AWS Certification Exam Cheat Sheet
AWS Certification Exams cover a lot of topics and a wide range of services with minute details for features, patterns, anti patterns and their integration with other services. This blog post is just to have a quick summary of all the services and key points for a quick glance before you appear for the exam
AWS Global Infrastructure
AWS Region, AZs, Edge locations
- Each region is a separate geographic area, completely independent, isolated from the other regions & helps achieve the greatest possible fault tolerance and stability
- Communication between regions is across the public Internet
- Each region has multiple Availability Zones
- Each AZ is physically isolated, geographically separated from each other and designed as an independent failure zone
- AZs are connected with low-latency private links (not public internet)
- Edge locations are locations maintained by AWS through a worldwide network of data centers for the distribution of content to reduce latency.
AWS Local Zones
- AWS Local Zones place select AWS services closer to end-users, which allows running highly-demanding applications that require single-digit millisecond latencies to the end-users such as media & entertainment content creation, real-time gaming, machine learning etc.
- AWS Local Zones provide a high-bandwidth, secure connection between local workloads and those running in the AWS Region, allowing you to seamlessly connect to the full range of in-region services through the same APIs and tool sets.
AWS Wavelength
- AWS infrastructure deployments embed AWS compute and storage services within the telecommunications providers’ datacenters and help seamlessly access the breadth of AWS services in the region.
- AWS Wavelength brings services to the edge of the 5G network, without leaving the mobile provider’s network reducing the extra network hops, minimizing the latency to connect to an application from a mobile device.
AWS Outposts
- AWS Outposts bring native AWS services, infrastructure, and operating models to virtually any data center, co-location space, or on-premises facility.
- AWS Outposts is designed for connected environments and can be used to support workloads that need to remain on-premises due to low latency, compliance or local data processing needs.
Refer details @ AWS Global Infrastructure
AWS Services
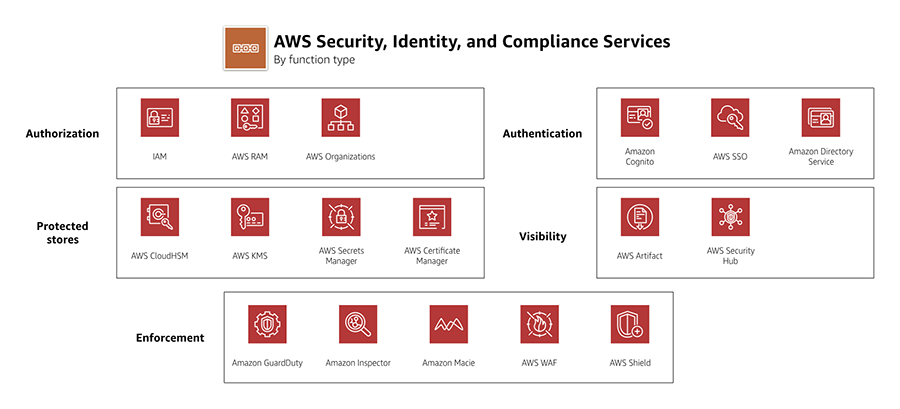
- AWS Security & Identity Service Cheat Sheet
- AWS Networking Services Cheat Sheet
- AWS Compute Services Cheat Sheet
- AWS Storage & Content Delivery Cheat Sheet
- AWS Database Services Cheat Sheet
- AWS Analytics Services Cheat Sheet
- AWS Application Services Cheat Sheet
- AWS Management Tools Cheat Sheet
AWS Organizations
- AWS Organizations offers policy-based management for multiple AWS accounts
- Organizations allows creation of groups of accounts and then apply policies to those groups
- Organizations enables you to centrally manage policies across multiple accounts, without requiring custom scripts and manual processes.
- Organizations helps simplify the billing for multiple accounts by enabling the setup of a single payment method for all the accounts in the organization through consolidated billing
Consolidate Billing
- Paying account with multiple linked accounts
- Paying account is independent and should be only used for billing purpose
- Paying account cannot access resources of other accounts unless given exclusively access through Cross Account roles
- All linked accounts are independent and soft limit of 20
- One bill per AWS account
- provides Volume pricing discount for usage across the accounts
- allows unused Reserved Instances to be applied across the group
- Free tier is not applicable across the accounts
Tags & Resource Groups
- are metadata, specified as key/value pairs with the AWS resources
- are for labelling purposes and helps managing, organizing resources
- can be inherited when created resources created from Auto Scaling, Cloud Formation, Elastic Beanstalk etc
- can be used for
- Cost allocation to categorize and track the AWS costs
- Conditional Access Control policy to define permission to allow or deny access on resources based on tags
- Resource Group is a collection of resources that share one or more tags
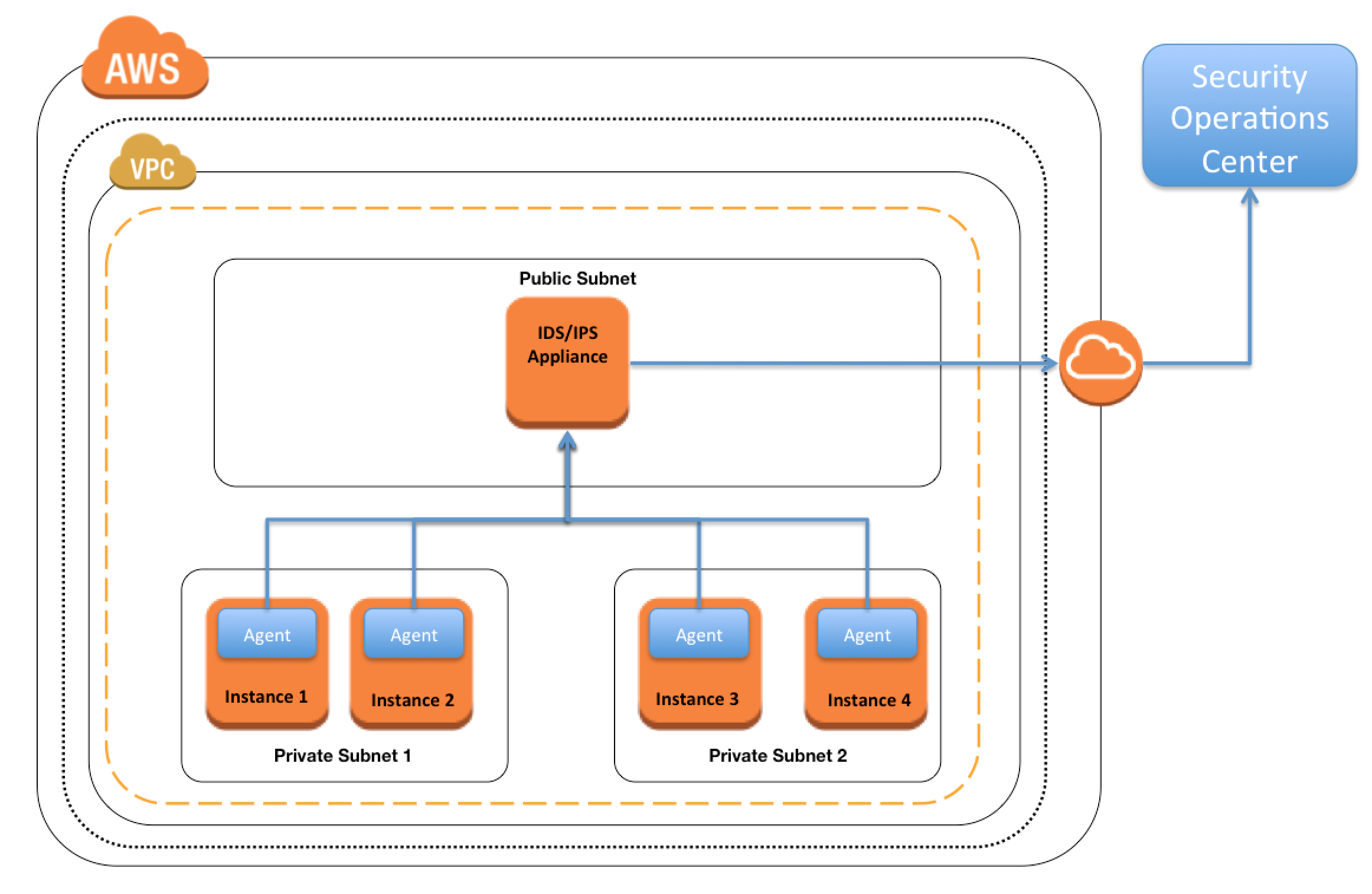
IDS/IPS
- Promiscuous mode is not allowed, as AWS and Hypervisor will not deliver any traffic to instances this is not specifically addressed to the instance
- IDS/IPS strategies
- Host Based Firewall – Forward Deployed IDS where the IDS itself is installed on the instances
- Host Based Firewall – Traffic Replication where IDS agents installed on instances which send/duplicate the data to a centralized IDS system
- In-Line Firewall – Inbound IDS/IPS Tier (like a WAF configuration) which identifies and drops suspect packets
DDOS Mitigation
- Minimize the Attack surface
- use ELB/CloudFront/Route 53 to distribute load
- maintain resources in private subnets and use Bastion servers
- Scale to absorb the attack
- scaling helps buy time to analyze and respond to an attack
- auto scaling with ELB to handle increase in load to help absorb attacks
- CloudFront, Route 53 inherently scales as per the demand
- Safeguard exposed resources
- user Route 53 for aliases to hide source IPs and Private DNS
- use CloudFront geo restriction and Origin Access Identity
- use WAF as part of the infrastructure
- Learn normal behavior (IDS/WAF)
- analyze and benchmark to define rules on normal behavior
- use CloudWatch
- Create a plan for attacks
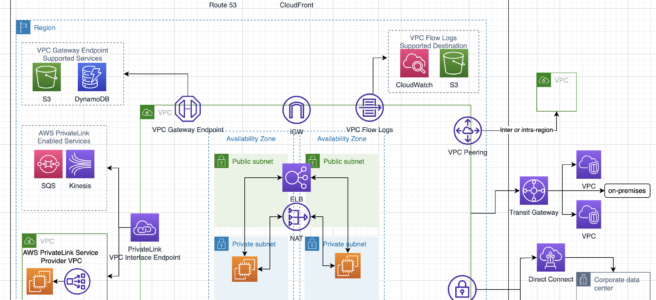
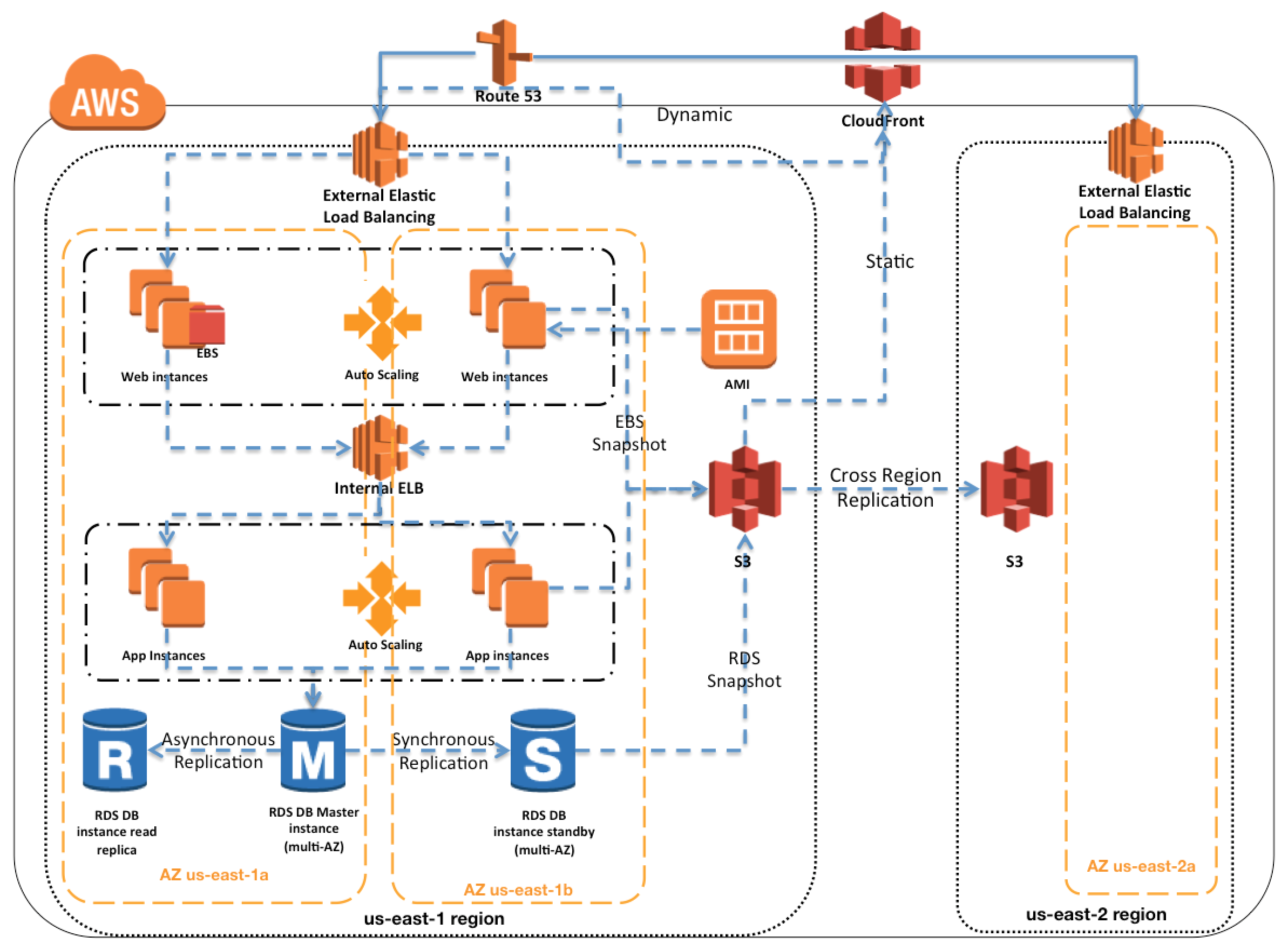
AWS Services Region, AZ, Subnet VPC limitations
- Services like IAM (user, role, group, SSL certificate), Route 53, STS are Global and available across regions
- All other AWS services are limited to Region or within Region and do not exclusively copy data across regions unless configured
- AMI are limited to region and need to be copied over to other region
- EBS volumes are limited to the Availability Zone, and can be migrated by creating snapshots and copying them to another region
- Reserved instances
are limited to Availability Zone and(can be migrated to other Availability Zone now) cannot be migrated to another region - RDS instances are limited to the region and can be recreated in a different region by either using snapshots or promoting a Read Replica
Placement groups are limited to the Availability Zone- Cluster Placement groups are limited to single Availability Zones
- Spread Placement groups can span across multiple Availability Zones
- S3 data is replicated within the region and can be move to another region using cross region replication
- DynamoDB maintains data within the region can be replicated to another region using DynamoDB cross region replication (using DynamoDB streams) or Data Pipeline using EMR (old method)
- Redshift Cluster span within an Availability Zone only, and can be created in other AZ using snapshots
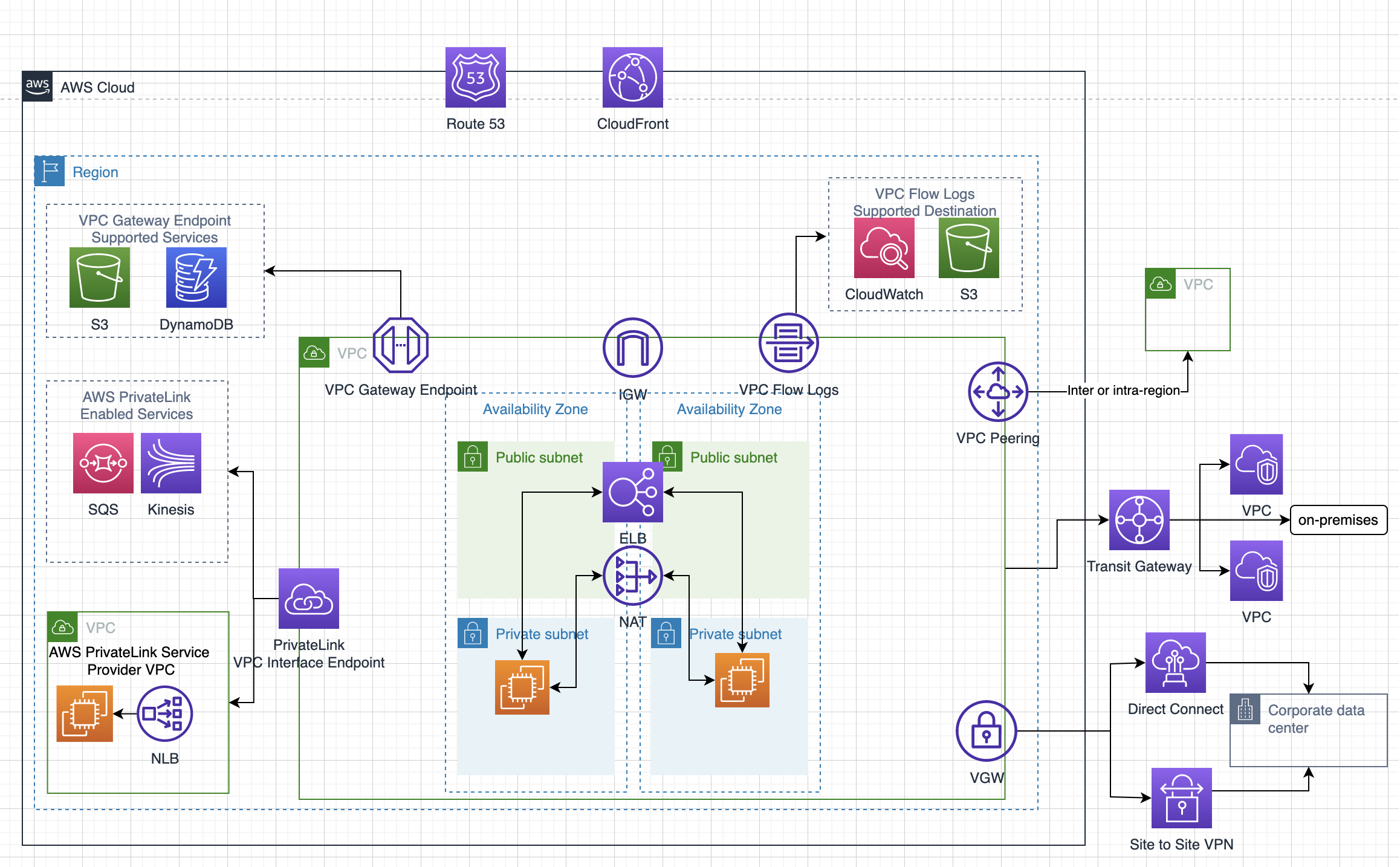
Disaster Recovery Whitepaper
- RTO is the time it takes after a disruption to restore a business process to its service level and RPO acceptable amount of data loss measured in time before the disaster occurs
- Techniques (RTO & RPO reduces and the Cost goes up as we go down)
- Backup & Restore – Data is backed up and restored, within nothing running
- Pilot light – Only minimal critical service like RDS is running and rest of the services can be recreated and scaled during recovery
- Warm Standby – Fully functional site with minimal configuration is available and can be scaled during recovery
- Multi-Site – Fully functional site with identical configuration is available and processes the load
- Services
- Region and AZ to launch services across multiple facilities
- EC2 instances with the ability to scale and launch across AZs
- EBS with Snapshot to recreate volumes in different AZ or region
- AMI to quickly launch preconfigured EC2 instances
- ELB and Auto Scaling to scale and launch instances across AZs
- VPC to create private, isolated section
- Elastic IP address as static IP address
- ENI with pre allocated Mac Address
- Route 53 is highly available and scalable DNS service to distribute traffic across EC2 instances and ELB in different AZs and regions
- Direct Connect for speed data transfer (takes time to setup and expensive then VPN)
- S3 and Glacier (with RTO of 3-5 hours) provides durable storage
- RDS snapshots and Multi AZ support and Read Replicas across regions
- DynamoDB with cross region replication
- Redshift snapshots to recreate the cluster
- Storage Gateway to backup the data in AWS
- Import/Export to move large amount of data to AWS (if internet speed is the bottleneck)
- CloudFormation, Elastic Beanstalk and Opsworks as orchestration tools for automation and recreate the infrastructure