Google Cloud – Mountkirk Games Case Study
Mountkirk Games makes online, session-based, multiplayer games for mobile platforms. They have recently started expanding to other platforms after successfully migrating their on-premises environments to Google Cloud. Their most recent endeavor is to create a retro-style first-person shooter (FPS) game that allows hundreds of simultaneous players to join a geo-specific digital arena from multiple platforms and locations. A real-time digital banner will display a global leaderboard of all the top players across every active arena.
Solution Concept
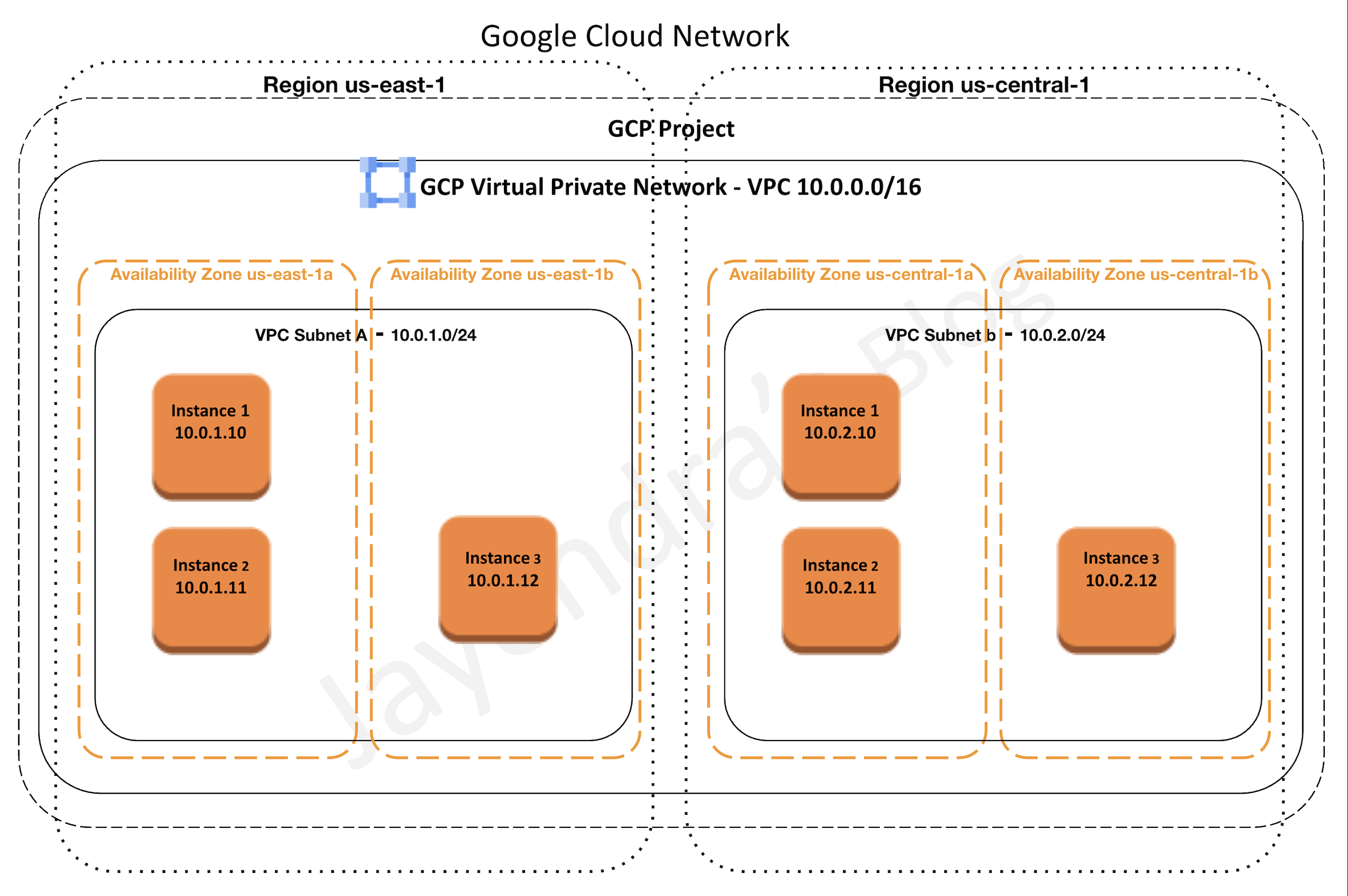
Mountkirk Games is building a new multiplayer game that they expect to be very popular. They plan to deploy the game’s backend on Google Kubernetes Engine so they can scale rapidly and use Google’s global load balancer to route players to the closest regional game arenas. In order to keep the global leader board in sync, they plan to use a multi-region Spanner cluster.
So the key here is the company wants to deploy the new game to Google Kubernetes Engine exposed globally using a Global Load Balancer and configured to scale rapidly and bring it closer to the users. Backend DB would be managed using a multi-region Cloud Spanner cluster.
Executive Statement
Our last game was the first time we used Google Cloud, and it was a tremendous success. We were able to analyze player behavior and game telemetry in ways that we never could before. This success allowed us to bet on a full migration to the cloud and to start building all-new games using cloud-native design principles. Our new game is our most ambitious to date and will open up doors for us to support more gaming platforms beyond mobile. Latency is our top priority, although cost management is the next most important challenge. As with our first cloud-based game, we have grown to expect the cloud to enable advanced analytics capabilities so we can rapidly iterate on our deployments of bug fixes and new functionality.
So the key points here are the company has moved to Google Cloud with great success and wants to build new games in the cloud. Key priorities are high performance, low latency, cost, advanced analytics, quick deployment, and time-to-market cycles.
Business Requirements
Support multiple gaming platforms.
Support multiple regions.
- Can be handled using a Global HTTP load balancer with GKE in each region.
- Can be handled using multi-region Cloud Spanner
- Other multi-regional services like Cloud Storage, Cloud Datastore, Cloud Pub/Sub, BigQuery can be used.
Support rapid iteration of game features.
- Can be handled using Deployment Manager and IaaC services like Terraform to automate infrastructure provisioning
- Cloud Build + Cloud Deploy/Spinnaker can be used for rapid continuous integration and deployment
Minimize latency
- can be reduced using a Global HTTP load balancer, which would route the user to the closest region
- using multi-regional resources like Cloud Spanner would also help reduce latency
Optimize for dynamic scaling
- can be done using GKE Cluster Autoscaler and Horizontal Pod Autoscaling to dynamically scale the nodes and applications as per the demand
- Cloud Spanner can be scaled dynamically
Use managed services and pooled resources.
- Using GKE, with Global Load Balancer for computing and Cloud Spanner would help cover the application stack using managed services
Minimize costs.
- Using minimal resources and enabling auto-scaling as per the demand would help minimize costs
Existing Technical Environment
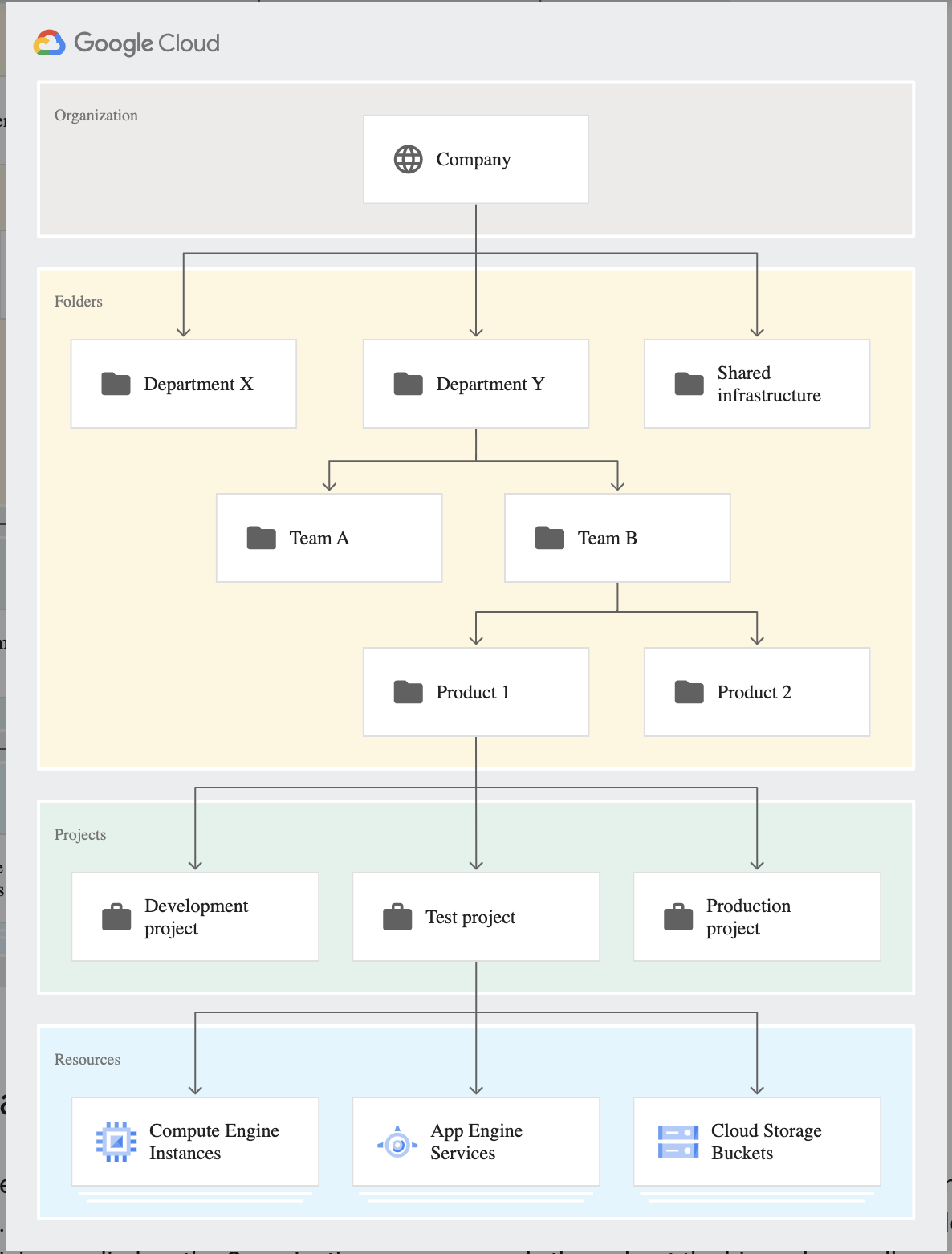
The existing environment was recently migrated to Google Cloud, and five games came across using lift-and-shift virtual machine migrations, with a few minor exceptions. Each new game exists in an isolated Google Cloud project nested below a folder that maintains most of the permissions and network policies. Legacy games with low traffic have been consolidated into a single project. There are also separate environments for development and testing.
Key points here are the resource hierarchy exists with a project for each new game under a folder to control access using Service Control Permissions. Also, some of the small games would be hosted in a single project. There are also different environments for development, testing, and production.
Technical Requirements
Dynamically scale based on game activity.
- can be done using GKE Cluster Autoscaler and Horizontal Pod Autoscaling to dynamically scale the nodes and applications as per the demand
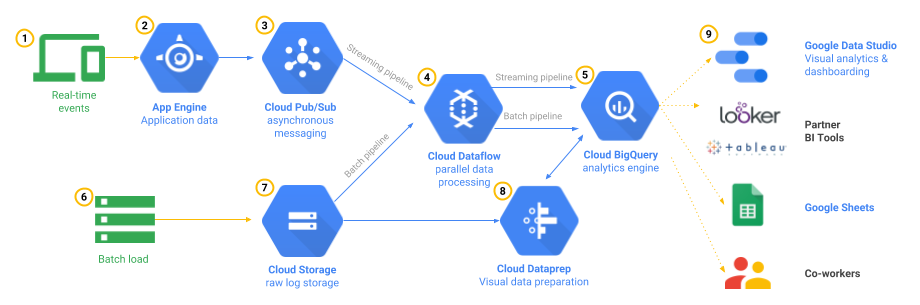
Publish scoring data on a near-real-time global leaderboard.
- can be handled using Pub/Sub for capturing data and Cloud DataFlow for processing the data on the fly i.e real time
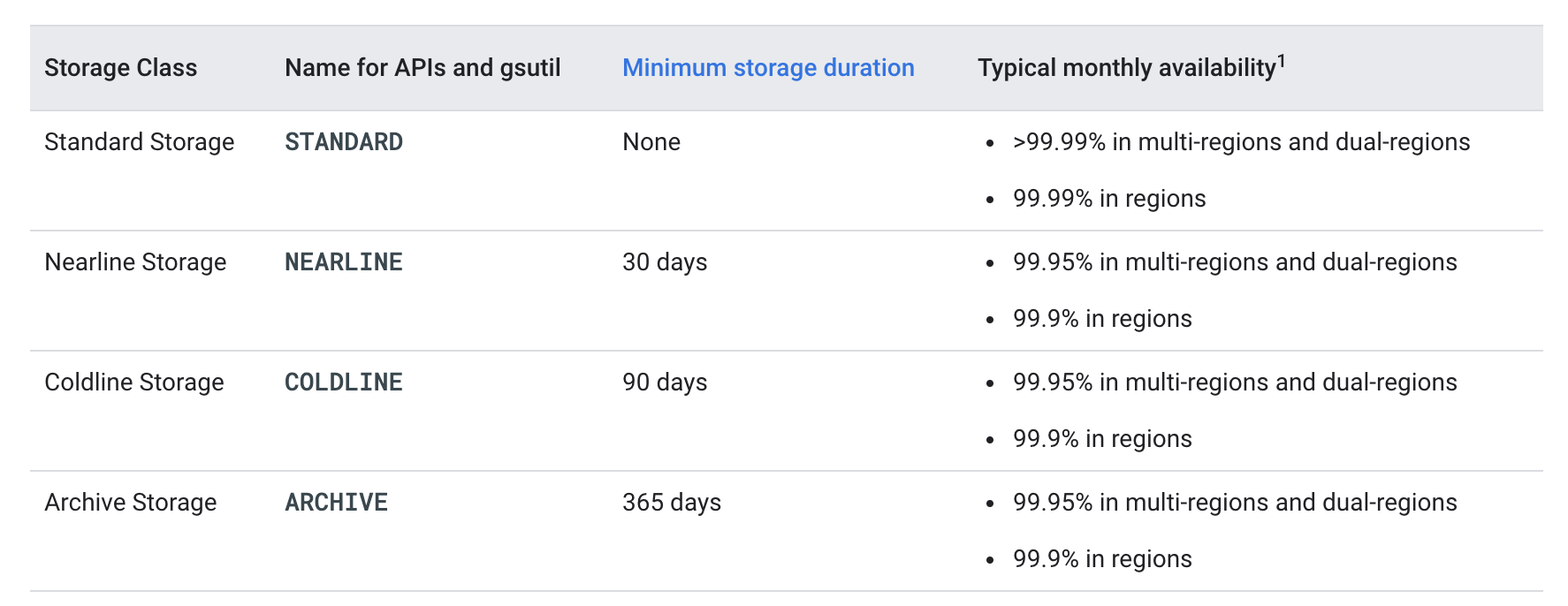
Store game activity logs in structured files for future analysis.
- can be handled using Cloud Storage to store logs for future analysis
- analysis can be handled using BigQuery either loading the data or using federated data source
- data can also be stored directly using BigQuery as it would provide a low-cost data storage (as compared to Bigtable) for analytics
- another advantage of BigQuery over Bigtable in this case its multi-regional, meeting the global footprint and latency requirements
Use GPU processing to render graphics server-side for multi-platform support.
- Support eventual migration of legacy games to this new platform.
Reference Architecture

Refer to Mobile Gaming Analysis Telemetry solution
Mountkirk Games References
- Google Cloud – Mountkrik Games