the distribution of data and tasks among other nodes for processing.
Primary node tracks the status of tasks and monitors the health of the cluster.
Every cluster has a primary node, and it’s possible to create a single-node cluster with only the primary node.
EMR supports multiple primary nodes (High Availability) to eliminate the single point of failure. If one primary node fails, Amazon EMR automatically fails over to a standby primary node and replaces the failed node with a new one.
Multi-primary node clusters are supported with EMR releases 5.36.1, 5.36.2, 6.8.1, 6.9.1, 6.10.1, 6.11.1, 6.12.0, and higher.
For single primary node clusters, if the master node goes down, the EMR cluster will be terminated and the job needs to be re-executed.
Slave Nodes – Core nodes and Task nodes
Core nodes
with software components that host persistent data using Hadoop Distributed File System (HDFS) and run Hadoop tasks
Multi-node clusters have at least one core node.
can be increased in an existing cluster
Task nodes
only run Hadoop tasks and do not store data in HDFS.
can be increased or decreased in an existing cluster.
EMR is fault tolerant for slave failures and continues job execution if a slave node goes down.
Currently, EMR does not automatically provision another node to take over failed slaves
EMR supports Bootstrap actions which allow
users a way to run custom set-up prior to the execution of the cluster.
can be used to install software or configure instances before running the cluster
EMR Storage
Hadoop Distributed File System (HDFS)
HDFS is a distributed, scalable file system for Hadoop.
HDFS distributes the data it stores across instances in the cluster, storing multiple copies of data on different instances to ensure that no data is lost if an individual instance fails.
HDFS is ephemeral storage that is reclaimed when you terminate a cluster.
HDFS is useful for caching intermediate results during MapReduce processing or for workloads that have significant random I/O.
EMR File System – EMRFS
EMR File System (EMRFS) helps extend Hadoop to add the ability to directly access data stored in S3 as if it were a file system like HDFS.
You can use either HDFS or S3 as the file system in your cluster. Most often, S3 is used to store input and output data and intermediate results are stored in HDFS.
Local file system
Local file system refers to a locally connected EC2 pre-attached disk instance store storage.
Data on instance store volumes persists only during the lifecycle of its Amazon EC2 instance.
Storing data on S3 provides several benefits
inherent features high availability, durability, lifecycle management, data encryption, and archival of data to Glacier
cost-effective as storing data in S3 is cheaper as compared to HDFS with the replication factor
ability to use Transient EMR cluster and shutdown the clusters after the job is completed, with data being maintained in S3
ability to use Spot instances and not having to worry about losing the spot instances at any time.
provides data durability from any HDFS node failures, where node failures exceed the HDFS replication factor
data ingestion with high throughput data stream to S3 is much easier than ingesting to HDFS
EMR Security
EMR cluster starts with different security groups for Master and Cluster nodes
Master security group
has a port open for communication with the service.
has an SSH port open to allow direct SSH into the instances, using the key specified at the startup.
Cluster security group
only allows interaction with the master instance
SSH to the slave nodes can be done by doing SSH to the master node and then to the slave node
Security groups can be configured with different access rules
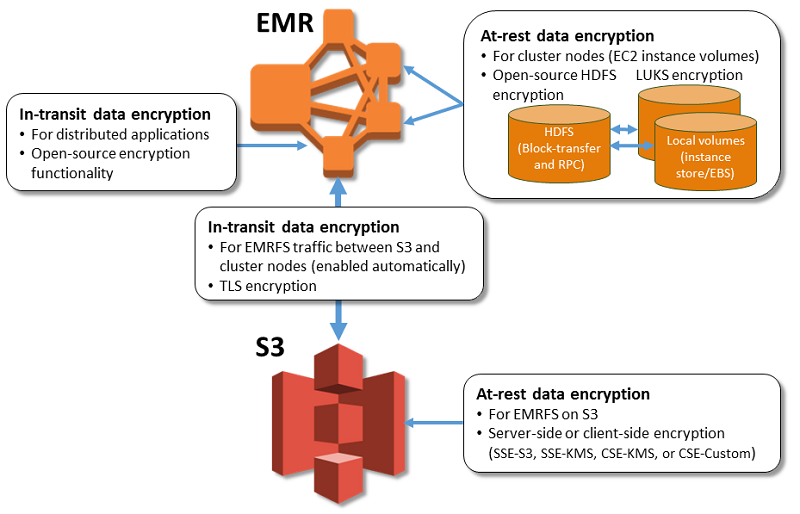
EMR always uses HTTPS to send data between S3 and EC2.
EMR enables the use of security configuration
which helps to encrypt data at rest, data in transit, or both
can be used to specify settings for S3 encryption with EMR file system (EMRFS), local disk encryption, and in-transit encryption
is stored in EMR rather than the cluster configuration making it reusable
gives the flexibility to choose from several options, including keys managed by AWS KMS, keys managed by S3, and keys and certificates from custom providers that you supply.
At-rest Encryption for S3 with EMRFS
EMRFS supports Server-side (SSE-S3, SSE-KMS) and Client-side encryption (CSE-KMS or CSE-Custom)
S3 SSE and CSE encryption with EMRFS are mutually exclusive; either one can be selected but not both
Transport layer security (TLS) encrypts EMRFS objects in-transit between EMR cluster nodes & S3
At-rest Encryption for Local Disks
Open-source HDFS Encryption
HDFS exchanges data between cluster instances during distributed processing, and also reads from and writes data to instance store volumes and the EBS volumes attached to instances
Open-source Hadoop encryption options are activated
Secure Hadoop RPC is set to “Privacy”, which uses Simple Authentication Security Layer (SASL).
Data encryption on HDFS block data transfer is set to true and is configured to use AES 256 encryption.
EBS Volume Encryption
EBS Encryption
EBS encryption option encrypts the EBS root device volume and attached storage volumes.
EBS encryption option is available only when you specify AWS KMS as your key provider.
LUKS
EC2 instance store volumes (except boot/root volumes) and the attached EBS volumes can be encrypted using LUKS.
In-Transit Data Encryption
Encryption artifacts used for in-transit encryption in one of two ways:
either by providing a zipped file of certificates that you upload to S3,
or by referencing a custom Java class that provides encryption artifacts
EMR block public access prevents a cluster in a public subnet from launching when any security group associated with the cluster has a rule that allows inbound traffic from anywhere (public access) on a port, unless the port has been specified as an exception.
EMR Runtime Roles help manage access control for each job or query individually, instead of sharing the EMR instance profile of the cluster.
EMR IAM service roles help perform actions on your behalf when provisioning cluster resources, running applications, dynamically scaling resources, and creating and running EMR Notebooks.
SSH clients can use an EC2 key pair or Kerberos to authenticate to cluster instances.
Lake Formation based access control can be applied to Spark, Hive, and Presto jobs that you submit to the EMR clusters.
Lake Formation supports table, row, column, and cell-level access control with Apache Iceberg on EMR.
EMR Cluster Types
EMR has two cluster types, transient and persistent
Transient EMR Clusters
Transient EMR clusters are clusters that shut down when the job or the steps (series of jobs) are complete
Transient EMR clusters can be used in situations
where total number of EMR processing hours per day < 24 hours and its beneficial to shut down the cluster when it’s not being used.
using HDFS as your primary data storage.
job processing is intensive, iterative data processing.
Persistent EMR Clusters
Persistent EMR clusters continue to run after the data processing job is complete
Persistent EMR clusters can be used in situations
frequently run processing jobs where it’s beneficial to keep the cluster running after the previous job.
processing jobs have an input-output dependency on one another.
In rare cases when it is more cost effective to store the data on HDFS instead of S3
EMR Managed Scaling
EMR Managed Scaling automatically increases or decreases the number of instances or units in a cluster based on workload.
EMR continuously evaluates cluster metrics to make scaling decisions that optimize clusters for cost and speed.
Available with EMR version 5.30.0 and higher (except 6.0.0).
Managed scaling only works with YARN applications such as Spark, Hadoop, Hive, and Flink. It does not support applications that are not based on YARN, such as Presto and HBase.
Managed Scaling Parameters:
Minimum (MinimumCapacityUnits) – Lower boundary of allowed EC2 capacity.
Maximum (MaximumCapacityUnits) – Upper boundary of allowed EC2 capacity.
On-Demand limit (MaximumOnDemandCapacityUnits) – Upper boundary for On-Demand market type; splits allocation between On-Demand and Spot.
Maximum core nodes (MaximumCoreCapacityUnits) – Upper boundary for core node type; splits allocation between core and task nodes.
Advanced Scaling (November 2024) provides a utilization-performance slider (values: 1, 25, 50, 75, 100) to configure desired resource utilization or performance levels.
Setting a higher value optimizes for performance.
Setting a lower value optimizes for resource conservation.
Setting value to 50 balances performance and resource conservation.
Managed scaling supports Node Labels (EMR 7.2.0+) allowing instances to be labeled by market type (ON_DEMAND, SPOT) or node type (CORE, TASK) for improved scaling decisions.
Managed scaling is Spark shuffle data aware – only scales down under-utilized instances that don’t contain actively used shuffle data.
EMR Instance Fleets
Instance fleets provide a flexible approach to provisioning EC2 instances, allowing specification of up to 30 EC2 instance types per node type (via CLI/API) with allocation strategies.
Instance fleets automatically manage the mix of instance types to meet specified target capacities for On-Demand and Spot.
Allows selection of multiple subnets for different Availability Zones, enabling Amazon EMR to optimally launch clusters.
On-Demand Allocation Strategies:
Prioritized – Define a priority order for instance types for precise control.
Lowest-price – Selects the lowest-priced instance type from available options.
Spot Allocation Strategies:
Price-capacity optimized – Selects instances with lowest price while considering available capacity.
Capacity-optimized-prioritized – Respects instance type priorities on a best-effort basis.
Capacity-optimized – Selects instances from the most available capacity pools.
Lowest-price – Selects the lowest-priced Spot Instances.
Diversified – Distributes instances across all pools.
Enhanced Subnet Selection reduces cluster launch failures from IP address shortage by evaluating available IPs across subnets to select the optimal subnet for launching all instance fleets.
High Availability Instance Fleets combines multi-primary node HA architecture with instance fleet flexibility for long-running clusters.
EMR Serverless
EMR Serverless helps run big data frameworks such as Apache Spark and Apache Hive without configuring, managing, and scaling clusters.
currently supports Apache Spark and Apache Hive engines.
automatically determines the resources that the application needs and gets these resources to process the jobs, and releases the resources when the jobs finish.
minimum and maximum number of concurrent workers and the vCPU and memory configuration for workers can be specified.
supports multiple AZs and provides resilience to AZ failures.
An EMR Serverless application internally uses workers to execute your workloads and it offers two options for workers
On-demand workers
are launched only when needed for a job and are released automatically when the job is complete.
scales the application up or down based on the workload, so you don’t have to worry about over- or under-provisioning resources.
takes up to 120 seconds to determine the required resources and provision them.
distributes jobs across multiple AZs by default, but each job runs only in one AZ.
automatically runs your job in another healthy AZ, if an AZ fails.
Pre-initialized workers
are an optional feature where you can keep workers ready to respond in seconds.
It effectively creates a warm pool of workers for an application which allows jobs to start instantly, making it ideal for iterative applications and time-sensitive jobs.
submits job in a healthy AZ from the specified subnets. Application needs to be restarted to switch to another healthy AZ, if an AZ becomes impaired.
Serverless Storage (re:Invent 2025)
Eliminates the need to configure local disks for Apache Spark workloads.
Stores intermediate data in fully managed serverless storage that scales automatically.
Enables Spark to release compute workers immediately when idle, reducing compute costs by up to 20%.
Eliminates job failures from disk capacity constraints.
Streaming Jobs (June 2024)
Supports continuous processing on streaming data with built-in job resiliency.
Provides real-time monitoring, enhanced log management, and integration with streaming connectors.
Spark Connect on EMR Serverless (May 2026)
Supports interactive sessions enabling development and running of Apache Spark applications from managed notebooks in Amazon SageMaker Unified Studio, Jupyter, and VS Code.
Each Spark Connect session has its own AWS resource with a unique ARN, enabling per-session IAM permissions, tag-based cost allocation, and audit through CloudTrail.
EMR Studio
EMR Studio is an IDE that helps data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark.
is a fully managed application with single sign-on, fully managed Jupyter Notebooks, automated infrastructure provisioning, and the ability to debug jobs without logging into the AWS Console or cluster.
supports AWS IAM Authentication from the console or federated access from your identity provider (IdP) via AWS IAM Identity Center.
supports interactive analytics on Amazon EMR Serverless (from release 6.14), allowing EMR Serverless applications as compute in addition to EMR on EC2 and EMR on EKS.
EMR Studio is integrated with Amazon SageMaker Unified Studio, providing a unified data and compute experience for analytics workflows.
EMR Notebooks
EMR Notebooks provide a managed environment, based on Jupyter Notebook, that allows data scientists, analysts, and developers to prepare and visualize data, collaborate with peers, build applications, and perform interactive analysis using EMR clusters.
EMR Notebooks are now available as EMR Studio Workspaces in the console. AWS recommends using EMR Studio instead of EMR Notebooks. The option to create new notebooks in the old EMR console has been turned off.
Users can create serverless notebooks directly from the console, attach them to an existing shared EMR cluster, or provision a cluster directly from the console and build Spark applications and run interactive queries.
Notebooks are auto-saved to S3 buckets, and can be retrieved from the console to resume work.
Notebooks can be detached and attached to new clusters.
Notebooks are prepackaged with the libraries found in the Anaconda repository, allowing you to import and use these libraries in the notebooks code and use them to manipulate data and visualize results.
EMR with Apache Iceberg
Amazon EMR natively supports Apache Iceberg from version 6.5.0 and later, enabling open, transactional data lakes on S3.
Apache Iceberg provides ACID transactions, schema evolution, time travel, and partition evolution for data lake tables.
Apache Iceberg v3 (EMR 7.12+, November 2025) introduces:
Deletion Vectors – Optimized delete files that speed up data pipelines and reduce data compaction costs.
Row Lineage – Better tracking for row-level changes, strengthening governance and compliance.
More granular data access control for enhanced data security.
Supports table, row, column, and cell-level access control with Apache Iceberg through AWS Lake Formation.
Fine-grained access control using Lake Formation is available for EMR on EKS from EMR 7.7 and higher.
Apache Spark 4.0 on EMR
Apache Spark 4.0.2 is generally available on Amazon EMR (May 2026) across EMR Serverless, EMR on EC2, and EMR on EKS.
Key features of Spark 4.0 on EMR:
VARIANT data type – Native support for semi-structured JSON data handling without complex parsing.
ANSI SQL compliance – Standard SQL support eliminating the need for Spark-specific syntax.
Apache Iceberg v3 table format – Native support for the latest Iceberg capabilities.
Spark Connect – Decoupled architecture allowing interactive development from local IDEs while using EMR for execution.
transformWithState API – Enables building stateful streaming applications in a serverless environment.
EMR optimized runtime runs Spark 4.0 workloads up to 4.5x faster than open-source Apache Spark.
Apache Spark Upgrade Agent (re:Invent 2025)
AI-powered agent that accelerates Spark version upgrades through automated code analysis and transformation.
Works directly within your IDE, analyzing code, applying fixes, and validating results.
Supports PySpark and Scala applications on EMR on EC2 and EMR Serverless.
Converts complex upgrade processes that typically take months into weeks.
Includes data quality validation to detect schema differences and value-level statistical drifts.
EMR on EKS
Amazon EMR on EKS is a deployment option that allows running open-source big data frameworks such as Apache Spark and Apache Flink on Amazon Elastic Kubernetes Service (EKS) clusters with the EMR runtime.
Provides the same EMR benefits (managed versions of Spark, automatic provisioning, performance-optimized runtime) on EKS that are available on EC2.
Supports Apache Flink on EKS (GA June 2024) for scalable, reliable stream processing.
Supports fine-grained access control for Iceberg tables using Lake Formation integration (EMR 7.7+).
Available as EMR on EKS release 7.9.0 (latest as of 2025).
Integrated with Amazon SageMaker Unified Studio for unified analytics workflows.
EMR Release Lifecycle and Support
24-Month Standard Support (July 2024) – Each Amazon EMR release receives 24 months of standard support including fixes for critical security, bugs, and data corruption issues.
After standard support ends, releases enter end-of-support where no further patches are provided.
Amazon EMR 3.10 and lower cannot create new clusters (since December 2023).
AWS strongly recommends using the latest EMR release (EMR 7.13.0 as of 2026) for all new clusters.
Managed Policies v2 – EMR is deprecating existing managed policies (v1) in favor of scoped-down v2 policies aligned with AWS best practices.
EMR Best Practices
Data Migration
Two tools – S3DistCp and DistCp – can be used to move data stored on the local (data center) HDFS storage to S3, from S3 to HDFS and between S3 and local disk (non HDFS) to S3
AWS Direct Connect can also be considered for moving data with consistent bandwidth and reduced latency for large-scale transfers.
Data Collection
Apache Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, & moving large amounts of log data
Flume agents can be installed on the data sources (web-servers, app servers etc) and data shipped to the collectors which can then be stored in persistent storage like S3 or HDFS
Data Aggregation
Data aggregation refers to techniques for gathering individual data records (for e.g. log records) and combining them into a large bundle of data files i.e. creating a large file from small files
Hadoop, on which EMR runs, generally performs better with fewer large files compared to many small files
Hadoop splits the file on HDFS on multiple nodes, while for the data in S3 it uses the HTTP Range header query to split the files which helps improve performance by supporting parallelization
Log collectors like Flume and Fluentd can be used to aggregate data before copying it to the final destination (S3 or HDFS)
Data aggregation has following benefits
Improves data ingest scalability by reducing the number of times needed to upload data to AWS
Reduces the number of files stored on S3 (or HDFS), which inherently helps provide better performance when processing data
Provides a better compression ratio as compressing large, highly compressible files is often more effective than compressing a large number of smaller files.
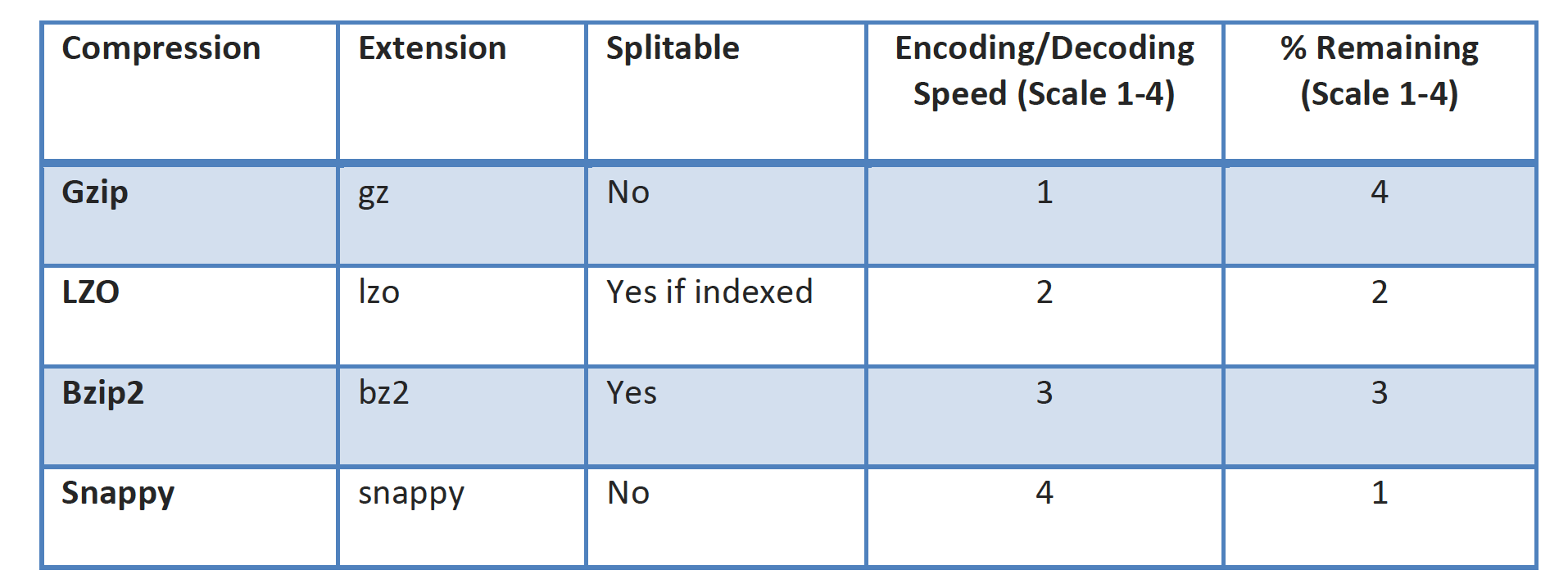
Data compression
Data compression can be used at the input as well as intermediate outputs from the mappers
Data compression helps
Lower storage costs
Lower bandwidth cost for data transfer
Better data processing performance by moving less data between data storage location, mappers, and reducers
Better data processing performance by compressing the data that EMR writes to disk, i.e. achieving better performance by writing to disk less frequently
Data Compression can have an impact on Hadoop data splitting logic as some of the compression techniques like gzip do not support it
Data Partitioning
Data partitioning helps in data optimizations and lets you create unique buckets of data and eliminate the need for a data processing job to read the entire data set
Data can be partitioned by
Data type (time series)
Data processing frequency (per hour, per day, etc.)
Data access and query pattern (query on time vs. query on geo location)
Cost Optimization
AWS offers different pricing models for EC2 instances
On-Demand instances
are a good option if using transient EMR jobs or if the EMR hourly usage is less than 17% of the time
Reserved instances
are a good option for persistent EMR cluster or if the EMR hourly usage is more than 17% of the time as is more cost effective
Spot instances
can be a cost effective mechanism to add compute capacity (up to 90% discount vs On-Demand)
can be used where the data persists on S3
can be used to add extra task capacity with Task nodes
is not suited for Master node, as if it is lost the cluster is lost and Core nodes (data nodes) as they host data and if lost needs to be recovered to rebalance the HDFS cluster
less than 5% of Spot workloads are interrupted (with a two-minute warning)
Architecture pattern can be used,
Run master node on On-Demand or Reserved Instances (if running persistent EMR clusters).
Run a portion of the EMR cluster on core nodes using On-Demand or Reserved Instances and
the rest of the cluster on task nodes using Spot Instances.
Use Graviton-based instances (e.g., m7g, c7g, r7g, r8g) for improved price-performance.
Use Instance Fleets with allocation strategies for optimal capacity and cost management.
Use EMR Managed Scaling to automatically right-size clusters.
Consider EMR Serverless for variable workloads to pay only for resources used.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You require the ability to analyze a large amount of data, which is stored on Amazon S3 using Amazon Elastic Map Reduce. You are using the cc2.8xlarge instance type, who’s CPUs are mostly idle during processing. Which of the below would be the most cost efficient way to reduce the runtime of the job? [PROFESSIONAL]
Create smaller files on Amazon S3.
Add additional cc2.8xlarge instances by introducing a task group.
Use smaller instances that have higher aggregate I/O performance.
Create fewer, larger files on Amazon S3.
A customer’s nightly EMR job processes a single 2-TB data file stored on Amazon Simple Storage Service (S3). The Amazon Elastic Map Reduce (EMR) job runs on two On-Demand core nodes and three On-Demand task nodes. Which of the following may help reduce the EMR job completion time? Choose 2 answers
Use three Spot Instances rather than three On-Demand instances for the task nodes.
Change the input split size in the MapReduce job configuration.
Use a bootstrap action to present the S3 bucket as a local filesystem.
Launch the core nodes and task nodes within an Amazon Virtual Cloud.
Adjust the number of simultaneous mapper tasks.
Enable termination protection for the job flow.
Your department creates regular analytics reports from your company’s log files. All log data is collected in Amazon S3 and processed by daily Amazon Elastic Map Reduce (EMR) jobs that generate daily PDF reports and aggregated tables in CSV format for an Amazon Redshift data warehouse. Your CFO requests that you optimize the cost structure for this system. Which of the following alternatives will lower costs without compromising average performance of the system or data integrity for the raw data? [PROFESSIONAL]
Use reduced redundancy storage (RRS) for PDF and CSV data in Amazon S3. Add Spot instances to Amazon EMR jobs. Use Reserved Instances for Amazon Redshift. (Only Spot instances impacts performance)
Use reduced redundancy storage (RRS) for all data in S3. Use a combination of Spot instances and Reserved Instances for Amazon EMR jobs. Use Reserved instances for Amazon Redshift (Combination of the Spot and reserved with guarantee performance and help reduce cost. Also, RRS would reduce cost and guarantee data integrity, which is different from data durability)
Use reduced redundancy storage (RRS) for all data in Amazon S3. Add Spot Instances to Amazon EMR jobs. Use Reserved Instances for Amazon Redshift (Only Spot instances impacts performance)
Use reduced redundancy storage (RRS) for PDF and CSV data in S3. Add Spot Instances to EMR jobs. Use Spot Instances for Amazon Redshift. (Spot instances impacts performance and Spot instance not available for Redshift)
A research scientist is planning for the one-time launch of an Elastic MapReduce cluster and is encouraged by her manager to minimize the costs. The cluster is designed to ingest 200TB of genomics data with a total of 100 Amazon EC2 instances and is expected to run for around four hours. The resulting data set must be stored temporarily until archived into an Amazon RDS Oracle instance. Which option will help save the most money while meeting requirements? [PROFESSIONAL]
Store ingest and output files in Amazon S3. Deploy on-demand for the master and core nodes and spot for the task nodes.
Optimize by deploying a combination of on-demand, RI and spot-pricing models for the master, core and task nodes. Store ingest and output files in Amazon S3 with a lifecycle policy that archives them to Amazon Glacier. (Master and Core must be RI or On Demand. Cannot be Spot)
Store the ingest files in Amazon S3 RRS and store the output files in S3. Deploy Reserved Instances for the master and core nodes and on-demand for the task nodes. (Need better durability for ingest file. Spot instances can be used for task nodes for cost saving. RI will not provide cost saving in this case)
Deploy on-demand master, core and task nodes and store ingest and output files in Amazon S3 RRS (Input should be in S3 standard, as re-ingesting the input data might end up being more costly then holding the data for limited time in standard S3)
Your company sells consumer devices and needs to record the first activation of all sold devices. Devices are not activated until the information is written on a persistent database. Activation data is very important for your company and must be analyzed daily with a MapReduce job. The execution time of the data analysis process must be less than three hours per day. Devices are usually sold evenly during the year, but when a new device model is out, there is a predictable peak in activation’s, that is, for a few days there are 10 times or even 100 times more activation’s than in average day. Which of the following databases and analysis framework would you implement to better optimize costs and performance for this workload? [PROFESSIONAL]
Amazon RDS and Amazon Elastic MapReduce with Spot instances.
Amazon DynamoDB and Amazon Elastic MapReduce with Spot instances.
Amazon RDS and Amazon Elastic MapReduce with Reserved instances.
Amazon DynamoDB and Amazon Elastic MapReduce with Reserved instances
A company runs daily ETL jobs on an EMR cluster processing data stored in S3. The cluster uses a single primary node and frequently fails during peak processing. The team wants to improve cluster resilience while maintaining cost efficiency. Which combination of actions should they take? (Choose 2)
Enable multiple primary nodes for high availability to eliminate the single point of failure.
Move all data from S3 to HDFS for faster processing.
Use instance fleets with the capacity-optimized allocation strategy for Spot task nodes.
Use a single large instance type for all nodes to simplify management.
Disable managed scaling to prevent automatic changes during processing.
A data engineering team needs to run Apache Spark jobs that vary significantly in resource requirements throughout the day. They want to minimize costs while ensuring jobs complete within SLA. Which EMR deployment option best meets these requirements?
EMR on EC2 with Reserved Instances for all nodes.
EMR on EC2 with On-Demand Instances and manual scaling.
EMR Serverless, which automatically provisions and releases resources based on workload demands.
EMR on EKS with a fixed number of pods.
A company wants to build an open data lakehouse using Apache Iceberg on Amazon EMR. They need ACID transactions, time travel queries, and the ability to efficiently handle record-level deletes on petabyte-scale data. Which EMR configuration best supports these requirements?
EMR 6.5.0 with Iceberg v1 using copy-on-write tables.
EMR 7.6.0 with Iceberg v2 using merge-on-read tables.
EMR 7.12+ with Iceberg v3 using deletion vectors for efficient deletes and row lineage for tracking.
EMR Serverless without Iceberg, using S3 versioning for time travel.
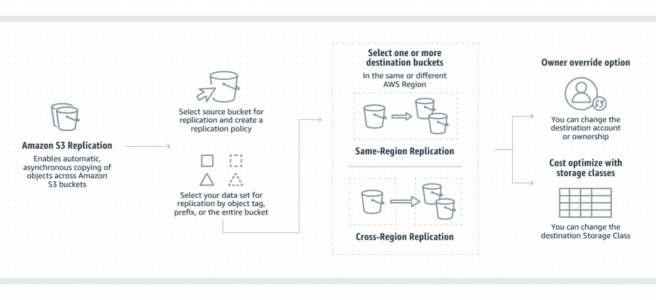
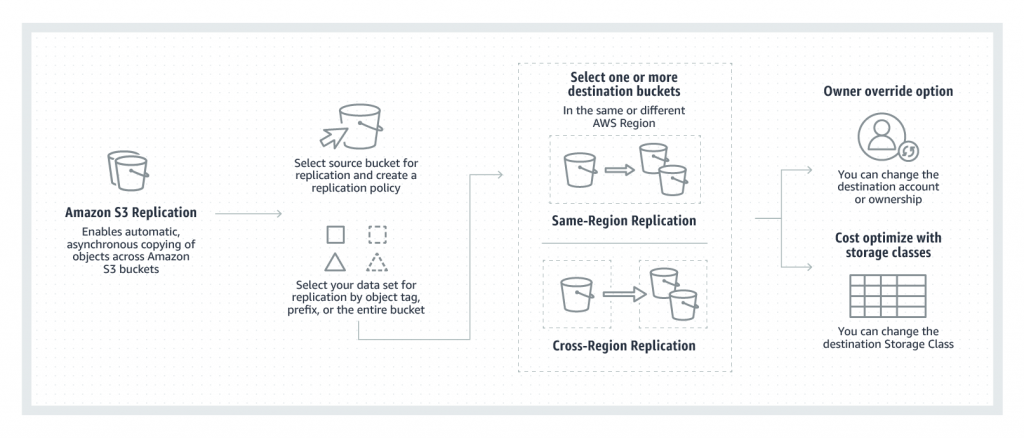
Replicate objects and fail over to a bucket in another AWS Region (with Multi-Region Access Points)
S3 can replicate all or a subset of objects with specific key name prefixes or object tags
S3 encrypts all data in transit across AWS regions using SSL
Object replicas in the destination bucket are exact replicas of the objects in the source bucket with the same key names and the same metadata.
Objects may be replicated to a single destination bucket or multiple destination buckets.
Cross-Region Replication can be useful for the following scenarios:-
Compliance requirement to have data backed up across regions
Minimize latency to allow users across geography to access objects
Operational reasons compute clusters in two different regions that analyze the same set of objects
Same-Region Replication can be useful for the following scenarios:-
Aggregate logs into a single bucket
Configure live replication between production and test accounts
Abide by data sovereignty laws to store multiple copies
S3 Replication Requirements
Source and destination buckets must be versioning-enabled
For CRR, the source and destination buckets must be in different AWS Regions.
The source bucket owner must have the source and destination AWS Regions enabled for their account. The destination bucket owner must have the destination Region enabled for their account.
S3 must have permission to replicate objects from that source bucket to the destination bucket on your behalf.
If the source bucket owner also owns the object, the bucket owner has full permission to replicate the object. If not, the object owner must grant the bucket owner READ and READ_ACP permissions with the object ACL.
Setting up cross-region replication in a cross-account scenario (where the source and destination buckets are owned by different AWS accounts), the destination bucket owner must grant the source bucket owner permissions to replicate objects with a bucket policy.
If the source bucket has S3 Object Lock enabled, the destination buckets must also have S3 Object Lock enabled. Additional permissions s3:GetObjectRetention and s3:GetObjectLegalHold are required on the IAM role.
Destination buckets cannot be configured as Requester Pays buckets.
S3 Batch Replication
S3 Batch Replication allows you to replicate existing objects to different buckets as an on-demand operation.
Live replication (CRR/SRR) only replicates new objects created after the replication rule is configured. Batch Replication addresses the gap for pre-existing objects.
Use cases for Batch Replication:
Backfill newly created buckets with existing objects from another bucket
Retry failed replications – replicate objects with a replication status of FAILED
Migrate data across accounts while preserving metadata and version IDs
Add new buckets to your data lake by replicating existing objects to new destinations
Replicate replicas – replicate objects that were created by another replication rule (not possible with live replication)
Batch Replication uses S3 Batch Operations jobs and provides a completion report when finished.
S3 RTC does not apply to Batch Replication; it is tracked via S3 Batch Operations.
S3 Replication Time Control (S3 RTC)
S3 Replication Time Control (RTC) provides a predictable replication time backed by a Service Level Agreement (SLA).
S3 RTC replicates 99.99% of new objects within 15 minutes after upload, with the majority replicated in seconds.
S3 RTC is backed by an SLA with a commitment to replicate 99.9% of objects within 15 minutes during any billing month.
S3 RTC, by default, includes S3 Replication Metrics and S3 Event Notifications.
S3 RTC is available in all AWS Regions including AWS GovCloud (US) Regions.
Delete marker replication does not adhere to the 15-minute SLA granted by S3 RTC.
S3 Two-Way Replication (Bidirectional)
S3 Replication supports two-way (bidirectional) replication between two or more buckets in the same or different AWS Regions.
Replica Modification Sync enables replicating metadata changes (ACLs, object tags, Object Lock settings) made to replica objects back to the source.
Replica Modification Sync must be enabled on both buckets for bidirectional metadata synchronization.
Two-way replication is essential for:
Building shared datasets across multiple AWS Regions
Keeping data synchronized during failover with S3 Multi-Region Access Points
Making applications highly available even during Regional traffic disruptions
To set up two-way replication, create replication rules in both directions between the source and destination buckets.
S3 Multi-Region Access Points with Replication
S3 Multi-Region Access Points provide a single global endpoint that routes S3 requests to the bucket closest to the requester.
Multi-Region Access Points include failover controls to shift S3 data request traffic between AWS Regions within minutes.
Supports active-active and active-passive configurations:
Active-Active – Traffic is distributed to multiple active Regions. If disruption occurs, traffic is automatically redirected.
Active-Passive – An active Region services all requests; a passive Region is on standby for failover.
Multi-Region Access Points require Cross-Region Replication (CRR) to be configured so that objects are available regardless of which bucket receives the request.
Two-way replication rules should be configured with Multi-Region Access Points to keep all objects and metadata in sync during failover.
Multi-Region Access Points accelerate performance by routing requests via AWS Global Accelerator, reducing latency by up to 60%.
S3 Replication Metrics and Notifications
S3 Replication provides detailed metrics and notifications to monitor replication status between buckets.
Replication metrics available in S3 console and Amazon CloudWatch:
Bytes Pending – total size of objects pending replication
Operations Pending – total number of operations pending replication
Replication Latency – maximum time to replicate
Operations Failed Replication – per-minute count of objects that failed to replicate
S3 Replication metrics are automatically enabled with S3 Replication Time Control (RTC).
S3 Event Notifications provide replication events:
s3:Replication:OperationFailedReplication
s3:Replication:OperationMissedThreshold
s3:Replication:OperationReplicatedAfterThreshold
s3:Replication:OperationNotTracked
Failure notifications do NOT require S3 RTC to be enabled.
Notifications can be sent to Amazon SNS, Amazon SQS, or AWS Lambda to diagnose configuration issues.
S3 Replication – Replicated & Not Replicated
Only new objects created after you add a replication configuration are replicated by live replication. Use S3 Batch Replication to replicate existing objects.
Objects encrypted using:
SSE-S3 (S3 managed keys) – replicated by default
SSE-KMS (AWS KMS keys) – replicated when the replication rule is configured with KMS key specification
DSSE-KMS (Dual-layer server-side encryption) – supported for replication
SSE-C (Customer-provided keys) – supported for replication (added October 2022)
S3 replicates only objects in the source bucket for which the bucket owner has permission to read objects and read ACLs.
Any object ACL updates are replicated, although there can be some delay before S3 can bring the two in sync.
S3 does NOT replicate objects in the source bucket for which the bucket owner does not have permission.
Updates to bucket-level S3 subresources are NOT replicated, allowing different bucket configurations on the source and destination buckets.
Only customer actions are replicated & actions performed by lifecycle configuration are NOT replicated.
Replication chaining is NOT allowed – objects that are replicas created by another replication rule are NOT replicated by live replication. Use Batch Replication to replicate replicas.
S3 does NOT replicate the delete marker by default. However, you can enable delete marker replication in non-tag-based rules to replicate delete markers.
Delete marker replication is NOT supported for tag-based replication rules.
Delete markers added by S3 Lifecycle expiration rules are NOT replicated even with delete marker replication enabled.
S3 does NOT replicate deletion by object version ID. This protects data from malicious deletions.
S3 Replication with Encryption
Starting January 5, 2023, Amazon S3 applies server-side encryption with S3 managed keys (SSE-S3) as the base level of encryption for every bucket.
SSE-S3 encrypted objects are replicated by default with no additional configuration.
SSE-KMS encrypted objects require specifying the destination KMS key in the replication rule. The IAM role must have kms:Decrypt permission on the source key and kms:Encrypt on the destination key.
DSSE-KMS (dual-layer encryption with KMS keys) is supported for replication.
SSE-C encrypted objects are supported for replication since October 2022. S3 automatically replicates newly uploaded SSE-C objects if eligible per replication configuration.
Note: Starting April 2026, SSE-C is disabled by default on all new S3 general purpose buckets. Applications requiring SSE-C must explicitly enable it via the PutBucketEncryption API.
S3 on Outposts Replication
S3 Replication on AWS Outposts enables automatic replication of S3 objects across different Outposts or between buckets on the same Outpost.
Available at no additional cost in all AWS Regions where AWS Outposts racks are available (since March 2023).
Helps meet local data residency requirements while providing data redundancy.
S3 on Outposts does NOT support replicating delete markers for tag-based rules.
Existing Object Replication is NOT supported for S3 on Outposts buckets.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company needs to replicate millions of existing objects from a source S3 bucket to a new destination bucket in another region. They also need to replicate any new objects going forward. What combination of features should they use?
Enable Cross-Region Replication for new objects and use S3 Batch Replication for existing objects
Use S3 Batch Replication only, as it handles both existing and new objects
Enable Cross-Region Replication with Replication Time Control
Use AWS DataSync to copy existing objects and CRR for new objects
Answer: a – CRR handles new objects automatically, while Batch Replication is the managed way to replicate existing objects on demand.
A company requires that all replicated objects arrive at the destination bucket within 15 minutes and needs an SLA guarantee. Which feature should they enable?
S3 Cross-Region Replication with Transfer Acceleration
S3 Replication Time Control (S3 RTC)
S3 Same-Region Replication with CloudWatch alarms
S3 Multi-Region Access Points
Answer: b – S3 RTC replicates 99.99% of objects within 15 minutes and is backed by an SLA guaranteeing 99.9% within 15 minutes.
A company wants to build a highly available multi-region application using S3. They need automatic failover of S3 data requests if a region becomes unavailable. What should they configure?
CRR with CloudFront distribution
S3 Multi-Region Access Points with two-way replication and failover controls
SRR with Route 53 failover routing
S3 Batch Operations with Lambda triggers
Answer: b – S3 Multi-Region Access Points with failover controls and two-way CRR provide a single global endpoint with the ability to shift traffic between regions.
Which of the following statements about S3 Replication are correct? (Choose 3)
Live replication automatically replicates objects that existed before the replication rule was configured
Versioning must be enabled on both source and destination buckets
S3 Batch Replication can replicate replicas that were created by another replication rule
Delete markers are replicated by default
SSE-C encrypted objects are supported for replication
Answer: b, c, e – Live replication does NOT replicate pre-existing objects (a is wrong). Delete markers are NOT replicated by default (d is wrong). Versioning is required, Batch Replication can replicate replicas, and SSE-C is supported since October 2022.
A company uses two-way replication between two S3 buckets. They want metadata changes (ACLs and tags) made to replica objects to be synchronized back to the source. What must they enable?
S3 Replication Time Control on both buckets
Replica Modification Sync on both buckets
S3 Batch Replication with metadata preservation
S3 Object Lock on both buckets
Answer: b – Replica Modification Sync must be enabled on both buckets to replicate metadata changes (ACLs, tags, Object Lock settings) bidirectionally.
Which S3 Replication metrics can be monitored via Amazon CloudWatch? (Choose 3)
Bytes Pending replication
Operations Pending replication
Number of buckets with replication enabled
Operations Failed Replication
Cost of data transfer for replication
Answer: a, b, d – S3 Replication metrics include Bytes Pending, Operations Pending, Replication Latency, and Operations Failed Replication. Number of buckets and cost are not replication metrics.
S3 notification feature enables notifications to be triggered when certain events happen in the bucket.
Notifications are enabled at the Bucket level.
Notifications can be configured to be filtered by the prefix and suffix of the key name of objects. However, filtering rules cannot be defined with overlapping prefixes, overlapping suffixes, or prefix and suffix overlapping.
S3 event notifications are designed to be delivered at least once. Typically, event notifications are delivered in seconds but can sometimes take a minute or longer.
Event notifications are not guaranteed to arrive in the same order that the events occurred. On rare occasions, S3’s retry mechanism might cause duplicate event notifications for the same object event.
Supported Event Types
S3 can publish the following events:
New Object Created events (s3:ObjectCreated:*)
Can be enabled for Put, Post, Copy, or CompleteMultipartUpload operations
You will not receive event notifications from failed operations
Object Removal events (s3:ObjectRemoved:*)
Can publish delete events for object deletion (s3:ObjectRemoved:Delete) or insertion of delete marker (s3:ObjectRemoved:DeleteMarkerCreated)
You will not receive event notifications from automatic deletes from lifecycle configurations or from failed operations.
Restore Object events (s3:ObjectRestore:*)
Restoration of objects archived to S3 Glacier Flexible Retrieval, S3 Glacier Deep Archive, S3 Intelligent-Tiering Archive Access tier, or Deep Archive Access tier
s3:Replication:OperationReplicatedAfterThreshold – object replicated after 15-minute threshold
s3:Replication:OperationNotTracked – object no longer tracked by replication metrics
Reduced Redundancy Storage (RRS) object lost events (s3:ReducedRedundancyLostObject)
Can be used to reproduce/recreate the Object
Note: RRS is no longer recommended. Standard S3 is more cost-effective with higher durability (99.999999999% vs 99.99%). Consider migrating to S3 Standard or other storage classes.
Supported Event Destinations
S3 can publish events to the following destinations:
Content-based filtering – filter by any attribute in the event (object size, key pattern, metadata)
Multiple targets – single rule can route to multiple targets
Over 20 supported targets including Lambda, Step Functions, SQS, SNS, Kinesis, ECS tasks, API destinations
Archive and replay – ability to archive events and replay them later
Schema discovery – auto-detect event schemas
No need for separate notification configurations per event type
EventBridge and traditional S3 event notifications (SNS/SQS/Lambda) can be configured simultaneously on the same bucket.
Event Notification Key Points
Notification configuration is stored in the notification subresource associated with the bucket.
If notifications write to the same bucket that triggers the notification, it could cause an execution loop. Use two buckets or configure the trigger with a specific prefix for incoming objects.
Event notifications do not alert for automatic deletes from lifecycle policies (use s3:LifecycleExpiration events instead).
Failed operations do not generate event notifications.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company uses S3 to store images. When an image is uploaded, a Lambda function must be triggered to generate thumbnails. What is the MOST efficient approach?
Configure CloudWatch Events to monitor S3 uploads and trigger Lambda
Configure S3 Event Notification with s3:ObjectCreated:* event to invoke the Lambda function
Use a scheduled Lambda function to poll S3 for new objects
Use S3 Batch Operations to process new images
Answer: b – S3 Event Notifications can directly invoke Lambda functions when objects are created. This is the most efficient event-driven approach.
A development team needs to send S3 object creation events to an SQS FIFO queue for ordered processing. Which approach should they use?
Configure S3 Event Notification directly to the SQS FIFO queue
Enable Amazon EventBridge on the bucket and create a rule to route events to the SQS FIFO queue
Use SNS FIFO topic as intermediary between S3 and SQS FIFO
Configure S3 Event Notification to Lambda, which forwards to SQS FIFO
Answer: b – SQS FIFO queues are not supported as a direct S3 event notification destination. Amazon EventBridge can route S3 events to SQS FIFO queues. SNS FIFO is also not supported as S3 event destination.
An application needs to be notified when objects are transitioned to Glacier by S3 Lifecycle rules, and separately when objects are deleted by lifecycle expiration. Which event types should be configured?
s3:ObjectRemoved:Delete and s3:ObjectRestore:Post
s3:LifecycleTransition and s3:LifecycleExpiration:Delete
s3:ObjectCreated:Copy and s3:ObjectRemoved:*
s3:IntelligentTiering and s3:ObjectRemoved:Delete
Answer: b – s3:LifecycleTransition fires when lifecycle transitions objects to another storage class. s3:LifecycleExpiration:Delete fires when lifecycle deletes objects. s3:ObjectRemoved:Delete does NOT fire for lifecycle deletions.
A company wants to filter S3 events by object size and route them to different Lambda functions – small objects to one function and large objects to another. Which approach supports this?
Configure two S3 Event Notification rules with different prefix filters
Enable Amazon EventBridge and create content-based filtering rules
Use SNS with message filtering policies
Configure S3 Event Notification to SQS and use Lambda to filter
Answer: b – Amazon EventBridge supports content-based filtering on any event attribute including object size, time range, and metadata fields. S3 Event Notifications natively only support prefix and suffix filtering on key names.
Which of the following are valid S3 event notification destinations? (Choose 3)
Amazon SNS FIFO topic
Amazon SQS Standard queue
AWS Lambda function
Amazon EventBridge
Amazon SQS FIFO queue
Answer: b, c, d – S3 event notifications support SNS Standard topics, SQS Standard queues, Lambda functions, and Amazon EventBridge. SNS FIFO and SQS FIFO are not supported as direct S3 event notification destinations.
📌 AWS Recommendation (October 2024): AWS now recommends using AWS Amplify Hosting to host static website content stored on S3. Amplify Hosting is a fully managed service that deploys your websites on a globally available CDN powered by Amazon CloudFront, with built-in HTTPS, custom domains, redirects, and custom headers. See AWS Amplify Hosting section below.
Amazon S3 can be used for Static Website hosting with Client-side scripts.
S3 does not support server-side scripting.
S3, in conjunction with Route 53, supports hosting a website at the root domain which can point to the S3 website endpoint
S3 website endpoints do not support HTTPS or access points. Use Amazon CloudFront to serve HTTPS traffic.
For S3 website hosting the content should be made publicly readable which can be provided using a bucket policy.
Since April 2023, all new S3 buckets have Block Public Access enabled and ACLs disabled by default. To use S3 static website hosting, Block Public Access must be explicitly disabled and a bucket policy must be configured for public read access.
Users can configure the index, and error document as well as configure the conditional routing of an object name
S3 supports up to 50 routing rules per website configuration for conditional redirects.
Requester Pays buckets do not allow access through the website endpoint. Any request to such a bucket will receive a 403 – Access Denied response.
If the S3 bucket is encrypted using SSE-KMS, the website endpoint cannot serve the content. Use CloudFront with Origin Access Control (OAC) instead.
S3 website endpoint domains are registered in the Public Suffix List (PSL). If setting sensitive cookies, use the __Host- prefix for CSRF protection.
S3 Website Endpoints
S3 provides two types of endpoints:
REST API endpoint (s3.amazonaws.com) – Supports HTTPS, access points, OAC
Website endpoint (s3-website-region.amazonaws.com or s3-website.region.amazonaws.com) – Supports only HTTP, no access points, no OAC
Website endpoints return HTML error documents for 4xx errors, while REST API endpoints return XML error responses.
Website endpoints support index documents and redirects; REST API endpoints do not.
S3 Static Website with CloudFront
CloudFront is the recommended approach to add HTTPS support, caching, and global distribution to S3-hosted websites.
Two approaches to use CloudFront with S3:
S3 REST API endpoint as origin with OAC (Recommended) – Keeps the bucket private; CloudFront uses Origin Access Control to authenticate requests to S3.
S3 website endpoint as custom origin – Bucket must be publicly accessible; does not support OAC/OAI. Can restrict access using a custom Referer header.
Origin Access Control (OAC) is the current best practice for securing S3 origins with CloudFront (replaces the legacy OAI).
OAI creation was deprecated in 2024.
As of March 2026, new CloudFront distributions can only use OAC.
OAC supports SSE-KMS encrypted objects, SigV4, and all AWS regions.
OAC requires S3 Object Ownership set to “Bucket owner enforced” (default for new buckets).
CloudFront Functions can handle URL rewriting (e.g., appending index.html to directory paths) when using the REST API endpoint with OAC, providing website-endpoint-like behavior while keeping the bucket private.
AWS Shield Standard is automatically included with every CloudFront distribution at no extra cost for DDoS protection.
AWS Amplify Hosting (Recommended Alternative)
AWS Amplify Hosting is a fully managed service for hosting static websites, officially recommended by AWS as of October 2024 for static content stored on S3.
Key benefits over S3 website hosting:
Built-in HTTPS with free SSL/TLS certificates
Global CDN powered by Amazon CloudFront
Custom domain configuration with automatic DNS setup
Custom headers and redirects without additional services
Atomic deployments and instant cache invalidation
No need to disable Block Public Access on S3 bucket
Amplify Hosting can deploy directly from an S3 general purpose bucket by selecting the location of objects within the bucket.
Does not support cross-account S3 bucket access.
Simplifies the setup compared to manually configuring S3 + CloudFront + Route 53 + ACM.
Security Best Practices
Prefer CloudFront + OAC or Amplify Hosting over making S3 buckets publicly accessible.
Keep Block Public Access enabled whenever possible; use CloudFront OAC to grant access to the distribution only.
If public access is required (S3 website endpoint), use a bucket policy (not ACLs) to grant read access, as ACLs are disabled by default on new buckets.
Enable access logging to track website requests.
Use CloudFront with WAF for additional security controls like geo-restriction, rate limiting, and IP filtering.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Company ABCD is currently hosting their corporate site in an Amazon S3 bucket with Static Website Hosting enabled. Currently, when visitors go to http://www.companyabcd.com the index.html page is returned. Company C now would like a new page welcome.html to be returned when a visitor enters http://www.companyabcd.com in the browser. Which of the following steps will allow Company ABCD to meet this requirement? Choose 2 answers.
Upload an html page named welcome.html to their S3 bucket
Create a welcome subfolder in their S3 bucket
Set the Index Document property to welcome.html
Move the index.html page to a welcome subfolder
Set the Error Document property to welcome.html
A company wants to host a static website on AWS with HTTPS support using a custom domain. The website files are stored in an S3 bucket. Which combination of services provides the MOST secure and recommended architecture? Choose 2 answers.
Enable S3 static website hosting and use the website endpoint directly
Use CloudFront with Origin Access Control (OAC) and the S3 REST API endpoint as origin
Use CloudFront with Origin Access Identity (OAI)
Keep S3 Block Public Access enabled on the bucket
Disable server-side encryption on the bucket
A developer needs to host a static single-page application on AWS. The requirements include HTTPS, a custom domain, atomic deployments, and minimal operational overhead. Which approach requires the LEAST configuration effort?
S3 static website hosting with CloudFront and ACM certificate
AWS Amplify Hosting with S3 as the source
S3 static website hosting with Route 53 alias record
EC2 instance with Nginx serving static files
An organization hosts a static website on S3 using the website endpoint. They want to ensure only CloudFront can access the S3 content while keeping the bucket private. However, they need S3 website features like index documents for subdirectories. What is the recommended solution?
Use OAC with the S3 website endpoint
Use CloudFront with the S3 REST API endpoint, OAC, and a CloudFront Function for URL rewriting
Use OAI with the S3 website endpoint
Make the bucket public and use a custom Referer header
A company created a new S3 bucket and enabled static website hosting. However, users are receiving 403 Forbidden errors when accessing the website. What is the MOST likely cause? (Choose 2)
S3 Block Public Access is still enabled on the bucket (default for new buckets since April 2023)
The bucket does not have versioning enabled
No bucket policy has been configured to allow public read access
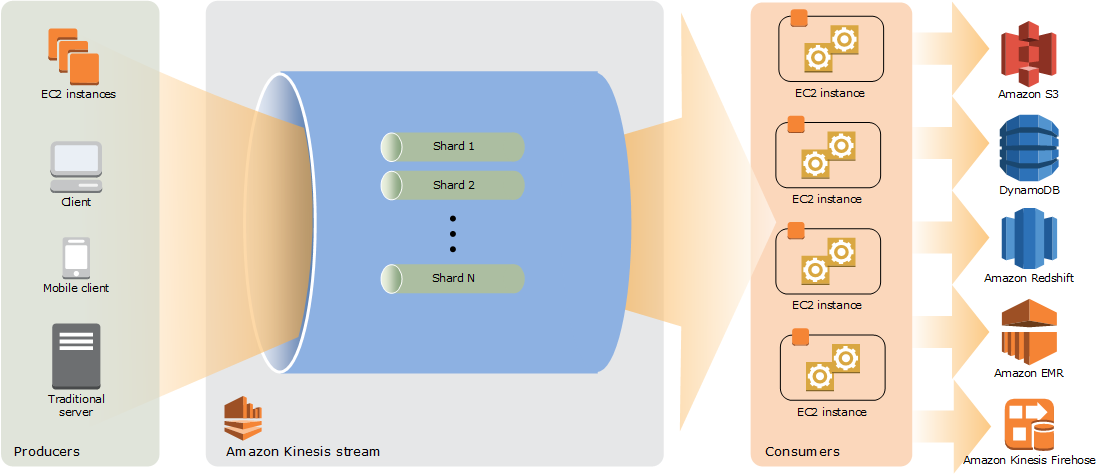
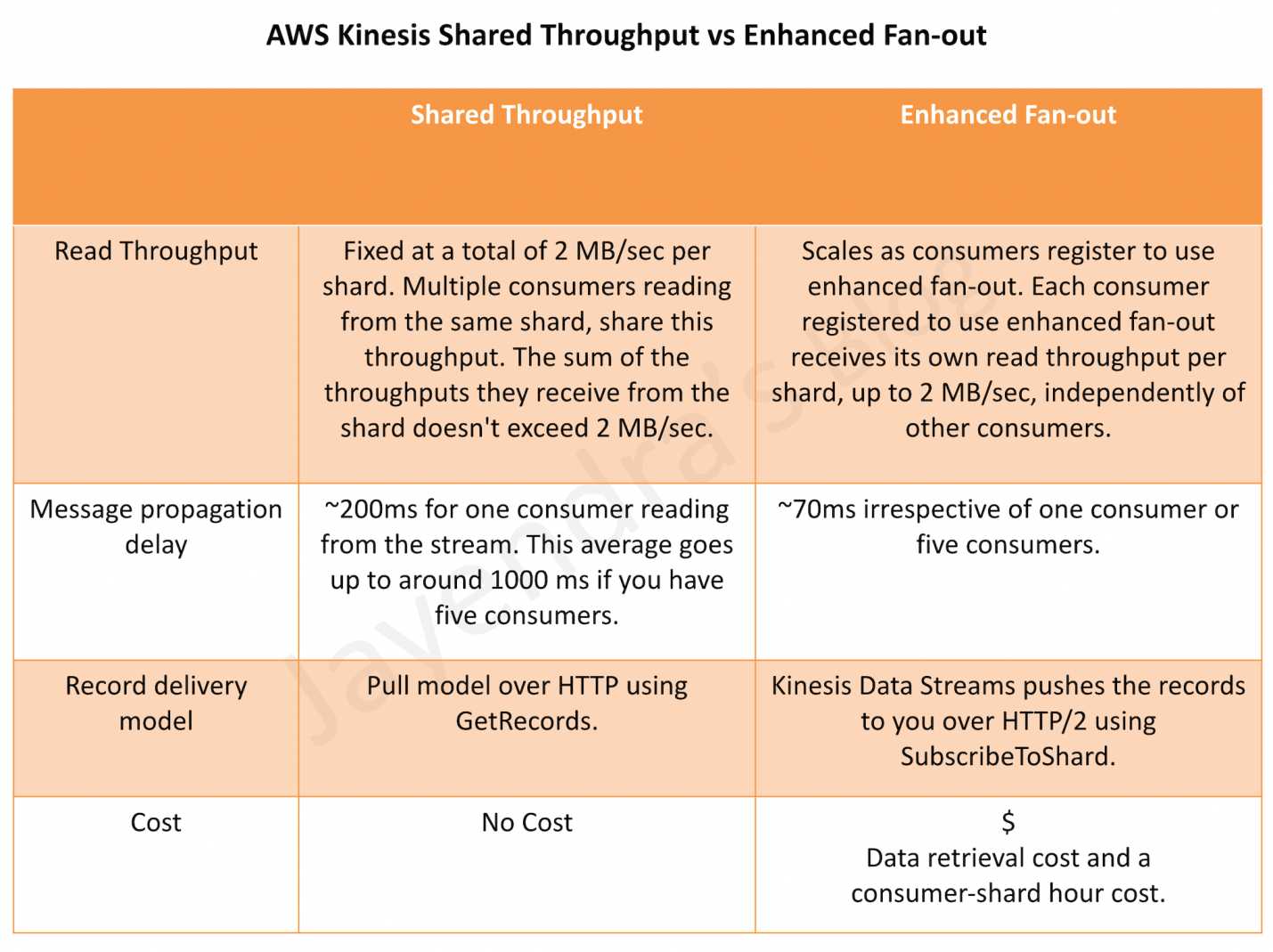
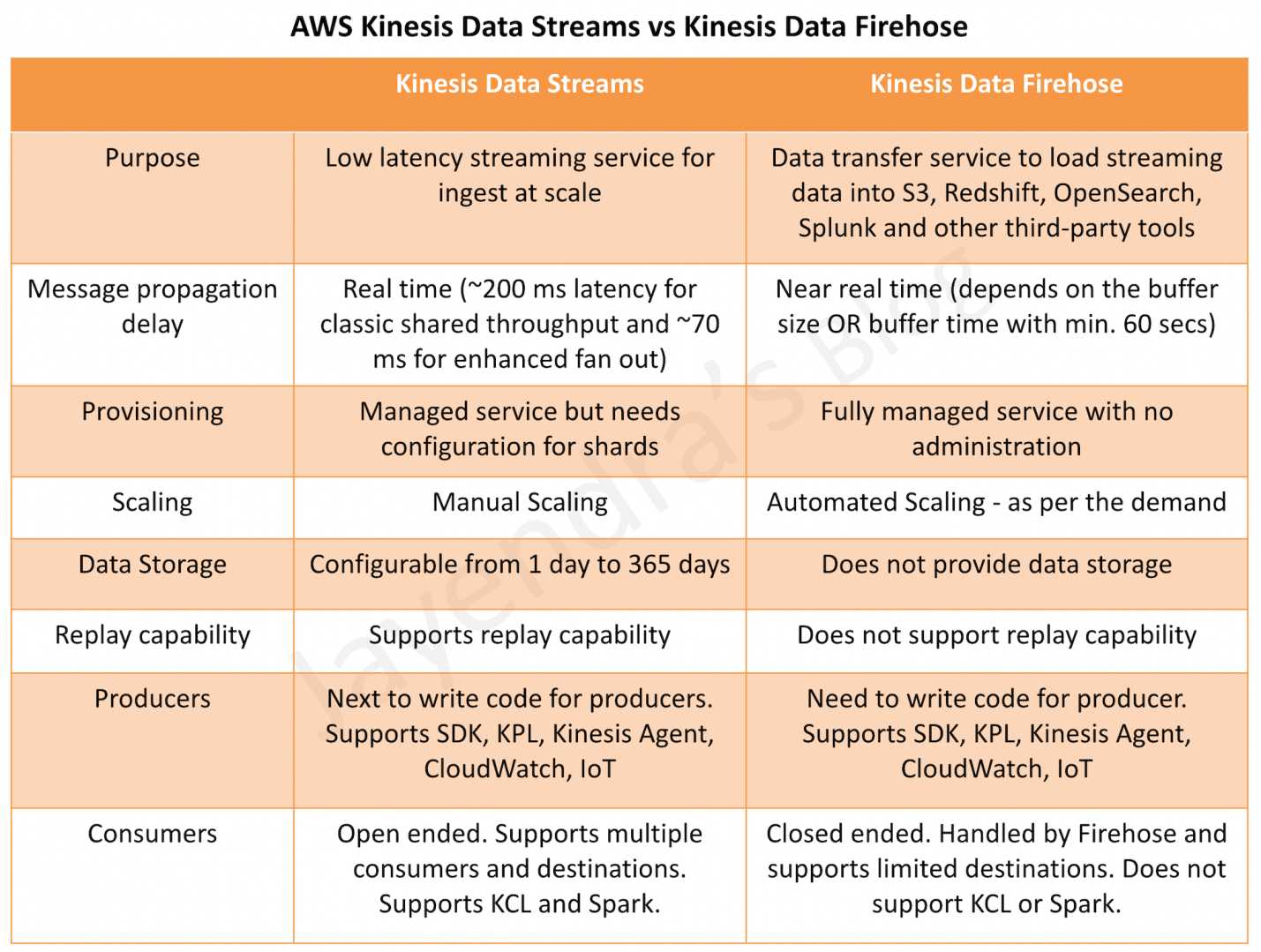
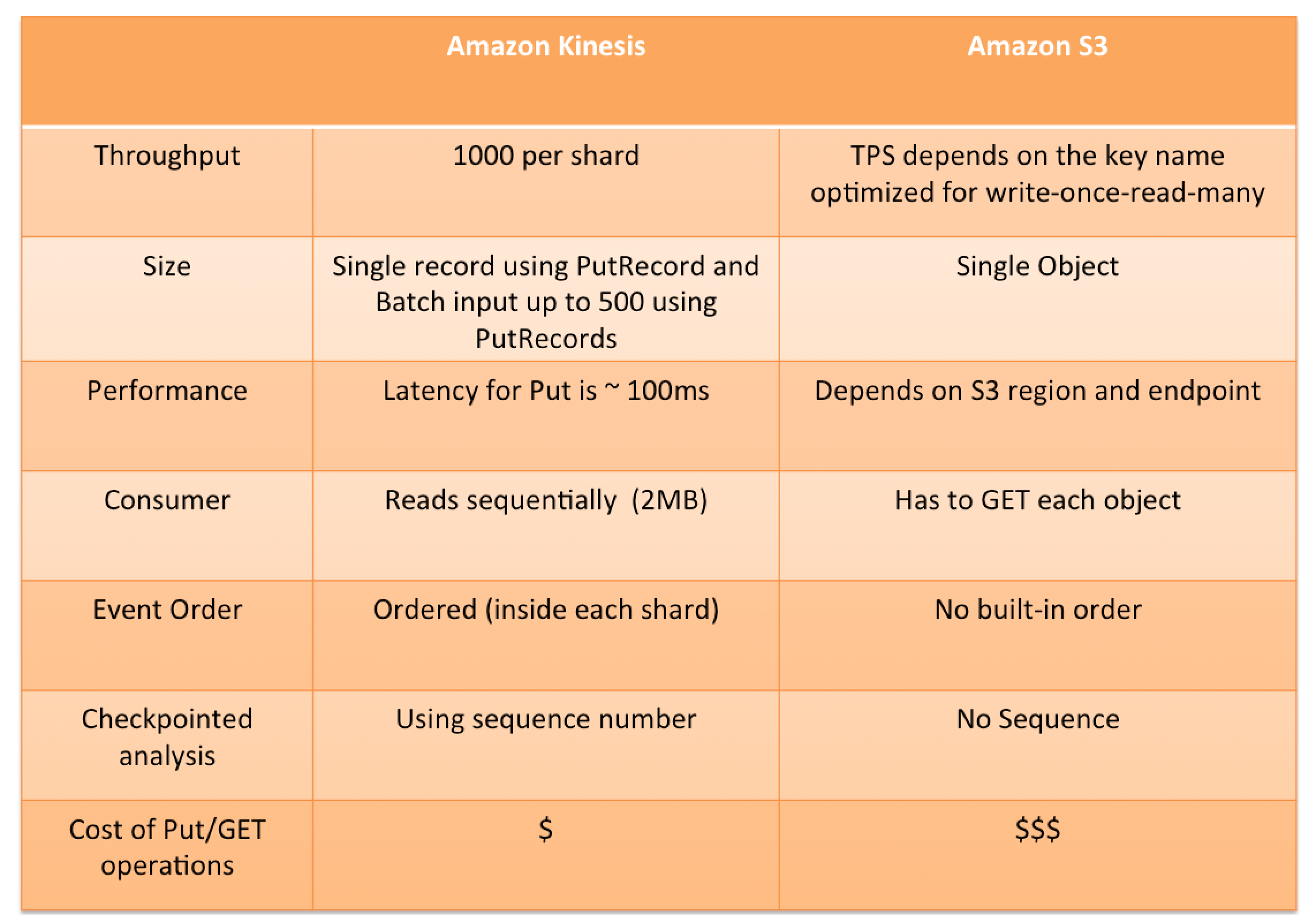
is an open-source, high-performance, fault-tolerant, and scalable streaming data store platform for building real-time streaming data pipelines and applications.
stores streaming data in a fault-tolerant way, providing a buffer between producers and consumers.
stores events as a continuous series of records and preserves the order in which the records were produced.
runs as a cluster and stores data records in topics, which are partitioned and replicated across one or more brokers that can be spread across multiple AZs for high availability.
allows many data producers and multiple consumers that can process data from Kafka topics on a first-in-first-out basis, preserving the order data were produced.
makes it easy for developers and DevOps managers to run Kafka applications and Kafka Connect connectors on AWS, without the need to become experts in operating Kafka.
operates, maintains, and scales Kafka clusters, provides enterprise-grade security features out of the box, and has built-in AWS integrations that accelerate development of streaming data applications.
always runs within a VPC managed by the MSK and is available to your own selected VPC, subnet, and security group when the cluster is setup.
IP addresses from the VPC are attached to the MSK resources through elastic network interfaces (ENIs), and all network traffic stays within the AWS network and is not accessible to the internet by default.
integrates with CloudWatch for monitoring, metrics, and logging.
MSK Serverless is a cluster type for MSK that makes it easy for you to run Apache Kafka clusters without having to manage compute and storage capacity. With MSK Serverless, you can run your applications without having to provision, configure, or optimize clusters, and you pay for the data volume you stream and retain.
MSK Serverless
MSK Serverless is a cluster type that helps run Kafka clusters without having to manage compute and storage capacity.
fully manages partitions, including monitoring and moving them to even load across a cluster.
creates 2 replicas for each partition and places them in different AZs. Additionally, MSK serverless automatically detects and recovers failed backend resources to maintain high availability.
allows clients to connect over a private connection using AWS PrivateLink without exposing the traffic to the public internet.
offers IAM Access Control to manage client authentication and client authorization to Kafka resources such as topics.
MSK Security
MSK uses EBS server-side encryption and KMS keys to encrypt storage volumes.
Clusters have encryption in transit enabled via TLS for inter-broker communication. For provisioned clusters, you can opt out of using encryption in transit when a cluster is created.
MSK clusters running Kafka version 2.5.1 or greater support TLS in-transit encryption between Kafka brokers and ZooKeeper nodes.
TLS certificate authentication (CA) for AuthN and access control lists for AuthZ
SASL/SCRAM for AuthN and access control lists for AuthZ.
MSK recommends using IAM Access Control as it defaults to least privilege access and is the most secure option.
For serverless clusters, IAM Access Control can be used for both authentication and authorization.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
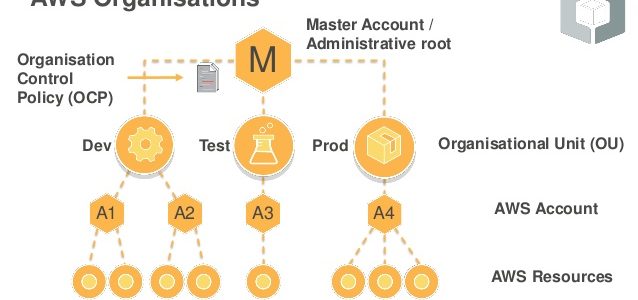
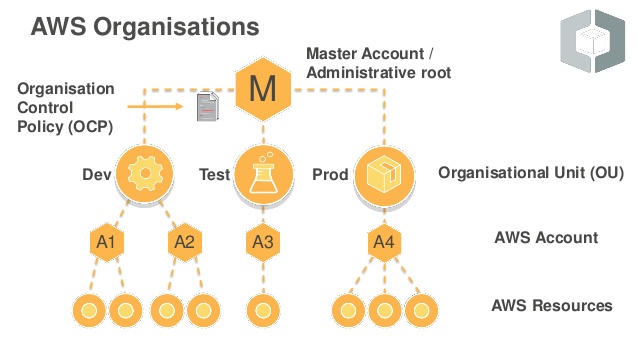
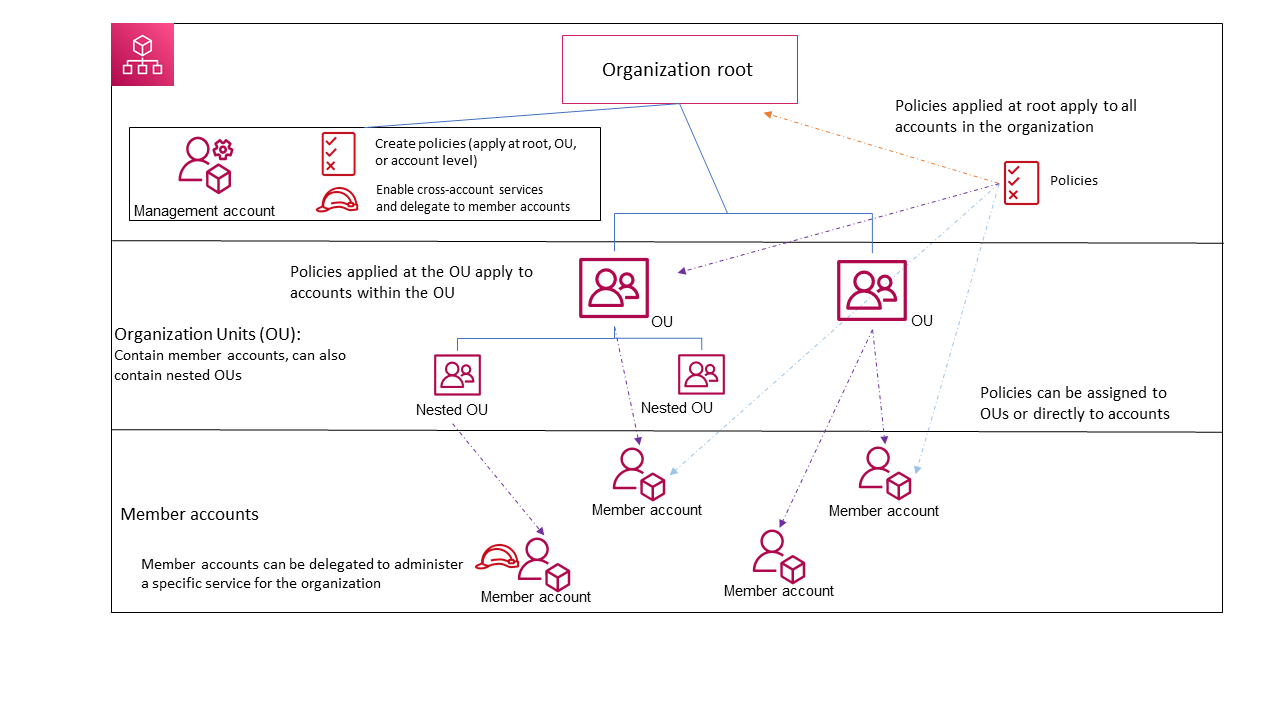
AWS Organizations is an account management service that enables consolidating multiple AWS accounts into an organization that can be created and centrally managed.
AWS Organizations include consolidated billing and account management capabilities that enable one to better meet the budgetary, security, and compliance needs of the business.
As an administrator of an organization, new accounts can be created in an organization, and existing accounts invited to join the organization.
AWS Organizations enables you to
Automate AWS account creation and management, and provision resources with AWS CloudFormation Stacksets.
Maintain a secure environment with policies and management of AWS security services
Govern access to AWS services, resources, and regions
Centrally manage policies across multiple AWS accounts
Audit the environment for compliance
View and manage costs with consolidated billing
Configure AWS services across multiple accounts
AWS Organization Features
Centralized management of all of the AWS accounts
Combine existing accounts into or create new ones within an organization that enables them to be managed centrally
Policies can be attached to accounts that affect some or all of the accounts
Management account of the organization can be used to consolidate and pay for all member accounts.
Hierarchical grouping of accounts to meet budgetary, security, or compliance needs
Accounts can be grouped into organizational units (OUs) and each OU can be attached to different access policies.
OUs can also be nested to a depth of five levels, providing flexibility in how you structure your account groups.
Control over AWS services and API actions that each account can access
As an administrator of the management account of an organization, access to users and roles in each member account can be restricted to which AWS services and individual API actions
This restriction even overrides the administrators of member accounts in the organization.
When AWS Organizations blocks access to a service or API action for a member account, a user or role in that account can’t access any prohibited service or API action, even if an administrator of a member account explicitly grants such permissions in an IAM policy.
Integration and support for AWS IAM
IAM provides granular control over users and roles in individual accounts.
Organizations expand that control to the account level by giving control over what users and roles in an account or a group of accounts can do.
Users can access only what is allowed by both the Organization policies and IAM policies.
Resulting permissions are the logical intersection of what is allowed by AWS Organizations at the account level, and what permissions are explicitly granted by IAM at the user or role level within that account.
If either blocks an operation, the user can’t access that operation.
Integration with other AWS services
Select AWS services can be enabled to access accounts in the organization and perform actions on the resources in the accounts.
When another service is configured and authorized to access the organization, AWS Organizations creates an IAM service-linked role for that service in each member account.
Service-linked role has predefined IAM permissions that allow the other AWS service to perform specific tasks in the organization and its accounts.
All accounts in an organization automatically have a service-linked role created, which enables the AWS Organizations service to create the service-linked roles required by AWS services for which you enable trusted access
These additional service-linked roles come with policies that enable the specified service to perform only those required tasks
Delegated Administrator
A member account can be designated as a delegated administrator for an AWS service integrated with Organizations.
Delegated administrator accounts can manage organization-level tasks for the specified service without requiring the management account.
Reduces reliance on the management account for day-to-day governance tasks.
When a delegated administrator is registered, it receives authorization to access all read-only Organizations API operations.
Trusted Access
Trusted access grants permissions to a specified AWS service to perform tasks in the organization and its accounts.
Enables AWS services like CloudTrail, Config, GuardDuty, Security Hub, and many others to operate across all accounts in the organization.
Creates the necessary service-linked roles automatically in member accounts.
Direct Account Transfers (2025)
AWS Organizations now provides the ability to directly transfer an account to a different organization without first having to remove the account from the current organization.
Eliminates the need for the account to go through a standalone phase during the transfer.
Reduces operational risk and simplifies multi-organization account migration workflows.
Centralized Root Access Management (2024)
Enables centralized management of root user credentials across member accounts in Organizations.
Can centrally remove root user credentials (passwords, access keys, signing certificates, MFA) for member accounts.
Perform tightly scoped privileged root tasks using short-lived root sessions without requiring root credentials.
Helps prevent unintended root access and improves account security at scale.
Member accounts can regain access to accidentally locked Amazon S3 buckets using privileged root sessions.
Data replication that is eventually consistent
AWS Organizations is eventually consistent.
AWS Organizations achieve high availability by replicating data across multiple servers in AWS data centers within its region.
If a request to change some data is successful, the change is committed and safely stored.
However, the change must then be replicated across multiple servers.
AWS Organizations Terminology and Concepts
Organization
An entity created to consolidate AWS accounts that can be administered as a single unit.
An organization has one management account along with zero or more member accounts.
An organization has the functionality that is determined by the feature set that you enable i.e. All features or Consolidated Billing only
Root
Parent container for all the accounts for the organization.
Policy applied to the root is applied to all the organizational units (OUs) and accounts in the organization.
There can be only one root currently and AWS Organization automatically creates it when an organization is created
Organizational Unit (OU)
A container for accounts within a root.
An OU also can contain other OUs, enabling hierarchy creation that resembles an upside-down tree, with a root at the top and branches of OUs that reach down, ending in accounts that are the leaves of the tree.
A policy attached to one of the nodes in the hierarchy flows down and affects all branches (OUs) and leaves (accounts) beneath it.
An OU can have exactly one parent, and currently, each account can be a member of exactly one OU.
Account
A standard AWS account that contains AWS resources.
Each account can be directly in the root or placed in one of the OUs in the hierarchy.
Policy can be attached to an account to apply controls to only that one account.
Accounts can be organized in a hierarchical, tree-like structure with a root at the top and organizational units nested under the root.
Management account (formerly Master account)
Primary account which creates the organization
can create new accounts in the organization, invite existing accounts, remove accounts, manage invitations, and apply policies to entities within the organization.
has the responsibilities of a payer account and is responsible for paying all charges that are accrued by the member accounts.
is not affected by any SCPs or RCPs that are attached to the organization.
can centrally manage root email addresses of member accounts.
Member account
Rest of the accounts within the organization are member accounts.
An account can be a member of only one organization at a time.
Can be directly transferred to a different organization without going through a standalone phase (2025 feature).
Invitation
Process of asking another account to join an organization.
An invitation can be issued only by the organization’s management account and is extended to either the account ID or the email address that is associated with the invited account.
Invited account becomes a member account in the organization after it accepts the invitation.
Invitations can be sent to existing member accounts as well, to approve the change from supporting only consolidated billing features to supporting all features.
Invitations work by accounts exchanging handshakes.
Handshake
A multi-step process of exchanging information between two parties.
Primary use in AWS Organizations is to serve as the underlying implementation for invitations.
Handshake messages are passed between and responded to by the handshake initiator (management account) and the recipient (member account) in such a way that it ensures that both parties always know what the current status is.
provides shared or consolidated billing functionality which includes pricing benefits for aggregated usage.
All Features
includes all the functionality of consolidated billing and advanced features that give more control over accounts in the organization.
allows the management account to have full control over what member accounts can do.
invited accounts must approve enabling all features
The Management account can apply SCPs and RCPs to restrict the services and actions that users (including the root user) and roles in an account can access, and it can prevent member accounts from leaving the organization
Member accounts can’t switch from All features to Consolidated Billing only mode.
Organization Policy Types
AWS Organizations offers policy types in two broad categories: Authorization policies and Management policies.
Authorization Policies
Authorization policies help centrally manage the security of AWS accounts across an organization.
Service Control Policies specify the services and actions that users and roles can use in the accounts that the SCP affects.
SCPs are similar to IAM permission policies except that they don’t grant any permissions.
SCPs are filters that allow only the specified services and actions to be used in affected accounts.
SCPs override the IAM permission policy. So even if a user is granted full administrator permissions with an IAM permission policy, any access that is not explicitly allowed or that is explicitly denied by the SCPs affecting that account is blocked. for e.g., if you assign an SCP that allows only database service access to your “database” account, then any user, group, or role in that account is denied access to any other service’s operations.
SCP can be attached to
A root, which affects all accounts in the organization
An OU, which affects all accounts in that OU and all accounts in any OUs in that OU subtree
An individual account
Organization’s Management account is not affected by any SCPs that are attached either to it or to any root or OU the management account might be in.
Updated SCP Quotas (May 2026): Maximum SCPs per node increased from 5 to 10, and maximum SCP size increased from 5,120 to 10,240 characters.
Resource Control Policies (RCPs) – Launched November 2024
Resource Control Policies (RCPs) are a type of authorization policy that centrally restricts access to AWS resources in the organization.
RCPs help establish a data perimeter in the AWS environment and restrict external access to resources at scale.
RCPs complement SCPs but work independently — SCPs restrict what principals can do, while RCPs restrict what access resources can grant.
RCPs are evaluated when resources are being accessed, irrespective of who is making the API request.
Neither SCPs nor RCPs grant any permissions; they only set the maximum permissions available.
RCPs do not affect resources in the management account — they only affect resources in member accounts.
Supported services at launch: Amazon S3, AWS STS, AWS KMS, Amazon SQS, and AWS Secrets Manager.
An AWS-managed policy called RCPFullAWSAccess is automatically attached to every entity when RCPs are enabled.
RCP can be attached to the root, an OU, or a specific AWS account.
Each RCP can contain up to 5,120 characters, up to 5 RCPs per node, and up to 1,000 RCPs per organization.
No additional charges for enabling and using RCPs.
Management Policies
Management policies help centrally configure and manage AWS services and their features across an organization.
Declarative Policies – Launched December 2024
Declarative policies help centrally declare and enforce desired configuration for a given AWS service at scale across an organization.
Once attached, the configuration is always maintained even when the service adds new features or APIs — no policy updates needed.
Prevents non-compliant actions regardless of whether they were invoked using an IAM role or by an AWS service using a service-linked role.
Supported services: Amazon EC2, Amazon VPC, and Amazon EBS.
Available attributes include: enforcing IMDSv2, serial console access, allowed AMI settings, image block public access, snapshot block public access, and VPC block public access.
Provides account status reports to assess readiness before attaching a policy.
Supports custom error messages to help end users understand why their action was blocked and how to remediate.
Policies can be applied at the organization, OU, or account level.
New accounts automatically inherit the declarative policy when they join the organization or OU.
Backup Policies
Allow you to centrally manage and apply backup plans to the AWS resources across an organization’s accounts.
Ensures consistent backup strategies across all member accounts.
Tag Policies
Allow you to standardize the tags attached to the AWS resources in an organization’s accounts.
Helps maintain consistent tag naming and values for cost allocation and resource management.
AI Services Opt-out Policies
Allow you to control data collection for AWS AI services for all the accounts in an organization.
Can opt out of data being used to improve AI/ML services across the organization.
Chatbot Policies
Allow centralized configuration and management of AWS Chatbot settings across the organization.
Whitelisting vs. Blacklisting (SCPs)
Whitelisting and blacklisting are complementary techniques used to apply SCPs to filter the permissions available to accounts.
Whitelisting (Allow List)
Explicitly specify the access that is allowed.
All other access is implicitly blocked or denied.
By default, all permissions are whitelisted.
AWS Organizations attaches an AWS-managed policy called FullAWSAccess to all roots, OUs, and accounts, which ensures the building of the organizations.
For restricting permissions, replace the FullAWSAccess policy with one that allows only the more limited, desired set of permissions.
Users and roles in the affected accounts can then exercise only that level of access, even if their IAM policies allow all actions.
If you replace the default policy on the root, all accounts in the organization are affected by the restrictions.
You can’t add them back at a lower level in the hierarchy because an SCP never grants permissions; it only filters them.
Blacklisting (Deny List)
The default behavior of AWS Organizations.
Explicitly specify the access that is not allowed.
Explicit deny of a service action overrides any allow of that action.
All other permissions are allowed unless explicitly blocked
By default, AWS Organizations attach an AWS-managed policy called FullAWSAccess to all roots, OUs, and accounts. This allows any account to access any service or operation with no AWS Organizations–imposed restrictions.
With blacklisting, additional policies are attached that explicitly deny access to the unwanted services and actions
Organizations Security and Monitoring
CloudTrail Integration
AWS Organizations logs all API calls as events in CloudTrail.
Supports account membership events (2026): AccountJoinedOrganization and AccountDepartedOrganization events provide visibility into organizational membership changes.
Helps detect unauthorized activities and potential security incidents.
MFA Enforcement for Root Users
AWS now requires MFA for root users across all account types (management, member, standalone).
MFA was first required for management account root users (May 2024), then standalone accounts (June 2024), and enforced for all (June 2025).
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
An organization that is currently using consolidated billing has recently acquired another company that already has a number of AWS accounts. How could an Administrator ensure that all AWS accounts, from both the existing company and the acquired company, are billed to a single account?
Merge the two companies, AWS accounts by going to the AWS console and selecting the “Merge accounts” option.
Invite the acquired company’s AWS account to join the existing company’s organization using AWS Organizations.
Migrate all AWS resources from the acquired company’s AWS account to the master payer account of the existing company.
Create a new AWS account and set it up as the master payer. Move the AWS resources from both the existing and acquired companies’ AWS accounts to the new account.
Which of the following are the benefits of AWS Organizations? Choose the 2 correct answers:
Centrally manage access polices across multiple AWS accounts.
Automate AWS account creation and management.
Analyze cost across all multiple AWS accounts.
Provide technical help (by AWS) for issues in your AWS account.
A company has several departments with separate AWS accounts. Which feature would allow the company to enable consolidate billing?
AWS Inspector
AWS Shield
AWS Organizations
AWS Lightsail
A security team wants to prevent any external AWS account from accessing S3 buckets within their organization. Which Organizations policy type should they use?
Service Control Policies (SCPs)
Resource Control Policies (RCPs)
Tag Policies
Backup Policies
A company wants to enforce that all EC2 instances across their organization use IMDSv2, and ensure this remains enforced even when new APIs are introduced. Which AWS Organizations feature should they use?
Service Control Policies (SCPs)
Resource Control Policies (RCPs)
Declarative Policies
AI Services Opt-out Policies
Which statement correctly describes the difference between SCPs and RCPs in AWS Organizations?
SCPs grant permissions while RCPs deny permissions.
SCPs restrict what principals can do, while RCPs restrict what access resources can grant.
RCPs affect the management account while SCPs do not.
SCPs and RCPs are the same policy type with different names.
A company wants to centrally remove root user credentials from all member accounts in their organization. Which feature enables this?
Service Control Policies (SCPs)
AWS IAM Access Analyzer
Centralized Root Access Management in AWS Organizations
AWS Config Rules
Which of the following are management policy types in AWS Organizations? (Choose 3)
SQS offers two types of queues – Standard & FIFO queues
SQS Standard vs FIFO Queue Features
Message Order
Standard queues provide best-effort ordering which ensures that messages are generally delivered in the same order as they are sent. Occasionally (because of the highly-distributed architecture that allows high throughput), more than one copy of a message might be delivered out of order
FIFO queues offer first-in-first-out delivery and exactly-once processing: the order in which messages are sent and received is strictly preserved
Delivery
Standard queues guarantee that a message is delivered at least once and duplicates can be introduced into the queue
FIFO queues ensure a message is delivered exactly once and remains available until a consumer processes and deletes it; duplicates are not introduced into the queue
Transactions Per Second (TPS)
Standard queues allow nearly-unlimited number of transactions per second
FIFO queues by default are limited to 300 transactions per second per API action (SendMessage, ReceiveMessage, DeleteMessage).
With High Throughput Mode enabled, FIFO queues can support up to 70,000 TPS per API action without batching in select regions (US East N. Virginia, US West Oregon, Europe Ireland), and up to 700,000 messages per second with batching.
High Throughput Mode can be enabled from the SQS console and uses message group-level partitioning to achieve higher throughput.
In other regions, high throughput quotas vary (up to 18,000 TPS in several regions).
In-Flight Messages
Standard queues support approximately 120,000 in-flight messages.
FIFO queues now support up to 120,000 in-flight messages (increased from 20,000 in November 2024). In-flight messages are those received by a consumer but not yet deleted from the queue.
Regions
Standard & FIFO queues are available in all regions where Amazon SQS is available.
SQS Buffered Asynchronous Client
FIFO queues are not compatible with the SQS Buffered Asynchronous Client, where messages are buffered at the client side and sent as a single request to the SQS queue to reduce cost.
Dead-Letter Queue (DLQ) Support
Both Standard and FIFO queues support dead-letter queues for handling messages that cannot be processed after a configured number of retries.
FIFO queues now support DLQ redrive, allowing messages to be moved from a FIFO dead-letter queue back to the FIFO source queue or a custom FIFO destination queue (launched 2023, expanded to GovCloud in April 2024).
CloudWatch Metrics
Standard queues support all standard SQS CloudWatch metrics.
FIFO queues support additional metrics (added July 2024):
AWS Lambda (SQS FIFO as event source mapping, with ordered processing per message group)
Amazon EventBridge (SQS FIFO as rule target; EventBridge Pipes supports FIFO as source)
Auto Scaling Lifecycle Hooks (SQS queue target)
Not Supported:
S3 Event Notifications (cannot directly target SQS FIFO; use EventBridge as intermediary)
Lambda Asynchronous Invocation Destinations (does not support SQS FIFO or SNS FIFO as destination)
Use Cases
Standard queues can be used in any scenario, as long as the application can process messages that arrive more than once and out of order
Decouple live user requests from intensive background work: Let users upload media while resizing or encoding it.
Allocate tasks to multiple worker nodes: Process a high number of credit card validation requests.
Batch messages for future processing: Schedule multiple entries to be added to a database.
FIFO queues are designed to enhance messaging between applications when the order of operations and events is critical, or where duplicates can’t be tolerated
Ensure that user-entered commands are executed in the right order.
Display the correct product price by sending price modifications in the right order.
Prevent a student from enrolling in a course before registering for an account.
E-commerce order management systems where order processing sequence is critical.
Online ticketing systems where tickets are distributed on a first-come-first-served basis.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A restaurant reservation application needs the ability to maintain a waiting list. When a customer tries to reserve a table, and none are available, the customer must be put on the waiting list, and the application must notify the customer when a table becomes free. What service should the Solutions Architect recommend ensuring that the system respects the order in which the customer requests are put onto the waiting list?
Amazon SNS
AWS Lambda with sequential dispatch
A FIFO queue in Amazon SQS
A standard queue in Amazon SQS
A solutions architect is designing an application for a two-step order process. The first step is synchronous and must return to the user with little latency. The second step takes longer, so it will be implemented in a separate component. Orders must be processed exactly once and in the order in which they are received. How should the solutions architect integrate these components?
Use Amazon SQS FIFO queues.
Use an AWS Lambda function along with Amazon SQS standard queues.
Create an SNS topic and subscribe an Amazon SQS FIFO queue to that topic.
Create an SNS topic and subscribe an Amazon SQS Standard queue to that topic.
A company needs to process over 50,000 messages per second with strict ordering within each customer’s message stream. The system uses Amazon SQS FIFO queues. What should a solutions architect recommend to meet the throughput requirement?
Use multiple standard queues with application-level ordering
Use Amazon Kinesis Data Streams instead of SQS
Enable High Throughput Mode on the FIFO queue and use unique message group IDs per customer
Increase the visibility timeout to allow more concurrent processing
An application sends S3 event notifications to an SQS FIFO queue for ordered processing of uploaded files. The team reports that messages are not being delivered. What is the most likely cause?
The SQS FIFO queue has reached its throughput limit
S3 Event Notifications do not support SQS FIFO queues as a direct destination
The queue’s message deduplication ID is not configured
The IAM role lacks permissions to publish to the queue
allows real-time processing of streaming big data and the ability to read and replay records to multiple Amazon Kinesis Applications.
Amazon Kinesis Client Library (KCL) delivers all records for a given partition key to the same record processor, making it easier to build multiple applications that read from the same Amazon Kinesis stream (for example, to perform counting, aggregation, and filtering).
offers a reliable, highly-scalable hosted queue for storing messages as they travel between applications or microservices.
It moves data between distributed application components and helps decouple these components.
provides common middleware constructs such as dead-letter queues and poison-pill management.
provides a generic web services API and can be accessed by any programming language that the AWS SDK supports.
supports both standard and FIFO queues
Scaling
Kinesis Data Streams offers two capacity modes:
Provisioned Mode: Requires manual provisioning and scaling by increasing shards
On-Demand Mode (November 2021): Fully managed with automatic scaling – no manual shard management required. Default capacity of 4 MB/s write, scales up to 200 MB/s (or 1 GB/s with limit increase)
SQS is fully managed, highly scalable and requires no administrative overhead and little configuration
Standard Queue: Unlimited throughput, nearly unlimited transactions per second
FIFO Queue: Default 300 TPS per API action, up to 3,000 TPS with high throughput mode (up to 70,000 TPS in select regions)
Ordering
Kinesis provides ordering of records, as well as the ability to read and/or replay records in the same order to multiple Kinesis Applications
SQS Standard Queue does not guarantee data ordering and provides at least once delivery of messages
SQS FIFO Queue guarantees data ordering within the message group and exactly-once processing
Data Retention Period
Kinesis Data Streams stores the data for up to 24 hours, by default, and can be extended to 365 days (8760 hours)
SQS stores the message for up to 4 days, by default, and can be configured from 1 minute to 14 days but clears the message once deleted by the consumer
Delivery Semantics
Kinesis and SQS Standard Queue both guarantee at least once delivery of the message.
SQS FIFO Queue guarantees exactly once delivery and processing
Parallel Clients
Kinesis supports multiple consumers reading from the same stream concurrently
Standard (shared throughput): 2 MB/sec per shard shared across all consumers
Enhanced fan-out: 2 MB/sec per shard per consumer (dedicated throughput)
SQS allows the messages to be delivered to only one consumer at a time and requires multiple queues to deliver messages to multiple consumers
Use Cases
Kinesis use cases requirements
Ordering of records.
Ability to consume records in the same order a few hours later
Ability for multiple applications to consume the same stream concurrently
Routing related records to the same record processor (as in streaming MapReduce)
Real-time analytics and processing
Data replay capability for reprocessing
SQS uses cases requirements
Messaging semantics like message-level ack/fail and visibility timeout
Leveraging SQS’s ability to scale transparently
Dynamically increasing concurrency/throughput at read time
Individual message delay, which can be delayed
Decoupling application components
Simple message queuing without need for replay
Key Differences Summary
Feature
Kinesis Data Streams
SQS
Purpose
Real-time streaming data processing
Message queuing and decoupling
Scaling
Provisioned or On-Demand (auto-scaling)
Fully managed (auto-scaling)
Ordering
Guaranteed per shard
Standard: No, FIFO: Yes (per message group)
Retention
24 hours to 365 days
1 minute to 14 days
Replay
✅ Supported
❌ Not supported
Multiple Consumers
✅ Yes (concurrent)
❌ No (one at a time)
Delivery Semantics
At least once
Standard: At least once, FIFO: Exactly once
Latency
~70-200 ms
Single-digit milliseconds
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You are deploying an application to track GPS coordinates of delivery trucks in the United States. Coordinates are transmitted from each delivery truck once every three seconds. You need to design an architecture that will enable real-time processing of these coordinates from multiple consumers. Which service should you use to implement data ingestion?
Amazon Kinesis
AWS Data Pipeline
Amazon AppStream
Amazon Simple Queue Service
Your customer is willing to consolidate their log streams (access logs, application logs, security logs etc.) in one single system. Once consolidated, the customer wants to analyze these logs in real time based on heuristics. From time to time, the customer needs to validate heuristics, which requires going back to data samples extracted from the last 12 hours? What is the best approach to meet your customer’s requirements?
Send all the log events to Amazon SQS. Setup an Auto Scaling group of EC2 servers to consume the logs and apply the heuristics.
Send all the log events to Amazon Kinesis develop a client process to apply heuristics on the logs (Can perform real time analysis and stores data for 24 hours which can be extended to 365 days)
Configure Amazon CloudTrail to receive custom logs, use EMR to apply heuristics the logs (CloudTrail is only for auditing)
Setup an Auto Scaling group of EC2 syslogd servers, store the logs on S3 use EMR to apply heuristics on the logs (EMR is for batch analysis)
A company needs to process streaming data with multiple independent consumers that need to read the same data concurrently. Which service should they use?
SQS Standard Queue
SQS FIFO Queue
Kinesis Data Streams
Amazon SNS
A company wants to decouple microservices and needs exactly-once message processing with ordering guarantees. Which service should they use?
Kinesis Data Streams
SQS Standard Queue
SQS FIFO Queue
Amazon SNS
A company wants to avoid manual shard management for their streaming data workload. Which Kinesis capacity mode should they use? (Assume November 2021 or later)
Amazon Kinesis Data Streams is a streaming data service that enables real-time processing of streaming data at a massive scale.
Kinesis Streams enables building of custom applications that process or analyze streaming data for specialized needs.
Kinesis Streams features
handles provisioning, deployment, ongoing-maintenance of hardware, software, or other services for the data streams.
manages the infrastructure, storage, networking, and configuration needed to stream the data at the level of required data throughput.
synchronously replicates data across three AZs in an AWS Region, providing high availability and data durability.
stores records of a stream for up to 24 hours, by default, from the time they are added to the stream. The limit can be raised to up to 365 days (8760 hours) by enabling extended data retention.
Data such as clickstreams, application logs, social media, etc can be added from multiple sources and within seconds is available for processing to the Kinesis Applications.
Kinesis provides the ordering of records, as well as the ability to read and/or replay records in the same order to multiple applications.
Kinesis is designed to process streaming big data and the pricing model allows heavy PUTs rate.
Multiple Kinesis Data Streams applications can consume data from a stream, so that multiple actions, like archiving and processing, can take place concurrently and independently.
Kinesis Data Streams application can start consuming the data from the stream almost immediately after the data is added and put-to-get delay is typically less than 1 second.
Kinesis Streams is useful for rapidly moving data off data producers and then continuously processing the data, be it to transform the data before emitting to a data store, run real-time metrics and analytics, or derive more complex data streams for further processing
Accelerated log and data feed intake: Data producers can push data to Kinesis stream as soon as it is produced, preventing any data loss and making it available for processing within seconds.
Real-time metrics and reporting: Metrics can be extracted and used to generate reports from data in real-time.
Real-time data analytics: Run real-time streaming data analytics.
Complex stream processing: Create Directed Acyclic Graphs (DAGs) of Kinesis Applications and data streams, with Kinesis applications adding to another Amazon Kinesis stream for further processing, enabling successive stages of stream processing.
Kinesis limits
stores records of a stream for up to 24 hours, by default, which can be extended to max 365 days (8760 hours)
maximum size of a data blob (the data payload before Base64-encoding) within one record is 1 megabyte (MB)
Each shard can support up to 1000 PUT records per second.
S3 is a cost-effective way to store the data, but not designed to handle a stream of data in real-time
Kinesis Data Streams Terminology
Data Record
A record is the unit of data stored in a Kinesis data stream.
A record is composed of a sequence number, partition key, and data blob, which is an immutable sequence of bytes.
Maximum size of a data blob is 1 MB
Partition key
Partition key is used to segregate and route records to different shards of a stream.
A partition key is specified by the data producer while adding data to a Kinesis stream.
Sequence number
A sequence number is a unique identifier for each record.
Kinesis assigns a Sequence number, when a data producer calls PutRecord or PutRecords operation to add data to a stream.
Sequence numbers for the same partition key generally increase over time; the longer the time period between PutRecord or PutRecords requests, the larger the sequence numbers become.
Data Stream
Data stream represents a group of data records.
Data records in a data stream are distributed into shards.
Shard
A shard is a uniquely identified sequence of data records in a stream.
Streams are made of shards and are the base throughput unit of a Kinesis stream, as pricing is per shard basis.
Each shard supports up to 5 transactions per second for reads, up to a maximum total data read rate of 2 MB per second, and up to 1,000 records per second for writes, up to a maximum total data write rate of 1 MB per second (including partition keys)
Each shard provides a fixed unit of capacity. If the limits are exceeded, either by data throughput or the number of PUT records, the put data call will be rejected with a ProvisionedThroughputExceeded exception.
This can be handled by
Implementing a retry on the data producer side, if this is due to a temporary rise of the stream’s input data rate
Dynamically scaling the number of shared (resharding) to provide enough capacity for the put data calls to consistently succeed
Capacity Mode
A data stream capacity mode determines the pricing and how the capacity is managed
Kinesis Data Streams supports two capacity modes: On-Demand (launched November 2021) and Provisioned
On-demand mode (Launched November 2021)
KDS automatically manages the shards in order to provide the necessary throughput.
No capacity planning required – automatically scales to handle gigabytes of write and read throughput per minute.
Default capacity of 4 MB/s write (4000 records/s), can scale up to 200 MB/s (or 1 GB/s with limit increase via AWS Support).
You are charged only for the actual throughput used (per GB of data written and read).
KDS automatically accommodates the workloads’ throughput needs as they ramp up or down.
Ideal for unpredictable or variable workloads.
Provisioned mode
Number of shards for the data stream must be specified.
Total capacity of a data stream is the sum of the capacities of its shards.
Shards can be increased or decreased in a data stream as needed and you are charged for the number of shards at an hourly rate.
Provides predictable costs for steady workloads.
Retention Period
All data is stored for 24 hours, by default, and can be increased to 8760 hours (365 days) maximum.
Extended data retention (beyond 24 hours) and long-term data retention (beyond 7 days up to 365 days) incur additional charges.
Producers
A producer puts data records into Kinesis data streams.
To put data into the stream, the name of the stream, a partition key, and the data blob to be added to the stream should be specified.
Partition key is used to determine which shard in the stream the data record is added to.
Consumers
A consumer is an application built to read and process data records from Kinesis data streams.
supports encryption in transit using HTTPS endpoints.
supports Interface VPC endpoint to keep traffic between VPC and Kinesis Data Streams from leaving the Amazon network. Interface VPC endpoints don’t require an IGW, NAT device, VPN connection, or Direct Connect.
Cross-Region PrivateLink Support (November 2025): Interface VPC endpoints now support cross-region connectivity to Kinesis Data Streams within the same AWS partition.
FIPS 140-3 Support (September 2024): Kinesis Data Streams supports FIPS 140-3 enabled interface VPC endpoints for compliance requirements.
IPv6 Support (May 2025): Kinesis Data Streams supports IPv6 with dual-stack AWS PrivateLink interface VPC endpoints.
integrated with IAM to control access to Kinesis Data Streams resources.
integrated with CloudTrail, which provides a record of actions taken by a user, role, or an AWS service in Kinesis Data Streams.
PutRecord & PutRecords operations are synchronous operation that sends single/multiple records to the stream per HTTP request.
use PutRecords to achieve a higher throughput per data producer
helps manage many aspects of Kinesis Data Streams (including creating streams, resharding, and putting and getting records)
Kinesis Agent
is a pre-built Java application that offers an easy way to collect and send data to the Kinesis stream.
can be installed on Linux-based server environments such as web servers, log servers, and database servers
can be configured to monitor certain files on the disk and then continuously send new data to the Kinesis stream
Kinesis Producer Library (KPL)
is an easy-to-use and highly configurable library that helps to put data into a Kinesis stream.
provides a layer of abstraction specifically for ingesting data
presents a simple, asynchronous, and reliable interface that helps achieve high producer throughput with minimal client resources.
batches messages, as it aggregates records to increase payload size and improve throughput.
Collects records and uses PutRecords to write multiple records to multiple shards per request
Writes to one or more Kinesis data streams with an automatic and configurable retry mechanism.
Integrates seamlessly with the Kinesis Client Library (KCL) to de-aggregate batched records on the consumer
Submits CloudWatch metrics to provide visibility into performance
Third Party and Open source
Log4j appender
Apache Kafka
Flume, fluentd, etc.
Kinesis Consumers
Kinesis Application is a data consumer that reads and processes data from a Kinesis Data Stream and can be built using either Kinesis API or Kinesis Client Library (KCL)
Shards in a stream provide 2 MB/sec of read throughput per shard, by default, which is shared by all the consumers reading from a given shard.
Kinesis Client Library (KCL)
is a pre-built library with multiple language support
delivers all records for a given partition key to same record processor
makes it easier to build multiple applications reading from the same stream for e.g. to perform counting, aggregation, and filtering
handles complex issues such as adapting to changes in stream volume, load-balancing streaming data, coordinating distributed services, and processing data with fault-tolerance
uses a unique DynamoDB table to keep track of the application’s state, so if the Kinesis Data Streams application receives provisioned-throughput exceptions, increase the provisioned throughput for the DynamoDB table
AWS Lambda, Kinesis Data Firehose, and Kinesis Data Analytics also act as consumers for Kinesis Data Streams
Kinesis Enhanced fan-out
allows customers to scale the number of consumers reading from a data stream in parallel, while maintaining high performance and without contending for read throughput with other consumers.
provides logical 2 MB/sec throughput pipes between consumers and shards for Kinesis Data Streams Consumers.
Each enhanced fan-out consumer gets dedicated 2 MB/sec per shard, independent of other consumers.
Reduces latency to ~70 ms compared to ~200 ms for shared throughput consumers.
Charged per consumer-shard-hour plus data retrieval charges.
Kinesis Data Streams Sharding
Resharding helps to increase or decrease the number of shards in a stream in order to adapt to changes in the rate of data flowing through the stream.
Resharding operations support shard split and shard merge.
Shard split helps divide a single shard into two shards. It increases the capacity and the cost.
Shard merge helps combine two shards into a single shard. It reduces the capacity and the cost.
Resharding is always pairwise and always involves two shards.
The shard or pair of shards that the resharding operation acts on are referred to as parent shards. The shard or pair of shards that result from the resharding operation are referred to as child shards.
Kinesis Client Library tracks the shards in the stream using a DynamoDB table and discovers the new shards and populates new rows in the table.
KCL ensures that any data that existed in shards prior to the resharding is processed before the data from the new shards, thereby, preserving the order in which data records were added to the stream for a particular partition key.
Data records in the parent shard are accessible from the time they are added to the stream to the current retention period.
Note: With On-Demand mode, resharding is handled automatically by AWS, eliminating manual shard management.
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You are deploying an application to track GPS coordinates of delivery trucks in the United States. Coordinates are transmitted from each delivery truck once every three seconds. You need to design an architecture that will enable real-time processing of these coordinates from multiple consumers. Which service should you use to implement data ingestion?
Amazon Kinesis
AWS Data Pipeline
Amazon AppStream
Amazon Simple Queue Service
You are deploying an application to collect votes for a very popular television show. Millions of users will submit votes using mobile devices. The votes must be collected into a durable, scalable, and highly available data store for real-time public tabulation. Which service should you use?
Amazon DynamoDB
Amazon Redshift
Amazon Kinesis
Amazon Simple Queue Service
Your company is in the process of developing a next generation pet collar that collects biometric information to assist families with promoting healthy lifestyles for their pets. Each collar will push 30kb of biometric data In JSON format every 2 seconds to a collection platform that will process and analyze the data providing health trending information back to the pet owners and veterinarians via a web portal Management has tasked you to architect the collection platform ensuring the following requirements are met. Provide the ability for real-time analytics of the inbound biometric data Ensure processing of the biometric data is highly durable, elastic and parallel. The results of the analytic processing should be persisted for data mining. Which architecture outlined below will meet the initial requirements for the collection platform?
Utilize S3 to collect the inbound sensor data analyze the data from S3 with a daily scheduled Data Pipeline and save the results to a Redshift Cluster.
Utilize Amazon Kinesis to collect the inbound sensor data, analyze the data with Kinesis clients and save the results to a Redshift cluster using EMR. (refer link)
Utilize SQS to collect the inbound sensor data analyze the data from SQS with Amazon Kinesis and save the results to a Microsoft SQL Server RDS instance.
Utilize EMR to collect the inbound sensor data, analyze the data from EUR with Amazon Kinesis and save me results to DynamoDB.
Your customer is willing to consolidate their log streams (access logs, application logs, security logs etc.) in one single system. Once consolidated, the customer wants to analyze these logs in real time based on heuristics. From time to time, the customer needs to validate heuristics, which requires going back to data samples extracted from the last 12 hours? What is the best approach to meet your customer’s requirements?
Send all the log events to Amazon SQS. Setup an Auto Scaling group of EC2 servers to consume the logs and apply the heuristics.
Send all the log events to Amazon Kinesis develop a client process to apply heuristics on the logs (Can perform real time analysis and stores data for 24 hours which can be extended to 365 days)
Configure Amazon CloudTrail to receive custom logs, use EMR to apply heuristics the logs (CloudTrail is only for auditing)
Setup an Auto Scaling group of EC2 syslogd servers, store the logs on S3 use EMR to apply heuristics on the logs (EMR is for batch analysis)
You require the ability to analyze a customer’s clickstream data on a website so they can do behavioral analysis. Your customer needs to know what sequence of pages and ads their customer clicked on. This data will be used in real time to modify the page layouts as customers click through the site to increase stickiness and advertising click-through. Which option meets the requirements for captioning and analyzing this data?
Log clicks in weblogs by URL store to Amazon S3, and then analyze with Elastic MapReduce
Push web clicks by session to Amazon Kinesis and analyze behavior using Kinesis workers
Write click events directly to Amazon Redshift and then analyze with SQL
Publish web clicks by session to an Amazon SQS queue men periodically drain these events to Amazon RDS and analyze with SQL
Your social media monitoring application uses a Python app running on AWS Elastic Beanstalk to inject tweets, Facebook updates and RSS feeds into an Amazon Kinesis stream. A second AWS Elastic Beanstalk app generates key performance indicators into an Amazon DynamoDB table and powers a dashboard application. What is the most efficient option to prevent any data loss for this application?
Use AWS Data Pipeline to replicate your DynamoDB tables into another region.
Use the second AWS Elastic Beanstalk app to store a backup of Kinesis data onto Amazon Elastic Block Store (EBS), and then create snapshots from your Amazon EBS volumes.
Add a second Amazon Kinesis stream in another Availability Zone and use AWS data pipeline to replicate data across Kinesis streams.
Add a third AWS Elastic Beanstalk app that uses the Amazon Kinesis S3 connector to archive data from Amazon Kinesis into Amazon S3.
You need to replicate API calls across two systems in real time. What tool should you use as a buffer and transport mechanism for API call events?
AWS SQS
AWS Lambda
AWS Kinesis (AWS Kinesis is an event stream service. Streams can act as buffers and transport across systems for in-order programmatic events, making it ideal for replicating API calls across systems)
AWS SNS
You need to perform ad-hoc business analytics queries on well-structured data. Data comes in constantly at a high velocity. Your business intelligence team can understand SQL. What AWS service(s) should you look to first?
Kinesis Firehose + RDS
Kinesis Firehose + RedShift (Kinesis Firehose provides a managed service for aggregating streaming data and inserting it into RedShift. RedShift also supports ad-hoc queries over well-structured data using a SQL-compliant wire protocol, so the business team should be able to adopt this system easily. Refer link)
EMR using Hive
EMR running Apache Spark
A company wants to avoid manual shard management for their Kinesis Data Streams. Which capacity mode should they use? (Assume November 2021 or later)
Provisioned mode with Auto Scaling
On-Demand mode
Enhanced fan-out mode
Standard mode
A company needs to access Kinesis Data Streams from an on-premises data center privately without traversing the public internet. Which solution should they use? (Assume November 2025 or later)
Use public Kinesis endpoints over VPN
Create Interface VPC endpoints with cross-region PrivateLink support
Amazon Redshift is a fully managed, fast, and powerful, petabyte-scale data warehouse service.
Redshift is an OLAP data warehouse solution based on PostgreSQL.
Redshift is built on cloud economics that scale with usage — powering modern analytics and autonomous agentic AI workloads on the data warehouse.
Redshift delivers up to 2.2x better price-performance and 7x better throughput than other cloud data warehouses.
Redshift automatically helps
set up, operate, and scale a data warehouse, from provisioning the infrastructure capacity.
patches and backs up the data warehouse, storing the backups for a user-defined retention period.
monitors the nodes and drives to help recovery from failures.
significantly lowers the cost of a data warehouse, but also makes it easy to analyze large amounts of data very quickly
provide fast querying capabilities over structured and semi-structured data using familiar SQL-based clients and business intelligence (BI) tools using standard ODBC and JDBC connections.
uses replication and continuous backups to enhance availability and improve data durability and can automatically recover from node and component failures.
scale up or down with a few clicks in the AWS Management Console or with a single API call
distributes & parallelize queries across multiple physical resources
supports VPC, SSL, AES-256 encryption, and Hardware Security Modules (HSMs) to protect the data in transit and at rest.
Redshift provides monitoring using CloudWatch and metrics for compute utilization, storage utilization, and read/write traffic to the cluster are available with the ability to add user-defined custom metrics
Redshift provides Audit logging and AWS CloudTrail integration
Redshift can be easily enabled to a second region for disaster recovery.
Redshift Node Types
RG Instances (Current Generation – GA May 2026)
Newest generation powered by AWS Graviton processors.
Delivers up to 2.2x better performance for data warehouse workloads and up to 2.4x faster for data lake workloads compared to RA3, at 30% lower price per vCPU.
Includes a custom-built vectorized data lake query engine that processes Apache Iceberg and Parquet data on cluster nodes.
Enables running SQL analytics across data warehouse and data lake using a single engine.
Uses Redshift Managed Storage (RMS) with independent scaling of compute and storage.
RA3 Instances
Previous generation with managed storage, allowing independent scaling of compute and storage.
Available in RA3.xlplus, RA3.4xlarge, RA3.16xlarge, and RA3.large sizes.
RA3.large launched in 2024 as a cost-effective option for smaller workloads.
Uses Redshift Managed Storage (RMS) backed by S3.
Supports data sharing, Multi-AZ, zero-ETL integrations.
DC2 Instances (DEPRECATED – EOL April 24, 2026)
Dense Compute nodes with fast CPUs, large amounts of RAM, and solid-state disks (SSDs).
DC2 nodes reached End of Life on April 24, 2026.
After May 15, 2025, creation of new DC2 clusters, resizing existing ones, or adding nodes was no longer allowed.
Migration options: Upgrade to RA3, RG instances, or Redshift Serverless using elastic resize.
DS2 Instances (DEPRECATED)
Dense Storage nodes using HDDs, previously used for large data warehouses.
DS2 has been deprecated and creation of new DS2 clusters is no longer allowed.
Migration options: Upgrade to RA3 or RG instances using elastic resize.
Redshift Performance
Massively Parallel Processing (MPP)
automatically distributes data and query load across all nodes.
makes it easy to add nodes to the data warehouse and enables fast query performance as the data warehouse grows.
Columnar Data Storage
organizes the data by column, as column-based systems are ideal for data warehousing and analytics, where queries often involve aggregates performed over large data sets
columnar data is stored sequentially on the storage media, and require far fewer I/Os, greatly improving query performance
Advance Compression
Columnar data stores can be compressed much more than row-based data stores because similar data is stored sequentially on a disk.
employs multiple compression techniques and can often achieve significant compression relative to traditional relational data stores.
doesn’t require indexes or materialized views and so uses less space than traditional relational database systems.
automatically samples the data and selects the most appropriate compression scheme, when the data is loaded into an empty table
Query Optimizer
Redshift query run engine incorporates a query optimizer that is MPP-aware and also takes advantage of columnar-oriented data storage.
Result Caching
Redshift caches the results of certain types of queries in memory on the leader node.
When a user submits a query, Redshift checks the results cache for a valid, cached copy of the query results. If a match is found in the result cache, Redshift uses the cached results and doesn’t run the query.
Result caching is transparent to the user.
Compiled Code
Leader node distributes fully optimized compiled code across all of the nodes of a cluster. Compiling the query decreases the overhead associated with an interpreter and therefore increases the runtime speed, especially for complex queries.
AQUA (Advanced Query Accelerator)
AQUA is a distributed and hardware-accelerated cache that boosts certain types of queries.
Amazon Redshift automatically determines whether to use AQUA — no manual configuration is required.
AQUA pushes the computation needed to handle reduction and aggregation queries closer to the data, reducing network traffic and offloading work from the cluster.
Autonomics
Redshift is a self-learning, self-tuning system that automatically generates and implements optimal data layout recommendations for distribution and sort keys.
Autonomics now extend to multi-cluster environments, eliminating manual performance tuning across consumer clusters.
Redshift Architecture
Clusters
Core infrastructure component of a Redshift data warehouse
Cluster is composed of one or more compute nodes.
If a cluster is provisioned with two or more compute nodes, an additional leader node coordinates the compute nodes and handles external communication.
Client applications interact directly only with the leader node.
Compute nodes are transparent to external applications.
Leader node
Leader node manages communications with client programs and all communication with compute nodes.
It parses and develops execution plans to carry out database operations
Based on the execution plan, the leader node compiles code, distributes the compiled code to the compute nodes, and assigns a portion of the data to each compute node.
Leader node distributes SQL statements to the compute nodes only when a query references tables that are stored on the compute nodes. All other queries run exclusively on the leader node.
Compute nodes
Leader node compiles code for individual elements of the execution plan and assigns the code to individual compute nodes.
Compute nodes execute the compiled code and send intermediate results back to the leader node for final aggregation.
Each compute node has its own dedicated CPU, memory, and attached disk storage, which is determined by the node type.
As the workload grows, the compute and storage capacity of a cluster can be increased by increasing the number of nodes, upgrading the node type, or both.
Node slices
A compute node is partitioned into slices.
Each slice is allocated a portion of the node’s memory and disk space, where it processes a portion of the workload assigned to the node.
Leader node manages distributing data to the slices and apportions the workload for any queries or other database operations to the slices. The slices then work in parallel to complete the operation.
Number of slices per node is determined by the node size of the cluster.
When a table is created, one column can optionally be specified as the distribution key. When the table is loaded with data, the rows are distributed to the node slices according to the distribution key that is defined for a table.
A good distribution key enables Redshift to use parallel processing to load data and execute queries efficiently.
Managed Storage
Data warehouse data is stored in a separate storage tier Redshift Managed Storage (RMS).
RMS provides the ability to scale the storage to petabytes using S3 storage.
RMS enables scale, pay for compute and storage independently so that the cluster can be sized based only on the computing needs.
RMS automatically uses high-performance SSD-based local storage as tier-1 cache.
It also takes advantage of optimizations, such as data block temperature, data block age, and workload patterns to deliver high performance while scaling storage automatically to S3 when needed without requiring any action.
RMS tables can now be accessed through Apache Iceberg REST APIs via Amazon SageMaker Lakehouse, enabling other engines (Spark, EMR) to read Redshift data.
Redshift Serverless
Redshift Serverless is a serverless option of Redshift that makes it more efficient to run and scale analytics in seconds without the need to set up and manage data warehouse infrastructure.
Redshift Serverless automatically provisions and intelligently scales data warehouse capacity to deliver high performance for demanding and unpredictable workloads.
Redshift Serverless helps any user to get insights from data by simply loading and querying data in the data warehouse.
Redshift Serverless supports concurrency Scaling feature that can support unlimited concurrent users and concurrent queries, with consistently fast query performance.
When concurrency scaling is enabled, Redshift automatically adds cluster capacity when the cluster experiences an increase in query queuing.
Redshift Serverless measures data warehouse capacity in Redshift Processing Units (RPUs). RPUs are resources used to handle workloads.
Redshift Serverless supports workgroups and namespaces to isolate workloads and manage different resources.
Redshift Serverless supports a capacity configuration of up to 1024 RPUs for larger workloads.
AI-Driven Scaling and Optimization (GA 2024)
Redshift Serverless now includes AI-driven scaling and optimization that automatically scales compute resources based on query complexity, data volume, and workload patterns.
Users can choose to optimize for cost, performance, or keep it balanced using a simple slider.
Delivers up to 10x price-performance improvements for variable workloads.
Scales the compute not only based on queuing, but also factoring data volume and query complexity.
AWS Graviton is available in Serverless, offering up to 30% better price-performance.
Redshift Single vs Multi-Node Cluster
Single Node
Single node configuration enables getting started quickly and cost-effectively & scale up to a multi-node configuration as the needs grow
Multi-Node
Multi-node configuration requires a leader node that manages client connections and receives queries, and two or more compute nodes that store data and perform queries and computations.
Leader node
provisioned automatically and not charged for
receives queries from client applications, parses the queries, and develops execution plans, which are an ordered set of steps to process these queries.
coordinates the parallel execution of these plans with the compute nodes, aggregates the intermediate results from these nodes, and finally returns the results back to the client applications.
Compute node
can contain from 1-128 compute nodes, depending on the node type
executes the steps specified in the execution plans and transmits data among themselves to serve these queries.
intermediate results are sent back to the leader node for aggregation before being sent back to the client applications.
Current node types: RG (Graviton-based, latest), RA3 (managed storage)
RG instances — Latest generation, Graviton-powered, up to 2.4x faster than RA3 at 30% lower cost per vCPU, includes integrated data lake query engine
RA3 instances — Managed storage with independent compute/storage scaling, supports data sharing and Multi-AZ
DC2 (DEPRECATED – EOL April 24, 2026) — Dense Compute with SSDs, no longer available for new clusters
DS2 (DEPRECATED) — Dense Storage with HDDs, no longer available for new clusters
direct access to compute nodes is not allowed
Redshift Multi-AZ
Redshift Multi-AZ deployment runs the data warehouse in multiple AWS AZs simultaneously and continues operating in unforeseen failure scenarios.
Multi-AZ deployment is managed as a single data warehouse with one endpoint and does not require any application changes.
Multi-AZ deployments support high availability requirements and reduce recovery time by guaranteeing capacity to automatically recover and are intended for customers with business-critical analytics applications that require the highest levels of availability and resiliency to AZ failures.
Redshift Multi-AZ supports RPO = 0 meaning data is guaranteed to be current and up to date in the event of a failure. RTO is under a minute.
Multi-AZ is supported for RA3 clusters (GA 2024).
Redshift Availability & Durability
Redshift replicates the data within the data warehouse cluster and continuously backs up the data to S3 (11 9’s durability).
Redshift mirrors each drive’s data to other nodes within the cluster.
Redshift will automatically detect and replace a failed drive or node.
RA3 and RG clusters and Redshift serverless are not impacted the same way since the data is stored in S3 and the local drive is just used as a data cache.
If a drive fails,
cluster will remain available in the event of a drive failure.
the queries will continue with a slight latency increase while Redshift rebuilds the drive from the replica of the data on that drive which is stored on other drives within that node.
single node clusters do not support data replication and the cluster needs to be restored from a snapshot on S3.
In case of node failure(s), Redshift
automatically provisions new node(s) and begins restoring data from other drives within the cluster or from S3.
prioritizes restoring the most frequently queried data so the most frequently executed queries will become performant quickly.
cluster will be unavailable for queries and updates until a replacement node is provisioned and added to the cluster.
In case of Redshift cluster AZ goes down, Redshift
cluster is unavailable until power and network access to the AZ are restored
cluster’s data is preserved and can be used once AZ becomes available
cluster can be restored from any existing snapshots to a new AZ within the same region
Multi-AZ deployments (RA3) continue operating automatically during AZ failures
Redshift Backup & Restore
Redshift always attempts to maintain at least three copies of the data – Original, Replica on the compute nodes, and a backup in S3.
Redshift replicates all the data within the data warehouse cluster when it is loaded and also continuously backs up the data to S3.
Redshift enables automated backups of the data warehouse cluster with a 1-day retention period, by default, which can be extended to max 35 days.
Automated backups can be turned off by setting the retention period as 0.
Redshift can also asynchronously replicate the snapshots to S3 in another region for disaster recovery.
Redshift only backs up data that has changed.
Restoring the backup will provision a new data warehouse cluster.
Starting June 8, 2026, Amazon Redshift introduced incremental snapshot billing for Serverless and RG instances — customers pay only for unique data blocks across active manual snapshots.
Redshift Scalability
Redshift allows scaling of the cluster either by
increasing the node instance type (Vertical scaling)
increasing the number of nodes (Horizontal scaling)
Redshift scaling changes are usually applied during the maintenance window or can be applied immediately
Elastic Resize
Elastic resize allows changing node types within minutes with a single operation.
Supports migration from deprecated DC2/DS2 to RA3 or RG instances.
Can be run at any time or scheduled for a future time.
Redshift scaling process
existing cluster remains available for read operations only, while a new data warehouse cluster gets created during scaling operations
data from the compute nodes in the existing data warehouse cluster is moved in parallel to the compute nodes in the new cluster
when the new data warehouse cluster is ready, the existing cluster will be temporarily unavailable while the canonical name record of the existing cluster is flipped to point to the new data warehouse cluster
Concurrency Scaling
Automatically adds query processing power in seconds when concurrency increases.
Supports thousands of concurrent users and queries with consistently fast performance.
Extra processing power is automatically removed when demand subsides — pay only for usage.
Each cluster earns up to one hour of free Concurrency Scaling credits per day.
Now supports auto-copy, zero-ETL ingestion workloads, and COPY queries from S3 (2026).
Redshift Zero-ETL Integrations
Zero-ETL integrations seamlessly make transactional or operational data available in Redshift without building and managing complex ETL pipelines.
Data replicates in near real-time from the source into Redshift.
Supported Sources (GA):
Amazon Aurora MySQL-Compatible Edition — First zero-ETL source, supports petabytes of transactional data
Amazon Aurora PostgreSQL-Compatible Edition — GA October 2024
Data filtering to selectively extract tables and schemas using regular expressions
Support for incremental and auto-refresh materialized views on replicated data
Configurable change data capture (CDC) refresh rates
Supports Enhanced VPC Routing warehouses
Concurrency scaling support for zero-ETL (2026)
Zero-ETL integrations can be created on Redshift Serverless workgroups or provisioned clusters using RA3/RG instance types.
Redshift Data Ingestion
Auto-Copy (GA 2024)
Simplifies continuous data ingestion from Amazon S3 into Redshift.
Set up ingestion rules to track S3 paths and automatically load new files without additional tools or custom solutions.
Uses S3 event integrations to detect and copy new files automatically.
Concurrency scaling support for auto-copy (2026).
Streaming Ingestion
Enables near real-time analytics by ingesting streaming data directly into Redshift without staging in S3.
Creates materialized views directly on top of data streams.
Supports Amazon Kinesis Data Streams, Amazon MSK, Confluent Managed Cloud, and self-managed Apache Kafka clusters.
Achieves low latency (measured in seconds) while ingesting hundreds of megabytes per second.
COPY Command — Traditional bulk loading from S3, DynamoDB, EMR, or remote hosts via SSH.
Redshift Data Sharing
Redshift data sharing allows sharing live, transactionally consistent data across different Redshift clusters without data copies or movement.
Supports sharing within the same AWS account, across accounts, and across regions.
Multi-Data Warehouse Writes (GA 2024) — Enables writing to shared Redshift databases from multiple Redshift data warehouses. Written data is available to all data warehouses as soon as committed.
Data sharing with data lake tables is now generally available — enables sharing Apache Iceberg/open format data.
Supports data sharing for use cases like customer 360, data monetization, and distributed ETL workloads.
First query execution for data sharing is up to 4x faster with improved metadata handling (2024).
Redshift and Amazon SageMaker Lakehouse
Amazon SageMaker Lakehouse (GA re:Invent 2024) unifies data across Amazon S3 data lakes and Redshift data warehouses.
Provides flexibility to access and query data using Apache Iceberg open standards.
Existing Redshift data warehouses can be made available through SageMaker Lakehouse via a simple publish step, exposing all data warehouse data with Iceberg REST API.
New data lake tables can be created using Redshift Managed Storage (RMS) as a native storage option.
Integrates with AWS Glue Data Catalog for unified metadata management.
Supports fine-grained permissions consistently applied across all analytics engines and AI tools.
Apache Iceberg Support in Redshift:
Query Iceberg tables stored in S3 and S3 Table Buckets.
Write support: INSERT, DELETE, UPDATE, and MERGE operations on Iceberg tables (2025-2026).
2x faster data lake query performance for Iceberg workloads (2025).
Incremental refresh for materialized views on data lake tables.
Redshift Generative AI and ML
Amazon Q Generative SQL for Redshift (GA 2024)
Uses generative AI to analyze user intent, query patterns, and schema metadata.
Allows users to express queries in natural language and receive SQL code recommendations.
Leverages query history and custom context (table/column descriptions, sample queries) for more relevant SQL recommendations.
Available in the Redshift Query Editor.
Amazon Bedrock Integration (GA 2024)
Enables invoking Large Language Models (LLMs) from simple SQL commands on Redshift data.
Supports generative AI tasks: language translation, text generation, summarization, sentiment analysis, and data enrichment.
Supports models from Anthropic Claude, Amazon Titan, Meta Llama, and Mistral AI.
Redshift as Knowledge Base in Amazon Bedrock
Amazon Bedrock Knowledge Bases supports natural language querying to retrieve structured data from Redshift.
Transforms natural language queries into SQL queries automatically.
Users can ask questions like “What were my top 5 selling products?” without writing SQL.
Redshift ML
Provides integration between Redshift and Amazon SageMaker.
Enables creating, training, and deploying ML models using SQL.
Supports inference within the Redshift cluster for predictions in queries and applications.
Note: Scalar Python UDFs will reach end of support after June 30, 2026. Migrate to Lambda UDFs or Redshift ML.
Redshift Security
Redshift supports encryption at rest and in transit
Redshift provides support for role-based access control – RBAC. Row-level access control helps assign one or more roles to a user and assign system and object permissions by role.
Redshift supports Lambda User-defined Functions – UDFs to enable external tokenization, data masking, identification or de-identification of data by integrating with vendors like Protegrity, and protect or unprotect sensitive data based on a user’s permissions and groups, in query time.
Redshift supports Single Sign-On (SSO) and integrates with third-party corporate or SAML-compliant identity providers.
Redshift supports federated permissions with AWS IAM Identity Center, now available in multiple AWS Regions (2026).
Redshift supports multi-factor authentication (MFA) for additional security when authenticating to the Redshift cluster.
Redshift supports encrypting an unencrypted cluster using KMS. However, you can’t enable hardware security module (HSM) encryption by modifying the cluster. Instead, create a new, HSM-encrypted cluster and migrate your data to the new cluster.
Redshift enhanced VPC routing forces all COPY and UNLOAD traffic between the cluster and the data repositories through the VPC.
Minimum TLS version requirement changes effective January 31, 2026 — ensure clients support TLS 1.2 or higher.
Redshift Distribution Style determines how data is distributed across compute nodes and helps minimize the impact of the redistribution step by locating the data where it needs to be before the query is executed.
Redshift enhanced VPC routing forces all COPY and UNLOAD traffic between the cluster and the data repositories through the VPC.
Redshift workload management (WLM) enables users to flexibly manage priorities within workloads so that short, fast-running queries won’t get stuck in queues behind long-running queries.
Redshift Spectrum helps query and retrieve structured and semistructured data from files in S3 without having to load the data into Redshift tables.
Redshift Federated Query feature allows querying and analyzing data across operational databases, data warehouses, and data lakes.
structured data and running traditional relational databases while offloading database administration
for online-transaction processing (OLTP) and for reporting and analysis
Redshift is ideal for
large volumes of structured data that needs to be persisted and queried using standard SQL and existing BI tools
analytic and reporting workloads against very large data sets by harnessing the scale and resources of multiple nodes and using a variety of optimizations to provide improvements over RDS
preventing reporting and analytic processing from interfering with the performance of the OLTP workload
unified analytics across data warehouses and data lakes using a single engine (especially with RG instances)
EMR is ideal for
processing and transforming unstructured or semi-structured data to bring in to Amazon Redshift and
for data sets that are relatively transitory, not stored for long-term use.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
With which AWS services CloudHSM can be used (select 2)
S3
DynamoDB
RDS
ElastiCache
Amazon Redshift
You have recently joined a startup company building sensors to measure street noise and air quality in urban areas. The company has been running a pilot deployment of around 100 sensors for 3 months. Each sensor uploads 1KB of sensor data every minute to a backend hosted on AWS. During the pilot, you measured a peak of 10 IOPS on the database, and you stored an average of 3GB of sensor data per month in the database. The current deployment consists of a load-balanced auto scaled Ingestion layer using EC2 instances and a PostgreSQL RDS database with 500GB standard storage. The pilot is considered a success and your CEO has managed to get the attention or some potential investors. The business plan requires a deployment of at least 100K sensors, which needs to be supported by the backend. You also need to store sensor data for at least two years to be able to compare year over year Improvements. To secure funding, you have to make sure that the platform meets these requirements and leaves room for further scaling. Which setup will meet the requirements?
Add an SQS queue to the ingestion layer to buffer writes to the RDS instance (RDS instance will not support data for 2 years)
Ingest data into a DynamoDB table and move old data to a Redshift cluster (Handle 10K IOPS ingestion and store data into Redshift for analysis)
Replace the RDS instance with a 6 node Redshift cluster with 96TB of storage (Does not handle the ingestion issue)
Keep the current architecture but upgrade RDS storage to 3TB and 10K provisioned IOPS (RDS instance will not support data for 2 years)
Which two AWS services provide out-of-the-box user configurable automatic backup-as-a-service and backup rotation options? Choose 2 answers
Amazon S3
Amazon RDS
Amazon EBS
Amazon Redshift
Your department creates regular analytics reports from your company’s log files. All log data is collected in Amazon S3 and processed by daily Amazon Elastic Map Reduce (EMR) jobs that generate daily PDF reports and aggregated tables in CSV format for an Amazon Redshift data warehouse. Your CFO requests that you optimize the cost structure for this system. Which of the following alternatives will lower costs without compromising average performance of the system or data integrity for the raw data?
Use reduced redundancy storage (RRS) for PDF and CSV data in Amazon S3. Add Spot instances to Amazon EMR jobs. Use Reserved Instances for Amazon Redshift. (Spot instances impacts performance)
Use reduced redundancy storage (RRS) for all data in S3. Use a combination of Spot instances and Reserved Instances for Amazon EMR jobs. Use Reserved instances for Amazon Redshift (Combination of the Spot and reserved with guarantee performance and help reduce cost. Also, RRS would reduce cost and guarantee data integrity, which is different from data durability)
Use reduced redundancy storage (RRS) for all data in Amazon S3. Add Spot Instances to Amazon EMR jobs. Use Reserved Instances for Amazon Redshift (Spot instances impacts performance)
Use reduced redundancy storage (RRS) for PDF and CSV data in S3. Add Spot Instances to EMR jobs. Use Spot Instances for Amazon Redshift. (Spot instances impacts performance and Spot instance not available for Redshift)
A company needs to make their operational database data available in near real-time in their Redshift data warehouse for analytics. They want to eliminate custom ETL pipeline management. Which approach is recommended?
Use AWS DMS to continuously replicate data from the source database to Redshift
Use zero-ETL integration between the source database and Amazon Redshift (Zero-ETL eliminates the need to build and manage data pipelines and makes transactional data available in near real-time)
Export data to S3 and use auto-copy to load into Redshift
Use Kinesis Data Streams to stream data into Redshift
A company wants to run analytics queries across both their Redshift data warehouse and Apache Iceberg tables stored in S3, using a single engine. Which Amazon Redshift capability best supports this requirement?
Redshift Spectrum
Redshift Federated Query
Amazon SageMaker Lakehouse with Redshift (SageMaker Lakehouse unifies data across S3 data lakes and Redshift warehouses using Apache Iceberg open standards, and RG instances include an integrated data lake query engine)
AWS Glue ETL to move data between S3 and Redshift
A company is migrating from Amazon Redshift DC2 node types that are reaching End of Life. Which of the following are valid migration options? (Select 2)
Migrate to RA3 instances using elastic resize
Create a new DC2 cluster with more nodes
Migrate to Amazon Redshift Serverless
Migrate to DS2 instances
Contact AWS to extend DC2 support
An analytics team wants to use natural language queries to get insights from their Redshift data warehouse without writing SQL. Which AWS service integration enables this?
Amazon Athena with natural language processing
Amazon Bedrock Knowledge Bases with Amazon Redshift as a structured data source (Bedrock Knowledge Bases supports natural language querying to retrieve structured data from Redshift by automatically translating natural language to SQL)