Cloud Pub/Sub
- Pub/Sub is a fully managed, asynchronous messaging service designed to be highly reliable and scalable with latencies on the order of 100 ms
- Pub/Sub offers at-least-once message delivery and best-effort ordering to existing subscribers
- Pub/Sub also supports exactly-once delivery (GA since 2022) for pull subscriptions and StreamingPull API, ensuring messages are not redelivered after successful acknowledgment. Push and export subscriptions do not support exactly-once delivery.
- Pub/Sub enables the creation of event producers and consumers, called publishers and subscribers.
- Pub/Sub messages should be no greater than 10MB in size.
- Messages can be received with pull or push delivery.
- Messages published before a subscription is created will not be delivered to that subscription
- Acknowledged messages are no longer available to subscribers and are deleted, by default. However, can be retained setting retention period.
- Publishers can send messages with an ordering key and message ordering is set, Pub/Sub delivers the messages in order.
- Pub/Sub support encryption at rest and encryption in transit.
- Seek feature allows subscribers to alter the acknowledgment state of messages in bulk to replay or purge messages in bulk.
- Supports BigQuery subscriptions to write messages directly to BigQuery tables without additional processing.
- Supports Cloud Storage subscriptions to write messages to Cloud Storage buckets in Avro or Text format.
- Message filtering allows subscribers to receive a subset of messages published to a topic using filter expressions.
- Pub/Sub Lite is deprecated (EOL March 18, 2026). Migrate to standard Pub/Sub for cost-effective messaging.
BigQuery
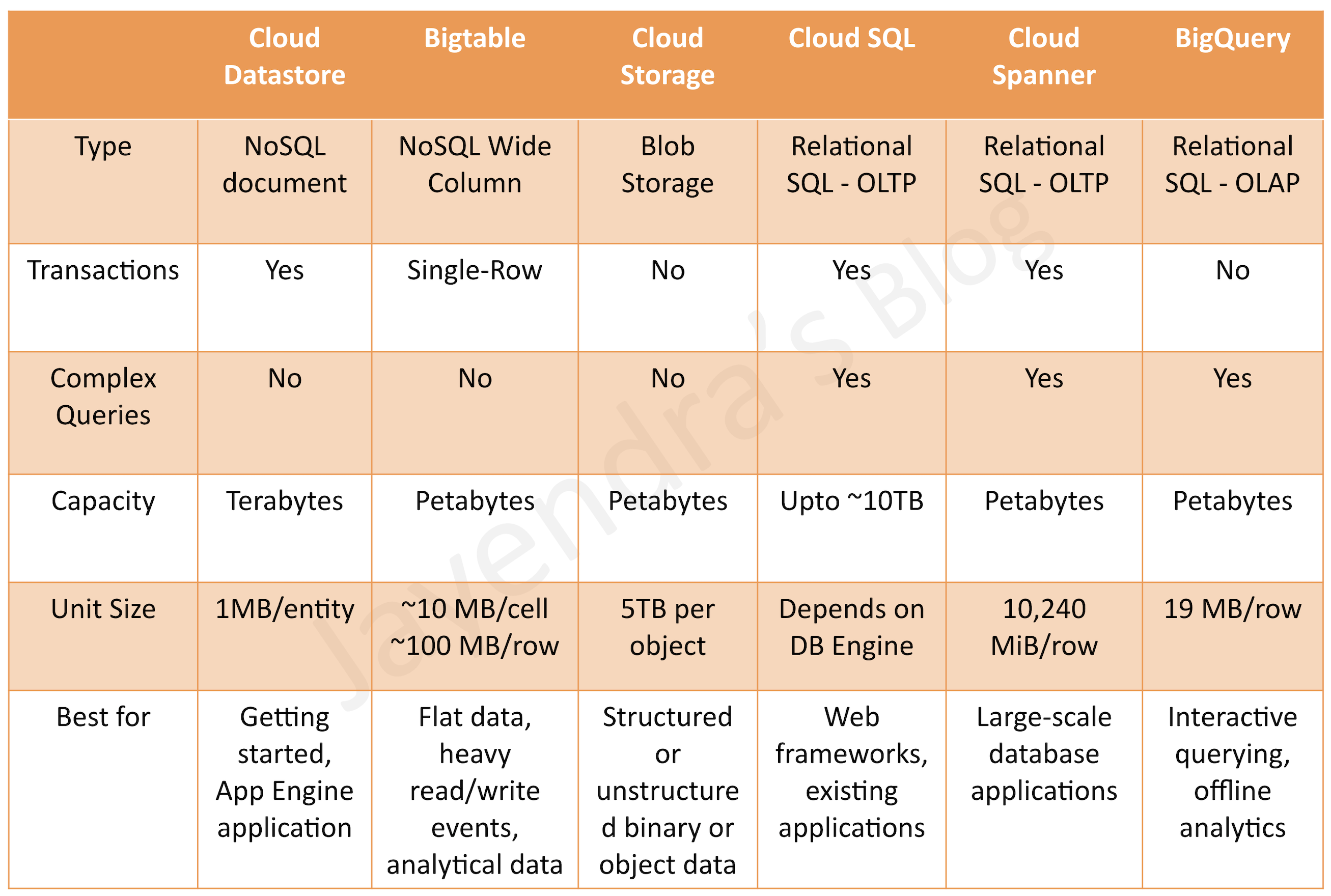
- BigQuery is a fully managed, durable, petabyte scale, serverless, highly scalable, and cost-effective multi-cloud data warehouse that has evolved into an AI data platform.
- supports a standard SQL dialect. Legacy SQL is deprecated — effective June 1, 2026, BigQuery limits legacy SQL use for organizations that have not used it between Nov 2025–Jun 2026.
- automatically replicates data and keeps a seven-day history of changes (time travel), allowing easy restoration and comparison of data from different times
- supports federated data and can process external data sources in GCS for Parquet and ORC open-source file formats, transactional databases (Bigtable, Cloud SQL), or spreadsheets in Drive without moving the data.
- BigLake provides a unified storage engine for data lakehouse workloads, supporting Apache Iceberg tables with fine-grained governance across multiple engines (Spark, Flink, Trino, BigQuery).
- Data model consists of Datasets, tables
- BigQuery performance can be improved using Partitioned tables and Clustered tables.
- BigQuery encrypts all data at rest and supports encryption in transit.
- BigQuery Data Transfer Service automates data movement into BigQuery on a scheduled, managed basis
- BigQuery Editions (Standard, Enterprise, Enterprise Plus) provide different capability tiers with slot-based pricing, autoscaling reservations, and capacity commitments.
- BigQuery Studio provides a unified workspace with SQL editor, notebooks (Colab Enterprise), and data canvas for end-to-end analytics workflows.
- BigQuery ML (BQML) allows building and deploying ML models using SQL, including integration with Gemini and Vertex AI for generative AI tasks like text summarization, sentiment analysis, and embeddings.
- Vector Search enables similarity search using embeddings directly in BigQuery, supporting RAG applications, semantic search, and KNN-based retrieval without needing external vector databases.
- BI Engine provides in-memory caching and vectorized processing for sub-second query response times, accelerating dashboards and visualization tools.
- Best Practices
- Control projection, avoid
select * - Estimate costs as queries are billed according to the number of bytes read and the cost can be estimated using
--dry-runfeature - Use the maximum bytes billed setting to limit query costs.
- Use clustering and partitioning to reduce the amount of data scanned.
- Avoid repeatedly transforming data via SQL queries. Materialize the query results in stages.
- Use streaming inserts only if the data must be immediately available as streaming data is charged.
- Prune partitioned queries, use the
_PARTITIONTIMEpseudo column to filter the partitions. - Denormalize data whenever possible using nested and repeated fields.
- Avoid external data sources, if query performance is a top priority
- Avoid using Javascript user-defined functions
- Optimize Join patterns. Start with the largest table.
- Use the expiration settings to remove unneeded tables and partitions
- Keep the data in BigQuery to take advantage of the long-term storage cost benefits rather than exporting to other storage options.
- Use BigQuery editions with autoscaling for predictable costs and optimal performance.
- Control projection, avoid
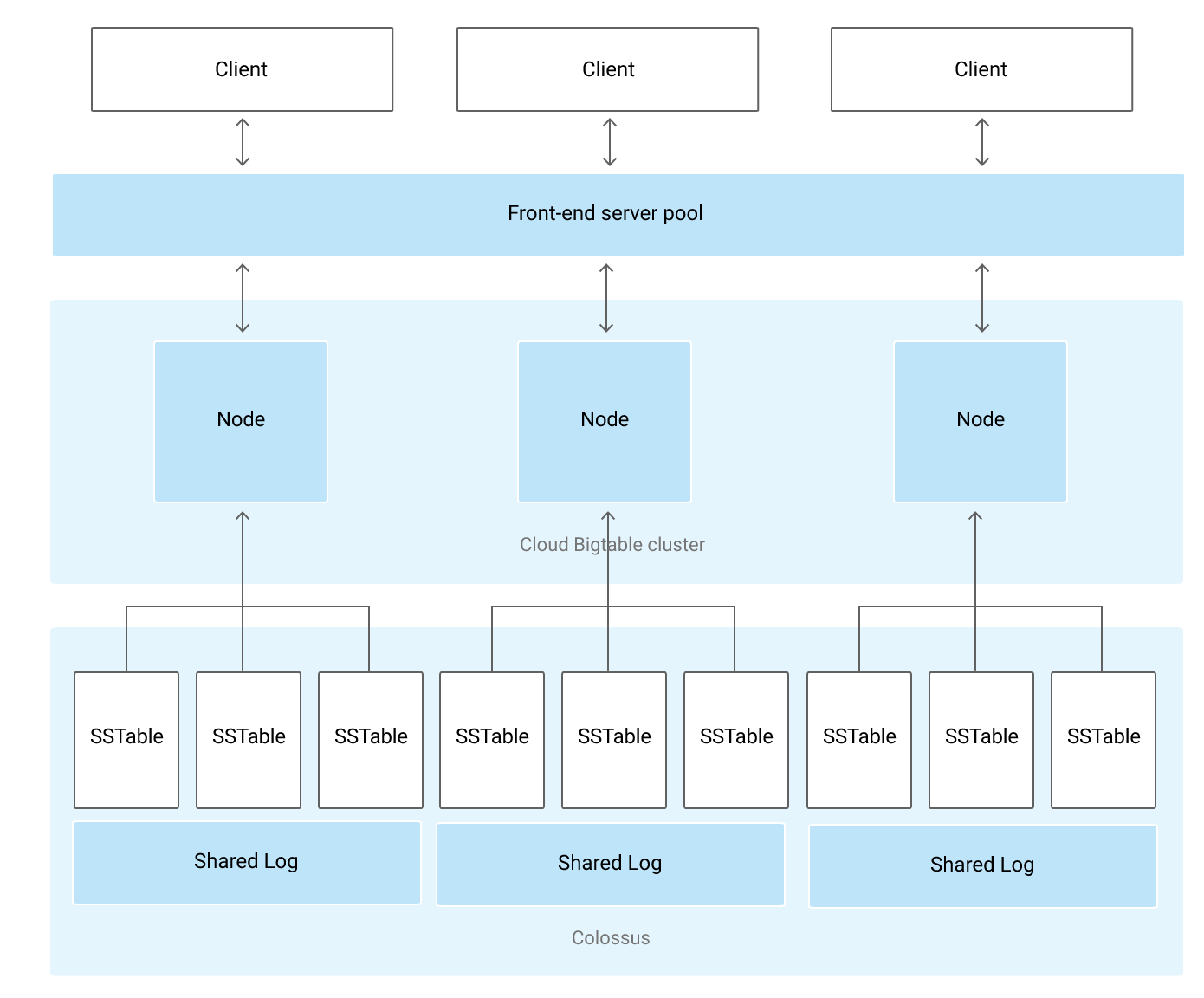
Bigtable
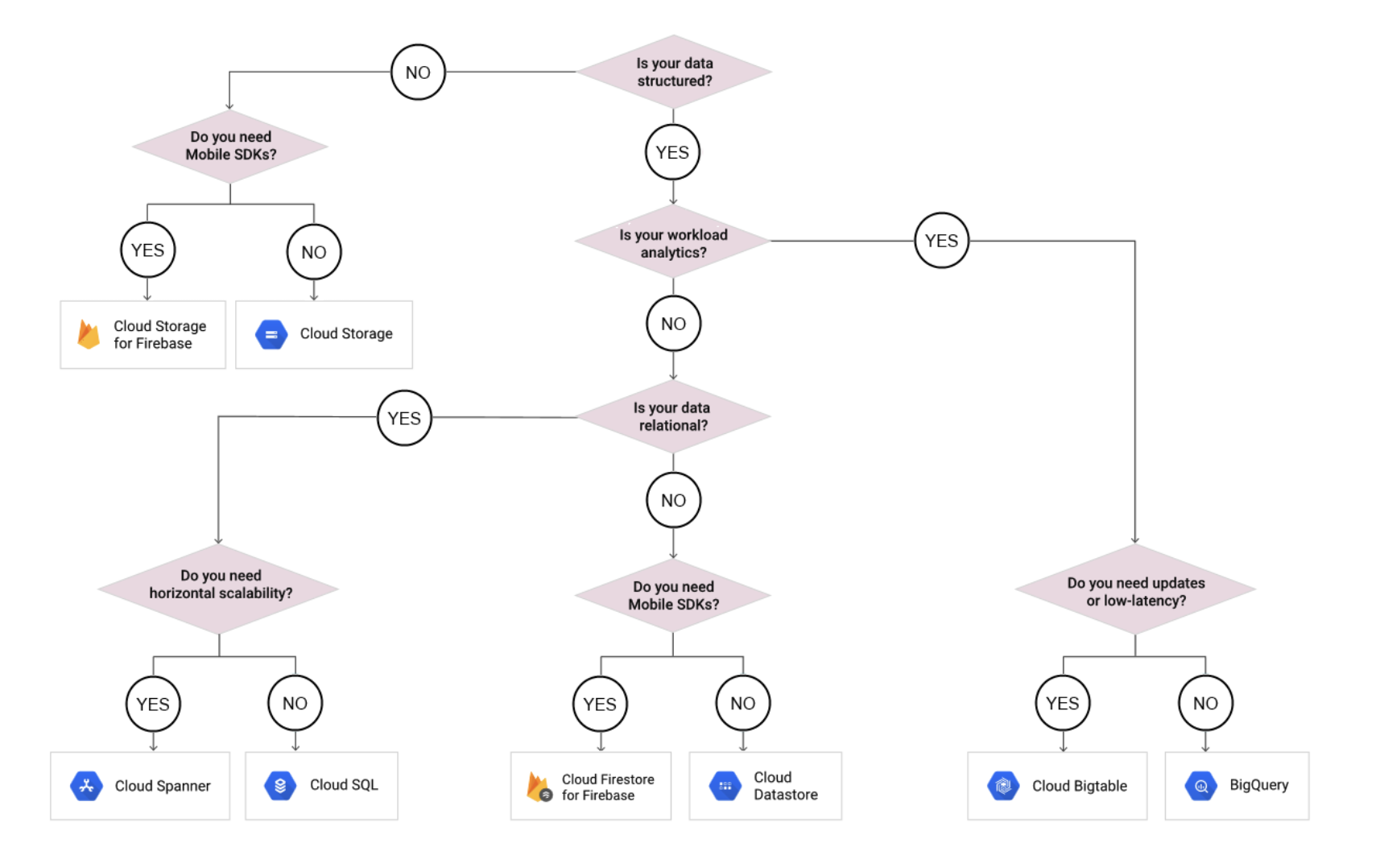
- Bigtable is a fully managed, scalable, wide-column NoSQL database service with up to 99.999% availability.
- ideal for applications that need very high throughput and scalability for key/value data, where each value is max. of 10 MB.
- supports high read and write throughput at low latency and provides consistent sub-10ms latency – handles millions of requests/second
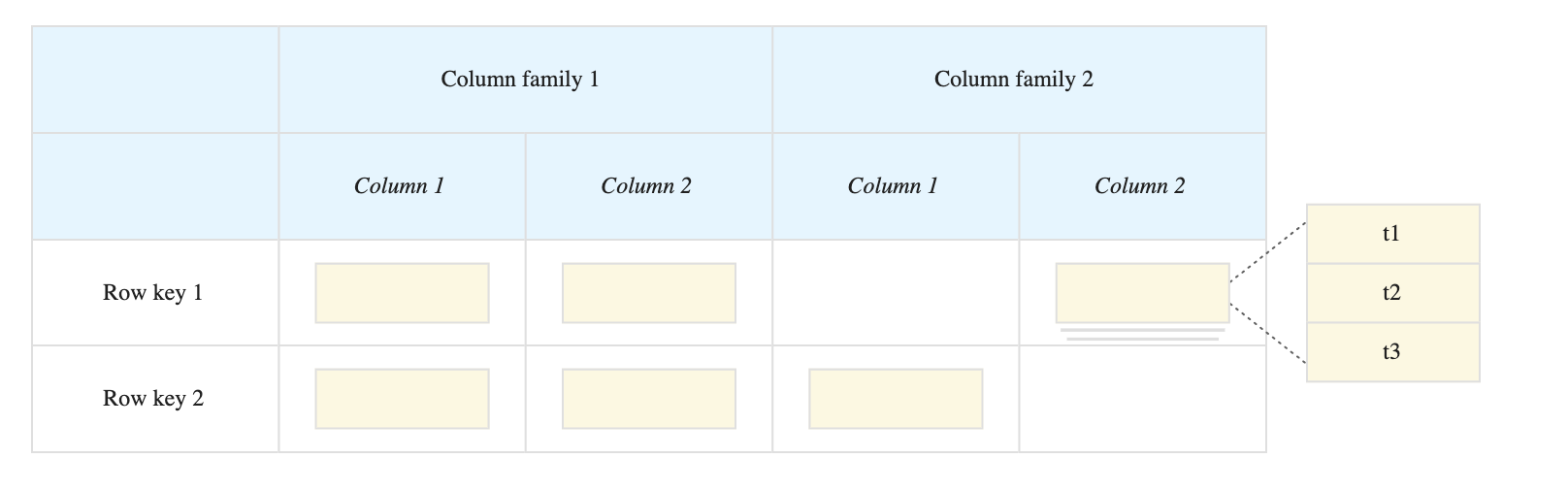
- is a sparsely populated table that can scale to billions of rows and thousands of columns,
- supports storage of terabytes or even petabytes of data
- is not a relational database. It does not support joins or multi-row transactions.
- Now supports GoogleSQL for querying data, including window functions for advanced analytic operations (GA 2026).
- handles upgrades and restarts transparently, and it automatically maintains high data durability.
- scales linearly in direct proportion to the number of nodes in the cluster
- stores data in tables, which is composed of rows, each of which typically describes a single entity, and columns, which contain individual values for each row.
- Each table has only one index, the row key. There are no secondary indices. Each row key must be unique.
- Single-cluster Bigtable instances provide strong consistency.
- Multi-cluster instances, by default, provide eventual consistency but can be configured to provide read-over-write consistency or strong consistency, depending on the workload and app profile settings
- Bigtable Editions (Enterprise and Enterprise Plus) provide advanced features for performance, analytic query capabilities, and resource management (GA 2026).
- Data Boost provides serverless compute for analytical queries without impacting operational workloads, eliminating the need for multiple data copies.
- In-memory tier delivers hotspot resistance supporting up to 120,000 queries per second on a single row for ultra-low latency use cases.
Cloud Dataflow
- Cloud Dataflow is a managed, serverless service for unified stream and batch data processing requirements
- provides Horizontal autoscaling to automatically choose the appropriate number of worker instances required to run the job.
- is based on Apache Beam, an open-source, unified model for defining both batch and streaming-data parallel-processing pipelines.
- supports Windowing which enables grouping operations over unbounded collections by dividing the collection into windows of finite collections according to the timestamps of the individual elements.
- supports drain feature to deploy incompatible updates
- Runner v2 supports cross-language transforms, allowing use of Java transforms from Python pipelines and vice versa.
- Dataflow Prime provides advanced features including Job Visualizer, Smart Recommendations, vertical autoscaling, and right-fitting for optimal resource utilization.
- GPU and TPU support (TPU V5E, V5P, V6E) enables running high-volume, low-latency ML inference workloads directly within Dataflow jobs.
- Global Compute enables enormous scaling by dynamically scheduling workloads across Google’s global infrastructure, automatically determining optimal locations based on data locality and resource availability.
- Speculative Execution for batch pipelines mitigates the impact of slow-running tasks (stragglers) by launching redundant executions.
- Scales to 4,000 workers per job and routinely processes petabytes of data.
- Dataflow SQL was deprecated (July 31, 2024) and is no longer available in Google Cloud CLI as of January 31, 2025.
Managed Service for Apache Spark (formerly Cloud Dataproc)
- Note: Cloud Dataproc has been rebranded to Managed Service for Apache Spark (2025), consolidating Dataproc on Compute Engine and Google Cloud Serverless for Apache Spark under a unified brand.
- Managed Service for Apache Spark is a managed Spark and Hadoop service to take advantage of open-source data tools for batch processing, querying, streaming, and machine learning.
- helps to create clusters quickly, manage them easily, and save money by turning clusters on and off as needed.
- helps reduce time and money spent on administration and lets you focus on your jobs and your data.
- has built-in integration with other GCP services, such as BigQuery, Cloud Storage, Bigtable, Cloud Logging, and Monitoring
- support preemptible instances (now called Spot VMs) that have lower compute prices to reduce costs further.
- also supports HBase, Flink, Hive WebHcat, Druid, Jupyter, Presto, Solr, Zeppelin, Ranger, Zookeeper, and much more.
- supports connectors for BigQuery, Bigtable, Cloud Storage
- can be configured for High Availability by specifying the number of master instances in the cluster
- All nodes in a High Availability cluster reside in the same zone. If there is a failure that impacts all nodes in a zone, the failure will not be mitigated.
- supports cluster scaling by increasing or decreasing the number of primary or secondary worker nodes (horizontal scaling)
- supports Autoscaling that provides a mechanism for automating cluster resource management and enables cluster autoscaling.
- supports initialization actions in executables or scripts that will run on all nodes in the cluster immediately after the cluster is set up
- Serverless Spark allows submitting batch workloads without provisioning or managing clusters, with automatic scaling and resource management.
- Supports Zero-Scale clusters for cost optimization when clusters are idle (2026).
- Includes Lightning Engine for boosted Spark performance.
Cloud Dataprep
⚠️ SERVICE END OF SUPPORT
Cloud Dataprep by Trifacta reached End of Support in December 2025. Trifacta was acquired by Alteryx, and the service has transitioned to Alteryx Designer Cloud.
Migration Options:
- Alteryx Designer Cloud — successor to Dataprep by Trifacta with enhanced AI/ML capabilities
- Cloud Data Fusion — Google Cloud’s managed data integration service for visual ETL/ELT pipelines
- Dataform — for SQL-based data transformations in BigQuery
- BigQuery Data Preparations — built-in data preparation within BigQuery Studio
- Cloud Dataprep by Trifacta was an intelligent data service for visually exploring, cleaning, and preparing structured and unstructured data for analysis, reporting, and machine learning.
- was fully managed, serverless, and scaled on-demand with no infrastructure to deploy or manage
- provided easy data preparation with clicks and no code.
- automatically identified data anomalies & helped take fast corrective action
- automatically detected schemas, data types, possible joins, and anomalies such as missing values, outliers, and duplicates
- used Dataflow or BigQuery under the hood, enabling unstructured or structured datasets processing of any size with the ease of clicks, not code
Cloud Datalab
⚠️ SERVICE DEPRECATED
Cloud Datalab was deprecated on September 2, 2022.
Migration Options:
- Vertex AI Workbench — managed notebook environment with JupyterLab, providing capabilities beyond Datalab with integrated ML workflows
- Colab Enterprise — collaborative notebook environment integrated with BigQuery Studio
- Cloud Datalab was a powerful interactive tool created to explore, analyze, transform and visualize data and build machine learning models using familiar languages, such as Python and SQL, interactively.
- ran on Google Compute Engine and connected to multiple cloud services easily so you could focus on data science tasks.
- was built on Jupyter (formerly IPython)
- enabled analysis of the data on Google BigQuery, Cloud Machine Learning Engine, Google Compute Engine, and Google Cloud Storage using Python, SQL, and JavaScript (for BigQuery user-defined functions).
Dataplex / Knowledge Catalog
- Dataplex (now Knowledge Catalog) is an AI-powered, unified data governance solution for managing, understanding, and governing data and AI assets across Google Cloud.
- Provides centralized inventory to discover, manage, and govern data across BigQuery, Cloud Storage, Pub/Sub, and Spanner.
- Supports data products — curated, ready-to-use packages of data assets, documentation, and governance controls assembled to solve specific business problems.
- Offers automated data discovery, metadata management, data quality checks, data lineage, and semantic search.
- Integrates with BigQuery Studio for unified governance across analytical workflows.