Auto Scaling Overview
- Auto Scaling provides the ability to ensure a correct number of EC2 instances are always running to handle the load of the application
- Auto Scaling helps
- to achieve better fault tolerance, better availability and cost management.
- helps specify scaling policies that can be used to launch and terminate EC2 instances to handle any increase or decrease in demand.
- Auto Scaling attempts to distribute instances evenly between the AZs that are enabled for the Auto Scaling group.
- Auto Scaling does this by attempting to launch new instances in the AZ with the fewest instances. If the attempt fails, it attempts to launch the instances in another AZ until it succeeds.
Auto Scaling Components
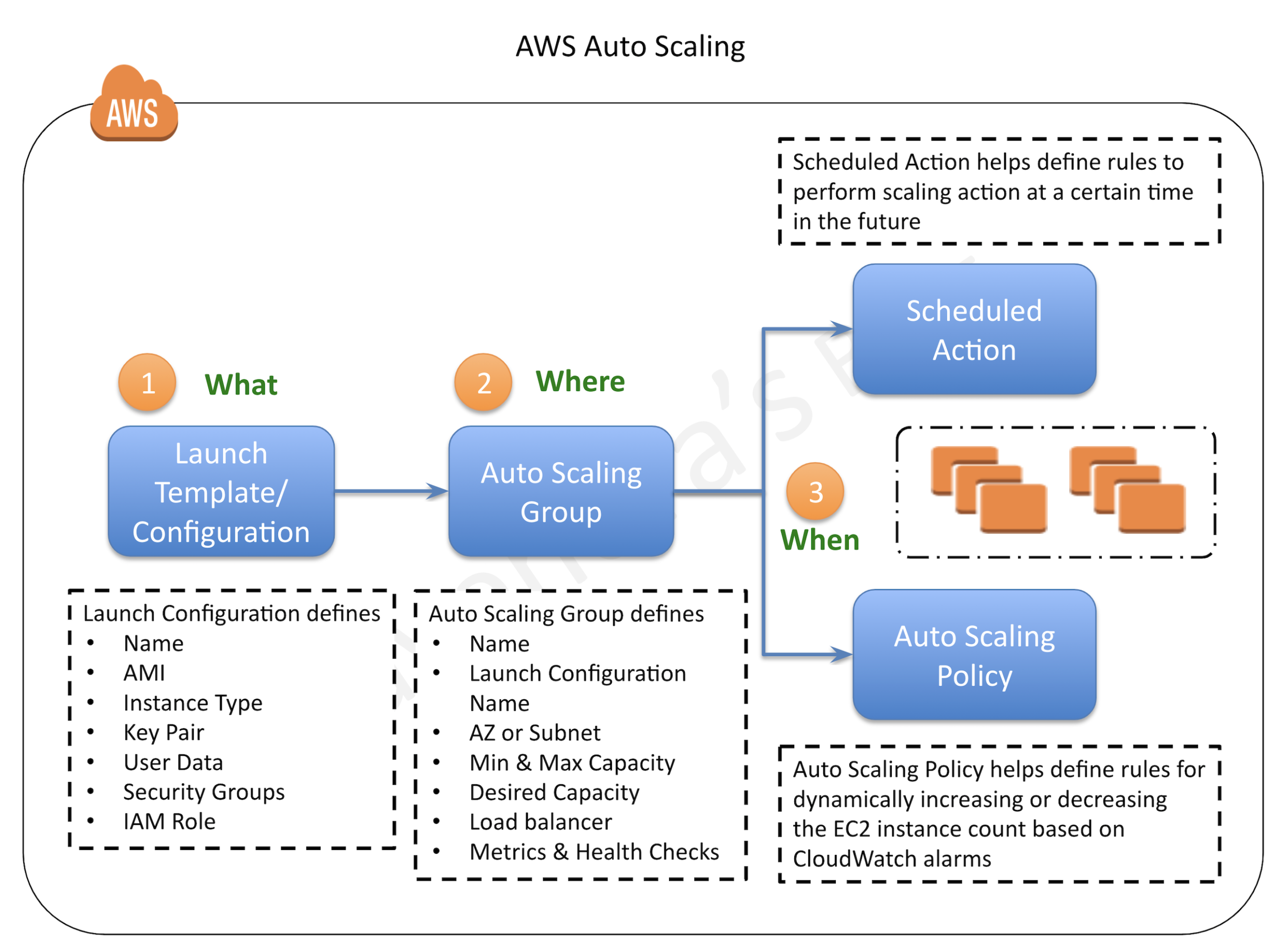
Auto Scaling Groups – ASG
- Auto Scaling groups are the core of Auto Scaling and contain a collection of EC2 instances that share similar characteristics and are treated as a logical grouping for the purposes of automatic scaling and management.
- ASG requires
- Launch Template (recommended) OR Launch Configuration (deprecated)
- determine the EC2 template to use for launching the instance
- Minimum & Maximum capacity
- determine the number of instances when an autoscaling policy is applied.
- Number of instances cannot grow beyond these boundaries
- Desired capacity
- to determine the number of instances the ASG must maintain at all times. If missing, it equals the minimum size.
- Desired capacity is different from minimum capacity.
- An Auto Scaling group’s desired capacity is the default number of instances that should be running. A group’s minimum capacity is the fewest number of instances the group can have running
- Availability Zones or Subnets in which the instances will be launched.
- Metrics & Health Checks
- metrics to determine when it should launch or terminate instances and health checks to determine if the instance is healthy or not
- ASG starts by launching a desired capacity of instances and maintains this number by performing periodic health checks.
- If an instance becomes unhealthy, the ASG terminates and launches a new instance.
- ASG can also use scaling policies to increase or decrease the number of instances automatically to meet changing demands
- An ASG can contain EC2 instances in one or more AZs within the same region.
- ASGs cannot span multiple regions.
- ASG can launch On-Demand Instances, Spot Instances, or both when configured to use a launch template.
- To merge separate single-zone ASGs into a single ASG spanning multiple AZs, rezone one of the single-zone groups into a multi-zone group, and then delete the other groups. This process works for groups with or without a load balancer, as long as the new multi-zone group is in one of the same AZs as the original single-zone groups.
- ASG can be associated with a single launch configuration or template
- As the Launch Configuration can’t be modified once created, the only way to update the Launch Configuration for an ASG is to create a new one and associate it with the ASG.
- When the launch configuration for the ASG is changed, any new instances launched, use the new configuration parameters, but the existing instances are not affected.
- ASG can be deleted from CLI, if it has no running instances else need to set the minimum and desired capacity to 0. This is handled automatically when deleting an ASG from the AWS management console.
- Deletion Protection (Jan 2026) – ASGs now support deletion protection with multiple protection levels to prevent accidental deletions. A new IAM policy condition key
autoscaling:ForceDelete controls the use of the ForceDelete parameter.
Launch Configuration
⚠️ LAUNCH CONFIGURATION – DEPRECATED
Launch Configurations are being phased out in favor of Launch Templates.
- As of January 1, 2023 – No new EC2 instance types are supported in launch configurations.
- As of June 1, 2023 – New accounts cannot create launch configurations via the console.
- As of October 1, 2024 – New accounts cannot create launch configurations using any method (console, API, CLI, or CloudFormation).
- Existing accounts can still use existing launch configurations but should migrate to Launch Templates.
Migration: Use Migrate to Launch Templates guide to transition.
- Launch configuration is an instance configuration template that an ASG uses to launch EC2 instances.
- Launch configuration is similar to EC2 configuration and involves the selection of the Amazon Machine Image (AMI), block devices, key pair, instance type, security groups, user data, EC2 instance monitoring, instance profile, kernel, ramdisk, the instance tenancy, whether the instance has a public IP address, and is EBS-optimized.
- Launch configuration can be associated with multiple ASGs
- Launch configuration can’t be modified after creation and needs to be created new if any modification is required.
- Basic or detailed monitoring for the instances in the ASG can be enabled when a launch configuration is created.
- By default, basic monitoring is enabled when you create the launch configuration using the AWS Management Console, and detailed monitoring is enabled when you create the launch configuration using the AWS CLI or an API
- AWS recommends using Launch Template instead. Launch Configurations are deprecated for new accounts.
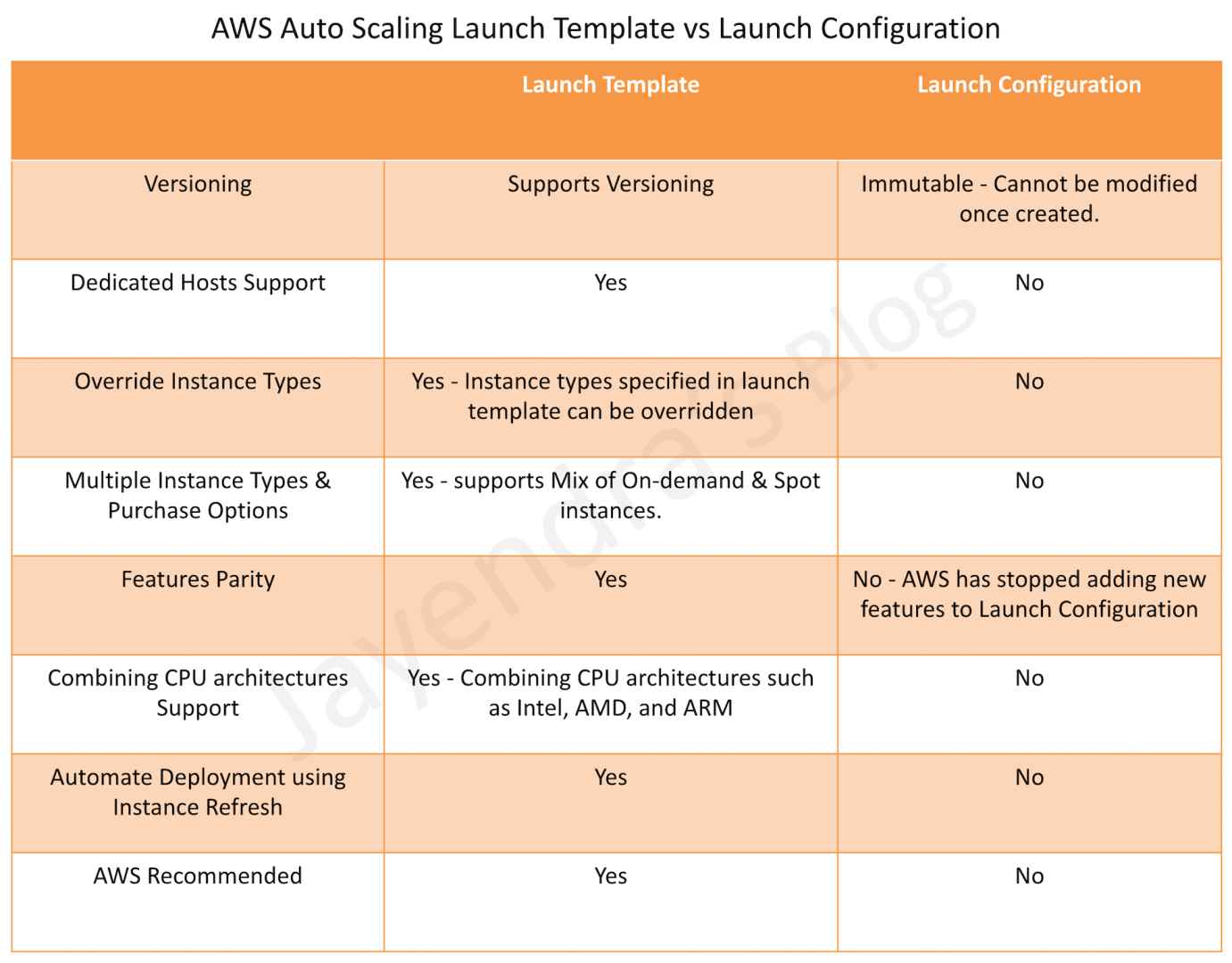
Launch Template
- A Launch Template is similar to a launch configuration, with additional features, and is the recommended and only supported option for new AWS accounts (since Oct 2024).
- Launch Template allows multiple versions of a template to be defined.
- With versioning, a subset of the full set of parameters can be created and then reused to create other templates or template versions for e.g, a default template that defines common configuration parameters can be created and allow the other parameters to be specified as part of another version of the same template.
- Launch Template allows the selection of both Spot and On-Demand Instances or multiple instance types.
- Launch templates support EC2 Dedicated Hosts. Dedicated Hosts are physical servers with EC2 instance capacity that are dedicated to your use.
- Launch templates provide the following features
- Support for multiple instance types and purchase options in a single ASG.
- Launching Spot Instances with the capacity-optimized allocation strategy.
- Support for launching instances into existing Capacity Reservations through an ASG.
- Support for unlimited mode for burstable performance instances.
- Support for Dedicated Hosts.
- Combining CPU architectures such as Intel, AMD, and ARM (Graviton2/Graviton3/Graviton4)
- Improved governance through IAM controls and versioning.
- Automating instance deployment with Instance Refresh.
- Support for all new EC2 instance types (required since Jan 2023 as launch configs no longer support new types).
Auto Scaling Launch Configuration vs Launch Template
Auto Scaling Policies
Refer blog post @ Auto Scaling Policies
Predictive Scaling
- Predictive Scaling uses machine learning to predict future traffic patterns and proactively scales capacity in advance of predicted changes.
- It analyzes historical load data to detect daily and weekly patterns and automatically adjusts forecasts.
- Predictive Scaling provisions EC2 instances ahead of anticipated demand, improving availability and reducing the need for over-provisioning.
- It works alongside dynamic scaling policies – predictive scaling handles anticipated load changes while dynamic scaling handles unexpected spikes.
- Predictive Scaling supports:
- Forecast-only mode for evaluation before activating scaling
- Forecast and scale mode for automatic capacity adjustment
- Custom metrics in addition to predefined CPU, network, and ALB request metrics
- Best suited for workloads with recurring, predictable traffic patterns (e.g., business-hour traffic, weekly patterns).
Auto Scaling Cooldown Period
- Auto Scaling Cooldown period is a configurable setting for the ASG that helps to ensure that Auto Scaling doesn’t launch or terminate additional instances before the previous scaling activity takes effect and allows the newly launched instances to start handling traffic and reduce load
- When ASG dynamically scales using a simple scaling policy and launches an instance, Auto Scaling suspends the scaling activities for the cooldown period (default 300 seconds) to complete before resuming scaling activities
- Example Use Case
- You configure a scale out alarm to increase the capacity, if the CPU utilization increases more than 80%
- A CPU spike occurs and causes the alarm to be triggered, Auto Scaling launches a new instance
- However, it would take time for the newly launched instance to be configured, instantiated, and started, let’s say 5 mins
- Without a cooldown period, if another CPU spike occurs Auto Scaling would launch a new instance again and this would continue for 5 mins till the previously launched instance is up and running and started handling traffic
- With a cooldown period, Auto Scaling would suspend the activity for the specified time period enabling the newly launched instance to start handling traffic and reduce the load.
- After the cooldown period, Auto Scaling resumes acting on the alarms
- When manually scaling the ASG, the default is not to wait for the cooldown period but can be overridden to honour the cooldown period.
- Note that if an instance becomes unhealthy, Auto Scaling does not wait for the cooldown period to complete before replacing the unhealthy instance.
- Cooldown periods are automatically applied to dynamic scaling activities for simple scaling policies and are not supported for step scaling or target tracking policies.
- Default Instance Warmup – a recommended alternative to cooldown periods. It specifies how long after an instance reaches InService state before it contributes to aggregated CloudWatch metrics. This prevents premature scaling decisions based on incomplete data from newly launched instances.
Auto Scaling Termination Policy
- Termination policy helps Auto Scaling decide which instances it should terminate first when Auto Scaling automatically scales in.
- Auto Scaling specifies a default termination policy and also provides the ability to create a customized one.
Default Termination Policy
Default termination policy helps ensure that the network architecture spans AZs evenly and instances are selected for termination as follows:-
- Selection of Availability Zone
- selects the AZ, in multiple AZs environments, with the most instances and at least one instance that is not protected from scale in.
- selects the AZ with instances that use the oldest launch template or configuration, if there is more than one AZ with the same number of instances
- Selection of an Instance within the Availability Zone
- terminates the unprotected instance using the oldest launch template or configuration if one exists.
- terminates unprotected instances closest to the next billing hour, If multiple instances with the oldest launch configuration. This helps in maximizing the use of the EC2 instances that have an hourly charge while minimizing the number of hours billed for EC2 usage.
- terminates instances at random, if more than one unprotected instance is closest to the next billing hour.
Customized Termination Policy
- Auto Scaling first assesses the AZs for any imbalance. If an AZ has more instances than the other AZs that are used by the group, then it applies the specified termination policy on the instances from the imbalanced AZ
- If the Availability Zones used by the group are balanced, then Auto Scaling applies the specified termination policy.
- Following Customized Termination policies are supported:
- OldestInstance – terminates the oldest instance in the group and can be useful to upgrade to new instance types
- NewestInstance – terminates the newest instance in the group and can be useful when testing a new launch configuration
- OldestLaunchConfiguration – terminates instances that have the oldest launch configuration
- OldestLaunchTemplate – terminates instances that have the oldest launch template
- ClosestToNextInstanceHour – terminates instances that are closest to the next billing hour and helps to maximize the use of your instances and manage costs.
- AllocationStrategy – terminates instances to align remaining instances to the allocation strategy for the instance type (Spot or On-Demand).
- Default – terminates as per the default termination policy
Custom Termination Policy with Lambda
- Auto Scaling supports using an AWS Lambda function as a custom termination policy for advanced termination logic.
- The Lambda function receives a JSON payload with candidate instances and returns which instances should be terminated.
- This provides fine-grained control over termination decisions, e.g., avoiding instances running critical workloads.
- Requires granting EC2 Auto Scaling permission via a Lambda resource-based policy.
Instance Refresh
- Instance refresh can be used to update the instances in the ASG instead of manually replacing instances a few at a time.
- An instance refresh can be helpful when you have a new AMI or a new user data script.
- Instance refresh also helps configure the minimum healthy percentage, instance warmup, and checkpoints.
- Instance refresh supports two strategies:
- Rolling strategy (default) – Terminates instances and launches new ones in batches while maintaining desired capacity and availability.
- Replace Root Volume strategy (Nov 2025) – Updates instances by replacing only the root EBS volume without terminating the instance. Preserves network interfaces, non-root EBS volumes, and instance store data.
- To use an instance refresh:
- Create a new launch template that specifies the new AMI or user data script.
- Start an instance refresh to begin updating the instances in the group immediately.
- EC2 Auto Scaling starts performing a rolling replacement of the instances.
- Skip Matching – When enabled, Auto Scaling compares each instance’s current configuration against the desired configuration and only replaces instances that don’t match, skipping already-updated instances.
Warm Pools
- A warm pool is a pool of pre-initialized EC2 instances that sits alongside the Auto Scaling group for faster scale-out.
- When the application needs to scale out, the ASG draws from the warm pool instead of launching cold instances, significantly reducing startup latency.
- Instances in a warm pool can be in one of three states: Stopped, Running, or Hibernated.
- Warm pools are ideal for applications with long boot times (e.g., instances that need to load large datasets or perform complex initialization).
- Warm pool supports lifecycle hooks to perform custom actions when instances transition between states.
- Supports ASGs with mixed instances policies (Nov 2025) – warm pools can now be used with groups that have multiple instance types and purchase options.
- Creating a warm pool when not required can lead to unnecessary costs for the stopped/running instances.
Instance Maintenance Policy
- Instance Maintenance Policy (Nov 2023) defines whether new instances are launched before or after existing instances are terminated during replacement operations.
- Controls replacement behavior for instance refresh, health checks, and AZ rebalancing.
- Three preset options:
- Launch before terminating – Provisions new instance first, then terminates old one. Favors availability over cost.
- Terminate and launch – Terminates and launches simultaneously. Favors cost savings over availability.
- Custom policy – Set custom min/max range for available capacity during replacement.
- Can be set at the ASG level and overridden for individual instance refresh operations.
Instance Protection
- Instance protection controls whether Auto Scaling can terminate a particular instance or not.
- Instance protection can be enabled on an ASG or an individual instance as well, at any time
- Instances launched within an ASG with Instance protection enabled would inherit the property.
- Instance protection starts as soon as the instance is InService and if the Instance is detached, it loses its Instance protection
- If all instances in an ASG are protected from termination during scale in and a scale-in event occurs, it can’t terminate any instance and will decrement the desired capacity.
- Instance protection does not protect for the below cases
- Manual termination through the EC2 console, the
terminate-instances command, or the TerminateInstances API.
- If it fails health checks and must be replaced
- Spot instances in an ASG from interruption
Standby State
Auto Scaling allows putting the InService instances in the Standby state during which the instance is still a part of the ASG but does not serve any requests. This can be used to either troubleshoot an instance or update an instance and return the instance back to service.
- An instance can be put into Standby state and it will continue to remain in the Standby state unless exited.
- Auto Scaling, by default, decrements the desired capacity for the group and prevents it from launching a new instance. If no decrement is selected, it would launch a new instance
- When the instance is in the standby state, the instance can be updated or used for troubleshooting.
- If a load balancer is associated with Auto Scaling, the instance is automatically deregistered when the instance is in Standby state and registered again when the instance exits the Standby state
Suspension
- Auto Scaling processes can be suspended and then resumed. This can be very useful to investigate a configuration problem or debug an issue with the application, without triggering the Auto Scaling process.
- Auto Scaling also performs Administrative Suspension where it would suspend processes for ASGs if the ASG has been trying to launch instances for over 24 hours but has not succeeded in launching any instances.
- Auto Scaling processes include
- Launch – Adds a new EC2 instance to the group, increasing its capacity.
- Terminate – Removes an EC2 instance from the group, decreasing its capacity.
- HealthCheck – Checks the health of the instances.
- ReplaceUnhealthy – Terminates instances that are marked as unhealthy and subsequently creates new instances to replace them.
- AlarmNotification – Accepts notifications from CloudWatch alarms that are associated with the group. If suspended, Auto Scaling does not automatically execute policies that would be triggered by an alarm
- ScheduledActions – Performs scheduled actions that you create.
- AddToLoadBalancer – Adds instances to the load balancer when they are launched.
- InstanceRefresh – Terminates and replaces instances using the instance refresh feature.
- AZRebalance – Balances the number of EC2 instances in the group across the Availability Zones in the region.
- If an AZ either is removed from the ASG or becomes unhealthy or unavailable, Auto Scaling launches new instances in an unaffected AZ before terminating the unhealthy or unavailable instances
- When the unhealthy AZ returns to a healthy state, Auto Scaling automatically redistributes the instances evenly across the Availability Zones for the group.
- Note that if you suspend AZRebalance and a scale out or scale in event occurs, Auto Scaling still tries to balance the Availability Zones for e.g. during scale out, it launches the instance in the Availability Zone with the fewest instances.
- If you suspend Launch, AZRebalance neither launches new instances nor terminates existing instances. This is because AZRebalance terminates instances only after launching the replacement instances.
- If you suspend Terminate, the ASG can grow up to 10% larger than its maximum size, because Auto Scaling allows this temporarily during rebalancing activities. If it cannot terminate instances, your ASG could remain above its maximum size until the Terminate process is resumed
Zonal Shift Integration
- Zonal Shift (Nov 2024) integrates with Amazon Application Recovery Controller (ARC) to rapidly recover from AZ impairments.
- When a zonal shift is activated, Auto Scaling stops dynamic scale-in to preserve capacity and launches new instances in healthy AZs only.
- Zonal Autoshift can automatically shift traffic away from an impaired AZ on a periodic basis to test resilience.
- Health checks can be configured to either remain enabled or be disabled in the impaired AZ during a zonal shift.
- Can be initiated from the EC2 Auto Scaling console, ARC console, or programmatically via AWS SDK.
Strict Availability Zone Balance
- Strict AZ Balance (Nov 2024) provides a new provisioning control to strictly balance workloads across Availability Zones.
- Unlike the default best-effort balancing, strict mode ensures exact equal distribution across configured AZs.
- Provides greater control over instance placement for compliance or performance requirements.
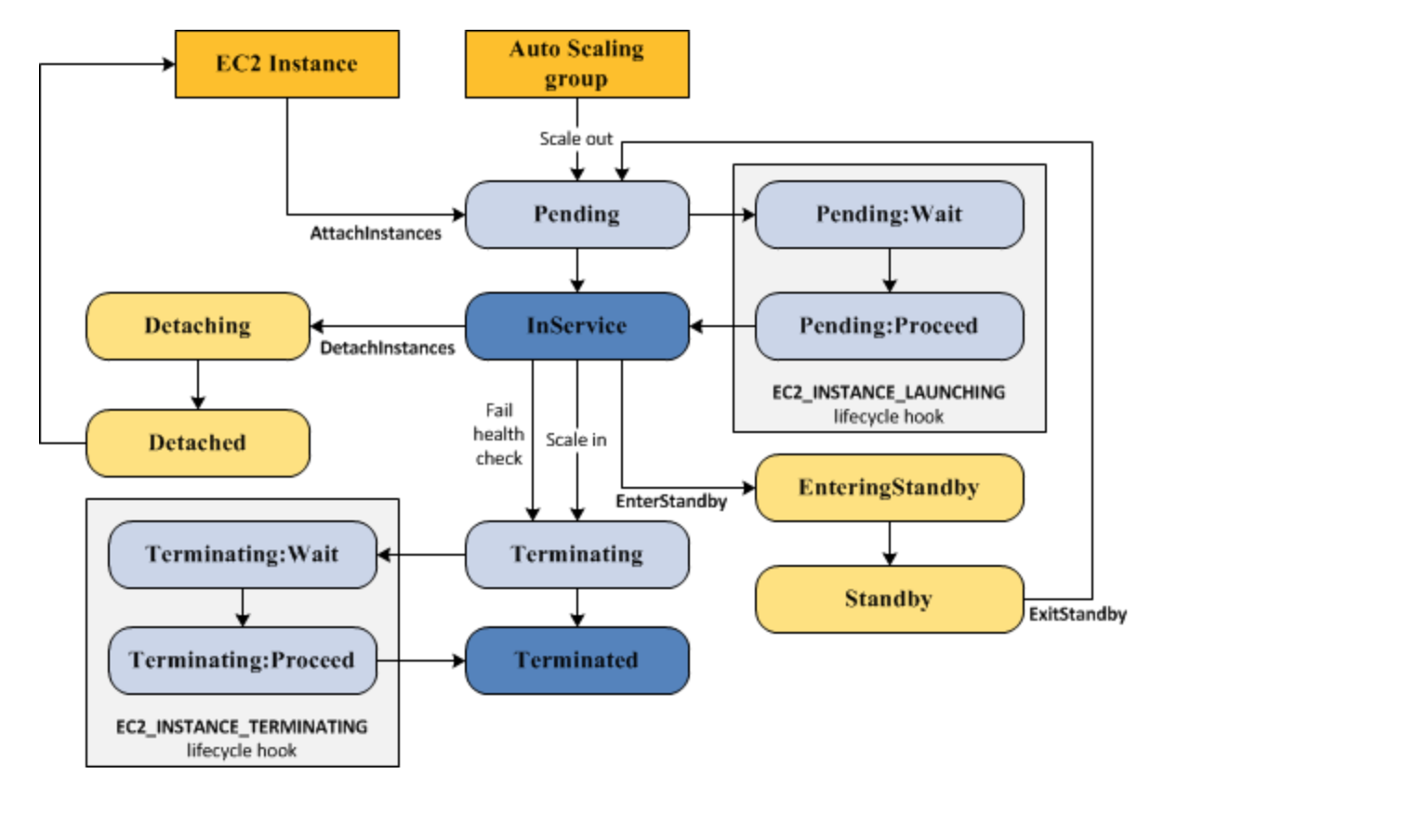
Auto Scaling Lifecycle
Refer to blog post @ Auto Scaling Lifecycle
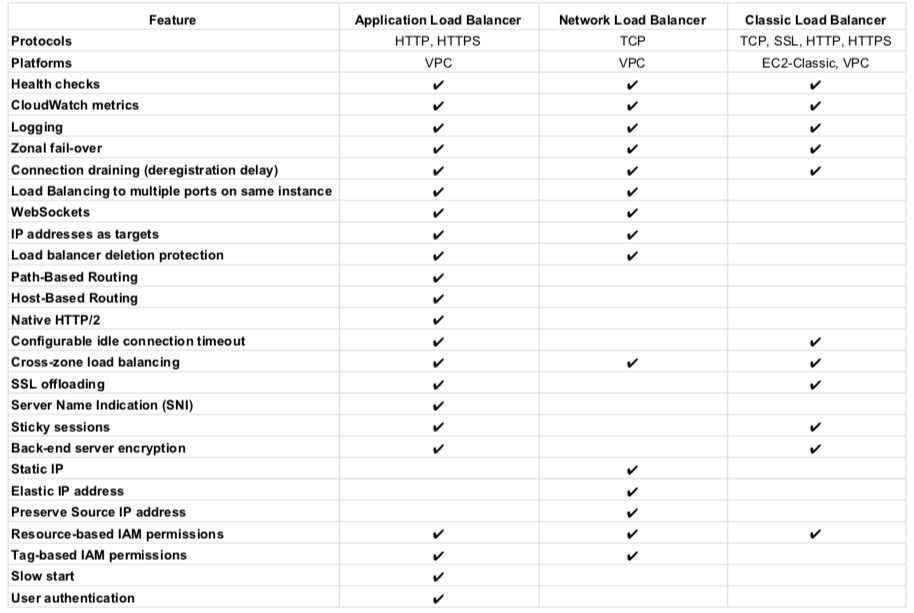
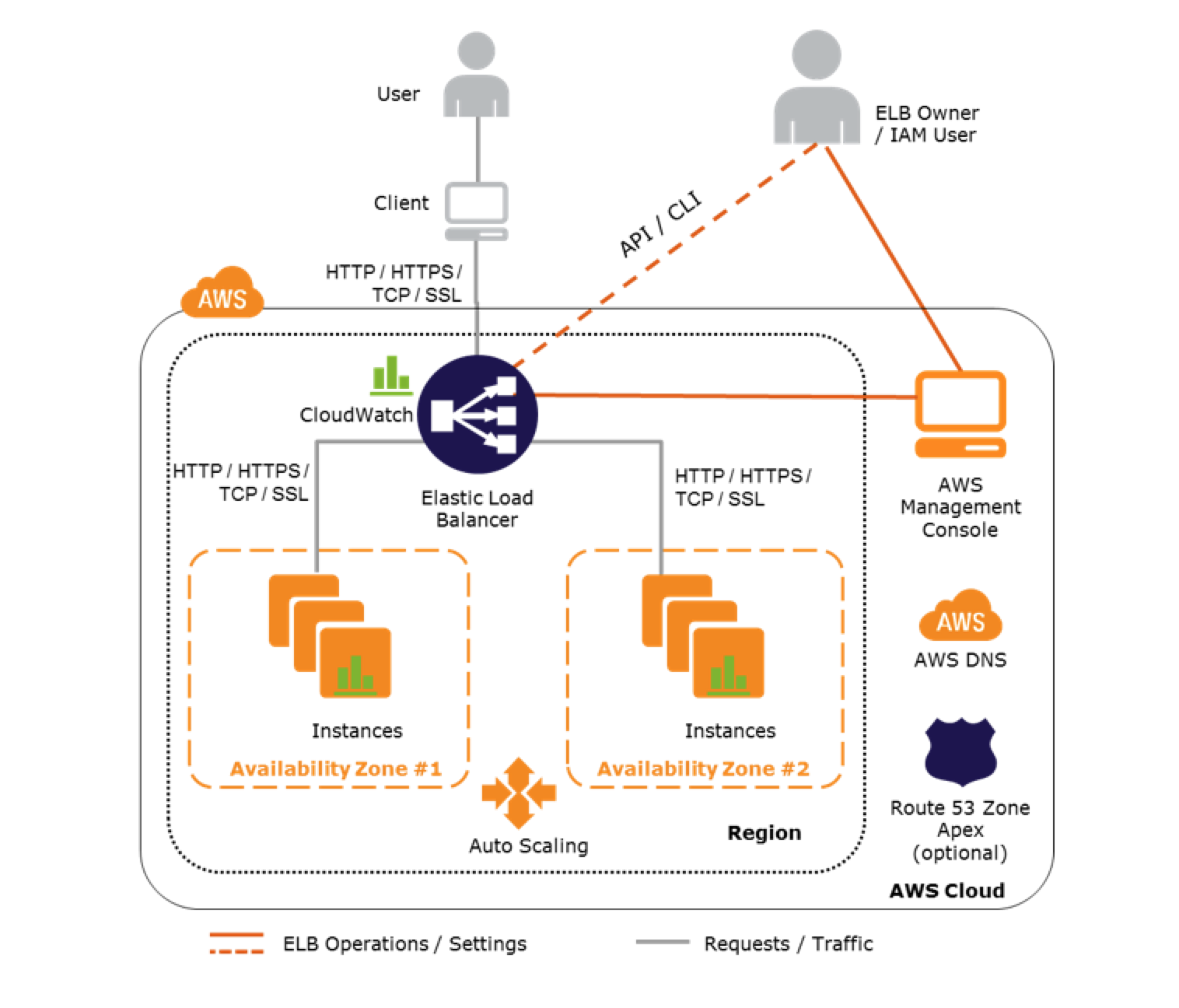
Autoscaling & ELB
Refer to blog post @ Autoscaling & ELB
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- A user is trying to setup a scheduled scaling activity using Auto Scaling. The user wants to setup the recurring schedule. Which of the below mentioned parameters is not required in this case?
- Maximum size
- Auto Scaling group name
- End time
- Recurrence value
- A user has configured Auto Scaling with 3 instances. The user had created a new AMI after updating one of the instances. If the user wants to terminate two specific instances to ensure that Auto Scaling launches an instances with the new launch configuration, which command should he run?
- as-delete-instance-in-auto-scaling-group <Instance ID> –no-decrement-desired-capacity
- as-terminate-instance-in-auto-scaling-group <Instance ID> –update-desired-capacity
- as-terminate-instance-in-auto-scaling-group <Instance ID> –decrement-desired-capacity
- as-terminate-instance-in-auto-scaling-group <Instance ID> –no-decrement-desired-capacity
- A user is planning to scale up an application by 8 AM and scale down by 7 PM daily using Auto Scaling. What should the user do in this case?
- Setup the scaling policy to scale up and down based on the CloudWatch alarms
- User should increase the desired capacity at 8 AM and decrease it by 7 PM manually
- User should setup a batch process which launches the EC2 instance at a specific time
- Setup scheduled actions to scale up or down at a specific time
- An organization has setup Auto Scaling with ELB. Due to some manual error, one of the instances got rebooted. Thus, it failed the Auto Scaling health check. Auto Scaling has marked it for replacement. How can the system admin ensure that the instance does not get terminated?
- Update the Auto Scaling group to ignore the instance reboot event
- It is not possible to change the status once it is marked for replacement
- Manually add that instance to the Auto Scaling group after reboot to avoid replacement
- Change the health of the instance to healthy using the Auto Scaling commands
- A user has configured Auto Scaling with the minimum capacity as 2 and the desired capacity as 2. The user is trying to terminate one of the existing instance with the command: as-terminate-instance-in-auto-scaling-group<Instance ID> –decrement-desired-capacity. What will Auto Scaling do in this scenario?
- Terminates the instance and does not launch a new instance
- Terminates the instance and updates the desired capacity to 1
- Terminates the instance and updates the desired capacity & minimum size to 1
- Throws an error
- An organization has configured Auto Scaling for hosting their application. The system admin wants to understand the Auto Scaling health check process. If the instance is unhealthy, Auto Scaling launches an instance and terminates the unhealthy instance. What is the order execution?
- Auto Scaling launches a new instance first and then terminates the unhealthy instance
- Auto Scaling performs the launch and terminate processes in a random order
- Auto Scaling launches and terminates the instances simultaneously
- Auto Scaling terminates the instance first and then launches a new instance
- A user has configured ELB with Auto Scaling. The user suspended the Auto Scaling terminate process only for a while. What will happen to the availability zone rebalancing process (AZRebalance) during this period?
- Auto Scaling will not launch or terminate any instances
- Auto Scaling will allow the instances to grow more than the maximum size
- Auto Scaling will keep launching instances till the maximum instance size
- It is not possible to suspend the terminate process while keeping the launch active
- An organization has configured Auto Scaling with ELB. There is a memory issue in the application which is causing CPU utilization to go above 90%. The higher CPU usage triggers an event for Auto Scaling as per the scaling policy. If the user wants to find the root cause inside the application without triggering a scaling activity, how can he achieve this?
- Stop the scaling process until research is completed
- It is not possible to find the root cause from that instance without triggering scaling
- Delete Auto Scaling until research is completed
- Suspend the scaling process until research is completed
- A user has configured ELB with Auto Scaling. The user suspended the Auto Scaling Alarm Notification (which notifies Auto Scaling for CloudWatch alarms) process for a while. What will Auto Scaling do during this period?
- AWS will not receive the alarms from CloudWatch
- AWS will receive the alarms but will not execute the Auto Scaling policy
- Auto Scaling will execute the policy but it will not launch the instances until the process is resumed
- It is not possible to suspend the AlarmNotification process
- An organization has configured two single availability zones. The Auto Scaling groups are configured in separate zones. The user wants to merge the groups such that one group spans across multiple zones. How can the user configure this?
- Run the command as-join-auto-scaling-group to join the two groups
- Run the command as-update-auto-scaling-group to configure one group to span across zones and delete the other group
- Run the command as-copy-auto-scaling-group to join the two groups
- Run the command as-merge-auto-scaling-group to merge the groups
- An organization has configured Auto Scaling with ELB. One of the instance health check returns the status as Impaired to Auto Scaling. What will Auto Scaling do in this scenario?
- Perform a health check until cool down before declaring that the instance has failed
- Terminate the instance and launch a new instance
- Notify the user using SNS for the failed state
- Notify ELB to stop sending traffic to the impaired instance
- A user has setup an Auto Scaling group. The group has failed to launch a single instance for more than 24 hours. What will happen to Auto Scaling in this condition
- Auto Scaling will keep trying to launch the instance for 72 hours
- Auto Scaling will suspend the scaling process
- Auto Scaling will start an instance in a separate region
- The Auto Scaling group will be terminated automatically
- A user is planning to setup infrastructure on AWS for the Christmas sales. The user is planning to use Auto Scaling based on the schedule for proactive scaling. What advise would you give to the user?
- It is good to schedule now because if the user forgets later on it will not scale up
- The scaling should be setup only one week before Christmas
- Wait till end of November before scheduling the activity
- It is not advisable to use scheduled based scaling
- A user is trying to setup a recurring Auto Scaling process. The user has setup one process to scale up every day at 8 am and scale down at 7 PM. The user is trying to setup another recurring process which scales up on the 1st of every month at 8 AM and scales down the same day at 7 PM. What will Auto Scaling do in this scenario
- Auto Scaling will execute both processes but will add just one instance on the 1st
- Auto Scaling will add two instances on the 1st of the month
- Auto Scaling will schedule both the processes but execute only one process randomly
- Auto Scaling will throw an error since there is a conflict in the schedule of two separate Auto Scaling Processes
- A sys admin is trying to understand the Auto Scaling activities. Which of the below mentioned processes is not performed by Auto Scaling?
- Reboot Instance
- Schedule Actions
- Replace Unhealthy
- Availability Zone Re-Balancing
- You have started a new job and are reviewing your company’s infrastructure on AWS. You notice one web application where they have an Elastic Load Balancer in front of web instances in an Auto Scaling Group. When you check the metrics for the ELB in CloudWatch you see four healthy instances in Availability Zone (AZ) A and zero in AZ B. There are zero unhealthy instances. What do you need to fix to balance the instances across AZs?
- Set the ELB to only be attached to another AZ
- Make sure Auto Scaling is configured to launch in both AZs
- Make sure your AMI is available in both AZs
- Make sure the maximum size of the Auto Scaling Group is greater than 4
- You have been asked to leverage Amazon VPC EC2 and SQS to implement an application that submits and receives millions of messages per second to a message queue. You want to ensure your application has sufficient bandwidth between your EC2 instances and SQS. Which option will provide the most scalable solution for communicating between the application and SQS?
- Ensure the application instances are properly configured with an Elastic Load Balancer
- Ensure the application instances are launched in private subnets with the EBS-optimized option enabled
- Ensure the application instances are launched in public subnets with the associate-public-IP-address=trueoption enabled
- Launch application instances in private subnets with an Auto Scaling group and Auto Scaling triggers configured to watch the SQS queue size
- You have decided to change the Instance type for instances running in your application tier that are using Auto Scaling. In which area below would you change the instance type definition?
- Auto Scaling launch configuration or launch template
- Auto Scaling group
- Auto Scaling policy
- Auto Scaling tags
- A user is trying to delete an Auto Scaling group from CLI. Which of the below mentioned steps are to be performed by the user?
- Terminate the instances with the ec2-terminate-instance command
- Terminate the Auto Scaling instances with the as-terminate-instance command
- Set the minimum size and desired capacity to 0
- There is no need to change the capacity. Run the as-delete-group command and it will reset all values to 0
- A user has created a web application with Auto Scaling. The user is regularly monitoring the application and he observed that the traffic is highest on Thursday and Friday between 8 AM to 6 PM. What is the best solution to handle scaling in this case?
- Add a new instance manually by 8 AM Thursday and terminate the same by 6 PM Friday
- Schedule Auto Scaling to scale up by 8 AM Thursday and scale down after 6 PM on Friday
- Schedule a policy which may scale up every day at 8 AM and scales down by 6 PM
- Configure a batch process to add a instance by 8 AM and remove it by Friday 6 PM
- A user has configured the Auto Scaling group with the minimum capacity as 3 and the maximum capacity as 5. When the user configures the AS group, how many instances will Auto Scaling launch?
- 3
- 0
- 5
- 2
- A sys admin is maintaining an application on AWS. The application is installed on EC2 and user has configured ELB and Auto Scaling. Considering future load increase, the user is planning to launch new servers proactively so that they get registered with ELB. How can the user add these instances with Auto Scaling?
- Increase the desired capacity of the Auto Scaling group
- Increase the maximum limit of the Auto Scaling group
- Launch an instance manually and register it with ELB on the fly
- Decrease the minimum limit of the Auto Scaling group
- In reviewing the auto scaling events for your application you notice that your application is scaling up and down multiple times in the same hour. What design choice could you make to optimize for the cost while preserving elasticity? Choose 2 answers.
- Modify the Amazon CloudWatch alarm period that triggers your auto scaling scale down policy.
- Modify the Auto scaling group termination policy to terminate the oldest instance first.
- Modify the Auto scaling policy to use scheduled scaling actions.
- Modify the Auto scaling group cool down timers.
- Modify the Auto scaling group termination policy to terminate newest instance first.
- You have a business critical two tier web app currently deployed in two availability zones in a single region, using Elastic Load Balancing and Auto Scaling. The app depends on synchronous replication (very low latency connectivity) at the database layer. The application needs to remain fully available even if one application Availability Zone goes off-line, and Auto scaling cannot launch new instances in the remaining Availability Zones. How can the current architecture be enhanced to ensure this? [PROFESSIONAL]
- Deploy in two regions using Weighted Round Robin (WRR), with Auto Scaling minimums set for 100% peak load per region.
- Deploy in three AZs, with Auto Scaling minimum set to handle 50% peak load per zone.
- Deploy in three AZs, with Auto Scaling minimum set to handle 33% peak load per zone. (Loss of one AZ will handle only 66% if the autoscaling also fails)
- Deploy in two regions using Weighted Round Robin (WRR), with Auto Scaling minimums set for 50% peak load per region.
- A user has created a launch configuration for Auto Scaling where CloudWatch detailed monitoring is disabled. The user wants to now enable detailed monitoring. How can the user achieve this?
- Update the Launch config with CLI to set InstanceMonitoringDisabled = false
- The user should change the Auto Scaling group from the AWS console to enable detailed monitoring
- Update the Launch config with CLI to set InstanceMonitoring.Enabled = true
- Create a new Launch Config with detail monitoring enabled and update the Auto Scaling group (Note: For new accounts, create a new Launch Template version instead)
- A user has created an Auto Scaling group with default configurations from CLI. The user wants to setup the CloudWatch alarm on the EC2 instances, which are launched by the Auto Scaling group. The user has setup an alarm to monitor the CPU utilization every minute. Which of the below mentioned statements is true?
- It will fetch the data at every minute but the four data points [corresponding to 4 minutes] will not have value since the EC2 basic monitoring metrics are collected every five minutes
- It will fetch the data at every minute as detailed monitoring on EC2 will be enabled by the default launch configuration of Auto Scaling
- The alarm creation will fail since the user has not enabled detailed monitoring on the EC2 instances
- The user has to first enable detailed monitoring on the EC2 instances to support alarm monitoring at every minute
- A customer has a website which shows all the deals available across the market. The site experiences a load of 5 large EC2 instances generally. However, a week before Thanksgiving vacation they encounter a load of almost 20 large instances. The load during that period varies over the day based on the office timings. Which of the below mentioned solutions is cost effective as well as help the website achieve better performance?
- Keep only 10 instances running and manually launch 10 instances every day during office hours.
- Setup to run 10 instances during the pre-vacation period and only scale up during the office time by launching 10 more instances using the AutoScaling schedule.
- During the pre-vacation period setup a scenario where the organization has 15 instances running and 5 instances to scale up and down using Auto Scaling based on the network I/O policy.
- During the pre-vacation period setup 20 instances to run continuously.
- When Auto Scaling is launching a new instance based on condition, which of the below mentioned policies will it follow?
- Based on the criteria defined with cross zone Load balancing
- Launch an instance which has the highest load distribution
- Launch an instance in the AZ with the fewest instances
- Launch an instance in the AZ which has the highest instances
- The user has created multiple AutoScaling groups. The user is trying to create a new AS group but it fails. How can the user know that he has reached the AS group limit specified by AutoScaling in that region?
- Run the command: as-describe-account-limits
- Run the command: as-describe-group-limits
- Run the command: as-max-account-limits
- Run the command: as-list-account-limits
- A user is trying to save some cost on the AWS services. Which of the below mentioned options will not help him save cost?
- Delete the unutilized EBS volumes once the instance is terminated
- Delete the Auto Scaling launch configuration after the instances are terminated (Auto Scaling Launch config does not cost anything)
- Release the elastic IP if not required once the instance is terminated
- Delete the AWS ELB after the instances are terminated
- To scale up the AWS resources using manual Auto Scaling, which of the below mentioned parameters should the user change?
- Maximum capacity
- Desired capacity
- Preferred capacity
- Current capacity
- For AWS Auto Scaling, what is the first transition state an existing instance enters after leaving steady state in Standby mode?
- Detaching
- Terminating:Wait
- Pending (You can put any instance that is in an InService state into a Standby state. This enables you to remove the instance from service, troubleshoot or make changes to it, and then put it back into service. Instances in a Standby state continue to be managed by the Auto Scaling group. However, they are not an active part of your application until you put them back into service. Refer link)
- EnteringStandby
- For AWS Auto Scaling, what is the first transition state an instance enters after leaving steady state when scaling in due to health check failure or decreased load?
- Terminating (When Auto Scaling responds to a scale in event, it terminates one or more instances. These instances are detached from the Auto Scaling group and enter the Terminating state. Refer link)
- Detaching
- Terminating:Wait
- EnteringStandby
- A user has setup Auto Scaling with ELB on the EC2 instances. The user wants to configure that whenever the CPU utilization is below 10%, Auto Scaling should remove one instance. How can the user configure this?
- The user can get an email using SNS when the CPU utilization is less than 10%. The user can use the desired capacity of Auto Scaling to remove the instance
- Use CloudWatch to monitor the data and Auto Scaling to remove the instances using scheduled actions
- Configure CloudWatch to send a notification to Auto Scaling Launch configuration when the CPU utilization is less than 10% and configure the Auto Scaling policy to remove the instance
- Configure CloudWatch to send a notification to the Auto Scaling group when the CPU Utilization is less than 10% and configure the Auto Scaling policy to remove the instance
- A user has enabled detailed CloudWatch metric monitoring on an Auto Scaling group. Which of the below mentioned metrics will help the user identify the total number of instances in an Auto Scaling group including pending, terminating and running instances?
- GroupTotalInstances (Refer link)
- GroupSumInstances
- It is not possible to get a count of all the three metrics together. The user has to find the individual number of running, terminating and pending instances and sum it
- GroupInstancesCount
- Your startup wants to implement an order fulfillment process for selling a personalized gadget that needs an average of 3-4 days to produce with some orders taking up to 6 months you expect 10 orders per day on your first day. 1000 orders per day after 6 months and 10,000 orders after 12 months. Orders coming in are checked for consistency then dispatched to your manufacturing plant for production quality control packaging shipment and payment processing. If the product does not meet the quality standards at any stage of the process employees may force the process to repeat a step. Customers are notified via email about order status and any critical issues with their orders such as payment failure. Your case architecture includes AWS Elastic Beanstalk for your website with an RDS MySQL instance for customer data and orders. How can you implement the order fulfillment process while making sure that the emails are delivered reliably? [PROFESSIONAL]
- Add a business process management application to your Elastic Beanstalk app servers and re-use the ROS database for tracking order status use one of the Elastic Beanstalk instances to send emails to customers.
- Use SWF with an Auto Scaling group of activity workers and a decider instance in another Auto Scaling group with min/max=1 Use the decider instance to send emails to customers.
- Use SWF with an Auto Scaling group of activity workers and a decider instance in another Auto Scaling group with min/max=1 use SES to send emails to customers.
- Use an SQS queue to manage all process tasks Use an Auto Scaling group of EC2 Instances that poll the tasks and execute them. Use SES to send emails to customers.
- An organization wants to reduce latency for their Auto Scaling group during scale-out events. Their application takes 5 minutes to boot and initialize. Which Auto Scaling feature should they use?
- Increase the desired capacity permanently
- Use Predictive Scaling to pre-provision
- Configure a Warm Pool with pre-initialized instances
- Set a longer cooldown period
- A company has an application with predictable traffic patterns that peaks every weekday at 9 AM and reduces at 6 PM. They want Auto Scaling to proactively provision capacity before the peak. Which scaling approach is most appropriate?
- Target tracking scaling policy with CPU metric
- Step scaling policy with CloudWatch alarms
- Scheduled scaling actions
- Predictive Scaling policy
- A company needs to update the AMI across all instances in their Auto Scaling group without terminating instances, preserving their network interfaces and non-root EBS volumes. Which approach should they use?
- Create new launch template version and wait for scale-in/scale-out to replace instances
- Use instance refresh with the rolling strategy
- Use instance refresh with the replace root volume strategy
- Manually stop and update each instance
- An application team wants to control the order in which instances are replaced during Auto Scaling health check replacements. They want new instances launched BEFORE unhealthy ones are terminated to maintain capacity. Which feature should they configure?
- Instance protection
- Lifecycle hooks
- Instance maintenance policy with “Launch before terminating”
- Custom termination policy
- An Auto Scaling group experiences an Availability Zone impairment. The team wants to quickly shift traffic away from the impaired AZ while preventing Auto Scaling from terminating instances in that zone. Which feature integrates with Auto Scaling to handle this? [PROFESSIONAL]
- Suspend the AZRebalance process
- Remove the AZ from the ASG configuration
- Use Amazon ARC Zonal Shift with the Auto Scaling group
- Enable cross-zone load balancing on the ELB
References
AWS Auto Scaling User Guide