Google Cloud – EHR Healthcare Case Study
EHR Healthcare is a leading provider of electronic health record software to the medical industry. EHR Healthcare provides its software as a service to multi-national medical offices, hospitals, and insurance providers.
Executive statement
Our on-premises strategy has worked for years but has required a major investment of time and money in training our team on distinctly different systems, managing similar but separate environments, and responding to outages. Many of these outages have been a result of misconfigured systems, inadequate capacity to manage spikes in traffic, and inconsistent monitoring practices. We want to use Google Cloud to leverage a scalable, resilient platform that can span multiple environments seamlessly and provide a consistent and stable user experience that positions us for future growth.
EHR Healthcare wants to move to Google Cloud to expand, build scalable and highly available applications. It also wants to leverage automation and IaaC to provide consistency across environments and reduce provisioning errors.
Solution Concept
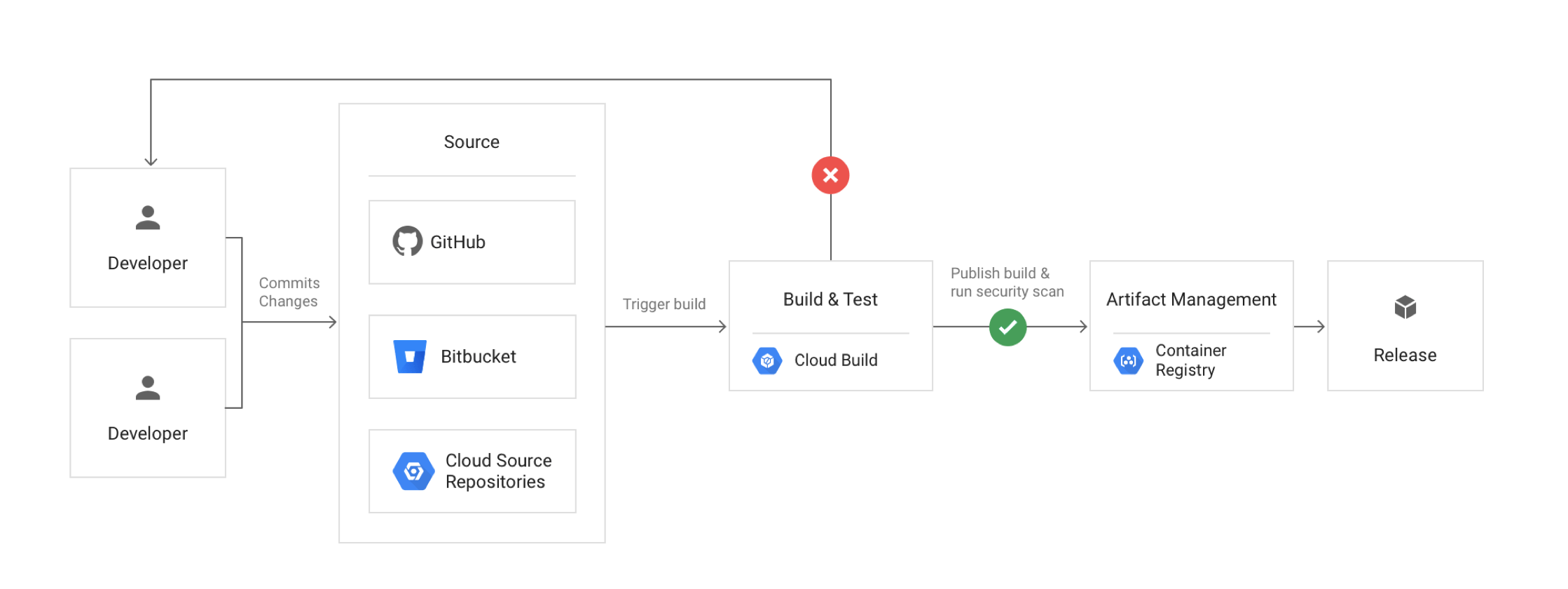
Due to rapid changes in the healthcare and insurance industry, EHR Healthcare’s business has been growing exponentially year over year. They need to be able to scale their environment, adapt their disaster recovery plan, and roll out new continuous deployment capabilities to update their software at a fast pace. Google Cloud has been chosen to replace its current colocation facilities.
EHR wants to build a scalable, Highly Available, Disaster Recovery setup and introduce Continuous Integration and Deployment in their setup.
Existing Technical Environment
EHR’s software is currently hosted in multiple colocation facilities. The lease on one of the data centers is about to expire.
Customer-facing applications are web-based, and many have recently been containerized to run on a group of Kubernetes clusters. Data is stored in a mixture of relational and NoSQL databases (MySQL, MS SQL Server, Redis, and MongoDB).
EHR is hosting several legacy file- and API-based integrations with insurance providers on-premises. These systems are scheduled to be replaced over the next several years. There is no plan to upgrade or move these systems at the current time.
Users are managed via Microsoft Active Directory. Monitoring is currently being done via various open-source tools. Alerts are sent via email and are often ignored.
- As the lease of one of the data centers is about to expire, time is critical
- Some web applications are containerized and have SQL and NoSQL databases and can be moved
- Some of the systems are legacy and would be replaced and need not be migrated
- Team has multiple monitoring tools and might need consolidation
Business requirements
On-board new insurance providers as quickly as possible.
Provide a minimum 99.9% availability for all customer-facing systems.
- Availability can be increased by hosting applications across multiple zones and using managed services which span multiple AZs
- GKE regional clusters with Autopilot mode provide built-in high availability across zones with automated node management
Provide centralized visibility and proactive action on system performance and usage.
- Google Cloud Observability (Cloud Monitoring + Cloud Logging + Cloud Trace) provides a unified platform for centralized visibility, alerting, and proactive action
- Application Monitoring (launched 2025) automatically labels and correlates telemetry for registered applications
- Cloud Logging can be used for log monitoring, analysis, and alerting
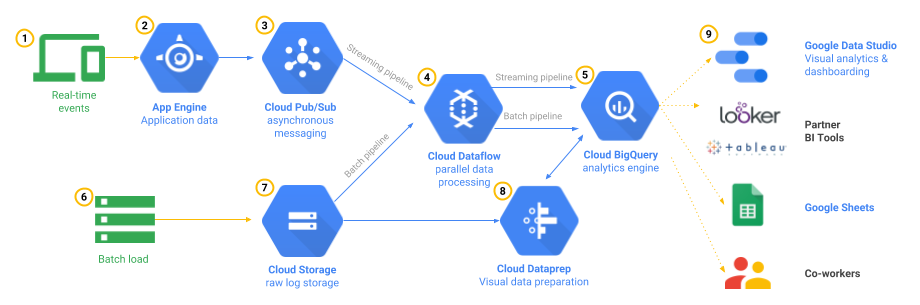
Increase ability to provide insights into healthcare trends.
- Data can be pushed and analyzed using BigQuery (now a unified AI-ready data platform) and insights visualized using Data Studio
- BigQuery ML enables building predictive ML models directly within BigQuery for healthcare trend analysis
Reduce latency to all customers.
- Performance can be improved using Global Load Balancer to expose the applications
- Applications can also be hosted across regions for low latency access
- Cloud CDN or Media CDN can further reduce latency for static content delivery
Maintain regulatory compliance.
- Regulatory compliance (HIPAA, HITRUST) can be maintained using data localization, data retention policies, as well as security measures
- Assured Workloads helps configure compliant environments with guardrails
- VPC Service Controls provides data exfiltration protection for sensitive healthcare data
- Cloud Healthcare API provides HIPAA-compliant FHIR, HL7v2, and DICOM data management
Decrease infrastructure administration costs.
- Infrastructure administration costs can be reduced using automation with Terraform or Infrastructure Manager (Google’s managed Terraform service)
- Note: Cloud Deployment Manager reached End of Life on March 31, 2026. Use Terraform or Infrastructure Manager for all new IaC deployments
Make predictions and generate reports on industry trends based on provider data.
- Data can be pushed and analyzed using BigQuery with built-in ML capabilities (BigQuery ML) for predictions
- Vertex AI can be used for advanced ML model training on healthcare data
Technical requirements
Maintain legacy interfaces to insurance providers with connectivity to both on-premises systems and cloud providers.
- Hybrid connectivity can be established using Cloud VPN, Dedicated Interconnect, or Partner Interconnect
- Cross-Cloud Interconnect enables private connectivity to other cloud providers (AWS, Azure) if needed
- Network Connectivity Center provides centralized hub-and-spoke network management for multi-cloud and hybrid environments
Provide a consistent way to manage customer-facing applications that are container-based.
- Container-based applications can be deployed on GKE (Autopilot mode recommended for reduced operational overhead) or Cloud Run for serverless containers
- GKE Enterprise (formerly Anthos) enables consistent multi-cluster management across environments with fleet-level policies
- Cloud Deploy provides managed continuous delivery pipelines for GKE and Cloud Run
Provide a secure and high-performance connection between on-premises systems and Google Cloud.
- Cloud VPN (HA VPN), Dedicated Interconnect, or Partner Interconnect connections can be established between on-premises and Google Cloud
- Dedicated Interconnect provides 10/100 Gbps connections with 99.99% SLA when configured with recommended topology
Provide consistent logging, log retention, monitoring, and alerting capabilities.
- Cloud Monitoring and Cloud Logging (part of Google Cloud Observability) provide a single pane of glass for monitoring, logging, and alerting
- Managed Service for Prometheus enables Kubernetes-native monitoring with PromQL
- OpenTelemetry Protocol (OTLP) support (2025) enables standardized telemetry collection
Maintain and manage multiple container-based environments.
- Use Terraform or Infrastructure Manager to provide consistent implementations across environments
- GKE Enterprise fleet management enables centralized policy and configuration across multiple GKE clusters
- Cloud Service Mesh (replaced Anthos Service Mesh, GA June 2024) provides traffic management, security, and observability across microservices
Dynamically scale and provision new environments.
- GKE Autopilot automatically provisions and scales nodes based on workload demands (recommended mode for new clusters)
- GKE Standard clusters can use Cluster Autoscaler and HPA/VPA for deployments
- Cloud Run provides automatic scaling from zero to thousands of instances
Create interfaces to ingest and process data from new providers.
- Cloud Healthcare API provides FHIR R4, HL7v2, and DICOM interfaces for healthcare data ingestion and exchange
- Pub/Sub enables real-time streaming data ingestion from multiple providers
- Dataflow provides serverless stream and batch data processing pipelines
Key Google Cloud Services for EHR Healthcare
| Requirement | Google Cloud Service |
|---|---|
| Container Orchestration | GKE (Autopilot mode), Cloud Run |
| Multi-cluster Management | GKE Enterprise (fleet management) |
| Hybrid Connectivity | Cloud VPN (HA), Dedicated/Partner Interconnect |
| Infrastructure as Code | Terraform, Infrastructure Manager |
| Observability | Cloud Monitoring, Cloud Logging, Cloud Trace |
| Data Analytics | BigQuery, Data Studio, BigQuery ML |
| Healthcare Data | Cloud Healthcare API (FHIR, HL7v2, DICOM) |
| Service Mesh | Cloud Service Mesh |
| CI/CD | Cloud Build, Cloud Deploy |
| Compliance | Assured Workloads, VPC Service Controls |
| Relational Databases | Cloud SQL (MySQL, SQL Server), AlloyDB |
| NoSQL Databases | Memorystore (Redis), MongoDB Atlas on GCP |
| Identity Management | Cloud Identity, Google Cloud Directory Sync (for AD) |
GCP Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- For this question, refer to the EHR Healthcare case study. In the past, configuration errors put IP addresses on backend servers that should not have been accessible from the internet. You need to ensure that no one can put external IP addresses on backend Compute Engine instances and that external IP addresses can only be configured on the front end Compute Engine instances. What should you do?
- Create an organizational policy with a constraint to allow external IP addresses on the front end Compute Engine instances
- Revoke the
compute.networkadminrole from all users in the project with front end instances - Create an Identity and Access Management (IAM) policy that maps the IT staff to the
compute.networkadminrole for the organization - Create a custom Identity and Access Management (IAM) role named GCE_FRONTEND with the
compute.addresses.createpermission
Explanation: The
constraints/compute.vmExternalIpAccessorganization policy constraint controls which VM instances can have external IP addresses. By configuring this constraint at the organization or project level and specifying only the front-end instances, you prevent backend instances from being assigned external IPs while allowing them on designated front-end instances. - For this question, refer to the EHR Healthcare case study. EHR Healthcare needs to ensure consistent environments across development, staging, and production while reducing provisioning errors. Their infrastructure team currently uses manual processes. What should you recommend?
- Use Cloud Console to manually configure all environments and document the steps
- Create custom scripts using gcloud CLI to provision resources
- Use Terraform with Infrastructure Manager to define infrastructure as code and automate deployments across all environments
- Use Cloud Deployment Manager templates to provision all environments
Explanation: Terraform with Infrastructure Manager (Google’s managed Terraform service) provides a declarative, version-controlled approach to infrastructure provisioning. Cloud Deployment Manager was deprecated and reached End of Life on March 31, 2026. Infrastructure Manager enables plan/apply workflows with built-in IAM, logging, and governance.
- For this question, refer to the EHR Healthcare case study. EHR Healthcare wants centralized visibility and proactive alerting for their containerized applications running on GKE. They want to consolidate their current fragmented monitoring tools. What should you recommend?
- Deploy Prometheus and Grafana on each GKE cluster independently
- Use Google Cloud Observability with Cloud Monitoring, Cloud Logging, and Managed Service for Prometheus for unified observability across all clusters
- Use a third-party monitoring solution deployed in a separate project
- Configure email alerts from each application individually
Explanation: Google Cloud Observability (Cloud Monitoring + Cloud Logging + Cloud Trace + Managed Service for Prometheus) provides a unified, fully managed observability platform. Managed Service for Prometheus allows teams familiar with Prometheus to continue using PromQL while benefiting from global, managed storage and querying.
- For this question, refer to the EHR Healthcare case study. EHR Healthcare needs to manage multiple containerized environments consistently while ensuring security best practices. They want to reduce the operational overhead of managing Kubernetes clusters. What is the recommended approach?
- Deploy all workloads on Compute Engine instances with Docker
- Use GKE Standard mode with manual node pool management in each environment
- Use GKE Autopilot mode with GKE Enterprise fleet management for centralized policy and configuration across environments
- Deploy each application as a separate Cloud Run service without orchestration
Explanation: GKE Autopilot mode provides a fully managed Kubernetes experience where Google manages nodes, scaling, and security hardening. GKE Enterprise fleet management enables centralized governance with fleet-level policies, Config Sync for GitOps, and Policy Controller for guardrails across multiple clusters and environments.
- For this question, refer to the EHR Healthcare case study. EHR Healthcare needs to maintain connectivity between their legacy on-premises insurance provider integrations and their new Google Cloud environment with high bandwidth and low latency. What should you recommend?
- Set up a standard VPN tunnel between on-premises and Google Cloud
- Use Dedicated Interconnect with redundant connections for high-bandwidth, low-latency, SLA-backed connectivity
- Use public internet with SSL/TLS encryption for all communications
- Migrate all legacy systems to Google Cloud immediately
Explanation: Dedicated Interconnect provides 10/100 Gbps private connections between on-premises networks and Google Cloud with up to 99.99% SLA when configured with recommended redundant topology. The case study specifies legacy systems cannot be migrated immediately and require high-performance connectivity.