By default, communications to and from DynamoDB use the HTTPS protocol, which protects network traffic by using SSL/TLS encryption.
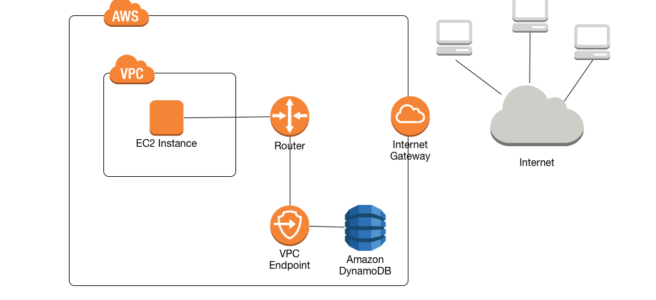
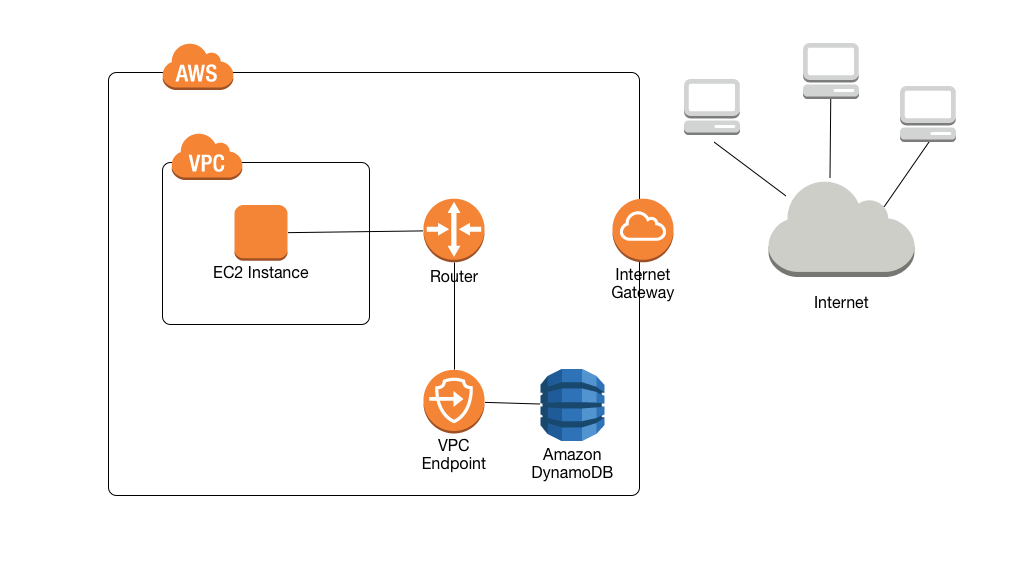
A VPC endpoint for DynamoDB enables EC2 instances in the VPC to use their private IP addresses to access DynamoDB with no exposure to the public internet.
Traffic between the VPC and the AWS service does not leave the Amazon network.
EC2 instances do not require public IP addresses, an internet gateway, a NAT device, or a virtual private gateway in the VPC.
VPC endpoint for DynamoDB routes any requests to a DynamoDB endpoint within the Region to a private DynamoDB endpoint within the Amazon network.
Applications running on EC2 instances in the VPC don’t need to be modified.
Endpoint name remains the same, but the route to DynamoDB stays entirely within the Amazon network and does not access the public internet.
VPC Endpoint Policies to control access to DynamoDB.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
What are the services supported by VPC endpoints, using the Gateway endpoint type?
Amazon EFS
Amazon DynamoDB
Amazon Glacier
Amazon SQS
A business application is hosted on Amazon EC2 and uses Amazon DynamoDB for its storage. The chief information security officer has directed that no application traffic between the two services should traverse the public internet. Which capability should the solutions architect use to meet the compliance requirements?
AWS Key Management Service (AWS KMS)
VPC endpoint
Private subnet
Virtual private gateway
A company runs an application in the AWS Cloud and uses Amazon DynamoDB as the database. The company deploys Amazon EC2 instances to a private network to process data from the database. The company uses two NAT instances to provide connectivity to DynamoDB.
The company wants to retire the NAT instances. A solutions architect must implement a solution that provides connectivity to DynamoDB and that does not require ongoing management. What is the MOST cost-effective solution that meets these requirements?
Create a gateway VPC endpoint to provide connectivity to DynamoDB.
Configure a managed NAT gateway to provide connectivity to DynamoDB.
Establish an AWS Direct Connect connection between the private network and DynamoDB.
Deploy an AWS PrivateLink endpoint service between the private network and DynamoDB.
DynamoDB Time to Live – TTL enables a per-item timestamp to determine when an item is no longer needed.
After the date and time of the specified timestamp, DynamoDB deletes the item from the table without consuming any write throughput.
DynamoDB TTL is provided at no extra cost and can help reduce data storage by retaining only required data.
Items that are deleted from the table are also removed from any local secondary index and global secondary index in the same way as a DeleteItem operation.
Expired items get removed from the table and indexes within about 48 hours.
DynamoDB Stream tracks the delete operation as a system delete, not a regular one.
TTL requirements
TTL attributes must use the Number data type. Other data types, such as String, aren’t supported.
TTL attributes must use the epoch time format.- Be sure that the timestamp is in seconds, not milliseconds
TTL is useful if the stored items lose relevance after a specific time. for e.g.
Remove user or sensor data after a year of inactivity in an application
Archive expired items to an S3 data lake via DynamoDB Streams and AWS Lambda.
Retain sensitive data for a certain amount of time according to contractual or regulatory obligations.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company developed an application by using AWS Lambda and
Amazon DynamoDB. The Lambda function periodically pulls data from the company’s S3 bucket based on date and time tags and inserts specific values into a DynamoDB table for further processing. The company must remove data that is older than 30 days from the DynamoDB table. Which solution will meet this requirement with the MOST operational efficiency?
Update the Lambda function to add the Version attribute in the DynamoDB table. Enable TTL on the DynamoDB table to expire entries that are older than 30 days based on the TTL attribute.
Update the Lambda function to add the TTL attribute in the DynamoDB table. Enable TTL on the DynamoDB table to expire entries that are older than 30 days based on the TTL attribute.
Use AWS Step Functions to delete entries that are older than 30 days.
Use EventBridge to schedule the Lambda function to delete entries that are older than 30 days.
DynamoDB Backup and Restore provides fully automated on-demand backup, restore, and point-in-time recovery for data protection and archiving.
On-demand backup allows the creation of full backups of DynamoDB table for data archiving, helping you meet corporate and governmental regulatory requirements.
Point-in-time recovery (PITR) provides continuous backups of your DynamoDB table data. When enabled, DynamoDB maintains incremental backups of your table for the last 35 days until you explicitly turn it off.
On-demand Backups
DynamoDB on-demand backup helps create full backups of the tables for long-term retention, and archiving for regulatory compliance needs.
Backup and restore actions run with no impact on table performance or availability.
Backups are preserved regardless of table deletion and retained until they are explicitly deleted.
On-demand backups are cataloged, and discoverable.
On-demand backups can be created using
DynamoDB
can be used to backup and restore DynamoDB tables.
DynamoDB on-demand backups cannot be copied to a different account or Region.
is a fully managed data protection service that makes it easy to centralize and automate backups across AWS services, in the cloud, and on-premises
provides enhanced backup features
can configure backup schedules & policies and monitor activity for the AWS resources and on-premises workloads in one place.
can copy the on-demand backups across AWS accounts and Regions,
encryption using an AWS KMS key that is independent of the DynamoDB table encryption key.
apply write-once-read-many (WORM) setting for the backups using the AWS Backup Vault Lock policy.
add cost allocation tags to on-demand backups, and
transition on-demand backups to cold storage for lower costs.
PITR – Point-In-Time Recovery
DynamoDB point-in-time recovery – PITR enables automatic, continuous, incremental backup of the table with per-second granularity.
PITR-enabled tables that were deleted can be recovered in the preceding 35 days and restored to their state just before they were deleted.
PITR helps protect against accidental writes and deletes.
PITR can back up tables with hundreds of terabytes of data with no impact on the performance or availability of the production applications.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A sysops engineer must create nightly backups of an Amazon DynamoDB table. Which backup methodology should the database specialist use to MINIMIZE management overhead?
Install the AWS CLI on an Amazon EC2 instance. Write a CLI command that creates a backup of the DynamoDB table. Create a scheduled job or task that runs the command on a nightly basis.
Create an AWS Lambda function that creates a backup of the DynamoDB table. Create an Amazon CloudWatch Events rule
that runs the Lambda function on a nightly basis.
Create a backup plan using AWS Backup, specify a backup frequency of every 24 hours, and give the plan a nightly backup window.
Configure DynamoDB backup and restore for an on-demand backup frequency of every 24 hours.
DynamoDB Global Tables is a fully managed, serverless, multi-master, active-active database.
Global tables provide 99.999% availability, increased application resiliency, and improved business continuity.
Global table’s automatic cross-region replication capability helps achieve fast, local read and write performance and regional fault tolerance for database workloads.
Applications can now perform reads and writes to DynamoDB in AWS regions around the world, with changes in any region propagated to every region where a table is replicated.
Global Tables help in building applications to advantage of data locality to reduce overall latency.
Global Tables supports eventual consistency & strong consistency for same region reads, but only eventual consistency for cross-region reads.
Global Tables replicates data among regions within a single AWS account and currently does not support cross-account access.
Global Tables uses the Last Write Wins approach for conflict resolution.
Global Tables Working
Global Table is a collection of one or more replica tables, all owned by a single AWS account.
A single Amazon DynamoDB global table can only have one replica table per AWS Region.
Each replica table stores the same set of data items, has the same table name, and the same primary key schema.
When an application writes data to a replica table in one Region, DynamoDB automatically replicates the writes to other replica tables in the other AWS Regions.
Global Tables requires DynamoDB streams enabled with New and Old image settings.
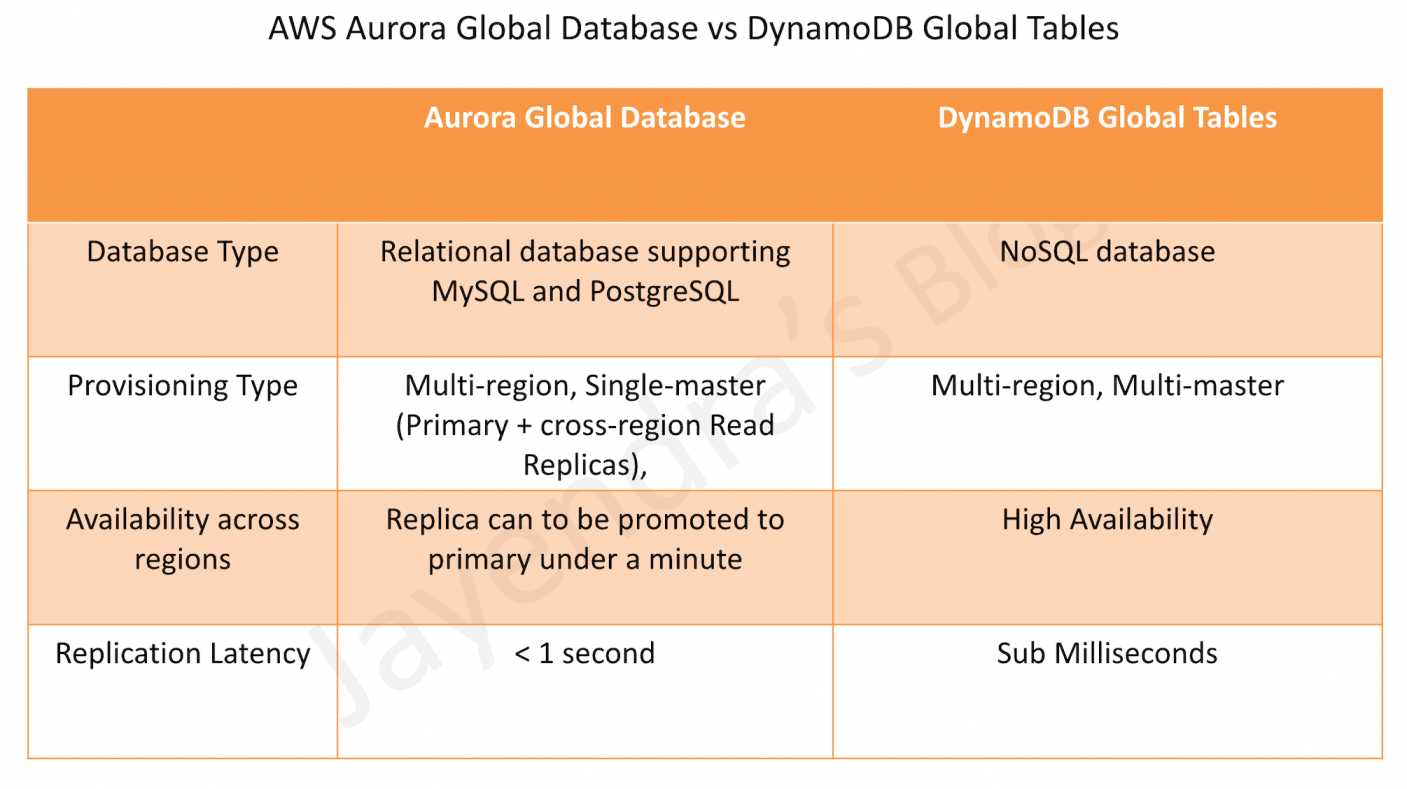
DynamoDB Global Tables vs. Aurora Global Databases
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company is building a web application on AWS. The application requires the database to support read and write operations in multiple AWS Regions simultaneously. The database also needs to propagate data changes between Regions as the changes occur. The application must be highly available and must provide a latency of single-digit milliseconds. Which solution meets these requirements?
Amazon DynamoDB global tables
Amazon DynamoDB streams with AWS Lambda to replicate the data
An Amazon ElastiCache for Redis cluster with cluster mode enabled and multiple shards
DynamoDB Streams provides a time-ordered sequence of item-level changes made to data in a table.
DynamoDB Streams stores the data for the last 24 hours, after which they are erased.
DynamoDB Streams maintains an ordered sequence of the events per item however, sequence across items is not maintained.
Example
For e.g., suppose that you have a DynamoDB table tracking high scores for a game and that each item in the table represents an individual player. If you make the following three updates in this order:
Update 1: Change Player 1’s high score to 100 points
Update 2: Change Player 2’s high score to 50 points
Update 3: Change Player 1’s high score to 125 points
DynamoDB Streams will maintain the order for Player 1 score events. However, it would not maintain order across the players. So Player 2 score event is not guaranteed between the 2 Player 1 events
Applications can access this log and view the data items as they appeared before and after they were modified, in near-real time.
DynamoDB Streams APIs help developers consume updates and receive the item-level data before and after items are changed.
Streams allow reads at up to twice the rate of the provisioned write capacity of the DynamoDB table.
Streams have to be enabled on a per-table basis. When enabled on a table, DynamoDB captures information about every modification to data items in the table.
Streams support Encryption at rest to encrypt the data.
Streams are designed for No Duplicates so that every update made to the table will be represented exactly once in the stream.
Streams write stream records in near-real time so that applications can consume these streams and take action based on the contents.
Streams can be used for multi-region replication to keep other data stores up-to-date with the latest changes to DynamoDB or to take actions based on the changes made to the table
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
An application currently writes a large number of records to a DynamoDB table in one region. There is a requirement for a secondary application to retrieve new records written to the DynamoDB table every 2 hours and process the updates accordingly. Which of the following is an ideal way to ensure that the secondary application gets the relevant changes from the DynamoDB table?
Insert a timestamp for each record and then scan the entire table for the timestamp as per the last 2 hours.
Create another DynamoDB table with the records modified in the last 2 hours.
Use DynamoDB Streams to monitor the changes in the DynamoDB table.
Transfer records to S3 which were modified in the last 2 hours.
AWS has a Region, which is a physical location around the world where we cluster data centers, with one or more Availability Zones which are discrete data centers with redundant power, networking, and connectivity in an AWS Region.
Amazon automatically stores each DynamoDB table in the three geographically distributed locations or AZs for durability.
DynamoDB consistency represents the manner and timing in which the successful write or update of a data item is reflected in a subsequent read operation of that same item.
DynamoDB Consistency Modes
Eventually Consistent Reads (Default)
Eventual consistency option maximizes the read throughput.
Consistency across all copies is usually reached within a second
However, an eventually consistent read might not reflect the results of a recently completed write.
Repeating a read after a short time should return the updated data.
DynamoDB uses eventually consistent reads, by default.
Strongly Consistent Reads
Strongly consistent read returns a result that reflects all writes that received a successful response prior to the read
Strongly consistent reads are 2x the cost of Eventually consistent reads
Strongly Consistent Reads come with disadvantages
A strongly consistent read might not be available if there is a network delay or outage. In this case, DynamoDB may return a server error (HTTP 500).
Strongly consistent reads may have higher latency than eventually consistent reads.
Strongly consistent reads are not supported on global secondary indexes.
Strongly consistent reads use more throughput capacity than eventually consistent reads.
DynamoDB allows the user to specify whether the read should be eventually consistent or strongly consistent at the time of the request
Read operations (such as GetItem, Query, and Scan) provide a ConsistentRead parameter, if set to true, DynamoDB uses strongly consistent reads during the operation.
Query, GetItem, and BatchGetItem operations perform eventually consistent reads by default.
Query and GetItem operations can be forced to be strongly consistent
Query operations cannot perform strongly consistent reads on Global Secondary Indexes
BatchGetItem operations can be forced to be strongly consistent on a per-table basis
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Which of the following statements is true about DynamoDB?
Requests are eventually consistent unless otherwise specified.
Requests are strongly consistent.
Tables do not contain primary keys.
None of the above
How is provisioned throughput affected by the chosen consistency model when reading data from a DynamoDB table?
Strongly consistent reads use the same amount of throughput as eventually consistent reads
Strongly consistent reads use variable throughput depending on read activity
Strongly consistent reads use more throughput than eventually consistent reads.
Strongly consistent reads use less throughput than eventually consistent reads
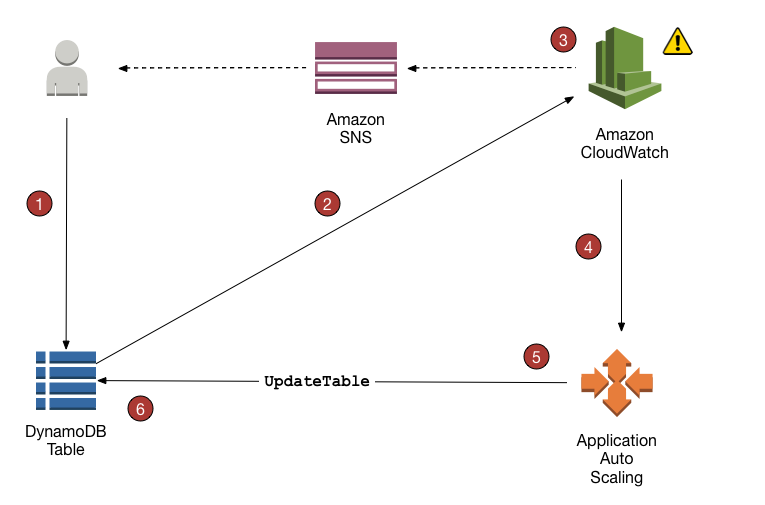
DynamoDB Auto Scaling uses the AWS Application Auto Scaling service to dynamically adjust provisioned throughput capacity on your behalf, in response to actual traffic patterns.
Application Auto Scaling enables a DynamoDB table or a global secondary index to increase its provisioned read and write capacity to handle sudden increases in traffic, without throttling.
When the workload decreases, Application Auto Scaling decreases the throughput so that you don’t pay for unused provisioned capacity.
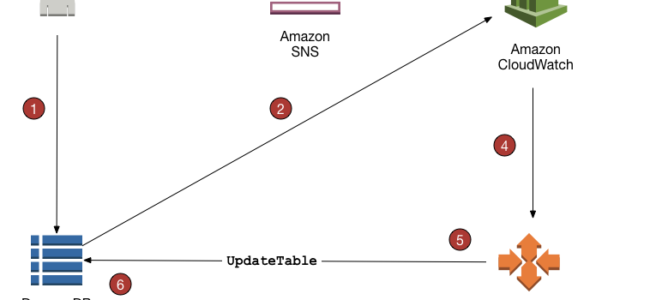
DynamoDB Auto Scaling Process
Application Auto Scaling policy can be created on the DynamoDB table.
DynamoDB publishes consumed capacity metrics to CloudWatch.
If the table’s consumed capacity exceeds the target utilization (or falls below the target) for a specific length of time, CloudWatch triggers an alarm. You can view the alarm on the console and receive notifications using Simple Notification Service – SNS.
The upper threshold alarm is triggered when consumed reads or writes breach the target utilization percent for two consecutive minutes.
The lower threshold alarm is triggered after traffic falls below the target utilization minus 20 percent for 15 consecutive minutes.
CloudWatch alarm invokes Application Auto Scaling to evaluate the scaling policy.
Application Auto Scaling issues an UpdateTable request to adjust the table’s provisioned throughput.
DynamoDB processes the UpdateTable request, dynamically increasing (or decreasing) the table’s provisioned throughput capacity so that it approaches your target utilization.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
An application running on Amazon EC2 instances writes data synchronously to an Amazon DynamoDB table configured for 60 write capacity units. During normal operation, the application writes 50KB/s to the table but can scale up to 500 KB/s during peak hours. The application is currently getting throttling errors from the DynamoDB table during peak hours. What is the MOST cost-effective change to support the increased traffic with minimal changes to the application?
Use Amazon SNS to manage the write operations to the DynamoDB table
Change DynamoDB table configuration to 600 write capacity units
Increase the number of Amazon EC2 instances to support the traffic
Configure Amazon DynamoDB Auto Scaling to handle the extra demand
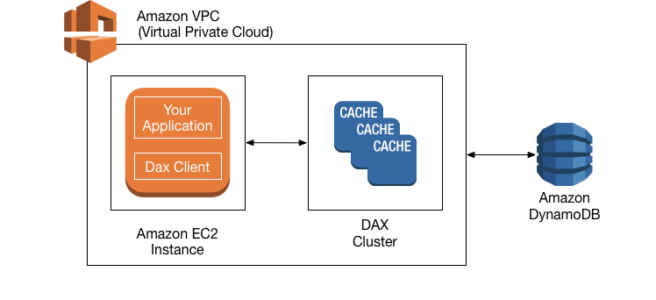
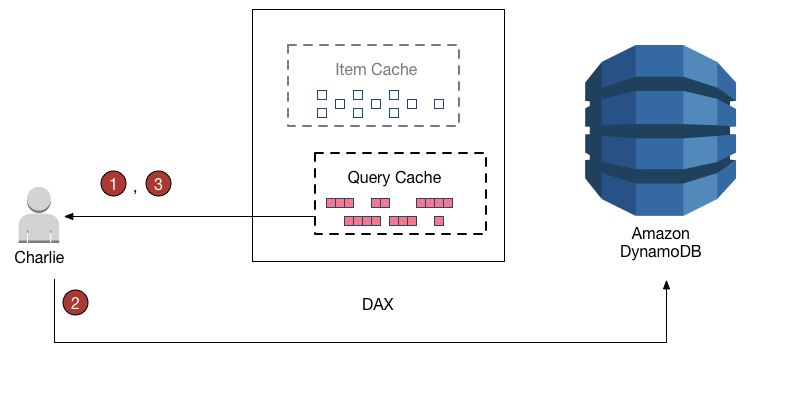
DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for DynamoDB that delivers up to a 10x performance improvement – from ms to µs – even at millions of requests per second.
DAX as a managed service handles the cache invalidation, data population, or cluster management.
DAX provides API compatibility with DynamoDB. Therefore, it requires only minimal functional changes to use with an existing application.
DAX saves costs by reducing the read load (RCU) on DynamoDB.
DAX helps prevent hot partitions.
DAX is intended for high-performance read applications. As a write-through cache, DAX writes directly so that the writes are immediately reflected in the item cache.
DAX only supports eventual consistency and strong consistency requests are passed through to DynamoDB.
DAX is fault-tolerant and scalable.
DAX cluster has a primary node and zero or more read-replica nodes. Upon a failure for a primary node, DAX will automatically failover and elect a new primary. For scaling, add or remove read replicas.
DAX supports server-side encryption.
DAX supports encryption in transit, ensuring that all requests and responses between the application and the cluster are encrypted by TLS, and connections to the cluster can be authenticated by verification of a cluster x509 certificate.
DAX Cluster
DAC cluster is a logical grouping of one or more nodes that DAX manages as a unit.
One of the nodes in the cluster is designated as the primary node, and the other nodes (if any) are read replicas.
Primary Node is responsible for
Fulfilling application requests for cached data.
Handling write operations to DynamoDB.
Evicting data from the cache according to the cluster’s eviction policy.
Read replicas are responsible for
Fulfilling application requests for cached data.
Evicting data from the cache according to the cluster’s eviction policy.
Only the primary node writes to DynamoDB, read replicas don’t write to DynamoDB.
For production, it is recommended to have DAX with at least three nodes with each node placed in different Availability Zones.
Three nodes are required for a DAX cluster to be fault-tolerant.
A DAX cluster in an AWS Region can only interact with DynamoDB tables that are in the same Region.
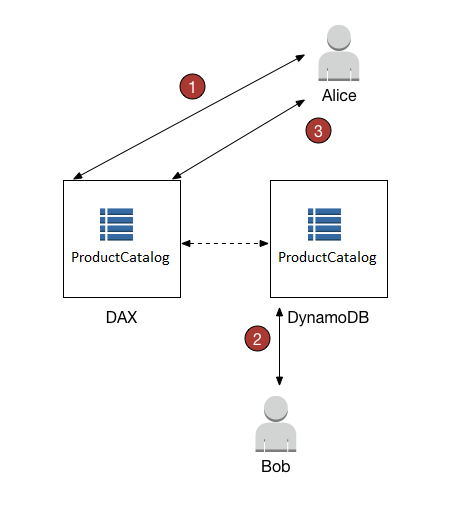
DynamoDB Accelerator Operations
Eventual Read operations
If DAX has the item available (a cache hit), DAX returns the item without accessing DynamoDB.
If DAX does not have the item available (a cache miss), DAX passes the request through to DynamoDB. When it receives the response from DynamoDB, DAX returns the results to the application. But it also writes the results to the cache on the primary node.
Strongly Consistent Read operations
DAX passes the request through to DynamoDB. The results from DynamoDB are not cached in DAX. but simply returned.
DAX is not ideal for applications that require strongly consistent reads (or that cannot tolerate eventually consistent reads).
For Write operations
Data is first written to the DynamoDB table, and then to the DAX cluster.
Operation is successful only if the data is successfully written to both the table and to DAX.
Is not ideal for applications that are write-intensive, or that do not perform much read activity.
DynamoDB Accelerator Caches
DAX cluster has two distinct caches – Item cache and Query cache
Item cache
item cache to store the results from GetItem and BatchGetItem operations.
Item remains in the DAX item cache, subject to the Time to Live (TTL) setting and the least recently used (LRU) algorithm for the cache
DAX provides a write-through cache, keeping the DAX item cache consistent with the underlying DynamoDB tables.
Query cache
DAX caches the results from Query and Scan requests in its query cache.
Query and Scan results don’t affect the item cache at all, as the result set is saved in the query cache – not in the item cache.
Writes to the Item cache don’t affect the Query cache
Item and Query cache has a default 5 minutes TTL setting.
DAX assigns a timestamp to every entry it writes to the cache. The entry expires if it has remained in the cache for longer than the TTL setting
DAX maintains an LRU list for both Item and Query cache. LRU list tracks the item addition and last read time. If the cache becomes full, DAX evicts older items (even if they haven’t expired yet) to make room for new entries
LRU algorithm is always enabled for both the item and query cache and is not user-configurable.
DynamoDB Accelerator Write Strategies
Write-Through
DAX item cache implements a write-through policy
For write operations, DAX ensures that the cached item is synchronized with the item as it exists in DynamoDB.
Write-Around
Write-around strategy reduces write latency
Ideal for bulk uploads or writing large quantities of data
Item cache doesn’t remain in sync with the data in DynamoDB.
DynamoDB Accelerator Scenarios
As an in-memory cache, DAX increases performance and reduces the response times of eventually consistent read workloads by an order of magnitude from single-digit milliseconds to microseconds.
DAX reduces operational and application complexity by providing a managed service that is API-compatible with DynamoDB. It requires only minimal functional changes to use with an existing application.
For read-heavy or bursty workloads, DAX provides increased throughput and potential operational cost savings by reducing the need to overprovision read capacity units.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
A company has setup an application in AWS that interacts with DynamoDB. DynamoDB is currently responding in milliseconds, but the application response guidelines require it to respond within microseconds. How can the performance of DynamoDB be further improved?
DynamoDB table classes are designed to help you optimize for cost.
DynamoDB currently supports two table classes
DynamoDB Standard table class is the default, and is recommended for the vast majority of workloads.
DynamoDB Standard-Infrequent Access (DynamoDB Standard-IA) table class which is optimized for tables where storage is the dominant cost. e.g, tables that store infrequently accessed data, such as logs, old social media posts, e-commerce order history, and past gaming achievements
Every DynamoDB table is associated with a table class.
All secondary indexes associated with the table use the same table class.
DynamoDB table class can be
set when creating the table (DynamoDB Standard by default) or
updating the table class of an existing table using the AWS Management Console, AWS CLI, or AWS SDK.
DynamoDB also supports managing the table class using AWS CloudFormation for single-region tables (tables that are not global tables).
Each table class offers different pricing for data storage as well as read and write requests.
You can select the most cost-effective table class for your table based on its storage and throughput usage patterns.
DynamoDB Table Classes Considerations
DynamoDB Standard table class offers lower throughput costs than DynamoDB Standard-IA and is the most cost-effective option for tables where throughput is the dominant cost.
DynamoDB Standard-IA table class offers lower storage costs than DynamoDB Standard and is the most cost-effective option for tables where storage is the dominant cost.
DynamoDB Standard-IA tables offer the same performance, durability, and availability as DynamoDB Standard tables.
Switching between the DynamoDB Standard and DynamoDB Standard-IA table classes does not require changing the application code. You use the same DynamoDB APIs and service endpoints regardless of the table class your tables use.
Cost-effectiveness of table class for the table depends on the table’s expected storage and throughput usage patterns. It is recommended to look at the table’s historical storage and throughput cost and usage with AWS Cost and Usage Reports and the AWS Cost Explorer.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
supports MySQL, MariaDB, PostgreSQL, Oracle, Microsoft SQL Server, and the new, MySQL-compatible Amazon Aurora DB engine
as it is a managed service, shell (root ssh) access is not provided
manages backups, software patching, automatic failure detection, and recovery
supports use initiated manual backups and snapshots
daily automated backups with database transaction logs enables Point in Time recovery up to the last five minutes of database usage
snapshots are user-initiated storage volume snapshot of DB instance, backing up the entire DB instance and not just individual databases that can be restored as a independent RDS instance
RDS Security
support encryption at rest using KMS as well as encryption in transit using SSL endpoints
supports IAM database authentication, which prevents the need to store static user credentials in the database, because authentication is managed externally using IAM.
supports Encryption only during creation of an RDS DB instance
existing unencrypted DB cannot be encrypted and you need to create a snapshot, created a encrypted copy of the snapshot and restore as encrypted DB
supports Secret Manager for storing and rotating secrets
for encrypted database
logs, snapshots, backups, read replicas are all encrypted as well
cross region replicas and snapshots does not work across region (Note – this is possible now with latest AWS enhancement)
Multi-AZ deployment
provides high availability and automatic failover support and is NOT a scaling solution
maintains a synchronous standby replica in a different AZ
transaction success is returned only if the commit is successful both on the primary and the standby DB
Oracle, PostgreSQL, MySQL, and MariaDB DB instances use Amazon technology, while SQL Server DB instances use SQL Server Mirroring
snapshots and backups are taken from standby & eliminate I/O freezes
during automatic failover, its seamless and RDS switches to the standby instance and updates the DNS record to point to standby
failover can be forced with the Reboot with failover option
Read Replicas
uses the PostgreSQL, MySQL, and MariaDB DB engines’ built-in replication functionality to create a separate Read Only instance
updates are asynchronously copied to the Read Replica, and data might be stale
can help scale applications and reduce read only load
requires automatic backups enabled
replicates all databases in the source DB instance
for disaster recovery, can be promoted to a full fledged database
can be created in a different region for disaster recovery, migration and low latency across regions
can’t create encrypted read replicas from unencrypted DB or read replica
RDS does not support all the features of underlying databases, and if required the database instance can be launched on an EC2 instance
RDS Components
DB parameter groups contains engine configuration values that can be applied to one or more DB instances of the same instance type for e.g. SSL, max connections etc.
Default DB parameter group cannot be modified, create a custom one and attach to the DB
Supports static and dynamic parameters
changes to dynamic parameters are applied immediately (irrespective of apply immediately setting)
changes to static parameters are NOT applied immediately and require a manual reboot.
RDS Monitoring & Notification
integrates with CloudWatch and CloudTrail
CloudWatch provides metrics about CPU utilization from the hypervisor for a DB instance, and Enhanced Monitoring gathers its metrics from an agent on the instance
Performance Insights is a database performance tuning and monitoring feature that helps illustrate the database’s performance and help analyze any issues that affect it
supports RDS Event Notification which uses the SNS to provide notification when an RDS event like creation, deletion or snapshot creation etc occurs
is a relational database engine that combines the speed and reliability of high-end commercial databases with the simplicity and cost-effectiveness of open source databases
is a managed services and handles time-consuming tasks such as provisioning, patching, backup, recovery, failure detection and repair
is a proprietary technology from AWS (not open sourced)
provides PostgreSQL and MySQL compatibility
is “AWS cloud optimized” and claims 5x performance improvement
over MySQL on RDS, over 3x the performance of PostgreSQL on RDS
scales storage automatically in increments of 10GB, up to 64 TB with no impact to database performance. Storage is striped across 100s of volumes.
no need to provision storage in advance.
provides self-healing storage. Data blocks and disks are continuously scanned for errors and repaired automatically.
provides instantaneous failover
replicates each chunk of my the database volume six ways across three Availability Zones i.e. 6 copies of the data across 3 AZ
requires 4 copies out of 6 needed for writes
requires 3 copies out of 6 need for reads
costs more than RDS (20% more) – but is more efficient
Read Replicas
can have 15 replicas while MySQL has 5, and the replication process is faster (sub 10 ms replica lag)
share the same data volume as the primary instance in the same AWS Region, there is virtually no replication lag
supports Automated failover for master in less than 30 seconds
supports Cross Region Replication using either physical or logical replication.
Security
supports Encryption at rest using KMS
supports Encryption in flight using SSL (same process as MySQL or Postgres)
Automated backups, snapshots and replicas are also encrypted
Possibility to authenticate using IAM token (same method as RDS)
supports protecting the instance with security groups
does not support SSH access to the underlying servers
allows a single Aurora database to span multiple AWS regions.
provides Physical replication, which uses dedicated infrastructure that leaves the databases entirely available to serve the application
supports 1 Primary Region (read / write)
replicates across up to 5 secondary (read-only) regions, replication lag is less than 1 second
supports up to 16 Read Replicas per secondary region
recommended for low-latency global reads and disaster recovery with an RTO of < 1 minute
failover is not automated and if the primary region becomes unavailable, a secondary region can be manually removed from an Aurora Global Database and promote it to take full reads and writes. Application needs to be updated to point to the newly promoted region.
Backtracking “rewinds” the DB cluster to the specified time
Backtracking performs in place restore and does not create a new instance. There is a minimal downtime associated with it.
Aurora Clone feature allows quick and cost-effective creation of Aurora Cluster duplicates
supports parallel or distributed query using Aurora Parallel Query, which refers to the ability to push down and distribute the computational load of a single query across thousands of CPUs in Aurora’s storage layer.
DynamoDB Global Tables provide multi-master, cross-region replication capability of DynamoDB to support data access locality and regional fault tolerance for database workloads.
DynamoDB Streams provides a time-ordered sequence of item-level changes made to data in a table
enables a per-item timestamp to determine when an item expiry
expired items are deleted from the table without consuming any write throughput.
DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for DynamoDB that delivers up to a 10x performance improvement – from milliseconds to microseconds – even at millions of requests per second.
allows identical copies (called replicas) of a DynamoDB table (called master table) to be maintained in one or more AWS regions.
using DynamoDB streams which leverages Kinesis and provides time-ordered sequence of item-level changes and can help for lower RPO, lower RTO disaster recovery
DynamoDB Triggers (just like database triggers) are a feature that allows the execution of custom actions based on item-level updates on a table.
VPC Gateway Endpoints provide private access to DynamoDB from within a VPC without the need for an internet gateway or NAT gateway.
managed web service that provides in-memory caching to deploy and run Memcached or Redis protocol-compliant cache clusters
ElastiCache with Redis,
like RDS, supports Multi-AZ, Read Replicas and Snapshots
Read Replicas are created across AZ within same region using Redis’s asynchronous replication technology
Multi-AZ differs from RDS as there is no standby, but if the primary goes down a Read Replica is promoted as primary
Read Replicas cannot span across regions, as RDS supports
cannot be scaled out and if scaled up cannot be scaled down
allows snapshots for backup and restore
AOF can be enabled for recovery scenarios, to recover the data in case the node fails or service crashes. But it does not help in case the underlying hardware fails
Enabling Redis Multi-AZ as a Better Approach to Fault Tolerance
ElastiCache with Memcached
can be scaled up by increasing size and scaled out by adding nodes
nodes can span across multiple AZs within the same region
cached data is spread across the nodes, and a node failure will always result in some data loss from the cluster
supports auto discovery
every node should be homogenous and of same instance type
ElastiCache Redis vs Memcached
complex data objects vs simple key value storage
persistent vs non persistent, pure caching
automatic failover with Multi-AZ vs Multi-AZ not supported
scaling using Read Replicas vs using multiple nodes
backup & restore supported vs not supported
can be used state management to keep the web application stateless
fully managed, fast and powerful, petabyte scale data warehouse service
uses replication and continuous backups to enhance availability and improve data durability and can automatically recover from node and component failures
provides Massive Parallel Processing (MPP) by distributing & parallelizing queries across multiple physical resources
columnar data storage improving query performance and allowing advance compression techniques
only supports Single-AZ deployments and the nodes are available within the same AZ, if the AZ supports Redshift clusters