TerramEarth manufactures heavy equipment for the mining and agricultural industries. They currently have over 500 dealers and service centers in 100 countries. Their mission is to build products that make their customers more productive.
Key points here are 500 dealers and service centers are spread across the world and they want to make their customers more productive.
Solution Concept
There are 2 million TerramEarth vehicles in operation currently, and we see 20% yearly growth. Vehicles collect telemetry data from many sensors during operation. A small subset of critical data is transmitted from the vehicles in real time to facilitate fleet management. The rest of the sensor data is collected, compressed, and uploaded daily when the vehicles return to home base. Each vehicle usually generates 200 to 500 megabytes of data per day
Key points here are TerramEarth has 2 million vehicles. Only critical data is transferred in real-time while the rest of the data is uploaded in bulk daily.
Executive Statement
Our competitive advantage has always been our focus on the customer, with our ability to provide excellent customer service and minimize vehicle downtimes. After moving multiple systems into Google Cloud, we are seeking new ways to provide best-in-class online fleet management services to our customers and improve operations of our dealerships. Our 5-year strategic plan is to create a partner ecosystem of new products by enabling access to our data, increasing autonomous operation capabilities of our vehicles, and creating a path to move the remaining legacy systems to the cloud.
Key point here is the company wants to improve further in operations, customer experience, and partner ecosystem by allowing them to reuse the data.
Existing Technical Environment
TerramEarth’s vehicle data aggregation and analysis infrastructure resides in Google Cloud and serves clients from all around the world. A growing amount of sensor data is captured from their two main manufacturing plants and sent to private data centers that contain their legacy inventory and logistics management systems. The private data centers have multiple network interconnects configured to Google Cloud.
The web frontend for dealers and customers is running in Google Cloud and allows access to stock management and analytics.
Key point here is the company is hosting its infrastructure in Google Cloud and private data centers. GCP has web frontend and vehicle data aggregation & analysis. Data is sent to private data centers.
Business Requirements
Predict and detect vehicle malfunction and rapidly ship parts to dealerships for just-in-time repair where possible.
-
⚠️ Note: Cloud IoT Core was shut down on August 16, 2023. For IoT device connectivity, Google Cloud now recommends a Pub/Sub-based architecture with a standalone MQTT broker (e.g., EMQX, HiveMQ, or ClearBlade IoT Core) for device management and ingestion. The downstream pipeline (Pub/Sub → Dataflow → BigQuery) remains the same.
- A Pub/Sub-based device messaging architecture with a third-party MQTT broker can provide secure device connectivity, management, and data ingestion from globally dispersed vehicles.
- Existing legacy inventory and logistics management systems running in the private data centers can be migrated to Google Cloud.
- Existing data can be migrated one time using Transfer Appliance.
Decrease cloud operational costs and adapt to seasonality.
-
- Google Cloud provides configuring elasticity and scalability for resources based on the demand.
Increase speed and reliability of development workflow.
-
- Google Cloud CI/CD tools like Cloud Build and Cloud Deploy can be used to increase the speed and reliability of the deployments. Cloud Deploy is a fully managed continuous delivery service for GKE and Cloud Run.
Allow remote developers to be productive without compromising code or data security.
- Cloud Run functions (formerly Cloud Functions) supports function-to-function authentication for secure internal communication.
Create a flexible and scalable platform for developers to create custom API services for dealers and partners.
- Google Cloud provides multiple fully managed serverless and scalable application hosting solutions like Cloud Run and Cloud Run functions (formerly Cloud Functions). Cloud Run now supports GPU workloads, worker pools, and deploying via Compose files.
- Managed Instance group with Compute Engines and GKE cluster with scaling can also be used to provide scalable, highly available compute services.
Technical Requirements
Create a new abstraction layer for HTTP API access to their legacy systems to enable a gradual move into the cloud without disrupting operations.
-
- Google Cloud API Gateway & Cloud Endpoints can be used to provide an abstraction layer to expose the data externally over a variety of backends. Cloud Endpoints now supports OpenAPI 3.0 specifications.
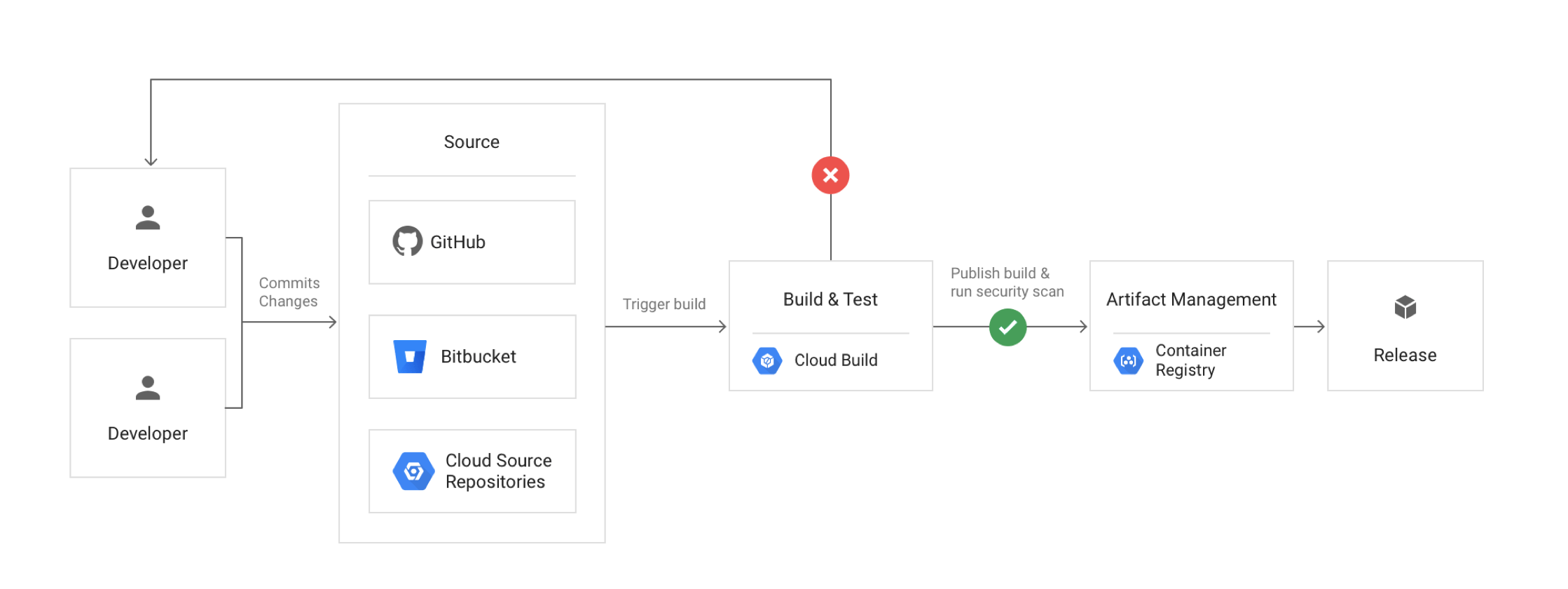
Modernize all CI/CD pipelines to allow developers to deploy container-based workloads in highly scalable environments.
-
- Google Cloud provides DevOps tools like Cloud Build and Cloud Deploy (fully managed continuous delivery) to provide CI/CD features. Spinnaker remains supported as an open-source option for multi-cloud deployments.
-
⚠️ Update: Cloud Source Repositories reached end-of-sale on June 17, 2024 and is no longer available to new customers. Secure Source Manager is the recommended replacement — a regionally deployed, single-tenant managed source code repository on Google Cloud.
- Cloud Build is a fully-managed, serverless service that executes builds on Google Cloud’s infrastructure.
-
⚠️ Update: Container Registry was shut down on March 18, 2025. Artifact Registry is the required replacement, supporting both container images and non-container artifacts (Maven, npm, Python, etc.).
- Artifact Registry is the single artifact management service for container images, language packages, and OS packages on Google Cloud.
- Cloud Deploy is a fully managed continuous delivery service that automates delivery to GKE and Cloud Run with promotion sequences, deploy policies, canary deployments, and automated rollbacks.
Allow developers to run experiments without compromising security and governance requirements
-
- Google Cloud Deploy supports canary deployments and automated rollbacks. Cloud Run provides traffic splitting for A/B testing and gradual rollouts.
Create a self-service portal for internal and partner developers to create new projects, request resources for data analytics jobs, and centrally manage access to the API endpoints.
Use cloud-native solutions for keys and secrets management and optimize for identity-based access
-
- Google Cloud supports Cloud Key Management Service (Cloud KMS) and Secret Manager for managing secrets and key management. Cloud KMS now supports quantum-safe key encapsulation mechanisms, and Secret Manager supports integrated secret synchronization with GKE clusters.
Improve and standardize tools necessary for application and network monitoring and troubleshooting.
-
- Google Cloud provides Cloud Operations Suite (Google Cloud Observability) which includes Cloud Monitoring and Logging to cover both on-premises and Cloud resources.
- Cloud Monitoring collects measurements of key aspects of the service and of the Google Cloud resources used. It now integrates with App Hub for Application Monitoring dashboards with trace span visibility.
- Cloud Monitoring Uptime check is a request sent to a publicly accessible IP address on a resource to see whether it responds.
- Cloud Logging is a service for storing, viewing, and interacting with logs.
- Error Reporting aggregates and displays errors produced in the running cloud services.
- Cloud Profiler helps with continuous CPU, heap, and other parameters profiling to improve performance and reduce costs.
- Cloud Trace is a distributed tracing system that collects latency data from the applications and displays it in the Google Cloud Console.
-
⚠️ Update: Cloud Debugger was shut down on May 31, 2023. For production debugging capabilities, use Snapshot Debugger (open-source) or Cloud Logging and Cloud Trace for troubleshooting.
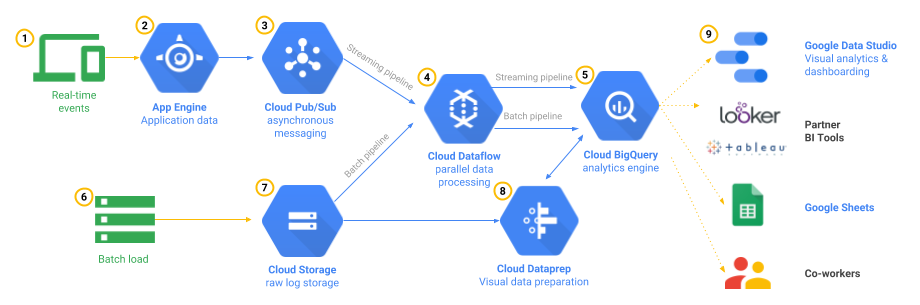
Reference Cellular Upload Architecture

Batch Upload Replacement Architecture

Key Updates for Certification Exam (2024-2026)
The TerramEarth case study remains part of the Professional Cloud Architect certification exam. When answering exam questions related to this case study, keep the following service changes in mind:
- IoT Device Connectivity: Cloud IoT Core is no longer available. Use Pub/Sub with a standalone MQTT broker for device telemetry ingestion.
- CI/CD Pipeline: Cloud Deploy is the preferred managed CD solution. Container Registry has been replaced by Artifact Registry. Cloud Source Repositories is replaced by Secure Source Manager.
- Serverless: Cloud Functions is now Cloud Run functions, unified under the Cloud Run platform.
- Observability: Cloud Debugger is no longer available. Use Cloud Trace, Cloud Logging, and Snapshot Debugger instead.
- Security: Cloud KMS now supports quantum-safe encryption. Secret Manager supports GKE secret synchronization.
Reference
- Google Cloud – Professional Cloud Architect Exam Guide
- Google Cloud – Migrate environments from IoT Core
- Google Cloud – Transition from Container Registry to Artifact Registry
- Google Cloud – Cloud Deploy
- Google Cloud – Cloud Functions is now Cloud Run functions