Table of Contents
hide
AWS DynamoDB Advanced Features
- DynamoDB Secondary indexes on a table allow efficient access to data with attributes other than the primary key.
- DynamoDB Time to Live – TTL enables a per-item timestamp to determine when an item is no longer needed.
- DynamoDB cross-region replication allows identical copies (called replicas) of a DynamoDB table (called master table) to be maintained in one or more AWS regions.
- DynamoDB Global Tables is a new multi-master, cross-region replication capability of DynamoDB to support data access locality and regional fault tolerance for database workloads.
- DynamoDB Streams provides a time-ordered sequence of item-level changes made to data in a table.
- DynamoDB Triggers (just like database triggers) are a feature that allows the execution of custom actions based on item-level updates on a table.
- DynamoDB Accelerator – DAX is a fully managed, highly available, in-memory cache for DynamoDB that delivers up to a 10x performance improvement – from ms to µs – even at millions of requests per second.
- VPC Gateway Endpoints provide private access to DynamoDB from within a VPC without the need for an internet gateway or NAT gateway.
DynamoDB Secondary Indexes
- DynamoDB Secondary indexes on a table allow efficient access to data with attributes other than the primary key.
- Global secondary index – an index with a partition key and a sort key that can be different from those on the base table.
- Local secondary index – an index that has the same partition key as the base table, but a different sort key.
DynamoDB TTL
- DynamoDB Time to Live (TTL) enables a per-item timestamp to determine when an item is no longer needed.
- After the date and time of the specified timestamp, DynamoDB deletes the item from the table without consuming any write throughput.
- DynamoDB TTL is provided at no extra cost and can help reduce data storage by retaining only required data.
- Items that are deleted from the table are also removed from any local secondary index and global secondary index in the same way as a DeleteItem operation.
- Expired items get removed from the table and indexes within about 48 hours.
- DynamoDB Stream tracks the delete operation as a system delete and not a regular delete.
- TTL is useful if the stored items lose relevance after a specific time. for e.g.
- Remove user or sensor data after a year of inactivity in an application
- Archive expired items to an S3 data lake via DynamoDB Streams and AWS Lambda.
- Retain sensitive data for a certain amount of time according to contractual or regulatory obligations.
DynamoDB Cross-region Replication
- DynamoDB cross-region replication allows identical copies (called replicas) of a DynamoDB table (called master table) to be maintained in one or more AWS regions.
- Writes to the table will be automatically propagated to all replicas.
- Cross-region replication currently supports a single master mode. A single master has one master table and one or more replica tables.
- Read replicas are updated asynchronously as DynamoDB acknowledges a write operation as successful once it has been accepted by the master table. The write will then be propagated to each replica with a slight delay.
- Cross-region replication can be helpful in scenarios
- Efficient disaster recovery, in case a data center failure occurs.
- Faster reads, for customers in multiple regions by delivering data faster by reading a DynamoDB table from the closest AWS data center.
- Easier traffic management, to distribute the read workload across tables and thereby consume less read capacity in the master table.
- Easy regional migration, by promoting a read replica to master
- Live data migration, to replicate data and when the tables are in sync, switch the application to write to the destination region
- Cross-region replication costing depends on
- Provisioned throughput (Writes and Reads)
- Storage for the replica tables.
- Data Transfer across regions
- Reading data from DynamoDB Streams to keep the tables in sync.
- Cost of EC2 instances provisioned, depending upon the instance types and region, to host the replication process.
- NOTE : Cross Region replication on DynamoDB was performed defining AWS Data Pipeline job which used EMR internally to transfer data before the DynamoDB streams and out-of-box cross-region replication support.
DynamoDB Global Tables
- DynamoDB Global Tables is a multi-master, active-active, cross-region replication capability of DynamoDB to support data access locality and regional fault tolerance for database workloads.
- Applications can now perform reads and writes to DynamoDB in AWS regions around the world, with changes in any region propagated to every region where a table is replicated.
- Global Tables help in building applications to advantage of data locality to reduce overall latency.
- Global Tables supports eventual consistency & strong consistency for same region reads, but only eventual consistency for cross-region reads.
- Global Tables replicates data among regions within a single AWS account and currently does not support cross-account access.
- Global Tables uses the Last Write Wins approach for conflict resolution.
- Global Tables requires DynamoDB streams enabled with New and Old image settings.
DynamoDB Streams
- DynamoDB Streams provides a time-ordered sequence of item-level changes made to data in a table.
- DynamoDB Streams stores the data for the last 24 hours, after which they are erased.
- DynamoDB Streams maintains an ordered sequence of the events per item however, sequence across items is not maintained.
- Example
- For e.g., suppose that you have a DynamoDB table tracking high scores for a game and that each item in the table represents an individual player. If you make the following three updates in this order:
- Update 1: Change Player 1’s high score to 100 points
- Update 2: Change Player 2’s high score to 50 points
- Update 3: Change Player 1’s high score to 125 points
- DynamoDB Streams will maintain the order for Player 1 score events. However, it would not maintain order across the players. So Player 2 score event is not guaranteed between the 2 Player 1 events
- For e.g., suppose that you have a DynamoDB table tracking high scores for a game and that each item in the table represents an individual player. If you make the following three updates in this order:
- DynamoDB Streams APIs help developers consume updates and receive the item-level data before and after items are changed.
- DynamoDB Streams allow reads at up to twice the rate of the provisioned write capacity of the DynamoDB table.
- DynamoDB Streams have to be enabled on a per-table basis.
- DynamoDB streams support Encryption at rest to encrypt the data.
- DynamoDB Streams is designed for No Duplicates so that every update made to the table will be represented exactly once in the stream.
- DynamoDB Streams writes stream records in near-real time so that applications can consume these streams and take action based on the contents.
- DynamoDB streams can be used for multi-region replication to keep other data stores up-to-date with the latest changes to DynamoDB or to take actions based on the changes made to the table
- DynamoDB steam records can be processed using Kinesis Data Streams, Lambda, or KCL application.
DynamoDB Triggers
- DynamoDB Triggers (just like database triggers) are a feature that allows the execution of custom actions based on item-level updates on a table.
- DynamoDB triggers can be used in scenarios like sending notifications, updating an aggregate table, and connecting DynamoDB tables to other data sources.
- DynamoDB Trigger flow
- Custom logic for a DynamoDB trigger is stored in an AWS Lambda function as code.
- A trigger for a given table can be created by associating an AWS Lambda function to the stream (via DynamoDB Streams) on a table.
- When the table is updated, the updates are published to DynamoDB Streams.
- In turn, AWS Lambda reads the updates from the associated stream and executes the code in the function.
DynamoDB Backup and Restore
- DynamoDB on-demand backup helps create full backups of the tables for long-term retention, and archiving for regulatory compliance needs.
- Backup and restore actions run with no impact on table performance or availability.
- Backups are preserved regardless of table deletion and retained until they are explicitly deleted.
- On-demand backups are cataloged, and discoverable.
- On-demand backups can be created using
- DynamoDB
- DynamoDB on-demand backups cannot be copied to a different account or Region.
- AWS Backup (Recommended)
- is a fully managed data protection service that makes it easy to centralize and automate backups across AWS services, in the cloud, and on-premises
- provides enhanced backup features
- can configure backup schedule, policies and monitor activity for the AWS resources and on-premises workloads in one place.
- can copy the on-demand backups across AWS accounts and Regions,
- encryption using an AWS KMS key that is independent of the DynamoDB table encryption key.
- apply write-once-read-many (WORM) setting for the backups using the AWS Backup Vault Lock policy.
- add cost allocation tags to on-demand backups, and
- transition on-demand backups to cold storage for lower costs.
- DynamoDB
DynamoDB PITR – Point-In-Time Recovery
- DynamoDB point-in-time recovery – PITR enables automatic, continuous, incremental backup of the table with per-second granularity.
- PITR-enabled tables that were deleted can be recovered in the preceding 35 days and restored to their state just before they were deleted.
- PITR helps protect against accidental writes and deletes.
- PITR can back up tables with hundreds of terabytes of data with no impact on the performance or availability of the production applications.
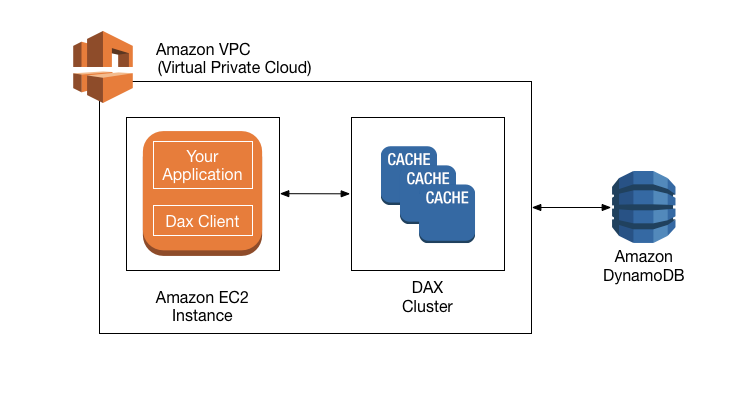
DynamoDB Accelerator – DAX
- DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for DynamoDB that delivers up to a 10x performance improvement – from milliseconds to microseconds – even at millions of requests per second.
- DAX is intended for high-performance read applications. As a write-through cache, DAX writes directly so that the writes are immediately reflected in the item cache.
- DAX as a managed service handles the cache invalidation, data population, or cluster management.
- DAX provides API-compatible with DynamoDB. Therefore, it requires only minimal functional changes to use with an existing application.
- DAX saves costs by reducing the read load (RCU) on DynamoDB.
- DAX helps prevent hot partitions.
- DAX only supports eventual consistency, and strong consistency requests are passed-through to DynamoDB.
- DAX is fault-tolerant and scalable.
- DAX cluster has a primary node and zero or more read-replica nodes. Upon a failure for a primary node, DAX will automatically failover and elect a new primary. For scaling, add or remove read replicas.
- DAX supports server-side encryption.
- DAX also supports encryption in transit, ensuring that all requests and responses between the application and the cluster are encrypted by TLS, and connections to the cluster can be authenticated by verification of a cluster x509 certificate
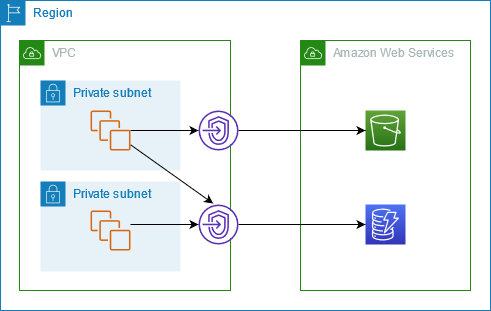
VPC Endpoints
- VPC endpoints for DynamoDB improve privacy and security, especially those dealing with sensitive workloads with compliance and audit requirements, by enabling private access to DynamoDB from within a VPC without the need for an internet gateway or NAT gateway.
- VPC endpoints for DynamoDB support IAM policies to simplify DynamoDB access control, where access can be restricted to a specific VPC endpoint.
- VPC endpoints can be created only for Amazon DynamoDB tables in the same AWS Region as the VPC
- DynamoDB Streams cannot be accessed using VPC endpoints for DynamoDB.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- What are the services supported by VPC endpoints, using Gateway endpoint type? Choose 2 answers
- Amazon S3
- Amazon EFS
- Amazon DynamoDB
- Amazon Glacier
- Amazon SQS
- A company has setup an application in AWS that interacts with DynamoDB. DynamoDB is currently responding in milliseconds, but the application response guidelines require it to respond within microseconds. How can the performance of DynamoDB be further improved? [SAA-C01]
- Use ElastiCache in front of DynamoDB
- Use DynamoDB inbuilt caching
- Use DynamoDB Accelerator
- Use RDS with ElastiCache instead
Hi Jayendra,
May i know the answer and explanation for the below question :
You have recently joined a startup company building sensors to measure street noise and air quality in urban areas.
The company has been running a pilot deployment of around 100 sensors for 3 months Each sensor uploads 1KB of sensor data every minute to a backend hosted on AWS.
During the pilot, you measured a peak or 10 IOPS on the database, and you stored an average of 3GB of sensor data per month in the database
The current deployment consists of a load-balanced auto scaled Ingestion layer using EC2 instances and a PostgreSQL RDS database with 500GB standard storage.
The pilot is considered a success and your CEO has managed to get the attention or some potential investors
The business plan requires a deployment of at least 1O0K sensors which needs to be supported by the backend
You also need to store sensor data for at least two years to be able to compare year over year Improvements.
To secure funding, you have to make sure that the platform meets these requirements and leaves room for further scaling
Which setup win meet the requirements?
A. Add an SOS queue to the ingestion layer to buffer writes to the RDS instance
B. Ingest data into a DynamoDB table and move old data to a Redshift cluster
C. Replace the RDS instance with a 6 node Redshift cluster with 96TB of storage
D. Keep the current architecture but upgrade RDS storage to 3TB and 10K provisioned IOPS
Would select #B. to ingest in DynamoDB and move to Redshift. Redshift cannot be used for ingestion. RDS would not scale.
Hey guys,
Jayendra, Karan guided me to this path. I also intend to pass the aws saa1 exam.
I like getting things done from the command console when possible. I find it frustrating dealing with the maze of GUI elements in certain complex environments. AWS and ServiceNow are both quite complex. I am aware that there is a CLI tool for AWS, and a PowerShell module. I tried installing their CLI tool but I am having trouble finding a nice step-by step hands on lab to guide me.
Is there one that comes to mind?
I appreciate your time.
Sincerely,
Anis
AWS CLI works fine if you have proper configuration with your region and access keys. What error did you encounter ?
Nice Information..