Let’s Talk About Cloud Security
Guest post by Dustin Albertson – Manager of Cloud & Applications, Product Management -Veeam.
I want to discuss something that’s important to me, security. Far too often I have discussions with customers and other engineers where they’re discussing an architecture or problem they are running into, and I spot issues with the design or holes in the thought process. One of the best things about the cloud model is also one of its worst traits: it’s “easy.” What I mean by this is that it’s easy to log into AWS and set up an EC2 instance, connect it to the internet and configure basic settings. This usually leads to issues down the road because the basic security or architectural best practices were not followed. Therefore, I want to talk about a few things that everyone should be aware of.
The Well-Architected Framework

AWS has done a great job at creating a framework for its customer to adhere to when planning and deploying workloads in AWS. This framework is called the AWS Well-Architected Framework. The framework has 6 pillars that helps you learn architectural best practices for designing and operating secure, reliable, efficient, cost-effective, and sustainable workloads in the AWS Cloud. The pillars are :
- Operational Excellence: The ability to support the development and run workloads effectively, gain insight into their operations, and continuously improve supporting processes and procedures to deliver business value.
- Security: The security pillar describes how to take advantage of cloud technologies to protect data, systems, and assets in a way that can improve your security posture.
- Reliability: The reliability pillar encompasses the ability of a workload to perform its intended function correctly and consistently when it’s expected to. This includes the ability to operate and test the workload through its total lifecycle. This paper provides in-depth, best practice guidance for implementing reliable workloads on AWS.
- Performance Efficiency: The ability to use computing resources efficiently to meet system requirements, and to maintain that efficiency as demand changes and technologies evolve.
- Cost Optimization: The ability to run systems to deliver business value at the lowest price point.
- Sustainability: The ability to continually improve sustainability impacts by reducing energy consumption and increasing efficiency across all components of a workload by maximizing the benefits from the provisioned resources and minimizing the total resources required.
This framework is important to read and understand for not only a customer but a software vendor or a services provider as well. As a company that provides software in the AWS marketplace, Veeam must go through a few processes prior to listing in the marketplace. Those processes are what’s called a W.A.R (Well-Architected Review) and a T.F.R (Technical Foundation Review). A W.A.R. is a deep dive into the product and APIs to make sure that the best practices are being used in the way the products not only interact with the APIs in AWS but also how the software is deployed and the architecture it uses. The T.F.R. is a review to validate that all the appropriate documentation and help guides are in place so that a customer can easily find out how to deploy, protect, secure, and obtain support when using a product deployed via the AWS Marketplace. This can give customers peace of mind when deploying software from the marketplace because they’ll know that it has been rigorously tested and validated.
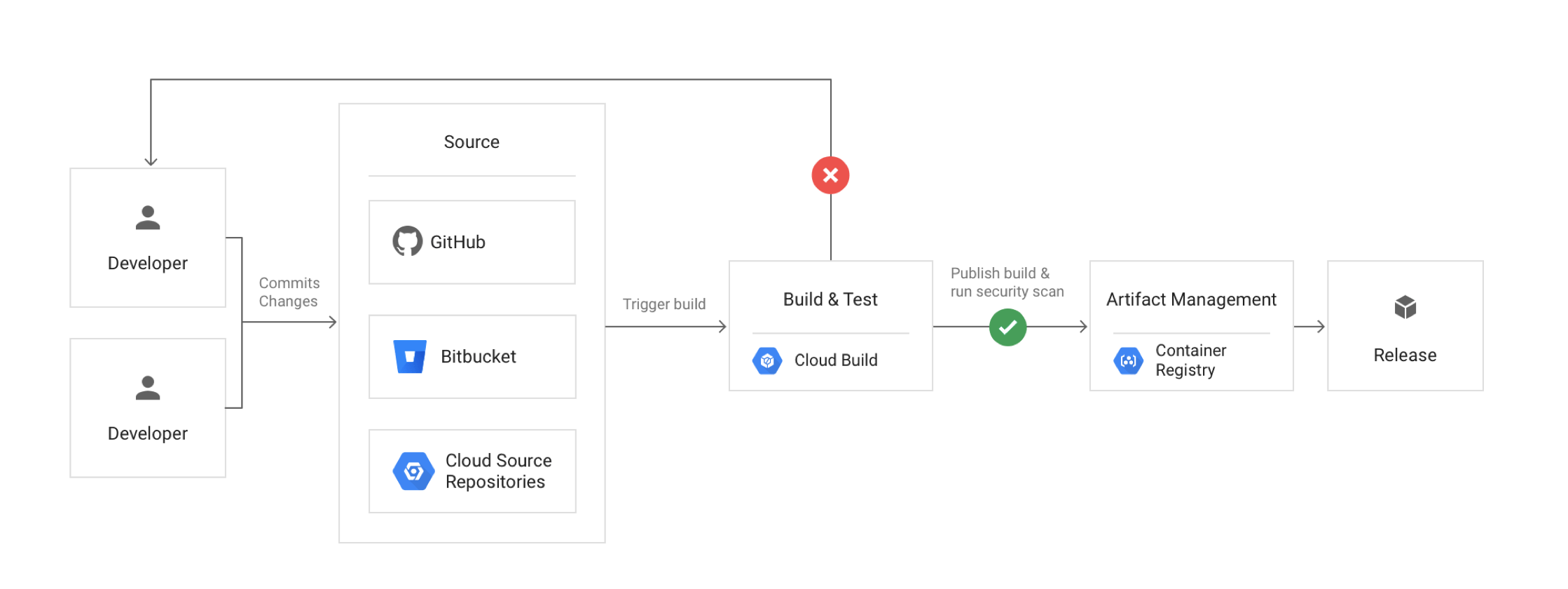
I have mostly been talking at a high level here and want to break this down into a real-world example. Veeam has a product in the AWS Marketplace called Veeam Backup for AWS. One of the best practices for this product is to deploy it into a separate AWS account than your production account.
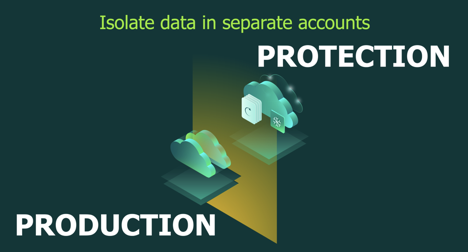
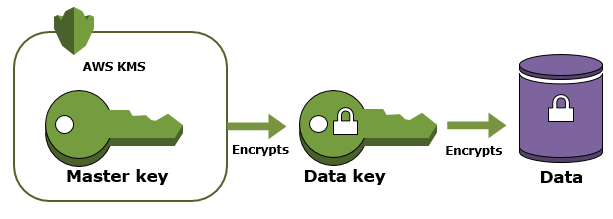
The reason for this is that the software will reach into the production account and back up the instances you wish to protect into an isolated protection account where you can limit the number of people who have access. It’s also a best practice to have your backup data stored away from production data. Now here is where the story gets interesting, a lot of people like to use encryption on their EBS volumes. But since it’s so easy to enable encryption, most people just turn it on and move on. The root of the issue is that AWS has made it easy to encrypt a volume since they have a default key that you choose when creating an instance.
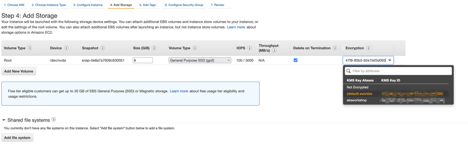
They have also made it easy to set a policy that every new volume is encrypted and the default choice is the default key.
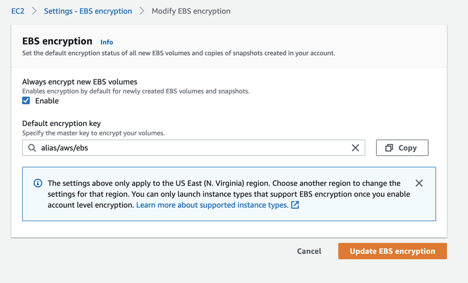
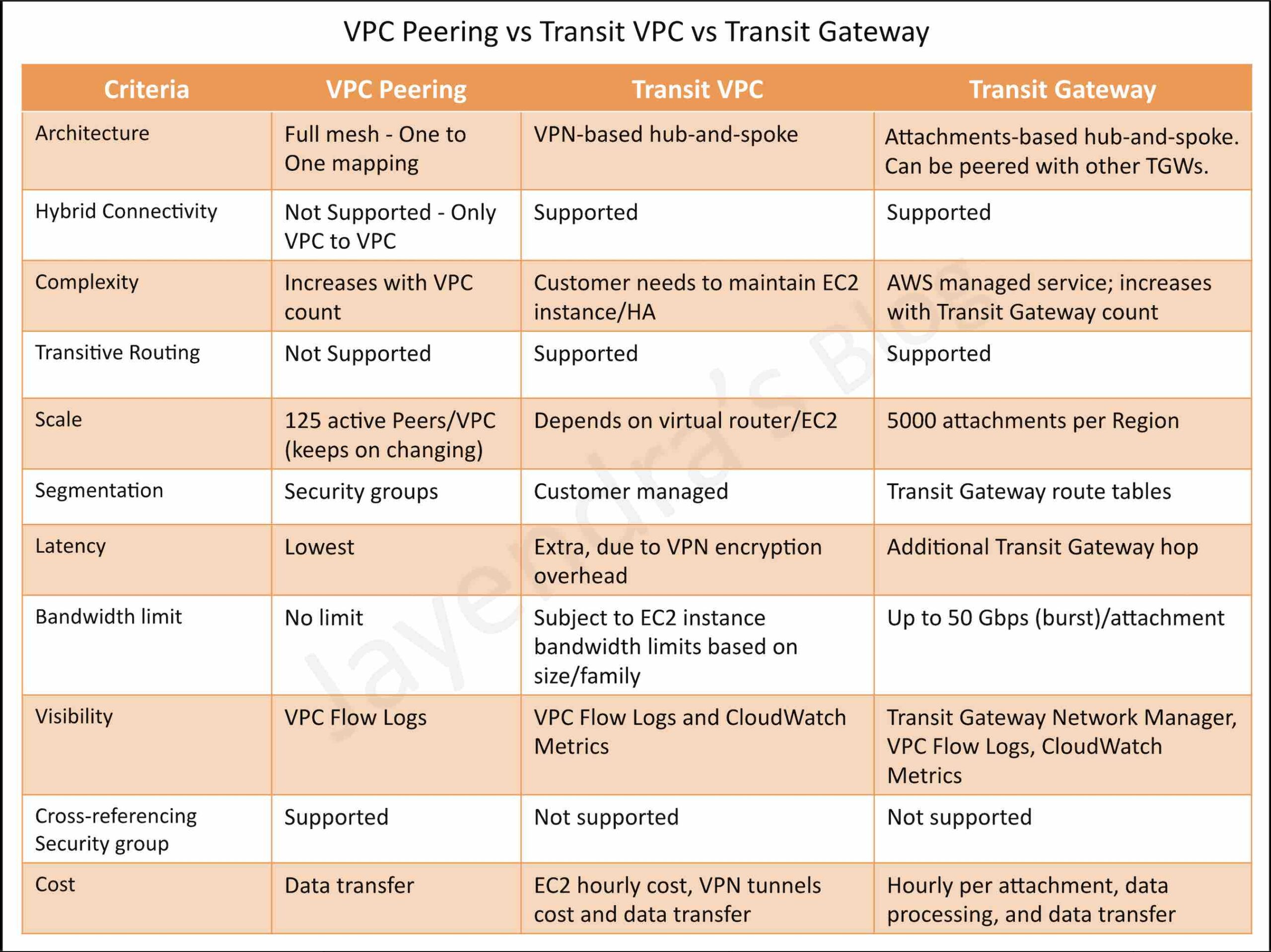
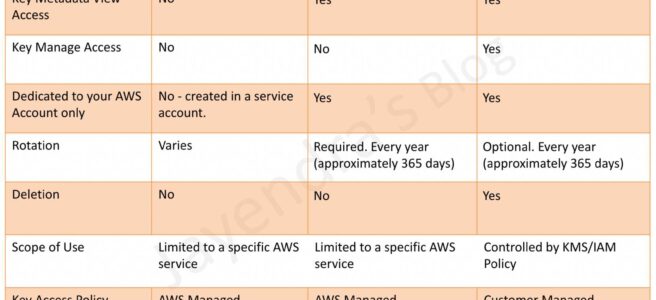
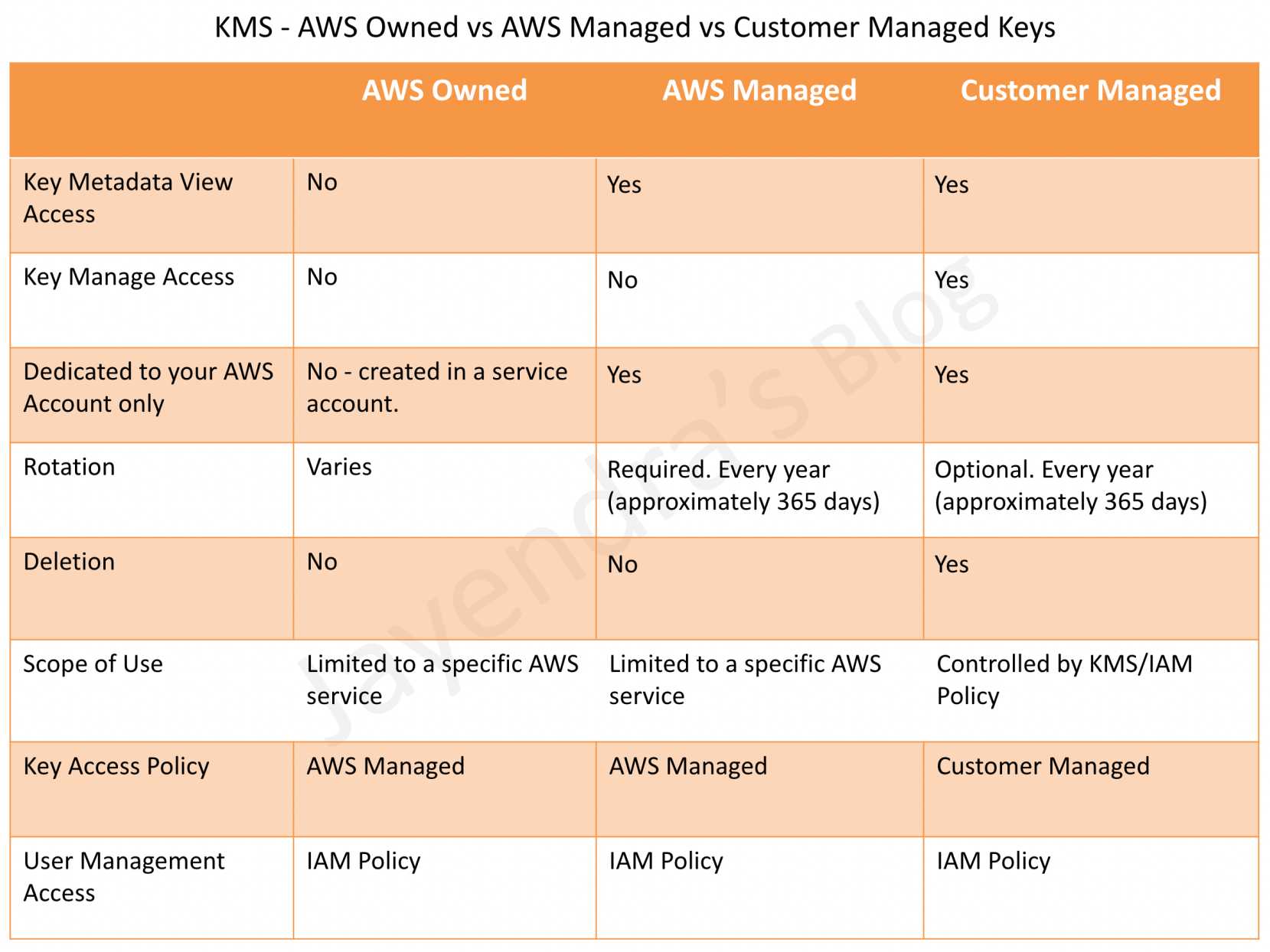
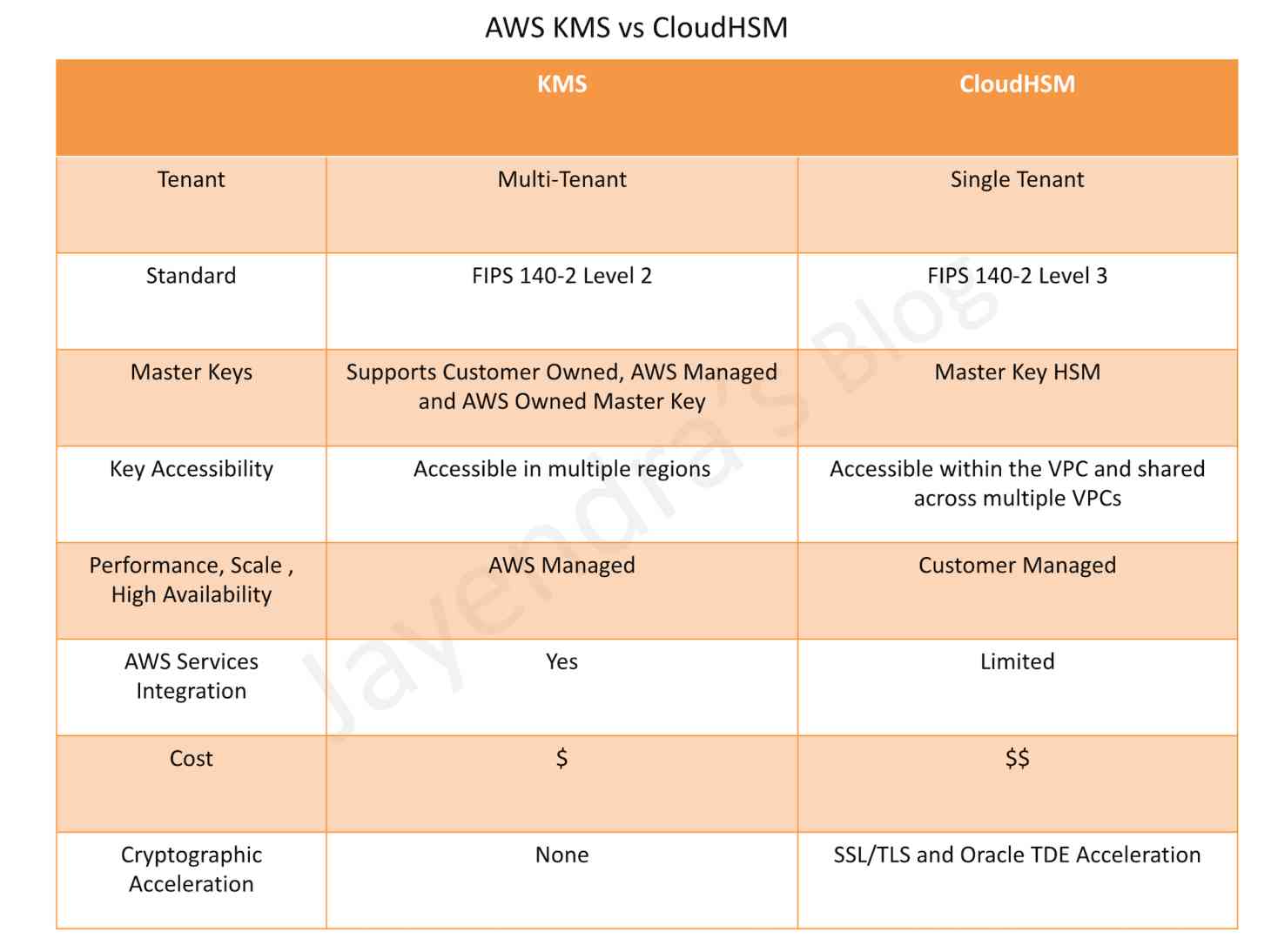
This is where the problem begins. Now, this may be fine for now or for a lot of users, but what this does is create issues later down the road. Default encryption keys cannot be shared outside of the account that the key resides in. This means that you would not be able to back that instance up to another account, you can’t rotate the keys, you can’t delete the keys, you can’t audit the keys, and more. Customer managed keys (CMK) give you the ability to create, rotate, disable, enable and audit the encryption key used to protect the data. I don’t want to go too deep here but this is an example that I run into a lot and people don’t realize the impact of this setting until it’s too late. To change from a default key to a CMK requires downtime of the instance and is a very manual process, although it can be scripted out, it still can be a very cumbersome task if we are talking about hundreds to thousands of instances.
Don’t just take my word for it, Trend Micro also lists this as a Medium Risk.
Aqua Vulnerability Database also lists this as a threat.

Conclusion
I’ am not trying to scare people or shame people for not knowing this information. A lot of the time in the field, we are so busy and just get things working and move on. My goal here is to try to get you to stop for a second and think about if the choices you are making are the best ones for your security. Take advantage of the resources and help that companies like AWS and Veeam are offering and learn about data protection and security best practices. Take a step back from time to time and evaluate the architecture or design that you are implementing. Get a second set of eyes on the project. It may sound complicated or confusing, but I promise it’s not that hard and the best bet is to just ask others. Also, don’t forget to check the “Choose Your Cloud Adventure” interactive e-book to learn how to manage your AWS data like a hero.
Thank you for reading.