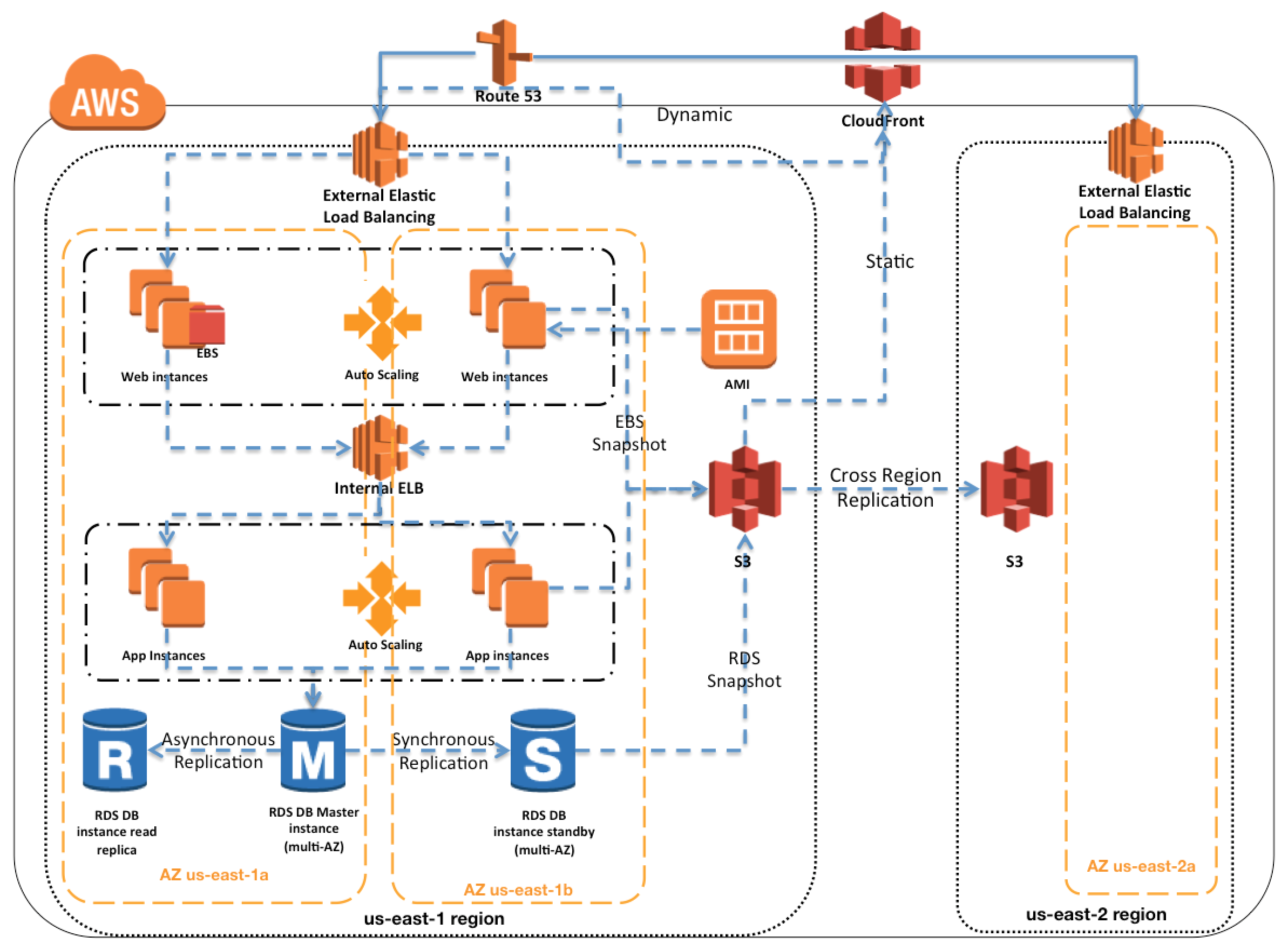
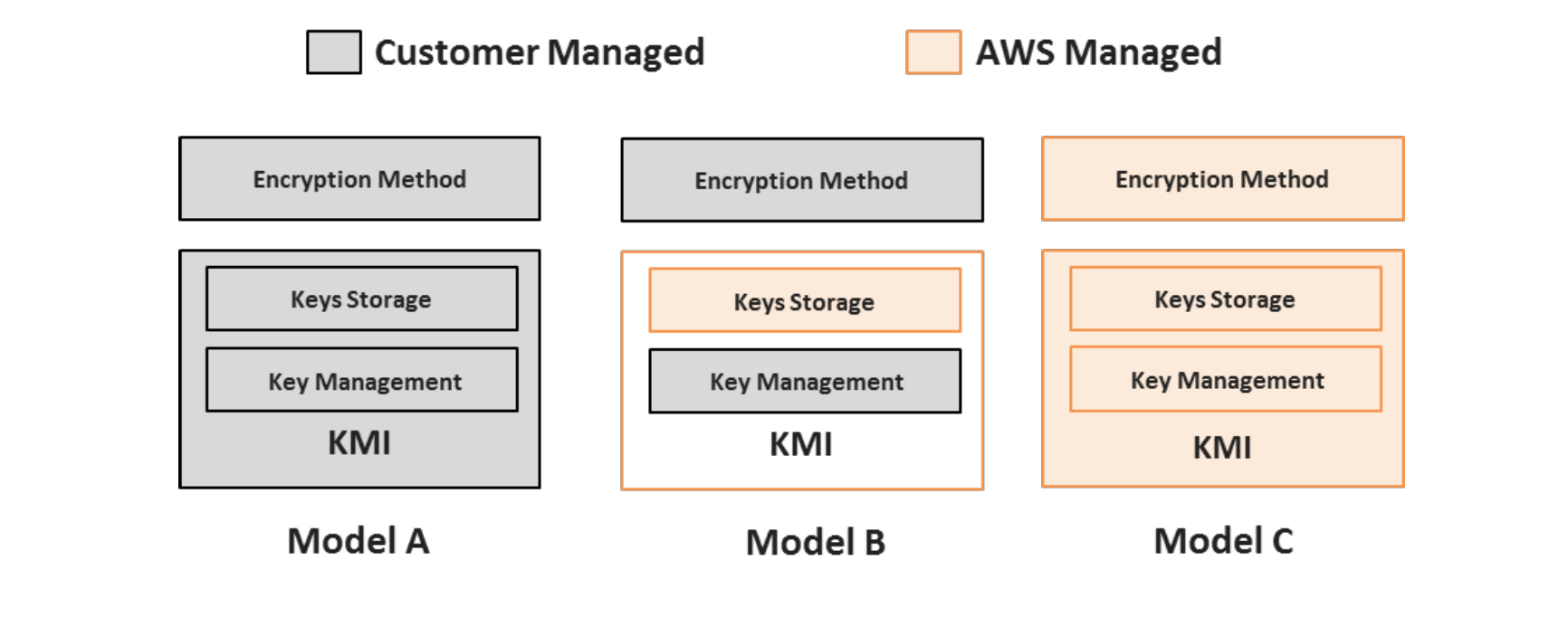
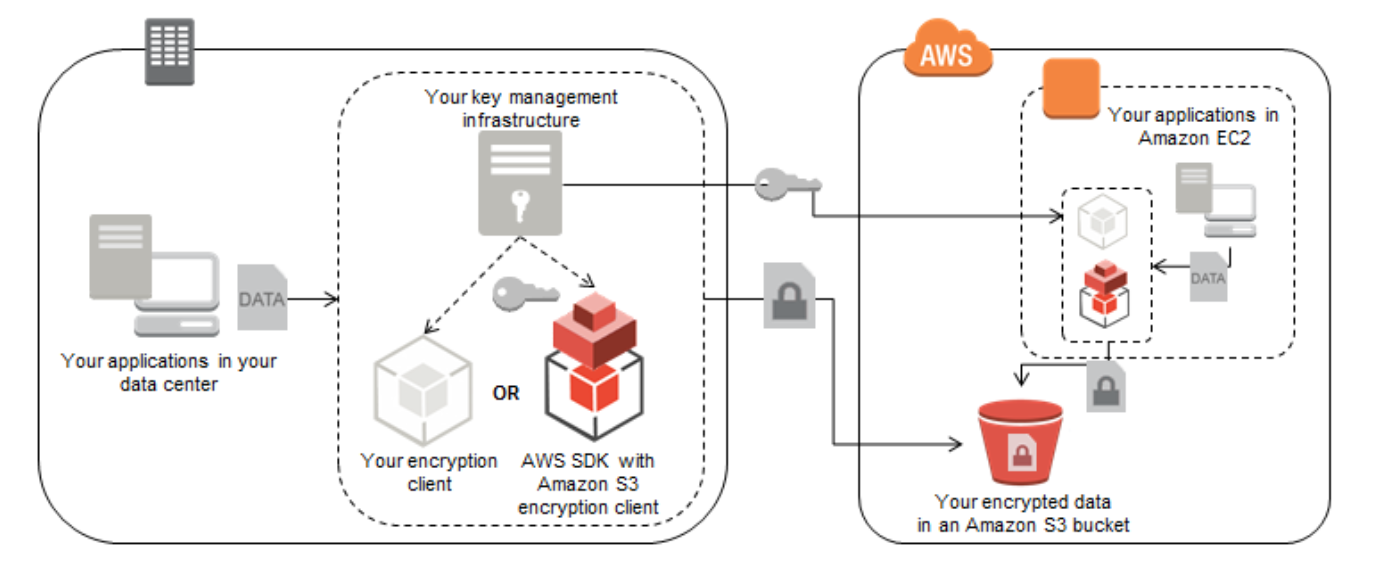
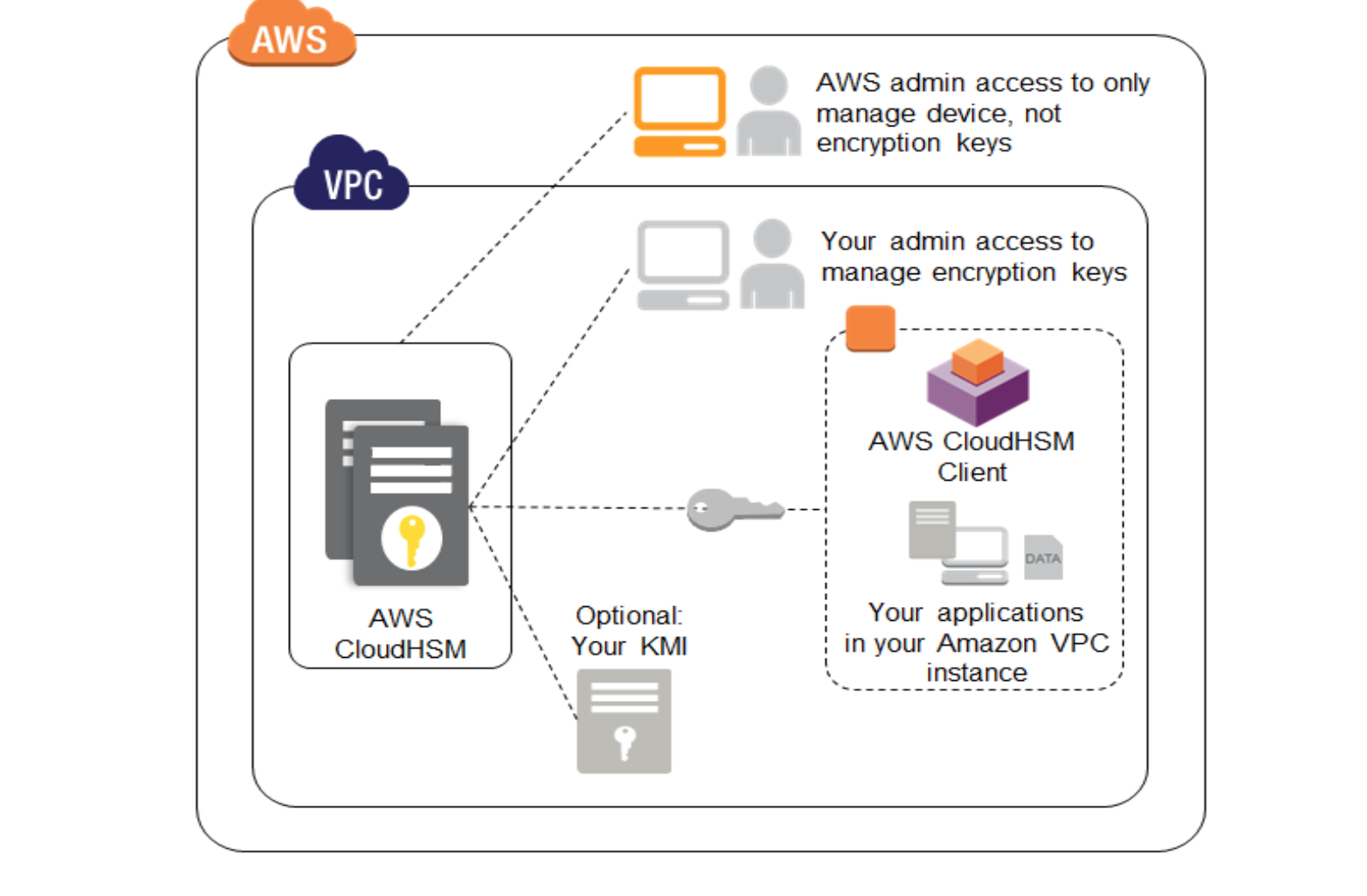
AWS Services Overview
AWS consists of many cloud services that can be use in combinations tailored to meet business or organizational needs. This section introduces the major AWS services by category.
NOTE – This post provides a brief overview of AWS services. Its is good introduction to start all certifications. However, It is more relevant and most important for AWS Cloud Practitioner Certification Exam.
Common Features
- Almost the features can be access control through AWS Identity Access Management – IAM
- Services managed by AWS are all made Scalable and Highly Available, without any changes needed from the user
AWS Access
AWS allows accessing its services through unified tools using
- AWS Management Console – a simple and intuitive user interface
- AWS Command Line Interface (CLI) – programatic access through scripts
- AWS Software Development Kits (SDKs) – programatic access through Application Program Interface (API) tailored for programming language (Java, .NET, Node.js, PHP, Python, Ruby, Go, C++, AWS Mobile SDK) or platform (Android, Browser, iOS)
Security, Identity, and Compliance
Amazon Cloud Directory
- enables building flexible, cloud-native directories for organizing hierarchies of data along multiple dimensions, whereas traditional directory solutions limit to a single directory
- helps create directories for a variety of use cases, such as organizational charts, course catalogs, and device registries.
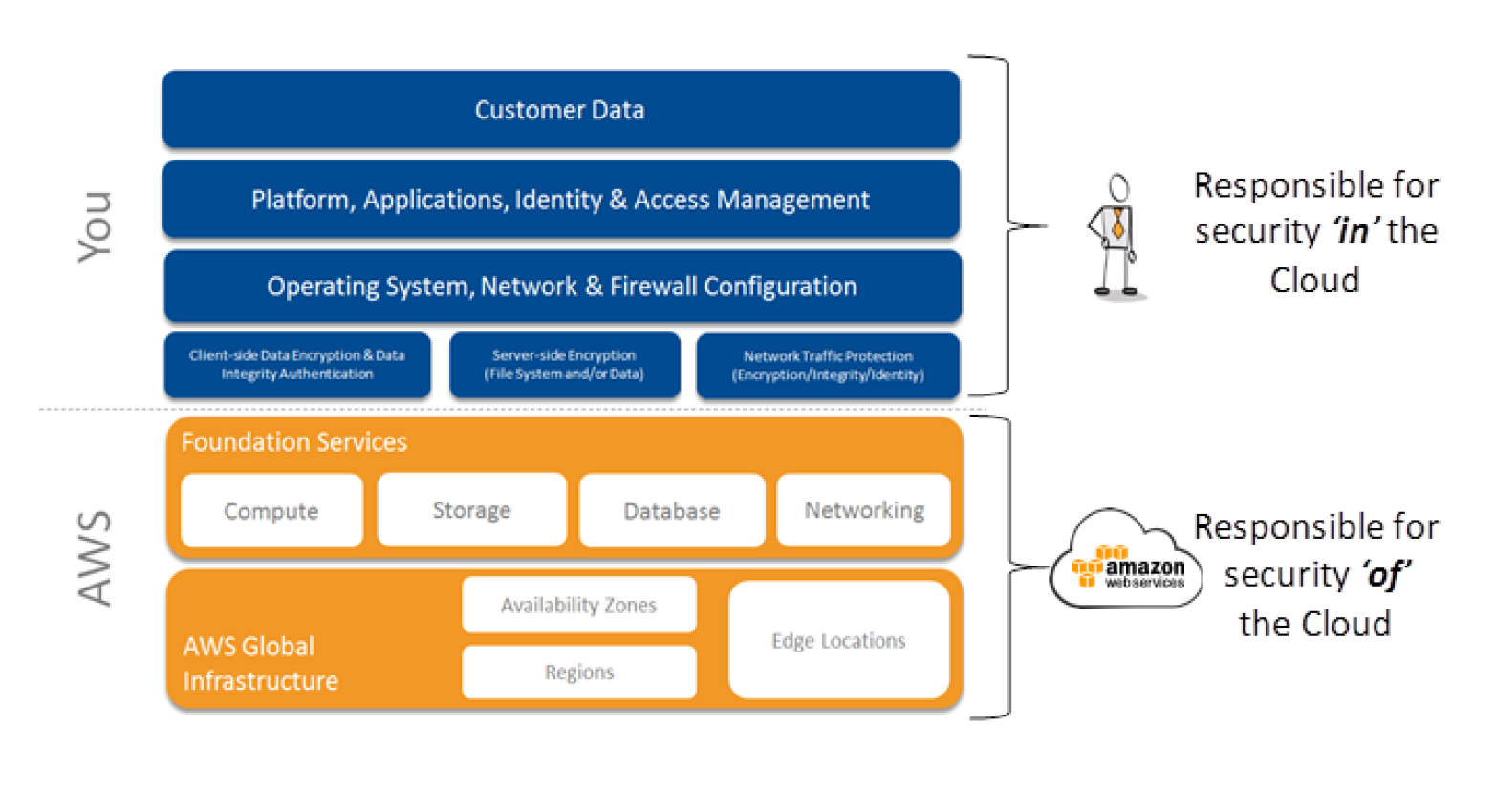
AWS Identity and Access Management
- enables you to securely control access to AWS services and resources for the users.
- allows creation of AWS users, groups and roles, and use permissions to allow and deny their access to AWS resources
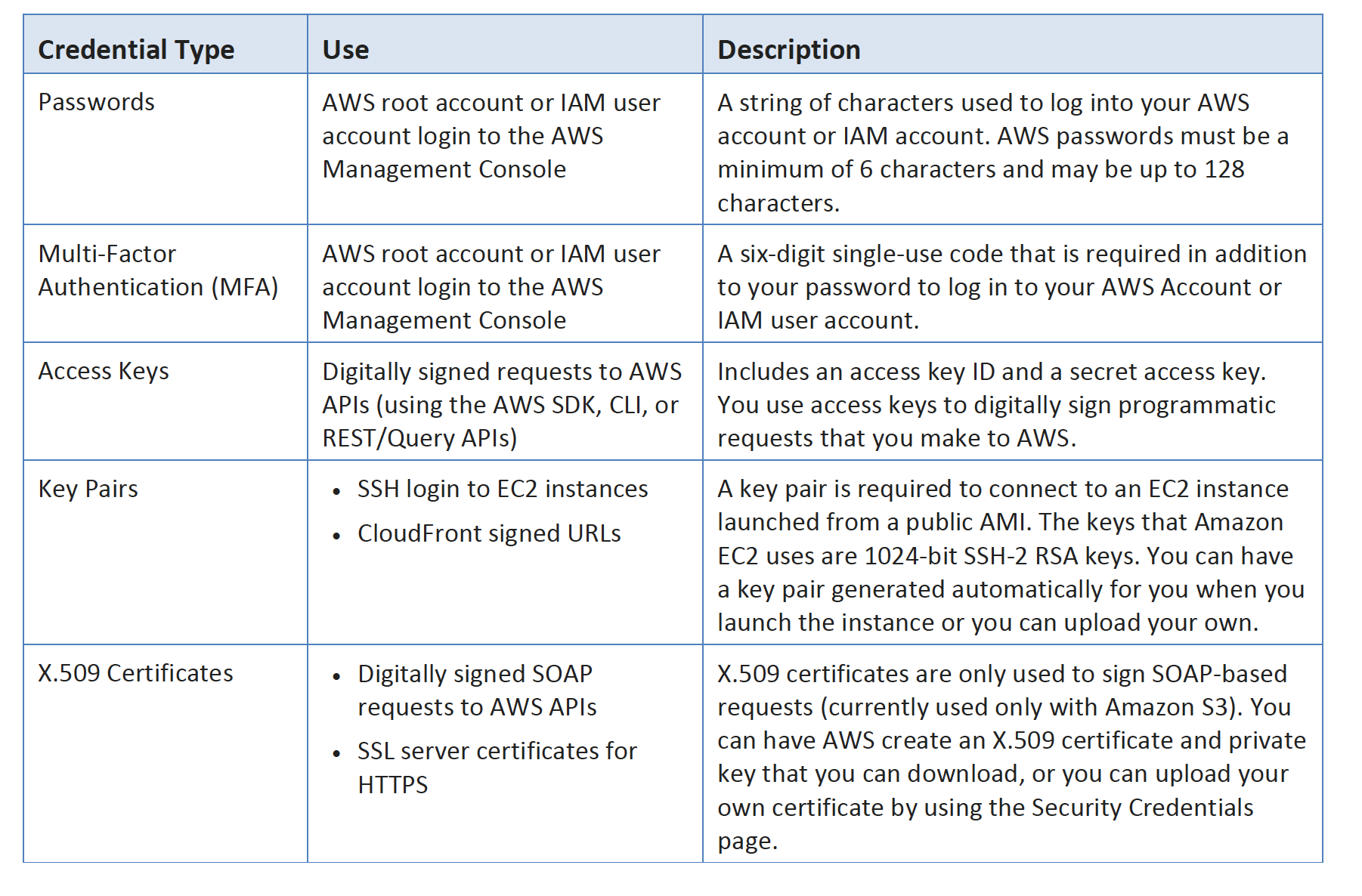
- helps manage IAM users and their access with individual security credentials like access keys, passwords, and multi-factor authentication devices, or request temporary security credentials to provide users
- helps role creation & manage permissions to control which operations can be performed by the which entity, or AWS service, that assumes the role
- enables identity federation to allow existing identities (users, groups, and roles) in the enterprise to access AWS Management Console, call AWS APIs, access resources, without the need to create an IAM user for each identity.
Amazon Inspector
- is an automated security assessment service that helps improve the security and compliance of applications deployed on AWS.
- automatically assesses applications for vulnerabilities or deviations from best practices
- produces a detailed list of security findings prioritized by level of severity.
AWS Certificate Manager
- helps provision, manage, and deploy Secure Sockets Layer/Transport Layer Security (SSL/TLS) certificates for use with AWS services like ELB
- removes the time-consuming manual process of purchasing, uploading, and renewing SSL/TLS certificates.
AWS CloudHSM
- helps meet corporate, contractual, and regulatory compliance requirements for data security by using dedicated Hardware Security Module (HSM) appliances within the AWS Cloud.
- allows protection of encryption keys within HSMs, designed and validated to government standards for secure key management.
- helps comply with strict key management requirements without sacrificing application performance.
AWS Directory Service
- provides Microsoft Active Directory (Enterprise Edition), also known as AWS Microsoft AD, that enables directory-aware workloads and AWS resources to use managed Active Directory in the AWS Cloud.
AWS Key Management Service
- is a managed service that makes it easy to create and control the encryption keys used to encrypt your data.
- uses HSMs to protect the security of your keys.
AWS Organizations
- allows creation of AWS accounts groups, to more easily manage security and automation settings collectively
- helps centrally manage multiple accounts to help scale.
- helps to control which AWS services are available to individual accounts, automate new account creation, and simplify billing.
AWS Shield
- is a managed Distributed Denial of Service (DDoS) protection service that safeguards web applications running on AWS.
- provides always-on detection and automatic inline mitigations that minimize application downtime and latency, so there is no need to engage AWS Support to benefit from DDoS protection.
- provides two tiers of AWS Shield: Standard and Advanced.
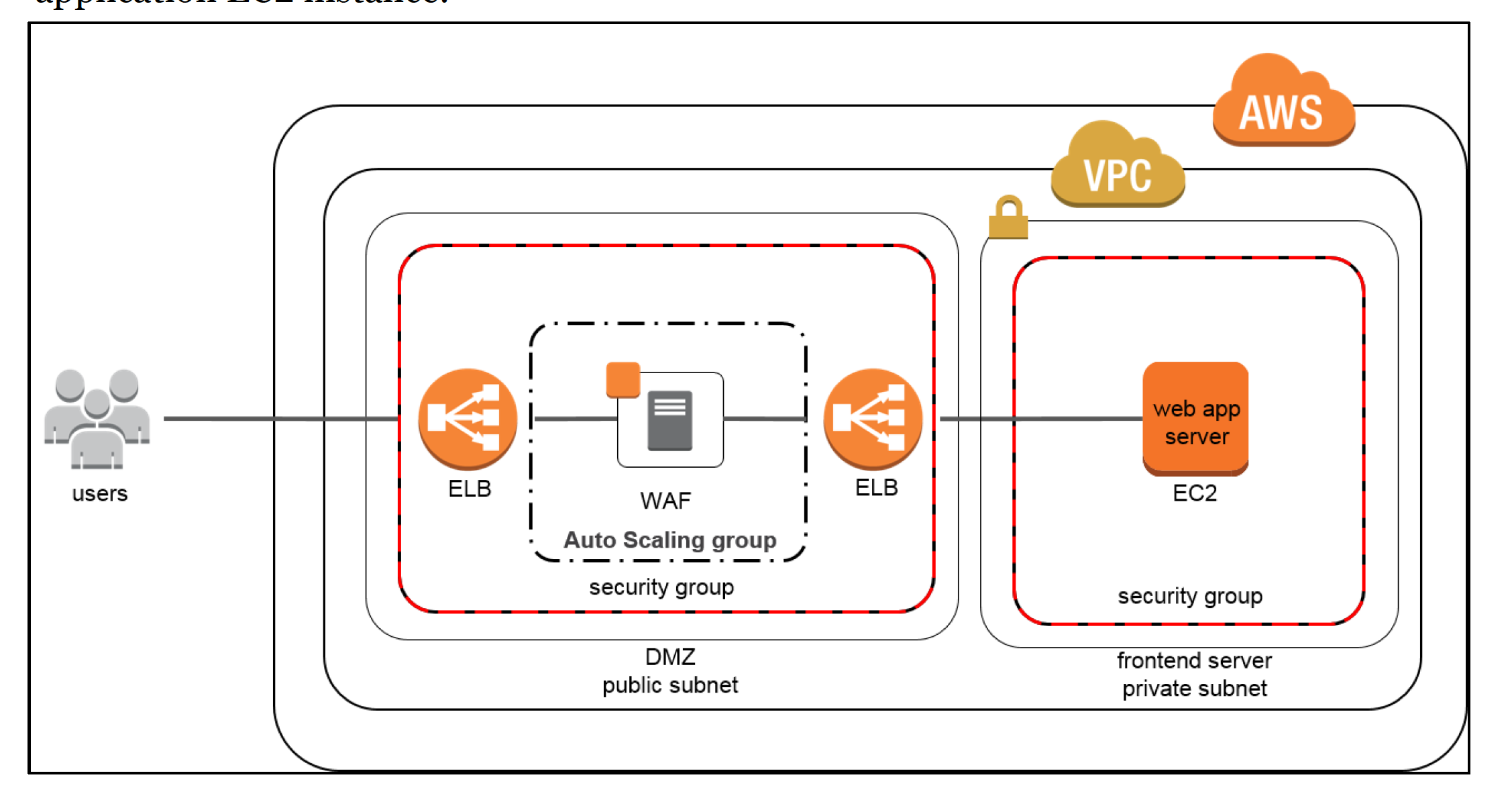
AWS WAF
- is a web application firewall that helps protect web applications from common web exploits that could affect application availability, compromise security, or consume excessive resources.
- gives complete control over which traffic to allow or block to web application by defining customizable web security rules.
AWS Compute Services
Amazon Elastic Compute Cloud (EC2)
- provides secure, resizable compute capacity
- provide complete control of the computing resources (root access, ability to start, stop, terminate instances etc.)
- reduces the time required to obtain and boot new instances to minutes
- allows quick scaling of capacity, both up and down, as the computing requirements changes
- provides developers and sysadmins tools to build failure resilient applications and isolate themselves from common failure scenarios.
- Benefits
- Elastic Web-Scale Computing
- enables scaling to increase or decrease capacity within minutes, not hours or days.
- Flexible Cloud Hosting Services
- flexibility to choose from multiple instance types, operating systems, and software packages.
- selection of memory configuration, CPU, instance storage, and boot partition size
- Reliable
- offers a highly reliable environment where replacement instances can be rapidly and predictably commissioned.
- runs within AWS’s proven network infrastructure and data centers.
- EC2 Service Level Agreement (SLA) commitment is 99.95% availability for each Region.
- Secure
- works in conjunction with VPC to provide security and robust networking functionality for your compute resources.
- allows control of IP address, exposure to Internet (using subnets), inbound and outbound access (using Security groups and NACLs)
- existing IT infrastructure can be connected to the resources in the VPC using industry-standard encrypted IPsec virtual private network (VPN) connections
- Inexpensive – pay only for the capacity actually used
- Elastic Web-Scale Computing
- EC2 Purchasing Options and Types
- On-Demand Instances
- pay for compute capacity by the hour with no long-term commitments
- enables to increase or decrease compute capacity depending on the demands and only pay the specified hourly rate for used instances
- frees from the costs and complexities of planning, purchasing, and maintaining hardware and transforms what are commonly large fixed costs into much smaller variable costs.
- also helps remove the need to buy “safety net” capacity to handle periodic traffic spikes.
- Reserved Instances
- provides significant discount (up to 75%) compared to On-Demand instance pricing.
- provides flexibility to change families, operating system types, and tenancies with Convertible Reserved Instances.
- Spot Instances
- allow you to bid on spare EC2 computing capacity.
- are often available at a discount compared to On-Demand pricing, helping reduce the application cost, grow it’s compute capacity and throughput for the same budget
- Dedicated Instances – that run on hardware dedicated to a single customer for additional isolation.
- Dedicated Hosts
- are physical servers with EC2 instance capacity fully dedicated to your use.
- can help you address compliance requirements and reduce costs by allowing you to use your existing server-bound software licenses.
- On-Demand Instances
Amazon EC2 Container Service
- is a highly scalable, high-performance container management service that supports Docker containers.
- allows running applications on a managed cluster of EC2 instances
- eliminates the need to install, operate, and scale cluster management infrastructure.
- can use to schedule the placement of containers across the cluster based on the resource needs and availability requirements.
- custom scheduler or third-party schedulers can be integrated to meet business or application-specific requirements.
Amazon EC2 Container Registry
- is a fully-managed Docker container registry that makes it easy for developers to store, manage, and deploy Docker container images.
- is integrated with Amazon EC2 Container Service (ECS), simplifying development to production workflow.
- eliminates the need to operate container repositories or worry about scaling the underlying infrastructure.
- hosts images in a highly available and scalable architecture
- pay only for the amount of data stored and data transferred to the Internet.
Amazon Lightsail
- is designed to be the easiest way to launch and manage a virtual private server with AWS.
- plans include everything needed to jumpstart a project – a virtual machine, SSD-based storage, data transfer, DNS management, and a static IP address- for a low, predictable price.
AWS Batch
- enables developers, scientists, and engineers to easily and efficiently run hundreds of thousands of batch computing jobs on AWS.
- dynamically provisions the optimal quantity and type of compute resources (e.g., CPU or memory-optimized instances) based on the volume and specific resource requirements of the batch jobs submitted.
- plans, schedules, and executes the batch computing workloads across the full range of AWS compute services and features
AWS Elastic Beanstalk
- is an easy-to-use service for deploying and scaling web applications and services developed with Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker on familiar servers such as Apache, Nginx, Passenger, and Internet Information Services (IIS)
- automatically handles the deployment, from capacity provisioning, load balancing, and auto scaling to application health monitoring.
- provides full control over the AWS resources with access to the underlying resources at any time.
AWS Lambda
- enables running code without zero administration, provisioning or managing servers, and scaling for high availability
- pay only for the compute time consumed – there is no charge when the code is not running
- can be setup to be automatically triggered from other AWS services, or called it directly from any web or mobile app.
Auto Scaling
- helps maintain application availability
- allows scaling EC2 capacity up or down automatically according to defined conditions or demand spikes to reduce cost
- helps ensure desired number of EC2 instances are running always
- well suited both to applications that have stable demand patterns and applications that experience hourly, daily, or weekly variability in usage.
Storage
Simple Storage Service
- is object storage with a simple web service interface to store and retrieve any amount of data from anywhere on the web.
- S3 Features
- Durable
- designed for durability of 99.999999999% of objects
- data is redundantly stored across multiple facilities and multiple devices in each facility.
- Available – designed for up to 99.99% availability (standard) of objects over a given year and is backed by the S3 Service Level Agreement
- Scalable – can help store virtually unlimited data
- Secure
- supports data in motion over SSL and data at rest encryption
- bucket policies and IAM can help manage object permissions and control access to the data
- Low Cost
- provides storage at a very low cost.
- using lifecycle policies, the data can be automatically tiered into lower cost, longer-term cloud storage classes like S3 Standard – Infrequent Access and Glacier for archiving.
- Durable
Elastic Block Store (EBS)
- provides persistent block storage volumes for use with EC2 instance
- offers the consistent and low-latency performance needed to run workloads.
- allows scaling up or down within minutes – all while paying a low price for only what is provisioned
- EBS Features
- High Performance Volumes – Choose between SSD backed or HDD backed volumes to deliver the performance needed
- Availability
- is designed for 99.999% availability
- automatically replicates within its Availability Zone to protect from component failure, offering high availability and durability.
- Encryption – provides seamless support for data-at-rest and data-in-transit between EC2 instances and EBS volumes.
- Snapshots – protect data by creating point-in-time snapshots of EBS volumes, which are backed up to S3 for long-term durability.
Elastic File System (EFS)
- provides simple, scalable file storage for use with EC2 instances
- storage capacity is elastic, growing and shrinking automatically as files are added and removed
- provides a standard file system interface and file system access semantics, when mounted on EC2 instances
- works in shared mode, where multiple EC2 instances can access an EFS file system at the same time, allowing EFS to provide a common data
source for workloads and applications running on more than one EC2 instance. - can be mounted on on-premises data center servers when connected to the VPC with AWS Direct Connect.
- can be mounted on on-premises servers to migrate data sets to EFS, enable cloud bursting scenarios, or backup on-premises data to EFS.
- is designed for high availability and durability, and provides performance for a broad spectrum of workloads and applications, including big data and analytics, media processing workflows, content management, web serving, and home directories.
Glacier
- provides secure, durable, and extremely low-cost storage service for data archiving and long-term backup
- To keep costs low yet suitable for varying retrieval needs, Glacier provides three options for access to archives, from a few minutes to several hours.
AWS Storage Gateway
- seamlessly enables hybrid storage between on-premises storage environments and the AWS Cloud
- combines a multi-protocol storage appliance with highly efficient network connectivity to AWS cloud storage services, delivering local
performance with virtually unlimited scale. - use it in remote offices and data centers for hybrid cloud workloads involving migration, bursting, and storage tiering
Databases
Aurora
- is a MySQL and PostgreSQL compatible relational database engine
- provides the speed and availability of high-end commercial databases with the simplicity and cost-effectiveness of open source databases.
- Benefits
- Highly Secure
- provides multiple levels of security, including
- network isolation using VPC
- encryption at rest using keys created and controlled through AWS Key Management Service (KMS), and
- encryption of data in transit using SSL.
- with an an encrypted Aurora instance, automated backups, snapshots, and replicas are also encrypted
- provides multiple levels of security, including
- Highly Scalable – automatically grows storage as needed
- High Availability and Durability
- designed to offer greater than 99.99% availability
- recovery from physical storage failures is transparent, and instance failover typically requires less than 30 seconds
- is fault-tolerant and self-healing. Six copies of the data are replicated across three AZs and continuously backed up to S3.
- automatically and continuously monitors and backs up your database to S3, enabling granular point-in-time recovery.
- Fully Managed – is a fully managed database service, and database management tasks such as hardware provisioning, software patching, setup, configuration, monitoring, or backups is taken care of
- Highly Secure
Relational Database Service (RDS)
- makes it easy to set up, operate, and scale a relational database
- provides cost-efficient and resizable capacity while managing time-consuming database administration tasks
- supports various, including Amazon Aurora, PostgreSQL, MySQL, MariaDB, Oracle, and Microsoft SQL Server
- Benefits
- Fast and Easy to Administer – No need for infrastructure provisioning, and no need for installing and maintaining database software.
- Highly Scalable
- allows quick and easy scaling of database’s compute and storage resources, often with no downtime.
- allows offloading read traffic from primary database using Read Replicas, for few RDS engine types
- Available and Durable
- runs on the same highly reliable infrastructure
- allows Multi-AZ DB instance, where RDS synchronously replicates the data to a standby instance in a different Availability Zone (AZ).
- enhances reliability for critical production databases, by enabling automated backups, database snapshots, and automatic host replacement.
- Secure
- provides multiple levels of security, including
- network isolation using VPC
- connect to on-premises existing IT infrastructure through an industry-standard encrypted IPsec VPN
- encryption at rest using keys created and controlled through AWS Key Management Service (KMS), and
- offer encryption at rest and encryption in transit.
- with an an encrypted instance, automated backups, snapshots, and replicas are also encrypted
- provides multiple levels of security, including
- Inexpensive – pay very low rates and only for the consumed resources, while taking advantage of on-demand and reserved instance types
DynamoDB
- fully managed, fast and flexible NoSQL database service for applications that need consistent, single-digit millisecond latency at any scale.
- supports both document and key-value data models.
- flexible data model and reliable performance make it a great fit for mobile, web, gaming, ad-tech, Internet of Things (IoT), and other applications
- Benefits
- Fast, Consistent Performance
- designed to deliver consistent, fast performance at any scale
- uses automatic partitioning and SSD technologies to meet throughput requirements and deliver low latencies at any scale.
- Highly Scalable – it manages all the scaling to achieve the specified throughput capacity requirements
- Event-Driven Programming – integrates with AWS Lambda to provide Triggers that enable architecting applications that automatically react to data changes.
- Fast, Consistent Performance
ElastiCache
- is a web service that makes it easy to deploy, operate, and scale an in-memory cache in the cloud.
- helps improves the performance of web applications by caching results and allowing to retrieve information from fast, managed, in-memory caches, instead of relying entirely on slower disk-based databases.
- supports two open-source in-memory caching engines: Redis and Memcached
Migration
AWS Application Discovery Service
- helps systems integrators quickly and reliably plan application migration projects by automatically identifying applications running in on-premises
data centers, their associated dependencies, and performance profiles - automatically collects configuration and usage data from servers, storage, and networking equipment to develop a list of applications, how they
perform, and how they are interdependent - information is retained in encrypted format in an AWS Application Discovery Service database, which you can export as a CSV or XML file into your preferred visualization tool or cloud migration solution to help reduce the complexity and time in planning your cloud migration.
AWS Database Migration Service
- helps migrate databases to AWS easily and securely
- source database remains fully operational during the migration, minimizing downtime to applications that rely on the database.
- supports homogenous migrations such as Oracle to Oracle, as well as heterogeneous migrations between different database platforms, such as Oracle to Amazon Aurora or Microsoft SQL Server to MySQL.
- allows streaming of data to Redshift from any of the supported sources including Aurora, PostgreSQL, MySQL, MariaDB, Oracle, SAP ASE, and SQL Server, enabling consolidation and easy analysis of data in the petabyte-scale data warehouse
- can also be used for continuous data replication with high availability.
AWS Server Migration Service
- is an agentless service which makes it easier and faster to migrate thousands of on-premises workloads to AWS
Snowball
- is a petabyte-scale data transport solution that uses secure appliances to transfer large amounts of data into and out of AWS.
- addresses common challenges with large-scale data transfers including high network costs, long transfer times, and security concerns.
- uses multiple layers of security designed to protect the data including tamper resistant enclosures, 256-bit encryption, and an industry-standard Trusted Platform Module (TPM) designed to ensure both security and full chain of custody of your data.
- performs a software erasure of the Snowball appliance, once the data transfer job has been processed
Snowball Edge
- is a 100 TB data transfer device with on-board storage and compute capabilities.
- can be used to move large amounts of data into and out of AWS, as a temporary storage tier for large local datasets, or to support local workloads in remote or offline locations.
- multiple devices can be clustered together to form a local storage tier and process the data on-premises, helping ensure the applications continue to run even when they are not able to access the cloud
Snowmobile
- is an exabyte-scale data transfer service used to move extremely large amounts of data to AWS.
- provides secure, fast, and cost effective transfer of data
- data cane be imported into S3 or Glacier, once data loaded
- uses multiple layers of security designed to protect the data including dedicated security personnel, GPS tracking, alarm monitoring, 24/7 video surveillance, and an optional escort security vehicle while in transit.
- all data is encrypted with 256-bit encryption keys managed through KMS and designed to ensure both security and full chain of custody of the data
Networking and Content Delivery
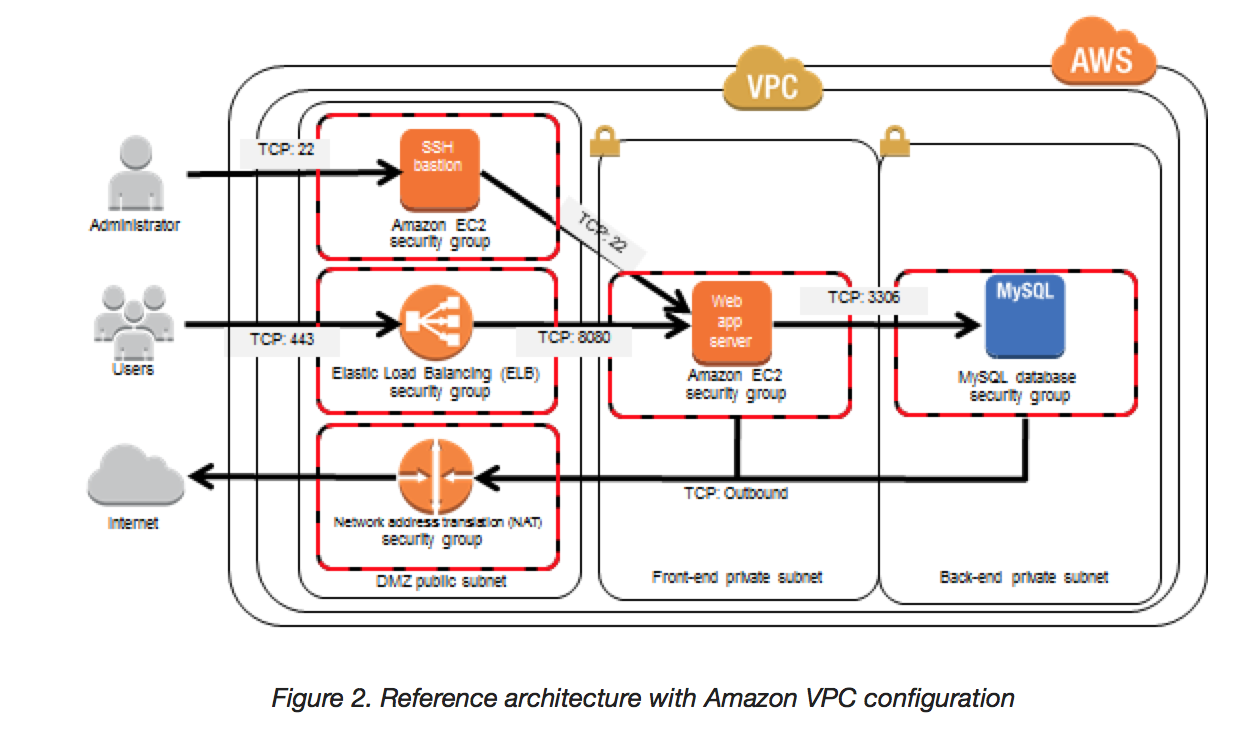
Virtual Private Cloud (VPC)
- helps provision a logically isolated section of the AWS Cloud where AWS resources can be launched in a virtual network that you define
- provides complete control over the virtual networking environment, including selection of IP address range, creation of subnets (public and private), and configuration of route tables and network gateways.
- allows use of both IPv4 and IPv6 for secure and easy access to resources and applications
- allows multiple layers of security, including security groups and network access control lists, to help control access resources
- allows creation of a hardware virtual private network (VPN) connection between the corporate data center and VPC and leverage the AWS Cloud as an extension of corporate data center.
CloudFront
- is a global content delivery network (CDN) service that accelerates delivery of websites, APIs, video content, or other web assets.
- can be used to deliver entire website, including dynamic, static, streaming, and interactive content using a global network of edge locations.
- allows requests for the content to be automatically routed to the nearest edge location, so content is delivered with the best possible performance.
- is optimized to work with other services in AWS, such as S3, EC2, ELB, and Route 53 as well as with any non-AWS origin server that stores the original, definitive versions of your files.
Route 53
- is a highly available and scalable Domain Name System (DNS) web service
- effectively connects user requests to infrastructure running in AWS – such as EC2 instances, ELB, or S3 buckets—and can also be used to route users to infrastructure outside of AWS.
- helps configure DNS health checks to route traffic to healthy endpoints or to independently monitor the health of your application and its endpoints.
- allows traffic management globally through a variety of routing types, including latency-based routing, Geo DNS, and weighted round robin – all of which can be combined with DNS Failover in order to enable a variety of low-latency, fault-tolerant architectures.
- is fully compliant with IPv6 as well
- offers Domain Name Registration service
Direct Connect
- makes it easy to establish a dedicated network connection with on- premises to AWS
- helps establish private connectivity between AWS and data center, office, or co-location environment,
- helps increase bandwidth throughput, reduce network costs, , and provide a more consistent network experience than Internet-based connections
Elastic Load Balancing (ELB)
- automatically distributes incoming application traffic across multiple EC2 instances
- enables achieve greater levels of fault tolerance by seamlessly providing the required amount of load balancing capacity needed to distribute application traffic.
- offers two types of load balancers that both feature high availability, automatic scaling, and robust security.
- Classic Load Balancer
- routes traffic based on either application or network level information
- ideal for simple load balancing of traffic across multiple EC2 instances
- Application Load Balancer
- routes traffic based on advanced application-level information that includes the content of the request
- ideal for applications needing advanced routing capabilities, microservices, and container-based architectures.
- offers the ability to route traffic to multiple services or load balance
across multiple ports on the same EC2 instance.
- Classic Load Balancer
Management Tools
AWS CloudWatch
- is a monitoring and logging service for AWS Cloud resources and the applications running on AWS.
- can be used to collect and track metrics, collect and monitor log files, set alarms, and automatically react to changes in the AWS resources.
AWS CloudFormation
- allows developers and systems administrators to implement “Infrastructure as Code”
- provides an easy way to create and manage a collection of related AWS resources, provisioning and updating them in an orderly and predictable fashion
- handles the order for provisioning AWS services or the subtleties of making those dependencies work.
- allows applying version control to the AWS infrastructure the same way its done with software
AWS CloudTrail
- helps records AWS API calls for the account and delivers log files
- including API calls made using the AWS Management Console, AWS SDKs, command line tools, and higher-level AWS services (such as AWS CloudFormation),
- recorded information includes the identity of the API caller, the time of the API call, the source IP address of the API caller, the request parameters, and the response elements returned by the AWS service.
- enables security analysis, resource change tracking, compliance auditing
AWS Config
- provides an AWS resource inventory, configuration history, and configuration change notifications to enable security and governance
- provides Config Rules feature, that enables rules creation that automatically check the configuration of AWS resources
- helps discover existing and deleted AWS resources, determine overall compliance against rules, and dive into configuration details of a resource at any point in time.
- enables compliance auditing, security analysis, resource change tracking, and troubleshooting.
AWS OpsWorks
- configuration management service that uses Chef, an automation platform that treats server configurations as code.
- uses Chef to automate how servers are configured, deployed, and managed across the EC2 instances or on-premises compute environments.
- has two offerings, OpsWorks for Chef Automate and OpsWorks Stacks
AWS Service Catalog
- allows organizations to create and manage catalogs of IT services that are approved for use on AWS.
- helps centrally manage commonly deployed IT services and helps to achieve consistent governance and meet compliance requirements, while enabling users to quickly deploy only approved IT services they need
- can include everything from virtual machine images, servers, software, and databases to complete multi-tier application architectures.
AWS Trusted Advisor
- is an online resource to help reduce cost, increase performance, and improve security by optimizing the AWS environment.
- provides real-time guidance to help provision the resources following AWS best practices.
AWS Personal Health Dashboard
- provides alerts and remediation guidance when AWS is experiencing events that might affect you.
- displays relevant and timely information to help you manage events in progress, and provides proactive notification to help you plan for scheduled activities.
- alerts are automatically triggered by changes in the health of AWS resources, providing event visibility and guidance to help quickly diagnose and resolve issues.
- provides a personalized view into the performance and availability of the AWS services underlying the AWS resources.
- Service Health Dashboard displays the general status of AWS services,
AWS Managed Services
- provides ongoing management of the AWS infrastructure so the focus can be on applications.
- helps reduce the operational overhead and risk, by implementing best practices to maintain the infrastructure
- automates common activities such as change requests, monitoring, patch management, security, and backup services, and provides full-lifecycle services to provision, run, and support the infrastructure.
- improves agility, reduces cost, and unburdens from infrastructure operations
Developer Tools
AWS CodeCommit
- is a fully managed source control service that makes to host secure and highly scalable private Git repositories
AWS CodeBuild
- is a fully managed build service that compiles source code, runs tests, and produces software packages that are ready to deploy
- also helps provision, manage, and scale the build servers.
- scales continuously and processes multiple builds concurrently, so the builds are not left waiting in a queue.
AWS CodeDeploy
- is a service that automates code deployments to any instance, including EC2 instances and instances running on premises.
- helps to rapidly release new features, avoid downtime during application deployment, and handles the complexity of updating the applications.
AWS CodePipeline
- is a continuous integration and continuous delivery service for fast and reliable application and infrastructure updates.
- builds, tests, and deploys the code every time there is a code change, based on the defined release process models
AWS X-Ray
- helps developers analyze and debug distributed applications in production or development, such as those built using a microservices architecture
- provides an end-to-end view of requests as they travel through the application, and shows a map of its underlying components.
- helps understand how the application and its underlying services are performing, to identify and troubleshoot the root cause of performance issues and errors.
Messaging
Amazon SQS
- is a fast, reliable, scalable, fully managed message queuing service.
- makes it simple and cost-effective to decouple the components of a cloud application.
- includes standard queues with high throughput and at-least-once processing, and FIFO queues
- provides FIFO (first-in, first-out) delivery and exactly-once processing.
Amazon SNS
- fast, flexible, fully managed push notification service to send individual messages or to fan-out messages to large numbers of recipients.
- makes it simple and cost effective to send push notifications to mobile device users, email recipients or even send messages to other distributed services
- notifications can be sent to Apple, Google, Fire OS, and Windows devices, as well as to Android devices in China with Baidu Cloud Push.
- can also deliver messages to SQS, Lambda functions, or HTTP endpoint
Amazon SES
- is a cost-effective email service built on the reliable and scalable infrastructure that Amazon.com developed to serve its own customer
- can send transactional email, marketing messages, or any other type of high-quality content to the customers.
- can receive messages and deliver them to an S3 bucket, call your custom code via an AWS Lambda function, or publish notifications to SNS.
Analytics
Amazon Athena
- is an interactive query service that helps to analyze data in S3 using standard SQL.
- is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
- removes the need for complex extract, transform, and load (ETL) jobs
Amazon EMR
- provides a managed Hadoop framework that makes it easy, fast, and costeffective to process vast amounts of data across dynamically scalable EC2 instances.
- enables you to run other popular distributed frameworks such as Apache Spark, HBase, Presto, and Flink, and interact with data in other AWS data stores such as S3 and DynamoDB.
- securely and reliably handles a broad set of big data use cases, including log analysis, web indexing, data transformations (ETL), machine learning, financial analysis, scientific simulation, and bioinformatics.
Amazon CloudSearch
- is a managed service and makes it simple and costeffective to set up, manage, and scale a search solution for website or application.
- supports 34 languages and popular search features such as highlighting, autocomplete, and geospatial search.
Amazon Elasticsearch Service
- makes it easy to deploy, operate, and scale Elasticsearch for log analytics, full text search, application monitoring, and more.
- is a fully managed service that delivers Elasticsearch’s easy-to-use APIs and real-time capabilities along with the availability, scalability, and security required by production workloads.
Amazon Kinesis
- is a platform for streaming data on AWS, offering powerful services to make it easy to load and analyze streaming data,
- provides the ability to build custom streaming data applications for specialized needs.
- offers three services:
- Amazon Kinesis Firehose,
- helps load streaming data into AWS.
- can capture, transform, and load streaming data into Amazon Kinesis Analytics, S3, Redshift, and Elasticsearch Service, enabling near real-time analytics with existing business intelligence tools and dashboards
- helps batch, compress, and encrypt the data before loading it, minimizing the amount of storage used at the destination and increasing security.
- Amazon Kinesis Analytics
- helps process streaming data in real time with standard SQL
- Amazon Kinesis Streams
- enables you to build custom applications that process or analyze streaming data for specialized needs.
- Amazon Kinesis Firehose,
Amazon Redshift
- provides a fast, fully managed, petabyte-scale data warehouse that makes it simple and cost-effective to analyze all your data using your existing business intelligence tools.
- has a massively parallel processing (MPP) data warehouse architecture, parallelizing and distributing SQL operations to take advantage of all available resources.
- provides underlying hardware designed for high performance data processing, using local attached storage to maximize throughput between the CPUs and drives, and a 10GigE mesh network to maximize throughput between nodes.
Amazon QuickSight
- provides fast, cloud-powered business analytics service that makes it easy to build visualizations, perform ad-hoc analysis, and quickly get business insights from your data.
AWS Data Pipeline
- helps reliably process and move data between different AWS compute and storage services, as well as on-premises data sources, at specified intervals
- can regularly access your data where it’s stored, transform and process it at scale, and efficiently transfer the results to AWS services such as S3, RDS, DynamoDB, and EMR.
- helps create complex data processing workloads that are fault tolerant, repeatable, and highly available.
- also allows you to move and process data that was previously locked up in on-premises data silos.
AWS Glue
- is a fully managed ETL service that makes it easy to move data between data stores.
- helps simplifies and automates the difficult and time-consuming tasks of data discovery, conversion, mapping, and job scheduling.
- helps schedules ETL jobs and provisions and scales all the infrastructure
- required so that ETL jobs run quickly and efficiently at any scale.
Application Services
AWS Step Functions
- makes it easy to coordinate the components of distributed applications and microservices using visual workflows.
- automatically triggers and tracks each step, and retries when there are errors, so the application executes in order and as expected.
Amazon API Gateway
- is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale.
- handles all the tasks involved in accepting and processing up to hundreds of thousands of concurrent API calls, including traffic management, authorization and access control, monitoring, and API version management.
Amazon Elastic Transcoder
- is media transcoding in the cloud
- is designed to be a highly scalable, easy-to-use, and cost-effective way for developers and businesses to convert (or transcode) media files from their source format into versions that will play back on devices like smartphones, tablets, and PCs.
Amazon SWF
- helps developers build, run, and scale background jobs that have parallel or sequential steps.
- is a fully-managed state tracker and task coordinator in the cloud.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- Which AWS services belong to the Compute services? Choose 2 answers
- Lambda
- EC2
- S3
- EMR
- CloudFront
- Which AWS service provides low cost storage option for archival and long-term backup?
- Glacier
- S3
- EBS
- CloudFront
- Which AWS services belong to the Storage services? Choose 2 answers
- EFS
- IAM
- EMR
- S3
- CloudFront
- A Company allows users to upload videos on its platform. They want to convert the videos to multiple formats supported on multiple devices and platforms. Which AWS service can they leverage for the requirement?
- AWS SWF
- AWS Video Converter
- AWS Elastic Transcoder
- AWS Data Pipeline
- Which analytic service helps analyze data in S3 using standard SQL?
- Athena
- EMR
- Elasticsearch
- Kinesis
- What features does AWS’s Route 53 service provide? Choose the 2 correct answers:
- Content Caching
- Domain Name System (DNS) service
- Database Management
- Domain Registration
- You are trying to organize and import (to AWS) gigabytes of data that are currently structured in JSON-like, name-value documents. What AWS service would best fit your needs?
- Lambda
- DynamoDB
- RDS
- Aurora
- What AWS database is primarily used to analyze data using standard SQL formatting with compatibility for your existing business intelligence tools? Choose the correct answer:
- Redshift
- RDS
- DynamoDB
- ElastiCache
- A company wants their application to use pre-configured machine image with software installed and configured. which AWS feature can help for the same?
- Amazon Machine Image
- AWS CloudFormation
- AWS Lambda
- AWS Lightsail
- What AWS service can be used for track API event calls for security analysis, resource change tracking?
- AWS CloudWatch
- AWS CloudFormation
- AWS CloudTrail
- AWS OpsWorks
- Which AWS service can help Offload the read traffic from your database in order to reduce latency caused by read-heavy workload?
- ElastiCache
- DynamoDB
- S3
- EFS
- What service allows system administrators to run “Infrastructure as code”?
- CloudFormation
- CloudWatch
- CloudTrail
- CodeDeploy