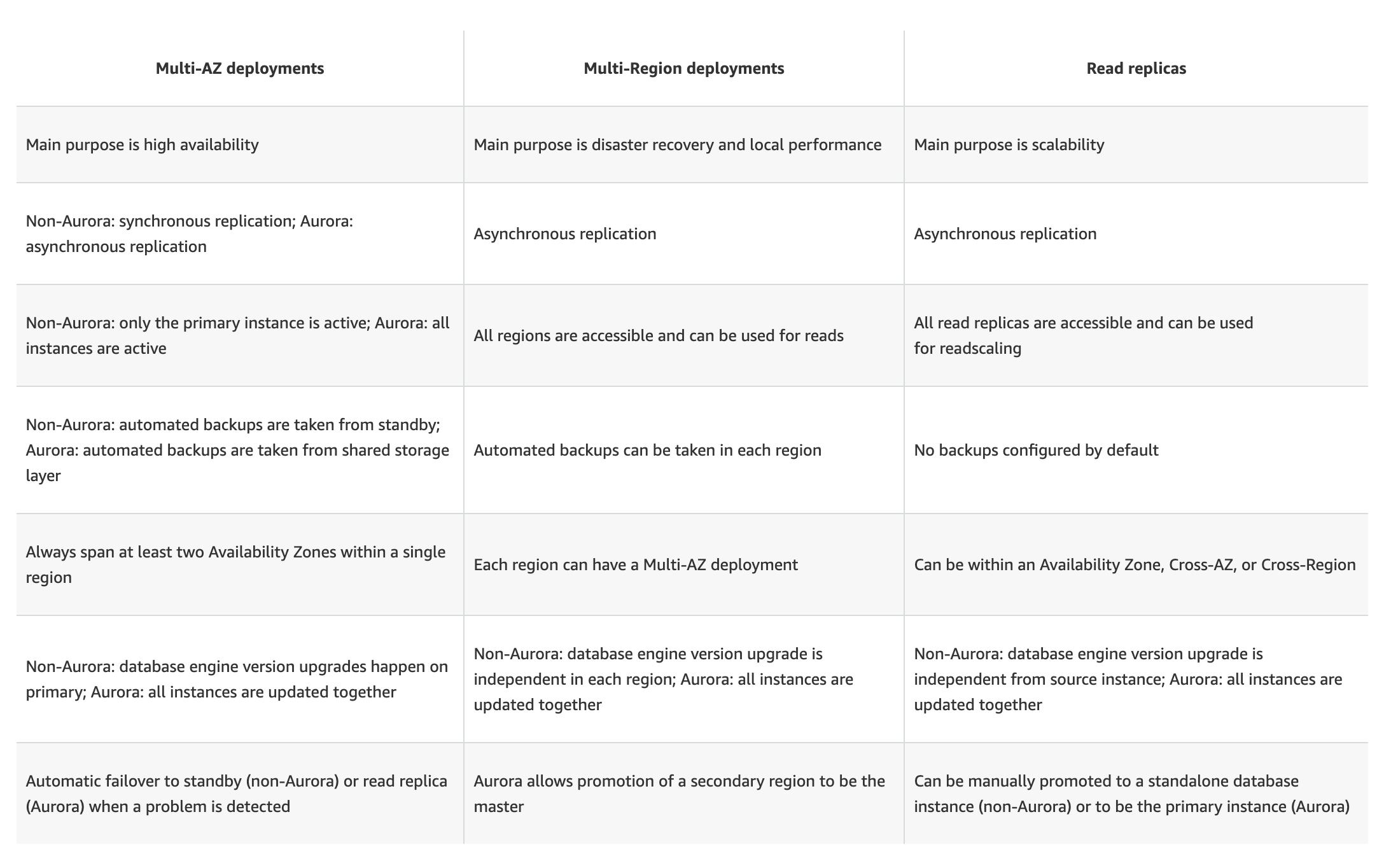
AWS RDS Storage
- RDS storage uses Elastic Block Store – EBS volumes for database and log storage.
- RDS automatically stripes across multiple EBS volumes to enhance performance, depending on the amount of storage requested and the database engine.
- For MariaDB, MySQL, PostgreSQL, and Db2 with 400 GiB or more storage, RDS stripes across 4 volumes. For Oracle, this threshold is 200 GiB. SQL Server does not support volume striping.
RDS Storage Types
- RDS provides three storage types: Provisioned IOPS SSD (io2 Block Express and io1), General Purpose SSD (gp3 and gp2), and Magnetic (legacy, deprecated).
- These storage types differ in performance characteristics and price, which allows tailoring of storage performance and cost to the database needs.
- Db2, MySQL, MariaDB, PostgreSQL RDS DB instances can be created with up to 64 TiB of storage.
- Oracle and SQL Server RDS DB instances support up to 256 TiB of storage with additional storage volumes (up to 64 TiB per volume, with up to 3 additional volumes).
- RDS for Db2 doesn’t support the gp2 and magnetic storage types.
⚠️ Magnetic Storage Deprecated
Amazon RDS is deprecating magnetic storage on April 30, 2026.
AWS recommends upgrading magnetic storage volumes to gp3 or io2 before April 29, 2026. After April 29, 2026, Amazon RDS will begin forced migration of magnetic storage volumes to gp3 storage volumes.
The default storage type when restoring snapshots of magnetic volumes will be changed to gp3 by June 1, 2026.
Magnetic (Standard) – Legacy, Deprecated
- Magnetic storage, also called standard storage, is a legacy storage type maintained only for backward compatibility.
- AWS recommends using General Purpose SSD (gp3) or Provisioned IOPS SSD (io2) for all new storage needs.
- Limited to a maximum size of 3 TiB and approximately 1,000 IOPS.
- Does not support storage autoscaling, elastic volumes, or zero-ETL integrations with Amazon Redshift.
- Does not allow storage type conversion or scaling when using the SQL Server database engine.
- Magnetic storage is not reserved for a single DB instance, so performance can vary greatly depending on the demands placed on shared resources by other customers.
- General Purpose SSD storage offers cost-effective storage ideal for a broad range of workloads running on medium-sized DB instances.
- Amazon RDS offers two types of General Purpose storage: gp3 (recommended) and gp2 (previous generation).
gp3 Storage (Recommended)
- gp3 allows you to customize storage performance independently of storage capacity.
- Provides a baseline performance of 3,000 IOPS and 125 MiB/s at any volume size.
- When storage size reaches the striping threshold (400 GiB for MySQL/MariaDB/PostgreSQL/Db2, 200 GiB for Oracle), baseline increases to 12,000 IOPS and 500 MiB/s due to volume striping across 4 volumes.
- Can provision additional IOPS up to 64,000 IOPS and throughput up to 4,000 MiB/s (for non-SQL Server engines).
- For SQL Server: up to 16,000 IOPS and 1,000 MiB/s (up to 80,000 IOPS and 2,000 MiB/s with June 2026 update).
- Storage size ranges from 20 GiB to 65,536 GiB (16,384 GiB for SQL Server per volume).
- Delivers single-digit millisecond latency consistently 99% of the time.
- General Purpose gp3 is excellent for development/testing environments and most production workloads that are not latency-sensitive.
gp2 Storage (Previous Generation)
- gp2 is the previous generation General Purpose SSD storage.
- Baseline I/O performance of 3 IOPS per GiB, with a minimum of 100 IOPS.
- Volumes below 1,000 GiB can burst to 3,000 IOPS using I/O credit balance.
- Maximum of 64,000 IOPS for volumes 4,000 GiB and larger (with striping).
- Cannot provision IOPS directly – IOPS varies with the allocated storage size.
- AWS recommends using gp3 for new workloads as it provides predictable baseline performance without relying on burst credits.
- Provisioned IOPS storage is designed to meet the needs of I/O-intensive workloads, particularly database workloads, that are sensitive to storage performance and consistency in random access I/O throughput.
- Amazon RDS offers two types of Provisioned IOPS storage: io2 Block Express (recommended) and io1 (previous generation).
- For any production application that requires fast and consistent I/O performance, Amazon recommends Provisioned IOPS storage.
- Provisioned IOPS storage is optimized for I/O intensive, online transaction processing (OLTP) workloads that have consistent performance requirements.
io2 Block Express (Recommended)
- io2 Block Express provides the highest performance within the RDS storage portfolio.
- Supports up to 256,000 IOPS, 4,000 MiB/s throughput, and up to 64 TiB per volume.
- Delivers consistent sub-millisecond latency (99.9% of the time) on AWS Nitro-based instances.
- Provides 99.999% durability (compared to 99.8-99.9% for other volume types).
- IOPS to storage ratio of up to 1,000:1 on Nitro-based instances (500:1 for non-Nitro).
- Available at the same price as io1 volumes.
- You can upgrade from io1 to io2 Block Express without any downtime using the ModifyDBInstance API.
- RDS delivers within 10 percent of the provisioned IOPS performance 99.9 percent of the time over a given year.
io1 Storage (Previous Generation)
- io1 is the previous generation Provisioned IOPS storage.
- Supports up to 256,000 IOPS (64,000 for SQL Server) and up to 4,000 MiB/s throughput.
- IOPS to storage ratio of up to 50:1.
- Delivers single-digit millisecond latency consistently 99.9% of the time.
- AWS recommends upgrading to io2 Block Express for better performance, higher durability, and same cost.
Adding Storage and Changing Storage Type
- DB instance can be modified to use additional storage and converted to a different storage type.
- Storage allocated for a DB instance cannot be decreased directly (you cannot reduce the amount of storage on a volume after allocation).
- Storage Volume Shrink (Nov 2024): Amazon RDS Blue/Green Deployments now supports shrinking storage volumes, allowing you to reduce storage size by creating a green environment with smaller storage and switching over.
- For SQL Server DB instances, you can scale storage for only the General Purpose SSD (gp3/gp2) and Provisioned IOPS SSD (io1/io2) storage types.
- During the scaling process, the DB instance will be available for reads and writes, but may experience performance degradation.
- After modifying storage, you can’t make further storage modifications for 6 hours or until storage optimization has completed, whichever is longer.
- While storage is being added, nightly backups are suspended and no other RDS operations can take place, including modify, reboot, delete, create Read Replica, and create DB Snapshot.
RDS Storage Autoscaling
- RDS Storage Autoscaling continuously monitors actual storage consumption and scales capacity up automatically when actual utilization approaches provisioned storage capacity.
- Enabled by setting a Maximum Storage Threshold – the upper limit to which RDS can automatically scale the storage.
- RDS automatically increases storage when:
- Free available space is less than 10% of the allocated storage
- The low-storage condition lasts at least 5 minutes
- At least 6 hours have passed since the last storage modification
- Storage autoscaling increases storage by the greater of: 10 GiB, 10% of currently allocated storage, or the predicted storage growth for the next 7 hours based on the past hour’s growth rate.
- Works with gp2, gp3, io1, and io2 storage types. Does not work with magnetic storage.
- Storage autoscaling doesn’t scale storage during the storage-optimization state.
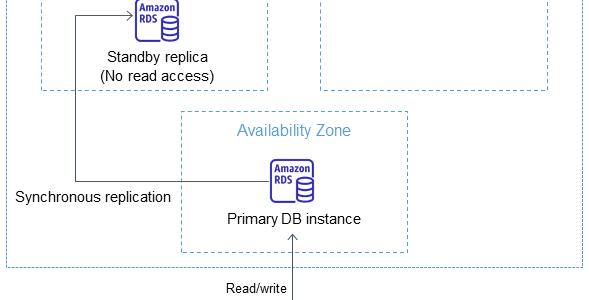
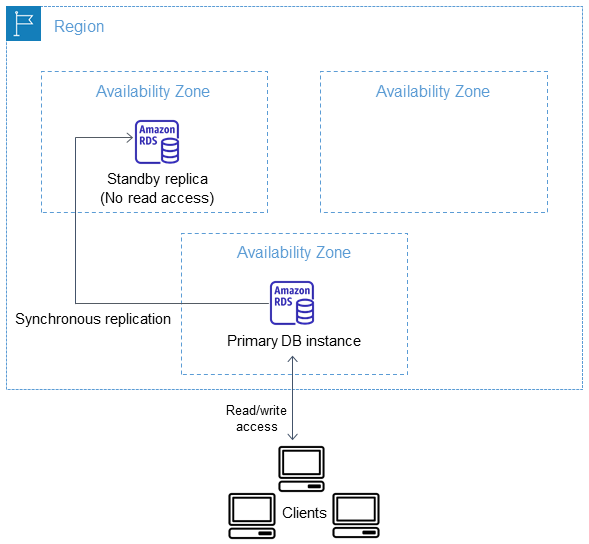
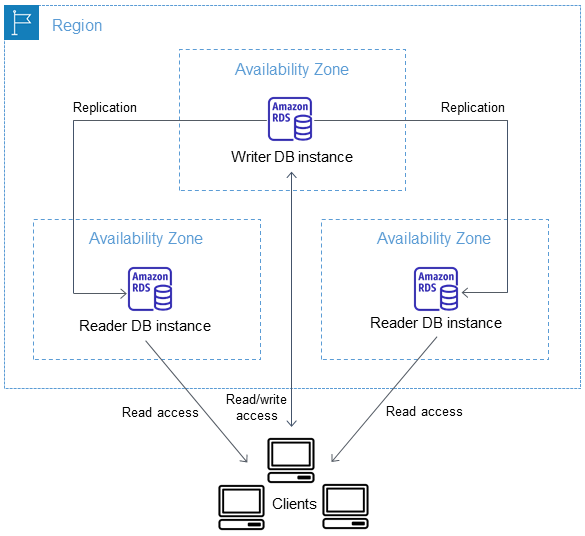
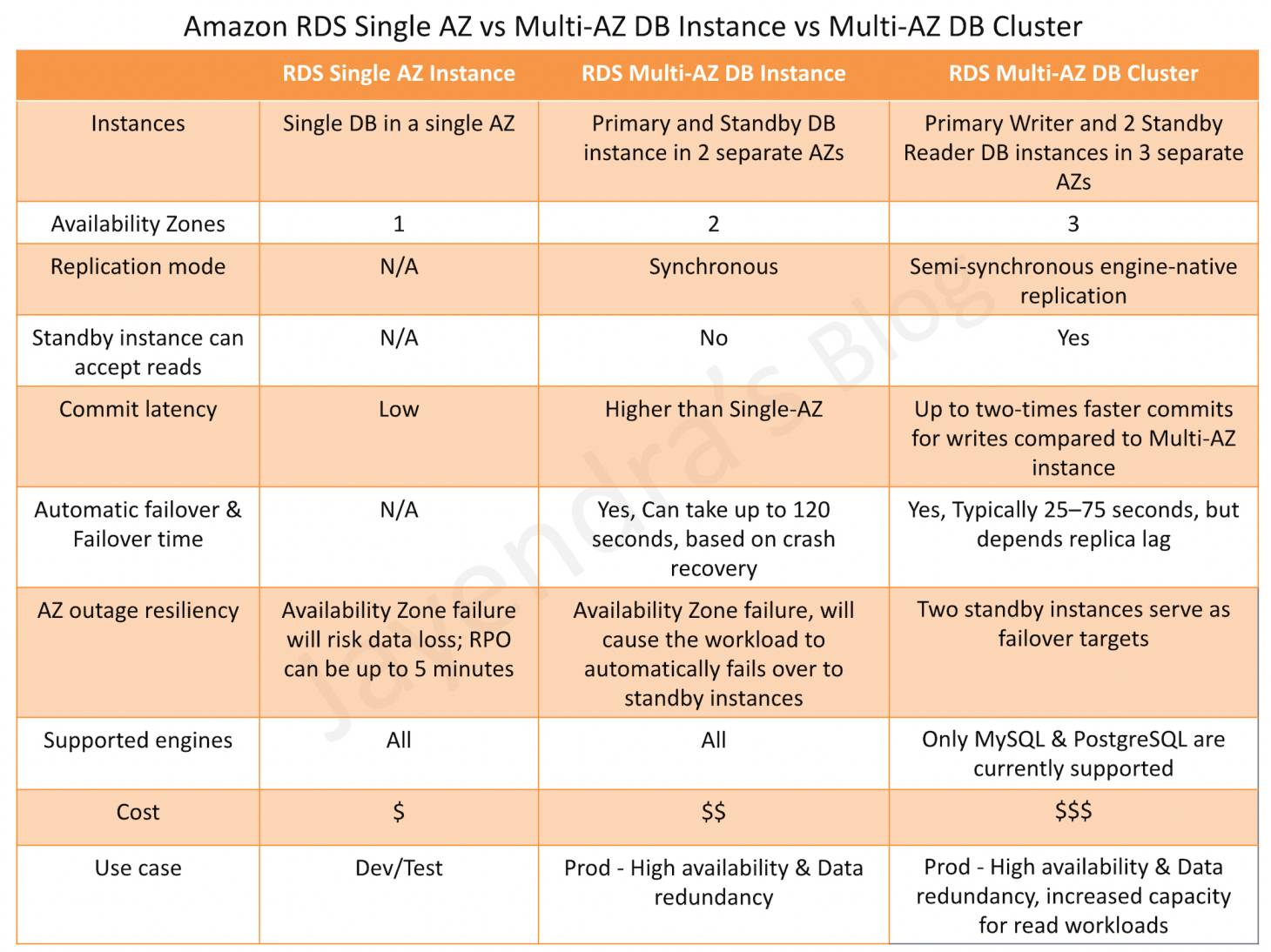
- Supported for Single-AZ and Multi-AZ DB instances. Multi-AZ DB clusters with two readable standbys do not support native storage autoscaling.
Additional Storage Volumes
- Available for RDS for Oracle and RDS for SQL Server (announced December 2025).
- You can attach up to 3 additional storage volumes to your DB instance, in addition to the primary volume.
- Each additional volume can be up to 64 TiB, enabling a total of up to 256 TiB per DB instance.
- You can choose between gp3 and io2 storage types for each additional volume independently.
- Allows mixing different storage types to optimize cost and performance based on data access patterns (e.g., frequently accessed data on io2, archival data on gp3).
- Additional volumes can be added and removed (but the primary volume cannot be removed).
- Volume names: For Oracle – rdsdbdata2, rdsdbdata3, rdsdbdata4. For SQL Server – H:, I:, J:.
Dedicated Log Volume (DLV)
- A Dedicated Log Volume (DLV) stores database transaction logs on a separate volume from the volume containing database tables (announced October 2023).
- Makes transaction write logging more efficient and consistent by eliminating I/O contention between data and log operations.
- DLVs are created with a fixed size of 1,024 GiB and 3,000 Provisioned IOPS.
- Supported only for PIOPS storage (io1 and io2 Block Express). Not supported for General Purpose storage (gp2/gp3).
- Ideal for databases with large allocated storage, high IOPS requirements, or latency-sensitive workloads.
- Supported for MariaDB 10.6.7+, MySQL 8.0.28+/8.4.3+, and PostgreSQL 13.10+/14.7+/15.2+/16+.
- Moves redo logs and binary logs (MySQL/MariaDB) or WAL segments (PostgreSQL) to the separate volume.
Performance Metrics
- Amazon RDS provides several metrics that can be used to determine how the DB instance is performing.
- IOPS (ReadIOPS / WriteIOPS)
- The number of I/O operations completed per second.
- It is reported as the average IOPS for a given time interval.
- RDS reports read and write IOPS separately on one minute intervals.
- Total IOPS is the sum of the read and write IOPS.
- Typical values for IOPS range from zero to tens of thousands per second.
- Measured IOPS values are independent of the size of the individual I/O operation.
- Latency (ReadLatency / WriteLatency)
- The elapsed time between the submission of an I/O request and its completion.
- It is reported as the average latency for a given time interval.
- RDS reports read and write latency separately on one minute intervals in units of seconds.
- Typical values for latency are in the millisecond (ms) range.
- Throughput (ReadThroughput / WriteThroughput)
- The number of bytes per second transferred to or from disk.
- It is reported as the average throughput for a given time interval.
- RDS reports read and write throughput separately on one minute intervals using units of bytes per second (B/s).
- Typical values for throughput range from zero to the I/O channel’s maximum bandwidth.
- Queue Depth
- The number of I/O requests in the queue waiting to be serviced.
- These are I/O requests that have been submitted by the application but have not been sent to the device because the device is busy servicing other I/O requests.
- It is reported as the average queue depth for a given time interval.
- RDS reports queue depth in one minute intervals. Typical values for queue depth range from zero to several hundred.
- Time spent waiting in the queue is a component of Latency and Service Time (not available as a metric).
RDS Storage Facts
- First time a DB instance is started and accesses an area of disk for the first time, the process can take longer than all subsequent accesses to the same disk area. This is known as the “first touch penalty“. Once an area of disk has incurred the first touch penalty, that area of disk does not incur the penalty again for the life of the instance, even if the DB instance is rebooted, restarted, or the DB instance class changes. Note that a DB instance created from a snapshot, a point-in-time restore, or a read replica is a new instance and does incur this first touch penalty.
- RDS manages the DB instance and it reserves overhead space on the instance. While the amount of reserved storage varies by DB instance class and other factors, this reserved space can be as much as one or two percent of the total storage.
- Provisioned IOPS provides a way to reserve I/O capacity by specifying IOPS. Like any other system capacity attribute, maximum throughput under load will be constrained by the resource that is consumed first, which could be IOPS, channel bandwidth, CPU, memory, or database internal resources.
- io2 Block Express volumes support throughput scaling proportionally up to 0.256 MiB/s per provisioned IOPS. Maximum throughput of 4,000 MiB/s can be achieved at 256,000 IOPS with a 16-KiB I/O size.
- EBS-optimized instances have a baseline and maximum IOPS rate enforced at the DB instance level. Combined IOPS from multiple volumes cannot exceed the instance-level threshold.
- The maximum ratio of IOPS to allocated storage is 1,000:1 for io2 Block Express on Nitro-based instances, 500:1 for io2 on non-Nitro instances, and 50:1 for io1.
Factors That Impact RDS Storage Performance
- Several factors can affect the performance of a DB instance, such as instance configuration, I/O characteristics, and workload demand.
- System related activities also consume I/O capacity and may reduce database instance performance while in progress:
- DB snapshot creation
- Nightly backups
- Multi-AZ standby creation
- Read replica creation
- Scaling storage
- Changing storage types
- System resources can constrain the throughput of a DB instance, but there can be other reasons for a bottleneck. Database could be the issue if:
- Channel throughput limit is not reached
- Queue depths are consistently low
- CPU utilization is under 80%
- Free memory available
- No swap activity
- Plenty of free disk space
- Application has dozens of threads all submitting transactions as fast as the database will take them, but there is clearly unused I/O capacity
- DB instance class determines the maximum bandwidth, throughput, and IOPS available. Using a current generation instance class with EBS-optimization and 10-gigabit network connectivity is recommended for best performance.
- When modifying storage so it goes from one volume to four volumes (crossing the striping threshold), RDS provisions new volumes and transparently moves data, consuming significant IOPS and throughput.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- When should I choose Provisioned IOPS over Standard RDS storage?
- If you have batch-oriented workloads
- If you use production online transaction processing (OLTP) workloads
- If you have workloads that are not sensitive to consistent performance
- Is decreasing the storage size of a DB Instance permitted?
- Depends on the RDMS used
- Yes
- No (Direct decrease is not supported. However, Blue/Green Deployments can be used to achieve storage shrink since November 2024)
- Because of the extensibility limitations of striped storage attached to Windows Server, Amazon RDS does not currently support increasing storage on a _____ DB Instance using magnetic storage.
- SQL Server
- MySQL
- Oracle
- If I want to run a database in an Amazon instance, which is the most recommended Amazon storage option?
- Amazon Instance Storage
- Amazon EBS
- You can’t run a database inside an Amazon instance.
- Amazon S3
- For each DB Instance class, what is the maximum size of associated storage capacity?
- 5 TiB
- 16 TiB
- 64 TiB (per volume; up to 256 TiB with additional storage volumes for Oracle/SQL Server)
- 128 TiB
- Which RDS storage type provides the highest durability with 99.999% durability guarantee?
- General Purpose gp3
- General Purpose gp2
- Provisioned IOPS io2 Block Express
- Provisioned IOPS io1
- Which feature allows RDS to automatically increase storage capacity when running low on space?
- Elastic Volumes
- RDS Storage Autoscaling
- Dynamic Scaling
- Predictive Scaling
- What is the purpose of a Dedicated Log Volume (DLV) in Amazon RDS?
- To store database backups on a separate volume
- To store transaction logs on a separate volume from database tables for improved write performance
- To provide additional read capacity
- To enable cross-region replication
- A company needs to deploy an RDS for Oracle database that requires more than 64 TiB of storage. What should they do?
- Use multiple RDS instances with application-level sharding
- Migrate to Aurora
- Use additional storage volumes to scale up to 256 TiB per DB instance
- Use magnetic storage which has higher limits
- Which of the following statements about RDS gp3 storage is correct? (Choose 2)
- gp3 provides a baseline of 3,000 IOPS and 125 MiB/s regardless of volume size
- gp3 IOPS scales with volume size at 3 IOPS per GiB
- gp3 allows independent provisioning of IOPS and throughput from storage capacity
- gp3 requires burst credits for performance above baseline
📖 Related: AWS RDS Backup, Snapshots & Restore – Complete Guide
References