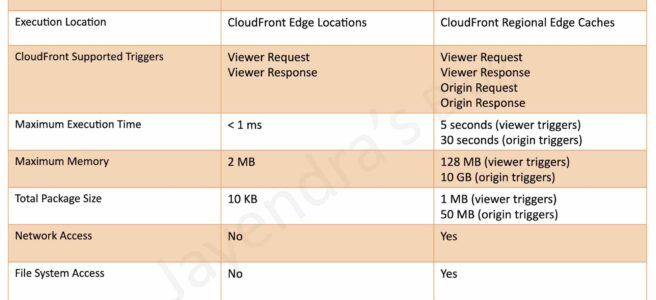
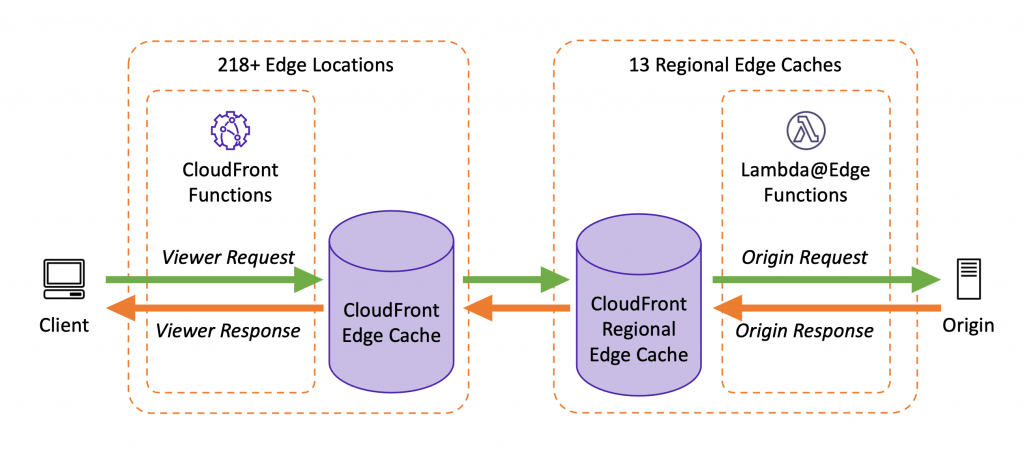
Viewer Request: after CloudFront receives the request from the Viewer
Viewer Response: before CloudFront forwards the response to the Viewer
Origin Request: before CloudFront forwards the request to the Origin
Origin Response: after CloudFront receives the response from the Origin
supports longer execution time, 5 seconds for viewer triggers and 30 seconds for origin triggers
scales to 1000s of requests/second
has network and file system access
can access the request body
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You’ve been given the requirement to customize the content which is distributed to users via a CloudFront Distribution. The content origin is an S3 bucket and the customization attribute exists in the request body. How could you achieve this?
Add an event to the S3 bucket. Make the event invoke a Lambda function to customize the content before rendering
Use CloudFront Functions
Use Lambda@Edge
Use a separate application on an EC2 Instance for this purpose.
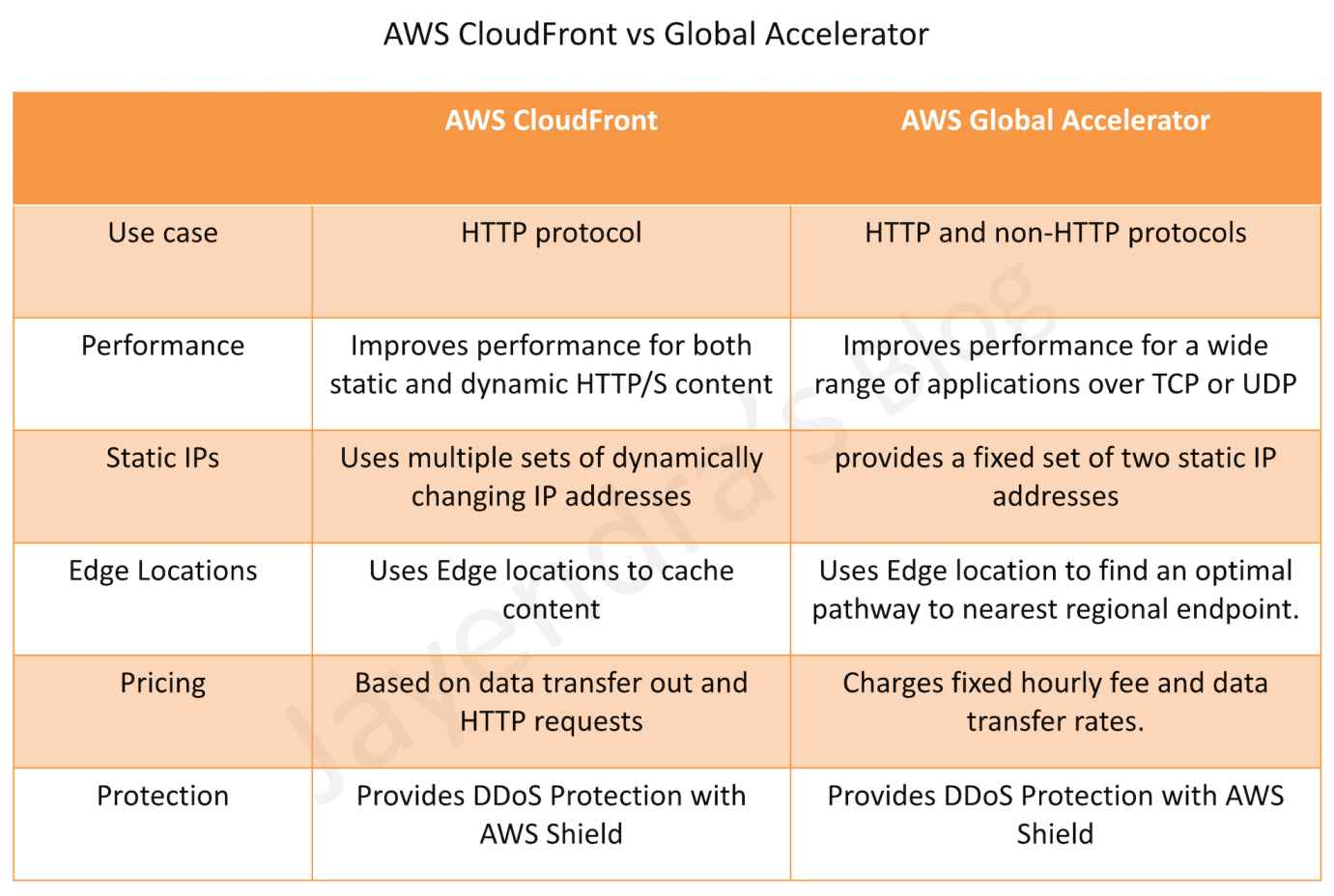
Both services integrate with AWS Shield for DDoS protection.
Performance
CloudFront improves performance for both cacheable content (such as images and videos) and dynamic content (such as API acceleration and dynamic site delivery).
Global Accelerator improves performance for a wide range of applications over TCP or UDP by proxying packets at the edge to applications running in one or more AWS Regions.
Use Cases
CloudFront is a good fit for HTTP use cases
Global Accelerator is a good fit for non-HTTP use cases, such as gaming (UDP), IoT (MQTT), or VoIP, as well as for HTTP use cases that require static IP addresses or deterministic, fast regional failover.
Caching
CloudFront supports Edge caching
Global Accelerator does not support Edge Caching.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company wants to improve the availability and performance of its stateless UDP-based workload. The workload is deployed on Amazon EC2 instances in multiple AWS Regions. What should a solutions architect recommend to accomplish this?
Place the EC2 instances behind Network Load Balancers (NLBs) in each Region. Create an accelerator using AWS Global Accelerator. Use the NLBs as endpoints for the accelerator.
Place the EC2 instances behind Application Load Balancers (ALBs) in each Region. Create an accelerator using AWS Global Accelerator. Use the ALBs as endpoints for the accelerator.
Place the EC2 instances behind Network Load Balancers (NLBs) in each Region. Create a CloudFront distribution with an origin that uses Route 53 latency-based routing to route requests to the NLBs.
Place the EC2 instances behind Application Load Balancers (ALBs) in each Region. Create a CloudFront distribution with an origin that uses Route 53 latency-based routing to route requests to the ALBs.
AWS CloudFront helps write your own code to customize how the CloudFront distributions process HTTP requests and responses.
The code runs close to the viewers (users) to minimize latency, and without having to manage servers or other infrastructure.
Custom code can manipulate the requests and responses that flow through CloudFront, perform basic authentication and authorization, generate HTTP responses at the edge, and more.
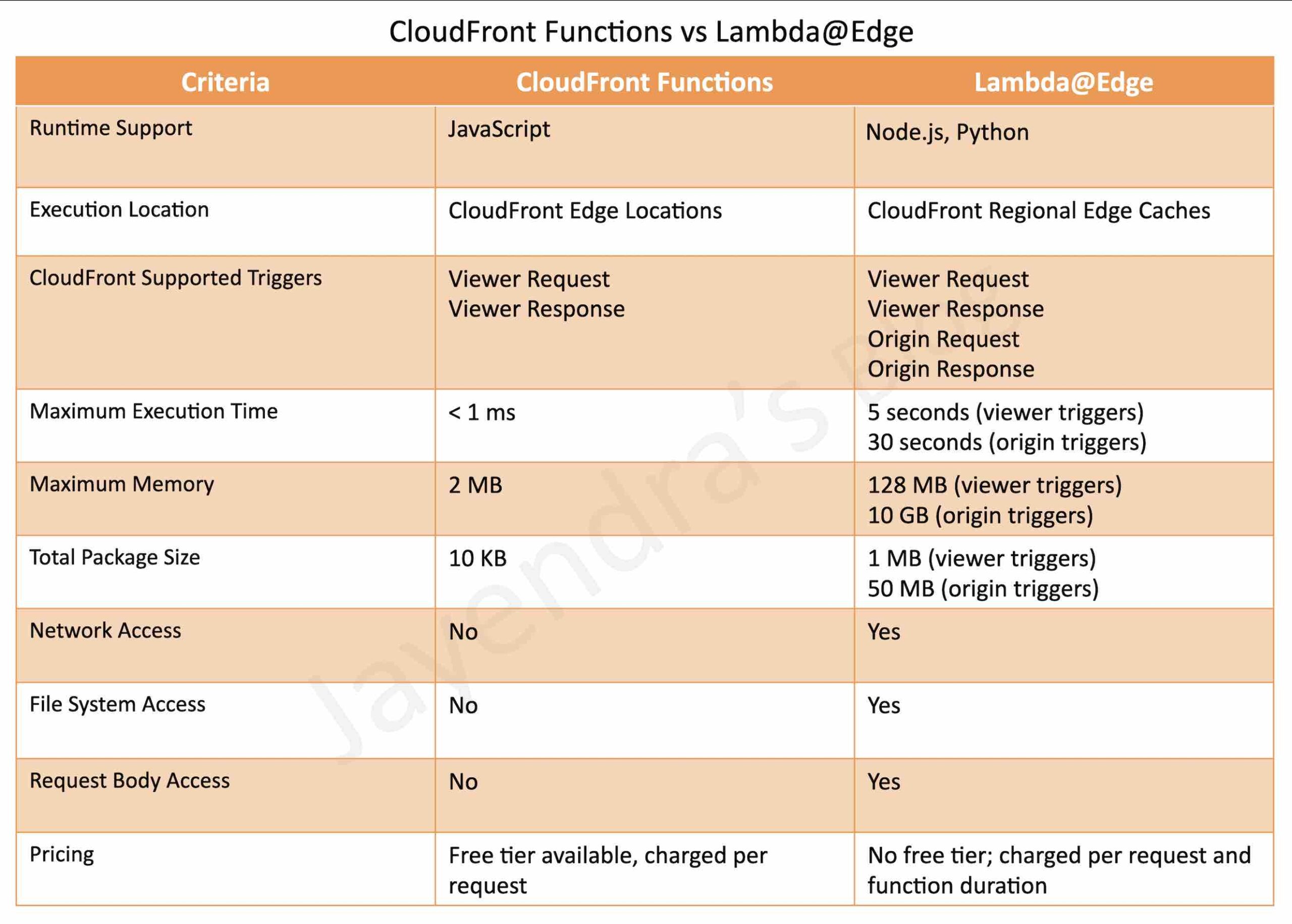
CloudFront Edge Functions currently supports two types
CloudFront Functions
Lambda@Edge
CloudFront Functions
is a CloudFront native feature (code is managed entirely within CloudFront) and visible only on the CloudFront dashboard.
supports lightweight functions written only in JavaScript language
runs in Edge Locations
has process-based isolation
supports Viewer Request, Viewer Response trigger events only
Viewer Request: after CloudFront receives the request from the Viewer
Viewer Response: before CloudFront forwards the response to the Viewer
supports sub-millisecond execution time
scales to millions of requests/second
as they are built to be more scalable, performant, and cost-effective, they have the following limitations
no network access
no file system access
cannot access the request body
use-cases ideal for lightweight processing of web requests like
Cache-key manipulations and normalization
URL rewrites and redirects
HTTP header manipulation
Access authorization
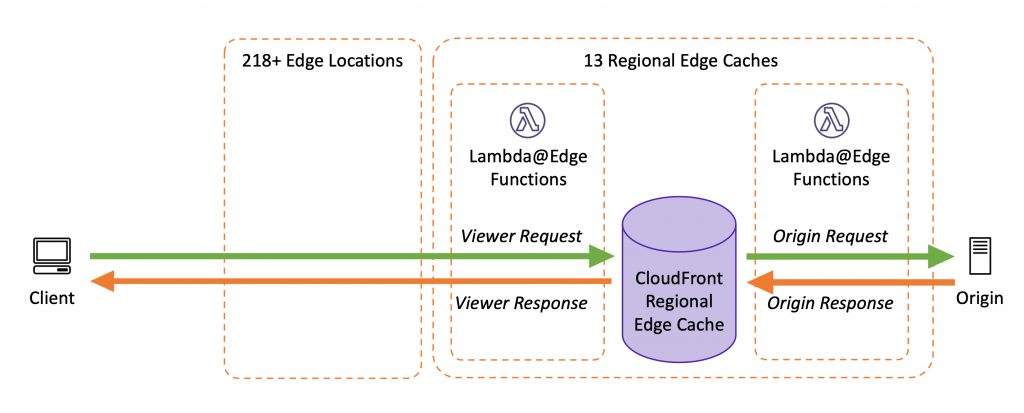
Lambda@Edge
are Lambda functions and visible on the Lambda dashboard.
Each event type (viewer request, origin request, origin response, and viewer response) can have only one edge function association.
CloudFront Functions and Lambda@Edge in viewer events (viewer request and viewer response) cannot be combined.
CloudFront does not invoke edge functions for viewer response events when the origin returns an HTTP status code 400 or higher.
Edge functions for viewer response events cannot modify the HTTP status code of the response, regardless of whether the response came from the origin or the CloudFront cache.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You’ve been given the requirement to customize the content which is distributed to users via a CloudFront Distribution. The content origin is an S3 bucket. How could you achieve this?
Add an event to the S3 bucket. Make the event invoke a Lambda function to customize the content before rendering
Add a Step Function. Add a step with a Lambda function just before the content gets delivered to the users.
Use Lambda@Edge
Use a separate application on an EC2 Instance for this purpose.
A company’s packaged application dynamically creates and returns single-use text files in response to user requests. The company is using Amazon CloudFront for distribution but wants to further reduce data transfer costs. The company cannot modify the application’s source code. What should a solutions architect do to reduce costs?
Use Lambda@Edge to compress the files as they are sent to users.
Enable Amazon S3 Transfer Acceleration to reduce the response times.
Enable caching on the CloudFront distribution to store generated files at the edge.
Use Amazon S3 multipart uploads to move the files to Amazon S3 before returning them to users.
CloudFront Security has multiple features, including
Support for Encryption at Rest and Transit.
Prevent users in specific geographic locations from accessing content
Configure HTTPS connections.
Use signed URLs or cookies to restrict access for selected users.
Restrict access to content in S3 buckets using origin access identity – OAI, to prevent users from using the direct URL of the file.
Set up field-level encryption for specific content fields
Use AWS WAF web ACLs to create a web access control list (web ACL) to restrict access to your content.
Use geo-restriction, also known as geoblocking, to prevent users in specific geographic locations from accessing content served through a CloudFront distribution.
Integration with AWS Shield to protect from DDoS attacks.
Data Protection
CloudFront supports both Encryption at Rest and in Transit.
CloudFront provides Encryption in Transit and can be configured
to require viewers to use HTTPS to request the files so that connections are encrypted when CloudFront communicates with viewers.
to use HTTPS to get files from the origin, so that connections are encrypted when CloudFront communicates with the origin.
HTTPS can be enforced using the Viewer Protocol Policy and Origin Protocol Policy.
CloudFront provides Encryption at Rest
using SSDs which are encrypted for edge location points of presence (POPs), and encrypted EBS volumes for Regional Edge Caches (RECs).
Function code and configuration are always stored in an encrypted format on the encrypted SSDs on the edge location POPs, and in other storage locations used by CloudFront.
Restrict Viewer Access
Serving Private Content
To securely serve private content using CloudFront
Require the users to access the private content by using special CloudFront signed URLs or signed cookies with the following restrictions
end date and time, after which the URL is no longer valid
start date-time, when the URL becomes valid
IP address or range of addresses to access the URLs
Require that users access the S3 content only using CloudFront URLs, not S3 URLs. Requiring CloudFront URLs isn’t required, but recommended to prevent users from bypassing the restrictions specified in signed URLs or signed cookies.
Signed URLs or Signed Cookies can be used with CloudFront using an HTTP server as an origin. It requires the content to be publicly accessible and care should be taken to not share the direct URL of the content
Restriction for Origin can be applied by
For S3, using Origin Access Identity – OAI to grant only CloudFront access using Bucket policies or Object ACL, to the content and removing any other access permissions
For a Load balancer OR HTTP server, custom headers can be added by CloudFront which can be used at Origin to verify the request has come from CloudFront.
Custom origins can also be configured to allow traffic from CloudFront IPs only. CloudFront managed prefix list can be used to allow inbound traffic to the origin only from CloudFront’s origin-facing servers, preventing any non-CloudFront traffic from reaching your origin
Trusted Signer
To create signed URLs or signed cookies, at least one AWS account (trusted signer) is needed that has an active CloudFront key pair
Once the AWS account is added as a trusted signer to the distribution, CloudFront starts to require that users use signed URLs or signed cookies to access the objects.
Private key from the trusted signer’s key pair to sign a portion of the URL or the cookie. When someone requests a restricted object, CloudFront compares the signed portion of the URL or cookie with the unsigned portion to verify that the URL or cookie hasn’t been tampered with. CloudFront also validates the URL or cookie is valid for e.g, that the expiration date and time hasn’t passed.
Each Trusted signer AWS account used to create CloudFront signed URLs or signed cookies must have its own active CloudFront key pair, which should be frequently rotated
A maximum of 5 trusted signers can be assigned for each cache behavior or RTMP distribution
Signed URLs vs Signed Cookies
CloudFront signed URLs and signed cookies help to secure the content and provide control to decide who can access the content.
Use signed URLs in the following cases:
for RTMP distribution as signed cookies aren’t supported
to restrict access to individual files, for e.g., an installation download for the application.
users using a client, for e.g. a custom HTTP client, that doesn’t support cookies
Use signed cookies in the following cases:
provide access to multiple restricted files, e.g., all of the video files in HLS format or all of the files in the subscribers’ area of a website.
don’t want to change the current URLs.
Signed URLs take precedence over signed cookies, if both signed URLs and signed cookies are used to control access to the same files and a viewer uses a signed URL to request a file, CloudFront determines whether to return the file to the viewer based only on the signed URL.
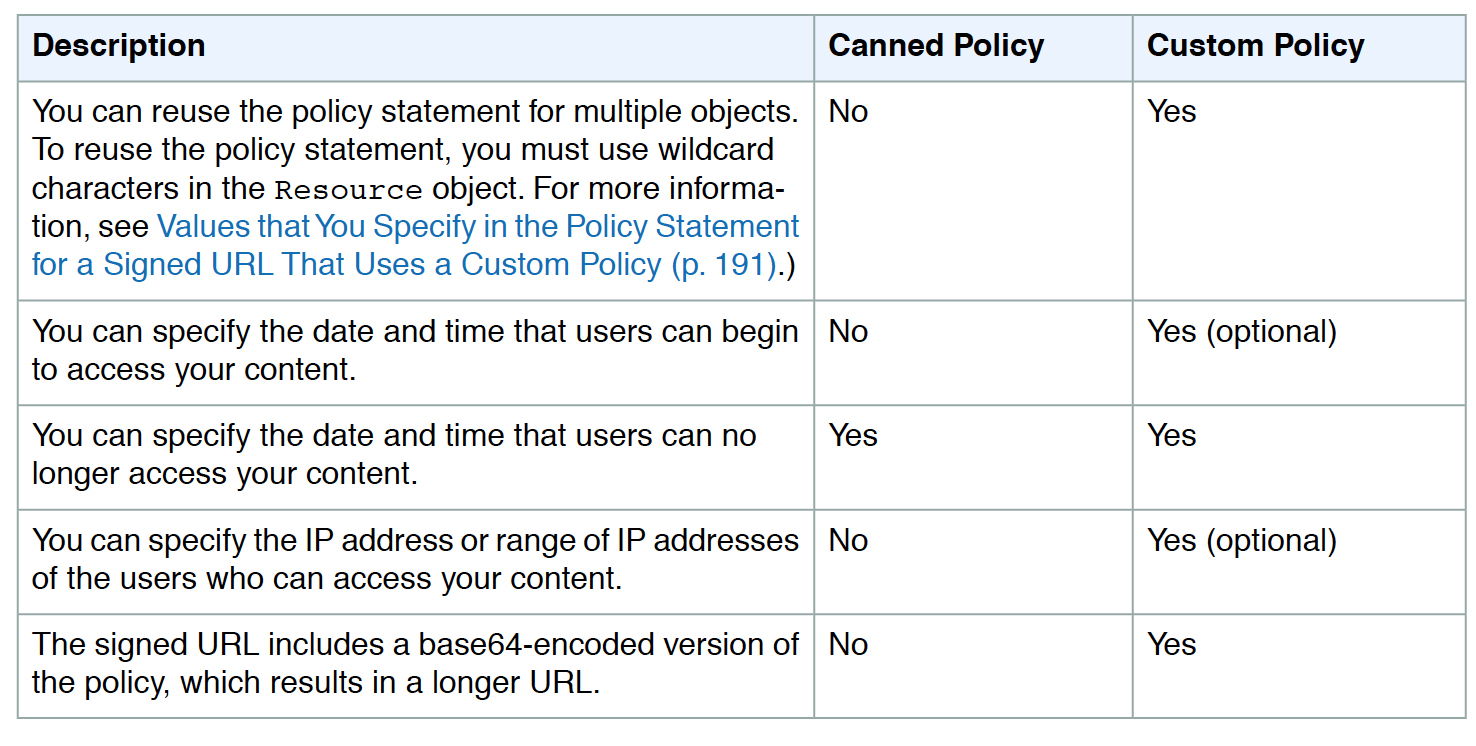
Canned Policy vs Custom Policy
Canned policy or a custom policy is a policy statement, used by the Signed URLs, that helps define the restrictions for e.g. expiration date and time
CloudFront validates the expiration time at the start of the event.
If the user is downloading a large object, and the URL expires the download would still continue, and the same for RTMP distribution.
However, if the user is using range GET requests, or while streaming video skips to another position which might trigger another event, the request would fail.
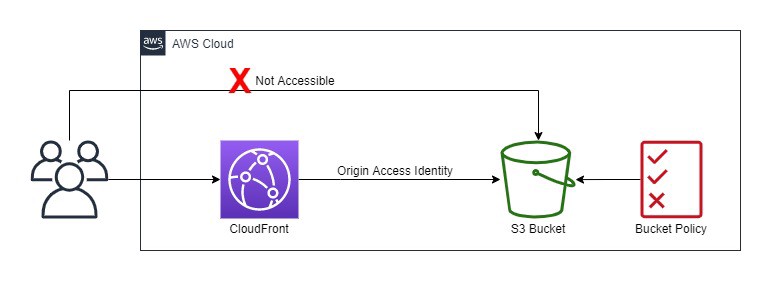
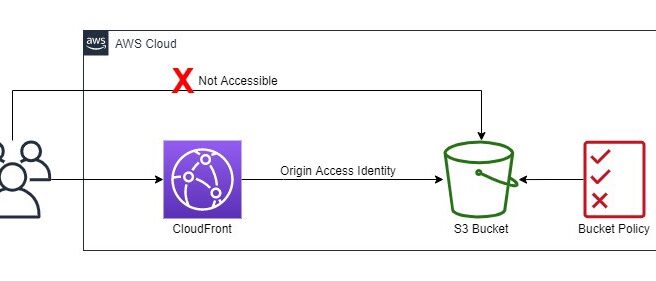
S3 Origin Access Identity – OAI
Origin Access Identity (OAI) can be used to prevent users from directly accessing objects from S3.
S3 origin objects must be granted public read permissions and hence the objects are accessible from both S3 as well as CloudFront.
Even though CloudFront does not expose the underlying S3 URL, it can be known to the user if shared directly or used by applications.
For using CloudFront signed URLs or signed cookies, it would be necessary to prevent users from having direct access to the S3 objects.
Users accessing S3 objects directly would
bypass the controls provided by CloudFront signed URLs or signed cookies, for e.g., control over the date-time that a user can no longer access the content and the IP addresses can be used to access content
CloudFront access logs are less useful because they’re incomplete.
Origin access identity, which is a special CloudFront user, can be created and associated with the distribution.
S3 bucket/object permissions need to be configured to only provide access to the Origin Access Identity.
When users access the object from CloudFront, it uses the OAI to fetch the content on the user’s behalf, while the S3 object’s direct access is restricted
Custom Headers
Custom headers can be added by CloudFront which can be used at Origin to verify the request has come from CloudFront.
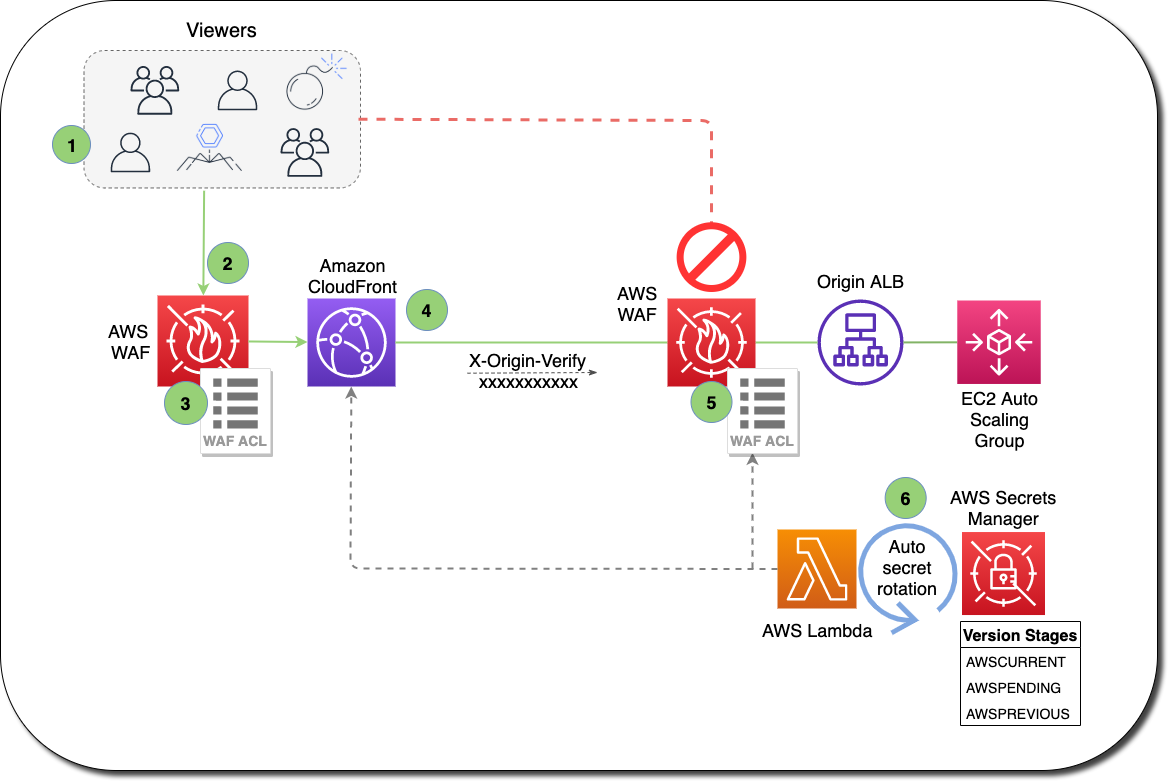
A viewer accesses the website or application and requests one or more files, such as an image file and an HTML file.
DNS routes the request to the CloudFront edge location that can best serve the request – typically the nearest edge location in terms of latency.
At the edge location, AWS WAF inspects the incoming request according to configured web ACL rules.
At the edge location, CloudFront checks its cache for the requested content.
If the content is in the cache, CloudFront returns it to the user.
If the content isn’t in the cache, CloudFront adds the custom header, X-Origin-Verify , with the value of the secret from Secrets Manager, and forwards the request to the origin.
At the origin ALB, ALB rules or AWS WAF inspects the incoming request header, X-Origin-Verify, and allows the request if the string value is valid. If the header isn’t valid, AWS WAF blocks the request.
At the configured interval, Secrets Manager automatically rotates the custom header value and updates the origin AWS WAF and CloudFront configurations.
Geo-Restriction – Geoblocking
Geo restriction can help allow or prevent users in selected countries from accessing the content,
CloudFront distribution can be configured either to allow users in
whitelist of specified countries to access the content or to
deny users in a blacklist of specified countries to access the content
Geo restriction can be used to restrict access to all of the files that are
associated with distribution and to restrict access at the country level.
CloudFront responds to a request from a viewer in a restricted country with an HTTP status code 403 (Forbidden).
Use a third-party geolocation service, if access is to be restricted to a subset of the files that are associated with a distribution or to restrict access at a finer granularity than the country level.
Field Level Encryption Config
CloudFront can enforce secure end-to-end connections to origin servers by using HTTPS.
Field-level encryption adds an additional layer of security that helps protect specific data throughout system processing so that only certain applications can see it.
Field-level encryption can be used to securely upload user-submitted sensitive information. The sensitive information provided by the clients is encrypted at the edge closer to the user and remains encrypted throughout the entire application stack, ensuring that only applications that need the data – and have the credentials to decrypt it – are able to do so.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You are building a system to distribute confidential training videos to employees. Using CloudFront, what method could be used to serve content that is stored in S3, but not publically accessible from S3 directly?
Create an Origin Access Identity (OAI) for CloudFront and grant access to the objects in your S3 bucket to that OAI.
Add the CloudFront account security group “amazon-cf/amazon-cf-sg” to the appropriate S3 bucket policy.
Create an Identity and Access Management (IAM) User for CloudFront and grant access to the objects in your S3 bucket to that IAM User.
Create a S3 bucket policy that lists the CloudFront distribution ID as the Principal and the target bucket as the Amazon Resource Name (ARN).
A media production company wants to deliver high-definition raw video for preproduction and dubbing to customer all around the world. They would like to use Amazon CloudFront for their scenario, and they require the ability to limit downloads per customer and video file to a configurable number. A CloudFront download distribution with TTL=0 was already setup to make sure all client HTTP requests hit an authentication backend on Amazon Elastic Compute Cloud (EC2)/Amazon RDS first, which is responsible for restricting the number of downloads. Content is stored in S3 and configured to be accessible only via CloudFront. What else needs to be done to achieve an architecture that meets the requirements? Choose 2 answers
Enable URL parameter forwarding, let the authentication backend count the number of downloads per customer in RDS, and return the content S3 URL unless the download limit is reached.
Enable CloudFront logging into an S3 bucket, leverage EMR to analyze CloudFront logs to determine the number of downloads per customer, and return the content S3 URL unless the download limit is reached. (CloudFront logs are logged periodically and EMR not being real time, hence not suitable)
Enable URL parameter forwarding, let the authentication backend count the number of downloads per customer in RDS, and invalidate the CloudFront distribution as soon as the download limit is reached. (Distribution are not invalidated but Objects)
Enable CloudFront logging into the S3 bucket, let the authentication backend determine the number of downloads per customer by parsing those logs, and return the content S3 URL unless the download limit is reached. (CloudFront logs are logged periodically and EMR not being real time, hence not suitable)
Configure a list of trusted signers, let the authentication backend count the number of download requests per customer in RDS, and return a dynamically signed URL unless the download limit is reached.
To enable end-to-end HTTPS connections from the user‘s browser to the origin via CloudFront, which of the following options are valid? Choose 2 answers
Use self-signed certificate in the origin and CloudFront default certificate in CloudFront. (Origin cannot be self-signed)
Use the CloudFront default certificate in both origin and CloudFront (CloudFront cert cannot be applied to origin)
Use a 3rd-party CA certificate in the origin and CloudFront default certificate in CloudFront
Use 3rd-party CA certificate in both origin and CloudFront
Use a self-signed certificate in both the origin and CloudFront (Origin cannot be self-signed)
CloudFront can be used to distribute the content from an S3 bucket.
For an RTMP distribution, the S3 bucket is the only supported origin, and custom origins cannot be used
Using CloudFront over S3 has the following benefits
can be more cost-effective if the objects are frequently accessed as at higher usage, and the price for CloudFront data transfer is much lower than the price for S3 data transfer.
downloads are faster with CloudFront than with S3 alone because the objects are stored closer to the users
CloudFront provides two ways to send authenticated requests to an S3 origin: Origin Access Control (OAC) and Origin Access Identity (OAI).
When using S3 as the origin for distribution and the bucket is moved to a different region, CloudFront can take up to an hour to update its records to include the change of region when both of the following are true:
Origin Access Control (OAC) and Origin Access Identity (OAI) are used to restrict access to the bucket.
Bucket is moved to an S3 region that requires Signature Version 4 for authentication
Origin Access Identity – OAI
S3 origin objects must be granted public read permissions and hence the objects are accessible from both S3 as well as CloudFront.
Even though CloudFront does not expose the underlying S3 URL, it can be known to the user if shared directly or used by applications.
For using CloudFront signed URLs or signed cookies to provide access to the objects, it would be necessary to prevent users from having direct access to the S3 objects.
Users accessing S3 objects directly would
bypass the controls provided by CloudFront signed URLs or signed cookies, for e.g., control over the date-time that a user can no longer access the content and the IP addresses can be used to access content
CloudFront access logs are less useful because they’re incomplete.
Origin Access Identity (OAI) can be used to prevent users from directly accessing objects from S3.
Origin access identity, which is a special CloudFront user, can be created and associated with the distribution.
S3 bucket/object permissions need to be configured to only provide access to the Origin Access Identity.
When users access the object from CloudFront, it uses the OAI to fetch the content on the user’s behalf, while the S3 object’s direct access is restricted
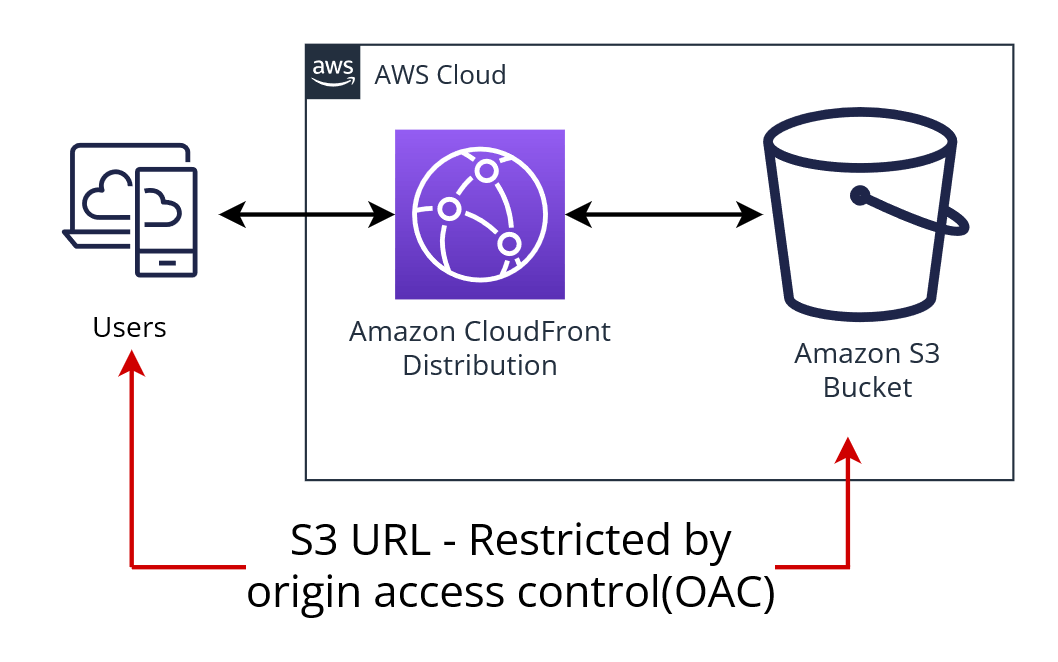
Origin Access Control – OAC
Origin Access Control – OAC is recommended over Origin Access Identity – OAI and supports
Enhanced security practices like short-term credentials, frequent credential rotations, and resource-based policies
All S3 buckets in all AWS Regions
S3 server-side encryption with AWS KMS (SSE-KMS)
Comprehensive HTTP methods support including dynamic requests – OAC supports GET, PUT, POST, PATCH, DELETE, OPTIONS, and HEAD.
CloudFront OAC needs to be setup with permissions to access the S3 bucket origin, which can be done after creating a CloudFront distribution, but before adding the OAC to the S3 origin in the distribution configuration.
For buckets with objects encrypted using server-side encryption with AWS Key Management Service (SSE-KMS), the OAC must be provided with permission to use the AWS KMS key.
CloudFront with S3 Objects
CloudFront can be configured to include custom headers or modify existing headers whenever it forwards a request to the origin, to
validate the user is not accessing the origin directly, bypassing CDN
identify the CDN from which the request was forwarded, if more than one CloudFront distribution is configured to use the same origin
if users use viewers that don’t support CORS, configure CloudFront to forward the Origin header to the origin. That will cause the origin to return the Access-Control-Allow-Origin header for every request
Adding & Updating Objects
Objects just need to be added to the Origin and CloudFront would start distributing them when accessed.
For objects served by CloudFront, the Origin can be updated either by
Overwriting the original object
Create a different version and update the links exposed to the user.
For updating objects, it is recommended to use versioning e.g. have files or the entire folders with versions, so links can be changed when the objects are updated forcing a refresh.
With versioning,
there is no wait time for an object to expire before CloudFront begins to serve a new version of it.
there is no difference in consistency in the object served from the edge
no cost is involved to pay for object invalidation.
Removing/Invalidating Objects
Objects, by default, would be removed upon expiry (TTL) and the latest object would be fetched from the Origin
Objects can also be removed from the edge cache before it expires
File or Object Versioning to serve a different version of the object that has a different name.
Invalidate the object from edge caches. For the next request, CloudFront returns to the Origin to fetch the object
Object or File Versioning is recommended over Invalidating objects
if the objects need to be updated frequently.
enables to control which object a request returns even when the user has a version cached either locally or behind a corporate caching proxy.
makes it easier to analyze the results of object changes as CloudFront access logs include the names of the objects
provides a way to serve different versions to different users.
simplifies rolling forward & back between object revisions.
is less expensive, as no charges for invalidating objects.
for e.g. change header-v1.jpg to header-v2.jpg
Invalidating objects from the cache
objects in the cache can be invalidated explicitly before they expire to force a refresh
allows to invalidate selected objects
allows to invalidate multiple objects for e.g. objects in a directory or all of the objects whose names begin with the same characters, you can include the * wildcard at the end of the invalidation path.
the user might continue to see the old version until it expires from those caches.
A specified number of invalidation paths can be submitted each month for free. Any invalidation requests more than the allotted no. per month, a fee is charged for each submitted invalidation path
The First 1,000 invalidation paths requests submitted per month are free; charges apply for each invalidation path over 1,000 in a month.
Invalidation path can be for a single object for e.g. /js/ab.js or for multiple objects for e.g. /js/* and is counted as a single request even if the * wildcard request may invalidate thousands of objects.
For RTMP distribution, objects served cannot be invalidated
Partial Requests (Range GETs)
Partial requests using Range headers in a GET request help to download the object in smaller units, improving the efficiency of partial downloads and the recovery from partially failed transfers.
For a partial GET range request, CloudFront
checks the cache in the edge location for the requested range or the entire object and if exists, serves it immediately
if the requested range does not exist, it forwards the request to the origin and may request a larger range than the client requested to optimize performance
if the origin supports range header, it returns the requested object range and CloudFront returns the same to the viewer
if the origin does not support range header, it returns the complete object and CloudFront serves the entire object and caches it for future.
CloudFront uses the cached entire object to serve any future range GET header requests
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You are building a system to distribute confidential training videos to employees. Using CloudFront, what method could be used to serve content that is stored in S3, but not publically accessible from S3 directly?
Create an Origin Access Identity (OAI) for CloudFront and grant access to the objects in your S3 bucket to that OAI.
Add the CloudFront account security group “amazon-cf/amazon-cf-sg” to the appropriate S3 bucket policy.
Create an Identity and Access Management (IAM) User for CloudFront and grant access to the objects in your S3 bucket to that IAM User.
Create an S3 bucket policy that lists the CloudFront distribution ID as the Principal and the target bucket as the Amazon Resource Name (ARN).
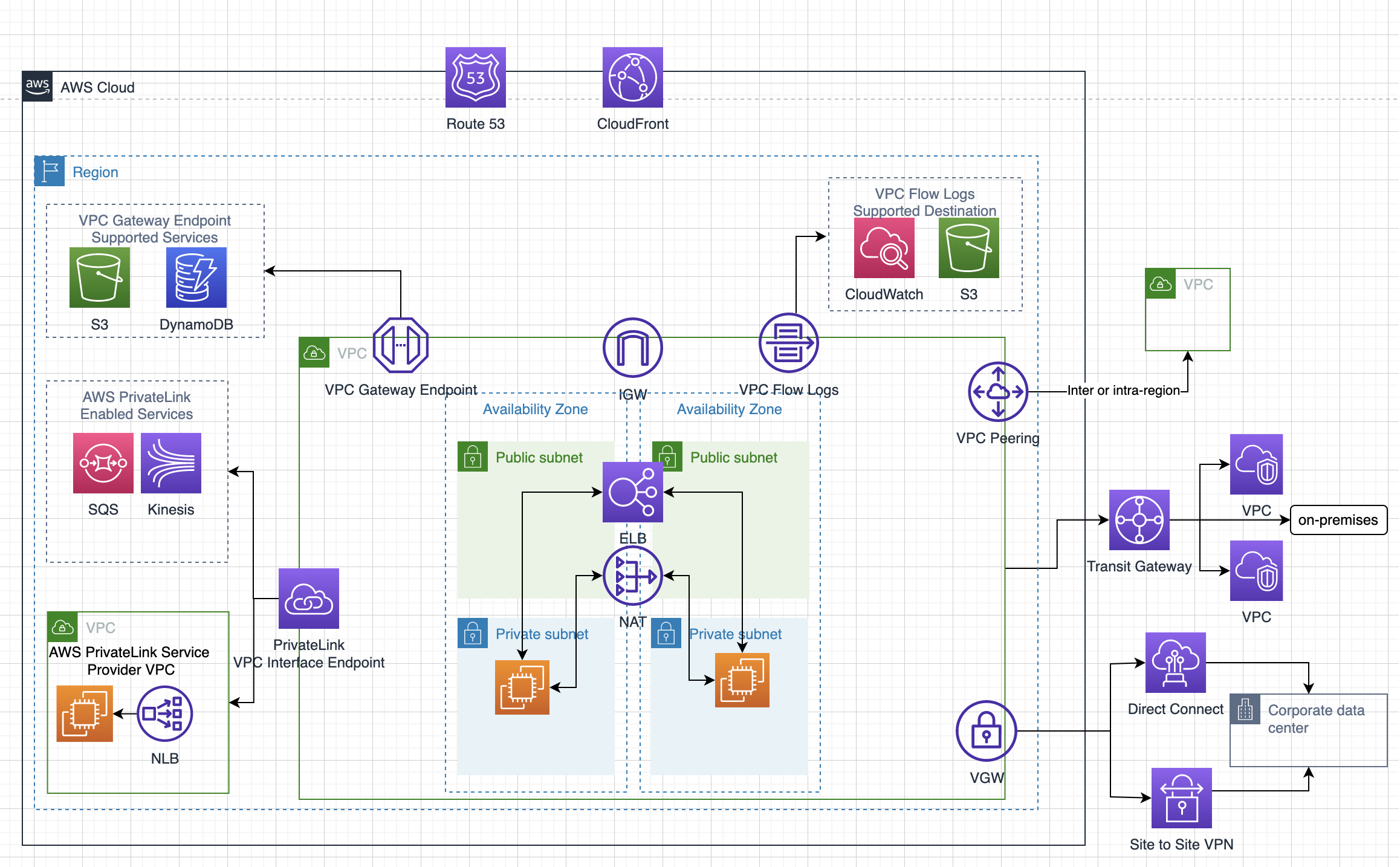
Flow logs – Capture information about the IP traffic going to and from network interfaces in your VPC
Tenancy option for instances
shared, by default, allows instances to be launched on shared tenancy
dedicated allows instances to be launched on a dedicated hardware
Route Tables
defines rules, termed as routes, which determine where network traffic from the subnet would be routed
Each VPC has a Main Route table and can have multiple custom route tables created
Every route table contains a local route that enables communication within a VPC which cannot be modified or deleted
Route priority is decided by matching the most specific route in the route table that matches the traffic
Subnets
map to AZs and do not span across AZs
have a CIDR range that is a portion of the whole VPC.
CIDR ranges cannot overlap between subnets within the VPC.
AWS reserves 5 IP addresses in each subnet – first 4 and last one
Each subnet is associated with a route table which define its behavior
Public subnets – inbound/outbound Internet connectivity via IGW
Private subnets – outbound Internet connectivity via an NAT or VGW
Protected subnets – no outbound connectivity and used for regulated workloads
Elastic Network Interface (ENI)
a default ENI, eth0, is attached to an instance which cannot be detached with one or more secondary detachable ENIs (eth1-ethn)
has primary private, one or more secondary private, public, Elastic IP address, security groups, MAC address and source/destination check flag attributes associated
AN ENI in one subnet can be attached to an instance in the same or another subnet, in the same AZ and the same VPC
Security group membership of an ENI can be changed
with pre-allocated Mac Address can be used for applications with special licensing requirements
allows internet access to instances in the private subnets.
performs the function of both address translation and port address translation (PAT)
needs source/destination check flag to be disabled as it is not the actual destination of the traffic for NAT Instance.
NAT gateway is an AWS managed NAT service that provides better availability, higher bandwidth, and requires less administrative effort
are not supported for IPv6 traffic
NAT Gateway supports private NAT with fixed private IPs.
Egress-Only Internet Gateways
outbound communication over IPv6 from instances in the VPC to the Internet, and prevents the Internet from initiating an IPv6 connection with your instances
supports IPv6 traffic only
Shared VPCs
allows multiple AWS accounts to create their application resources, such as EC2 instances, RDS databases, Redshift clusters, and AWS Lambda functions, into shared, centrally-managed VPCs
enables private connectivity from VPC to supported AWS services and VPC endpoint services powered by PrivateLink
does not require a public IP address, access over the Internet, NAT device, a VPN connection, or Direct Connect
traffic between VPC & AWS service does not leave the Amazon network
are virtual devices.
are horizontally scaled, redundant, and highly available VPC components that allow communication between instances in the VPC and services without imposing availability risks or bandwidth constraints on the network traffic.
Gateway Endpoints
is a gateway that is a target for a specified route in the route table, used for traffic destined to a supported AWS service.
only S3 and DynamoDB are currently supported
Interface Endpoints OR Private Links
is an elastic network interface with a private IP address that serves as an entry point for traffic destined to a supported service
supports services include AWS services, services hosted by other AWS customers and partners in their own VPCs (referred to as endpoint services), and supported AWS Marketplace partner services.
provides low latency and high data transfer speeds for the distribution of static, dynamic web, or streaming content to web users.
delivers the content through a worldwide network of data centers called Edge Locations or Point of Presence (PoPs)
keeps persistent connections with the origin servers so that the files can be fetched from the origin servers as quickly as possible.
dramatically reduces the number of network hops that users’ requests must pass through
supports multiple origin server options, like AWS hosted service for e.g. S3, EC2, ELB, or an on-premise server, which stores the original, definitive version of the objects
single distribution can have multiple origins and Path pattern in a cache behavior determines which requests are routed to the origin
Web distribution supports static, dynamic web content, on-demand using progressive download & HLS, and live streaming video content
supports HTTPS using either
dedicated IP address, which is expensive as a dedicated IP address is assigned to each CloudFront edge location
Server Name Indication (SNI), which is free but supported by modern browsers only with the domain name available in the request header
For E2E HTTPS connection,
Viewers -> CloudFront needs either a certificate issued by CA or ACM
CloudFront -> Origin needs a certificate issued by ACM for ELB and by CA for other origins
Security
Origin Access Identity (OAI) can be used to restrict the content from S3 origin to be accessible from CloudFront only
supports Geo restriction (Geo-Blocking) to whitelist or blacklist countries that can access the content
Signed URLs
to restrict access to individual files, for e.g., an installation download for your application.
users using a client, for e.g. a custom HTTP client, that doesn’t support cookies
Signed Cookies
provide access to multiple restricted files, for e.g., video part files in HLS format or all of the files in the subscribers’ area of a website.
don’t want to change the current URLs
integrates with AWS WAF, a web application firewall that helps protect web applications from attacks by allowing rules configured based on IP addresses, HTTP headers, and custom URI strings
supports GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE to get object & object headers, add, update, and delete objects
only caches responses to GET and HEAD requests and, optionally, OPTIONS requests
does not cache responses to PUT, POST, PATCH, DELETE request methods and these requests are proxied back to the origin
object removal from the cache
would be removed upon expiry (TTL) from the cache, by default 24 hrs
can be invalidated explicitly, but has a cost associated, however, might continue to see the old version until it expires from those caches
objects can be invalidated only for Web distribution
use versioning or change object name, to serve a different version
supports adding or modifying custom headers before the request is sent to origin which can be used to
validate if a user is accessing the content from CDN
identifying CDN from which the request was forwarded, in case of multiple CloudFront distributions
for viewers not supporting CORS to return the Access-Control-Allow-Origin header for every request
supports Partial GET requests using range header to download objects in smaller units improving the efficiency of partial downloads and recovery from partially failed transfers
supports compression to compress and serve compressed files when viewer requests include Accept-Encoding: gzip in the request header
supports different price classes to include all regions, or only the least expensive regions and other regions without the most expensive regions
supports access logs which contain detailed information about every user request for both web and RTMP distribution
is a network service that uses a private dedicated network connection to connect to AWS services.
helps reduce costs (long term), increases bandwidth, and provides a more consistent network experience than internet-based connections.
supports Dedicated and Hosted connections
Dedicated connection is made through a 1 Gbps, 10 Gbps, or 100 Gbps Ethernet port dedicated to a single customer.
Hosted connections are sourced from an AWS Direct Connect Partner that has a network link between themselves and AWS.
provides Virtual Interfaces
Private VIF to access instances within a VPC via VGW
Public VIF to access non VPC services
requires time to setup probably months, and should not be considered as an option if the turnaround time is less
does not provide redundancy, use either second direct connection or IPSec VPN connection
Virtual Private Gateway is on the AWS side and Customer Gateway is on the Customer side
route propagation is enabled on VGW and not on CGW
A link aggregation group (LAG) is a logical interface that uses the link aggregation control protocol (LACP) to aggregate multiple dedicated connections at a single AWS Direct Connect endpoint and treat them as a single, managed connection
Direct Connect vs VPN IPSec
Expensive to Setup and Takes time vs Cheap & Immediate
Dedicated private connections vs Internet
Reduced data transfer rate vs Internet data transfer cost
Consistent performance vs Internet inherent variability
It’s similar to a CNAME resource record set, but supports both for root domain – zone apex e.g. example.com, and for subdomains for e.g. www.example.com.
supports ELB load balancers, CloudFront distributions, Elastic Beanstalk environments, API Gateways, VPC interface endpoints, and S3 buckets that are configured as websites.
CNAME resource record sets can be created only for subdomains and cannot be mapped to the zone apex record
supports Private DNS to provide an authoritative DNS within the VPCs without exposing the DNS records (including the name of the resource and its IP address(es) to the Internet.
Split-view (Split-horizon) DNS enables mapping the same domain publicly and privately. Requests are routed as per the origin.
Weighted routing – assign weights to resource records sets to specify the proportion for e.g. 80%:20%
Latency based routing – helps improve global applications as requests are sent to the server from the location with minimal latency, is based on the latency and cannot guarantee users from the same geography will be served from the same location for any compliance reasons
Geolocation routing – Specify geographic locations by continent, country, the state limited to the US, is based on IP accuracy
Geoproximity routing policy – Use to route traffic based on the location of the resources and, optionally, shift traffic from resources in one location to resources in another.
Multivalue answer routing policy – Use to respond to DNS queries with up to eight healthy records selected at random.
Failover routing – failover to a backup site if the primary site fails and becomes unreachable
Weighted, Latency and Geolocation can be used for Active-Active while Failover routing can be used for Active-Passive multi-region architecture
Traffic Flow is an easy-to-use and cost-effective global traffic management service. Traffic Flow supports versioning and helps create policies that route traffic based on the constraints they care most about, including latency, endpoint health, load, geoproximity, and geography.
Route 53 Resolver is a regional DNS service that helps with hybrid DNS
Inbound Endpoints are used to resolve DNS queries from an on-premises network to AWS
Outbound Endpoints are used to resolve DNS queries from AWS to an on-premises network
is a networking service that helps you improve the availability and performance of the applications to global users.
utilizes the Amazon global backbone network, improving the performance of the applications by lowering first-byte latency, and jitter, and increasing throughput as compared to the public internet.
provides two static IP addresses serviced by independent network zones that provide a fixed entry point to the applications and eliminate the complexity of managing specific IP addresses for different AWS Regions and AZs.
always routes user traffic to the optimal endpoint based on performance, reacting instantly to changes in application health, the user’s location, and configured policies
improves performance for a wide range of applications over TCP or UDP by proxying packets at the edge to applications running in one or more AWS Regions.
is a good fit for non-HTTP use cases, such as gaming (UDP), IoT (MQTT), or Voice over IP, as well as for HTTP use cases that specifically require static IP addresses or deterministic, fast regional failover.
is a highly available and scalable service to consolidate the AWS VPC routing configuration for a region with a hub-and-spoke architecture.
acts as a Regional virtual router and is a network transit hub that can be used to interconnect VPCs and on-premises networks.
traffic always stays on the global AWS backbone, data is automatically encrypted, and never traverses the public internet, thereby reducing threat vectors, such as common exploits and DDoS attacks.
is a Regional resource and can connect VPCs within the same AWS Region.
TGWs across the same or different regions can peer with each other.
provides simpler VPC-to-VPC communication management over VPC Peering with a large number of VPCs.
scales elastically based on the volume of network traffic.
CloudFront is a fully managed, fast content delivery network (CDN) service that speeds up the distribution of static, dynamic web, or streaming content to end-users.
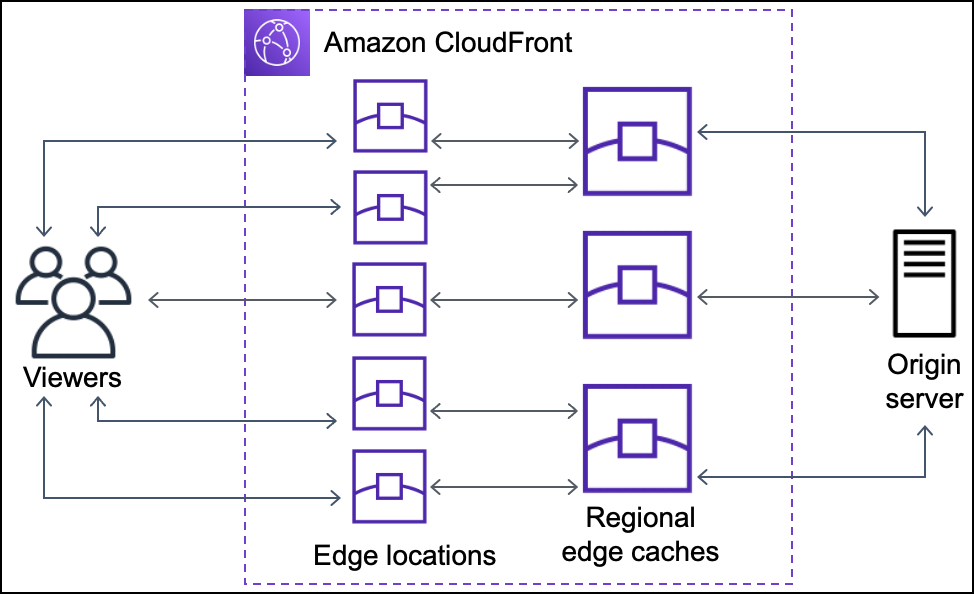
CloudFront delivers the content through a worldwide network of data centers called edge locations or Point of Presence (POP).
CloudFront securely delivers data, videos, applications, and APIs to customers globally with low latency, and high transfer speeds, all within a developer-friendly environment.
CloudFront gives businesses and web application developers an easy and cost-effective way to distribute content with low latency and high data transfer speeds.
CloudFront speeds up the distribution of the content by routing each user request to the edge location that can best serve the content thus providing the lowest latency (time delay).
CloudFront uses the AWS backbone network that dramatically reduces the number of network hops that users’ requests must pass through and helps improve performance, provide lower latency and higher data transfer rate
CloudFront is a good choice for the distribution of frequently accessed static content that benefits from edge delivery – like popular website images, videos, media files, or software downloads
CloudFront Benefits
CloudFront eliminates the expense and complexity of operating a network of cache servers in multiple sites across the internet and eliminates the need to over-provision capacity in order to serve potential spikes in traffic.
CloudFront also provides increased reliability and availability because copies of objects are held in multiple edge locations around the world.
CloudFront keeps persistent connections with the origin servers so that those files can be fetched from the origin servers as quickly as possible.
CloudFront also uses techniques such as collapsing simultaneous viewer requests at an edge location for the same file into a single request to the origin server reducing the load on the origin.
CloudFront offers the most advanced security capabilities, including field-level encryption and HTTPS support.
CloudFront Edge Locations or POPs make sure that popular content can be served quickly to the viewers.
CloudFront also has Regional Edge Caches that help bring more content closer to the viewers, even when the content is not popular enough to stay at a POP, to help improve performance for that content.
Regional Edge Caches are deployed globally, close to the viewers, and are located between the origin servers and the Edge Locations.
Regional edge caches support multiple Edge Locations and support a larger cache size so objects remain in the cache longer at the nearest regional edge cache location.
Regional edge caches help with all types of content, particularly content that tends to become less popular over time.
Configuration & Content Delivery
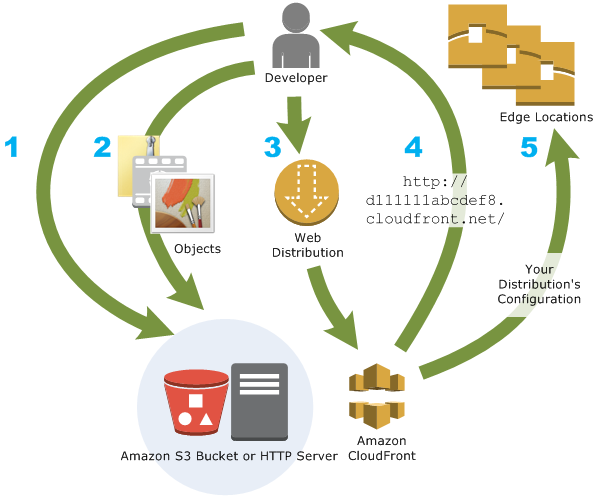
Configuration
Origin servers need to be configured to get the files for distribution. An origin server stores the original, definitive version of the objects and can be an AWS hosted service for e.g. S3, EC2, or an on-premise server
Files or objects can be added/uploaded to the Origin servers with public read permissions or permissions restricted to Origin Access Identity (OAI).
Create a CloudFront distribution, which tells CloudFront which origin servers to get the files from when users request the files.
CloudFront sends the distribution configuration to all the edge locations.
The website can be used with the CloudFront provided domain name or a custom alternate domain name.
An origin server can be configured to limit access protocols, caching behaviour, add headers to the files to add TTL, or the expiration time.
Content delivery to Users
When a user accesses the website, file, or object – the DNS routes the request to the CloudFront edge location that can best serve the user’s request with the lowest latency.
CloudFront returns the object immediately if the requested object is present in the cache at the Edge location.
If the requested object does not exist in the cache at the edge location, the POP typically goes to the nearest regional edge cache to fetch it.
If the object is in the regional edge cache, CloudFront forwards it to the POP that requested it.
For objects not cached at either the POP or the regional edge cache location, the objects are requested from the origin server and returned it to the user via the regional edge cache and POP
CloudFront begins to forward the object to the user as soon as the first byte arrives from the regional edge cache location.
CloudFront also adds the object to the cache in the regional edge cache location in addition to the POP for the next time a viewer requests it.
When the object reaches its expiration time, for any new request CloudFront checks with the Origin server for any latest versions, if it has the latest it uses the same object. If the Origin server has the latest version the same is retrieved, served to the user, and cached as well
CloudFront Origins
Each origin is either an S3 bucket, a MediaStore container, a MediaPackage channel, or a custom origin like an EC2 instance or an HTTP server
For the S3 bucket, use the bucket URL or the static website endpoint URL, and the files either need to be publicly readable or secured using OAI.
Origin restrict access, for S3 only, can be configured using Origin Access Identity to prevent direct access to the S3 objects.
For the HTTP server as the origin, the domain name of the resource needs to be mapped and files must be publicly readable.
Distribution can have multiple origins for each bucket with one or more cache behaviors that route requests to each origin. Path pattern in a cache behavior determines which requests are routed to the origin (S3 bucket) that is associated with that cache behavior.
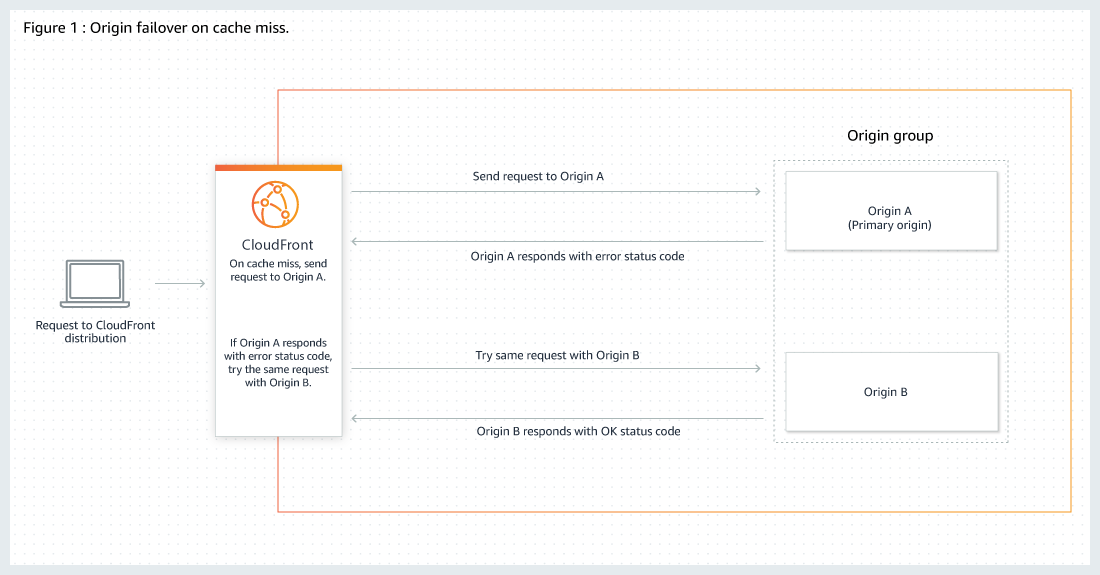
CloudFront Origin Groups
Origin Groups can be used to specify two origins to configure origin failover for high availability.
Origin failover can be used to designate a primary origin plus a second origin that CloudFront automatically switches to when the primary origin returns specific HTTP status code failure responses.
An origin group includes two origins (a primary origin and a second origin to failover to) and specified failover criteria.
CloudFront routes all incoming requests to the primary origin, even when a previous request has failed over to the secondary origin. CloudFront only sends requests to the secondary origin after a request fails to the primary origin.
CloudFront fails over to a secondary origin only when the HTTP method of the consumer request is GET, HEAD, or OPTIONS and does not fail over when the consumer sends a different HTTP method (for example POST, PUT, etc.).
CloudFront Delivery Methods
Web distributions
supports both static and dynamic content for e.g. HTML, CSS, js, images, etc using HTTP or HTTPS.
supports multimedia content on-demand using progressive download and Apple HTTP Live Streaming (HLS).
supports a live event, such as a meeting, conference, or concert, in real-time. For live streaming, distribution can be created automatically using an AWS CloudFormation stack.
origin servers can be either an S3 bucket or an HTTP server, for e.g., a web server or an AWS ELB, etc.
RMTP distributions (Support Discontinued)
supports streaming of media files using Adobe Media Server and the Adobe Real-Time Messaging Protocol (RTMP)
must use an S3 bucket as the origin.
To stream media files using CloudFront, two types of files are needed
Media files
Media player for e.g. JW Player, Flowplayer, or Adobe flash
End-users view media files using the media player that is provided; not the locally installed on the computer of the device
When an end-user streams the media file, the media player begins to play the file content while the file is still being downloaded from CloudFront.
The media file is not stored locally on the end user’s system.
Two CloudFront distributions are required, Web distribution for media Player and RMTP distribution for media files
Media player and Media files can be stored in a same-origin S3 bucket or different buckets
Cache Behavior Settings
Path Patterns
Path Patterns help define which path the Cache behaviour would apply to.
A default (*) pattern is created and multiple cache distributions can be added with patterns to take priority over the default path.
Viewer Protocol Policy (Viewer -> CloudFront)
Viewer Protocol policy can be configured to define the allowed access protocol.
Between CloudFront & Viewers, cache distribution can be configured to either allow
HTTPS only – supports HTTPS only
HTTP and HTTPS – supports both
HTTP redirected to HTTPS – HTTP is automatically redirected to HTTPS
Origin Protocol Policy (CloudFront -> Origin)
Between CloudFront & Origin, cache distribution can be configured with
HTTP only (for S3 static website).
HTTPS only – CloudFront fetches objects from the origin by using HTTPS.
Match Viewer – CloudFront uses the protocol that the viewer used to request the objects.
For S3 as origin,
For the website, the protocol has to be HTTP as HTTPS is not supported.
For the S3 bucket, the default Origin protocol policy is Match Viewer and cannot be changed. So When CloudFront is configured to require HTTPS between the viewer and CloudFront, it automatically uses HTTPS to communicate with S3.
HTTPS Connection
CloudFront can also be configured to work with HTTPS for alternate domain names by using:-
Serving HTTPS Requests Using Dedicated IP Addresses
CloudFront associates the alternate domain name with a dedicated IP address, and the certificate is associated with the IP address when a request is received from a DNS server for the IP address.
CloudFront uses the IP address to identify the distribution and the SSL/TLS certificate to return to the viewer.
This method works for every HTTPS request, regardless of the browser or other viewer that the user is using.
An additional monthly charge (of about $600/month) is incurred for using a dedicated IP address.
Serving HTTPS Requests Using Server Name Indication – SNI
SNI Custom SSL relies on the SNI extension of the TLS protocol, which allows multiple domains to be served over the same IP address by including the hostname, viewers are trying to connect to
With the SNI method, CloudFront associates an IP address with the alternate domain name, but the IP address is not dedicated.
CloudFront can’t determine, based on the IP address, which domain the request is for as the IP address is not dedicated.
Browsers that support SNI automatically get the domain name from the request URL & add it to a new field in the request header.
When CloudFront receives an HTTPS request from a browser that supports SNI, it finds the domain name in the request header and responds to the request with the applicable SSL/TLS certificate.
Viewer and CloudFront perform SSL negotiation, and CloudFront returns the requested content to the viewer.
Older browsers do not support SNI.
SNI Custom SSL is available at no additional cost beyond standard CloudFront data transfer and request fees
For End-to-End HTTPS connections certificate needs to be applied both between the Viewers and CloudFront & CloudFront and Origin, with the following requirements
HTTPS between viewers and CloudFront
A certificate that was issued by a trusted certificate authority (CA) such as Comodo, DigiCert, or Symantec;
If the origin is not an ELB load balancer, the certificate must be issued by a trusted CA such as Comodo, DigiCert, or Symantec.
For load balancer, a certificate provided by ACM can be used
Self-signed certificates CAN NOT be used.
ACM certificate for CloudFront must be requested or imported in the US East (N. Virginia) region. ACM certificates in this region that are associated with a CloudFront distribution are distributed to all the geographic locations configured for that distribution.
Allowed HTTP methods
CloudFront supports GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE to get, add, update, and delete objects, and to get object headers.
GET, HEAD methods to use to get objects, object headers
GET, HEAD, OPTIONS methods to use to get objects, object headers or retrieve a list of the options supported from the origin
GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE operations can also be performed for e.g. submitting data from a web form, which are directly proxied back to the Origin server
CloudFront only caches responses to GET and HEAD requests and, optionally, OPTIONS requests. CloudFront does not cache responses to PUT, POST, PATCH, DELETE request methods and these requests are directed to the origin.
PUT, POST HTTP methods also help for accelerated content uploads, as these operations will be sent to the origin e.g. S3 via the CloudFront edge location, improving efficiency, reducing latency, and allowing the application to benefit from the monitored, persistent connections that CloudFront maintains from the edge locations to the origin servers.
CloudFront Edge Caches
Control the cache max-age
To increase the cache hit ratio, the origin can be configured to add a Cache-Control: max-age directive to the objects.
Longer the interval less frequently it would be retrieved from the origin
Caching Based on Query String Parameters
CloudFront can be configured to cache based on the query parameters
None (Improves Caching) – if the origin returns the same version of an object regardless of the values of query string parameters.
Forward all, cache based on whitelist – if the origin server returns different versions of the objects based on one or more query string parameters. Then specify the parameters that you want CloudFront to use as a basis for caching in the Query String Whitelist field.
Forward all, cache based on all – if the origin server returns different versions of the objects for all query string parameters.
Caching performance can be improved by
Configure CloudFront to forward only the query strings for which the origin will return unique objects.
Using the same case for the parameters’ values for e.g. parameter value A or a, CloudFront would cache the same request twice even if the response or object returned is identical
Using the same parameter order for e.g. for request a=x&b=y and b=y&a=x, CloudFront would cache the same request twice even though the response or object returned is identical
For RTMP distributions, when CloudFront requests an object from the origin server, it removes any query string parameters.
Caching Based on Cookie Values
CloudFront can be configured to cache based on cookie values.
By default, it doesn’t consider cookies while caching on edge locations
Caching performance can be improved by
Configure CloudFront to forward only specified cookies instead of forwarding all cookies for e.g. if the request has 2 cookies with 3 possible values, CloudFront would cache all possible combinations even if the response takes into account a single cookie
Cookie names and values are both case sensitive so better to stick with the same case
Create separate cache behaviors for static and dynamic content, and configure CloudFront to forward cookies to the origin only for dynamic content for e.g. for CSS files, the cookies do not make sense as the object does not change with the cookie value
If possible, create separate cache behaviors for dynamic content for which cookie values are unique for each user (such as a user ID) and dynamic content that varies based on a smaller number of unique values reducing the number of combinations
For RTMP distributions, CloudFront cannot be configured to process cookies. When CloudFront requests an object from the origin server, it removes any cookies before forwarding the request to your origin. If your origin returns any cookies along with the object, CloudFront removes them before returning the object to the viewer.
Caching Based on Request Headers
CloudFront can be configured to cache based on request headers
By default, CloudFront doesn’t consider headers when caching the objects in edge locations.
CloudFront configured to cache based on request headers, does not change the headers that CloudFront forwards, only whether CloudFront caches objects based on the header values.
Caching performance can be improved by
Configure CloudFront to forward and cache based only on specified headers instead of forwarding and caching based on all headers.
Try to avoid caching based on request headers that have large numbers of unique values.
CloudFront is configured to forward all headers to the origin, CloudFront doesn’t cache the objects associated with this cache behaviour. Instead, it sends every request to the origin
CloudFront caches based on header values, it doesn’t consider the case of the header name but considers the case of the header value
For RTMP distributions, CloudFront cannot be configured to cache based on header values.
Object Caching & Expiration
Object expiration determines how long the objects stay in a CloudFront cache before it fetches it again from Origin.
Low expiration time helps serve content that changes frequently and high expiration time helps improve performance and reduce the origin load.
By default, each object automatically expires after 24 hours
After expiration time, CloudFront checks if it still has the latest version
If the cache already has the latest version, the origin returns a 304 status code (Not Modified).
If the CloudFront cache does not have the latest version, the origin returns a 200 status code (OK), and the latest version of the object
If an object in an edge location isn’t frequently requested, CloudFront might evict the object, and remove the object before its expiration date to make room for objects that have been requested more recently.
For Web distributions, the default behaviour can be changed by
for the entire path pattern, cache behaviour can be configured by the setting Minimum TTL, Maximum TTL, and Default TTL values
for individual objects, the origin can be configured to add a Cache-Control max-age or Cache-Control s-maxage directive, or an Expires header field to the object.
AWS recommends using Cache-Control max-age directive over Expires header to control object caching behaviour.
CloudFront uses only the value of Cache-Control max-age , if both the Cache-Control max-age directive and Expires header is specified
HTTP Cache-Control or Pragma header fields in a GET request from a viewer can’t be used to force CloudFront to go back to the origin server for the object
By default, when the origin returns an HTTP 4xx or 5xx status code, CloudFront caches these error responses for five minutes and then submit the next request for the object to the origin to see whether
the requested object is available and the problem has been resolved
For RTMP distributions
Cache-Control or Expires headers can be added to objects to change the amount of time that CloudFront keeps objects in edge caches before it forwards another request to the origin.
Minimum duration is 3600 seconds (one hour). If you specify a lower value, CloudFront uses 3600 seconds.
CloudFront Origin Shield
CloudFront Origin Shield provides an additional layer in the CloudFront caching infrastructure that helps to minimize the origin’s load, improve its availability, and reduce its operating costs.
Origin Shield provides a centralized caching layer that helps increase the cache hit ratio to reduce the load on your origin.
Origin Shield decreases the origin operating costs by collapsing requests across regions so as few as one request goes to the origin per object.
Origin Shield can be configured by choosing the Regional Edge Cache closest to the origin to become the Origin Shield Region
CloudFront Origin Shield is beneficial for many use cases like
Viewers that are spread across different geographical regions
Origins that provide just-in-time packaging for live streaming or on-the-fly image processing
On-premises origins with capacity or bandwidth constraints
Workloads that use multiple content delivery networks (CDNs)
Serving Compressed Files
CloudFront can be configured to automatically compress files of certain types and serve the compressed files when viewer requests include Accept-Encoding in the request header
Compressing content, downloads are faster because the files are smaller as well as less expensive as the cost of CloudFront data transfer is based on the total amount of data served.
CloudFront can compress objects using the Gzip and Brotli compression formats.
If serving from a custom origin, it can be used to
configure to compress files with or without CloudFront compression
compress file types that CloudFront doesn’t compress.
If the origin returns a compressed file, CloudFront detects compression by the Content-Encoding header value and doesn’t compress the file again.
CloudFront serves content using compression as below
CloudFront distribution is created and configured to compress content.
A viewer requests a compressed file by adding the Accept-Encoding header with includes gzip, br, or both to the request.
At the edge location, CloudFront checks the cache for a compressed version of the file that is referenced in the request.
If the compressed file is already in the cache, CloudFront returns the file to the viewer and skips the remaining steps.
If the compressed file is not in the cache, CloudFront forwards the request to the origin server (S3 bucket or a custom origin)
Even if CloudFront has an uncompressed version of the file in the cache, it still forwards a request to the origin.
Origin server returns an uncompressed version of the requested file
CloudFront determines whether the file is compressible:
file must be of a type that CloudFront compresses.
file size must be between 1,000 and 10,000,000 bytes.
response must include a Content-Length header to determine the size within valid compression limits. If the Content-Length header is missing, CloudFront won’t compress the file.
value of the Content-Encoding header on the file must not be gzip i.e. the origin has already compressed the file.
the response should have a body.
response HTTP status code should be 200, 403, or 404
If the file is compressible, CloudFront compresses it, returns the compressed file to the viewer, and adds it to the cache.
The viewer uncompresses the file.
Distribution Details
Price Class
CloudFront has edge locations all over the world and the cost for each edge location varies and the price charged for serving the requests also varies
CloudFront edge locations are grouped into geographic regions, and regions have been grouped into price classes
Price Class – includes all the regions
Another price class includes most regions (the United States; Europe; Hong Kong, Korea, and Singapore; Japan; and India regions) but excludes the most expensive regions
Price Class 200 – Includes All regions except South America and Australia and New Zealand.
Price Class 100 – A third price class includes only the least-expensive regions (North America and Europe regions)
Price class can be selected to lower the cost but this would come only at the expense of performance (higher latency), as CloudFront would serve requests only from the selected price class edge locations
CloudFront may, sometimes, service requests from a region not included within the price class, however, you would be charged the rate for the least-expensive region in your selected price class
WAF Web ACL
AWS WAF can be used to allow or block requests based on specified criteria, choose the web ACL to associate with this distribution.
Alternate Domain Names (CNAMEs)
CloudFront by default assigns a domain name for the distribution for e.g. d111111abcdef8.cloudfront.net
An alternate domain name, also known as a CNAME, can be used to use own custom domain name for links to objects
Both web and RTMP distributions support alternate domain names.
CloudFront supports * wildcard at the beginning of a domain name instead of specifying subdomains individually.
However, a wildcard cannot replace part of a subdomain name for e.g. *domain.example.com, or cannot replace a subdomain in the middle of a domain name for e.g. subdomain.*.example.com.
Distribution State
Distribution state indicates whether you want the distribution to be enabled or disabled once it’s deployed.
Geo-Restriction – Geoblocking
Geo restriction can help allow or prevent users in selected countries from accessing the content,
CloudFront distribution can be configured either to allow users in
whitelist of specified countries to access the content or to
deny users in a blacklist of specified countries to access the content
Geo restriction can be used to restrict access to all of the files that are
associated with distribution and to restrict access at the country level
CloudFront responds to a request from a viewer in a restricted country with an HTTP status code 403 (Forbidden)
Use a third-party geolocation service, if access is to be restricted to a subset of the files that are associated with a distribution or to restrict access at a finer granularity than the country level.
CloudFront provides Encryption in Transit and can be configured to require that viewers use HTTPS to request the files so that connections are encrypted when CloudFront communicates with viewers.
CloudFront provides Encryption at Rest
uses SSDs which are encrypted for edge location points of presence (POPs), and encrypted EBS volumes for Regional Edge Caches (RECs).
Function code and configuration are always stored in an encrypted format on the encrypted SSDs on the edge location POPs, and in other storage locations used by CloudFront.
Restricting access to content
Configure HTTPS connections
Use signed URLs or cookies to restrict access for selected users
Restrict access to content in S3 buckets using origin access identity – OAI, to prevent users from using the direct URL of the file.
Restrict direct to load balancer using custom headers, to prevent users from using the direct load balancer URLs.
Set up field-level encryption for specific content fields
Use AWS WAF web ACLs to create a web access control list (web ACL) to restrict access to your content.
Use geo-restriction, also known as geoblocking, to prevent users in specific geographic locations from accessing content served through a CloudFront distribution.
CloudFront can be configured to create log files that contain detailed information about every user request that CloudFront receives.
Access logs are available for both web and RTMP distributions.
With logging enabled, an S3 bucket can be specified where CloudFront would save the files
CloudFront delivers access logs for a distribution periodically, up to several times an hour
CloudFront usually delivers the log file for that time period to the S3 bucket within an hour of the events that appear in the log. Note, however, that some or all log file entries for a time period can sometimes be delayed by up to 24 hours
CloudFront Cost
CloudFront charges are based on actual usage of the service in four areas:
Data Transfer Out to Internet
charges are applied for the volume of data transferred out of the CloudFront edge locations, measured in GB
Data transfer out from AWS origin (e.g., S3, EC2, etc.) to CloudFront are no longer charged. This applies to data transfer from all AWS regions to all global CloudFront edge locations
HTTP/HTTPS Requests
number of HTTP/HTTPS requests made for the content
Invalidation Requests
per path in the invalidation request
A path listed in the invalidation request represents the URL (or multiple URLs if the path contains a wildcard character) of the object you want to invalidate from the CloudFront cache
Dedicated IP Custom SSL certificates associated with a CloudFront distribution
$600 per month for each custom SSL certificate associated with one or more CloudFront distributions using the Dedicated IP version of custom SSL certificate support, pro-rated by the hour
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Your company Is moving towards tracking web page users with a small tracking Image loaded on each page Currently you are serving this image out of US-East, but are starting to get concerned about the time It takes to load the image for users on the west coast. What are the two best ways to speed up serving this image? Choose 2 answers
Use Route 53’s Latency Based Routing and serve the image out of US-West-2 as well as US-East-1
Serve the image out through CloudFront
Serve the image out of S3 so that it isn’t being served oft of your web application tier
Use EBS PIOPs to serve the image faster out of your EC2 instances
You deployed your company website using Elastic Beanstalk and you enabled log file rotation to S3. An Elastic Map Reduce job is periodically analyzing the logs on S3 to build a usage dashboard that you share with your CIO. You recently improved overall performance of the website using Cloud Front for dynamic content delivery and your website as the origin. After this architectural change, the usage dashboard shows that the traffic on your website dropped by an order of magnitude. How do you fix your usage dashboard’? [PROFESSIONAL]
Enable CloudFront to deliver access logs to S3 and use them as input of the Elastic Map Reduce job
Turn on Cloud Trail and use trail log tiles on S3 as input of the Elastic Map Reduce job
Change your log collection process to use Cloud Watch ELB metrics as input of the Elastic Map Reduce job
Use Elastic Beanstalk “Rebuild Environment” option to update log delivery to the Elastic Map Reduce job.
Use Elastic Beanstalk ‘Restart App server(s)” option to update log delivery to the Elastic Map Reduce job.
An AWS customer runs a public blogging website. The site users upload two million blog entries a month. The average blog entry size is 200 KB. The access rate to blog entries drops to negligible 6 months after publication and users rarely access a blog entry 1 year after publication. Additionally, blog entries have a high update rate during the first 3 months following publication; this drops to no updates after 6 months. The customer wants to use CloudFront to improve his user’s load times. Which of the following recommendations would you make to the customer? [PROFESSIONAL]
Duplicate entries into two different buckets and create two separate CloudFront distributions where S3 access is restricted only to Cloud Front identity
Create a CloudFront distribution with “US & Europe” price class for US/Europe users and a different CloudFront distribution with All Edge Locations for the remaining users.
Create a CloudFront distribution with S3 access restricted only to the CloudFront identity and partition the blog entry’s location in S3 according to the month it was uploaded to be used with CloudFront behaviors
Create a CloudFront distribution with Restrict Viewer Access Forward Query string set to true and minimum TTL of 0.
Your company has on-premises multi-tier PHP web application, which recently experienced downtime due to a large burst in web traffic due to a company announcement. Over the coming days, you are expecting similar announcements to drive similar unpredictable bursts, and are looking to find ways to quickly improve your infrastructures ability to handle unexpected increases in traffic. The application currently consists of 2 tiers a web tier, which consists of a load balancer, and several Linux Apache web servers as well as a database tier which hosts a Linux server hosting a MySQL database. Which scenario below will provide full site functionality, while helping to improve the ability of your application in the short timeframe required? [PROFESSIONAL]
Offload traffic from on-premises environment Setup a CloudFront distribution and configure CloudFront to cache objects from a custom origin Choose to customize your object cache behavior, and select a TTL that objects should exist in cache.
Migrate to AWS Use VM Import/Export to quickly convert an on-premises web server to an AMI create an Auto Scaling group, which uses the imported AMI to scale the web tier based on incoming traffic Create an RDS read replica and setup replication between the RDS instance and on-premises MySQL server to migrate the database.
Failover environment: Create an S3 bucket and configure it tor website hosting Migrate your DNS to Route53 using zone (lie import and leverage Route53 DNS failover to failover to the S3 hosted website.
Hybrid environment Create an AMI which can be used of launch web serfers in EC2 Create an Auto Scaling group which uses the * AMI to scale the web tier based on incoming traffic Leverage Elastic Load Balancing to balance traffic between on-premises web servers and those hosted in AWS.
You are building a system to distribute confidential training videos to employees. Using CloudFront, what method could be used to serve content that is stored in S3, but not publically accessible from S3 directly?
Create an Origin Access Identity (OAI) for CloudFront and grant access to the objects in your S3 bucket to that OAI.
Add the CloudFront account security group “amazon-cf/amazon-cf-sg” to the appropriate S3 bucket policy.
Create an Identity and Access Management (IAM) User for CloudFront and grant access to the objects in your S3 bucket to that IAM User.
Create a S3 bucket policy that lists the CloudFront distribution ID as the Principal and the target bucket as the Amazon Resource Name (ARN).
A media production company wants to deliver high-definition raw video for preproduction and dubbing to customer all around the world. They would like to use Amazon CloudFront for their scenario, and they require the ability to limit downloads per customer and video file to a configurable number. A CloudFront download distribution with TTL=0 was already setup to make sure all client HTTP requests hit an authentication backend on Amazon Elastic Compute Cloud (EC2)/Amazon RDS first, which is responsible for restricting the number of downloads. Content is stored in S3 and configured to be accessible only via CloudFront. What else needs to be done to achieve an architecture that meets the requirements? Choose 2 answers [PROFESSIONAL]
Enable URL parameter forwarding, let the authentication backend count the number of downloads per customer in RDS, and return the content S3 URL unless the download limit is reached.
Enable CloudFront logging into an S3 bucket, leverage EMR to analyze CloudFront logs to determine the number of downloads per customer, and return the content S3 URL unless the download limit is reached. (CloudFront logs are logged periodically and EMR not being real time, hence not suitable)
Enable URL parameter forwarding, let the authentication backend count the number of downloads per customer in RDS, and invalidate the CloudFront distribution as soon as the download limit is reached. (Distribution are not invalidated but Objects)
Enable CloudFront logging into the S3 bucket, let the authentication backend determine the number of downloads per customer by parsing those logs, and return the content S3 URL unless the download limit is reached. (CloudFront logs are logged periodically and EMR not being real time, hence not suitable)
Configure a list of trusted signers, let the authentication backend count the number of download requests per customer in RDS, and return a dynamically signed URL unless the download limit is reached.
Your customer is implementing a video on-demand streaming platform on AWS. The requirements are to support for multiple devices such as iOS, Android, and PC as client devices, using a standard client player, using streaming technology (not download) and scalable architecture with cost effectiveness [PROFESSIONAL]
Store the video contents to Amazon Simple Storage Service (S3) as an origin server. Configure the Amazon CloudFront distribution with a streaming option to stream the video contents
Store the video contents to Amazon S3 as an origin server. Configure the Amazon CloudFront distribution with a download option to stream the video contents (Refer link)
Launch a streaming server on Amazon Elastic Compute Cloud (EC2) (for example, Adobe Media Server), and store the video contents as an origin server. Configure the Amazon CloudFront distribution with a download option to stream the video contents
Launch a streaming server on Amazon Elastic Compute Cloud (EC2) (for example, Adobe Media Server), and store the video contents as an origin server. Launch and configure the required amount of streaming servers on Amazon EC2 as an edge server to stream the video contents
You are an architect for a news -sharing mobile application. Anywhere in the world, your users can see local news on of topics they choose. They can post pictures and videos from inside the application. Since the application is being used on a mobile phone, connection stability is required for uploading content, and delivery should be quick. Content is accessed a lot in the first minutes after it has been posted, but is quickly replaced by new content before disappearing. The local nature of the news means that 90 percent of the uploaded content is then read locally (less than a hundred kilometers from where it was posted). What solution will optimize the user experience when users upload and view content (by minimizing page load times and minimizing upload times)? [PROFESSIONAL]
Upload and store the content in a central Amazon Simple Storage Service (S3) bucket, and use an Amazon Cloud Front Distribution for content delivery.
Upload and store the content in an Amazon Simple Storage Service (S3) bucket in the region closest to the user, and use multiple Amazon Cloud Front distributions for content delivery.
Upload the content to an Amazon Elastic Compute Cloud (EC2) instance in the region closest to the user, send the content to a central Amazon Simple Storage Service (S3) bucket, and use an Amazon Cloud Front distribution for content delivery.
Use an Amazon Cloud Front distribution for uploading the content to a central Amazon Simple Storage Service (S3) bucket and for content delivery.
To enable end-to-end HTTPS connections from the user‘s browser to the origin via CloudFront, which of the following options are valid? Choose 2 answers [PROFESSIONAL]
Use self signed certificate in the origin and CloudFront default certificate in CloudFront. (Origin cannot be self signed)
Use the CloudFront default certificate in both origin and CloudFront (CloudFront cert cannot be applied to origin)
Use 3rd-party CA certificate in the origin and CloudFront default certificate in CloudFront
Use 3rd-party CA certificate in both origin and CloudFront
Use a self signed certificate in both the origin and CloudFront (Origin cannot be self signed)
Your application consists of 10% writes and 90% reads. You currently service all requests through a Route53 Alias Record directed towards an AWS ELB, which sits in front of an EC2 Auto Scaling Group. Your system is getting very expensive when there are large traffic spikes during certain news events, during which many more people request to read similar data all at the same time. What is the simplest and cheapest way to reduce costs and scale with spikes like this? [PROFESSIONAL]
Create an S3 bucket and asynchronously replicate common requests responses into S3 objects. When a request comes in for a precomputed response, redirect to AWS S3
Create another ELB and Auto Scaling Group layer mounted on top of the other system, adding a tier to the system. Serve most read requests out of the top layer
Create a CloudFront Distribution and direct Route53 to the Distribution. Use the ELB as an Origin and specify Cache Behaviors to proxy cache requests, which can be served late. (CloudFront can server request from cache and multiple cache behavior can be defined based on rules for a given URL pattern based on file extensions, file names, or any portion of a URL. Each cache behavior can include the CloudFront configuration values: origin server name, viewer connection protocol, minimum expiration period, query string parameters, cookies, and trusted signers for private content.)
Create a Memcached cluster in AWS ElastiCache. Create cache logic to serve requests, which can be served late from the in-memory cache for increased performance.
You are designing a service that aggregates clickstream data in batch and delivers reports to subscribers via email only once per week. Data is extremely spikey, geographically distributed, high-scale, and unpredictable. How should you design this system?
Use a large RedShift cluster to perform the analysis, and a fleet of Lambdas to perform record inserts into the RedShift tables. Lambda will scale rapidly enough for the traffic spikes.
Use a CloudFront distribution with access log delivery to S3. Clicks should be recorded as query string GETs to the distribution. Reports are built and sent by periodically running EMR jobs over the access logs in S3. (CloudFront is a Gigabit-Scale HTTP(S) global request distribution service and works fine with peaks higher than 10 Gbps or 15,000 RPS. It can handle scale, geo-spread, spikes, and unpredictability. Access Logs will contain the GET data and work just fine for batch analysis and email using EMR. Other streaming options are expensive as not required as the need is to batch analyze)
Use API Gateway invoking Lambdas which PutRecords into Kinesis, and EMR running Spark performing GetRecords on Kinesis to scale with spikes. Spark on EMR outputs the analysis to S3, which are sent out via email.
Use AWS Elasticsearch service and EC2 Auto Scaling groups. The Autoscaling groups scale based on click throughput and stream into the Elasticsearch domain, which is also scalable. Use Kibana to generate reports periodically.
Your website is serving on-demand training videos to your workforce. Videos are uploaded monthly in high resolution MP4 format. Your workforce is distributed globally often on the move and using company-provided tablets that require the HTTP Live Streaming (HLS) protocol to watch a video. Your company has no video transcoding expertise and it required you might need to pay for a consultant. How do you implement the most cost-efficient architecture without compromising high availability and quality of video delivery? [PROFESSIONAL]
Elastic Transcoder to transcode original high-resolution MP4 videos to HLS. S3 to host videos with lifecycle Management to archive original flies to Glacier after a few days. CloudFront to serve HLS transcoded videos from S3
A video transcoding pipeline running on EC2 using SQS to distribute tasks and Auto Scaling to adjust the number or nodes depending on the length of the queue S3 to host videos with Lifecycle Management to archive all files to Glacier after a few days CloudFront to serve HLS transcoding videos from Glacier
Elastic Transcoder to transcode original high-resolution MP4 videos to HLS EBS volumes to host videos and EBS snapshots to incrementally backup original rues after a few days. CloudFront to serve HLS transcoded videos from EC2.
A video transcoding pipeline running on EC2 using SQS to distribute tasks and Auto Scaling to adjust the number of nodes depending on the length of the queue. EBS volumes to host videos and EBS snapshots to incrementally backup original files after a few days. CloudFront to serve HLS transcoded videos from EC2
provides low latency by caching and delivering content from a global network of edge locations located nearest to the user
supports both HTTP to allows static, dynamic content and Real Time Messaging Protocol (RTMP) for streaming of videos
optimized to work as with Amazon services like S3, ELB etc. as well as works seamlessly with any non-AWS origin server
Ideal Usage Patterns
is ideal for distribution of frequently accessed static content, or dynamic content or for streaming audio or video that benefits from edge delivery
Anti-Pattern
Infrequently accessed data
If the data is infrequently accessed, it would be better to serve the data from the Origin server
Programmatic cache invalidation
CloudFront supports cache invalidation, however AWS recommends using object versioning rather than programmatic cache invalidation.
Performance
is designed for low latency and high bandwidth delivery of content by redirecting the user to the nearest edge location in terms of latency and caching the content preventing the round trip to the origin server
Durability & Availability
provides high Availability by delivering content from a distributed global network of edge locations. Amazon also constantly monitors the network paths connecting Origin servers to CloudFront
does not provide durable storage, which is more of the responsibility of the underlying Origin server providing the content for e.g. S3
Cost Model
has two pricing components:
regional data transfer out (per GB) and
requests (per 10,000)
Scalability & Elasticity
provides seamless scalability & elasticity by automatically responding to the increase or the decrease in the demand
is a webservice that makes it easy to deploy, operate, and scale a distributed, in-memory cache in the cloud
helps improves performance of the applications by allowing retrieval of data from fast, managed, in-memory caching system
supports Memcached (object caching) & Redis (key value store that supports data structure) open source caching engines
Ideal Usage Patterns
improving application performance by storing critical data in-memory for low latency access
use cases involve usage as a database front end for read heavy applications, improving performance and reducing load on databases, or managing user session data, cache dynamically generated pages, or compute intensive calculations etc.
Anti-Patterns
Persistent Data
If the application needs fast access to data coupled with strong data durability, Amazon DynamoDB would be a better option
Performance
Although ElastiCache provides low latency access to the data, the performance depends on the caching strategy and the hit ratio at the application level
Durability & Availability
stores transient data or transient copies of durable data, so the data durability is managed by the source
With the Memcached engine
all ElastiCache nodes in a single cache cluster are provisioned in a single Availability Zone.
ElastiCache automatically monitors the health of your cache nodes and replaces them in the event of network partitioning, host hardware, or software failure.
In the event of cache node failure, the cluster remains available, but performance may be reduced due to time needed to repopulate the cache in the new “cold” cache nodes.
To provide enhanced fault-tolerance for Availability Zone failures or cold-cache effects, you can run redundant cache clusters in different Availability Zones.
With the Redis engine,
ElastiCache supports replication to up to five read replicas for scaling. To improve availability, you can place read replicas in other Availability Zones.
ElastiCache monitors the primary node, and if the node becomes unavailable, ElastiCache will repair or replace the primary node if possible, using the same DNS name.
If the primary cache node recovery fails or its Availability Zone is unavailable, primary node can be failed over to one of the read replicas with an API call.
Cost Model
has a single pricing component:
pricing is per cache node-hour consumed
Scalability & Elasticity
ElastiCache is highly scalable and elastic.
Cache node can be added or deleted to the cache cluster
Auto Discovery enables automatic discovery of Memcached cache nodes by ElastiCache Clients when the nodes are added to or removed from an ElastiCache cluster.