⚠️ CERTIFICATION RETIRED
AWS Certified Data Analytics – Specialty (DAS-C01) was retired on April 9, 2024.
AWS retired the DAS-C01 exam along with two other specialty certifications (Database – Specialty and SAP on AWS – Specialty) in April 2024.
This content is maintained for historical reference and for learning AWS analytics services.
Replacement Certification:
- AWS Certified Data Engineer – Associate (DEA-C01) – Launched March 2024, validates ability to implement data pipelines, monitor and troubleshoot issues, and optimize cost and performance. Covers data ingestion, transformation, storage, operations, security, and governance. 65 questions, 130 minutes, $150, passing score 720.
Key Differences (DEA-C01 vs DAS-C01):
- Associate-level (vs. Specialty-level) – broader accessibility
- Stronger focus on data pipeline orchestration (Step Functions, MWAA, EventBridge)
- Includes newer services: AWS Lake Formation, Amazon MSK, Amazon Managed Service for Apache Flink, Amazon AppFlow, S3 Tables
- Reduced emphasis on legacy services like EMR Hadoop ecosystem
- Programming concepts and Git source control knowledge expected
AWS Certified Data Analytics – Specialty (DAS-C01) Exam Learning Path
- Recertified with the AWS Certified Data Analytics – Specialty (DAS-C01) which tends to cover a lot of big data topics focused on AWS services.
- Data Analytics – Specialty (DAS-C01) has replaced the previous Big Data – Specialty (BDS-C01).
- Note: DAS-C01 was retired on April 9, 2024. The replacement certification is AWS Certified Data Engineer – Associate (DEA-C01).
AWS Certified Data Analytics – Specialty (DAS-C01) exam basically validates
- Define AWS data analytics services and understand how they integrate with each other.
- Explain how AWS data analytics services fit in the data lifecycle of collection, storage, processing, and visualization.
Refer AWS Certified Data Analytics – Specialty Exam Guide for details
AWS Certified Data Analytics – Specialty (DAS-C01) Exam Resources
- Online Courses
- Stephane Maarek – AWS Certified Data Analytics Specialty Exam
- Whizlabs – AWS Certified Data Analytics – Specialty Course
- Practice tests
- For the replacement DEA-C01 exam resources, refer to the AWS Certified Data Engineer – Associate (DEA-C01) Exam Learning Path
AWS Certified Data Analytics – Specialty (DAS-C01) Exam Summary
-
Specialty exams are tough, lengthy, and tiresome. Most of the questions and answers options have a lot of prose and a lot of reading that needs to be done, so be sure you are prepared and manage your time well.
- DAS-C01 exam has 65 questions to be solved in 170 minutes which gives you roughly 2 1/2 minutes to attempt each question.
- DAS-C01 exam includes two types of questions, multiple-choice and multiple-response.
- DAS-C01 has a scaled score between 100 and 1,000. The scaled score needed to pass the exam is 750.
- Specialty exams currently cost $ 300 + tax.
- You can get an additional 30 minutes if English is your second language by requesting Exam Accommodations. It might not be needed for Associate exams but is helpful for Professional and Specialty ones.
- As always, mark the questions for review and move on and come back to them after you are done with all.
- As always, having a rough architecture or mental picture of the setup helps focus on the areas that you need to improve. Trust me, you will be able to eliminate 2 answers for sure and then need to focus on only the other two. Read the other 2 answers to check the difference area and that would help you reach the right answer or at least have a 50% chance of getting it right.
- AWS exams can be taken either remotely or online, I prefer to take them online as it provides a lot of flexibility. Just make sure you have a proper place to take the exam with no disturbance and nothing around you.
- Also, if you are taking the AWS Online exam for the first time try to join at least 30 minutes before the actual time as I have had issues with both PSI and Pearson with long wait times.
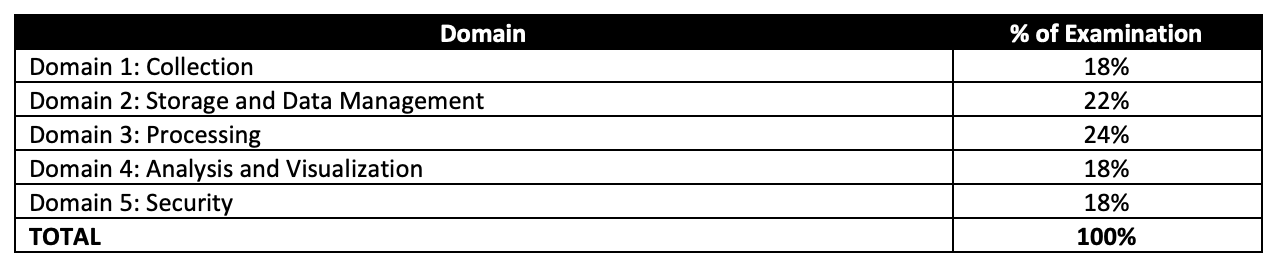
AWS Certified Data Analytics – Specialty (DAS-C01) Exam Topics
- AWS Certified Data Analytics – Specialty exam, as its name suggests, covers a lot of Big Data concepts right from data collection, ingestion, transfer, storage, pre and post-processing, analytics, and visualization with the added concepts for data security at each layer.
Analytics
- Make sure you know and cover all the services in-depth, as 80% of the exam is focused on topics like Glue, Kinesis, and Redshift.
- AWS Analytics Services Cheat Sheet
- Glue
- DAS-C01 covers Glue in great detail.
- AWS Glue is a fully managed, ETL service that automates the time-consuming steps of data preparation for analytics.
- supports server-side encryption for data at rest and SSL for data in motion.
- Glue ETL engine to Extract, Transform, and Load data that can automatically generate Scala or Python code.
- Glue Data Catalog is a central repository and persistent metadata store to store structural and operational metadata for all the data assets. It works with Apache Hive as its metastore.
- Glue Crawlers scan various data stores to automatically infer schemas and partition structures to populate the Data Catalog with corresponding table definitions and statistics.
- Glue Job Bookmark tracks data that has already been processed during a previous run of an ETL job by persisting state information from the job run.
- Glue Streaming ETL enables performing ETL operations on streaming data using continuously-running jobs.
- Glue provides flexible scheduler that handles dependency resolution, job monitoring, and retries.
- Glue Studio offers a graphical interface for authoring AWS Glue jobs to process data allowing you to define the flow of the data sources, transformations, and targets in the visual interface and generating Apache Spark code on your behalf.
- Glue Data Quality helps reduces manual data quality efforts by automatically measuring and monitoring the quality of data in data lakes and pipelines.
- Glue DataBrew helps prepare, visualize, clean, and normalize data directly from the data lake, data warehouses, and databases, including S3, Redshift, Aurora, and RDS.
- Redshift
- Redshift is also covered in depth.
- Cover Redshift Advanced topics
- Redshift Distribution Style determines how data is distributed across compute nodes and helps minimize the impact of the redistribution step by locating the data where it needs to be before the query is executed.
- Redshift Enhanced VPC routing forces all COPY and UNLOAD traffic between the cluster and the data repositories through the VPC.
- Workload management (WLM) enables users to flexibly manage priorities within workloads so that short, fast-running queries won’t get stuck in queues behind long-running queries.
- Redshift Spectrum helps query and retrieve structured and semistructured data from files in S3 without having to load the data into Redshift tables.
- Federated Query feature allows querying and analyzing data across operational databases, data warehouses, and data lakes.
- Short query acceleration (SQA) prioritizes selected short-running queries ahead of longer-running queries.
- Redshift Serverless is a serverless option of Redshift that makes it more efficient to run and scale analytics in seconds without the need to set up and manage data warehouse infrastructure.
- Redshift Best Practices w.r.t selection of Distribution style, Sort key, importing/exporting data
- COPY command which allows parallelism, and performs better than multiple COPY commands
- COPY command can use manifest files to load data
- COPY command handles encrypted data
- COPY command which allows parallelism, and performs better than multiple COPY commands
- Redshift Resizing cluster options (elastic resize did not support node type changes before, but does now)
- Redshift supports encryption at rest and in transit
- Redshift supports encrypting an unencrypted cluster using KMS. However, you can’t enable hardware security module (HSM) encryption by modifying the cluster. Instead, create a new, HSM-encrypted cluster and migrate your data to the new cluster.
- Know Redshift views to control access to data.
- Elastic Map Reduce
- Understand EMRFS
- Use Consistent view to make sure S3 objects referred by different applications are in sync. Although, it is not needed now.
- Know EMR Best Practices (hint: start with many small nodes instead of few large nodes)
- Know EMR Encryption options
- supports SSE-S3, SS3-KMS, CSE-KMS, and CSE-Custom encryption for EMRFS
- supports LUKS encryption for local disks
- supports TLS for data in transit encryption
- supports EBS encryption
- Hive metastore can be externally hosted using RDS, Aurora, and AWS Glue Data Catalog
- Know also different technologies
- Presto is a fast SQL query engine designed for interactive analytic queries over large datasets from multiple sources
- Spark is a distributed processing framework and programming model that helps do machine learning, stream processing, or graph analytics using Amazon EMR clusters
- Zeppelin/Jupyter as a notebook for interactive data exploration and provides open-source web application that can be used to create and share documents that contain live code, equations, visualizations, and narrative text
- Phoenix is used for OLTP and operational analytics, allowing you to use standard SQL queries and JDBC APIs to work with an Apache HBase backing store
- Understand EMRFS
- Kinesis
- Understand Kinesis Data Streams and Amazon Data Firehose (formerly Kinesis Data Firehose) in depth
- Know Kinesis Data Streams vs Data Firehose
- Know Kinesis Data Streams is open-ended for both producer and consumer. It supports KCL and works with Spark.
- Know Amazon Data Firehose is open-ended for producers only. Data is stored in S3, Redshift, and OpenSearch.
- Data Firehose works in batches with minimum 60secs intervals and in near-real time.
- Data Firehose supports out-of-the-box transformation and custom transformation using Lambda
- Kinesis supports encryption at rest using server-side encryption
- Kinesis Producer Library supports batching
- Amazon Managed Service for Apache Flink (formerly Kinesis Data Analytics)
- helps transform and analyze streaming data in real time using Apache Flink.
- supports anomaly detection using Random Cut Forest ML
- supports reference data stored in S3.
- Note: Kinesis Data Analytics for SQL applications was discontinued effective January 27, 2026. Migrate to Amazon Managed Service for Apache Flink or Apache Flink Studio.
- OpenSearch
- OpenSearch is a search service that supports indexing, full-text search, faceting, etc.
- OpenSearch can be used for analysis and supports visualization using OpenSearch Dashboards which can be real-time.
- OpenSearch Service Storage tiers support Hot, UltraWarm, and Cold and the data can be transitioned using Index State management.
- QuickSight
- Know Visual Types (hint: esp. word clouds, plotting line, bar, and story based visualizations)
- Know Supported Data Sources
- QuickSight provides IP addresses that need to be whitelisted for QuickSight to access the data store.
- QuickSight provides direct integration with Microsoft AD
- QuickSight supports Row level security using dataset rules to control access to data at row granularity based on permissions associated with the user interacting with the data.
- QuickSight supports ML insights as well
- QuickSight supports users defined via IAM or email signup.
- Athena
- is a serverless, interactive analytics service built on open-source frameworks, supporting open-table and file formats.
- provides a simplified, flexible way to analyze data in an S3 data lake and 30 data sources, including on-premises data sources or other cloud systems using SQL or Python without loading the data.
- integrates with QuickSight for visualizing the data or creating dashboards.
- uses a managed Glue Data Catalog to store information and schemas about the databases and tables that you create for the data stored in S3
- Workgroups can be used to separate users, teams, applications, or workloads, to set limits on the amount of data each query or the entire workgroup can process, and to track costs.
- Athena best practices recommended partitioning the data, partition projection, and using the Columnar file format like ORC or Parquet as they support compression and are splittable.
- Know Data Pipeline for data transfer
- Note: AWS Data Pipeline was closed to new customers effective July 25, 2024. The service is in maintenance mode. Consider AWS Glue, Amazon MWAA, or AWS Step Functions as alternatives.
Security, Identity & Compliance
- Data security is a key concept controlled in the Data Analytics – Specialty exam
- Identity and Access Management (IAM)
- Understand IAM in depth
- Understand IAM Roles
- Understand Identity Providers & Federation
- Understand IAM Policies
- Deep dive into Key Management Service (KMS). There would be quite a few questions on this.
- Understand how KMS works
- Understand IAM Policies, Key Policies, Grants
- Know KMS are regional and how to use in other regions.
- Amazon Macie is a security service that uses machine learning to automatically discover, classify, and protect sensitive data in S3.
- Understand AWS Cognito esp. authentication across devices
Management & Governance Tools
- Understand AWS CloudWatch for Logs and Metrics.
- CloudWatch Subscription Filters can be used to route data to Kinesis Data Streams, Amazon Data Firehose, and Lambda.
Whitepapers and articles
On the Exam Day
- Make sure you are relaxed and get some good night’s sleep. The exam is not tough if you are well-prepared.
- If you are taking the AWS Online exam
- Try to join at least 30 minutes before the actual time as I have had issues with both PSI and Pearson with long wait times.
- The online verification process does take some time and usually, there are glitches.
- Remember, you would not be allowed to take the take if you are late by more than 30 minutes.
- Make sure you have your desk clear, no hand-watches, or external monitors, keep your phones away, and nobody can enter the room.
Finally, All the Best 🙂