AWS S3 Security
- AWS S3 Security is a shared responsibility between AWS and the Customer
- S3 is a fully managed service that is protected by the AWS global network security procedures
- AWS handles basic security tasks like guest operating system (OS) and database patching, firewall configuration, and disaster recovery.
- Security and compliance of S3 are assessed by third-party auditors as part of multiple AWS compliance programs including SOC, PCI DSS, HIPAA, etc.
- S3 provides several other features to handle security, which are the customers’ responsibility.
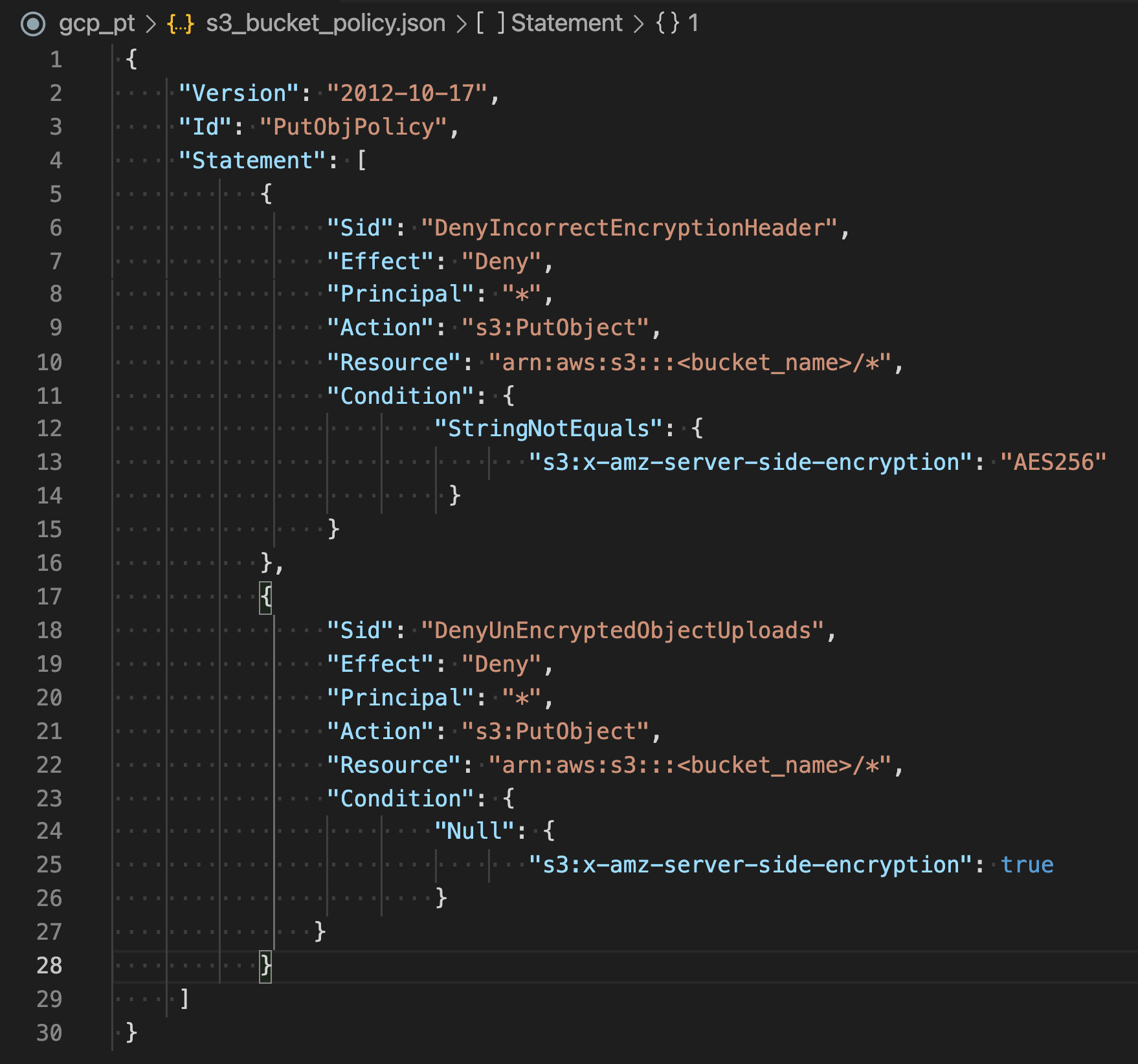
- S3 Encryption supports both data at rest and data in transit encryption.
- Data in transit encryption can be provided by enabling communication via SSL or using client-side encryption
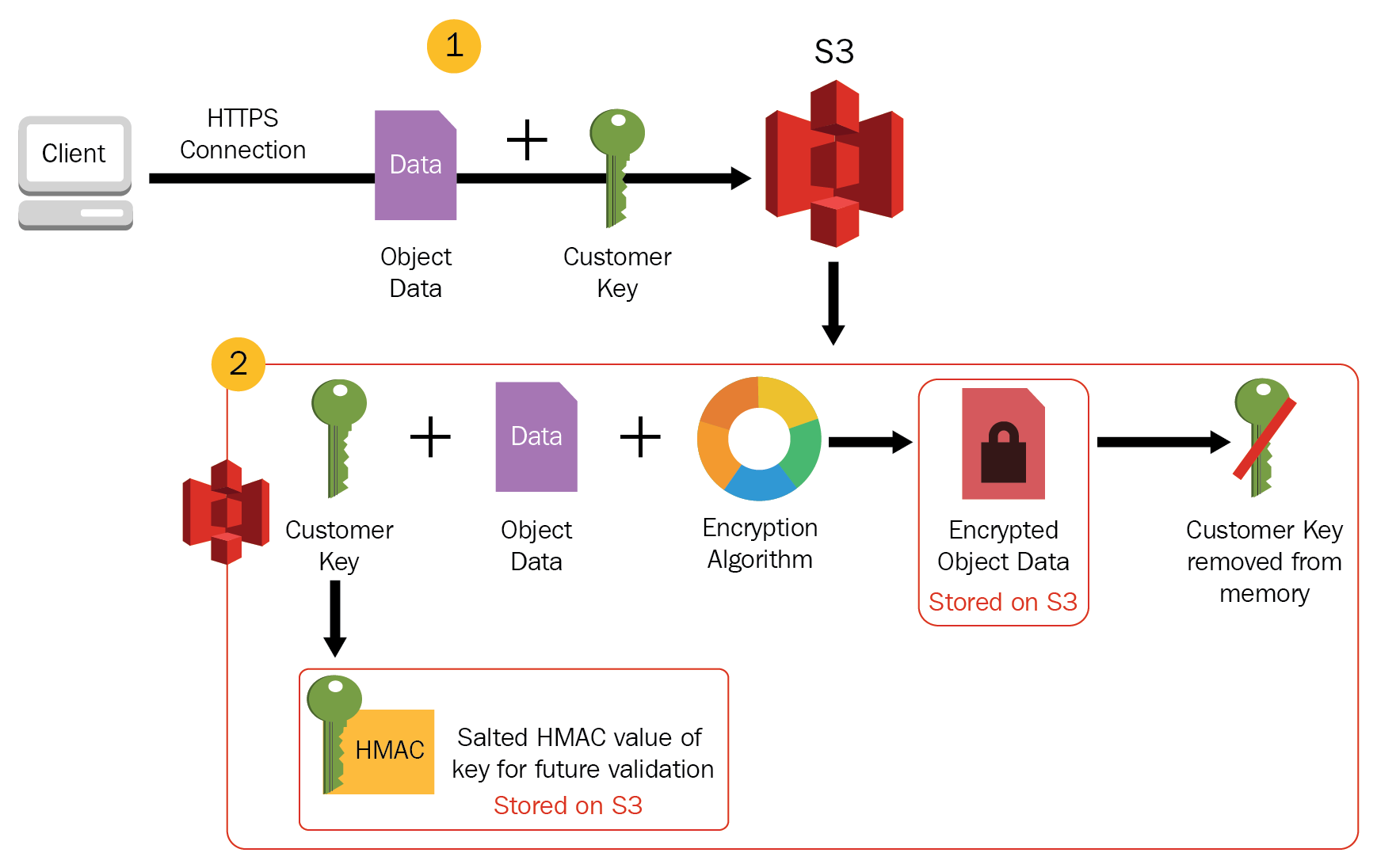
- Data at rest encryption can be provided using Server Side or Client Side encryption
- S3 permissions can be handled using
- IAM User Policies
- Resource-based policies which include Bucket policies, Bucket ACL, and Object ACL
- S3 Access Points
- S3 Object Lock helps to store objects using a WORM model and can help prevent objects from being deleted or overwritten for a fixed amount of time or indefinitely.
- S3 Access Points simplify data access for any AWS service or customer application that stores data in S3.
- S3 Versioning with MFA Delete can be enabled on a bucket to ensure that data in the bucket cannot be accidentally overwritten or deleted.
- S3 Block Public Access provides controls across an entire AWS Account or at the individual S3 bucket level to ensure that objects never have public access, now and in the future.
- S3 Access Analyzer monitors the access policies, ensuring that the policies provide only the intended access to your S3 resources.
S3 Encryption
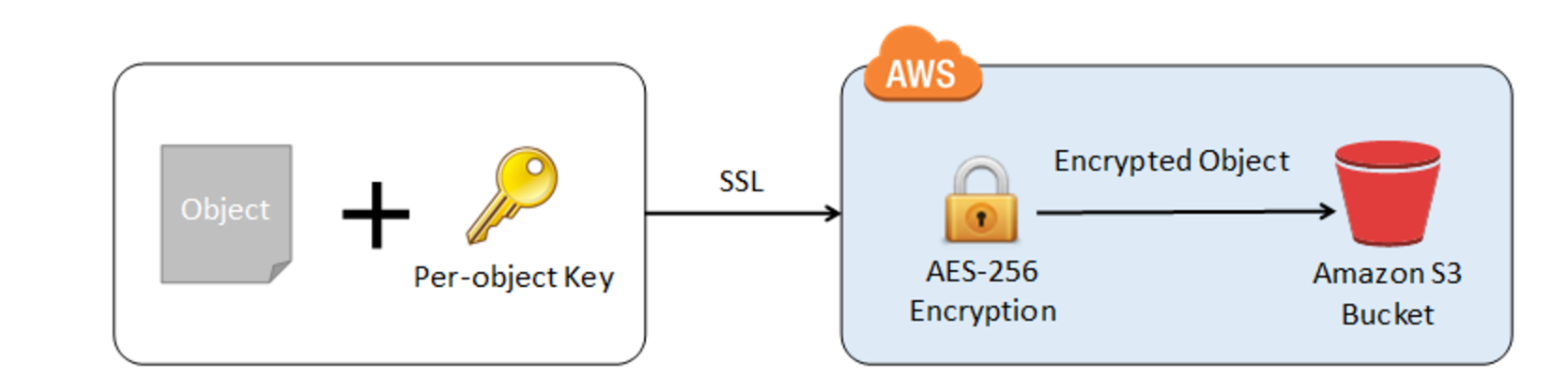
- S3 allows the protection of data in transit by enabling communication via SSL or using client-side encryption
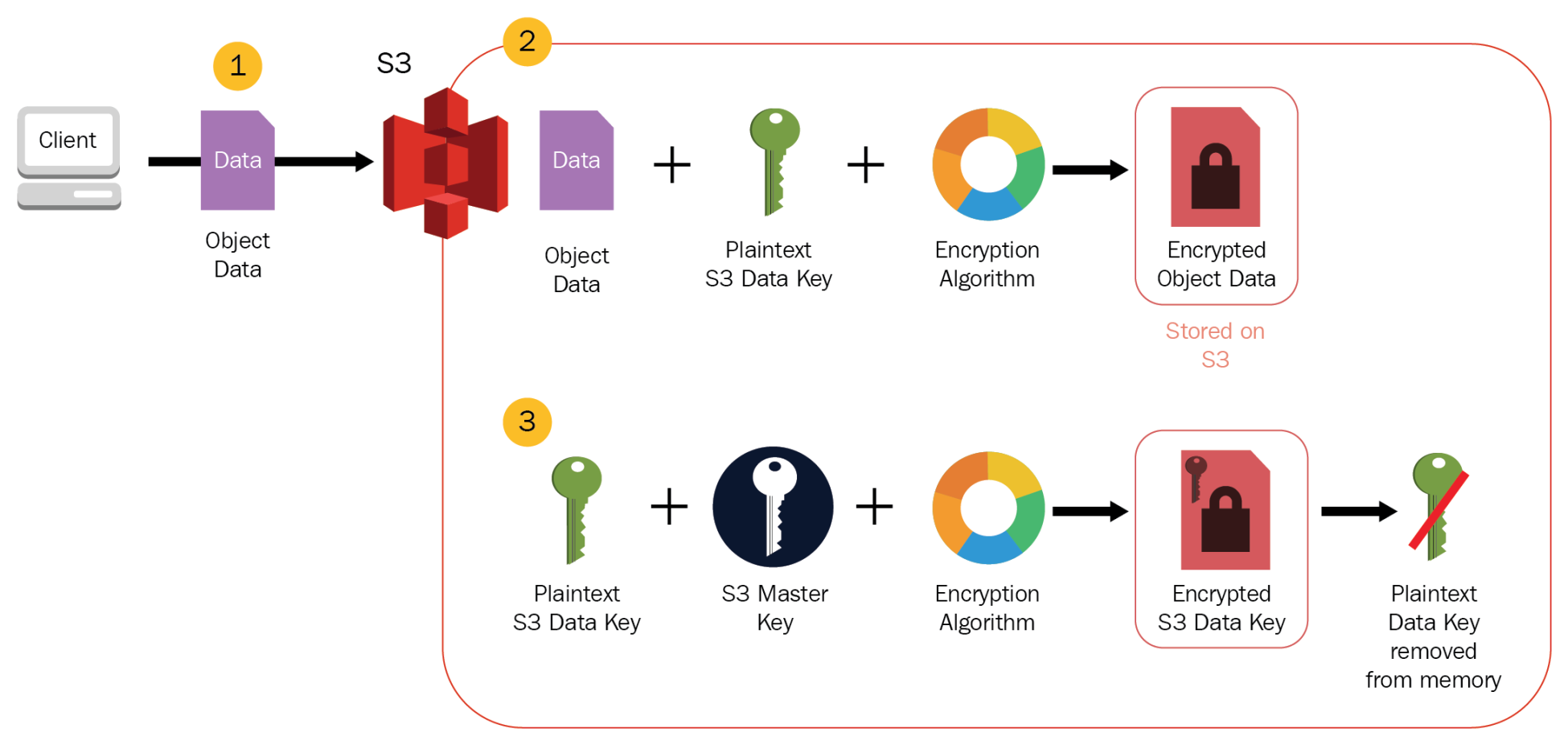
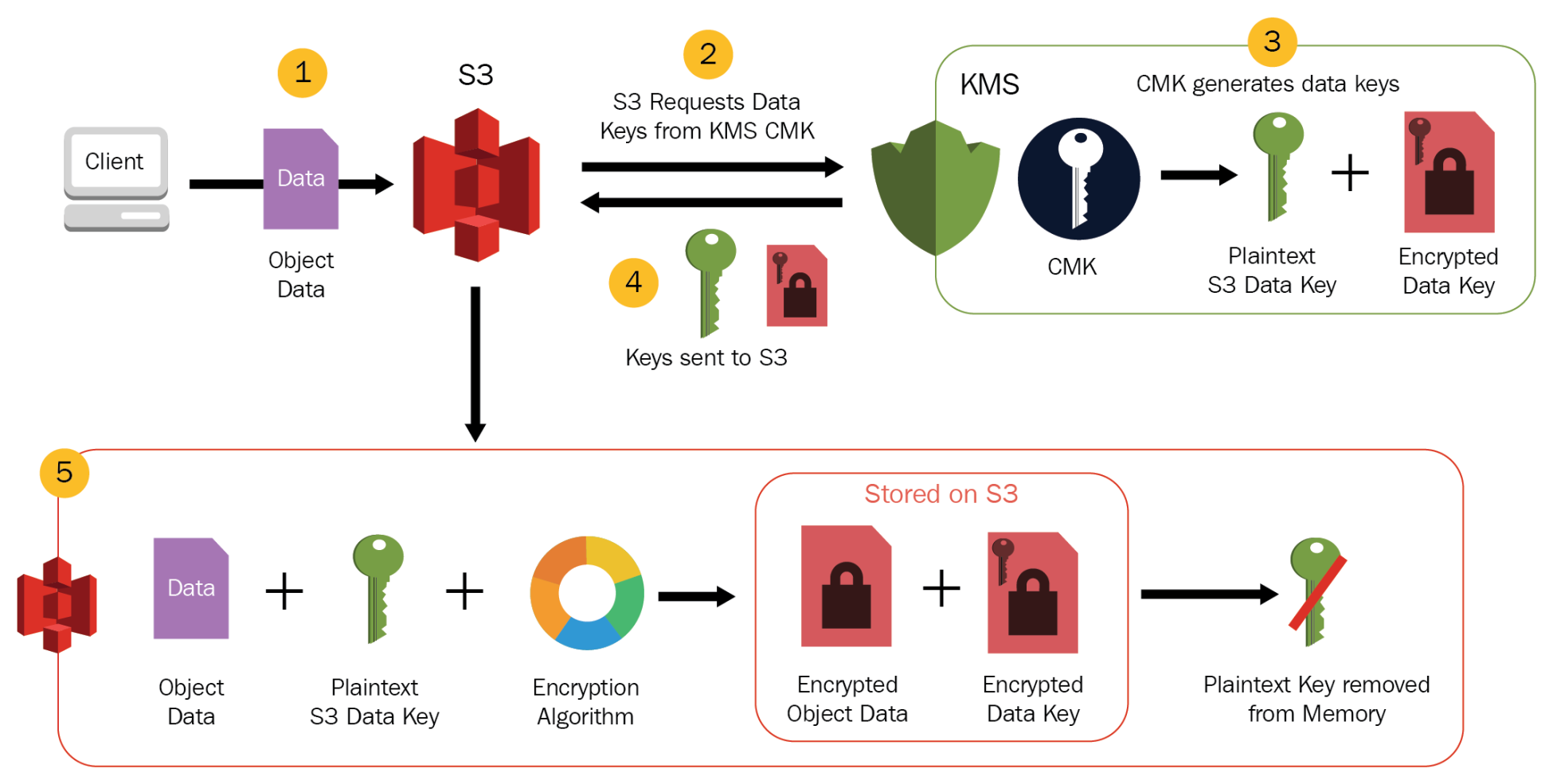
- S3 provides data-at-rest encryption using
- Server-Side Encryption: S3 handles the encryption
- Client Side Encryption: Customer handles the encryption
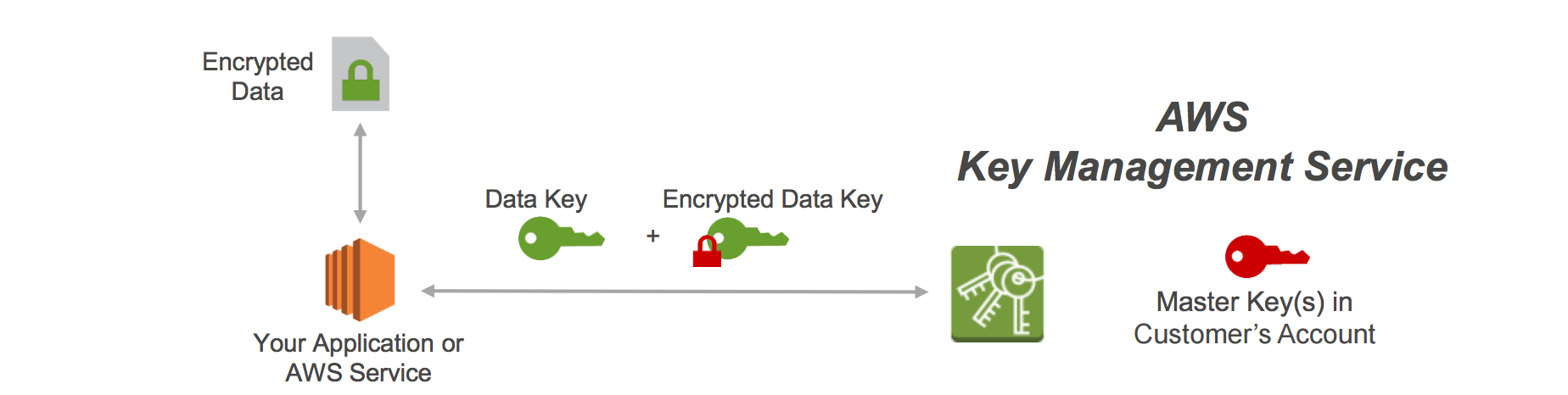
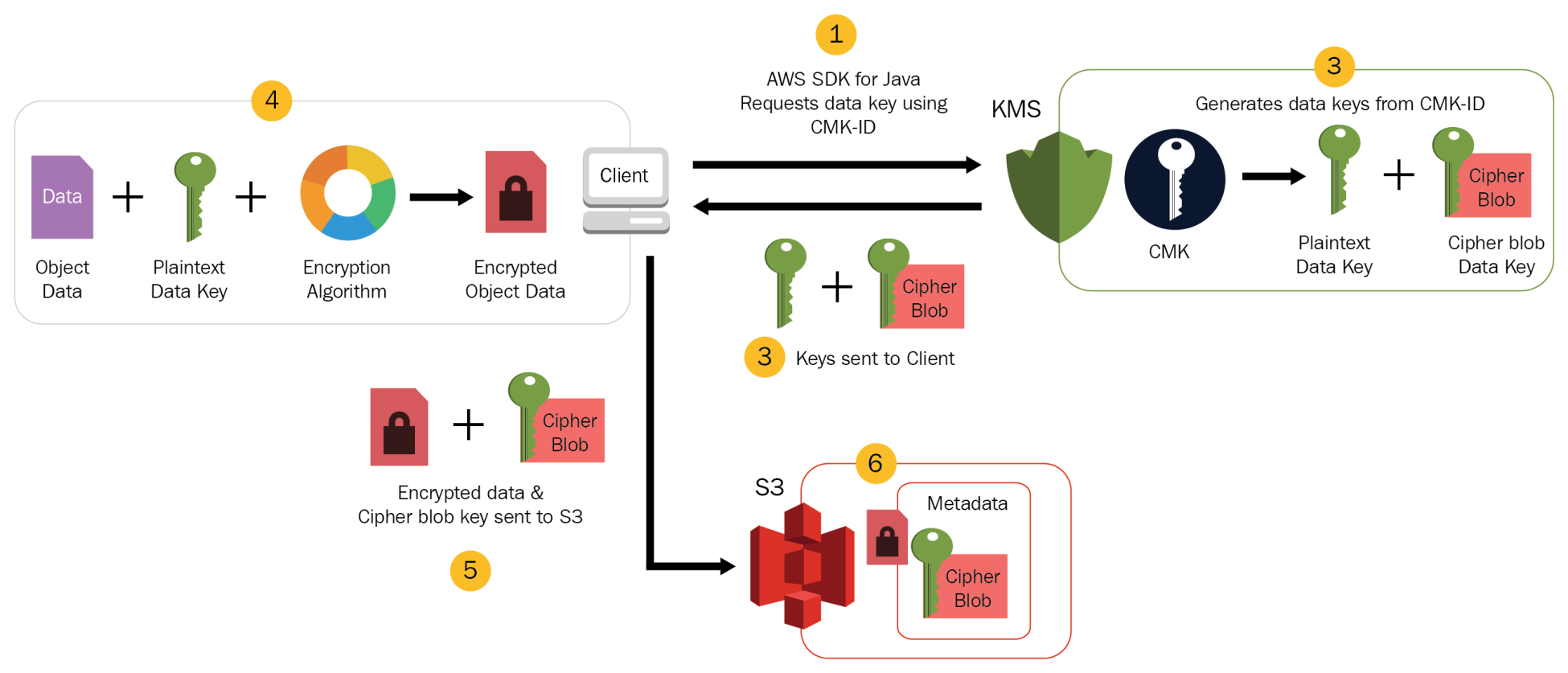
- CSE-CMK
- Customer handles the encryption and decryption using keys managed through AWS KMS.
- Client-side Master Key
- Customer handles the encryption and decryption using keys managed by them.
- CSE-CMK
S3 Permissions
Refer blog post @ S3 Permissions
S3 Object Lock
- S3 Object Lock helps to store objects using a write-once-read-many (WORM) model.
- can help prevent objects from being deleted or overwritten for a fixed amount of time or indefinitely.
- can help meet regulatory requirements that require WORM storage or add an extra layer of protection against object changes and deletion.
- can be enabled only for new buckets and works only in versioned buckets.
- provides two retention modes that apply different levels of protection to the objects
- Governance mode
- Users can’t overwrite or delete an object version or alter its lock settings unless they have special permissions.
- Objects can be protected from being deleted by most users, but some users can be granted permission to alter the retention settings or delete the object if necessary.
- Can be used to test retention-period settings before creating a compliance-mode retention period.
- Compliance mode
- A protected object version can’t be overwritten or deleted by any user, including the root user in the AWS account.
- Object retention mode can’t be changed, and its retention period can’t be shortened.
- Object versions can’t be overwritten or deleted for the duration of the retention period.
- Governance mode
S3 Access Points
- S3 access points simplify data access for any AWS service or customer application that stores data in S3.
- Access points are named network endpoints that are attached to buckets and can be used to perform S3 object operations, such as
GetObjectandPutObject. - Each access point has distinct permissions and network controls that S3 applies for any request that is made through that access point.
- Each access point enforces a customized access point policy that works in conjunction with the bucket policy, attached to the underlying bucket.
- An access point can be configured to accept requests only from a VPC to restrict S3 data access to a private network.
- Custom block public access settings can be configured for each access point.
S3 VPC Gateway Endpoint
- A VPC endpoint enables connections between a VPC and supported services, without requiring that you use an internet gateway, NAT device, VPN connection, or AWS Direct Connect connection.
- VPC is not exposed to the public internet.
- A Gateway Endpoint is a gateway that is a target for a route in your route table used for traffic destined to either S3.
S3 Block Public Access
- S3 Block Public Access provides controls across an entire AWS Account or at the individual S3 bucket level to ensure that objects never have public access, now and in the future.
- S3 Block Public Access provides settings for access points, buckets, and accounts to help manage public access to S3 resources.
- By default, new buckets, access points, and objects don’t allow public access. However, users can modify bucket policies, access point policies, or object permissions to allow public access.
- S3 Block Public Access settings override these policies and permissions so that public access to these resources can be limited.
- S3 Block Public Access allows account administrators and bucket owners to easily set up centralized controls to limit public access to their S3 resources that are enforced regardless of how the resources are created.
- S3 doesn’t support block public access settings on a per-object basis.
- S3 Block Public Access settings when applied to an account apply to all AWS Regions globally.
S3 Access Analyzer
- S3 Access Analyzer monitors the access policies, ensuring that the policies provide only the intended access to your S3 resources.
- S3 Access Analyzer evaluates the bucket access policies and enables you to discover and swiftly remediate buckets with potentially unintended access.
S3 Security Best Practices
S3 Preventative Security Best Practices
- Ensure S3 buckets use the correct policies and are not publicly accessible
- Use S3 block public access
- Identify Bucket policies and ACLs that allow public access
- Use AWS Trusted Advisor to inspect the S3 implementation.
- Implement least privilege access
- Use IAM roles for applications and AWS services that require S3 access
- Enable Multi-factor authentication (MFA) Delete to help prevent accidental bucket deletions
- Consider Data at Rest Encryption
- Enforce Data in Transit Encryption
- Consider S3 Object Lock to store objects using a “Write Once Read Many” (WORM) model.
- Enable versioning to easily recover from both unintended user actions and application failures.
- Consider S3 Cross-Region replication
- Consider VPC endpoints for S3 access to provide private S3 connectivity and help prevent traffic from potentially traversing the open internet.
S3 Monitoring and Auditing Best Practices
- Identify and Audit all S3 buckets to have visibility of all the S3 resources to assess their security posture and take action on potential areas of weakness.
- Implement monitoring using AWS monitoring tools
- Enable S3 server access logging, which provides detailed records of the requests that are made to a bucket useful for security and access audits
- Use AWS CloudTrail, which provides a record of actions taken by a user, a role, or an AWS service in S3.
- Enable AWS Config, which enables you to assess, audit, and evaluate the configurations of the AWS resources
- Consider using Amazon Macie with S3 to automatically discover, classify, and protect sensitive data in AWS.
- Monitor AWS security advisories to regularly check security advisories posted in Trusted Advisor for the AWS account.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.