Google Cloud BigQuery
- Google Cloud BigQuery is a fully managed, peta-byte scale, serverless, highly scalable, and cost-effective multi-cloud data warehouse.
- BigQuery supports a standard SQL dialect that is ANSI:2011 compliant, which reduces the need for code rewrites.
- BigQuery transparently and automatically provides highly durable, replicated storage in multiple locations and high availability with no extra charge and no additional setup.
- BigQuery supports federated data and can process external data sources in GCS for Parquet and ORC open-source file formats, transactional databases (Bigtable, Cloud SQL), or spreadsheets in Drive without moving the data.
- BigQuery automatically replicates data and keeps a seven-day history of changes, allowing easy restoration and comparison of data from different times
- BigQuery Data Transfer Service automatically transfers data from external data sources, like Google Marketing Platform, Google Ads, YouTube, external sources like S3 or Teradata, and partner SaaS applications to BigQuery on a scheduled and fully managed basis
- BigQuery provides a REST API for easy programmatic access and application integration. Client libraries are available in Java, Python, Node.js, C#, Go, Ruby, and PHP.
BigQuery Resources
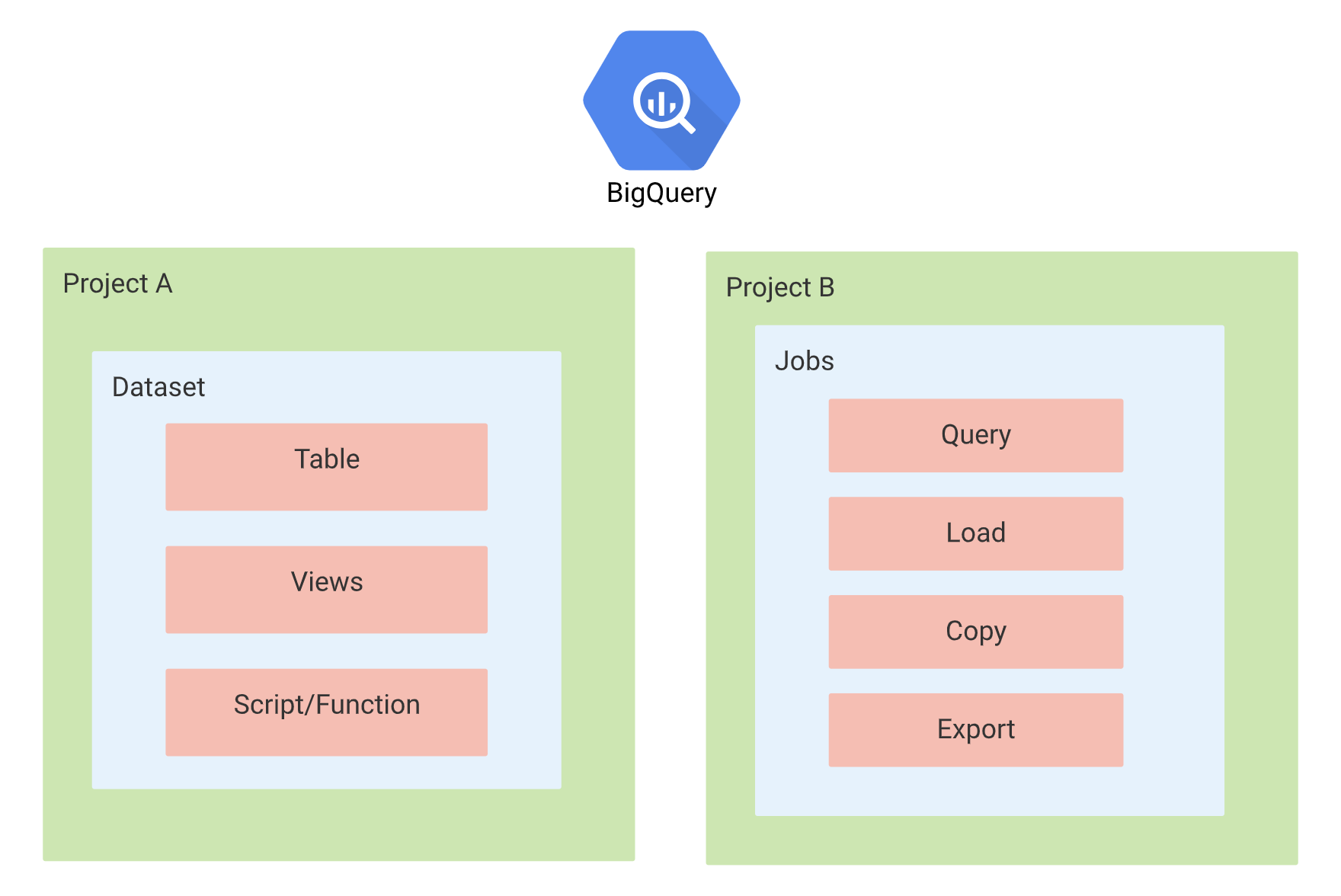
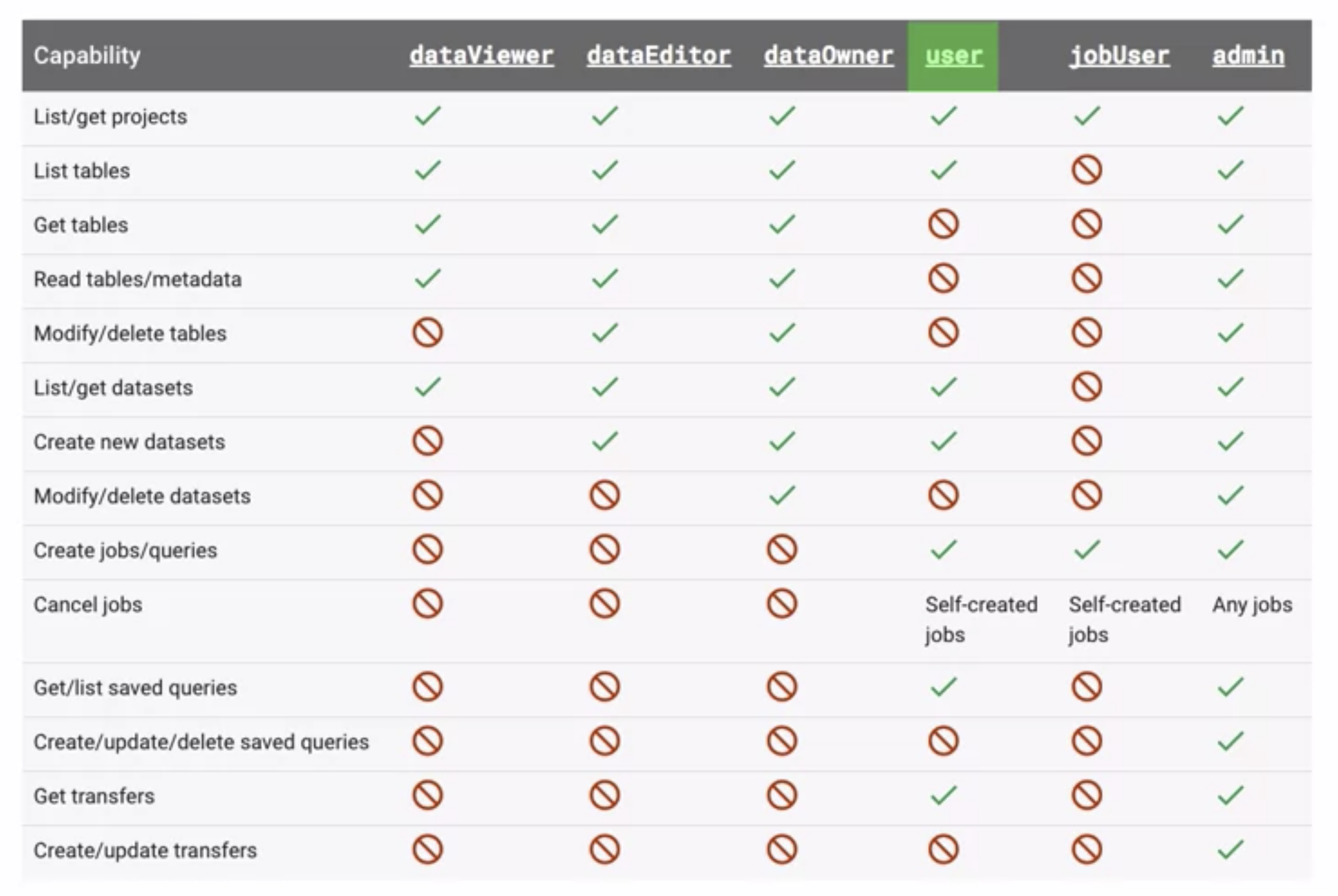
Datasets
- Datasets are the top-level containers used to organize and control access to the BigQuery tables and views.
- Datasets frequently map to schemas in standard relational databases and data warehouses.
- Datasets are scoped to the Cloud project
- A dataset is bound to a location and can be defined as
- Regional: A specific geographic place, such as London.
- Multi-regional: A large geographic area, such as the United States, that contains two or more geographic places.
- Dataset location can be set only at the time of its creation.
- A query can contain tables or views from different datasets in the same location.
- Dataset names must be unique for each project.
Tables
- BigQuery tables are row-column structures that hold the data.
- A BigQuery table contains individual records organized in rows. Each record is composed of columns (also called fields).
- Every table is defined by a schema that describes the column names, data types, and other information.
- BigQuery has the following types of tables:
- Native tables: Tables backed by native BigQuery storage.
- External tables: Tables backed by storage external to BigQuery.
- Views: Virtual tables defined by a SQL query.
- Schema of a table can either be defined during creation or specified in the query job or load job that first populates it with data.
- Schema auto-detection is also supported when data is loaded from BigQuery or an external data source. BigQuery makes a best-effort attempt to automatically infer the schema for CSV and JSON files
- Columns datatype cannot be changed once defined.
Partitioned Tables
- A partitioned table is a special table that is divided into segments, called partitions, that make it easier to manage and query your data.
- By dividing a large table into smaller partitions, query performance and costs can be controlled by reducing the number of bytes read by a query.
- BigQuery tables can be partitioned by:
- Time-unit column: Tables are partitioned based on a TIMESTAMP, DATE, or DATETIME column in the table.
- Ingestion time: Tables are partitioned based on the timestamp when BigQuery ingests the data.
- Integer range: Tables are partitioned based on an integer column.
- If a query filters on the value of the partitioning column, BigQuery can scan the partitions that match the filter and skip the remaining partitions. This process is called pruning.
Clustered Tables
- With Clustered tables, the table data is automatically organized based on the contents of one or more columns in the table’s schema.
- Columns specified are used to colocate the data.
- Clustering can be performed on multiple columns, where the order of the columns is important as it determines the sort order of the data
- Clustering can improve query performance for specific filter queries or ones that aggregate data as BigQuery uses the sorted blocks to eliminate scans of unnecessary data
- Clustering does not provide cost guarantees before running the query.
- Partitioning can be used with clustering where data is first partitioned and then data in each partition is clustered by the clustering columns. When the table is queried, partitioning sets an upper bound of the query cost based on partition pruning.
Views
- A View is a virtual table defined by a SQL query.
- View query results contain data only from the tables and fields specified in the query that defines the view.
- Views are read-only and do not support DML queries
- Dataset that contains the view and the dataset that contains the tables referenced by the view must be in the same location.
- View does not support BigQuery job that exports data
- View does not support JSON API to retrieve data from the view
- Standard SQL and legacy SQL queries cannot be mixed
- Legacy SQL view cannot be automatically updated to standard SQL syntax.
- No user-defined functions allowed
- No wildcard table references allowed
Materialized Views
- Materialized views are precomputed views that periodically cache the results of a query for increased performance and efficiency.
- BigQuery leverages pre-computed results from materialized views and whenever possible reads only delta changes from the base table to compute up-to-date results.
- Materialized views can be queried directly or can be used by the BigQuery optimizer to process queries to the base tables.
- Materialized views queries are generally faster and consume fewer resources than queries that retrieve the same data only from the base table
- Materialized views can significantly improve the performance of workloads that have the characteristic of common and repeated queries.
Jobs
- Jobs are actions that BigQuery runs on your behalf to load data, export data, query data, or copy data.
- Jobs are not linked to the same project that the data is stored in. However, the location where the job can execute is linked to the dataset location.
External Data Sources
- An external data source (federated data source) is a data source that can be queried directly even though the data is not stored in BigQuery.
- Instead of loading or streaming the data, a table can be created that references the external data source.
- BigQuery offers support for querying data directly from:
- Cloud Bigtable
- Cloud Storage
- Google Drive
- Cloud SQL
- Supported formats are:
- Avro
- CSV
- JSON (newline delimited only)
- ORC
- Parquet
- External data sources use cases
- Loading and cleaning the data in one pass by querying the data from an external data source (a location external to BigQuery) and writing the cleaned result into BigQuery storage.
- Having a small amount of frequently changing data that needs to be joined with other tables. As an external data source, the frequently changing data does not need to be reloaded every time it is updated.
- Permanent vs Temporary external tables
- The external data sources can be queried in BigQuery by using a permanent table or a temporary table.
- Permanent Table
- is a table that is created in a dataset and is linked to the external data source.
- access controls can be used to share the table with others who also have access to the underlying external data source, and you can query the table at any time.
- Temporary Table
- you submit a command that includes a query and creates a non-permanent table linked to the external data source.
- no table is created in the BigQuery datasets.
- cannot be shared with others.
- Querying an external data source using a temporary table is useful for one-time, ad-hoc queries over external data, or for extract, transform, and load (ETL) processes.
- Limitations
- does not guarantee data consistency for external data sources
- query performance for external data sources may not be as high as querying data in a native BigQuery table
- cannot reference an external data source in a wildcard table query.
- support table partitioning or clustering in limited ways
- results are not cached and would be charged for each query execution
BigQuery Security
Refer blog post @ BigQuery Security
BigQuery Best Practices
- Cost Control
- Query only the needed columns and avoid
select * as BigQuery does a full scan of every column in the table.
- Don’t run queries to explore or preview table data. Use preview option
- Before running queries, preview them to estimate costs. Queries are billed according to the number of bytes read and the cost can be estimated using
--dry-run feature
- Use the maximum bytes billed setting to limit query costs.
- Use clustering and partitioning to reduce the amount of data scanned.
- For non-clustered tables, do not use a
LIMIT clause as a method of cost control. Applying a LIMIT clause to a query does not affect the amount of data read, but shows limited results only. With a clustered table, a LIMIT clause can reduce the number of bytes scanned
- Partition the tables by date which helps query relevant subsets of data which improves performance and reduces costs.
- Materialize the query results in stages. Break the query into stages where each stage materializes the query results by writing them to a destination table. Querying the smaller destination table reduces the amount of data that is read and lowers costs. The cost of storing the materialized results is much less than the cost of processing large amounts of data.
- Use streaming inserts only if the data must be immediately available as streaming data is charged.
- Query Performance
- Control projection, Query only the needed columns. Avoid
SELECT *
- Prune partitioned queries, use the
_PARTITIONTIME pseudo column to filter the partitions.
- Denormalize data whenever possible using nested and repeated fields.
- Avoid external data sources, if query performance is a top priority
- Avoid repeatedly transforming data via SQL queries, use materialized views instead
- Avoid using Javascript user-defined functions
- Optimize Join patterns. Start with the largest table.
- Optimizing Storage
- Use the expiration settings to remove unneeded tables and partitions
- Keep the data in BigQuery to take advantage of the long-term storage cost benefits rather than exporting to other storage options.
BigQuery Data Transfer Service
Refer GCP blog post @ Google Cloud BigQuery Data Transfer Service
GCP Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
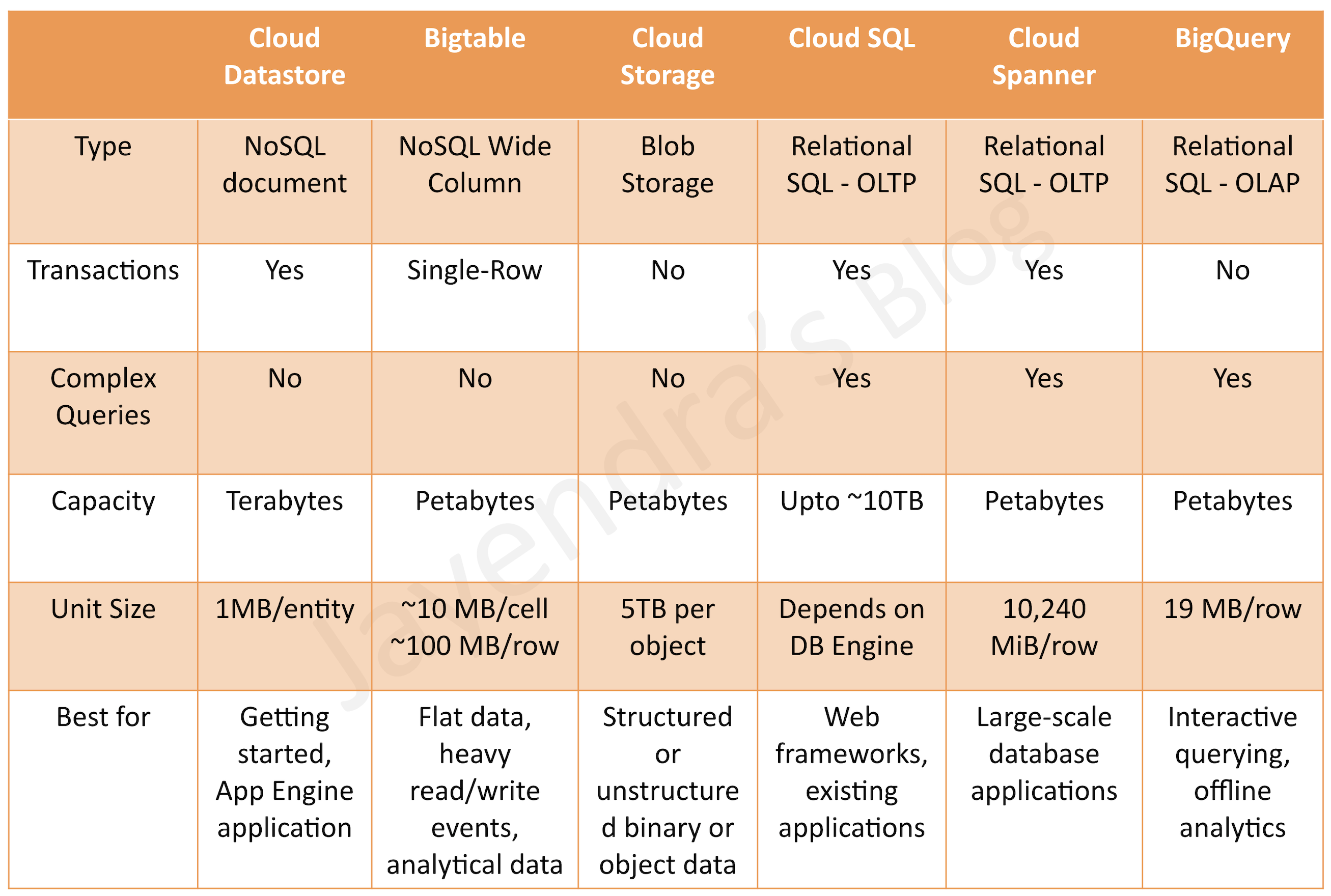
- A user wishes to generate reports on petabyte-scale data using Business Intelligence (BI) tools. Which storage option provides integration with BI tools and supports OLAP workloads up to petabyte-scale?
- Bigtable
- Cloud Datastore
- Cloud Storage
- BigQuery
- Your company uses Google Analytics for tracking. You need to export the session and hit data from a Google Analytics 360 reporting view on a scheduled basis into BigQuery for analysis. How can the data be exported?
- Configure a scheduler in Google Analytics to convert the Google Analytics data to JSON format, then import directly into BigQuery using
bq command line.
- Use
gsutil to export the Google Analytics data to Cloud Storage, then import into BigQuery and schedule it using Cron.
- Import data to BigQuery directly from Google Analytics using Cron
- Use BigQuery Data Transfer Service to import the data from Google Analytics
References
Google_Cloud_BigQuery_Architecture