GCP Storage Options
GCP provides various storage options and the selection can be based on
- Structured vs Unstructured
- Relational (SQL) vs Non-Relational (NoSQL)
- Transactional (OLTP) vs Analytical (OLAP)
- Fully Managed vs Requires Provisioning
- Global vs Regional
- Horizontal vs Vertical scaling
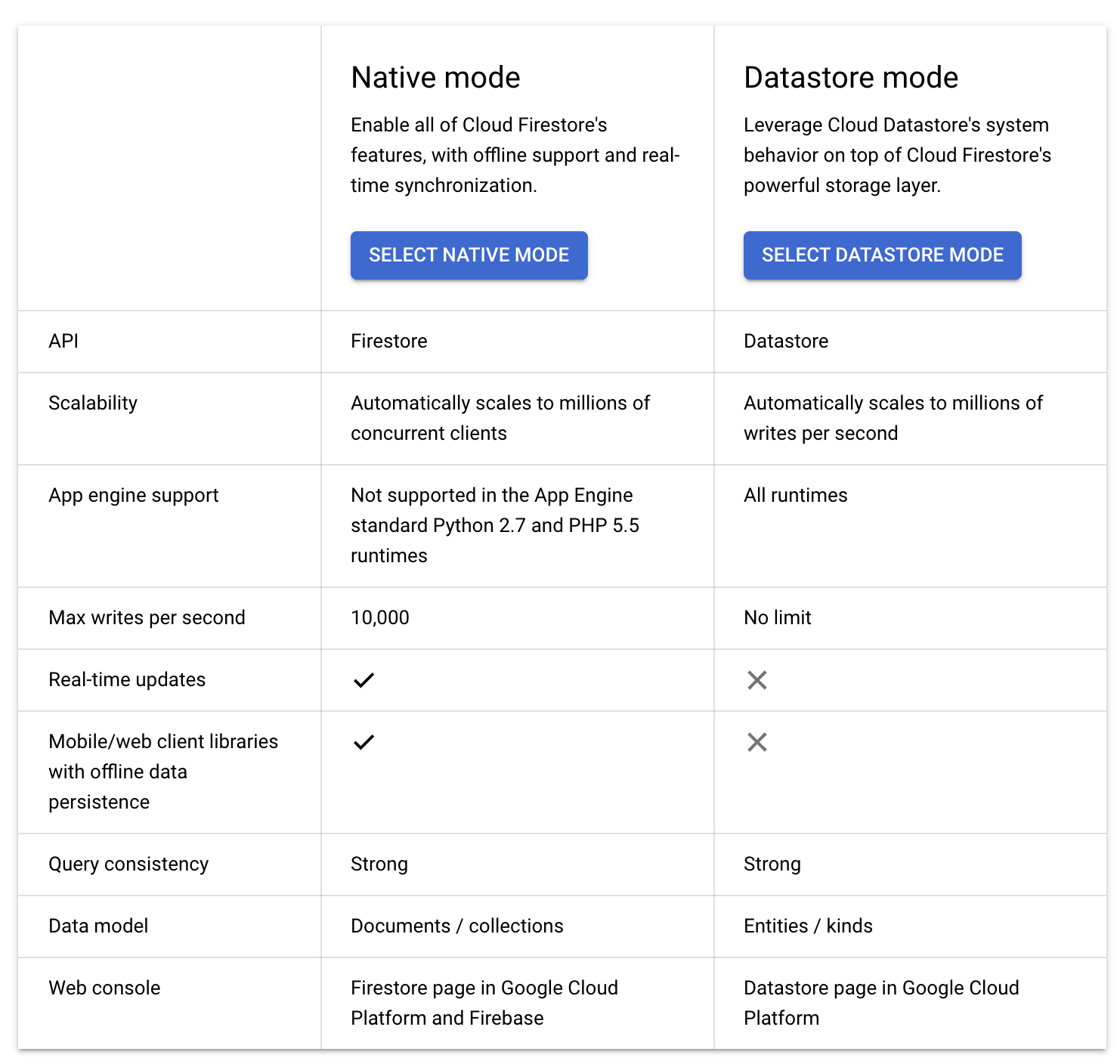
- Cloud Firestore is a fully managed, highly scalable, serverless, non-relational NoSQL document database
- fully managed with no-ops and no planned downtime and no need to provision database instances (vs Bigtable)
- uses a distributed architecture to automatically manage scaling.
- queries scale with the size of the result set, not the size of the data set
- supports ACID Atomic transactions – all or nothing (vs Bigtable)
- provides High availability of reads and writes – runs in Google data centers, which use redundancy to minimize impact from points of failure.
- provides massive scalability with high performance – uses a distributed architecture to automatically manage scaling.
- scales from zero to terabytes with flexible storage and querying of data
- provides SQL-like query language
- supports strong consistency
- supports data encryption at rest and in transit
- provides terabytes of capacity with a maximum unit size of 1 MB per entity (vs Bigtable)
- Firestore Editions (2025)
- Standard edition – core Firestore capabilities with standard querying support
- Enterprise edition – provides MongoDB API compatibility, a new pipeline query engine with 200+ query operations, additional data types, new index types, and text/geospatial search
- Enterprise Edition Features
- MongoDB Compatibility (GA Aug 2025) – use existing MongoDB application code, drivers, and tools as a drop-in replacement while getting Firestore’s auto-scaling and high availability
- Pipeline Query Engine – supports 200+ new query capabilities (pipeline operations) for complex queries directly within the database
- Text Search and Geospatial Search – native full-text and geospatial query support without external services
- Maximum document size increased to 16 MiB (Enterprise edition)
- Indexes are not required for queries in Enterprise edition
- Consider using Cloud Firestore if you need to store semi-structured objects, or if require support for transactions and SQL-like queries.
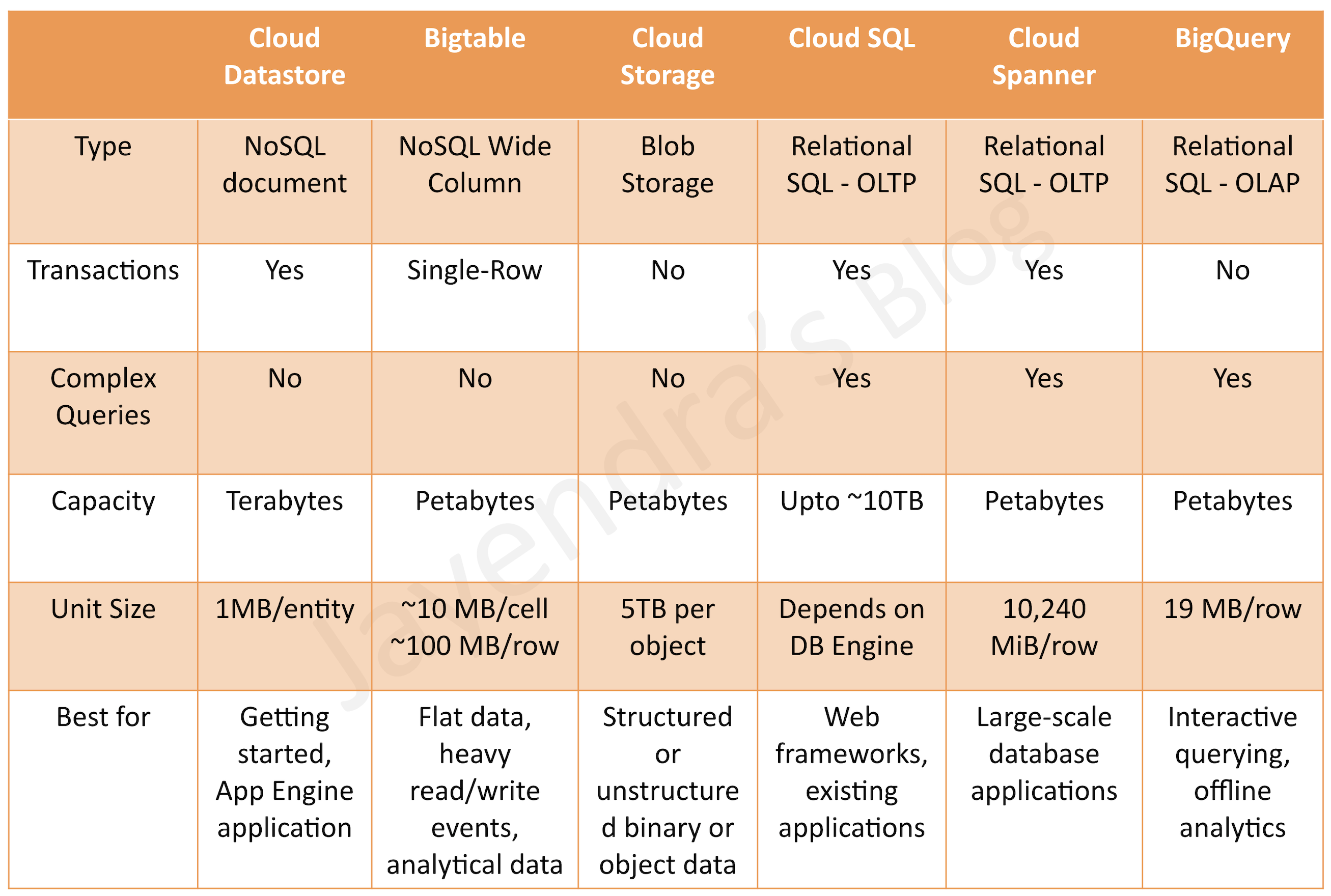
- Bigtable provides a scalable, fully managed, non-relational NoSQL wide-column analytical big data database service suitable for both low-latency single-point lookups and precalculated analytics.
- supports large quantities (>1 TB) of semi-structured or structured data (vs Datastore)
- supports high throughput or rapidly changing data (vs BigQuery)
- managed, but needs provisioning of nodes and can be expensive (vs Datastore and BigQuery)
- does not support transactions or strong relational semantics (vs Datastore)
- Now supports GoogleSQL queries (GA 2024) – familiar SQL syntax for querying Bigtable data directly
- Not Transactional and does not support ACID
- provides eventual consistency
- ideal for time-series or natural semantic ordering data
- can run asynchronous batch or real-time processing on the data
- can run machine learning algorithms on the data
- provides petabytes of capacity with a maximum unit size of 10 MB per cell and 100 MB per row.
- Bigtable Editions (GA April 2026)
- Enterprise edition – advanced features in performance, analytic query capability, and resource management
- Enterprise Plus edition – includes in-memory tier with sub-millisecond latency and hotspot resistance supporting up to 120,000 queries per second on a single row
- New Features (2024-2026)
- Bigtable SQL (GoogleSQL) – query data using familiar SQL syntax with specialized features preserving flexible schema
- Data Boost – serverless analytical queries without impacting operational workloads
- Incremental Materialized Views – simplify creation of real-time metrics
- Window Functions (GA April 2026) – advanced analytic operations over multiple table rows
- KNN Vector Search – K nearest neighbors similarity search for AI/ML use cases
- Distributed Counting – instant metric retrieval for real-time dashboards
- In-Memory Tier – hotspot resistance with sub-millisecond latency
- Agent Skills (April 2026) – let AI agents assist with schema design, SQL queries, and infrastructure management
- Usage Patterns
- Low-latency read/write access
- High-throughput data processing
- Time series support
- Anti Patterns
- Not an ideal storage option for future analysis – Use BigQuery instead
- Not an ideal storage option for transactional data – Use relational database or Datastore
- Common Use cases
- IoT, finance, adtech
- Personalization, recommendations
- Monitoring
- Geospatial datasets
- Graphs
- Real-time AI/ML inference and vector search
- Consider using Cloud Bigtable, if you need high-performance datastore to perform analytics on a large number of structured objects
- Cloud Storage provides durable and highly available object storage.
- fully managed, simple administration, cost-effective, and scalable service that does not require capacity management
- supports unstructured data storage like binary or raw objects
- provides high performance, internet-scale
- supports data encryption at rest and in transit
- provides 99.999999999% (11 nines) annual durability
- Storage Classes: Standard, Nearline (30-day min), Coldline (90-day min), Archive (365-day min)
- Autoclass – automatically transitions objects to appropriate storage classes based on access patterns
- New Features (2024-2026)
- Cloud Storage Rapid (2025-2026) – high-performance storage tier for AI/ML workloads
- Rapid Bucket (formerly Rapid Storage) – zonal object storage with <1ms random read/write latency, 6 TB/s throughput
- Rapid Cache (formerly Anywhere Cache) – accelerates reads and colocates compute with data, up to 20 Tbps throughput
- Smart Storage – automated metadata annotation for unstructured data with AI agent connectivity via MCP
- Storage Intelligence – zero-configuration dashboards, aggregated activity views, and enhanced batch operations
- Bucket Relocation – move buckets between regions with minimal downtime
- Batch Operations Dry Run Mode – simulate batch jobs without modifying data
- Consider using Cloud Storage, if you need to store immutable blobs larger than 10 MB, such as large images or movies. This storage service provides petabytes of capacity with a maximum unit size of 5 TB per object.
- Usage Patterns
- Images, pictures, and videos
- Objects and blobs
- Unstructured data
- Long term storage for archival or compliance
- AI/ML training data and model checkpoints
- Anti Patterns
- Not ideal for structured/relational data
- Not ideal for frequently changing data requiring low-latency updates
- Common Use cases
- Storing and streaming multimedia
- Storage for custom data analytics pipelines
- Archive, backup, and disaster recovery
- AI/ML training datasets and model serving
- provides fully managed, relational SQL databases
- offers MySQL, PostgreSQL, and SQL Server databases as a service
- manages OS & Software installation, patches and updates, backups and configuring replications, failover however needs to select and provision machines (vs Cloud Spanner)
- single region only – although it now supports cross-region read replicas (vs Cloud Spanner)
- Cloud SQL Editions
- Enterprise edition – core capabilities, suitable for applications with less stringent availability/performance requirements. Up to 96 vCPU, 624 GB RAM.
- Enterprise Plus edition – highest performance with optimized software/hardware stack. Up to 128 vCPU, 864 GB RAM. Includes data cache, up to 35-day point-in-time log retention, sub-second maintenance downtime, and advanced disaster recovery.
- Scaling
- provides vertical scalability (Max. storage of 64 TB)
- storage can be increased without incurring any downtime
- provides an option to increase the storage automatically
- storage CANNOT be decreased
- supports Horizontal scaling for read-only using read replicas (vs Cloud Spanner)
- performance is linked to the disk size
- Security
- data is encrypted when stored in database tables, temporary files, and backups.
- external connections can be encrypted by using SSL, or by using the Cloud SQL Proxy.
- Private Service Connect (PSC) support for simplified private connectivity
- High Availability
- fault-tolerance across zones can be achieved by configuring the instance for high availability by adding a failover replica
- failover is automatic
- can be created from primary instance only
- replication from the primary instance to failover replica is semi-synchronous.
- failover replica must be in the same region as the primary instance, but in a different zone
- only one instance for every primary instance allowed
- supports managed backups and backups are created on primary instance only
- supports automatic replication
- Enterprise Plus: sub-second maintenance downtime (vs up to 120 seconds for Enterprise)
- Backups
- Automated backups can be configured and are stored for 7 days
- Manual backups (snapshots) can be created and are not deleted automatically
- Fast Clone (GA) – clone operations within the same zone for rapid environment creation
- Point-in-time recovery
- requires binary logging enabled.
- every update to the database is written to an independent log, which involves a small reduction in write performance.
- performance of the read operations is unaffected by binary logging, regardless of the size of the binary log files.
- Enterprise Plus: up to 35-day log retention (vs 7 days for Enterprise)
- Usage Patterns
- direct lift and shift for MySQL, PostgreSQL, SQL Server database only
- relational database service with strong consistency
- OLTP workloads
- Anti Patterns
- need data storage more than 64 TB or horizontal write scaling, use Cloud Spanner
- need global availability with low latency, use Cloud Spanner
- not a direct replacement for Oracle – use installation on GCE or consider AlloyDB for PostgreSQL workloads
- Common Use cases
- Websites, blogs, and content management systems (CMS)
- Business intelligence (BI) applications
- ERP, CRM, and eCommerce applications
- Geospatial applications
- Consider using Cloud SQL for full relational SQL support for OLTP and lift and shift of MySQL, PostgreSQL, SQL Server databases
- Cloud Spanner provides fully managed, relational SQL databases with joins and secondary indexes
- provides cross-region, global, horizontal scalability, and availability
- supports strong consistency, including strongly consistent secondary indexes
- provides high availability through synchronous and built-in data replication.
- provides strong global consistency
- supports database sizes exceeding ~2 TB (vs Cloud SQL)
- does not provide direct lift and shift for relational databases (vs Cloud SQL)
- expensive as compared to Cloud SQL
- Multi-Model Database (2024-2025)
- Spanner Graph (GA Jan 2025) – supports industry-standard Graph Query Language (GQL) with full SQL interoperability for querying structured and connected data
- Vector Search – native vector embeddings and similarity search for AI/ML and RAG applications
- Full-Text Search – native text search capabilities without external services
- Hybrid Search – combine vector search, full-text search, and ML model reranking in a unified platform
- Vertex AI Integration – native integration for model serving and inferencing with SQL
- Spanner Omni (2026 Preview)
- Self-managed version of Spanner that runs on-premises, across clouds, or on a laptop
- Brings Spanner’s scalability, high availability, strong consistency, and multi-model capabilities anywhere
- Supports air-gapped or connected deployments, single machine to clusters of thousands
- Tiered Storage (GA) – store data across SSD or HDD tiers for cost optimization
- Consider using Cloud Spanner for full relational SQL support, with horizontal scalability spanning petabytes for OLTP, or as a multi-model database supporting relational, graph, vector, and text search workloads
- provides fully managed, no-ops, OLAP, enterprise data warehouse (EDW) with SQL and fast ad-hoc queries.
- provides high capacity, data warehousing analytics solution
- ideal for big data exploration and processing
- not ideal for operational or transactional databases
- provides SQL interface
- A scalable, fully managed data-to-AI platform
- BigQuery Editions – Standard, Enterprise, and Enterprise Plus with different pricing and feature tiers
- New Features (2024-2026)
- Conversational Analytics (Preview Jan 2026) – analyze data using natural language with AI-powered data agents that understand context and generate SQL
- BigQuery Graph – uncover complex relationships and patterns in data
- Vector Search – embeddings and hybrid search for RAG applications
- BigQuery ML – train and run ML models directly in BigQuery using SQL
- Data Engineering Agent – automates data preparation, error detection, and pipeline building
- Data Science Agent – automates data loading, feature engineering, model training and evaluation
- BigQuery Studio – unified workspace with Gemini-powered assistant for resource discovery and query generation
- MCP Integration – Model Context Protocol for AI agent connectivity
- Usage Patterns
- OLAP workloads up to petabyte-scale
- Big data exploration and processing
- Reporting via business intelligence (BI) tools
- AI/ML model training and inference at scale
- Anti Patterns
- Not an ideal storage option for transactional data or OLTP – Use Cloud SQL or Cloud Spanner instead
- Low-latency read/write access – Use Bigtable instead
- Common Use cases
- Analytical reporting on large data
- Data science and advanced analyses
- Big data processing using SQL
- GenAI and agentic AI applications with data
AlloyDB for PostgreSQL
- AlloyDB is a fully managed, PostgreSQL-compatible database designed for enterprise-grade OLTP and hybrid transactional/analytical (HTAP) workloads
- wire-compatible with PostgreSQL 14 and 15 – existing drivers, ORMs, and most extensions work without modification
- provides up to 4x faster for transactional workloads and up to 100x faster for analytical queries compared to standard PostgreSQL
- uses a scale-out architecture with compute and storage separation
- built-in AI capabilities with Google’s cutting-edge technology
- AlloyDB AI
- Generate vector embeddings from within the database
- Native vector search with up to 10x faster index creation and 4x faster search queries
- Filtered vector search up to 10x faster than standard PostgreSQL HNSW
- Integration with Vertex AI for model serving and inferencing
- AlloyDB AI query engine with Vertex AI Ranking API
- AlloyDB Omni – downloadable version that runs on-premises or in other clouds
- 99.99% availability SLA with automated backups, replication, and failover
- Usage Patterns
- Enterprise PostgreSQL workloads requiring high performance
- HTAP (hybrid transactional/analytical) workloads
- AI-powered applications requiring vector search
- Migration from commercial databases (Oracle, SQL Server) to PostgreSQL
- Anti Patterns
- Need global horizontal scaling – Use Cloud Spanner
- Need non-relational/NoSQL – Use Firestore or Bigtable
- Need MySQL or SQL Server compatibility – Use Cloud SQL
- Consider using AlloyDB for PostgreSQL workloads requiring high performance, AI integration, or migration from commercial databases
Memorystore
- provides scalable, secure, and highly available in-memory service
- fully managed as provisioning, replication, failover, and patching are all automated
- is protected from the internet using VPC networks and private IP and comes with IAM integration
- Supported Engines
- Memorystore for Valkey (GA 2025) – open-source, high-performance key-value store (successor to Redis OSS). Supports Valkey 8.0 and 9.0. 99.99% availability SLA, instances up to 14.5 TB, cross-region replication, Private Service Connect, multi-VPC access.
- Memorystore for Redis Cluster – managed Redis cluster mode with zero-downtime scaling
- Memorystore for Redis – standard Redis instances (standalone and high availability)
- Memorystore for Memcached – distributed in-memory caching
- Valkey 9.0 Features (GA 2026)
- SIMD optimizations for improved throughput and latency
- Enhanced performance over previous versions
- Full compatibility with Redis OSS commands
- Usage Patterns
- Lift and shift migration of applications
- Low latency data caching and retrieval
- Session management
- Real-time leaderboards and counting
- Anti Patterns
- Relational or NoSQL database
- Analytics solution
- Persistent primary data store (use as cache layer)
- Common Use cases
- User session management
- Application caching
- Real-time analytics and pub/sub
- Gaming leaderboards
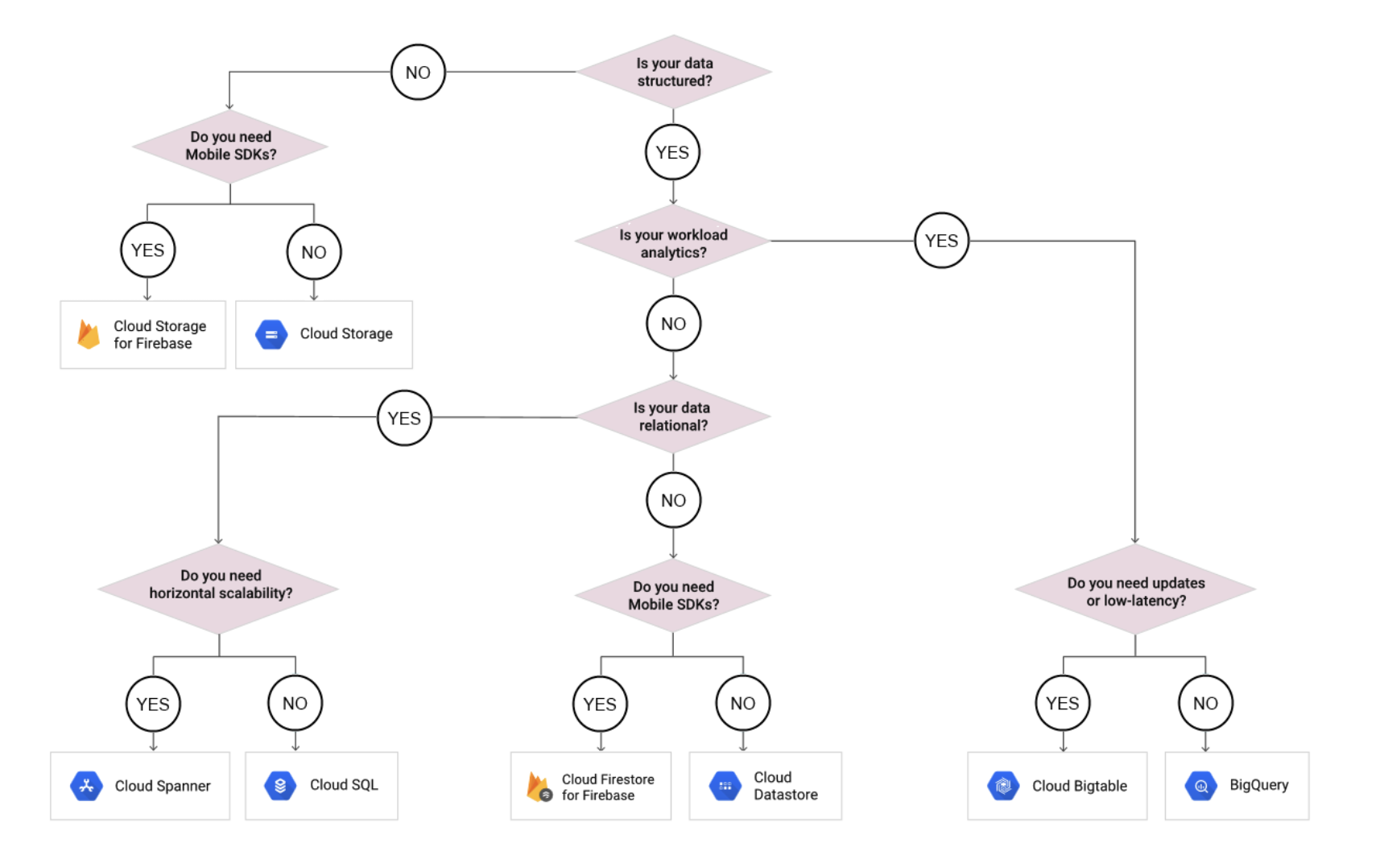
GCP Storage Options Decision Tree
GCP Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- Your application is hosted across multiple regions and consists of both relational database data and static images. Your database has over 10 TB of data. You want to use a single storage repository for each data type across all regions. Which two products would you choose for this task? (Choose two)
- Cloud Bigtable
- Cloud Spanner
- Cloud SQL
- Cloud Storage
- You are building an application that stores relational data from users. Users across the globe will use this application. Your CTO is concerned about the scaling requirements because the size of the user base is unknown. You need to implement a database solution that can scale with your user growth with minimum configuration changes. Which storage solution should you use?
- Cloud SQL
- Cloud Spanner
- Cloud Firestore
- Cloud Datastore
- Your company processes high volumes of IoT data that are time-stamped. The total data volume can be several petabytes. The data needs to be written and changed at a high speed. You want to use the most performant storage option for your data. Which product should you use?
- Cloud Datastore
- Cloud Storage
- Cloud Bigtable
- BigQuery
- Your App Engine application needs to store stateful data in a proper storage service. Your data is non-relational database data. You do not expect the database size to grow beyond 10 GB and you need to have the ability to scale down to zero to avoid unnecessary costs. Which storage service should you use?
- Cloud Bigtable
- Cloud Dataproc
- Cloud SQL
- Cloud Firestore (Datastore mode)
- A financial organization wishes to develop a global application to store transactions happening from different part of the world. The storage system must provide low latency transaction support and horizontal scaling. Which GCP service is appropriate for this use case?
- Bigtable
- Datastore
- Cloud Storage
- Cloud Spanner
- You work for a mid-sized enterprise that needs to move its operational system transaction data from an on-premises database to GCP. The database is about 20 TB in size. Which database should you choose?
- Cloud SQL
- Cloud Bigtable
- Cloud Spanner
- Cloud Datastore
Note: With Cloud SQL now supporting up to 64 TB, Cloud SQL could also be a valid option for 20 TB. However, for operational transactional data requiring high scalability, Cloud Spanner remains the better choice.
- Your team needs a PostgreSQL-compatible database that can handle both transactional and analytical queries with high performance. The application also requires built-in vector search capabilities for an AI-powered recommendation engine. Which GCP service should you choose?
- Cloud SQL for PostgreSQL
- AlloyDB for PostgreSQL
- Cloud Spanner
- BigQuery
- Your company is building a real-time fraud detection system that needs to query relationships between entities (accounts, transactions, merchants) while also performing vector similarity searches on transaction patterns. The system must provide strong consistency and global availability. Which database should you use?
- Cloud Bigtable
- BigQuery
- Cloud Spanner
- Cloud Firestore
- Your organization is migrating from MongoDB to Google Cloud. You want to minimize code changes and use existing MongoDB drivers and tools. The application requires automatic scaling and high availability. Which GCP service should you use?
- Cloud SQL for PostgreSQL
- Cloud Bigtable
- Cloud Firestore (Enterprise edition with MongoDB compatibility)
- AlloyDB for PostgreSQL
- You need a high-performance caching layer for your microservices application on GCP. The solution must support cross-region replication, provide 99.99% availability, and be compatible with open-source tooling. Which service should you choose?
- Memorystore for Redis
- Cloud CDN
- Memorystore for Valkey
- Cloud Firestore
See also: Google Cloud Storage Services Cheat Sheet